Endmember Learning with K-Means through SCD Model in Hyperspectral Scene Reconstructions


Abstract
:1. Introduction
2. Prior Work in Dictionary Learning (DL)
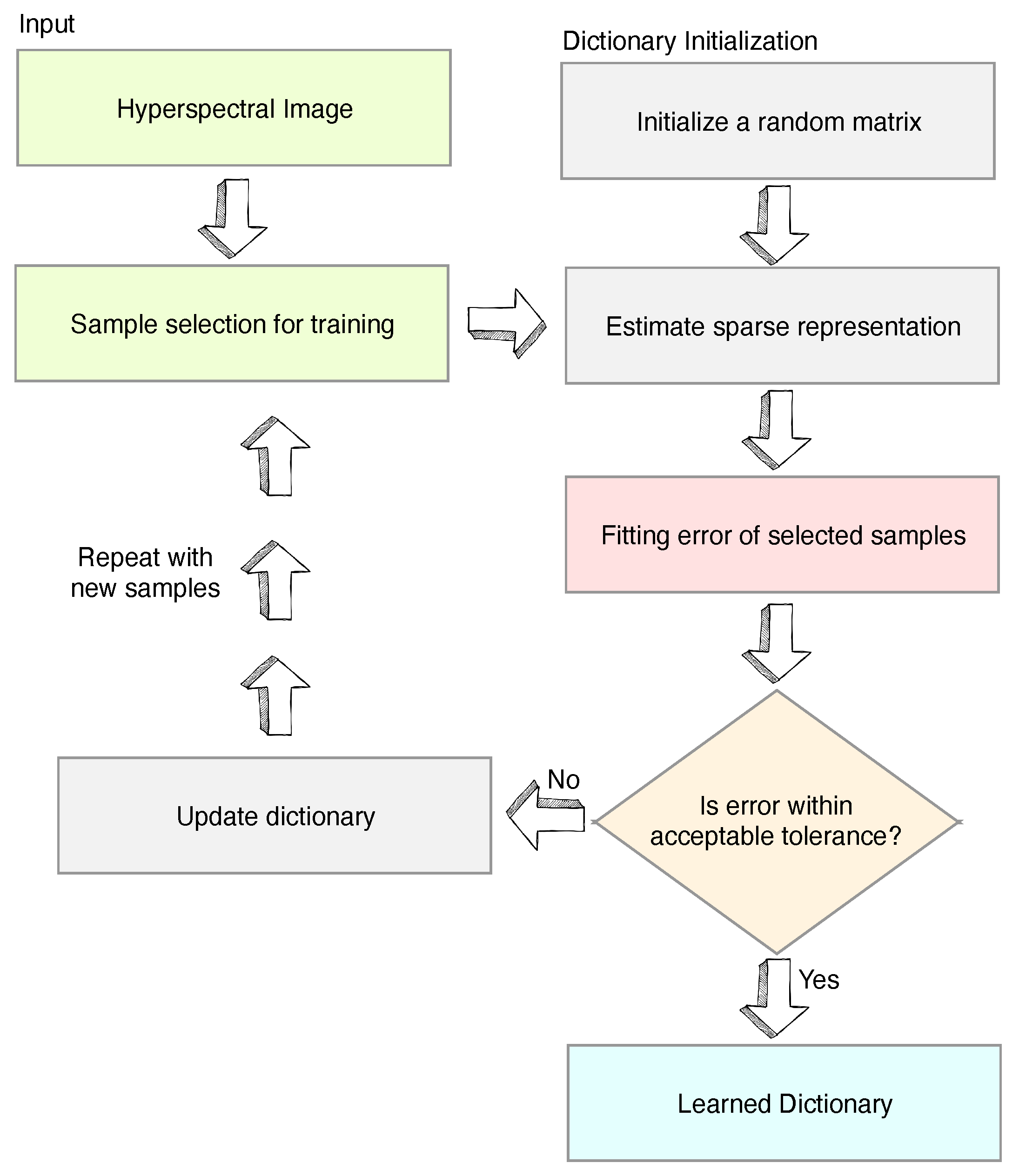
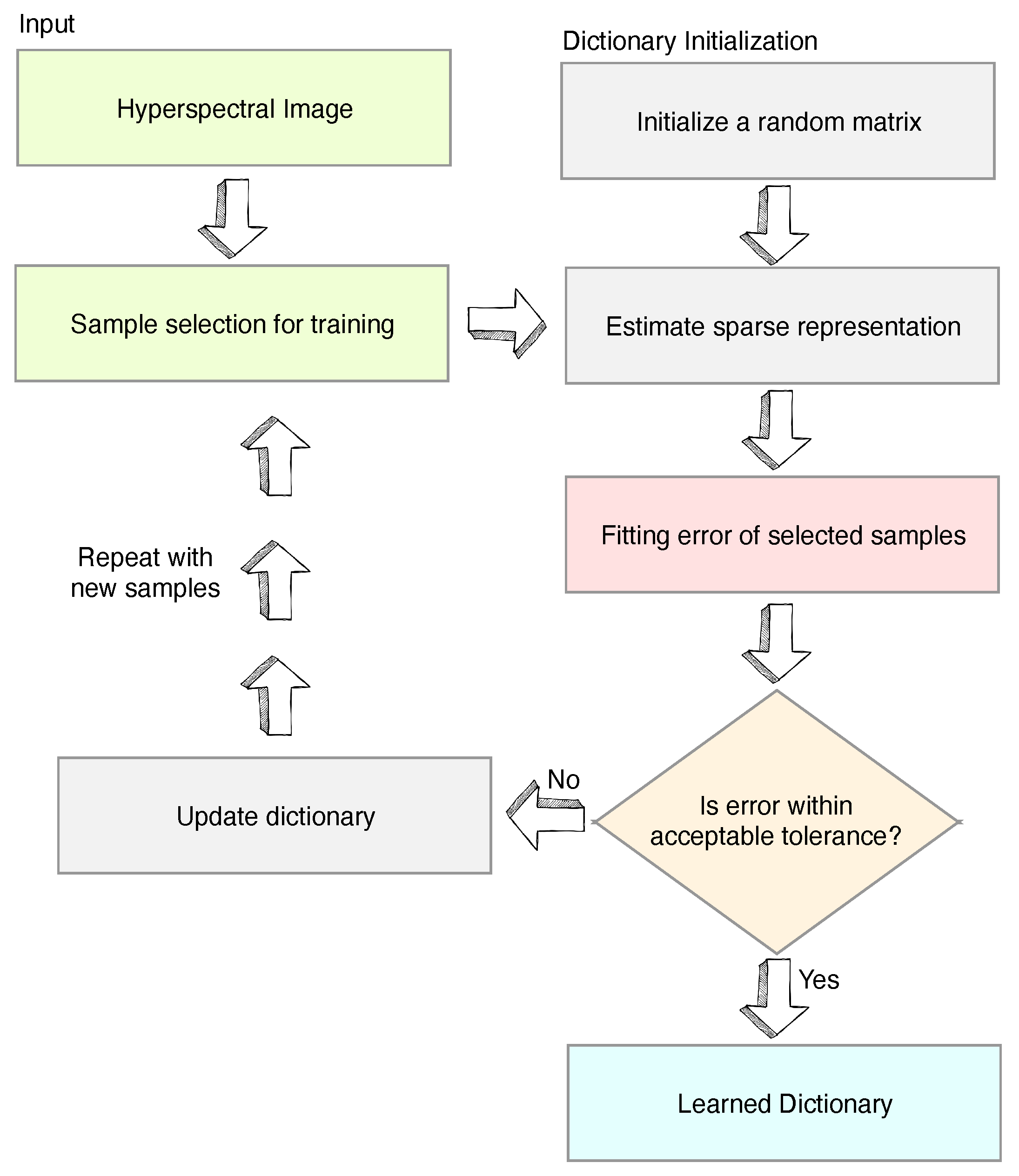
3. Proposed Algorithm for Dictionary Learning (DL)
| Algorithm 1 Proposed K-Means SCD (KMSCD) algorithm. |
|
| Algorithm 2 Proposed for scene simulators: KMSCD+FNNOMP. |
|
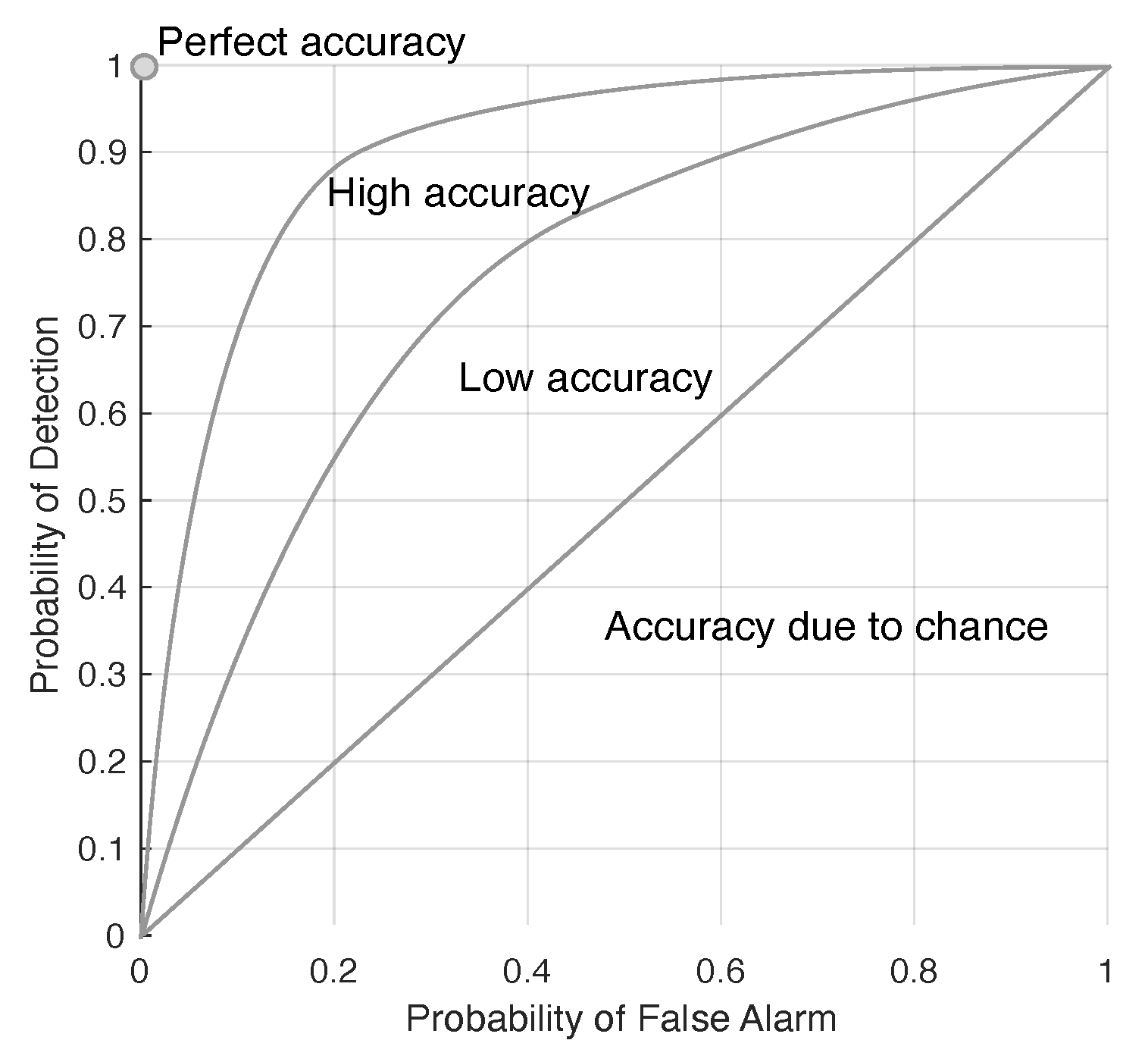
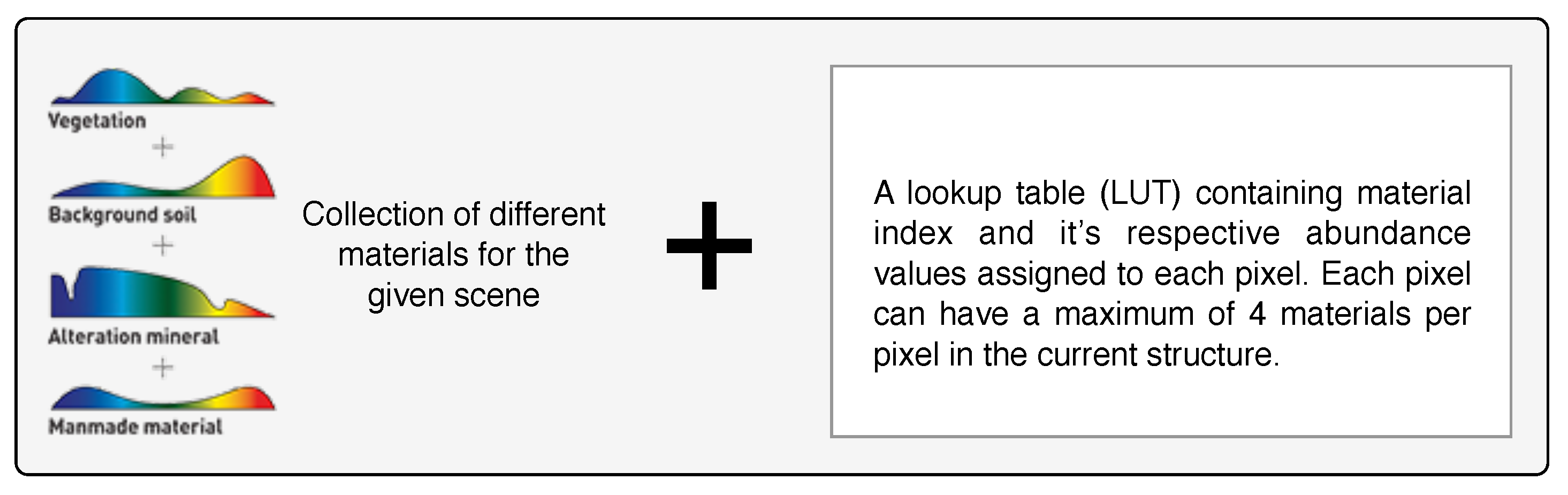
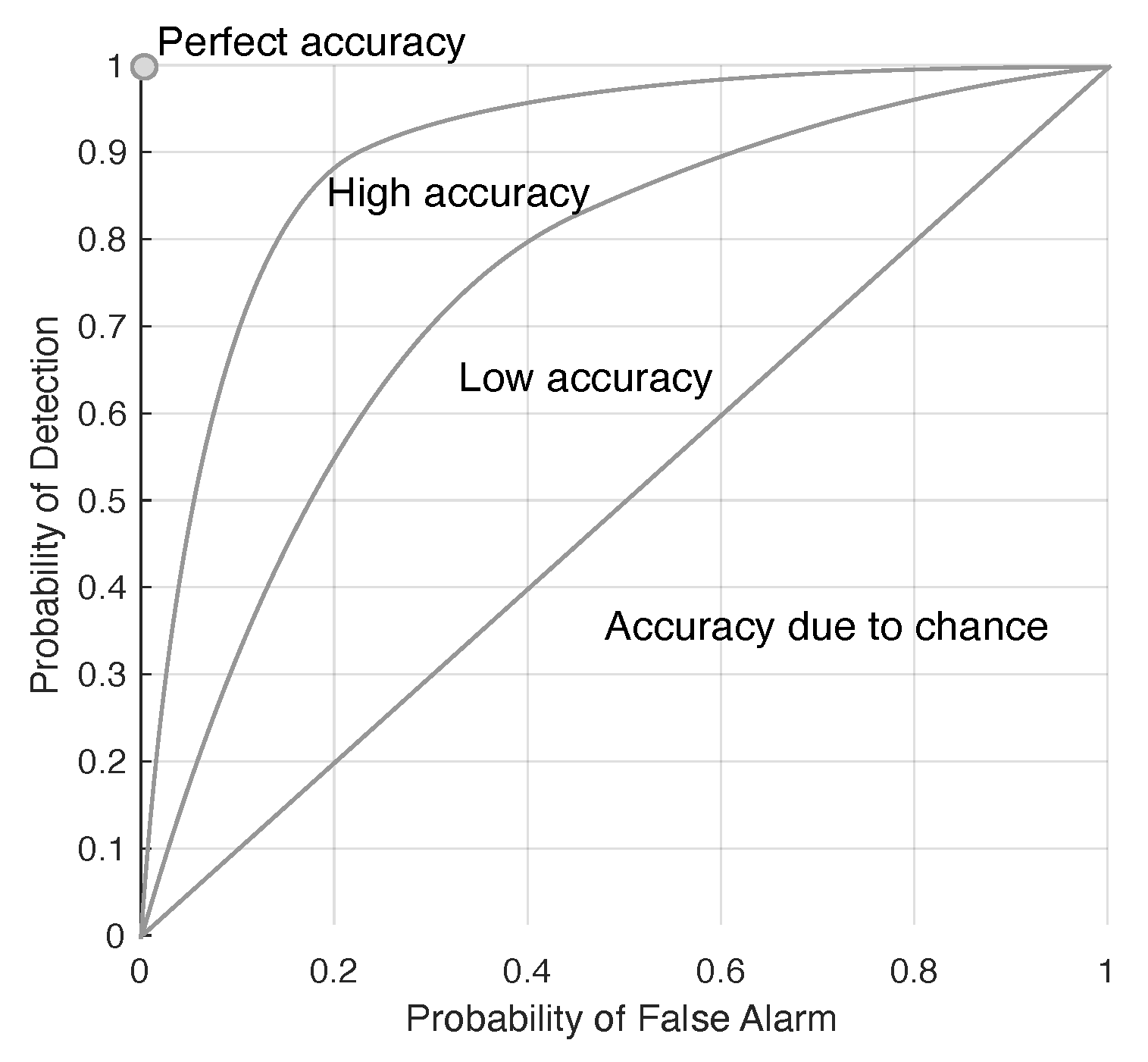
4. Data Sets and Accuracy of Scene Reconstruction Assessments
5. Results
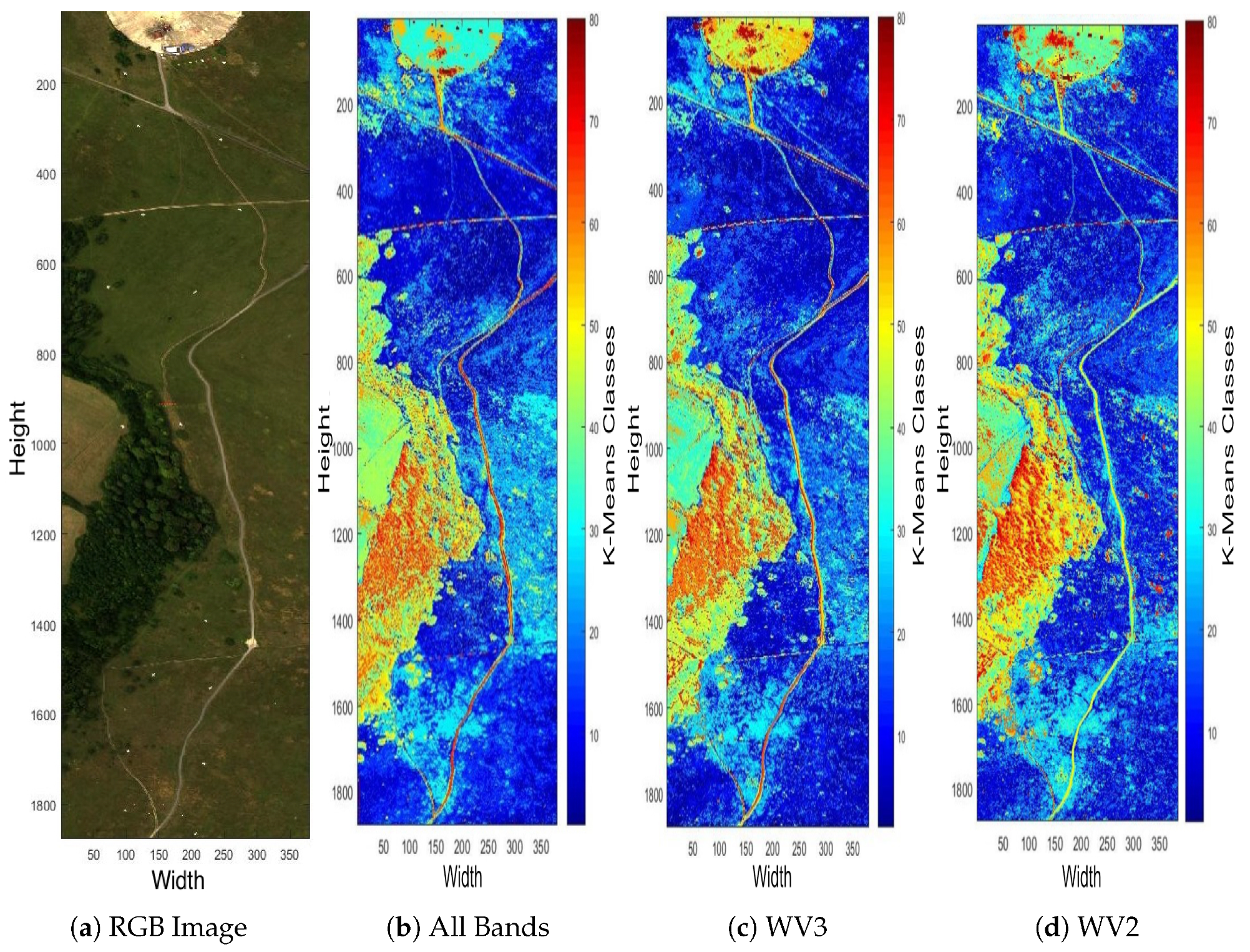
5.1. Feasibility of K-Means Clustering for Multispectral Data Set
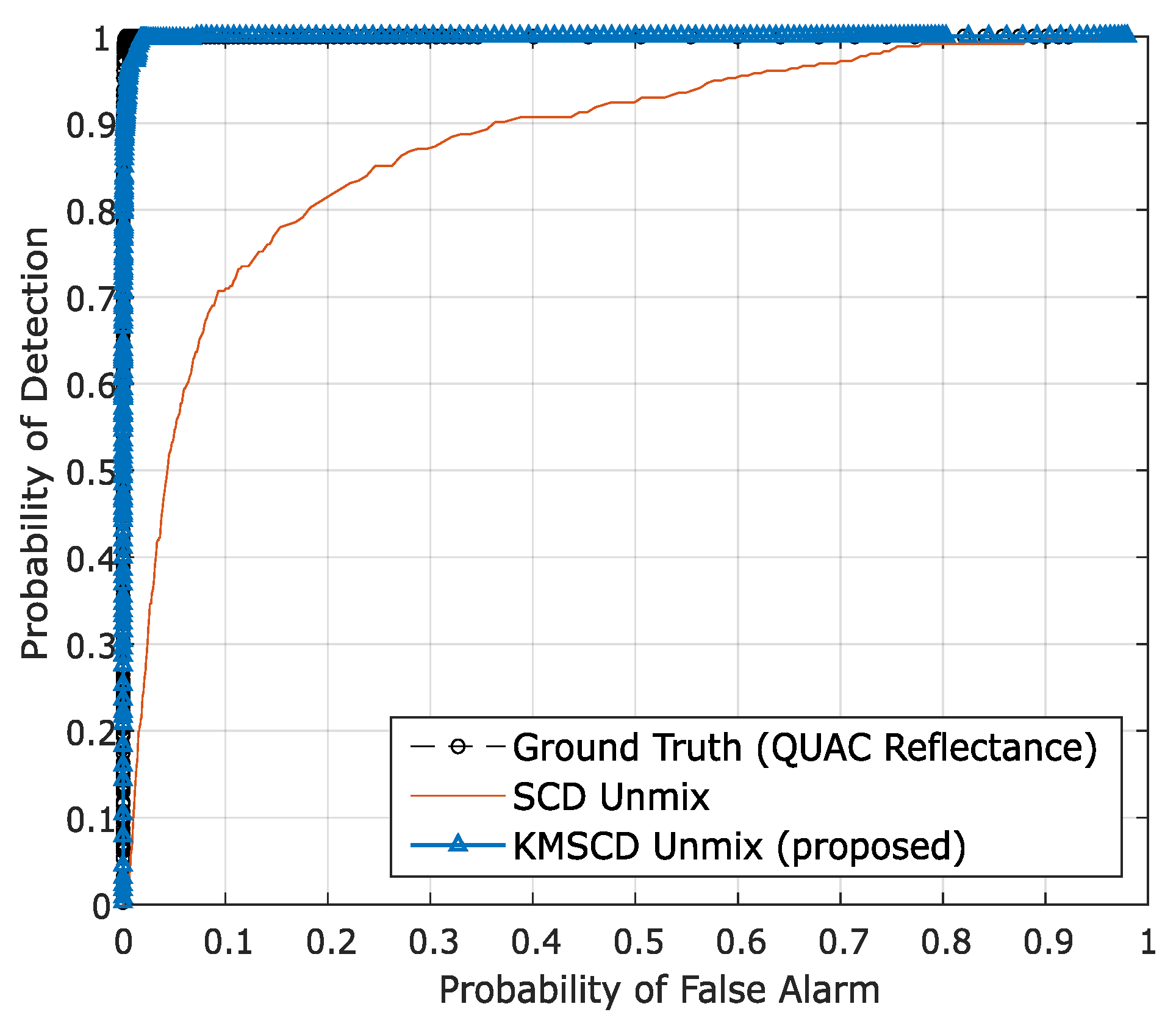
5.2. C-SCD vs. KMSCD: Reconstruction of Background Pixels
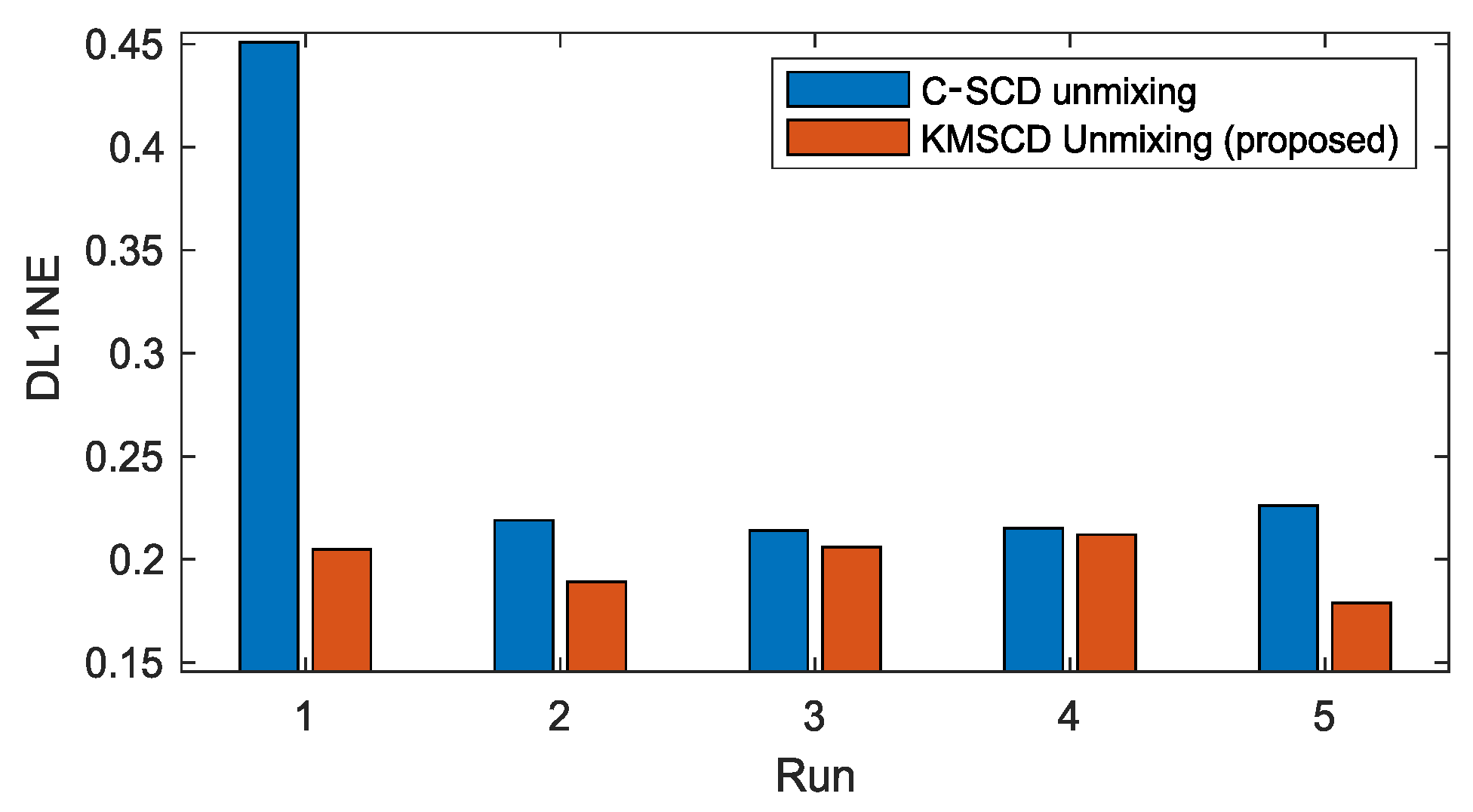
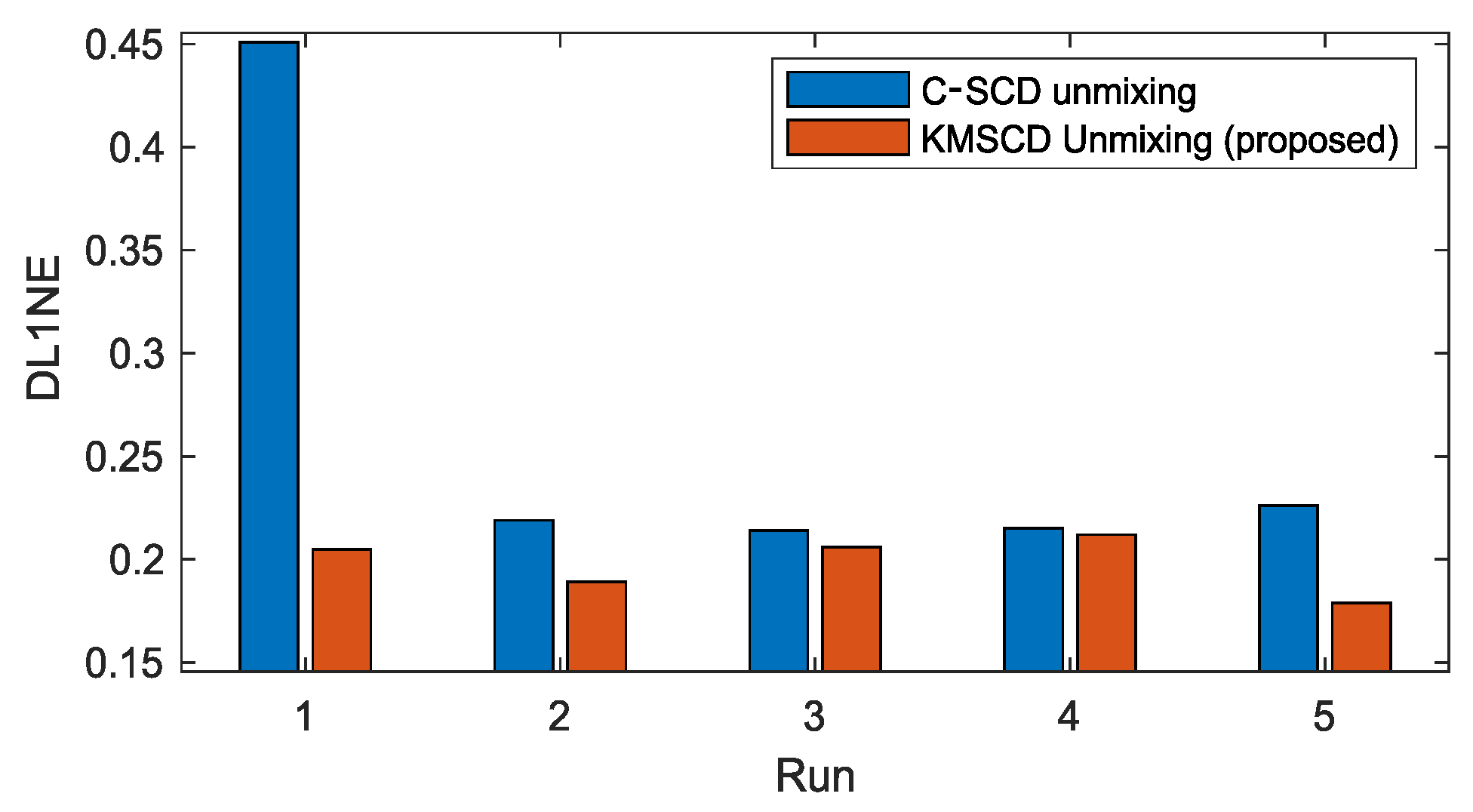
5.2.1. Robustness of C-SCD and the Proposed KMSCD
5.2.2. Accuracy of C-SCD and KMSCD: Background Pixels
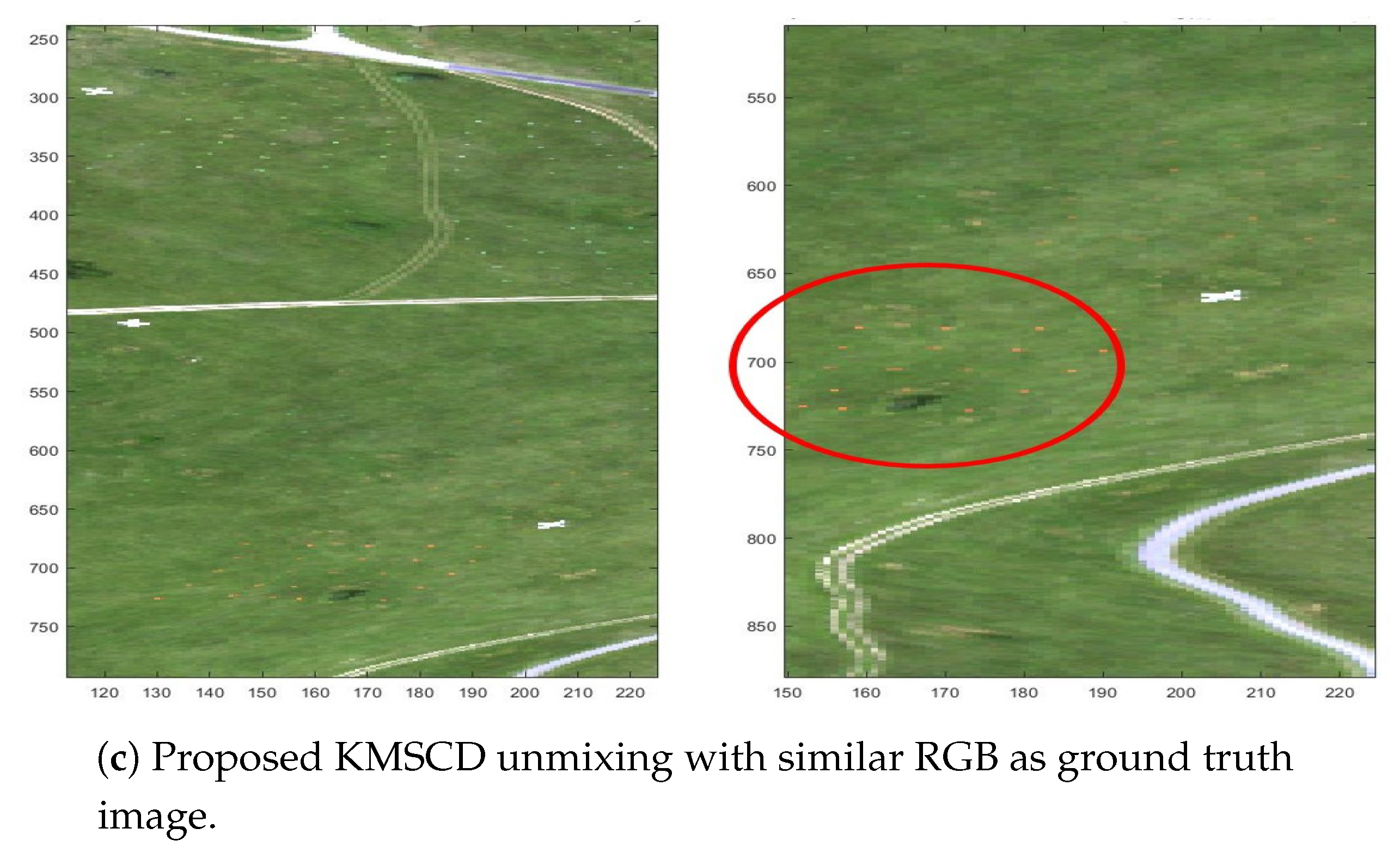
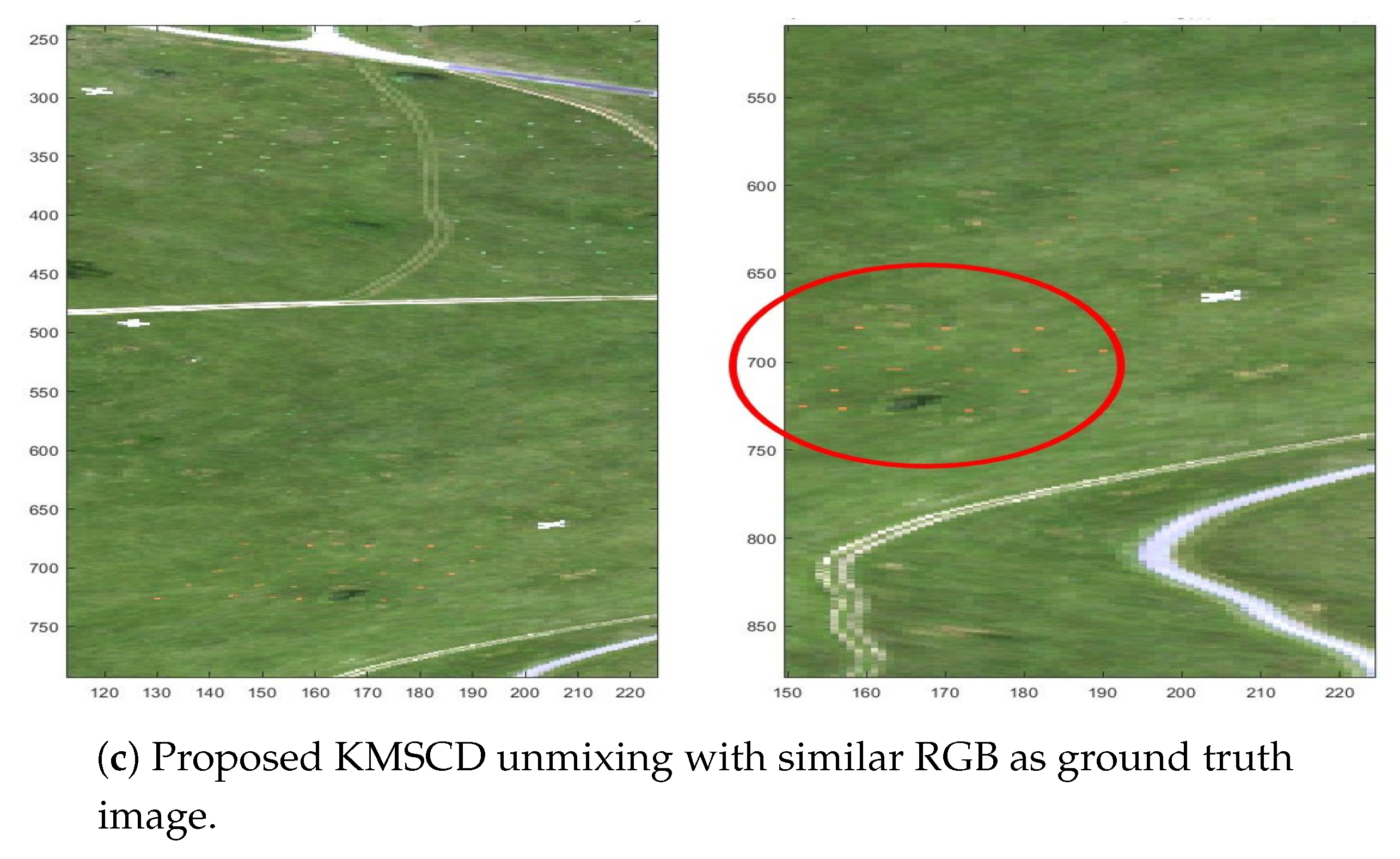
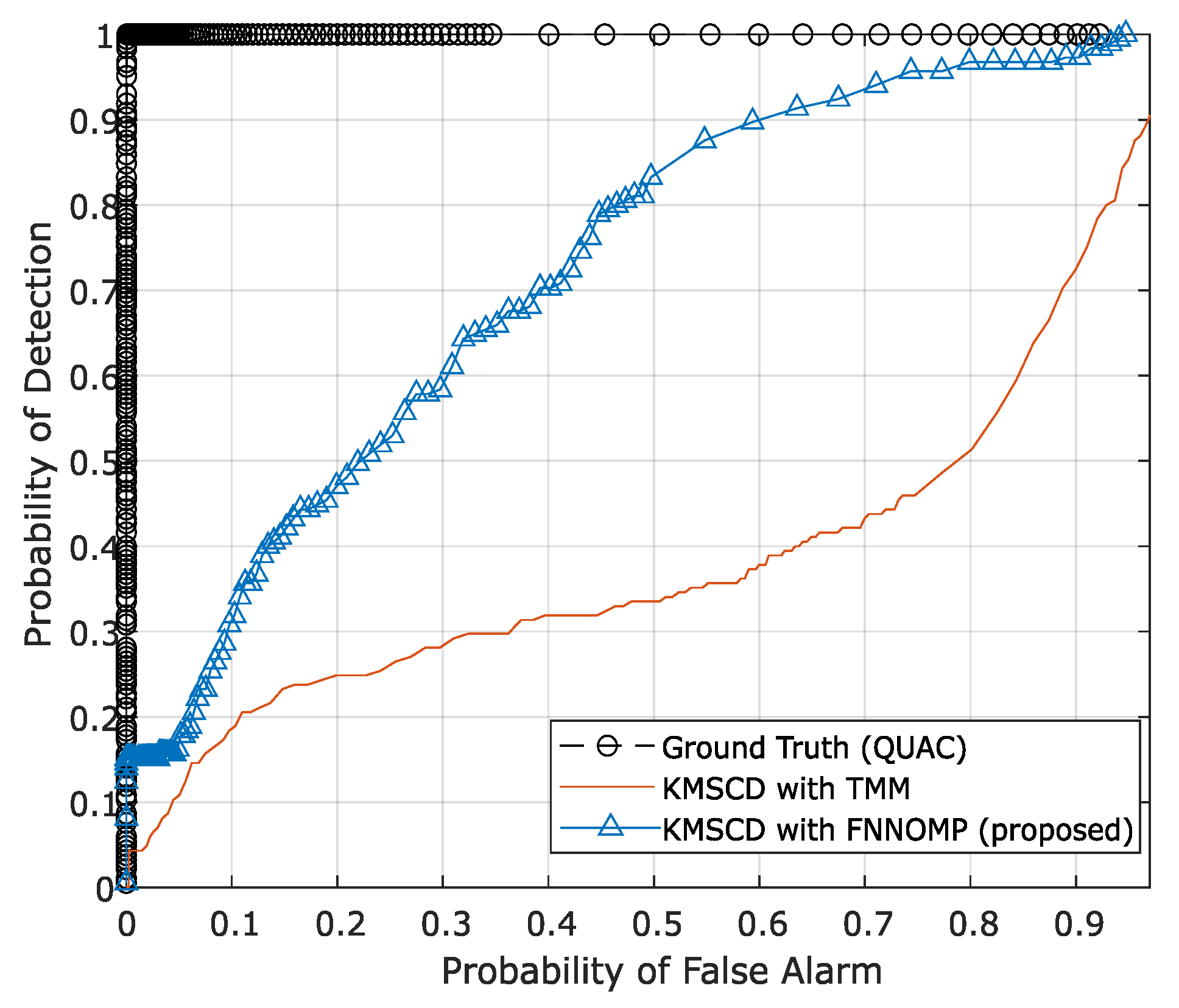
5.3. Reconstruction of Trace Materials in the Scene
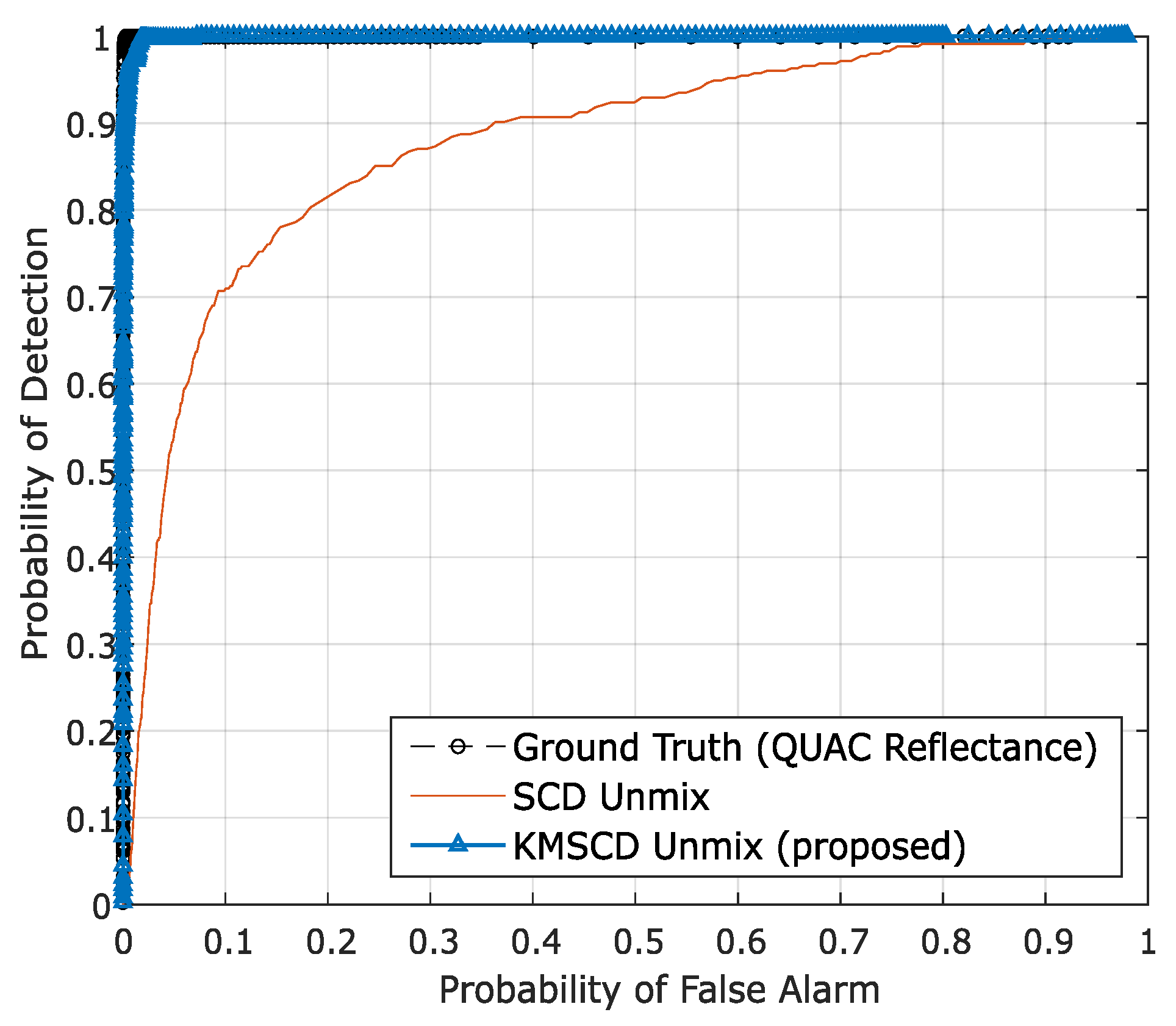
5.3.1. C-SCD vs. KMSCD
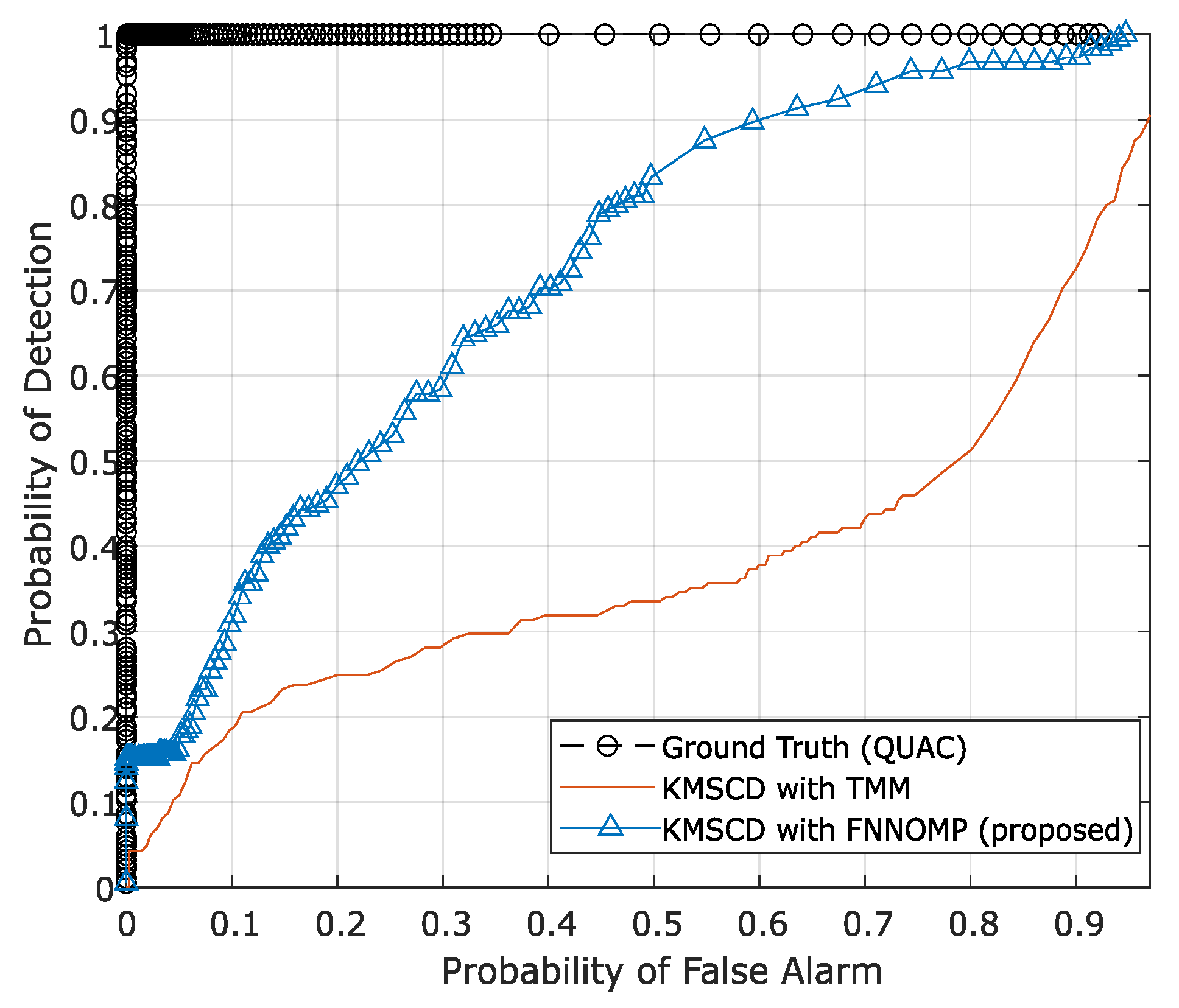
5.3.2. KMSCD for Scene Simulation Applications
6. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ACE | Adaptive Cosine Estimator |
| AUC | Area Under Curve |
| C-SCD | Classic Sparse Coding Dictionary |
| DL | Dictionary Learning |
| ED | Euclidean Distance |
| EM | Endmember |
| GSD | Ground Sampling Distance |
| KMSCD | K-Means Sparse Coding Dictionary |
| LUT | Lookup Table |
| ROC | Receiver Operating Characteristic |
| SCD | Sparse Coding Dictionary |
| HSI | Hyperspectral Image |
| MD | Manhattan Distance |
| MSI | Multispectral Image |
| ROC | Receiver Operating Characteristics |
| TMM | Texture Material Mapper |
References
- Yuen, P.W.; Richardson, M. An introduction to hyperspectral imaging and its application for security, surveillance and target acquisition. Imaging Sci. J. 2010, 58, 241–253. [Google Scholar] [CrossRef]
- Ward, J.T. Realistic Texture in Simulated Thermal Infrared Imagery. Ph.D. Thesis, Chester F. Carlson Center for Imaging Science, Rochester Institute of Technology, Rochester, NY, USA, 2008. [Google Scholar]
- Pereira, W.; Richtsmeier, S.; Carr, S.; Kharabash, S.; Brady, A. A comparison of MCScene and CameoSim simulations of a real scene. In Proceedings of the 2014 6th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Lausanne, Switzerland, 24–27 June 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Evans, R. Modeling of SOC-700 Hyperspectral Imagery with the CAMEO-SIM Code. Proceedings of the 2007 Ground Systems Modeling, Validation & Testing Conference. 2007. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.1000.5149&rep=rep1&type=pdf (accessed on 13 November 2019).
- James, I.; Richardson, M.; O’Keefe, E. Comparison of empirical and predicted ultraviolet aircraft signatures. Opt. Eng. 2019, 58, 025103. [Google Scholar] [CrossRef]
- Li, H.; Shen, H.; Yuan, Q.; Zhang, H.; Zhang, L.; Zhang, L. Quality improvement of hyperspectral remote sensing images: A technical overview. In Proceedings of the 2016 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Los Angeles, CA, USA, 21–24 August 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Charles, A.S.; Olshausen, B.A.; Rozell, C.J. Learning Sparse Codes for Hyperspectral Imagery. IEEE J. Sel. Top. Signal Process. 2011, 5, 963–978. [Google Scholar] [CrossRef]
- Han, X.; Yu, J.; Luo, J.; Sun, W. Reconstruction From Multispectral to Hyperspectral Image Using Spectral Library-Based Dictionary Learning. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1325–1335. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Fu, X.; Ma, W.; Chan, T.; Bioucas-Dias, J.M. Self-Dictionary Sparse Regression for Hyperspectral Unmixing: Greedy Pursuit and Pure Pixel Search Are Related. IEEE J. Sel. Top. Signal Process. 2015, 9, 1128–1141. [Google Scholar] [CrossRef]
- Degerickx, J.; Okujeni, A.; Iordache, M.D.; Hermy, M.; Van der Linden, S.; Somers, B. A Novel Spectral Library Pruning Technique for Spectral Unmixing of Urban Land Cover. Remote Sens. 2017, 9, 565. [Google Scholar] [CrossRef]
- Fu, X.; Ma, W.; Bioucas-Dias, J.M.; Chan, T. Semiblind Hyperspectral Unmixing in the Presence of Spectral Library Mismatches. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5171–5184. [Google Scholar] [CrossRef]
- Kapoor, A.; Singhal, A. A comparative study of K-Means, K-Means++ and Fuzzy C-Means clustering algorithms. In Proceedings of the 2017 3rd International Conference on Computational Intelligence Communication Technology (CICT), Ghaziabad, India, 9–10 Februay 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.; Plaza, J.; Plaza, A. Cloud implementation of the K-means algorithm for hyperspectral image analysis. J. Supercomput. 2017, 73, 514–529. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, Y.; Li, F.; Xin, L.; Huang, P. Sparse Dictionary Learning for Blind Hyperspectral Unmixing. IEEE Geosci. Remote Sens. Lett. 2019, 16, 578–582. [Google Scholar] [CrossRef]
- Nascimento, J.M.P.; Dias, J.M.B. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef]
- Li, J.; Agathos, A.; Zaharie, D.; Bioucas-Dias, J.M.; Plaza, A.; Li, X. Minimum Volume Simplex Analysis: A Fast Algorithm for Linear Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5067–5082. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A.; Liu, L. Robust Collaborative Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6076–6090. [Google Scholar] [CrossRef]
- Gao, D.; Hu, Z.; Ye, R. Self-Dictionary Regression for Hyperspectral Image Super-Resolution. Remote Sens. 2018, 10, 1574. [Google Scholar] [CrossRef]
- Fang, L.; Li, S.; Kang, X.; Benediktsson, J.A. Spectral–Spatial Classification of Hyperspectral Images With a Superpixel-Based Discriminative Sparse Model. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4186–4201. [Google Scholar] [CrossRef]
- Bao, C.; Ji, H.; Quan, Y.; Shen, Z. Dictionary Learning for Sparse Coding: Algorithms and Convergence Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1356–1369. [Google Scholar] [CrossRef]
- Schnass, K. Average Performance of Orthogonal Matching Pursuit (OMP) for Sparse Approximation. IEEE Signal Process. Lett. 2018, 25, 1865–1869. [Google Scholar] [CrossRef]
- Yaghoobi, M.; Wu, D.; Davies, M.E. Fast Non-Negative Orthogonal Matching Pursuit. IEEE Signal Process. Lett. 2015, 22, 1229–1233. [Google Scholar] [CrossRef]
- Chang, C. Adaptive Linear Spectral Mixture Analysis. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1240–1253. [Google Scholar] [CrossRef]
- Jacobsson, J. Terrain Model Generation for the Infra Red Scene Simulation Software SensorVision(TM). Master’s Thesis, School of Computer Science and Engineering, Royal Institute of Technology, Stockholm, Sweden, 2005. [Google Scholar]
- Piper, J. A new dataset for analysis of hyperspectral target detection performance. In Proceedings of the HSI 2014, Hyperspectral Imaging and Applications Conference, Coventry UK, 15–16 October 2014. [Google Scholar]
- Bernstein, L.S.; Jin, X.; Gregor, B.; Adler-Golden, S.M. Quick atmospheric correction code: Algorithm description and recent upgrades. Opt. Eng. 2012, 51, 111719. [Google Scholar] [CrossRef]
- Nasrabadi, N.M. Hyperspectral Target Detection: An Overview of Current and Future Challenges. IEEE Signal Process. Mag. 2014, 31, 34–44. [Google Scholar] [CrossRef]
- Basener, W.F.; Allen, B.; Bretney, K. Geometry of statistical target detection. J. Appl. Remote Sens. 2017, 11, 015012. [Google Scholar] [CrossRef]
- Houlbrook, A.W.; Gilmore, M.A.; Moorhead, I.R.; Filbee, D.R.; Stroud, C.A.; Hutchings, G.; Kirk, A. Scene simulation for camouflage assessment. In Targets and Backgrounds VI: Characterization, Visualization, and the Detection Process; International Society for Optics and Photonics: Bellingham, WA, USA, 2000; Volume 4029. [Google Scholar] [CrossRef]
- Sun, K.; Li, Y.; Gao, J.; Wang, J.; Wang, J.; Xie, J.; Ding, N.; Sun, D. Simulation system of airborne FLIR searcher. In International Symposium on Optoelectronic Technology and Application 2014: Infrared Technology and Applications; Guina, M., Gong, H., Niu, Z., Lu, J., Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2014; Volume 9300, pp. 480–485. [Google Scholar] [CrossRef]
- AI, Z.; Zhang, L.; Zhang, J. A practical method of texture segmentation and transformation for radar image simulation. In Proceedings of the 2012 IEEE International Conference on Computer Science and Automation Engineering (CSAE), Zhangjiajie, China, 25–27 May 2012; Volume 3, pp. 311–317. [Google Scholar] [CrossRef]
- Zhou, Q. Dynamic scene simulation technology used for infrared seeker. In International Symposium on Photoelectronic Detection and Imaging 2009: Advances in Infrared Imaging and Applications; Puschell, J., Gong, H., Cai, Y., Lu, J., Fei, J., Eds.; International Society for Optics and Photonics: Bellingham, WA, USA, 2009; Volume 7383, pp. 792–797. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperspectral Images | Lines | Samples | Bands | Spectral Range (in m) |
|---|---|---|---|---|
| Selene H23 VNIR | 3752 | 1600 | 160 | 0.41 to 1 |
| Selene H23 Dual | 1876 | 380 | 448 | 0.41 to 2.5 |
| Paso Robles-Monterey | 5115 | 741 | 224 | 0.36 to 2.5 |
| Virginia City 1807-1211 | 6349 | 320 | 178 | 0.4 to 2.45 |
| Virginia City 1807-1220 | 6758 | 320 | 178 | 0.4 to 2.45 |
| Virginia City 1807-1259 | 6904 | 320 | 178 | 0.4 to 2.45 |
| Hyperspectral Images | Proposed | C-SCD Unmix | SD-SOMP | CoNMF | MVSA | VCA |
|---|---|---|---|---|---|---|
| Selene H23 VNIR | 1.249 | 1.601 | 2.542 | 2.327 | 2.990 | 2.344 |
| Selene H23 Dual | 0.282 | 0.405 | 1.376 | 0.606 | 0.986 | 1.319 |
| Paso Robles-Monterey | 1.227 | 1.222 | 4.274 | 0.768 | 9.037 | 9.037 |
| Virginia City 1807-1220 | 0.054 | 0.110 | 0.858 | 0.155 | 2.574 | 2.572 |
| Virginia City 1807-1259 | 0.061 | 0.128 | 1.057 | 0.173 | 2.827 | 2.825 |
| Mean error | 0.57 | 0.69 | 2.02 | 0.81 | 3.68 | 3.62 |
| ± Std | ±0.61 | ±0.68 | ±1.42 | ±0.89 | ±3.1 | ±3.08 |
| Enhanced reconstruction accuracy | ||||||
| over 5 datasets w.r.t. KMSCD | 20.64% | 251.79% | 40.24% | 540.93% | 529.9% | |
| Hyperspectral Images | Proposed | SCD Unmix | SD-SOMP | CoNMF | MVSA | VCA |
|---|---|---|---|---|---|---|
| Selene H23 VNIR | 1.47 | 1.6 | 2.65 | 2.29 | 2.77 | 2.83 |
| Selene H23 Dual | 2.33 | 2.51 | 3.94 | 2.69 | 3.63 | 5.46 |
| Paso Robles-Monterey | 1.93 | 1.99 | 7.37 | 1.93 | 15.79 | 15.79 |
| Virginia City 1807-1220 | 0.25 | 0.3 | 0.94 | 0.25 | 0.84 | 0.99 |
| Virginia City 1807-1259 | 0.25 | 0.28 | 0.98 | 0.25 | 0.82 | 0.99 |
| Mean error | 1.24 | 1.34 | 3.18 | 1.48 | 4.77 | 5.21 |
| ± Std | ±0.96 | ±1.01 | ±2.66 | ±1.16 | ±6.28 | ±6.19 |
| Enhanced reconstruction accuracy | ||||||
| over 5 datasets w.r.t. KMSCD | 7.22% | 154.9% | 18.94% | 282.83% | 318.4% | |
| Hyperspectral Images | Proposed | SCD Unmix | SD-SOMP | CoNMF | MVSA | VCA |
|---|---|---|---|---|---|---|
| Selene H23 VNIR | 9.2e-03 | 1.0e-03 | 1.66e-02 | 1.43e-02 | 1.73e-02 | 1.77e-02 |
| Selene H23 Dual | 5.2e-03 | 5.6e-03 | 8.8e-02 | 6.0e-03 | 8.1e-03 | 1.22e-02 |
| Paso Robles-Monterey | 8.6e-03 | 8.9e-03 | 3.29e-02 | 8.6e-03 | 7.05e-02 | 7.05e-02 |
| Virginia City 1807-1220 | 1.4e-03 | 1.7e-03 | 5.3e-03 | 1.4e-03 | 4.7e-03 | 5.6e-03 |
| Virginia City 1807-1259 | 1.4e-03 | 1.6e-03 | 5.5e-03 | 1.4e-03 | 4.6e-03 | 5.6e-03 |
| Mean error | 5.2e-03 | 5.6e-03 | 1.38e-02 | 6.3e-03 | 2.1e-02 | 2.23e-02 |
| ± Std | ±3.8e-03 | ±3.9e-03 | ±1.16e-02 | ±5.4e-03 | ±2.81e-02 | ±2.74e-02 |
| Enhanced reconstruction accuracy | ||||||
| over 5 datasets w.r.t. KMSCD | 7.75% | 167.83% | 22.87% | 307.75% | 332.56% | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chatterjee, A.; Yuen, P.W.T. Endmember Learning with K-Means through SCD Model in Hyperspectral Scene Reconstructions. J. Imaging 2019, 5, 85. https://doi.org/10.3390/jimaging5110085
Chatterjee A, Yuen PWT. Endmember Learning with K-Means through SCD Model in Hyperspectral Scene Reconstructions. Journal of Imaging. 2019; 5(11):85. https://doi.org/10.3390/jimaging5110085
Chicago/Turabian StyleChatterjee, Ayan, and Peter W. T. Yuen. 2019. "Endmember Learning with K-Means through SCD Model in Hyperspectral Scene Reconstructions" Journal of Imaging 5, no. 11: 85. https://doi.org/10.3390/jimaging5110085
APA StyleChatterjee, A., & Yuen, P. W. T. (2019). Endmember Learning with K-Means through SCD Model in Hyperspectral Scene Reconstructions. Journal of Imaging, 5(11), 85. https://doi.org/10.3390/jimaging5110085