
Dense Descriptors for Optical Flow Estimation: A Comparative Study



Abstract
:1. Introduction
- Given the framework proposed by Liu et al. [34], here, a comprehensive analysis is provided for the use of the framework for optical flow estimation. This is done by thorough comparisons using the widely-used Middlebury optical flow dataset [3]. This is to fill the gap in the original paper as no quantitative comparisons are given with the state-of-the-art in optical flow estimation.
- Aiming at extending the framework to include more dense descriptors, the use of a few other descriptors, namely the Leung–Malik (LM) filter bank, the Gabor filter bank, the Schmid filter bank, Root Filter Set (RFS) filters, steerable filters, Histogram of Oriented Gradients (HOG) and Speeded Up Robust Features (SURF), has been investigated and discussed for optical flow estimation.
- To the best of our knowledge, this work is the first to utilize several of the proposed descriptors in a dense manner in the context of optical flow estimation. Therefore, we believe that this work will stimulate more interest in the field of computer vision for devising more rigorous algorithms based on the use of dense descriptors for optical flow estimation and dense correspondence.
2. Feature Descriptors
2.1. Gabor Filter Bank
2.2. Schmid Filters
2.3. Leung–Malik Filters
2.4. Root Filter Set Filters
2.5. Steerable Filters
2.6. Histogram of Oriented Gradients
2.7. Speeded Up Robust Features
2.8. Scale-Invariant Feature Transform
3. Methods
3.1. Problem Statement
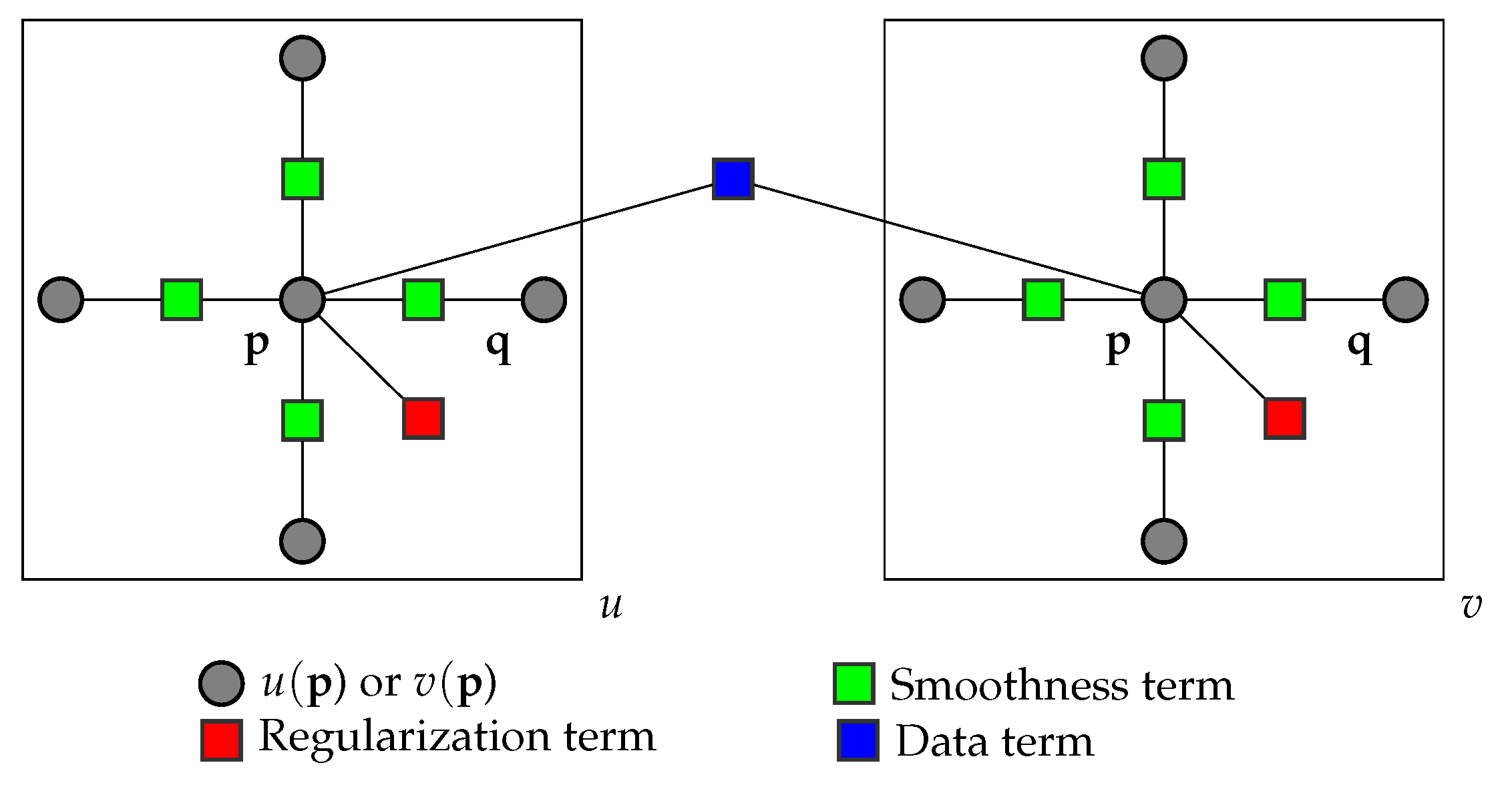
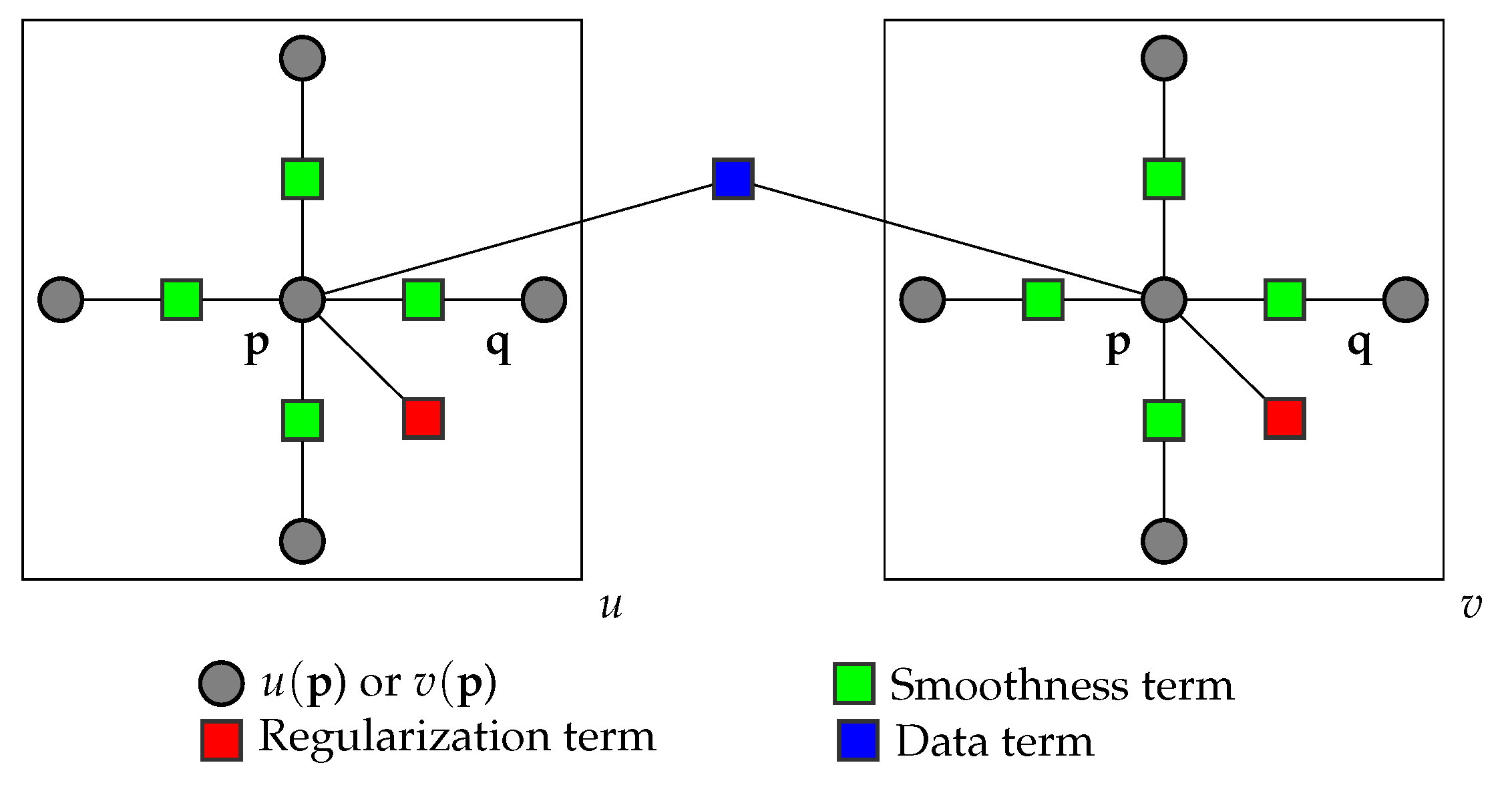
3.2. Belief Propagation
3.3. Comparison Metrics
4. Results and Discussion
4.1. Evaluations and Discussions
4.2. Possible Enhancements and Future Directions
4.2.1. Parameter Optimization
4.2.2. Color Descriptors
4.2.3. Segmentation-Aware Descriptors
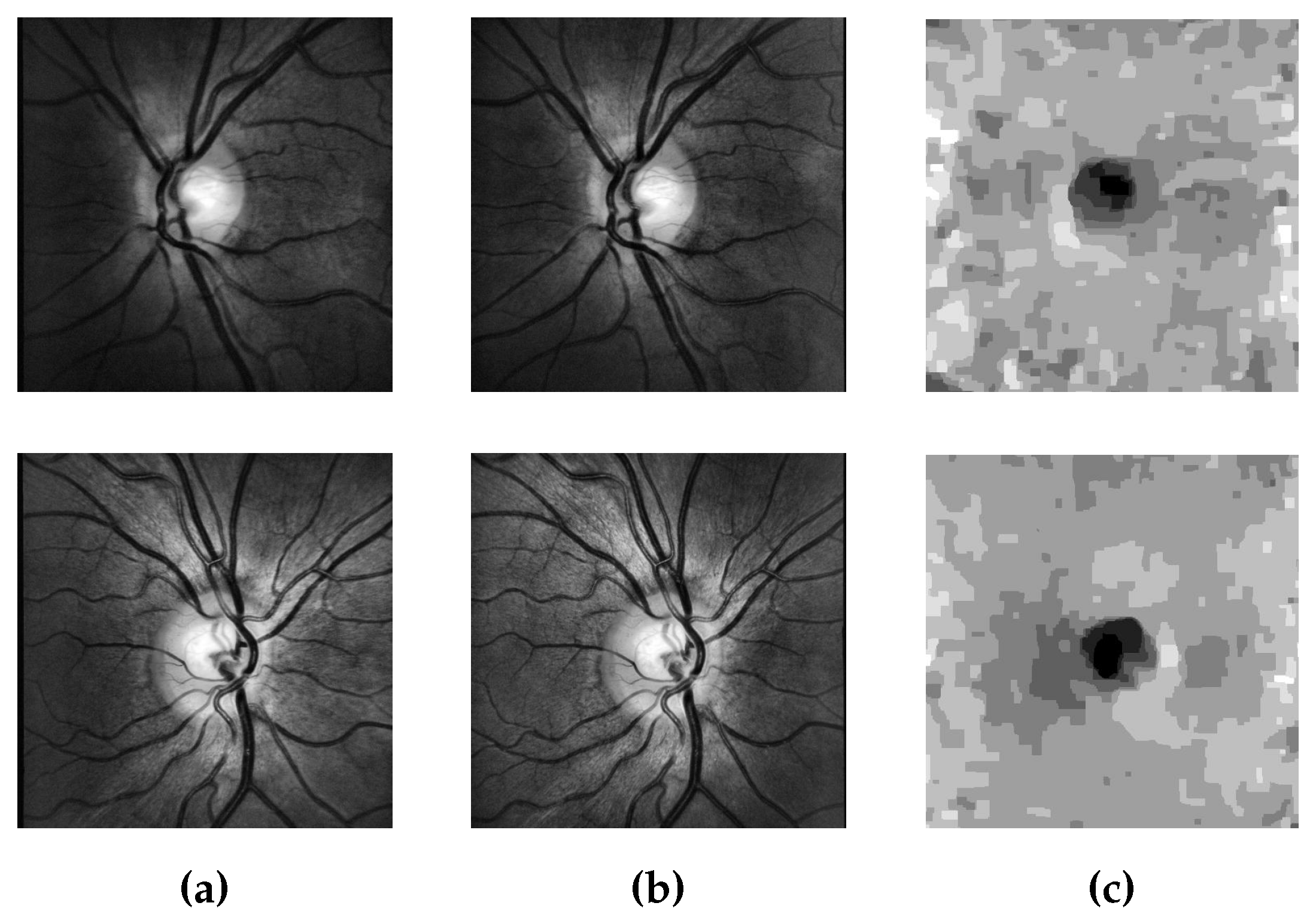
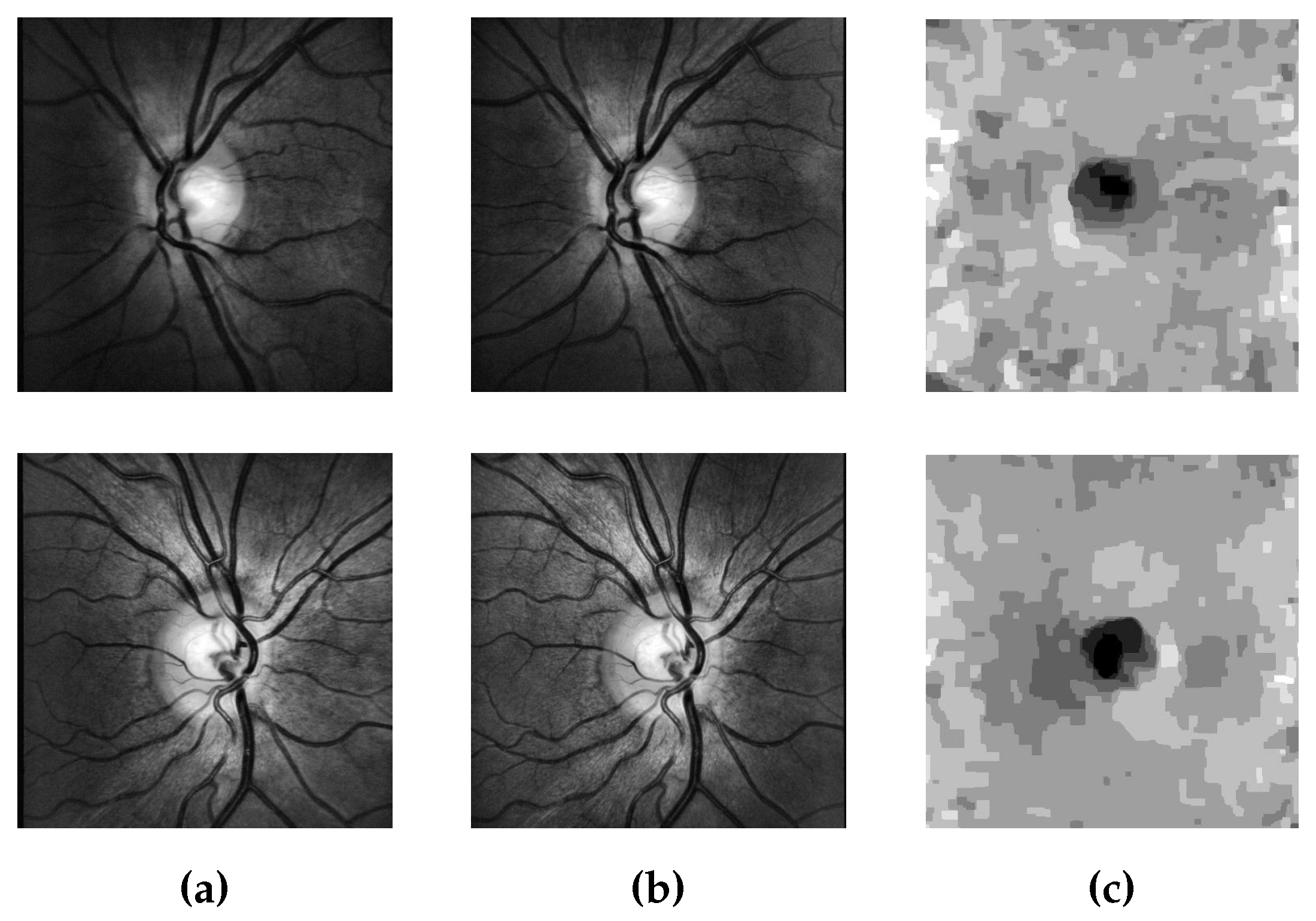
4.2.4. Applications in Biomedical Image Processing
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Horn, B.K.; Schunck, B.G. Determining optical flow. In Proceedings of the 1981 Technical Symposium East. International Society for Optics and Photonics, Washington, DC, USA, 21 April 1981; pp. 319–331.
- Fortun, D.; Bouthemy, P.; Kervrann, C. Optical flow modeling and computation: A survey. Comput. Vis. Image Underst. 2015, 134, 1–21. [Google Scholar] [CrossRef]
- Baker, S.; Scharstein, D.; Lewis, J.; Roth, S.; Black, M.J.; Szeliski, R. A database and evaluation methodology for optical flow. Int. J. Comput. Vis. 2011, 92, 1–31. [Google Scholar] [CrossRef]
- Vedula, S.; Rander, P.; Collins, R.; Kanade, T. Three-dimensional scene flow. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 475–480. [Google Scholar] [CrossRef]
- Brox, T.; Bruhn, A.; Papenberg, N.; Weickert, J. High accuracy optical flow estimation based on a theory for warping. In Proceedings of the 8th European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2014; pp. 25–36.
- Papenberg, N.; Bruhn, A.; Brox, T.; Didas, S.; Weickert, J. Highly accurate optic flow computation with theoretically justified warping. Int. J. Comput. Vis. 2006, 67, 141–158. [Google Scholar] [CrossRef]
- Mileva, Y.; Bruhn, A.; Weickert, J. Illumination-robust variational optical flow with photometric invariants. In Pattern Recognition; Springer: Berlin, Germany, 2007; pp. 152–162. [Google Scholar]
- Zimmer, H.; Bruhn, A.; Weickert, J.; Valgaerts, L.; Salgado, A.; Rosenhahn, B.; Seidel, H.P. Complementary optic flow. In Energy Minimization Methods in Computer Vision and Pattern Recognition; Springer: Berlin, Germany, 2009; pp. 207–220. [Google Scholar]
- Black, M.J.; Anandan, P. The robust estimation of multiple motions: Parametric and piecewise-smooth flow fields. Comput. Vis. Image Underst. 1996, 63, 75–104. [Google Scholar] [CrossRef]
- Cohen, I. Nonlinear variational method for optical flow computation. In Proceedings of the 8th Scandinavian Conference on Image Analysis; Tromssa, Norway, 1993; Volume 1, pp. 523–530. [Google Scholar]
- Mémin, E.; Pérez, P. Dense estimation and object-based segmentation of the optical flow with robust techniques. IEEE Trans. Image Process. 1998, 7, 703–719. [Google Scholar] [CrossRef] [PubMed]
- Lazebnik, S.; Schmid, C.; Ponce, J. A sparse texture representation using affine-invariant regions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 16–22 June 2003; Volume 2, pp. 319–324.
- Tuzel, O.; Porikli, F.; Meer, P. Region covariance: A fast descriptor for detection and classification. In Computer Vision—ECCV 2006; Springer: Berlin, Germany, 2006; pp. 589–600. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 511–518.
- Zhu, Q.; Yeh, M.C.; Cheng, K.T.; Avidan, S. Fast human detection using a cascade of histograms of oriented gradients. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1491–1498.
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571.
- Fei-Fei, L.; Perona, P. A bayesian hierarchical model for learning natural scene categories. In Proceedings of the Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 524–531.
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision (ECCV), Prague, Czech Republic, 15–26 May 2004; Volume 1, pp. 1–2.
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1470–1477.
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.E.; Hebert, M. Recognizing objects by matching oriented points. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 684–689.
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Gabor, D. Theory of communication. Part 1: The analysis of information. J. Inst. Electr. Eng. Part III Radio Commun. Eng. 1946, 93, 429–441. [Google Scholar] [CrossRef]
- Vetterli, M.; Kovacevic, J. Wavelets and Subband Coding; Number LCAV-BOOK-1995-001; Prentice-Hall: Upper Saddle River, NJ, USA, 1995. [Google Scholar]
- Freeman, W.T.; Adelson, E.H. The design and use of steerable filters. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 891–906. [Google Scholar] [CrossRef]
- Baumberg, A. Reliable feature matching across widely separated views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 3–15 June 2000; Volume 1, pp. 774–781.
- Schaffalitzky, F.; Zisserman, A. Multi-view matching for unordered image sets, or “How do I organize my holiday snaps?”. In Computer Vision—ECCV 2002; Springer: Berlin, Germany, 2002; pp. 414–431. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Action recognition by dense trajectories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 3169–3176.
- Tola, E.; Lepetit, V.; Fua, P. Daisy: An efficient dense descriptor applied to wide-baseline stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 815–830. [Google Scholar] [CrossRef] [PubMed]
- Sangineto, E. Pose and expression independent facial landmark localization using dense-SURF and the Hausdorff distance. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 624–638. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Dieg, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893.
- Uijlings, J.; Duta, I.; Sangineto, E.; Sebe, N. Video classification with Densely extracted HOG/HOF/MBH features: An evaluation of the accuracy/computational efficiency trade-off. Int. J. Multimed. Inf. Retr. 2015, 4, 33–44. [Google Scholar] [CrossRef]
- Liu, C.; Yuen, J.; Torralba, A. Sift flow: Dense correspondence across scenes and its applications. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 978–994. [Google Scholar] [CrossRef] [PubMed]
- Brox, T.; Malik, J. Large displacement optical flow: Descriptor matching in variational motion estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 500–513. [Google Scholar] [CrossRef] [PubMed]
- Baghaie, A.; D’Souza, R.M.; Yu, Z. Dense Correspondence and Optical Flow Estimation Using Gabor, Schmid and Steerable Descriptors. In Advances in Visual Computing; Springer: Berlin, Germany, 2015; pp. 406–415. [Google Scholar]
- Leung, T.; Malik, J. Representing and recognizing the visual appearance of materials using three-dimensional textons. Int. J. Comput. Vis. 2001, 43, 29–44. [Google Scholar] [CrossRef]
- Schmid, C. Constructing models for content-based image retrieval. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001; Volume 2, pp. 39–45.
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Bernal, J.; Vilarino, F.; Sánchez, J. Feature Detectors and Feature Descriptors: Where We Are Now; Universitat Autonoma de Barcelona: Barcelona, Spain, 2010. [Google Scholar]
- Movellan, J.R. Tutorial on Gabor filters. Open Source Document. 2002. Available online: http://mplab.ucsd.edu/tutorials/gabor.pdf (accessed on 25 February 2017).
- Ilonen, J.; Kämäräinen, J.K.; Kälviäinen, H. Efficient Computation of Gabor Features; Lappeenranta University of Technology: Lappeenranta, Finland, 2005. [Google Scholar]
- Varma, M.; Zisserman, A. A statistical approach to texture classification from single images. Int. J. Comput. Vis. 2005, 62, 61–81. [Google Scholar] [CrossRef]
- Jacob, M.; Unser, M. Design of steerable filters for feature detection using canny-like criteria. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1007–1019. [Google Scholar] [CrossRef] [PubMed]
- Aguet, F.; Jacob, M.; Unser, M. Three-dimensional feature detection using optimal steerable filters. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Genova, Italy, 11–14 September 2005; Volume 2, pp. 1158–1161.
- Brown, M.; Lowe, D.G. Invariant Features from Interest Point Groups; BMVC 2002: 13th British Machine Vision Conference; University of Bath: Bath, England, 2002. [Google Scholar]
- Lindeberg, T. Scale-space theory: A basic tool for analyzing structures at different scales. J. Appl. Stat. 1994, 21, 225–270. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. An affine invariant interest point detector. In Computer Vision—ECCV 2002; Springer: Berlin, Germany, 2002; pp. 128–142. [Google Scholar]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks Of Plausible Inference; Morgan Kaufmann: Burlington, MA, USA, 2014. [Google Scholar]
- Szeliski, R.; Zabih, R.; Scharstein, D.; Veksler, O.; Kolmogorov, V.; Agarwala, A.; Tappen, M.; Rother, C. A comparative study of energy minimization methods for markov random fields with smoothness-based priors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1068–1080. [Google Scholar] [CrossRef] [PubMed]
- Murphy, K.P.; Weiss, Y.; Jordan, M.I. Loopy belief propagation for approximate inference: An empirical study. In Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, Stockholm, Sweden, 30 July–1 August 1999; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1999; pp. 467–475. [Google Scholar]
- Kschischang, F.R.; Frey, B.J.; Loeliger, H.A. Factor graphs and the sum-product algorithm. IEEE Trans. Inf. Theory 2001, 47, 498–519. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012.
- yves Bouguet, J. Pyramidal Implementation of the Lucas Kanade Feature Tracker; Intel: Longmont, CO, USA, 2000. [Google Scholar]
- Le Besnerais, G.; Champagnat, F. Dense optical flow by iterative local window registration. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Genova, Italy, 11–14 September 2005; Volume 1, pp. 137–140.
- Corpetti, T.; Mémin, E. Stochastic uncertainty models for the luminance consistency assumption. IEEE Trans. Image Process. 2012, 21, 481–493. [Google Scholar] [CrossRef] [PubMed]
- Alba, A.; Arce-Santana, E.; Rivera, M. Optical flow estimation with prior models obtained from phase correlation. In Advances in Visual Computing; Springer: Berlin, Germany, 2010; pp. 417–426. [Google Scholar]
- Solari, F.; Chessa, M.; Medathati, N.K.; Kornprobst, P. What can we expect from a V1-MT feedforward architecture for optical flow estimation? Signal Process. Image Commun. 2015, 39, 342–354. [Google Scholar] [CrossRef]
- Van De Sande, K.E.; Gevers, T.; Snoek, C.G. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1582–1596. [Google Scholar] [CrossRef] [PubMed]
- Trulls, E.; Kokkinos, I.; Sanfeliu, A.; Moreno-Noguer, F. Dense segmentation-aware descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2890–2897.
- Baghaie, A.; Yu, Z.; D’Souza, R.M. State-of-the-art in retinal optical coherence tomography image analysis. Quant. Imaging Med. Surg. 2015, 5, 603. [Google Scholar] [PubMed]
- Baghaie, A.; D’souza, R.M.; Yu, Z. Application of Independent Component Analysis Techniques in Speckle Noise Reduction of Single-Shot Retinal OCT Images. arXiv 2015. [Google Scholar]
- Baghaie, A.; D’souza, R.M.; Yu, Z. Sparse and low rank decomposition based batch image alignment for speckle reduction of retinal OCT images. In Proceedings of the 2015 IEEE 12th International Symposium on Biomedical Imaging (ISBI), New York, NY, USA, 16–19 April 2015; pp. 226–230.
- Pena-Betancor, C.; Gonzalez-Hernandez, M.; Fumero-Batista, F.; Sigut, J.; Medina-Mesa, E.; Alayon, S.; de la Rosa, M.G. Estimation of the Relative Amount of Hemoglobin in the Cup and Neuroretinal Rim Using Stereoscopic Color Fundus ImagesNeuroretinal Rim Hemoglobin. Investig. Ophthalmol. Vis. Sci. 2015, 56, 1562–1568. [Google Scholar] [CrossRef] [PubMed]
- Baghaie, A. Study of Computational Image Matching Techniques: Improving Our View of Biomedical Image Data. Ph.D. Thesis, University of Wisconsin-Milwaukee (UWM), Milwaukee, WI, USA, 2016. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | d-Gabor | d-Schmid | d-LM | d-RFS | d-Steerable | d-HOG | d-SURF | d-SIFT |
|---|---|---|---|---|---|---|---|---|
| # of Dim. | 80 | 13 | 48 | 38 | 40 | 200 | 64 | 128 |
| Method | Dimetrodon | Grove2 | Grove3 | Hydrangea | RubberWhale | Urban2 | Urban3 | Venus | Avg. Rank |
|---|---|---|---|---|---|---|---|---|---|
| d-Gabor | 16.43 | 8.11 | 13.27 | 10.98 | 13.47 | 28.09 | 18.64 | 9.30 | 4.50 |
| d-Schmid | 18.87 | 12.55 | 17.49 | 15.05 | 17.50 | 16.08 | 18.15 | 14.77 | 7.00 |
| d-LM | 18.42 | 12.76 | 17.05 | 12.36 | 15.82 | 19.36 | 18.48 | 11.88 | 6.62 |
| d-RFS | 19.06 | 10.20 | 15.70 | 11.83 | 13.75 | 14.54 | 17.16 | 8.68 | 5.37 |
| d-Steerable | 21.18 | 8.73 | 13.82 | 13.77 | 13.61 | 12.67 | 16.83 | 6.80 | 4.75 |
| d-HOG | 16.24 | 8.60 | 12.99 | 9.86 | 11.09 | 28.30 | 16.00 | 6.45 | 3.12 |
| d-SURF | 17.99 | 8.97 | 12.72 | 10.51 | 10.73 | 14.27 | 13.81 | 6.78 | 2.87 |
| d-SIFT | 17.24 | 8.29 | 12.22 | 9.77 | 10.47 | 14.67 | 11.02 | 4.79 | 1.75 |
| Method | Dimetrodon | Grove2 | Grove3 | Hydrangea | RubberWhale | Urban2 | Urban3 | Venus | Avg. Rank |
|---|---|---|---|---|---|---|---|---|---|
| d-Gabor | 0.504 | 0.656 | 1.343 | 0.598 | 0.424 | 6.432 | 3.005 | 0.609 | 3.25 |
| d-Schmid | 0.650 | 0.907 | 1.721 | 0.737 | 0.519 | 2.389 | 3.454 | 0.952 | 6.87 |
| d-LM | 0.626 | 0.937 | 1.626 | 0.613 | 0.479 | 4.223 | 3.173 | 0.916 | 6.00 |
| d-RFS | 0.651 | 0.785 | 1.608 | 0.550 | 0.435 | 2.218 | 3.341 | 0.638 | 5.12 |
| d-Steerable | 2.681 | 0.751 | 1.456 | 3.462 | 0.438 | 1.882 | 3.399 | 0.581 | 5.25 |
| d-HOG | 0.504 | 0.696 | 1.360 | 0.402 | 0.369 | 6.448 | 3.459 | 0.478 | 3.75 |
| d-SURF | 0.647 | 0.740 | 1.378 | 0.447 | 0.362 | 1.989 | 3.936 | 0.565 | 3.87 |
| d-SIFT | 0.563 | 0.687 | 1.305 | 0.393 | 0.356 | 2.321 | 3.015 | 0.401 | 1.87 |
| Method | Dimetrodon | Grove2 | Grove3 | Hydrangea | RubberWhale | Urban2 | Urban3 | Venus | Avg. Rank |
|---|---|---|---|---|---|---|---|---|---|
| d-Gabor | 3.59 | 9.80 | 15.11 | 7.26 | 3.54 | 14.97 | 8.50 | 6.34 | 7.00 |
| d-Schmid | 3.49 | 10.00 | 15.35 | 7.07 | 3.71 | 5.63 | 6.32 | 6.73 | 6.87 |
| d-LM | 3.46 | 10.23 | 14.99 | 6.58 | 3.45 | 9.46 | 5.75 | 6.52 | 5.87 |
| d-RFS | 3.39 | 9.19 | 12.72 | 6.10 | 3.16 | 4.55 | 5.78 | 6.24 | 3.25 |
| d-Steerable | 11.13 | 9.41 | 13.32 | 10.50 | 3.12 | 4.76 | 6.03 | 6.33 | 5.37 |
| d-HOG | 3.28 | 9.06 | 12.51 | 6.14 | 3.19 | 14.10 | 5.27 | 5.86 | 3.00 |
| d-SURF | 3.15 | 8.71 | 11.50 | 5.52 | 3.12 | 4.22 | 5.49 | 5.75 | 1.25 |
| d-SIFT | 3.31 | 9.30 | 13.15 | 6.40 | 3.34 | 4.70 | 5.27 | 6.00 | 3.75 |
| Method | Army | Mequon | Schefflera | Wooden | Grove | Urban | Yosemite | Teddy | Average Ranking |
|---|---|---|---|---|---|---|---|---|---|
| Pyramid LK [55] | 13.9(17.0) | 24.1(31.7) | 20.9(32.9) | 22.2(29.4) | 18.7(31.7) | 21.2(29.9) | 6.41(9.01) | 25.6(39.9) | 118.0(119.4) |
| FOLKI [56] | 10.5(16.2) | 20.9(32.5) | 17.6(29.4) | 15.4(29.1) | 6.16(9.58) | 12.2(25.7) | 4.67(7.71) | 18.2(36.5) | 115.2(116.0) |
| SLK [57] | 11.6(17.2) | 15.3(21.3) | 17.8(27.9) | 25.4(31.4) | 5.25(6.6) | 10.3(22.8) | 2.89(3.90) | 14.9(33.3) | 110.1(108.9) |
| PGAM+ LK [58] | 11.8(14.9) | 14.8(25.5) | 13.2(21.9) | 16.2(26.0) | 5.40(9.61) | 12.3(24.3) | 7.42(6.19) | 13.2(34.3) | 113.5(108.7) |
| FFV1MT [59] | 12.0(13.9) | 10.7(20.9) | 15.6(21.8) | 16.6(31.0) | 6.51(9.97) | 16.2(23.8) | 3.41(2.99) | 12.3(37.6) | 110.8(106.1) |
| d-SURF | 13.2(11.7) | 8.96(11.1) | 11.4(17.8) | 11.3(16.9) | 10.6(11.3) | 19.7(29.2) | 17.0(15.8) | 8.34(29.3) | 108.8(96.9) |
| d-SIFT | 13.3(12.1) | 8.66(10.9) | 10.7(15.8) | 10.9(15.9) | 9.70(8.33) | 15.4(22.6) | 14.5(11.3) | 7.89(30.0) | 107.9(92.4) |
| Method | Army | Mequon | Schefflera | Wooden | Grove | Urban | Yosemite | Teddy | Average Ranking |
|---|---|---|---|---|---|---|---|---|---|
| Pyramid LK [55] | 0.39(0.68) | 1.67(1.94) | 1.50(2.43) | 1.57(2.36) | 2.94(4.19) | 3.33(7.35) | 0.30(0.57) | 3.20(4.63) | 118.1(118.7) |
| FOLKI [56] | 0.29(0.55) | 1.52(2.45) | 1.23(2.12) | 0.99(1.75) | 1.53(2.10) | 2.14(5.86) | 0.26(0.52) | 2.67(5.03) | 114.8(117.0) |
| SLK [57] | 0.30(0.47) | 1.09(1.13) | 1.25(2.12) | 1.56(1.72) | 1.54(1.86) | 2.02(5.75) | 0.17(0.32) | 2.43(3.61) | 109.9(107.7) |
| PGAM + LK [58] | 0.37(0.66) | 1.08(1.64) | 0.94(1.46) | 1.40(2.59) | 1.37(1.75) | 2.10(6.62) | 0.36(0.40) | 1.89(2.95) | 113.7(106.5) |
| FFV1MT [59] | 0.33(0.41) | 0.79(1.11) | 1.33(1.62) | 1.38(2.02) | 1.76(2.00) | 2.33(4.48) | 0.16(0.18) | 1.81(3.19) | 109.9(102.1) |
| d-SURF | 0.37(0.36) | 0.84(0.79) | 1.70(1.75) | 1.04(1.31) | 2.04(2.21) | 2.61(5.91) | 0.91(1.16) | 1.28(2.94) | 112.3(107.3) |
| d-SIFT | 0.37(0.34) | 0.82(0.73) | 1.61(1.52) | 1.01(1.22) | 1.98(1.98) | 2.35(5.66) | 0.70(0.63) | 1.21(2.77) | 110.8(101.8) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baghaie, A.; D’Souza, R.M.; Yu, Z. Dense Descriptors for Optical Flow Estimation: A Comparative Study. J. Imaging 2017, 3, 12. https://doi.org/10.3390/jimaging3010012
Baghaie A, D’Souza RM, Yu Z. Dense Descriptors for Optical Flow Estimation: A Comparative Study. Journal of Imaging. 2017; 3(1):12. https://doi.org/10.3390/jimaging3010012
Chicago/Turabian StyleBaghaie, Ahmadreza, Roshan M. D’Souza, and Zeyun Yu. 2017. "Dense Descriptors for Optical Flow Estimation: A Comparative Study" Journal of Imaging 3, no. 1: 12. https://doi.org/10.3390/jimaging3010012
APA StyleBaghaie, A., D’Souza, R. M., & Yu, Z. (2017). Dense Descriptors for Optical Flow Estimation: A Comparative Study. Journal of Imaging, 3(1), 12. https://doi.org/10.3390/jimaging3010012