
UIDF-Net: Unsupervised Image Dehazing and Fusion Utilizing GAN and Encoder–Decoder

Abstract
1. Introduction
- We propose a novel Unsupervised Image Dehazing Fusion Network, UIDF-Net, to enhance the quality of dehazed images.
- We have designed a haze encoder named Mist-Encode, which integrates frequency domain processing with attention mechanisms to enhance the efficiency of image dehazing.
- We have designed a deep learning-based image perceptual fusion model that effectively enhances image quality.
2. Preliminaries
2.1. Atmospheric Scattering Model
2.2. Dark Channel Prior
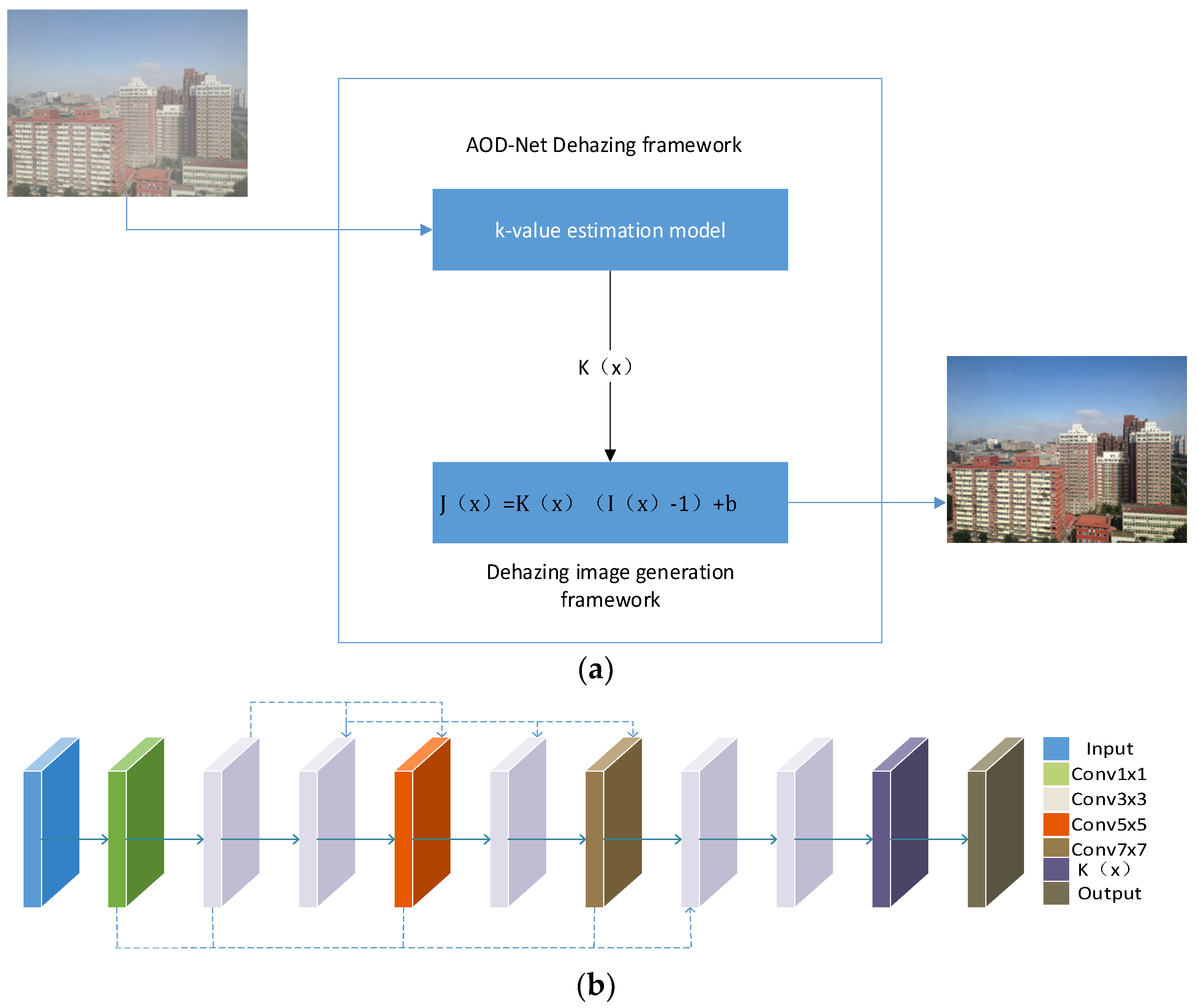
2.3. AOD-Net Network Architecture
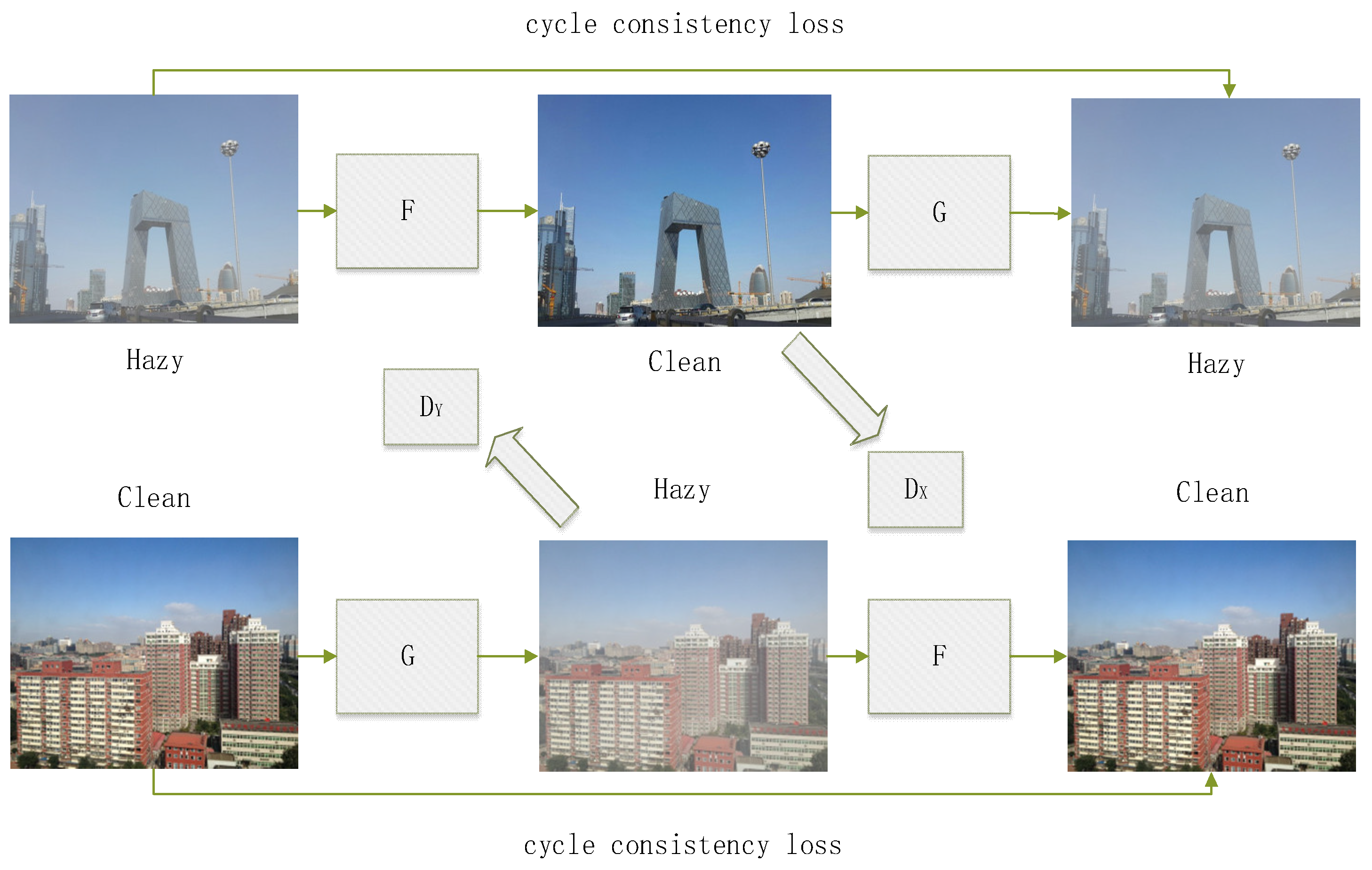
2.4. CycleGAN Network Architecture
3. Proposed Method
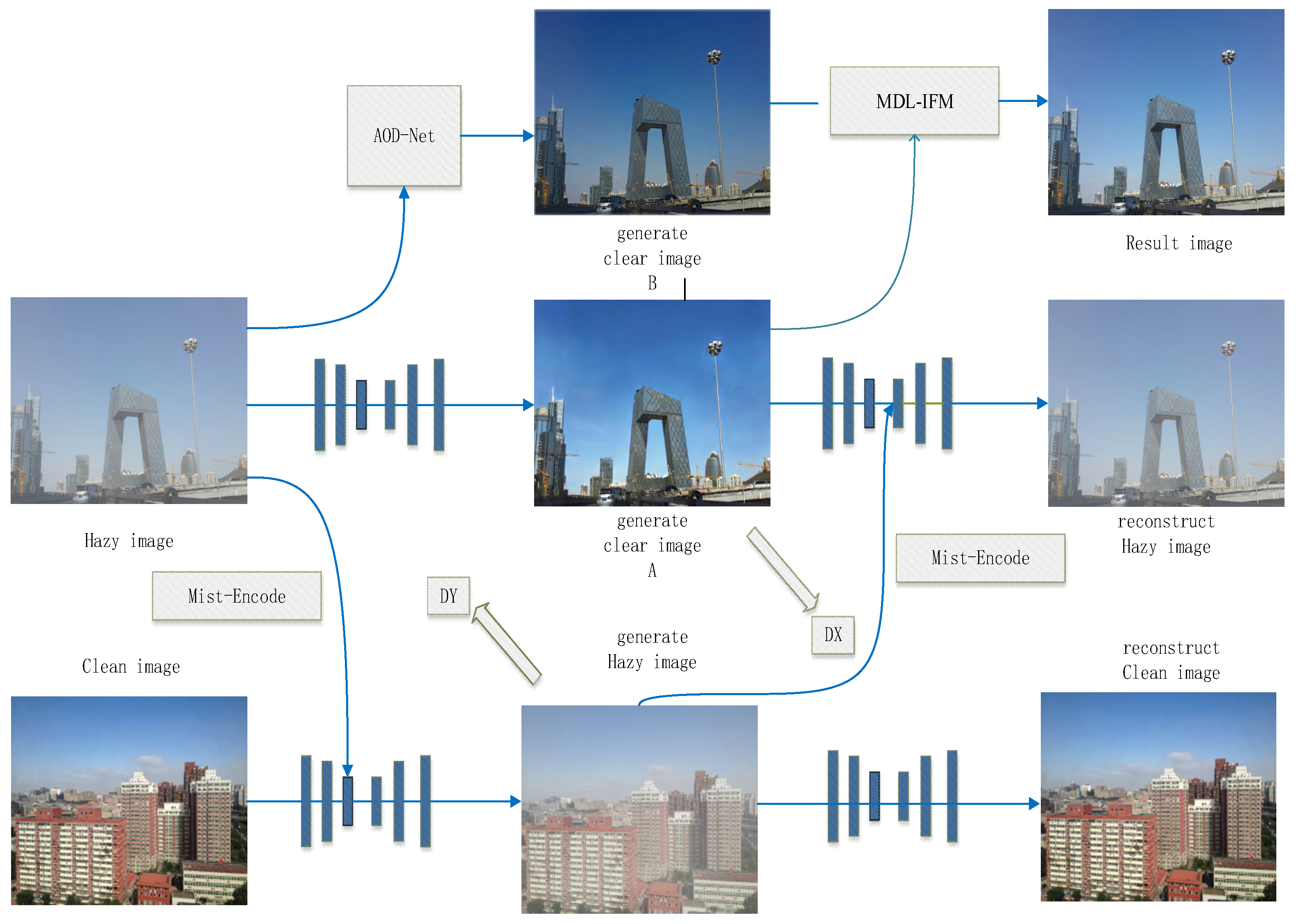
3.1. UIDF-Net Network Structure
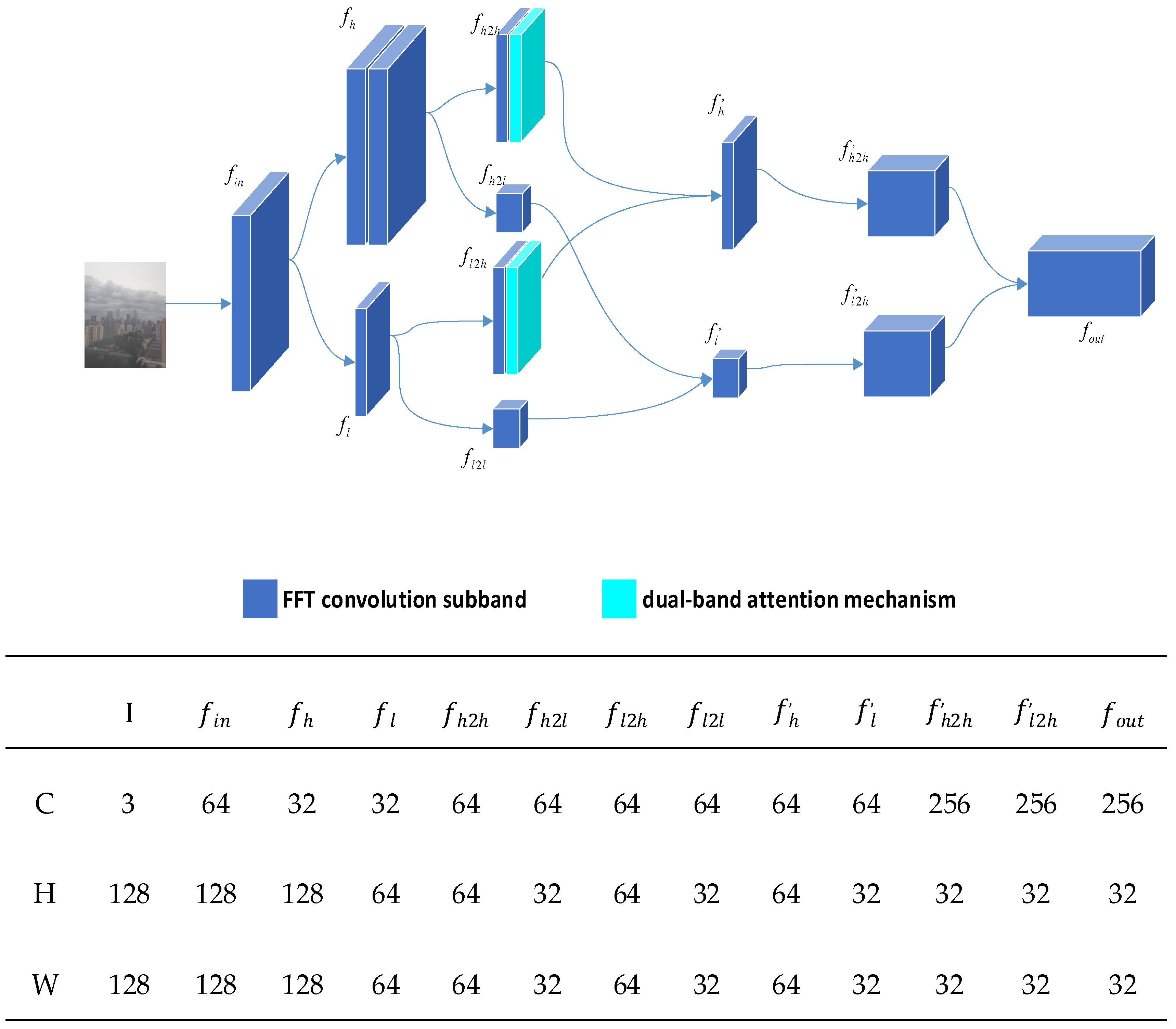
3.2. Mist-Encode
3.3. Perception Fusion Strategy MDL-IFM Model
4. Experiment
4.1. Experimental Details
4.2. Comparison of Dehazing Effects with Different Algorithms
4.3. Component Removal Study
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Che, C.; Zheng, H.; Huang, Z.; Jiang, W.; Liu, B. Intelligent Robotic Control System Based on Computer Vision Technology. arXiv 2024, arXiv:2404.01116. [Google Scholar] [CrossRef]
- Tan, K.; Wu, J.; Zhou, H.; Wang, Y.; Chen, J. Integrating Advanced Computer Vision and AI Algorithms for Autonomous Driving Systems. J. Theory Pract. Eng. Sci. 2024, 4, 41–48. [Google Scholar]
- Li, W.; Zhang, H.; Wang, G.; Xiong, G.; Zhao, M.; Li, G.; Li, R. Deep learning based online metallic surface defect detection method for wire and arc additive anufacturing. Robot. Comput.-Integr. Manuf. 2023, 80, 102470. [Google Scholar] [CrossRef]
- Li, M.; Jiang, Y.; Zhang, Y.; Zhu, H. Medical image analysis using deep learning algorithms. Front. Public Health 2023, 11, 1273253. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.H.; Huang, S.C.; Li, C.Y.; Kuo, S.Y. Haze removal using radial basis function networks for visibility restoration applications. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3828–3838. [Google Scholar] [CrossRef]
- Li, G.; Yang, Y.; Qu, X. Deep learning approaches on pedestrian detection in hazy weather. IEEE Trans. Ind. Electron. 2019, 67, 8889–8899. [Google Scholar] [CrossRef]
- Narasimhan, S.G.; Nayar, S.K. Removing weather effects from monochrome images. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; CVPR 2001. IEEE: Piscataway, NJ, USA, 2001; Volume 2, pp. II-186–II-193. [Google Scholar]
- Rahman, Z.U.; Jobson, D.J.; Woodell, G.A. Retinex processing for automatic image enhancement. In Human Vision and Electronic Imaging VII; SPIE: Bellingham, WA, USA, 2002; Volume 4662, pp. 390–401. [Google Scholar]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 154–169. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Liu, W.; Hou, X.; Duan, J.; Qiu, G. End-to-end single image fog removal using enhanced cycle consistent adversarial networks. IEEE Trans. Image Process. 2020, 29, 7819–7833. [Google Scholar] [CrossRef]
- Andriyanov, N.A.; Vasiliev, K.K.; Dementiev, V.E.; Belyanchikov, A.V. Restoration of Spatially Inhomogeneous Images Based on a Doubly Stochastic Model. Optoelectron. Instrum. Data Process. 2022, 58, 465–471. [Google Scholar] [CrossRef]
- Nishino, K.; Kratz, L.; Lombardi, S. Bayesian defogging. Int. J. Comput. Vis. 2012, 98, 263–278. [Google Scholar] [CrossRef]
- Chen, H.; Chen, R.; Ma, L.; Li, N. Single-image dehazing via depth-guided deep retinex decomposition. Vis. Comput. 2023, 39, 5279–5291. [Google Scholar] [CrossRef]
- Deng, Z.; Zhu, L.; Hu, X.; Fu, C.W.; Xu, X.; Zhang, Q.; Qin, J.; Heng, P.A. Deep multi-model fusion for single-image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2453–2462. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3194–3203. [Google Scholar]
- Li, J.; Li, Y.; Zhuo, L.; Kuang, L.; Yu, T. USID-Net: Unsupervised single image dehazing network via disentangled representations. IEEE Trans. Multimed. 2022, 25, 3587–3601. [Google Scholar] [CrossRef]
- Li, B.; Gou, Y.; Liu, J.Z.; Zhu, H.; Zhou, J.T.; Peng, X. Zero-shot image dehazing. IEEE Trans. Image Process. 2020, 29, 8457–8466. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Zhang, L.; Shen, Y.; Zhou, Y. RefineDNet: A weakly supervised refinement framework for single image dehazing. IEEE Trans. Image Process. 2021, 30, 3391–3404. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Wang, C.; Liu, R.; Zhang, L.; Guo, X.; Tao, D. Self-augmented unpaired image dehazing via density and depth decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2037–2046. [Google Scholar]
- Qu, Y.; Chen, Y.; Huang, J.; Xie, Y. Enhanced pix2pix dehazing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8160–8168. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated fusion network for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3253–3261. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Chen, S.; Chen, Y.; Qu, Y.; Huang, J.; Hong, M. Multi-scale adaptive dehazing network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Engin, D.; Genç, A.; Kemal Ekenel, H. Cycle-dehaze: Enhanced cyclegan for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 825–833. [Google Scholar]
- Priyadharshini, R.A.; Aruna, S. Visibility enhancement technique for hazy scenes. In Proceedings of the 2018 4th International Conference on Electrical Energy Systems (ICEES), Chennai, India, 7–9 February 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 540–545. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- de Curtó, J.; Duvall, R. Cycle-consistent Generative Adversarial Networks for Neural Style Transfer using data from Chang’E-4. arXiv 2020, arXiv:2011.11627. [Google Scholar]
- Wang, K.; Gou, C.; Duan, Y.; Lin, Y.; Zheng, X.; Wang, F.Y. Generative adversarial networks: Introduction and outlook. IEEE/CAA J. Autom. Sin. 2017, 4, 588–598. [Google Scholar] [CrossRef]
- Hong, Y.; Hwang, U.; Yoo, J.; Yoon, S. How generative adversarial networks and their variants work: An overview. ACM Comput. Surv. (CSUR) 2019, 52, 1–43. [Google Scholar] [CrossRef]
- Ratliff, L.J.; Burden, S.A.; Sastry, S.S. Characterization and computation of local Nash equilibria in continuous games. In Proceedings of the 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–4 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 917–924. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Sun, Y.; Liu, B.; Yu, X.; Yu, A.; Xue, Z.; Gao, K. Resolution reconstruction classification: Fully octave convolution network with pyramid attention mechanism for hyperspectral image classification. Int. J. Remote Sens. 2022, 43, 2076–2105. [Google Scholar] [CrossRef]
- Ashraf, M.; Chen, L.; Zhou, X.; Rakha, M.A. A Joint Architecture of Mixed-Attention Transformer and Octave Module for Hyperspectral Image Denoising. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4331–4349. [Google Scholar] [CrossRef]
- Abtahi, T.; Shea, C.; Kulkarni, A.; Mohsenin, T. Accelerating convolutional neural network with FFT on embedded hardware. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1737–1749. [Google Scholar] [CrossRef]
- Zheng, H.; Gong, M.; Liu, T.; Jiang, F.; Zhan, T.; Lu, D.; Zhang, M. HFA-Net: High frequency attention siamese network for building change detection in VHR remote sensing images. Pattern Recognit. 2022, 129, 108717. [Google Scholar] [CrossRef]
- Yeshurun, Y.; Carrasco, M. Spatial attention improves performance in spatial resolution tasks. Vis. Res. 1999, 39, 293–306. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Gunasekaran, K.P. Ultra sharp: Study of single image super resolution using residual dense network. In Proceedings of the 3rd International Conference on Computer Communication and Artificial Intelligence (CCAI), Taiyuan, China, 26–28 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 261–266. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking singleimage dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Methods | Dataset A | Dataset B | ||
|---|---|---|---|---|---|
| PSNR | SSIM | DCPI | DCPI | ||
| Prior | DCP | 18.20 | 0.81 | - | - |
| CAP | 22.45 | 0.90 | 48.53 | 45.41 | |
| Supervised | DehazeNet | 19.52 | 0.82 | 24.81 | 29.71 |
| AOD-Net | 21.01 | 0.89 | 64.81 | 53.56 | |
| Unsupervised | Cycle-Dehaze | 18.87 | 0.83 | 53.64 | 48.26 |
| RefineDNet | 20.79 | 0.88 | 64.73 | 55.69 | |
| USID-Net | 21.40 | 0.81 | 51.15 | 44.12 | |
| Ours | 22.58 | 0.87 | 72.36 | 51.85 | |
| Type | Methods | Parameters (M) | Runtime (s) |
|---|---|---|---|
| Prior | DCP | - | 0.1837 |
| CAP | - | 0.9235 | |
| Supervised | DehazeNet | 0.008 | 1.5269 |
| AOD-Net | 0.002 | 0.0038 | |
| Unsupervised | Cycle-Dehaze | 11.380 | - |
| RefineDNet | 64.375 | 0.5626 | |
| USID-Net | 3.820 | 0.0189 | |
| Ours | 3.996 | 0.0275 |
| Methods | Dataset A | Dataset B | ||
|---|---|---|---|---|
| PSNR | SSIM | DCPI | DCPI | |
| M1 | 21.40 | 0.81 | 51.15 | 44.12 |
| M2 | 21.42 | 0.80 | 51.25 | 46.26 |
| M3 | 22.40 | 0.86 | 66.54 | 49.38 |
| UIDF | 22.58 | 0.87 | 72.36 | 51.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, A.; Li, L.; Liu, S. UIDF-Net: Unsupervised Image Dehazing and Fusion Utilizing GAN and Encoder–Decoder. J. Imaging 2024, 10, 164. https://doi.org/10.3390/jimaging10070164
Zhao A, Li L, Liu S. UIDF-Net: Unsupervised Image Dehazing and Fusion Utilizing GAN and Encoder–Decoder. Journal of Imaging. 2024; 10(7):164. https://doi.org/10.3390/jimaging10070164
Chicago/Turabian StyleZhao, Anxin, Liang Li, and Shuai Liu. 2024. "UIDF-Net: Unsupervised Image Dehazing and Fusion Utilizing GAN and Encoder–Decoder" Journal of Imaging 10, no. 7: 164. https://doi.org/10.3390/jimaging10070164
APA StyleZhao, A., Li, L., & Liu, S. (2024). UIDF-Net: Unsupervised Image Dehazing and Fusion Utilizing GAN and Encoder–Decoder. Journal of Imaging, 10(7), 164. https://doi.org/10.3390/jimaging10070164