1. Introduction
Recently, the utilization of 3D models has seen a significant expansion in various fields, including virtual and mixed reality, computer-aided diagnosis, architecture, and the preservation of cultural heritage. However, when these 3D models undergo operations such as simplification and compression, they can potentially introduce different distortion types that negatively impact the visual quality of 3D point clouds. To tackle this problem, there is a growing demand for robust methods to evaluate perceived quality. Traditionally, assessing distortion levels in 3D models has depended on human observers, which is time-consuming and resource-intensive. To streamline this, objective methods have emerged as a practical solution [
1]. These methods involve the implementation of automated metrics that aim to replicate the judgments of an ideal human observer. These metrics can generally be categorized into three groups: full reference (FR) [
2,
3,
4,
5,
6], reduced reference (RR) [
7,
8], and no-reference (NR) [
9,
10,
11,
12,
13,
14,
15]. Among these, blind methods, which do not rely on reference models, have gained particular significance, especially in real-world applications [
16,
17,
18,
19].
Three-dimensional point cloud is a collection of points, each characterized by geometric coordinates and potentially additional attributes such as color, reflectance, and surface normals.
Unlike 2D media, such as images and videos, which are organized in a regular grid, the points in 3D point clouds are scattered throughout space. Therefore, there is a need to explore methods for extracting effective features from these scattered points to assess quality.
To date, only a limited set of metrics for assessing the quality of point clouds without reference, known as NR-PCQA (No-Reference Point Cloud Quality Assessment), have been developed. Chetouani et al. [
20] adopted an approach involving extracting hand-crafted features at the patch level and using traditional CNN models for quality regression. PQA-net [
9] employs multi-view projection as a method for feature extraction. Zhang et al. [
13] took a distinct approach by using various statistical distributions to estimate quality-related parameters based on the distributions of geometry and color attributes. Fan et al. [
21] focus on inferring the visual quality of point clouds through the analysis of captured video sequences. Liu et al. [
10] utilized an end-to-end sparse CNN to predict quality. Yang et al. [
22] extended their efforts by transferring quality information from natural images to enhance the understanding of the quality of point cloud rendering images, employing domain adaptation techniques.
Recently, Convolutional Neural Networks (CNNs) have emerged as the predominant choice for various Computer Vision and Machine Learning tasks. CNNs are feedforward Artificial Neural Networks (ANN) characterized by their convolutional and subsampling layer arrangement. Deep 2D CNNs, with numerous hidden layers and millions of parameters, can learn intricate objects and patterns, particularly when trained on extensive visual datasets with ground-truth labels. When properly trained, this capability positions them as the primary tool for various engineering applications that involve 2D signals, such as images and video frames.
However, this strategy may not always be feasible for numerous applications dealing with 1D signals, particularly when the training dataset is constrained to a specific application. To address this challenge, 1D CNNs have been recently introduced and have rapidly demonstrated cutting-edge performance across multiple domains. These domains include personalized biomedical data classification and early diagnosis, structural health monitoring, anomaly detection, identification in power electronics, and detecting faults in electrical motors. Among the technical applications of the 1D CNNs we quote automatic speech recognition, vibration-based structural damage detection in civil infrastructure, and real-time electrocardiogram monitoring [
23].
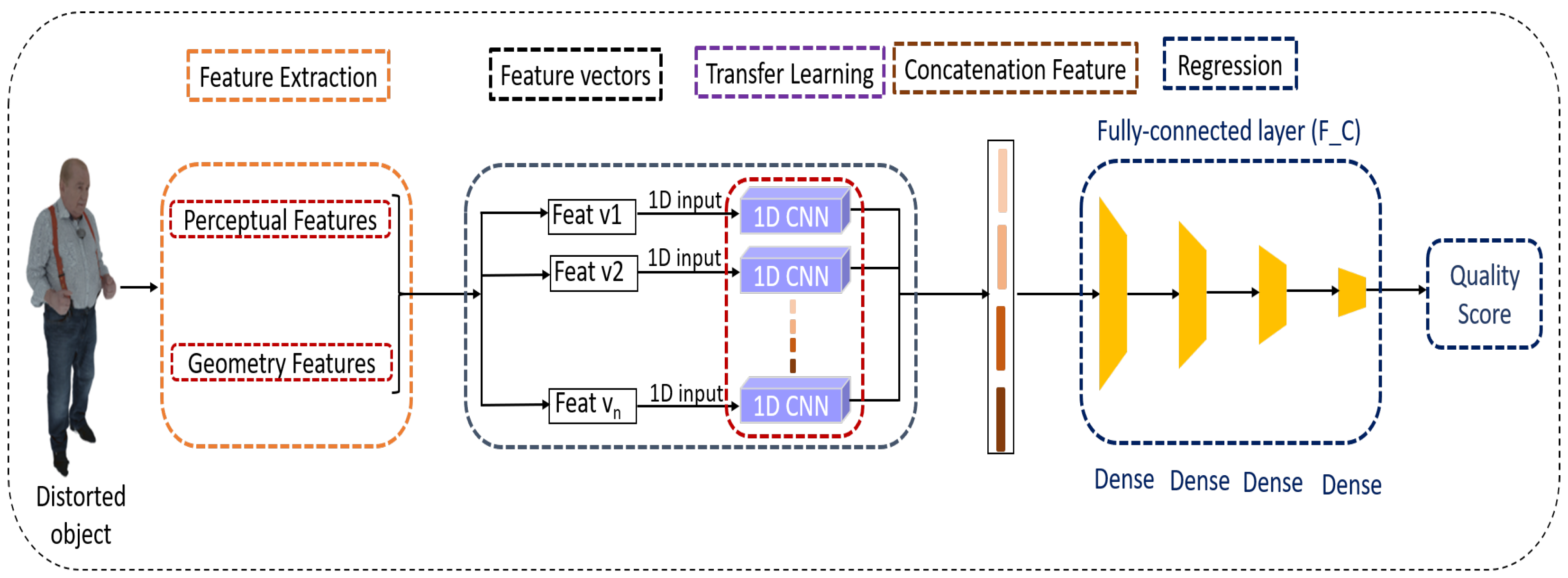
Despite the growing importance of 1D CNNs in various applications, there exists a current void in the literature regarding point cloud quality assessment using these networks. In this context, we introduce a novel method in this paper for evaluating the visual quality of 3D point clouds. Our method revolves around a transfer learning model grounded in a one-dimensional CNN architecture. The main contributions of this paper are summarized as follows:
The introduction of a novel methodology that adapts a one-dimensional Convolutional Neural Network (1DCNN) architecture for evaluating the visual quality of 3D point clouds.
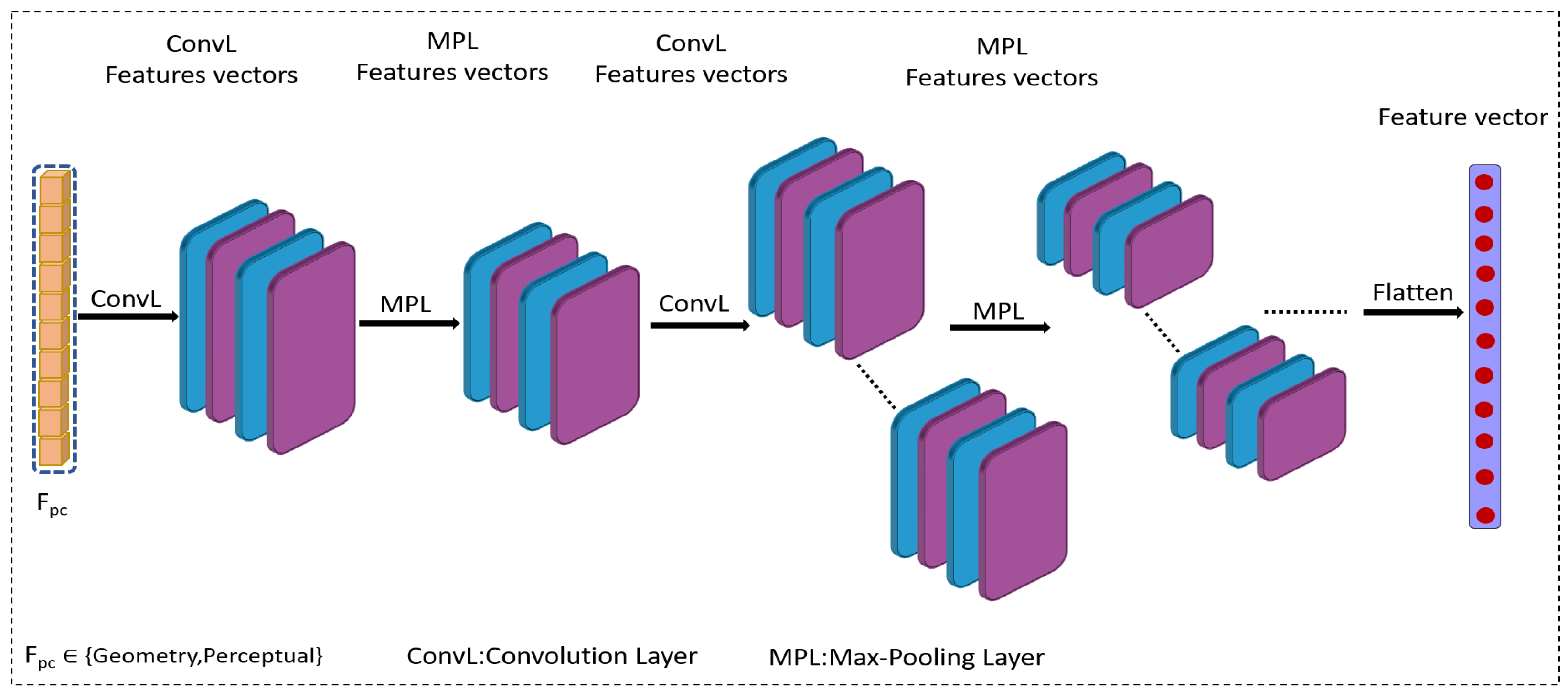
The design of the 1DCNN network tailored for point clouds by transforming a 2D CNN model into a 1D variant.
The incorporation of transfer learning using a pre-trained ImageNet model to initialize the 1DCNN network for point cloud quality evaluation.
The rest of this paper is structured as follows:
Section 2 provides an overview of the related work,
Section 3 introduces the proposed method,
Section 4 presents the experimental setup and the results of a comparative evaluation against alternative solutions, and finally,
Section 5 concludes the paper.
2. Related Work
In the literature, the most current PCQA approaches can be broadly grouped into point-based, feature-based, and projection-based methods. A point-based quality metric directly compares the geometry or characteristics between the reference and distorted point clouds, assessing them point by point and establishing necessary point correspondences. The Point-to-Point (Po2Po) [
24] and Point-to-Plane (Po2Pl) [
25] metrics stand out as the most popular point-based geometry quality evaluation methods. In the Po2Po metric, each point in a degraded or reference point cloud is matched with its nearest corresponding point in the opposite cloud, and subsequently, the Hausdorff distance or Mean Squared Error (MSE) distance is computed for all point pairs. One significant limitation of these metrics is their failure to consider that point cloud points represent the surfaces of objects in the visual scene. Tian et al. [
25] introduced Point-to-Plane (Po2Pl) metrics to address this issue. These metrics represent the underlying surface at each point as a plane perpendicular to the normal vector at that specific point. This approach yields smaller errors for points closer to the point cloud’s surface, which is modeled as a plane. Currently, the MPEG-endorsed point cloud geometry quality metrics include Po2Po and Po2Pl and their corresponding Peak Signal-to-Noise Ratio (PSNR) [
5]. In addition, Alexiou et al. [
26] proposed a Plane-to-Plane (Pl2Pl) metric, which evaluates the similarity between the underlying surfaces associated with corresponding points in the reference and degraded point clouds. In this scenario, tangent planes are estimated for both the reference and degraded points, and the angular similarity between them is examined.
In their work [
27], Javaheri et al. introduced a geometry quality metric that relies on the Generalized Hausdorff distance. This metric measures the maximum distance for a specific percentage of data rather than the entire dataset, effectively filtering out some outlier points. The Generalized Hausdorff distance is calculated between two point clouds, and it can be applied to both the Po2Po and Po2Pl metrics. Furthermore, in [
28], Javaheri et al. proposed a Point-to-Distribution (Po2D) metric. This metric is based on the Mahalanobis distance between a point in one point cloud and its K nearest neighbors in the other point cloud. They compute the mean and covariance matrix of the corresponding distribution and employ it to measure the Mahalanobis distance between points in one point cloud and their respective set of nearest neighbors in the other point cloud. These distances are then averaged to determine the final quality score. In [
29], they presented a joint color and geometry point-to-distribution quality metric. This metric leverages the scale-invariance property of the Mahalanobis distance. In [
30], Javaheri et al. proposed resolution-adaptive metrics. These metrics enhance the existing D1-PSNR and D2-PSNR metrics by incorporating normalization factors based on the point cloud’s rendering and intrinsic resolutions.
A feature-based point cloud quality approach computes a quality score by analyzing the differences in local and global features extracted from reference and degraded point clouds. In [
31], Meynet et al. introduced the Point Cloud Multi-Scale Distortion metric (PC-MSDM). This metric serves as a measure of the geometric quality of point clouds, drawing its foundations from structural similarity principles and relying on the statistical examination of local curvature.
Viola et al. introduced a quality metric for point clouds using the histogram and correlogram of the luminance component [
32]. Then, they integrated the newly proposed color quality metric with the Po2Pl MSE geometry metric (D2) using a linear model. The weighting parameter for this fusion is determined through a grid search approach.
Diniz et al. introduced the Geotex metric, a novel approach based on Local Binary Pattern (LBP) descriptors developed for point clouds, particularly focusing on the luminance component [
33]. To implement this metric to point clouds, the LBP descriptor is computed within a local neighborhood corresponding to the K-nearest neighbors of each point in the other point cloud. The histograms of the extracted feature maps are generated for both the reference and degraded point clouds, and are used to calculate the final quality score employing a distance metric, such as the f-divergence [
34]. In [
35], Diniz et al. presented an extension of the Geotex metric. This extension incorporates various distances, with a notable focus on the Po2Pl Mean Squared Error (MSE) for assessing geometry and the distance between Local Binary Pattern (LBP) statistics [
33] for evaluating color. Additionally, Diniz et al. introduced a novel quality metric in their study [
36], which calculates Local Luminance Patterns (LLP) based on the K-nearest neighbors of each point in the alternative point cloud.
Meynet et al. introduced the Point Cloud Quality Metric (PCQM) [
3]. It integrates geometric characteristics from a previous study [
31] with five color-related features, including lightness, chroma, and hue. The PCQM is calculated as the weighted mean of the geometric and color attributes differences between the reference and degraded point clouds. In an another study, Viola et al. [
7] presented the first reduced-reference quality metric, which concurrently evaluates geometry and color aspects. The authors extracted seven statistical features, including measures such as mean and standard deviation, from point clouds in reference and degraded states across various domains, including geometry, texture, and normal vectors. This process yielded a total of 21 features. The reduced quality score is calculated as the weighted average of the differences in all these features between the reference and degraded point clouds.
Inspired by the SSIM quality metric designed for 2D images, Alexiou et al. introduced a quality metric in [
37] that utilizes local statistical dispersion features. These statistical characteristics are derived within a local neighborhood surrounding each point within the reference and degraded point clouds, including four distinct attributes: geometry, color, normal vectors, and curvature information. The final quality metric is derived by aggregating the differences in feature values between corresponding points in the reference and degraded point clouds. In [
6], Yang et al. proposed a quality metric based on graph similarity. They identify key points by resampling the reference point cloud and construct local graphs centered at these key points for both the reference and degraded point clouds. Several local similarity features are then computed based on the graph topology, with the quality metric value corresponding to the degree of similarity between these features. Additionally, in [
38], Diniz et al. extracted local descriptors that capture geometry-aware texture information from the point clouds. These descriptors include the Local Color Pattern (LCP) and various adaptations of the Local Binary Pattern (LBP) descriptor. The statistics of these descriptors are computed and used to determine the objective quality score.
A quality metric for point clouds that relies on projection involves mapping the 3D reference and degraded point clouds onto specific 2D planes. The quality score is then determined by comparing these projected images using various 2D image quality metrics. The first projection-based point cloud quality metric was introduced by Queiroz et al. in [
39]. This metric begins by projecting the reference and degraded point clouds onto the six faces of a bounding cube that includes the entire point cloud. It combines the corresponding projected images and evaluates the 2D Peak Signal-to-Noise Ratio (PSNR) between the concatenated projected images from the degraded and reference point clouds. In [
40], Torlig et al. introduced rendering software for visualizing point clouds on 2D screens. This software accomplishes the orthographic projection of a point cloud onto the six faces of its bounding box. Then, a 2D quality metric is applied to the projected images obtained by rendering, both for the reference and degraded point clouds. The final quality score is determined by averaging the results from the six projected image pairs. In [
41], Alexiou et al. investigated how the quantity of projected 2D images impacts the correlation between subjective and objective assessments in projection-based quality metrics. The study reveals that even a single view can yield a reasonable correlation performance. Furthermore, they proposed a projection-based point cloud quality metric that assigns weights to the projected images based on user interactions during the subjective testing phase. In [
42], the quality metric proposed in [
40] is evaluated using different parameters, such as the number of views and pooling functions, to establish benchmarks and assess its performance under various conditions.
In [
9], Liu et al. introduced a no-reference quality metric based on deep learning named the Point Cloud Quality Assessment Network (PQA-Net). This method begins by projecting the point cloud into six distinct images which undergo feature extraction through a convolutional neural network. These features are then processed by a distortion-type identification network and a quality vector prediction network to derive the final quality score. In [
43], Bourbia et al. utilized a multi-view projection in 2D, which is segmented into patches, in combination with a deep convolutional neural network for evaluating the quality of point clouds.
In [
44], Wu et al. introduced two objective quality metrics based on projection: a weighted view projection-based metric and a patch-projection-based metric. In both cases, 2D quality metrics are employed to assess the quality of texture and geometry maps. In particular, the patch-projection-based metric demonstrates a significant performance advantage over the weighted view projection-based metric. In [
45], Liu et al. proposed a quality metric for point clouds that leverages attention mechanisms and the principle of information content-weighted pooling. Their proposed metric involves translating, rotating, scaling, and orthogonally projecting point clouds into 12 different views, and it evaluates the quality of these projected images using the IW-SSIM [
46] 2D metric.
Point-based methods often prioritize geometry at the point level, neglecting color information. This limitation can be a drawback in situations where color details are significant. Focusing only on geometry may lead to an incomplete evaluation, especially when color plays a crucial role in the overall quality of the content.
The quality of feature-based methods heavily relies on the effectiveness of feature extraction techniques. Inaccurate or inadequate features can result in biased assessments.
Projection-based methods encounter the challenge of unavoidable information loss during the projection process. This loss can affect the accuracy of quality assessment, especially when critical details are compromised. Furthermore, the quality of projected images may be influenced by the angles and viewpoints employed in the projection. This sensitivity can lead to variations in the assessment results based on different projection configurations.
5. Experimental Results
This section deals with our experimental results, including the performance analysis of the studied networks, the ablation study, results achieved through comparisons with state-of-the-art methods, and cross-database evaluations.
5.1. Network Performance
Convolutional Neural Networks (CNNs) come in various architectures and configurations, each designed for specific tasks and use cases. To explore how CNNs impact performance quality, we execute experiments using six distinct CNN architectures pre-trained on the ImageNet dataset: MobileNet, ResNet, DenseNet, ResNeXt, SE-ResNet, and VGG.
ResNet [53]: Kaiming et al. introduced the Residual Neural Network (ResNet). This network was designed to simplify the training process of deep networks by expediting training speeds. Various iterations of ResNet, such as ResNet 18, ResNet 34, ResNet 50, and ResNet 101, among others, have been suggested.
ResNeXt [54]: ResNeXt is a convolutional neural network architecture aiming to improve deep learning models’ efficiency and performance. ResNeXt builds upon the Residual Network (ResNet) architecture by introducing “cardinality”.
MobileNet [55]: MobileNet is a family of neural network architectures designed explicitly for efficient inference on mobile and embedded devices. MobileNets are known for their lightweight and computationally efficient nature while maintaining reasonable accuracy on various tasks, especially in computer vision.
DenseNet [56]: DenseNet, short for Densely Connected Convolutional Network, is a neural network architecture proposed by Huang et al. DenseNet introduces a unique connectivity pattern among layers, aiming to address some limitations of traditional neural network architectures, such as vanishing gradients, feature reusability, and ease of training deeper networks.
SEResNet [57]: SEResNet (Squeeze-and-Excitation ResNet) is an extension of the ResNet (Residual Network) architecture that incorporates a mechanism called “Squeeze-and-Excitation” to enhance feature learning and representation.
VGG [58]: The VGG network, a deep Convolutional Neural Network (CNN) demonstrated notable success in the ILSVRC 2014 competition. Diverse iterations of VGG, featuring distinct convolutional layer configurations have been created, including VGG11, VGG13, VGG16, and VGG19.
The characteristics of these networks are illustrated in
Table 1 and their corresponding results can be found in
Table 2 and
Table 3.
We evaluate the impact of network architecture and depth on the proposed method’s performance. Residual Networks (ResNets) demonstrate progressive improvement with increasing depth, with ResNet34 achieving better inter-database correlation than ResNet18. However, ResNeXt50 exhibits superior performance on SJTU and ICIP2020 datasets, but struggles on the WPC dataset. MobileNetV2 stands out for its consistent performance across all datasets despite having fewer parameters and lower memory footprint. DenseNet201 suffers from performance degradation and higher Root Mean Squared Error (RMSE) across databases. SE-ResNet50 emerges as the top performer with exceptional metrics such as Pearson Correlation Coefficient (PLCC), Spearman Rank Correlation Coefficient (SRCC), Kendall Rank Correlation Coefficient (KRCC), and consistently low RMSE across all datasets. Surprisingly, VGG16 and VGG19, known for strong performance, excel on all metrics, demonstrating remarkable generalizability, particularly on SJTU and ICIP2020 datasets.
Results obtained from
Table 1,
Table 2 and
Table 3 reveal a classic complexity-accuracy trade-off within the evaluated DCNN architectures. While deeper models such as VGG-16 and VGG-19 achieve higher accuracy, they exhibit significantly larger numbers of parameters and require more computational resources for inference compared to lightweight models such as MobileNetV2. ResNet-101, SEResNet-50, ResNeXt-50, and DenseNet-201 offer a potential middle ground, balancing accuracy with computational efficiency. However, these models come at the cost of increased memory footprint and processing power compared to shallower architectures such as ResNet-18 or ResNet-34. Our evaluation of the impact of varying depth and parameter counts across MobileNet, ResNet, DenseNet, and VGG models suggests that these factors may not significantly influence performance outcomes. This finding warrants further investigation to determine the optimal architecture for specific tasks considering the application’s resource constraints and target accuracy requirements.
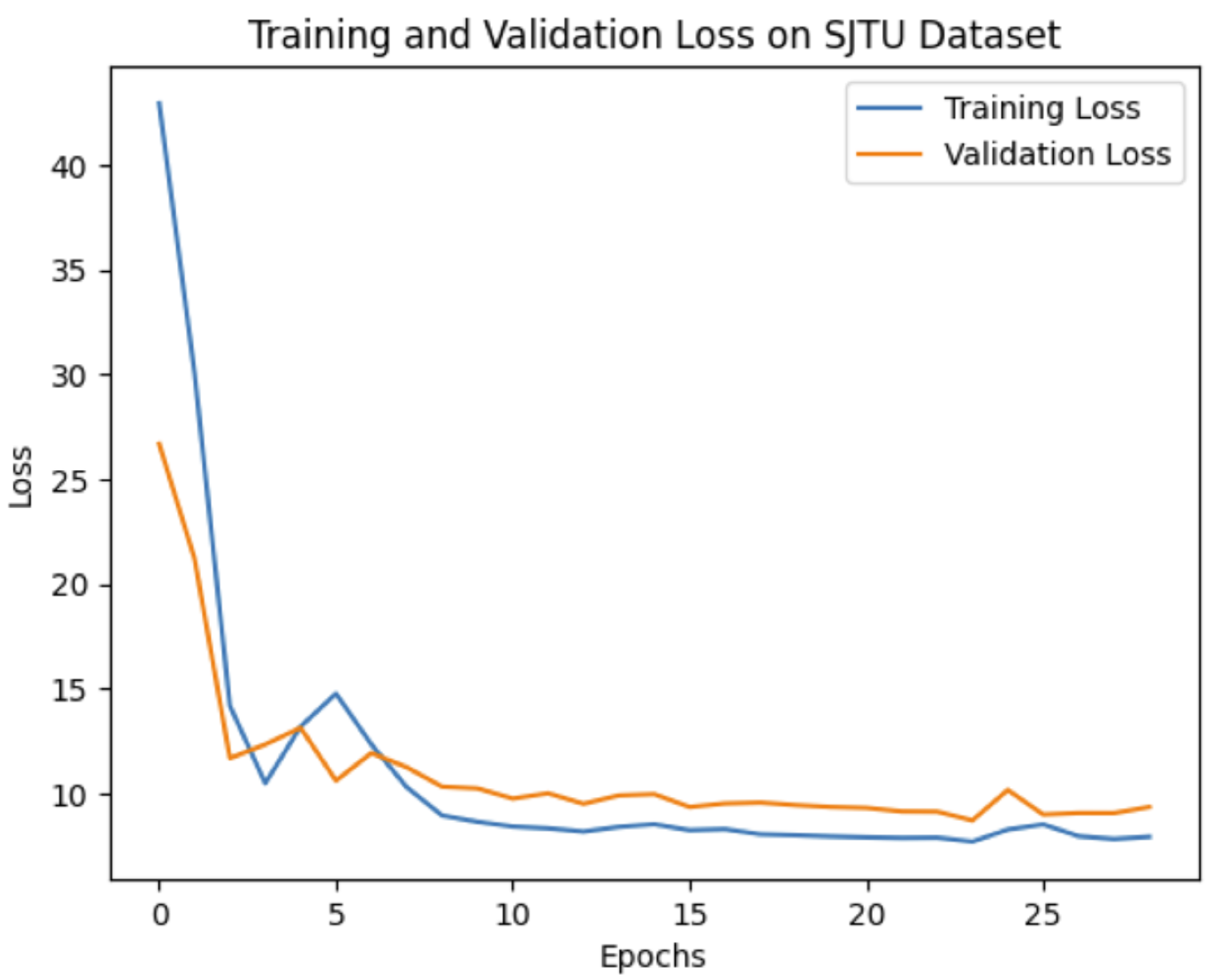
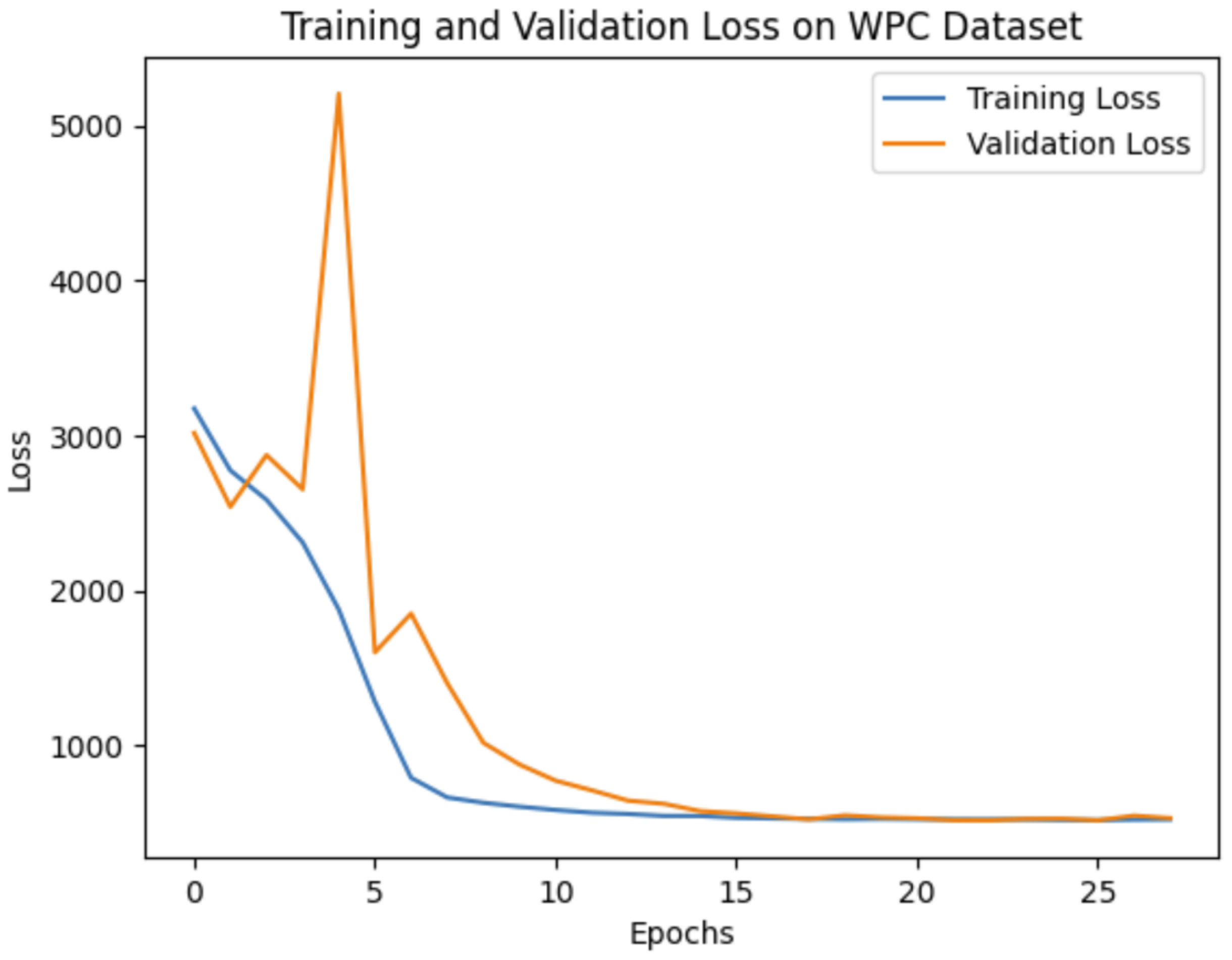
Our experiments demonstrate that the choice of network architecture significantly impacts model performance, even more so than increasing the depth or number of parameters in the model. When selecting a model, it is crucial to consider the application’s specific requirements. If prioritizing real-time performance or running on mobile devices is essential, then a lightweight model like MobileNetV2 might be preferable. On the other hand, if achieving the highest possible accuracy is the primary goal, then deeper models such as VGG16 or SE-ResNet50 are more suitable options. To evaluate our method’s effectiveness against leading benchmarks, we opted to leverage the pre-trained VGG16 convolutional neural network (CNN). The training and validation curves for VGG16 on all three databases are shown in
Figure 4,
Figure 5 and
Figure 6.
Since the suggested approach functions directly from the 3D model, we also pay attention to computational efficiency. The results of execution time on the SJTU-PCQA database are presented in
Figure 7. The proposed method has an average time cost of 29.27 s, compared to approximately 39.14 s for PCQM. Although the FR method for PCQM needs to load both deformed and reference point cloud models simultaneously, while the proposed NR method only needs to load the deformed point cloud model, our method demonstrates a lower average time cost. This suggests that our approach achieves relatively significant computational efficiency.
5.2. Ablation Study
To assess the effectiveness and contributions of various types of features perceptual and geometry, we conducted individual performance tests for each feature. This allowed us to analyze the contributions of features by assessing their performance within various combinations.
Table 4,
Table 5 and
Table 6 present the performance outcomes of the ablation study. Where ‘Anis’, ‘Lin’, ‘Plan’, ‘Sph’, ‘Omni’, ‘Sph_fit’, ‘Eigen’, ‘Curv’, ‘Sal’, ‘All_geom’, and ‘All_perceptual’ correspond to Anisotropy, Linearity, Planarity, Sphericity, Omnivariance, Sphere-fit, Eigenentropy, Curvature, Saliency, all geometry features, and all perceptual features, respectively. Additionally, ‘L’, ‘A’, and ‘B’ represent the luminance and chrominance channels within the LAB color space.
Results obtained on ICIP2020 dataset (
Table 4) show distinct performances among various features (e.g., ‘Anis’, ‘Lin’, ‘Plan’). ‘Anis’ and ‘Sph’ exhibit strong individual performance, while ‘Lin’, ‘Plan’, and ‘Omni’ are less effective. However, progressively integrating these features with ‘Anis’ significantly improves all evaluation metrics. The ‘All_geom’ feature set, combining all geometric features, achieves superior performance throughout, highlighting the benefit of this combination.
For perceptual features, ‘Curv’ is the best performer, while ‘L’, ‘A’, ‘B’, and ‘Sal’ have less individual impact. Merging ‘L’, ‘A’, and ‘B’ followed by ’Curv’ integration results in substantial gains, emphasizing the importance of their collective influence. The ‘All_perceptual’ set, regrouping all perceptual features, demonstrates significant performance, suggesting a complementary interaction between these features.
Finally, integrating geometric and perceptual features, the ‘All’ combination outperforms all individual and grouped sets across all metrics. This comprehensive set not only achieves optimal performance but also underscores the efficacy of combining complementary features for enhanced point cloud quality assessment.
Analyzing the SJTU dataset (
Table 5) reveals interesting insights into feature performance. Among geometric features, ‘Plan’ exhibits the strongest overall performance across all metrics (PLCC, SRCC, KRCC). ‘Sph’ follows closely, particularly excelling in PLCC and SRCC compared to ‘Plan’. While ‘Anis’ demonstrates decent performance, particularly in SRCC, it falls behind ‘Plan’ and ‘Sph’. ‘Omni’ achieves the highest PLCC but struggles with SRCC and KRCC compared to ‘Sph’. ‘Sph_fit’ stands out with significant improvements across all metrics, surpassing other geometric features in a performance jump. However, ‘Engein’ performs similarly to the moderate ‘Anis’. Combining all geometric features in ‘All_geom’ significantly improves individual or partial combinations, highlighting the benefit of feature fusion.
For perceptual features, ‘L’, ‘A’, and ‘B’ exhibit moderate performance, with ‘B’ slightly edging out the others. ‘Curv’ demonstrates improvement over this group, while ‘Sal’ substantially gains performance. As with geometric features, combining these perceptual features into ‘All_perceptual’ leads to further metric improvements.
Finally, the ‘All’ combination, integrating geometric and perceptual features, outperforms all individual and partial combinations across all metrics. This comprehensive feature set stresses the importance of incorporating diverse feature information for optimal point cloud quality assessment. The observed incremental improvements with feature additions, the impact of combining features on metrics, and the context-dependent selection of features all emphasize the effectiveness of a holistic approach in this task.
The scores reported on WPC dataset (
Table 6) reveal distinct characteristics for each geometric feature (‘Anis’, ‘Lin’, ‘Plan’, ‘Sph’, ‘Omni’, ‘Sph_fit’, ‘Engein’). ‘Plan’ demonstrates superior performance with higher correlations (PLCC: 0.29) and lower error (RMSE: 22.57) compared to ‘Sph’ (PLCC: 0.10, RMSE: 23.45). However, feature fusion leads to significant improvements. Combining ‘Anis’ + ‘Lin’ + ‘Plan’ elevates PLCC to 0.41 and reduces RMSE to 21.57. The ‘All_geom’ feature set, which combines all the geometric features, greatly improves (PLCC: 0.67, RMSE: 17.42). This means that using all these features together works much better than using them alone. Similar observations hold for perceptual features (‘L’, ‘A’, ‘B’, ‘Curv’, ‘Sal’). While individual features exhibit varying performance impacts, their combination (‘L’ + ‘A’ + ‘B’ + ‘Curv’) leads to improved metrics compared to their contributions. Furthermore, the ‘All_perceptual’ set, regrouping all perceptual features, demonstrates significant gains in correlations (PLCC: 0.61) and error reduction (RMSE: 21.43).
The ‘All’ combination, integrating geometric and perceptual features, achieves the peak performance across all metrics. This comprehensive set boasts strong correlations (PLCC: 0.93) and minimal error (RMSE: 8.55). This analysis highlights the cumulative improvements observed as more features are incorporated, with the ‘All’ set demonstrably superior for point cloud quality assessment. This underlines the critical role of geometric and perceptual information in achieving optimal quality evaluation.
Across the three evaluated datasets, the results indicate that geometry features play a more significant role in determining the final quality score. This observation could be attributed to the fact that three databases contain a greater variety of geometry distortions than perceptual distortions, and human perception of point clouds tends to place a higher emphasis on geometry-related information.
5.3. Performance Comparison with the State-of-the-Art
In this section, we perform a comparative analysis of our proposed method against current benchmarks, including FR-PCQA (PSNR [
5], SSIM [
5], PB-PCQA [
51], M-p2po [
24], M-p2pl [
4], H-p2po [
24], H-p2pl [
4], PSNRYUV [
40], PCQM [
3], GraphSIM [
6], PointSSIM [
37], TCDM [
59], and MMD [
28]), RR-PCQA (PCMRR [
7]), and NR-PCQA (BRISQUE [
11], PQA-Net [
9], NIQE [
12], ResSCNN [
10], MVP-PCQA [
43], MM-PCQA [
60], and 3D-NSS [
13]).
The experimental outcomes of PCQA using the SJTU-PCQA, WPC, and ICIP2020 databases are presented in
Table 7,
Table 8 and
Table 9. The top-performing results in each column are highlighted in bold. Across all three databases, it is evident that the FR-PCQA methods (PSNR [
5], M-p2po [
24], M-p2pl [
4], H-p2po [
24], and H-p2pl [
4]) demonstrate comparatively lower performance. This can be attributed to their reliance solely on geometric structure without incorporating color information. In contrast, superior performance is observed in metrics such as MMD [
28], PSNRYUV [
40], PCQM [
3], GraphSIM [
6], PointSSIM [
37], and TCDM [
59], which includes color information for assessing point clouds. However, it is important to note that evaluating these methods relies on reference information, a component often unavailable in practical applications. Regarding RR methods, The PCMRR metric produces poor results for all correlation metrics. This might be explained by the extensive use of features within their method, which could make it less generalized to different types of degradation.
For NR methods, one can see that our method presents the most superior performance across all three databases, outperforming the compared NR-PCQA methods by a significant margin. For example, our approach outperforms the NR-PCQA method in second place by approximately 0.04, 0.04 (PLCC, SRCC) for MM-PCQA on the SJTU-PCQA database, and by 0.08, 0.07 (PLCC, SRCC) for MVP-PCQA on the WPC database. There are significant performance drops from the SJTU-PCQA and ICIP2020 databases to the WPC database because the latter contains more complex distortion parameters, which are more difficult for PCQA models. Moreover, within the SJTUPCQA database, distorted point clouds contain mixed distortions, while the WPC database introduces a single type of distortion to individual point clouds. Point clouds with mixed distortions appear to exhibit greater quality distinguishability when subjected to similar distortion levels. Furthermore, the WPC database contains twice the number of reference point clouds compared to the SJTU-PCQA database. Our approach exhibits a relatively small drop in performance compared to most other methods. For instance, when moving from the SJTU-PCQA database to the WPC database, our method demonstrates a decrease of 0.03 in PLCC and 0.02 in SRCC values. Top-performing PCQA methods, except for PQA-Net, exhibit a larger performance decline of 0.15 and 0.14 in both PLCC and SRCC values, respectively. Therefore, it is clear that our approach is more robust to more complex distortions.
The overall effectiveness may not accurately reflect the performance for specific distortion types. Consequently, we assess how FR, RR, and NR metrics perform in the face of various point cloud distortions across the three databases. Evaluation measures such as PLCC and SRCC scores are presented in
Table 10,
Table 11 and
Table 12. The top performance for each distortion type within each database is highlighted in bold, indicating the best results among all competing metrics.
On the ICIP2020 database (
Table 10), our method surpasses all the compared methods across various distortion types (VPCC, G-PCC Trisoup, and G-PCC Octree), demonstrating superior performance across the entire database.
Within the SJTU-PCQA database (
Table 11), our method shows the strongest correlation coefficient outcomes across all distortions, outperforming the state-of-the-art metrics in both PLCC and SRCC correlation coefficients. It is important to highlight that the correlation values of our method and all other state-of-the-art methods are lower in the SJTU-PCQA dataset compared to the ICIP2020 dataset. This difference could be explained by the various types of degradation present in the two databases. While the ICIP2020 database mostly features compression-related distortions, the SJTU database presents more difficult degradation types such as acquisition noise, resampling, and their combinations (Octree-based compression (OT), Color noise (CN), Geometry Gaussian noise (GGN), Downsampling (DS), Downscaling and Color noise (D + C), Downscaling and Geometry Gaussian noise (D + G), and Color noise and Geometry Gaussian noise (C + G)). We conduct a comparison of PLCC and SRCC values for each of the seven degradation types. As depicted in
Table 11, our model demonstrates robust performance across all degradation types, exhibiting strong correlations with the subjective quality scores.
In the WPC database (
Table 12), our method shows top correlation coefficient results across all distortions, outperforming all the methods compared throughout the entire database. It is important to highlight that our model performs better even on the larger and more complex databases, demonstrating its remarkable robustness.
Based on these results, it can be concluded that our proposed model ranks first among NR methods on SJTU-PCQA, WPC, and ICIP2020 databases. Additionally, our model achieves satisfactory results compared to state-of-the-art FR 3D-QA metrics. A notable advantage of our method is that it does not require original point clouds for reference, demonstrating its ability to extract quality-aware features and provide relatively accurate quality levels for colored point clouds.
5.4. Cross-Database Evaluation
A cross-database evaluation was performed to assess the generalization capability of the proposed method, and the experimental results are displayed in
Table 13. Considering the size of the WPC database (740 samples), our primary focus was training the models using this database and conducting the test on the SJTU PCQA dataset (378 samples). Among the comparison models, 3D-NSS [
13] demonstrates the lowest PLCC and SRCC values at 0.2344 and 0.1817, respectively. PQA-net [
9] follows with improved scores of 0.6102 (PLCC) and 0.5411 (SRCC), displaying improved performance. MM-PCQA [
60] further elevates the evaluation metrics, achieving 0.7779 (PLCC) and 0.7693 (SRCC). However, the best performance results come from the proposed model, with higher PLCC (0.8119) and SRCC (0.8193) values, surpassing all other models assessed in this study. These results suggest that the proposed model exhibits a higher correlation with ground truth data for evaluating point cloud quality, indicating its potential for more accurate quality evaluations compared to existing NR-PCQA methods such as 3D-NSS, PQA-net, and MM-PCQA within this context.
6. Conclusions
In this paper, we have introduced a novel methodology for assessing the quality of 3D point clouds using a one-dimensional model based on the Convolutional Neural Network (1D CNN). Through extensive experiments and evaluations, we have demonstrated the effectiveness of our approach in predicting subjective point cloud quality under various distortions. Our model consistently outperformed all competing methods by leveraging transfer learning and focusing on geometric and perceptual features.
The results of our evaluations across different distortion types and databases provide valuable insights into the performance of the proposed method. Our model achieves robust performance across all distortion types within each database in the ICIP2020 and WPC databases by recording top correlation coefficient results across all distortions.
The success of our approach can be attributed to its ability to effectively capture and analyze geometric and perceptual features in 3D point clouds, enabling accurate quality assessment without the need for reference information. The model’s generalization capability, as demonstrated in cross-database evaluations, further highlights its potential for real-world applications.
In conclusion, the proposed method is a promising solution for automated point cloud quality assessment, offering enhanced accuracy and reliability compared to existing techniques. By combining advanced deep learning strategies with transfer learning, our approach advances the field of point cloud quality assessment and opens up new possibilities for improving visual quality evaluation in diverse domains.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}