
Day-to-Night Street View Image Generation for 24-Hour Urban Scene Auditing Using Generative AI




Abstract
1. Introduction
1.1. Public Space and Safety Perception
1.2. Knowledge Gaps
1.3. Research Design and Contributions
2. Literature Review
2.1. Urban Public Space and Human Perceptions
2.2. SVI Data for Urban Scene Auditing
2.3. GenAI and Nighttime Image Translation
2.3.1. Generative Adversarial Networks (GANs)
2.3.2. StableDiffusion
2.3.3. Day-and-Night Image Translation
3. Data and Method
3.1. Research Design and Study Area
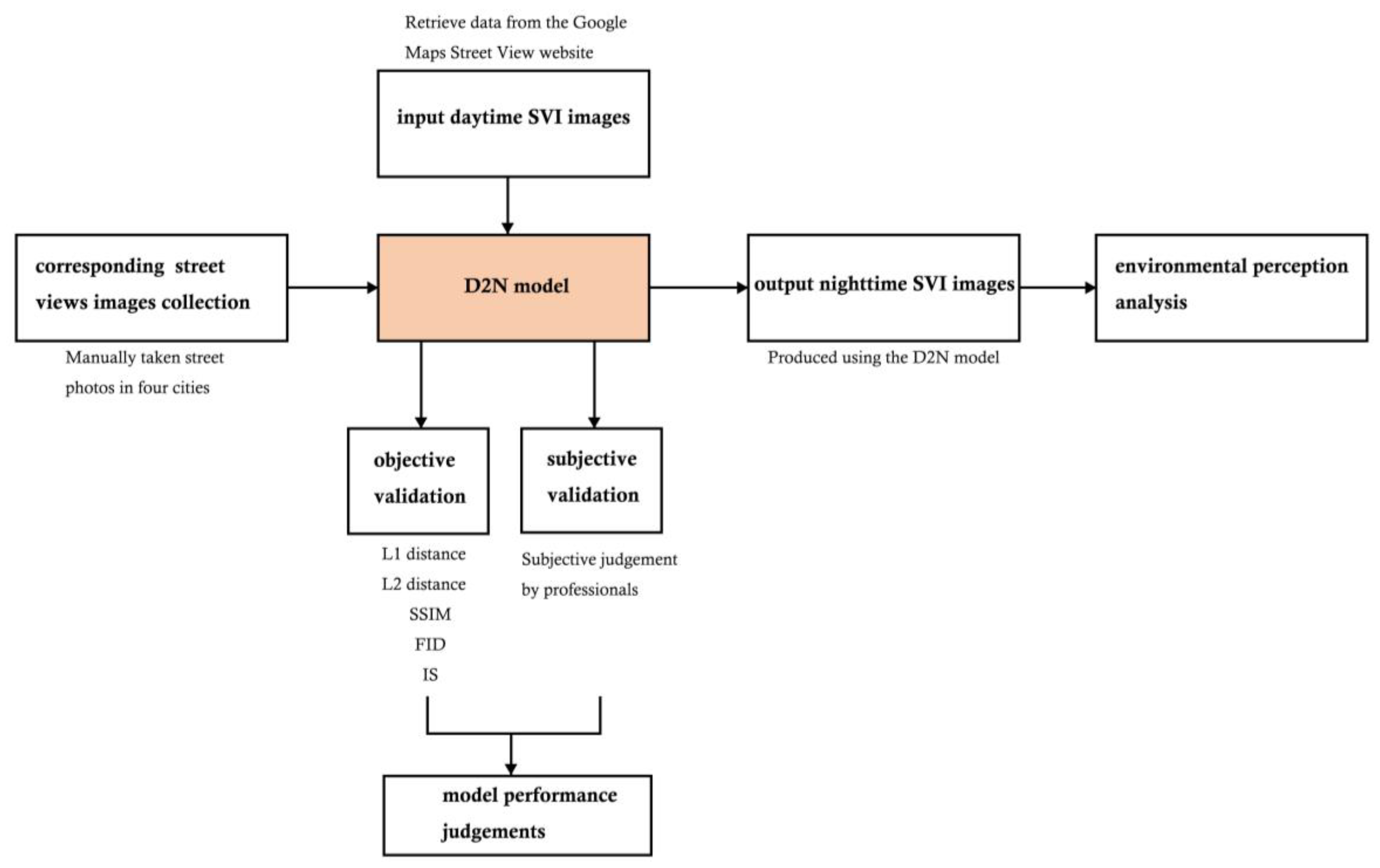
3.1.1. Conceptual Framework
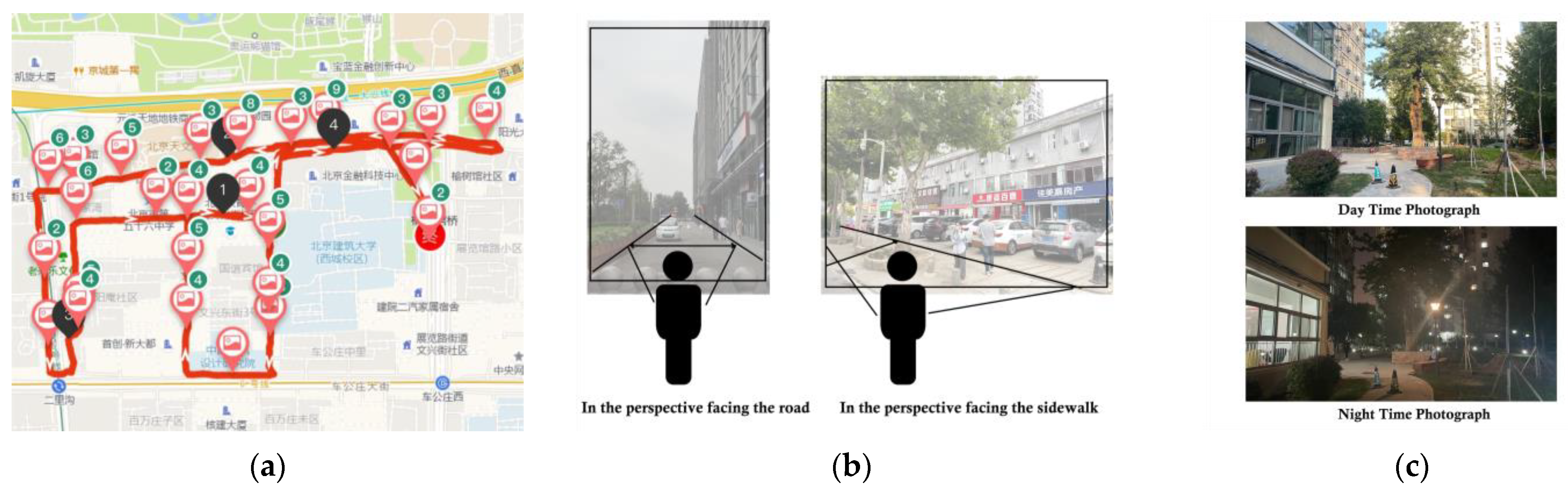
3.1.2. Training and Testing Area
3.2. Data
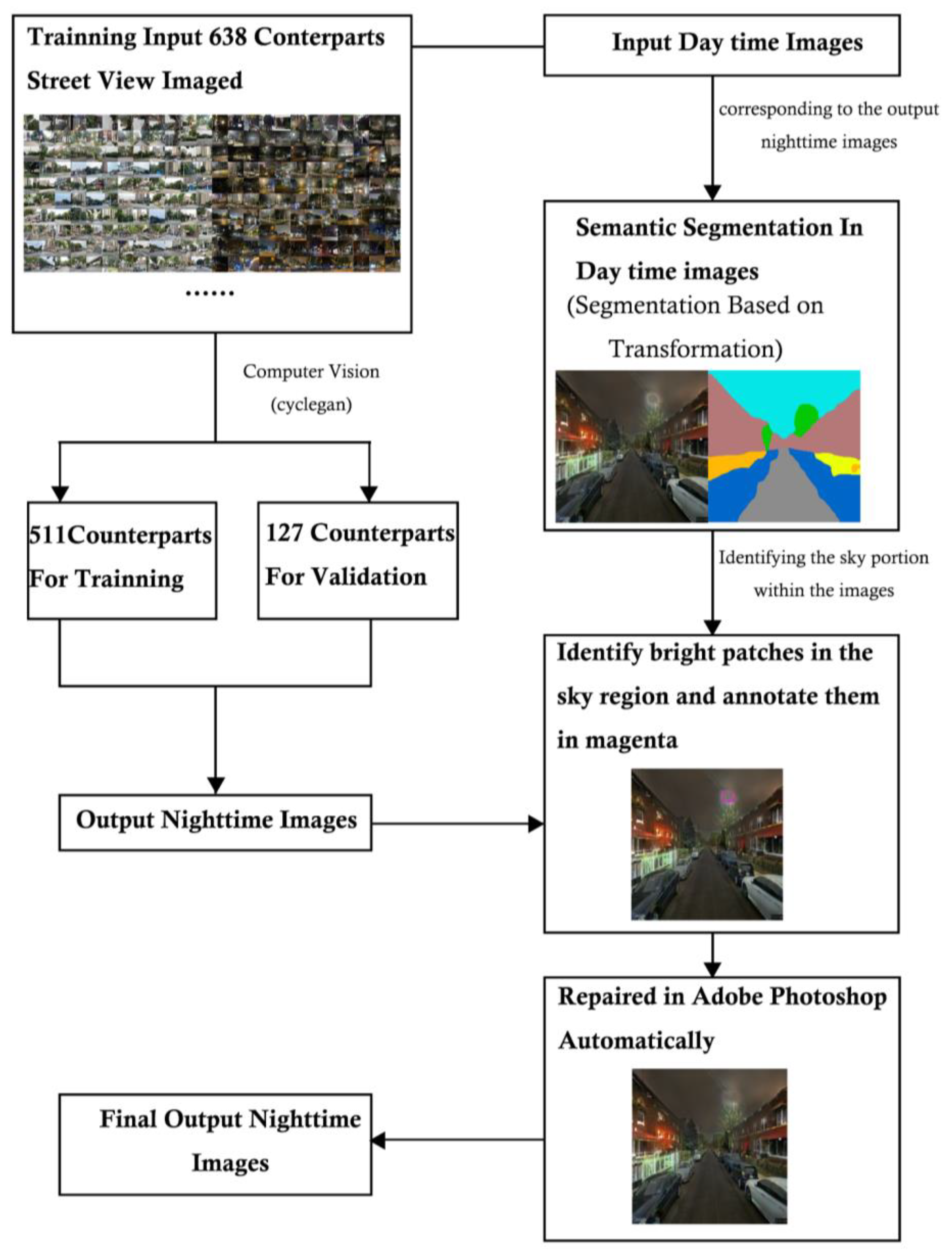
3.2.1. Training Data
3.2.2. D2N Model Efficacy
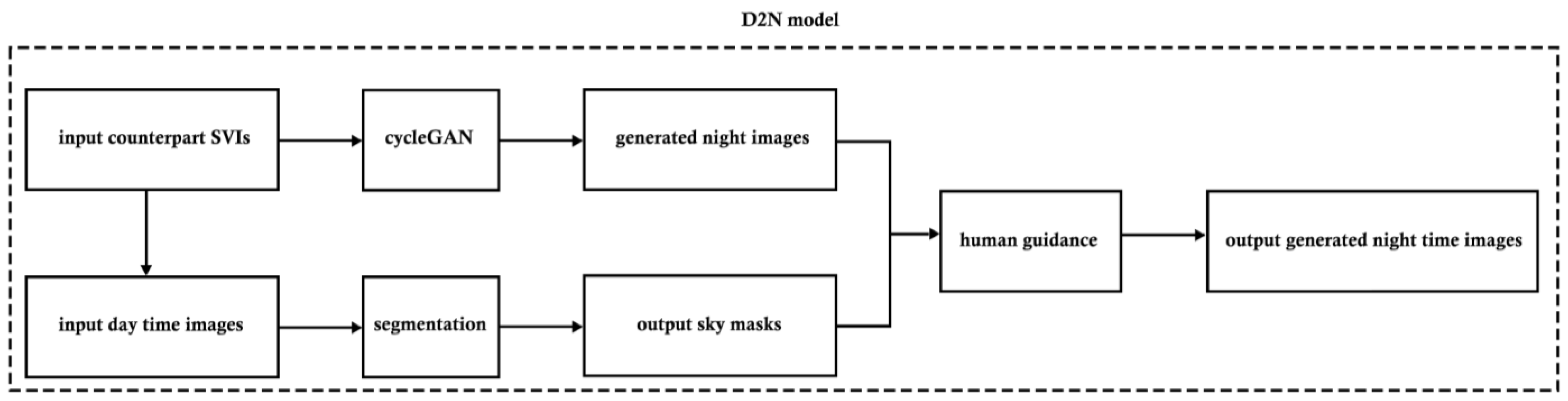
3.3. Model Architecture
3.3.1. Generative Models
3.3.2. Semantic Segmentation for Adjustment
3.4. D2N Model Training
3.5. Model Performance Validation
3.5.1. Objective Judgements in Model Performance
- n: the dimensions of vectors x and y, indicating the number of elements they contain;
- and represent the ith element of vectors x and y, respectively;
- L1 represents the L1 distance between x and y, also known as the Manhattan distance, which is the sum of the absolute differences of corresponding elements in the two vectors.
- n: the dimensions of vectors x and y, indicating the number of elements they contain;
- and represent the ith element of vectors x and y, respectively;
- L2 distance represents the L2 distance between x vectors and y, also known as the Euclidean distance, which is the square root of the sum of the squares of the differences of corresponding elements in the two vectors.
3.5.2. Human Validation
3.6. Validating D2N with NYC Street Scenes
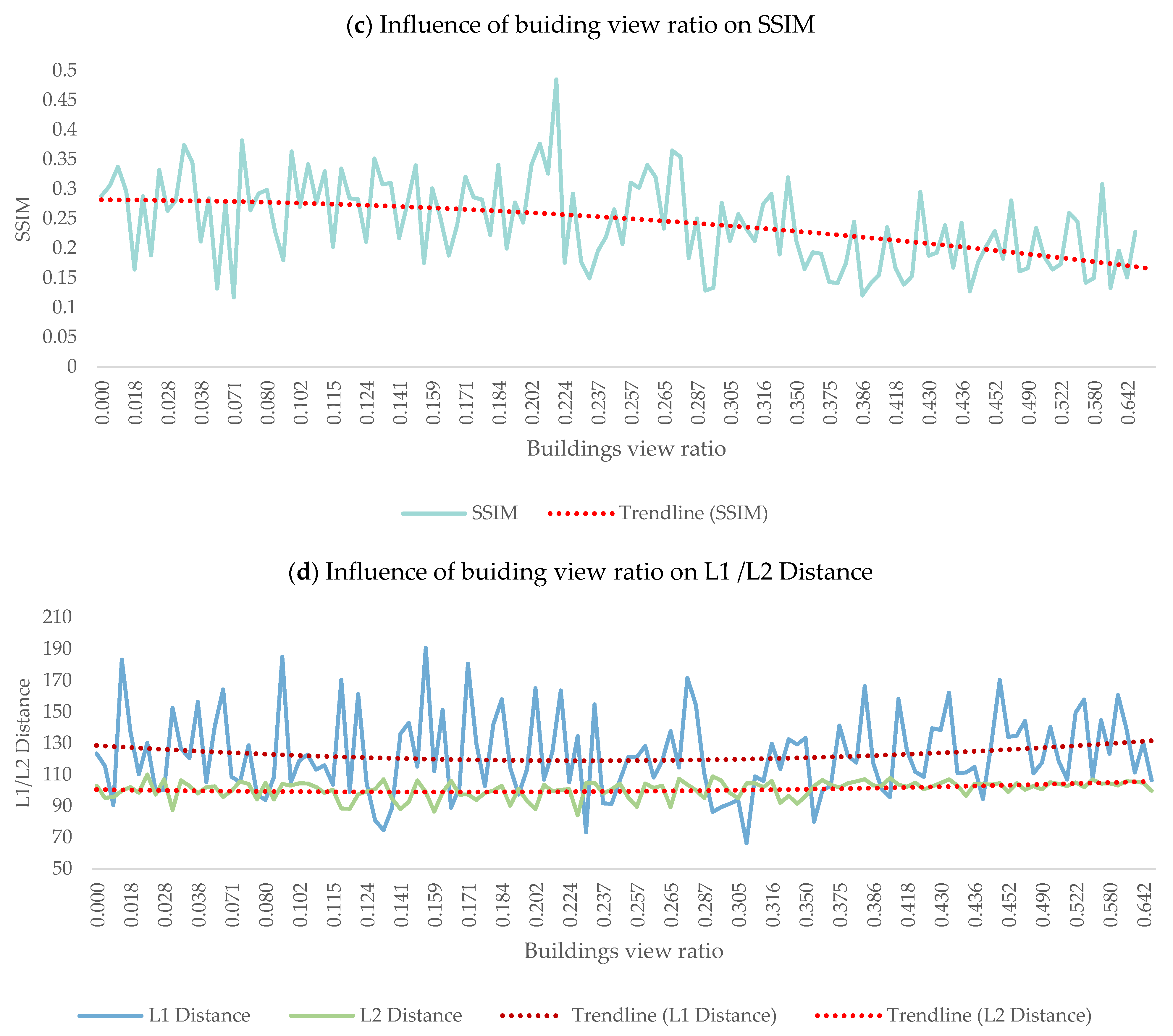
3.7. Quantifying Impact of Streetscape Elements on D2N Accuracy Using OLS
- n represents the total number of pixels in the object of interest;
- m represents the total number of pixels in the entire image;
- PIXELobj represents the number of pixels in the object of interest, which is the sum of all pixels belonging to the object of interest;
- PIXELtotal represents the total number of pixels in the entire image, i.e., the sum of all pixels;
- obj ∈ {tree, building, sky, etc.} represents the categories of the object of interest: trees, buildings, sky, etc.
4. Results and Findings
4.1. Comparison of Three GenAI Models
4.2. Model Accuracies in Subjective and Objective Assessments
4.3. Divergence between Subjective and Objective Evaluations
4.4. Impact of Streetscape Elements on D2N Transformation
4.5. Improving the Dataset
4.5.1. Using CycleGAN to Generate and Transform Night Scenes
4.5.2. Ways to Make Night Scenes More Realistic
5. Discussion
5.1. Generating Night Scenes
5.2. Model Accuracy
5.3. Limitations
6. Conclusions
6.1. CycleGAN Demonstrates Best Adaptability for D2N Transformation
6.2. Urban Density or the Height–to-Width (H-W) Ratio of Streets Are Crucial
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

References
- McPhearson, T.; Pickett, S.T.A.; Grimm, N.B.; Niemelä, J.; Alberti, M.; Elmqvist, T.; Weber, C.; Haase, D.; Breuste, J.; Qureshi, S. Advancing Urban Ecology toward a Science of Cities. Bioscience 2016, 66, 198–212. [Google Scholar] [CrossRef]
- McCormack, G.R.; Rock, M.; Toohey, A.M.; Hignell, D. Characteristics of Urban Parks Associated with Park Use and Physical Activity: A Review of Qualitative Research. Health Place 2010, 16, 712–726. [Google Scholar] [CrossRef]
- Whyte, W.H. The Social Life of Small Urban Spaces the Social Life of Small Urban Spaces, 8th ed.; Project for Public Spaces: New York, NY, USA, 2021; ISBN 978-0-9706324-1-8. [Google Scholar]
- Gehl, J. Cities for People; Island Press: Washington, DC, USA, 2010; ISBN 978-1-59726-573-7. [Google Scholar]
- Kweon, B.-S.; Sullivan, W.C.; Wiley, A.R. Green Common Spaces and the Social Integration of Inner-City Older Adults. Environ. Behav. 1998, 30, 832–858. [Google Scholar] [CrossRef]
- Jacobs, J. The Death and Life of Great American Cities; Penguin Books: Harlow, UK, 1994; ISBN 978-0-14-017948-4. [Google Scholar]
- Xu, N. Review of Urban Public Space Researches from Multidisciplinary Perspective. Landsc. Archit. 2021, 28, 52–57. [Google Scholar] [CrossRef]
- Curtis, J.W.; Shiau, E.; Lowery, B.; Sloane, D.; Hennigan, K.; Curtis, A. The Prospects and Problems of Integrating Sketch Maps with Geographic Information Systems to Understand Environmental Perception: A Case Study of Mapping Youth Fear in Los Angeles Gang Neighborhoods. Environ. Plan. B Plan. Des. 2014, 41, 251–271. [Google Scholar] [CrossRef]
- Kelly, C.M.; Wilson, J.S.; Baker, E.A.; Miller, D.K.; Schootman, M. Using Google Street View to Audit the Built Environment: Inter-Rater Reliability Results. Ann. Behav. Med. 2013, 45, 108–112. [Google Scholar] [CrossRef] [PubMed]
- Dubey, A.; Naik, N.; Parikh, D.; Raskar, R.; Hidalgo, C.A. Deep Learning the City: Quantifying Urban Perception at A Global Scale. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 196–212. [Google Scholar]
- Naik, N.; Philipoom, J.; Raskar, R.; Hidalgo, C. Streetscore–Predicting the Perceived Safety of One Million Streetscapes. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 793–799. [Google Scholar]
- Salesses, P.; Schechtner, K.; Hidalgo, C.A. The Collaborative Image of The City: Mapping the Inequality of Urban Perception. PLoS ONE 2013, 8, e68400. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Song, Y. Evaluating Street View Cognition of Visible Green Space in Fangcheng District of Shenyang with the Green View Index. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 22–24 August 2020. [Google Scholar]
- Li, X.; Zhang, C.; Li, W. Does the Visibility of Greenery Increase Perceived Safety in Urban Areas? Evidence from the Place Pulse 1.0 Dataset. ISPRS Int. J. Geoinf. 2015, 4, 1166–1183. [Google Scholar] [CrossRef]
- Min, W.; Mei, S.; Liu, L.; Wang, Y.; Jiang, S. Multi-Task Deep Relative Attribute Learning for Visual Urban Perception. IEEE Trans. Image Process. 2019, 29, 657–669. [Google Scholar] [CrossRef]
- Yao, Y.; Liang, Z.; Yuan, Z.; Liu, P.; Bie, Y.; Zhang, J.; Wang, R.; Wang, J.; Guan, Q. A Human-Machine Adversarial Scoring Framework for Urban Perception Assessment Using Street-View Images. Geogr. Inf. Syst. 2019, 33, 2363–2384. [Google Scholar] [CrossRef]
- Dong, L.; Jiang, H.; Li, W.; Qiu, B.; Wang, H.; Qiu, W. Assessing Impacts of Objective Features and Subjective Perceptions of Street Environment on Running Amount: A Case Study of Boston. Landsc. Urban Plan. 2023, 235, 104756. [Google Scholar] [CrossRef]
- Wang, Y.; Qiu, W.; Jiang, Q.; Li, W.; Ji, T.; Dong, L. Drivers or Pedestrians, Whose Dynamic Perceptions Are More Effective to Explain Street Vitality? A Case Study in Guangzhou. Remote Sens. 2023, 15, 568. [Google Scholar] [CrossRef]
- He, Y.; Zhao, Q.; Sun, S.; Li, W.; Qiu, W. Measuring the Spatial-Temporal Heterogeneity of Helplessness Sentiment and Its Built Environment Determinants during the COVID-19 Quarantines: A Case Study in Shanghai. ISPRS Int. J. Geo-Inf. 2024, 13, 112. [Google Scholar] [CrossRef]
- Wang, R.; Yuan, Y.; Liu, Y.; Zhang, J.; Liu, P.; Lu, Y.; Yao, Y. Using Street View Data and Machine Learning to Assess How Perception of Neighborhood Safety Influences Urban Residents’ Mental Health. Health Place 2019, 59, 102186. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; He, Y.; Wang, Y.; Li, W.; Wu, L.; Qiu, W. Investigating the Civic Emotion Dynamics during the COVID-19 Lockdown: Evidence from Social Media. Sustain. Cities Soc. 2024, 107, 105403. [Google Scholar] [CrossRef]
- Tan, Y.; Li, W.; Chen, D.; Qiu, W. Identifying Urban Park Events through Computer Vision-Assisted Categorization of Publicly-Available Imagery. ISPRS Int. J. Geo-Inf. 2023, 12, 419. [Google Scholar] [CrossRef]
- Qiu, W.; Zhang, Z.; Liu, X.; Li, W.; Li, X.; Xu, X.; Huang, X. Subjective or Objective Measures of Street Environment, Which Are More Effective in Explaining Housing Prices? Landsc. Urban Plan. 2022, 221, 104358. [Google Scholar] [CrossRef]
- Song, Q.; Liu, Y.; Qiu, W.; Liu, R.; Li, M. Investigating the Impact of Perceived Micro-Level Neighborhood Characteristics on Housing Prices in Shanghai. Land 2022, 11, 2002. [Google Scholar] [CrossRef]
- Su, N.; Li, W.; Qiu, W. Measuring the Associations between Eye-Level Urban Design Quality and on-Street Crime Density around New York Subway Entrances. Habitat. Int. 2023, 131, 102728. [Google Scholar] [CrossRef]
- Shi, W.; Xiang, Y.; Ying, Y.; Jiao, Y.; Zhao, R.; Qiu, W. Predicting Neighborhood-Level Residential Carbon Emissions from Street View Images Using Computer Vision and Machine Learning. Remote Sens. 2024, 16, 1312. [Google Scholar] [CrossRef]
- Google Maps How Street View Works and Where We Will Collect Images Next. Available online: https://www.google.com/streetview/how-it-works/ (accessed on 28 February 2024).
- Anoosheh, A.; Sattler, T.; Timofte, R.; Pollefeys, M.; Van Gool, L. Night To-Day Image Translation for Retrieval-Based Localization. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Narasimhan, S.G.; Wang, C.; Nayar, S.K. All the Images of an Outdoor Scene. In Computer Vision—ECCV 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 148–162. ISBN 978-3-540-43746-8. [Google Scholar]
- Teller, S.; Antone, M.; Bodnar, Z.; Bosse, M.; Coorg, S.; Jethwa, M.; Master, N. Calibrated, Registered Images of an Extended Urban Area. Int. J. Comput. Vis. 2003, 53, 93–107. [Google Scholar] [CrossRef]
- Tuite, K.; Snavely, N.; Hsiao, D.-Y.; Tabing, N.; Popovic, Z. PhotoCity: Training Experts at Large-Scale Image Acquisition through a Competitive Game. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011. [Google Scholar]
- Jensen, H.W.; Durand, F.; Dorsey, J.; Stark, M.M.; Shirley, P.; Premože, S. A Physically-Based Night Sky Model; ACM: New York, NY, USA, 2001. [Google Scholar]
- Tadamura, K.; Nakamae, E.; Kaneda, K.; Baba, M.; Yamashita, H.; Nishita, T. Modeling of Skylight and Rendering of Outdoor Scenes. Comput. Graph. Forum 1993, 12, 189–200. [Google Scholar] [CrossRef]
- Sun, L.; Wang, K.; Yang, K.; Xiang, K. See Clearer at Night: Towards Robust Nighttime Semantic Segmentation through Day–night Image Conversion. arXiv 2019, arXiv:1908.05868. [Google Scholar]
- Xiang, K.; Wang, K.; Yang, K. Importance-Aware Semantic Segmentation with Efficient Pyramidal Context Network for Navigational Assistant Systems. arXiv 2019, arXiv:1907.11066. [Google Scholar]
- Xiang, K.; Wang, K.; Yang, K. A Comparative Study of High-Recall Real-Time Semantic Segmentation Based on Swift Factorized Network. arXiv 2019, arXiv:1907.11394. [Google Scholar]
- Van Hecke, L.; Ghekiere, A.; Van Cauwenberg, J.; Veitch, J.; De Bourdeaudhuij, I.; Van Dyck, D.; Clarys, P.; Van De Weghe, N.; Deforche, B. Park Characteristics Preferred for Adolescent Park Visitation and Physical Activity: A Choice-Based Conjoint Analysis Using Manipulated Photographs. Landsc. Urban Plan. 2018, 178, 144–155. [Google Scholar] [CrossRef]
- Carr, S.; Francis, M.; Rivlin, L.G.; Stone, A.M. Environment and Behavior: Public Space; Stokols, D., Altman, I., Eds.; Cambridge University Press: Cambridge, UK, 1993; ISBN 978-0-521-35960-3. [Google Scholar]
- Lindal, P.J.; Hartig, T. Architectural Variation, Building Height, and the Restorative Quality of Urban Residential Streetscapes. J. Environ. Psychol. 2013, 33, 26–36. [Google Scholar] [CrossRef]
- Jackson, P.I.; Ferraro, K.F. Fear of Crime: Interpreting Victimization Risk. Contemp. Sociol. 1996, 25, 246. [Google Scholar] [CrossRef]
- Wekerle, S.R.; Whitzman, C. Safe Cities: Guidelines for Planning, Design, and Management; Van Nostrand Reinhold: New York, NY, USA, 1995; 154p. [Google Scholar]
- Koskela, H.; Pain, R. Revisiting Fear and Place: Women’s Fear of Attack and the Built Environment. Geoforum 2000, 31, 269–280. [Google Scholar] [CrossRef]
- Trench, S.; Oc, T.; Tiesdell, S. Safer Cities for Women: Perceived Risks and Planning Measures. Town Plan. Rev. 1992, 63, 279. [Google Scholar] [CrossRef]
- Huang, W.-J.; Wang, P. “All That’s Best of Dark and Bright”: Day and Night Perceptions of Hong Kong Cityscape. Tour. Manag. 2018, 66, 274–286. [Google Scholar] [CrossRef]
- Lee, S.; Byun, G.; Ha, M. Exploring the Association between Environmental Factors and Fear of Crime in Residential Streets: An Eye-Tracking and Questionnaire Study. J. Asian Archit. Build. Eng. 2023, 1–18. [Google Scholar] [CrossRef]
- Rossetti, T.; Lobel, H.; Rocco, V.; Hurtubia, R. Explaining Subjective Perceptions of Public Spaces as a Function of the Built Environment: A Massive Data Approach. Landsc. Urban Plan. 2019, 181, 169–178. [Google Scholar] [CrossRef]
- Runge, N.; Samsonov, P.; Degraen, D.; Schoning, J. No More Autobahn: Scenic Route Generation Using Googles Street View. In Proceedings of the International Conference on Intelligent User Interfaces, Sonoma, CA, USA; 2016; pp. 7–10. [Google Scholar]
- Yin, L.; Cheng, Q.; Wang, Z.; Shao, Z. Big Data’ for Pedestrian Volume: Exploring the Use of Google Street View Images for Pedestrian Counts. Appl. Geogr. 2015, 63, 337–345. [Google Scholar] [CrossRef]
- Ozkan, U.Y. Assessment of Visual Landscape Quality Using IKONOS Imagery. Environ. Monit. Assess. 2014, 186, 4067–4080. [Google Scholar] [CrossRef] [PubMed]
- Anguelov, D.; Dulong, C.; Filip, D.; Frueh, C.; Lafon, S.; Lyon, R.; Ogale, A.; Vincent, L.; Weaver, J. Google Street View: Capturing the World at Street Level. Comput. Long. Beach Calif. 2010, 43, 32–38. [Google Scholar] [CrossRef]
- Gong, Z.; Ma, Q.; Kan, C.; Qi, Q. Classifying Street Spaces with Street View Images for a Spatial Indicator of Urban Functions. Sustainability 2019, 11, 6424. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, D.; Liu, Y.; Lin, H. Representing Place Locales Using Scene Elements. Comput. Environ. Urban Syst. 2018, 71, 153–164. [Google Scholar] [CrossRef]
- Moreno-Vera, F. Understanding Safety Based on Urban Perception. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 54–64. [Google Scholar]
- Xu, Y.; Yang, Q.; Cui, C.; Shi, C.; Song, G.; Han, X.; Yin, Y. Visual Urban Perception with Deep Semantic-Aware Network. In MultiMedia Modeling; Springer International Publishing: Cham, Switzerland, 2019; pp. 28–40. ISBN 978-3-030-05715-2. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. arXiv 2013, arXiv:1310.1531. [Google Scholar]
- Liu, X.; Chen, Q.; Zhu, L.; Xu, Y.; Lin, L. Place-Centric Visual Urban Perception with Deep Multi-Instance Regression; ACM: New York, NY, USA, 2017. [Google Scholar]
- Porzi, L.; Rota Bulò, S.; Lepri, B.; Ricci, E. Predicting and Understanding Urban Perception with Convolutional Neural Networks; ACM: New York, NY, USA, 2015. [Google Scholar]
- Dai, M.; Gao, C.; Nie, Q.; Wang, Q.-J.; Lin, Y.-F.; Chu, J.; Li, W. Properties, Synthesis, and Device Applications of 2D Layered InSe. Adv. Mater. Technol. 2022, 7, 202200321. [Google Scholar] [CrossRef]
- Park, S.; Kim, K.; Yu, S.; Paik, J. Contrast Enhancement for Low-Light Image Enhancement: A Survey. IEIE Trans. Smart Process. Comput. 2018, 7, 36–48. [Google Scholar] [CrossRef]
- Wang, Y.-F.; Liu, H.-M.; Fu, Z.-W. Low-Light Image Enhancement via the Absorption Light Scattering Model. IEEE Trans. Image Process. 2019, 28, 5679–5690. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.-F.; Zhang, X.-S.; Li, Y.-J. A Biological Vision Inspired Framework for Image Enhancement in Poor Visibility Conditions. IEEE Trans. Image Process. 2020, 29, 1493–1506. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Guo, C.; Han, L.; Jiang, J.; Cheng, M.-M.; Gu, J.; Loy, C.C. Low-Light Image and Video Enhancement Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9396–9416. [Google Scholar] [CrossRef] [PubMed]
- Sugimura, D.; Mikami, T.; Yamashita, H.; Hamamoto, T. Enhancing Color Images of Extremely Low Light Scenes Based on RGB/NIR Images Acquisition with Different Exposure Times. IEEE Trans. Image Process. 2015, 24, 3586–3597. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Gu, S.; Zhang, L.; Zhang, L. Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to See in the Dark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement without Paired Supervision. arXiv 2021, arXiv:1906.06972. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Ma, L.; Xu, Q.; Xu, X.; Cao, X.; Du, J.; Yang, M.-H. Low-Light Image Enhancement via a Deep Hybrid Network. IEEE Trans. Image Process. 2019, 28, 4364–4375. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, Q.; Fu, C.-W.; Shen, X.; Zheng, W.-S.; Jia, J. Underexposed Photo Enhancement Using Deep Illumination Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6842–6850. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Pan, Z.; Yu, W.; Wang, B.; Xie, H.; Sheng, V.S.; Lei, J.; Kwong, S. Loss Functions of Generative Adversarial Networks (GANs): Opportunities and Challenges. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 500–522. [Google Scholar] [CrossRef]
- Hong, Y.; Hwang, U.; Yoo, J.; Yoon, S. How Generative Adversarial Networks and Their Variants Work: An Overview. ACM Comput. Surv. 2019, 52, 1–43. [Google Scholar] [CrossRef]
- Smolensky, P. Information Processing in Dynamical Systems: Foundations of Harmony Theory. Parallel Distrib. Process 1986, 1, 194–281. [Google Scholar]
- StableDiffusion Stable Diffusion API Docs|Stable Diffusion API Documentation. Available online: https://stablediffusionapi.com/docs/ (accessed on 28 February 2024).
- Ulhaq, A.; Akhtar, N.; Pogrebna, G. Efficient Diffusion Models for Vision: A Survey. arXiv 2022, arXiv:2210.09292. [Google Scholar]
- Stöckl, A. Evaluating a Synthetic Image Dataset Generated with Stable Diffusion. In Proceedings of the Eighth International Congress on Information and Communication Technology, London, UK, 20–23 February 2023; Yang, X.-S., Sherratt, R.S., Dey, N., Joshi, A., Eds.; Springer: Singapore, 2023; pp. 805–818. [Google Scholar]
- Du, C.; Li, Y.; Qiu, Z.; Xu, C. Stable Diffusion Is Unstable. arXiv 2023, arXiv:2306.02583. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv 2017, arXiv:1611.07004. [Google Scholar]
- Lu, G.; Zhou, Z.; Song, Y.; Ren, K.; Yu, Y. Guiding the One-to-One Mapping in CycleGAN via Optimal Transport. Proc. AAAI Conf. Artif. Intell. 2019, 33, 4432–4439. [Google Scholar] [CrossRef]
- Upadhyay, U.; Chen, Y.; Akata, Z. Uncertainty-Aware Generalized Adaptive CycleGAN. arXiv 2021, arXiv:2102.11747. [Google Scholar]
- Talen, E. City Rules: How Regulations Affect Urban Form; Shearwater Books; Island Press: Washington, DC, USA, 2011; Available online: https://www.semanticscholar.org/paper/City-Rules:-How-Regulations-Affect-Urban-Form-Talen-Duany/1017b0381cf51d419bd87e1b149774cfc9dbf7c6 (accessed on 16 April 2024).
- Newman, O. Creating Defensible Space; DIANE Publishing: Darby, PA, USA, 1996. Available online: https://www.huduser.gov/portal/publications/pubasst/defensib.html (accessed on 16 April 2024).
- Tian, H.; Han, Z.; Xu, W.; Liu, X.; Qiu, W.; Li, W. Evolution of Historical Urban Landscape with Computer Vision and Machine Learning: A Case Study of Berlin. J. Digit. Landsc. Archit. 2021, 2021, 436–451. [Google Scholar] [CrossRef]
- Yang, S.; Krenz, K.; Qiu, W.; Li, W. The Role of Subjective Perceptions and Objective Measurements of the Urban Environment in Explaining House Prices in Greater London: A Multi-Scale Urban Morphology Analysis. ISPRS Int. J. Geo-Inf. 2023, 12, 249. [Google Scholar] [CrossRef]
- Ewing, R.; Handy, S.; Brownson, R.C.; Clemente, O.; Winston, E. Identifying and Measuring Urban Design Qualities Related to Walkability. J. Phys. Act. Health 2006, 3, S223–S240. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic Understanding of Scenes Through the ADE20K Dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Changsha, China, 20–23 November 2016. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. arXiv 2018, arXiv:1706.08500. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | IRR | Average IRR | ICC Values | |
|---|---|---|---|---|
| % Agreement | % Agreement | Single-Measure ICC (1,1) | Avg-Measure ICC (1,k) | |
| The discernible difference in perception | 56.69 | 90.30 | 0.226 | 0.467 |
| Within-Group Correlation | 95% Confidence Interval | F-Test for True Value 0 | |||||
|---|---|---|---|---|---|---|---|
| Lower Bound | Upper Bound | Value | df1 | df2 | p-Value | ||
| Single Measure ICC (1,1) | 0.226 | 0.117 | 0.343 | 1.879 | 126 | 254 | 0.000 *** |
| Avg-Measure ICC (1,k) | 0.467 | 0.285 | 0.61 | 1.879 | 126 | 254 | 0.000 *** |
| L1 | L2 | SSIM | IS | FID | |||||
|---|---|---|---|---|---|---|---|---|---|
| Avg. | S.D. | Avg. | S.D. | Avg. | S.D. | Avg. | S.D. | Avg. | |
| Pix2Pix | 129.70 | 23.88 | 101.79 | 5.60 | 0.22 | 0.07 | 1.86 | 0.08 | 178.68 |
| CycleGAN | 123.03 | 25.53 | 100.53 | 5.39 | 0.24 | 0.07 | 2.54 | 0.18 | 115.23 |
| Stable Diffusion | 141.74 | 13.03 | 104.75 | 2.08 | 0.18 | 0.07 | 2.41 | 0.33 | 156.17 |
| D2N (ours) | 122.89 | 25.73 | 100.54 | 5.38 | 0.24 | 0.07 | 2.48 | 0.31 | 115.17 |
| OLS Coefficients | ||||
|---|---|---|---|---|
| Variables | VIF | L1 Distance | L2 Distance | SSIM |
| Constant | / | 134.7943 | 0.5100 | 0.2755 |
| Building | 4.42 | −17.5975 | 0.2874 | −0.1753 *** |
| Earth | 1.05 | −306.7485 | −0.6346 | 0.6700 |
| Fence | 1.10 | −100.0013 | 1.8497 *** | −0.4104** |
| Grass | 1.25 | −25.5067 | −0.8303 | 0.3663 ** |
| Plant | 1.39 | −37.3540 | 0.8065 ** | −0.0471 |
| Sidewalk | 1.29 | 66.4387 | 0.7130 ** | 0.0156 |
| Sky | 3.06 | −24.9585 | 0.6250 *** | 0.3496 *** |
| Tree | 4.58 | −14.9638 | −0.3477 * | −0.0675 |
| Wall | 2.84 | −11.2872 | 0.1433 | −0.0319 |
| Day/Real Night/Generated Night | Sky View | L1 | L2 | SSIM |
|---|---|---|---|---|


 | 0 | 130.1384 | 110.0487 | 0.1879 |


 | 0.166 | 128.6256 | 104.0358 | 0.2639 |


 | 0.3725 | 147.409 | 93.0938 | 0.4559 |
| Day/Real Night/Generated Night | Building View | L1 | L2 | SSIM |
|---|---|---|---|---|


 | 0 | 147.409 | 93.0938 | 0.4559 |


 | 0.2639 | 108.0863 | 101.4729 | 0.34041 |


 | 0.6231 | 139.394 | 105.7735 | 0.1330 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Li, T.; Ren, T.; Chen, D.; Li, W.; Qiu, W. Day-to-Night Street View Image Generation for 24-Hour Urban Scene Auditing Using Generative AI. J. Imaging 2024, 10, 112. https://doi.org/10.3390/jimaging10050112
Liu Z, Li T, Ren T, Chen D, Li W, Qiu W. Day-to-Night Street View Image Generation for 24-Hour Urban Scene Auditing Using Generative AI. Journal of Imaging. 2024; 10(5):112. https://doi.org/10.3390/jimaging10050112
Chicago/Turabian StyleLiu, Zhiyi, Tingting Li, Tianyi Ren, Da Chen, Wenjing Li, and Waishan Qiu. 2024. "Day-to-Night Street View Image Generation for 24-Hour Urban Scene Auditing Using Generative AI" Journal of Imaging 10, no. 5: 112. https://doi.org/10.3390/jimaging10050112
APA StyleLiu, Z., Li, T., Ren, T., Chen, D., Li, W., & Qiu, W. (2024). Day-to-Night Street View Image Generation for 24-Hour Urban Scene Auditing Using Generative AI. Journal of Imaging, 10(5), 112. https://doi.org/10.3390/jimaging10050112