
Current Status and Challenges and Future Trends of Deep Learning-Based Intrusion Detection Models

Abstract
1. Introduction
2. Dataset of Network Intrusion Detection
2.1. KDDCup99
2.2. NSL-KDD
2.3. UNSW-NB15
2.4. CIC-IDS 2017
2.5. Kyoto2006+
2.6. ISCX2012
2.7. MQTTset2020
2.8. Brief Summary
3. Data Preprocessing Methods and Feature Engineering Techniques
3.1. Common Data Preprocessing Methods
3.1.1. Data Numerical Processing
3.1.2. Data Standardization Processing
3.1.3. Handling Imbalanced Datasets
3.1.4. Graphical Data Processing
3.2. Common Feature Engineering Techniques
3.2.1. Feature Selection and Dimensionality Reduction
3.2.2. Deep Feature Extraction
3.2.3. Feature Construction
4. Intrusion Detection Model Based on DL
4.1. Introduction to DAE-IDMs
4.2. Introduction to DBN-IDMs
4.3. Introduction to DNN-IDMs
4.4. Introduction to CNN-IDMs
4.5. Introduction to RNN-IDMs
4.5.1. IDM Based on an LSTM
4.5.2. IDM Based on a Gated Recurrent Neural Network (GRNN)
4.6. Introduction to GAN-IDMs
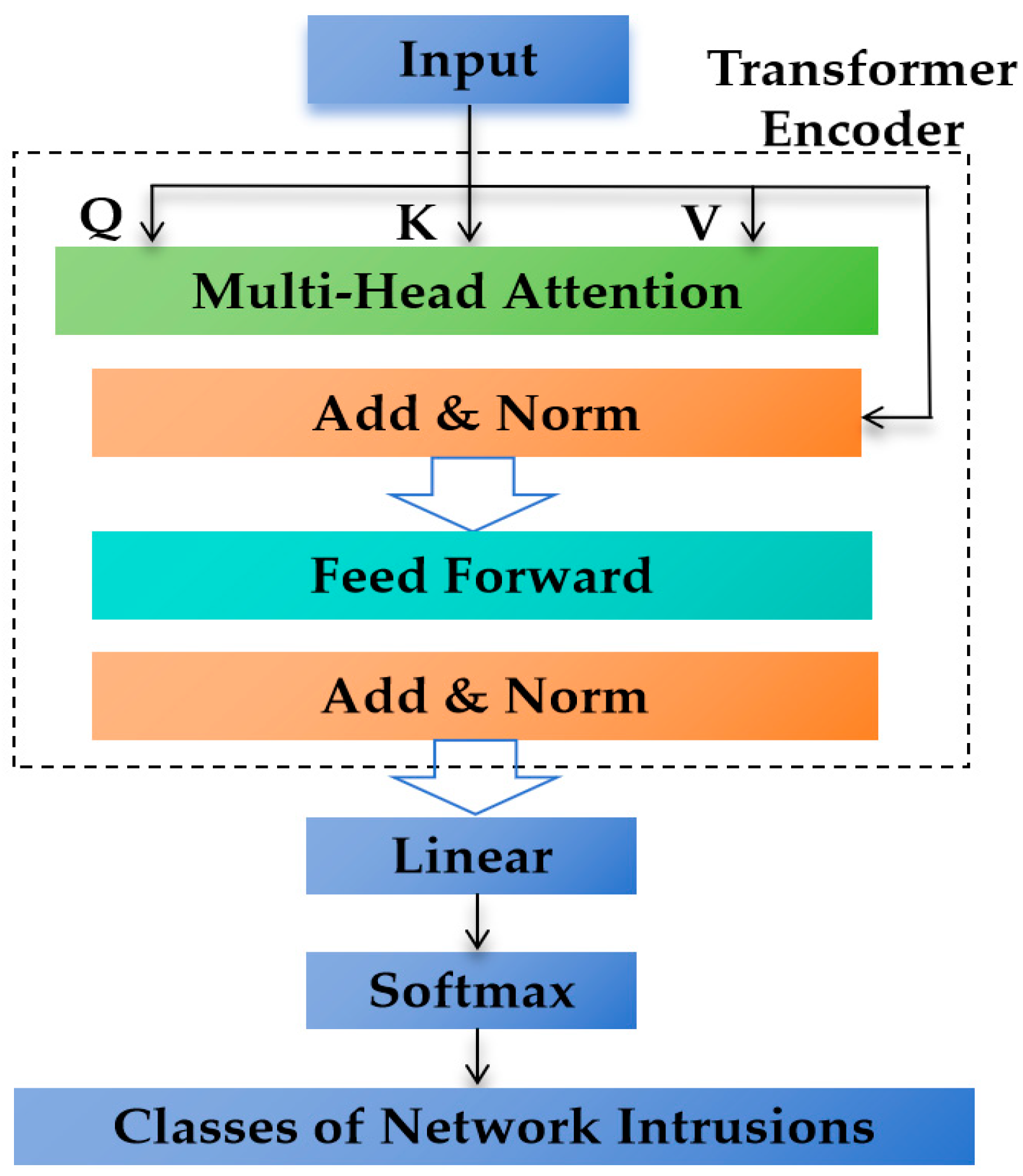
4.7. Introduction to TF-IDMs
4.8. Introduction to BERT-IDMs
4.9. Introduction to GPT-IDMs
4.10. Summary
5. Challenges and Future Trends
5.1. Challenges
5.1.1. Unavailability of System Datasets
5.1.2. Imbalanced Datasets Leading to Reduced Detection Accuracy
5.1.3. Low Performance in Real-World Environments
5.1.4. Resources Consumed by Complex Models
5.2. Future Development Trend
5.2.1. Efficient NIDS Framework
5.2.2. Updating Datasets and Adapting to the Real Network Environment
5.2.3. Optimizing Models in Resource-Constrained Environments
5.2.4. Evolution and Integration of NIDSs
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Serinelli, B.; Collen, A.; Nijdam, N. Training Guidance with KDD Cup 1999 and NSL-KDD Datasets of ANIDINR: Anomaly-Based Network Intrusion Detection System. Procedia Comput. Sci. 2020, 175, 560–565. [Google Scholar] [CrossRef]
- Hindy, H.; Atkinson, R.; Tachtatzis, C.; Colin, J.; Bellekens, X. Utilizing Deep Learning Techniques for Effective Zero-Day Attack Detection. Electronics 2020, 9, 1684. [Google Scholar] [CrossRef]
- Gumusbas, D.; Yildirim, T.; Genovese, A. A Comprehensive Survey of Databases and Deep Learning Methods for Cybersecurity and Intrusion Detection Systems. IEEE Syst. J. 2020, 15, 1717–1731. [Google Scholar] [CrossRef]
- Tidjon, L.N.; Frappier, M.; Mammar, A. Intrusion Detection Systems: A Cross-Domain Overview. IEEE Commun. Surv. Tutor. 2019, 21, 3639–3681. [Google Scholar] [CrossRef]
- Alrawashedeh, K.; Purdy, C. Toward an Online Anomaly Intrusion Detection System Based on Deep Learning. In Proceedings of the 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 195–200. [Google Scholar] [CrossRef]
- Tavallaee, M.; Stakhanova, N.; Ghorbani, A. Toward Credible Evaluation of Anomaly-Based Intrusion-Detection Methods. IEEE Trans. Syst. Man Cybern. Part C 2010, 40, 516–524. [Google Scholar] [CrossRef]
- Radivilova, T.; Kirichenko, L.; Alghawli, A.S.; Ageyev, D.; Mulesa, O.; Baranovskyi, O.; Ilkov, A.; Kulbachnyi, V.; Bondarenko, O. Statistical and Signature Analysis Methods of Intrusion Detection. In Information Security Technologies in the Decentralized Distributed Networks; Lecture Notes on Data Engineering and Communications Technologies; Oliynykov, R., Kuznetsov, O., Lemeshko, O., Radivilova, T., Eds.; Springer: Cham, Switzerland, 2022; Volume 115, pp. 115–136. [Google Scholar] [CrossRef]
- Gamage, S.; Samarabandu, J. Deep Learning Methods in Network Intrusion Detection: A Survey and an Objective Comparison. J. Netw. Comput. Appl. 2020, 169, 102767. [Google Scholar] [CrossRef]
- Ayo, F.E.; Folorunso, S.O.; Abayomi-alli, A.A. Network Intrusion Detection Based on Deep Learning Model Optimized with Rule-Based Hybrid Feature Selection. Inf. Secur. J. 2020, 29, 267–283. [Google Scholar] [CrossRef]
- Gurung, S.; Ghose, M.K.; Subedi, A. Deep Learning Approach on Network Intrusion Detection System Using NSL-KDD Dataset. Int. J. Comput. Netw. Inf. Secur. 2019, 11, 8–14. [Google Scholar] [CrossRef]
- Sai, S.; Lu, Z. Overview of Network Intrusion Detection Technology. J. Inf. Secur. 2020, 5, 96–122. [Google Scholar] [CrossRef]
- Stolfo, S.; Fan, W.; Lee, W.; Prodromidis, A.; Chan, P. KDD Cup 1999 Data. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/datasets/kdd+cup+1999+data (accessed on 5 March 2024).
- Siddique, K.; Akhtar, Z.; Khan, F.A.; Kim, Y. KDD Cup 99 Datasets: A Perspective on the Role of Datasets in Network Intrusion Detection Research. Computer 2019, 52, 41–51. [Google Scholar] [CrossRef]
- Thomas, R.; Pavithran, D. A Survey of Intrusion Detection Models Based on NSL-KDD Data Set. In Proceedings of the 2018 Fifth HCT Information Technology Trends (ITT), Dubai, United Arab Emirates, 28–29 November 2018; pp. 286–291. [Google Scholar] [CrossRef]
- Hassan, M.M.; Gumaei, A.; Alsanad, A.; Alrubaian, M.; Fortino, G. A Hybrid Deep Learning Model for Efficient Intrusion Detection in Big Data Environment. Inf. Sci. 2020, 513, 386–396. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Gharib, A.; Lashkari, A.H.; Ghorbani, A.A. Towards a Reliable Intrusion Detection Benchmark Dataset. Softw. Netw. 2018, 2018, 177–200. [Google Scholar] [CrossRef]
- Song, J.; Takakura, H.; Okabe, Y. Statistical Analysis of Honeypot Data and Building of Kyoto 2006+ Dataset for NIDS Evaluation. In Proceedings of the First Workshop on Building Analysis Datasets and Gathering Experience Returns for Security, Salzburg, Austria, 10–13 April 2011; pp. 29–36. [Google Scholar] [CrossRef]
- Shiravi, A.; Shiravi, H.; Tavallaee, M. Toward Developing a Systematic Approach to Generate Benchmark Datasets for Intrusion Detection. Comput. Secur. 2012, 31, 357–374. [Google Scholar] [CrossRef]
- Vaccari, I.; Chiola, G.; Aiello, M.; Mongelli, M.; Cambiaso, E. MQTTset: A New Dataset for Machine Learning Techniques on MQTT. Sensors 2020, 20, 6578. [Google Scholar] [CrossRef]
- Neto, E.C.P.; Dadkhah, S.; Ferreira, R.; Zohourian, A.; Lu, R.; Ghorbani, A.A. CICIoT2023: A Real-Time Dataset and Benchmark for Large-Scale Attacks in IoT Environment. Sensors 2023, 23, 5941. [Google Scholar] [CrossRef] [PubMed]
- Moustafa, N.; Slay, J. UNSW-NB15: A Comprehensive Data Set for Network Intrusion Detection Systems (UNSW-NB15 Network Data Set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Booij, T.M.; Chiscop, I.; Meeuwissen, E.; Moustafa, N.; Hartog, F.T.H.D. ToN_IoT: The Role of Heterogeneity and the Need for Standardization of Features and Attack Types in IoT Network Intrusion Data Sets. IEEE Internet Things J. 2022, 9, 1–10. [Google Scholar] [CrossRef]
- Lin, S. Intrusion Detection Model Based on Deep Learning. Control Eng. 2021, 28, 1873–1878. [Google Scholar] [CrossRef]
- Yan, Y.; Qi, L.; Wang, J. A Network Intrusion Detection Method Based on Stacked Auto-Encoder and LSTM. In Proceedings of the 2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Hu, Z.; Wang, L.; Qi, L. A Novel Wireless Network Intrusion Detection Method Based on Adaptive Synthetic Sampling and an Improved Convolutional Neural Network. IEEE Access 2020, 8, 195741–195751. [Google Scholar] [CrossRef]
- Liu, C.; Liu, Y.; Yan, Y. An Intrusion Detection Model with Hierarchical Attention Mechanism. IEEE Access 2020, 8, 67542–67554. [Google Scholar] [CrossRef]
- Shahriar, M.H.; Haque, N.I.; Rahman, M.A. G-IDS: Generative Adversarial Networks Assisted Intrusion Detection System. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 376–385. [Google Scholar] [CrossRef]
- Liu, D.; Zhong, S.; Lin, L.; Zhao, M.; Fu, X.; Liu, X. Deep Attention SMOTE: Data Augmentation with a Learnable Interpolation Factor for Imbalanced Anomaly Detection of Gas Turbines. Comput. Ind. 2023, 151, 103972. [Google Scholar] [CrossRef]
- Li, H.; Liu, H.; Hu, Y. Prediction of Unbalanced Financial Risk Based on GRA-TOPSIS and SMOTE-CNN. Sci. Prog. 2022, 2022, 8074516. [Google Scholar] [CrossRef]
- Ali, B.S.; Ullah, I.; Al Shloul, T.; Khan, I.A.; Khan, I.; Ghadi, Y.Y.; Abdusalomov, A.; Nasimov, R.; Ouahada, K.; Hamam, H. ICS-IDS: Application of Big Data Analysis in AI-Based Intrusion Detection Systems to Identify Cyberattacks in ICS Networks. J. Supercomput. 2024, 80, 7876–7905. [Google Scholar] [CrossRef]
- Chen, J.; Qi, X.; Chen, L. Quantum-Inspired Ant Lion Optimized Hybrid K-Means for Cluster Analysis and Intrusion Detection. Knowl.-Based Syst. 2020, 203, 106167. [Google Scholar] [CrossRef]
- Chen, L.; Weng, E.; Peng, C.J.; Shuai, H.H.; Cheng, W.H. ZYELL-NCTU NetTraffic-1.0: A Large-Scale Dataset for Real-World Network Anomaly Detection. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Penghu, Taiwan, 15–17 September 2021; pp. 1–2. [Google Scholar] [CrossRef]
- Farahnakian, F.; Heikkonen, J. A Deep Auto-Encoder Based Approach for Intrusion Detection System. In Proceedings of the 2018 20th International Conference on Advanced Communication Technology (ICACT), Chuncheon, Republic of Korea, 11–14 February 2018; pp. 178–183. [Google Scholar] [CrossRef]
- Farid, D.M.; Harbi, N.; Rahman, M.Z. Combining Naive Bayes and Decision Tree for Adaptive Intrusion Detection. arXiv 2010, arXiv:1005.4496. [Google Scholar] [CrossRef]
- Farnaaz, N.; Jabbar, M.A. Random Forest Modeling for Network Intrusion Detection System. Procedia Comput. Sci. 2016, 89, 213–217. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Maglaras, L.; Moschoyiannis, S. Deep Learning for Cybersecurity Intrusion Detection: Approaches, Datasets, and Comparative Study. J. Inf. Secur. Appl. 2020, 50, 102419. [Google Scholar] [CrossRef]
- Patsakis, C.; Casino, F.; Lykousas, N. Assessing LLMs in Malicious Code Deobfuscation of Real-World Malware Campaigns. arXiv 2024, arXiv:2404.19715. [Google Scholar] [CrossRef]
- Shone, N.; Ngoc, T.N.; Phai, V.D. A Deep Learning Approach to Network Intrusion Detection. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 41–50. [Google Scholar] [CrossRef]
- Khan, F.A.; Gumaei, A.; Derhab, A. A Novel Two-Stage Deep Learning Model for Efficient Network Intrusion Detection. IEEE Access 2019, 7, 30373–30385. [Google Scholar] [CrossRef]
- Yan, B.; Han, G. Effective Feature Extraction via Stacked Sparse Autoencoder to Improve Intrusion Detection System. IEEE Access 2018, 6, 41238–41248. [Google Scholar] [CrossRef]
- Peng, W.; Kong, X.; Peng, G. Network Intrusion Detection Based on Deep Learning. In Proceedings of the 2019 International Conference on Communications, Information System and Computer Engineering (CISCE), Haikou, China, 5–7 July 2019; pp. 431–435. [Google Scholar] [CrossRef]
- Thaseen, I.S.; Kumar, C.A. Intrusion Detection Model Using Fusion of PCA and Optimized SVM. In Proceedings of the 2014 International Conference on Contemporary Computing and Informatics (IC3I), Mysore, India, 27–29 November 2014; pp. 879–884. [Google Scholar] [CrossRef]
- Al-Qatf, M.L.; Habib, Y.; Al-Sabahi, M.K. Deep Learning Approach Combining Sparse Autoencoder with SVM for Network Intrusion Detection. IEEE Access 2018, 6, 52843–52856. [Google Scholar] [CrossRef]
- Zavrak, S.; İskefiyeli, M. Anomaly-Based Intrusion Detection from Network Flow Features Using Variational Autoencoder. IEEE Access 2020, 8, 108346–108358. [Google Scholar] [CrossRef]
- Aldwairi, T.; Perera, D.; Novotny, M.A. An Evaluation of the Performance of Restricted Boltzmann Machines as a Model for Anomaly Network Intrusion Detection. Comput. Netw. 2018, 144, 111–119. [Google Scholar] [CrossRef]
- Wu, G.; Li, C.; Yin, L.; Wang, J.; Zheng, X. Comparison between Support Vector Machine (SVM) and Deep Belief Network (DBN) for Multi-Classification of Raman Spectroscopy for Cervical Diseases. Photodiagnosis Photodyn. Ther. 2023, 42, 103340. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Lv, Z. A Real-Time and Ubiquitous Network Attack Detection Based on Deep Belief Network and Support Vector Machine. IEEE/CAA J. Autom. Sinica 2020, 7, 790–799. [Google Scholar] [CrossRef]
- Zhao, G.; Zhang, C.; Zheng, L. Intrusion Detection Using Deep Belief Network and Probabilistic Neural Network. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; pp. 639–642. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, C.; Niu, X.; Yang, Y. Building an Effective Intrusion Detection System Using the Modified Density Peak Clustering Algorithm and Deep Belief Networks. Appl. Sci. 2019, 9, 238. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, P.; Wang, X. Intrusion Detection for IoT Based on Improved Genetic Algorithm and Deep Belief Network. IEEE Access 2019, 7, 31711–31722. [Google Scholar] [CrossRef]
- Wang, Z.; Zeng, Y.; Liu, Y. Deep Belief Network Integrating Improved Kernel-Based Extreme Learning Machine for Network Intrusion Detection. IEEE Access 2021, 9, 16062–16091. [Google Scholar] [CrossRef]
- Vigneswaran, R.K.; Vinayakumar, R.; Soman, K.P. Evaluating Shallow and Deep Neural Networks for Network Intrusion Detection Systems in Cyber Security. In Proceedings of the 2018 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ma, T.; Wang, F.; Cheng, J. A Hybrid Spectral Clustering and Deep Neural Network Ensemble Algorithm for Intrusion Detection in Sensor Networks. Sensors 2016, 16, 1701. [Google Scholar] [CrossRef]
- Khare, N.; Devan, P.; Chowdhary, C.L. SMO-DNN: Spider Monkey Optimization and Deep Neural Network Hybrid Classifier Model for Intrusion Detection. Electronics 2020, 9, 692. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, K.; Wu, C.; Yang, Y. Improving the Classification Effectiveness of Intrusion Detection by Using Improved Conditional Variational Autoencoder and Deep Neural Network. Sensors 2019, 19, 2528. [Google Scholar] [CrossRef] [PubMed]
- Khan, R.U.; Zhang, X.; Alazab, M.; Kumar, R. An Improved Convolutional Neural Network Model for Intrusion Detection in Networks. In Proceedings of the 2019 Cybersecurity and Cyberforensics Conference (CCC), Melbourne, VIC, Australia, 8–9 May 2019; pp. 74–77. [Google Scholar] [CrossRef]
- Riyaz, B.; Ganapathy, S. A Deep Learning Approach for Effective Intrusion Detection in Wireless Networks Using CNN. Soft Comput. 2020, 24, 17265–17278. [Google Scholar] [CrossRef]
- Wu, K.; Chen, Z.; Li, W. A Novel Intrusion Detection Model for a Massive Network Using Convolutional Neural Networks. IEEE Access 2018, 6, 50850–50859. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, L.; Wu, C.Q.; Li, Z. An Effective Convolutional Neural Network Based on SMOTE and Gaussian Mixture Model for Intrusion Detection in Imbalanced Dataset. Comput. Netw. 2020, 177, 107315. [Google Scholar] [CrossRef]
- Wu, Q.; Huang, S. Intrusion Detection Algorithm Based on Convolutional Neural Network and Three Branch Decision. Comput. Eng. Appl. 2022, 58, 119–127. [Google Scholar] [CrossRef]
- Wang, W.; Sheng, Y.; Wang, J. HAST-IDS: Learning Hierarchical Spatial-Temporal Features Using Deep Neural Networks to Improve Intrusion Detection. IEEE Access 2017, 6, 1792–1806. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A Deep Learning Approach for Intrusion Detection Using Recurrent Neural Networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Su, T.; Sun, H.; Zhu, J. BAT: Deep Learning Methods on Network Intrusion Detection Using NSL-KDD Dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Mirza, A.H.; Cosan, S. Computer Network Intrusion Detection Using Sequential LSTM Neural Networks Autoencoders. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turke, 2–5 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Agarap, A.F. A Neural Network Architecture Combining Gated Recurrent Unit (GRU) and Support Vector Machine (SVM) for Intrusion Detection in Network Traffic Data. In Proceedings of the 2018 10th International Conference on Machine Learning and Computing, Macau, China, 26–28 February 2018; pp. 26–30. [Google Scholar] [CrossRef]
- Xu, C.; Shen, J.; Du, X.; Fan, Z. An Intrusion Detection System Using a Deep Neural Network with Gated Recurrent Units. IEEE Access 2018, 6, 48697–48707. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Soman, K.P.; Poornachandran, P. Applying Convolutional Neural Network for Network Intrusion Detection. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1222–1228. [Google Scholar] [CrossRef]
- Altunay, H.C.; Albayrak, Z. A Hybrid CNN+LSTM-Based Intrusion Detection System for Industrial IoT Networks. Eng. Sci. Technol. Int. J. 2023, 38, 101322. [Google Scholar] [CrossRef]
- Salem, M.; Taheri, S.; Yuan, J.S. Anomaly Generation Using Generative Adversarial Networks in Host-Based Intrusion Detection. In Proceedings of the IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 8–10 November 2018; pp. 683–687. [Google Scholar] [CrossRef]
- Li, D.; Kotani, D.; Okabe, Y. Improving Attack Detection Performance in NIDS Using GAN. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 817–825. [Google Scholar] [CrossRef]
- Liu, X.; Li, T.; Zhang, R. A GAN and Feature Selection-Based Oversampling Technique for Intrusion Detection. Secur. Commun. Netw. 2021, 2021, 9947059. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Yin, S.; Zhang, X.; Liu, S. Intrusion Detection for Capsule Networks Based on Dual Routing Mechanism. Comput. Netw. 2021, 197, 108328. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, X. Intrusion Detection System Based on Dual Attention. NetInfo Secur. 2022, 22, 80–86. [Google Scholar] [CrossRef]
- Yao, R.; Wang, N.; Chen, P.; Ma, D.; Sheng, X. A CNN-Transformer Hybrid Approach for an Intrusion Detection System in Advanced Metering Infrastructure. Multimed. Tools Appl. 2023, 82, 19463–19486. [Google Scholar] [CrossRef]
- Han, X.; Cui, S.; Liu, S.; Zhang, C.; Jiang, B.; Lu, Z. Network Intrusion Detection Based on N-Gram Frequency and Time-Aware Transformer. Comput. Secur. 2023, 128, 103171. [Google Scholar] [CrossRef]
- Wang, S.; Xu, W.; Liu, Y. Res-TranBiLSTM: An Intelligent Approach for Intrusion Detection in the Internet of Things. Comput. Netw. 2023, 235, 109982. [Google Scholar] [CrossRef]
- Long, Z.; Yan, H.; Shen, G.; Zhang, X.; He, H.; Cheng, L. A Transformer-Based Network Intrusion Detection Approach for Cloud Security. J. Cloud Comput. 2024, 13, 5. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Nguyen, G.L.; Watabe, K. A Method for Network Intrusion Detection Using Flow Sequence and BERT Framework. In Proceedings of the ICC 2023—IEEE International Conference on Communications, Rome, Italy, 28 May–1 June 2023; pp. 3006–3011. [Google Scholar] [CrossRef]
- Waisberg, E.; Ong, J.; Masalkhi, M.; Kamran, S.A.; Zaman, N.; Sarker, P.; Lee, A.G.; Tavakkoli, A. GPT-4: A New Era of Artificial Intelligence in Medicine. Ir. J. Med. Sci. 2023, 192, 3197–3200. [Google Scholar] [CrossRef] [PubMed]
- Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al. The LLaMA 3 Herd of Models. arXiv 2024, arXiv:2407.21783. [Google Scholar] [CrossRef]
- Houssel, P.R.; Singh, P.; Layeghy, S.; Portmann, M. Towards Explainable Network Intrusion Detection Using Large Language Models. arXiv 2024, arXiv:2408.04342. [Google Scholar] [CrossRef]
- Xie, Y.; Yu, B.; Lv, S.; Zhang, C.; Wang, G.; Gong, M. A Survey on Heterogeneous Network Representation Learning. Pattern Recognit. 2021, 116, 107936. [Google Scholar] [CrossRef]
- Wang, Z.; Li, J.; Yang, S.; Luo, X.; Li, D.; Mahmoodi, S. A Lightweight IoT Intrusion Detection Model Based on Improved BERT-of-Theseus. Expert Syst. Appl. 2023, 238, 122045. [Google Scholar] [CrossRef]
- Halgamuge, M.N.; Niyato, D. Adaptive Edge Security Framework for Dynamic IoT Security Policies in Diverse Environments. Comput. Secur. 2025, 148, 104128. [Google Scholar] [CrossRef]
- Song, X.; Chen, Q.; Wang, S.; Song, T. Cross-Domain Resources Optimization for Hybrid Edge Computing Networks: Federated DRL Approach. Digit. Commun. Netw. 2024. [Google Scholar] [CrossRef]
- Liu, F.; Li, H.; Hu, W.; He, Y. Review of Neural Network Model Acceleration Techniques Based on FPGA Platforms. Neurocomputing 2024, 610, 128511. [Google Scholar] [CrossRef]
- Zeng, L.; Liu, Q.; Shen, S.; Liu, X. Improved Double Deep Q Network-Based Task Scheduling Algorithm in Edge Computing for Makespan Optimization. Tsinghua Sci. Technol. 2024, 29, 806–817. [Google Scholar] [CrossRef]
- Abdulkareem, S.A.; Foh, C.H.; Carrez, F.; Moessner, K. A Lightweight SEL for Attack Detection in IoT/IIoT Networks. J. Netw. Comput. Appl. 2024, 230, 103980. [Google Scholar] [CrossRef]
- Kaur, A. Intrusion Detection Approach for Industrial Internet of Things Traffic Using Deep Recurrent Reinforcement Learning Assisted Federated Learning. IEEE Trans. Artif. Intell. 2024. [Google Scholar] [CrossRef]
- Wei, S.; Yu, C.; Liao, X.; Siyu, W. Smart Infrastructure Design: Machine Learning Solutions for Securing Modern Cities. Sustain. Cities Soc. 2024, 107, 105439. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Bharany, S.; Abulfaraj, A.W.; Osman Ibrahim, A.; Nagmeldin, W.A. Fortifying Home IoT Security: A Framework for Comprehensive Examination of Vulnerabilities and Intrusion Detection Strategies for Smart Cities. Egypt. Inform. J. 2024, 25, 100443. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Dataset | Year of Creation | Numbers of Network Attacks | Attack Types |
|---|---|---|---|
| KDDCUP99 | 1998 | 4 | Probe, DOS, U2R, R2L |
| NSL-KDD | 2009 | 4 | DoS, Probe, R2L, U2R |
| UNSW-NB15 | 2015 | 9 | Backdoors, DoS, Exploits, Fuzzers, Generic, Analysis, Reconnaissance, Shellcode, Worms |
| CIC-IDS2017 | 2017 | 7 | Brute Force, HeartBleed, Botnet, DoS, DDoS, Web, Infiltration |
| Kyoto2006+ | 2006 | 3 | Normal, Attacks, Unknown Attacks |
| ISCX2012 | 2012 | 4 | HTTPDos, DDos using an IRC botnet, SSH brute force |
| MQTTet2020 | 2020 | 5 | DoS, Brute force, Malformed, SlowITe, Flood |
| Refs | DL Technology | Feature Election/Extraction | Dataset | Task Classes | Performance Evaluation |
|---|---|---|---|---|---|
| [33] | AE | AE | KDDCup99 | BC;MC | BC: ACC: 96.53%, FPR: 0.35% MC: 94.71% |
| [38] | DAE | DAE | NSL-KDD; KDDCup99 | MC | NSL-KDD: ACC: 85.42%, Recall: 85.42%, F1: 87.37% KDDCup99: ACC: 97.85%, Recall: 97.85%, F1: 98.15% |
| [39] | SDAE | SDAE | KDDCup99; UNSW-NB15 | MC | KDDCup99: ACC: 99.996%, FPR: 0.00001% UNSW-NB15: ACC: 89.134%, FPR: 0.7495% |
| [40] | SSAE | SSAE | NSL-KDD | MC | ACC: 99.35%, Recall: 99.01%, FPR: 0.13% Recall: 99.43% (Normal), 99.35% (Dos), 99.03% (Probe), 83.43% (R2L), 67.94% (U2R) |
| [46] | DBN | DBN | 10%KDDCup99 | BC | ACC: 95.45% |
| [47] | DBN | DBN | CIC-IDS2017 | MC | Precision: 97.8%, Recall: 97.73%, F1: 97.74% |
| [48] | DBN, PNN | DBN | KDDCup99 | MC | ACC: 99.14%, DR: 93.25%, FPR: 0.615% |
| [49] | DBN | DBN | NSL-KDD; UNSW-NB15 | MC | NSL-KDD: ACC: 82.08%, Recall: 70.51%, Precision: 97.27%, F1: 81.75%, FPR: 2.62% UNSW-NB15: ACC: 90.21%, Recall: 90.22%, Precision: 87.3%, F1: 91.54%, FPR: 17.15% |
| [50] | DBN | GA | NSL-KDD | MC | ACC: 98.82%, Recall: 97.67%, FAR: 2.65% |
| [51] | DBN, KELM | DBN | KDDCup99; NSL-KDD;UNSW-NB15;CIC-IDS2017 | BC;MC | BC: KDDCup99: Precision: 94%, Recall: 98.73%, F1: 96.31% NSL-KDD: Precision: 93.64%, Recall: 98.4%, F1: 96.6% UNSW-NB15: Precision: 82.3%, Recall: 96.4%, F1: 88.79% CIC-IDS2017: Precision: 96.8%, Recall: 98.19%, F1: 97.49% |
| [53] | DNN | SC | KDDCup99;NSL-KDD | MC | ACC: 92.1%, Recall: 92.23% |
| [54] | DNN | SMO | KDDCup99; NSL-KDD | BC | NSL-KDD: Precision: 99.5%, Recall: 99.5%, F1: 99.6% KDDCup99: Precision: 92.7%, Recall: 92.8%, F1: 92.7% |
| [55] | AE, DNN | ICVAE | NSL-KDD; UNSW-NB15 | MC | UNSW-NB15: ACC: 89.08%, Precision: 86.05%, Recall: 95.68%, F1: 90.61%, FPR: 19.01% NSL-KDD: ACC: 85.97%, Precision: 97.39%, Recall: 77.43%, F1: 86.27%, FPR: 2.74% |
| [56] | CNN | CNN | KDDCup99 | BC | ACC: 99.23% |
| [57] | CNN | CRF, LCFS | KDDCup99 | MC | Precision: 98.88% |
| [58] | CNN | CNN | NSL-KDD | MC | ACC: 70.09%, FPR: 2.35% (Dos), 2.09% (Probe), 0.69% (R2L), 0.06% (U2R), Recall: 83.21% (Dos), 81.87% (Probe), 21.68% (R2L), 13% (U2R) |
| [59] | CNN | CNN | UNSW-NB15; CIC-IDS2017 | BC;MC | BC: UNSW-NB15: Recall: 99.74% MC: UNSW-NB15: Recall: 96.54% CIC-IDS2017: Recall: 99.85% |
| [60] | CNN | CNN | NSL-KDD; CIC-IDS2017 | MC | NSL-KDD: ACC: 96.1%, Recall: 92.3%, FPR: 2%, F1: 94% CIC-IDS2017: ACC: 95.6%, Recall: 94.1%, FPR: 5%, F1: 94.6% |
| [61] | CNN, LSTM | \ | ISCX2012 | MC | ACC: 99.69%, Recall: 96.91%, FPR: 0.22% |
| [64] | LSTM | \ | NSL-KDD | MC | ACC: 84.25%, Recall: 97.5%, FPR: 25.7% |
| [65] | LSTM, AE | AE | ISCX2012 | BC | F1: 85.83% |
| [66] | GRU | \ | Kyoto2006+ | BC | ACC: 84.15% |
| [67] | GRU, MLP | GRU | NSL-KDD; KDDCup99 | MC | NSL-KDD: ACC: 99.24%, Recall: 99.31%, FPR: 0.84% KDDCup99: ACC: 99.84%, Recall: 99.42%, FPR: 0.05% |
| [68] | CNN, RNN, LSTM, GRU | CNN | NSL-KDD | MC | CNN-2layer-LSTM: ACC: 99.7%, Precision: 99.9%, Recall: 99.6%, F1: 99.8% CNN-2layer-GRU: ACC: 98.1%, Precision: 99.9%, Recall: 97.6%, F1: 98.8% CNN-2layer-RNN: ACC: 97.3%, Precision: 100%, Recall: 96.7%, F1: 98.3% |
| [69] | CNN, LSTM | CNN | KDDCup99 | MC | ACC: 86.4% |
| [71] | DBSCAN + GAN | PCA | NSL-KDD; UNSW-NB15;Kyoto2006 | MC | ACC: 98.65% |
| [75] | Transformer | Self-attention | NSL-KDD;CIC-IDS2017 | MC | NSL-KDD: ACC: 95.88%, F1: 95.87% CIC-IDS2017: ACC: 97.56%, F1: 97.74% |
| [77] | Transformer | DNN, Transformer | ISCX2012;CICIDS2017 | MC | ISCX2012: Accuracy: 99.42, Precision: 99.41, Recall99.34, F1: 99.37 CICIDS2017: Accuracy: 97.87, Precision: 98.16, Recall: 97.59, F1: 97.83 |
| [81] | BERT | \ | NSL-KDD;CIC-IDS2017 | MC | NSL-KDD: Accuracy: 97.9% CIC-IDS2017: Accuracy: 95.8% |
| [84] | GPT-4, Llama3 | \ | NSL-KDD;CIC-IDS2017 | MC | GPT-4: NSL-KDD: Accuracy: 98.2%;CIC-IDS2017: Accuracy: 96.7% Llama3: NSL-KDD: Accuracy: 97.5%;CIC-IDS2017: Accuracy: 95.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Zou, B.; Cao, Y. Current Status and Challenges and Future Trends of Deep Learning-Based Intrusion Detection Models. J. Imaging 2024, 10, 254. https://doi.org/10.3390/jimaging10100254
Wu Y, Zou B, Cao Y. Current Status and Challenges and Future Trends of Deep Learning-Based Intrusion Detection Models. Journal of Imaging. 2024; 10(10):254. https://doi.org/10.3390/jimaging10100254
Chicago/Turabian StyleWu, Yuqiang, Bailin Zou, and Yifei Cao. 2024. "Current Status and Challenges and Future Trends of Deep Learning-Based Intrusion Detection Models" Journal of Imaging 10, no. 10: 254. https://doi.org/10.3390/jimaging10100254
APA StyleWu, Y., Zou, B., & Cao, Y. (2024). Current Status and Challenges and Future Trends of Deep Learning-Based Intrusion Detection Models. Journal of Imaging, 10(10), 254. https://doi.org/10.3390/jimaging10100254