
FTIR-Based Microplastic Classification: A Comprehensive Study on Normalization and ML Techniques
 , ,
, ,  , , and
, , and
Abstract
1. Introduction
2. Related Works
3. Theoretical Foundations
3.1. Machine Learning
- k-Nearest Neighbors (kNN):This supervised classification method is based on proximity, assigning a class to a new datapoint based on the classes of its closest neighbors in the feature space [35]. The simplicity of kNN lies in its structure, as it does not require a pre-trained model or assumptions about data distribution. The model’s accuracy heavily depends on the choice of “k” (number of neighbors); a low value of k may result in sensitivity to noise, while a high value may overly smooth class boundaries [36]. kNN is suitable for classification tasks in areas such as image recognition, recommendation systems, and pattern recognition where classes are well-defined.
- Support Vector Machines (SVM):The SVM is a supervised classification algorithm designed to find the optimal hyperplane that maximizes the margin of separation between classes in the feature space [37]. This approach minimizes the probability of misclassification on test data. For non-linearly separable data, kernel functions are employed to project the data into higher-dimensional spaces, facilitating separation [38]. SVM has proven effective in tasks like text classification, pattern recognition, and image analysis, particularly where clear boundaries between classes exist.
- Bayesian Networks:Bayesian networks are probabilistic graphical models that represent causal relationships among variables and utilize Bayes’ theorem to update event probabilities based on available evidence [39]. These models integrate prior knowledge and represent conditional dependencies between variables, making them suitable for problems involving interdependent variables [40]. They have demonstrated efficacy in decision-making under uncertainty and in contexts with prior knowledge, such as medical diagnosis, financial risk assessment, and recommendation systems.
- Random Forest:Random forest is an ensemble learning algorithm that combines multiple decision trees to enhance prediction accuracy and reduce overfitting risk [41]. The algorithm constructs several independent decision trees using different random samples of the dataset and aggregates their outputs through methods such as majority voting for classification or averaging for regression. Its ability to handle redundant or irrelevant features and mitigate overfitting makes random forest a robust tool for complex problems with high-dimensional data. It is commonly applied in classification tasks such as image analysis, bioinformatics, and fraud detection [42].
- Multilayer Perceptron (MLP):The multilayer perceptron is a type of artificial neural network that includes at least one hidden layer. In the context of deep learning, it incorporates multiple hidden layers between the input and output layers [46]. In MLPs, each neuron is connected to the neurons in the subsequent layer through synaptic weights, which are adjusted during training via the backpropagation method. This optimization process enables the MLP to capture complex, non-linear patterns in data, making it suitable for classification and regression tasks [47]. Its versatility and capacity to approximate any continuous function have made it popular for applications such as time series prediction, speech recognition, and image classification.
- Convolutional Neural Networks (CNN):Convolutional neural networks are specialized neural networks designed for processing grid-like data structures, such as images [48]. CNNs consist of convolutional layers that apply filters to extract spatial features and visual patterns, as well as pooling layers that reduce dimensionality in the representations obtained during convolution. This architecture enables CNNs to detect hierarchical patterns in data, making them highly effective for tasks such as image classification, semantic segmentation, and video analysis [49]. CNNs have transformed the field of deep learning, demonstrating exceptional performance in applications like facial recognition, medical diagnosis, and real-time object detection.
3.2. Normalization Techniques
- Min-Max Normalization:This technique scales data to fit within a specific range, typically []. This is especially useful for algorithms sensitive to the range of input data, such as neural networks that use activation functions like sigmoid or tanh, which operate best with inputs in a constrained range (Equation (1)).where x represents a data point, is the minimum value, and is the maximum value in the dataset.
- Max-Absolute Normalization:This method divides each data point by the maximum absolute value in the dataset, adjusting values to lie within the range []. This technique is particularly beneficial when datasets contain negative values and need to maintain their relative magnitude relationships (Equation (2)).Here, x is a data point, and represents the maximum absolute value in the dataset.
- Sum of Squares:Although not a direct normalization technique, this concept is fundamental in statistical model fitting, such as ANOVA and linear regression. In spectral data analysis, it addresses inherent variabilities like noise, sample variations, and light dispersion. The sum of squares quantifies variability across sample groups for each polymer, aiding in identifying significant differences between spectra (Equation (3)).where x is a data point, and denotes the sum of squared data points.
- Z-score Standardization:Z-score standardization measures the relative position of an observation within a dataset in terms of standard deviations from the mean. This technique is critical when comparing datasets with different distributions or identifying outliers. Moreover, it is particularly suited for algorithms assuming normally distributed input data, such as principal component analysis (PCA) (Equation (4)).Here, x is a data point, is the dataset mean, and is the standard deviation.
3.3. Classifier Performance
- True positive (TP): number of instances that are positive and correctly predicted as positive by the model;
- False negative (FN): number of instances that are positive but incorrectly predicted as negative by the model;
- True negative (TN): number of instances that are negative and correctly predicted as negative by the model;
- False positive (FP): number of instances that are negative but incorrectly predicted as positive by the model.
- Accuracy:Indicates the overall classification performance of the model on the test dataset and is calculated as by Equation (5).
- Recall:Reflects the model’s ability to correctly identify positive cases as a percentage of the total actual positive cases (Equation (6)).
- Precision:Represents the proportion of predicted positive cases that are actually positive (Equation (7)).
- F1-score:Provides a comprehensive evaluation of classification model performance by calculating the harmonic mean of precision and recall (Equation (8)).
- Micro-average: weighs each instance equally, suitable for datasets with balanced or unbalanced class distributions;
- Macro-average: averages the metrics for all classes equally, regardless of the class size, providing a balanced view;
- Weighted average: accounts for class frequency, emphasizing the contribution of larger classes.
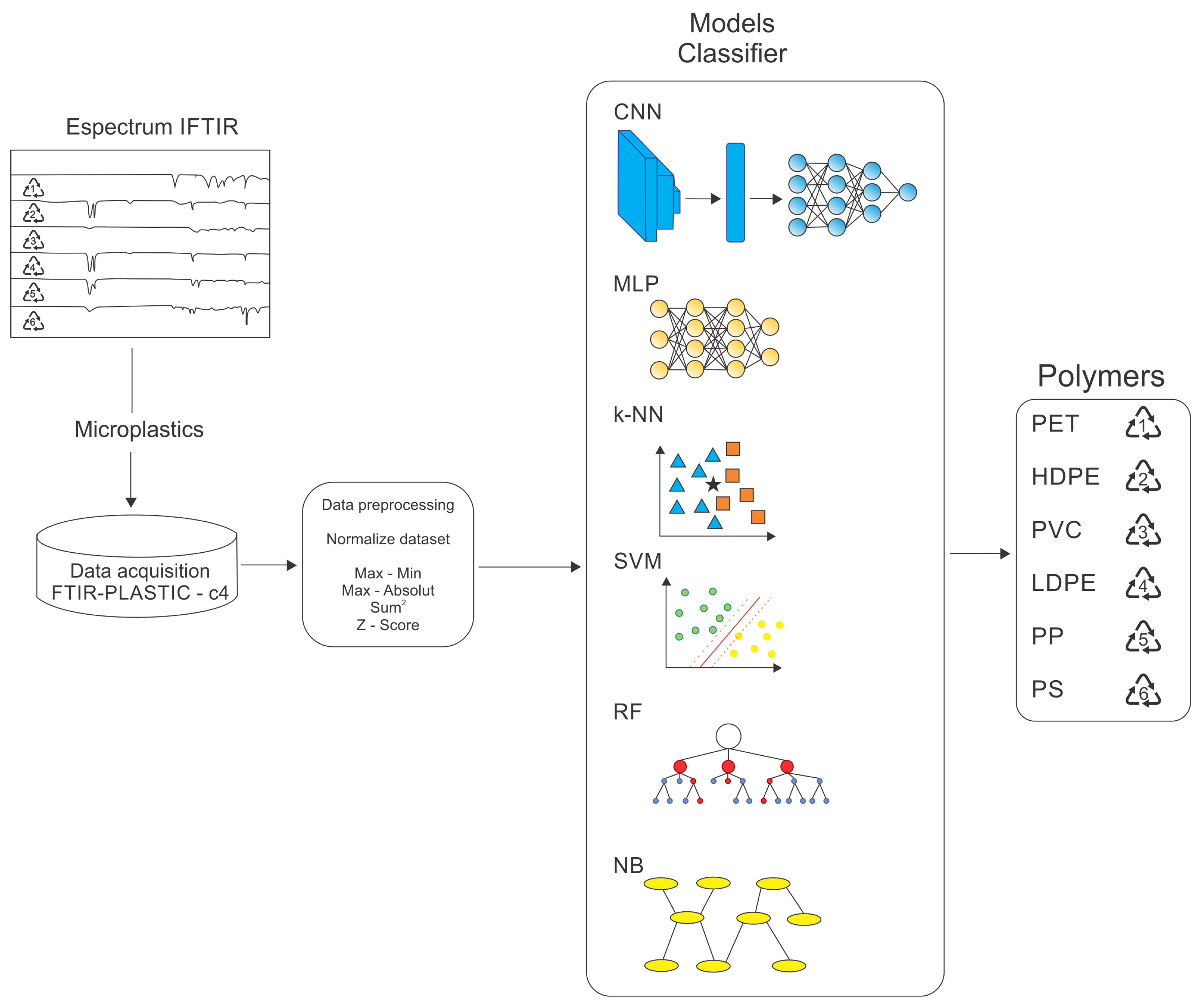
4. Methods
- Dataset acquisition: preparing and curating the FTIR-PLASTIC-c4 dataset;
- Data preprocessing: implementation of data cleaning, normalization, and transformation techniques to enhance data quality and ensure compatibility with the selected models;
- Choosing classifier models: identifying the most appropriate algorithms and architectures designed for the classification task;
- Training and testing: ML (or classifier) models involve the iterative optimization of model hyperparameters and validation with suitable evaluation protocols;
- Performance evaluation of classification models: a comprehensive analysis of performance metrics to assess the effectiveness, robustness, and generalization capability of the models.
4.1. Dataset
4.2. Set-Up Parameters for the Studied Machine Learning Models
- k-NN: Seven neighbors were used for classification. The distance between neighbors was measured using the Euclidean metric, and uniform weights were assigned to all neighbors to ensure equal contribution.
- SVM: A cost parameter (C) of 1.00 was selected to control misclassification penalties. The RBF (radial basis function) kernel was used to capture non-linear similarities. Convergence criteria included a numerical tolerance of 0.0001 and an iteration limit of 500.
- Random Forest: The model utilized seven trees. In the growth control configuration, subsets with fewer than five samples were not further split. In this sense, growth control establishes a constraint to prevent overfitting. Also, no depth limit was imposed on the trees.
- MLP: This model consists of three dense layers with 64, 32, and 6 neurons, using ReLU and Sigmoid as activation functions. It was trained with a learning rate of 0.0001, a batch size of 32, and 500 epochs, using the Adam optimizer.
- CNN_1: Feature extraction was performed using four convolutional layers with kernel sizes of 4, 16, 16, and 4, combined with MaxPooling layers of sizes 2 and 3, and additional kernel sizes of 4, 2, 3, and 2. Classification was performed through four dense layers with 8, 32, 64, and 6 neurons. Training was conducted over 20 epochs using Adam with a learning rate of 0.001.
- CNN_2: Feature extraction included two convolutional layers with kernel sizes of 16 and 64, MaxPooling layers of sizes 3 and 2, and kernel sizes of 4, 6, and 3. Classification utilized four dense layers with 4, 16, 8, and 6 neurons. The model was trained over 30 epochs using Adam with a learning rate of 0.001.
5. Results and Discussion
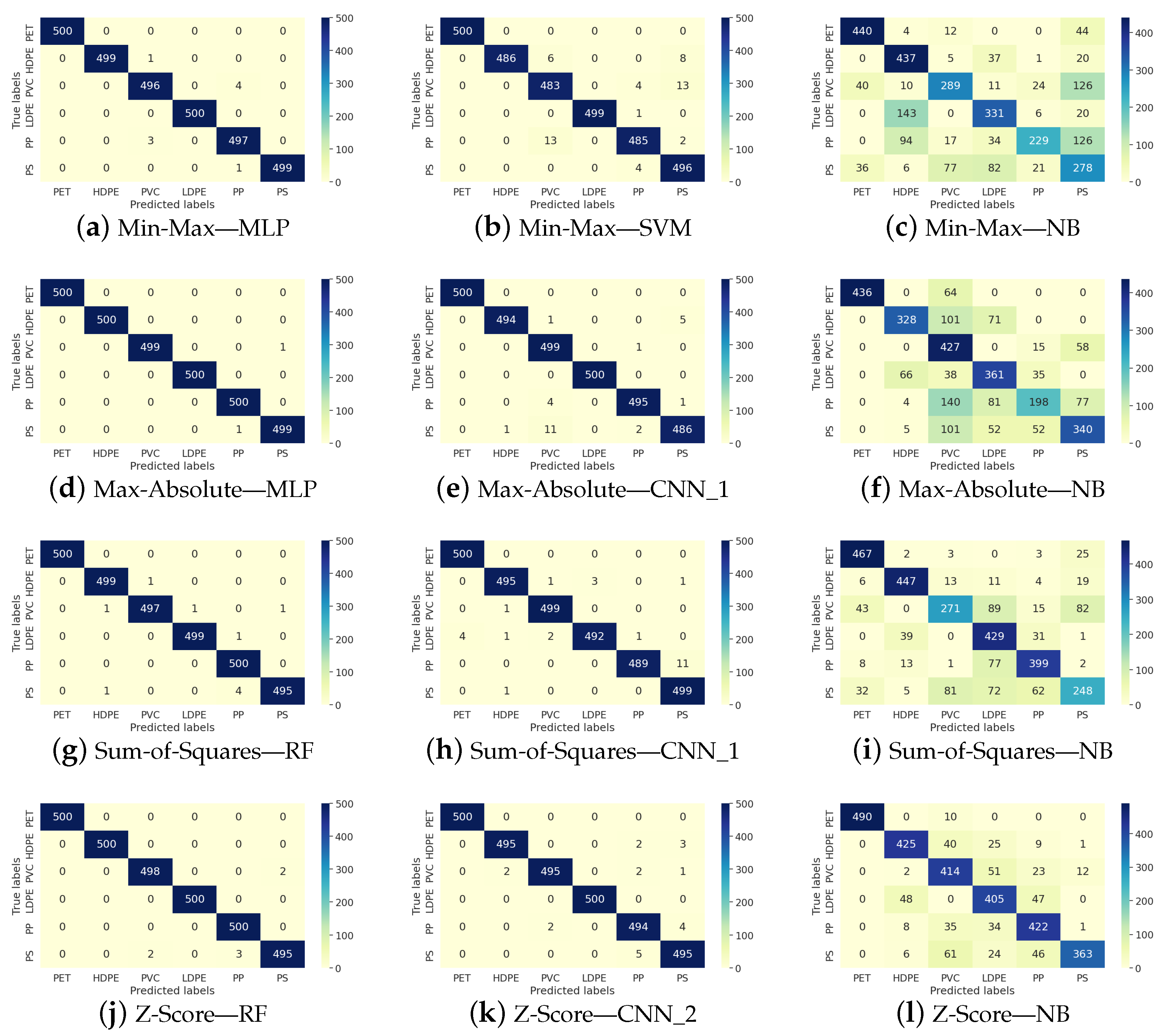
5.1. Min-Max Normalization
5.2. Max-Absolute Normalization
5.3. Sum-of-Squares Normalization
5.4. Z-Score Normalization
6. Discussion and Implications
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alimba, C.G.; Faggio, C. Microplastics in the marine environment: Current trends in environmental pollution and mechanisms of toxicological profile. Environ. Toxicol. Pharmacol. 2019, 68, 61–74. [Google Scholar] [CrossRef] [PubMed]
- Haward, M. Plastic pollution of the world’s seas and oceans as a contemporary challenge in ocean governance. Nat. Commun. 2018, 9, 667. [Google Scholar] [CrossRef] [PubMed]
- Ai, W.; Liu, S.; Liao, H.; Du, J.; Cai, Y.; Liao, C.; Shi, H.; Lin, Y.; Junaid, M.; Yue, X.; et al. Application of hyperspectral imaging technology in the rapid identification of microplastics in farmland soil. Sci. Total Environ. 2022, 807, 151030. [Google Scholar] [CrossRef]
- Hopewell, J.; Dvorak, R.; Kosior, E. Plastics recycling: Challenges and opportunities. Philos. Trans. R Soc. Lond. B Biol. Sci. 2009, 364, 2115–2126. [Google Scholar] [CrossRef]
- Leal Filho, W.; Saari, U.; Fedoruk, M.; Iital, A.; Moora, H.; Klöga, M.; Voronova, V. An overview of the problems posed by plastic products and the role of extended producer responsibility in Europe. J. Clean. Prod. 2019, 214, 550–558. [Google Scholar] [CrossRef]
- Thompson, R.C.; Moore, C.J.; vom Saal, F.S.; Swan, S.H. Plastics, the environment and human health: Current consensus and future trends. Philos. Trans. R. Soc. 2009, B364, 2153–2166. [Google Scholar] [CrossRef]
- Rillig, M.C. Microplastic in Terrestrial Ecosystems and the Soil? Environ. Sci. Technol. 2012, 46, 6453. [Google Scholar] [CrossRef]
- Neto, J.G.B.; Rodrigues, F.L.; Ortega, I.; dos S. Rodrigues, L.; Lacerda, A.L.; Coletto, J.L.; Kessler, F.; Cardoso, L.G.; Madureira, L.; Proietti, M.C. Ingestion of plastic debris by commercially important marine fish in southeast-south Brazil. Environ. Pollut. 2020, 267, 115508. [Google Scholar] [CrossRef]
- Boerger, C.M.; Lattin, G.L.; Moore, S.L.; Moore, C.J. Plastic ingestion by planktivorous fishes in the North Pacific Central Gyre. Mar. Pollut. Bull. 2010, 60, 2275–2278. [Google Scholar] [CrossRef]
- Nolan, J.P.; Soar, J.; Zideman, D.A.; Biarent, D.; Bossaert, L.L.; Deakin, C.; Koster, R.W.; Wyllie, J.; Böttiger, B.; Group, E.G.W.; et al. European resuscitation council guidelines for resuscitation 2010 section 1. Executive summary. Resuscitation 2010, 81, 1219–1276. [Google Scholar]
- Almeshal, I.; Tayeh, B.A.; Alyousef, R.; Alabduljabbar, H.; Mustafa Mohamed, A.; Alaskar, A. Use of recycled plastic as fine aggregate in cementitious composites: A review. Constr. Build. Mater. 2020, 253, 119146. [Google Scholar] [CrossRef]
- Kuptsov, A.; Zhizhin, G.N. Handbook of Fourier Transform Raman and Infrared Spectra of Polymers; Elsevier: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Maes, T.; Jessop, R.; Wellner, N.; Haupt, K.; Mayes, A. A rapid-screening approach to detect and quantify microplastics based on fluorescent tagging with Nile Red. Sci. Rep. 2017, 7, 44501. [Google Scholar] [CrossRef] [PubMed]
- Araujo, C.F.; Nolasco, M.M.; Ribeiro, A.M.; Ribeiro-Claro, P.J. Identification of microplastics using Raman spectroscopy: Latest developments and future prospects. Water Res. 2018, 142, 426–440. [Google Scholar] [CrossRef] [PubMed]
- Rebelein, A.; Int-Veen, I.; Kammann, U.; Scharsack, J.P. Microplastic fibers—Underestimated threat to aquatic organisms? Sci. Total Environ. 2021, 777, 146045. [Google Scholar] [CrossRef]
- Nivitha, M.; Prasad, E.; Krishnan, J. Ageing in modified asphalt using FTIR spectroscopy. Int. J. Pavement Eng. 2015, 17, 565–577. [Google Scholar] [CrossRef]
- Käppler, A.; Fischer, D.; Oberbeckmann, S.; Schernewski, G.; Labrenz, M.; Eichhorn, K.J.; Voit, B. Analysis of environmental microplastics by vibrational microspectroscopy: FTIR, Raman or both? Anal. Bioanal. Chem. 2016, 408, 8377–8391. [Google Scholar] [CrossRef]
- Munno, K.; De Frond, H.; O’Donnell, B.; Rochman, C.M. Increasing the accessibility for characterizing microplastics: Introducing new application-based and spectral libraries of plastic particles (SLoPP and SLoPP-E). Anal. Chem. 2020, 92, 2443–2451. [Google Scholar] [CrossRef]
- Ballabio, D.; Consonni, V. Classification tools in chemistry. Part 1: Linear models. PLS-DA. Anal. Methods 2013, 5, 3790–3798. [Google Scholar] [CrossRef]
- Díez-Pastor, J.F.; Jorge-Villar, S.E.; Arnaiz-González, Á.; García-Osorio, C.I.; Díaz-Acha, Y.; Campeny, M.; Bosch, J.; Melgarejo, J.C. Machine learning algorithms applied to R aman spectra for the identification of variscite originating from the mining complex of G avà. J. Raman Spectrosc. 2020, 51, 1563–1574. [Google Scholar] [CrossRef]
- Altikat, A.; Gulbe, A.; Altikat, S. Intelligent solid waste classification using deep convolutional neural networks. Int. J. Environ. Sci. Technol. 2022, 19, 1285–1292. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, Q.; Zhang, X.; Bao, Q.; Su, J.; Liu, X. Waste image classification based on transfer learning and convolutional neural network. Waste Manag. 2021, 135, 150–157. [Google Scholar] [CrossRef] [PubMed]
- Bobulski, J.; Kubanek, M. Deep learning for plastic waste classification system. Appl. Comput. Intell. Soft Comput. 2021, 2021, 6626948. [Google Scholar] [CrossRef]
- Singh, M.K.; Hait, S.; Thakur, A. Hyperspectral imaging-based classification of post-consumer thermoplastics for plastics recycling using artificial neural network. Process Saf. Environ. Prot. 2023, 179, 593–602. [Google Scholar] [CrossRef]
- Zinchik, S.; Jiang, S.; Friis, S.; Long, F.; Høgstedt, L.; Zavala, V.M.; Bar-Ziv, E. Accurate characterization of mixed plastic waste using machine learning and fast infrared spectroscopy. ACS Sustain. Chem. Eng. 2021, 9, 14143–14151. [Google Scholar] [CrossRef]
- Jeon, Y.; Seol, W.; Kim, S.; Kim, K.S. Robust near-infrared-based plastic classification with relative spectral similarity pattern. Waste Manag. 2023, 166, 315–324. [Google Scholar] [CrossRef]
- Yan, X.; Cao, Z.; Murphy, A.; Ye, Y.; Wang, X.; Qiao, Y. FRDA: Fingerprint Region based Data Augmentation using explainable AI for FTIR based microplastics classification. Sci. Total Environ. 2023, 896, 165340. [Google Scholar] [CrossRef]
- Hufnagl, B.; Steiner, D.; Renner, E.; Löder, M.G.; Laforsch, C.; Lohninger, H. A methodology for the fast identification and monitoring of microplastics in environmental samples using random decision forest classifiers. Anal. Methods 2019, 11, 2277–2285. [Google Scholar] [CrossRef]
- Coleman, B.R. An introduction to machine learning tools for the analysis of microplastics in complex matrices. Environ. Sci. Processes Impacts 2024, 27, 10–23. [Google Scholar] [CrossRef]
- Phan, S.; Luscombe, C.K. Recent trends in marine microplastic modeling and machine learning tools: Potential for long-term microplastic monitoring. J. Appl. Phys. 2023, 133, 020701. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, D.; Zhang, Z. A critical review on artificial intelligence—Based microplastics imaging technology: Recent advances, hot-spots and challenges. Int. J. Environ. Res. Public Health 2023, 20, 1150. [Google Scholar] [CrossRef]
- Kamin, S.N. Programming Languages: An Interpreter-Based Approach; Addison-Wesley Longman Publishing Co., Inc.: Redwood City, CA, USA, 1990. [Google Scholar]
- Deisenroth, M.P.; Faisal, A.A.; Ong, C.S. Mathematics for Machine Learning; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Thomas, R.; McSharry, P. Big Data Revolution: What Farmers, Doctors and Insurance Agents Teach Us About Discovering Big Data Patterns; John Wiley & Sons: West Sussex, UK, 2015. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Cristianini, N. Support Vector Machines; Cambridge University Press: Cambridge, UK, 2000; Volume 2. [Google Scholar]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann: San Francisco, CA, USA, 1988. [Google Scholar]
- Friedman, B. Human Values and the Design of Computer Technology; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Liaw, A. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Berzal, F. Redes Neuronales & Deep Learning (Spanish Edition); Apache License: Granada, Spain, 2018. [Google Scholar]
- Kubat, M. Neural networks: A comprehensive foundation by Simon Haykin. Knowl. Eng. Rev. 1999, 13, 409–412. [Google Scholar] [CrossRef]
- Block, H.D.; Knight, B., Jr.; Rosenblatt, F. Analysis of a four-layer series-coupled perceptron. II. Rev. Mod. Phys. 1962, 34, 135. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation, parallel distributed processing, explorations in the microstructure of cognition, ed. de rumelhart and j. mcclelland. Biometrika 1986, 71, 6. [Google Scholar] [CrossRef]
- Simard, P.; Bottou, L.; Haffner, P.; LeCun, Y. Boxlets: A fast convolution algorithm for signal processing and neural networks. In Advances in Neural Information Processing Systems, Proceedings of the 12th International Conference on Neural Information Processing Systems, Denver, CO, USA, 1–3 December 1998; MIT Press: Cambridge, MA, USA, 1998; Volume 11. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar] [CrossRef]
- Walpole, R.E.; Myers, R.H.; Myers, S.L.; Ye, K. Probability & Statistics for Engineers & Scientists; Pearson Education: Boston, MA, USA, 2012. [Google Scholar]
- Alejo, R.; Antonio, J.A.; Valdovinos, R.M.; Pacheco-Sánchez, J.H. Assessments Metrics for Multi-class Imbalance Learning: A Preliminary Study. In Pattern Recognition, Proceedings of the 5th Mexican Conference, Queretaro, Mexico, 26–29 June 2013; Carrasco-Ochoa, J.A., Martínez-Trinidad, J.F., Rodríguez, J.S., di Baja, G.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 335–343. [Google Scholar] [CrossRef]
- Fan, M.; Zuo, K.; Wang, J.; Zhu, J. A lightweight multiscale convolutional neural network for garbage sorting. Syst. Soft Comput. 2023, 5, 200059. [Google Scholar] [CrossRef]
- Villegas-Camacho, O.; Alejo-Eleuterio, R.; Francisco-Valencia, I.; Granda-Gutiérrez, E.; Martínez-Gallegos, S.; Illescas, J. FTIR-Plastics: A Fourier Transform Infrared Spectroscopy dataset for the six most prevalent industrial plastic polymers. Data Brief 2024, 55, 110612. [Google Scholar] [CrossRef]
- Magaña-Olivé, P.; Martinez-Tavera, E.; Sujitha, S.; Cunill-Flores, J.; Martinez-Gallegos, S.; Sierra, J.; Rovira, J. Evaluation of microplastics and metal accumulation in domestic ducks (Anas platyrhynchos f. domesticus) of a contaminated reservoir in Central Mexico. Mar. Pollut. Bull. 2025, 213, 117639. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Dataset | Size (Samples) | Range (cm−1) | International Number (SPI) | Feature Data |
|---|---|---|---|---|
| PET | 500 | 4000–400 | 1 | 3751 |
| HDPE | 500 | 4000–400 | 2 | 3751 |
| PVC | 500 | 4000–400 | 3 | 3751 |
| LDPE | 500 | 4000–400 | 4 | 3751 |
| PP | 500 | 4000–400 | 5 | 3751 |
| PS | 500 | 4000–400 | 6 | 3751 |
| Parameters | MLP | CNN_1 | CNN_2 |
|---|---|---|---|
| Neuron | |||
| Layers | 3, Dense | 4, Dense | 4, Dense |
| Relu | Relu | Relu | |
| Activation Function | Sigmoid | Sigmoid | Relu |
| – | Relu | Sigmoid | |
| Learning Rate | |||
| Batch Size | 32 | 32 | 16 |
| Epochs | 500 | 20 | 30 |
| Optimizer | Adam | Adam | Adam |
| Conv1D = 4 | Conv1D = 2 | ||
| kernel = {4, 16, 16, 4} | kernel = {16, 64} | ||
| Convolutional | – | MaxPooling1D = {2, 3} | MaxPooling1D = {3, 2} |
| Layers | kernel = {4, 2, 3, 2} | kernel = {4, 6, 3} | |
| Flatten | Flatten | ||
| Output Function | Softmax | Softmax | Softmax |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| CNN_1 | 0.98 ± 0.02 | 0.99 ± 0.02 | 0.99 ± 0.01 | 0.99 ± 0.02 |
| CNN_2 | 0.97 ± 0.02 | 0.97 ± 0.02 | 0.97 ± 0.02 | 0.97 ± 0.02 |
| MLP | 0.99 ± 0.02 | 0.99 ± 0.01 | 0.99 ± 0.02 | 0.99 ± 0.02 |
| kNN | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 |
| Random Forest | 0.99 ± 0.01 | 0.99 ± 0.00 | 0.99 ± 0.00 | 0.99 ± 0.00 |
| SVM | 0.99 ± 0.00 | 0.99 ± 0.00 | 0.99 ± 0.00 | 0.99 ± 0.00 |
| Naive Bayes | 0.69 ± 0.00 | 0.71 ± 0.02 | 0.69 ± 0.00 | 0.69 ± 0.00 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| CNN_1 | 0.97 ± 0.03 | 0.98 ± 0.03 | 0.97 ± 0.03 | 0.97 ± 0.03 |
| CNN_2 | 0.81 ± 0.02 | 0.98 ± 0.02 | 0.98 ± 0.02 | 0.80 ± 0.09 |
| MLP | 0.96 ± 0.02 | 0.96 ± 0.02 | 0.96 ± 0.02 | 0.96 ± 0.03 |
| kNN | 0.99 ± 0.00 | 0.99 ± 0.00 | 0.99 ± 0.00 | 0.99 ± 0.00 |
| Random Forest | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| SVM | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 |
| Naive Bayes | 0.62 ± 0.00 | 0.62 ± 0.02 | 0.62 ± 0.00 | 0.61 ± 0.00 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| CNN_1 | 0.97 ± 0.02 | 0.97 ± 0.02 | 0.97 ± 0.02 | 0.97 ± 0.02 |
| CNN_2 | 0.71 ± 0.07 | 0.71 ± 0.09 | 0.71 ± 0.07 | 0.69 ± 0.09 |
| MLP | 0.85 ± 0.03 | 0.85 ± 0.02 | 0.85 ± 0.02 | 0.85 ± 0.02 |
| kNN | 0.99 ± 0.00 | 0.99 ± 0.00 | 0.99 ± 0.00 | 0.99 ± 0.00 |
| Random Forest | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| SVM | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 |
| Naive Bayes | 0.62 ± 0.00 | 0.62 ± 0.02 | 0.62 ± 0.00 | 0.61 ± 0.00 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| CNN_1 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| CNN_2 | 0.99 ± 0.01 | 0.99 ± 0.01 | 0.99 ± 0.01 | 0.99 ± 0.01 |
| MLP | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| kNN | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 |
| Random Forest | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 | 1.00 ± 0.00 |
| SVM | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 | 0.98 ± 0.00 |
| Naive Bayes | 0.62 ± 0.00 | 0.62 ± 0.02 | 0.62 ± 0.00 | 0.62 ± 0.00 |
| Ref. | Model | Data Source | Metric | Value | Distinction |
|---|---|---|---|---|---|
| [25] | CNN SVM RF k-NN | MIR | Accuracy | 100% 100% 98.7% 81.4% | Mid-infrared 12 polymers 4000–1400 cm−1 |
| [26] | LDA PCA | NIR | Precision Recall F1-Score | 99–99% 98–93% 98–95% | Near-infrared 4 polymers 50 spectra 1450–1150 nm |
| [27] | SVM | ATR-FTIR | Kappa Accuracy Precision Recall | 99% 71% 87% 99% | ATR 4 Polymers 798 spectra 4000–400 cm−1 |
| [28] | CNN SVM DT k-NN | RAMAN NIR | Accuracy | 97% 94% 77.1% 89.9% | 2 Espectroscopy techniques 4 Polymers |
| [21] | CNN | Image | Sensitivity Specificity Precision F-Score Accuracy | 56% 91% 63% 60% 61% | 400 images sizes 224 × 224 |
| [22] | CNN | Image | Accuracy | 82.8 | Macroplastics |
| [23] | CNN | Image | Sensitivity Specificity Precision F-Score Accuracy | 56% 91% 63% 60% 61% | Images RGB Sizes 224 × 224 4 polymers |
| [24] | CNN | Image | Accuracy | 74% | Images Sizes 227 × 227 |
| Our work | CNN MLP SVM RF k-NN | FTIR | Accuracy Precision Recall F1-Score | 98–100% 98–100% 98–100% 98–100% | 6 Polymers 3000 espectra FTIR 4000–400 cm−1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villegas-Camacho, O.; Francisco-Valencia, I.; Alejo-Eleuterio, R.; Granda-Gutiérrez, E.E.; Martínez-Gallegos, S.; Villanueva-Vásquez, D. FTIR-Based Microplastic Classification: A Comprehensive Study on Normalization and ML Techniques. Recycling 2025, 10, 46. https://doi.org/10.3390/recycling10020046
Villegas-Camacho O, Francisco-Valencia I, Alejo-Eleuterio R, Granda-Gutiérrez EE, Martínez-Gallegos S, Villanueva-Vásquez D. FTIR-Based Microplastic Classification: A Comprehensive Study on Normalization and ML Techniques. Recycling. 2025; 10(2):46. https://doi.org/10.3390/recycling10020046
Chicago/Turabian StyleVillegas-Camacho, Octavio, Iván Francisco-Valencia, Roberto Alejo-Eleuterio, Everardo Efrén Granda-Gutiérrez, Sonia Martínez-Gallegos, and Daniel Villanueva-Vásquez. 2025. "FTIR-Based Microplastic Classification: A Comprehensive Study on Normalization and ML Techniques" Recycling 10, no. 2: 46. https://doi.org/10.3390/recycling10020046
APA StyleVillegas-Camacho, O., Francisco-Valencia, I., Alejo-Eleuterio, R., Granda-Gutiérrez, E. E., Martínez-Gallegos, S., & Villanueva-Vásquez, D. (2025). FTIR-Based Microplastic Classification: A Comprehensive Study on Normalization and ML Techniques. Recycling, 10(2), 46. https://doi.org/10.3390/recycling10020046