
Early Prediction of Battery Lifetime Using Centered Isotonic Regression with Quantile-Transformed Features



Abstract
1. Introduction
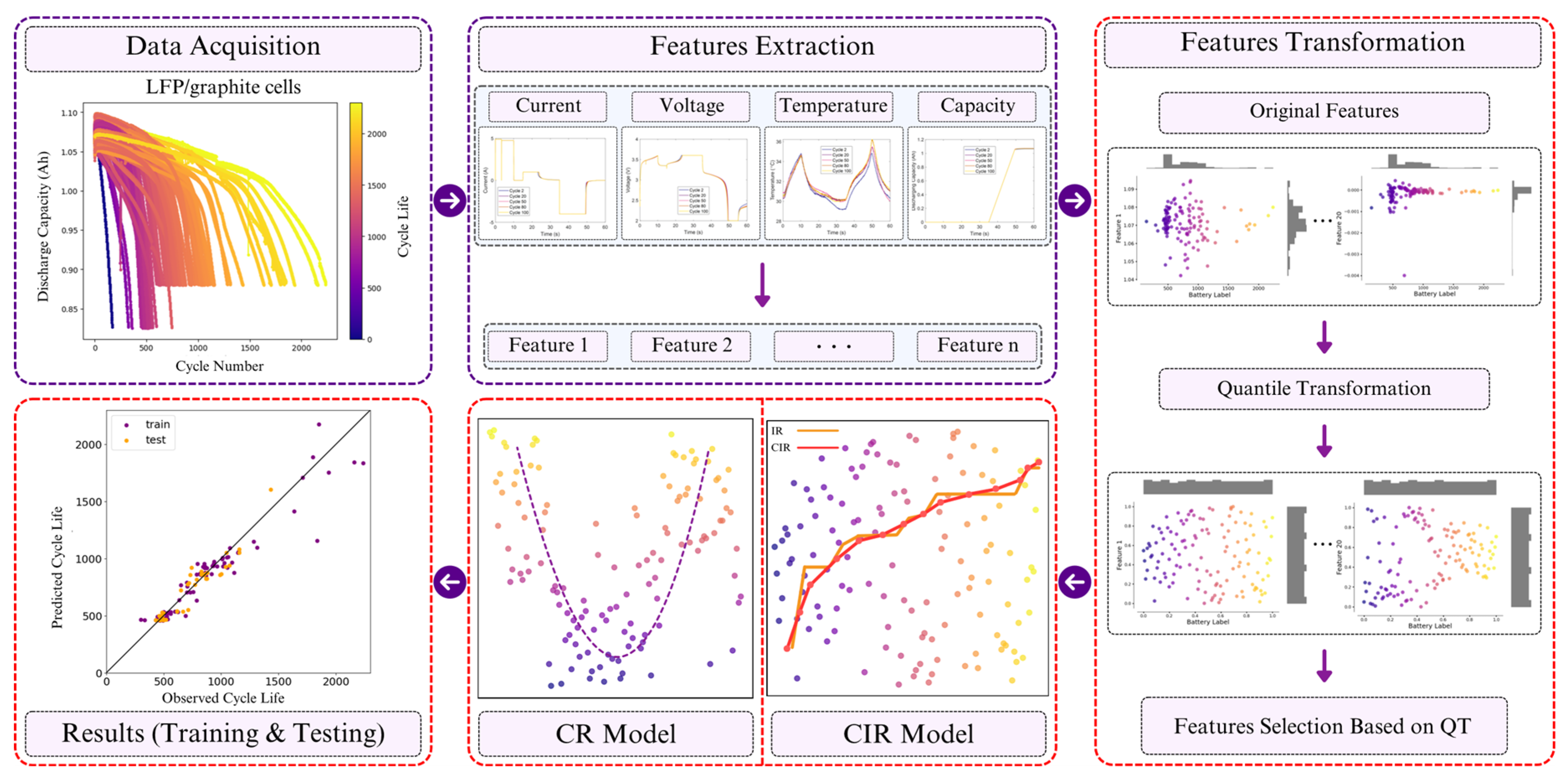
- We demonstrate the effectiveness of applying QT to both features and battery cycle life. This technique reduces the impact of outliers and non-normality in battery degradation data, resulting in a more stable and informative feature representation for modeling. The improved feature distribution enhances prediction accuracy.
- We introduce CIR, a variant of IR approach, to capture the monotonic relationship between transformed features and battery cycle life. By centering feature values, CIR mitigates overfitting and improves the model’s ability to identify underlying trends, leading to more accurate predictions, particularly in the early stages of battery life.
- To address cases where the monotonicity assumption of CIR is insufficient, we employ CR. It enables the model to capture specific patterns in battery dataset, further enhancing battery cycle life forecasts and overall predictive accuracy.
2. Methods
2.1. Quantile Transformation
2.2. Isotonic Regression
| Algorithm 1: Pooled-Adjacent-Violators Algorithm (PAVA) | |
Input:
| |
Output:
| |
| Procedure: Initialization:
| |
| |
| |
while loop:
| |
| |
| |
| |
| |
| |
| |
| |
| |
| end while loop | |
| return | |
| end Procedure | |
2.3. Centered Isotonic Regression
| Algorithm 2: Centered Isotonic Regression (CIR) Algorithm | |
Input:
| |
Output:
| |
| Procedure: Initialization:
| |
| |
while loop:
| |
| |
| |
| |
| end while loop: | |
# Boundary Conditions:
| |
| |
| |
| |
| |
| |
| return | |
| end Procedure | |
2.4. Convex Regression
2.5. Data-Driven Framework for Battery Lifetime Prediction
3. Dataset and Feature Analysis
3.1. Dataset Description
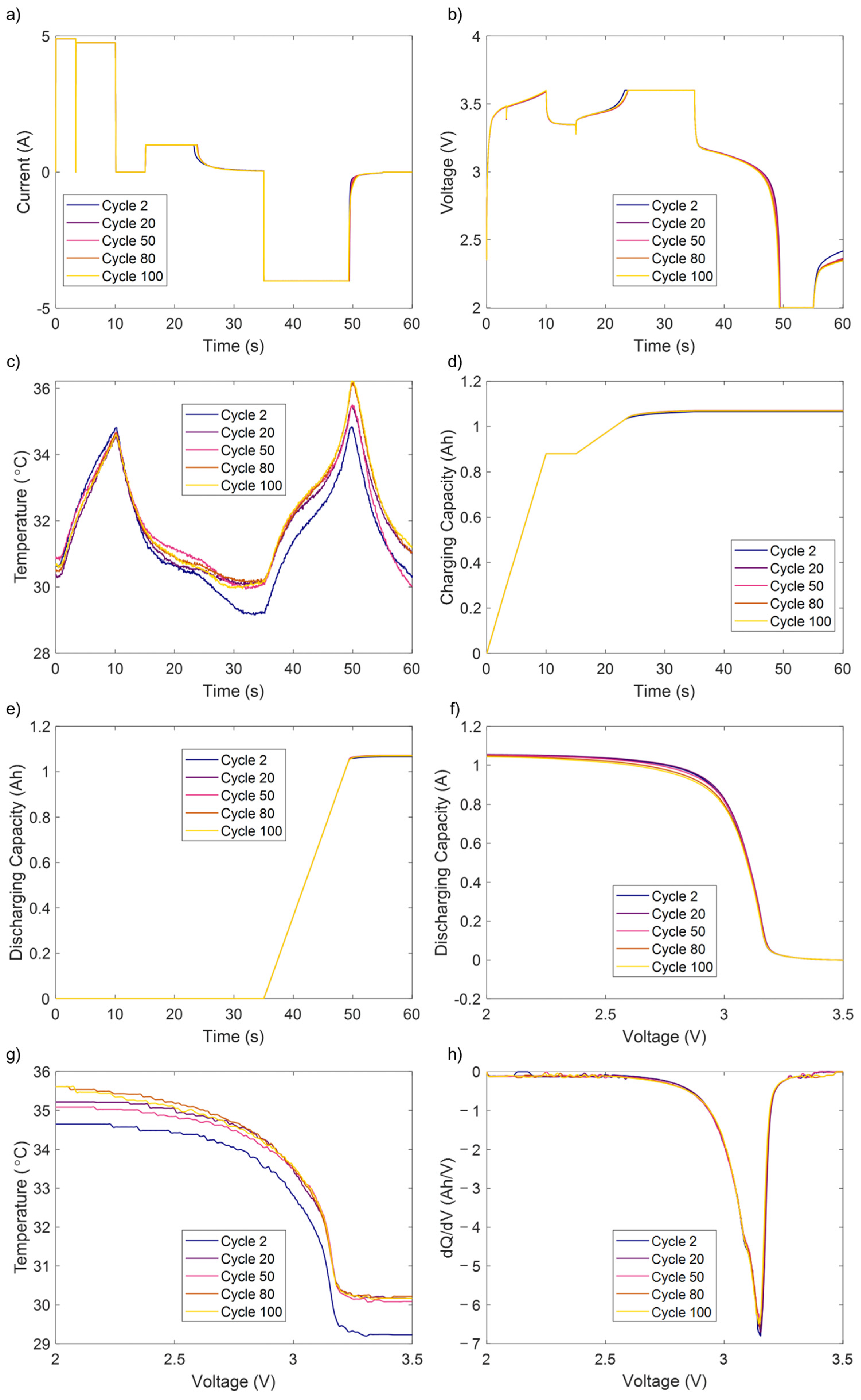
3.2. Features Extraction
4. Experimental Results
4.1. Feature Selection Using Quantile Transformation
4.2. Results Comparison with Benchmarks
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature No. | Feature Details | Feature Representation |
|---|---|---|
| F-1 | Discharge capacity at cycle 2 | |
| F-2 | Difference between maximum discharge capacity and cycle 2 | |
| F-3 | Discharge capacity at cycle 100 | |
| F-4 | Integral of temperature over time, cycles 2–100 | |
| F-5 | Average charge time first 5 cycles | |
| F-6 | Minimum of voltage discharge curve | |
| F-7 | Mean of voltage discharge curve | |
| F-8 | Variance of voltage discharge curve | |
| F-9 | Skewness of voltage discharge curve | |
| F-10 | Kurtosis of voltage discharge curve | |
| F-11 | Value at 2V of voltage discharge curve | |
| F-12 | Maximum temperature cycles 2–100 | |
| F-13 | Minimum temperature cycles 2–100 | |
| F-14 | Slope of the capacity fade curve, cycles 2–100 | |
| F-15 | Intercept of the capacity fade curve, cycles 2–100 | |
| F-16 | Slope of the capacity fade curve, cycles 91–100 | |
| F-17 | Intercept of the capacity fade curve, cycles 91–100 | |
| F-18 | Minimum internal resistance, cycles 2-100 | |
| F-19 | Internal resistance cycle 2 | |
| F-20 | Internal resistance difference between cycle 100 and cycle 2 |
References
- Bhadriraju, B.; Kwon, J.S., II; Khan, F. An Adaptive Data-Driven Approach for Two-Timescale Dynamics Prediction and Remaining Useful Life Estimation of Li-Ion Batteries. Comput. Chem. Eng. 2023, 175, 108275. [Google Scholar] [CrossRef]
- Cho, S.; Jeong, H.; Han, C.; Jin, S.; Lim, J.H.; Oh, J. State-of-Charge Estimation for Lithium-Ion Batteries under Various Operating Conditions Using an Equivalent Circuit Model. Comput. Chem. Eng. 2012, 41, 1–9. [Google Scholar] [CrossRef]
- Cui, X.; Shen, W.; Zhang, Y.; Hu, C.; Zheng, J. Novel Active LiFePO4 Battery Balancing Method Based on Chargeable and Dischargeable Capacity. Comput. Chem. Eng. 2017, 97, 27–35. [Google Scholar] [CrossRef]
- Homan, B.; ten Kortenaar, M.V.; Hurink, J.L.; Smit, G.J.M. A Realistic Model for Battery State of Charge Prediction in Energy Management Simulation Tools. Energy 2019, 171, 205–217. [Google Scholar] [CrossRef]
- Wang, S.; Guo, D.; Han, X.; Lu, L.; Sun, K.; Li, W.; Sauer, D.U.; Ouyang, M. Impact of Battery Degradation Models on Energy Management of a Grid-Connected DC Microgrid. Energy 2020, 207, 118228. [Google Scholar] [CrossRef]
- Severson, K.A.; Attia, P.M.; Jin, N.; Perkins, N.; Jiang, B.; Yang, Z.; Chen, M.H.; Aykol, M.; Herring, P.K.; Fraggedakis, D.; et al. Data-Driven Prediction of Battery Cycle Life before Capacity Degradation. Nat. Energy 2019, 4, 383–391. [Google Scholar] [CrossRef]
- Wang, D.; Yang, F.; Tsui, K.L.; Zhou, Q.; Bae, S.J. Remaining Useful Life Prediction of Lithium-Ion Batteries Based on Spherical Cubature Particle Filter. IEEE Trans. Instrum. Meas. 2016, 65, 1282–1291. [Google Scholar] [CrossRef]
- Zheng, X.; Fang, H. An Integrated Unscented Kalman Filter and Relevance Vector Regression Approach for Lithium-Ion Battery Remaining Useful Life and Short-Term Capacity Prediction. Reliab. Eng. Syst. Saf. 2015, 144, 74–82. [Google Scholar] [CrossRef]
- Burgess, W.L. Valve Regulated Lead Acid Battery Float Service Life Estimation Using a Kalman Filter. J. Power Sources 2009, 191, 16–21. [Google Scholar] [CrossRef]
- Micea, M.V.; Ungurean, L.; Cârstoiu, G.N.; Groza, V. Online State-of-Health Assessment for Battery Management Systems. IEEE Trans. Instrum. Meas. 2011, 60, 1997–2006. [Google Scholar] [CrossRef]
- He, W.; Williard, N.; Osterman, M.; Pecht, M. Prognostics of Lithium-Ion Batteries Based on Dempster-Shafer Theory and the Bayesian Monte Carlo Method. J. Power Sources 2011, 196, 10314–10321. [Google Scholar] [CrossRef]
- Yang, F.; Wang, D.; Xing, Y.; Tsui, K.L. Prognostics of Li(NiMnCo)O2-Based Lithium-Ion Batteries Using a Novel Battery Degradation Model. Microelectron. Reliab. 2017, 70, 70–78. [Google Scholar] [CrossRef]
- Hu, C.; Ye, H.; Jain, G.; Schmidt, C. Remaining Useful Life Assessment of Lithium-Ion Batteries in Implantable Medical Devices. J. Power Sources 2018, 375, 118–130. [Google Scholar] [CrossRef]
- Chen, X.; Liu, X.; Shen, X.; Zhang, Q. Applying Machine Learning to Rechargeable Batteries: From the Microscale to the Macroscale. Angew. Chemie 2021, 133, 24558–24570. [Google Scholar] [CrossRef]
- Liu, D.; Zhou, J.; Liao, H.; Peng, Y.; Peng, X. A Health Indicator Extraction and Optimization Framework for Lithium-Ion Battery Degradation Modeling and Prognostics. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 915–928. [Google Scholar] [CrossRef]
- Nuhic, A.; Terzimehic, T.; Soczka-Guth, T.; Buchholz, M.; Dietmayer, K. Health Diagnosis and Remaining Useful Life Prognostics of Lithium-Ion Batteries Using Data-Driven Methods. J. Power Sources 2013, 239, 680–688. [Google Scholar] [CrossRef]
- Zhang, Y.; Feng, X.; Zhao, M.; Xiong, R. In-Situ Battery Life Prognostics amid Mixed Operation Conditions Using Physics-Driven Machine Learning. J. Power Sources 2023, 577, 233246. [Google Scholar] [CrossRef]
- Paulson, N.H.; Kubal, J.; Ward, L.; Saxena, S.; Lu, W.; Babinec, S.J. Feature Engineering for Machine Learning Enabled Early Prediction of Battery Lifetime. J. Power Sources 2022, 527, 231127. [Google Scholar] [CrossRef]
- Yang, F.; Wang, D.; Xu, F.; Huang, Z.; Tsui, K.L. Lifespan Prediction of Lithium-Ion Batteries Based on Various Extracted Features and Gradient Boosting Regression Tree Model. J. Power Sources 2020, 476, 228654. [Google Scholar] [CrossRef]
- Fei, Z.; Yang, F.; Tsui, K.L.; Li, L.; Zhang, Z. Early Prediction of Battery Lifetime via a Machine Learning Based Framework. Energy 2021, 225, 120205. [Google Scholar] [CrossRef]
- Zhang, Y.; Peng, Z.; Guan, Y.; Wu, L. Prognostics of Battery Cycle Life in the Early-Cycle Stage Based on Hybrid Model. Energy 2021, 221, 119901. [Google Scholar] [CrossRef]
- Fei, Z.; Zhang, Z.; Yang, F.; Tsui, K.L.; Li, L. Early-Stage Lifetime Prediction for Lithium-Ion Batteries: A Deep Learning Framework Jointly Considering Machine-Learned and Handcrafted Data Features. J. Energy Storage 2022, 52, 104936. [Google Scholar] [CrossRef]
- Gong, D.; Gao, Y.; Kou, Y.; Wang, Y. Early Prediction of Cycle Life for Lithium-Ion Batteries Based on Evolutionary Computation and Machine Learning. J. Energy Storage 2022, 51, 104376. [Google Scholar] [CrossRef]
- He, N.; Wang, Q.; Lu, Z.; Chai, Y.; Yang, F. Early Prediction of Battery Lifetime Based on Graphical Features and Convolutional Neural Networks. Appl. Energy 2024, 353, 122048. [Google Scholar] [CrossRef]
- Zhao, W.; Ding, W.; Zhang, S.; Zhang, Z. Yong. A deep learning approach incorporating attention mechanism and transfer learning for lithium-ion battery lifespan prediction. J. Energy Storage 2024, 75, 109647. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiong, R.; He, H.; Pecht, M.G. Lithium-Ion Battery Remaining Useful Life Prediction With Box–Cox Transformation and Monte Carlo Simulation. IEEE Trans. Ind. Electron. 2019, 66, 1585–1597. [Google Scholar] [CrossRef]
- Mahedy Hasan, S.M.; Uddin, M.P.; Al Mamun, M.; Sharif, M.I.; Ulhaq, A.; Krishnamoorthy, G. A Machine Learning Framework for Early-Stage Detection of Autism Spectrum Disorders. IEEE Access 2023, 11, 15038–15057. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2012, 12, 2825–2830. [Google Scholar]
- Müller, M.; Huber, F.; Arnaud, M.; Kraemer, A.I.; Altimiras, E.R.; Michaux, J.; Taillandier-Coindard, M.; Chiffelle, J.; Murgues, B.; Gehret, T.; et al. Machine Learning Methods and Harmonized Datasets Improve Immunogenic Neoantigen Prediction. Immunity 2023, 56, 2650–2663.e6. [Google Scholar] [CrossRef]
- Barlow, R.E. Statistical Inference Under Order Restrictions: The Theory and Application of Isotonic Regression; John Wiley & Sons Ltd.: Oxford, UK, 1972. [Google Scholar]
- Robertson, T. Order Restricted Statistical Inference; John Wiley & Sons Ltd.: Oxford, UK, 1988. [Google Scholar]
- Oron, A.P.; Flournoy, N. Centered Isotonic Regression: Point and Interval Estimation for Dose–Response Studies. Stat. Biopharm. Res. 2017, 9, 258–267. [Google Scholar] [CrossRef]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Simonetto, A. Smooth Strongly Convex Regression. arXiv 2021. [Google Scholar] [CrossRef]
- Wang, Y.; Jiang, B. Attention Mechanism-Based Neural Network for Prediction of Battery Cycle Life in the Presence of Missing Data. Batteries 2024, 10, 229. [Google Scholar] [CrossRef]
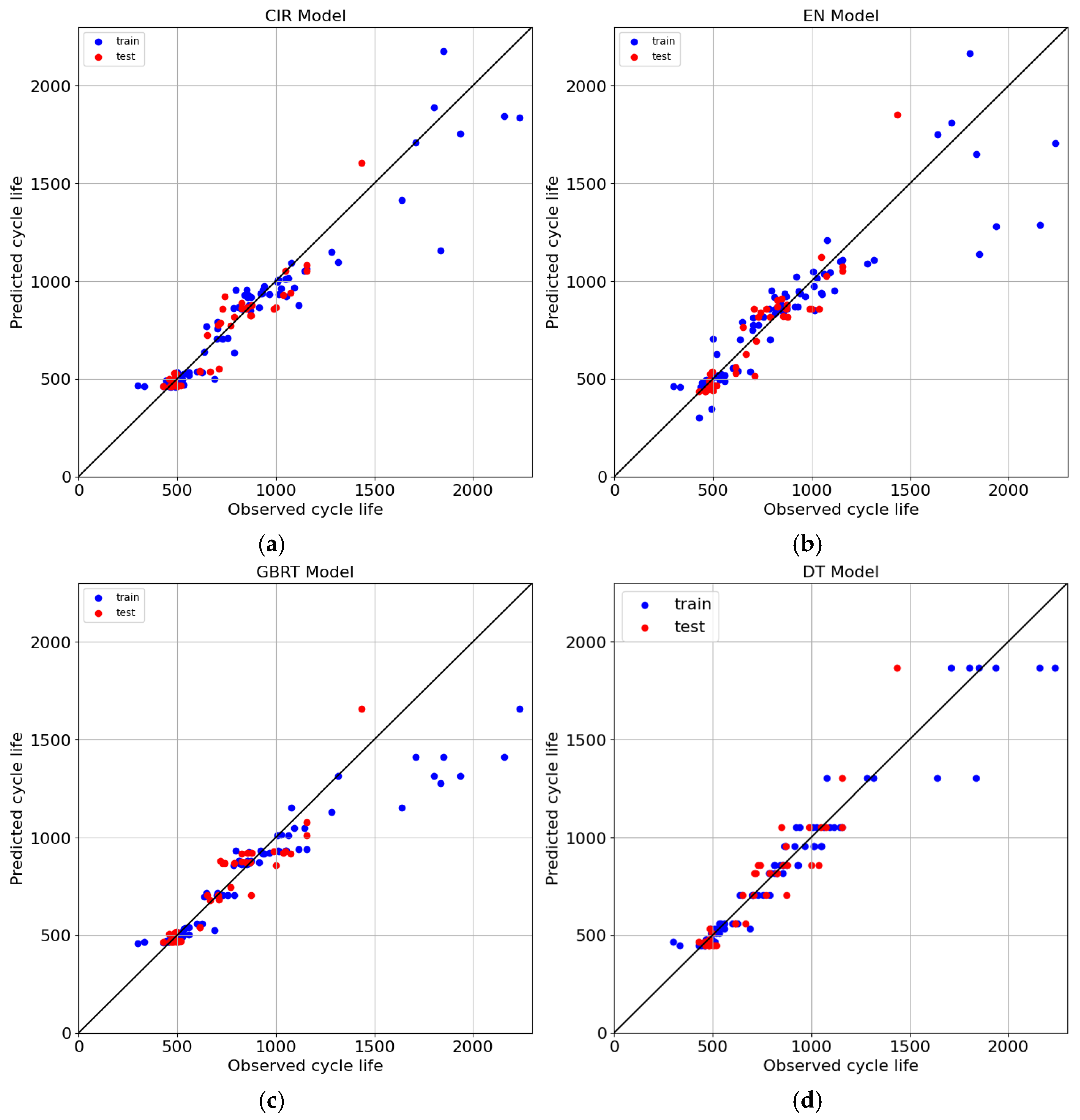

| Model | APE (%) | RMSE (Cycles) | ||
|---|---|---|---|---|
| Train | Test | Train | Test | |
| CIR Model | 7.3 | 9.8 | 120 | 149 |
| EN | 8.9 | 10.8 | 172 | 179 |
| GBRT | 7.7 | 10.8 | 161 | 181 |
| DT | 6.5 | 11.3 | 107 | 157 |
| SVM | 9.7 | 11.5 | 210 | 214 |
| RF | 8.5 | 11.4 | 206 | 217 |
| GPR | 8.6 | 10.4 | 164 | 180 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.A.; Wang, Y.; Jiang, B. Early Prediction of Battery Lifetime Using Centered Isotonic Regression with Quantile-Transformed Features. Batteries 2025, 11, 145. https://doi.org/10.3390/batteries11040145
Khan MA, Wang Y, Jiang B. Early Prediction of Battery Lifetime Using Centered Isotonic Regression with Quantile-Transformed Features. Batteries. 2025; 11(4):145. https://doi.org/10.3390/batteries11040145
Chicago/Turabian StyleKhan, Muhammad Arslan, Yixing Wang, and Benben Jiang. 2025. "Early Prediction of Battery Lifetime Using Centered Isotonic Regression with Quantile-Transformed Features" Batteries 11, no. 4: 145. https://doi.org/10.3390/batteries11040145
APA StyleKhan, M. A., Wang, Y., & Jiang, B. (2025). Early Prediction of Battery Lifetime Using Centered Isotonic Regression with Quantile-Transformed Features. Batteries, 11(4), 145. https://doi.org/10.3390/batteries11040145