1. Introduction
Given the prevailing energy crisis and the rapid advancements in alternative energy sources, the lithium-ion power battery has emerged as a pivotal determinant of the progress of electric vehicles [
1,
2]. The state of charge (SOC) of a lithium-ion power battery is a critical parameter reflecting the ratio between its remaining capacity and maximum available capacity [
3]. This parameter plays a fundamental role in assessing the durability, reliability monitoring, and cruising range estimation within the battery management system [
4,
5]. Accurate SOC estimation is crucial for optimizing battery performance, including the control strategy, balancing technology, energy utilization efficiency, and cycle life. However, direct measurement of the SOC is challenging, necessitating the estimation of the SOC through the battery characteristic variables such as charge/discharge current, terminal voltage, internal resistance, temperature, etc., which poses challenges to achieving accurate real-time SOC estimation [
6,
7]. Furthermore, during the operation of electric vehicles, the performance of lithium-ion batteries is affected by various factors, including aging, temperature shocks, and dynamic driving conditions [
8,
9]. These factors pose challenges to the implementation of rapid and accurate SOC estimation techniques in the battery management system. As a result, accurate SOC estimation in real time is significant.
SOC estimation methods can be classified into four categories: lookup table, ampere-hour integration, model-based state observer, and data-driven modeling approaches [
10,
11,
12,
13]. The lookup table method establishes a correlation between the SOC and measurable data, such as open circuit voltage (OCV), to estimate the SOC [
14,
15]. However, achieving accurate OCV measurement necessitates a well-conditioned battery to stabilize parameters, restricting the online application of SOC estimation in battery management systems [
16]. On the other hand, the ampere-hour integration method involves assessing the total current intake throughout a specified period to obtain available charge information but relies on initial SOC values or regular measurements/estimation of battery capacity [
17]. Consequently, the current emphasis on SOC estimation methods is primarily directed toward the battery model-based state observer and the data-driven modeling method.
Battery model-based state observer methods use battery models (equivalent circuit or electrochemical modeling) and integrate state observers like Kalman filters, nonlinear observers, sliding mode observers, etc., to continuously improve SOC estimation through closed-loop feedback. Tian et al. [
18] proposed a gain nonlinear observer and a second-order RC model optimized with the particle swarm optimization (PSO) algorithm for SOC estimation, which exhibited excellent performance in various working conditions. Shrivastava et al. [
19] investigated the adaptive extended Kalman filter (AEKF) with double forgetting factors and developed a second-order RC model to predict battery SOC and SOE together. Three battery cells with different materials were tested under various dynamic operating conditions, demonstrating the capability to rapidly obtain precise SOC estimates, even from inaccurate initial states. Sun et al. [
20] developed an intelligent AEKF with a Thevenin model for accurate SOC estimation, addressing changes in residual sequence distribution caused by dynamic load current, battery model error, and Taylor approximation. The experiment results indicated the method’s robustness to parameter uncertainty. Sakile et al. [
21] explored an extended nonlinear state observer that utilized a second-order resistor-capacitance (RC) model for predicting SOC. It represented the OCV-SOC relationship employing a 9th-order polynomial and evaluated the stability and convergence rate of the observer through Lyapunov criterion analysis. Comparative analysis with an unscented Kalman filter (UKF) and sliding mode observer demonstrated the improved dynamic performance and estimation accuracy of this method.
Data-driven modeling methods, utilizing machine learning or deep learning technology, train on measurable data. By inputting the acquired data into the trained model, accurate SOC estimation is achieved. Yang et al. [
22] explored an integrated data-driven model employing both long short-term memory (LSTM) and an UKF for accurate SOC estimation. Measurable data like voltage, current, and temperature were utilized as input variables. By effectively mitigating noise in the LSTM network, the UKF enhanced the accuracy of the SOC estimation. The findings demonstrated precise SOC estimation within a temperature range spanning from 0 to 50 °C. Hannan et al. [
23] proposed a self-supervised Transformer model for SOC estimation without marked features or adaptive filtering, demonstrating accurate results even in various ambient temperatures. Yang et al. [
24] explored the bidirectional LSTM network for SOC estimation, enhancing information integrity and timing dependence. Moreover, the Bayesian optimization algorithm was utilized to search for optimal network parameters, improving model performance. Experimental results demonstrated the high accuracy and generalizability of this model across various battery types and temperature environments. Yan et al. [
25] introduced a hybrid data-driven method that combines LSTM and an improved particle filter (IPF), enhancing the precision of the SOC estimation by augmenting the particle filter with an adaptive algorithm. The results demonstrated low estimation errors for various battery types, temperatures, and driving cycles.
Model-based state observer estimation methods effectively reduce Gaussian white noise effects on measurement data. Accurate battery models are crucial for precise SOC estimation; however, commonly used models like the equivalent circuit model introduce modeling errors. Moreover, nonlinear prediction capabilities are essential for the state observer. Data-driven modeling methods do not necessitate the consideration of complex electrochemical and physical attributes in the battery system, enabling better battery SOC estimation. LSTM networks are commonly used for accurate SOC estimation due to their effective capture of timing and nonlinear characteristics in the battery SOC [
26,
27]. However, they may face overfitting issues with limited training data and encounter gradient-vanishing challenges in longer sequences [
28]. Transformers, with their self-attention mechanism, address the gradient vanishing problem and find applications in SOC prediction [
29]. Nevertheless, the self-attention mechanism’s association of each position with all others introduces sparsity issues due to an abundance of weight parameters. Furthermore, the Transformer exhibits increased computational complexity in longer sequences [
30]. Hence, selecting a deep learning network that efficiently captures long-term dependencies, is robust against gradient vanishing, and maintains high computational efficiency is crucial for accurate SOC estimation.
S. Bai et al. [
31] optimized the basic architecture of temporal convolutional networks (TCNs), applying them to sequence data modeling. This type of temporal convolutional neural network has made significant advancements in the field of time-series data processing. Its design aims to better capture long-range dependencies in temporal data. Compared to traditional recurrent neural networks and LSTM, TCNs efficiently capture information in time series through parallel convolution operations. The TCN has found widespread applications and garnered attention in various domains, including natural language processing [
32], speech recognition [
33], and time-series prediction [
34,
35]. The TCN is widely used in time-series prediction for its flexible receptive fields, resistance to gradient vanishing, and effective capture of long-term dependencies [
36,
37,
38]. By employing convolutional operations, a TCN enables parallel computation across the entire input sequence, enhancing both training and inference speed. Notably, the TCN excels in capturing diverse long-term dependencies and demonstrates enhanced generalization, particularly in scenarios with limited data. Its convolutional operations simplify the handling of multivariate inputs in time-series prediction tasks. In contrast to LSTM, the TCN is less susceptible to gradient vanishing issues, making it a promising choice for SOC estimation. The primary contributions of this work include a novel data-driven method using a TCN and multi-verse optimization (MVO) that was proposed for SOC estimation; MVO was employed to optimize the hyperparameters of the TCN. Various measurable data, such as battery terminal voltage, current, and surface temperature, were used as inputs to the driving model to achieve SOC estimation. Data from nine different dynamic working conditions at different ambient temperatures was used for the training, validation, and testing of data-driven models. The sections of this paper are organized as follows:
Section 2 presents the framework of the SOC estimation method based on TCN-MVO;
Section 3 discusses the performance of the different data-driven methods under nine dynamic working conditions at various ambient temperatures; and
Section 4 provides a concise conclusion.
2. SOC Estimation Method Based on TCN-MVO
In this section, the SOC estimation method based on TCN-MVO is described in detail. Firstly, the evaluation metrics used to assess SOC estimation performance are introduced. Next, the overall SOC estimation framework employed in this study is proposed. In this framework, the time-varying sequential data of battery terminal voltage, current, and surface temperature are used as input for training and prediction in the data-driven model. Subsequently, a comprehensive explanation of the TCN modeling approach for SOC estimation is presented. Additionally, the method of optimizing TCN hyperparameters using the MVO algorithm is outlined. Finally, the objective function used in optimizing deep learning networks through the MVO algorithm is introduced.
2.1. Evaluation Metrics
For a thorough examination of SOC estimation performance across different deep learning networks in lithium-ion batteries, this work employs multiple metrics for a comprehensive assessment.
2.1.1. Root-Mean-Square Error
The root-mean-square error (
RMSE) is used as an evaluation metric to measure the deviation between estimated values and their corresponding truth values, and it is given by:
where
n represents the number of estimations,
ŷi denotes the estimated value, and
yi refers to the true value.
2.1.2. Mean Absolute Error
The mean absolute error (
MAE) is primarily employed for assessing the accuracy and extent of deviation in prediction models. Unlike
RMSE,
MAE remains unaffected by outliers and solely focuses on the absolute value of errors. Consequently, it finds extensive application in scenarios necessitating outlier handling or emphasizing the magnitude of prediction errors. It is defined as follows:
2.1.3. Maximum Error
The maximum error (
MAX) is primarily used to calculate the maximum predictive error of a model for the entire dataset. It directly considers the absolute value of the error without undergoing any square operations, making it highly sensitive to outliers. It is expressed as follows:
2.1.4. Coefficient of Determination R2
The coefficient of determination, denoted as
R2, represents the proportion of the regression sum of squares to the total sum of squares in a regression model. It serves as a metric for assessing the fit and excellence of the regression model. The closer
R2 is to 1, the higher the proportion of the regression sum of squares to the total sum of squares, indicating a better fit. Conversely, if
R2 is close to 0, it suggests a poor model fit. It is expressed as follows:
where
denotes the average value of
yi.
2.2. SOC Estimation Framework
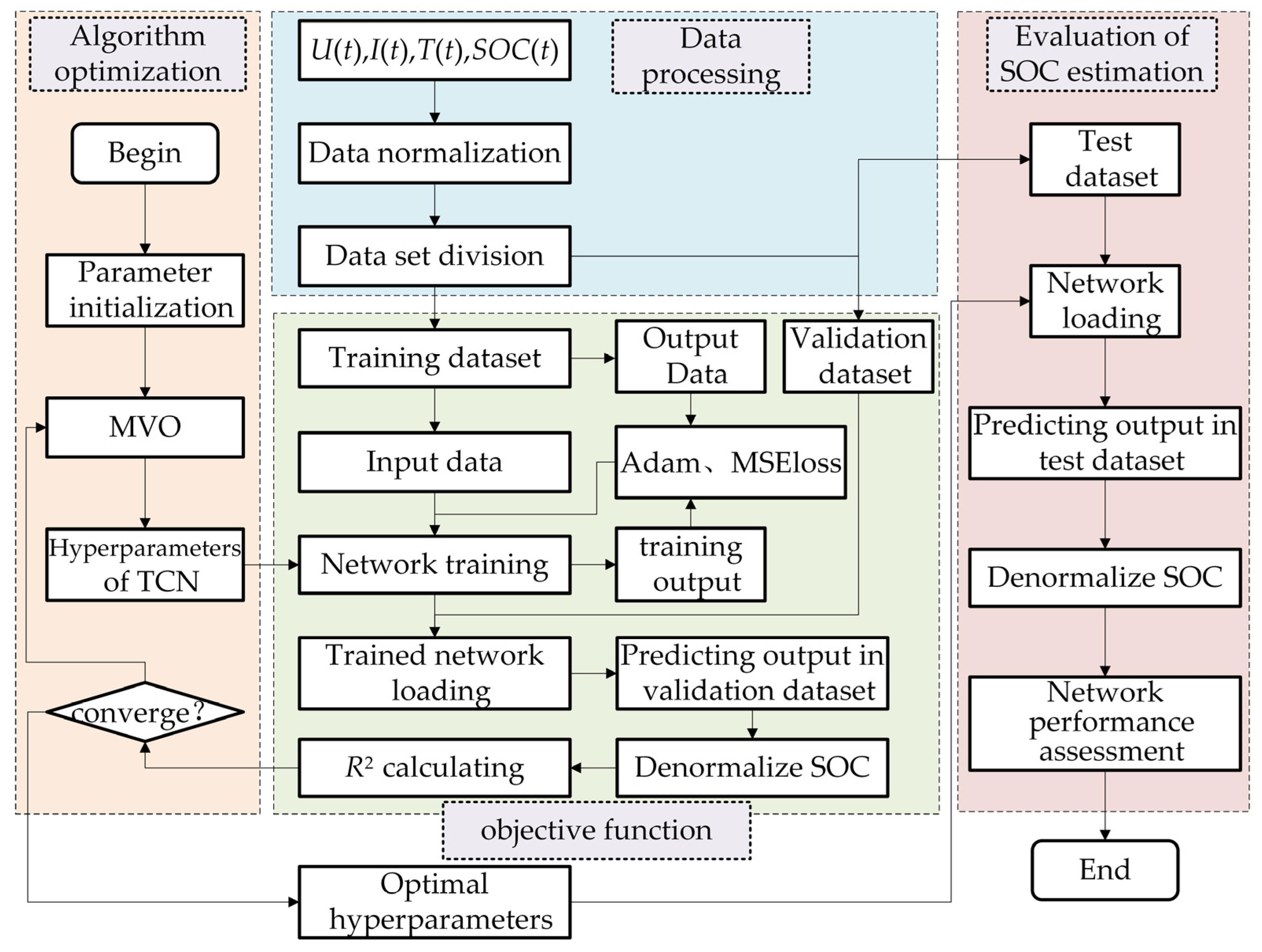
Figure 1 is the flowchart depicting the SOC estimation framework based on TCN-MVO. It is structured into four modules: data processing, algorithm optimization, objective function, and evaluation of the SOC estimation.
Data processing includes the techniques of data normalization and the division of datasets. The MVO algorithm is employed for optimizing the optimal hyperparameter solution of the TCN in algorithmic optimization. The objective function mainly implements the training and verification processes of deep learning. The network training uses the Adam optimizer, the loss function uses mean square error (MSE) loss, and the network verification uses the indicator R2 of Equation (4) for evaluation. The closer R2 is to 1, the more optimal its hyperparameters are, indicating superior performance of the training network. Finally, the optimized TCN is employed for SOC estimation, and the metrics are subsequently computed and evaluated using Equations (1)–(3).
2.3. TCN Modeling for SOC Estimation
The TCN can effectively mitigate common deficiencies in recurrent neural networks, such as gradient vanishing and exploding. Through parallel computation, the network’s performance can be enhanced. The SOC estimation will be performed utilizing the TCN in this work.
Figure 2 illustrates the basic architecture of the TCN. It is apparent that the TCN model is primarily constructed through the interconnection of residual blocks. These blocks comprise causal convolutions, dilated convolutions, weight normalization, rectified linear unit (ReLU) activation function, random dropout, and 1 × 1 convolution. The incorporation of a 1 × 1 convolution facilitates the transfer of network information across layers while maintaining consistency in input–output dimensions. The symbol “*” following ReLU indicates its presence in all layers except the final one, ensuring the potential for negative output values.
Figure 3 depicts a schematic of dilated causal convolution. Causal convolution is unidirectional, implying that the data in layer
i at time
k only depend on the data at or before time
k in layer
i − 1. The augmentation of network layers holds the potential to enhance the capabilities of acquiring long-range data. Dilated convolution refers to the insertion of gaps or holes within the conventional convolution operation, where the sampling rate is regulated by a dilation factor denoted as
d. It achieves an increased receptive field by employing spaced sampling. With a larger dilation factor
d, the convolutional output can capture information from longer temporal sequences without compromising information integrity. This method allows for a larger receptive field with fewer network layers. Meanwhile,
n refers to the number of residual blocks, and
b denotes the dilation base. It follows that d can be calculated as
d =
b(n−1). Zero-padding is necessary for each layer of the network due to the incorporation of holes in dilated convolutions. The padding amount
p is determined by the convolution kernel size
ks and satisfies the condition
ks ≥
b, where
p = (
ks − 1) ·
d.
As a residual block is composed of two causal convolution layers, the total receptive field size, denoted as
rf, for the TCN is given by:
The minimum number of residual blocks required to fully cover the input sequence is given by:
where
l denotes the length of the input sequence, and ⌈
x⌉ represents rounding
x up to the nearest integer. Computing this value ensures that the TCN is sufficiently deep to cover all the information in the input sequence.
The network employs a sliding window method to process the input data.
Figure 4 presents the input and output data format schematic for the SOC estimation method. At time
k, the vector
= [
U(
k),
I(
k),
T(
k)]
T denotes a vector consisting of the terminal voltage, current, and surface temperature of the battery, with
indicating a vector of the estimated SOC.
Additionally, the min–max normalization method is employed for data normalization, aiming to enhance the training adaptability of deep learning networks, alleviate neuron saturation, and improve algorithmic estimation accuracy. The formula for min–max normalization is:
At time
k, the network’s overall input and output are mathematically expressed as:
where
Lwindow denotes the window size of the input data.
After obtaining the network’s predicted output value, denoted as
, the inverse normalization is performed, and the estimated SOC is given by:
Moreover, the network training will employ the MSE loss function. Given a total of
n training data samples, the loss function can be represented as follows:
2.4. MVO Method for Optimization of TCN Hyperparameters
Mirjalili et al. [
39] proposed a multi-verse optimizer derived from the principles of the multiverse theory. This algorithm simulates the transfer of objects through white-hole/black-hole tunnels to search for the best solution. The MVO algorithm comprises exploration and exploitation phases, where white holes repel objects during higher cosmic expansion rates, while black holes attract and absorb objects during lower rates. The algorithm introduces “white hole/black hole tunnels” connecting universes for object transfer. In the exploitation phase, wormholes connect universes to the optimal one, allowing for potential object transfer. Wormhole generation probability is independent of the cosmic expansion rate. The algorithm leverages the trend of objects from high to low inflation rates in the random generation process, facilitating object migration and progressive exploration of the search space toward optimal positions based on cosmological principles.
Figure 5 depicts the schematic diagram of the MVO algorithm. The inflation rate of the
nth universe is represented by
I(
Un), as shown in
Figure 5, where
I(
U1) >
I(
U2) > … >
I(
Un). In the establishment of tunnels connecting two universes, a universe characterized by a higher inflation rate is more inclined to accommodate a white hole, whereas a universe with a lower inflation rate is more likely to host a black hole. The transfer of objects from a universe with a high inflation rate to one with a low inflation rate is highly likely, thereby contributing to the overall average inflation rate of the universe during successive iterations.
As depicted in
Figure 5, the objects are symbolized by the white dots that are transported via wormholes. The generation of these wormholes does not take into account the inflation rate of the universe, thereby presenting optimization opportunities for each individual universe. The utilization of wormholes is exclusively limited to connecting the currently optimal individual universes in order to achieve optimization in the search space. By employing white hole/black hole tunnels and wormholes, the MVO algorithm facilitates the continuous transfer of objects between other universes and the current optimal universe, thereby iterating toward optimization. In this process, individuals in each universe symbolize feasible solutions to the optimization problem, where objects in the universe denote design variables, and the inflation rate of the universe acts as the fitness value for the objective function.
Figure 6 illustrates the flowchart of the MVO algorithm, where
U represents the randomly initialized universes,
d denotes the number of design variables, and
Np signifies the population size. In the exploration phase, mathematical modeling is employed to study the inter-universe exchange of objects through white-/black-hole tunnels. The algorithm incorporates a roulette wheel selection mechanism, where universes are ranked based on their inflation rates in each iteration, and a universe containing a white hole is chosen using this selection method. Let
denote the
jth design variable in the
ith universe, where
Ui denotes the
ith universe and
NI(
i) indicates its normalized inflation rate. Let
r1 be a uniformly distributed random number between 0 and 1, and let
represent the
jth design variable in the
kth universe selected through a roulette wheel mechanism.
is given by:
During the exploitation phase, any universe has the potential to generate a wormhole, thereby establishing a connection with the currently optimal universe and facilitating the exchange of objects. Let
denote the current optimal value of the
jth design variable,
ltdr represent the rate of travel distance,
pwep be the probability of wormhole existence in the universe, and
ubj and
lbj indicate the upper and lower bounds for the
jth design variable. Additionally,
r2,
r3, and
r4 are random numbers within the range [0, 1].
is updated by:
The current iteration number is denoted as
Nc, the maximum iteration number as
Nepoch, and
pwep_min and
pwep_max denote the minimum and maximum values of
pwep, respectively. Additionally,
p represents the exploitation rate.
pwep and
ltdr are given by:
2.5. Objective Function
The objective function is of paramount importance in optimizing deep learning networks through MVO. In this investigation, the design variables represent the hyperparameters of the deep learning network, and the output is indicated by −
R2 on the validation set. The objective function subjected to optimization in the MVO process for deep learning networks cannot be directly expressed through a mathematical equation. To construct the objective function, we present the pseudocode outlined in
Table 1, which delineates the process. Steps 1 to 4 involve data preprocessing; Step 5 pertains to network model construction; Steps 6 to 12 encompass network training; and Steps 13 to 17 cover the calculation of the objective function value.
3. Results and Discussion
In this study, three distinct deep learning networks, including LSTM, Transformer, and TCN, are employed for estimating the SOC, and their respective performances are thoroughly compared. During the training process, the number of training epochs was set to 150, with a training batch size of 128. The deep learning networks in this section were implemented using the Pytorch framework and trained on an NVIDIA GeForce RTX 3090 (24 GB) GPU running Windows 10 (64-bit) with Python 3.8.
The hyperparameters subject to optimization for various deep learning networks are as follows: (1) LSTM: Sliding window length (), Hidden layer output dimension (), Fully connected layer output dimension (), Random dropout rate (), Learning rate (). (2) Transformer: Sliding window length (), Number of attention heads (), Embedding dimension (), Feedforward network dimension (), Number of encoder layers (), Random dropout rate (), Learning rate (). (3) TCN: Sliding window length (), Number of hidden layer channels (, , ), Convolutional kernel size (), Random dropout rate (), and Learning rate ().
3.1. Dataset
A publicly accessible dataset graciously provided by the University of Wisconsin-Madison [
40] was utilized to estimate the SOC for the Panasonic 18650PF battery with a nominal voltage of 3.6 V. The dataset includes nine operating conditions, covering four fundamental scenarios: aggressive driving (SFTP-US06), high-speed (HWFET), urban road cycling (UDDS), and LA92. Additionally, five mixed conditions—Cycles 1 to 4 and a neural network (NN) condition—are included. Cycles 1 to 4 are randomly formed from US06, HWFET, UDDS, LA92, and NN conditions. The NN condition intricately blends segments of the US06 and LA92 driving cycles, introducing supplementary dynamics beneficial for neural network training. This comprehensive method aims to reveal the comparative performance of LSTM, Transformer, and TCN under diverse real-world conditions.
The NN condition, intentionally designed to encompass dynamic scenarios that are beneficial for neural network training within the dataset, was consistently utilized for training in all subsequent design examples. Training, optimization, and testing were conducted at both fixed and varied ambient temperatures. To facilitate a comprehensive comparison of different deep learning networks, two distinct dataset splitting methods were employed:
(A) The training set includes basic scenarios (US06 + UDDS + LA92 + HWFET) along with the NN condition; the validation set includes mixed scenarios (Cycle 1 + Cycle 2); and the testing set includes mixed scenarios (Cycle 3 + Cycle 4).
(B) The training set includes mixed scenarios (Cycle 1~4 + NN); the validation set includes basic scenarios (LA92 + HWFET); and the testing set includes basic scenarios (US06 + UDDS).
3.2. Network Training and Testing at a Fixed Ambient Temperature
This section begins by describing the preliminary tests to evaluate the SOC estimation capabilities of different networks, namely, LSTM, Transformer, and TCN. The focus is on examining their mapping abilities for the nonlinear relationships between LIB voltage, current, surface temperature, and SOC at a fixed ambient temperature of 25 °C. The deep learning networks undergo training, optimization, and testing specifically at this fixed temperature.
The MVO algorithm was employed to optimize the hyperparameters for LSTM, Transformer, and TCN at a fixed temperature of 25 °C using two distinct dataset splitting methods. After optimization using the MVO algorithm, the
R2 values for the validation datasets, obtained through two distinct dataset splitting methods, were very close to 1, indicating the convergence of the algorithm. Furthermore, this signifies a robust fit to the validation set, reflecting a high level of model fitting.
Table 2 presents the optimization results of the hyperparameters for different networks using the MVO algorithm at a fixed temperature of 25 °C.
Table 3 presents the evaluation metrics results for the test dataset at a fixed temperature of 25 °C. Observations suggest that in dataset splitting method A, the
RMSE and
MAE for all three networks remained below 1%, with the TCN exhibiting the smallest values for both, measuring 0.6959% and 0.4945%, respectively. The TCN’s
MAX, although positioned in the middle among these three methods, exhibited a mere 0.5604% deviation from the lowest
MAX observed with LSTM. In dataset splitting method B, the TCN achieved the lowest
RMSE,
MAE, and
MAX, with only the TCN’s
RMSE being below 1%, measuring 0.9160%. Additionally, its
MAE and
MAX were recorded at 0.7937% and 2.8759%, respectively. These results validate that at a constant ambient temperature, the proposed MVO-TCN method surpasses the other two methods in achieving optimal performance in SOC estimation.
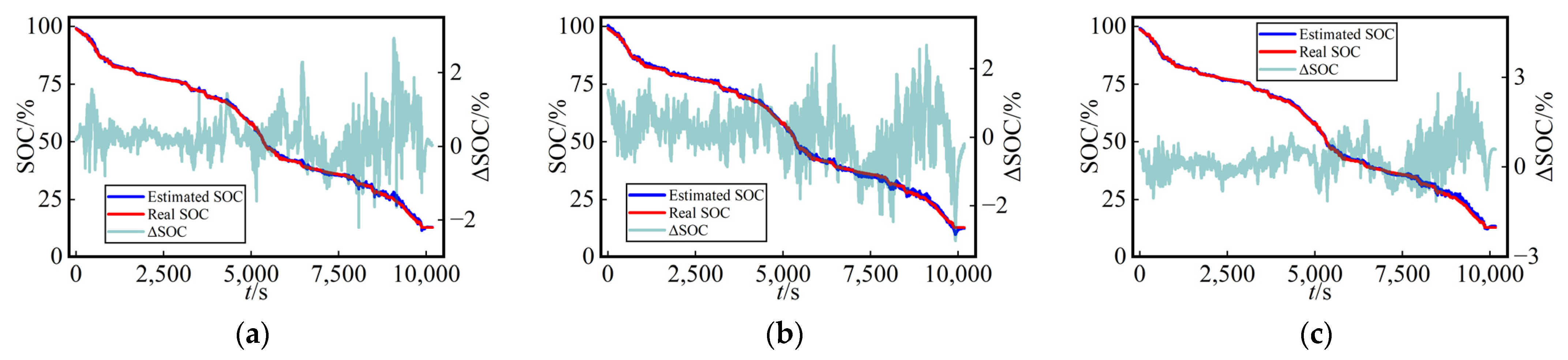
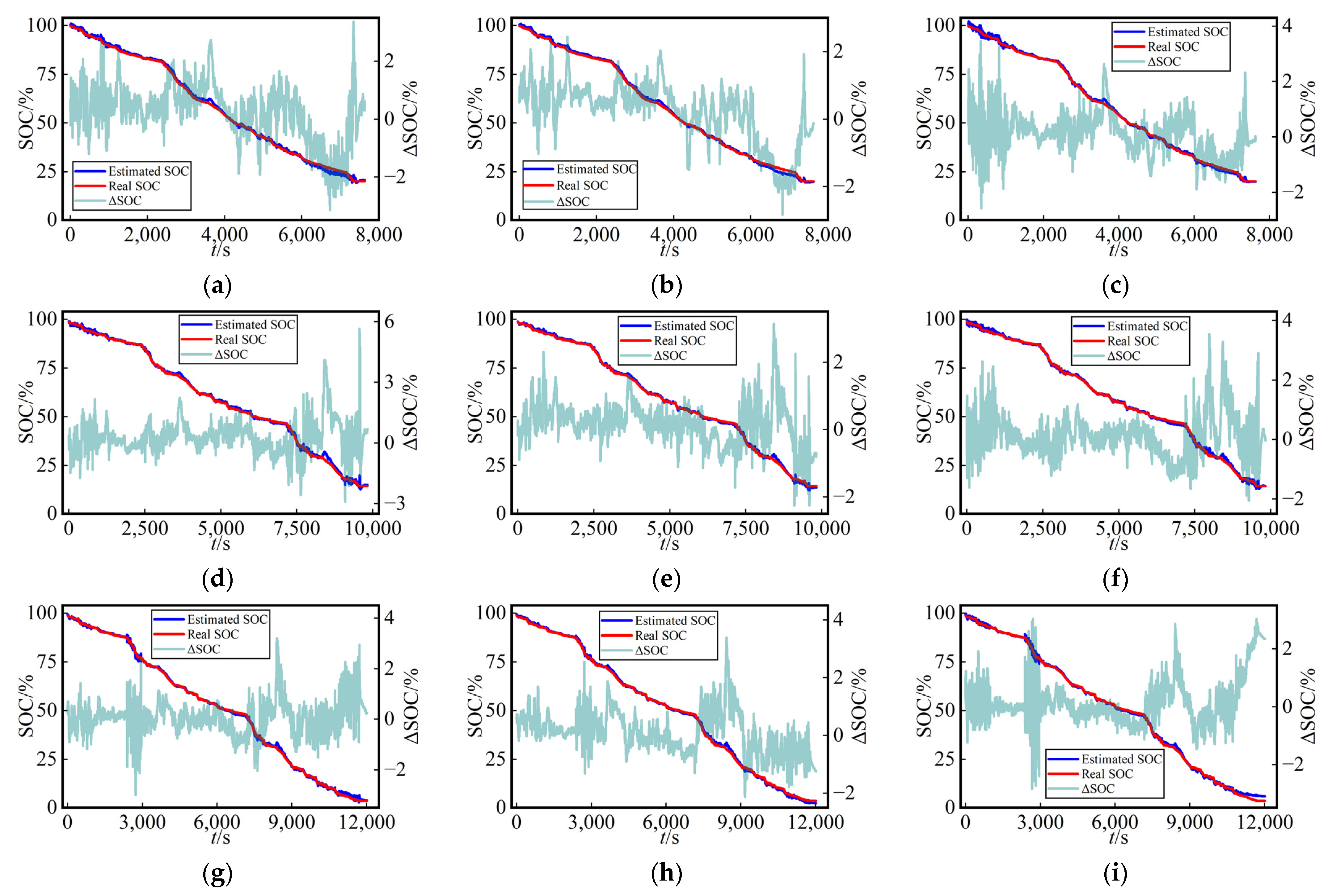
For a more straightforward assessment of the SOC estimation performance among the three methods in the test dataset,
Figure 7 presents the curves of SOC estimation values and their errors (ΔSOC, calculated as the estimated value minus the true value) for the test dataset using three different networks at a fixed temperature (25 °C) with various dataset split methods. The SOC estimation curves and true SOC curves demonstrated a remarkably high level of consistency for the three methods employed, providing compelling evidence for the viability of this work.
3.3. Network Training and Testing at Various Ambient Temperatures
To further compare the mapping capabilities of the three distinct deep learning networks for characterizing the nonlinear dependencies among voltage, current, surface temperature, and SOC in lithium-ion batteries, simultaneous training, optimization, and testing were conducted at various ambient temperatures (0 °C, 10 °C, and 25 °C). Because the dataset covers various operating conditions at multiple ambient temperatures, the nonlinear relationship among the voltage, current, surface temperature, and SOC becomes more complex. This complexity necessitates a more comprehensive evaluation of the different deep learning networks’ performances. The performances of these three methods were compared using both aforementioned dataset splitting methods at various ambient temperatures.
3.3.1. Network Training and Testing Using the Dataset Splitting Method A
The MVO algorithm was adopted to optimize the hyperparameters for three networks, namely, LSTM, Transformer, and TCN, using dataset splitting method A. The dataset encompasses nine dynamic operating conditions across various ambient temperatures.
Table 4 presents the optimization results of the hyperparameters for the different networks using the MVO algorithm at various ambient temperatures (0 °C, 10 °C, and 25 °C) using dataset splitting method A. After optimization using the MVO algorithm, the
R2 values for the validation dataset (Cycle1 + Cycle2) were close to 1 across all three deep learning networks, indicating that the MVO algorithm effectively converged. Additionally, the results reveal that all three networks demonstrate exceptional fitting of the intricate relationships among voltage, current, surface temperature, and SOC for the validation dataset through the data from diverse dynamic working conditions at various temperatures.
Table 5 presents the evaluation metrics results for the test dataset (Cycle 3+ Cycle 4) at various ambient temperatures (0 °C, 10 °C, and 25 °C) using dataset splitting method A. The
RMSE and
MAE values below 1% were obtained for the SOC estimation on the test dataset across all three methods. Notably, the proposed MVO-TCN achieved the smallest
RMSE and
MAE, measuring 0.6790% and 0.4904%, respectively. Among these methods, the TCN exhibited a moderate
MAX value of SOC estimation at 4.2517%, but it was only 0.3944% larger than the lowest
MAX observed with Transformer. In summary, the proposed MVO-TCN demonstrates the optimal performance in SOC estimation among the three methods considered in this study.
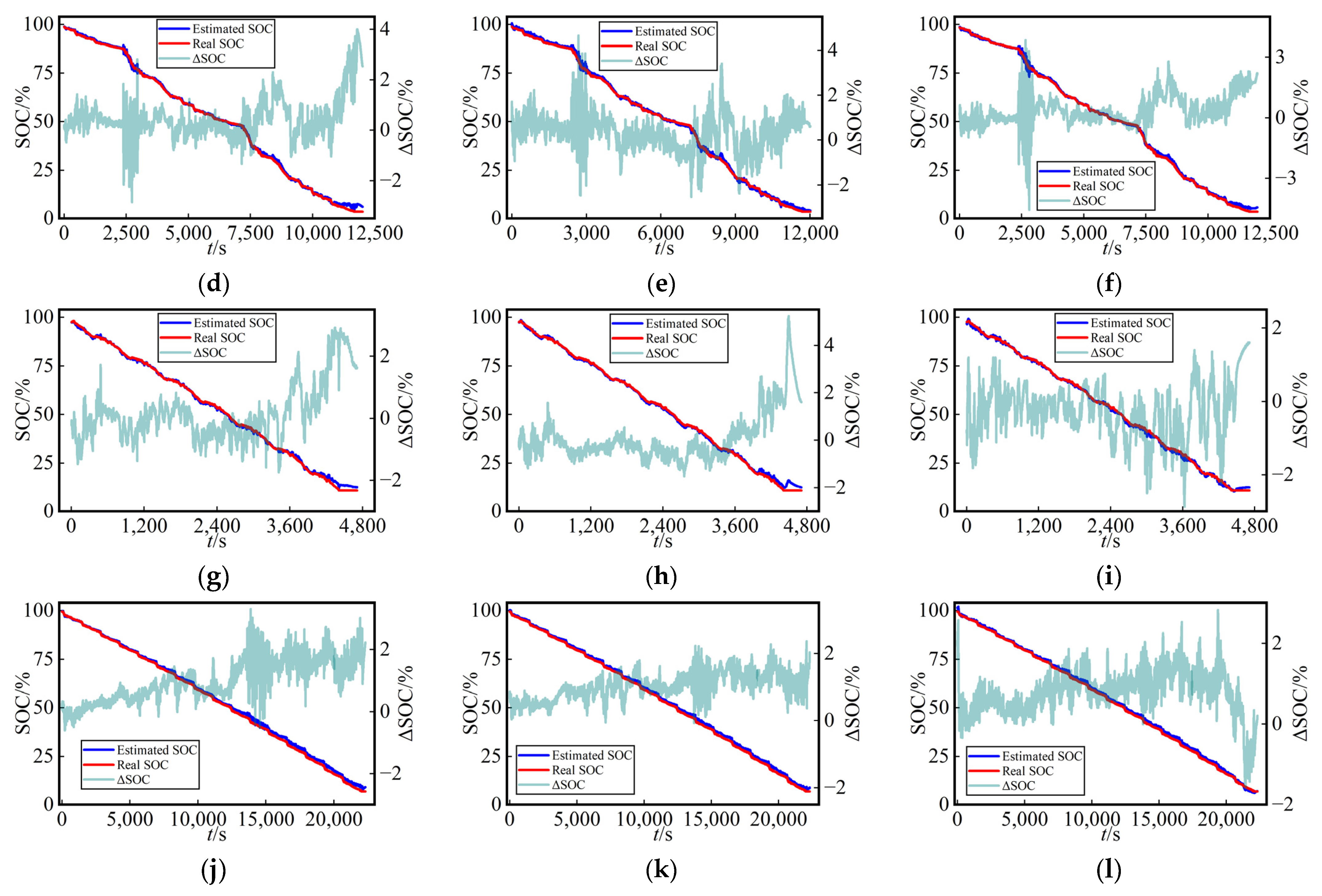
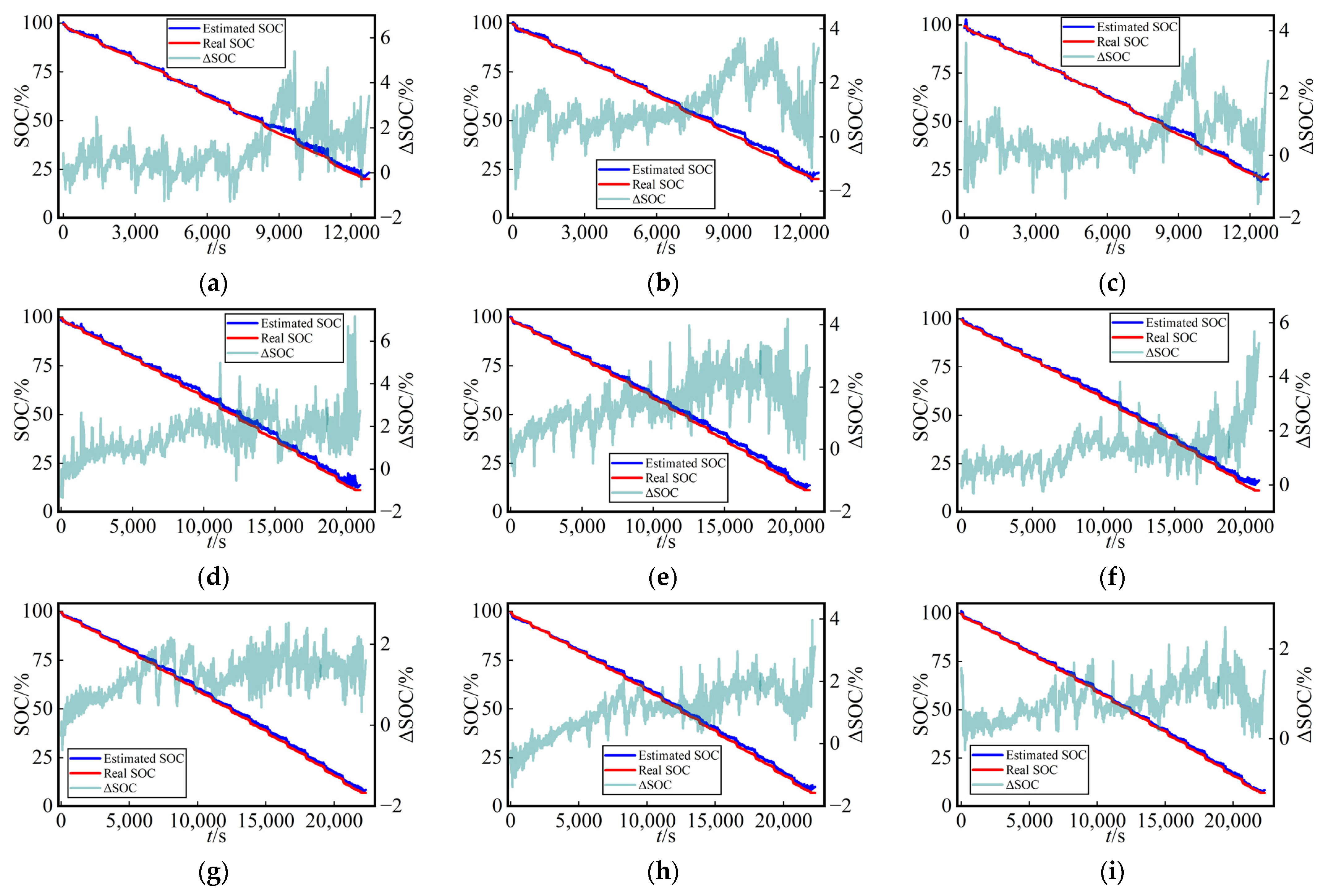
Similarly, for a comparison that is more easily interpretable in terms of the battery’s SOC estimation at various ambient temperatures in the test dataset, as depicted in
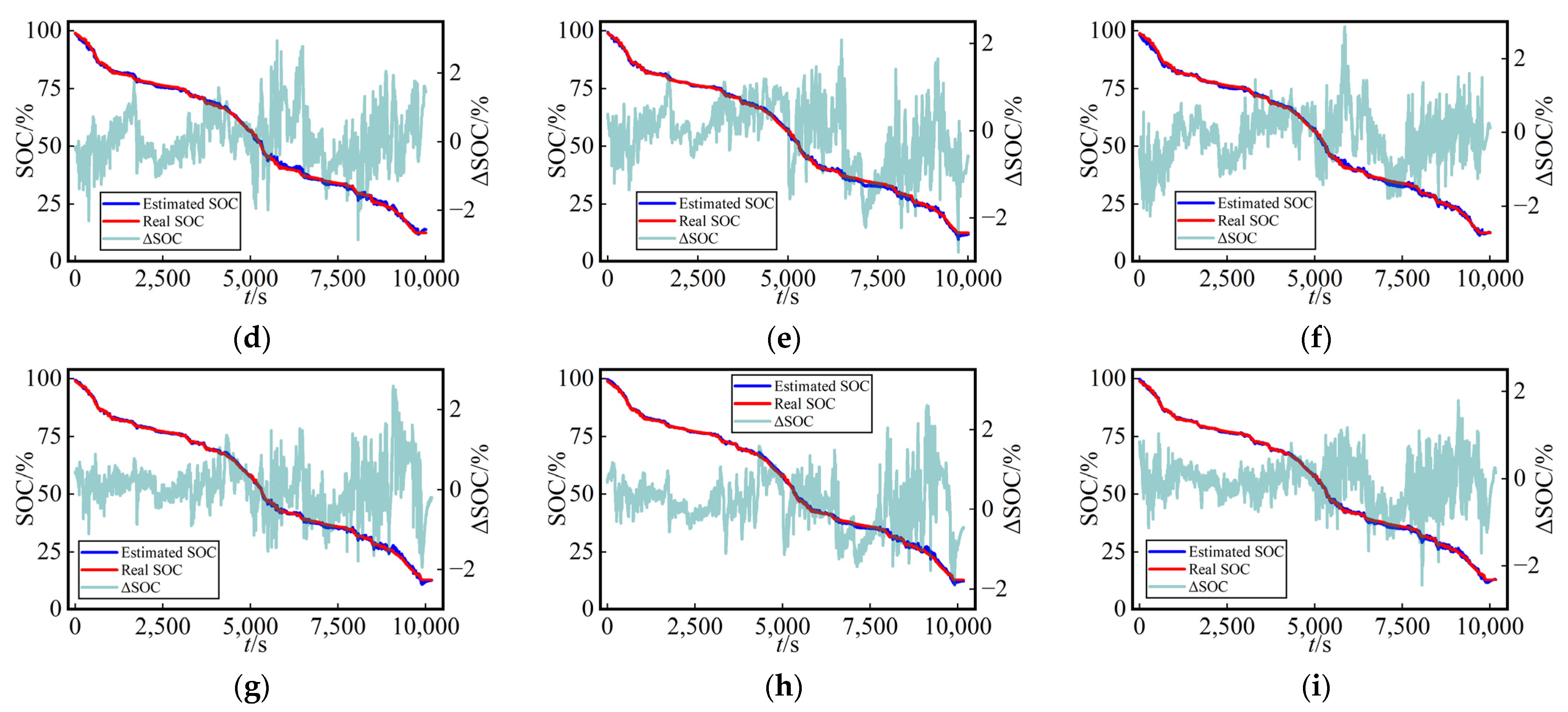
Figure 8 and
Figure 9, the following figure presents the curves of estimated SOC values, actual values, and their errors (ΔSOC, calculated as the estimated value minus the true value) for the three networks at different ambient temperatures in test Cycles 3 and 4. The three methods yielded accuracy curves representing the estimated SOC. The error curves directly reflected the SOC estimation performance for different networks under various working conditions.
3.3.2. Network Training and Testing Using Dataset Splitting Method B
To study the robustness of the proposed method, we conducted training, optimization, and testing under various working conditions at various temperatures using dataset splitting method B.
Table 6 presents the optimization results of the hyperparameters for different networks using the MVO algorithm at various ambient temperatures (0 °C, 10 °C, and 25 °C) using dataset splitting method B. After optimization with the MVO algorithm, the
R2 values for all three methods on the validation dataset (LA92 + HWFET) were also very close to 1. This suggests that MVO converged, and all three methods exhibit a good fit for the SOC estimation on the validation dataset.
As depicted in
Table 7, among the three methods using splitting method B, the proposed MVO-TCN in this study consistently exhibited the smallest
RMSE and
MAE for SOC estimation across various temperatures and working conditions for the test dataset (US06 + UDDS), measuring 1.2388% and 0.9909%, respectively. Despite having a moderate
MAX, it was only 1.0222% larger than the smallest
MAX observed with Transformer. Overall, compared with the other two methods, this method exhibits the most optimal performance in SOC estimation.
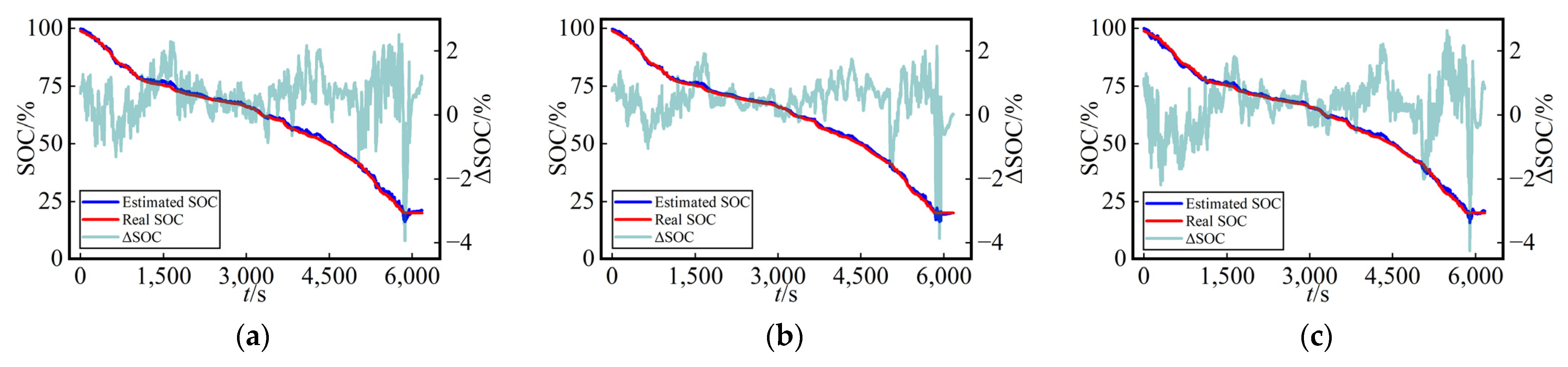
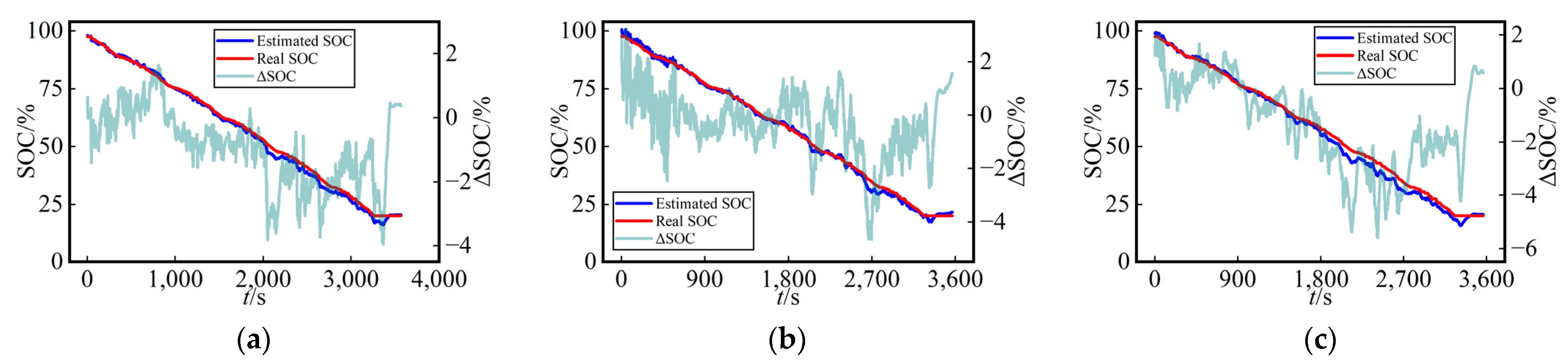
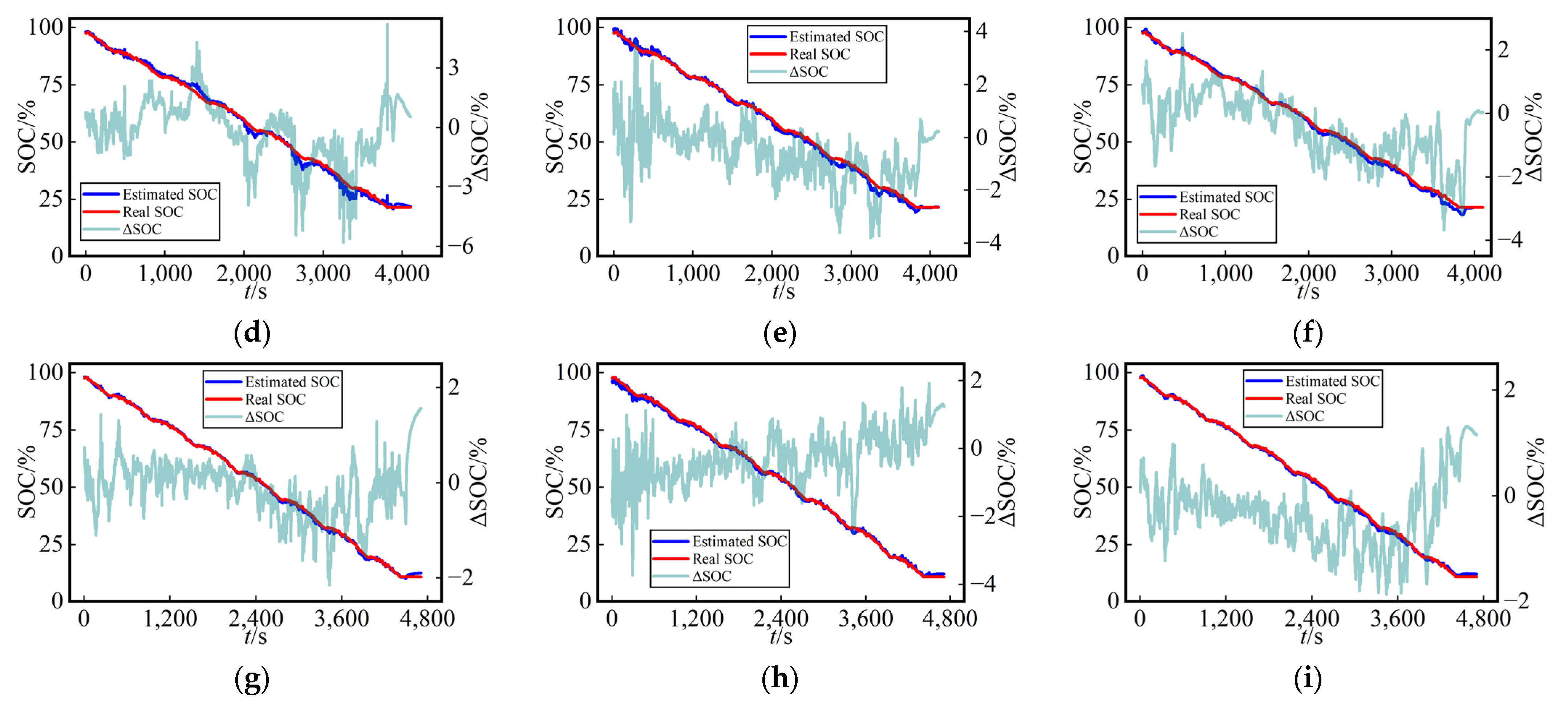
As depicted in
Figure 10 and
Figure 11, we noted that the estimated SOC curves and true SOC curves were nearly identical, indicating that all three networks exhibited high precision in the SOC estimation using dataset splitting method A. Additionally, the figures provide a visual representation of the error variations for each network across different temperatures and working conditions. This suggests that the proposed MVO-TCN algorithm in this study possesses a high level of robustness.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}