

RSWD-YOLO: A Walnut Detection Method Based on UAV Remote Sensing Images

 and
and
Abstract
1. Introduction
- We propose RSWD-YOLO, a UAV remote sensing-based detection model for walnut object detection under aerial perspectives. Building upon YOLOv11s, the proposed method reconstructs the feature fusion component with hierarchical scale principles to enhance multi-scale detection capabilities. The feature extraction section incorporates partial convolution operations and an Efficient Multi-Scale Attention module, achieving model lightweighting without compromising the detection accuracy, thereby ensuring practical deployment viability.
- Knowledge distillation is applied to RSWD-YOLO, improving the walnut detection accuracy without increasing the model complexity or computational costs. This enables the model to achieve high-accuracy walnut detection while remaining compatible with edge device deployment constraints.
- RSWD-YOLO is successfully deployed and tested on Raspberry Pi 5. The results demonstrate an average processing time of 492.28 ms per image, meeting practical deployment requirements and proving RSWD-YOLO’s capability for deployment on UAV-mounted edge devices.
2. Related Works
2.1. Crop Detection Based on CNN and UAV Remote Sensing Images
2.2. Applications of Knowledge Distillation in Object Detection Tasks
2.3. Deep Learning Model Deployment
3. Materials and Methods
3.1. Dataset
3.1.1. Study Area
3.1.2. Image Acquisition
3.1.3. Dataset Creation
3.2. YOLOv11
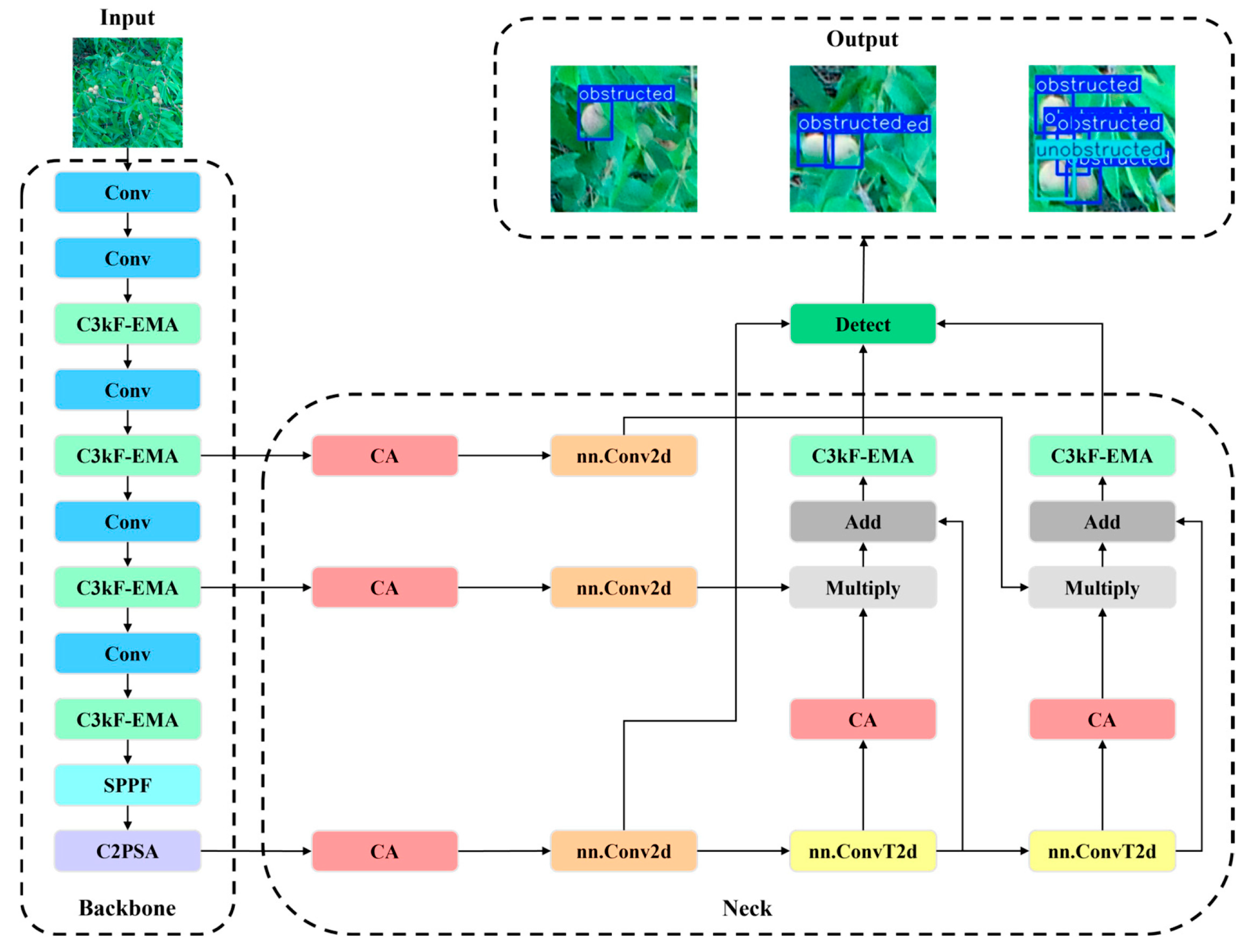
3.3. RSWD-YOLO
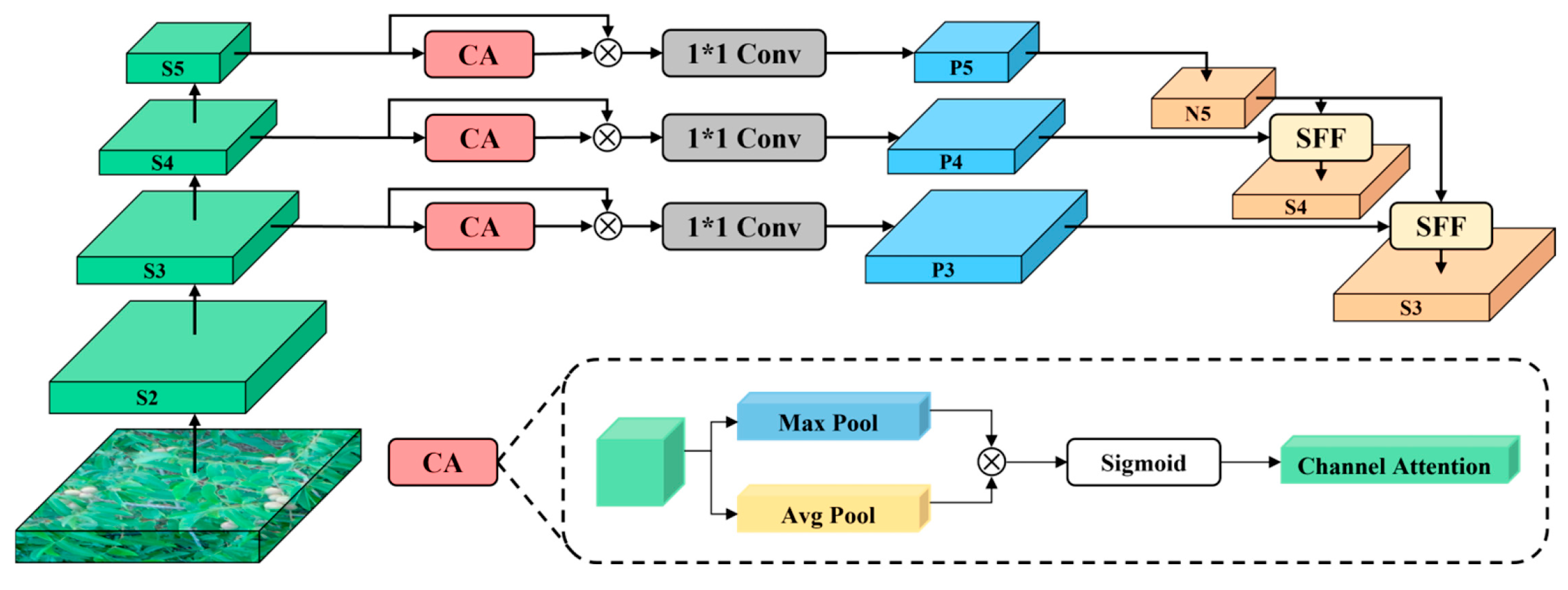
3.3.1. Feature Fusion Enhancement
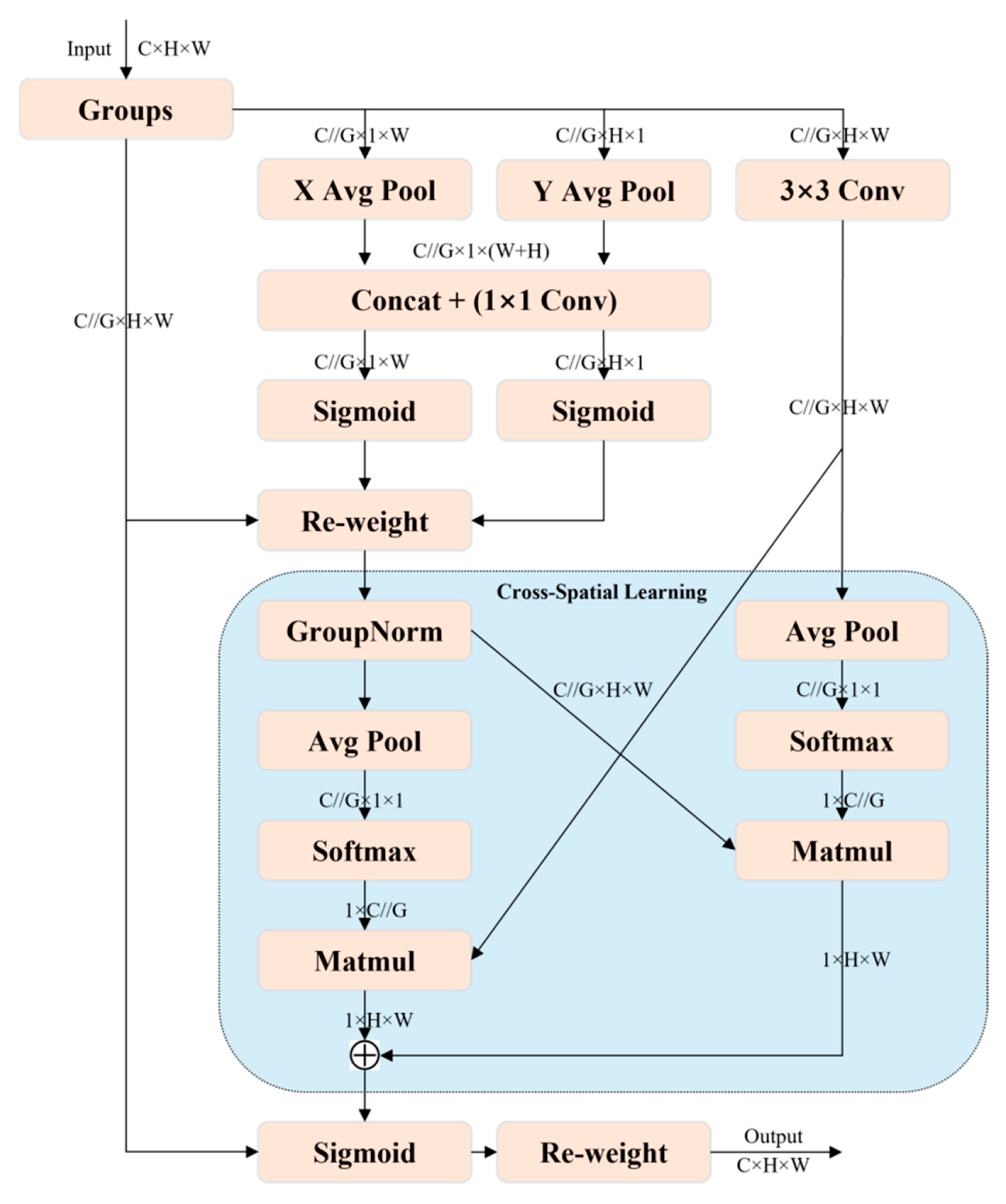
3.3.2. Efficient Multi-Scale Attention
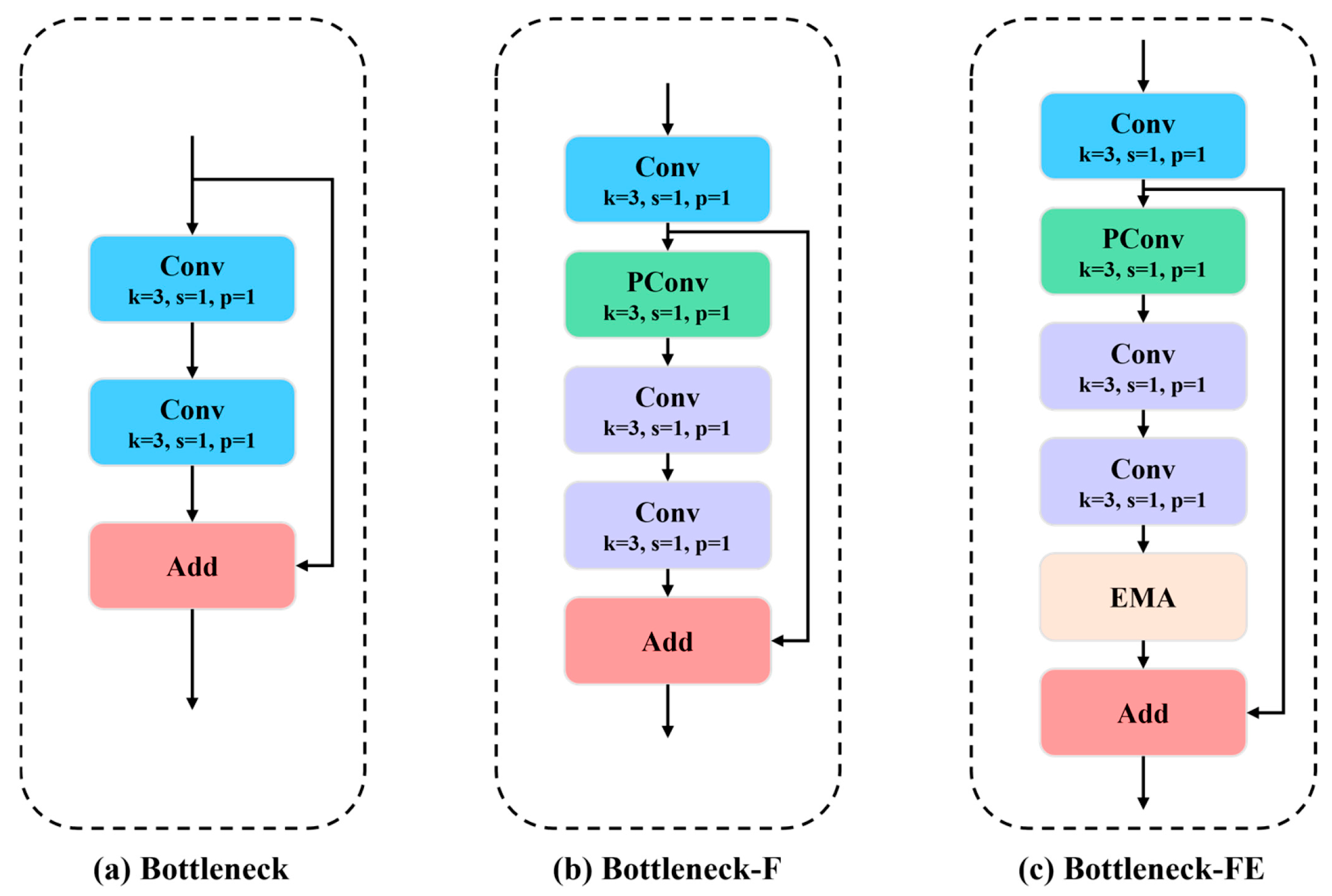
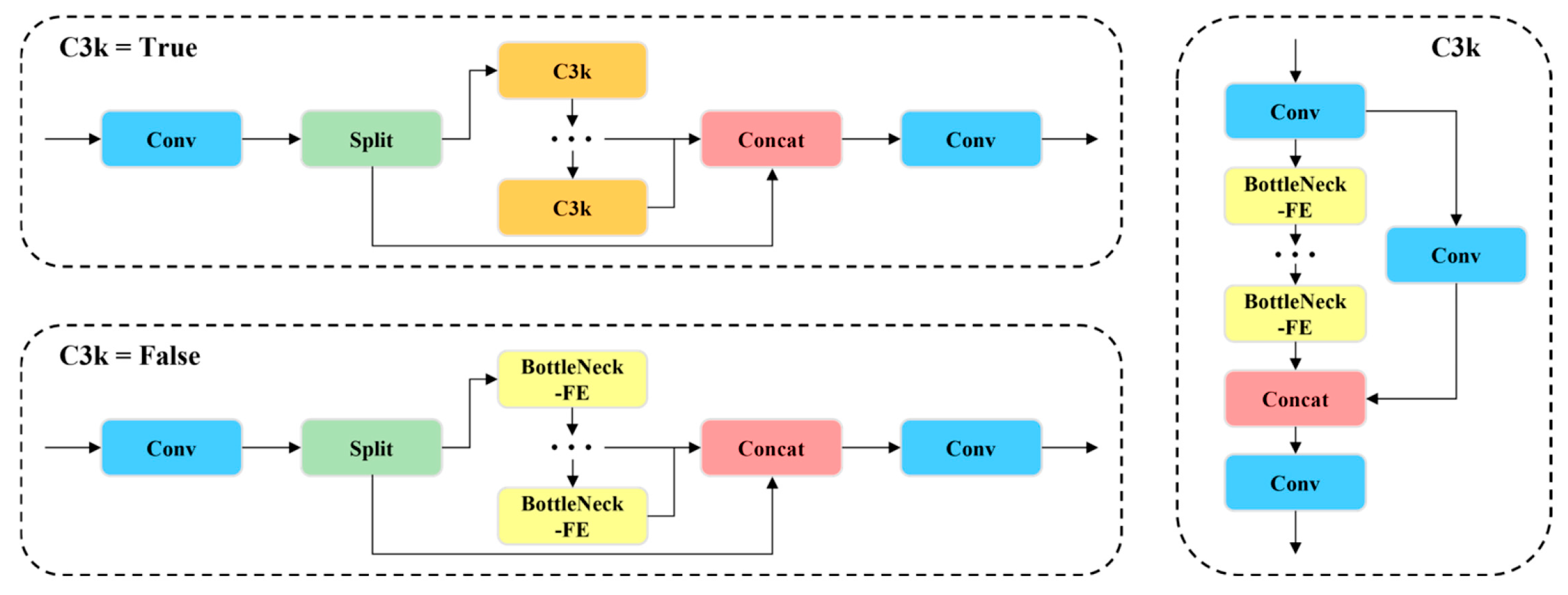
3.3.3. Feature Extraction Enhancement
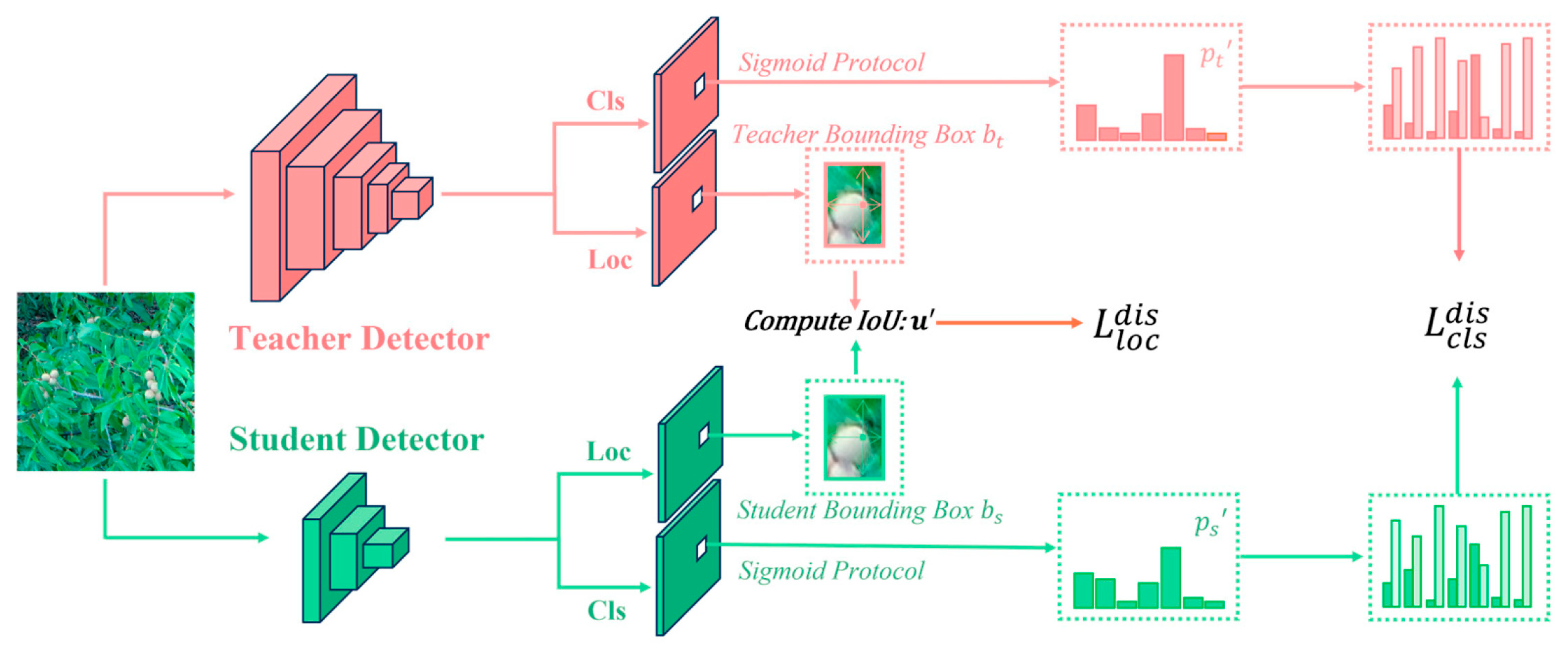
3.4. Knowledge Distillation
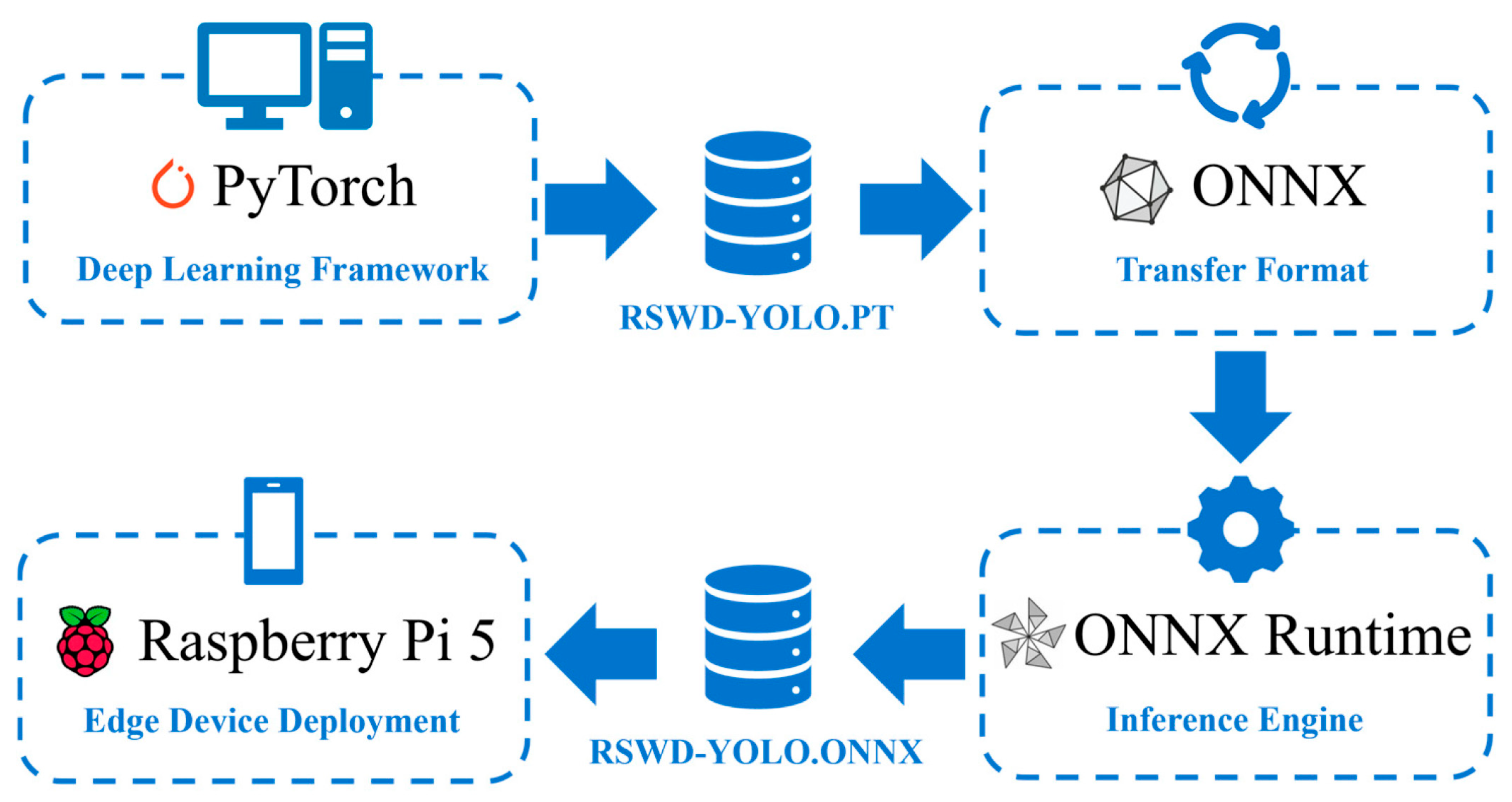
3.5. Model Deployment
4. Experiments and Results
4.1. Training Environment
4.2. Evaluation Metrics
4.3. Ablation Experiments
4.4. Comparative Experiments
5. Discussion
5.1. Discussion on Neck Network Performance
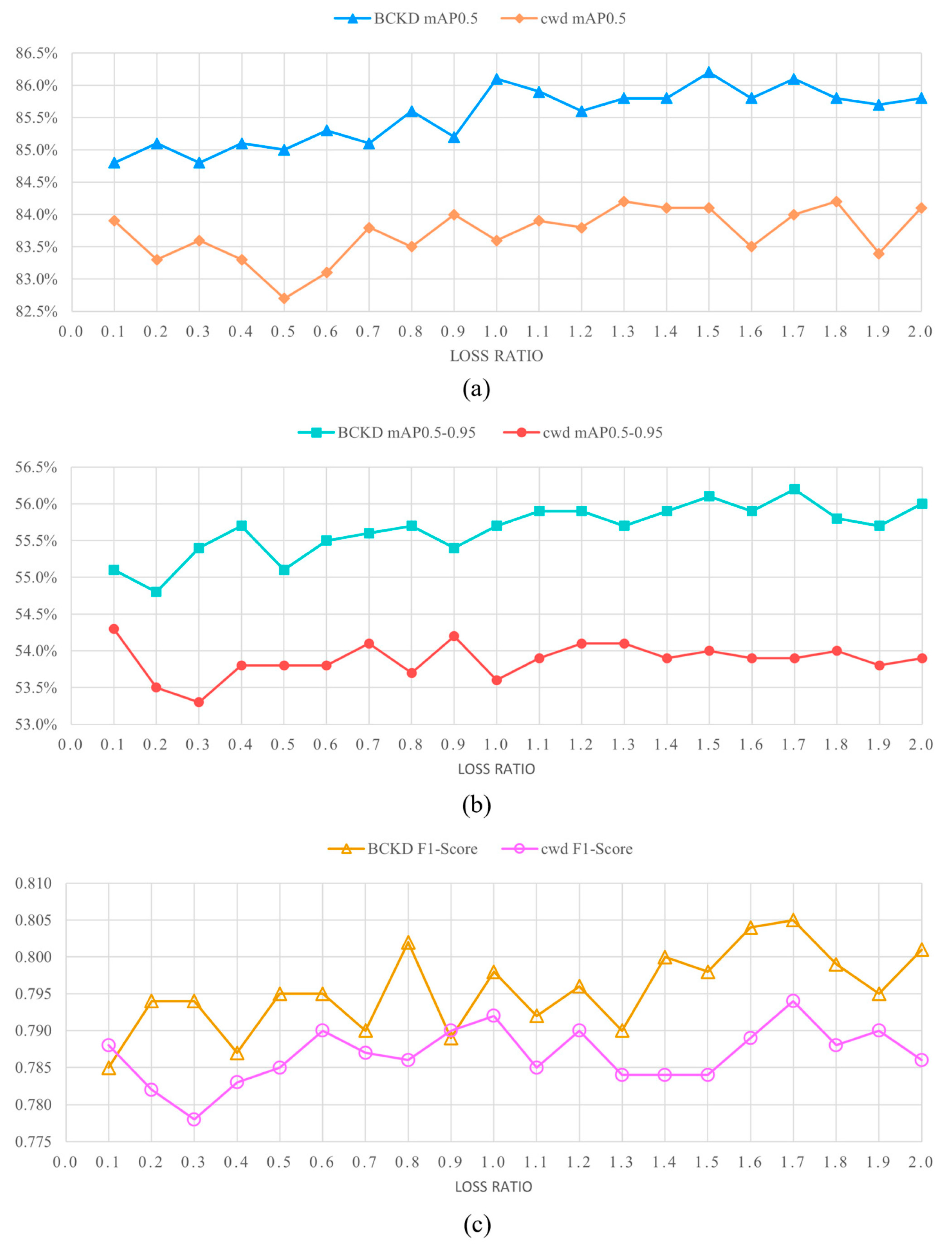
5.2. Discussion on Knowledge Distillation Performance
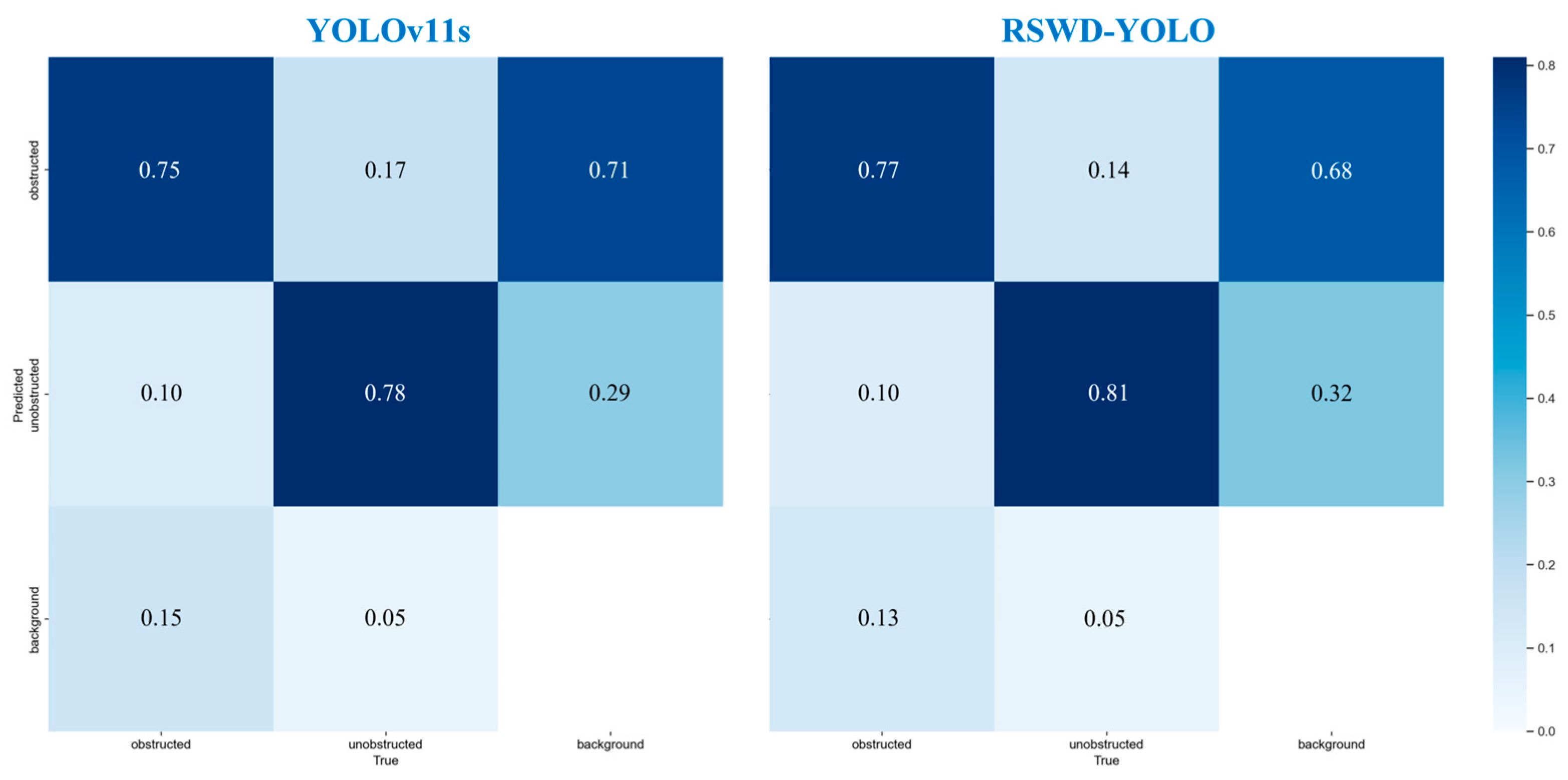
5.3. Discussion on Model Deployment Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Prentović, M.; Radišić, P.; Smith, M.; Šikoparija, B. Predicting walnut (Juglans spp.) crop yield using meteorological and airborne pollen data. Ann. Appl. Biol. 2014, 165, 249–259. [Google Scholar] [CrossRef]
- Guo, P.; Chen, F.; Zhu, X.; Yu, Y.; Lin, J. Phenotypic-Based Maturity Detection and Oil Content Prediction in Xiangling Walnuts. Agriculture 2024, 14, 1422. [Google Scholar] [CrossRef]
- Ni, P.; Hu, S.; Zhang, Y.; Zhang, W.; Xu, X.; Liu, Y.; Ma, J.; Liu, Y.; Niu, H.; Lan, H. Design and Optimization of Key Parameters for a Machine Vision-Based Walnut Shell–Kernel Separation Device. Agriculture 2024, 14, 1632. [Google Scholar] [CrossRef]
- Li, Y.H.; Zheng, J.; Fan, Z.P.; Wang, L. Sentiment analysis-based method for matching creative agri-product scheme demanders and suppliers: A case study from China. Comput. Electron. Agric. 2021, 186, 106196. [Google Scholar] [CrossRef]
- Jafarbiglu, H.; Pourreza, A. A comprehensive review of remote sensing platforms, sensors, and applications in nut crops. Comput. Electron. Agric. 2022, 197, 106844. [Google Scholar] [CrossRef]
- Staff, A.C. The two-stage placental model of preeclampsia: An update. J. Reprod. Immunol. 2019, 134, 1–10. [Google Scholar] [CrossRef]
- Kecen, L.; Xiaoqiang, W.; Hao, L.; Leixiao, L.; Yanyan, Y.; Chuang, M.; Jing, G. Survey of one-stage small object detection methods in deep learning. J. Front. Comput. Sci. Technol. 2022, 16, 41. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Liang, S.; Wu, H.; Zhen, L.; Hua, Q.; Garg, S.; Kaddoum, G.; Hassan, M.M.; Yu, K. Edge YOLO: Real-time intelligent object detection system based on edge-cloud cooperation in autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25345–25360. [Google Scholar] [CrossRef]
- Kang, M.; Ting, C.M.; Ting, F.F.; Phan, R.C.W. RCS-YOLO: A fast and high-accuracy object detector for brain tumor detection. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer Nature: Cham, Switzerland, 2023; pp. 600–610. [Google Scholar]
- Wu, M.; Yang, X.; Yun, L.; Yang, C.; Chen, Z.; Xia, Y. A General Image Super-Resolution Reconstruction Technique for Walnut Object Detection Model. Agriculture 2024, 14, 1279. [Google Scholar] [CrossRef]
- Liu, Q.; Jiang, R.; Xu, Q.; Wang, D.; Sang, Z.; Jiang, X.; Wu, L. YOLOv8n_BT: Research on Classroom Learning Behavior Recognition Algorithm Based on Improved YOLOv8n. IEEE Access 2024, 12, 36391–36403. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. Msft-yolo: Improved yolov5 based on transformer for detecting defects of steel surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef]
- Wu, M.; Lin, H.; Shi, X.; Zhu, S.; Zheng, B. MTS-YOLO: A Multi-Task Lightweight and Efficient Model for Tomato Fruit Bunch Maturity and Stem Detection. Horticulturae 2024, 10, 1006. [Google Scholar] [CrossRef]
- Qiu, Z.; Huang, Z.; Mo, D.; Tian, X.; Tian, X. GSE-YOLO: A Lightweight and High-Precision Model for Identifying the Ripeness of Pitaya (Dragon Fruit) Based on the YOLOv8n Improvement. Horticulturae 2024, 10, 852. [Google Scholar] [CrossRef]
- Shi, L.; Wei, Z.; You, H.; Wang, J.; Bai, Z.; Yu, H.; Ji, R.; Bi, C. OMC-YOLO: A lightweight grading detection method for Oyster Mushrooms. Horticulturae 2024, 10, 742. [Google Scholar] [CrossRef]
- Hassler, S.C.; Baysal-Gurel, F. Unmanned aircraft system (UAS) technology and applications in agriculture. Agronomy 2019, 9, 618. [Google Scholar] [CrossRef]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and systems for fruit detection and localization: A review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Liu, J.; Liu, Z. YOLOv5s-BC: An improved YOLOv5s-based method for real-time apple detection. J. Real-Time Image Process. 2024, 21, 1–16. [Google Scholar] [CrossRef]
- Fu, X.; Wang, J.; Zhang, F.; Pan, W.; Zhang, Y.; Zhao, F. Study on Target Detection Method of Walnuts during Oil Conversion Period. Horticulturae 2024, 10, 275. [Google Scholar] [CrossRef]
- Yang, C.; Cai, Z.; Wu, M.; Yun, L.; Chen, Z.; Xia, Y. Research on Detection Algorithm of Green Walnut in Complex Environment. Agriculture 2024, 14, 1441. [Google Scholar] [CrossRef]
- Sun, J.; He, X.; Ge, X.; Wu, X.; Shen, J.; Song, Y. Detection of key organs in tomato based on deep migration learning in a complex background. Agriculture 2018, 8, 196. [Google Scholar] [CrossRef]
- Zhao, B.; Li, J.; Baenziger, P.S.; Belamkar, V.; Ge, Y.F.; Zhang, J.; Shi, Y.Y. Automatic wheat lodging detection and mapping in aerial imagery to support high-throughput phenotyping and in-season crop management. Agronomy 2020, 10, 1762. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, W.; Gao, P.; Li, Y.; Tan, F.; Zhang, Y.; Ruan, S.; Xing, P.; Guo, L. YOLO SSPD: A small target cotton boll detection model during the boll-spitting period based on space-to-depth convolution. Front. Plant Sci. 2024, 15, 1409194. [Google Scholar] [CrossRef]
- Jia, Y.; Fu, K.; Lan, H.; Wang, X.; Su, Z. Maize tassel detection with CA-YOLO for UAV images in complex field environments. Comput. Electron. Agric. 2024, 217, 108562. [Google Scholar] [CrossRef]
- Li, Y.; Rao, Y.; Jin, X.; Jiang, Z.; Wang, Y.; Wang, T.; Wang, F.; Luo, Q.; Liu, L. YOLOv5s-FP: A novel method for in-field pear detection using a transformer encoder and multi-scale collaboration perception. Sensors 2022, 23, 30. [Google Scholar] [CrossRef]
- Junos, M.H.; Mohd Khairuddin, A.S.; Thannirmalai, S.; Dahari, M. Automatic detection of oil palm fruits from UAV images using an improved YOLO model. Vis. Comput. 2022, 38, 2341–2355. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Liu, X.; Gong, S.; Hua, X.; Chen, T.; Zhao, C. Research on temperature detection method of liquor distilling pot feeding operation based on a compressed algorithm. Sci. Rep. 2024, 14, 13292. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Yang, Z. Csb-yolo: A rapid and efficient real-time algorithm for classroom student behavior detection. J. Real-Time Image Process. 2024, 21, 140. [Google Scholar] [CrossRef]
- Liu, R.M.; Su, W.H. APHS-YOLO: A Lightweight Model for Real-Time Detection and Classification of Stropharia Rugoso-Annulata. Foods 2024, 13, 1710. [Google Scholar] [CrossRef] [PubMed]
- Panigrahy, S.; Karmakar, S. Real-time Condition Monitoring of Transmission Line Insulators Using the YOLO Object Detection Model with a UAV. IEEE Trans. Instrum. Meas. 2024, 73, 1–9. [Google Scholar] [CrossRef]
- Lawal, O.M.; Zhao, H.; Zhu, S.; Chuanli, L.; Cheng, K. Lightweight fruit detection algorithms for low-power computing devices. IET Image Process. 2024, 18, 2318–2328. [Google Scholar] [CrossRef]
- Feng, Z.; Wang, N.; Jin, Y.; Cao, H.; Huang, X.; Wen, S.; Ding, M. Enhancing cotton whitefly (Bemisia tabaci) detection and counting with a cost-effective deep learning approach on the Raspberry Pi. Plant Methods 2024, 20, 161. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, C.; Wang, Z.; Liu, M.; Zhou, D.; Li, J. Application of lightweight YOLOv5 for walnut kernel grade classification and endogenous foreign body detection. J. Food Compos. Anal. 2024, 127, 105964. [Google Scholar] [CrossRef]
- Song, Z.; Ban, S.; Hu, D.; Xu, M.; Yuan, T.; Zheng, X.; Sun, H.; Zhou, S.; Tian, M.; Li, L. A Lightweight YOLO Model for Rice Panicle Detection in Fields Based on UAV Aerial Images. Drones 2024, 9, 1. [Google Scholar] [CrossRef]
- Yakovlev, A.; Lisovychenko, O. An approach for image annotation automatization for artificial intelligence models learning. Адаптивні системи автoматичнoгo управління 2020, 1, 32. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Chen, Y.; Zhang, C.; Chen, B.; Huang, Y.; Sun, Y.; Wang, C.; Fu, X.; Dai, Y.; Qin, F.; Peng, Y.; et al. Accurate leukocyte detection based on deformable-DETR and multi-level feature fusion for aiding diagnosis of blood diseases. Comput. Biol. Med. 2024, 170, 107917. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Yang, L.; Zhou, X.; Li, X.; Qiao, L.; Li, Z.; Yang, Z.; Wang, G.; Li, X. Bridging cross-task protocol inconsistency for distillation in dense object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 17175–17184. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2025; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. Damo-yolo: A report on real-time object detection design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic feature pyramid network for object detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Oahu, HI, USA, 1–4 October 2023; pp. 2184–2189. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 2023, 36, 51094–51112. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Kang, M.; Ting, C.M.; Ting, F.F.; Phan, R.C.W. ASF-YOLO: A novel YOLO model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 2024, 147, 105057. [Google Scholar] [CrossRef]
- Shu, C.; Liu, Y.; Gao, J.; Yan, Z.; Shen, C. Channel-wise knowledge distillation for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5311–5320. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Value |
|---|---|
| Weight | Empty weight (including propellers and battery): 1388 g |
| Diagonal Wheelbase | 350 mm |
| Vertical Hovering Accuracy | ±0.1 m (with normal visual positioning) |
| ±0.5 m (with normal GPS positioning) | |
| Horizontal Hovering Accuracy | ±0.3 m (with normal visual positioning) |
| ±1.5 m (with normal GPS positioning) | |
| Operating Temperature | 0 °C to 40 °C |
| Item | Value |
|---|---|
| Image Sensor | 1-inch CMOS; Effective Pixels: 20 million |
| Aperture | f/2.8–f/11 |
| Focal Length | 8.8 mm |
| Focus Distance | 1 m to ∞ |
| Photo Resolution | 5472 × 3648 (3:2 aspect ratio) |
| Operating Temperature | 0 °C to 40 °C |
| Parameter | Description | Value |
|---|---|---|
| mosaic | Probability of applying Mosaic data augmentation | 1.0 |
| translate | Range of random translation (relative to image size) | 0.1 |
| scale | Range of random scaling | 0.5 |
| fliplr | Probability of horizontal flipping | 0.5 |
| val | Enable validation during training | True |
| conf | Confidence threshold for detections | 0.001 (val) |
| iou | IoU threshold for Non-Maximum Suppression | 0.7 |
| max_det | Maximum number of detections per image | 300 |
| Group | A | B | C | D | E |
|---|---|---|---|---|---|
| HSFPN | √ | √ | √ | √ | |
| C3KF | √ | √ | √ | ||
| EMA | √ | √ | |||
| distill | √ | ||||
| mAP0.5 (%) | 84.4 | 84.8 | 84.4 | 85.1 | 86.1 |
| P (%) | 78.8 | 78.7 | 78.6 | 74.7 | 79.3 |
| R (%) | 79.5 | 78.8 | 80.5 | 83.1 | 81.8 |
| F1-Score | 0.791 | 0.787 | 0.795 | 0.787 | 0.805 |
| Parameters (M) | 9.41 | 6.77 | 6.13 | 6.14 | 6.14 |
| Model Size (MB) | 19.2 | 13.9 | 12.6 | 12.6 | 12.6 |
| Model | P (%) | R (%) | mAP0.5 (%) | mAP0.5–0.95 (%) | F1-Score | Parameters (M) | GFLOPs | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 81.1 | 77.0 | 81.6 | 51.9 | 0.790 | 61.50 | 154.6 | 123.5 |
| YOLOv3-spp | 79.5 | 76.3 | 81.2 | 51.4 | 0.779 | 62.55 | 155.4 | 125.6 |
| YOLOv3-tiny | 71.8 | 73.8 | 75.5 | 44.9 | 0.728 | 8.67 | 12.9 | 17.4 |
| YOLOv5n | 75.6 | 77.5 | 81.3 | 50.2 | 0.765 | 1.76 | 4.1 | 3.9 |
| YOLOv5s | 78.9 | 77.6 | 80.6 | 51.6 | 0.782 | 7.02 | 15.8 | 14.4 |
| YOLOv5m | 79.4 | 76.6 | 81.6 | 52.6 | 0.780 | 20.86 | 47.9 | 42.2 |
| YOLOv5l | 78.3 | 78.0 | 83.2 | 52.8 | 0.781 | 46.11 | 107.7 | 92.8 |
| YOLOv5x | 80.7 | 77.3 | 82.7 | 52.9 | 0.790 | 86.18 | 203.8 | 173.1 |
| YOLOv6n [54] | 77.3 | 77.8 | 82.0 | 52.6 | 0.775 | 4.16 | 11.5 | 8.6 |
| YOLOv6s | 76.8 | 78.7 | 82.4 | 52.8 | 0.777 | 15.98 | 42.8 | 32.2 |
| YOLOv6m | 78.4 | 79.1 | 82.7 | 53.4 | 0.787 | 51.25 | 158.3 | 102.9 |
| YOLOv6l | 76.2 | 79.0 | 82.0 | 52.9 | 0.776 | 109.57 | 386.1 | 219.7 |
| YOLOv6x | 78.4 | 77.8 | 82.4 | 52.1 | 0.781 | 170.95 | 602.3 | 342.5 |
| YOLOv7 [55] | 76.4 | 74.1 | 80.4 | 49.0 | 0.752 | 37.20 | 105.1 | 74.8 |
| YOLOv7-tiny | 70.2 | 75.6 | 76.7 | 46.3 | 0.728 | 6.02 | 13.2 | 12.3 |
| YOLOv8n | 71.2 | 79.8 | 81.2 | 51.4 | 0.753 | 3.01 | 8.1 | 6.2 |
| YOLOv8s | 71.0 | 80.4 | 82.4 | 52.2 | 0.754 | 11.13 | 28.4 | 22.5 |
| YOLOv8m | 73.8 | 77.9 | 80.7 | 51.4 | 0.758 | 25.84 | 78.7 | 52.0 |
| YOLOv8l | 75.0 | 77.5 | 81.9 | 51.9 | 0.762 | 43.61 | 164.8 | 87.6 |
| YOLOv8x | 75.9 | 77.1 | 82.7 | 52.6 | 0.765 | 68.13 | 257.4 | 136.7 |
| YOLOv9-T [56] | 78.3 | 77.4 | 83.8 | 53.6 | 0.778 | 2.62 | 10.7 | 6.1 |
| YOLOv9-S | 77.7 | 80.7 | 84.1 | 54.3 | 0.792 | 9.60 | 38.7 | 20.3 |
| YOLOv9-M | 77.4 | 79.3 | 84.0 | 54.5 | 0.783 | 32.55 | 130.7 | 66.3 |
| YOLOv9-C | 78.1 | 79.4 | 83.2 | 54.6 | 0.787 | 50.70 | 236.6 | 102.8 |
| YOLOv9-E | 77.2 | 80.6 | 84.8 | 55.3 | 0.789 | 68.55 | 240.7 | 139.9 |
| YOLOv10-N [57] | 70.8 | 77.3 | 80.0 | 50.7 | 0.739 | 2.27 | 6.5 | 5.7 |
| YOLOv10-S | 72.6 | 77.2 | 81.2 | 51.7 | 0.748 | 7.22 | 21.4 | 16.5 |
| YOLOv10-M | 72.5 | 78.6 | 81.3 | 52.4 | 0.754 | 15.31 | 58.9 | 33.5 |
| YOLOv10-B | 75.3 | 77.1 | 81.8 | 51.9 | 0.762 | 19.01 | 91.6 | 41.4 |
| YOLOv10-L | 70.4 | 78.7 | 80.9 | 51.8 | 0.743 | 24.31 | 120.0 | 52.2 |
| YOLOv10-X | 75.2 | 74.7 | 81.4 | 51.9 | 0.749 | 29.40 | 160.0 | 64.1 |
| YOLOv11n | 75.0 | 81.3 | 82.8 | 53.3 | 0.780 | 2.58 | 6.3 | 5.5 |
| YOLOv11s | 78.8 | 79.5 | 84.4 | 54.7 | 0.791 | 9.41 | 21.3 | 19.2 |
| YOLOv11m | 77.2 | 80.6 | 84.2 | 54.6 | 0.789 | 20.03 | 67.7 | 40.5 |
| YOLOv11l | 78.9 | 78.6 | 83.8 | 55.1 | 0.787 | 25.28 | 86.6 | 51.2 |
| YOLOv11x | 79.0 | 79.2 | 83.9 | 54.5 | 0.791 | 56.83 | 194.4 | 114.4 |
| RSWD-YOLO | 79.3 | 81.8 | 86.1 | 56.2 | 0.805 | 6.14 | 18.0 | 12.6 |
| Model | Class | P (%) | R (%) | mAP0.5 (%) | mAP0.5–0.95 (%) | F1-Score |
|---|---|---|---|---|---|---|
| w-YOLO | all | 73.6 | 75.1 | 79.5 | 47.9 | 0.743 |
| obstructed | 79.1 | 66.3 | 78.4 | 43.7 | 0.721 | |
| unobstructed | 68.1 | 83.8 | 80.5 | 52.1 | 0.751 | |
| GDA-YOLOv5 | all | 71.0 | 76.1 | 77.0 | 48.0 | 0.735 |
| obstructed | 74.2 | 68.7 | 75.1 | 42.8 | 0.713 | |
| unobstructed | 67.7 | 83.5 | 79.0 | 53.3 | 0.748 | |
| GDAD-YOLOv5 | all | 70.0 | 74.9 | 76.2 | 46.9 | 0.724 |
| obstructed | 73.5 | 67.1 | 73.9 | 41.6 | 0.702 | |
| unobstructed | 66.6 | 82.7 | 78.6 | 52.2 | 0.738 | |
| OW-YOLO | all | 73.2 | 77.1 | 81.9 | 52.2 | 0.751 |
| obstructed | 81.0 | 69.8 | 82.3 | 48.0 | 0.750 | |
| unobstructed | 65.4 | 84.4 | 81.5 | 56.5 | 0.737 | |
| RSWD-YOLO | all | 79.3 | 81.8 | 86.1 | 56.2 | 0.805 |
| obstructed | 83.8 | 76.1 | 85.7 | 51.8 | 0.798 | |
| unobstructed | 74.8 | 87.5 | 86.5 | 60.6 | 0.807 |
| Neck | mAP0.5 (%) | Parameters (M) | GFLOPs | Model Size (MB) | FPS |
|---|---|---|---|---|---|
| FPN-PAN | 84.4 | 9.41 | 21.3 | 19.2 | 204.1 |
| GFPN | 81.8 | 13.72 | 28.8 | 28.4 | 196.1 |
| AFPN | 84.5 | 9.50 | 28.8 | 19.5 | 133.3 |
| BiFPN | 83.9 | 7.08 | 21.6 | 14.5 | 166.7 |
| goldyolo | 82.8 | 14.61 | 28.4 | 29.8 | 142.9 |
| slimneck | 82.6 | 9.34 | 19.7 | 19.1 | 185.2 |
| asf | 82.7 | 12.61 | 30.3 | 25.6 | 185.2 |
| RCSOSA | 83.1 | 29.05 | 88.0 | 63.8 | 158.7 |
| HSFPN | 84.8 | 6.77 | 19.4 | 13.9 | 204.1 |
| Model | Inference Time (ms per Image) |
|---|---|
| YOLOv11s | 559.53 |
| RSWD-YOLO | 492.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Yang, X.; Wang, H.; Wang, H.; Chen, Z.; Yun, L. RSWD-YOLO: A Walnut Detection Method Based on UAV Remote Sensing Images. Horticulturae 2025, 11, 419. https://doi.org/10.3390/horticulturae11040419
Wang Y, Yang X, Wang H, Wang H, Chen Z, Yun L. RSWD-YOLO: A Walnut Detection Method Based on UAV Remote Sensing Images. Horticulturae. 2025; 11(4):419. https://doi.org/10.3390/horticulturae11040419
Chicago/Turabian StyleWang, Yansong, Xuanxi Yang, Haoyu Wang, Huihua Wang, Zaiqing Chen, and Lijun Yun. 2025. "RSWD-YOLO: A Walnut Detection Method Based on UAV Remote Sensing Images" Horticulturae 11, no. 4: 419. https://doi.org/10.3390/horticulturae11040419
APA StyleWang, Y., Yang, X., Wang, H., Wang, H., Chen, Z., & Yun, L. (2025). RSWD-YOLO: A Walnut Detection Method Based on UAV Remote Sensing Images. Horticulturae, 11(4), 419. https://doi.org/10.3390/horticulturae11040419