
GSE-YOLO: A Lightweight and High-Precision Model for Identifying the Ripeness of Pitaya (Dragon Fruit) Based on the YOLOv8n Improvement


Abstract

1. Introduction
2. Materials and Methods
2.1. Production of Pitaya Dataset
- (1)
- Items that are difficult to distinguish or cannot be judged by the human eye will not be labeled.
- (2)
- Fruits that are obstructed by more than 90% and completely overlap will not be labeled.
- (3)
- Objects that are similar in color to the fruit but do not have the basic shape of the fruit will not be labeled.
- (1)
- Bud: Small in size, resembling a circular or elliptical shape, with a light green or slightly dark red color.
- (2)
- Immature: The fruit has taken shape, and the entire surface is covered with light green flesh thorns.
- (3)
- Semi-mature: The fruit color displays a gradient of red and green as it begins to mature.
- (4)
- Mature: The fruit has a large area of bright red color, meeting the harvesting requirements.
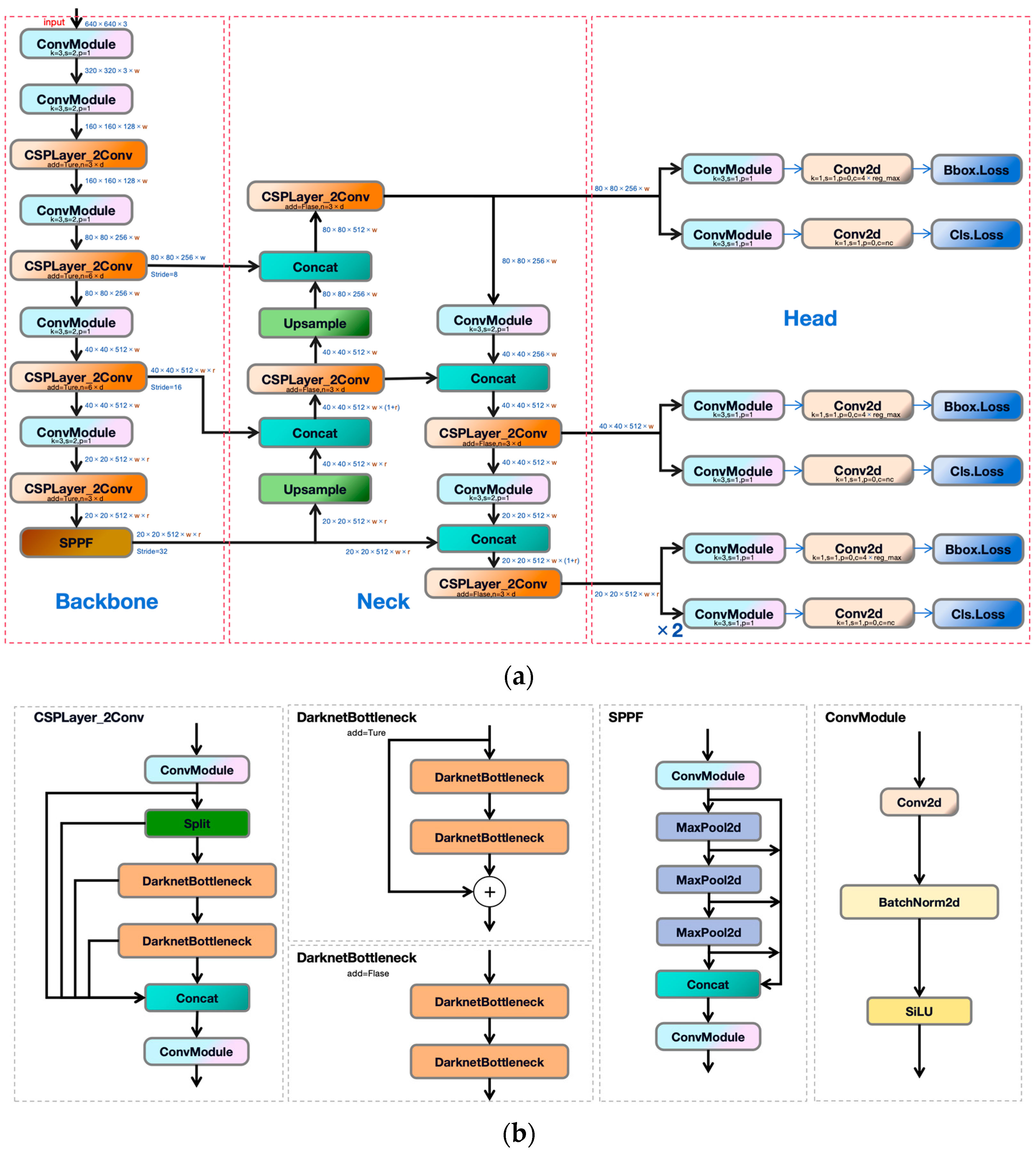
2.2. YOLOv8 Model
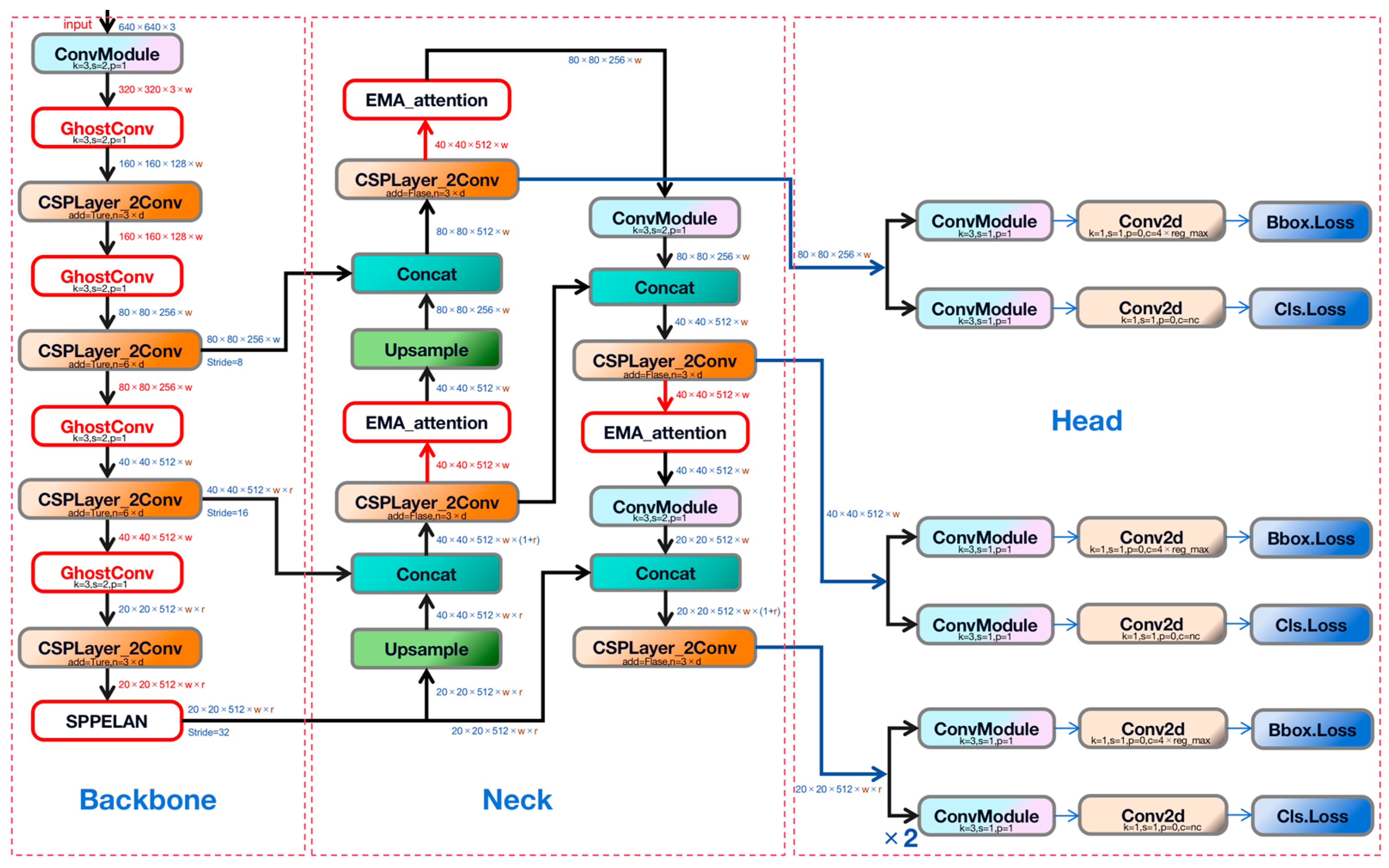
2.3. Improved YOLOv8n Model
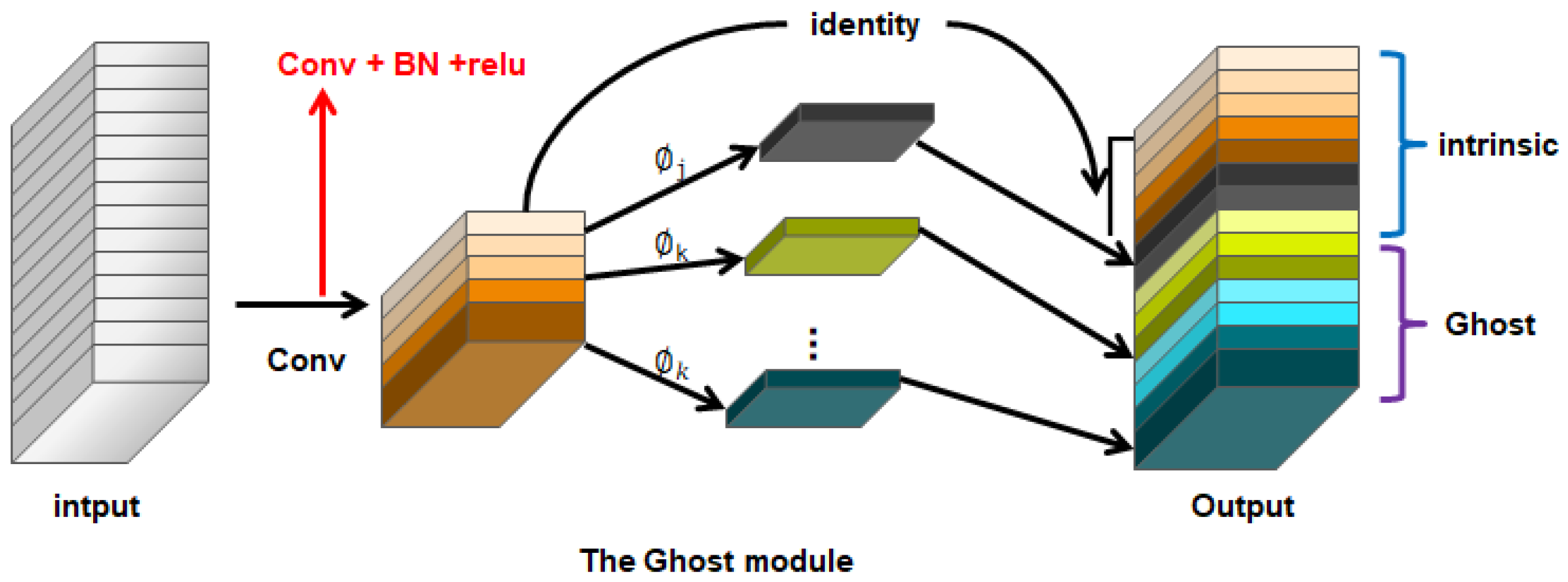
2.3.1. GhostConv Convolutional Module
- (1)
- Firstly, we use conventional ordinary convolution to obtain the (intrinsic feature maps), which requires approximately the same amount of computation (ignoring bias terms). Here, X is the input and is the convolution.
- (2)
- Then, we use to generate the Ghost feature map for each channel of Y′:
- (3)
- Finally, we concatenate the original feature map obtained in the first step with the Ghost feature map obtained in the second step (identity concatenation) to obtain the final result.
- Step 1: A small number of convolutions are used (e.g., instead of using the typical 128 convolution kernels, only 64 are used here to reduce the computational load by half);
- Step 2: Cheep operations, represented by ∅ in the graph, such as convolutions with ∅ of 3 × 3 and 5 × 5, and depth-wise convolutions are performed on each feature map.
2.3.2. SPPELAN Pyramid Pooling Structure
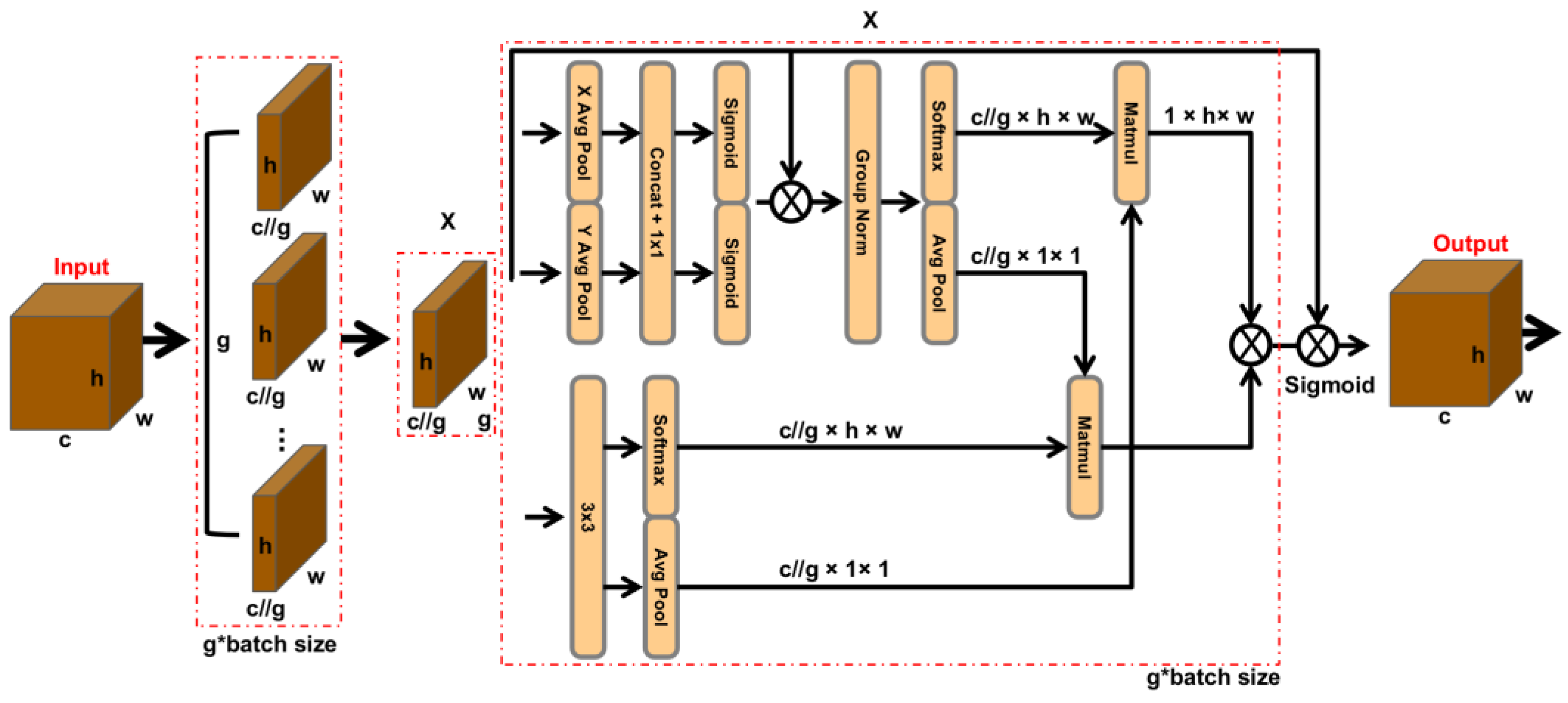
2.3.3. EMA_Attention Attention Mechanism
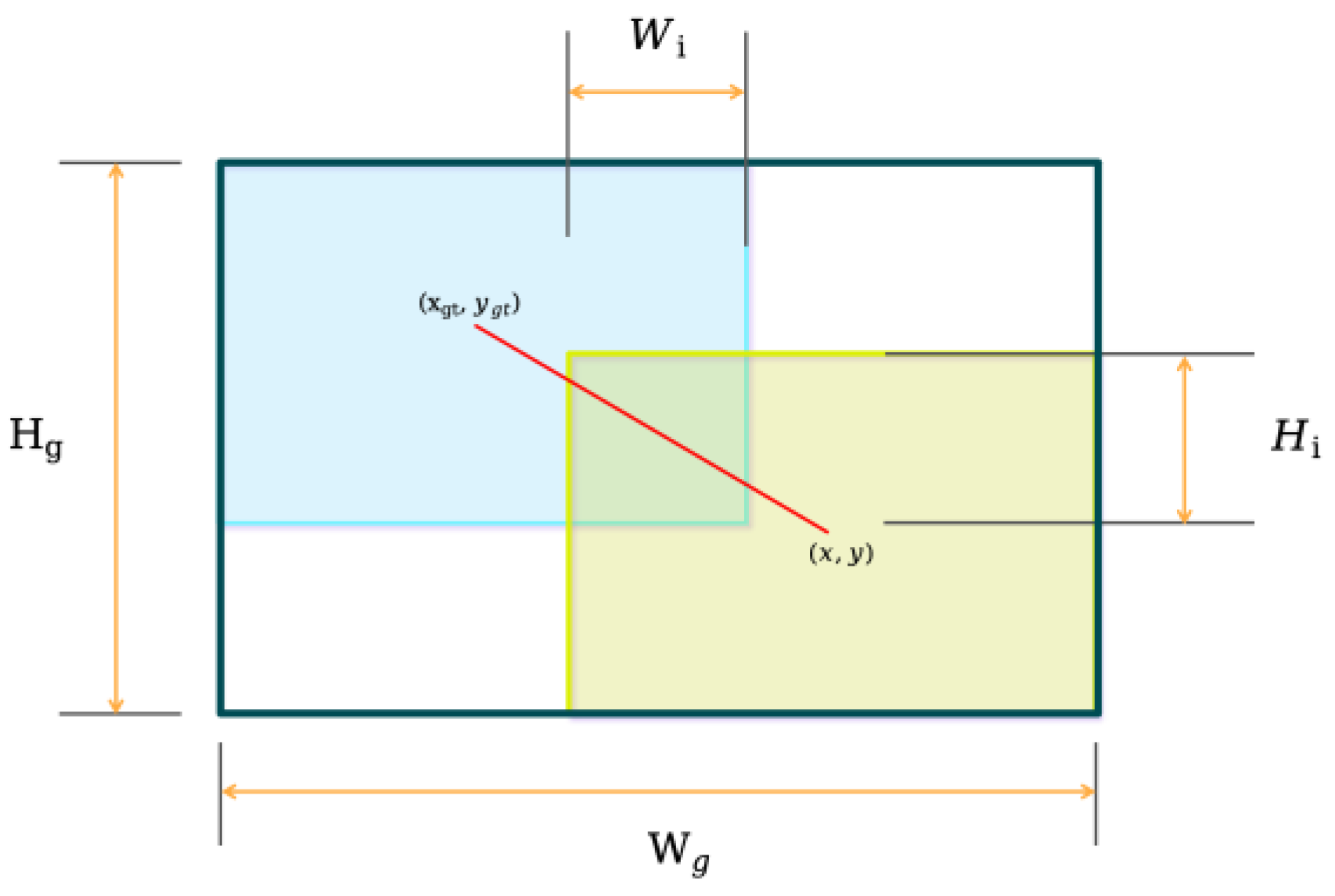
2.3.4. WIoU Loss Function
- (1)
- Wise IoU v1: Distance attention was constructed based on distance metrics, resulting in Wise IoU v1 with a two-layer attention mechanism:
- (2)
- Wise IoU v2: A monotonic focusing mechanism, WIoU v2, for cross-entropy was designed based on Focal Loss. This mechanism effectively reduces the influence of inter-examples on the loss value, the monotone focusing coefficient .
- (3)
- Wise-IoU v3: A Wise-IoU v3 with dynamic non-monotonic FM is obtained by constructing a non-monotonic focusing coefficient using β and applying it to Wise-IoU v1.
2.4. Experimental Environment Configuration and Network Parameter Settings
2.5. Model Evaluation Indicators
3. Experimental Results and Analysis
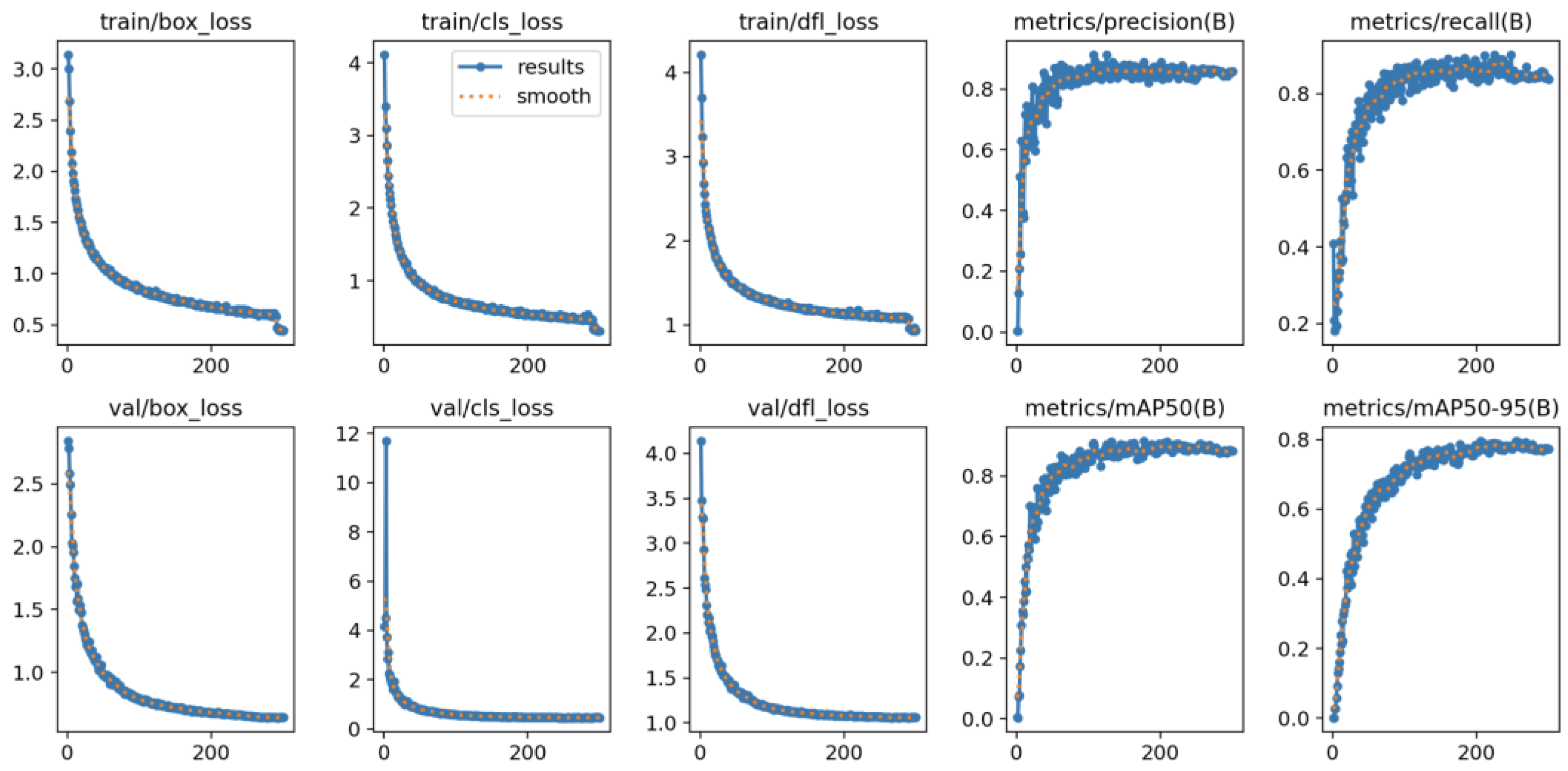
3.1. Improved YOLOv8n Test
3.2. Improvement of YOLOv8n Ablation Test
3.3. Analysis of Comparison Results of Different Object Detection Networks
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nan, Y.; Zhang, H.; Zeng, Y.; Zheng, J.; Ge, Y. Intelligent detection of Multi-Class pitaya fruits in target picking row based on WGB-YOLO network. Comput. Electron. Agric. 2023, 208, 107780. [Google Scholar] [CrossRef]
- Fang, W.; Wu, Z.; Li, W.; Sun, X.; Mao, W.; Li, R.; Majeed, Y.; Fu, L. Fruit detachment force of multiple varieties kiwifruit with different fruit-stem angles for designing universal robotic picking end-effector. Comput. Electron. Agric. 2023, 213, 108225. [Google Scholar] [CrossRef]
- Wang, C.; Sun, W.; Wu, H.; Zhao, C.; Teng, G.; Yang, Y.; Du, P. A Low-Altitude Remote Sensing Inspection Method on Rural Living Environments Based on a Modified YOLOv5s-ViT. Remote Sens. 2022, 14, 4784. [Google Scholar] [CrossRef]
- Ma, H.; Liu, Y.; Ren, Y.; Yu, J. Detection of Collapsed Buildings in Post-Earthquake Remote Sensing Images Based on the Improved YOLOv3. Remote Sens. 2019, 12, 44. [Google Scholar] [CrossRef]
- Su, X.; Zhang, J.; Ma, Z.; Dong, Y.; Zi, J.; Xu, N.; Zhang, H.; Xu, F.; Chen, F. Identification of Rare Wildlife in the Field Environment Based on the Improved YOLOv5 Model. Remote Sens. 2024, 16, 1535. [Google Scholar] [CrossRef]
- Ding, W.; Abdel-Basset, M.; Alrashdi, I.; Hawash, H. Next generation of computer vision for plant disease monitoring in precision agriculture: A contemporary survey, taxonomy, experiments, and future direction. Inf. Sci. 2024, 665, 120338. [Google Scholar] [CrossRef]
- Lu, Y.; Young, S. A survey of public datasets for computer vision tasks in precision agriculture. Comput. Electron. Agric. 2020, 178, 105760. [Google Scholar] [CrossRef]
- Patrício, D.I.; Rieder, R. Computer vision and artificial intelligence in precision agriculture for grain crops: A systematic review. Comput. Electron. Agric. 2018, 153, 69–81. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, S.; Li, E.; Yang, G.; Liang, Z.; Tan, M. MD-YOLO: Multi-scale Dense YOLO for small target pest detection. Comput. Electron. Agric. 2023, 213, 108233. [Google Scholar] [CrossRef]
- Xu, J.; Lu, Y.; Olaniyi, E.; Harvey, L. Online volume measurement of sweetpotatoes by A LiDAR-based machine vision system. J. Food Eng. 2024, 361, 111725. [Google Scholar] [CrossRef]
- Wang, K.; Li, Z.; Li, J.; Lin, H. Raman spectroscopic techniques for nondestructive analysis of agri-foods: A state-of-the-art review. Trends Food Sci. Technol. 2021, 118, 490–504. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Jiang, Y.; Bian, B.; Zheng, B.; Chu, J. A time space network optimization model for integrated fresh fruit harvest and distribution considering maturity. Comput. Ind. Eng. 2024, 190, 110029. [Google Scholar] [CrossRef]
- Mazen, F.M.A.; Nashat, A.A. Ripeness Classification of Bananas Using an Artificial Neural Network. Arab. J. Sci. Eng. 2019, 44, 6901–6910. [Google Scholar] [CrossRef]
- Fu, L.; Wu, F.; Zou, X.; Jiang, Y.; Lin, J.; Yang, Z.; Duan, J. Fast detection of banana bunches and stalks in the natural environment based on deep learning. Comput. Electron. Agric. 2022, 194, 106800. [Google Scholar] [CrossRef]
- Mim, F.S.; Galib, S.M.; Hasan, M.F.; Jerin, S.A. Automatic detection of mango ripening stages—An application of information technology to botany. Sci. Hortic. 2018, 237, 156–163. [Google Scholar] [CrossRef]
- Kalopesa, E.; Gkrimpizis, T.; Samarinas, N.; Tsakiridis, N.L.; Zalidis, G.C. Rapid Determination of Wine Grape Maturity Level from pH, Titratable Acidity, and Sugar Content Using Non-Destructive In Situ Infrared Spectroscopy and Multi-Head Attention Convolutional Neural Networks. Sensors 2023, 23, 9536. [Google Scholar] [CrossRef] [PubMed]
- Silva, R.; Freitas, O.; Melo-Pinto, P. Evaluating the generalization ability of deep learning models: An application on sugar content estimation from hyperspectral images of wine grape berries. Expert Syst. Appl. 2024, 250, 123891. [Google Scholar] [CrossRef]
- Mohammadi, V.; Kheiralipour, K.; Ghasemi-Varnamkhasti, M. Detecting maturity of persimmon fruit based on image processing technique. Sci. Hortic. 2015, 184, 123–128. [Google Scholar] [CrossRef]
- Attri, I.; Awasthi, L.K.; Sharma, T.P.; Rathee, P. A review of deep learning techniques used in agriculture. Ecol. Inform. 2023, 77, 102217. [Google Scholar] [CrossRef]
- Ariza-Sentís, M.; Vélez, S.; Martínez-Peña, R.; Baja, H.; Valente, J. Object detection and tracking in Precision Farming: A systematic review. Comput. Electron. Agric. 2024, 219, 108757. [Google Scholar] [CrossRef]
- Gonzales Martinez, R.; van Dongen, D. Deep learning algorithms for the early detection of breast cancer: A comparative study with traditional machine learning. Inform. Med. Unlocked 2023, 41, 101317. [Google Scholar] [CrossRef]
- Ma, B.; Hua, Z.; Wen, Y.; Deng, H.; Zhao, Y.; Pu, L.; Song, H. Using an improved lightweight YOLOv8 model for real-time detection of multi-stage apple fruit in complex orchard environments. Artif. Intell. Agric. 2024, 11, 70–82. [Google Scholar] [CrossRef]
- Liu, G.; Hu, Y.; Chen, Z.; Guo, J.; Ni, P. Lightweight object detection algorithm for robots with improved YOLOv5. Eng. Appl. Artif. Intel. 2023, 123, 106217. [Google Scholar] [CrossRef]
- Ma, W.; Guan, Z.; Wang, X.; Yang, C.; Cao, J. YOLO-FL: A target detection algorithm for reflective clothing wearing inspection. Displays 2023, 80, 102561. [Google Scholar] [CrossRef]
- Gao, S.; Chu, M.; Zhang, L. A detection network for small defects of steel surface based on YOLOv7. Digit. Signal Process. 2024, 149, 104484. [Google Scholar] [CrossRef]
- Wang, A.; Qian, W.; Li, A.; Xu, Y.; Hu, J.; Xie, Y.; Zhang, L. NVW-YOLOv8s: An improved YOLOv8s network for real-time detection and segmentation of tomato fruits at different ripeness stages. Comput. Electron. Agric. 2024, 219, 108833. [Google Scholar] [CrossRef]
- Kothala, L.P.; Jonnala, P.; Guntur, S.R. Localization of mixed intracranial hemorrhages by using a ghost convolution-based YOLO network. Biomed. Signal Process. Control 2023, 80, 104378. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef]
- Zhang, P.; Dai, N.; Liu, X.; Yuan, J.; Xin, Z. A novel lightweight model HGCA-YOLO: Application to recognition of invisible spears for white asparagus robotic harvesting. Comput. Electron. Agric. 2024, 220, 108852. [Google Scholar] [CrossRef]
- Xie, T.; Wang, Z.; Li, H.; Wu, P.; Huang, H.; Zhang, H.; Alsaadi, F.E.; Zeng, N. Progressive attention integration-based multi-scale efficient network for medical imaging analysis with application to COVID-19 diagnosis. Comput. Biol. Med. 2023, 159, 106947. [Google Scholar] [CrossRef] [PubMed]
- Cai, H.; Lan, L.; Zhang, J.; Zhang, X.; Zhan, Y.; Luo, Z. IoUformer: Pseudo-IoU prediction with transformer for visual tracking. Neural Netw. 2024, 170, 548–563. [Google Scholar] [CrossRef] [PubMed]
- Du, X.; Cheng, H.; Ma, Z.; Lu, W.; Wang, M.; Meng, Z.; Jiang, C.; Hong, F. DSW-YOLO: A detection method for ground-planted strawberry fruits under different occlusion levels. Comput. Electron. Agric. 2023, 214, 108304. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
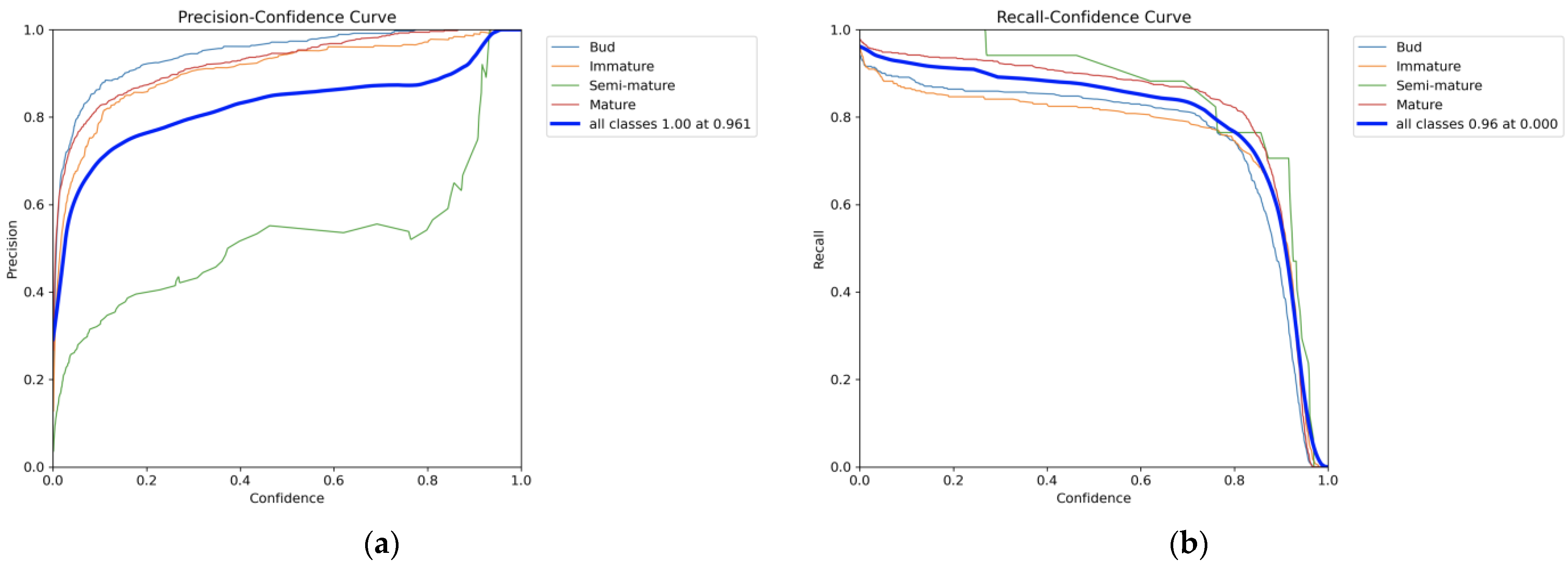
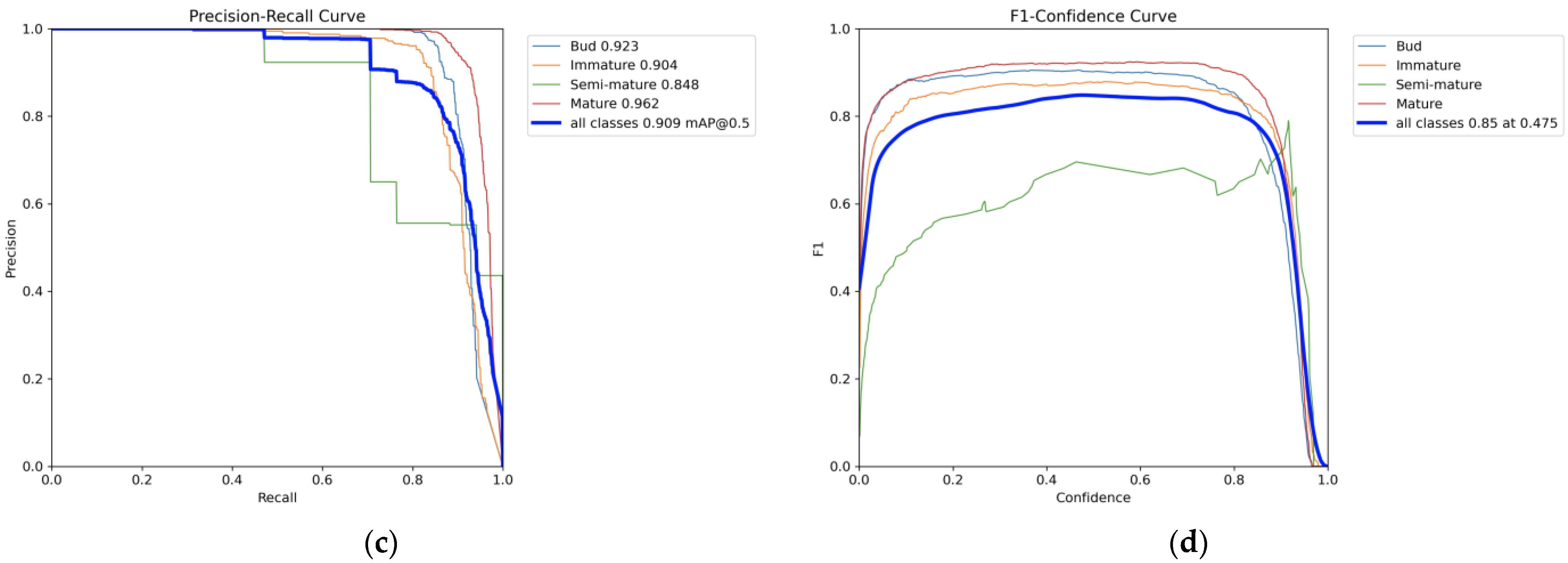
| Class | Precision | Recall | F1-Score | mAP50 |
|---|---|---|---|---|
| Bud | 0.971 | 0.842 | 90.19 | 92.3% |
| Immature | 0.942 | 0.822 | 87.79 | 90.4% |
| Semi-mature | 0.549 | 0.931 | 69.07 | 84.8% |
| Mature | 0.946 | 0.897 | 92.08 | 96.2% |
| All | 0.852 | 0.873 | 86.23 | 90.9% |
| GhostConv | SPPELAN | EMA_Attention | WIoU | mAP50 | |
|---|---|---|---|---|---|
| YOLOv8n | √ | 88.3% | |||
| YOLOv8n | 89.7% | ||||
| YOLOv8n | √ | √ | √ | 89.8% | |
| YOLOv8n | √ | √ | 90.3% | ||
| YOLOv8n | √ | √ | 90.8% | ||
| YOLOv8n | √ | √ | √ | √ | 90.9% |
| Precision | Recall | F1-Score | Parameters | mAP50 | Weight | |
|---|---|---|---|---|---|---|
| YOLOv5n | 82.5% | 90.0% | 88.90 | 1,764,577 | 89.4% | 3.64 MB |
| YOLOv6n | 87.0% | 86.6% | 86.79 | 5,005,904 | 87.7% | 9.98 MB |
| YOLOv7 | 84.7% | 87.2% | 85.93 | 37,212,738 | 88.3% | 71.3 MB |
| YOLOv8n | 86.1% | 85.5% | 79.88 | 3,006,428 | 89.7% | 5.94 MB |
| Ours | 85.2% | 87.3% | 86.23 | 2,660,358 | 90.9% | 5.30 MB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Z.; Huang, Z.; Mo, D.; Tian, X.; Tian, X. GSE-YOLO: A Lightweight and High-Precision Model for Identifying the Ripeness of Pitaya (Dragon Fruit) Based on the YOLOv8n Improvement. Horticulturae 2024, 10, 852. https://doi.org/10.3390/horticulturae10080852
Qiu Z, Huang Z, Mo D, Tian X, Tian X. GSE-YOLO: A Lightweight and High-Precision Model for Identifying the Ripeness of Pitaya (Dragon Fruit) Based on the YOLOv8n Improvement. Horticulturae. 2024; 10(8):852. https://doi.org/10.3390/horticulturae10080852
Chicago/Turabian StyleQiu, Zhi, Zhiyuan Huang, Deyun Mo, Xuejun Tian, and Xinyuan Tian. 2024. "GSE-YOLO: A Lightweight and High-Precision Model for Identifying the Ripeness of Pitaya (Dragon Fruit) Based on the YOLOv8n Improvement" Horticulturae 10, no. 8: 852. https://doi.org/10.3390/horticulturae10080852
APA StyleQiu, Z., Huang, Z., Mo, D., Tian, X., & Tian, X. (2024). GSE-YOLO: A Lightweight and High-Precision Model for Identifying the Ripeness of Pitaya (Dragon Fruit) Based on the YOLOv8n Improvement. Horticulturae, 10(8), 852. https://doi.org/10.3390/horticulturae10080852