Abstract
(1) Background: Patients with acute myocardial infarction (AMI) still experience many major adverse cardiovascular events (MACEs), including myocardial infarction, heart failure, kidney failure, coronary events, cerebrovascular events, and death. This retrospective study aims to assess the prognostic value of machine learning (ML) for the prediction of MACEs. (2) Methods: Five-hundred patients diagnosed with AMI and who had undergone successful percutaneous coronary intervention were included in the study. Logistic regression (LR) analysis was used to assess the relevance of MACEs and 24 selected clinical variables. Six ML models were developed with five-fold cross-validation in the training dataset and their ability to predict MACEs was compared to LR with the testing dataset. (3) Results: The MACE rate was calculated as 30.6% after a mean follow-up of 1.42 years. Killip classification (Killip IV vs. I class, odds ratio 4.386, 95% confidence interval 1.943–9.904), drug compliance (irregular vs. regular compliance, 3.06, 1.721–5.438), age (per year, 1.025, 1.006–1.044), and creatinine (1 µmol/L, 1.007, 1.002–1.012) and cholesterol levels (1 mmol/L, 0.708, 0.556–0.903) were independent predictors of MACEs. In the training dataset, the best performing model was the random forest (RDF) model with an area under the curve of (0.749, 0.644–0.853) and accuracy of (0.734, 0.647–0.820). In the testing dataset, the RDF showed the most significant survival difference (log-rank p = 0.017) in distinguishing patients with and without MACEs. (4) Conclusions: The RDF model has been identified as superior to other models for MACE prediction in this study. ML methods can be promising for improving optimal predictor selection and clinical outcomes in patients with AMI.
1. Introduction
Acute myocardial infarction (AMI) is one of the major causes of mortality worldwide [1]. Advancements in healthcare, the survival rate, clinical symptoms, and quality of life after successful percutaneous coronary intervention (PCI) and other therapeutic strategies have improved outcomes for patients with AMI [2]. However, major adverse cardiovascular events (MACEs), including myocardial infarction, heart failure, kidney failure, coronary events, cerebrovascular events, and death, still occur in 20–40% of patients with AMI within 2 years after disease onset [3,4].
Accurate prediction of the incidence of MACEs after AMI, identification of high-risk clinical predictors, and strengthening the management of high-risk patients can improve the long-term prognosis of patients, which may also effectively reduce the rate of MACEs. Traditionally, various scores were used for risk stratification in patients with AMI, such as Thrombolysis in Myocardial Infarction and the Global Registry of Acute Coronary Events [5,6]. However, these traditional methods for evaluating the severity and prognosis of the disease were time consuming, labour-intensive, and inaccurate, which was unsuitable for the assessment of prognosis [7,8,9,10]. Therefore, advanced and precise prediction methods for MACEs in patients with AMI were desperately needed.
Machine learning (ML), as an important branch of artificial intelligence, has a substantial effect on many areas of technology and science [11]. It realizes prediction or decision-making tasks with algorithms and statistical models using computer systems [12]. Depending on the task and type of feedback, ML can be divided into supervised learning, unsupervised learning, and reinforcement learning [13]. Supervised learning is the most widely used ML method in the diagnosis, treatment, and rehabilitation of patients with cardiovascular diseases [14]. In supervised learning, an annotated label is available for each sample and the purpose is to reduce the error between the observed and predictive labels by feeding the model with processed data [15]. In other words, the objective of supervised learning is to determine a function that produces an output based on the corresponding input so as to estimate the annotated label approximately.
The mainstream supervised ML algorithms mainly consist of decision tree (DT), Naive Bayes (NB), support vector machine (SVM), random decision forest (RDF), gradient boosting (GB), multilayer perceptron (MLP) methods, and so on, and different ML models have different characteristics. DT recursively partitions the input space and then fits a local model in each resulting region of the input space, but it tends to deliver high variance estimators in that they are unstable [16]. NB is a probabilistic classifier that assumes the input variables are conditionally independent given the class label and requires few data to estimate the small number of parameters, making NB relatively immune to overfitting [17]. SVM attempts to find an optimal hyperplane in an N-dimensional input space that maximizes the distance between the data points of the two classes and is famous for its generalization performance and ability to handle high dimensional data [18]. RDF is an ensemble learning method that built on DT. In order to address the drawback of DT, it uses a technique referred to as bagging to reduce the variance of an estimate by averaging together many estimates. RDF has high prediction accuracy, good tolerance to outliers and noise, and is not prone to overfitting [19]. GB is another ensemble learning algorithm also based on DTs. Unlike RDF, a method known as boosting converts weak learners into strong learners while reducing the bias of the model at each round, which results in accurate predictions [20]. MLP is a class of models that can serve as universal function approximators capable of modelling non-linear interactions between features. They can meet the requirements of solving accuracy and generalization with lower informational inputs [21]. The research on ML algorithms has developed rapidly and is widely used in practice.
Recently, ML has been widely used in various aspects of the management of cardiovascular diseases [11], such as rapid diagnostics, precise treatment, and prognostication, including the prediction of mortality and other adverse prognoses. Liu et al. [22] found that ML models showed marginal value in improving the prediction of 30-day MACEs for emergency department chest pain patients and finally developed the best multidimensional scaling algorithm, with an area under the curve (AUC) of 0.901. Khera et al. [23] drew the conclusion that ML offered resolution for high-risk AMI individuals and reported the best meta-classifier with an AUC of 0.90. Overall, the use of ML has resulted in improved management of cardiovascular diseases [24,25]. ML also has great potential for predicting MACEs in patients with AMI [22,26]. However, the comparison or combination of different algorithms may increase the predictive accuracy for diseases, which deserves further investigation so as to improve the prognoses of patients with AMI.
Thus, in this study, we explored the independent predictors of MACEs in patients with AMI by LR analysis using medical records from the hospital information system. Moreover, the performance of traditional LR was compared with those of the optimized DT, NB, SVM, RDF, GB, and MLP approaches. The aim of this study was to explore predictors of MACEs in patients with AMI and identify the most appropriate algorithm for prediction by comparing six ML algorithms with traditional LR analysis.
2. Materials and Methods
2.1. Study Population and Statistical Analysis
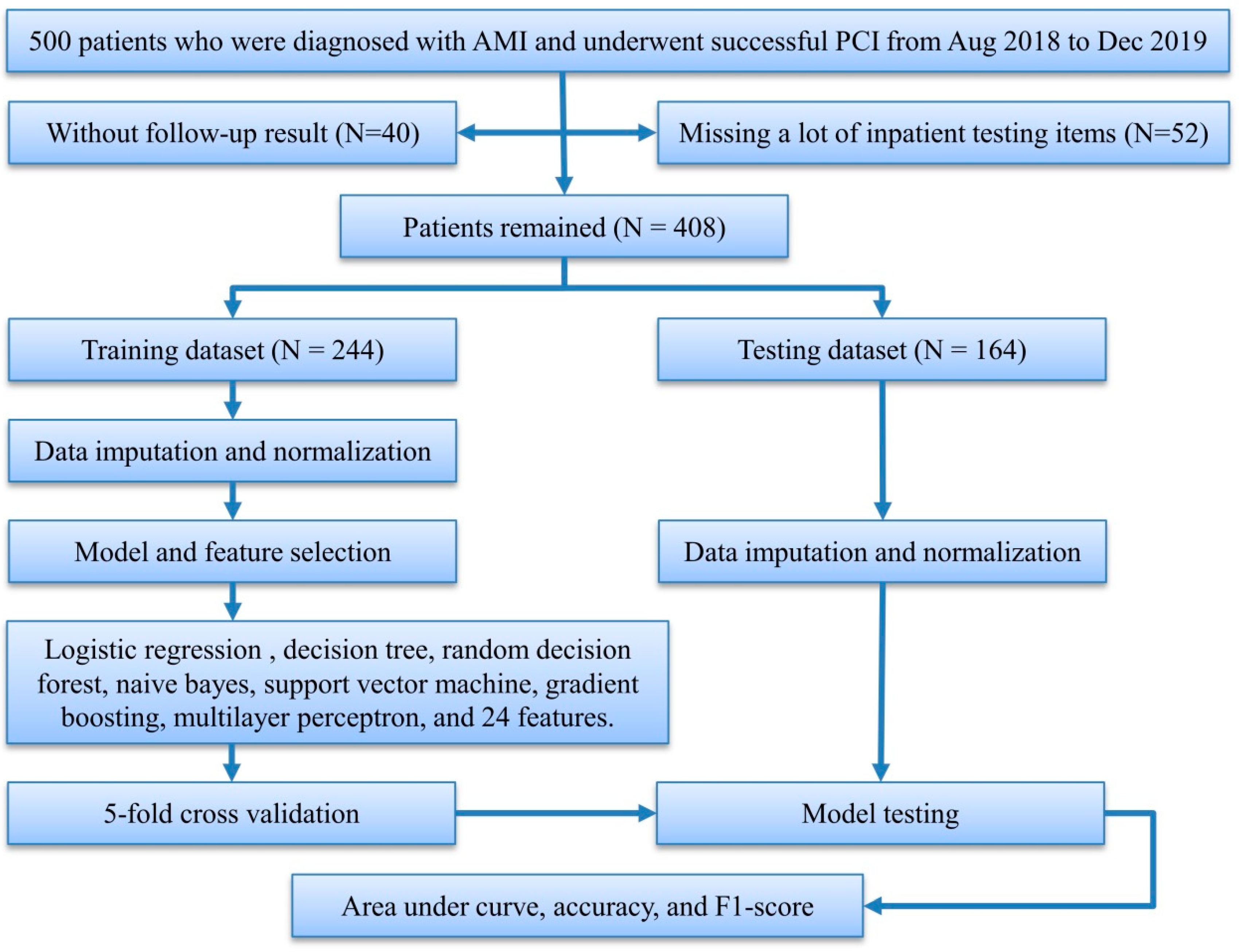
We initially collected 500 patients who were enrolled in the hospital information system of Zhuzhou Central Hospital from August 2018 to December 2019, underwent coronary angiography and successful PCI, and were diagnosed with AMI, after excluding patients who did not receive standard treatment and died during hospitalization, and followed up these patients during November to December 2020. Forty patients who were lost to the follow-up and 52 patients without necessary in-patient testing items were excluded. In all, 408 patients were included for the prediction of MACEs and the mean follow-up time was calculated as 1.42 years (Figure 1).
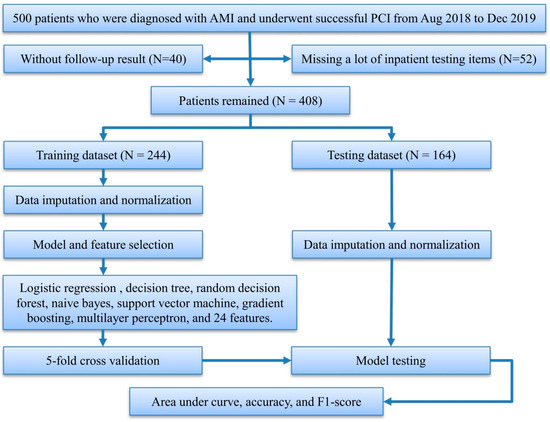
Figure 1.
Study flowchart. AMI, acute myocardial infarction; PCI, percutaneous coronary intervention.
Subsequently, the collected raw data was translated into our structured database for further analysis. The continuous variables were recorded as means ± standard deviation, and categorical variables were recorded as the sample rate. SPSS Statistics version 20 (IBM Co. Ltd., Armonk, NY, USA) was used for statistical analysis. Statistical differences of continuous variables were calculated using the Student’s t-test, and differences of categorical variables were evaluated using a chi-squared test. Significance was set at p < 0.05.
2.2. Preprocessing and Feature Selection
The structured data was divided into training and testing datasets in a ratio of six to four, and imputation and normalization of data were carried out for these datasets, respectively. Since data distribution characteristics differed between categorical and continuous variables, different methods were used to impute missing values. For a categorical variable, the proportion of each category in the existing values was calculated, and missing values were imputed with a set of categories which retained the same categorical proportion as the existing values. A continuous variable was imputed with random numbers that were generated by Gaussian distribution, the mean and standard deviation of which were calculated from the existing values. If the random numbers were out of the range of the existing values, the missing values were imputed with the mean of the existing values. Due to the wide distribution range of the diverse predictors and some of the prediction models used requiring the normalization of values, the min–max scaler was used after data imputation.
The structured dataset consisted of 41 clinical variables (Table S1), and feature selection was performed only on the training dataset. First, features with missing values greater than 20% were discarded, and discrete variables whose variance did not meet the set threshold of 0.09 were removed according to the calculation method of variance for Bernoulli random variables. Second, recursive feature elimination with random decision forest (RFE-RDF) identified the optimal number of features.
2.3. LR Analysis
This study was designed to judge whether the AMI patient has MACEs or not, which is discrete. To further assess the association between occurrence of MACEs and the selected features, an LR analysis [27] performed with discrete cutoffs was used to determine the independent predictors of MACEs, then odds ratio (OR) and significant differences were recorded to evaluate the prognostic relevance of these features.
2.4. Model Development
By using patients’ medical records, those with AMI were randomly divided into two groups, as mentioned earlier: 60% of the patients were assigned to model development and 40% to testing. Hyperparameters were optimized using five-fold cross-validation in five ML (including DT, NB, SVM, RDF, and GB) and LR models, and a manual grid search was used for parameter optimization in the rest of the MLP models (Table S2). The training dataset was divided into five exclusive subsets by the five-fold cross-validation, using four for model development and the remainder for model validation. This process was repeated five times. The validation datasets were used for assessing the performance (such as AUC, accuracy, and F1-score) of all ML models. In the manual grid search, some parameters of models, such as epoch, batch size, learning rate, momentum, activation function, rate of dropout, and the number of hidden layer neurons, were tuned.
Unbalanced data is a common issue in dichotomous classification which results in the models having poor sensitivity. To address class imbalances, we provided a different weight that was inversely proportional to class frequencies in the training dataset for each class. All analyses were performed using Anaconda3-5.1.0-Windows. LR, DT, RDF, NB, SVM, and GB were implemented using scikit-learn v0.19.1. MLP was implemented using Keras v2.2.4.
2.5. Model Testing
To evaluate the models’ performance for the prediction of MACEs, the accuracy, F1-score, and AUC were calculated in the testing dataset. The probabilities of these models were calibrated using Platt’s scaling, and the calibration was measured by the Brier score.
To further identify the discriminative ability among all ML and LR models, the patients were initially divided into two subgroups according to predictive probability. The first subgroup of patients were predicted with good prognosis (predictive probability was less than 0.5) and the second was predicted with poor prognosis (predictive probability was greater than 0.5). The cumulative survival of MACEs was compared across the above groups using Kaplan–Meier analysis. In addition, the patients in the testing dataset were randomly divided into equal subgroups to verify existing survival differences. Finally, all the patients in the testing dataset were analyzed by Kaplan–Meier to assess the incidence of MACEs.
3. Results
3.1. Clinical Characteristics of the Selected Patients
A total of 408 patients were included in our database and 258 (63.2%) of them were diagnosed as ST-segment elevated myocardial infarction. In total, MACEs occurred in 125 (30.6%) patients after a mean of 1.42 years follow-up. A comparison of the MACE and non-MACE groups is shown in Table 1. On the one hand, the patients in the MACE group were older, had more coronary lesion vessels and greater left ventricular diameters, and showed higher Killip classification and levels of creatinine and uric acid compared with the non-MACE group. On the other hand, the patients in the MACE group exhibited lower levels of cholesterol, low-density lipoprotein, and left ventricular ejection fractions. In addition, MACEs were closely related to past medical history and drug compliance, and patients in the MACE group suffered from other diseases and took medicine irregularly.

Table 1.
Patients’ characteristics of included subjects.
3.2. The Selected and Independent Predictors
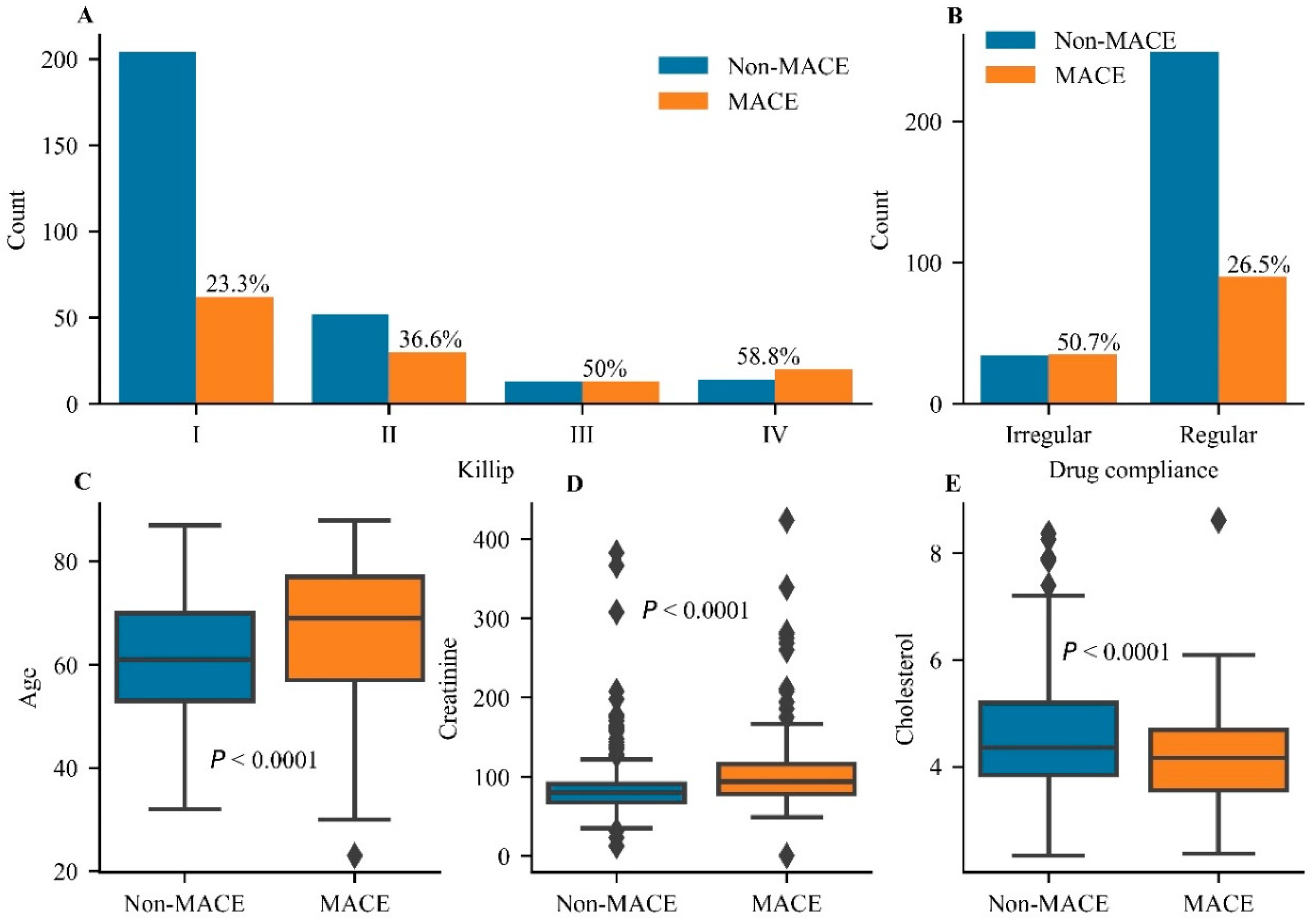
Twenty-four predictors were retained and no feature was excluded after RFE-RDF (Figure S1 in Supplementary Material). As shown in Table 2 and Figure 2, Killip classification (Killip IV class vs. I class, odds ratio 4.386, 95% confidence interval 1.943–9.904), drug compliance (irregular vs. regular compliance, 3.06, 1.721–5.438), age (per year, 1.025, 1.006–1.044), creatinine (1 µmol/L, 1.007, 1.002–1.012), and cholesterol (1 mmol/L, 0.708, 0.556–0.903) were independent predictors of MACEs. The MACE rate gradually increased from Killip I to IV, suggesting that it was positively related to cardiac function (Figure 2A). Taking drugs regularly reduced the MACE rate to 26.5% in comparison with the rate in those who took drugs irregularly (Figure 2B). Age and the level of creatinine exhibited significant differences in distribution between the MACE and non-MACE groups (Figure 2C,D), suggesting a positive correlation of these variables with the MACE rate. The level of cholesterol showed a negative correlation with the MACE rate (Figure 2E). Overall, Killip classification, drug compliance, age, and levels of creatinine and cholesterol were considered as independent predictors of MACEs and showed better predictive value than others.
Table 2.
The result of logistic regression analysis.
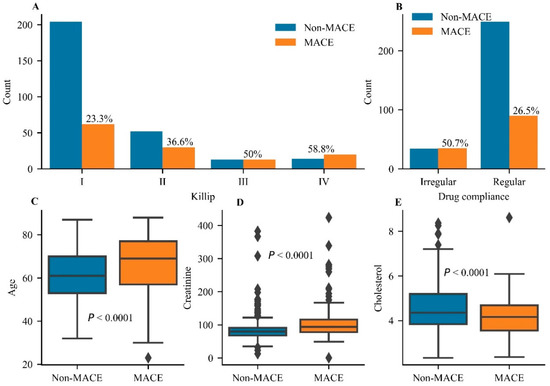
Figure 2.
The statistical analysis for independent predictors of major adverse cardiovascular events. (A) The comparison of major adverse cardiovascular event (MACE) rates in different grades of the Killip classification. (B) The comparison of MACE rates between irregular and regular groups of drug compliance. Analysis of differences for the distribution of age (C) and the levels of creatinine (D) and cholesterol (E) between the Non-MACE group and the MACE group. A significant difference was set at p < 0.05.
3.3. Comparative Performance between the ML and LR Models
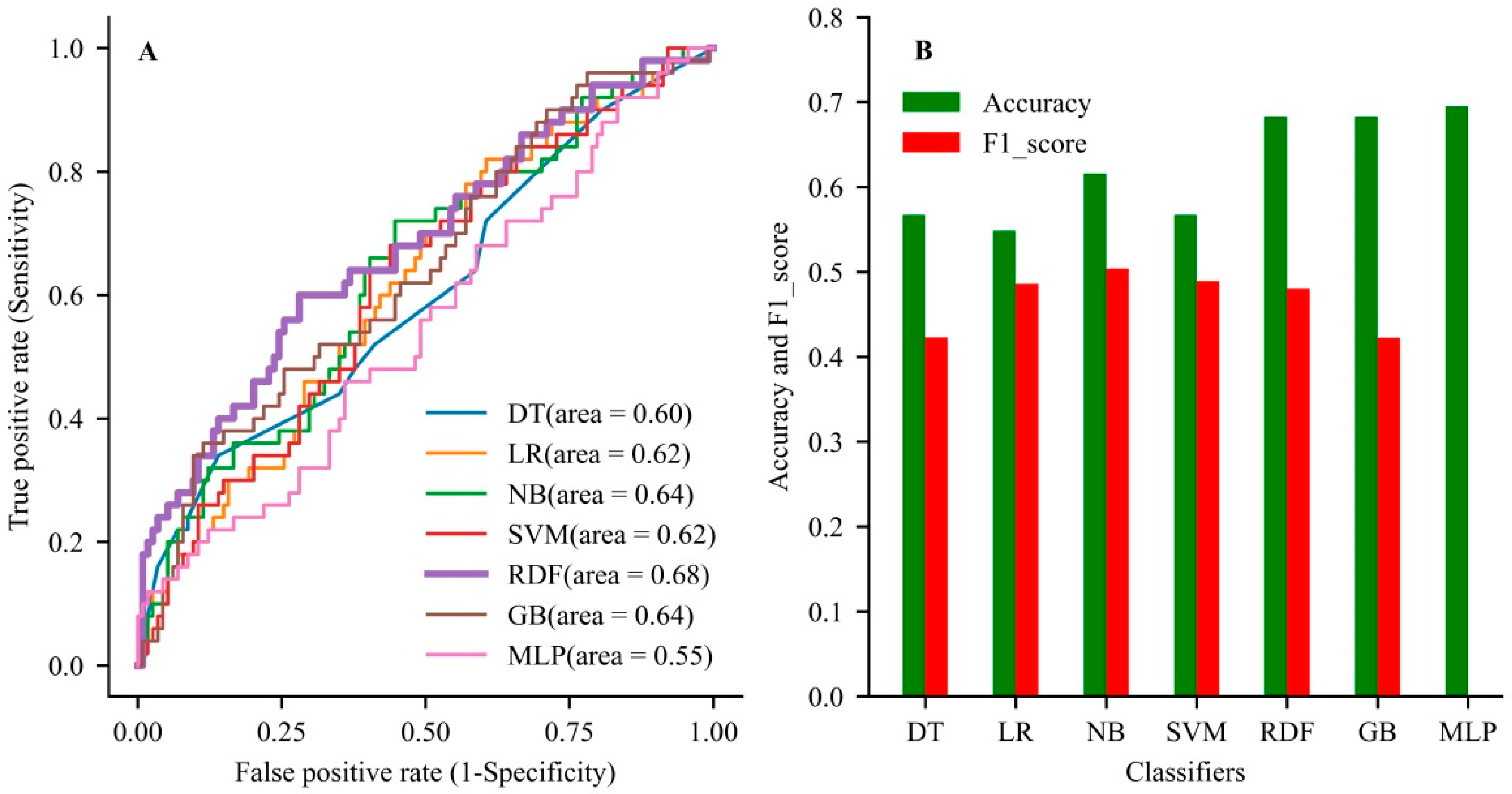
In the validation dataset, the RDF had the best discrimination with an AUC of 0.749 (95% CI, 0.644–0.85), accuracy of 0.734 (0.647–0.820), and F1-score of 0.480 (0.358–0.603) among all models (Table 3). In the testing dataset, the RDF also showed the better generalization ability with an AUC of 0.68, accuracy of 0.68, and F1-score of 0.48 compared with the other models (Figure 3 and Table S3 in Supplementary Material). The RDF showed better performance than the other models when comprehensively evaluating the accuracy and AUC value of the model.
Table 3.
Comparison of performance between various models in the validation dataset.
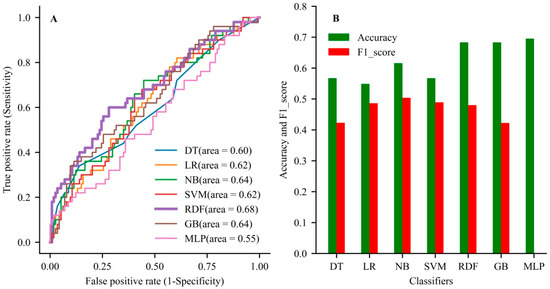
Figure 3.
The comparison of generalization ability among the developed models. (A) The area under the curve for all models used in the testing dataset. (B) The evaluation of accuracy rate and F1-score among the used models in the testing dataset. DT, decision tree; LR, logistic regression; NB, Naive Bayes; SVM, support vector machine; GB, gradient boosting; MLP, multilayer perceptron.
3.4. Calibration Plots for All Models
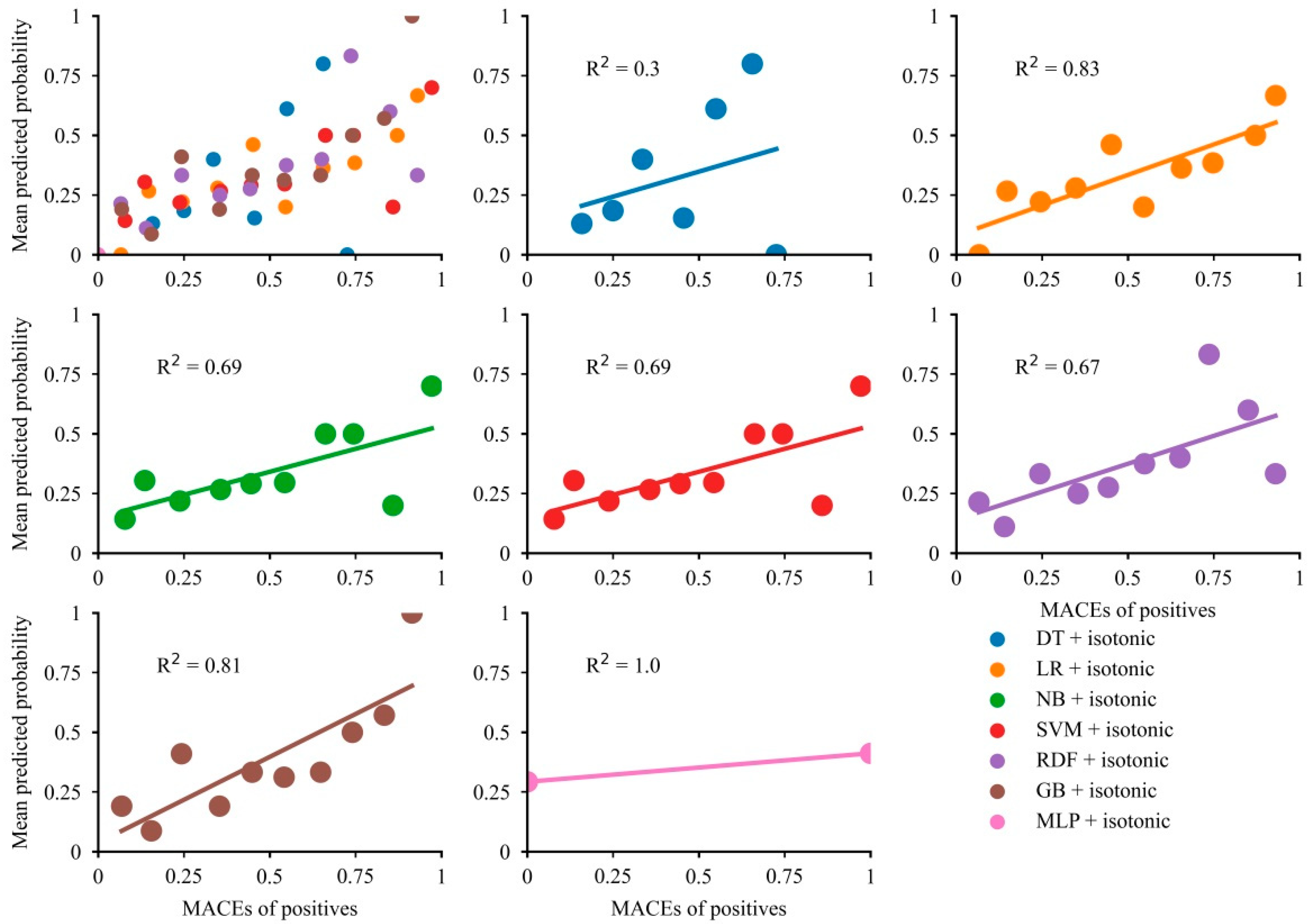
Overall, the majority of models showed modest concordance between the mean predictive probability and fraction of MACEs (Figure 4). The calibration curves indicated good alignment between the mean predictive probability and fraction of MACEs in LR and GB (R2 = 0.83 for LR and R2 = 0.81 for GB), while the predictive probability of MACEs in LR was limited below 0.75. The NB, SVM, and RDF models showed modest calibration. Although the predictive probabilities for the DT model showed a wide range, the calibration curve showed poor concordance. The predicted probability of MLP was a range of 0.25 to 0.45, so the effect of model calibration is very poor. After calibration, the Brier score became smaller, suggesting that the models were well calibrated (Table S4).
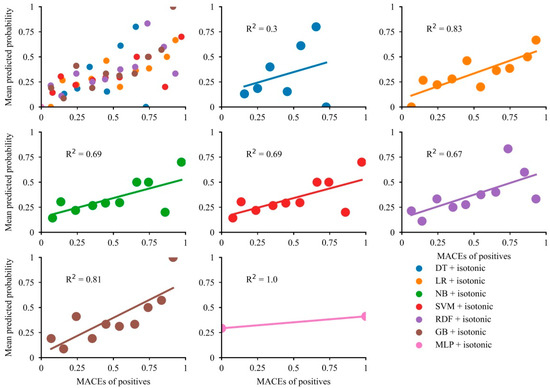
Figure 4.
Calibration plots for the developed models.
3.5. Kaplan–Meier Analysis for MACEs
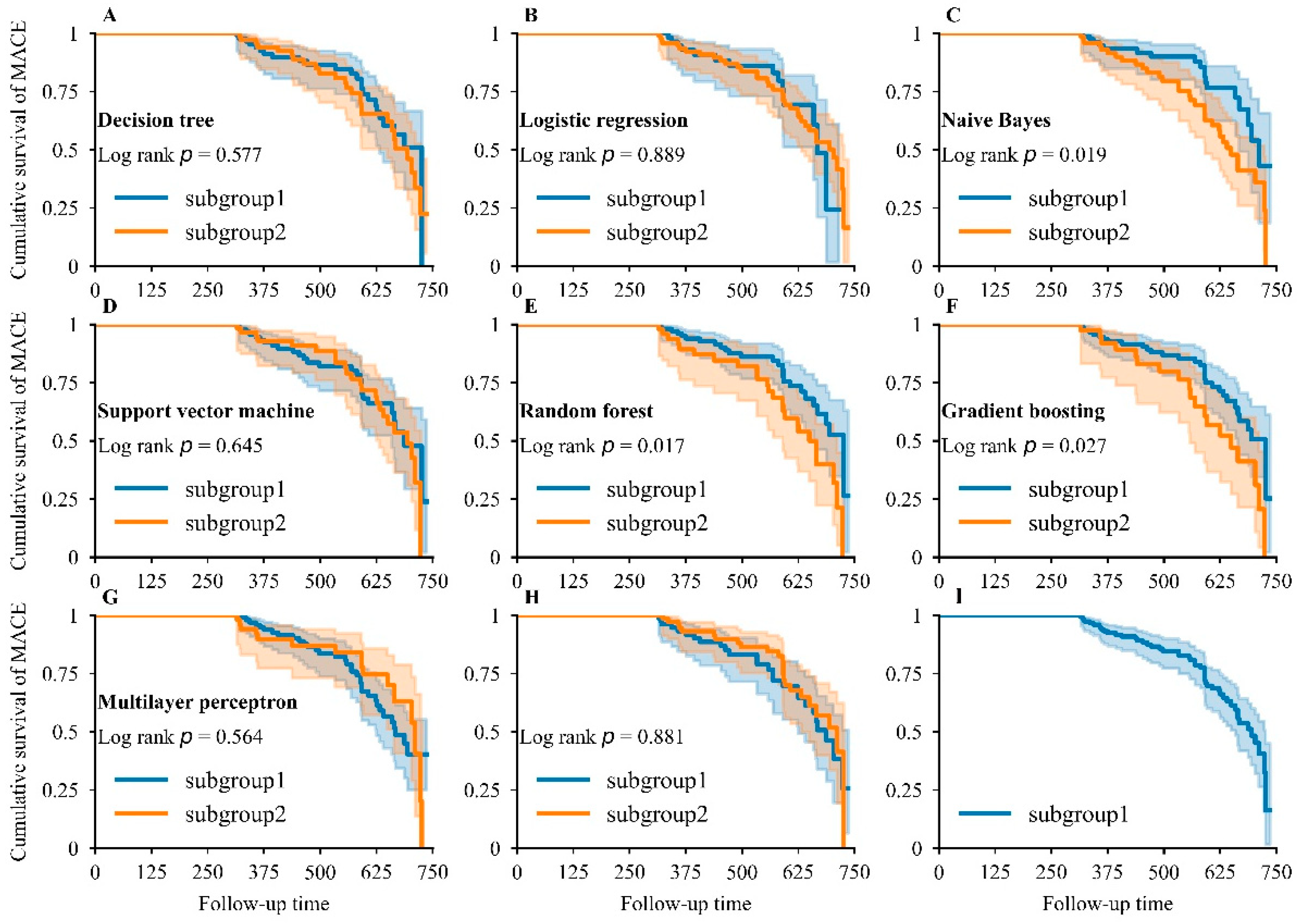
The NB, RDF, and GB showed significant differences in survival distribution (Figure 5C,E,F) across two subgroups, and RDF showed the smallest p-value (log-rank p = 0.017) and was the most appropriate model for distinguishing MACEs. However, LR, DT, SVM, and MLP did not exhibit obvious differences in survival distribution (Figure 5A,B,D,G). In random subgroups, no striking difference was found in survival distribution (Figure 5H), indicating that our developed models had strong discrimination ability. The cumulative survival of patients dropped sharply, highlighting the poor prognosis in patients during an average follow-up period of 1.42 years (Figure 5I).
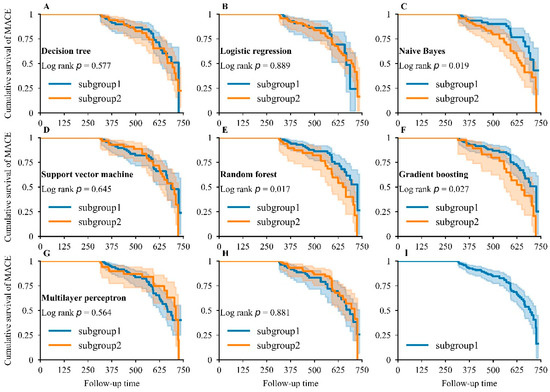
Figure 5.
Kaplan–Meier analysis for major adverse cardiovascular events. Kaplan–Meier curve for MACEs in DT (A), LR (B), NB (C), SVM (D), RDF (E), GB (F), and MLP (G) models: subgroup1—patients who were predicted to show a good prognosis by the corresponding model; subgroup2—patients who were predicted to show a bad prognosis by the corresponding model. Kaplan–Meier curve for MACEs when the study population in the testing dataset was randomly partitioned into two equal groups (H) and when the whole study population in the testing dataset was included (I).
4. Discussion
In this study, we identified five independent predictors that were closely related to adverse prognoses of AMI, namely, Killip classification, drug compliance, age, and levels of creatinine and cholesterol. Among these, Killip classification was considered as the most important predictor since the predictive accuracy increased obviously with the inclusion of this feature in all models. In addition, we developed and validated six ML models to predict MACEs in patients with AMI after the onset of an average follow-up period of 1.42 years, and compared these six ML models with LR to determine the predictive effect of these ML models. Among the ML models, the RDF model showed greater predictive and discriminative advantages compared to the other models.
Identification of independent predictors of MACEs guides and assists precise treatment and rehabilitation and improves the prognoses of patients. In this study, Killip classification, drug compliance, age, and levels of creatinine and cholesterol were identified as independent predictors of MACEs. These predictors could help accurately predict the prognoses of AMI patients and thereby strengthen individualized treatment for patients, such as taking medicine regularly and regular subsequent visits. Li et al. [10] recruited 87 patients with AMI to explore the value of S100A1 for early diagnosis and prognostic assessment. The results showed that a higher concentration of plasma S100A1 was notably associated with a poor prognosis for patients after the first PCI. Topal et al. [28] used 1603 patients to estimate the influence of age on long-term prognosis in ST-segment elevation myocardial infarction and concluded that the risk of death and re-hospitalization depended on both advanced age and infarct size. These results are partly consistent with our findings, although we identified five independent predictors for MACE prediction in this study, which could more effectively avoid the deviations caused by insufficient indicators. Many of these predictors of AMI outcomes have been discussed in previous studies, including creatinine, age, and Killip classification [29,30,31,32].
Despite the importance of MACE prediction, its application is still limited in clinical practice [33], necessitating more advanced methods to improve the prediction of prognoses in patients with AMI. Sax et al. [34] used ML to develop a risk-stratification tool for emergency department patients with acute heart failure and they concluded that the use of an XGBoost classifier (AUC of 0.85) improved 30-day risk prediction in comparison with LR. However, their primary outcomes were 30-day serious adverse events, and the applicability of the tool for longer follow-up periods was unknown. Thus, using the medical records of patients with AMI after the onset of an average follow-up period of 1.42 years, we have established six ML models and compared them with LR to identify an appropriate model for MACE prediction. The ML models showed advantages of high precision, automation, rapid response, and the ability to process large-scale data simultaneously [35,36], and could integrate electronic medical data and provide quick predictive outcomes and personalized rehabilitation programs based on the prognostic predictors. The application of ML methods in clinical practice has been also found to improve the predictive accuracy of MACEs when compared with the traditional LR model, which can be used to assist diagnosis and treatment of cardiovascular disease and improve the outcomes of patients.
We found that the RDF produced the better generalization ability compared with the rest of the ML models even though the sample size in our dataset was small. RDF is an ensemble learning algorithm that comprehensively evaluates the results of multiple DTs. Parts of random predictors and samples are selected to train each single tree, after which a final response measurement is generated by vote. When predicting the prognosis of a patient, each DT in the RDF will make a decision to obtain the classification. Through the statistics of the decision results, the classification with the highest number of votes will be determined as the result of the prognosis. RDF can be trained in parallel and has strong generalization ability for prediction of cardiovascular disease. Zhang et al. [37] used the clinical data of AMI patients to predict 30 days of all-cause hospital readmissions, and they found that the AUC value of the RDF model for discriminating cases from controls was 0.701. Yeung et al. [38] developed an RDF model to predict the death of patients with left ventricular thrombus and the results showed that the RDF model achieved an AUC of 0.700 (95% CI 0.553–0.863) on a validation dataset. These studies showed that RDF could be a good model for cardiovascular disease evaluation, which is consistent with our findings. Distinctively, the RDF model in our study showed greater discrimination and its performance has also been compared with other ML and the LR models, which may yield more authentic and reliable results.
AUC is an essential indicator to evaluate the performance of ML models, which could be affected by various factors. Generally, the original dataset is a decisive factor for the value of AUC, and a dataset of high quality and a larger sample size guarantees an authoritative AUC, otherwise missing values or unbalanced data may lead to a lower AUC [39,40]. Additionally, factors resulting in false negative errors also produce a lower AUC value, especially in predictive studies; for example, a shorter follow-up time means a lower probability for a model to learn positive events and thereby causes data unbalance and false negative errors [41]. Moreover, overfitting for ML models is still a common problem, which may result in failure to generate true predictions for unseen datasets and lead to lower AUC values [42]. In this study, the AUC of the studied ML models is modest, which may be caused by missing values, outliers, sample size, and follow-up time. Therefore, we have used AUC and accuracy together with F1-score to evaluate the reliability of models, which could be more objective in predicting MACEs in patients with AMI.
5. Limitations
This study had some limitations. The sample size for model development was not large enough, which may have affected the AUC and accuracy and discrimination of prediction, requiring validation with a larger dataset in future studies. Moreover, the dataset in this study came from a single medical center and the representativeness of the research data may also be limited, calling for further investigation.
6. Conclusions
AMI, as the most severe manifestation of coronary artery disease, is a threat to human life all over the world. Precise and quick assessment of MACEs in patients with AMI could improve the prognoses of patients. Therefore, based on the medical records from the hospital information system, we demonstrated that Killip classification, drug compliance, age, and levels of creatinine and cholesterol were independent predictors of MACEs. Although the performance of RDF for MACE prediction was not great after comprehensive evaluation, it was superior to LR and other models, which could provide sufficient predictive performance for MACEs in patients after AMI in this study. Overall, the ML methods are promising tools for cardiovascular disease management and the prognostication of patients by increasing predictive accuracy.
Supplementary Materials
The following are available online at https://www.mdpi.com/article/10.3390/jcdd9020056/s1, Figure S1: Clinical feature selection, Table S1: Detailed information about the collected clinical features, Table S2: Hyper-parameter optimization using five-fold cross-validation, Table S3: Predictive performance of developed machine learning models and logistic regression in the test dataset, Table S4: The Brier score for model calibration.
Author Contributions
Conceptualization, Z.C. and Y.G.; methodology, Z.C. and Y.G.; software, C.X.; validation, C.X., K.Z. and S.L.; formal analysis, C.X.; investigation, N.H.; resources, Z.C. and Y.G.; data curation, S.G. and Y.H.; writing—original draft preparation, C.X.; writing—review and editing, Z.C. and Y.G.; visualization, C.X.; supervision, Z.C. and Y.G.; project administration, Y.G.; funding acquisition, Z.C. and Y.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China, grant number 82002405 and 61901168; the Postdoctoral Research Foundation of China, grant number 2021M693570; the Hunan Health Committee Scientific Research Project of China, grant number 202103010009; and the Science and Technology Innovation Program of Hunan Province, grant number 2021RC2031.
Institutional Review Board Statement
The study was conducted in accordance with the guidelines of the Declaration of Helsinki and approved by the ethics committee of Zhuzhou Central Hospital (number: ZZCHEC2021102901; date: 27 May 2021).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Data cannot be made available.
Conflicts of Interest
The authors declare no conflict of interests.
References
- Virani, S.S.; Alonso, A.; Benjamin, E.J.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Chang, A.R.; Cheng, S.; Delling, F.N.; et al. Heart disease and stroke statistics-2020 update: A report from the American Heart Association. Circulation 2020, 141, e139–e596. [Google Scholar] [CrossRef]
- Sanchez-Perez, I.; Abellan-Huerta, J.; Jurado-Roman, A.; Lopez-Lluva, M.T.; Pinilla-Echeverri, N.; Perez-Diaz, P.; Piqueras-Flores, J.; Lozano-Ruiz-Poveda, F. Long-term follow-up of percutaneous coronary intervention with paclitaxel-eluting balloon catheter. Angiology 2021, 72, 364–370. [Google Scholar] [CrossRef]
- Kim, J.M.; Stewart, R.; Lee, Y.S.; Lee, H.J.; Kim, M.C.; Kim, J.W.; Kang, H.J.; Bae, K.Y.; Kim, S.W.; Shin, I.S.; et al. Effect of Escitalopram vs. Placebo treatment for depression on long-term cardiac outcomes in patients with acute coronary syndrome A randomized clinical trial. JAMA 2018, 320, 350–357. [Google Scholar] [CrossRef] [Green Version]
- Benz, D.C.; Kaufmann, P.A.; von Felten, E.; Benetos, G.; Rampidis, G.; Messerli, M.; Giannopoulos, A.A.; Fuchs, T.A.; Grani, C.; Gebhard, C.; et al. Prognostic value of quantitative metrics from positron emission tomography in ischemic heart failure. Cardiovasc. Imaging 2021, 14, 454–464. [Google Scholar] [CrossRef]
- Guo, Y.Y.; Zhao, X.; Wang, L.; Zhao, X.Y. Related factors of left ventricular thrombus formation within two weeks in patients with acute ST-segment elevation myocardial infarction and left ventricular aneurysm. Zhonghua Xin Xue Guan Bing Za Zhi 2021, 49, 360–367. [Google Scholar]
- Sato, T.; Saito, Y.; Matsumoto, T.; Yamashita, D.; Saito, K.; Wakabayashi, S.; Kitahara, H.; Sano, K.; Kobayashi, Y. Impact of CADILLAC and GRACE risk scores on short- and long-term clinical outcomes in patients with acute myocardial infarction. J. Cardiol. 2021, 78, 201–205. [Google Scholar] [CrossRef]
- Maznyczka, A.M.; McCartney, P.J.; Oldroyd, K.G.; Lindsay, M.; McEntegart, M.; Eteiba, H.; Rocchiccioli, J.P.; Good, R.; Shaukat, A.; Robertson, K.; et al. Risk stratification guided by the index of microcirculatory resistance and left ventricular end-diastolic pressure in acute myocardial infarction. Cardiovasc. Interv. 2021, 14, e009529. [Google Scholar]
- Mitarai, T.; Tanabe, Y.; Akashi, Y.J.; Maeda, A.; Ako, J.; Ikari, Y.; Ebina, T.; Namiki, A.; Fukui, K.; Michishita, I.; et al. A novel risk stratification system “Angiographic GRACE Score” for predicting in-hospital mortality of patients with acute myocardial infarction: Data from the K-ACTIVE Registry. J. Cardiol. 2021, 77, 179–185. [Google Scholar] [CrossRef]
- Ito, H.; Masuda, J.; Kurita, T.; Ida, M.; Yamamoto, A.; Takasaki, A.; Takeuchi, T.; Sato, Y.; Omura, T.; Sawai, T.; et al. Effect of left ventricular ejection fraction on the prognostic impact of chronic total occlusion in a non-infarct-related artery in patients with acute myocardial infarction. Int. J. Cardiol. Heart Vasc. 2021, 33, 100738. [Google Scholar] [CrossRef]
- Li, X.; Wang, X.; Sun, T.; Ping, Y.; Dai, Y.; Liu, Z.; Wang, Y.; Wang, D.; Xia, X.; Shan, H.; et al. S100A1 is a sensitive and specific cardiac biomarker for early diagnosis and prognostic assessment of acute myocardial infarction measured by chemiluminescent immunoassay. Clin. Chim. Acta 2021, 516, 71–76. [Google Scholar] [CrossRef]
- Chen, Z.; Xiao, C.; Qiu, H.; Tan, X.; Jin, L.; He, Y.; Guo, Y.; He, N. Recent advances of artificial intelligence in cardiovascular disease. J. Biomed. Nanotechnol. 2020, 16, 1065–1081. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Al’Aref, S.J.; Anchouche, K.; Singh, G.; Slomka, P.J.; Kolli, K.K.; Kumar, A.; Pandey, M.; Maliakal, G.; van Rosendael, A.R.; Beecy, A.N.; et al. Clinical applications of machine learning in cardiovascular disease and its relevance to cardiac imaging. Eur. Heart J. 2019, 40, 1975–1986. [Google Scholar] [CrossRef]
- Jamin, A.; Abraham, P.; Humeau-Heurtier, A. Machine learning for predictive data analytics in medicine: A review illustrated by cardiovascular and nuclear medicine examples. Clin. Physiol. Funct. Imaging 2021, 41, 113–127. [Google Scholar] [CrossRef]
- Gambella, C.; Ghaddar, B.; Naoum-Sawaya, J. Optimization problems for machine learning: A survey. Eur. J. Oper. Res. 2021, 290, 807–828. [Google Scholar] [CrossRef]
- Maheswari, S.; Pitchai, R. Heart disease prediction system using decision tree and naive bayes Algorithm. Curr. Med. Imaging 2019, 15, 712–717. [Google Scholar] [CrossRef]
- Jackins, V.; Vimal, S.; Kaliappan, M.; Lee, M.Y. AI-based smart prediction of clinical disease using random forest classifier and Naive Bayes. J. Supercomput. 2021, 77, 5198–5219. [Google Scholar] [CrossRef]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narandes, S.; Wang, Y.; Xu, W. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Gumaei, A.; Al-Rakhami, M.; Al Rahhal, M.M.; Albogamy, F.R.H.; Al Maghayreh, E.; AlSalman, H. Prediction of COVID-19 confirmed cases using gradient boosting regression method. Comput. Mater. Contin. 2021, 66, 315–329. [Google Scholar] [CrossRef]
- Masih, N.; Naz, H.; Ahuja, S. Multilayer perceptron based deep neural network for early detection of coronary heart disease. Health Technol. 2021, 11, 127–138. [Google Scholar] [CrossRef]
- Liu, N.; Chee, M.L.; Koh, Z.X.; Leow, S.L.; Ho, A.F.W.; Guo, D.; Ong, M.E.H. Utilizing machine learning dimensionality reduction for risk stratification of chest pain patients in the emergency department. BMC Med. Res. Methodol. 2021, 21, 74. [Google Scholar] [CrossRef] [PubMed]
- Khera, R.; Haimovich, J.; Hurley, N.C.; McNamara, R.; Spertus, J.A.; Desai, N.; Rumsfeld, J.S.; Masoudi, F.A.; Huang, C.; Normand, S.-L.; et al. Use of machine learning models to predict death after acute myocardial infarction. JAMA Cardiol. 2021, 6, 633–641. [Google Scholar] [CrossRef]
- Lee, H.C.; Park, J.S.; Choe, J.C.; Ahn, J.H.; Lee, H.W.; Oh, J.H.; Choi, J.H.; Cha, K.S.; Hong, T.J.; Jeong, M.H.; et al. Prediction of 1-year mortality from acute myocardial infarction using machine learning. Am. J. Cardiol. 2020, 133, 23–31. [Google Scholar] [CrossRef]
- Tokodi, M.; Schwertner, W.R.; Kovacs, A.; Toser, Z.; Staub, L.; Sarkany, A.; Lakatos, B.K.; Behon, A.; Boros, A.M.; Perge, P.; et al. Machine learning-based mortality prediction of patients undergoing cardiac resynchronization therapy: The SEMMELWEIS-CRT score. Eur. Heart J. 2020, 41, 1747–1756. [Google Scholar] [CrossRef]
- Liu, W.C.; Lin, C.S.; Tsai, C.S.; Tsao, T.P.; Cheng, C.C.; Liou, J.T.; Lin, W.S.; Cheng, S.M.; Lou, Y.S.; Lee, C.C.; et al. A deep learning algorithm for detecting acute myocardial infarction. EuroIntervention 2021, 17, 765–773. [Google Scholar] [CrossRef]
- Kuderer, N.M.; Choueiri, T.K.; Shah, D.P.; Shyr, Y.; Rubinstein, S.M.; Rivera, D.R.; Shete, S.; Hsu, C.Y.; Desai, A.; de Lima Lopes, G., Jr.; et al. Clinical impact of COVID-19 on patients with cancer (CCC19): A cohort study. Lancet 2020, 395, 1907–1918. [Google Scholar] [CrossRef]
- Topal, D.G.; Aleksov Ahtarovski, K.; Lonborg, J.; Hofsten, D.; Nepper-Christensen, L.; Kyhl, K.; Schoos, M.; Ghotbi, A.A.; Goransson, C.; Bertelsen, L.; et al. Impact of age on reperfusion success and long-term prognosis in ST-segment elevation myocardial infarction—A cardiac magnetic resonance imaging study. Int. J. Cardiol. Heart Vasc. 2021, 33, 100731. [Google Scholar]
- Wang, S.J.; Cheng, Z.X.; Fan, X.T.; Lian, Y.G. Development of an optimized risk score to predict short-term death among acute myocardial infarction patients in rural China. Clin. Cardiol. 2021, 44, 699–707. [Google Scholar] [CrossRef]
- Kang, Y.; Fang, X.-Y.; Wang, D.; Wang, X.-J. Factors associated with acute myocardial infarction in older patients after hospitalization with community-acquired pneumonia: A cross-sectional study. BMC Geriatr. 2021, 21, 113. [Google Scholar] [CrossRef]
- Shivakumar, B.G.; Shivakumar, N.; Gosavi, S.; Shastry, S. The importance of serum uric acid levels and Killip classification in predicting prognosis of acute myocardial infarction. J. Evol. Med. Dent. Sci. 2021, 10, 409–413. [Google Scholar]
- Fox, K.A.A.; Goldberg, R.J.; Pieper, K.; Cannon, C.P.; Van de Werfs, F.; Goodman, S.G.; Dabbous, O.; Granger, C.B.; Investigators, G. Predictors of in-hospital mortality in the global registry of acute coronary events (GRACE). Eur. Heart J. 2002, 23, 626. [Google Scholar]
- Li, Z.; Hui, Z.; Zheng, Y.; Yu, J.; Zhang, J. Comparative study on the effect of phase II remote home-based rehabilitation and traditional outpatient rehabilitation in patients with acute myocardial infarction after PCI. Basic Clin. Pharmacol. Toxicol. 2020, 127, 107. [Google Scholar]
- Sax, D.R.; Mark, D.G.; Huang, J.; Sofrygin, O.; Rana, J.S.; Collins, S.P.; Storrow, A.B.; Liu, D.; Reed, M.E. Use of machine learning to develop a risk-stratification tool for emergency department patients with acute heart failure. Ann. Emerg. Med. 2021, 77, 237–248. [Google Scholar] [CrossRef]
- Gupta, S.; Ko, D.T.; Azizi, P.; Bouadjenek, M.R.; Koh, M.; Chong, A.; Austin, P.C.; Sanner, S. Evaluation of machine learning algorithms for predicting readmission after acute myocardial infarction using routinely collected clinical data. Can. J. Cardiol. 2020, 36, 878–885. [Google Scholar] [CrossRef]
- Zhang, P.I.; Hsu, C.C.; Kao, Y.; Chen, C.J.; Kuo, Y.W.; Hsu, S.L.; Liu, T.L.; Lin, H.J.; Wang, J.J.; Liu, C.F.; et al. Real-time AI prediction for major adverse cardiac events in emergency department patients with chest pain. Scand. J. Trauma Resusc. Emerg. Med. 2020, 28, 93. [Google Scholar] [CrossRef]
- Zhang, Z.; Qiu, H.; Li, W.; Chen, Y. A stacking-based model for predicting 30-day all-cause hospital readmissions of patients with acute myocardial infarction. BMC Med. Inform. Decis. Mak. 2020, 20, 335. [Google Scholar] [CrossRef]
- Yeung, W.; Sia, C.-H.; Pollard, T.; Leow, A.S.-T.; Tan, B.Y.-Q.; Kaur, R.; Yeo, T.-C.; Tay, E.L.-W.; Yeo, L.L.-L.; Chan, M.Y.-Y.; et al. Predicting mortality, thrombus recurrence and persistence in patients with post-acute myocardial infarction left ventricular thrombus. J. Thromb. Thrombolysis 2021, 52, 654–661. [Google Scholar] [CrossRef]
- Ozer, I.; Cetin, O.; Gorur, K.; Temurtas, F. Improved machine learning performances with transfer learning to predicting need for hospitalization in arboviral infections against the small dataset. Neural Comput. Appl. 2021, 33, 14975–14989. [Google Scholar] [CrossRef]
- Wong, N.C.; Lam, C.; Patterson, L.; Shayegan, B. Use of machine learning to predict early biochemical recurrence after robot-assisted prostatectomy. BJU Int. 2019, 123, 51–57. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.W.; Jiang, A.P.; Li, T.; Xue, Y.Y.; Wang, G.T. LR-SMOTE—An improved unbalanced data set oversampling based on K-means and SVM. Knowl.-Based Syst. 2020, 196, 105845. [Google Scholar] [CrossRef]
- Pandey, S.K.; Mishra, R.B.; Tripathi, A.K. Machine learning based methods for software fault prediction: A survey. Expert Syst. Appl. 2021, 172, 114595. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).