

Adaptive RAG-Assisted MRI Platform (ARAMP) for Brain Metastasis Detection and Reporting: A Retrospective Evaluation Using Post-Contrast T1-Weighted Imaging

 , , , and
, , , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Population
2.2. Subgroup Analysis
Inter-Rater Reliability Analysis
2.3. Data Preparation for Radiomic and Multimodal Analysis
2.3.1. Data Preprocessing
2.3.2. Feature Extraction
- (1)
- First-order statistical features: These features capture basic intensity distribution characteristics within the image, such as mean, standard deviation, skewness, and kurtosis.
- (2)
- Shape features: These features quantify the geometric properties of the region of interest (ROI), including volume, surface area, sphericity, and maximum diameter.
- (3)
- LoG features: These features are based on the Laplacian of Gaussian (LoG) filter, which enhances edges and boundaries within the image. LoG features capture the texture and heterogeneity of the ROI.
- (4)
- Wavelet features: These features decompose the image into different frequency subbands, capturing texture information at multiple scales.
2.3.3. Image Enhancement and Normalization
2.3.4. DICOM-to-PNG Conversion
2.4. Feature Extraction and De-Identification
2.4.1. Feature Classification
2.4.2. Data Merging and De-Identification
2.5. Creating the Brain ARAMP
2.5.1. Reference Integration
2.5.2. Dataset Validation
2.5.3. Image Data and Workflow
- Step 1: Image Definition and Assessment: this initial step involved defining the imaging type (MRI), specifying the organ being scanned (brain), and setting appropriate MRI scan parameters (e.g., T1-weighted, T2-weighted; axial, sagittal, coronal views; pre-contrast and post-contrast) based on the clinical context and diagnostic objectives.
- Step 2: Lesion Analysis and Differential Diagnosis: in this step, the model analyzed any detected lesions, characterizing their size, intensity, and enhancement patterns. It then developed a differential diagnosis based on these lesion characteristics, dynamically retrieving and referencing relevant diagnostic criteria from the integrated medical literature [17,18,19,20,21]. Lesion descriptors served as semantic triggers within the RAG system to retrieve guideline-based diagnostic criteria, enabling precise matching with literature-defined imaging patterns.
- Step 3: Treatment Strategy for Brain Metastases: if brain metastases were suspected or confirmed, the model proceeded to formulate a potential treatment plan based on the imaging findings and diagnosis. This involved matching the imaging features with established treatment criteria and dynamically integrating relevant treatment recommendations from the medical literature [17,18,19,20,21]. Literature retrieval was tailored through prompt-linked indexing aligned with oncology treatment standards, allowing context-specific adaptation.
- Step 4: Conclusion and Follow-Up: in the final step, the model summarized the diagnostic findings, proposed a recommended treatment plan (if applicable), and defined appropriate follow-up requirements, tailoring imaging intervals and plans using dynamic references to the medical literature [17,18,19,20,21]. Each output included traceable reasoning and literature-cited justifications to enhance interpretability and transparency.
2.6. Inquiry Procedure and Evaluation
- GPT-4o Inquiry: An initial inquiry was made in GPT-4o, a large language model, to generate a baseline analysis report for each set of “Meta” images. This baseline assessment served as a reference point for comparison with the subsequent RAG-enhanced analysis.
- Brain ARAMP Inquiries: Following the GPT-4o inquiry, a series of four inquiries was performed in the Brain ARAMP. These inquiries were conducted at different stages of the model’s training process:
- (1)
- After Training: The first inquiry assessed the model’s performance immediately after the initial training phase.
- (2)
- Post-Training 1, 2, and 3: The subsequent inquiries evaluated the model’s performance after three rounds of iterative post-training refinement, allowing for assessment of the model’s learning and improvement over time.
- Pre-Trained Inference Difference: Assesses the discrepancy between initial model outputs (prior to structured prompting) and expert-confirmed diagnoses, illustrating baseline diagnostic variance.
- Inter-Inference Agreement: Measures consistency among different post-training model outputs across three prompt iterations, indicating the stability and reproducibility of ARAMP’s diagnostic reasoning.
- Post-Trained Inference Difference: Evaluates deviation between refined model outputs (after full RAG-enhanced prompting) and expert diagnoses, serving as a proxy for overall interpretive accuracy.
2.7. Statistical Analysis
3. Result
3.1. Patient Characteristics
3.2. DICOM Feature Extraction and Image Conversion
3.3. GPT Model Performance
- Post-Trained Inference Difference: The model’s post-trained inference difference was 67.45%, reflecting a substantial improvement in interpretive quality following implementation of the ARAMP prompting framework. In this context, “training” refers to a structured, multi-round prompting process—incorporating radiomic features, composite images, and literature-assisted reasoning via Retrieval-Augmented Generation (RAG)—rather than any form of parameter fine-tuning or supervised model updates.
- Inter-Inference Agreement: The average inter-inference agreement between the three expert radiologists was 30.20%, reflecting modest exact-match consistency in their scoring of the model’s diagnostic outputs. To formally assess inter-rater reliability, the intraclass correlation coefficient (ICC) was computed, yielding a statistically significant result (ICC = 0.192, p = 0.01).

{kind=link}
| Evaluator | Post-Trained Inference Difference (Mean ± SD) | Inter-Inference Agreement (Mean ± SD) |
|---|---|---|
| Dr. A | 56.20 ± 25.54 | 22.80 ± 8.54 |
| Dr. B | 73.20 ± 17.57 | 40.40 ± 13.33 |
| Dr. C | 75.60 ± 18.77 | 35.40 ± 11.67 |
| Gemini | 68.00 ± 22.74 | 22.00 ± 6.03 |
| Average of Drs. A–C | 68.33 ± 20.63 | 32.87 ± 11.18 |
3.3.1. Mention Type Definitions
- Listed as First: Brain metastasis was explicitly ranked as the first differential diagnosis.
- Listed but Not First: Brain metastasis was included in the differential diagnoses, but not was not listed first.
- Not Mentioned: Brain metastasis was not included in the differential diagnosis at all.
3.3.2. Post-Trained Inference Difference
3.3.3. Inter-Inference Agreement
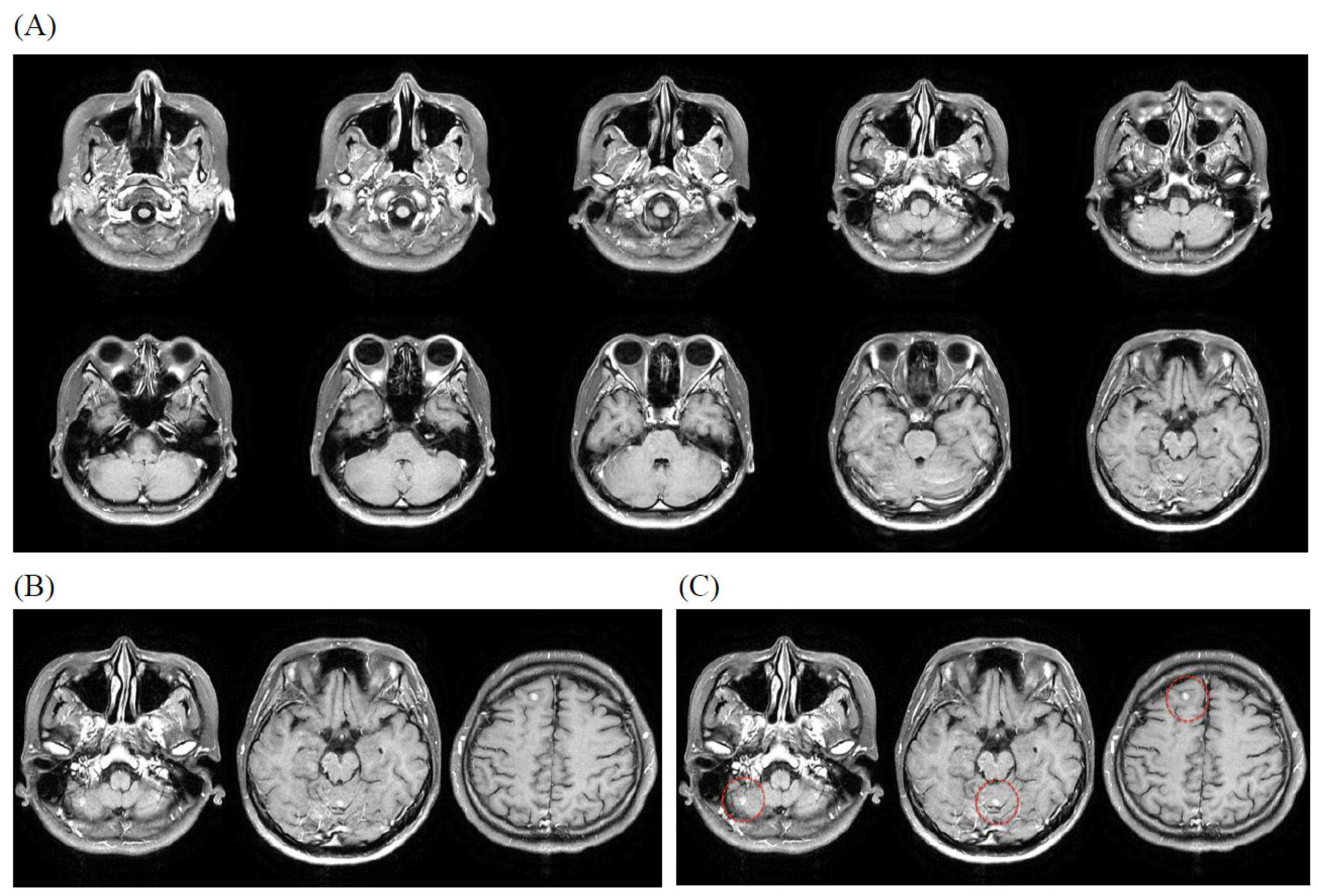
3.4. Illustrative Case
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, I.; Yamamoto, M.; Knisely, J.P. CH11. Multiple brain metastases. In Adult CNS Radiation Oncology: Principles and Practice; Chang, E.L., Brown, P.D., Lo, S.S., Sahgal, A., Suh, J.H., Eds.; Springer: Berlin/Heidelberg, Germany, 2024; pp. 475–495. [Google Scholar]
- Robin, A.M.; Kalkanis, S.N. CH10. 87C10 Brain Metastases. In Surgical Neuro-Oncology; Lonser, R., Elder, B., Eds.; Oxford Academic: Oxford, UK, 2018; pp. 87–96. [Google Scholar]
- Chilukuri, S.; Jalali, R. Brain metastasis: Momentum towards understanding the molecular milieu. Neurol. India 2019, 67, 755–756. [Google Scholar] [PubMed]
- Mirawati, D.K.; Soewondo, W. MRI sequencing of brain metastasis from lung malignancy: Literature review. GSC Adv. Res. Rev. 2023, 15, 105–109. [Google Scholar] [CrossRef]
- Kosiorowska, P.; Pasieka, K.; Perenc, H.; Majka, K. Overview of medical analysis capabilities in radiology of current Artificial Intelligence models. Qual. Sport 2024, 20, 53933. [Google Scholar] [CrossRef]
- Aerts, H.J.; Velazquez, E.R.; Leijenaar, R.T.; Parmar, C.; Grossmann, P.; Carvalho, S.; Bussink, J.; Monshouwer, R.; Haibe-Kains, B.; Rietveld, D.; et al. Decoding tumour phenotype by noninvasive imaging using a quantitative radiomics approach. Nat. Commun. 2014, 5, 4006. [Google Scholar] [CrossRef]
- Yang, H.C.; Wu, C.C.; Lee, C.C.; Huang, H.E.; Lee, W.K.; Chung, W.Y.; Wu, H.-M.; Guo, W.-Y.; Wu, Y.-T.; Lu, C.-F. Prediction of pseudoprogression and long-term outcome of vestibular schwannoma after Gamma Knife radiosurgery based on preradiosurgical MR radiomics. Radiother. Oncol. 2021, 155, 123–130. [Google Scholar] [CrossRef]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.H.; Aerts, H.J.W.L. Artificial intelligence in radiology. Nat. Rev. Cancer 2018, 18, 500–510. [Google Scholar] [CrossRef] [PubMed]
- Tong, E.; McCullagh, K.L.; Iv, M. Advanced Imaging of Brain Metastases: From Augmenting Visualization and Improving Diagnosis to Evaluating Treatment Response. Front. Neurol. 2020, 11, 270. [Google Scholar] [CrossRef] [PubMed]
- Ocaña-Tienda, B.; Pérez-Beteta, J.; Villanueva-García, J.D.; Romero-Rosales, J.A.; Molina-García, D.; Suter, Y.; Asenjo, B.; Albillo, D.; de Mendivil, A.O.; Pérez-Romasanta, L.A.; et al. A comprehensive dataset of annotated brain metastasis MR images with clinical and radiomic data. Sci. Data 2023, 10, 208. [Google Scholar] [CrossRef] [PubMed]
- Najjar, R. Redefining Radiology: A Review of Artificial Intelligence Integration in Medical Imaging. Diagnostics 2023, 13, 2760. [Google Scholar] [CrossRef] [PubMed]
- Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.-T.; Rocktäschel, T.; Riedel, S.; Kiela, D. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020, 33, 9459–9474. [Google Scholar]
- Yang, R.; Ning, Y.; Keppo, E.; Liu, M.; Hong, C.; Bitterman, D.S.; Ong, J.C.L.; Ting, D.S.W.; Liu, N. Retrieval-Augmented Generation for Generative Artificial Intelligence in Medicine. arXiv 2024, arXiv:2406.12449. [Google Scholar]
- Zakka, C.; Shad, R.; Chaurasia, A.; Dalal, A.R.; Kim, J.L.; Moor, M.; Fong, R.; Phillips, C.; Alexander, K.; Ashley, E.; et al. Almanac—Retrieval-Augmented Language Models for Clinical Medicine. NEJM AI 2024, 1, AIoa2300068. [Google Scholar] [CrossRef] [PubMed]
- Pristoupil, J.; Oleaga, L.; Junquero, V.; Merino, C.; Sureyya, O.S.; Kyncl, M.; Burgetova, A.; Lambert, L. Generative pre-trained transformer 4o (GPT-4o) in solving text-based multiple response questions for European Diploma in Radiology (EDiR): A comparative study with radiologists. Insights Imaging 2025, 16, 66. [Google Scholar] [CrossRef] [PubMed]
- Sau, S.; George, D.D.; Singh, R.; Kohli, G.S.; Li, A.; Jalal, M.I.; Singh, A.; Furst, T.J.; Rahmani, R.; Vates, G.E.; et al. Accuracy and quality of ChatGPT-4o and Google Gemini performance on image-based neurosurgery board questions. Neurosurg. Rev. 2025, 48, 320. [Google Scholar] [CrossRef] [PubMed]
- Bostwick, P. Medical Terminology: Learning Through Practice, 2nd ed.; McGraw Hill LLC: Columbus, OH, USA, 2014. [Google Scholar]
- Nader, R.; Sabbagh, A.J.; Elbabaa, S.K. Neurosurgery Case Review: Questions and Answers, 2nd ed.; Georg Thieme Verlag: Stuttgart, Germany, 2019. [Google Scholar]
- Citow, J.S.; Spinner, R.J.; Puffer, R.C. Neurosurgery Oral Board Review, 3rd ed.; Georg Thieme Verlag: Stuttgart, Germany, 2019. [Google Scholar]
- Osborn, A.G.; Hedlund, G.L.; Salzman, K.L. Osborn’s Brain, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Barkhof, F.; Jager, R.; Thurnher, M.; Cañellas, A.R. Clinical Neuroradiology: The ESNR Textbook, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Oommen, C.; Howlett-Prieto, Q.; Carrithers, M.D.; Hier, D.B. Inter-rater agreement for the annotation of neurologic signs and symptoms in electronic health records. Front. Digit. Health 2023, 5, 1075771. [Google Scholar] [CrossRef] [PubMed]
- Grovik, E.; Yi, D.; Iv, M.; Tong, E.; Rubin, D.; Zaharchuk, G. Deep learning enables automatic detection and segmentation of brain metastases on multisequence MRI. Radiology 2020, 297, 670–678. [Google Scholar] [CrossRef] [PubMed]
- Pennig, L.; Shahzad, R.; Caldeira, L.; Lennartz, S.; Thiele, F.; Goertz, L.; Zopfs, D.; Maintz, D.; Perkuhn, M.; Borggrefe, J. Automated detection of brain metastases on T1-weighted contrast-enhanced MRI using an ensemble of convolutional neural networks: Impact of volume-aware loss and sampling strategy. J. Magn. Reson. Imaging 2022, 56, 535–545. [Google Scholar] [CrossRef]
- Zhang, M.; Young, G.S.; Chen, H.; Li, J.; Qin, L.; McFaline-Figueroa, J.R.; Reardon, D.A.; Cao, X.; Wu, X.; Xu, X. Deep-learning detection of cancer metastases to the brain on MRI. Neuro-Oncology 2022, 24, 1594–1602. [Google Scholar] [CrossRef] [PubMed]
- Machura, B.; Kucharski, D.; Bozek, O.; Eksner, B.; Kokoszka, B.; Pekala, T.; Radom, M.; Strzelczak, M.; Zarudzki, L.; Gutiérrez-Becker, B.; et al. Deep learning ensembles for detecting brain metastases in longitudinal multi-modal MRI studies. Comput. Med. Imaging Graph. 2024, 116, 102401. [Google Scholar] [CrossRef] [PubMed]
| Characteristics | Value |
|---|---|
| Gender (male/female) | 52/48 |
| Age (male/female) | |
| 20–30 | 1/1 |
| 30–40 | 2/2 |
| 40–50 | 5/6 |
| 50–60 | 12/12 |
| 60–70 | 17/14 |
| 70–80 | 12/9 |
| 80+ | 3/4 |
| Clinical diagnosis | |
| Biliary or pancreatic cancer | 1 |
| Breast cancer | 11 |
| Cervical cancer | 1 |
| Colorectal cancer | 3 |
| Esophageal carcinoma | 3 |
| Gastric cancer | 1 |
| Head and neck cancer (excluding NPC_brain_spine_thyroid cancer) | 2 |
| Liver cancer | 1 |
| Lung cancer | 65 |
| Melanoma | 1 |
| Non-Hodgkin’s disease | 3 |
| Other cancers | 3 |
| Prostate cancer | 2 |
| Secondary malignant neoplasm | 1 |
| Upper lower respiratory tract cancer (excluding lung cancer) | 1 |
| Urologic cancer (excluding renal_bladder_prostate cancer) | 1 |
| Measure | Pre-Trained | Post-Trained | Inter-Inference Agreement |
|---|---|---|---|
| Mean ± SD | 59.90 ± 17.99 | 67.45 ± 21.60 | 30.20 ± 12.98 |
| Sum of Converted Scores | 11,980 | 26,980 | 12,080 |
| Range (Min–Max) | 20–100 | 20–100 | 20–100 |
| Metric | Before | Post |
|---|---|---|
| True Positive (TP) | 84 | 98 |
| False Negative (FN) | 16 | 2 |
| True Negative (TN) | 0 | 0 |
| False Positive (FP) | 0 | 0 |
| Sensitivity | 0.84 | 0.98 |
| Specificity | NA | NA |
| Precision | 84% | 98% |
| Mention Type | Before | Post 1 | Post 2 | Post 3 |
|---|---|---|---|---|
| Listed as First | 78 | 95 | 95 | 95 |
| Listed but Not First | 6 | 3 | 3 | 3 |
| Not Mentioned | 16 | 2 | 2 | 2 |
| Analysis Context | ICC Type | Intraclass Correlation b | 95% CI (Lower–Upper) | F (df1, df2) | p-Value |
|---|---|---|---|---|---|
| Post-trained inference differences | Single measures | 0.286 a | 0.161~0.415 | 2.200 (99, 198) | 0.00 |
| Average measures | 0.546 c | 0.366~0.681 | 2.200 (99, 198) | 0.00 | |
| Inter-inference agreement of post-trained model | Single measures | 0.192 a | 0.071~0.324 | 1.714 (99, 198) | 0.01 |
| Average measures | 0.417 c | 0.186~0.590 | 1.714 (99, 198) | 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, K.-C.; Chew, F.Y.; Cheng, K.-L.; Shen, W.-C.; Yeh, P.-C.; Kao, C.-H.; Guo, W.-Y.; Chang, S.-S. Adaptive RAG-Assisted MRI Platform (ARAMP) for Brain Metastasis Detection and Reporting: A Retrospective Evaluation Using Post-Contrast T1-Weighted Imaging. Bioengineering 2025, 12, 698. https://doi.org/10.3390/bioengineering12070698
Wu K-C, Chew FY, Cheng K-L, Shen W-C, Yeh P-C, Kao C-H, Guo W-Y, Chang S-S. Adaptive RAG-Assisted MRI Platform (ARAMP) for Brain Metastasis Detection and Reporting: A Retrospective Evaluation Using Post-Contrast T1-Weighted Imaging. Bioengineering. 2025; 12(7):698. https://doi.org/10.3390/bioengineering12070698
Chicago/Turabian StyleWu, Kuo-Chen, Fatt Yang Chew, Kang-Lun Cheng, Wu-Chung Shen, Pei-Chun Yeh, Chia-Hung Kao, Wan-Yuo Guo, and Shih-Sheng Chang. 2025. "Adaptive RAG-Assisted MRI Platform (ARAMP) for Brain Metastasis Detection and Reporting: A Retrospective Evaluation Using Post-Contrast T1-Weighted Imaging" Bioengineering 12, no. 7: 698. https://doi.org/10.3390/bioengineering12070698
APA StyleWu, K.-C., Chew, F. Y., Cheng, K.-L., Shen, W.-C., Yeh, P.-C., Kao, C.-H., Guo, W.-Y., & Chang, S.-S. (2025). Adaptive RAG-Assisted MRI Platform (ARAMP) for Brain Metastasis Detection and Reporting: A Retrospective Evaluation Using Post-Contrast T1-Weighted Imaging. Bioengineering, 12(7), 698. https://doi.org/10.3390/bioengineering12070698