1. Introduction
Biomedical information extraction scans text to identify structured data, including entities, relations, and events [
1]. This process is vital for drug design, repurposing, and clinical meta-analysis by systematically retrieving key patient characteristics, therapeutic interventions, and clinical outcomes [
2]. Leveraging and synthesizing biomedical literature accelerates drug development, drug repurposing improves treatment efficacy, and enhances evidence-based decision-making [
3,
4,
5,
6,
7,
8]. With over 28,000 active biomedical journals and 3000 new articles published daily, automation of biomedical information extraction is essential for extracting and synthesizing information efficiently [
9].
1.1. Biomedical Information Extraction for PICO and Meta-Analysis
Biomedical information extraction for PICO and meta-analysis is central to the front end of clinical research. PICO is a framework used in evidence-based medicine to formulate clear, focused clinical research questions. It stands for Patient/Population/Problem (P), Intervention (I), Comparator/Control (C), and Outcome (O) [
10]. By structuring questions systematically, PICO enhances the quality of systematic reviews, randomized controlled trials, and guideline development to ensure that clinical questions are specific, relevant, and answerable. Meta-analysis, on the other hand, is a statistical method used to combine and analyze data from multiple studies to derive a pooled estimate of an intervention’s effect. Clinical meta-analysis quantitatively combines multiple studies to evaluate treatment efficacy, patient outcomes, and disease risk factors [
11]. However, manual methods are reliant on search filters and manual data extraction. It takes 6–10 months for a five-person team to complete a single meta-analysis [
12]. Hence, automated biomedical information extraction is necessary to scale these front-end clinical research processes.
1.2. Challenges for Automating Biomedical Information Extraction
Natural-language processing (NLP) models offer a promising approach to automating the extraction of key biomedical data [
13,
14,
15]. BERT (bidirectional encoder representations from transformers) models have significantly advanced biomedical named entity recognition (BioNER) by leveraging deep contextualized embeddings to capture complex linguistic patterns in biomedical texts. Variants such as BioBERT [
16] and PubMedBERT [
17], pretrained on biomedical literature, further enhance performance by incorporating domain-specific knowledge. Nonetheless, the complexity of biomedical language—characterized by synonyms, abbreviations, and context-dependent meanings—still poses challenges [
13,
15].
Biocuration, the manual annotation of biomedical text, plays a crucial role in training NLP models [
14,
15]. This process is highly detailed and traditionally performed by medical experts [
18], making it resource-intensive. Maintaining annotation quality is essential for model reliability, necessitating the use of multiple annotators and inter-annotator agreement metrics [
19,
20]. The development of a well-structured and generalizable annotation schema is critical for effective manual and automated biocuration [
21].
1.3. The TrialSieve Framework
TrialSieve streamlines biomedical information extraction through a structured annotation protocol that balances expert and non-expert contributions, enhancing scalability while maintaining quality. Expanding beyond traditional PICO methodologies, TrialSieve supports robust meta-analyses and drug repurposing by integrating NLP-based biomedical text mining with PICO principles to improve data reliability for treatment evaluation. The TrialSieve schema comprises 20 annotation categories applied to 1609 PubMed abstracts, enabling deeper quantitative, evidence-based research. An annotation user study and experiments with state-of-the-art NLP models highlight TrialSieve’s ability to improve biomedical information extraction and frontend biomedical research.
2. Materials and Methods
The Methods section outlines TrialSieve schema design criteria; document selection; annotator selection and training; annotation and quality control; annotator survey to evaluate the tree-based schema and annotation aids; data preprocessing; and methods related to the evaluated NLP and LLM models, which automated TrialSieve entity labeling.
2.1. TrialSieve Schema Design Criteria and Construction
A key contribution of the TrialSieve framework was the development of a comprehensive schema that could be utilized by both human annotators or automated models to label and extract information from published biomedical literature needed for PICO and quantitative meta-analysis. Design criteria were determined to guide the development of the TrialSieve schema and included the following:
Schema must integrate all elements necessary for qualitative PICO and quantitative meta-analysis.
Schema must be flexible and generalizable to any clinical domain or clinical sub-specialty (e.g., cardiology, oncology, neurology, gastroenterology, endocrinology, etc.)
Schema must accommodate annotation of a wide variety of clinical study types, including clinical trials (phase 1, phase 2, phase 3, or phase 4), cohort study, case-control study, cross-sectional study, case study, etc.
Schema should be optimized for biomedical information extraction from abstracts but remain sufficiently flexible for full-text structured biomedical information extraction.
Schema design should be intuitive for annotators, including non-subject matter experts trained to do biomedical annotation.
Schema should not require explicit identification or differentiation of the designated comparator population. Rather, the schema should enable the interventions and outcomes of all included study populations to be captured using a shared, standardized structure.
Schema should enable the specification of global attributes relevant to the entire study versus elements that are attached to a specific patient group or arm of the study.
Schema should enable biomedical named entity recognition using existing available NLP models.
Schema should enable future structured biomedical information extraction for an end-to-end machine learning pipeline that extracts all elements required for performing quantitative data aggregation and statistical analysis.
The TrialSieve schema design was constructed through an iterative process that included annotators; the open-source NLP annotation software, LightTag; engineers; and clinicians. To facilitate accurate data annotation, a schema was developed through multiple iterations of feedback and refinement. The initial design comprised 14 primary tags, which were refined and ultimately expanded to 20 tags through annotation team discussions, iterative solving sessions, and quality control (QC) feedback. These refinements included the addition of new labels and the structuring of data into network graphs (also referred to as a tree-based structure) representing relationships between patient groups, drugs, dosages, outcomes, and other relevant elements. These refinements were subsequently evaluated by annotators and quality control reviewers as part of a user study.
2.2. Document Selection
It is well-known that many articles indexed and retrieved by PubMed for a given search will not be relevant to the research question being investigated for a clinical meta-analysis. Examples include studies that do not measure clinical outcomes, do not contain human subjects, or are not focused on a specific target disease [
22]. To address this challenge, the BioSift dataset [
22] was used, which presented 10,000 PubMed abstracts labeled with seven inclusion criteria well-suited to drug repurposing studies. To ensure data quality, only BioSift abstracts that met all inclusion criteria were included in the present study. Additionally, fewer than 100 abstracts deemed relevant for meta-analysis were included based on expert review.
2.3. Annotator Selection and Training
Seventy-two undergraduate students from a midsized university (enrollment <18,000 undergraduate students) were recruited as annotators for this project. Participants were selected from a range of science, technology, engineering, and medicine (STEM) majors, including biology, neuroscience, computer science, biomedical engineering, and chemistry. To qualify, students were required to pass two rounds of assessment: a graded annotation pre-assessment and a behavioral interview evaluating motivation. The pre-assessment utilized a simplified schema with only five labels, designed to assess candidates’ annotation aptitude prior to formal training. Candidates who scored above 68% on this assessment and demonstrated enthusiasm during the behavioral interview were accepted into the program. Ultimately, 72 students were recruited, corresponding to an acceptance rate of 64%.
Recruited annotators underwent two weeks of mandatory training, which included two 1.5-hour team-based learning sessions conducted both in-person and virtually. These sessions incorporated lectures covering the annotation schema and tools, along with collaborative annotation exercises in small groups. Training emphasized proper schema usage, annotation software proficiency, and practice annotating beta abstracts that were not included in the final TrialSieve dataset. Throughout this period, graded assessments were administered to evaluate annotators’ comprehension and accuracy.
Following the training period, annotation of TrialSieve commenced. Concurrently, annotators participated in weekly focus groups alongside peers and researchers to provide feedback on the effectiveness of the labeling schema. Based on this feedback, the schema was iteratively refined to enhance dataset quality and annotator accuracy. Throughout the project, annotators were provided with communication tools to seek support from peers, senior annotators, and project researchers. Weekly focus groups and communication support continued throughout the project duration.
In addition to the 72 annotators, 10 quality control (QC) managers were appointed to resolve annotation conflicts. These managers were required to have at least six months of prior annotation experience. Alongside conflict resolution, senior annotators were surveyed weekly to identify common annotation conflicts, monitor annotator performance, and recognize high-performing contributors. Survey findings were used to (1) inform focus group discussions and (2) provide feedback for selecting annotators for increased responsibilities, rewards, or corrective actions.
All annotators and quality control personnel were given the option to receive university credit for fulfilling an undergraduate research requirement. Those who opted out of credit were allowed to volunteer, with the flexibility to withdraw from the project at any time without penalty.
2.4. Annotation and Quality Control
The abstracts in
TrialSieve were all labeled by 3+ annotators using the open-source annotation software, LightTag [
23]. The annotators used annotation guides and open communication tools to collaborate with researchers and peers when annotating abstracts. Annotators were instructed to mark or “flag” particularly challenging abstracts or annotations made with uncertainty. These flags aided quality control managers (QC) in selecting abstracts for quality assurance review. QC managers were required to resolve all annotations that had conflicts between annotators as well as all abstract annotators flagged as challenging. The quality control protocol consisted of revising any errors in the annotations. Example revisions include misaligned text span labeling, resolving inter-annotator disagreements, and effectively defining the ground truth for a given annotation.
All annotations with no conflict and/or annotator flags were automatically accepted. On a weekly basis, the QC managers were asked to record consistently misused labels, frequently misunderstood terms, and concerns about annotator understanding or performance and submit the report to the research coordinators. Quality control reports were used to guide discussion topics in weekly annotator meetings. Finally, the QC managers were required to participate in upfront formal training and ongoing weekly meetings with the research coordinators to ensure the implementation of schema updates made during the annotator focus groups.
2.5. Annotator Survey to Evaluate the Tree-Based Schema and Annotation Aids
An annotator user survey was conducted to assess annotator opinions of the tree-based annotation structure and schema. Given the use of human subjects that were part of a university research course, the annotation user survey protocol was submitted to the Georgia Institute of Technology Internal Review Board (IRB) under protocol H23399. The Georgia Institute of Technology IRB protocol determined the anonymous user study to be of minimal risk and was thus “exempt” under the U.S. Department of Health and Human Services regulations for 45 CFR 46 104d.2. The study protocol H23399 was approved by the IRB on the 31st January 2024.
A 5-point Likert scale survey was developed and sent to the project annotators to explore their sentiments regarding three of the main training tools and motivational aids used in this research: (1) motivational aids, (2) relationship trees, and (3) team-learning sessions. Annotators were asked to rate a series of 32 questions using a value between 1 and 5, where 1 corresponded to “strongly agree” and 5 corresponded to “strongly disagree”. Several questions were given per category (motivational aids, 10 questions; relationship trees, 12 questions; team-training sessions, 10 questions). Of the 72 students asked to complete the survey, 38 annotators fully completed the survey, resulting in a sample size of n = 38. The survey was anonymous, and annotators were not compensated for their participation. The survey questions sought to relate annotators’ experiences with each of these tools to their willingness to make accurate annotations and their confidence in the accuracy of their annotations.
Cronbach’s alpha was used to assess the internal consistency among related groups of questions by comparing the proportion of shared variance (covariance) among survey items to the total variance observed across the survey. Cronbach alpha ranges from 0 to 1, with 0.7 to 0.95 typically deemed as optimal for retaining consistency without redundancy [
24]. The Cronbach’s alpha for this survey was 0.87.
Survey responses were assessed for a normal distribution using a Q-Q plot and histogram method. A t-test was performed on each of the questions individually to determine if there was a difference in the sample means and an expected population mean of 3. An alpha of 0.05 was used for the statistical tests. Each question was treated as a univariate independent test.
2.6. Annotated Data Postprocessing
Data were post-processed following annotation and quality control. Each annotation was normalized to remove leading/trailing whitespace. Annotations made using earlier versions of the schema were discarded. Annotations from annotators whom quality control managers flagged as having consistently lower accuracy were also discarded from the final dataset. This filtering process left a total of 170,557 annotations.
Establishing consensus on span boundaries is a well-known challenge in the process of extracting evidence from clinical cohort studies [
25]. A manual review of abstracts affirmed that annotators generally agreed on a large proportion of characters tagged with a specific label. However, discrepancies often occur near the boundaries of entities. In cases where multiple annotators or QC managers provided overlapping annotations, character span annotations were consolidated by adopting the majority vote label for each character. An “O” label (indicating “outside of tagged span”) was allocated to all spans without a clear majority from at least 2 annotators or QC personnel. This approach proved to be the most efficient in resolving discrepancies and maintaining high-quality span annotations. Annotators were instructed to annotate entire words; therefore, word breaks were not observed when aggregating at a character level.
Abstracts with fewer than 5 distinct span annotations after postprocessing were flagged for not having sufficient data and were removed. After aggregating, postprocessing, and removing low-annotation abstracts, the resultant dataset had 52,638 distinct, non-overlapping, high-quality span annotations and 1609 abstracts. These abstracts and annotations were used to train and evaluate the included models.
2.7. Models to Automate TrialSieve Entity Labeling
Four BERT-based models were utilized for this study: BioBERT (dmis-lab/biobert-base-cased-v1.2); BioLinkBERT (michiyasunaga/BioLinkBERT-base), KRISSBERT (microsoft/BiomedNLP-KRISSBERT-PubMed-UMLS-EL), and PubMedBERT (microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext). Each model was pretrained on large biomedical corpora and was selected for high performance on other biomedical named entity recognition tasks. All models were fine-tuned on our dataset for the named entity recognition task in TrialSieve.
This work primarily centered on NLP-based models. Nonetheless, one large language model (LLM), GPT-4o, was also included in the evaluation. It was chosen as a representative LLM candidate based on its success in prior foundational work examining biomedical information extraction tasks [
14].
2.7.1. Evaluation Metrics
The performance of these models was evaluated based on four standard metrics used for named entity recognition: accuracy, precision, recall, and F1-score. The evaluation was performed on a held-out test set comprising 15% of the abstracts.
2.7.2. Implementation Details
Tokenizers and pretrained weights of all models were downloaded from Huggingface at the time of model training. Abstracts longer than 500 tokens were split along sentence boundaries into chunks with fewer than 500 tokens. A predefined split of 70% of abstracts was used for training and 15% each for validation and testing. Each model was trained for 100 epochs using a batch size of 128. Parameters were optimized using AdamW [
26] with a learning rate of 0.0005. A linear decay learning rate schedule was implemented, with the first 20% of training epochs designated as a warmup.
3. Results
This study introduces,
TrialSieve, an assortment of 1609 abstracts annotated for biomedical entity recognition.
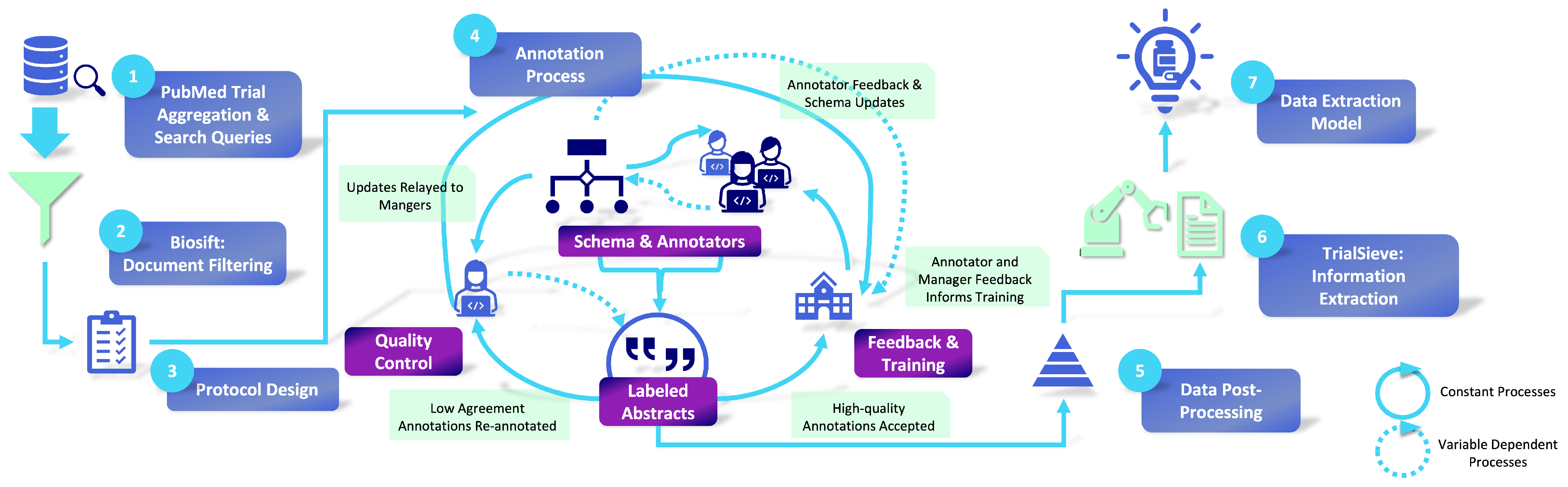
TrialSieve is aimed at identifying clinically significant elements crucial for drug repurposing clinical meta-analysis. The comprehensive process of abstract selection, annotation, and quality control is illustrated in
Figure 1. The selection criteria for these abstracts were formulated in partnership with licensed clinicians to ensure the labeled information was pertinent to drug repurposing and pharmacovigilance. Abstracts were preemptively screened to ensure that annotated abstracts contained relevant clinical data [
22]. Specifics regarding these criteria and other dataset characteristics are provided in
Figure 2. Each abstract was annotated by at least three annotators. Expert senior annotators cross-checked a subset of inconsistently labeled abstracts during a quality assurance phase.
3.1. TrialSieve Schema: A Tree-Based Approach for Accurate, Comprehensive Annotation
The final schema, illustrated in
Figure 2, consists of 20 text labels and introduces a hierarchical categorization strategy that addresses prior annotation limitations. It was designed to encompass all necessary fields for conducting both qualitative PICO and quantitative meta-analyses using published clinical trial and cohort study records. Importantly, the schema is sufficiently detailed to capture key variables while maintaining generalizability across diverse clinical domains. Consequently, the
TrialSieve schema is not restricted to a single disease, outcome, or pharmaceutical class. To ensure its applicability in real-world clinical settings, the schema and annotation protocol underwent review by clinicians from the Morningside Center for Innovative and Affordable Care at Emory University (see Acknowledgment Section).
3.1.1. Global Versus Group Attributes
Briefly, the
TrialSieve schema (
Figure 2) specifies attributes based on properties that apply globally to all parts of the study abstract versus properties that only apply to one or more specific groups (or arms) of the study. Global attributes include a group characteristic shared by all groups in the study, the follow-up period, and other global attributes, which are specified by the annotator. The group-specific attributes are applied to each patient group or population. The tags include three tags from the abstract level (disease, study duration, study years) and 17 tags shown in Level 2, which are divided into 3 branches: group attributes that define the population, study outcomes that define and quantify the types of measure used to assess outcomes, and study interventions that specify the drug(s), intervention(s), or methods(s) the population received.
Beyond biomedical entity annotation, the schema incorporates relationships between spans, allowing for the organization of patient groups following the same treatment protocol. Each patient group is structured as a tree consisting of two node types: (1) tagged spans, representing text annotations, and (2) pseudo-nodes, which serve as organizational elements without direct text correspondence (e.g., “group”, “subgroup”). The root of each tree is a “group” pseudo-node to which sample size and population characteristics are attached. Interventions—including pharmaceutical and non-pharmaceutical treatments—are linked to this node, with drug treatments further associated with dosage, route of administration, frequency, and duration. Outcomes and adverse effects are connected to their respective quantitative measurements, measurement types (e.g., odds ratio, count), and statistical significance. The complete set of tags and relations is depicted in
Figure 2.
3.1.2. Example Application of the TrialSieve Schema
Figure 3a shows a detailed example abstract from a study published by Gabryelewciz and colleagues [
27] that was annotated using the
TrialSieve schema. The color-coding matches the schema tree shown in
Figure 2. Notice there are 54 spans, including 21 unique spans, labeled in this abstract, which collectively enable all biomedical information extraction required for quantitative data analysis.
Figure 3b shows the tree-like nature that compares the two populations from the duodenal ulcer study of Gabryelewicz and colleagues [
27]. This study contained two main patient populations, which received either a placebo and or the study drug of interest, ebrotidine. The left side of
Figure 3b shows the tree-like relational data structure used to annotate both groups. The right side shows the study summary with the three main levels (participants, intervention, outcomes). Note that the
TrialSieve schema does not explicitly state the comparator group. Rather, each group within the study has the same tagging structure available. This design choice avoids the ambiguity of either a human or a computer algorithm having to choose a single comparator group in studies with multiple arms. Moreover, it makes the schema more flexible for future large-scale automated biomedical information extraction.
The first main level of the tree illustrates the population size was 110 patients (olive color), the frequency of the follow-up period (shown in yellow), and the primary disease being examined (shown in orange), duodenal ulcer. The second main level branches into the arms of the study. On the left was the comparator group, which was the placebo (shown in grey) that was given no intervention. On the right was the study intervention group, which was given ebrotidine (shown in light pink). The study intervention drug arm records the frequency of the intervention (shown in lime green), the quantitative dose (shown in red), and the dose units (shown in grey). Since the comparator group, placebo, was given no intervention in this example abstract, there were no additional intervention details recorded. In this example, the third main level of the tree contains the study outcome characteristics, which include the specified outcome of ulcer healing rate (shown in aqua). Finally, the quantitative p-value significance reported by the authors is tagged (shown in magenta).
Figure 2 not only shows the schema, but it also represents the relationship trees completed by annotators as part of the annotation process. Each node in the relationship tree constitutes a label in the annotation schema, and the connections between nodes constitute the relationships applied between entities. The relationship tree represents a template structure that is repeatable and can be applied to most texts. Student annotators were expected to learn the tree structure and annotate texts by finding the appropriate entities in the text and filling in the nodes of the tree based on these entities. Trees were allowed to be pruned for texts missing some of the template nodes or expanded depending on the number of different independent entities provided in the text. The use of visual tree-based completion as the key process for annotation differed greatly from traditional written rule-based only protocols [
18,
28,
29].
3.2. Dataset Statistics
The statistics for the dataset annotated using the
TrialSieve framework are presented in
Table 1. The final annotated dataset consists of 1609 abstracts, 170,557 annotations, and 52,638 final spans. The user-driven
TrialSieve schema facilitated a more intuitive annotation process for clinical trial records, which often contain complex terminology. Utilizing undergraduate students instead of time-constrained subject matter experts (e.g., licensed clinicians) enabled the curation of a larger number of sample abstracts. Incorporating user feedback into the schema design enhanced both annotation accuracy and inter-annotator agreement. Additionally, the annotated labels improved the tagging of non-contiguous text spans, allowing compatibility with annotation software that assigns a single label per text span.
3.3. Automated Model Performance
Each of the models (BioLinkBERT, BioBERT, KRISSBERT, PubMedBERT, GPT-4o) was evaluated to determine the ability to detect entities in
TrialSieve.
Table 2 presents the overall results of the evaluation, including accuracy, precision, recall, and F1-score. Among the evaluated models, BioLinkBERT demonstrated the highest performance in terms of accuracy (0.875) and recall (0.679). PubMedBERT scored the best on precision (0.614) and F1-score (0.639). Both BioLinkBERT and PubMedBERT outperformed BioBERT and GPT-4o across all metrics. BioBERT had the lowest accuracy (0.808) and precision (0.468), whereas GPT-4o had the lowest recall (0.459) and F1-score (0.506).
To gain deeper insights into entity-specific performance, we analyzed the results for each entity category, as shown in
Table 3. Notably, PubMedBERT consistently achieved the highest precision, recall, and F1 scores for most entity categories. Importantly, different models showed varying strengths and weaknesses in entity detection. For instance, BioBERT demonstrated higher performance in the follow-up period, while KRISSBERT achieved better results in Intervention Frequency. When examining solely the traditional PICO elements, the
TrialSieve schema resulted in similar performance as previous 2-stage NLP pipelines that use both sentence classification and named entity recognition with BERT-based models [
30].
3.4. Error Analysis
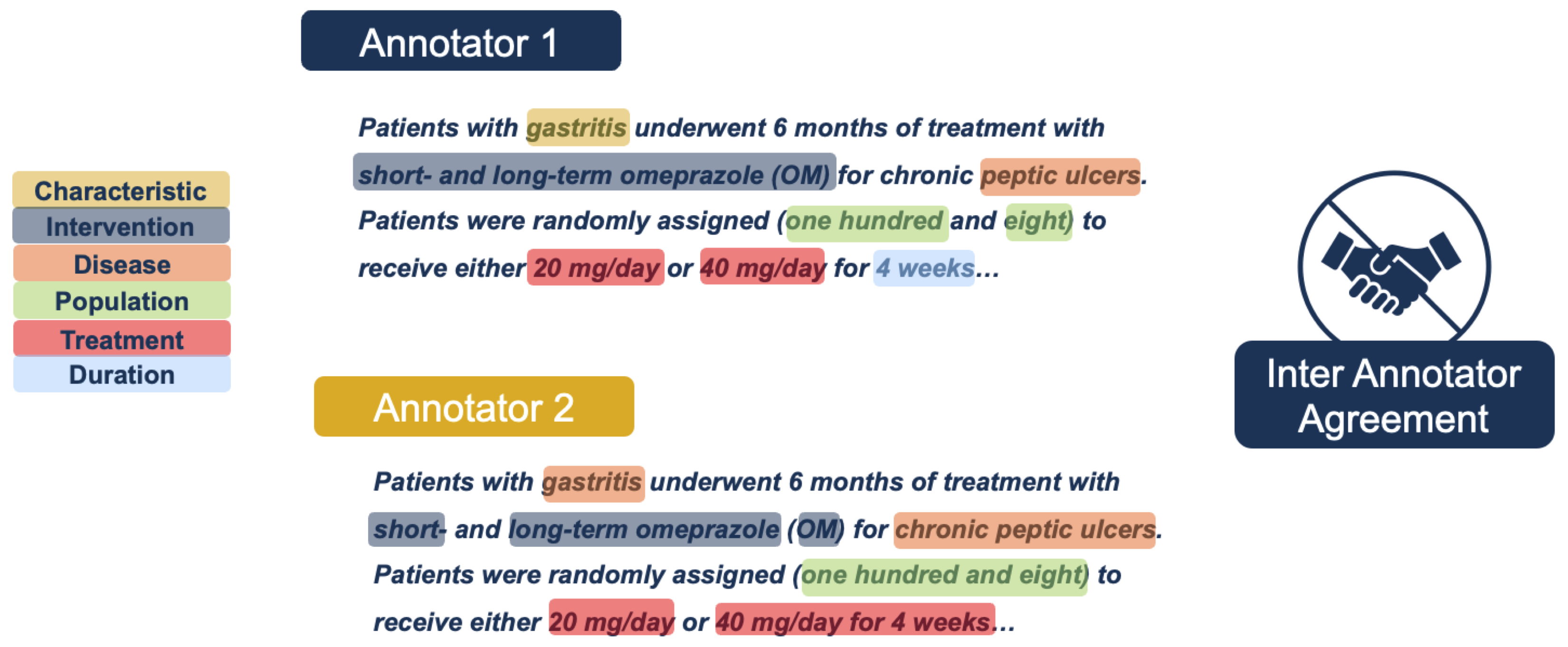
Enhancing annotation accuracy presents a significant challenge due to the inherent variability in how different annotators may interpret and label the same text. Inter-annotater agreement is one way to assess variability. Inter-annotator agreement (IAA) is a measure of consistency between multiple annotators when labeling the same data, reflecting the reliability and reproducibility of the annotation process. See
Figure 4 as a simplified example of inter-annotator disagreements. Traditional annotation projects typically rely on predefined rules and guidelines to mitigate low inter-annotator agreement. However, it is impractical to account for all possible scenarios that may lead to classification discrepancies. Furthermore, research suggests that excessively detailed guidelines do not necessarily improve annotation accuracy, as their complexity and time-consuming nature reduce the likelihood of consistent adherence [
28].
An error analysis was conducted on the human-annotated data and one of the top-performing models, BioLinkBERT. In this process, highly experienced annotators re-examined a randomly selected subset of 237 abstracts annotated by humans and BERT.
An annotation is considered an error if any of the following four situations occur:
Wrong label: The assigned label is incorrect.
Wrong overlap: The tagged text is either too short, missing important information, or too long, including unnecessary words.
Multiple entities: The tagged text includes more than one entity.
Invalid tag: The text was tagged when it should not have been.
Table 4 summarizes the details of errors in the re-examined subset compared to BioLinkBERT. The BERT-based model correctly annotated 71.48% whereas humans correctly annotated 50.35%. The biggest difference between humans and the BioLinkBERT model trained with a portion of the
TrialSieve dataset was the span length. However, evaluation of the accuracy results for the re-examined subset requires careful consideration of context, namely error type.
Table 5 presents the percentage of errors made by human annotators and BioBERT across four classified error types. Humans were more prone to errors in span selection, either under-selecting or over-selecting entity boundaries—categorized as ’wrong overlap’ in the table. These span-based tagging errors primarily stemmed from annotation inaccuracies when using a mouse, often resulting in extra whitespace at the end of an entity tag or the inadvertent truncation of a span.
Additionally, during this re-evaluation, only previously annotated spans were assessed, while missed spans—text that should have been tagged but was overlooked—were not considered. If these omissions were taken into account, human performance would lag even further behind BERT. Human annotation was not only less precise but also covered 20% fewer spans than BERT.
Despite the inherent noise in manual human annotation, the error analysis indicates that NLP models trained on such data can match or, in most cases, surpass human performance. This finding highlights the feasibility of fully automating biomedical information extraction, even when relying on noisy human-annotated datasets.
3.5. TrialSieve User Study: Annotator Opinions on the Tree-Based Approach and Annotation Aids
This study introduces a novel visual, hierarchical annotation structure—relationship trees—designed to enhance the learnability of the annotation schema and improve annotation consistency, thereby increasing inter-annotator agreement (IAA) and accuracy. To assess the effectiveness of the TrialSieve framework, a user study was conducted to evaluate annotator perceptions of three key novel components.
Annotator perceptions of relationship trees were evaluated regarding their effectiveness in facilitating schema learnability and enhancing annotation accuracy.
The influence of motivational aids, including awards, course credit, and perceived initiative value, on annotator accuracy and motivation was assessed.
Annotator perspectives on the impact of team-training sessions on annotation accuracy and inter-annotator agreement were examined.
The voluntary, anonymous survey had ten questions with statistically significant results. Five of these questions discussed the use of relationship trees in the curation of biomedical texts. Four of the significant questions concerned motivational aids, and only one question with significant results concerned team-based training sessions (see
Table 6).
Annotators indicated that the most important motivators for producing accurate annotations were letter grades, awards, and the opportunity to be promoted to a management role on the project. The most de-motivating factor was the experience of any technical issues with the LightTag annotation software, which impeded their ability to annotate.
The results indicate a high preference for the usage of relationship trees and a high degree of perceived accuracy while using relationship trees rather than conventional annotation methods. Questions such as “I found that using relationship trees made it easier for me to label text accurately”, “I believe I may have made LESS errors when I used relationship trees when annotating”, and “Using relationship trees improves my ability to annotate accurately”, all express the same sentiment, indicating that annotators feel more confident about annotations made using relationship trees and that the use of this tool aids annotation accuracy.
The only significant result from the team-based learning section of the survey indicated that students feel that collaborating with peers during annotation training is a useful learning tool; however, compared to the other two categories, team-based training sessions seem less influential in the eyes of annotators.
4. Discussion
Prior datasets for biomedical information extraction automation have largely remained private and/or have not utilized a schema that labels quantitative information necessary for downstream analysis common in drug repurposing and design. The TrialSieve framework, including the TrialSieve schema and corresponding annotation protocol, was used to construct a large, open-source annotated dataset consisting of 1609 PubMed abstracts. Each TrialSieve abstract was annotated by 3+ annotators. Thus, TrialSieve is suitable for generalizable, structured quantitative biomedical information at scale, whether by humans or NLP automation.
4.1. Role of the TrialSieve Tree-Based Schema in Improved Biomedical Information Annotation
TrialSieve was developed through an iterative process that incorporated relationship trees to create a more flexible and generalizable schema. This approach enables the extraction of labeled, quantitative data for clinical meta-analysis and drug design. The user study on TrialSieve demonstrated that annotators found that relationship trees significantly improved both the ease and precision of annotation. In particular, this advantage persisted even among annotators initially trained on an earlier, non-tree-based annotation protocol before transitioning to the final tree-based schema TrialSieve.
Studies suggest that visual annotation schema, such as tree-like structures with nodes linked to specific elements, can aid text categorization [
28]. While slight improvements in label accuracy were observed, overall annotation accuracy and inter-annotator agreement did not significantly improve. In particular, the study by Langer and colleagues involved only two annotators with prior experience in traditional annotation methods, which may have limited the impact of the tool on skill acquisition or statistical significance [
28].
In biological text analysis, orthogonal neighboring trees have improved visualization [
31]. Similarly, in the medical field, structured visual representations such as treatment trees improve the comprehension of complex information [
29,
32,
33]. Studies indicate that doctors and patients benefit from visual aids over numerical or textual data [
32,
33]. Learning clinical concepts is challenging, even for medical students, but audiovisual tools enhance motivation, engagement, and concentration [
34,
35].
4.2. TrialSieve Dataset Compared to Prior PICO Datasets
A range of corpora annotated with PICO elements across abstracts and full-text articles have been assembled over time. However, the majority are still not publicly accessible. One such corpus was generated by Kiritchenko et al. [
36], containing 182 full-text articles annotated for 21 entities, including elements like treatment dosage and funding institution details. Summerscales et al. [
37] similarly annotated a corpus of 263 abstracts, which emphasized treatment groups and outcomes. However, their annotations have a narrower focus, and their corpus remains private.
Wallace et al. [
38] offered a solution to the prohibitive costs of constructing large corpora. They used a distant supervision approach to create an extensive full-text article corpus, with 133 articles being manually annotated for evaluation. This method, while cost-effective, raises questions about the quality of the resultant data.
Most datasets in this field are non-public, with a few notable exceptions like the EBM-NLP corpus by Nye et al. [
15], which is one of the largest publicly available corpora. This corpus includes approximately 5000 abstracts from randomized clinical trials (RCTs), primarily for cardiovascular diseases, cancer, and autism. However, it did not include all required fields for meta-analysis, such as numeric texts detailing the number of participants experiencing specific outcomes. The example abstract annotated in
Figure 5 shows how the annotations from
TrialSieve compare to those of EBM-PICO. In particular,
TrialSieve better enables the extraction of data required for quantitative clinical meta-analysis.
In a move towards more comprehensive open-access resources, Mutinda et al. [
39] curated a corpus that encapsulates 1011 abstracts from breast cancer RCTs pulled from PubMed. This work primarily focused on the annotation of outcomes. Nonetheless, it is a step forward towards robust evidence-based medicine.
Despite these efforts, there remains a clear need for a comprehensive, publicly accessible biomedical entity dataset with annotations suitable for clinical meta-analysis. TrialSieve aims to address this gap by expanding annotation categories beyond the traditional PICO framework, introducing new annotation aids to enhance human annotation quality and scalability, and providing a comprehensive, open-source annotated dataset. With these advancements, the TrialSieve dataset has the potential to accelerate frontend clinical research and workflows, including quantitative meta-analysis and drug repurposing.
4.3. TrialSieve Enables Scalable Annotation by Non-Subject Matter Experts
While the long-term goal is to fully automate biomedical information extraction, some manually annotated datasets are still required for model training and validation. The ability to use non-subject matter experts (e.g., those other than highly specialized clinicians or researchers holding a medical and/or doctoral degree) is one way to increase annotation scalability.
The error analysis (see
Table 4) showed that there was a high degree of inter-annotator variability. However, the variance of annotators using the more comprehensive
TrialSieve schema was not higher than SMEs [
14] using other previous PICO frameworks. The ability to use non-subject matter experts, such as the undergraduate student annotators of the present study, is one way to increase scalability [
18].
The annotator survey study found that annotation aids, including the use of motivational aids, relationship trees, and problem-solving sessions, were helpful in increasing non-subject matter expert annotator success. Interestingly, external motivation, such as internal “annotator of the month awards”, were significantly (p < 0.05) helpful in increasing morale, productivity, and confidence in accuracy.
4.4. Limitations
The TrialSieve dataset annotations were performed by undergraduate students who came from multiple academic disciplines. While all annotators in this study were screened and given thorough training and support to effectively complete the task, there is still disagreement in some annotations that lead to noise in the final dataset.
Additionally, the data consisted of annotated abstracts of scientific articles. Although substantial data are contained in abstracts, some of the elements, particularly quantitative results, are more fully described in the full text of research articles. Future work addressing biomedical information extraction and annotation of full-text articles could provide a more complete picture of the outcomes of each article.
4.5. Broader Impacts and Future Directions
While fully automating data extraction for clinical meta-analysis remains a challenge, the
TrialSieve framework combined with the state of the NLP or LLM models represents foundational progress. Notably, despite the noisiness of annotated data, BERT-based models trained on such data consistently outperformed most human annotators. The proposed annotation schema can facilitate analyses of various drug-disease, drug-drug, drug-therapy, drug-population, and drug-behavior interactions, positioning
TrialSieve as a valuable resource for streamlining frontend clinical research and workflows [
40]. Future work should focus on broader testing and implementation, evaluation of relationship extraction, and deploying methods that enable zero-shot annotation by LLMs with accuracies that approach supervised NLP models. Additionally, further evaluation of noise by intentional "poisoning" of annotations to evaluate machine learning defenses will be important for analyzing and improving the robustness and accuracy of automated annotation models despite inevitable human-generated data noise [
41].
5. Conclusions
TrialSieve introduces a novel biomedical information extraction framework that extends beyond the traditional PICO approach by structuring annotated spans into hierarchical treatment group-based graphs, enabling quantitative outcome comparisons across regimens. TrialSieve was used to annotate 1609 PubMed abstracts with 20 unique entity types relevant to systematic reviews. This publicly available TrialSieve dataset provides an important data resource for biomedical entity recognition projects and related annotation models. The NLP BERT-based models (BioLinkBERT, BioBERT, KRISSBERT, PubMedBERT) and GPT-4o LLM evaluations use TrialSieve as a benchmark to demonstrate that state-of-the-art sequence tagging models can outperform human annotators. Study findings highlight the potential for the TrialSieve framework to improve automated biomedical information extraction that expedites frontend clinical research and streamlines workflows.
Author Contributions
Conceptualization, D.K., H.T. and C.S.M.; methodology, D.K., H.T., C.Y., I.A.-H., B.N., J.D., C.C., H.C., E.L.D., C.J., C.E.S., S.Y.T., S.R. and C.S.M.; software, D.K., C.Y., I.A.-H., B.N., A.J.B.L., J.D. and S.R.; validation, D.K., H.T., C.Y., I.A.-H., B.N., J.D., C.C., H.C., E.L.D., C.J., C.E.S., S.Y.T., S.R. and C.S.M.; formal analysis, D.K., H.T., C.Y. and C.S.M.; investigation, D.K., H.T. and C.S.M.; resources, C.S.M.; data curation and quality control, D.K., H.T., C.Y., C.C., H.C., E.L.D., C.J., C.E.S. and S.Y.T.; writing—original draft preparation, D.K., H.T., C.Y. and C.S.M.; writing—review and editing, C.Y., B.N., A.J.B.L. and C.S.M.; visualization, D.K. and H.T.; supervision, D.K., H.T. and C.S.M.; project administration, C.S.M.; funding acquisition, C.S.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science Foundation CAREER grant 1944247 to C.S.M., the National Institute of Health grant R35GM152245 to C.S.M. and sub-awards from U19AG056169 and R01AG070937 to C.S.M., the Chan Zuckerberg Foundation grant 253558 to C.S.M., the Morningside Center for Innovative and Affordable Medicine at Emory University via the Brown Innovation to Market Fund to C.M.
Institutional Review Board Statement
The annotation user study was conducted in accordance with the Declaration of Helsinki and approved by the Institutional Review Board of Georgia Institute of Technology (protocol H23399, 31 January 2024).
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
The authors would like to thank Michael Lowe, who is a clinician at the Morningside Center for Innovative and Affordable Healthcare at Emory University, for his review and feedback on TrialSieve. Additionally, the authors sincerely acknowledge the invaluable contributions of the following annotators, whose efforts were instrumental in supporting this research: Jiwon Ahn, Jessica Allibone, Shaquille D. Ancrum, Charles H. Anderson, William T. Anong, Natalie Arokiasamy, Joanna Arulraj, Jackson A. Banks, Taylor A. Baugher, Anna L. Butler, Aishwarya E. Chakravarthy, Eric L. Chang, Jelena S. Clementraj Prema, Yllona M. Coronado, Ivy Y. Diamond, Vania M. Dominick, Emma R Downey, Mert Duezguen, Pranjal Gehlot, Jadyn C. Hill, Pranitha S. Kaza, Jennifer M. Kim, Rahav Kothuri, Fabio G. La Pietra, Victory A. Ladipo, Kavya Laghate, Afeni S. Laws, Tabitha M. Lee, Cici Liang, Dawei Liu, Mari Cagle L. Lockhart, Melissa J. Lucht, Donovan X. Mack, Abigail G. Martin, Henry M. Mastrion, Cecilia M. Mateo, Vaibhav Mishra, Anam R. Muhammad, Daniel F. Ng, Lu Niu, Jeonghoon Park, Kabir S. Patel, Marco A. Piazzi, Nola E. Pickering, Jivitesh Praveen, Caitlin R. Ramiscal, Aditi D. Rao, Vaughn Roverse, Kayden N. Shuster, Ashika Srivastava, Randal E. Tart, Sophia W. Tran, Steven Z. Vacha, Stephanie D. Vagelos, Juan A. Vasquez Grimaldo, Kuancheng Wang, Elaine C. Wang, Terry D. Winters, Jifei Xiao, Colton S. Yee, Arda Yigitkanli, Moises H. Zendejas, Benjamin D. Zhao.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| PICO | Patient Intervention Comparator Outcome |
| NLP | Natural-Language Processing |
| BioNER | Biomedical Named Entity Recognition |
| BERT | Bidirectional Encoder Representations from Transformers |
| DPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open-access journals |
Appendix A
Table A1.
Insignificant findings from the annotator user study. An anonymous survey was deployed to examine annotator opinions on motivational aids, the use of relationship tress, and team annotation sessions. A total of 38 of the 72 annotators in the study completed the voluntary survey. A standard 1 to 5 Likert scale was utilized where one was “strongly agree” and 5 was “strongly disagree”. Mean, standard deviation (SD), and
p-value is shown. Significance/insignificance was based on a standard alpha of 0.05. Remaining survey questions (with significant
p-value) are shown in
Table 6.
Table A1.
Insignificant findings from the annotator user study. An anonymous survey was deployed to examine annotator opinions on motivational aids, the use of relationship tress, and team annotation sessions. A total of 38 of the 72 annotators in the study completed the voluntary survey. A standard 1 to 5 Likert scale was utilized where one was “strongly agree” and 5 was “strongly disagree”. Mean, standard deviation (SD), and
p-value is shown. Significance/insignificance was based on a standard alpha of 0.05. Remaining survey questions (with significant
p-value) are shown in
Table 6.
| Aid | Survey Question | Mean | SD | |
|---|
| Motivational Aids | The “Curator of the Month” award was not something I considered when I made annotations | 3.059 | 1.301 | 0.602 |
| My grade for this course was not something I thought about when I made annotations | 2.882 | 1.320 | 0.303 |
| I did not think about potential team promotions when I made my annotations | 2.806 | 1.238 | 0.176 |
| Technical issues with the curation software were not something that affected my accuracy | 3.250 | 1.180 | 0.893 |
| Relationship Trees | I found that using relationship trees made it more difficult for me to label text | 3.750 | 1.016 | 0.999 |
| Relationship trees have added stress for me when labeling texts | 3.114 | 1.132 | 0.723 |
| Team Sessions | I felt that the written dictionary/annotation guides were just as effective as the in-person/virtual sessions | 3.000 | 1.163 | 0.500 |
| I believe the in-person/virtual sessions helped me make less errors | 3.235 | 1.161 | 0.872 |
References
- Hobbs, J.R. Information extraction from biomedical text. J. Biomed. Inform. 2002, 35, 260–264. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, L.; Rastegar-Mojarad, M.; Moon, S.; Shen, F.; Afzal, N.; Liu, S.; Zeng, Y.; Mehrabi, S.; Sohn, S.; et al. Clinical information extraction applications: A literature review. J. Biomed. Inform. 2018, 77, 34–49. [Google Scholar] [CrossRef] [PubMed]
- Prasad, V.; Mailankody, S. Research and development spending to bring a single cancer drug to market and revenues after approval. JAMA Intern. Med. 2017, 177, 1569–1575. [Google Scholar] [CrossRef] [PubMed]
- Wouters, O.J.; McKee, M.; Luyten, J. Estimated research and development investment needed to bring a new medicine to market, 2009–2018. JAMA 2020, 323, 844–853. [Google Scholar] [CrossRef]
- Chong, C.R.; Sullivan, D.J., Jr. New uses for old drugs. Nature 2007, 448, 645–646. [Google Scholar] [CrossRef]
- Bakowski, M.A.; Beutler, N.; Wolff, K.C.; Kirkpatrick, M.G.; Chen, E.; Nguyen, T.T.H.; Riva, L.; Shaabani, N.; Parren, M.; Ricketts, J.; et al. Drug repurposing screens identify chemical entities for the development of COVID-19 interventions. Nat. Commun. 2021, 12, 3309. [Google Scholar] [CrossRef]
- Masoudi-Sobhanzadeh, Y.; Omidi, Y.; Amanlou, M.; Masoudi-Nejad, A. Drug databases and their contributions to drug repurposing. Genomics 2020, 112, 1087–1095. [Google Scholar] [CrossRef]
- Ashburn, T.T.; Thor, K.B. Drug repositioning: Identifying and developing new uses for existing drugs. Nat. Rev. Drug Discov. 2004, 3, 673–683. [Google Scholar] [CrossRef]
- Kim, H.; Kang, J. How do your biomedical named entity recognition models generalize to novel entities? IEEE Access 2022, 10, 31513–31523. [Google Scholar] [CrossRef]
- Schiavenato, M.; Chu, F. PICO: What it is and what it is not. Nurse Educ. Pract. 2021, 56, 103194. [Google Scholar] [CrossRef]
- Muka, T.; Glisic, M.; Milic, J.; Verhoog, S.; Bohlius, J.; Bramer, W.; Chowdhury, R.; Franco, O.H. A 24-step guide on how to design, conduct, and successfully publish a systematic review and meta-analysis in medical research. Eur. J. Epidemiol. 2020, 35, 49–60. [Google Scholar] [CrossRef] [PubMed]
- Borah, R.; Brown, A.W.; Capers, P.L.; Kaiser, K.A. Analysis of the time and workers needed to conduct systematic reviews of medical interventions using data from the PROSPERO registry. BMJ Open 2017, 7, e012545. [Google Scholar] [CrossRef] [PubMed]
- Al-Hussaini, I.; Nakajima An, D.; Lee, A.J.; Bi, S.; Mitchell, C.S. CCS Explorer: Relevance Prediction, Extractive Summarization, and Named Entity Recognition from Clinical Cohort Studies. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 5173–5181. [Google Scholar] [CrossRef]
- Kartchner, D.; Ramalingam, S.; Al-Hussaini, I.; Kronick, O.; Mitchell, C. Zero-Shot Information Extraction for Clinical Meta-Analysis using Large Language Models. In Proceedings of the the 22nd Workshop on Biomedical Natural Language Processing and BioNLP Shared Tasks, Toronto, ON, Canada, 13 July 2023; pp. 396–405. [Google Scholar] [CrossRef]
- Nye, B.; Li, J.J.; Patel, R.; Yang, Y.; Marshall, I.; Nenkova, A.; Wallace, B. A Corpus with Multi-Level Annotations of Patients, Interventions and Outcomes to Support Language Processing for Medical Literature. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 197–207. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. arXiv 2020, arXiv:2007.15779. [Google Scholar] [CrossRef]
- Mitchell, C.S.; Cates, A.; Kim, R.B.; Hollinger, S.K. Undergraduate biocuration: Developing tomorrow’s researchers while mining today’s data. J. Undergrad. Neurosci. Educ. 2015, 14, A56–A65. [Google Scholar]
- Artstein, R. Inter-annotator Agreement. In Handbook of Linguistic Annotation; Springer: Dordrecht, The Netherlands, 2017; pp. 297–313. [Google Scholar]
- Newman-Griffis, D.; Lehman, J.F.; Rosé, C.; Hochheiser, H. Translational NLP: A New Paradigm and General Principles for Natural Language Processing Research. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 4125–4138. [Google Scholar] [CrossRef]
- Sanchez-Graillet, O.; Witte, C.; Grimm, F.; Cimiano, P. An annotated corpus of clinical trial publications supporting schema-based relational information extraction. J. Biomed. Semant. 2022, 13, 14. [Google Scholar] [CrossRef]
- Kartchner, D.; Al-Hussaini, I.; Haydn, T.; Deng, J.; Lohiya, S.; Bathala, P.; Mitchell, C. BioSift: A Dataset for Filtering Biomedical Abstracts for Drug Repurposing and Clinical Meta-Analysis. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), Taipei, Taiwan, 23–27 July 2023. [Google Scholar]
- Perry, T. LightTag: Text Annotation Platform. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 20–27. [Google Scholar] [CrossRef]
- Collins, L.M. Research Design and Methods. In Encyclopedia of Gerontology; Elsevier: Amsterdam, The Netherlands, 2007; pp. 433–442. [Google Scholar]
- Lee, G.E.; Sun, A. A Study on Agreement in PICO Span Annotations. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, New York, NY, USA, 21–25 July 2019; SIGIR’19; pp. 1149–1152. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Gabryelewicz, A.; Czajkowski, A.; Skrodzka, D.; Marlicz, K.; Luca de Tena, F.; Aldeguer, M.; Chantar, C.; Márquez, M.; Torres, J.; Ortiz, J. Comparison of the efficacy and safety of ebrotidine in the treatment of duodenal ulcer. A multicentre, double-blind, placebo-controlled phase II study. Arzneimittel-Forschung 1997, 47, 545–550. [Google Scholar]
- Langer, H.; Lungen, H.; Bayerl, P.S. Text Type Structure and Logical Document Structure. In Proceedings of the Workshop on Discourse Annotation, Barcelona, Spain, 25–26 July 2004; pp. 49–56. [Google Scholar]
- Garcia-Retamero, R.; Hoffrage, U. Visual representation of statistical information improves diagnostic inferences in doctors and their patients. Soc. Sci. Med. 2013, 83, 27–33. [Google Scholar] [CrossRef]
- Hu, Y.; Keloth, V.K.; Raja, K.; Chen, Y.; Xu, H. Towards precise PICO extraction from abstracts of randomized controlled trials using a section-specific learning approach. Bioinformatics 2023, 39, btad542. [Google Scholar] [CrossRef]
- Ge, T.; Luo, X.; Wang, Y.; Sedlmair, M.; Cheng, Z.; Zhao, Y.; Liu, X.; Deussen, O.; Chen, B. Optimally ordered orthogonal neighbor joining trees for hierarchical cluster analysis. IEEE Trans. Vis. Comput. Graph. 2024, 30, 5034–5046. [Google Scholar] [CrossRef] [PubMed]
- Woloshin, S.; Yang, Y.; Fischhoff, B. Communicating health information with visual displays. Nat. Med. 2023, 29, 1085–1091. [Google Scholar] [CrossRef] [PubMed]
- Finson, K.; Pederson, J. What are Visual Data and What Utility do they have in Science Education? J. Vis. Lit. 2011, 30, 66–85. [Google Scholar] [CrossRef]
- Arain, S.A.; Afsar, N.A.; Rohra, D.K.; Zafar, M. Learning clinical skills through audiovisual aids embedded in electronic-PBL sessions in undergraduate medical curriculum: Perception and performance. Adv. Physiol. Educ. 2019, 43, 378–382. [Google Scholar] [CrossRef]
- Naqvi, S.H.; Mobasher, F.; Afzal, M.A.R.; Umair, M.; Kohli, A.N.; Bukhari, M.H. Effectiveness of teaching methods in a medical institute: Perceptions of medical students to teaching aids. J. Pak. Med. Assoc. 2013, 63, 859–864. [Google Scholar]
- Kiritchenko, S.; De Bruijn, B.; Carini, S.; Martin, J.; Sim, I. ExaCT: Automatic extraction of clinical trial characteristics from journal publications. BMC Med. Inform. Decis. Mak. 2010, 10, 56. [Google Scholar] [CrossRef]
- Summerscales, R.L.; Argamon, S.; Bai, S.; Hupert, J.; Schwartz, A. Automatic summarization of results from clinical trials. In Proceedings of the 2011 IEEE International Conference on Bioinformatics and Biomedicine, Washington, DC, USA, 12–15 November 2011; pp. 372–377. [Google Scholar]
- Wallace, B.C.; Kuiper, J.; Sharma, A.; Zhu, M.; Marshall, I.J. Extracting PICO sentences from clinical trial reports using supervised distant supervision. J. Mach. Learn. Res. 2016, 17, 4572–4596. [Google Scholar]
- Mutinda, F.; Liew, K.; Yada, S.; Wakamiya, S.; Aramaki, E. PICO Corpus: A Publicly Available Corpus to Support Automatic Data Extraction from Biomedical Literature. In Proceedings of the First Workshop on Information Extraction from Scientific Publications, Online, November 2022; pp. 26–31. [Google Scholar]
- Nia, A.M.; Mozaffari-Kermani, M.; Sur-Kolay, S.; Raghunathan, A.; Jha, N.K. Energy-Efficient Long-term Continuous Personal Health Monitoring. IEEE Trans.-Multi-Scale Comput. Syst. 2015, 1, 85–98. [Google Scholar] [CrossRef]
- Mozaffari-Kermani, M.; Sur-Kolay, S.; Raghunathan, A.; Jha, N.K. Systematic Poisoning Attacks on and Defenses for Machine Learning in Healthcare. IEEE J. Biomed. Health Inform. 2015, 19, 1893–1905. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}