
Leveraging Artificial Intelligence and Machine Learning for Characterizing Protein Corona, Nanobiological Interactions, and Advancing Drug Discovery


Abstract
1. Introduction
1.1. Understanding Protein Functions
1.2. Exploring Nanobio Interactions: The Essential Role of Nanoinformatics
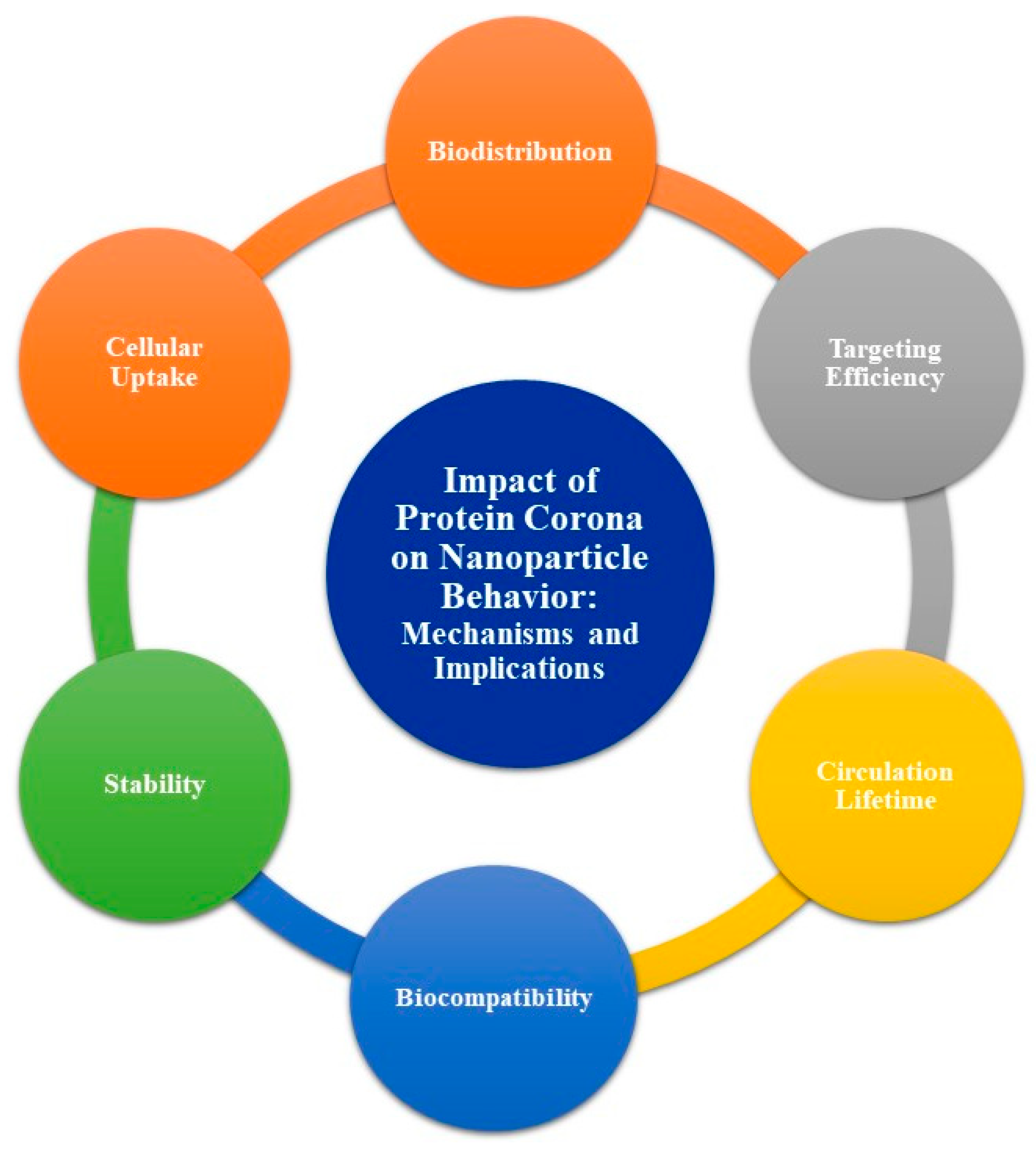
- Biodistribution: The protein corona can alter the distribution of NPs within the body, influencing their travel and accumulation in various tissues and organs.
- Cellular uptake: The composition and structure of the protein corona can affect how cells recognize and internalize NPs, impacting their efficacy in drug delivery and other therapeutic applications.
- Stability: The protein corona may enhance or reduce the stability of NPs in biological environments, affecting their aggregation and solubility.
- Biocompatibility: The presence of a protein corona can modify the immune response to NPs, potentially increasing or decreasing their immunogenicity and toxicity.
- Circulation lifetime: The protein corona may influence the circulation time of NPs in the bloodstream, affecting their ability to reach target sites before being cleared from the body.
- Targeting efficiency: The protein corona can mask or alter the surface properties of NPs, potentially hindering their ability to bind to specific target cells or tissues.
- Characterize protein corona: The paper illustrates the use of ML models to predict the relative protein abundance (RPA) in the protein corona, which reduces the reliance on traditional experimental techniques and offers insights for designing the protein corona.
- Understand nanobio interactions: It emphasizes the importance of systematically investigating nanobio interactions and the role of nanoinformatics in assessing risks and revealing complex interactions at the nanobio interface.
- Advance nanomedicine and drug discovery: The review discusses how AI and ML can enhance the design and application of NPs in areas such as nanomedicine, biosensing, and organ targeting, and improve drug discovery processes by integrating data from various omics fields.
- Predict PPIs: The paper reviews ML and DL methods for predicting PPIs, highlighting the potential of these techniques to deepen our understanding of protein functions and interactions.
- Address challenges and future directions: It critically examines the advantages and limitations of these approaches, emphasizing the need for comprehensive datasets, advanced learning models, and multimodal data integration to enhance model accuracy and reliability.
2. Evaluating the Literature on the Application of AI and ML Techniques for Characterizing Protein Corona, Nanobio Interactions, Nanomedicines and Drug Discovery, and Protein–Protein Interactions
2.1. Protein Corona Characterization
2.2. Nanobio Interactions
2.3. Nanomedicines and Drug Discovery
2.4. Protein–Protein Interactions
3. Machine-Learning Training Models and Databases in the Field of Protein Interactions, Drug Discovery, and Bioinformatics
4. Opportunities, Limitations, and Challenges in the Application of AI and ML Techniques for Characterizing Protein Corona, Nanobio Interactions, Nanomedicines and Drug Discovery, and Protein–Protein Interactions
5. Conclusions
- Nanotoxicology and nanomaterial research: ML algorithms can effectively predict cell and nuclear shapes and polarity functions as phenotypic markers for diverse categories of NMs, aiding in understanding NM interactions with biological systems. Establishing standardized protocols and interdisciplinary collaboration is crucial for advancing nanotoxicology research.
- Protein corona prediction: ML models can predict the RPA of multiple proteins on the protein corona, reducing the need for traditional experimental techniques. The key attributes associated with RPA analysis have been identified, providing insights for protein corona design. Future improvements should focus on integrating more comprehensive datasets and advanced ML techniques.
- Nanomedicine and drug discovery: ML and AI significantly enhance the design and application of NPs in nanomedicine, biosensing, and organ targeting. Combining data from various omics fields can provide a comprehensive understanding of NM interactions. Real-world validation of ML models is essential to ensure their accuracy and reliability in practical applications.
- Protein function prediction: DL methods have improved protein function prediction, but challenges remain in integrating multiple data modalities and predicting rare or novel functions. Collaboration among the ML, AI, and bioinformatics fields is necessary to develop cutting-edge techniques for predicting protein functions.
- Nanobio interactions and nanoinformatics: Systematic exploration of the physicochemical properties of NPs and their interactions with biological systems is needed. High-throughput synthesis and testing methods, combined with advanced computational models, can accelerate the comprehension of nanobio interactions. Effective data management and sharing protocols are essential for handling large datasets.
- Environmental risk assessment: ML can enhance ERA by improving data gathering, exposure assessment, hazard identification, and risk characterization. The development of comprehensive strategies and standard controls for ML in the ERA is crucial for ensuring accuracy and reliability.
- Drug discovery and development: AI has the potential to greatly reduce both the time and expenses associated with drug discovery by automating and optimizing various stages of the process. AI-driven predictive modeling and simulation can enable virtual testing of drug candidates, accelerating the drug development process. Ethical and regulatory frameworks are needed to promote the ethical application of AI in drug discovery.
- Protein–protein interactions: ML models can predict PPIs with increased accuracy by integrating multiple data sources and leveraging advanced computational techniques. Moving beyond interaction prediction to understand the functional and contextual relevance of PPIs is a significant advancement. Combining sequence features, docking scoring functions, and protein binding site predictions can increase the accuracy of AI models.
- Explainable AI: Explainability is crucial for the adoption of ML as a scientific tool, ensuring reliability and interpretability. Ontologies and knowledge graphs can improve the interpretability of ML applications in the biomedical domain. The development of scalable methods to handle large datasets and complex knowledge graphs efficiently is essential.
- Deep learning for PPI analysis: DL presents a transformative platform for predicting PPIs, significantly advancing our understanding of protein interactions and biological systems. Addressing challenges such as data quality, model interpretability, and the integration of diverse data sources is crucial for further advancements. The application of DL models to interdisciplinary domains, such as drug discovery and personalized medicine, holds significant potential.
6. Future Perspectives
- Nanotoxicology and nanomaterial research: Enhance ML algorithms for better prediction of NM–cell interactions; include diverse cell types and models to study NM effects; standardize the protocols for reporting NM interactions with biological systems; address the need for standardized nanodescriptors in ML models to accurately predict the behavior of NPs; and foster collaboration among material scientists, biologists, toxicologists, and computational experts.
- Protein corona prediction: Enhance feature representation by extracting additional protein-related features; create generalized models using comprehensive datasets and advanced ML techniques; investigate advanced neural network architectures to prevent overfitting and increase performance; build integrated models for efficient classification and regression; and prioritize interpretable ML methods for better decision-making transparency.
- Nanomedicine and drug discovery: Combine data from genomics, proteomics, and metabolomics for a comprehensive understanding of NM interactions; optimize computational models such as PCRO-RLRM for enhanced predictive performance; develop advanced DL and AI techniques to integrate diverse input data; use evolutionary data from protein sequences to enhance function prediction; create next-generation LLMPs tailored for multimodal data and function prediction; and foster collaboration among ML, AI, and bioinformatics for innovative protein function prediction methods.
- Nanobio interactions and nanoinformatics: Explore the physicochemical properties of NPs and their biological interactions; use combinatorial chemistry and high-throughput methods to create diverse datasets; develop computational models to predict NP biological effects; accelerate data generation on nanobio interactions through high-throughput synthesis and testing; and enhance data management and sharing for the effective handling of large datasets.
- Environmental risk assessment: Develop strategies to implement ML in ERA, focusing on data foundations and methodologies; standardize and validate ML models for accuracy and reliability; integrate ML with the IoT for real-time environmental monitoring; and target complex data areas, such as spatial–temporal analysis and omics.
- Drug discovery and development: AI will increase the efficiency and accuracy of drug design, leading to the discovery of new therapeutic compounds; it will aid in customized healthcare through the examination of individual patient data for tailored treatments; AI will integrate omics data for a thorough comprehension of disease mechanisms and drug responses; AI-driven predictive modeling and simulations will allow virtual testing of drug candidates, reducing the need for extensive experiments; clinical trials will be optimized through better patient selection, outcome prediction, and real-time monitoring; AI will facilitate drug repurposing by finding new uses for existing medications; quantum computing will significantly advance AI’s role in drug discovery; and it is essential to develop ethical and regulatory frameworks for responsible AI use in this field.
- Protein–protein interactions: Develop ML algorithms, including DL, to improve PPI prediction accuracy; integrate atomic resolution structures with proteome-wide interaction networks for comprehensive predictions; increase the representation of protein sequences and structures for ML models; improve the computational efficiency of ML models for broader access to advanced techniques; and focus on the functional and contextual relevance of PPIs in various cellular environments.
- Explainable AI: Developing scalable methods for large datasets and complex knowledge graphs; improving feature extraction and selection from diverse data sources; enhancing model transparency via attention mechanisms and saliency maps; and applying DL models in drug discovery, personalized medicine, and environmental genomics.
- Deep learning for PPI analysis: Refine fold-and-dock algorithms for better protein pair structure predictions; integrate sequence features, docking scores, and protein binding site predictions into AI models; use advanced computing resources for training AI on larger datasets; and apply AI models in drug discovery to identify targets and design therapies.
- General future directions: Create centralized databases for data sharing and collaboration; implement real-time monitoring of nanomedicine performance; focus on developing safe, sustainable nanomaterials; conduct in vivo studies to understand protein corona dynamics; use AI and ML to analyze nanobio interaction data; and develop in silico models to predict nanobio interactions.
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| BindingDB | Binding Database |
| BioGRID | Biological General Repository for Interaction Datasets |
| BioLiP | Biologically Relevant Ligand–Protein Binding Interactions Database |
| BSA | Bovine Serum Albumin |
| CAFA | Critical Assessment of Protein Function Annotation |
| ChEMBL | Chemogenomic Database |
| CNN | Convolutional Neural Network |
| CNTs | Carbon Nanotubes |
| CSI | Cell Shape Index |
| DFT | Density Functional Theory |
| DIP | Database of Interacting Proteins |
| DL | Deep Learning |
| DNA | Deoxyribonucleic Acid |
| DNNs | Deep Neural Networks |
| DrugBank | Drug and Drug Target Database |
| DWCNTs | Doublewalled Carbon Nanotubes |
| ENMs | Engineered Nanomaterials |
| ERA | Environmental Risk Assessment |
| ERT | Extremely Randomized Tree |
| FAIR | Findable, Accessible, Interoperable, and Reusable |
| GBDT | Gradient-Boosting Decision Tree |
| GLASS | GPCR–Ligand Association |
| GO | Gene Ontology |
| GPCR | G-Protein-Coupled Receptor |
| GPCRdb | G-Protein-Coupled Receptor Database |
| His | Histidine |
| HPRD | Human Protein Reference Database |
| IntAct | Molecular Interaction Database |
| KGsim2vec | Knowledge-Graph-Based Method |
| KNN | K-Nearest Neighbor |
| LigAsite | Ligand Attachment Site Database |
| LightGBM | Light Gradient-Boosting Machine |
| LLMPs | Large Language Models for Proteins |
| MD | Molecular Dynamics |
| ML | Machine Learning |
| MWCNTs | Multiwalled Carbon Nanotubes |
| NAFs | Nuclear Area Factors |
| NBRP | NP Blood Removal Pathways |
| NMs | Nanomaterials |
| NN | Neural Networks |
| NPs | Nanoparticles |
| RPA | Relative Protein Abundance |
| PCRO-RLRM | Polypeptide Chemical Reaction Optimized Resistant Logistic Regression Model |
| PDB | Protein Data Bank |
| PDBbind | Binding Affinity Data for Biomolecular Complexes Deposited in the PDB |
| PepPIs/PPIs | Peptide/Protein–Protein Interactions |
| Phe | Phenylalanine |
| Phos | Phosphorylation |
| PLIs | Protein–Ligand Interactions |
| PSSM | Position-Specific Scoring Matrix |
| PPIs | Protein–Protein Interactions |
| QSAR | Quantitative Structure–Activity Relationship |
| PubChem | Public Chemical Information Resource |
| R2 | Coefficient of Determination |
| RF | Random Forest |
| RNA | Ribonucleic Acid |
| SHAP | SHapley Additive exPlanations |
| SKEMPI | Structural Kinetic and Energetic Database of Mutant Protein Interactions |
| SOM | Self-Organizing Map |
| STRING | Search Tool for the Retrieval of Interacting Genes/Proteins |
| SVM | Support Vector Machine |
| Trp | Tryptophan |
| Tyr | Tyrosine |
| UMOD | Uromodulin |
| UniProt | Universal Protein Resource |
| XGBoost | Extreme Gradient Boosting |
References
- Kessel, A.; Ben-Tal, N. Introduction to Proteins: Structure, Function, and Motion, 2nd ed.; Mathematical and computational biology series; CRC Press; Taylor & Francis Group; Chapman & Hall/CRC: Boca Raton, FL, USA, 2018. [Google Scholar] [CrossRef]
- Casadio, R.; Martelli, P.L.; Savojardo, C. Machine learning solutions for predicting protein–protein interactions. WIREs Comput. Mol. Sci. 2022, 12, e1618. [Google Scholar] [CrossRef]
- Giri, N.; Cheng, J. De novo atomic protein structure modeling for cryoEM density maps using 3D transformer and HMM. Nat. Commun. 2024, 15, 5511. [Google Scholar] [CrossRef] [PubMed]
- Bull, S.C.; Doig, A.J. Properties of protein drug target classes. PLoS ONE 2015, 10, e0117955. [Google Scholar] [CrossRef]
- Santos, R.; Ursu, O.; Gaulton, A.; Bento, A.P.; Donadi, R.S.; Bologa, C.G.; Karlsson, A.; Al-Lazikani, B.; Hersey, A.; Oprea, T.I.; et al. A comprehensive map of molecular drug targets. Nat. Rev. Drug Discov. 2017, 16, 19–34. [Google Scholar] [CrossRef]
- Dhakal, A.; McKay, C.; Tanner, J.J.; Cheng, J. Artificial intelligence in the prediction of protein–ligand interactions: Recent advances and future directions. Brief. Bioinform. 2022, 23, bbab476. [Google Scholar] [CrossRef]
- Balasco, N.; Ruggiero, A.; Smaldone, G.; Pecoraro, G.; Coppola, L.; Pirone, L.; Pedone, E.M.; Esposito, L.; Berisio, R.; Vitagliano, L. Structural studies of KCTD1 and its disease-causing mutant P20S provide insights into the protein function and misfunction. Int. J. Biol. Macromol. 2024, 277, 134390. [Google Scholar] [CrossRef] [PubMed]
- Choi, S.; Lee, Y.; Hwang, J.; Chun, D.; Koo, H.; Lee, Y. Self-cleaving protein linkers with modulated pH-responsiveness: A new platform for selective control of protein drug function. Chem. Eng. J. 2023, 457, 141229. [Google Scholar] [CrossRef]
- Zhang, R.; Wang, M.; Cheng, A.; Yang, Q.; Ou, X.; Sun, D.; Tian, B.; He, Y.; Wu, Z.; Huang, J.; et al. DHAV-1 3C protein promotes viral proliferation by antagonizing type I interferon via upregulating the ANXA2 protein. Int. J. Biol. Macromol. 2025, 291, 139040. [Google Scholar] [CrossRef]
- Boadu, F.; Lee, A.; Cheng, J. Deep learning methods for protein function prediction. Proteomics 2024, 25, e2300471. [Google Scholar] [CrossRef]
- Rao, V.S.; Srinivas, K.; Sujini, G.N.; Kumar, G.S. Protein-protein interaction detection: Methods and analysis. Int. J. Proteom. 2014, 2014, 147648. [Google Scholar] [CrossRef]
- Kopac, T. Protein corona, understanding the nanoparticle–protein interactions and future perspectives: A critical review. Int. J. Biol. Macromol. 2021, 169, 290–301. [Google Scholar] [CrossRef]
- Xu, M.L.; Gao, Y.; Han, X.X. Structure information analysis and relative content determination of protein and chitin from yellow mealworm larvae using Raman spectroscopy. Int. J. Biol. Macromol. 2024, 272, 132787. [Google Scholar] [CrossRef]
- Hou, J.; Wu, T.; Cao, R.; Cheng, J. Protein tertiary structure modeling driven by deep learning and contact distance prediction in CASP13. Proteins Struct. Funct. Bioinf. 2019, 87, 1165–1178. [Google Scholar] [CrossRef] [PubMed]
- Senior, A.W.; Evans, R.; Jumper, J.; Kirkpatrick, J.; Sifre, L.; Green, T.; Qin, C.; Žídek, A.; Nelson, A.W.R.; Bridgland, A.; et al. Protein structure prediction using multiple deep neural networks in the 13th Critical Assessment of Protein Structure Prediction (CASP13). Proteins Struct. Funct. Bioinf. 2019, 87, 1141–1148. [Google Scholar] [CrossRef] [PubMed]
- Baek, M.; DiMaio, F.; Anishchenko, I.; Dauparas, J.; Ovchinnikov, S.; Lee, G.R.; Wang, J.; Cong, Q.; Kinch, L.N.; Schaeffer, R.D.; et al. Accurate prediction of protein structures and interactions using a three-track neural network. Science 2021, 373, 871–876. [Google Scholar] [CrossRef] [PubMed]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly accurate protein structure prediction with alphafold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Le, N.Q.K.; Li, W.; Cao, Y. Sequence-based prediction model of protein crystallization propensity using machine learning and two-level feature selection. Brief. Bioinform. 2023, 24, bbad319. [Google Scholar] [CrossRef]
- Su, Z.; Dhusia, K.; Wu, Y. Encoding the space of protein-protein binding interfaces by artificial intelligence. Comput. Biol. Chem. 2024, 110, 108080. [Google Scholar] [CrossRef]
- Speer, S.L.; Zheng, W.; Jiang, X.; Chu, I.; Guseman, A.J.; Liu, M.; Pielak, G.J.; Li, C. The intracellular environment affects protein–protein interactions. Proc. Natl. Acad. Sci. USA 2021, 118, e2019918118. [Google Scholar] [CrossRef]
- Morris, R.; Black, K.A.; Stollar, E.J. Uncovering protein function: From classification to complexes. Essays Biochem. 2022, 66, 255–285. [Google Scholar] [CrossRef]
- Song, Y.Q.; Xu, Y.; Yang, L.J.; Wang, L.; Jing, S.; Yang, G.J.; Chan, D.S.H.; Wong, C.Y.; Wang, W.; Wong, V.K.W.; et al. Probing the AFF4–CCNT1 protein–protein interaction using a metal–organic conjugate for treating triple-negative breast cancer. Chem. Eng. J. 2024, 496, 153685. [Google Scholar] [CrossRef]
- Yu, X.; Zheng, X.; Yang, B.; Wang, J. Investigating the interaction of CdTe quantum dots with plasma protein transferrin and their interacting consequences at the molecular and cellular level. Int. J. Biol. Macromol. 2021, 185, 434–440. [Google Scholar] [CrossRef]
- Sun, Z.; Cheng, Y.; Wang, Y.; Liu, W.; Jiang, W.; Zhang, G. Protein-inspired hierarchical interactions for constructing healable, recyclable, assembled energetic composites. Chem. Eng. J. 2025, 504, 158965. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, Y.; Gao, C.; Sun, X.; Li, S.; Han, J. Effect of supramolecular chirality on nano-protein/cell interaction: An experimental and computational investigation. Int. J. Biol. Macromol. 2024, 283, 137613. [Google Scholar] [CrossRef]
- Pan, H.; Wu, X.; Han, R.; He, S.; Li, N.; Yan, H.; Chen, X.; Zhu, Z.; Du, Z.; Wang, H.; et al. Nanoparticle-protein interactions: Spectroscopic probing of the adsorption of serum albumin to graphene oxide-gold nanocomplexes surfaces. Int. J. Biol. Macromol. 2025, 284, 138126. [Google Scholar] [CrossRef] [PubMed]
- Jia, Y.; Hou, X.; Wang, Z.; Hu, X. Machine Learning Boosts the Design and Discovery of Nanomaterials. ACS Sustain. Chem. Eng. 2021, 9, 6130–6147. [Google Scholar] [CrossRef]
- Lu, Y.; Aimetti, A.A.; Langer, R.; Gu, Z. Bioresponsive materials. Nat. Rev. Mater. 2016, 1, 16075. [Google Scholar] [CrossRef]
- Stater, E.P.; Sonay, A.Y.; Hart, C.; Grimm, J. The ancillary effects of nanoparticles and their implications for nanomedicine. Nat. Nanotechnol. 2021, 16, 1180–1194. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.; Chen, X.; Gong, J.; Liu, J.; Gong, L.; Yang, Z.; Zhu, Z.; Zhang, Q.; Li, T.; Liang, L.; et al. An elastase nanocomplex with metal cofactors for enhancement of target protein cleavage activity and synergistic antitumor effect. Chem. Eng. J. 2025, 485, 149902. [Google Scholar] [CrossRef]
- Hong, G.; Diao, S.; Antaris, A.L.; Dai, H. Carbon nanomaterials for biological imaging and nanomedicinal therapy. Chem. Rev. 2015, 115, 10816–10906. [Google Scholar] [CrossRef]
- Tao, H.; Wu, T.; Aldeghi, M.; Wu, T.C.; Aspuru-Guzik, A.; Kumacheva, E. Nanoparticle synthesis assisted by machine learning. Nat. Rev. Mater. 2021, 6, 701–716. [Google Scholar] [CrossRef]
- Özdemir, O.; Kopac, T. Recent Progress on the Applications of Nanomaterials and Nano-Characterization Techniques in Endodontics: A Review. Materials 2022, 15, 5109. [Google Scholar] [CrossRef] [PubMed]
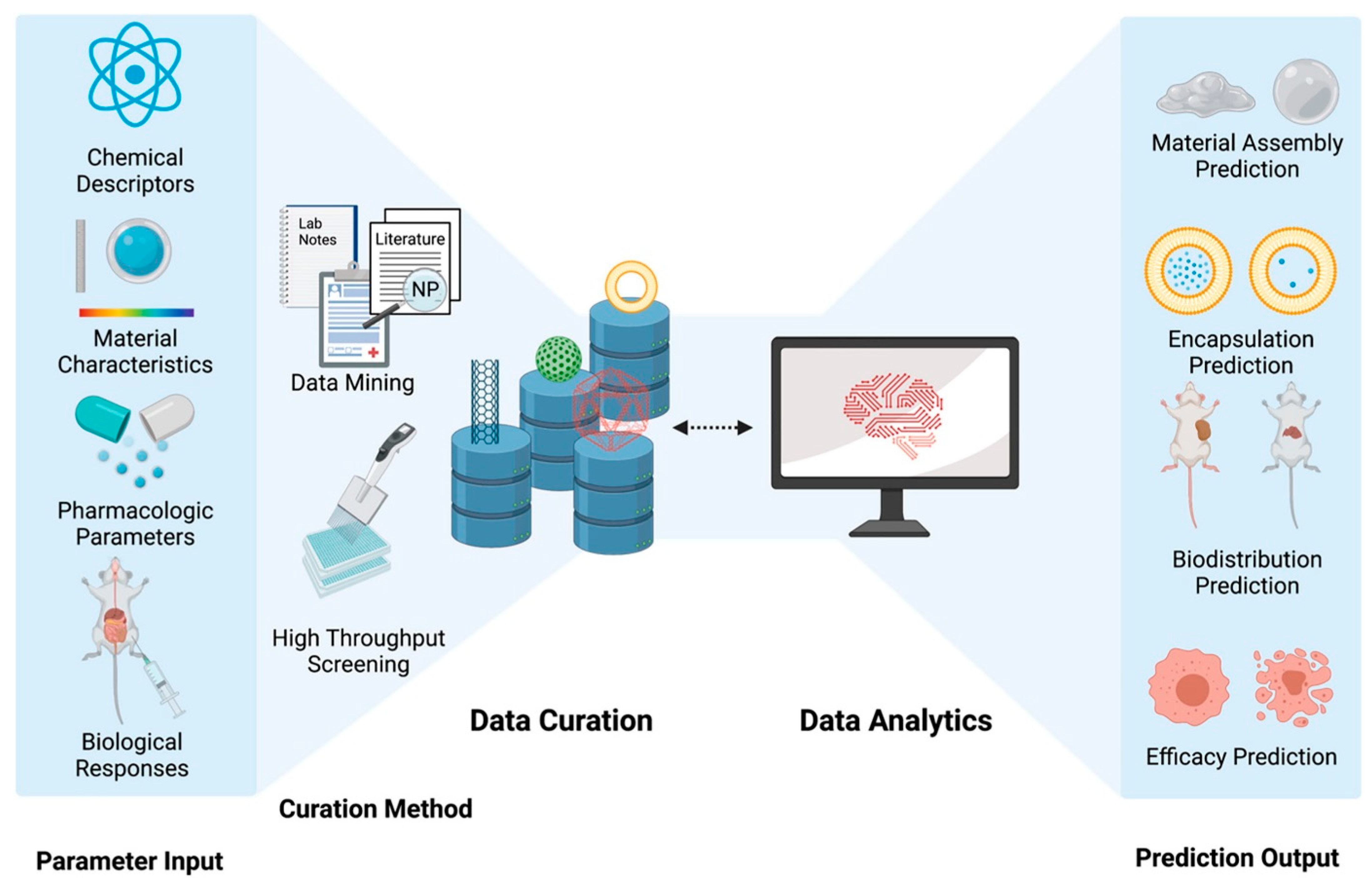
- Chen, C.; Yaari, Z.; Apfelbaum, E.; Grodzinski, P.; Shamay, Y.; Heller, D.A. Merging data curation and machine learning to improve nanomedicines. Adv. Drug Deliv. Rev. 2022, 183, 114172. [Google Scholar] [CrossRef]
- Özdemir, O.; Kopac, T. Cytotoxicity and biocompatibility of root canal sealers: A review on recent studies. J. Appl. Biomater. Functional Mater. 2022, 20, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Özdemir, O.; Kopac, T. Assessment of cytotoxicity and biocompatibility of chitosan nanostructures. In Chitosan-Based Hybrid Nanomaterials; Ali, N., Bilal, M., Khan, A., Nguyen, T.A., Eds.; Elsevier: Amsterdam, The Netherlands, 2024; pp. 375–394. [Google Scholar] [CrossRef]
- Panigrahi, A.R.; Sahu, A.; Yadav, P.; Beura, S.K.; Singh, J.; Mondal, K.; Singh, S.K. Nanoinformatics based insights into the interaction of blood plasma proteins with carbon based nanomaterials: Implications for biomedical applications. In Advances in Protein Chemistry and Structural Biology; Prajapati, V.K., Ed.; Elsevier: Amsterdam, The Netherlands, 2024; Volume 139, pp. 263–288. [Google Scholar] [CrossRef]
- Mishra, R.K.; Ahmad, A.; Vyawahare, A.; Alam, P.; Khan, T.H.; Khan, R. Biological effects of formation of protein corona onto nanoparticles. Int. J. Biol. Macromol. 2021, 175, 1–18. [Google Scholar] [CrossRef]
- Nayak, P.S.; Borah, S.M.; Gogoi, H.; Asthana, S.; Bhatnagar, R.; Jha, A.N.; Jha, S. Lactoferrin adsorption onto silver nanoparticle interface: Implications of corona on protein conformation, nanoparticle cytotoxicity and the formulation adjuvanticity. Chem. Eng. J. 2019, 361, 470–484. [Google Scholar] [CrossRef]
- Yu, Y.; Luan, Y.; Dai, W. Dynamic process, mechanisms, influencing factors and study methods of protein corona formation. Int. J. Biol. Macromol. 2022, 205, 731–739. [Google Scholar] [CrossRef]
- Chen, H.; Ye, D.; Huang, Y.; Luo, X.; Wu, X.; Zhang, J.; Zou, Q.; Wang, H.; Wang, S. Thermo-sensitive amylase-starch double-layer polymer nanoparticles with self-polishing and protein corona-free property for drug delivery applications. Int. J. Biol. Macromol. 2023, 226, 211–219. [Google Scholar] [CrossRef]
- Guo, F.; Luo, S.; Wang, L.; Wang, M.; Wu, F.; Wang, Y.; Jiao, Y.; Du, Y.; Yang, Q.; Yang, X.; et al. Protein corona, influence on drug delivery system and its improvement strategy: A review. Int. J. Biol. Macromol. 2024, 256, 128513. [Google Scholar] [CrossRef]
- Marques, C.; Maroni, P.; Maurizi, L.; Jordan, O.; Borchard, G. Understanding protein-nanoparticle interactions leading to protein corona formation: In vitro—In vivo correlation study. Int. J. Biol. Macromol. 2024, 256, 128339. [Google Scholar] [CrossRef]
- Bozgeyik, K.; Kopac, T. Adsorption of Bovine Serum Albumin onto Metal Oxides: Adsorption Equilibrium and Kinetics onto Alumina and Zirconia. Int. J. Chem. React. Eng. 2010, 8, 1–24. [Google Scholar] [CrossRef]
- Kopac, T.; Kulac, E. Investigation of the interactions and adsorption of ovalbumin with titanium dioxide and zirconia surfaces. J. Fac. Eng. Archit. Gazi Univ. 2017, 32, 489–497. [Google Scholar] [CrossRef]
- Yang, H.; Hao, C.; Nan, Z.; Sun, R. Bovine hemoglobin adsorption onto modified silica nanoparticles: Multi-spectroscopic measurements based on kinetics and protein conformation. Int. J. Biol. Macromol. 2020, 155, 208–215. [Google Scholar] [CrossRef] [PubMed]
- Lan, T.; Shao, Z.Q.; Wang, J.Q.; Gu, M.J. Fabrication of hydroxyapatite nanoparticles decorated cellulose triacetate nanofibers for protein adsorption by coaxial electrospinning. Chem. Eng. J. 2015, 260, 818–825. [Google Scholar] [CrossRef]
- Carvalho, D.T.D.; Santos, M.G.; Hirata, D.B.; Gorup, L.F.; Figueiredo, E.C. Interaction between modified magnetic nanoparticles and human albumin: Kinetics and isotherm studies and application in protein depletion. Int. J. Biol. Macromol. 2024, 280, 135763. [Google Scholar] [CrossRef] [PubMed]
- Bozgeyik, K.; Kopac, T. Adsorption Properties of Arc Produced Multi Walled Carbon Nanotubes for Bovine Serum Albumin. Int. J. Chem. React. Eng. 2016, 14, 549–558. [Google Scholar] [CrossRef]
- Bozgeyik, K.; Kopac, T. Synthesis of Multi-Walled Carbon Nanotube-Zirconia Composite and Bovine Serum Albumin Adsorption Characteristics. Mater. Sci. Forum. 2017, 900, 27–31. [Google Scholar] [CrossRef]
- Kopac, T.; Bozgeyik, K. Equilibrium, Kinetics and Thermodynamics of Bovine Serum Albumin Adsorption on Single-Walled Carbon Nanotubes. Chem. Eng. Commun. 2016, 203, 1198–1206. [Google Scholar] [CrossRef]
- Kopac, T.; Bozgeyik, K.; Flahaut, E. Adsorption and Interactions of the Bovine Serum Albumin-Double Walled Carbon Nanotube System. J. Mol. Liq. 2018, 252, 1–8. [Google Scholar] [CrossRef]
- Kopac, T.; Bozgeyik, K.; Yener, J. Effect of pH and Temperature on the Adsorption of Bovine Serum Albumin onto Titanium Dioxide. Colloids Surf. A Physicochem. Eng. Aspects. 2008, 322, 19–28. [Google Scholar] [CrossRef]
- Kopac, T.; Bozgeyik, K. Effect of Surface Area Enhancement on the Adsorption of Bovine Serum Albumin onto Titanium Dioxide. Colloids Surf. B Biointerfaces 2010, 76, 265–271. [Google Scholar] [CrossRef]
- Saikia, D.; Deka, J.R.; Wu, C.E.; Yang, Y.C.; Kao, H.M. pH responsive selective protein adsorption by carboxylic acid functionalized large pore mesoporous silica nanoparticles SBA-1. Mater. Sci. Eng. C 2019, 94, 344–356. [Google Scholar] [CrossRef]
- Maojo, V.; Martin-Sanchez, F.; Kulikowski, C.; Rodriguez-Paton, A.; Fritts, M. Nanoinformatics and DNA-Based Computing: Catalyzing Nanomedicine. Pediatr. Res. 2010, 67, 481–489. [Google Scholar] [CrossRef]
- Panneerselvam, S.; Choi, S. Nanoinformatics: Emerging databases and available tools. Int. J. Mol. Sci. 2014, 15, 7158–7182. [Google Scholar] [CrossRef] [PubMed]
- Butler, K.T.; Davies, D.W.; Cartwright, H.; Isayev, O.; Walsh, A. Machine learning for molecular and materials science. Nature 2018, 559, 547–555. [Google Scholar] [CrossRef]
- Yan, X.; Zhang, J.; Russo, D.P.; Zhu, H.; Yan, B. Prediction of Nano–Bio Interactions through Convolutional Neural Network Analysis of Nanostructure Images. ACS Sustain. Chem. Eng. 2020, 8, 19096–19104. [Google Scholar] [CrossRef]
- Suwardi, A.; Wang, F.; Xue, K.; Han, M.Y.; Teo, P.; Wang, P.; Wang, S.; Liu, Y.; Ye, E.; Li, Z.; et al. Machine learning-driven biomaterials evolution. Adv. Mater. 2022, 34, 2102703. [Google Scholar] [CrossRef] [PubMed]
- Merchant, A.; Batzner, S.; Schoenholz, S.S.; Aykol, M.; Cheon, G.; Cubuk, E.D. Scaling deep learning for materials discovery. Nature 2023, 624, 80–85. [Google Scholar] [CrossRef]
- Rao, L.; Yuan, Y.; Shen, X.; Yu, G.; Chen, X. Designing nanotheranostics with machine learning. Nat. Nanotechnol. 2024, 19, 1769–1781. [Google Scholar] [CrossRef]
- Baldi, P. Deep Learning in Science, 1st ed.; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Cui, F.; Zhang, Z.; Cao, C.; Zou, Q.; Chen, D.; Su, X. Protein–DNA/RNA interactions: Machine intelligence tools and approaches in the era of artificial intelligence and big data. Proteomics 2022, 22, e2100197. [Google Scholar] [CrossRef]
- Singh, A.V.; Maharjan, R.S.; Kanase, A.; Siewert, K.; Rosenkranz, D.; Singh, R.; Laux, P.; Luch, A. Machine-Learning-Based Approach to Decode the Influence of Nanomaterial Properties on Their Interaction with Cells. ACS Appl. Mater. Interfaces 2021, 13, 1943–1955. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Yang, C.; Su, Y.; Liu, C.; Qiu, H.; Yu, Y.; Su, G.; Zhang, Q.; Wei, L.; Cui, F.; et al. Machine Learning Enables Comprehensive Prediction of the Relative Protein Abundance of Multiple Proteins on the Protein Corona. Research 2024, 7, 0487. [Google Scholar] [CrossRef]
- William, P.; Yogeesh, N.; Lingaraju Chetana, R.; Vasanthakumar, T.N.; Verma, V. Artificial Intelligence Analysis of Protein Compositions on Engineered Nanomaterials. J. Nano-Electron. Phys. 2024, 16, 04037. [Google Scholar] [CrossRef]
- Hirano, A.; Kameda, T. Aromaphilicity Index of Amino Acids: Molecular Dynamics Simulations of the Protein Binding Affinity for Carbon Nanomaterials. ACS Appl. Nano Mater. 2021, 4, 2486–2495. [Google Scholar] [CrossRef]
- Bai, X.; Liu, F.; Liu, Y.; Li, C.; Wang, S.; Zhou, H.; Wang, W.; Zhu, H.; Winkler, D.A.; Yan, B. Toward a systematic exploration of nano-bio interactions. Toxicol. Appl. Pharmacol. 2017, 323, 66–73. [Google Scholar] [CrossRef]
- Wang, L.; Quine, S.; Frickenstein, A.N.; Lee, M.; Yang, W.; Sheth, V.M.; Bourlon, M.D.; He, Y.; Lyu, S.; Garcia-Contreras, L.; et al. Exploring and Analyzing the Systemic Delivery Barriers for Nanoparticles. Adv. Funct. Mater. 2024, 34, 2308446. [Google Scholar] [CrossRef]
- Scott-Fordsmand, J.J.; Amorim, M.J.B. Using Machine Learning to make nanomaterials sustainable. Sci. Total Environ. 2023, 859, 160303. [Google Scholar] [CrossRef]
- Gupta, R.; Srivastava, D.; Sahu, M.; Tiwari, S.; Ambasta, R.K.; Kumar, P. Artificial intelligence to deep learning: Machine intelligence approach for drug discovery. Mol. Divers. 2021, 25, 1315–1360. [Google Scholar] [CrossRef]
- Nguyen, A.T.N.; Nguyen, D.T.N.; Koh, H.Y.; Toskov, J.; MacLean, W.; Xu, A.; Zhang, D.; Webb, G.I.; May, L.T.; Halls, M.L. The application of artificial intelligence to accelerate G protein-coupled receptor drug discovery. Br. J. Pharmacol. 2024, 181, 2371–2384. [Google Scholar] [CrossRef]
- Hong, X.; Lv, J.; Li, Z.; Xiong, Y.; Zhang, J.; Chen, H.F. Sequence-based machine learning method for predicting the effects of phosphorylation on protein-protein interactions. Int. J. Biol. Macromol. 2023, 243, 125233. [Google Scholar] [CrossRef]
- Ye, J.; Li, A.; Zheng, H.; Yang, B.; Lu, Y. Machine Learning Advances in Predicting Peptide/Protein-Protein Interactions Based on Sequence Information for Lead Peptides Discovery. Adv. Biol. 2023, 7, 2200232. [Google Scholar] [CrossRef] [PubMed]
- Sousa, R.T.; Silva, S.; Pesquita, C. Explaining protein–protein interactions with knowledge graph-based semantic similarity. Comput. Biol. Med. 2024, 170, 108076. [Google Scholar] [CrossRef] [PubMed]
- Lee, M. Recent Advances in Deep Learning for Protein-Protein Interaction Analysis: A Comprehensive Review. Molecules 2023, 28, 5169. [Google Scholar] [CrossRef]
- Jovine, L. Using machine learning to study protein–protein interactions: From the uromodulin polymer to egg zona pellucida filaments. Mol. Reprod. Dev. 2021, 88, 686–693. [Google Scholar] [CrossRef] [PubMed]
- Mahmoudi, M. Debugging Nano−Bio Interfaces: Systematic Strategies to Accelerate Clinical Translation of Nanotechnologies. Trends Biotechnol. 2018, 36, 755–769. [Google Scholar] [CrossRef]
- Zhao, J.; Wu, S.; Qin, J.; Shi, D.; Wang, Y. Electrical-Charge-Mediated Cancer Cell Targeting via Protein Corona-Decorated Superparamagnetic Nanoparticles in a Simulated Physiological Environment. ACS Appl. Mater. Interfaces 2018, 10, 41986–41998. [Google Scholar] [CrossRef]
- Lin, Y.; Xu, J.; Lan, H. Tumor-associated macrophages in tumor metastasis:biological roles and clinical therapeutic applications. J. Hematol. Oncol. 2019, 12, 76. [Google Scholar] [CrossRef]
- Deng, Z.; Wu, S.; Wang, Y.; Shi, D. Circulating tumor cell isolation for cancer diagnosis and prognosis. eBioMedicine 2022, 83, 104237. [Google Scholar] [CrossRef]
- Karaca, E.; Prévost, C.; Sacquin-Mora, S. Modeling the Dynamics of Protein–Protein Interfaces. How and Why? Molecules 2022, 27, 1841. [Google Scholar] [CrossRef]
- Livesey, B.J.; Marsh, J.A. The properties of human disease mutations at protein interfaces. PLoS Comput. Biol. 2022, 18, e1009858. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Key Factors | |
|---|---|
| Nanoparticle characteristics | The critical factors influencing NPs include their size, surface chemistry, charge, and shape. |
| Physicochemical properties | The physicochemical properties of NPs include their hydrophilic or hydrophobic characteristics, solubility, and surface functionality. |
| Environmental conditions | The biological environment is influenced by factors such as temperature, pH, and ionic strength. |
| Protein binding affinities | Different proteins have varying affinities for NPs, influencing the composition and stability of the protein corona. |
| Exposure time | The duration of NP exposure to the biological environment affects the dynamic nature of the protein corona. |
| Vroman effect | Initially adsorbed proteins with lower affinity are replaced by higher affinity proteins over time. |
| Protein concentration | The abundance of proteins in the biological medium can impact the formation and composition of the protein corona. |
| Factors | Influence |
|---|---|
| Surface properties | Protein adsorption can change the surface chemistry, charge, and hydrophobicity/hydrophilicity of nanoparticles, affecting their interaction with biological systems. |
| Stability | Protein adsorption can either stabilize or destabilize NPs. It can prevent aggregation by providing a steric barrier or induce aggregation if the proteins cause cross-linking between particles. |
| Biocompatibility | The type and amount of proteins adsorbed can influence the biocompatibility of nanoparticles, potentially reducing or increasing their toxicity and immunogenicity. |
| Cellular uptake | The protein corona formed by adsorbed proteins can affect how NPs are recognized and internalized by cells, impacting their efficiency in drug delivery and other therapeutic applications. |
| Circulation time | Adsorbed proteins can influence the circulation time of NPs in the bloodstream, affecting their ability to reach target sites before being cleared by the body. |
| Targeting and functionality | Protein adsorption can mask or alter the functional groups on the NP surface, potentially interfering with their ability to bind to specific target cells or tissues and perform their intended function. |
| Toxicity | The adsorption of certain proteins can mitigate or exacerbate the toxic effects of NPs, influencing their safety profile in biomedical applications. |
| Overview | Main Findings | References |
|---|---|---|
| Protein Corona Characterization | ||
| The study examines a ML method to decode the relationship between NM properties and cell interactions, focusing on cell shape index and nuclear area. |
| Singh et al. [65] |
| The document is a research article investigating the use of ML to predict the RPA of proteins on the protein corona of NPs, which is vital for their biomedicine applications. |
| Fu et al. [66] |
| The document analyzes protein compositions in ENMs using a novel AI approach called the PCRO-RLRM to predict these compositions. |
| William et al. [67] |
| The document reviews DL methods for protein function prediction, addressing recent advancements, challenges, and future directions. It analyzes the use of various data sources—sequences, structures, and interactions—and categorizes DL techniques into sequence-based, structure-based, interaction-based, and integrative approaches, detailing the models used in each category. |
| Boadu et al. [10] |
| Nanobio Interactions | ||
| The document examines the aromaphilicity index of amino acids and presents MD simulations related to protein binding affinity for carbon NMs, including CNTs and graphene. An “aromaphilicity index” was developed to quantify the affinity of 20 amino acids for aromatic carbon surfaces, aiding in the prediction of protein binding hotspots on NMs, which is crucial for assessing their bioavailability and potential cytotoxicity. |
| Hirano and Kameda [68] |
| The document presents a novel approach for predicting nanobio interactions using convolutional neural networks (CNNs) to analyze nanostructure images. This method simplifies the analysis by transforming nanostructures into images, allowing for direct learning of features without complex calculations. |
| Yan et al. [59] |
| The document examines the role of ML in enhancing the design and discovery of NMs. It notes that traditional methods involve costly experiments, while ML can streamline material testing and enable high-throughput screening. The discussion includes improvements in NM structure design, properties, adsorption, and catalysis, as well as challenges related to nanobiology and the interactions of NMs with biological systems. |
| Jia et al. [27] |
| The document reviews the use of ML in designing nanotheranostics for improved disease management. It highlights the integration of ML with nanotechnology to enhance the development of nanotheranostics, which combines diagnostic and therapeutic functions. This approach offers benefits like improved drug delivery, reduced toxicity, and real-time treatment feedback. |
| Rao et al. [62] |
| The document focuses on the interaction of blood plasma proteins with carbon-based NMs (CBNs) and their implications for biomedical applications. It highlights the growing use of CBNs in drug delivery and diagnostics while addressing challenges in translating lab research to clinical settings due to the complex nanobio interface. This interface involves the formation of a biocorona that affects protein function, cellular interactions, and toxicity. Computational simulations, including MD and DFT, are emphasized as vital tools in understanding these interactions, contributing to the field of nanoinformatics. The document also covers the classification of CBNs by structure and the need for advanced techniques to study nanobio dynamics. It underscores the importance of nanoinformatics in enhancing nanobiotechnology for safe and effective biomedical applications. |
| Panigrahi et al. [37] |
| The article reviews the systematic exploration of nanobio interactions, emphasizing the importance of understanding how NPs’ physicochemical properties affect biological systems. It calls for systematic studies to clarify these interactions, highlighting the limitations of non-systematic approaches and advocating for data-driven AI methods, such as ML, to create predictive models. |
| Bai et al. [69] |
| Nanomedicines and Drug Discovery | ||
| The document reviews the integration of data curation and ML in advancing nanomedicine development. It discusses the challenges and opportunities in this field and emphasizes the need for collaboration between researchers and data scientists to leverage large datasets for predictive analytics. |
| Chen et al. [34] |
| The document analyzes systemic delivery barriers of NPs in nanomedicine, introducing “NP blood removal pathways” (NBRP) and strategies to improve NP. It emphasizes the challenges NPs face due to interactions with the body’s blood clearance mechanisms. |
| Wang et al. [70] |
| The document discusses the use of ML in the environmental risk assessment (ERA) of NMs to promote sustainability. It highlights how ML can improve data collection, exposure assessment, hazard identification, and risk characterization within ERA. The article emphasizes the need for clear strategies and standards to integrate ML, ensuring data reliability, transparency, and traceability. |
| Scott-Fordsmand and Amorim [71] |
| The document discusses the role of AI and DL in transforming drug discovery and development. It highlights challenges in traditional drug design, such as low efficacy, off-target delivery, high costs, and lengthy timelines. Advances in AI and ML have modernized processes like peptide synthesis, virtual screening, toxicity prediction, and pharmacophore modeling. The text traces the evolution from ML to DL and the integration of big data, covering stages of drug development, including drug screening, QSAR modeling, drug repurposing, and predicting physicochemical properties. It also explores AI’s use in de novo drug design, manufacturing, and clinical trial design, particularly for neurodegenerative diseases, emphasizing AI’s potential to enhance efficiency, reduce costs, and improve accuracy in drug discovery. |
| Gupta et al. [72] |
| The document reviews the role of AI in accelerating drug discovery for G-protein-coupled receptors (GPCRs). It highlights AI’s application at various stages of the drug discovery process, from gaining insights into GPCRs to predicting ligand interactions and clinical outcomes. The review emphasizes AI’s benefits, such as increased speed, efficiency, and cost effectiveness, while also addressing challenges like the need for large datasets and complex models. Lastly, it anticipates future advancements in AI that could further revolutionize GPCR drug discovery, focusing on the importance of open-source data, unsupervised learning, interpretable models, and precision medicine. |
| Nguyen et al. [73] |
| The document reviews the role of AI in predicting protein–ligand interactions (PLIs), focusing on its applications in drug discovery. |
| Dhakal et al. [6] |
| Protein–Protein Interactions | ||
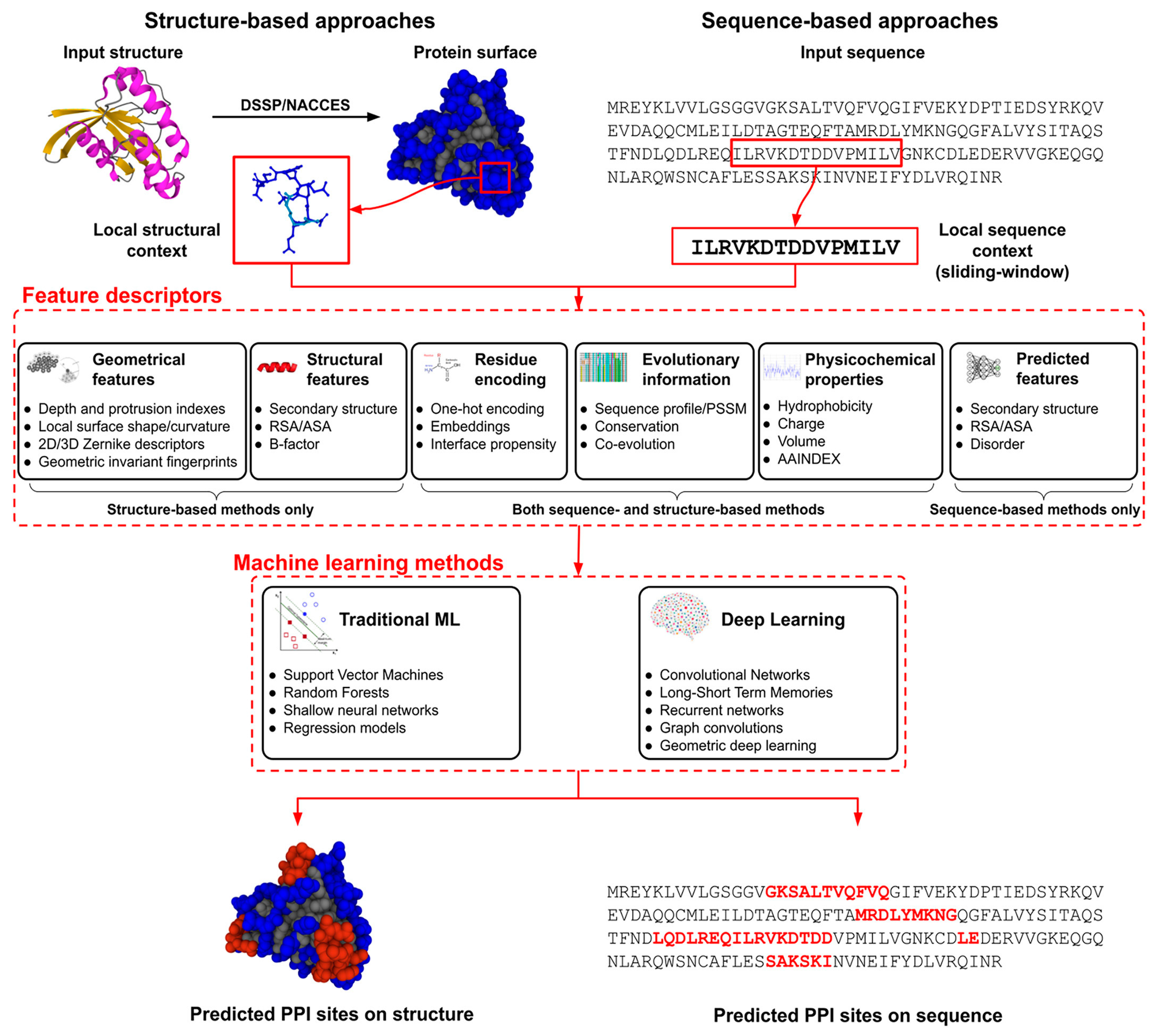
| The document reviews ML solutions for predicting PPIs, emphasizing the importance of proteins in biological processes and biomolecular condensates. It highlights the role of ML, especially DL, in PPI prediction and the need for high-quality training data and effective data representation. The review covers various ML methodologies, including traditional techniques like support vector machines (SVMs) and random forests (RFs), as well as DL approaches like CNNs and GCNs. It also outlines challenges in PPI prediction, such as false positives and the need for more comprehensive datasets. |
| Casadio et al. [2] |
| The article explores the use of AI to characterize PP binding interfaces, aiming to improve the assembly of protein complexes and enhance the predictions of PPIs based on their structural properties. |
| Su et al. [19] |
| The document outlines a sequence-based ML method, PhosPPI, for predicting how phosphorylation affects PPIs and identifies functional phosphorylation sites influencing PPI. It also discusses the role of phosphorylation in diseases like cancer and Alzheimer’s, emphasizing the need for computational methods due to the labor-intensive and costly nature of traditional experimental techniques. |
| Hong et al. [74] |
| The document reviews advancements in ML and DL techniques for predicting PepPIs and PPIs using sequence information. These predictions are crucial for understanding disease mechanisms and drug development. It examines relevant databases, data formats, and feature representations, categorizing ML and DL methods while analyzing their pros and cons. Additionally, it discusses the validation protocols and evaluation metrics for assessing model performance. |
| Ye et al. [75] |
| The document discusses the importance of explainable AI in predicting PPIs using knowledge-graph-based semantic similarity. It introduces KGsim2vec, a novel approach designed to address the limitations of traditional ML models in providing explainability for these predictions. |
| Sousa et al. [76] |
| This document reviews recent advancements in DL techniques for analyzing PPIs from 2021 to 2023. It highlights the impact of DL methods in computational biology, particularly in understanding the PPIs crucial for various biological functions and therapies. |
| Lee [77] |
| The document highlights the use of ML in studying PPIs, focusing on uromodulin (UMOD) activation and polymerization related to egg zona pellucida (ZP) filaments. It examines ML techniques like AlphaFold2 and ColabFold for predicting protein structures and interactions. The findings suggest that these tools can effectively model conformational changes and interactions in protein polymerization, even without prior structural knowledge, demonstrating the potential of ML to elucidate complex biological processes. |
| Jovine [78] |
| The document reviews protein–DNA/RNA interactions using machine intelligence tools, focusing on computational methods for predicting these interactions. It discusses the evolution from traditional ML to DL, outlining the strengths and weaknesses of each approach. The review also covers strategies for digitizing biological sequences and their applications in studying protein–DNA/RNA interactions. |
| Cui et al. [64] |
| Model | Description | Advantages | Limitations |
|---|---|---|---|
| Random Forests (RFs) | RFs are ensemble learning methods that create multiple decision trees during training and output the mode of the classes (classification) or mean prediction (regression) of the individual trees. | Robustness, versatility, and feature importance | Computationally intensive, less interpretable |
| Neural Networks (NNs) | NNs consist of layers of interconnected nodes (neurons) that process input data to predict outputs. They can be shallow (few layers) or deep (many layers). | Flexibility, scalability | Long training time, prone to overfitting, less interpretable |
| Support Vector Machines (SVMs) | SVMs are supervised learning models that find the optimal hyperplane to separate data into different classes. They can handle linear and non-linear classification using kernel functions. | Effective in high-dimensional spaces, flexible with kernels | Not suitable for large datasets; requires careful parameter tuning |
| Extreme Gradient Boosting (XGBoost) | XGBoost is an optimized gradient boosting algorithm that builds an ensemble of decision trees sequentially, where each tree corrects the errors of the previous ones. | High accuracy, fast training, regularization to prevent overfitting | Complex implementation, resource-intensive |
| Database | Description | Applications | URL |
|---|---|---|---|
| IntAct Molecular Interaction Database | A freely accessible, open-source database that provides molecular interaction data curated from the scientific literature. | Researchers can use IntAct to obtain high-quality, experimentally validated PPI data for training ML models. It is particularly useful for creating training sets for supervised learning algorithms. | https://www.ebi.ac.uk/intact (accessed on 8 March 2025). |
| Biological General Repository for Interaction Datasets (BioGRID) | A comprehensive database that archives and disseminates genetic and protein interaction data, including chemical interactions, from model organisms and humans. | Researchers can use BioGRID to construct PPI networks for different organisms, which can be used to identify essential proteins and study disease mechanisms. The extensive interaction data can be used to train machine-learning models for predicting new PPIs. | https://thebiogrid.org/ (accessed on 8 March 2025). |
| Search Tool for the Retrieval of Interacting Genes/Proteins (STRING) | A database of known and predicted PPIs, including functional associations derived from various sources, such as genomic context, high-throughput experiments, co-expression, and text mining. | STRING can be used to analyze functional networks and identify key proteins involved in specific biological processes. The predicted interactions in STRING can be used to augment training datasets for ML models, especially when experimental data are limited. | https://string-db.org/ (accessed on 8 March 2025). |
| Protein Data Bank (PDB) | A repository for the 3D structural data of large biological molecules, such as proteins and nucleic acids. | PDB is essential for researchers focusing on structure-based PPI predictions. It provides atomic-resolution structures that can extract features for ML models. | www.wwpdb.org (accessed on 8 March 2025). http://www.rcsb.org (accessed on 8 March 2025). |
| PDBbind | A comprehensive collection of experimentally measured binding affinity data for biomolecular complexes deposited in the PDB. | Researchers can use PDBbind to obtain binding affinity data, which are crucial for training models predicting PPIs’ strength. | https://www.pdbbind-plus.org.cn/ (accessed on 8 March 2025). |
| Structural Kinetic and Energetic Database of Mutant Protein Interactions (SKEMPI) | Contains data on changes in thermodynamic parameters and kinetic rate constants upon mutation for PPIs. | SKEMPI is useful for studying the effects of mutations on PPIs and for training ML models to predict these effects. | https://life.bsc.es/pid/skempi2 (accessed on 8 March 2025). |
| Human Protein Reference Database (HPRD) | A protein-centric database that provides information on human protein interactions, including the relationships between proteins and diseases; it covers over 30,000 human proteins. | HPRD can be used to study the relationships between proteins and various diseases, aiding in identifying potential therapeutic targets. The curated interaction data can serve as positive samples for training ML models to predict PPIs. | http://www.hprd.org/ https://www.hsls.pitt.edu/obrc/index.php?page=URL1055173331 (accessed on 8 March 2025). |
| Universal Protein Resource (UniProt) | A comprehensive resource for protein sequence and functional information, including reviewed entries in Swiss-Prot and unreviewed entries in TrEMBL, as well as 3D structural data. | Researchers can extract detailed protein information, including sequence, structure, and function, for use as features in ML models. The high-quality, curated data in UniProt can be used to train and validate models for predicting PPIs and PepPIs. | https://www.uniprot.org/ (accessed on 8 March 2025). |
| Database of Interacting Proteins (DIP) | A curated database of experimentally determined PPIs, including interactions from various organisms; it provides a gold standard dataset for PPI studies. | DIP can benchmark the performance of ML models by providing a reliable set of positive and negative interaction samples. The interaction data can train models for predicting PPIs, especially in yeast and other model organisms. | http://dip.doe-mbi.ucla.edu/ (accessed on 9 March 2025). |
| GPCR–Ligand Association (GLASS) | A comprehensive database that contains experimentally validated GPCR–ligand associations. | It is used to train models for predicting GPCR–ligand interactions, which is critical for drug discovery and repurposing programs. The database provides a wealth of information on known GPCR–ligand pairings, helping to identify potential drug candidates. | https://zhanggroup.org/GLASS/ (accessed on 9 March 2025). |
| BindingDB | A public, web-accessible database of measured binding affinities, focusing on the interactions of proteins considered to be drug targets with small, drug-like molecules. | Researchers use BindingDB to train ML models to predict binding affinities and perform virtual screening of potential drug candidates. It is particularly useful for understanding the strength of interactions between ligands and their target proteins. | http://www.bindingdb.org (accessed on 9 March 2025). |
| Drug and Drug Target Database (DrugBank) | A comprehensive resource that combines detailed drug data with comprehensive drug target information. | DrugBank is used for repurposing, understanding drug mechanisms, and predicting off-target effects. It provides a rich dataset for training ML models to predict drug–target interactions and explore drug pharmacological properties. | https://www.drugbank.com/ (accessed on 9 March 2025). |
| A Chemogenomic Database (ChEMBL) | A large-scale bioactivity database containing information on small molecules’ bioactivity and their drug-like properties. | ChEMBL is widely used to train ML models in virtual screening, bioactivity prediction, and de novo drug design. It provides extensive data on the biological activities of compounds, which are essential for developing predictive models. | https://www.ebi.ac.uk/chembl/ (accessed on 9 March 2025). |
| A public chemical information resource (PubChem) | A free chemistry database maintained by the National Center for Biotechnology Information (NCBI), containing deep-learning information on the biological activities of small molecules. | PubChem is used for chemical informatics research, including training ML models to predict chemical properties, bioactivity, and toxicity. It is a valuable resource for researchers exploring the chemical space and identifying potential drug candidates. | http://pubchem.ncbi.nlm.nih.gov/ (accessed on 9 March 2025). |
| G-protein-coupled receptor database (GPCRdb) | A database dedicated to G-protein-coupled receptors, providing information on receptor sequences, structures, and functions. | GPCRdb is used for structural modeling, understanding receptor–ligand interactions, and exploring receptor functions. It supports the development of ML models for predicting GPCR activity and designing receptor-specific drugs. | https://gpcrdb.org/ (accessed on 9 March 2025). |
| Topic | Opportunities | Limitations and Challenges |
|---|---|---|
| Nanotoxicology and nanomaterial research |
|
|
| Protein corona prediction |
|
|
| Nanomedicine and drug discovery |
|
|
| Protein function prediction |
|
|
| Nanobio interactions and nanoinformatics |
|
|
| Environmental risk assessment |
|
|
| Drug discovery and development |
|
|
| Protein–protein interactions |
|
|
| Explainable AI |
|
|
| Deep learning for PPI analysis |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kopac, T. Leveraging Artificial Intelligence and Machine Learning for Characterizing Protein Corona, Nanobiological Interactions, and Advancing Drug Discovery. Bioengineering 2025, 12, 312. https://doi.org/10.3390/bioengineering12030312
Kopac T. Leveraging Artificial Intelligence and Machine Learning for Characterizing Protein Corona, Nanobiological Interactions, and Advancing Drug Discovery. Bioengineering. 2025; 12(3):312. https://doi.org/10.3390/bioengineering12030312
Chicago/Turabian StyleKopac, Turkan. 2025. "Leveraging Artificial Intelligence and Machine Learning for Characterizing Protein Corona, Nanobiological Interactions, and Advancing Drug Discovery" Bioengineering 12, no. 3: 312. https://doi.org/10.3390/bioengineering12030312
APA StyleKopac, T. (2025). Leveraging Artificial Intelligence and Machine Learning for Characterizing Protein Corona, Nanobiological Interactions, and Advancing Drug Discovery. Bioengineering, 12(3), 312. https://doi.org/10.3390/bioengineering12030312