
Genetic Algorithms for Feature Selection in the Classification of COVID-19 Patients

 , , , ,
, , , ,  , and
, and 
Abstract
1. Introduction
2. Methods
- Group 0 (control group): 50 healthy subjects (age = 45 ± 23 years and male/female ratio = 0.47);
- Group 1 (study group): 47 COVID-19-affected subjects (age = 70 ± 15 years and male/female ratio = 1.61) with , a/min. and at 2 h, at 6 h and at 12 h. In addition, the subjects required receiving low-flow oxygen therapy (nasal cannula or face masks) or High-Flow Nasal Cannula (HFNC) only without positive pressure ventilatory support. PPG signals were acquired during the infection period.
2.1. HRV Parameters Extraction
- MEAN RR (ms): mean value of RR time intervals;
- STD RR (ms): standard deviation of RR time intervals;
- RMSSD (ms): root mean square between successive RR time intervals differences;
- NN50 (–): the number of times that successive RR time intervals exceed more than 50 ms;
- pNN50 (%): NN50 divided by the total number of RR time intervals;
- NN20 (–): the number of times that successive RR time intervals exceed more than 20 ms;
- pNN20 (%): NN20 divided by the total number of RR time intervals;
- HRV TRIANGULAR INDEX (–): the integral of the RR interval histogram divided by the height of the histogram;
- VLF Power (ms2): the absolute power spectrum density of the VLF band;
- LF Power (ms2): the absolute power spectrum density of the LF band;
- LF Power (n.u.): the absolute power spectrum of LF band in normalized units. The normalization is defined as LF/(HF + LF);
- HF Power (ms2): the absolute power spectrum density of the HF band;
- HF Power (n.u.): the absolute power spectrum of HF band in normalized units. The normalization is defined as HF/(HF + LF);
- LF/HF Power: the ratio between Low-Frequency Power and High-Frequency Power is sometimes used as a quantitative mirror of the SNS/PNS balance.
- Total Power: total power density spectrum.
- sd1 (ms2): the standard deviation of projection of the Poincarè plot on the line perpendicular to the line of identity;
- sd2 (ms2): the standard deviation of projection of the Poincarè plot on the line of identity;
- sd2/sd1: ration between sd2 and sd1;
- Sample entropy: provides an estimate of the complexity of a numerical series [32].
- Shannon entropy: is a statistical quantifier extensively used to characterize complex processes. It can detect non-linearity aspects in model series, contributing to a more reliable explanation of the nonlinear dynamics of different analysis points [33].
- pV0, pV1, pLV2, pUV2: Porta’s symbolic parameter related to, respectively, patterns with no variations, patterns with one variation, patterns with two like variations, and patterns with two unlike variations [34];
- alpha1, alpha2: respectively, scaling exponent characterizing short-term correlations (range of n: [4–16]) and scaling exponent characterizing long-term correlations (range of n: [16–64]) [35].
2.2. Statistical Analysis
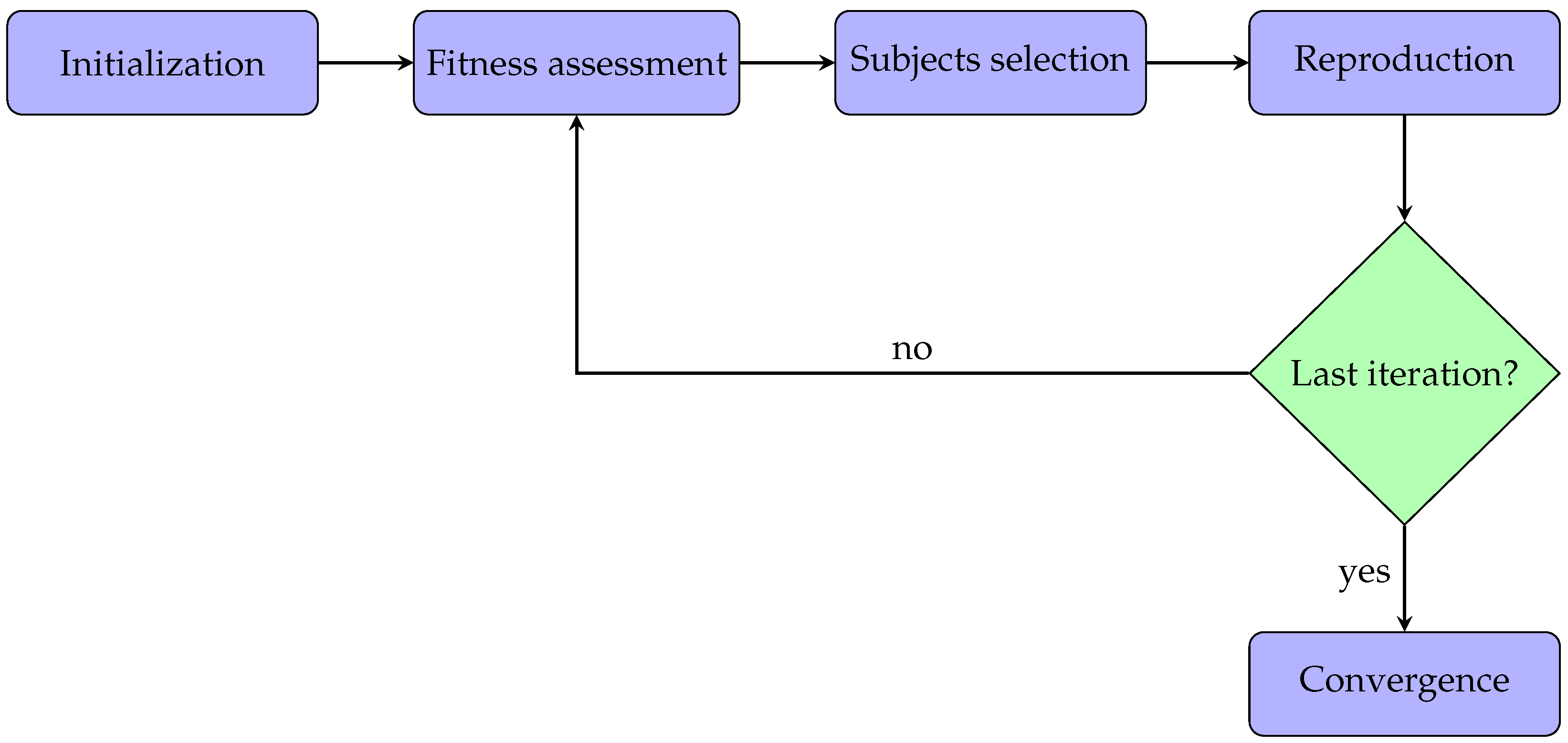
2.3. Genetic Algorithm
- Initialization: the optimization process begins with an initial population. In particular, every subject within the population has some features.
- Fitness assessment: among the available subjects, it is crucial to select the best ones to reproduce offspring, so each subject is associated with a fitness score, meaning the probability of being chosen during the selection phase.
- Subjects selection: at each iteration, two subjects are selected for the reproduction phase. The idea is to combine the parents’ features to create a new offspring subject.
- Reproduction: generation of offspring subjects usually occurs in two ways, i.e., crossover (mixing the parents’ features) and mutation (applying random features changing).
- Convergence: when there is no improvement in the quality of the solution or after completing a previously established number of iterations, the algorithm is stopped.
2.3.1. Initialization
2.3.2. Fitness Assessment
- Features transfer: if the subject being evaluated possessed only certain specific features, the initial dataset consisting of 97 subjects was processed in such a way that each subject within it contained only these features;
- Accuracy evaluation: the accuracy of different machine learning classifiers in discriminating between the two classes (Group 0 and 1), once trained with those features only, was assessed.
2.3.3. Selection Phase
- Two-random-subjects selection method: within the population, two subjects, and , are chosen randomly. They generate two new subjects, and , that take the place of and within the population, so that the total number of individuals remains equal to N; then, the cycle starts again. This method is the least robust because the individuals are randomly chosen and not fitness-based chosen.
- Five-subjects tournament selection method: within the population, five subjects are selected randomly and sorted in ascending order, concerning the fitness value. Then, the first two, in terms of fitness, are selected, and two new subjects are created. This procedure is repeated until a new population consisting exclusively of new subjects of the same size as the starting population has been created; then, the cycle starts again.
- Roulette wheel selection method: the fitness value of each subject belonging to the population is evaluated. Then, two subjects are selected, based on the subjects’ fitness value: subjects with a greater fitness value will have a greater chance of being chosen than subjects with a smaller one. Finally, two new subjects, and , are created. This procedure is repeated until a new population, consisting exclusively of new subjects of the same size as the starting population, has been created; then, the cycle starts again.
2.3.4. Reproduction Phase
- Crossover: once subjects and were chosen within the population, their features were mixed. In particular, random features from subject were assigned to subject , leading to the creation of two new subjects, and . This process was then inverted, by assigning random features from subject to subject , and so creating subjects and . Finally, only the two subjects with the greater fitness value were maintained.
- Mutation: the mutation phase was applied, using a mutation coefficient of 0.5, i.e., each of the two maintained subjects had a 50% chance of undergoing random features mutations. This meant that there was a possibility of some features in that subject being replaced by others or being added or removed.
2.4. Data Extraction
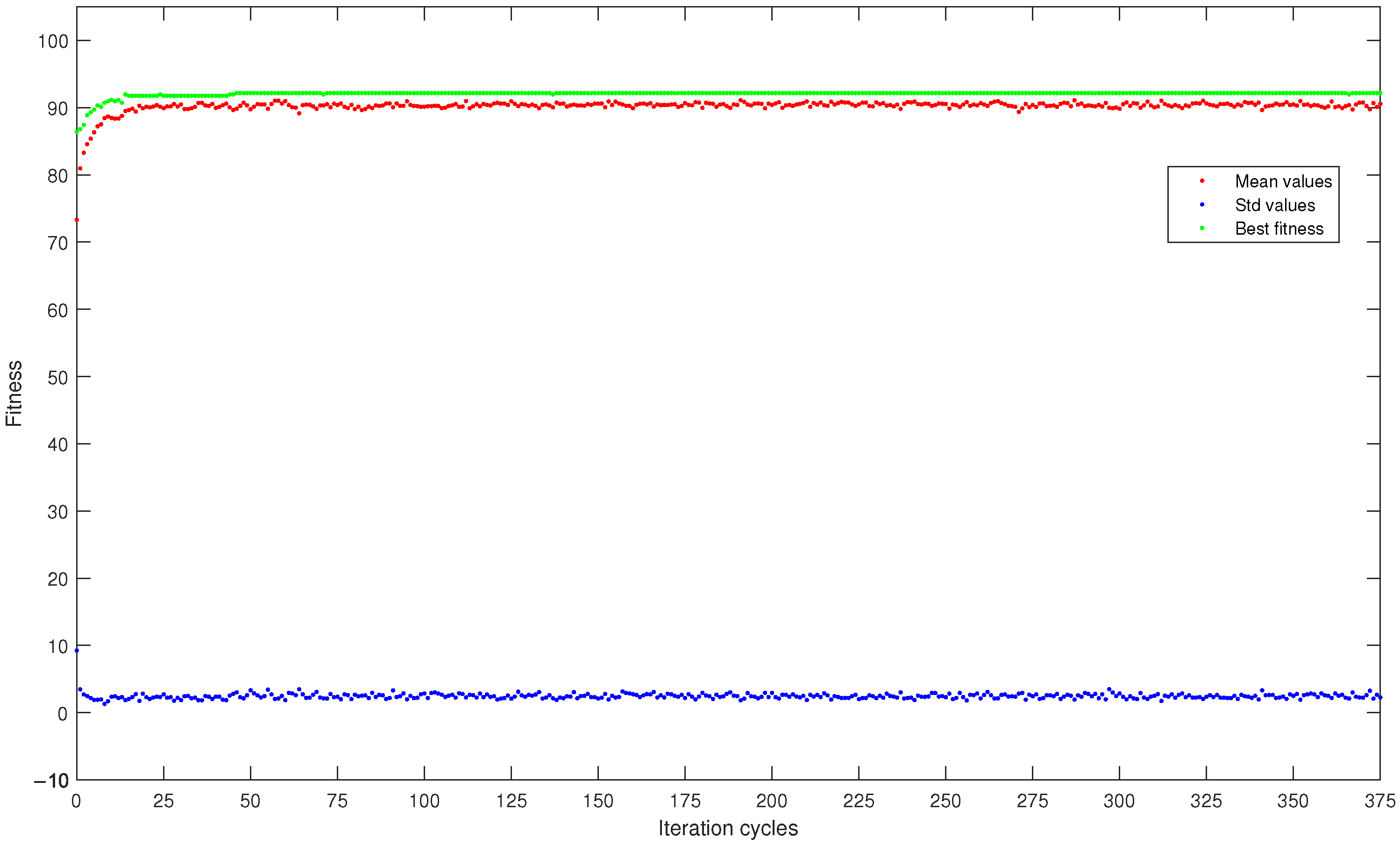
- Mean fitness: represented how much, on average, that population comprised individuals with significant features.
- Std fitness: represented fitness-level variability within the population.
- Best fitness: represented the highest fitness value within that population.
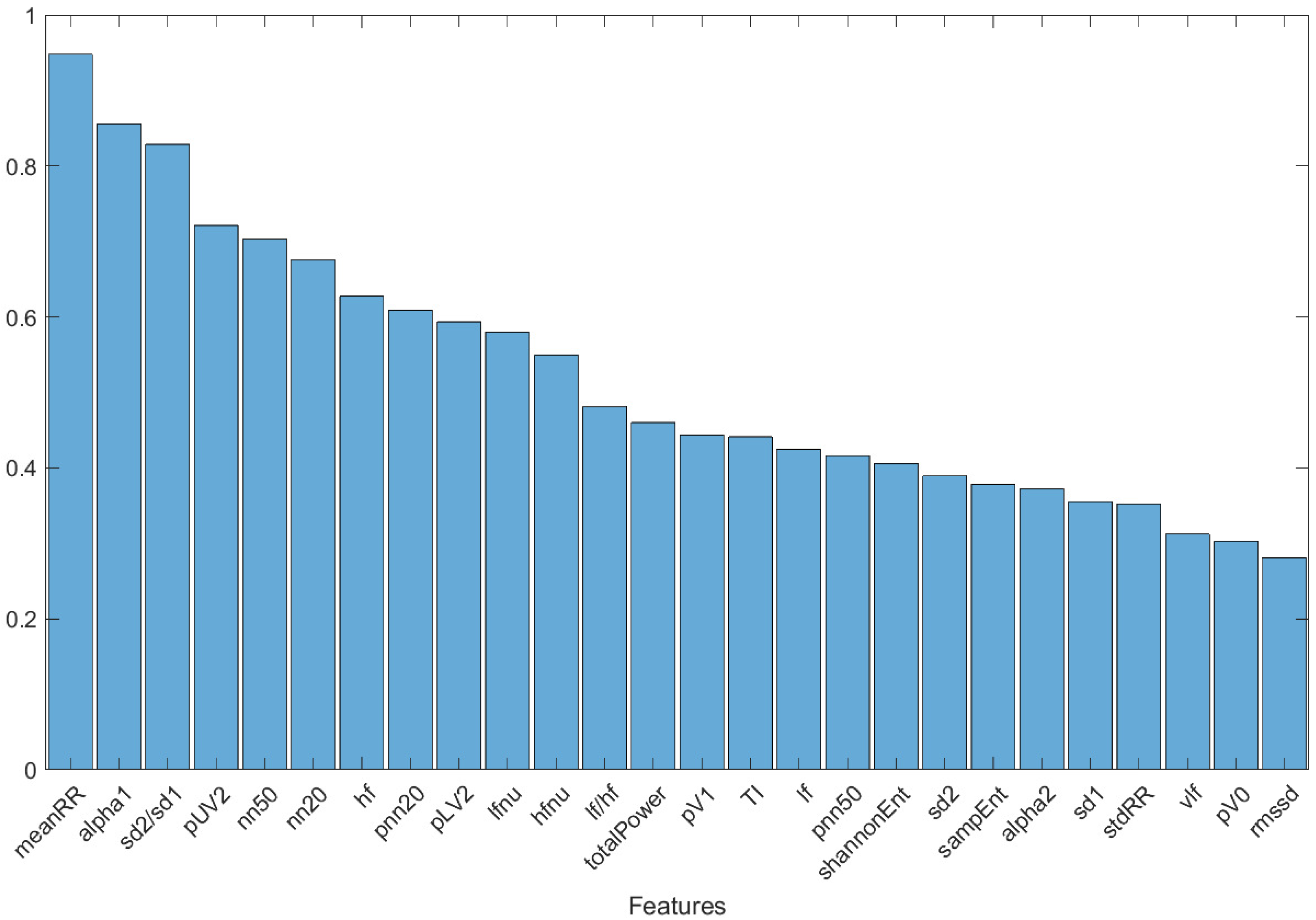
- Features of the best five subjects: represented the features present in the five subjects with the highest fitness.
3. Results
4. Discussions
5. Conclusions
- This study demonstrates the efficacy of the described genetic algorithm in identifying key HRV-related features, extracted from PPG signals, for discriminating between control and study groups using machine learning classifiers.
- The consistent fitness end value across different subject selection methods and machine learning classifiers implies that the choice of classifier significantly influences fitness assessment, rather than how subjects are chosen within the population.
- Three features, , , and , were revealed by the genetic algorithm as pivotal in distinguishing between healthy individuals and COVID-19 patients with mild disease severity.
- A binary Decision Tree classifier, trained and tested with these three parameters only, achieved 82% accuracy, demonstrating strong discriminatory power.
- The differences in HRV parameters, particularly those related to the Parasympathetic Nervous System, between the control and study groups aligned with the existing literature on COVID-19 patients’ physiological changes during infection and recovery. Furthermore, similarities with risk prediction models for other medical conditions, such as sepsis, underscore the clinical relevance of the findings.
- Since the PPG signal is commonly acquired and used in clinical practice, the described methodology could represent the first step towards developing more targeted, patient-specific approaches for diagnosis and monitoring.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| HRV | Heart Rate Variability |
| ECG | ElectroCardioGraphy |
| PPG | PhotoPlethysmoGraphy |
| Laser Doppler Flowmetry | (LDF) |
| VLF | Very Low Frequency |
| LF | Low Frequency |
| HF | High Frequency |
| SNS | Sympathetic Nervous System |
| PNS | Parasympathetic Nervous System |
| LOSO | Leave One Subject Out |
| DISCR | Discriminant analysis classification |
| DT | Decision Tree |
| KNN | K-Nearest Neighbor |
| NB | Naive Bayes |
| LOGIT | LOGIsTic regression model |
References
- Coronavirus Disease (COVID-19). Available online: https://www.who.int/health-topics/coronavirus#tab=tab_1 (accessed on 22 September 2024).
- COVID-19 Epidemiological Update—29 September 2023. Available online: https://www.who.int/publications/m/item/covid-19-epidemiological-update---29-september-2023 (accessed on 22 September 2024).
- Statement on the Fifteenth Meeting of the IHR (2005) Emergency Committee on the COVID-19 Pandemic. Available online: https://www.who.int/news/item/05-05-2023-statement-on-the-fifteenth-meeting-of-the-international-health-regulations-(2005)-emergency-committee-regarding-the-coronavirus-disease-(covid-19)-pandemic (accessed on 22 September 2024).
- Colantuoni, A.; Martini, R.; Caprari, P.; Ballestri, M.; Capecchi, P.L.; Gnasso, A.; Lo Presti, R.; Marcoccia, A.; Rossi, M.; Caimi, G. COVID-19 sepsis and microcirculation dysfunction. Front. Physiol. 2020, 11, 747. [Google Scholar] [CrossRef]
- Charfeddine, S.; Ibn Hadj Amor, H.; Jdidi, J.; Torjmen, S.; Kraiem, S.; Hammami, R.; Bahloul, A.; Kallel, N.; Moussa, N.; Touil, I.; et al. Long COVID 19 syndrome: Is it related to microcirculation and endothelial dysfunction? Insights from TUN-EndCOV study. Front. Cardiovasc. Med. 2021, 8, 1702. [Google Scholar] [CrossRef]
- Andalib, S.; Biller, J.; Di Napoli, M.; Moghimi, N.; McCullough, L.D.; Rubinos, C.A.; O’Hana Nobleza, C.; Azarpazhooh, M.R.; Catanese, L.; Elicer, I.; et al. Peripheral nervous system manifestations associated with COVID-19. Curr. Neurol. Neurosci. Rep. 2021, 21, 1–14. [Google Scholar] [CrossRef]
- Nersesjan, V.; Amiri, M.; Lebech, A.M.; Roed, C.; Mens, H.; Russell, L.; Fonsmark, L.; Berntsen, M.; Sigurdsson, S.T.; Carlsen, J.; et al. Central and peripheral nervous system complications of COVID-19: A prospective tertiary center cohort with 3-month follow-up. J. Neurol. 2021, 268, 3086–3104. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Xiang, M.; Jing, H.; Wang, C.; Novakovic, V.A.; Shi, J. Damage to endothelial barriers and its contribution to long COVID. Angiogenesis 2024, 27, 5–22. [Google Scholar] [CrossRef]
- Fogarty, H.; Townsend, L.; Morrin, H.; Ahmad, A.; Comerford, C.; Karampini, E.; Englert, H.; Byrne, M.; Bergin, C.; O’Sullivan, J.M.; et al. Persistent endotheliopathy in the pathogenesis of long COVID syndrome. J. Thromb. Haemost. 2021, 19, 2546–2553. [Google Scholar] [CrossRef] [PubMed]
- Singh, N.; Moneghetti, K.J.; Christle, J.W.; Hadley, D.; Plews, D.; Froelicher, V. Heart Rate Variability: An Old Metric with New Meaning in the Era of using mHealth Technologies for Health and Exercise Training Guidance. Part One: Physiology and Methods. Arrhythmia Electrophysiol. Rev. 2018, 7, 193–198. [Google Scholar] [CrossRef]
- Rovas, A.; Osiaevi, I.; Buscher, K.; Sackarnd, J.; Tepasse, P.; Fobker, M.; Kühn, J.; Braune, S.; Goebel, U.; Thölking, G.; et al. Microvascular dysfunction in COVID-19: The MYSTIC study. Angiogenesis 2021, 24, 3. [Google Scholar] [CrossRef] [PubMed]
- Jan, H.Y.; Chen, M.F.; Fu, T.C.; Lin, W.C.; Tsai, C.L.; Lin, K.P. Evaluation of Coherence Between ECG and PPG Derived Parameters on Heart Rate Variability and Respiration in Healthy Volunteers with/without Controlled Breathing. J. Med. Biol. Eng. 2019, 39, 783–795. [Google Scholar] [CrossRef]
- Rossi, E.; Aliani, C.; Francia, P.; Deodati, R.; Calamai, I.; Luchini, M.; Spina, R.; Bocchi, L. COVID-19 detection using a model of photoplethysmography (PPG) signals. Med. Eng. Phys. 2022, 109, 103904. [Google Scholar] [CrossRef]
- Aliani, C.; Rossi, E.; Luchini, M.; Calamai, I.; Deodati, R.; Spina, R.; Francia, P.; lanatà, A.; Bocchi, L. Automatic COVID-19 severity assessment from HRV. Sci. Rep. 2023, 13, 1713. [Google Scholar] [CrossRef] [PubMed]
- Soliński, M.; Pawlak, A.; Petelczyc, M.; Buchner, T.; Aftyka, J.; Gil, R.; Król, Z.J.; Żebrowski, J.J. Heart rate variability comparison between young males after 4–6 weeks from the end of SARS-CoV-2 infection and controls. Sci. Rep. 2022, 12, 8832. [Google Scholar] [CrossRef] [PubMed]
- Moradian, N.; Ochs, H.D.; Sedikies, C.; Hamblin, M.R.; Camargo, C.A.; Martinez, J.A.; Biamonte, J.D.; Abdollahi, M.; Torres, P.J.; Nieto, J.J.; et al. The urgent need for integrated science to fight COVID-19 pandemic and beyond. J. Transl. Med. 2020, 18, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Navazi, F.; Yuan, Y.; Archer, N. An examination of the hybrid meta-heuristic machine learning algorithms for early diagnosis of type II diabetes using big data feature selection. Healthc. Anal. 2023, 4, 100227. [Google Scholar] [CrossRef]
- Golap, M.A.u.; Raju, S.T.U.; Haque, M.R.; Hashem, M. Hemoglobin and glucose level estimation from PPG characteristics features of fingertip video using MGGP-based model. Biomed. Signal Process. Control 2021, 67, 102478. [Google Scholar] [CrossRef]
- Miao, F.; Wang, X.; Yin, L.; Li, Y. A Wearable Sensor for Arterial Stiffness Monitoring Based on Machine Learning Algorithms. IEEE Sens. J. 2019, 19, 1426–1434. [Google Scholar] [CrossRef]
- Albadr, M.A.A.; Tiun, S.; Ayob, M.; Al-Dhief, F.T.; Omar, K.; Hamzah, F.A. Optimised genetic algorithm-extreme learning machine approach for automatic COVID-19 detection. PLoS ONE 2020, 15, e0242899. [Google Scholar] [CrossRef]
- Manav, M.; Goyal, M.; Kumar, A. Role of Optimal Features Selection with Machine Learning Algorithms for Chest X-ray Image Analysis. J. Med. Phys. 2023, 48, 195–203. [Google Scholar] [CrossRef]
- Rabby, G.; Berka, P. Multi-class classification of COVID-19 documents using machine learning algorithms. J. Intell. Inf. Syst. 2023, 60, 571–591. [Google Scholar] [CrossRef]
- Qorib, M.; Oladunni, T.; Denis, M.; Ososanya, E.; Cotae, P. Covid-19 vaccine hesitancy: Text mining, sentiment analysis and machine learning on COVID-19 vaccination Twitter dataset. Expert Syst. Appl. 2023, 212, 118715. [Google Scholar] [CrossRef]
- Alqarni, A.; Rahman, A. Arabic tweets-based sentiment analysis to investigate the impact of COVID-19 in KSA: A deep learning approach. Big Data Cogn. Comput. 2023, 7, 16. [Google Scholar] [CrossRef]
- Rogai, F.; Manfredi, C.; Bocchi, L. Metaheuristics for specialization of a segmentation algorithm for ultrasound images. IEEE Trans. Evol. Comput. 2016, 20, 730–741. [Google Scholar] [CrossRef]
- Sorelli, M.; Stoyneva, Z.; Mizeva, I.; Bocchi, L. Spatial heterogeneity in the time and frequency properties of skin perfusion. Physiol. Meas. 2017, 38, 860. [Google Scholar] [CrossRef] [PubMed]
- Horovitz, J.H.; Carrico, C.J.; Shires, G.T. Pulmonary Response to Major Injury. Arch. Surg. 1974, 108, 349–355. [Google Scholar] [CrossRef] [PubMed]
- Roca, O.; Messika, J.; Caralt, B.; García-de Acilu, M.; Sztrymf, B.; Ricard, J.D.; Masclans, J.R. Predicting success of high-flow nasal cannula in pneumonia patients with hypoxemic respiratory failure: The utility of the ROX index. J. Crit. Care 2016, 35, 200–205. [Google Scholar] [CrossRef]
- WMA Declaration of Helsinki – Ethical Principles for Medical Research Involving Human Subjects. Available online: https://www.wma.net/policies-post/wma-declaration-of-helsinki-ethical-principles-for-medical-research-involving-human-subjects/ (accessed on 22 September 2024).
- Shaffer, F.; Ginsberg, J.P. An Overview of Heart Rate Variability Metrics and Norms. Front. Public Health 2017, 5, 258. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. -Physiol.-Heart Circ. Physioly 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [PubMed]
- Kurths, J.; Voss, A.; Saparin, P.; Witt, A.; Kleiner, H.J.; Wessel, N. Quantitative analysis of heart rate variability. Chaos Interdiscip. J. Nonlinear Sci. 1995, 5, 88–94. [Google Scholar] [CrossRef]
- Porta, A.; Guzzetti, S.; Montano, N.; Furlan, R.; Pagani, M.; Malliani, A.; Cerutti, S. Entropy, entropy rate, and pattern classification as tools to typify complexity in short heart period variability series. IEEE Trans. Biomed. Eng. 2001, 48, 1282–1291. [Google Scholar] [CrossRef]
- Peng, C.K.; Havlin, S.; Stanley, H.E.; Goldberger, A.L. Quantification of scaling exponents and crossover phenomena in nonstationary heartbeat time series. Chaos 1995, 5, 82–87. [Google Scholar] [CrossRef]
- Conover, W. Practical Nonparametric Statistics, 3rd ed.; Wiley Series in Probability and Statistics; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Buchhorn, R.; Baumann, C.; Willaschek, C. Heart Rate Variability in a Patient with Coronavirus Disease 2019. Int. Cardiovasc. Forum J. 2020, 20. [Google Scholar] [CrossRef]
- Kaliyaperumal, D.; RK, K.; Alagesan, M.; Ramalingam, S. Characterization of cardiac autonomic function in COVID-19 using heart rate variability: A hospital based preliminary observational study. J. Basic Clin. Physiol. Pharmacol. 2021, 32, 247–253. [Google Scholar] [CrossRef] [PubMed]
- Asarcikli, L.D.; Hayiroglu, M.İ.; Osken, A.; Keskin, K.; Kolak, Z.; Aksu, T. Heart rate variability and cardiac autonomic functions in post-COVID period. J. Interv. Card. Electrophysiol. 2022, 63, 715–721. [Google Scholar] [CrossRef] [PubMed]
- Mol, M.B.; Strous, M.T.; van Osch, F.H.; Vogelaar, F.J.; Barten, D.G.; Farchi, M.; Foudraine, N.A.; Gidron, Y. Heart-rate-variability (HRV), predicts outcomes in COVID-19. PLoS ONE 2021, 16, e0258841. [Google Scholar] [CrossRef]
- Kop, W.J.; Stein, P.K.; Tracy, R.P.; Barzilay, J.I.; Schulz, R.; Gottdiener, J.S. Autonomic Nervous System Dysfunction and Inflammation Contribute to the Increased Cardiovascular Mortality Risk Associated With Depression. Psychosom. Med. 2010, 72, 626–635. [Google Scholar] [CrossRef]
- Chiew, C.J.; Liu, N.; Tagami, T.; Wong, T.H.; Koh, Z.X.; Ong, M.E. Heart rate variability based machine learning models for risk prediction of suspected sepsis patients in the emergency department. Medicine 2019, 98, e14197. [Google Scholar] [CrossRef]
- U, R.A.; N, K.; Sing, O.W.; Ping, L.Y.; Chua, T. Heart rate analysis in normal subjects of various age groups. Biomed. Eng. Online 2004, 3, 1–8. [Google Scholar] [CrossRef]
- van den Berg, M.E.; Rijnbeek, P.R.; Niemeijer, M.N.; Hofman, A.; van Herpen, G.; Bots, M.L.; Hillege, H.; Swenne, C.A.; Eijgelsheim, M.; Stricker, B.H.; et al. Normal Values of Corrected Heart-Rate Variability in 10-Second Electrocardiograms for All Ages. Front. Physiol. 2018, 9, 424. [Google Scholar] [CrossRef]
- Voss, A.; Heitmann, A.; Schroeder, R.; Peters, A.; Perz, S. Short-term heart rate variability—age dependence in healthy subjects. Physiol. Meas. 2012, 33, 1289–1311. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Control | Study | p-Value |
|---|---|---|---|
| * | |||
| * | |||
| ** | |||
| * | |||
| * | |||
| ** | |||
| ** | |||
| ** | |||
| ** | |||
| * | |||
| * | |||
| * | |||
| * | |||
| * | |||
| * | |||
| ** | |||
| ** | |||
| Population | Fitness | KNN | DT | DISCR | NB | LOGIT | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 6 | Start | 65 ± 8 | 75.9 | 74.6 ± 8.7 | 83.7 | 73.6 ± 6.7 | 83.5 | 63.7 ± 5.2 | 70.9 | 76.9 ± 5 | 84.1 |
| End | 79.8 ± 3.9 | 81.9 | 87.5 ± 2 | 88.9 | 87.4 ± 1.3 | 89.1 | 84.7 ± 2.3 | 86.4 | 87.2 ± 2.1 | 89.1 | |
| 16 | Start | 67.7 ± 7.6 | 79.6 | 75.4 ± 8.1 | 86.8 | 73 ± 8.4 | 84.3 | 64.7 ± 5.8 | 75.3 | 73.3 ± 7.3 | 84.3 |
| End | 81.2 ± 2.4 | 82.3 | 88.5 ± 1.6 | 89.3 | 88 ± 2.5 | 90.7 | 85.3 ± 3 | 88.5 | 87.6 ± 2.4 | 90.1 | |
| 26 | Start | 66.3 ± 7.7 | 80 | 74.6 ± 8.3 | 86.2 | 72.9 ± 8.6 | 85.8 | 64.7 ± 5.8 | 76.9 | 72 ± 9.3 | 84.3 |
| End | 81.2 ± 2.8 | 82.3 | 88 ± 2 | 88.9 | 88.8 ± 2 | 91.3 | 84.9 ± 3 | 88.5 | 87.6 ± 2.3 | 90.5 | |
| 36 | Start | 67.2 ± 6.9 | 80.8 | 74.5 ± 8.3 | 87.2 | 73.1 ± 9.3 | 85.6 | 65 ± 6 | 78.1 | 70.9 ± 10.2 | 84.5 |
| End | 81.7 ± 2.5 | 82.5 | 88 ± 2 | 88.7 | 89 ± 1.9 | 91.8 | 85.6 ± 3.3 | 89.3 | 88.6 ± 2 | 91.3 | |
| Population | Fitness | KNN | DT | DISCR | NB | LOGIT | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 6 | Start | 69.7 ± 7.2 | 79.6 | 76.4 ± 8.8 | 84.7 | 71 ± 9 | 80.8 | 64.1 ± 4.9 | 70.9 | 72.7 ± 8.7 | 81.2 |
| End | 82.4 ± 1.5 | 83.1 | 89.8 ± 1 | 90.3 | 90.1 ± 2 | 91.3 | 87.5 ± 2.8 | 89.3 | 89.6 ± 2.9 | 91.5 | |
| 16 | Start | 68.4 ± 7.6 | 81 | 75.3 ± 7.2 | 84.5 | 72.9 ± 8.1 | 83.7 | 64.6 ± 5.6 | 75.9 | 72.1 ± 9.4 | 83.5 |
| End | 81.6 ± 2.1 | 82.5 | 90.6 ± 1.2 | 91.1 | 89.9 ± 1.9 | 91.3 | 88.2 ± 2.1 | 89.5 | 89.9 ± 2.6 | 91.3 | |
| 26 | Start | 67.4 ± 7 | 81 | 75.7 ± 7.9 | 85.6 | 74.3 ± 7.6 | 85.8 | 64.5 ± 5.2 | 75.1 | 71.3 ± 7.8 | 82.7 |
| End | 81.3 ± 3.2 | 82.3 | 87.6 ± 2.6 | 88.7 | 90.4 ± 2.4 | 91.8 | 87.5 ± 3.6 | 89.5 | 89.9 ± 2.7 | 91.3 | |
| 36 | Start | 67.2 ± 7.2 | 80.6 | 73.9 ± 9 | 86.6 | 73.6 ± 8.7 | 85.2 | 64.4 ± 5.5 | 78.1 | 72.2 ± 8.5 | 83.3 |
| End | 81.5 ± 3.3 | 82.5 | 89.8 ± 2.6 | 90.7 | 89.7 ± 2.9 | 91.5 | 87.7 ± 3.5 | 89.7 | 90.4 ± 2.5 | 91.8 | |
| Population | Fitness | KNN | DT | DISCR | NB | LOGIT | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 6 | Start | 64.9 ± 8.5 | 75.1 | 75.1 ± 8.8 | 84.9 | 71.2 ± 7.1 | 79.6 | 63.4 ± 5.5 | 70.1 | 71.6 ± 8.8 | 81.9 |
| End | 81.3 ± 1.7 | 82.1 | 87.9 ± 1.3 | 88.7 | 89.6 ± 2.9 | 91.8 | 86.3 ± 2.9 | 88.2 | 89.2 ± 2 | 90.7 | |
| 16 | Start | 66.9 ± 7 | 79.4 | 75.6 ± 7.3 | 86.2 | 73.3 ± 9.2 | 86.4 | 65.1 ± 5.6 | 75.9 | 71.5 ± 7.9 | 82.9 |
| End | 82.1 ± 1.3 | 82.5 | 88.8 ± 1.7 | 89.5 | 90.5 ± 2.3 | 92.2 | 86.8 ± 3.7 | 89.3 | 90.1 ± 1.6 | 91.1 | |
| 26 | Start | 66.8 ± 7.4 | 80.2 | 73.6 ± 9.3 | 85.6 | 74 ± 7.8 | 86 | 64.3 ± 5.1 | 76.3 | 71.7 ± 8.6 | 84.9 |
| End | 81.8 ± 2.9 | 82.5 | 88.9 ± 2 | 89.7 | 90 ± 2.3 | 91.5 | 87.1 ± 3 | 89.3 | 89.8 ± 2.6 | 91.5 | |
| 36 | Start | 67.8 ± 7.8 | 81.9 | 74.2 ± 8.7 | 87 | 73.3 ± 8.5 | 87 | 65.1 ± 5.9 | 76.7 | 71.7 ± 8.8 | 83.9 |
| End | 81.5 ± 3.1 | 82.5 | 89.1 ± 1.4 | 89.5 | 89.9 ± 2.6 | 91.5 | 87.4 ± 3 | 89.5 | 90.1 ± 2.7 | 91.8 | |
| Classifier | n° of Features | Accuracy | Specificity | Sensibility |
|---|---|---|---|---|
| KNN | All (3) | 75 (45) | 76 (50) | 74 (40) |
| DT | All (3) | 80 (82) | 84 (86) | 77 (79) |
| DISCR | All (3) | 82 (75) | 80 (80) | 85 (87) |
| NB | All (3) | 65 (78) | 90 (86) | 38 (70) |
| LOGIT | All (3) | 78 (79) | 80 (81) | 76 (77) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aliani, C.; Rossi, E.; Soliński, M.; Francia, P.; Lanatà, A.; Buchner, T.; Bocchi, L. Genetic Algorithms for Feature Selection in the Classification of COVID-19 Patients. Bioengineering 2024, 11, 952. https://doi.org/10.3390/bioengineering11090952
Aliani C, Rossi E, Soliński M, Francia P, Lanatà A, Buchner T, Bocchi L. Genetic Algorithms for Feature Selection in the Classification of COVID-19 Patients. Bioengineering. 2024; 11(9):952. https://doi.org/10.3390/bioengineering11090952
Chicago/Turabian StyleAliani, Cosimo, Eva Rossi, Mateusz Soliński, Piergiorgio Francia, Antonio Lanatà, Teodor Buchner, and Leonardo Bocchi. 2024. "Genetic Algorithms for Feature Selection in the Classification of COVID-19 Patients" Bioengineering 11, no. 9: 952. https://doi.org/10.3390/bioengineering11090952
APA StyleAliani, C., Rossi, E., Soliński, M., Francia, P., Lanatà, A., Buchner, T., & Bocchi, L. (2024). Genetic Algorithms for Feature Selection in the Classification of COVID-19 Patients. Bioengineering, 11(9), 952. https://doi.org/10.3390/bioengineering11090952