


A Convolutional Neural Network for SSVEP Identification by Using a Few-Channel EEG

 ,
,
Abstract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Materials and Methods
2.1. Datasets
2.1.1. Dataset 1
2.1.2. Dataset 2
2.2. SSVEP Identification
2.2.1. Data Processing
2.2.2. Network Structure
2.2.3. Filter-Wise Attention Mechanism
2.2.4. Training Hypermeters
2.3. Performance Evaluation
2.3.1. Baseline Methods
2.3.2. Metrics
3. Results
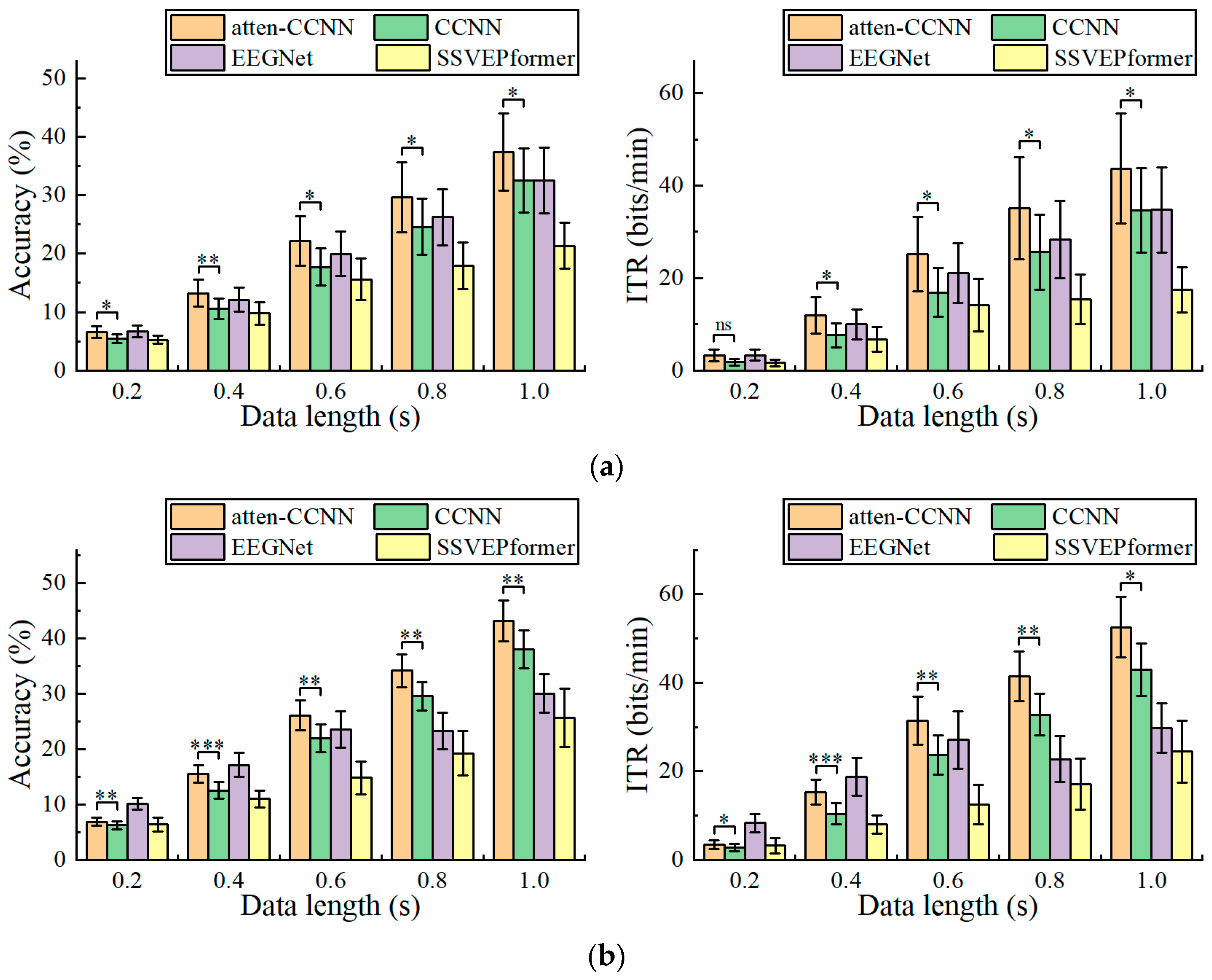
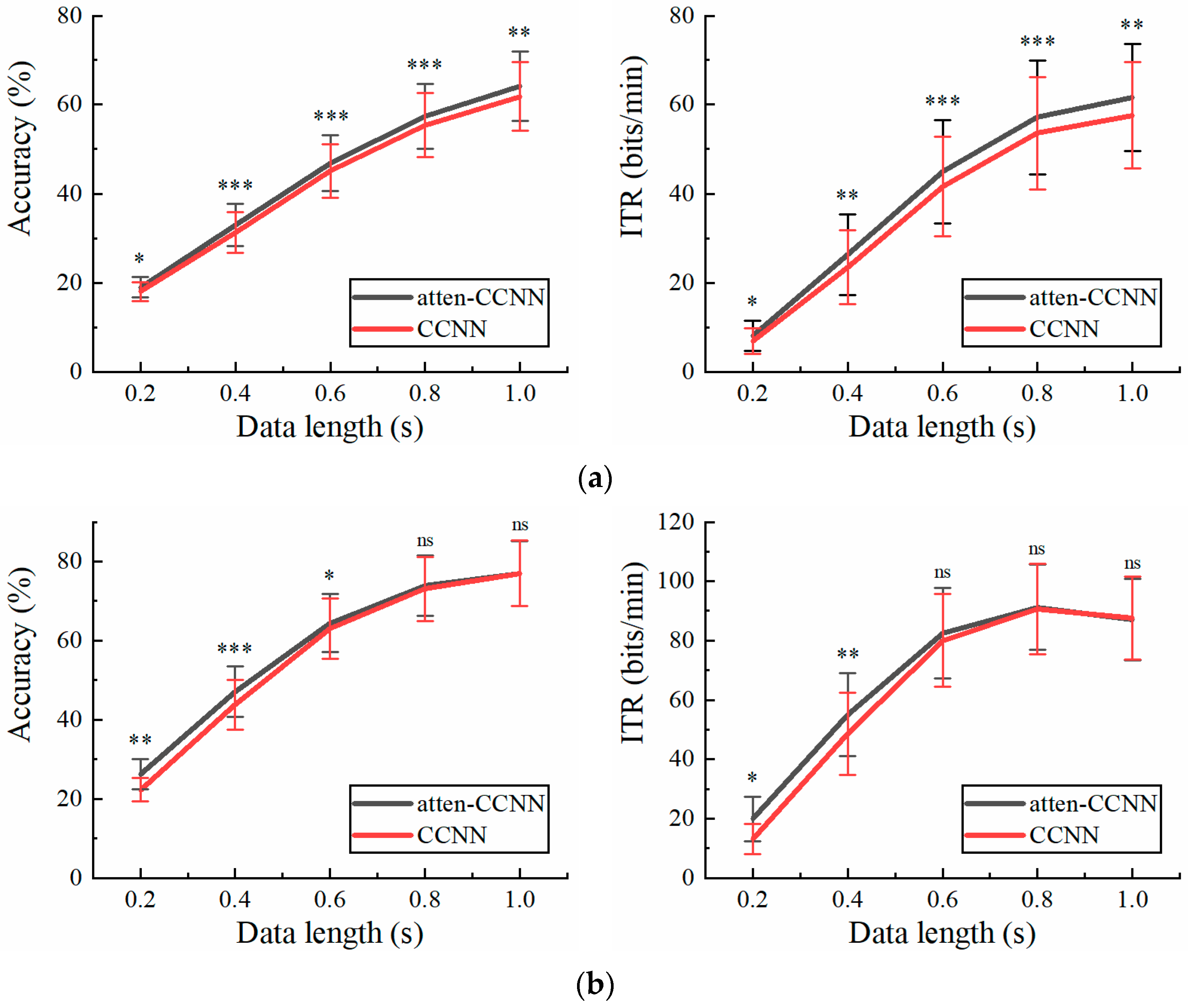
3.1. Dataset 1
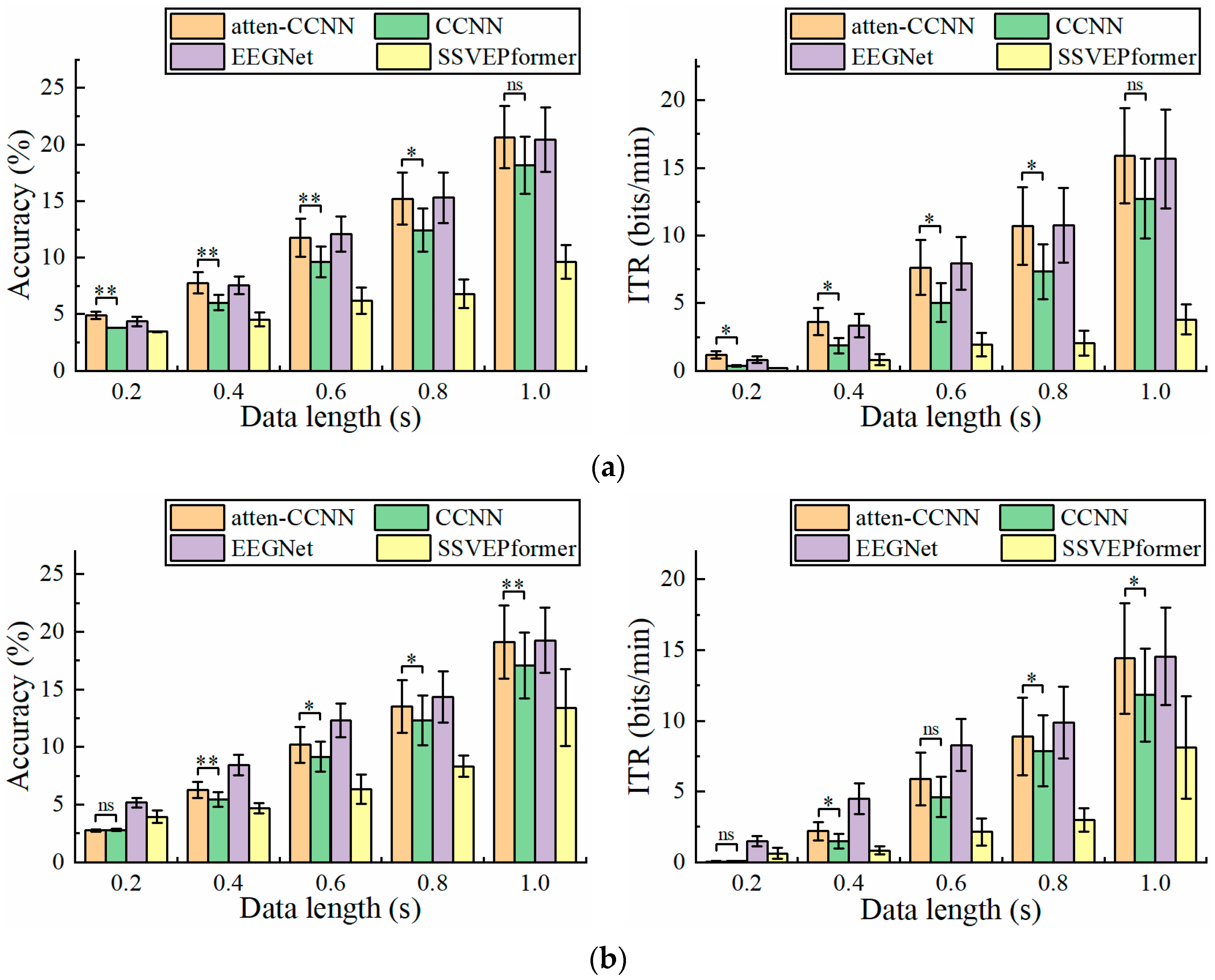
3.2. Dataset 2
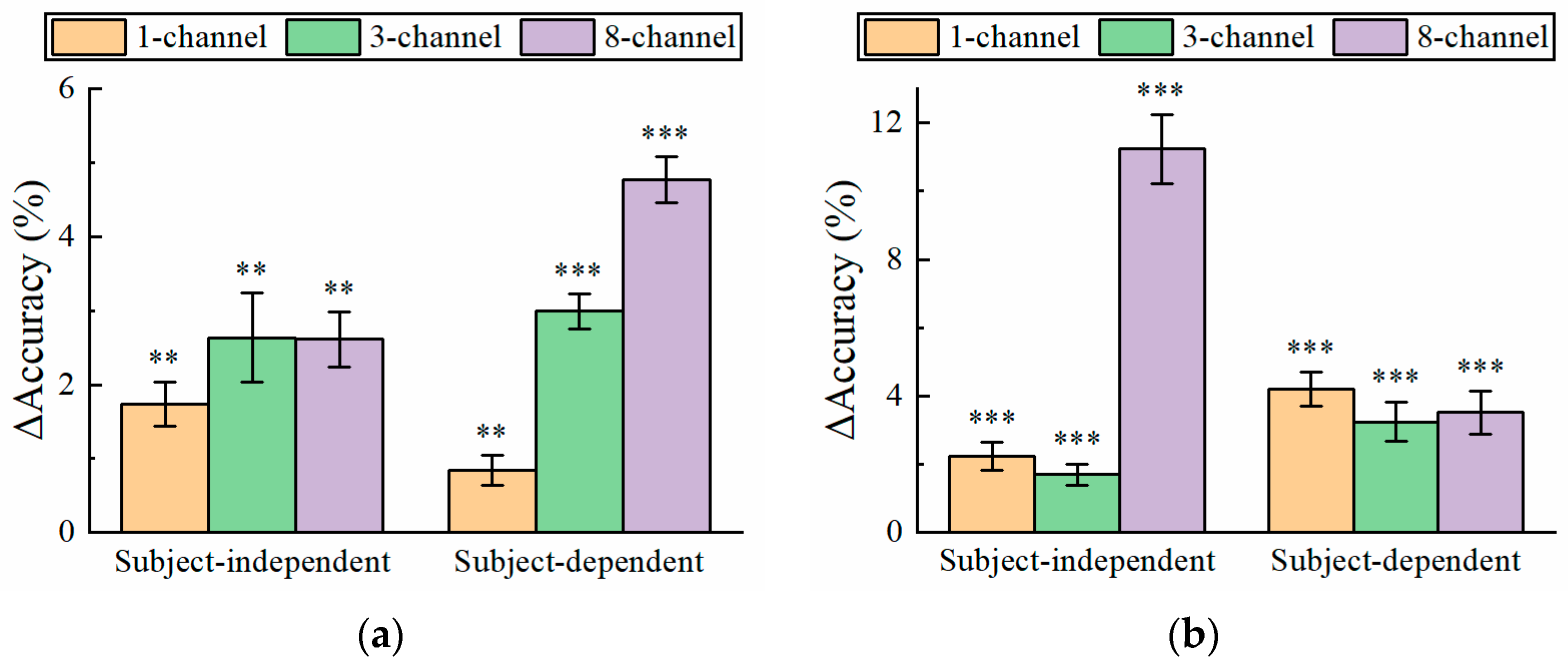
3.3. Effect of Number of EEG Channels
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arpaia, P.; Duraccio, L.; Moccaldi, N.; Rossi, S. Wearable brain–computer interface instrumentation for robot-based rehabilitation by augmented reality. IEEE Trans. Instrum. Meas. 2020, 69, 6362–6371. [Google Scholar] [CrossRef]
- Arpaia, P.; De Benedetto, E.; Duraccio, L. Design, implementation, and metrological characterization of a wearable, integrated AR-BCI hands-free system for health 4.0 monitoring. Measurement 2021, 177, 109280. [Google Scholar] [CrossRef]
- Wu, W.; Ma, L.; Lian, B.; Cai, W.; Zhao, X.J.B. Few-electrode EEG from the wearable devices using domain adaptation for depression detection. Biosensors 2022, 12, 1087. [Google Scholar] [CrossRef] [PubMed]
- Ahn, J.; Ku, Y.; Kim, D.; Sohn, J.; Kim, J.H.; Kim, H. Wearable in-the-ear EEG system for SSVEP-based brain–computer interface. Electron. Lett. 2018, 54, 413–414. [Google Scholar] [CrossRef]
- Hu, Y. Special issue on brain–computer interface and neurostimulation. J. Neurorestoratology 2020, 8, 60. [Google Scholar] [CrossRef]
- Zhuang, M.; Wu, Q.; Wan, F.; Hu, Y. State-of-the-art non-invasive brain–computer interface for neural rehabilitation: A review. J. Neurorestoratology 2020, 8, 12–25. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, D.; Liu, Z.; Liu, M.; Ming, Z.; Liu, T.; Suo, D.; Funahashi, S.; Yan, T. Review of brain–computer interface based on steady-state visual evoked potential. Brain Sci. Adv. 2022, 8, 258–275. [Google Scholar] [CrossRef]
- Zhu, F.; Jiang, L.; Dong, G.; Gao, X.; Wang, Y. An open dataset for wearable ssvep-based brain-computer interfaces. Sensors 2021, 21, 1256. [Google Scholar] [CrossRef]
- Na, R.; Zheng, D.; Sun, Y.; Han, M.; Wang, S.; Zhang, S.; Hui, Q.; Chen, X.; Zhang, J.; Hu, C. A Wearable Low-Power Collaborative Sensing System for High-Quality SSVEP-BCI Signal Acquisition. IEEE Internet Things J. 2021, 9, 7273–7285. [Google Scholar] [CrossRef]
- Ge, S.; Jiang, Y.; Zhang, M.; Wang, R.; Iramina, K.; Lin, P.; Leng, Y.; Wang, H.; Zheng, W. SSVEP-based brain-computer interface with a limited number of frequencies based on dual-frequency biased coding. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 760–769. [Google Scholar] [CrossRef]
- Chen, S.-C.; Chen, Y.-J.; Zaeni, I.A.; Wu, C.-M. A single-channel SSVEP-based BCI with a fuzzy feature threshold algorithm in a maze game. Int. J. Fuzzy Syst. 2017, 19, 553–565. [Google Scholar] [CrossRef]
- Angrisani, L.; Arpaia, P.; Casinelli, D.; Moccaldi, N. A single-channel SSVEP-based instrument with off-the-shelf components for trainingless brain-computer interfaces. IEEE Trans. Instrum. Meas. 2018, 68, 3616–3625. [Google Scholar] [CrossRef]
- Nguyen, T.-H.; Chung, W.-Y. A single-channel SSVEP-based BCI speller using deep learning. IEEE Access 2018, 7, 1752–1763. [Google Scholar] [CrossRef]
- Autthasan, P.; Du, X.; Arnin, J.; Lamyai, S.; Perera, M.; Itthipuripat, S.; Yagi, T.; Manoonpong, P.; Wilaiprasitporn, T. A single-channel consumer-grade EEG device for brain–computer interface: Enhancing detection of SSVEP and its amplitude modulation. IEEE Sens. J. 2019, 20, 3366–3378. [Google Scholar] [CrossRef]
- Kapgate, D. Hybrid SSVEP+P300 brain-computer interface can deal with non-stationary cerebral responses with the use of adaptive classification. J. Neurorestoratology 2024, 12, 100109. [Google Scholar] [CrossRef]
- Zhang, Y.; Xie, S.Q.; Wang, H.; Zhang, Z. Data analytics in steady-state visual evoked potential-based brain–computer interface: A review. IEEE Sens. J. 2020, 21, 1124–1138. [Google Scholar] [CrossRef]
- Hong, J.; Qin, X. Signal processing algorithms for SSVEP-based brain computer interface: State-of-the-art and recent developments. J. Intell. Fuzzy Syst. 2021, 40, 10559–10573. [Google Scholar] [CrossRef]
- Lin, Z.; Zhang, C.; Wu, W.; Gao, X. Frequency recognition based on canonical correlation analysis for SSVEP-based BCIs. IEEE Trans. Biomed. Eng. 2006, 53, 2610–2614. [Google Scholar] [CrossRef] [PubMed]
- Nakanishi, M.; Wang, Y.; Wang, Y.-T.; Mitsukura, Y.; Jung, T.-P. A high-speed brain speller using steady-state visual evoked potentials. Int. J. Neural Syst. 2014, 24, 1450019. [Google Scholar] [CrossRef]
- Chen, X.; Wang, Y.; Gao, S.; Jung, T.-P.; Gao, X. Filter bank canonical correlation analysis for implementing a high-speed SSVEP-based brain–computer interface. J. Neural Eng. 2015, 12, 046008. [Google Scholar] [CrossRef]
- Albahri, A.; Al-Qaysi, Z.; Alzubaidi, L.; Alnoor, A.; Albahri, O.; Alamoodi, A.; Bakar, A.A. A systematic review of using deep learning technology in the steady-state visually evoked potential-based brain-computer interface applications: Current trends and future trust methodology. Int. J. Telemed. Appl. 2023, 2023, 7741735. [Google Scholar] [CrossRef] [PubMed]
- Amrani, G.; Adadi, A.; Berrada, M.; Souirti, Z.; Boujraf, S. EEG signal analysis using deep learning: A systematic literature review. In Proceedings of the 2021 Fifth International Conference On Intelligent Computing in Data Sciences (ICDS), Fez, Morocco, 20–22 October 2021; pp. 1–8. [Google Scholar]
- Aggarwal, S.; Chugh, N. Review of machine learning techniques for EEG based brain computer interface. Arch. Comput. Methods Eng. 2022, 29, 3001–3020. [Google Scholar] [CrossRef]
- Cecotti, H.; Graeser, A. Convolutional neural network with embedded Fourier transform for EEG classification. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Ravi, A.; Beni, N.H.; Manuel, J.; Jiang, N. Comparing user-dependent and user-independent training of CNN for SSVEP BCI. J. Neural Eng. 2020, 17, 026028. [Google Scholar] [CrossRef] [PubMed]
- Xing, J.; Qiu, S.; Ma, X.; Wu, C.; Li, J.; Wang, S.; He, H. A CNN-based comparing network for the detection of steady-state visual evoked potential responses. Neurocomputing 2020, 403, 452–461. [Google Scholar] [CrossRef]
- Zhao, D.; Wang, T.; Tian, Y.; Jiang, X. Filter bank convolutional neural network for SSVEP classification. IEEE Access 2021, 9, 147129–147141. [Google Scholar] [CrossRef]
- Ding, W.; Shan, J.; Fang, B.; Wang, C.; Sun, F.; Li, X. Filter bank convolutional neural network for short time-window steady-state visual evoked potential classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 2615–2624. [Google Scholar] [CrossRef] [PubMed]
- Guney, O.B.; Oblokulov, M.; Ozkan, H. A deep neural network for ssvep-based brain-computer interfaces. IEEE Trans. Biomed. Eng. 2021, 69, 932–944. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Ma, C.; Dang, W.; Wang, R.; Liu, Y.; Gao, Z. DSCNN: Dilated Shuffle CNN model for SSVEP signal classification. IEEE Sens. J. 2022, 22, 12036–12043. [Google Scholar] [CrossRef]
- Xu, D.; Tang, F.; Li, Y.; Zhang, Q.; Feng, X. An analysis of deep learning models in SSVEP-based BCI: A survey. Brain Sci. 2023, 13, 483. [Google Scholar] [CrossRef]
- Chen, X.; Wang, Y.; Nakanishi, M.; Gao, X.; Jung, T.-P.; Gao, S. High-speed spelling with a noninvasive brain-computer interface. Proc. Natl. Acad. Sci. USA 2015, 112, E6058–E6067. [Google Scholar] [CrossRef]
- Li, X.; Wang, J.; Cao, X.; Huang, Y.; Huang, W.; Wan, F.; To, M.K.-T.; Xie, S.Q. Evaluation of an online SSVEP-BCI with fast system setup. J. Neurorestoratology 2024, 12, 100122. [Google Scholar] [CrossRef]
- Nakanishi, M.; Wang, Y.; Wang, Y.-T.; Jung, T.-P. A comparison study of canonical correlation analysis based methods for detecting steady-state visual evoked potentials. PLoS ONE 2015, 10, e0140703. [Google Scholar] [CrossRef] [PubMed]
- Ravi, A.; Heydari, N.; Jiang, N. User-independent SSVEP BCI using complex FFT features and CNN classification. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 4175–4180. [Google Scholar]
- Chen, J.; Zhang, Y.; Pan, Y.; Xu, P.; Guan, C. A transformer-based deep neural network model for SSVEP classification. Neural Netw. 2023, 164, 521–534. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain-computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef] [PubMed]
- Nath, D.; Anubhav; Singh, M.; Sethia, D.; Kalra, D.; Indu, S. A comparative study of subject-dependent and subject-independent strategies for EEG-based emotion recognition using LSTM network. In Proceedings of the 2020 the 4th International Conference on Compute and Data Analysis, Silicon Valley, CA, USA, 9–12 March 2020; pp. 142–147. [Google Scholar]
- Gupta, A.; Siddhad, G.; Pandey, V.; Roy, P.P.; Kim, B.-G. Subject-specific cognitive workload classification using EEG-based functional connectivity and deep learning. Sensors 2021, 21, 6710. [Google Scholar] [CrossRef] [PubMed]
- Shishavan, H.H.; Behzadi, M.M.; Lohan, D.J.; Dede, E.M.; Kim, I. Closed-loop brain machine interface system for in-vehicle function controls using head-up display and deep learning algorithm. IEEE Trans. Intell. Transp. Syst. 2024, 2024, 1–10. [Google Scholar] [CrossRef]
- Pan, Y.; Chen, J.; Zhang, Y.; Zhang, Y. An efficient CNN-LSTM network with spectral normalization and label smoothing technologies for SSVEP frequency recognition. J. Neural Eng. 2022, 19, 056014. [Google Scholar] [CrossRef] [PubMed]
- Yao, H.; Liu, K.; Deng, X.; Tang, X.; Yu, H. FB-EEGNet: A fusion neural network across multi-stimulus for SSVEP target detection. J. Neurosci. Methods 2022, 379, 109674. [Google Scholar] [CrossRef] [PubMed]
- Sun, B.; Zhao, X.; Zhang, H.; Bai, R.; Li, T. EEG motor imagery classification with sparse spectrotemporal decomposition and deep learning. IEEE Trans. Autom. Sci. Eng. 2020, 18, 541–551. [Google Scholar] [CrossRef]
- Eldele, E.; Chen, Z.; Liu, C.; Wu, M.; Kwoh, C.-K.; Li, X.; Guan, C. An attention-based deep learning approach for sleep stage classification with single-channel EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 809–818. [Google Scholar] [CrossRef]
- Altuwaijri, G.A.; Muhammad, G.; Altaheri, H.; Alsulaiman, M. A multi-branch convolutional neural network with squeeze-and-excitation attention blocks for eeg-based motor imagery signals classification. Diagnostics 2022, 12, 995. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Xiong, S.; Wang, X.; Liang, T.; Wang, H.; Liu, X. A compact multi-branch 1D convolutional neural network for EEG-based motor imagery classification. Biomed. Signal Process. Control 2023, 81, 104456. [Google Scholar] [CrossRef]
- Bassi, P.R.; Attux, R. FBDNN: Filter banks and deep neural networks for portable and fast brain-computer interfaces. Biomed. Phys. Eng. Express 2022, 8, 035018. [Google Scholar] [CrossRef]
- Qin, K.; Wang, R.; Zhang, Y. Filter bank-driven multivariate synchronization index for training-free SSVEP BCI. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 934–943. [Google Scholar] [CrossRef]
- Xu, D.; Tang, F.; Li, Y.; Zhang, Q.; Feng, X. FB-CCNN: A Filter Bank Complex Spectrum Convolutional Neural Network with Artificial Gradient Descent Optimization. Brain Sci. 2023, 13, 780. [Google Scholar] [CrossRef] [PubMed]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Yang, S.; Fei, N.; Wang, J.; Huang, W.; Hu, Y. A Convolutional Neural Network for SSVEP Identification by Using a Few-Channel EEG. Bioengineering 2024, 11, 613. https://doi.org/10.3390/bioengineering11060613
Li X, Yang S, Fei N, Wang J, Huang W, Hu Y. A Convolutional Neural Network for SSVEP Identification by Using a Few-Channel EEG. Bioengineering. 2024; 11(6):613. https://doi.org/10.3390/bioengineering11060613
Chicago/Turabian StyleLi, Xiaodong, Shuoheng Yang, Ningbo Fei, Junlin Wang, Wei Huang, and Yong Hu. 2024. "A Convolutional Neural Network for SSVEP Identification by Using a Few-Channel EEG" Bioengineering 11, no. 6: 613. https://doi.org/10.3390/bioengineering11060613
APA StyleLi, X., Yang, S., Fei, N., Wang, J., Huang, W., & Hu, Y. (2024). A Convolutional Neural Network for SSVEP Identification by Using a Few-Channel EEG. Bioengineering, 11(6), 613. https://doi.org/10.3390/bioengineering11060613