1. Introduction
Dental air turbine handpieces stand as the most prevalent medical apparatus employed by dentists in the treatment of teeth. The primary mechanical operation of the aforementioned equipment entails the infusion of high-pressure air into the head to activate microturbine blades, which in turn drive the rotation of bearings that power a tooth drill. Prior to or during treatment, dentists are unable to discern the state of health (SOH) or detect any damage within the internal components of a dental handpiece. Due to the high rotational velocity of a dental handpiece, its internal bearings progressively deteriorate and incur damage over prolonged usage. As a result, ceramic balls are unable to maintain stable operation along their confined track, leading to heightened internal friction within the machine head’s housing and an increase in temperature. The heat is transferred to the bur via the rotor, thereby elevating the temperature of the bur. When the temperature of the bur’s milling contact surface exceeds 42.5 °C [
1], it has the potential to inflict irreversible damage to teeth. Furthermore, at 52 °C, it may lead to pulp necrosis. The temperature rise causes the rotor collet to loosen. This may cause unbalanced vibration in the bur and even cause it to fly out of the DATH. In addition, the vibrations generated by the bur induce discomfort to the patient and result in an uneven surface on the tooth.
The mean clinical force applied to the DATH with a bur in the chuck was reported as 99.3 g, substantiating the range 50–150-g range [
2]. A high-speed handpiece with cutting efficiency according to the bur eccentricity with a constant weight load of 0.9 N for 15 s was also studied in [
3]. An experimental custom-made device was used to hold the high-speed handpiece and specimen in their cutting test. In their in vitro study, the user’s loading configuration was set to apply a load using the handpiece within the patient’s oral cavity. The handpiece and the specimen were fixed during the test. Therefore, this loading to the DATH was mimicked in this study.
Zakeri and Arzanpour [
4] utilized an accelerometer and a laser Doppler vibrometer to capture vibration signals while operating a dental handpiece. Through the comparison of spectrograms between the handpiece operating without load (free running) and under load (milling teeth), the aforementioned authors discerned a decrease in vibration frequency during milling. As the diagnostic perspective point of view, the vibration information from the free running after the milling process will be applied in this study after milling the specimen with a load of 0.9 N. Wei, Dyson and Darvell [
5,
6] used different operating conditions for a DATH to generate an experimental group and a control group. Dental handpieces were used according to pre-established testing procedures until their bearings failed, through which they analyzed factors affecting the service life of the bearing. In [
6], they noted that the ball bearing’s failure typically stemmed from faults in the cage (the non-metallic component of the bearing). Upon bearing failure, the cage incurs significant damage due to the instrument operating under load and the presence of corrosion during high-pressure sterilization. While it remains uncertain whether wear and fracture of the cage directly cause bearing faults, damage to the cage undoubtedly impedes the stable functioning of the ball within the raceways, thus leading to damage of the ball and raceways after relatively few rotations. From our in-laboratory experimental experiences, the failure of the cage, which may be caused by ceramic ball bearings, will unbalance the rotor. The unbalanced rotor can come into contact with the housing and lead to frictional force. A picture of the damaged rotor showed a brown color, frictional marks, and corrosion patterns. Consequently, frictional heat is generated, resulting in the formation of a heat-affected zone. When a dentist uses the handpiece, this heat is inevitably transferred to the dental drill. Such an issue should be prevented and diagnosed in advance in vivo in dental operations.
The advent of artificial intelligence has been accompanied by diverse maintenance strategies, and the assessment of machine health has become a significant focus. Among these methods, the support vector machine (SVM) has garnered attention due to its effective classification capabilities and minimal training and testing time requirements. Notably, SVM excels in classifying diverse classes even with limited training and testing data, reducing computational load [
7]. However, the SVM algorithm has its limitations. Optimal parameter selection for various kernel functions and managing cost parameters are crucial for SVM performance since each classification problem corresponds to an optimal parameter set. Additionally, SVM’s diagnostic accuracy may suffer if training data for different classes are ambiguous or poorly differentiated.
Today, the rapid technological evolution of hardware and software has opened up avenues for research leveraging artificial intelligence [
8], image processing, computer vision, and machine learning.
The application of the convolutional neural network (CNN) is the main research area of artificial intelligence, especially in image diagnosis. In [
9], a CNN was used for fault identification and classification in gearboxes. In their study, the vibration signals were preprocessed using statistical measures from the time-domain signal, such as the standard deviation, skewness, and kurtosis of the raw data. In the frequency domain, they divided the spectrum obtained with FFT into multiple bands, and calculated the root mean square (RMS) value for each one. So, the vibration energy, maintaining the shape of the associated spectrum peaks, could be acquired. The diagnosis accuracy indicated that the proposed CNN approach was more reliable than the SVM. In [
10], a deep-structure CNN was proposed as a method for diagnosing bearing faults by using vibration signals directly as input data. They transferred the vibrational signal into a vibration image, and then, learned using a CNN without requiring any feature extraction techniques. Their method was for an automatic fault diagnosis system under noisy environments. In [
11], a 1D CNN was used as a classifier with a compact architecture configuration for real-time bearing fault detection and monitoring. The motor vibration and current datasets were experimentally validated.
The long short-term memory (LSTM) network has demonstrated its capability to transfer memory and learn from time-series data. Current research has applied this network in various areas, including fault prediction, prognostics, health management, system status monitoring, and predictive maintenance. Recent studies have developed LSTM prediction models specifically tailored for monitoring the health and degradation of dental air turbine handpieces (DATHs). In one such study [
12], a handpiece was utilized to perform cutting operations on a glass porcelain block repeatedly. An accelerometer was employed to capture vibration signals during the free-running mode of the handpiece, enabling the identification of characteristic frequencies in the vibration spectrum. The gathered data were then used to establish a health index (HI) for constructing predictive models. In that research, the cutting force applied to the DATH was not studied. The LSTM model can be a useful tool for predicting the degradation trajectory of real dental handpieces. In addressing the precise classification of health states, the development of feature engineering, based on the principles of data mining to expand the dimensions of raw data, proves advantageous. Subsequently, the selection of optimal combinations of characteristic features from the expanded dataset ensues. Data preprocessing has emerged as a more resilient and sophisticated method for diagnosis, especially with the rise of artificial intelligence. In [
13], a systematic assessment was conducted on generic convolutional and recurrent architectures for sequence modeling. Results from the described generic temporal convolutional network (TCN) architecture convincingly outperformed the LSTM and gated recurrent unit (GRU) on many test datasets, such as the sequential MNIST. The advantages of using TCNs for sequence modeling include parallelism, flexible receptive field size, stable gradients, low memory requirement for training, and variable-length inputs [
13]. A framework was proposed by using time empirical mode decomposition (EMD) and a TCN for remaining useful life (RUL) estimation for the bearing failure in [
14]. They decomposed the original signal data by EMD and expanded the data to 12 dimensions. Then, the processed datasets were used to train the TCN. Their results indicated that LSTM and CNN struggled to capture the degrading trend exactly but EMD-TCN was effective in prediction by combining the historical condition and convolution. In [
15], the RULs of the bearing datasets were predicted by a TCN by conducting vibrational signal segmentation and using statistical features as the input of the TCN. The RUL results showed the proposed TCN’s superiority when the random forest (RF), LSTM network, and gated recurrent unit (GRU) were compared. Modifications of the TCN’s structure can be found in [
16,
17] by using the Squeeze excitation block and residue block of the TCN for reducing the training time, prevention of overfitting, and improving model accuracy.
This paper deploys the TCN architecture for feature learning and performing accurate predictions with different fault diagnoses for the DATH. Notable advantages and improvements are observed with the TCN model’s prediction accuracy in this research compared to the 1D CNN and LSTM approaches. The experimental results with the applied load on the DATH suggest future practical dental implementations and pilot studies of the proposed predictive model in clinical settings. The rest of the paper is organized as follows. In
Section 2, the theoretical background for feature engineering with feature extraction and selection are described. The fundamentals of the TCN with nine diagnostic health classification (DHC) labels for the DATH are introduced.
Section 3 presents the experimental setup and results by using feature engineering followed by 1D CNN, LSTM, and TCN.
Section 4 provides a discussion. Some concluding remarks and recommendations for future work are summarized in
Section 5.
2. Theoretical Background of Feature Engineering, TCN, CNN, and LSTM
2.1. Feature Engineering, Feature Extraction, and Feature Selection
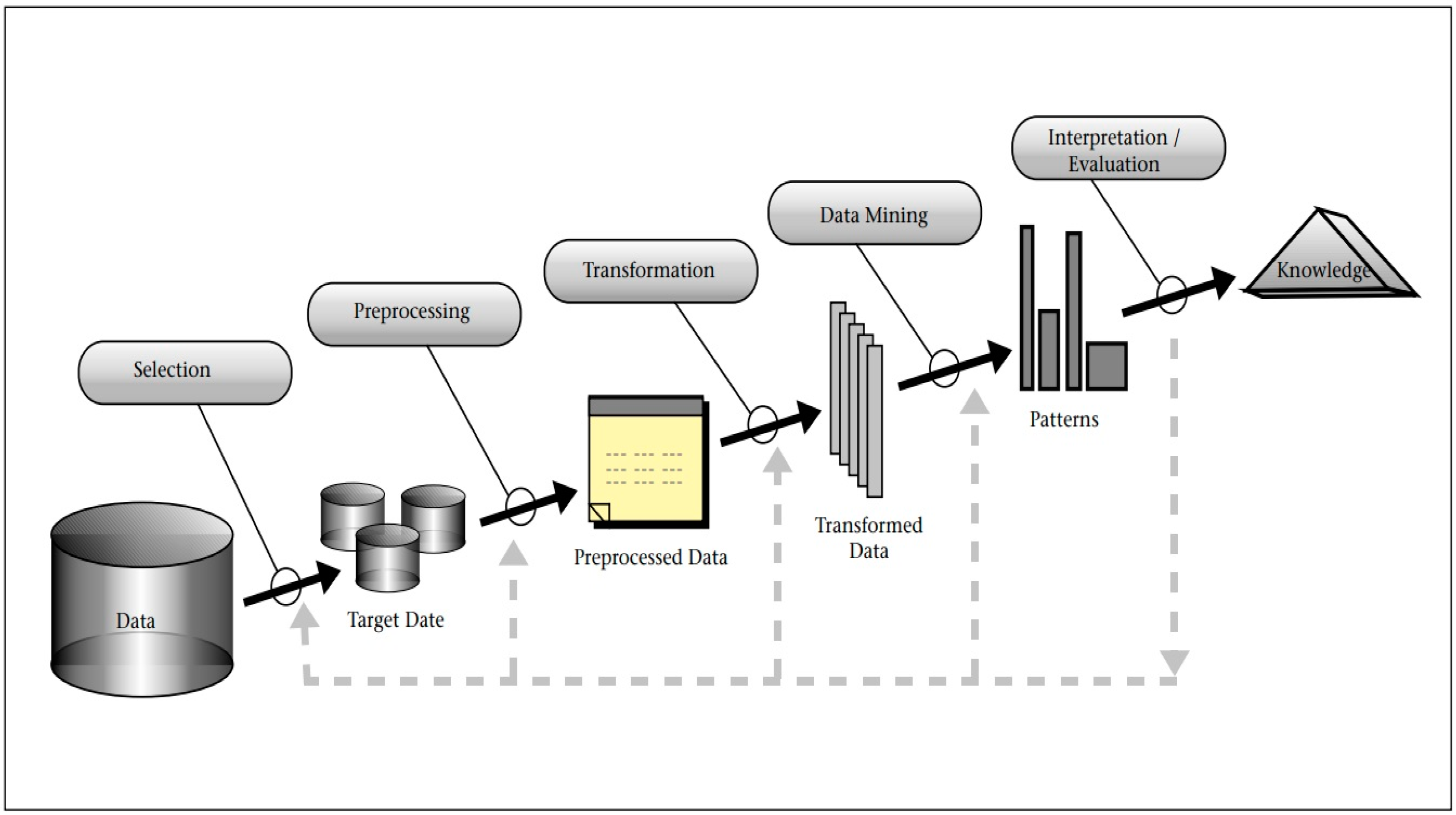
Knowledge Discovery Databases (KDDs) [
18], as illustrated in
Figure 1, pertain to a paradigm for data consolidation encompassing feature extraction and feature selection. The five tiers of sensor fusion delineated in the Dasarathy model [
19] are as follows. Initially, spanning level one to level three, input and output data undergo data-driven feature analysis, followed by feature selection preceding feature extraction, culminating in decision-making at level four and five. Lately, numerous researchers have employed KDDs or data fusion for diagnosing mechanical faults. Data preprocessing has emerged as a more robust and sophisticated approach to diagnosis, especially given the ascendance of artificial intelligence. The fundamental principle of feature engineering is to discern the most discriminative features from raw data through systematic operations. In [
20], the raw vibration data were segmented followed by using feature extraction methods in an attempt to extract representative quantitative values that could reflect the ball screw system’s behavior properties. Feature extraction reduced the data quantity and complexity, and then, it was followed by selection based on Fisher criteria or principal component analysis (PCA). Machine learning methods via self-organizing maps (SOMs), Mahalanobis distance, and Gaussian mixture model (GMMs) were used for ball screw fault diagnosis. In this study, the concept of KDD following a systematic feature extraction procedure is adopted.
First, statistical features consisting of the mean, root mean square (RMS), kurtosis, skewness, crest factor, variance, and standard deviation are extracted in each section of the time domain. In the second step, the vibration raw data (denoted as xi) in the time domain with a sampling rate of 12.8 kHz are transformed into power spectrum density amplitude (PSD-Amp) and PSD shape (PSD-Shape) in the frequency domain. Four statistical features, namely, mean, standard deviation, skewness, and kurtosis are extracted in each section of PSD-Amp and PSD-Shape. They are extracted from both the time and frequency domains. Last, the vibrational data in the frequency domain are divided into 256 sectors, with a width of 25 Hz for each frequency sector. Then, the frequency bandwidth goes up to 6400 Hz. Within each section, the mean value of the amplitude sum is computed as a feature.
Table 1 and
Table 2 present the six features in the time domain and the eight features calculated from the frequency-domain amplitudes for each section with divisions every 25 Hz. In addition, the 256 sections featured in the frequency domain are gathered with the above 14 features. Thus, a total of 270 (6 plus 8 and plus 256) extracted features are fed for feature selection. Typically, outliers for each feature type are eliminated using the Z-score formula to prevent their influence during algorithm training. In this study, the Z-score was not applied for the sake of testing the robustness of the developed 1D CNN, LSTM, and TCN. In the feature selection step, the most discriminative feature among all features is determined using Fisher’s criteria. The score obtained from Fisher’s criteria serves as an index of the degree of distinctiveness. Each feature can be given a Fisher score with two different diagnosed items, such as the normal DATH and the failure of the DATH’s rotor. Subsequently, the two, three, or more highest scoring features are selected as training data for the algorithm. In this study, five features were selected. Before all the selected features were fed as the input items of the NNs (1D CNN, LSTM, and TCN), the feature data were all scaled to the same order using a normalization process to reduce the computation complexity.
2.2. Fundamentals of TCN
TCN [
13] is a kind of sequential prediction model that is designed to learn the hidden temporal dependencies within input sequences. It takes the sequence of the input, and the corresponding parameters as the expected outputs. The architecture of TCN is characterized with dilated convolution, causal convolution, residue connection, and a fully connected layer. Some details about TCN are as follows.
First, the dilated convolution allows a receptive field with more wide convolutions among the hidden layers, since the filter serves as the function for the feature map. As the number of hidden layers increases, introducing a dilated factor enlarges the receptive field in the feature extraction domain.
The dilated factor
increases with the number of hidden layers
, as in Equation (1). For a sequence input
and a filter
, Equation (2) presents the dilated convolution operation
on data point
of the sequence, where
, where
is the filtering value, and
is the size of filter in dilated convolutions. The conventional discrete convolution * is simply the 1-dilated convolution. Here, we refer to ∗
as a dilated convolution or a
-dilated convolution.
is the stacked number of dilated causal convolution layers in one TCN layer, it is usually set as 1. The relationships between the receptive field and the filter size, stacked number, and dilated factor is shown in Equation (3).
Secondly, the causal convolution can deal with the sequenced vibrational signal and prevent the future data information being convoluted with past information. This reduces the computation time.
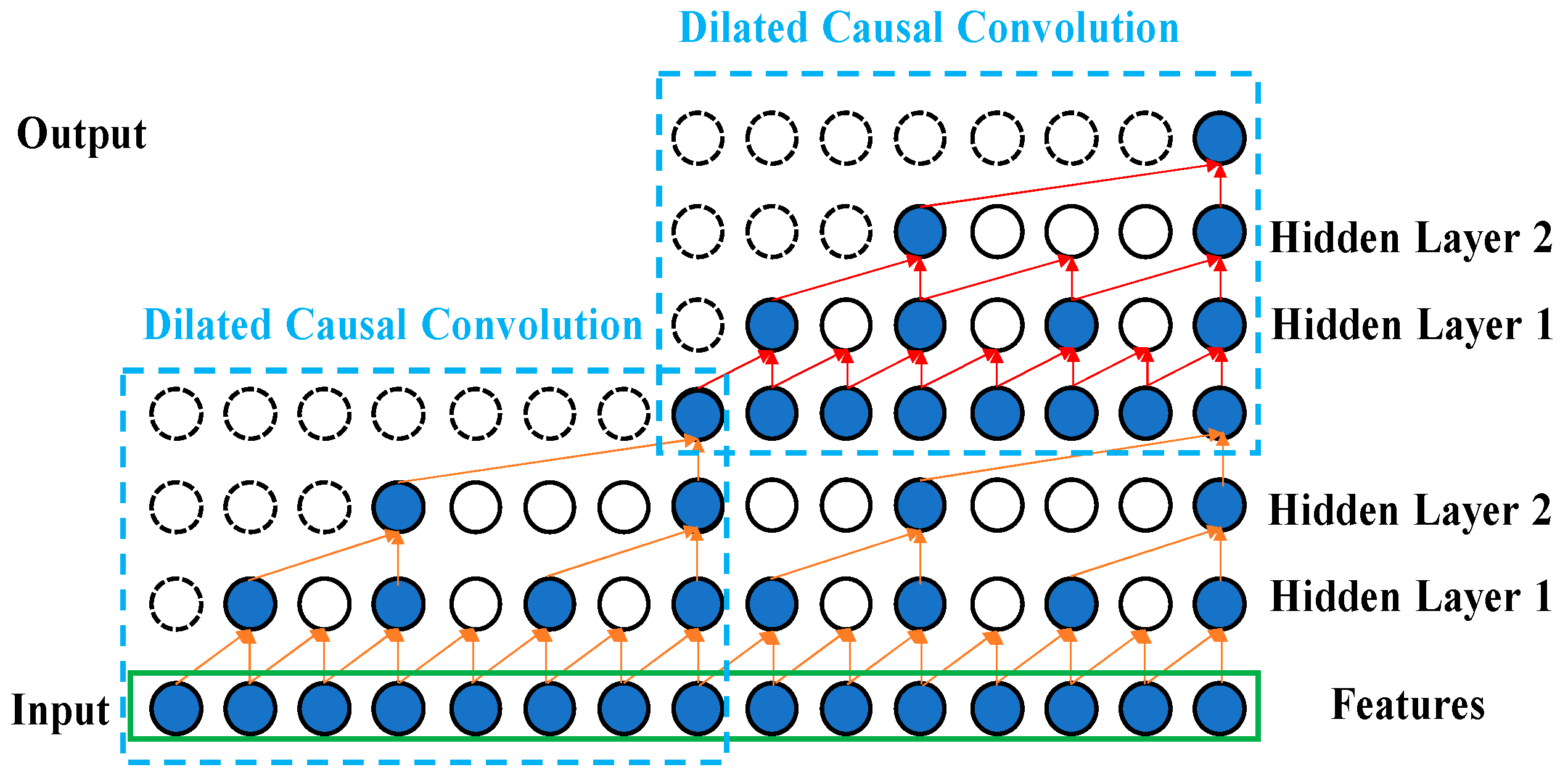
Figure 2 illustrates the efficiency of using the dilated convolution with
d = 4 (upper right) compared to with
= 1 (lower right) for the same input receptive field of five neurons. The inputs are the selected Fisher score features processed by feature engineering. Causal convolution allows the TCN, 1D CNN, and LSTM models to make predictions on continuous vibrational data for performing the diagnostics of the DATH’s health. The residue connection was proposed in [
21]. In
Figure 3, this network structure preserves the initial input value by a feedforward loop of identity mapping together with two hidden layers where the vanishing gradient problem is avoided. As shown in
Figure 4, two dilated causal convolution layers associated with the identity mapping form the architecture elements of a TCN residue block.
2.3. Fundamentals of Convolutional Neural Network
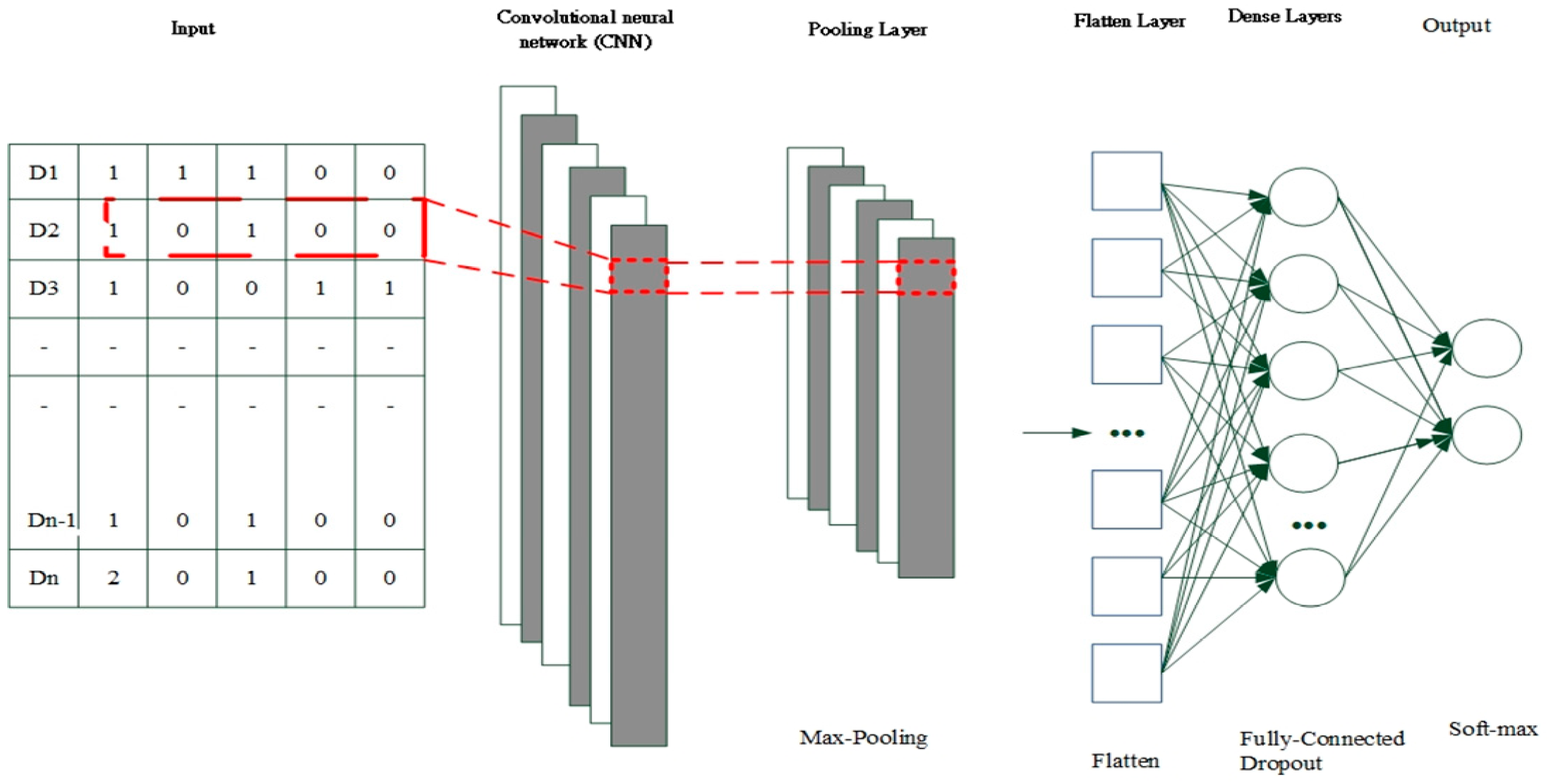
CNNs hold promise for processing sensor measurement data and deriving intricate spatial features. CNN architectures typically encompass a convolutional layer, a pooling layer, a fully connected (FC) layer with dropout, and a softmax layer for classification (see
Figure 5). Within the convolutional layer, convolutional filters are leveraged to derive features from the input data, thereby facilitating feature extraction and mapping. Subsequently, an activation function is applied to yield the feature map for the subsequent layer. The output of the convolution filter is computed utilizing the following formula:
Where ∗ denotes the convolutional operation, is the layer number in the network, and and are the input and output of the convolution filter, respectively. Moreover, is the activation function, is the input of the activation function, is the weight matrix of the convolutional filter, and is the additive bias vector.
Within the pooling layer, the output of the convolutional layer undergoes downsampling by an appropriate factor to diminish the resolution of the feature map. Among the prevalent methods, average pooling and maximum pooling stand out, with the latter being employed in this study. The formula for maximum pooling is delineated as follows:
where
represents the downsample function for maximum pooling.
FC layers integrated with dropout are employed to facilitate training in deep neural networks. During each training batch, half of the feature detectors are disregarded, leading to a significant reduction in overfitting. This technique diminishes the interdependence among feature detectors, thereby preventing some detectors from becoming overly reliant on others to perform their functions.
Upon applying the softmax operation, the summation of the probability distributions of the outputs from the final layer equates to 1. For instance, in a classification scenario featuring two categories, where the input is an image signal, the softmax activation function outputs the probabilities associated with the image belonging to the aforementioned categories. The cumulative sum of these probabilities amounts to 1.
In Equation (7),
is in the range (0, 1), which is required for this value to be a probability. The
input vector for the softmax function is given as (
, …,
), with elements
. The standard exponential function is applied to each element of the input vector. Division by
ensures that the sum of the softmax output values is 1; this term is the normalization term.
is the number of classes in the multiclass classifier [
22].
2.4. Fundamentals of Long Short-Term Memory
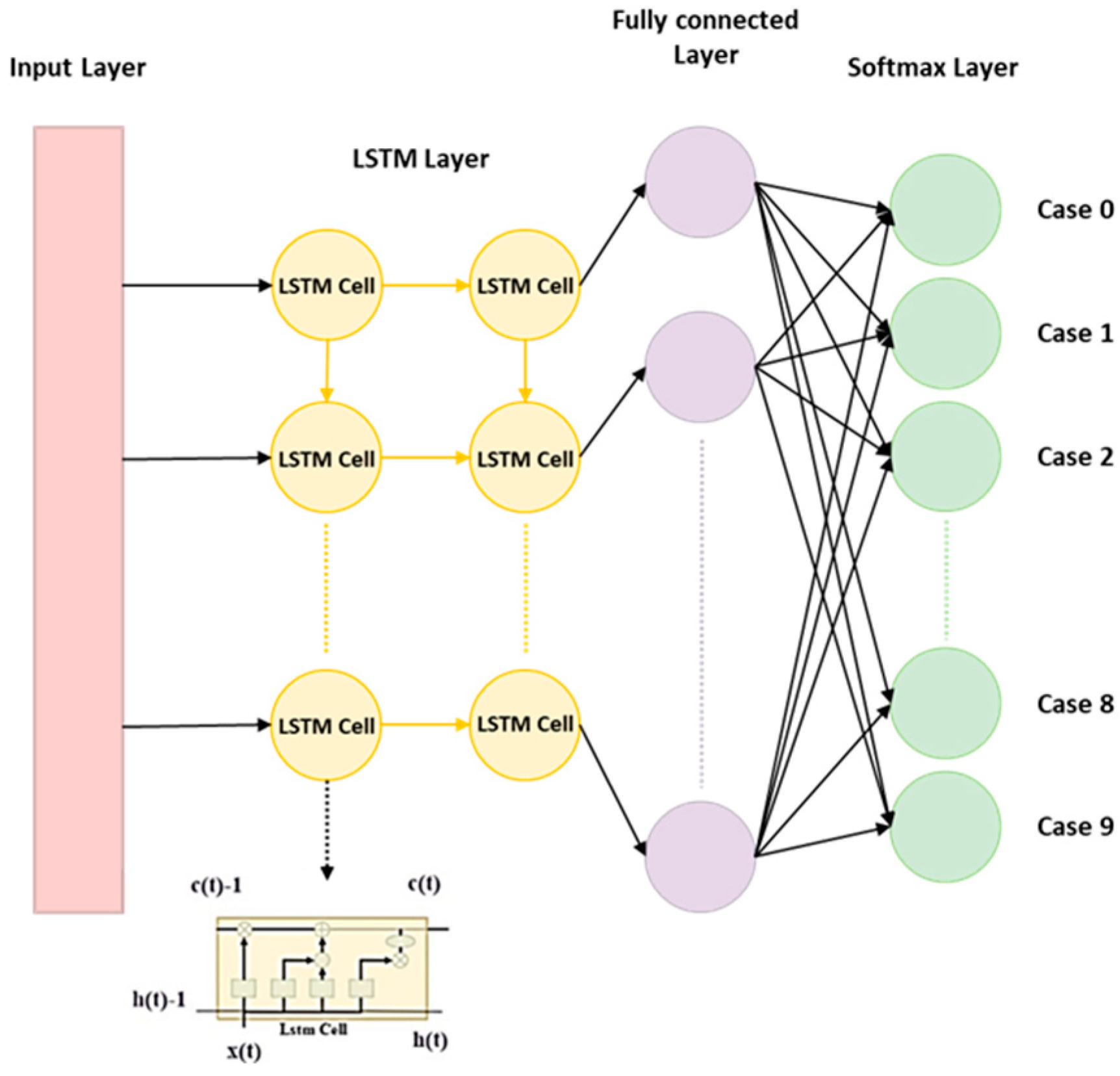
An LSTM network possesses a memory structure comprising memory cells that facilitate the addition and retention of information as the time series progresses, effectively addressing the vanishing gradient problem.
Figure 6 delineates the fundamental architecture of an LSTM network. The cell state serves as a repository for storing and transmitting memory, thereby ensuring that the information contained therein is only susceptible to writing or deletion. Without external influence, the aforementioned information remains unaltered. The parameter
signifies the input data at time
, while
denotes the hidden state at time
. The cell state at time
is denoted as
, which undergoes modification to yield the current cell state
within the hidden layer at time
.
The hidden layer within an LSTM network comprises an input node, denoted as
, and three controlled gates, namely,
. These variables
,
are computed using Equations (1)–(4), respectively. The input node
plays a role in updating the cell state, while the controlled gates are responsible for determining whether to permit the passage of information through them. Specifically, the controlled gates consist of the forget gate, input gate, and output gate. The forget gate
is instrumental in deciding which information from the previous cell states (
) may pass through it. On the other hand, the input gate (
) dictates which information from the input nodes
can pass through it. The vectors (information) that traverse through the input gate contribute to updating the cell state through element-wise addition with the vectors from the forget gate, ultimately generating the cell state at time
, denoted as
. This computation process is expressed in Equation (5). Moving forward, the output gate determines which information from the current cell state
can pass through it. The information vectors that pass through the output gate contribute to the hidden state at time
, denoted as
, serving as the output vectors of the ongoing hidden layer. The computation method for
is elucidated in Equation (6). Moreover, the cell state
and hidden state
obtained at time
are propagated to the hidden layer at time
. This iterative process, progressing with the time series, facilitates the transmission and acquisition of memory, contributing to the learning process.
where
and
represent the weights,
denotes the bias,
is the symbol for element-wise addition,
is the symbol for element-wise multiplication,
denotes the hyperbolic tangent, and
represents the sigmoid function. The parameters
and
represent activation functions. The current study adopted the LSTM structure as shown in
Figure 7. The structure is used to predict the health status of the dental handpiece with 9 classifications.
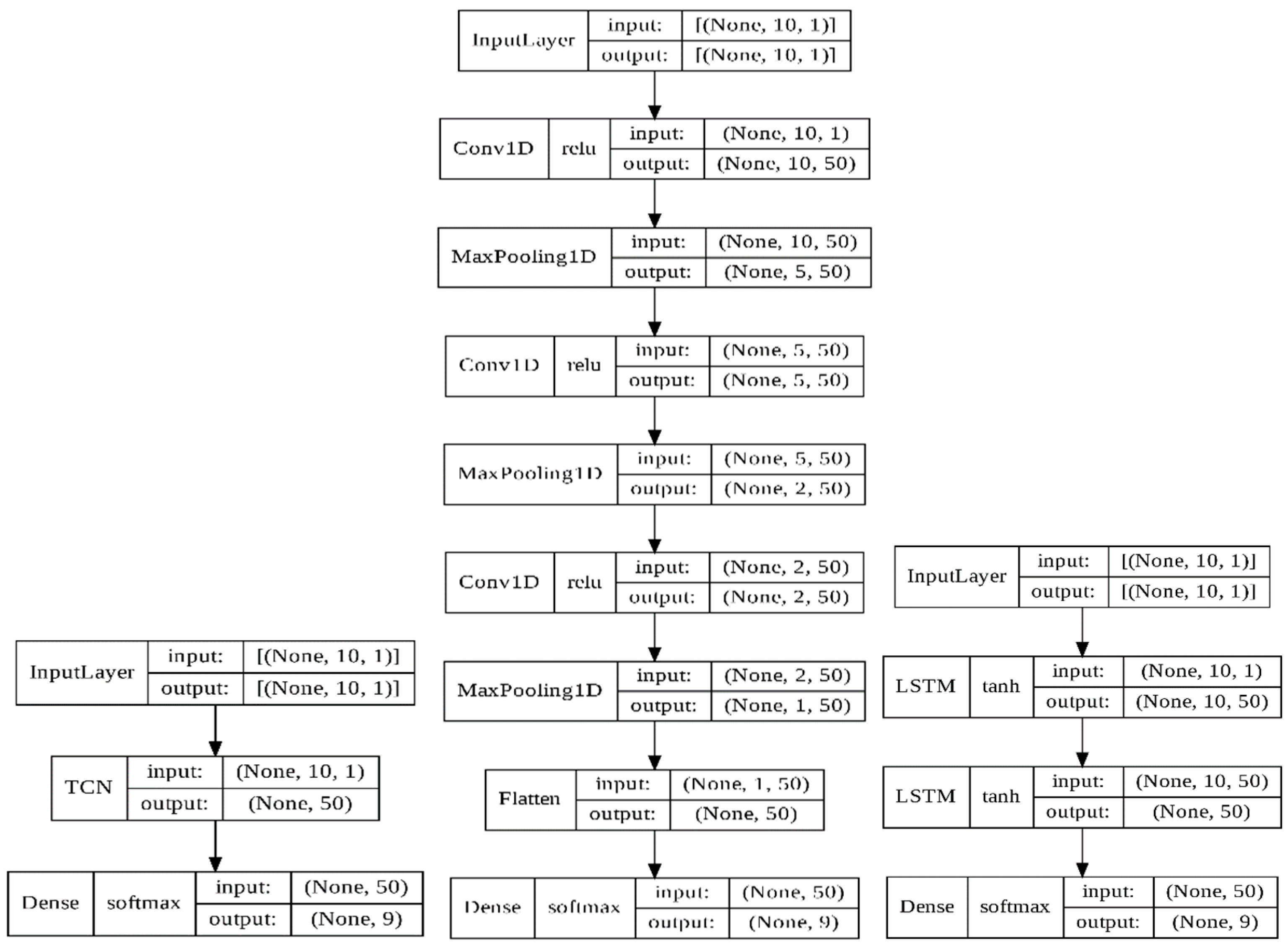
2.5. Summary of the Framework of TCN, 1D CNN, and LSTM Prediction Models
Table 3 and
Figure 8 detail the parameters of the TCN, 1D CNN, and LSTM by Keras. The notation ‘none’ in
Table 3 indicates that the input and output dimensions were changed in the 1D CNN and LSTM models’ computations.









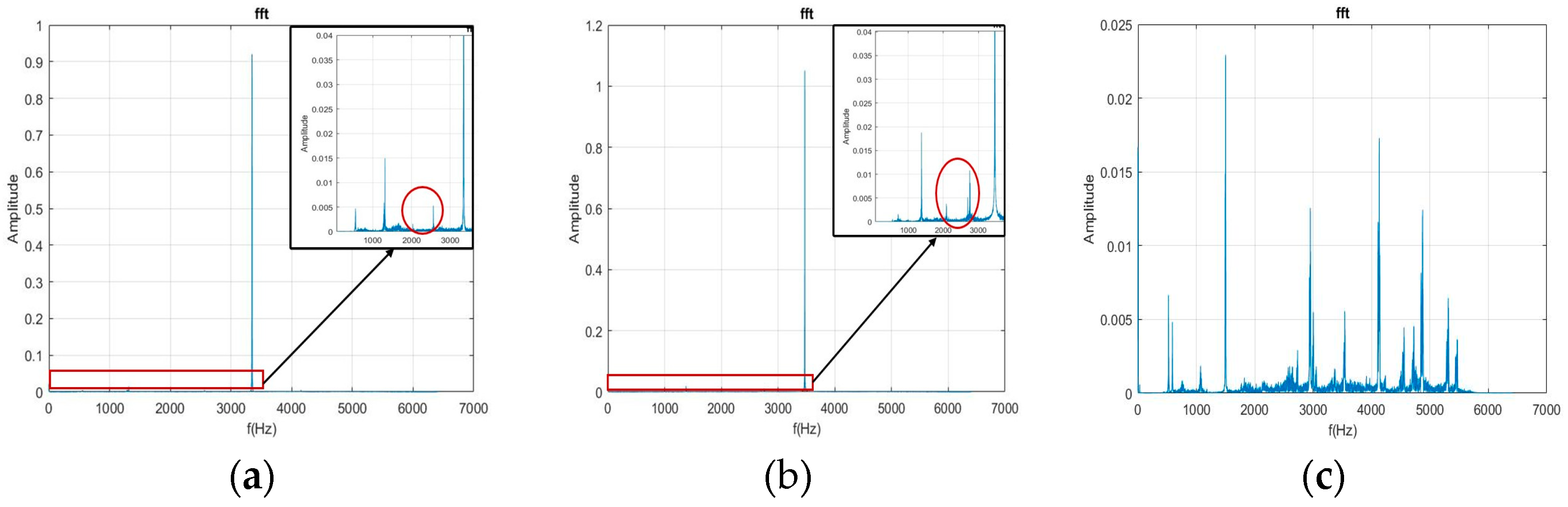
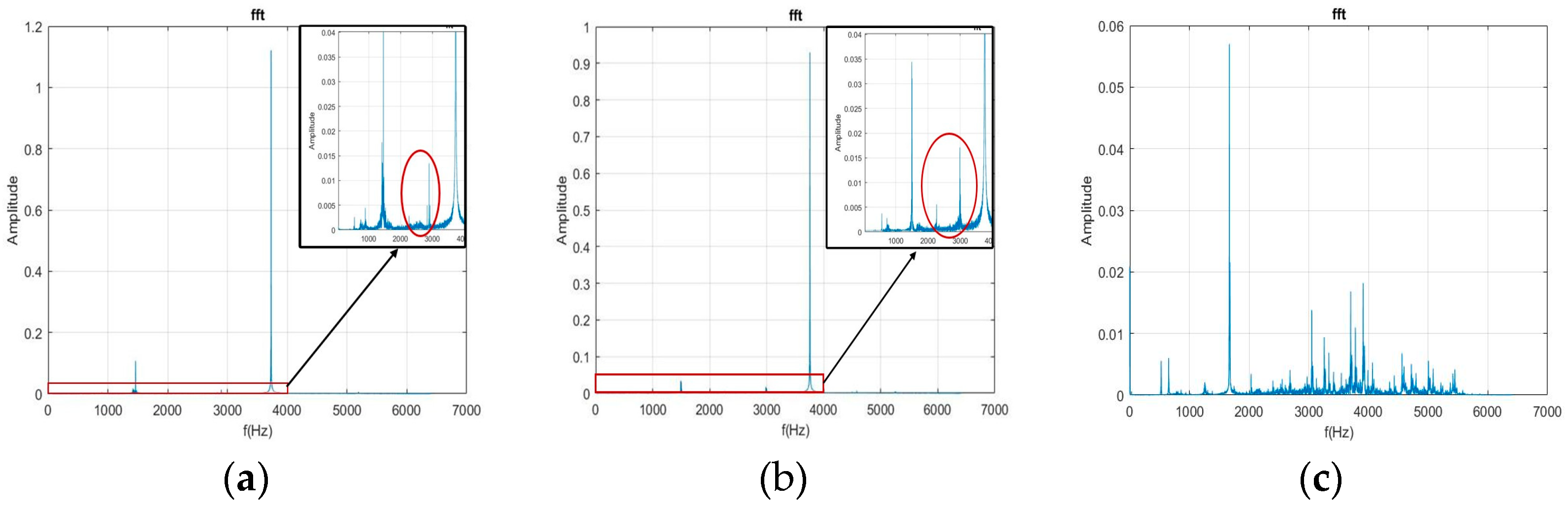

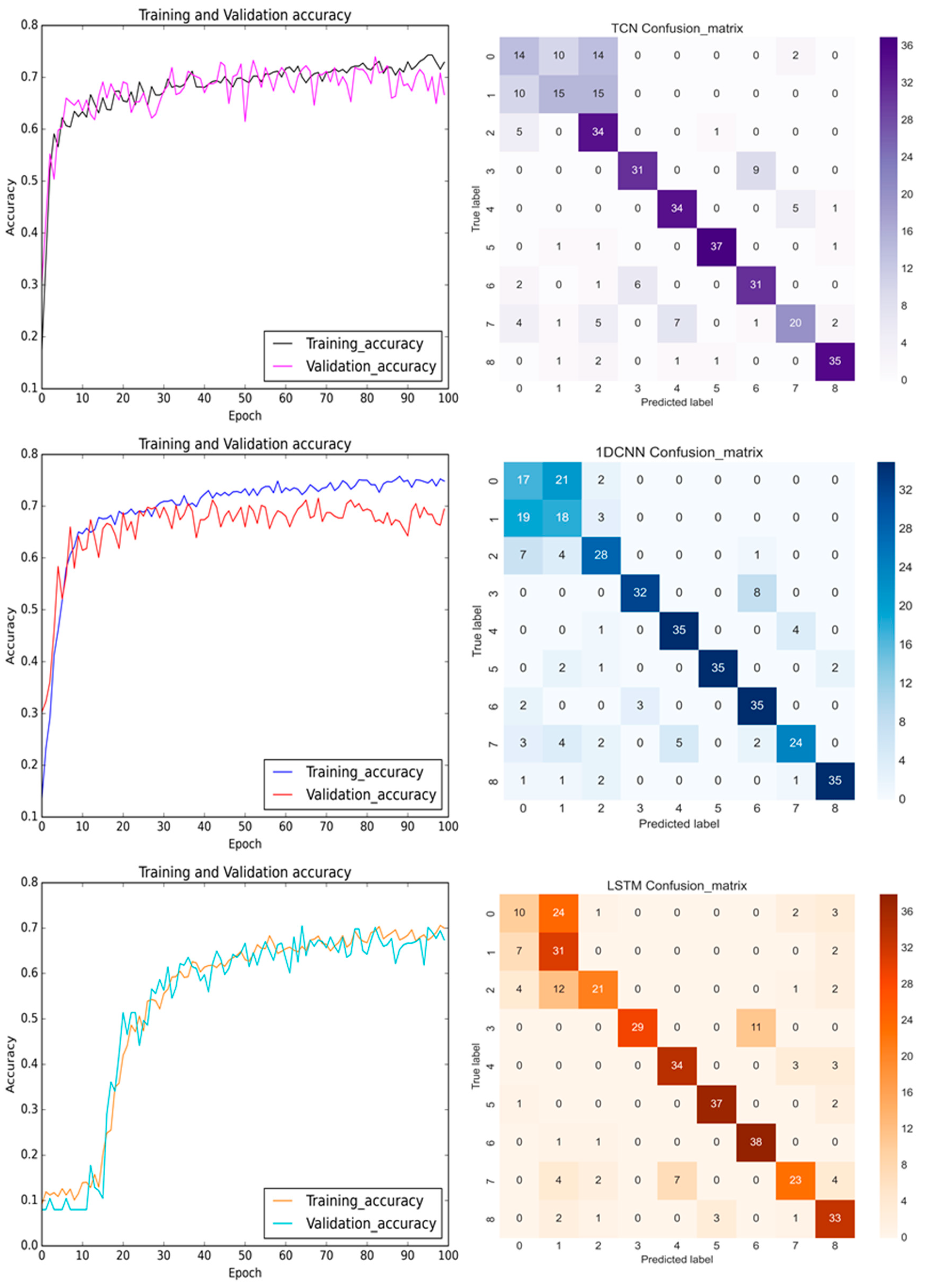
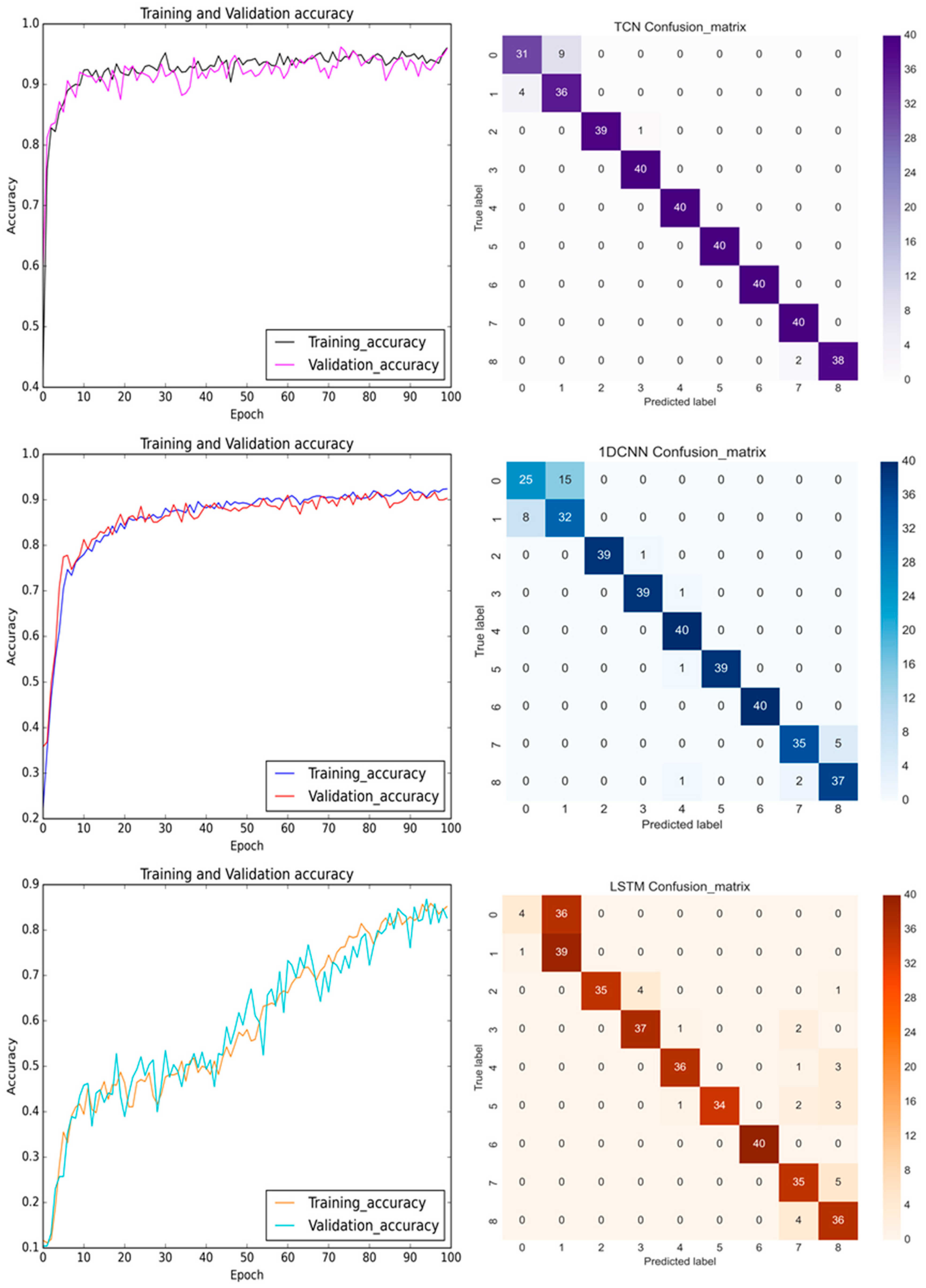



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}