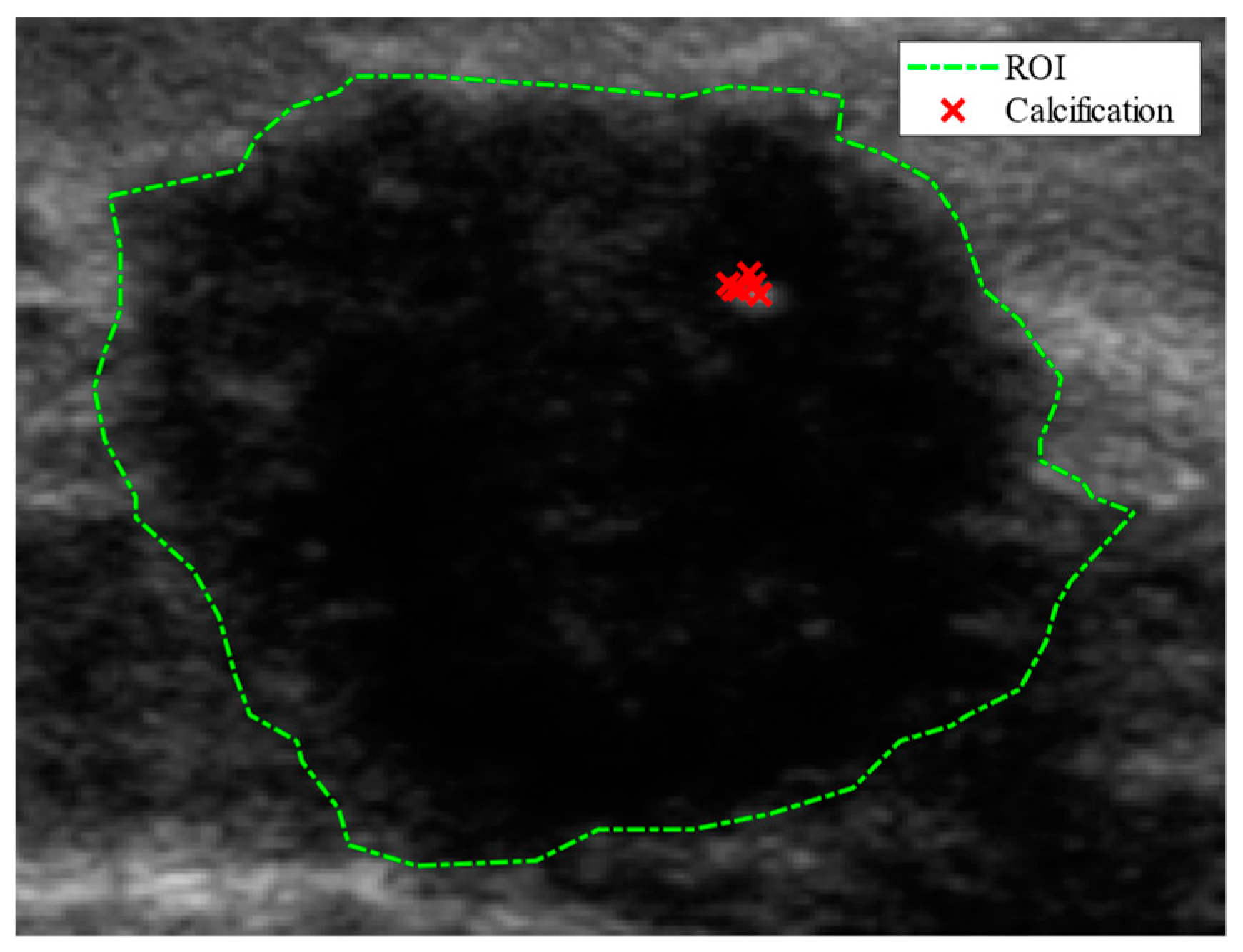
This section provides an overview of the research background, followed by a discussion of related work. First, the known US characteristics or signs of breast lesions are summarized. These signs will support the DCNN decision analysis as described in
Section 3. Second, we provide background information on the explainability of DCNN. Third, we present a literature review of breast lesion classification methods and the applications of explainability in DCNN using breast US images.
2.2. Explainability of DCNN Model Decisions
DCNNs consist of numerous weight parameters, finely adjusted during training, making the resulting features—achieved through convolution, activation, and pooling—challenging to interpret. Recognizing this, significant progress has been made in developing visualization techniques to map the connection between specific input regions or pixels and DCNN predictions. There are two types of techniques: post hoc methods, such as vanilla gradients [
15], Smoothgrad [
16], CAM [
9], and Grad-CAM [
8], which highlight the significant input features that influence model decisions, and explainable-by-design approaches, which integrate explainability directly into the model’s architecture. These approaches either adopt simpler, inherently interpretable structures—like linear regression or decision trees [
17]—or design more complex configurations, such as certain types of deep neural networks, to be transparent [
18]. In this study, we mainly focus on post hoc methods and review some of the most promising ones.
LIME (Local Interpretable Model-Agnostic Explanations). LIME is a general-purpose explanation scheme for classifiers built with machine learning for natural images. By generating local explanations, LIME helps to identify the regions within an input image that contribute most significantly to the classification decisions [
19]. Although LIME can be applied to explain cancer prediction models on US images, certain limitations should be acknowledged. The local explanations may not capture the global relationships and dependencies of certain cancer signs present in the image. The localized nature of LIME may also miss the broader context necessary to interpret lesion predictions correctly. The stability and consistency of LIME explanations may also vary, depending on the choice of hyperparameters and perturbation methods. Reliable explanations, therefore, require careful parameter tuning and robustness evaluations [
19].
SHAP (SHapley Additive exPlanations). SHAP has attracted attention in explaining cancer prediction models based on ultrasound images. By assigning importance values to features, SHAP offers insights into the relative contributions of different visual attributes in ultrasound images to the model’s predictions. Such global and local explanations help elucidate individual features’ impact on the cancer prediction [
20]. However, the computational complexity of SHAP can pose serious challenges, particularly with large-scale datasets and complex models. The interpretation of SHAP explanations also requires certain levels of expertise due to its reliance on game theory, limiting its accessibility to non-experts [
20].
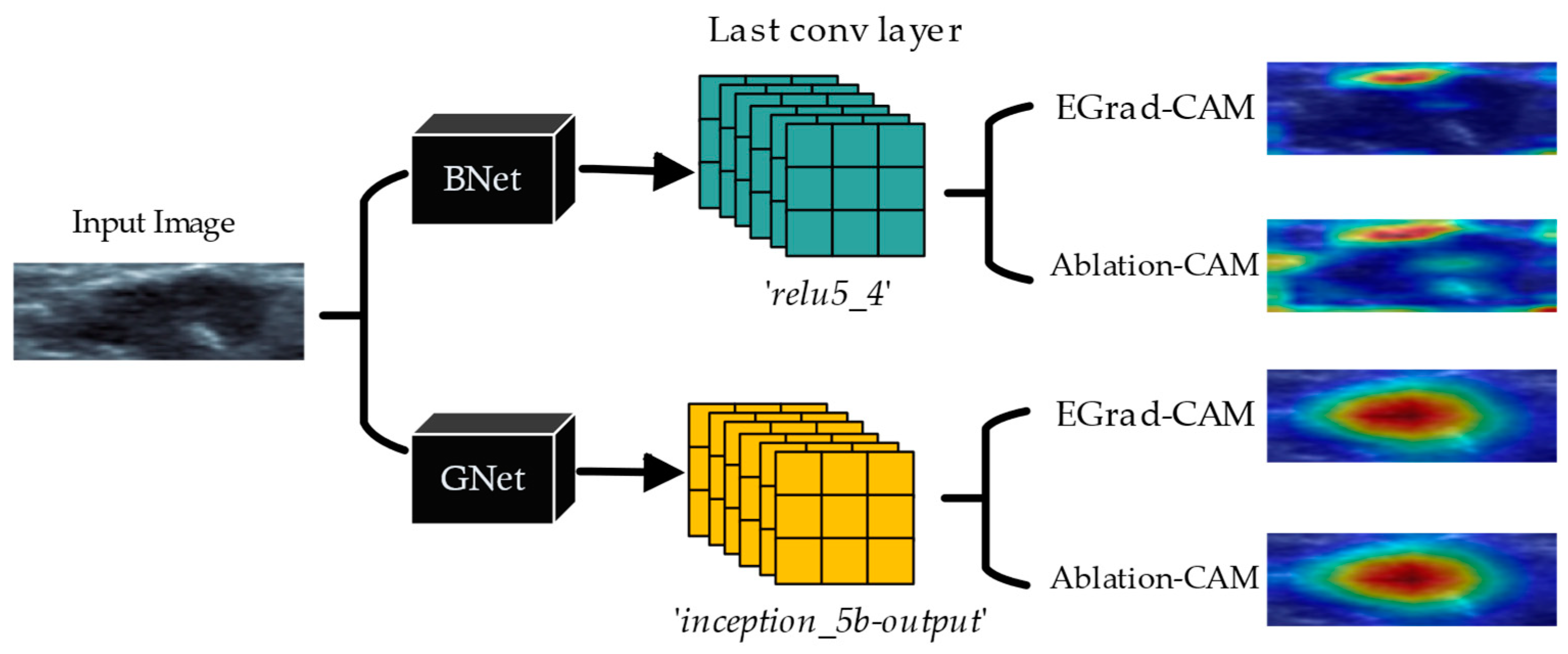
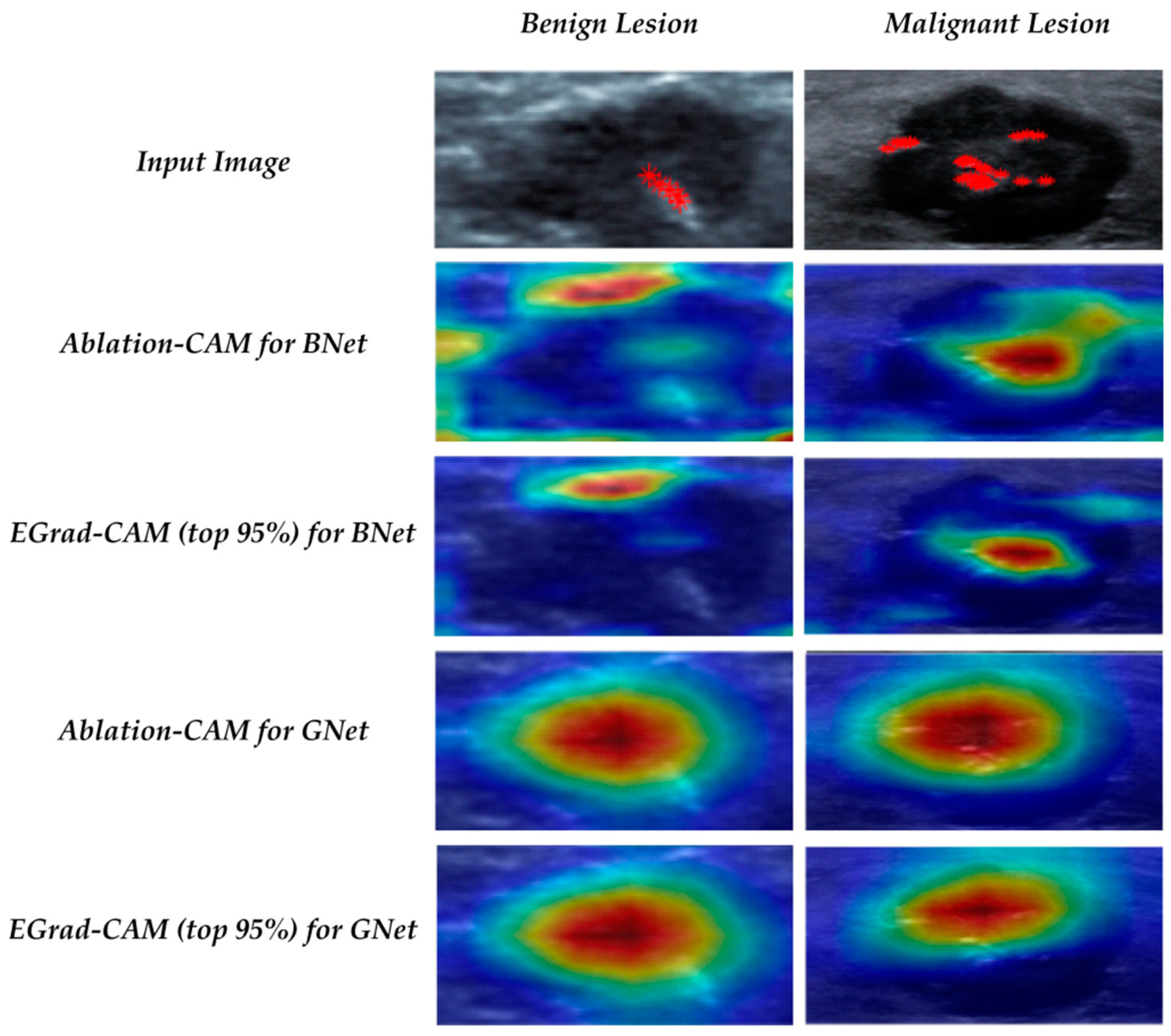
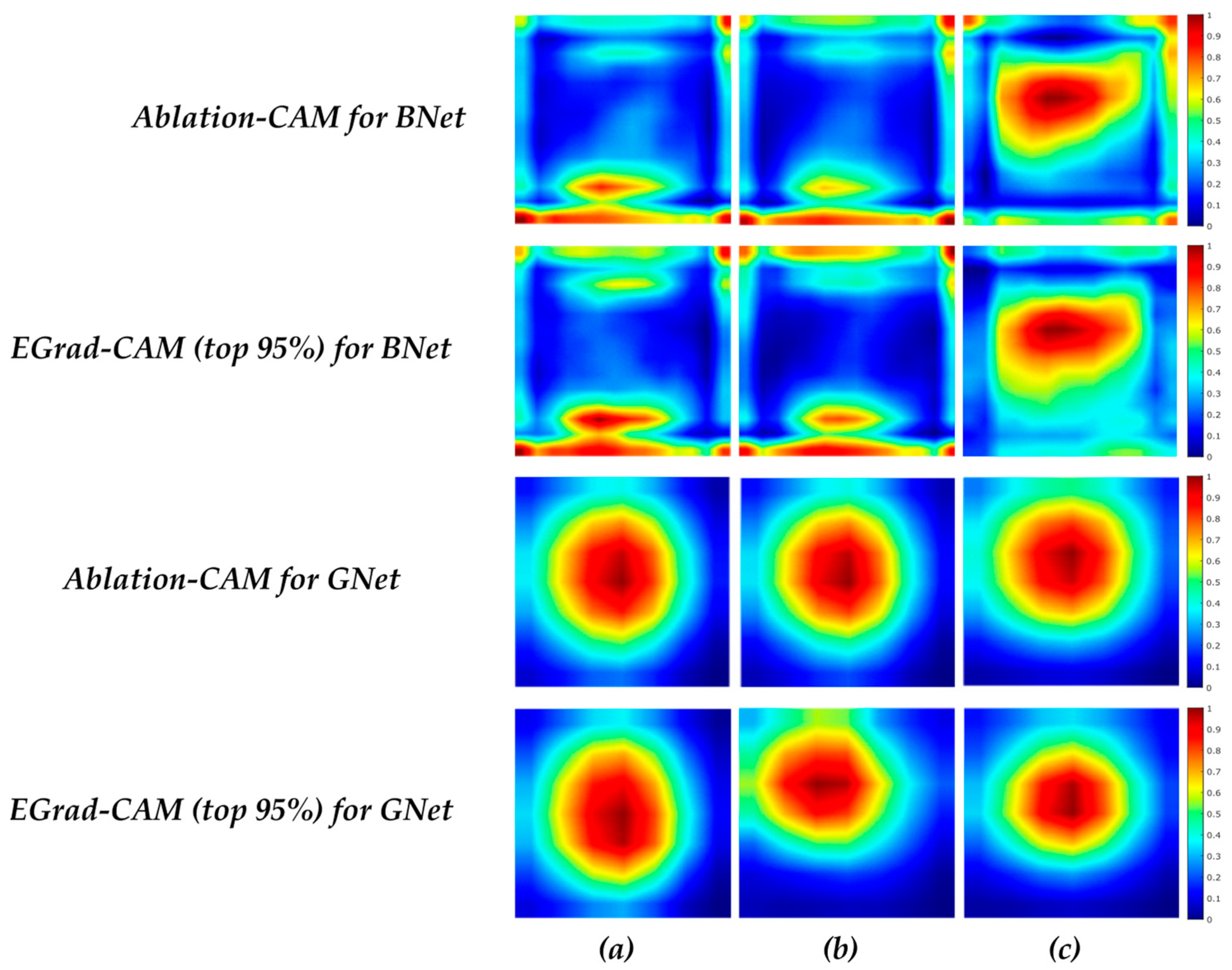
CAM (Class Activation Mapping). CAM is an approach that produces a heatmap showing how each input image pixel contributes to CNN classification decisions [
9]. In the CAM methods, a GAP layer is required to visualize the weighted sum of the resulting feature maps at the pre-softmax layer. Grad-CAM, a gradient-weighted class activation mapping scheme, was developed to generalize CAM without requiring a GAP layer [
8]. EGrad-CAM [
21] further uses the entropy of feature maps as a measure to select and only visualize feature maps with a high amount of information. Another approach of utilizing the gradient-free methods to visualize CNN is introduced by Score-CAM [
22], Ablation-CAM [
23], and Clustered-CAM [
24]. In this study, we investigate the effectiveness of EGrad-CAM and Ablation-CAM in visualizing classification decisions by CNN models for breast lesions.
The gradient of the score for class
c (pre-softmax)
is computed by EGrad-CAM using Equation (1), where
k is the index of the feature map at a spatial location
.
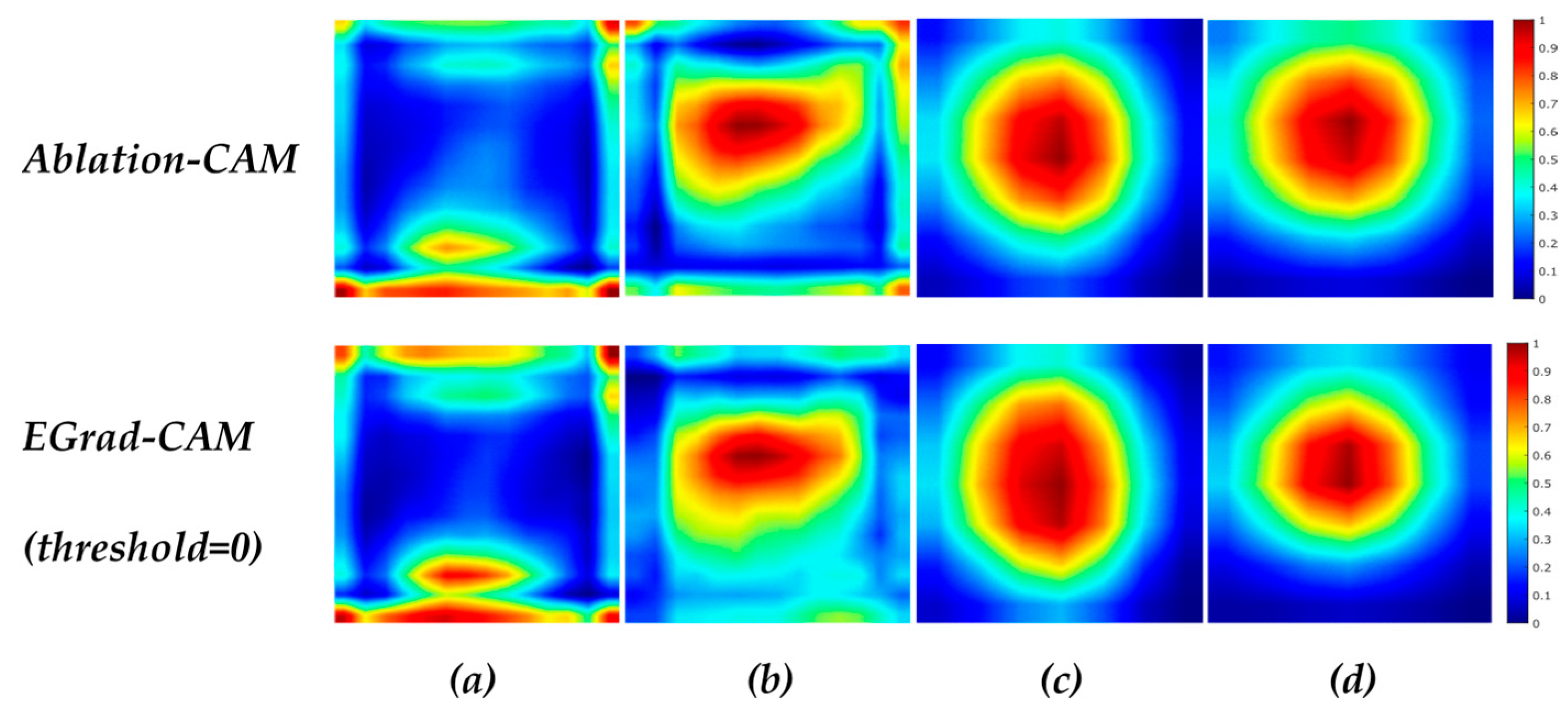
EGrad-CAM uses the entropy of feature maps to measure the amount of information within each feature map and visualizes the most informative feature maps. The entropy is calculated using Equation (2), where represents the probability of value appearing in the feature map.
Following that, a weighted sum of all these feature maps is calculated. Then, a ReLU function is applied to remove negative weights. Finally, heatmap scores are produced by aggregating feature maps with entropy greater than 0 or a predefined threshold. The final visualization output of EGrad-CAM is calculated using Equation (3).
Ablation-CAM determines which feature map units are most important based on their class, using ablation analysis. The basic principle behind Ablation-CAM is to freeze (or remove) each feature map from the last convolution layer and then check whether the prediction class remains the same. The ablated or deleted feature map is not a characteristic feature when the classification decision is not changed. Feature maps’ significance value
is the reduction in activation score (pre-softmax) when the feature map
is deleted.
where
is the activation score of class
c, and
is the score for class
c when feature map
k is eliminated. In Ablation-CAM, activation maps and associated weights are combined linearly from Equation (4), and the heatmap visualization is generated using Equation (5) [
23].
2.3. Lesion Classification from US Images
Many DCNN models have been developed to classify objects in natural images. It has been shown that VGG19 [
25] and GoogleNet [
26] among those DCNN models perform particularly well on the ImageNet dataset. VGG19 has 47 layers, 16 convolutional layers, 3 fully connected layers, and approximately 144 million weight parameters, whereas GoogleNet has 9 inception modules, is 22 layers deep (27 including the pooling layers), has a GAP layer at the end of the last inception module, and has approximately 7 million weight parameters. The use of DCNN architectures in the medical field has been investigated in several studies [
27]. Large datasets are often required to train such complex DCNN architectures. Medical image datasets are often limited in size, and so transfer learning (e.g., [
25,
26]) has been utilized to overcome the limitation. Several studies have followed this approach for classifying breast lesions in US images and achieved high performance [
2,
10,
28]. A generic VGG19-based DCNN architecture was adapted for classifying thyroid nodules and breast lesions from US images [
2]. The breast lesion model, trained on 672 breast lesion images, achieved an accuracy of 89%. Therefore, we built breast lesion classification models based on the adapted VGG19 (BNet) and GoogleNet architectures for this study.
Neiman et al. [
11] trained GoogleNet-based models using mammography and ultrasound images. The Grad-CAM method was used to gain insight into the decisions of lesion malignancy made by the models. Their study revealed that the models’ decisions over malignant lesions depend mainly on the boundaries of the lesions. Tanaka et al. [
10] developed an ensemble DCNN model using VGG19 and Resnet152 over US images of 897 malignant and 639 benign cases. Using the deconvnet method, they visualized the important input image regions for the model decisions. They found that benign cases are more likely to be detected than malignant ones. In [
29], the authors trained a Resnet18 network to classify breast lesions from US images. They applied Grad-CAM to locate the lesions and found that the main attention of their models focused on the lesion regions. In [
12], a weakly-supervised deep learning algorithm was developed to diagnose breast cancer without requiring image annotation. A weakly-supervised algorithm was applied to VGG16, ResNet34, and GoogleNet. They applied the CAM method to locate breast masses. Recently, AlZoubi et al. [
13] presented a comprehensive evaluation on transfer learning based solutions and automatically designed networks. The authors explored the use of saliency maps (EGrad-CAM and Ablation-CAM) to explain the classification decisions made by six DCNN models. The investigation showed that saliency maps can assist in comprehending the classification decisions.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}