

Cancerous and Non-Cancerous MRI Classification Using Dual DCNN Approach

 , , , and
, , , and
Abstract
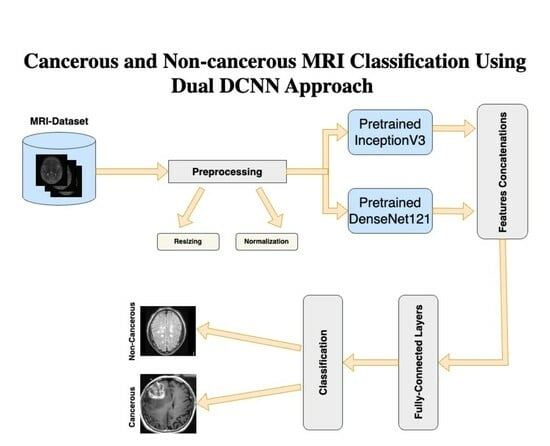
1. Introduction
- Our proposed Dual DCNN model with denseNet121 and inceptionV3 has shown promising results. We observed significant improvements in various performance metrics especially the accuracy demonstrating the capability to accurately classify cancerous and non-cancerous MRI samples.
- We have implemented SOTA DL models, i.e., denseNet121, inceptionV3, resNet50, resNet34, resNet18, efficientNetB2, squeezeNet, VGG16, alexNet, leNet-5, and compared results with our methodology. We have highlighted the best performance of our approach.
- We have compared the performance of each SOTA DL model with different learning rates and identified the best learning rate for each model.
- We compared our approach with the latest research in cancer detection and classification and through benchmarking we found our proposed approach outperformed existing methods.
2. Related Work
3. Methodology
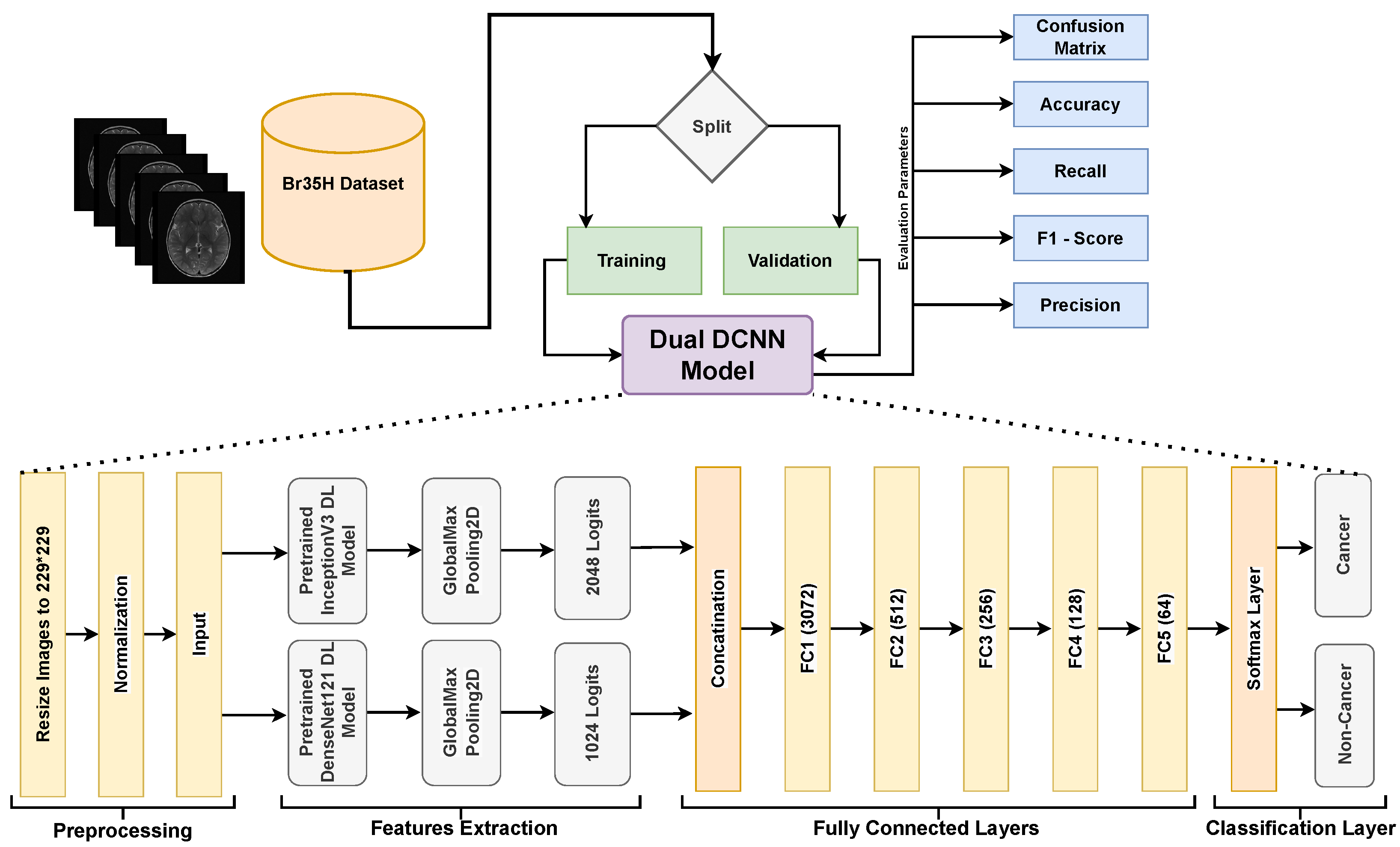
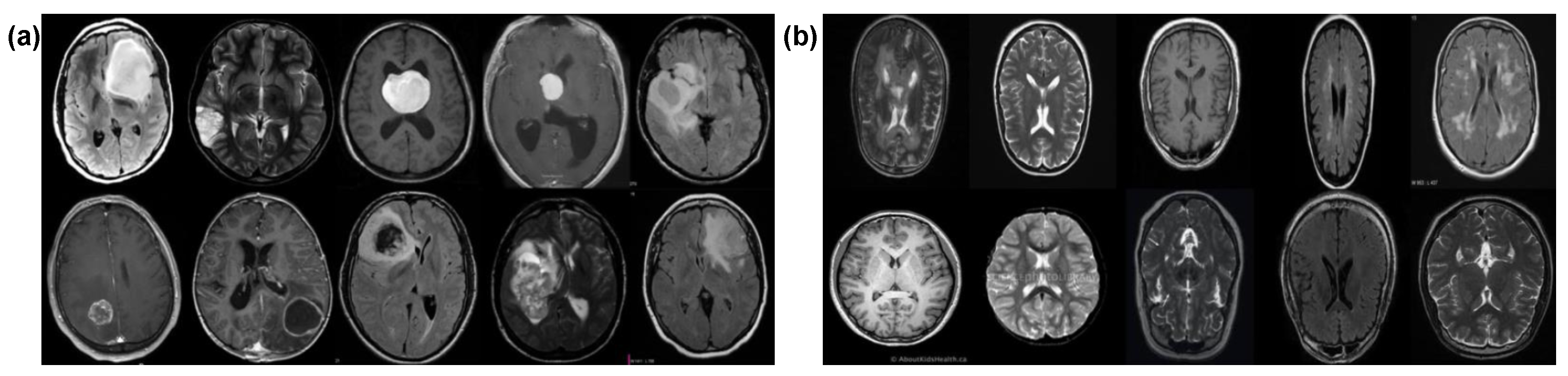
3.1. Dataset Description
3.2. Dual DCNN Model
3.2.1. Preprocessing
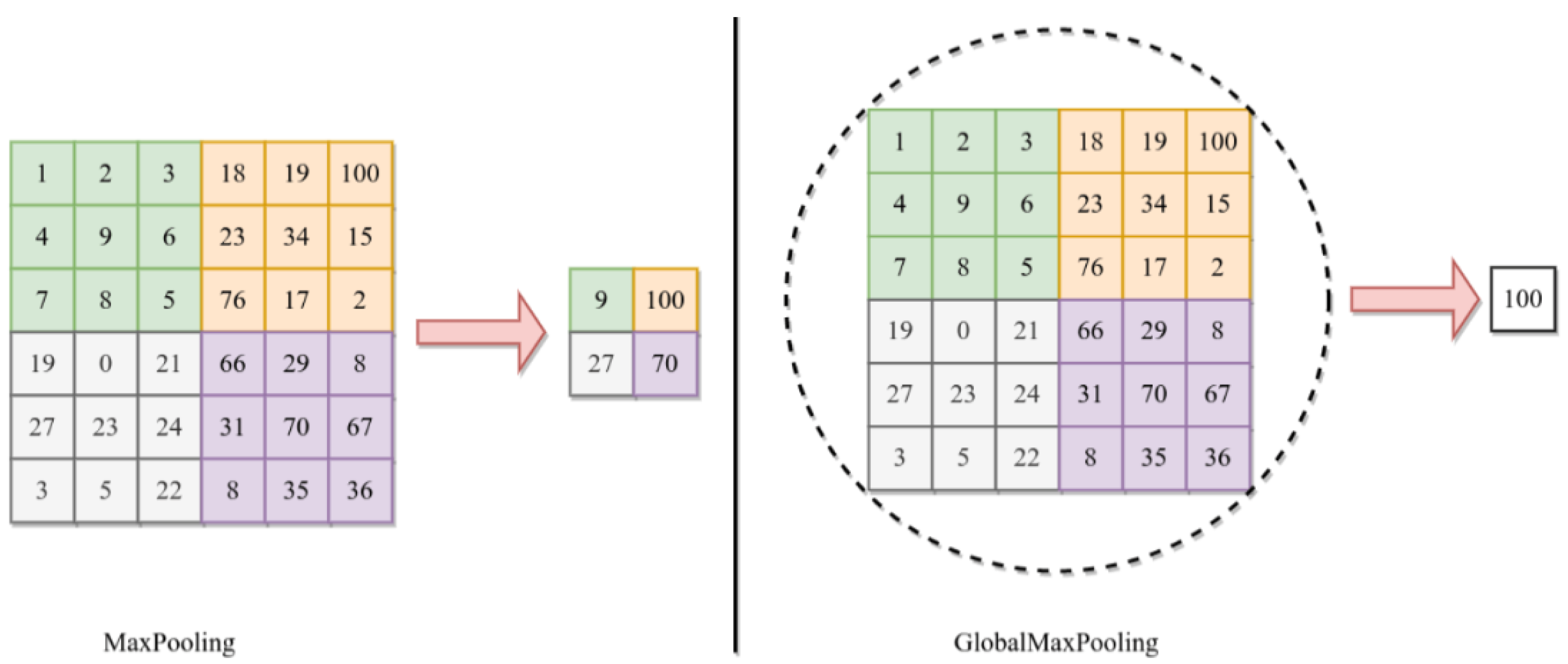
3.2.2. Features Extraction
3.2.3. Fully Connected Layers
3.2.4. Output Layer
3.3. SOTA DL Models
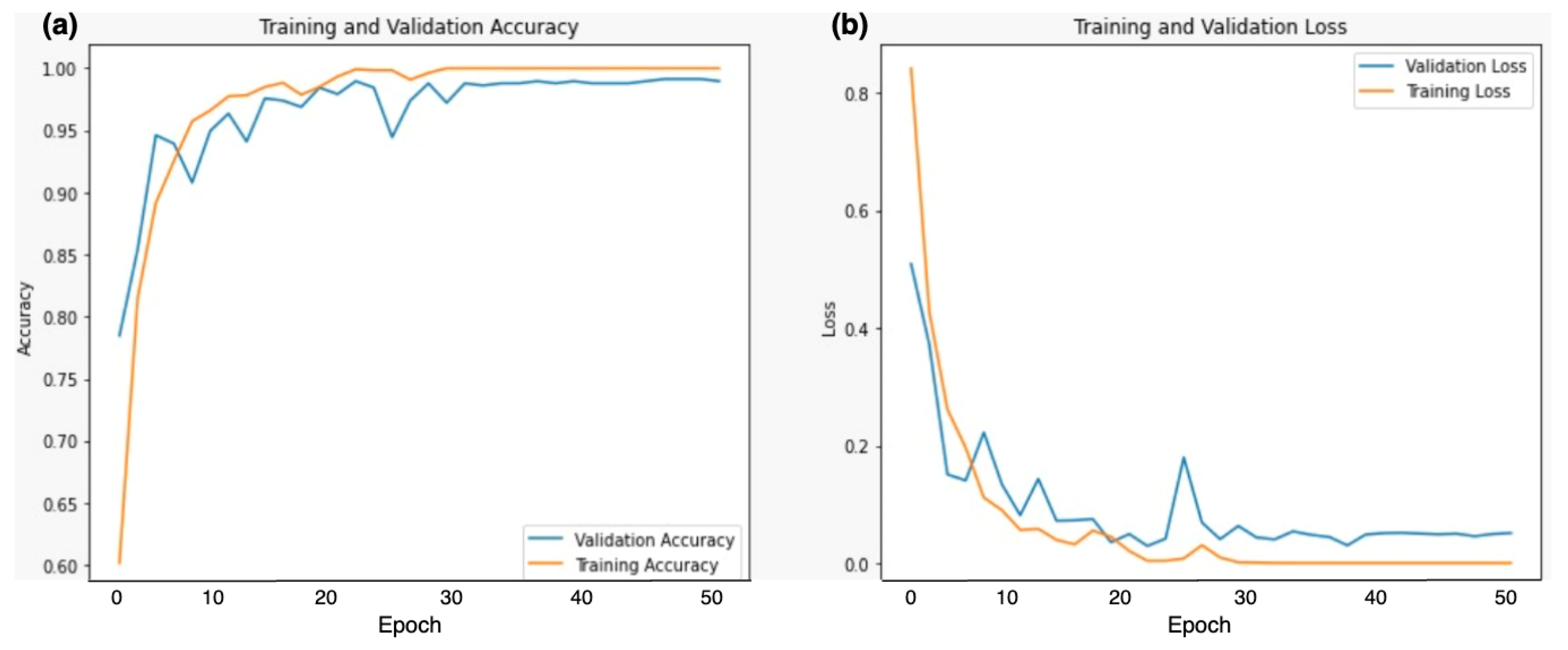
3.4. Training Parameters
4. Experimentation and Results Discussion
4.1. Experimental Setup
4.2. Evaluation Protocol
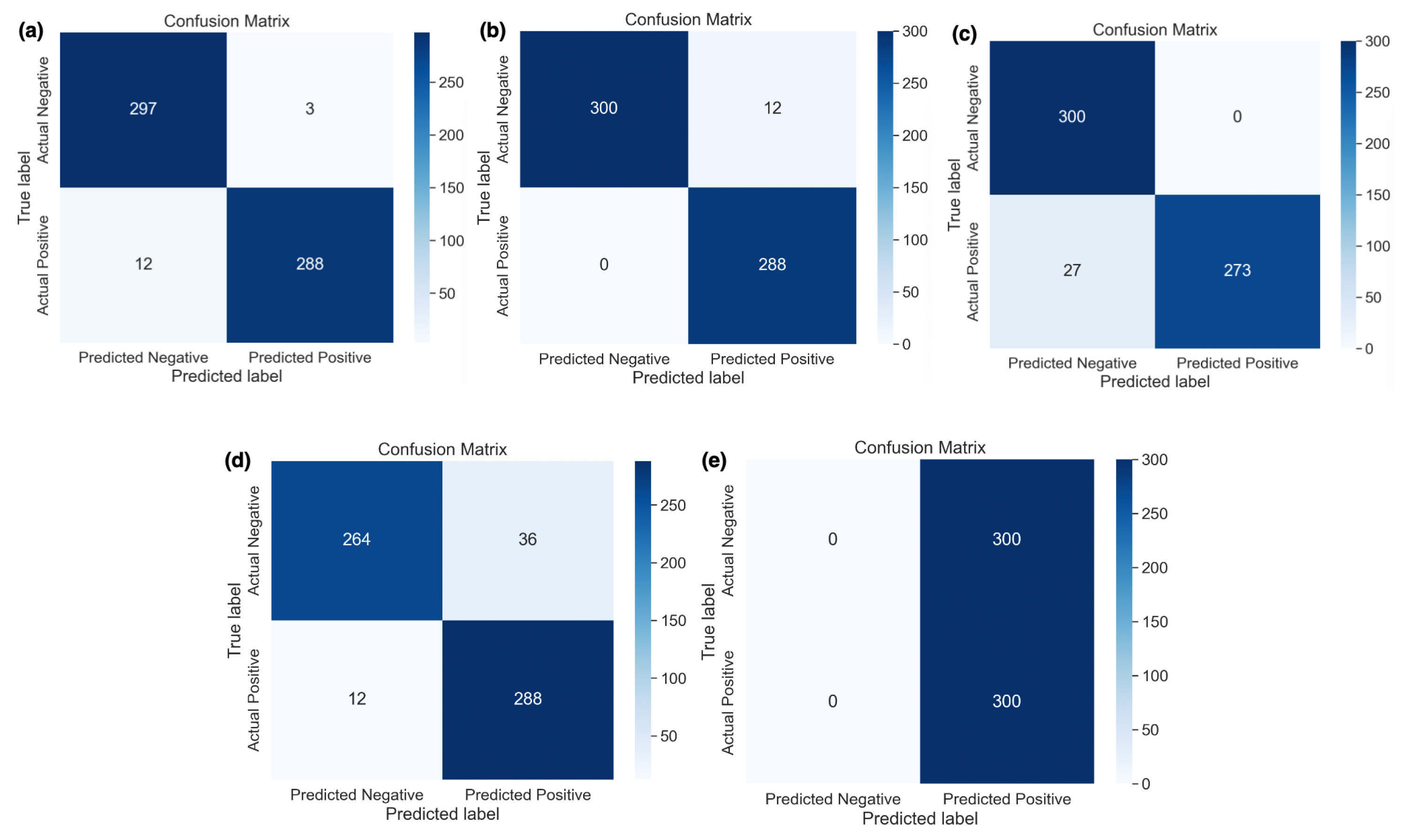
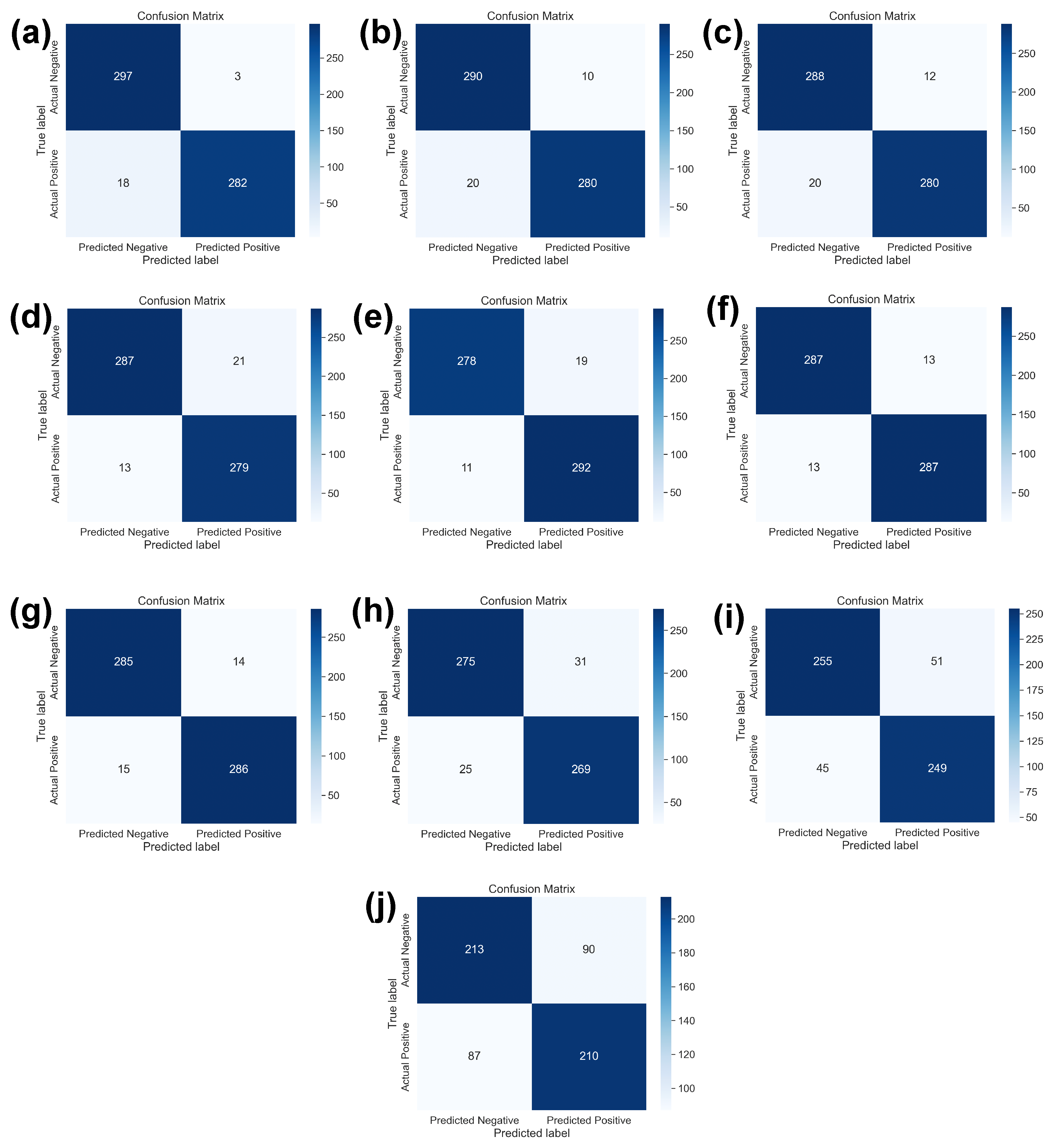
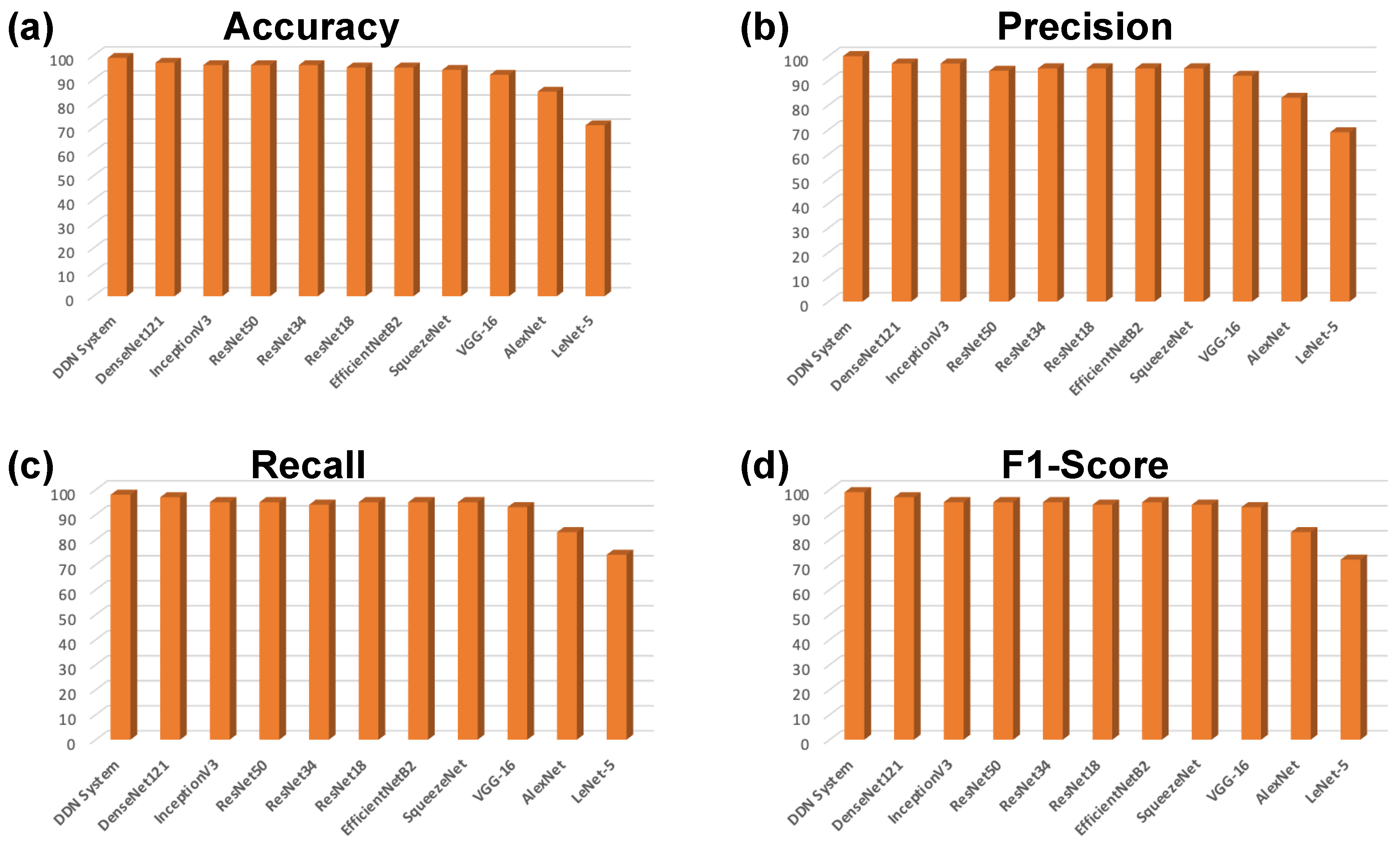
4.3. Results Discussion
4.4. Comparison of SOTA versus DDCNN Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohta, S.; Sharma, S.; Saraya, A. Improvement in adipocytic indices as a predictor of improved outcomes after TIPS: Right conclusion? Liver Int. Off. J. Int. Assoc. Study Liver 2021, 42, 253. [Google Scholar] [CrossRef]
- Ye, Z.; Srinivasa, K.; Meyer, A.; Sun, P.; Lin, J.; Viox, J.D.; Song, C.; Wu, A.T.; Song, S.K.; Dahiya, S.; et al. Diffusion histology imaging differentiates distinct pediatric brain tumor histology. Sci. Rep. 2021, 11, 4749. [Google Scholar] [CrossRef]
- Chen, Y.; Schönlieb, C.B.; Liò, P.; Leiner, T.; Dragotti, P.L.; Wang, G.; Rueckert, D.; Firmin, D.; Yang, G. AI-based reconstruction for fast MRI—A systematic review and meta-analysis. Proc. IEEE 2022, 110, 224–245. [Google Scholar] [CrossRef]
- Zacharaki, E.I.; Wang, S.; Chawla, S.; Soo, Y.D.; Wolf, R.; Melhem, E.R.; Davatzikos, C. Classification of brain tumor type and grade using MRI texture and shape in a machine learning scheme. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2009, 62, 1609–1618. [Google Scholar] [CrossRef]
- Saeed, Z.; Masood, M.; Khan, M.U. A review: Cybersecurity challenges and their solutions in connected and autonomous vehicles (CAVs). JAREE (J. Adv. Res. Electr. Eng.) 2023, 7. [Google Scholar] [CrossRef]
- Saeed, Z.; Awan, M.N.M.; Yousaf, M.H. A Robust Approach for Small-Scale Object Detection From Aerial-View. In Proceedings of the 2022 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Sydney, Australia, 30 November–2 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–7. [Google Scholar]
- Ishtiaq, A.; Saeed, Z.; Khan, M.U.; Samer, A.; Shabbir, M.; Ahmad, W. Fall detection, wearable sensors & artificial intelligence: A short review. JAREE (J. Adv. Res. Electr. Eng.) 2022, 6. [Google Scholar] [CrossRef]
- Naqvi, S.Z.H.; Khan, M.U.; Raza, A.; Saeed, Z.; Abbasi, Z.; Ali, S.Z.E.Z. Deep Learning Based Intelligent Classification of COVID-19 & Pneumonia Using Cough Auscultations. In Proceedings of the 2021 6th International Multi-Topic ICT Conference (IMTIC), Jamshoro & Karachi, Pakistan, 10–12 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Srinivas, C.; K. S., N.P.; Zakariah, M.; Alothaibi, Y.A.; Shaukat, K.; Partibane, B.; Awal, H. Deep transfer learning approaches in performance analysis of brain tumor classification using MRI images. J. Healthc. Eng. 2022, 2022, 3264367. [Google Scholar] [CrossRef]
- Abiwinanda, N.; Hanif, M.; Hesaputra, S.T.; Handayani, A.; Mengko, T.R. Brain tumor classification using convolutional neural network. In Proceedings of the World Congress on Medical Physics and Biomedical Engineering 2018, Prague, Czech Republic, 3–8 June 2018; Springer: Singapore, 2019; Volume 1, pp. 183–189. [Google Scholar]
- Song, G.; Xie, G.; Nie, Y.; Majid, M.S.; Yavari, I. Noninvasive grading of glioma brain tumors using magnetic resonance imaging and deep learning methods. J. Cancer Res. Clin. Oncol. 2023, 149, 16293–16309. [Google Scholar] [CrossRef]
- Fathima, M.N.; Shiney, J.; Singh, P. Deep Learning and Machine Learning Approaches for Brain Tumor Detection and Classification. In Proceedings of the 2023 International Conference on Circuit Power and Computing Technologies (ICCPCT), Kollam, India, 10–11 August 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 952–960. [Google Scholar] [CrossRef]
- Ghosal, P.; Nandanwar, L.; Kanchan, S.; Bhadra, A.; Chakraborty, J.; Nandi, D. Brain tumor classification using ResNet-101 based squeeze and excitation deep neural network. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Nawaz, M.; Nazir, T.; Masood, M.; Mehmood, A.; Mahum, R.; Khan, M.A.; Kadry, S.; Thinnukool, O. Analysis of brain MRI images using improved cornernet approach. Diagnostics 2021, 11, 1856. [Google Scholar] [CrossRef]
- Mohammed, B.A.; Senan, E.M.; Alshammari, T.S.; Alreshidi, A.; Alayba, A.M.; Alazmi, M.; Alsagri, A.N. Hybrid Techniques of Analyzing MRI Images for Early Diagnosis of Brain Tumours Based on Hybrid Features. Processes 2023, 11, 212. [Google Scholar] [CrossRef]
- Nassar, S.E.; Yasser, I.; Amer, H.M.; Mohamed, M.A. A robust MRI-based brain tumor classification via a hybrid deep learning technique. J. Supercomput. 2024, 80, 2403–2427. [Google Scholar] [CrossRef]
- Saha, P.; Das, R.; Das, S.K. BCM-VEMT: Classification of brain cancer from MRI images using deep learning and ensemble of machine learning techniques. Multimed. Tools Appl. 2023, 82, 44479–44506. [Google Scholar] [CrossRef]
- Badhon, A.I.M.; Hasan, M.S.; Haque, M.S.; Pranto, M.S.H.; Ghosh, S.; Alam, M.G.R. Diagnosing Prostate Cancer: An Implementation of Deep Machine Learning Fusion Network in MRI Using a Transfer Learning Approach. In Proceedings of the 2023 6th International Conference on Software Engineering and Information Management, Palmerston North, New Zealand, 31 January–2 February 2023; pp. 33–43. [Google Scholar]
- Al Rub, S.A.; Alaiad, A.; Hmeidi, I.; Quwaider, M.; Alzoubi, O. Hydrocephalus classification in brain computed tomography medical images using deep learning. Simul. Model. Pract. Theory 2023, 123, 102705. [Google Scholar] [CrossRef]
- Mehnatkesh, H.; Jalali, S.M.J.; Khosravi, A.; Nahavandi, S. An intelligent driven deep residual learning framework for brain tumor classification using MRI images. Expert Syst. Appl. 2023, 213, 119087. [Google Scholar] [CrossRef]
- Hamada, A. “Br35H: Brain Tumor Detection”, version 5; Kaggle: San Francisco, CA, USA, 2020; Available online: https://www.kaggle.com/datasets/viveknarayanuppala/br35h-binary (accessed on 13 August 2023).
- Raza, A.; Khan, M.U.; Saeed, Z.; Samer, S.; Mobeen, A.; Samer, A. Classification of eye diseases and detection of cataract using digital fundus imaging (DFI) and inception-V4 deep learning model. In Proceedings of the 2021 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 13–14 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 137–142. [Google Scholar] [CrossRef]
- Saeed, Z.; Khan, M.U.; Raza, A.; Khan, H.; Javed, J.; Arshad, A. Classification of pulmonary viruses X-ray and detection of COVID-19 based on invariant of inception-V 3 deep learning model. In Proceedings of the 2021 International Conference on Computing, Electronic and Electrical Engineering (ICE Cube), Quetta, Pakistan, 26–27 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Saeed, Z.; Khan, M.U.; Raza, A.; Sajjad, N.; Naz, S.; Salal, A. Identification of leaf diseases in potato crop using Deep Convolutional Neural Networks (DCNNs). In Proceedings of the 2021 16th International Conference on Emerging Technologies (ICET), Islamabad, Pakistan, 22–23 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Saeed, Z.; Yousaf, M.H.; Ahmed, R.; Velastin, S.A.; Viriri, S. On-board small-scale object detection for unmanned aerial vehicles (UAVs). Drones 2023, 7, 310. [Google Scholar] [CrossRef]
- Khan, M.U.; Abbasi, M.A.; Saeed, Z.; Asif, M.; Raza, A.; Urooj, U. Deep learning based intelligent emotion recognition and classification system. In Proceedings of the 2021 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 13–14 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 25–30. [Google Scholar]
- Saeed, Z.; Raza, A.; Qureshi, A.H.; Yousaf, M.H. A multi-crop disease detection and classification approach using cnn. In Proceedings of the 2021 International Conference on Robotics and Automation in Industry (ICRAI), Rawalpindi, Pakistan, 26–27 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Zulfiqar, F.; Bajwa, U.I.; Mehmood, Y. Multi-class classification of brain tumor types from MR images using EfficientNets. Biomed. Signal Process. Control. 2023, 84, 104777. [Google Scholar] [CrossRef]
- Yerukalareddy, D.R.; Pavlovskiy, E. Brain tumor classification based on mr images using GAN as a pre-trained model. In Proceedings of the 2021 IEEE Ural-Siberian Conference on Computational Technologies in Cognitive Science, Genomics and Biomedicine (CSGB), Novosibirsk-Yekaterinburg, Russia, 26–28 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 380–384. [Google Scholar] [CrossRef]
- Verma, A.; Singh, V.P. Design, analysis and implementation of efficient deep learning frameworks for brain tumor classification. Multimed. Tools Appl. 2022, 81, 37541–37567. [Google Scholar] [CrossRef]
- Deepak, S.; Ameer, P.M. Brain tumor classification using deep CNN features via transfer learning. Comput. Biol. Med. 2019, 111, 103345. [Google Scholar] [CrossRef]
- Díaz-Pernas, F.J.; Martínez-Zarzuela, M.; Antón-Rodríguez, M.; González-Ortega, D. A deep learning approach for brain tumor classification and segmentation using a multiscale convolutional neural network. Healthcare 2021, 9, 153. [Google Scholar] [CrossRef]
- Hilles, S.M.; Saleh, N.S. Image Segmentation and Classification Using CNN Model to Detect Brain Tumors. In Proceedings of the 2021 2nd International Informatics and Software Engineering Conference (IISEC), Ankara, Turkey, 16–17 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Vidyarthi, A.; Agarwal, R.; Gupta, D.; Sharma, R.; Draheim, D.; Tiwari, P. Machine Learning Assisted Methodology for multiclass classification of malignant brain tumors. IEEE Access 2022, 10, 50624–50640. [Google Scholar] [CrossRef]
- Molder, C.; Lowe, B.; Zhan, J. Learning Medical Materials From Radiography Images. Front. Artif. Intell. 2021, 4, 638299. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
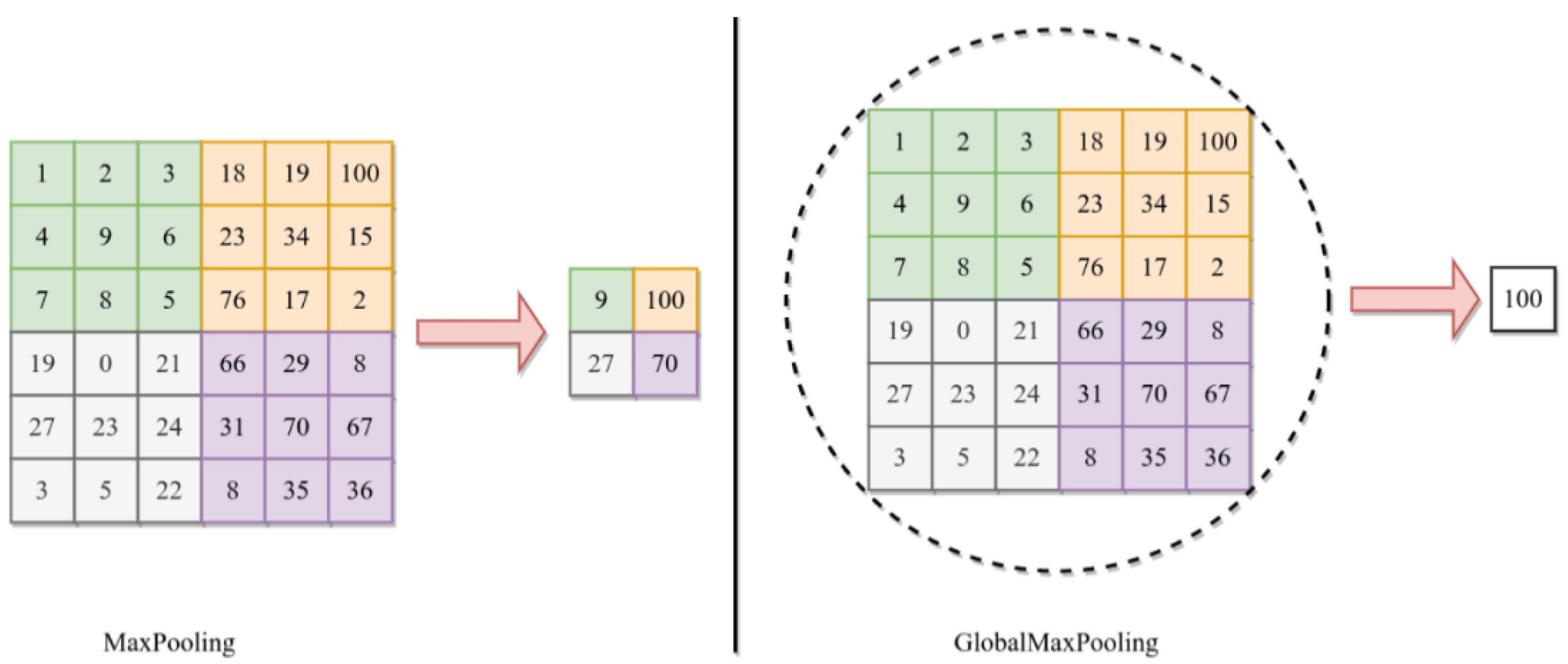{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Images | Train | Validation | Label |
|---|---|---|---|---|
| Cancerous | 1500 | 1200 | 300 | 1 “Yes” |
| Non-Cancerous | 1500 | 1200 | 300 | 0 “No” |
| Total | 3000 | 2400 | 600 |
| Sr. No | Parameters | Value |
|---|---|---|
| 1 | Learning Rates | 0.1, 0.01, 0.001, 0.0001, and 0.00001 |
| 2 | Batch Size | 128 |
| 3 | Number of Epochs | 50 |
| 4 | Loss Function | Adam Optimizer With Binary Cross-Entropy |
| 5 | Shuffle | Every Epoch |
| Model | Learning Rate | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| DDCNN | 0.0001 | 99 | 99 | 98 | 99 |
| DenseNet121 | 0.001 | 97 | 97 | 97 | 97 |
| InceptionV3 | 0.01 | 96 | 97 | 95 | 95 |
| ResNet50 | 0.00001 | 96 | 94 | 95 | 95 |
| ResNet34 | 0.00001 | 96 | 95 | 94 | 95 |
| ResNet18 | 0.0001 | 95 | 94 | 95 | 94 |
| EfficinetNetB2 | 0.00001 | 95 | 95 | 95 | 95 |
| SqueezeNet | 0.0001 | 94 | 95 | 95 | 94 |
| VGG-16 | 0.0001 | 92 | 92 | 93 | 93 |
| AlexNet | 0.0001 | 85 | 83 | 83 | 83 |
| LeNet-5 | 0.001 | 71 | 69 | 74 | 72 |
| Model | Learning Rate | Class | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| DDCNN model | 0.0001 | 0 | 99 | 99 | 98 | 99 |
| 1 | 99 | 99 | 99 | 99 | ||
| DenseNet121 | 0.001 | 0 | 98 | 97 | 97 | 97 |
| 1 | 96 | 96 | 96 | 96 | ||
| InceptionV3 | 0.01 | 0 | 97 | 96 | 95 | 95 |
| 1 | 95 | 96 | 96 | 94 | ||
| ResNet50 | 0.00001 | 0 | 97 | 97 | 96 | 95 |
| 1 | 95 | 96 | 94 | 95 | ||
| ResNet34 | 0.00001 | 0 | 97 | 96 | 95 | 96 |
| 1 | 95 | 95 | 93 | 94 | ||
| ResNet18 | 0.0001 | 0 | 96 | 94 | 96 | 94 |
| 1 | 94 | 94 | 94 | 95 | ||
| EfficinetNetB2 | 0.00001 | 0 | 96 | 95 | 95 | 95 |
| 1 | 94 | 94 | 94 | 95 | ||
| SqueezeNet | 0.0001 | 0 | 95 | 96 | 95 | 94 |
| 1 | 93 | 94 | 94 | 94 | ||
| VGG-16 | 0.0001 | 0 | 93 | 92 | 93 | 93 |
| 1 | 91 | 92 | 92 | 93 | ||
| AlexNet | 0.0001 | 0 | 90 | 84 | 81 | 84 |
| 1 | 80 | 81 | 80 | 81 | ||
| LeNet-5 | 0.001 | 0 | 79 | 75 | 78 | 79 |
| 1 | 64 | 61 | 66 | 68 |
| Model | Learning Rate | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| DDCNN Model | 0.1 | 50 | 25 | 50 | 33 |
| 0.01 | 92 | 92 | 92 | 92 | |
| 0.001 | 95 | 96 | 96 | 95 | |
| 0.0001 | 99 | 99 | 98 | 99 | |
| 0.00001 | 98 | 98 | 98 | 98 | |
| DenseNet121 | 0.1 | 70 | 71 | 71 | 70 |
| 0.01 | 68 | 71 | 68 | 66 | |
| 0.001 | 97 | 97 | 97 | 97 | |
| 0.0001 | 95 | 96 | 96 | 95 | |
| 0.00001 | 83 | 86 | 83 | 83 | |
| InceptionV3 | 0.1 | 48 | 46 | 48 | 42 |
| 0.01 | 96 | 97 | 95 | 95 | |
| 0.001 | 94 | 95 | 94 | 94 | |
| 0.0001 | 74 | 78 | 74 | 74 | |
| 0.00001 | 50 | 50 | 50 | 50 | |
| ResNet50 | 0.1 | 67 | 67 | 67 | 66 |
| 0.01 | 93 | 93 | 93 | 93 | |
| 0.001 | 95 | 95 | 96 | 95 | |
| 0.0001 | 77 | 79 | 77 | 78 | |
| 0.00001 | 96 | 94 | 95 | 95 | |
| ResNet34 | 0.1 | 68 | 68 | 68 | 67 |
| 0.01 | 94 | 94 | 94 | 93 | |
| 0.001 | 95 | 94 | 95 | 94 | |
| 0.0001 | 67 | 69 | 67 | 66 | |
| 0.00001 | 96 | 95 | 94 | 95 | |
| ResNet18 | 0.1 | 58 | 74 | 58 | 50 |
| 0.01 | 66 | 80 | 66 | 61 | |
| 0.001 | 94 | 94 | 94 | 93 | |
| 0.0001 | 95 | 94 | 95 | 94 | |
| 0.00001 | 93 | 94 | 93 | 93 | |
| EfficinetNetB2 | 0.1 | 67 | 66 | 66 | 65 |
| 0.01 | 85 | 87 | 85 | 85 | |
| 0.001 | 89 | 91 | 89 | 89 | |
| 0.0001 | 93 | 94 | 93 | 94 | |
| 0.00001 | 95 | 95 | 95 | 95 | |
| SqueezeNet | 0.1 | 50 | 25 | 50 | 33 |
| 0.01 | 60 | 62 | 62 | 61 | |
| 0.001 | 91 | 92 | 91 | 91 | |
| 0.0001 | 94 | 95 | 95 | 94 | |
| 0.00001 | 90 | 90 | 90 | 90 | |
| VGG-16 | 0.1 | 50 | 25 | 50 | 33 |
| 0.01 | 88 | 78 | 84 | 80 | |
| 0.001 | 91 | 92 | 91 | 91 | |
| 0.0001 | 92 | 92 | 93 | 93 | |
| 0.00001 | 90 | 90 | 90 | 90 | |
| AlexNet | 0.1 | 50 | 25 | 50 | 33 |
| 0.01 | 60 | 55 | 58 | 54 | |
| 0.001 | 83 | 83 | 83 | 83 | |
| 0.0001 | 85 | 83 | 83 | 83 | |
| 0.00001 | 84 | 83 | 82 | 82 | |
| LeNet-5 | 0.1 | 54 | 29 | 54 | 37 |
| 0.01 | 61 | 64 | 59 | 61 | |
| 0.001 | 71 | 69 | 74 | 72 | |
| 0.0001 | 67 | 66 | 66 | 65 | |
| 0.00001 | 70 | 69 | 69 | 68 |
| Research | Methodology | Model | Accuracy |
|---|---|---|---|
| In [28] | CNN-Fine Tuned | EfficientNetB2 | 98.86% |
| In [29], | Generative Adversarial Network (GAN) | MSGGAN | 98.57% |
| In [30], | DCNN-Transfer Learning | DenseNet201 | 98.22% |
| In [31], | CNN-Transfer Learning | GoogleNet | 98% |
| In [32], | CNN-Novel | Self CNN | 97.3% |
| In [33], | CNN-Cross Validation | Self CNN | 96.56% |
| In [34], | Neural Network (NN) | Self NN | 95.86% |
| In [35], | Siamese Neural Network (SNN) | MAC-CNN | 92.8% |
| Our Approach | Dual DCNN Model | DDCNN | 99% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeed, Z.; Bouhali, O.; Ji, J.X.; Hammoud, R.; Al-Hammadi, N.; Aouadi, S.; Torfeh, T. Cancerous and Non-Cancerous MRI Classification Using Dual DCNN Approach. Bioengineering 2024, 11, 410. https://doi.org/10.3390/bioengineering11050410
Saeed Z, Bouhali O, Ji JX, Hammoud R, Al-Hammadi N, Aouadi S, Torfeh T. Cancerous and Non-Cancerous MRI Classification Using Dual DCNN Approach. Bioengineering. 2024; 11(5):410. https://doi.org/10.3390/bioengineering11050410
Chicago/Turabian StyleSaeed, Zubair, Othmane Bouhali, Jim Xiuquan Ji, Rabih Hammoud, Noora Al-Hammadi, Souha Aouadi, and Tarraf Torfeh. 2024. "Cancerous and Non-Cancerous MRI Classification Using Dual DCNN Approach" Bioengineering 11, no. 5: 410. https://doi.org/10.3390/bioengineering11050410
APA StyleSaeed, Z., Bouhali, O., Ji, J. X., Hammoud, R., Al-Hammadi, N., Aouadi, S., & Torfeh, T. (2024). Cancerous and Non-Cancerous MRI Classification Using Dual DCNN Approach. Bioengineering, 11(5), 410. https://doi.org/10.3390/bioengineering11050410