
Brain Age Prediction Using Multi-Hop Graph Attention Combined with Convolutional Neural Network
 ,
,
Abstract
1. Introduction
2. Materials and Methods
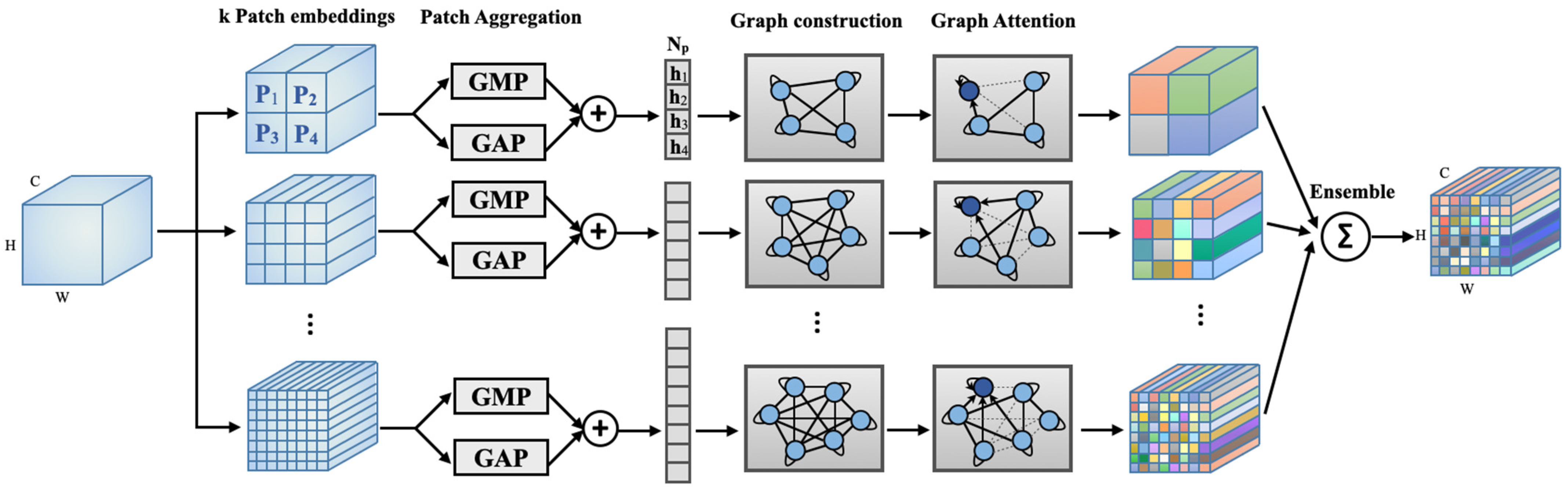
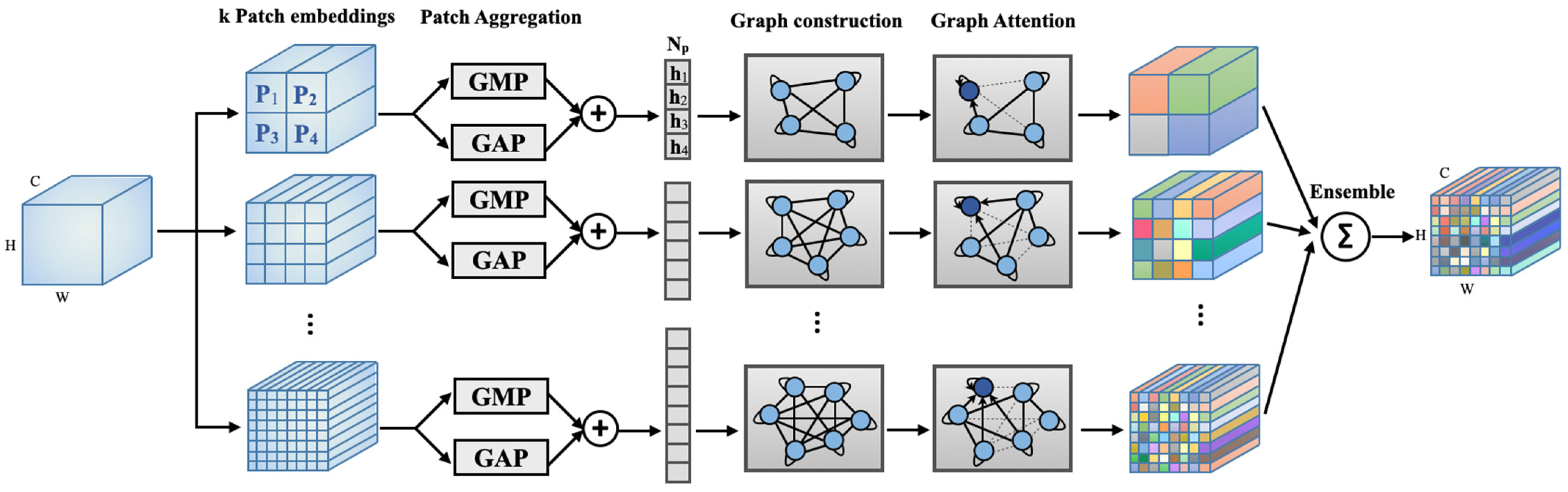
2.1. Overview of Multi-Hop Graph Attention
2.2. Graph Construction
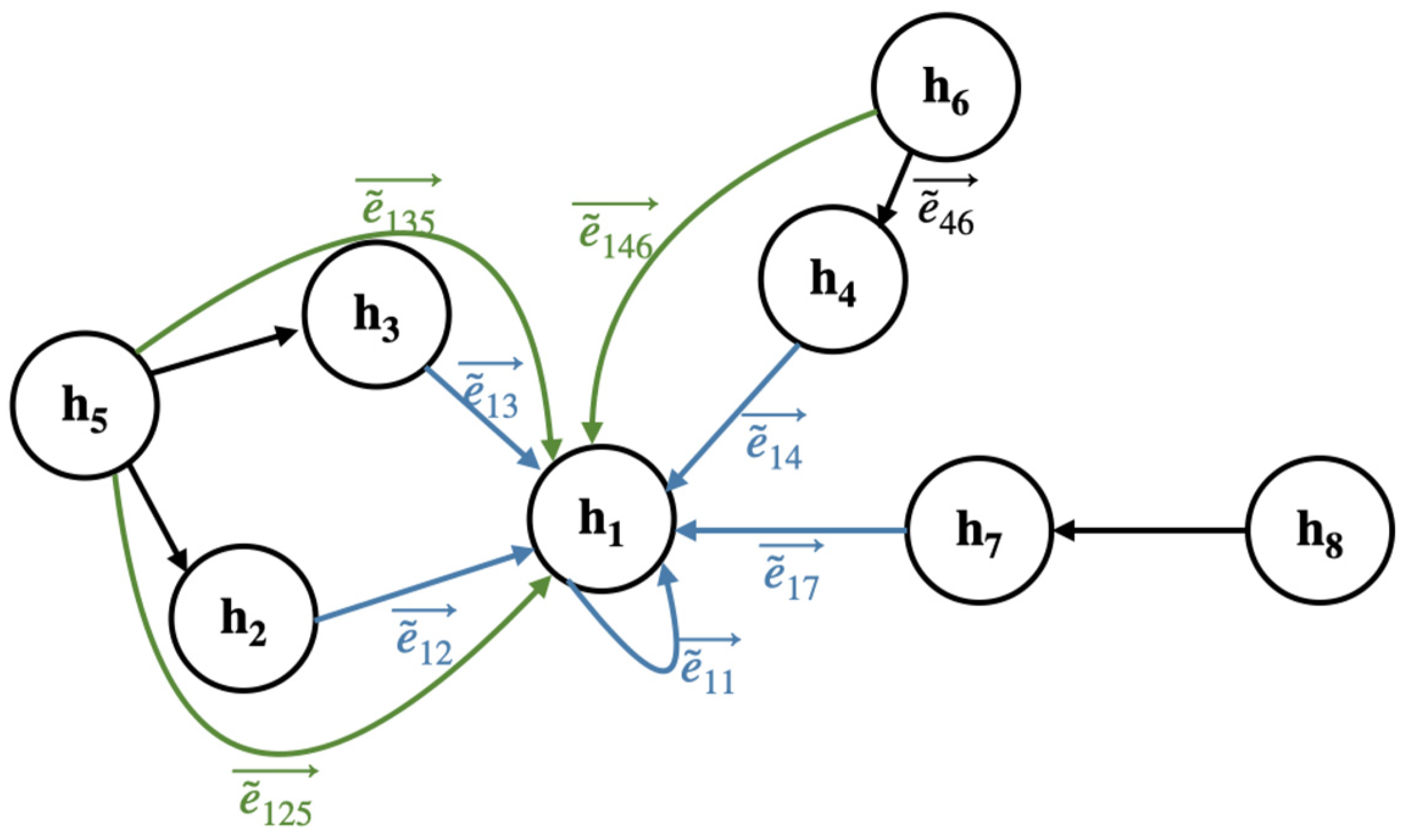
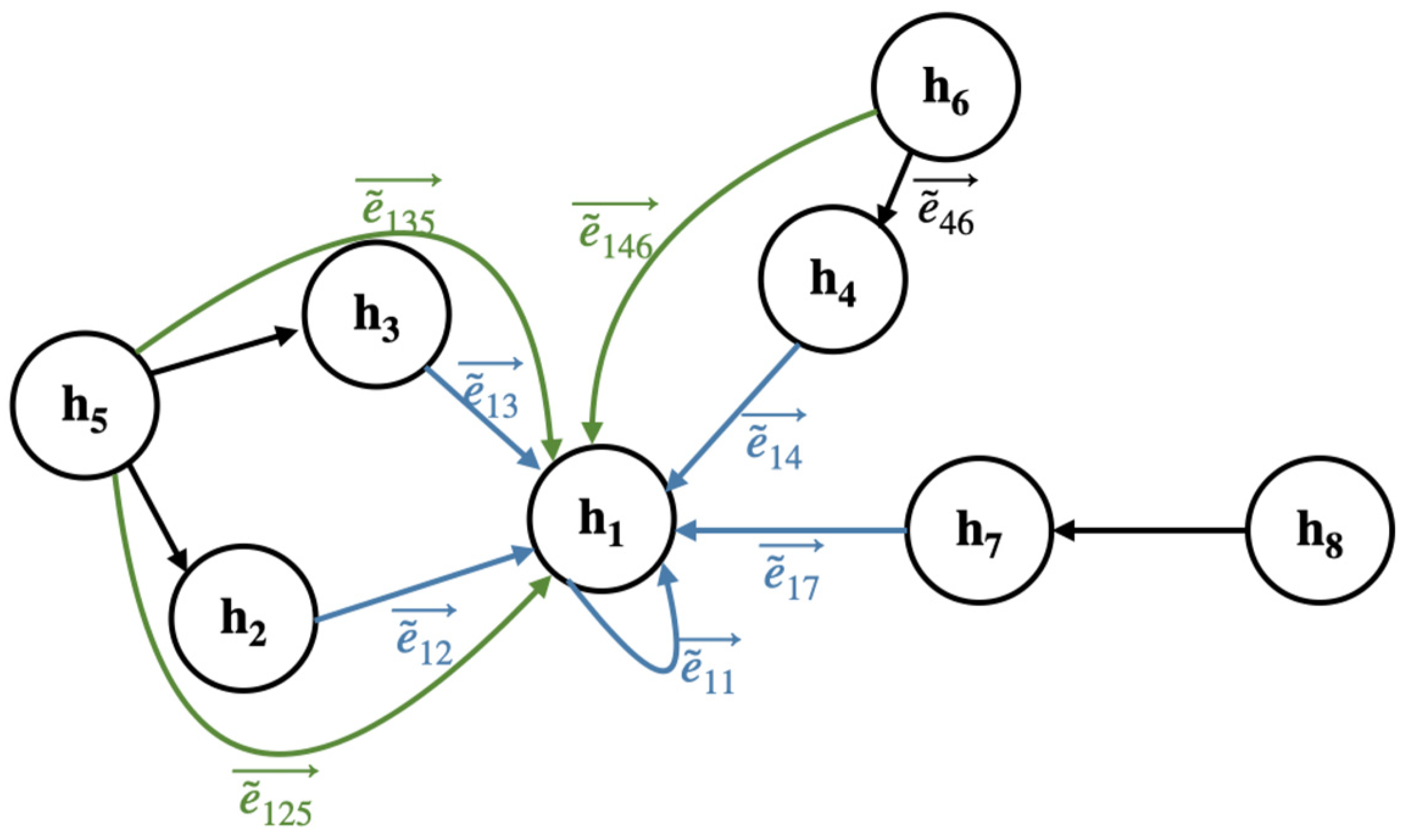
2.3. The Multi-Hop Neighborhood of Nodes
2.4. Updating Nodes via Graph Attention
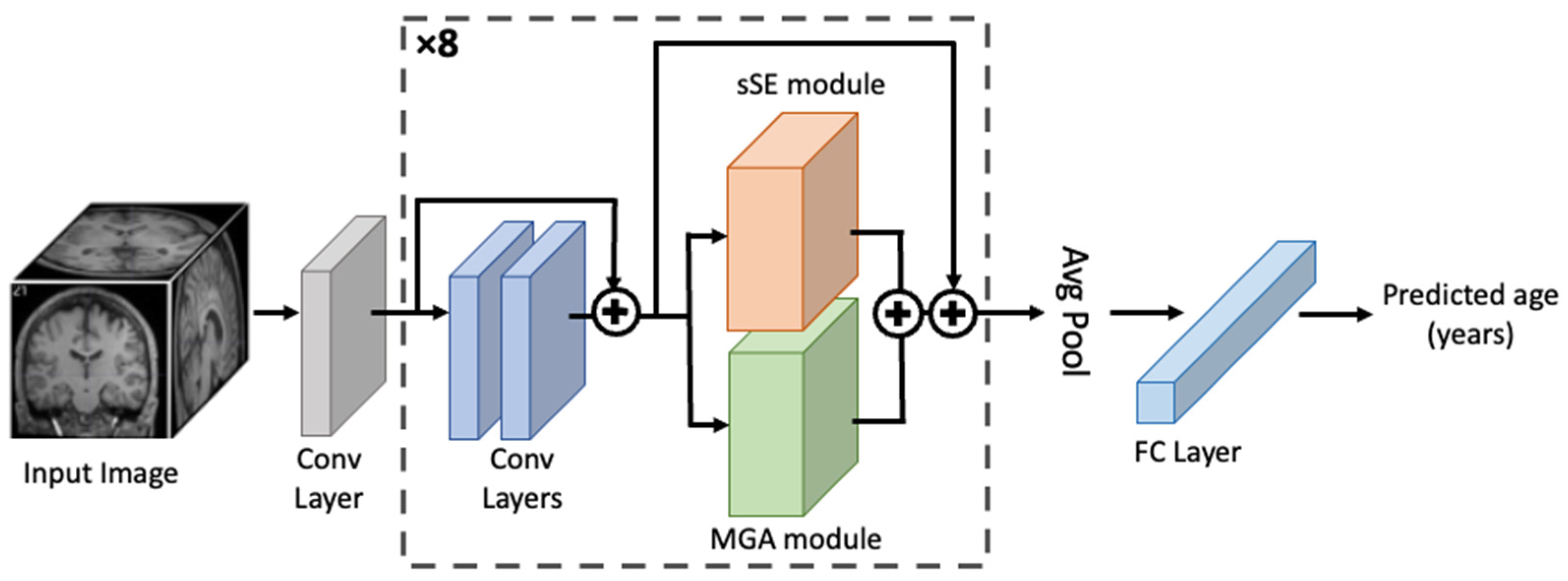
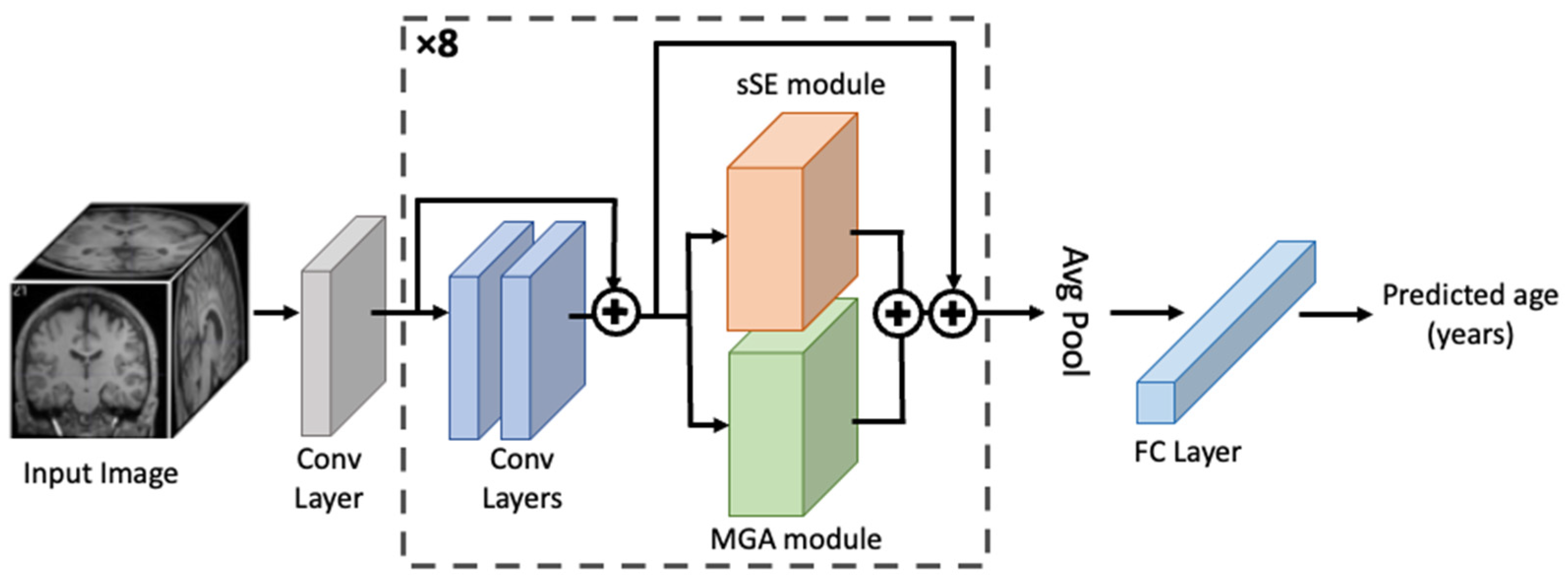
2.5. MGA-sSE-ResNet18
3. Experiments
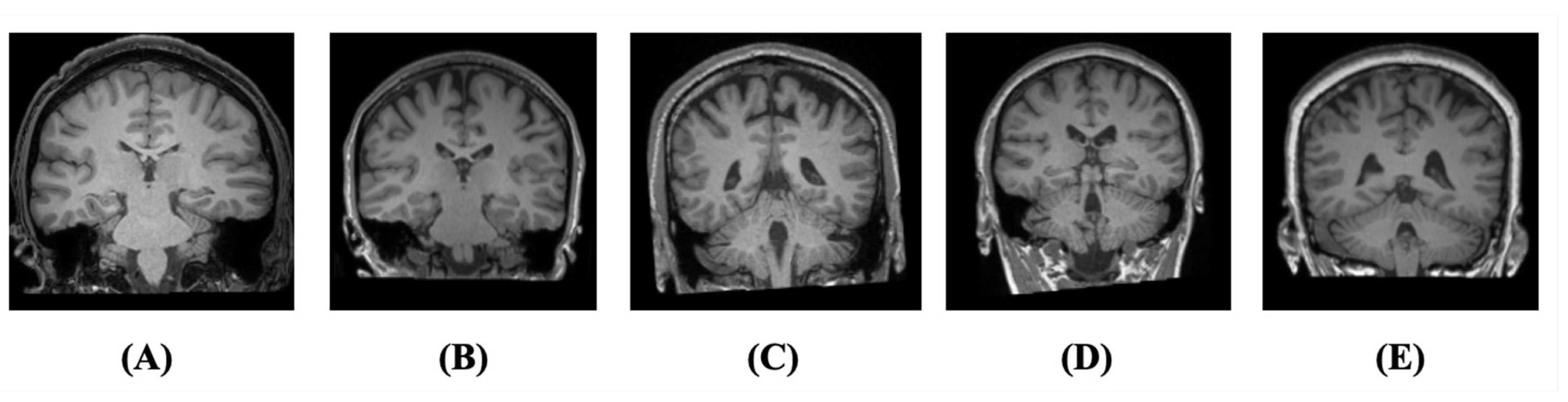
3.1. Dataset
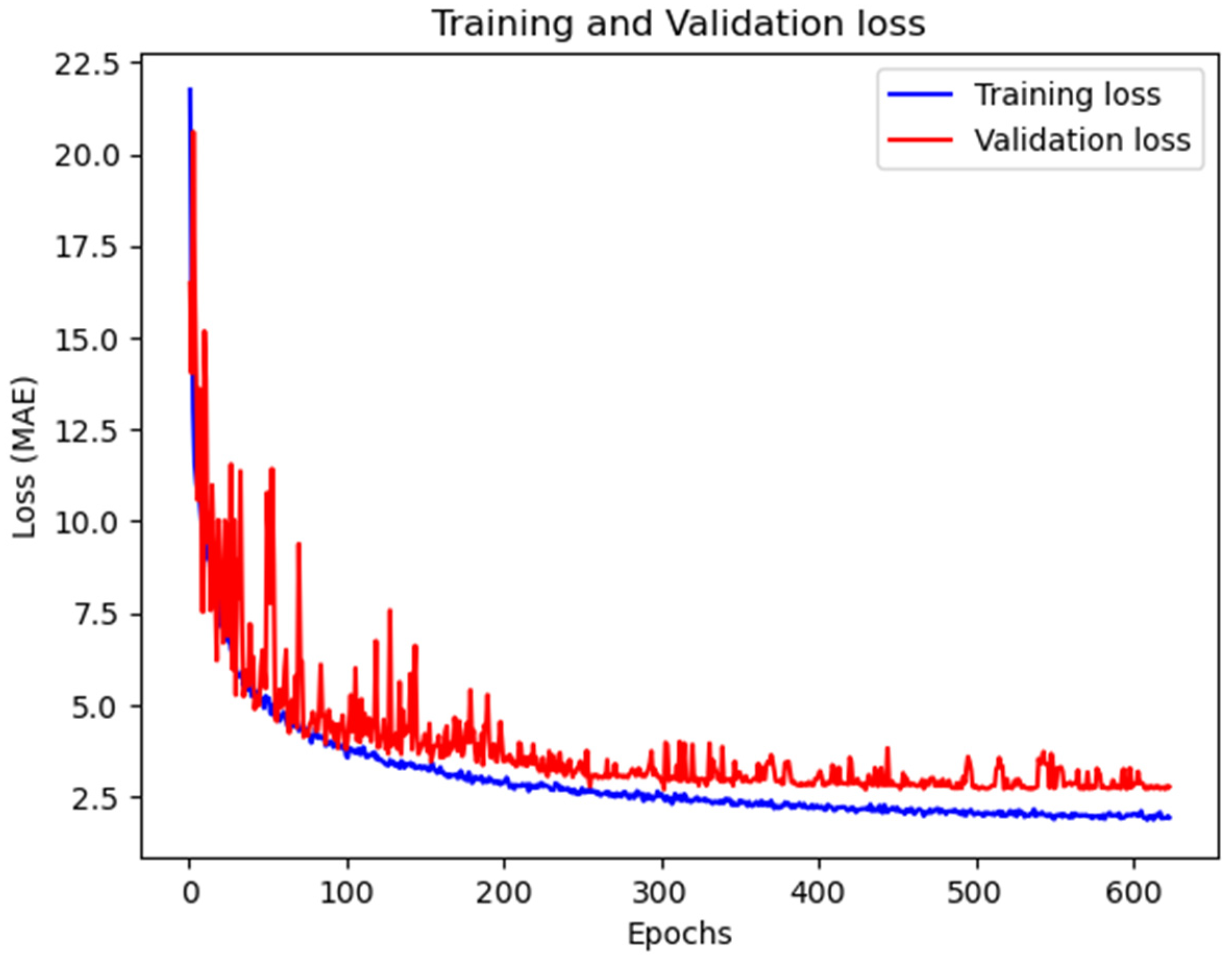
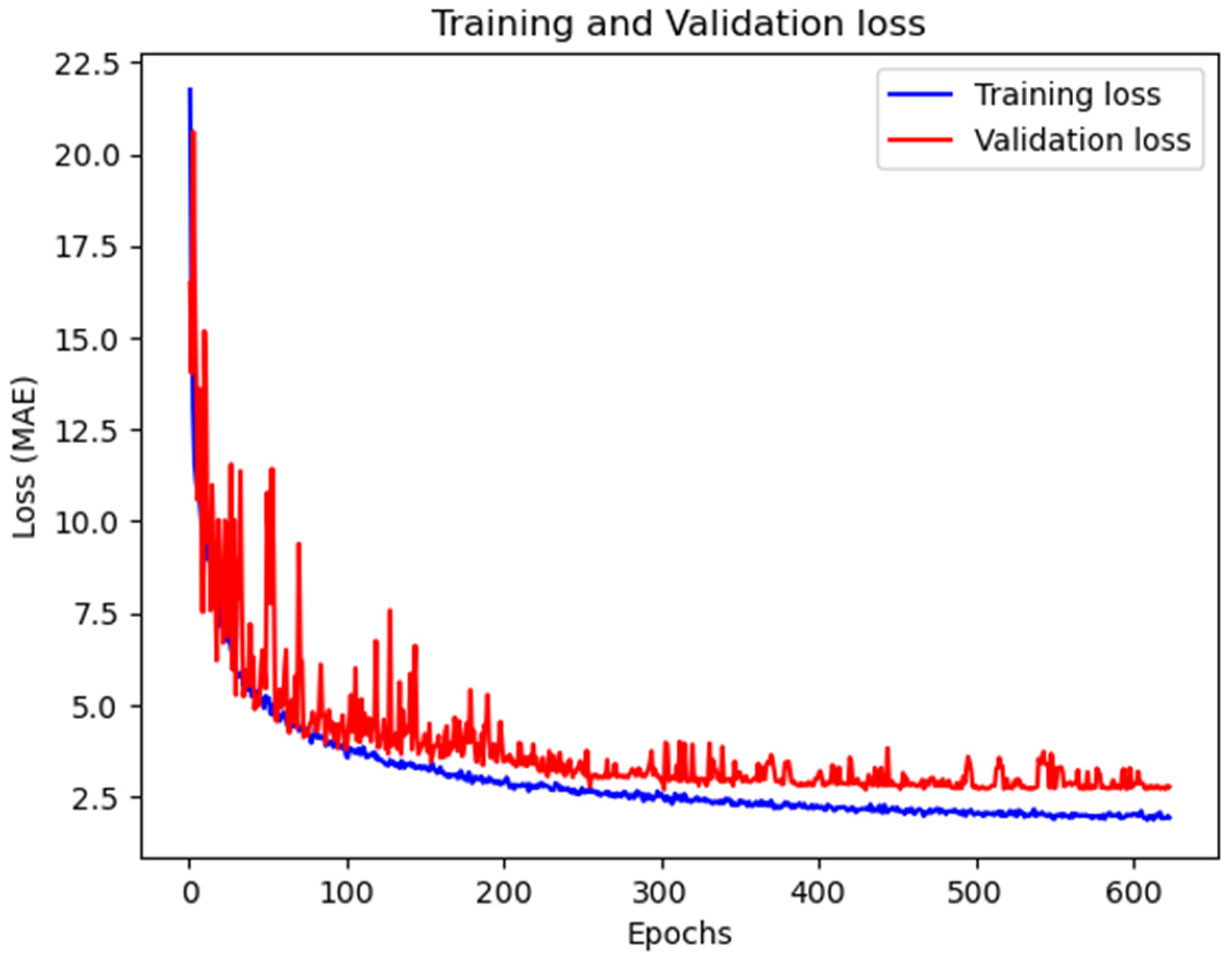
3.2. Experimental Settings
3.3. Comparisons with Other Models
4. Results
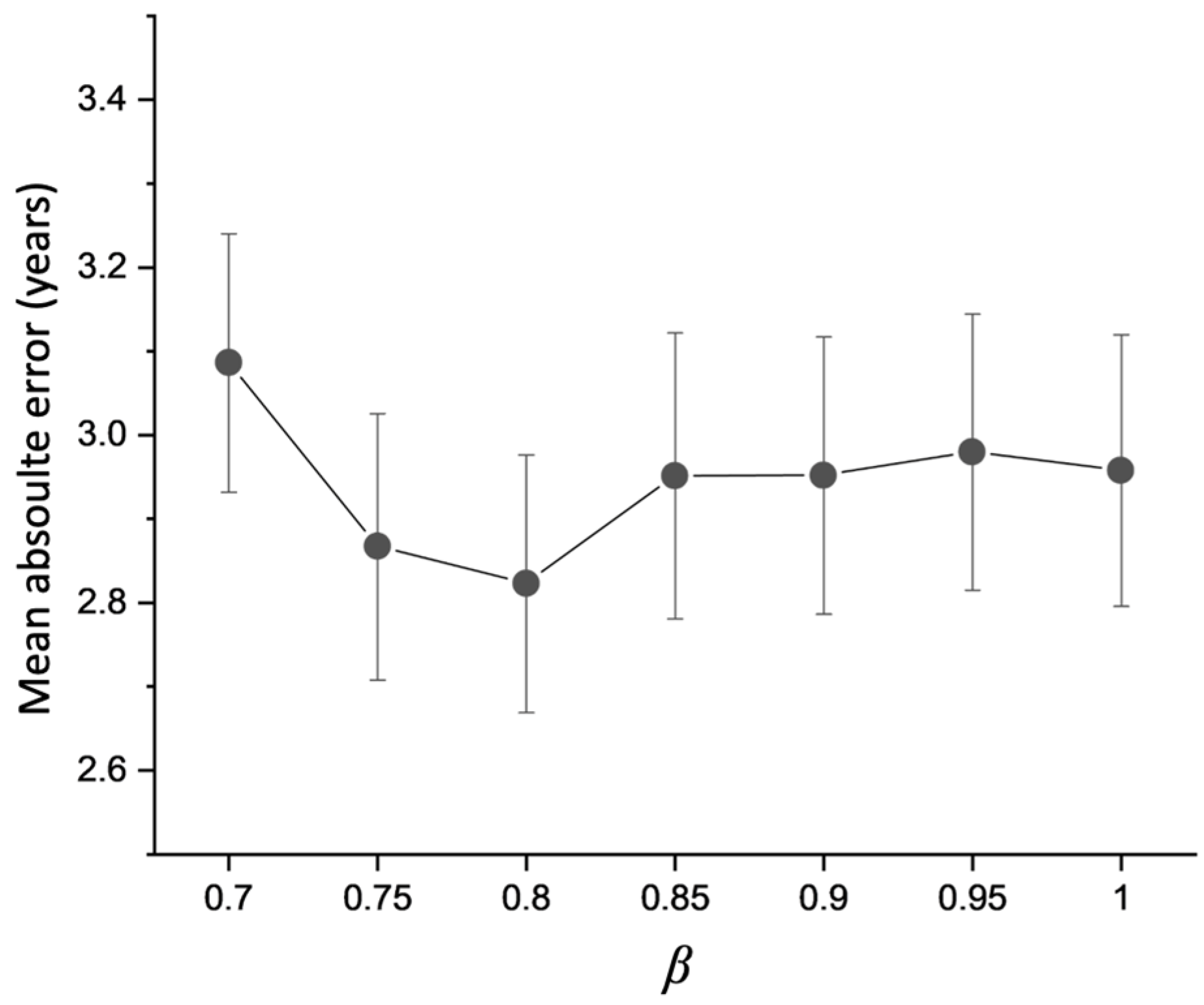
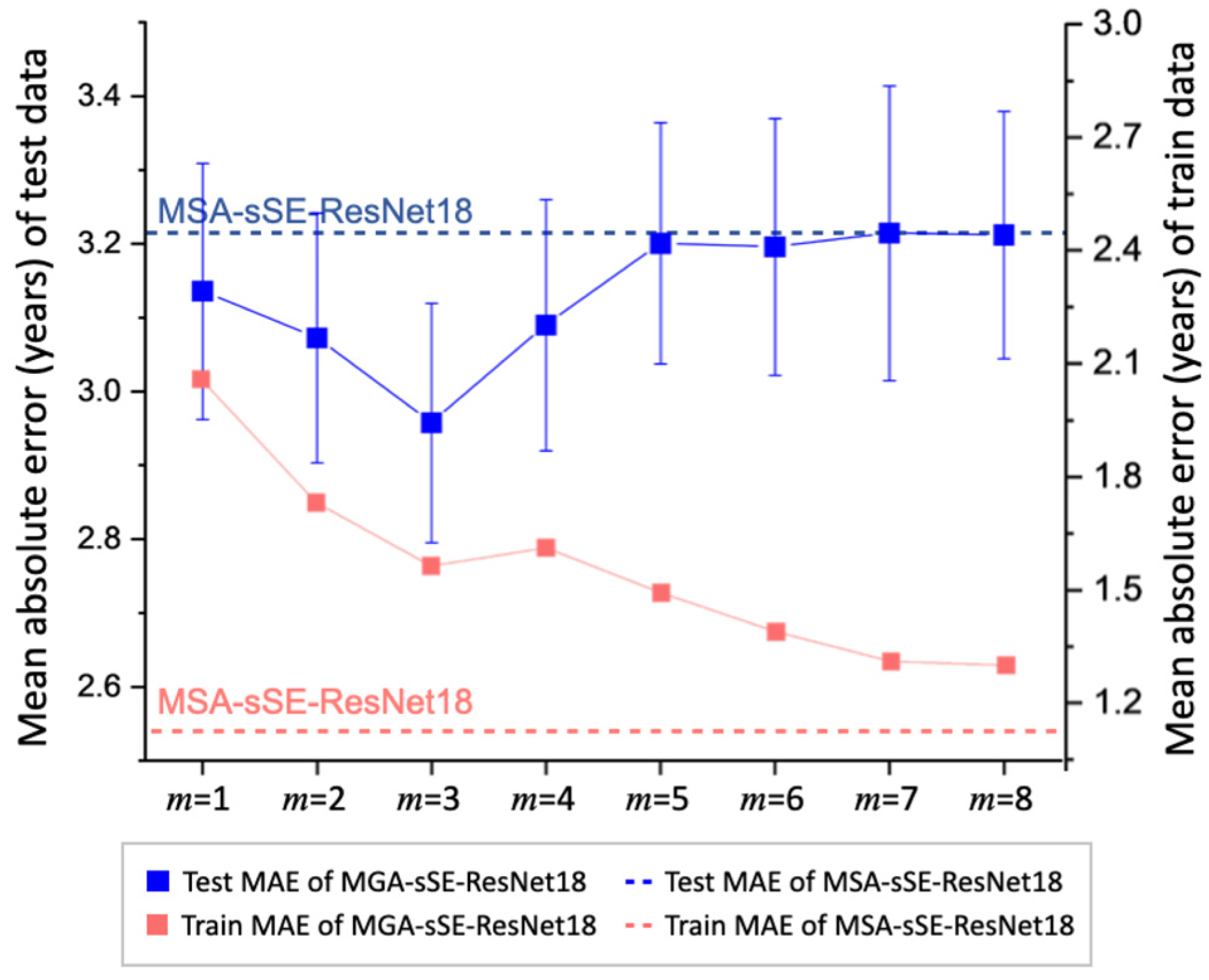
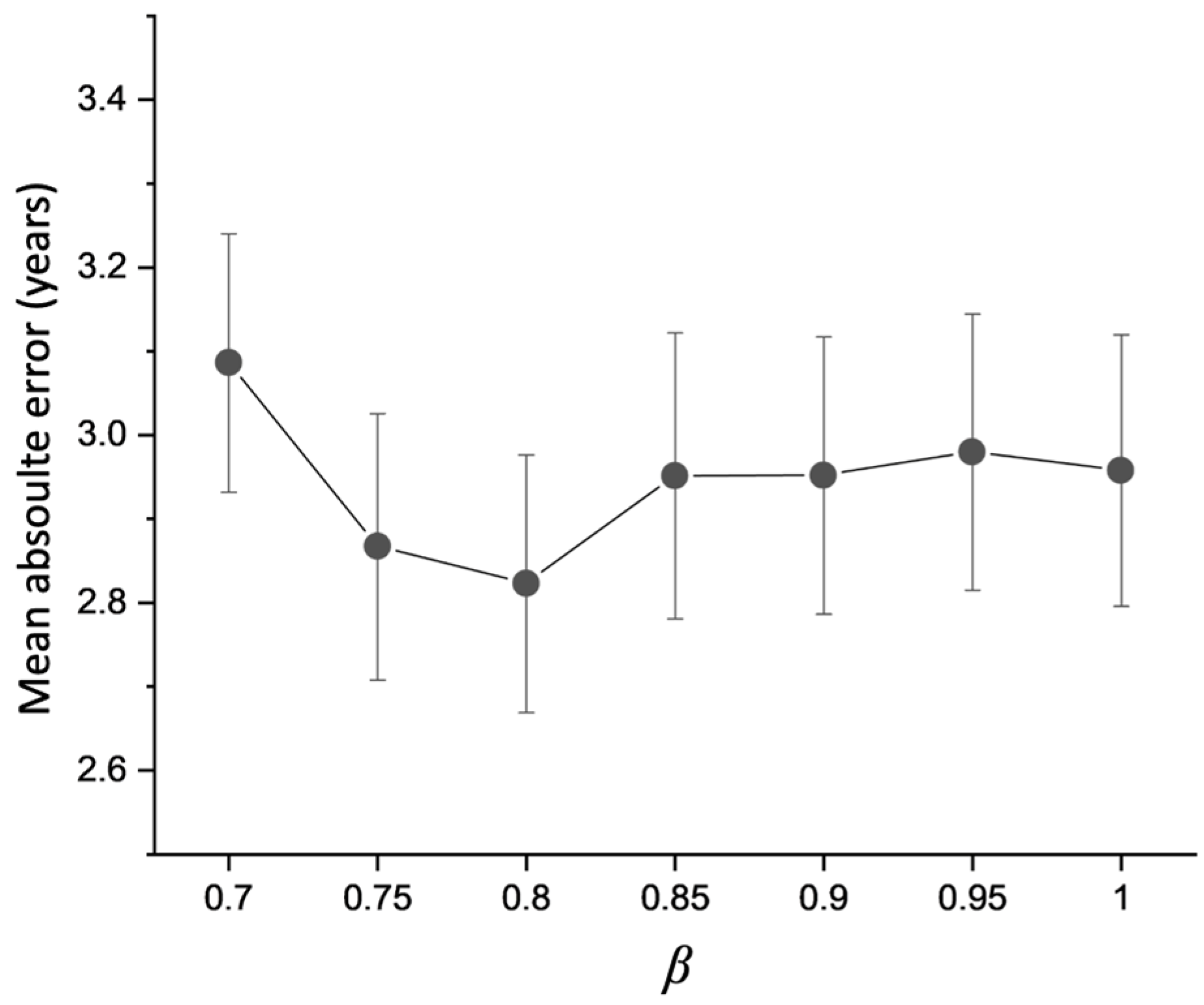
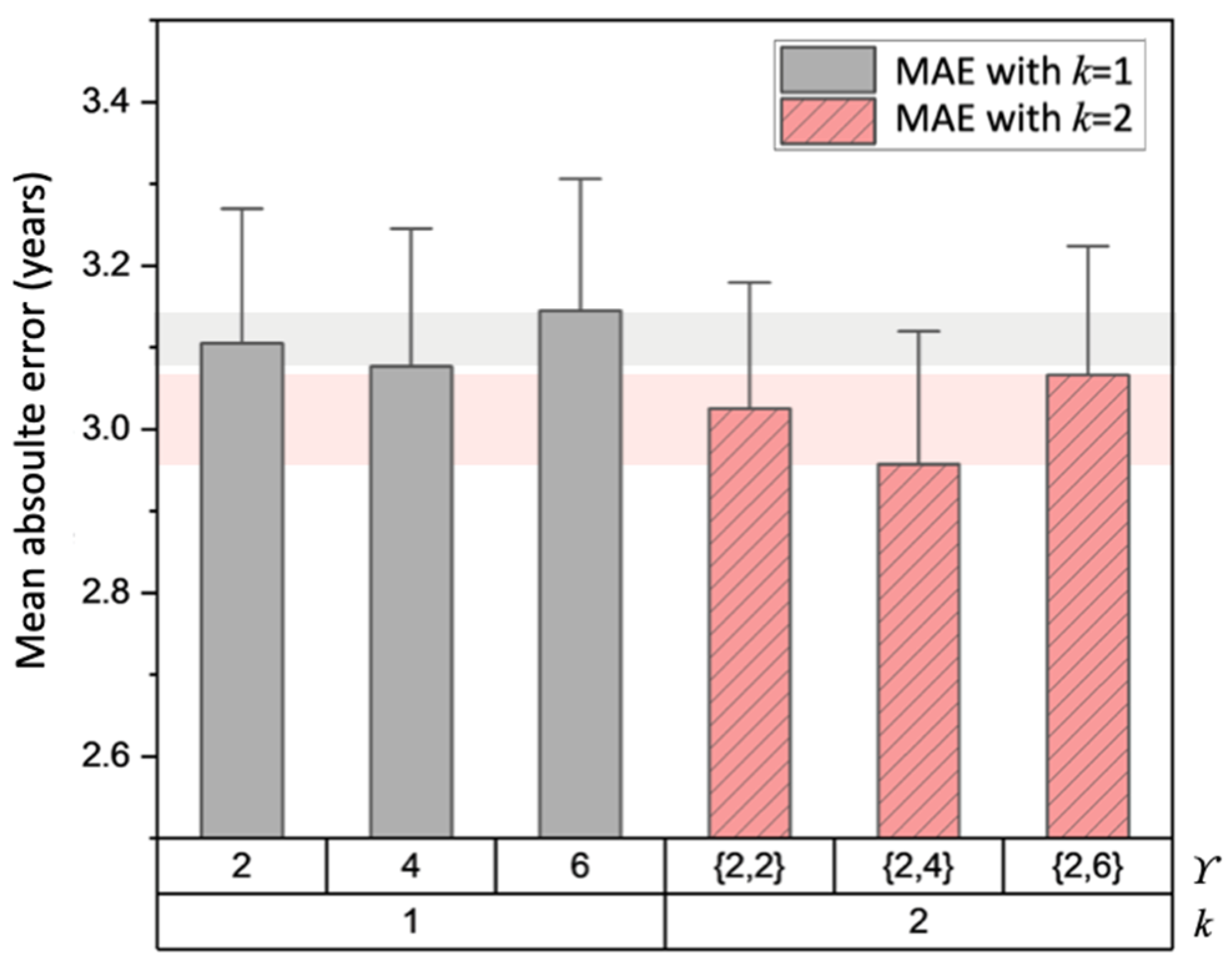
4.1. Hyperparameter Evaluation in MGA-sSE-ResNet18
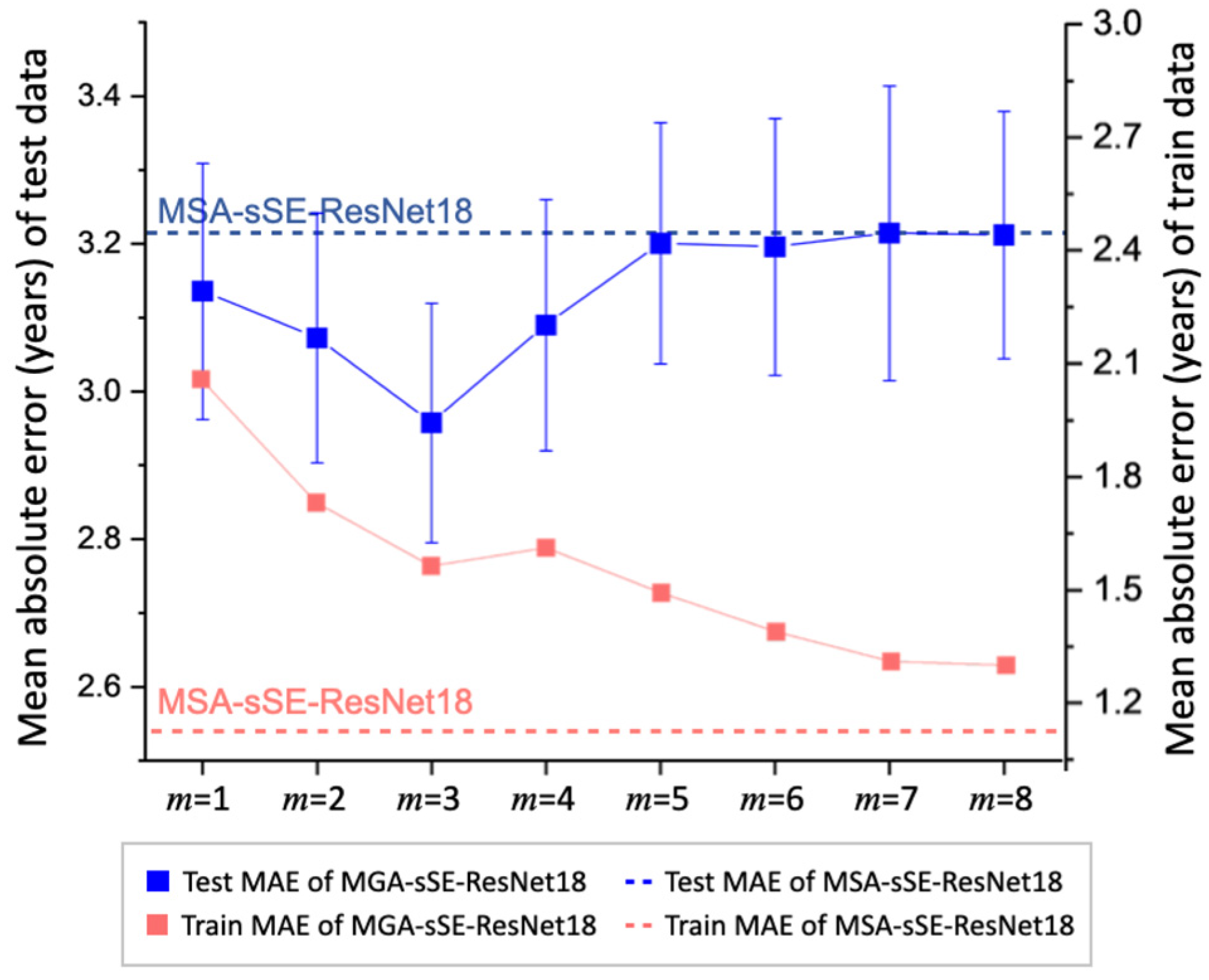
4.2. Comparison with Multi-Head Self Attention (MSA)
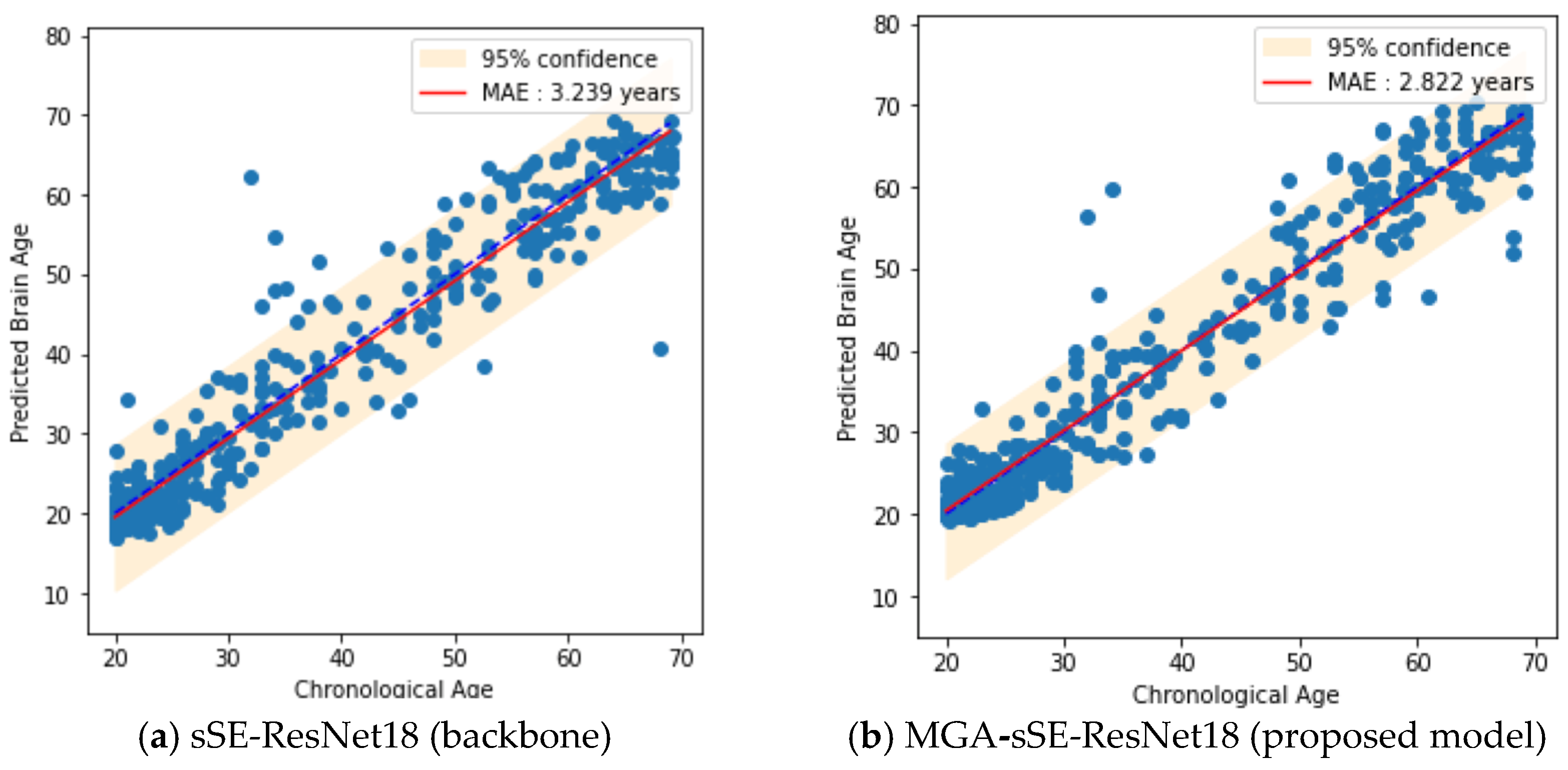
4.3. Comparison with State-of-the-Art Models
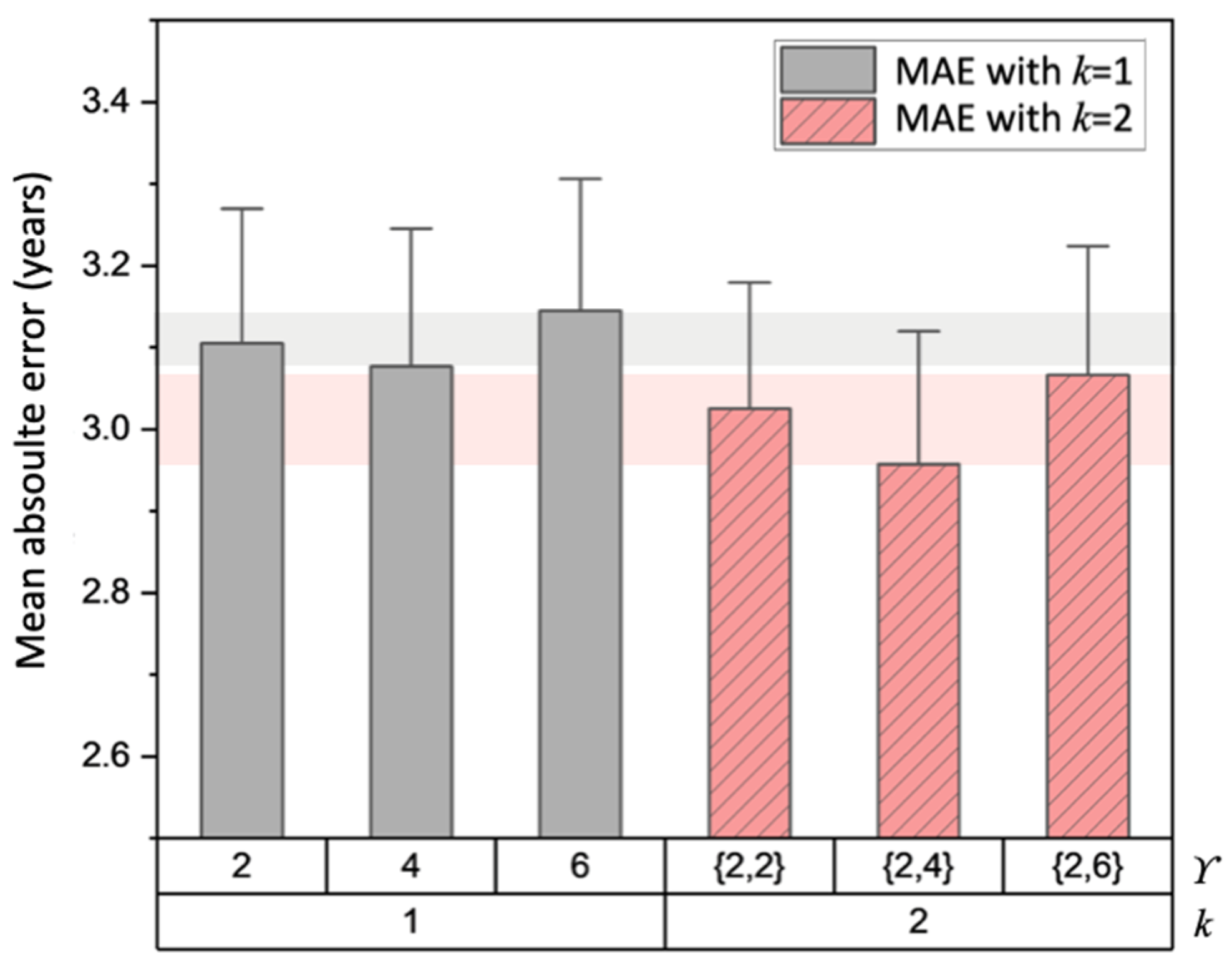
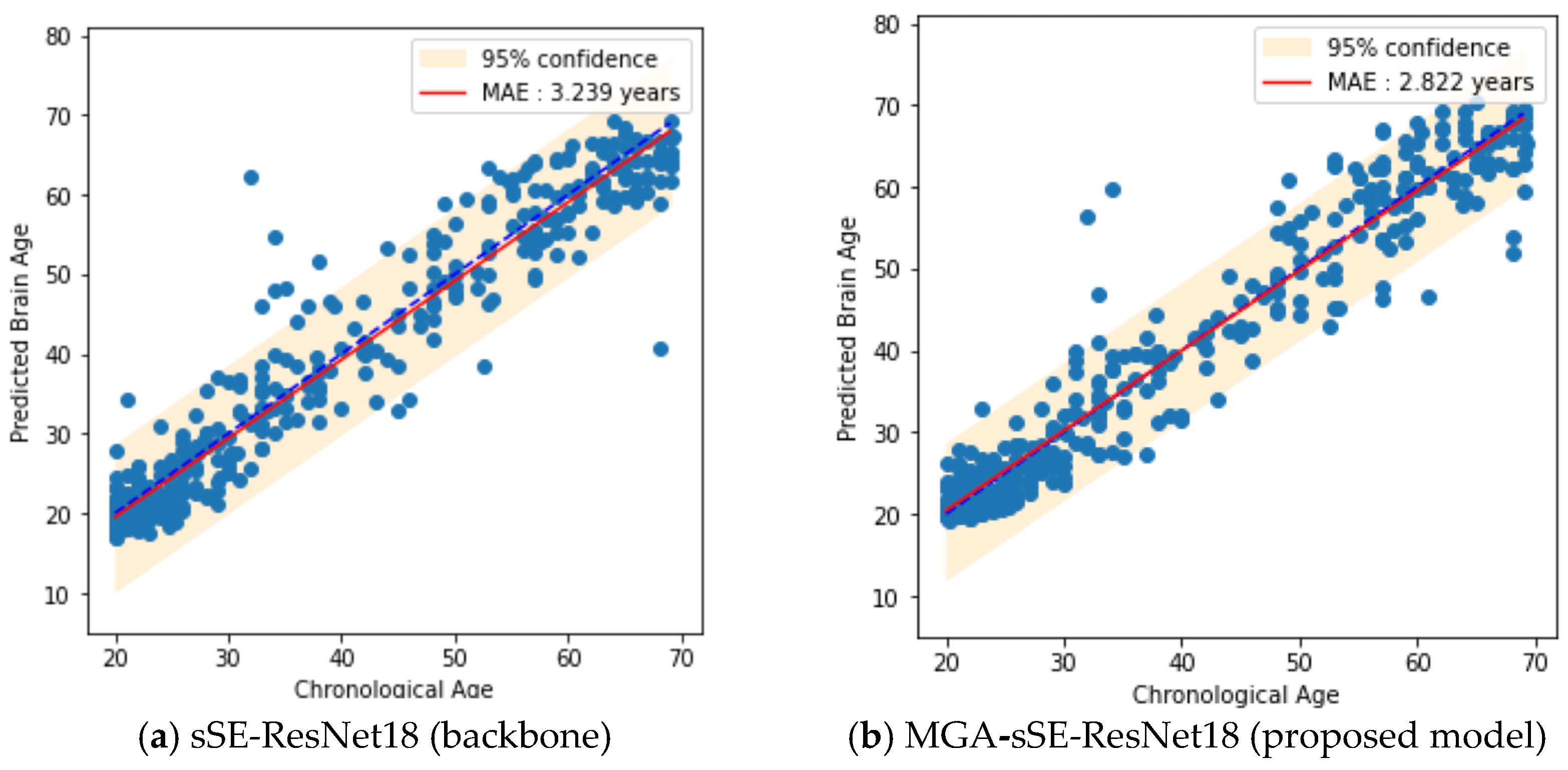
4.4. Ablation Study about MGA
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cole, J.H.; Franke, K. Predicting age using neuroimaging: Innovative brain ageing biomarkers. Trends Neurosci. 2017, 40, 681–690. [Google Scholar] [CrossRef] [PubMed]
- Franke, K.; Gaser, C. Ten years of BrainAGE as a neuroimaging biomarker of brain aging: What insights have we gained? Front. Neurol. 2019, 10, 789. [Google Scholar] [CrossRef] [PubMed]
- Cole, J.H.; Ritchie, S.J.; Bastin, M.E.; Hernández, V.; Muñoz Maniega, S.; Royle, N.; Corley, J.; Pattie, A.; Harris, S.E.; Zhang, Q.; et al. Brain age predicts mortality. Mol. Psychiatry 2017, 23, 1385–1392. [Google Scholar] [CrossRef] [PubMed]
- Lewis, J.D.; Evans, A.C.; Tohka, J.; Brain Development Cooperative Group. T1 white/gray contrast as a predictor of chronological age, and an index of cognitive performance. Neuroimage 2018, 173, 341–350. [Google Scholar] [CrossRef] [PubMed]
- Jonsson, B.A.; Bjornsdottir, G.; Thorgeirsson, T.E.; Ellingsen, L.M.; Walters, G.B.; Gudbjartsson, D.F.; Stefansson, H.; Stefansson, K.; Ulfarsson, M.O. Brain age prediction using deep learning uncovers associated sequence variants. Nat. Commun. 2019, 10, 5409. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.-L.; Hsu, Y.-C.; Yang, L.-Y.; Tung, Y.-H.; Luo, W.-B.; Liu, C.-M.; Hwang, T.-J.; Hwu, H.-G.; Tseng, W.-Y.I. Generalization of diffusion magnetic resonance imaging–based brain age prediction model through transfer learning. NeuroImage 2020, 217, 116831. [Google Scholar] [CrossRef]
- Cole, J.H.; Raffel, J.; Friede, T.; Eshaghi, A.; Brownlee, W.J.; Chard, D.; De Stefano, N.; Enzinger, C.; Pirpamer, L.; Filippi, M.; et al. Longitudinal assessment of multiple sclerosis with the brain-age paradigm. Ann. Neurol. 2020, 88, 93–105. [Google Scholar] [CrossRef]
- Peng, H.; Gong, W.; Beckmann, C.F.; Vedaldi, A.; Smith, S.M. Accurate brain age prediction with lightweight deep neural networks. Med. Image Anal. 2020, 68, 101871. [Google Scholar] [CrossRef]
- Cole, J.H.; Leech, R.; Sharp, D.J.; Alzheimer’s Disease Neuroimaging Initiative. Prediction of brain age suggests accelerated atrophy after traumatic brain injury. Ann. Neurol. 2015, 77, 571–581. [Google Scholar] [CrossRef]
- Du, L.; Roy, S.; Wang, P.; Li, Z.; Qiu, X.; Zhang, Y.; Yuan, J.; Guo, B. Unveiling the Future: Advancements in MRI Imaging for Neurodegenerative Disorders. Ageing Res. Rev. 2024, 95, 102230. [Google Scholar] [CrossRef]
- Wang, J.; Knol, M.J.; Tiulpin, A.; Dubost, F.; de Bruijne, M.; Vernooij, M.W.; Adams, H.H.H.; Ikram, M.A.; Niessen, W.J.; Roshchupkin, G.V. Gray matter age prediction as a biomarker for risk of dementia. Proc. Natl. Acad. Sci. USA 2019, 116, 21213–21218. [Google Scholar] [CrossRef]
- Biondo, F.; Jewell, A.; Pritchard, M.; Mueller, C.; Steves, C.J.; Cole, J. Brain-age predicts subsequent dementia in memory clinic patients. medRxiv 2020. [Google Scholar] [CrossRef]
- Gaser, C.; Franke, K.; Klöppel, S.; Koutsouleris, N.; Sauer, H.; Alzheimer’s Disease Neuroimaging Initiative. BrainAGE in mild cognitive impaired patients: Predicting the conversion to Alzheimer’s disease. PLoS ONE 2013, 8, e67346. [Google Scholar] [CrossRef]
- Beheshti, I.; Maikusa, N.; Matsuda, H. The association between “brain-age score”(BAS) and traditional neuropsychological screening tools in Alzheimer’s disease. Brain Behav. 2018, 8, e01020. [Google Scholar] [CrossRef]
- Koutsouleris, N.; Davatzikos, C.; Borgwardt, S.; Gaser, C.; Bottlender, R.; Frodl, T.; Falkai, P.; Riecher-Rössler, A.; Möller, H.-J.; Reiser, M.; et al. Accelerated brain aging in schizophrenia and beyond: A neuroanatomical marker of psychiatric disorders. Schizophr. Bull. 2013, 40, 1140–1153. [Google Scholar] [CrossRef]
- Koutsouleris, N.; Meisenzahl, E.M.; Borgwardt, S.; Riecher-Rössler, A.; Frodl, T.; Kambeitz, J.; Köhler, Y.; Falkai, P.; Möller, H.-J.; Reiser, M.; et al. Individualized differential diagnosis of schizophrenia and mood disorders using neuroanatomical biomarkers. Brain 2015, 138, 2059–2073. [Google Scholar] [CrossRef] [PubMed]
- Kuchinad, A.; Schweinhardt, P.; Seminowicz, D.A.; Wood, P.B.; Chizh, B.A.; Bushnell, M.C. Accelerated brain gray matter loss in fibromyalgia patients: Premature aging of the brain? J. Neurosci. 2007, 27, 4004–4007. [Google Scholar] [CrossRef]
- Liem, F.; Varoquaux, G.; Kynast, J.; Beyer, F.; Masouleh, S.K.; Huntenburg, J.M.; Lampe, L.; Rahim, M.; Abraham, A.; Craddock, R.C.; et al. Predicting brain-age from multimodal imaging data captures cognitive impairment. NeuroImage 2016, 148, 179–188. [Google Scholar] [CrossRef] [PubMed]
- Chung, Y.; Addington, J.; Bearden, C.E.; Cadenhead, K.; Cornblatt, B.; Mathalon, D.H.; McGlashan, T.; Perkins, D.; Seidman, L.J.; Tsuang, M.; et al. Use of machine learning to determine deviance in neuroanatomical maturity associated with future psychosis in youths at clinically high risk. JAMA Psychiatry 2018, 75, 960–968. [Google Scholar] [CrossRef]
- Schnack, H.G.; van Haren, N.E.; Nieuwenhuis, M.; Pol, H.E.H.; Cahn, W.; Kahn, R.S. Accelerated brain aging in schizophrenia: A longitudinal pattern recognition study. Am. J. Psychiatry 2016, 173, 607–616. [Google Scholar] [CrossRef] [PubMed]
- Guan, S.; Jiang, R.; Meng, C.; Biswal, B. Brain age prediction across the human lifespan using multimodal MRI data. GeroScience 2023, 46, 1–20. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Cole, J.H.; Poudel, R.P.; Tsagkrasoulis, D.; Caan, M.W.; Steves, C.; Spector, T.D.; Montana, G. Predicting brain age with deep learning from raw imaging data results in a reliable and heritable biomarker. NeuroImage 2017, 163, 115–124. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Lu, N.; Chen, K.; Yao, L.; Li, K.; Zhang, J.; Guo, X. Predicting brain age of healthy adults based on structural MRI parcellation using convolutional neural networks. Front. Neurol. 2020, 10, 1346. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Guo, J.; Du, H.; Xu, J.; Qiu, B. Transfer learning on T1-weighted images for brain age estimation. Math. Biosci. Eng. 2019, 16, 4382–4398. [Google Scholar] [CrossRef] [PubMed]
- Lam, P.; Zhu, A.H.; Gari, I.B.; Jahanshad, N.; Thompson, P.M. 3D Grid-Attention Networks for Interpretable Age and Alzheimer’s Disease Prediction from Structural MRI. arXiv 2020, arXiv:2011.09115. [Google Scholar]
- Cheng, J.; Liu, Z.; Guan, H.; Wu, Z.; Zhu, H.; Jiang, J.; Wen, W.; Tao, D.; Liu, T. Brain age estimation from MRI using cascade networks with ranking loss. IEEE Trans. Med. Imaging 2021, 40, 3400–3412. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Pereira, D.; Perez, J.D.; Gollub, R.L.; Murphy, S.N.; Prabhu, S.; Ou, Y. Multi-channel attention-fusion neural network for brain age estimation: Accuracy, generality, and interpretation with 16,705 healthy MRIs across lifespan. Med. Image Anal. 2021, 72, 102091. [Google Scholar] [CrossRef]
- Zhang, Y.; Xie, R.; Beheshti, I.; Liu, X.; Zheng, G.; Wang, Y.; Zhang, Z.; Zheng, W.; Yao, Z.; Hu, B. Improving brain age prediction with anatomical feature attention-enhanced 3D-CNN. Comput. Biol. Med. 2024, 169, 107873. [Google Scholar] [CrossRef]
- Sporns, O. Brain connectivity. Scholarpedia 2007, 2, 4695. [Google Scholar] [CrossRef]
- Jun, E.; Jeong, S.; Heo, D.W.; Suk, H.I. Medical transformer: Universal brain encoder for 3D MRI analysis. arXiv 2021, arXiv:2104.13633. [Google Scholar] [CrossRef]
- He, S.; Grant, P.E.; Ou, Y. Global-Local transformer for brain age estimation. IEEE Trans. Med. Imaging 2021, 41, 213–224. [Google Scholar] [CrossRef] [PubMed]
- Kawahara, J.; Brown, C.J.; Miller, S.P.; Booth, B.G.; Chau, V.; Grunau, R.E.; Zwicker, J.G.; Hamarneh, G. BrainNetCNN: Convolutional neural networks for brain networks; towards predicting neurodevelopment. NeuroImage 2017, 146, 1038–1049. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.; Kim, S.; Duffy, B.; Yuan, S.; Cole, J.H.; Toga, A.W.; Kim, H. Brain age predicted using graph convolutional neural network explains developmental trajectory in preterm neonates. bioRxiv 2021. [Google Scholar] [CrossRef]
- Cai, H.; Gao, Y.; Liu, M. Graph transformer geometric learning of brain networks using multimodal MR images for brain age estimation. IEEE Trans. Med. Imaging 2022, 42, 456–466. [Google Scholar] [CrossRef] [PubMed]
- Roy, A.G.; Navab, N.; Wachinger, C. Recalibrating fully convolutional networks with spatial and channel “squeeze and excitation” blocks. IEEE Trans. Med. Imaging 2018, 38, 540–549. [Google Scholar] [CrossRef]
- Bao, L.; Ma, B.; Chang, H.; Chen, X. Masked graph attention network for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Dong, Y.; Liu, Q.; Du, B.; Zhang, L. Weighted feature fusion of convolutional neural network and graph attention network for hyperspectral image classification. IEEE Trans. Image Process. 2022, 31, 1559–1572. [Google Scholar] [CrossRef] [PubMed]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Liao, R.; Li, Y.; Song, Y.; Wang, S.; Hamilton, W.; Duvenaud, D.K.; Zemel, R. Efficient graph generation with graph recurrent attention networks. Adv. Neural Inf. Process. Syst. 2019, 32, 4257–4267. [Google Scholar]
- Xiong, Z.; Wang, D.; Liu, X.; Zhong, F.; Wan, X.; Li, X.; Li, Z.; Luo, X.; Chen, K.; Jiang, H.; et al. Pushing the boundaries of molecular representation for drug discovery with the graph attention mechanism. J. Med. Chem. 2019, 63, 8749–8760. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, X.; Song, M.; Yuan, J.; Tao, D. Spagan: Shortest path graph attention network. arXiv 2021, arXiv:2101.03464. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liao, L.; Zhang, X.; Zhao, F.; Lou, J.; Wang, L.; Xu, X.; Zhang, H.; Li, G. Multi-branch deformable convolutional neural network with label distribution learning for fetal brain age prediction. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 424–427. [Google Scholar]
- Gorgolewski, K.; Esteban, O.; Schaefer, G.; Wandell, B.; Poldrack, R. OpenNeuro—A Free Online Platform for Sharing and Analysis of Neuroimaging Data; Organization for Human Brain Mapping: Vancouver, BC, Canada, 2017; Volume 1677. [Google Scholar]
- Mayer, A.R.; Ruhl, D.; Merideth, F.; Ling, J.; Hanlon, F.M.; Bustillo, J.; Cañive, J. Functional imaging of the hemodynamic sensory gating response in schizophrenia. Hum. Brain Mapp. 2012, 34, 2302–2312. [Google Scholar] [CrossRef] [PubMed]
- Poldrack, R.A.; Barch, D.M.; Mitchell, J.P.; Wager, T.D.; Wagner, A.D.; Devlin, J.T.; Cumba, C.; Koyejo, O.; Milham, M.P. Toward open sharing of task-based fMRI data: The OpenfMRI project. Front. Neurosci. 2013, 7, 12. [Google Scholar] [CrossRef] [PubMed]
- Mennes, M.; Biswal, B.B.; Castellanos, F.X.; Milham, M.P. Making data sharing work: The FCP/INDI experience. NeuroImage 2013, 82, 683–691. [Google Scholar] [CrossRef] [PubMed]
- Simonovsky, M.; Gutiérrez-Becker, B.; Mateus, D.; Navab, N.; Komodakis, N. A deep metric for multimodal registration. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany; pp. 10–18. [Google Scholar]
- Biswal, B.B.; Mennes, M.; Zuo, X.-N.; Gohel, S.; Kelly, C.; Smith, S.M.; Beckmann, C.F.; Adelstein, J.S.; Buckner, R.L.; Colcombe, S.; et al. Toward discovery science of human brain function. Proc. Natl. Acad. Sci. USA 2010, 107, 4734–4739. [Google Scholar] [CrossRef] [PubMed]
- Herrick, R.; Horton, W.; Olsen, T.; McKay, M.; Archie, K.A.; Marcus, D.S. XNAT Central: Open sourcing imaging research data. NeuroImage 2016, 124, 1093–1096. [Google Scholar] [CrossRef]
- Song, S.; Zheng, Y.; He, Y. A review of methods for bias correction in medical images. Biomed. Eng. Rev. 2017, 1, 1–10. [Google Scholar] [CrossRef]
- Larsson, G.; Maire, M.; Shakhnarovich, G. Fractalnet: Ultra-deep neural networks without residuals. arXiv 2016, arXiv:1605.07648. [Google Scholar]
- Smith, S.M.; Vidaurre, D.; Alfaro-Almagro, F.; Nichols, T.E.; Miller, K.L. Estimation of brain age delta from brain imaging. NeuroImage 2019, 200, 528–539. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using CNN with attention mechanism. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Ji, J.; Lu, X.; Huo, H.; Fang, T.; Li, D. Global-local attention network for aerial scene classification. IEEE Access 2019, 7, 67200–67212. [Google Scholar] [CrossRef]
- Reed, R. Pruning algorithms—A survey. IEEE Trans. Neural Netw. 1993, 4, 740–747. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output Size | MGA-sSE-ResNet18 | ||
|---|---|---|---|
| 101 × 101 × 121 | 7 × 7 × 7, 64, stride 2 | ||
| 50 × 50 × 60 | 3 × 3 × 3, max pool, stride 2 | ||
| Conv, 3 × 3 × 3, 64 Conv, 3 × 3 × 3, 64 | ×2 | ||
| sSE: Conv, 1 × 1 × 1, 64 Sigmoid | MGA: m = 3, k = 2, ϒ = {2, 4}, β = 0.8 | ||
| 25 × 25 × 30 | Conv, 3 × 3 × 3, 128 Conv, 3 × 3 × 3, 128 | ×2 | |
| sSE: Conv, 1 × 1 × 1, 128 Sigmoid | MGA: m = 3, k = 2, ϒ = {2, 4}, β = 0.8 | ||
| 12 × 12 × 15 | Conv, 3 × 3 × 3, 256 Conv, 3 × 3 × 3, 256 | ×2 | |
| sSE: Conv, 1 × 1 × 1, 256 Sigmoid | MGA: m = 3, k = 2, ϒ = {2, 4}, β = 0.8 | ||
| 6 × 6 × 7 | Conv, 3 × 3 × 3, 512 Conv, 3 × 3 × 3, 512 | ×2 | |
| sSE: Conv, 1 × 1 × 1, 512 Sigmoid | MGA: m = 3, k = 2, ϒ = {2, 4}, β = 0.8 | ||
| 1 × 1 × 1 | Global average pool, 1-d fc, softmax | ||
| Nsamples | Female | Male | Mean Age | Min Age | Max Age | |
|---|---|---|---|---|---|---|
| OpenNeuro | 542 | 323 | 219 | 26.71 | 20 | 69 |
| COBRE | 71 | 22 | 49 | 36.45 | 20 | 65 |
| Open fMRI | 353 | 170 | 183 | 35.85 | 20 | 69 |
| INDI | 696 | 398 | 298 | 50.23 | 30 | 69 |
| IXI | 123 | 61 | 62 | 50.54 | 30.89 | 69.55 |
| FCP1000 | 835 | 477 | 358 | 27.50 | 20 | 69 |
| XNAT | 168 | 0 | 168 | 63.46 | 42 | 69 |
| Model | MAE | PCC |
|---|---|---|
| ResNet18 | 3.249 | 0.948 |
| sSE-ResNet18 | 3.239 | 0.956 |
| DenseNet121 | 3.340 | 0.961 |
| MobileNetV2 | 3.295 | 0.950 |
| SFCN | 3.233 | 0.949 |
| TSAN | 2.892 | 0.956 |
| MSA-sSE-ResNet18 | 3.216 | 0.960 |
| MGA-sSE-ResNet18 | 2.822 | 0.968 |
| MGA-ResNet18 | 3.065 | 0.955 |
| MGA-sSE-ResNet18 (with sex label) | 2.859 | 0.960 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, H.; Joo, Y.; Ha, E.; Song, Y.; Yoon, S.; Shin, T. Brain Age Prediction Using Multi-Hop Graph Attention Combined with Convolutional Neural Network. Bioengineering 2024, 11, 265. https://doi.org/10.3390/bioengineering11030265
Lim H, Joo Y, Ha E, Song Y, Yoon S, Shin T. Brain Age Prediction Using Multi-Hop Graph Attention Combined with Convolutional Neural Network. Bioengineering. 2024; 11(3):265. https://doi.org/10.3390/bioengineering11030265
Chicago/Turabian StyleLim, Heejoo, Yoonji Joo, Eunji Ha, Yumi Song, Sujung Yoon, and Taehoon Shin. 2024. "Brain Age Prediction Using Multi-Hop Graph Attention Combined with Convolutional Neural Network" Bioengineering 11, no. 3: 265. https://doi.org/10.3390/bioengineering11030265
APA StyleLim, H., Joo, Y., Ha, E., Song, Y., Yoon, S., & Shin, T. (2024). Brain Age Prediction Using Multi-Hop Graph Attention Combined with Convolutional Neural Network. Bioengineering, 11(3), 265. https://doi.org/10.3390/bioengineering11030265