


Proactive Decision Support for Glaucoma Treatment: Predicting Surgical Interventions with Clinically Available Data


 , , ,
, , ,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Datasets
2.2. Patient Exams and Interviews
2.3. OCT Imaging
2.4. Visual Field Testing
2.5. Multi-Modal Models
2.6. Model Evaluation
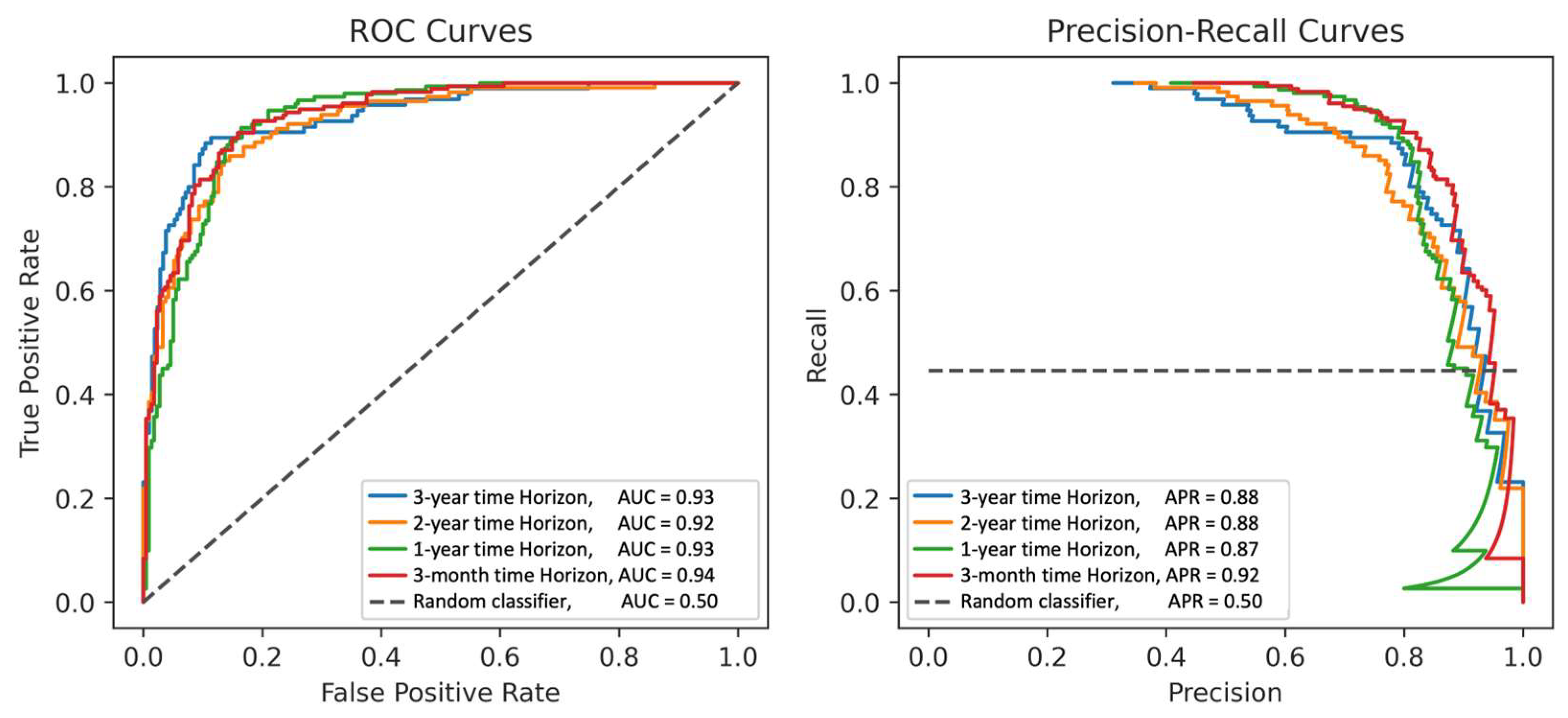
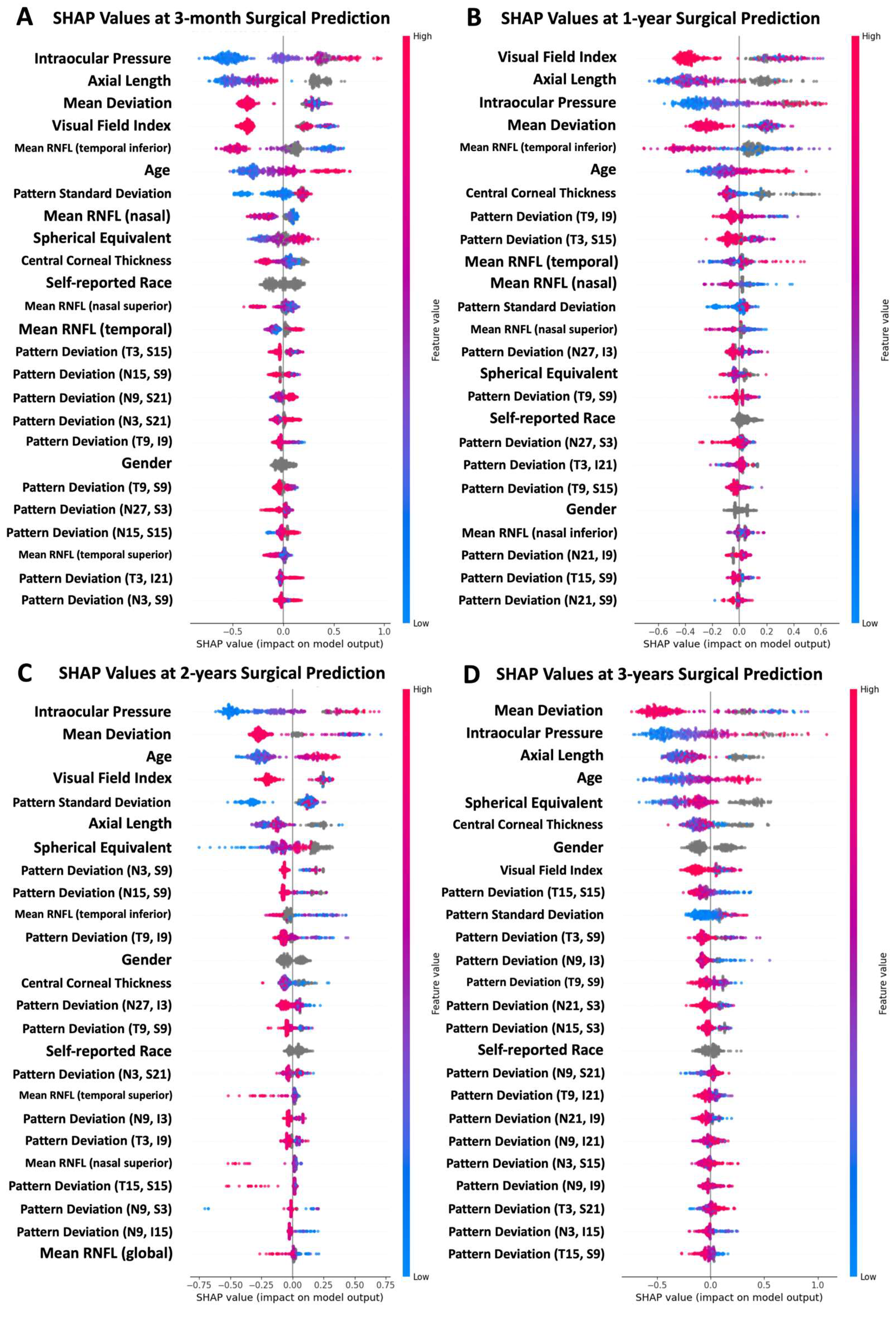
3. Results
4. Discussion
4.1. Model Performance
4.2. Feature Importance
4.3. Limitations and Future Directions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tham, Y.C.; Li, X.; Wong, T.Y.; Quigley, H.A.; Aung, T.; Cheng, C.Y. Global prevalence of glaucoma and projections of glaucoma burden through 2040: A systematic review and meta-analysis. Ophthalmology 2014, 121, 2081–2090. [Google Scholar] [CrossRef]
- Kass, M.A.; Heuer, D.K.; Higginbotham, E.J.; Johnson, C.; Keltner, J.L.; Miller, J.P.; Parrish, R.K.; Wilson, M.R.; Gordon, M.O. The Ocular Hypertension Treatment Study: A randomized trial determines that topical ocular hypotensive medication delays or prevents the onset of primary open-angle glaucoma. Arch. Ophthalmol. 2002, 120, 701–713; discussion 829–830. [Google Scholar] [CrossRef]
- Heijl, A.; Leske, M.C.; Hyman, L.; Bengtsson, B.; Hussein, M. Reduction of intraocular pressure and glaucoma progression: Results from the Early Manifest Glaucoma Trial. Arch. Ophthalmol. 2002, 120, 1268–1279. [Google Scholar] [CrossRef]
- Gordon, M.O.; Beiser, J.A.; Brandt, J.D.; Heuer, D.K.; Higginbotham, E.J.; Johnson, C.A.; Keltner, J.L.; Miller, J.P.; Parrish, R.K.; Wilson, M.R.; et al. The Ocular Hypertension Treatment Study: Baseline factors that predict the onset of primary open-angle glaucoma. Arch. Ophthalmol. 2002, 120, 714–720; discussion 829–830. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Saunders, L.J.; Daga, F.B.; Diniz-Filho, A.; Medeiros, F.A. Frequency of Testing to Detect Visual Field Progression Derived Using a Longitudinal Cohort of Glaucoma Patients. Ophthalmology 2017, 124, 786–792. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 25–29. [Google Scholar] [CrossRef]
- Ting, D.S.W.; Pasquale, L.R.; Peng, L.; Campbell, J.P.; Lee, A.Y.; Raman, R.; Tan, G.S.W.; Schmetterer, L.; Keane, P.A.; Wong, T.Y. Artificial intelligence and deep learning in ophthalmology. Br. J. Ophthalmol. 2019, 103, 167–175. [Google Scholar] [CrossRef] [PubMed]
- Devalla, S.K.; Liang, Z.; Pham, T.H.; Boote, C.; Strouthidis, N.G.; Thiery, A.H.; A Girard, M.J. Glaucoma management in the era of artificial intelligence. Br. J. Ophthalmol. 2019, 104, 301–311. [Google Scholar] [CrossRef]
- Thompson, A.C.; Jammal, A.A.; Medeiros, F.A. A Review of Deep Learning for Screening, Diagnosis, and Detection of Glaucoma Progression. Transl. Vis. Sci. Technol. 2020, 9, 42. [Google Scholar] [CrossRef]
- European Glaucoma Society Terminology and Guidelines for Glaucoma, 5th Edition. Br. J. Ophthalmol. 2021, 105 (Suppl. S1), 1–169. [CrossRef] [PubMed]
- Christopher, M.; Belghith, A.; Bowd, C.; Proudfoot, J.A.; Goldbaum, M.H.; Weinreb, R.N.; Girkin, C.A.; Liebmann, J.M.; Zangwill, L.M. Performance of Deep Learning Architectures and Transfer Learning for Detecting Glaucomatous Optic Neuropathy in Fundus Photographs. Sci. Rep. 2018, 8, 16685. [Google Scholar] [CrossRef]
- Christopher, M.; Bowd, C.; Proudfoot, J.A.; Belghith, A.; Goldbaum, M.H.; Rezapour, J.; Fazio, M.A.; Girkin, C.A.; De Moraes, G.; Liebmann, J.M. Deep Learning Estimation of 10-2 and 24-2 Visual Field Metrics Based on Thickness Maps from Macula OCT. Ophthalmology 2021, 128, 1534–1548. [Google Scholar] [CrossRef]
- Baxter, S.L.; Marks, C.; Kuo, T.T.; Ohno-Machado, L.; Weinreb, R.N. Machine Learning-Based Predictive Modeling of Surgical Intervention in Glaucoma Using Systemic Data From Electronic Health Records. Am. J. Ophthalmol. 2019, 208, 30–40. [Google Scholar] [CrossRef]
- Wang, R.; Bradley, C.; Herbert, P.; Hou, K.; Ramulu, P.; Breininger, K.; Unberath, M.; Yohannan, J. Deep Learning-Based Identification of Eyes at Risk for Glaucoma Surgery. Sci. Rep. 2024, 14, 599. [Google Scholar] [CrossRef]
- Devalla, S.K.; Chin, K.S.; Mari, J.-M.; Tun, T.A.; Strouthidis, N.G.; Aung, T.; Thiéry, A.H.; Girard, M.J.A. A Deep Learning Approach to Digitally Stain Optical Coherence Tomography Images of the Optic Nerve Head. Invest. Ophthalmol. Vis. Sci. 2018, 59, 63–74. [Google Scholar] [CrossRef]
- Medeiros, F.A.; Jammal, A.A.; Thompson, A.C. From Machine to Machine: An OCT-Trained Deep Learning Algorithm for Objective Quantification of Glaucomatous Damage in Fundus Photographs. Ophthalmology 2019, 126, 513–521. [Google Scholar] [CrossRef]
- Acosta, J.N.; Falcone, G.J.; Rajpurkar, P.; Topol, E.J. Multimodal biomedical AI. Nat. Med. 2022, 28, 1773–1784. [Google Scholar] [CrossRef]
- Zheng, W.; Dryja, T.P.; Wei, Z.; Song, D.; Tian, H.; Kahler, K.H.; Khawaja, A.P. Systemic Medication Associations with Presumed Advanced or Uncontrolled Primary Open-Angle Glaucoma. Ophthalmology 2018, 125, 984–993. [Google Scholar] [CrossRef] [PubMed]
- De Moraes, C.G.; Cioffi, G.A.; Weinreb, R.N.; Liebmann, J.M. New Recommendations for the Treatment of Systemic Hypertension and their Potential Implications for Glaucoma Management. J. Glaucoma 2018, 27, 567–571. [Google Scholar] [CrossRef] [PubMed]
- Sample, P.A.; Girkin, C.A.; Zangwill, L.M.; Jain, S.; Racette, L.; Becerra, L.M.; Weinreb, R.N.; Medeiros, F.A.; Wilson, M.R.; De León-Ortega, J.; et al. The African Descent and Glaucoma Evaluation Study (ADAGES): Design and baseline data. Arch. Ophthalmol. 2009, 127, 1136–1145. [Google Scholar] [CrossRef] [PubMed]
- WHO Collaborating Centre for Drug Statistics Methodology. Guidelines for ATC Classification and DDD Assignment, 2023; WHO: Oslo, Norway, 2022. [Google Scholar]
- Zeng, K.; Bodenreider, O.; Kilbourne, J.; Nelson, S. RxNav: A web service for standard drug information. AMIA Annu. Symp. Proc. 2006, 2006, 1156. Available online: https://www.ncbi.nlm.nih.gov/pubmed/17238775 (accessed on 30 September 2023). [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. arXiv 2016, arXiv:1603.02754. [Google Scholar] [CrossRef]
- h2o: R Interface for H2O. (2022). Available online: https://github.com/h2oai/h2o-3 (accessed on 1 July 2023).
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4 December 2017. [Google Scholar]
- Haymond, S.; Master, S.R. How Can We Ensure Reproducibility and Clinical Translation of Machine Learning Applications in Laboratory Medicine? Clin. Chem. 2022, 68, 392–395. [Google Scholar] [CrossRef]
- Haibe-Kains, B.; Adam, G.A.; Hosny, A.; Khodakarami, F.; Shraddha, T.; Kusko, R.; Sansone, S.-A.; Tong, W.; Wolfinger, R.D.; Mason, C.E.; et al. Transparency and reproducibility in artificial intelligence. Nature 2020, 586, E14–E16. [Google Scholar] [CrossRef]
- Bleeker, S.E.; Moll, H.A.; Steyerberg, E.W.; Donders, A.R.T.; Derksen-Lubsen, G.; Grobbee, D.; Moons, K.G.M. External validation is necessary in prediction research: A clinical example. J. Clin. Epidemiol. 2003, 56, 826–832. [Google Scholar] [CrossRef] [PubMed]
- Obermeyer, Z.; Powers, B.; Vogeli, C.; Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 2019, 366, 447–453. [Google Scholar] [CrossRef]
- Hong, C.; Pencina, M.J.; Wojdyla, D.M.; Hall, J.L.; Judd, S.E.; Cary, M.; Engelhard, M.M.; Berchuck, S.; Xian, Y.; D’agostino, R. Predictive Accuracy of Stroke Risk Prediction Models Across Black and White Race, Sex, and Age Groups. JAMA 2023, 329, 306–317. [Google Scholar] [CrossRef]
- Coley, R.Y.; Johnson, E.; Simon, G.E.; Cruz, M.; Shortreed, S.M. Racial/Ethnic Disparities in the Performance of Prediction Models for Death by Suicide After Mental Health Visits. JAMA Psychiatry 2021, 78, 726–734. [Google Scholar] [CrossRef]
- Delavar, A.; Saseendrakumar, B.R.; Weinreb, R.N.; Baxter, S.L. Racial and Ethnic Disparities in Cost-Related Barriers to Medication Adherence Among Patients With Glaucoma Enrolled in the National Institutes of Health All of Us Research Program. JAMA Ophthalmol. 2022, 140, 354–361. [Google Scholar] [CrossRef]
- Melchior, B.; Valenzuela, I.A.; De Moraes, C.G.; Paula, J.S.; Fazio, M.A.; Girkin, C.A.; Proudfoot, J.; Cioffi, G.A.; Weinreb, R.N.; Zangwill, L.M.; et al. Glaucomatous Visual Field Progression in the African Descent and Glaucoma Evaluation Study (ADAGES): Eleven Years of Follow-up. Am. J. Ophthalmol. 2022, 239, 122–129. [Google Scholar] [CrossRef]
- Gu, B.; Sidhu, S.; Weinreb, R.N.; Christopher, M.; Zangwill, L.M.; Baxter, S.L. Review of Visualization Approaches in Deep Learning Models of Glaucoma. Asia Pac. J. Ophthalmol. 2023, 12, 392–401. [Google Scholar] [CrossRef]
- Yang, S.A.; Mitchell, W.; Hall, N.; Elze, T.; Lorch, A.C.; Miller, J.W.; Zebardast, N.; Pershing, S.; Hyman, L.; Haller, J.A.; et al. Trends and Usage Patterns of Minimally Invasive Glaucoma Surgery in the United States: IRIS(R) Registry Analysis 2013–2018. Ophthalmol. Glaucoma 2021, 4, 558–568. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.Y.; Tseng, B.; Hernandez-Boussard, T. Deep Learning Approaches for Predicting Glaucoma Progression Using Electronic Health Records and Natural Language Processing. Ophthalmol. Sci. 2022, 2, 100127. [Google Scholar] [CrossRef] [PubMed]
- Marino, M.; Lucas, J.; Latour, E.; Heintzman, J.D. Missing data in primary care research: Importance, implications and approaches. Fam. Pract. 2021, 38, 200–203. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
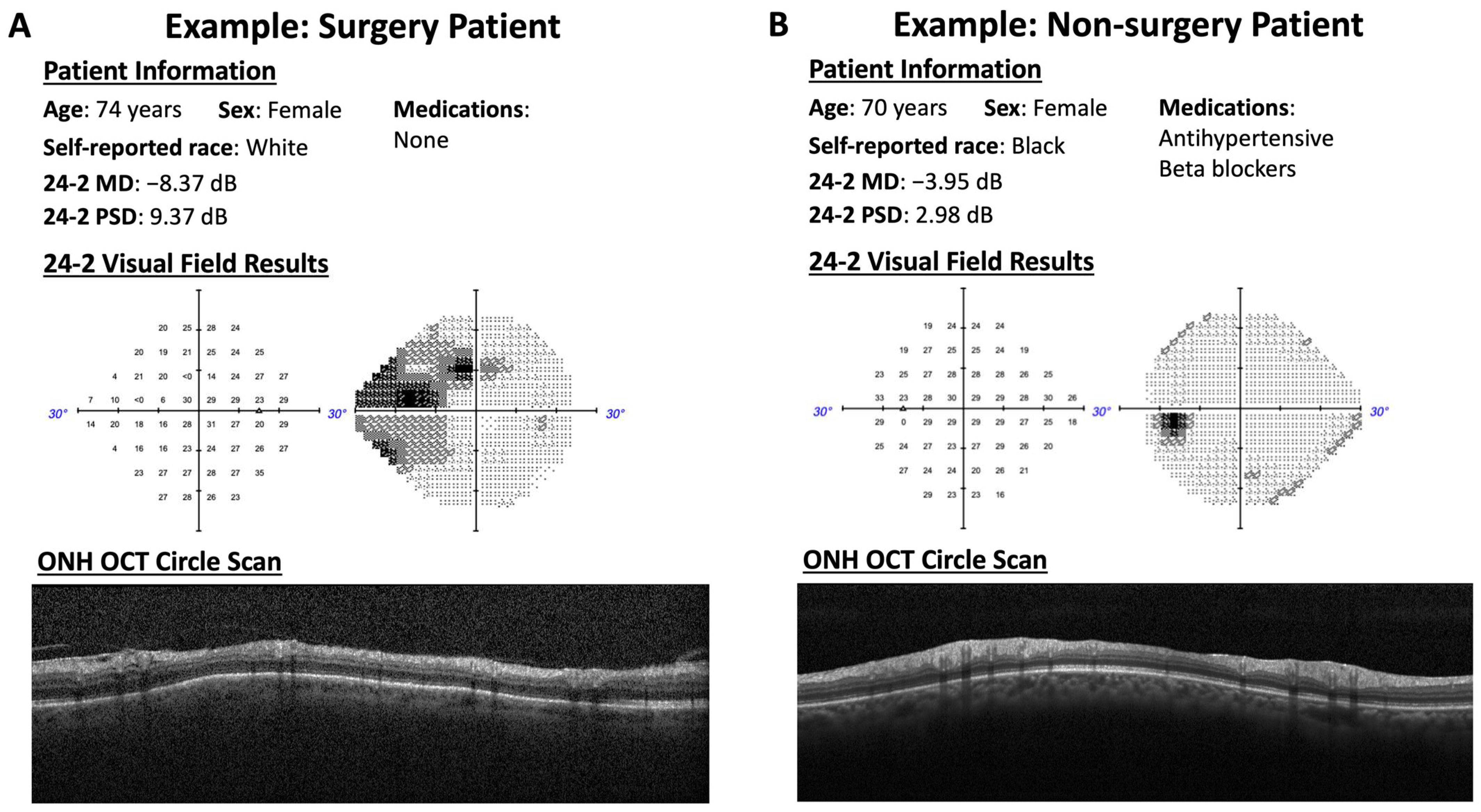
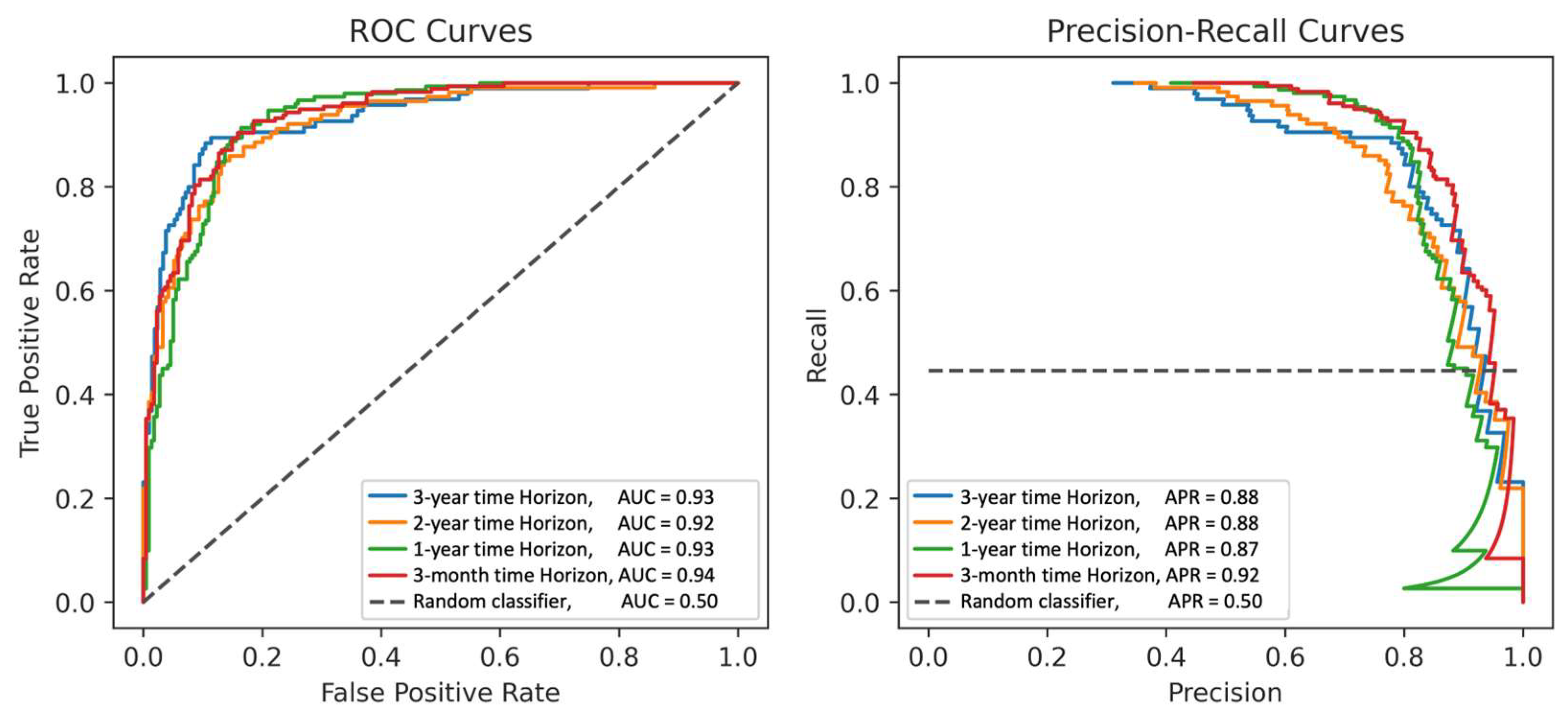
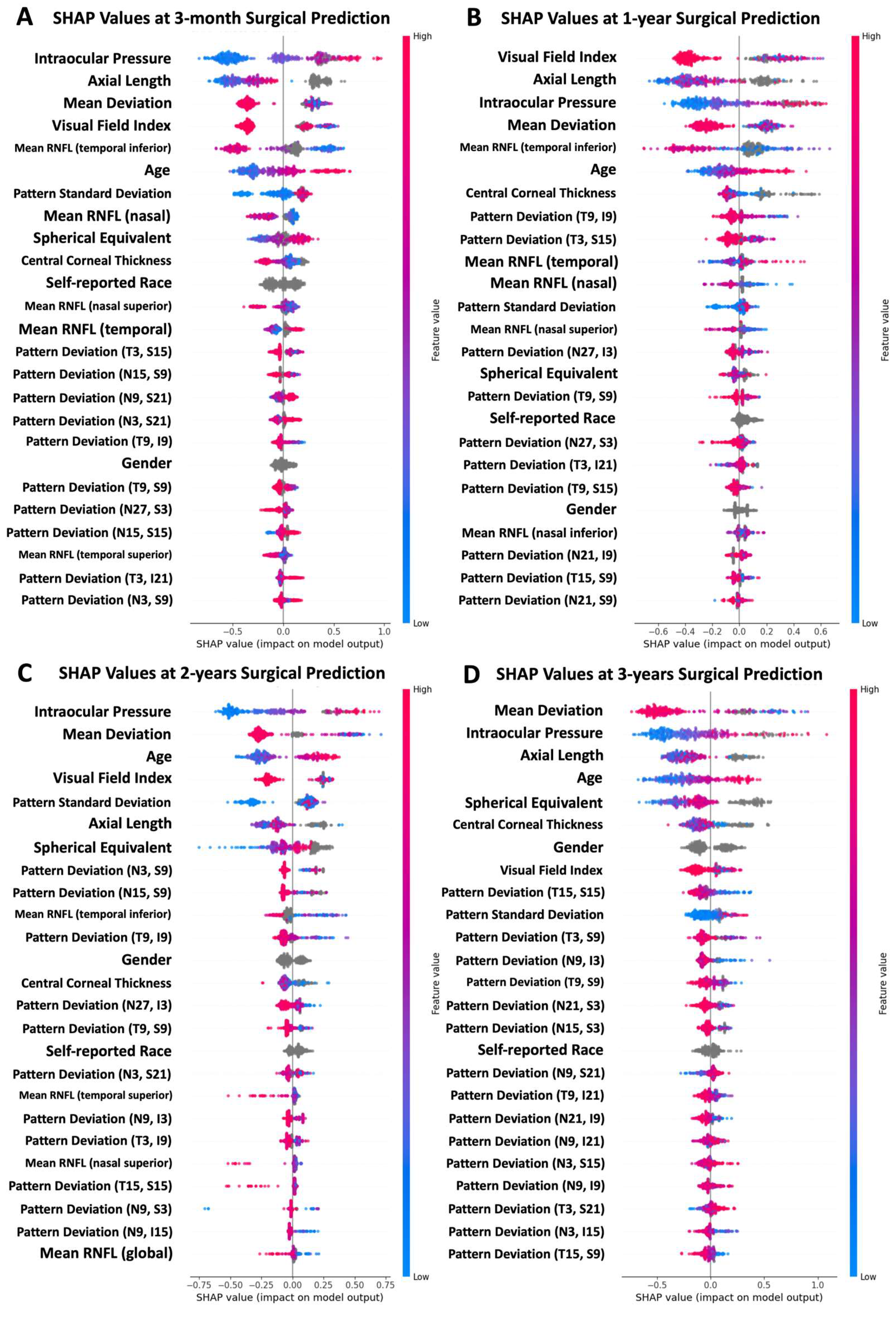

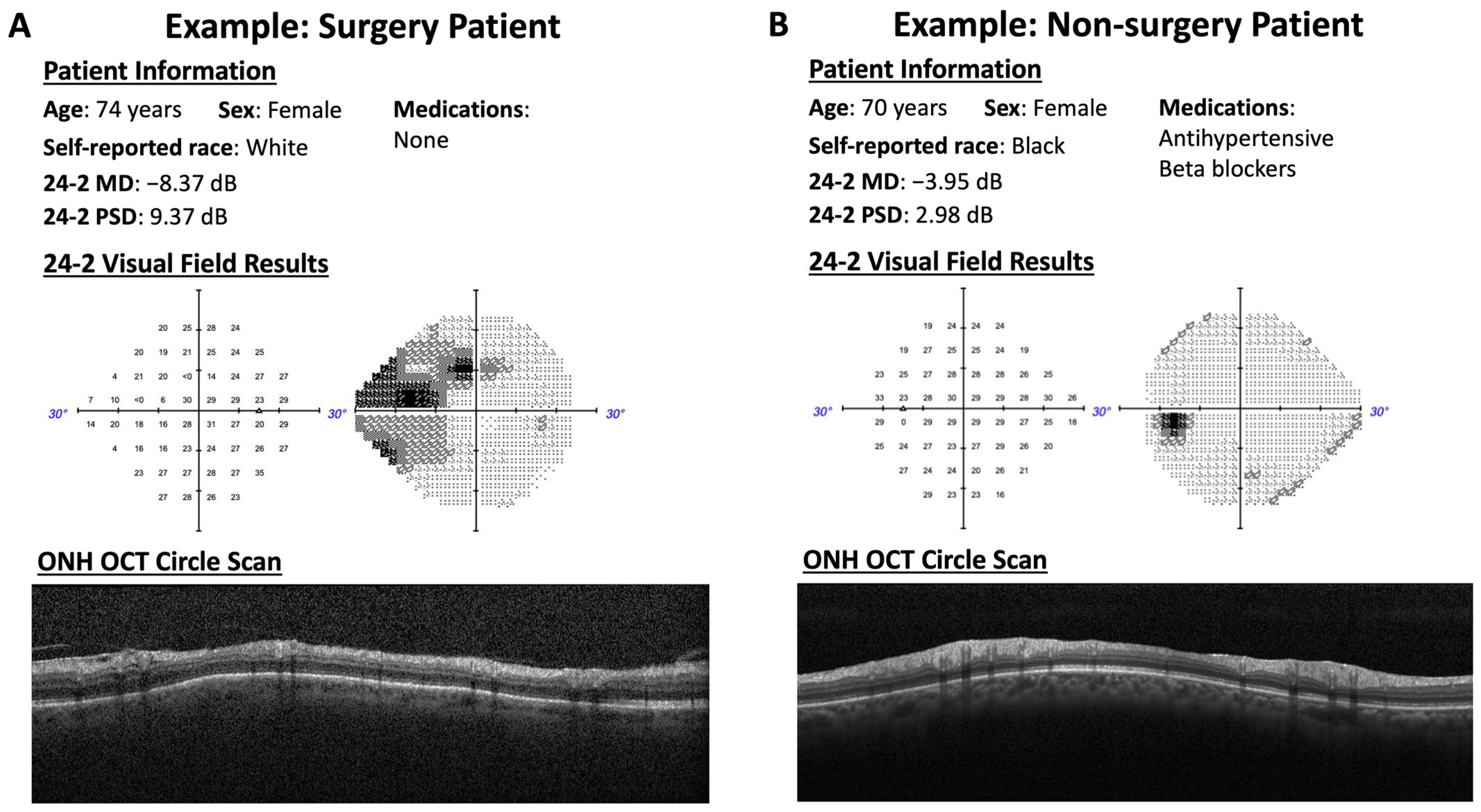{kind=link}
{kind=link}
{kind=link}
| Training | Testing | |||
|---|---|---|---|---|
| Glaucoma Surgery | No Surgery | Glaucoma Surgery | No Surgery | |
| Participants/eyes (n, %) | 419/610 (45.8%) | 496/830 (54.2%) | 137/178 (51.9%) | 127/221 (48.1%) |
| Age (years, 95% CI) | 68.4 (67.5–69.4) | 63.2 (62.3–64.2) | 66.3 (64.5–68.0) | 59.8 (58.0–61.6) |
| 24-2 MD (dB, 95% CI) | −7.17 (−7.70–−6.63) | −1.40 (−1.85–−0.94) | −8.39 (−9.74–−7.05) | −1.19 (−2.18–−0.20) |
| Mean RNFL thickness (μm, 95% CI) | 75.2 (72.2–78.1) | 86.6 (84.8–88.3) | 73.3 (68.1–78.5) | 84.4 (79.6–89.2) |
| Sex (n, % female) | 217 (51.8%) | 306 (61.7%) | 91 (66.4%) | 71 (55.9%) |
| Self-reported race (n, %) | ||||
| Black/African American | 217 (51.8%) | 205 (41.3%) | 90 (65.7%) | 67 (52.8%) |
| White | 194 (46.3%) | 253 (51.0%) | 47 (34.3%) | 60 (47.2%) |
| Other/not reported | 8 (1.9%) | 38 (7.7%) | 0 (0.0%) | 0 (0.0%) |
| Surgery type | ||||
| Incisional | 170 (27.9%) | - | 67 (37.6%) | - |
| MIGS | 1 (0.2%) | - | 6 (3.4%) | - |
| Laser | 439 (72.0%) | - | 105 (59.0%) | - |
| None | 0 (0.0%) | 830 (100.0%) | 0 (0.0%) | 221 (100.0%) |
| Precision at Time Horizons | AUC | Precision | Recall/Sensitivity | Specificity |
|---|---|---|---|---|
| 3 months | 0.94 (0.91–0.96) | |||
| 0.75 precision | 0.75 (0.71–0.79) | 0.94 (0.91–0.98) | 0.75 (0.69–0.80) | |
| 0.80 precision | 0.80 (0.76–0.85) | 0.93 (0.89–0.96) | 0.81 (0.76–0.86) | |
| 0.85 precision | 0.85 (0.80–0.90) | 0.83 (0.78–0.88) | 0.88 (0.84–0.92) | |
| 0.90 precision | 0.90 (0.85–0.95) | 0.68 (0.61–0.75) | 0.94 (0.91–0.97) | |
| 0.95 precision | 0.95 (0.91–0.99) | 0.56 (0.49–0.63) | 0.98 (0.96–1.00) | |
| 1 year | 0.93 (0.90–0.95) | |||
| 0.75 precision | 0.75 (0.71–0.80) | 0.95 (0.91–0.98) | 0.79 (0.73–0.84) | |
| 0.80 precision | 0.80 (0.75–0.85) | 0.89 (0.84–0.93) | 0.85 (0.80–0.90) | |
| 0.85 precision | 0.85 (0.80–0.91) | 0.66 (0.59–0.74) | 0.92 (0.89–0.95) | |
| 0.90 precision | 0.91 (0.84–0.97) | 0.45 (0.37–0.53) | 0.97 (0.94–0.99) | |
| 0.95 precision | 0.96 (0.89–1.00) | 0.30 (0.22–0.38) | 0.99 (0.98–1.00) | |
| 2 years | 0.92 (0.89–0.95) | |||
| 0.75 precision | 0.75 (0.70–0.82) | 0.86 (0.79–0.92) | 0.85 (0.80–0.90) | |
| 0.80 precision | 0.80 (0.74–0.86) | 0.77 (0.69–0.85) | 0.90 (0.86–0.94) | |
| 0.85 precision | 0.85 (0.78–0.91) | 0.70 (0.61–0.78) | 0.94 (0.90–0.97) | |
| 0.90 precision | 0.90 (0.84–0.97) | 0.58 (0.48–0.67) | 0.97 (0.94–0.99) | |
| 0.95 precision | 0.96 (0.90–1.00) | 0.39 (0.30–0.47) | 0.99 (0.98–1.00) | |
| 3 years | 0.93 (0.89–0.97) | |||
| 0.75 precision | 0.75 (0.69–0.82) | 0.90 (0.83–0.95) | 0.87 (0.82–0.92) | |
| 0.80 precision | 0.80 (0.74–0.88) | 0.86 (0.79–0.93) | 0.91 (0.87–0.94) | |
| 0.85 precision | 0.85 (0.78–0.92) | 0.75 (0.66–0.83) | 0.94 (0.91–0.97) | |
| 0.90 precision | 0.90 (0.84–0.97) | 0.67 (0.58–0.77) | 0.97 (0.94–0.99) | |
| 0.95 precision | 0.97 (0.90–1.00) | 0.33 (0.23–0.43) | 0.99 (0.99–1.00) |
| 3 Months | 1 Year | 2 Years | 3 Years | |
|---|---|---|---|---|
| Glaucoma severity | ||||
| MD > −6.0 dB (n = 153) | 0.89 (0.84–0.93) | 0.90 (0.86–0.94) | 0.87 (0.79–0.92) | 0.88 (0.79–0.94) |
| MD ≤ −6.0 dB (n = 50) | 0.88 (0.72–0.97) | 0.78 (0.58–0.92) | 0.86 (0.70–0.96) | 0.96 (0.84–1.00) |
| Age | ||||
| >60 years (n = 113) | 0.93 (0.88–0.96) | 0.91 (0.86–0.95) | 0.92 (0.86–0.96) | 0.92 (0.86–0.96) |
| ≤60 years (n = 107) | 0.94 (0.89–0.97) | 0.93 (0.89–0.96) | 0.92 (0.85–0.96) | 0.94 (0.87–0.99) |
| Self-reported race | ||||
| Black/African American (n = 134) | 0.93 (0.89–0.96) | 0.91 (0.87–0.95) | 0.92 (0.86–0.96) | 0.94 (0.88–0.97) |
| White (n = 86) | 0.94 (0.90–0.97) | 0.94 (0.90–0.97) | 0.94 (0.88–0.97) | 0.93 (0.85–0.98) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Christopher, M.; Gonzalez, R.; Huynh, J.; Walker, E.; Radha Saseendrakumar, B.; Bowd, C.; Belghith, A.; Goldbaum, M.H.; Fazio, M.A.; Girkin, C.A.; et al. Proactive Decision Support for Glaucoma Treatment: Predicting Surgical Interventions with Clinically Available Data. Bioengineering 2024, 11, 140. https://doi.org/10.3390/bioengineering11020140
Christopher M, Gonzalez R, Huynh J, Walker E, Radha Saseendrakumar B, Bowd C, Belghith A, Goldbaum MH, Fazio MA, Girkin CA, et al. Proactive Decision Support for Glaucoma Treatment: Predicting Surgical Interventions with Clinically Available Data. Bioengineering. 2024; 11(2):140. https://doi.org/10.3390/bioengineering11020140
Chicago/Turabian StyleChristopher, Mark, Ruben Gonzalez, Justin Huynh, Evan Walker, Bharanidharan Radha Saseendrakumar, Christopher Bowd, Akram Belghith, Michael H. Goldbaum, Massimo A. Fazio, Christopher A. Girkin, and et al. 2024. "Proactive Decision Support for Glaucoma Treatment: Predicting Surgical Interventions with Clinically Available Data" Bioengineering 11, no. 2: 140. https://doi.org/10.3390/bioengineering11020140
APA StyleChristopher, M., Gonzalez, R., Huynh, J., Walker, E., Radha Saseendrakumar, B., Bowd, C., Belghith, A., Goldbaum, M. H., Fazio, M. A., Girkin, C. A., De Moraes, C. G., Liebmann, J. M., Weinreb, R. N., Baxter, S. L., & Zangwill, L. M. (2024). Proactive Decision Support for Glaucoma Treatment: Predicting Surgical Interventions with Clinically Available Data. Bioengineering, 11(2), 140. https://doi.org/10.3390/bioengineering11020140