
Shape-Aware Adversarial Learning for Scribble-Supervised Medical Image Segmentation with a MaskMix Siamese Network: A Case Study of Cardiac MRI Segmentation


Abstract

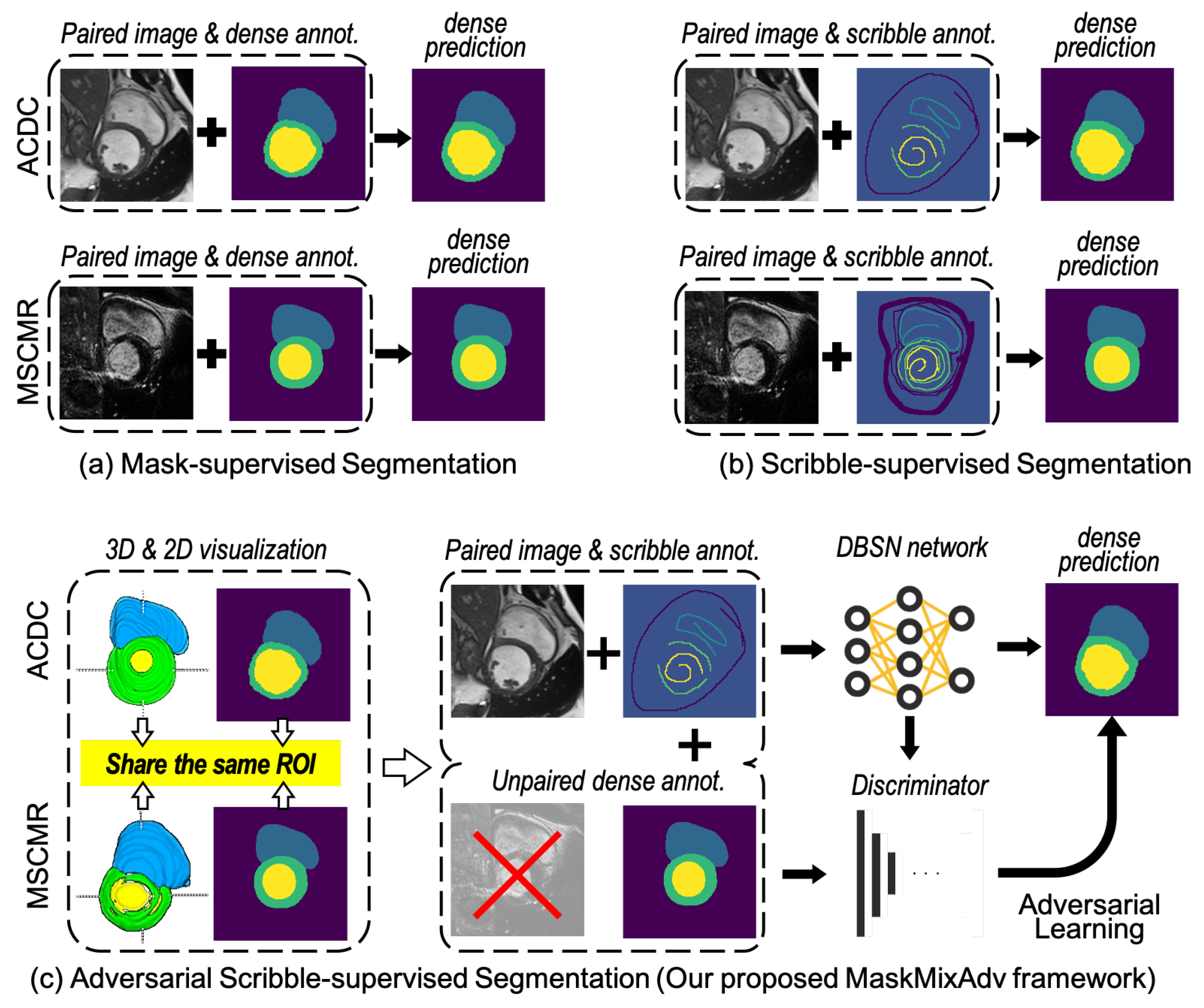
1. Introduction
2. Related Work
3. MaskMixAdv: Framework Enabling Scribble-Supervised Medical Image Segmentation
3.1. Overall Design of the MaskMixAdv Framework
- MaskMix phase receives medical image X and paired scribble annotations Y as input. In this phase, the proposed MaskMix strategy first carries out masking augmentation towards X at the image-level or feature-level. Then, the shared encoder extracts perturbed features from X after augmentation. Next, two independent decoders , perform scribble-supervised training with Y and obtain coarsely segmentation results . Meanwhile, another decoder () is used for masked image modeling from perturbations. Finally, MaskMix integrates and to generate pseudo labels , which is sent to the next phase for model fine-tuning.
- Adversarial phase receives pseudo labels and unpaired mask Z as input. In this phase, Z is regarded as real and is labelled as fake. Then, the discriminator receives or Z as input and outputs a bool prediction representing the prediction of the input source, i.e., whether it is real or fake. An adversarial loss is designed to minimize the above discrepancy of binary predictions, optimizing the training of segmentation network and discriminator. Finally, the refined pseudo labels participant in model fine-tuning as ground truth to optimize segmentation network.
3.2. Pseudo Label Generation: MaskMix Masking upon Siamese Network
- Data augmentation: A novel masking strategy (MaskMix) is proposed to add perturbations into the siamese network and generate two complementary binary masks, which are used for masking the input X at image-level or feature-level (See Section 3.2.2 for more details).
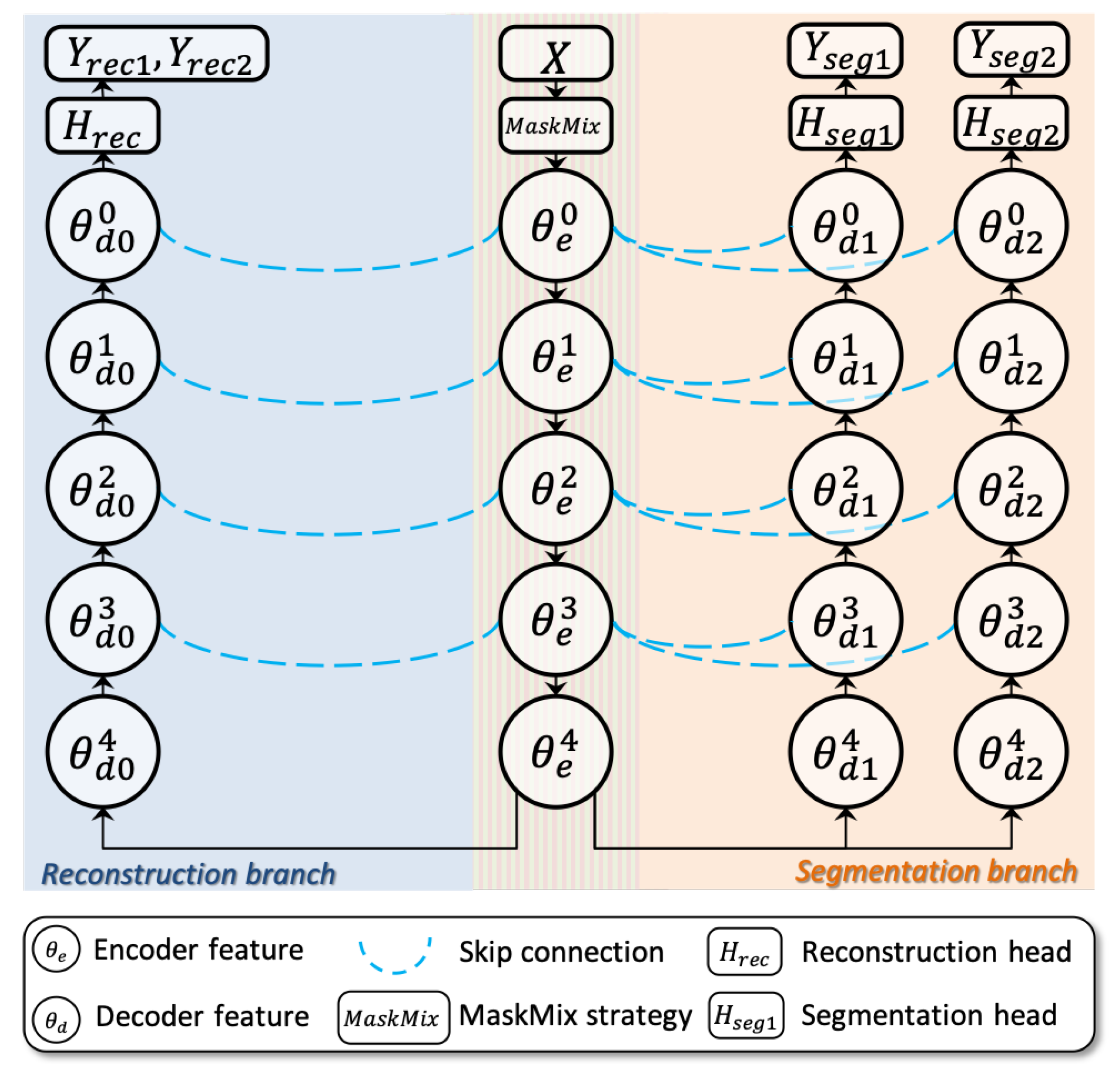
- Features extraction: The shared encoder () extracts the perturbed features of X, which are then used for masked reconstruction via the and dense prediction via the and (See Section 3.2.1 for more details).
- Coarsely training: The extracted the features from shared encoder () are then sent to two segmentation decoders ( and ) for scribble-supervised coarsely training. The outputs are the pixel-wise segmentation predictions with N classes (See Section 3.2.3 for more details).
- Masked image modeling: The proposed siamese network also supports self-supervised masked image modeling by reconstructing the input images X from MaskMix-based masking via reconstruction branch (). The output is the reconstruction prediction with the same resolution as X. This step aims to optimize the the proposed siamese network for feature extraction from sparse supervision (See Section 3.2.4 for more details).
3.2.1. Dual-Branch Siamese Network for Scribble-Supervised Learning
- Segmentation branch consists of the shared encoder and two independent decoders , . This branch outputs mask-like predictions , , respectively. Above two predictions take part in the following scribble-supervised coarsely training (Section 3.2.3) and pseudo label-supervised finely training (Section 3.3.2).
- Reconstruction branch consists of the shared encoder and one independent decoder . This branch restores the original image from perturbations of and then outputs image-like reconstructions , respectively. Above two predictions take part in the self-supervised masked image modeling (See Section 3.2.4 for more details).
3.2.2. MaskMix: A Mixup-Based Masking and Pseudo Label Generating Strategy
- At the image level: masks () are multiplied with images X. The regions of the mask ( or ) corresponding to 1 keep the pixel values of X unchanged, while the other regions are filled with 0. Then these masked images () are fed into encoder for pixel-wise perturbation. Figure 4a illustrates the workflow of Mask step at the image-level. Figure 4c–k compare other common data perturbation strategies at the image-level.
- At the feature level: images X are directly fed into encoder to obtain the encoded feature , which is then multiplied with masks () for feature-wise perturbation. The regions of mask ( or ) corresponding to 1 keep the feature of unchanged, while the others are filled with 0. Figure 4b illustrates the workflow of Mask step at feature-level. Note that the features are visualized by GradCAM [36].
3.2.3. Scribble-Supervised Coarsely Training
3.2.4. Self-Supervised Masked Image Modeling
3.3. Pseudo Labels Optimization: Shape-Aware Adversarial Learning
3.3.1. Additional Unpaired Masks-Based Adversarial Learning Refinement
3.3.2. MaskMix-Based Pseudo Label-Supervised Finely Training
3.4. Summary
- During the training phase, the MaskMixAdv framework incorporates the MaskMix augmentation strategy into the DBSN network (, , , ) to generate fine-grained pseudo labels. The shape-aware adversarial learning component regularizes the contours of these pseudo labels, facilitating model fine-tuning.
- During the testing phase, the reconstruction decoder is no longer required, as its function is to facilitate training through self-supervised learning. The MaskMix strategy, which includes the mask step and the subsequent mix step, is not employed during inference because it serves to augment the sparse annotations specifically during the training phase. Considering that the output results and accuracy of the two segmentation decoders ( and ) in the DBSN network are almost identical after adversarial scribble-supervised training, with no significant difference, the MaskMixAdv framework directly adopts the segmentation prediction result from as the final output. Additionally, the adversarial discriminator is not utilized during inference, as its role is to refine pseudo labels during the training phase.
4. Case Study
- Cardiac MRI images were affected by the constant motion of the heart, making it challenging to acquire clear images and perform accurate segmentation.
- The heart’s anatomy was complex, featuring multiple chambers, valves, and vascular structures closely packed together.
- Effective cardiac MRI segmentation should not only achieve high accuracy but also be efficient in terms of processing time to integrate seamlessly with clinical workflows.
- Compared the MaskMixAdv framework with several state-of-the-art scribble-supervised methods in terms of Dice and Hausdorff Distance (Section 4.2).
- Compared the MaskMix strategy with different masking augmentation techniques for scribble-supervised cardiac MRI segmentation (Section 4.2).
- Examined the sensitivity of MaskMixAdv to different combinations of scribble and mask annotations (Section 4.3).
- Validated the effectiveness of the shared shape prior extracted from other datasets for enhancing scribble-supervised cardiac MRI segmentation (Section 4.3).
4.1. Datasets and Settings
- When the source dataset was ACDC, the dataset was randomly divided into a training set and a test set in a 4:1 ratio, and then a five-fold cross-validation was completed. Apart from the paired image and scribble annotations from the source dataset (ACDC), dense annotations from the additional unpaired dataset (MSCMR) were used as unpaired masks Z for adversarial scribble-supervised segmentation.
- When the source dataset was MSCMR, this study adopted the same dataset split in ref. [20,33], i.e., 45 patients were divided into 25 cases as the training set, 5 cases as the validation set, and the remaining 15 cases as the test set. Apart from the paired image and scribble annotations from the source dataset (MSCMR), the unpaired masks Z were dense annotations from the additional unpaired dataset (ACDC).
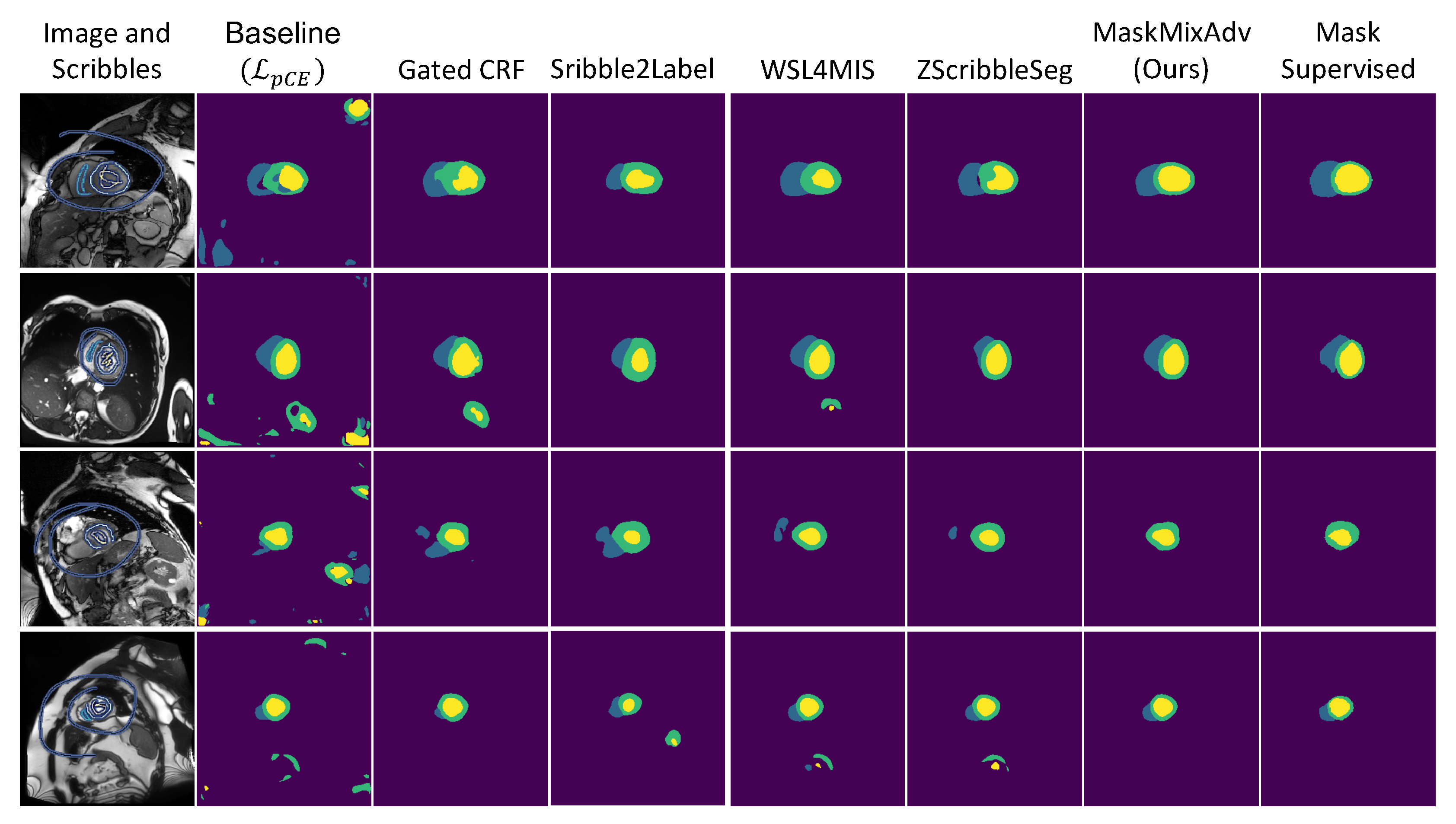
4.2. Comparison with the State-of-the-Art Methods
- If all methods incorporated these external masks, the proposed MaskMixAdv (0.8870.051) outperformed the second-best one (WSL4MIS, 0.8750.050) with statistical significance (p-value was 0.0182 < 0.05).
- If all methods did not use any external mask, the 3D Dice of MaskMixAdv (0.8700.056) was still the-state-of-art and not statistically different from the best reported one (WSL4MIS, 0.8720.077) with p-value of 0.7617 > 0.05. But MaskMixAdv still outperformed the re-implemented WSL4MIS (0.8630.050).
- The proposed shape-aware adversarial learning (Section 3.3) was compatible to most scribble-supervised methods, whose performances improved after introducing external masks. Above observation demonstrated that it was possible to break the upper bound of scribble-supervised segmentation with the help of shape priors.
4.3. Ablation Study
- Scribble-supervised methods performed poorly when only and were applied. In contrast, performance improved after introducing , demonstrating the effectiveness of the reconstruction branch in helping the dual-branch siamese network to extract features from sparse supervision.
- The performance of was still not satisfied but the pseudo labelling component () improved it a lot, demonstrating the effectiveness of the pseudo labels in enhancing scribble-supervised segmentation.
- The of was still far below that of mask-supervised methods. This meant that predictions on some cardiac structures were incorrect with imprecise boundaries. However, the proposed adversarial learning () optimized this drawback, reducing the discrepancy between the scribble-supervised and mask-supervised methods.
- As expected, the performance of MaskMixAdv trended upwards as the percentage of labelled data increased.
- With decreasing amounts of labelled data, MaskMixAdv retained a high performance on cardiac MRI segmentation. Specifically, when only 50% of the labelled samples were accessible, MaskMixAdv could reach about 98% of the performance after training with all labelled samples.
- MaskMixAdv could also be trained on a few labelled datasets to achieve comparable performance to the full-labelled dataset. For instance, MaskMixAdv trained with 10% labelled data sacrificed only 12% of performance compared to training with all labelled data, but reduced the number of labelled samples by 90%, saving more on labelling costs.
- If only a small number of masks cases (<10 in this study) were incorporated, the optimization of pseudo labelling was rather harmful, as shown by the decrease of 3D Dice and the increase of Hausdorff distance.
- When a sufficient number of masks cases (≥10 in this study) were introduced, the performance of the model was rapidly improved, as shown by the increase of 3D Dice and the significant decrease of Hausdorff distance.
4.4. Discussions
4.4.1. Extension to Point-Supervised Cardiac MRI Segmentation
4.4.2. Efficiency of Scribble-Based Cardiac MRI Annotations
4.4.3. Advantages and Limitations
- The MaskMixAdv proposed in this manuscript was designed for 2D MRI images with 2D scribbles. Therefore, the direct application of the current MaskMixAdv to 3D volumes with 3D scribbles or other coarse-grained annotations for weakly-supervised learning was not validated.
- The external masks for MaskMixAdv were from the same modality as source dataset, i.e., the ACDC and MSCMR in this study. So the superiority of this method to perform adversarial scribble-supervised learning on cross-modality medical images dataset remained to be validated.
5. Conclusions
- Pseudo label generation: This task was facilitated by a dual-branch siamese network equipped with the MaskMix augmentation strategy. The siamese network, utilizing MaskMix-based augmentation, enriched the coarse-grained annotations through both reconstruction and segmentation branches, effectively enhancing the quality of the scribble annotations.
- Pseudo label optimization: In this task, adversarial learning was employed to refine the generated pseudo labels by transferring shape priors from additional datasets. This process aimed to ensure that the pseudo labels accurately matched real shapes.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Pseudocode of MaskMixAdv
| Algorithm A1 Pytorch-like pseudocode of MaskMixAdv |
| # e: the shared encoder (backbone is resnet50 in this study) # d0: the decoder in the reconstruction branch # d1: the first decoder in the segmentation branch # d2: the second decoder in the segmentation branch # dis: the discriminator # load a batch with paired images and scribbles <X,Y> from source dataset and a batch with unpaired masks Z from additional dataset for X,Y,Z in dataloader: M1.generator() # randomly generate a binary mask M2 = 1-M1 # generate another mask complementary to M1 ---------------------------------------------------------- # (Alternative) MaskMix-based perturbations at the image level X1 = M1(X) # mask input images with M1 X2 = M2(X) # mask input images with M2 r1 = e.forward(X1) # encoder representation r2 = e.forward(X2) # encoder representation ---------------------------------------------------------- # (Alternative) MaskMix-based perturbations at the feature level r = e.forward(X) # extract representation via the shared encoder r1 = M1(r) # mask extracted representation with M1 r2 = M2(r) # mask extracted representation with M2 ---------------------------------------------------------- y1 = d1.forward(r1) # Segmentation from the representation via the first decoder y2 = d2.forward(r2) # Segmentation from the representation via the second decoder loss_DpCE = Func_DpCE_loss(y1, y2, Y) # Scribble-superivsed coarsely training pse_y = 1(M1)y1 + 1(M2)y2 # MaskMix-based pseudo label generation rec_y1 = d0.forward(r1) # reconstruct from masked representations rec_y2 = d0.forward(r2) # reconstruct from masked representations loss_rec = Func_rec_loss(X, rec_y1, rec_y2) # self-superivsed masked image modeling dis_y = dis.forward(pse_y) # discriminate the pseudo labels dis_z = dis.forward(Z) # discriminate the additional unpaired masks loss_adv = Func_adv_loss(dis_y,dis_z) # Shape-aware adversarial learning loss_pse = Func_pse_loss(y1, y2, pse_y) # Pseudo label-superivsed finely training (loss_DpCE + loss_rec + loss_adv + loss_pse).backward() #back propagation update(e.params, d0.params, d1.params, d2.params, dis.params) # optimizer update def Func_DpCE_loss(y1, y2, Y): # Dual-branch partial cross-entropy loss for scribble-supervised coarsely training CrossEntropyLoss = torch.nn.CrossEntropyLoss(ignore_index=4) loss = CrossEntropyLoss(y1, Y.long()) + torch.nn.CrossEntropyLoss(y2, Y.long()) return loss def Func_rec_loss(X, rec_y1, rec_y2): # Reconstruction loss for self-supervised masked image modeling return torch.nn.L2Loss(X, rec_y1) + torch.nn.L2Loss(X, rec_y2) + torch.nn.L2Loss(rec_y1, rec_y2) def Func_adv_loss(dis_y, dis_z): # Adversarial loss for pseudo label optimization return torch.nn.BCEWithLogitsLoss(dis_y, 1).mean() + torch.nn.BCEWithLogitsLoss(dis_z, 1).mean() def Func_pse_loss(y1, y2, pse_y): # Pseudo label-superivsed loss for pseudo label-supervised finely training intersection_1 = (y1 * pse_y).sum(1) unionset_1 = y1.sum(1) + pse_y.sum(1) intersection_2 = (y2 * pse_y).sum(1) unionset_2 = y2.sum(1) + pse_y.sum(1) loss = (1 - intersection_1 / unionset_1 - intersection_2 / unionset_2) return loss |
Appendix B. Comparison Between Hausdorff Distance and Minimal Distance
References
- Chen, Z.; Tian, Z.; Zhu, J.; Li, C.; Du, S. C-CAM: Causal CAM for Weakly Supervised Semantic Segmentation on Medical Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 11–15 June 2022; pp. 11676–11685. [Google Scholar]
- Lei, W.; Su, Q.; Jiang, T.; Gu, R.; Wang, N.; Liu, X.; Wang, G.; Zhang, X.; Zhang, S. One-Shot Weakly-Supervised Segmentation in 3D Medical Images. IEEE Trans. Med. Imag. 2024, 43, 175–189. [Google Scholar] [CrossRef] [PubMed]
- Gao, F.; Hu, M.; Zhong, M.E.; Feng, S.; Tian, X.; Meng, X.; Ni-jia-ti, M.-y.-d.-l.; Huang, Z.; Lv, M.; Song, T.; et al. Segmentation only uses sparse annotations: Unified weakly and semi-supervised learning in medical images. Med. Image Anal. 2022, 80, 102515. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Hu, M.; Liao, W.; Zhai, S.; Song, T.; Wang, G.; Zhang, S. Scribble-supervised medical image segmentation via dual-branch network and dynamically mixed pseudo labels supervision. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Singapore, 18–22 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 528–538. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. GrabCut: Interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Vernaza, P.; Chandraker, M. Learning Random-Walk Label Propagation for Weakly-Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2953–2961. [Google Scholar] [CrossRef]
- Grady, L. Random Walks for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [PubMed]
- Tang, M.; Perazzi, F.; Djelouah, A.; Ben Ayed, I.; Schroers, C.; Boykov, Y. On regularized losses for weakly-supervised cnn segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 507–522. [Google Scholar]
- Lafferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML), Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Tang, M.; Marin, D.; Ayed, I.B.; Boykov, Y. Normalized Cut Meets MRF. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 748–765. [Google Scholar]
- Can, Y.B.; Chaitanya, K.; Mustafa, B.; Koch, L.M.; Konukoglu, E.; Baumgartner, C.F. Learning to segment medical images with scribble-supervision alone. In Proceedings of the Deep Learning in Medical Image Analysis Workshop with MICCAI, Munich, Germany, 5–9 October 2018; pp. 236–244. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials. In Proceedings of the 24th International Conference on Neural Information Processing Systems (NeurIPS), Granada, Spain, 12–15 December 2011; pp. 109–117. [Google Scholar]
- Pu, M.; Huang, Y.; Guan, Q.; Zou, Q. GraphNet: Learning Image Pseudo Annotations for Weakly-Supervised Semantic Segmentation. In Proceedings of the 26th ACM International Conference on Multimedia (MM), Seoul, Republic of Korea, 22–26 October 2018; pp. 483–491. [Google Scholar]
- Ji, Z.; Shen, Y.; Ma, C.; Gao, M. Scribble-based hierarchical weakly supervised learning for brain tumor segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Shenzhen, China, 13–17 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 175–183. [Google Scholar]
- Boykov, Y.Y.; Jolly, M.P. Interactive graph cuts for optimal boundary & region segmentation of objects in ND images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001; Volume 1, pp. 105–112. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, K.; Zhuang, X. CycleMix: A Holistic Strategy for Medical Image Segmentation From Scribble Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 11656–11665. [Google Scholar]
- Kim, J.; Choo, W.; Jeong, H.; Song, H.O. Co-Mixup: Saliency Guided Joint Mixup with Supermodular Diversity. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Kim, J.H.; Choo, W.; Song, H.O. Puzzle Mix: Exploiting Saliency and Local Statistics for Optimal Mixup. In Proceedings of the International Conference on Machine Learning (ICML), Vienna, Austria, 12–18 July 2020; Volume 489, p. 11. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on challenges in representation learning, ICML, Atlanta, GE, USA, 16–21 June 2013; Volume 3, p. 896. [Google Scholar]
- Zou, Y.; Zhang, Z.; Zhang, H.; Li, C.L.; Bian, X.; Huang, J.B.; Pfister, T. PseudoSeg: Designing Pseudo Labels for Semantic Segmentation. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4 May 2021. [Google Scholar]
- Pan, Z.; Jiang, P.; Wang, Y.; Tu, C.; Cohn, A.G. Scribble-supervised semantic segmentation by uncertainty reduction on neural representation and self-supervision on neural eigenspace. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7416–7425. [Google Scholar]
- Lee, H.; Jeong, W.K. Scribble2label: Scribble-supervised cell segmentation via self-generating pseudo-labels with consistency. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Lima, Peru, 4–8 October 2020; pp. 14–23. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, X.; Yuan, Q.; Gao, Y.; He, K.; Wang, S.; Tang, X.; Tang, J.; Shen, D. Weakly supervised segmentation of COVID19 infection with scribble annotation on CT images. Pattern Recognit. 2022, 122, 108341. [Google Scholar] [CrossRef] [PubMed]
- Kulharia, V.; Chandra, S.; Agrawal, A.; Torr, P.; Tyagi, A. Box2seg: Attention weighted loss and discriminative feature learning for weakly supervised segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 290–308. [Google Scholar]
- Cholakkal, H.; Sun, G.; Khan, F.S.; Shao, L. Object counting and instance segmentation with image-level supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12397–12405. [Google Scholar]
- Zhang, K.; Zhuang, X. ShapePU: A New PU Learning Framework Regularized by Global Consistency for Scribble Supervised Cardiac Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Singapore, 18–22 September 2022; pp. 162–172. [Google Scholar]
- Saerens, M.; Latinne, P.; Decaestecker, C. Adjusting the outputs of a classifier to new a priori probabilities: A simple procedure. Neural Comput. 2002, 14, 21–41. [Google Scholar] [CrossRef] [PubMed]
- Adiga, S.; Dolz, J.; Lombaert, H. Anatomically-aware uncertainty for semi-supervised image segmentation. Med. Image Anal. 2024, 91, 103011. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Huo, X.; Xie, L.; He, J.; Yang, Z.; Zhou, W.; Li, H.; Tian, Q. Atso: Asynchronous teacher-student optimization for semi-supervised image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 1235–1244. [Google Scholar]
- Bernard, O.; Lalande, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.A.; Cetin, I.; Lekadir, K.; Camara, O.; Ballester, M.A.G.; et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: Is the problem solved? IEEE Trans. Med. Imag. 2018, 37, 2514–2525. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, X. Multivariate mixture model for cardiac segmentation from multi-sequence MRI. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Athens, Greece, 17–21 October 2016; pp. 581–588. [Google Scholar]
- Zhuang, X. Multivariate mixture model for myocardial segmentation combining multi-source images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2933–2946. [Google Scholar] [CrossRef] [PubMed]
- Valvano, G.; Leo, A.; Tsaftaris, S.A. Learning to segment from scribbles using multi-scale adversarial attention gates. IEEE Trans. Med. Imag. 2021, 40, 1990–2001. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Obukhov, A.; Georgoulis, S.; Dai, D.; Van Gool, L. Gated CRF loss for weakly supervised semantic image segmentation. arXiv 2019, arXiv:1906.04651. [Google Scholar]
- Kim, B.; Ye, J.C. Mumford-Shah loss functional for image segmentation with deep learning. IEEE Trans. Image Process. 2019, 29, 1856–1866. [Google Scholar] [CrossRef] [PubMed]
- Grandvalet, Y.; Bengio, Y. Semi-supervised learning by entropy minimization. Adv. Neural Inf. Process. Syst. 2004, 17, 529–536. [Google Scholar]
- Garg, S.; Wu, Y.; Smola, A.J.; Balakrishnan, S.; Lipton, Z. Mixture Proportion Estimation and PU Learning: A Modern Approach. Adv. Neural Inf. Process. Syst. 2021, 34, 8532–8544. [Google Scholar]
- Kiryo, R.; Niu, G.; du Plessis, M.C.; Sugiyama, M. Positive-Unlabeled Learning with Non-Negative Risk Estimator. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Zhang, K.; Zhuang, X. ZScribbleSeg: Zen and the Art of Scribble Supervised Medical Image Segmentation. arXiv 2023, arXiv:2301.04882. [Google Scholar]
- Rajchl, M.; Lee, M.C.; Oktay, O.; Kamnitsas, K.; Passerat-Palmbach, J.; Bai, W.; Damodaram, M.; Rutherford, M.A.; Hajnal, J.V.; Kainz, B.; et al. Deepcut: Object segmentation from bounding box annotations using convolutional neural networks. IEEE Trans. Med. Imag. 2016, 36, 674–683. [Google Scholar] [CrossRef] [PubMed]
- Zhao, T.; Yin, Z. Weakly supervised cell segmentation by point annotation. IEEE Trans. Med. Imag. 2020, 40, 2736–2747. [Google Scholar] [CrossRef] [PubMed]
- Ahn, J.; Kwak, S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4981–4990. [Google Scholar]
- Meyer, P.G.; Cherstvy, A.G.; Seckler, H.; Hering, R.; Blaum, N.; Jeltsch, F.; Metzler, R. Directedeness, correlations, and daily cycles in springbok motion: From data via stochastic models to movement prediction. Phys. Rev. Res. 2023, 5, 043129. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbr. | Dataset Source | Modality | Input Size | Patients |
|---|---|---|---|---|
| ACDC | Automated Cardiac Diagnosis Challenge | MRI | 212 × 212 | 100 |
| MSCMR | Multi-sequence Cardiac MR Segmentation Challenge | MRI | 224 × 224 | 45 |
| Source Dataset: ACDC, Additional Unpaired Dataset: MSCMR | ||||||||
|---|---|---|---|---|---|---|---|---|
| Methods | 3D Dice ↑ | |||||||
| RV | Myo | LV | Average | RV | Myo | LV | Average | |
| ScribbleSup [6] | ||||||||
| RandomWalker [9] | ||||||||
| USTM-Net [30] | ||||||||
| Sribble2Label [28] | ||||||||
| Gated CRF [43] | ||||||||
| MumfordLoss [44] | ||||||||
| EntropyMini [45] | ||||||||
| Regularized [10] | ||||||||
| Puzzle Mix [24] | / | / | / | / | ||||
| WSL4MIS [4] (reported) | ||||||||
| WSL4MIS [4] (implemented) | ||||||||
| ShapePU [33] | / | / | / | / | ||||
| CycleMix [20] | / | / | / | / | ||||
| ZScribbleSeg [48] | ||||||||
| MaskMix (Ours w/o ) | ||||||||
| MaskMixAdv (Ours w/ ) | ||||||||
| Source Dataset: MSCMR, Additional Unpaired Dataset: ACDC | ||||||||
|---|---|---|---|---|---|---|---|---|
| Methods | 3D Dice ↑ | |||||||
| RV | Myo | LV | Average | RV | Myo | LV | Average | |
| CVIR [46] | ||||||||
| nnPU [47] | ||||||||
| ShapePU [33] | ||||||||
| CycleMix [20] | ||||||||
| WSL4MIS [4] | ||||||||
| Gated CRF [43] | ||||||||
| ZScribbleSeg [48] | ||||||||
| MaskMix (Ours w/o ) | ||||||||
| MaskMixAdv (Ours w/ ) | ||||||||
| Source Dataset: ACDC, Additional Unpaired Dataset: MSCMR | ||||
|---|---|---|---|---|
| Method | 3D Dice | |||
| RV | Myo | LV | Average | |
| Baseline 0 | ||||
| Mixup | ||||
| Cutout | ||||
| CutMix | ||||
| Puzzle Mix | ||||
| Co-mixup | ||||
| CycleMix | ||||
| Uniform Noise | ||||
| Gaussian Noise | ||||
| Salt&Pepper Noise | ||||
| Image-level MaskMix 1 | ||||
| Dropout | ||||
| Uniform Noise | ||||
| Gauss Noise | ||||
| Salt&Pepper Noise | ||||
| Feature-level MaskMix 1 | ||||
| Source Dataset: ACDC, Additional Unpaired Dataset: MSCMR | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | 3D Dice ↑ | ↓ | ||||||||
| RV | Myo | LV | Average | Average | ||||||
| Baseline | ✓ | |||||||||
| MaskMixAdv | ✓ | |||||||||
| ✓ | ✓ | |||||||||
| ✓ | ✓ | ✓ | ||||||||
| ✓ | ✓ | ✓ | ✓ | |||||||
| Source Dataset: MSCMR, Additional Unpaired Dataset: ACDC | ||||||||||
| Method | 3D Dice ↑ | ↓ | ||||||||
| RV | Myo | LV | Average | Average | ||||||
| Baseline | ✓ | |||||||||
| MaskMixAdv | ✓ | |||||||||
| ✓ | ✓ | |||||||||
| ✓ | ✓ | ✓ | ||||||||
| ✓ | ✓ | ✓ | ✓ | |||||||
| Label Ratio | Num of Scribbles | 3D Dice ↑ | ↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RV | Myo | LV | Average | RV | Myo | LV | Average | ||
| 10% | 8 | ||||||||
| 20% | 16 | ||||||||
| 30% | 24 | ||||||||
| 40% | 32 | ||||||||
| 50% | 40 | ||||||||
| 60% | 48 | ||||||||
| 70% | 56 | ||||||||
| 80% | 64 | ||||||||
| 90% | 72 | ||||||||
| 100% | 80 | ||||||||
| Supervision | 3D Dice ↑ | |||||||
|---|---|---|---|---|---|---|---|---|
| RV | Myo | LV | Average | RV | Myo | LV | Average | |
| Baseline * | ||||||||
| 1 Point | ||||||||
| 2 Points | ||||||||
| 3 Points | ||||||||
| Scribble | ||||||||
| Mask | ||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Zheng, Z.; Wu, D. Shape-Aware Adversarial Learning for Scribble-Supervised Medical Image Segmentation with a MaskMix Siamese Network: A Case Study of Cardiac MRI Segmentation. Bioengineering 2024, 11, 1146. https://doi.org/10.3390/bioengineering11111146
Li C, Zheng Z, Wu D. Shape-Aware Adversarial Learning for Scribble-Supervised Medical Image Segmentation with a MaskMix Siamese Network: A Case Study of Cardiac MRI Segmentation. Bioengineering. 2024; 11(11):1146. https://doi.org/10.3390/bioengineering11111146
Chicago/Turabian StyleLi, Chen, Zhong Zheng, and Di Wu. 2024. "Shape-Aware Adversarial Learning for Scribble-Supervised Medical Image Segmentation with a MaskMix Siamese Network: A Case Study of Cardiac MRI Segmentation" Bioengineering 11, no. 11: 1146. https://doi.org/10.3390/bioengineering11111146
APA StyleLi, C., Zheng, Z., & Wu, D. (2024). Shape-Aware Adversarial Learning for Scribble-Supervised Medical Image Segmentation with a MaskMix Siamese Network: A Case Study of Cardiac MRI Segmentation. Bioengineering, 11(11), 1146. https://doi.org/10.3390/bioengineering11111146