1. Introduction
Mitral regurgitation (MR) is a prevalent heart valve disease in clinical practice [
1], with its incidence increasing with age, reaching up to 10% in individuals over 75 years old [
2]. Without therapeutic intervention, severe MR can lead to complications such as cardiac arrhythmias and significantly elevate the risk of mortality [
1]. Additionally, the distribution of MR severity is uneven, with mild MR being relatively more prevalent. A large-scale echocardiography database analysis conducted by a team from Zhongshan Hospital affiliated with Fudan University in 2016 revealed detection rates of mild, moderate, and severe MR at 42.44%, 1.63%, and 1.44%, respectively [
3]. Similarly, a large-sample survey conducted by a team from the Second Affiliated Hospital of Zhejiang University School of Medicine in 2017 reported a detection rate of 0.68% for severe MR [
4]. Hence, an accurate assessment of MR severity is essential for preoperative assessment, intraoperative monitoring, and postoperative evaluation of MR patients.
Transthoracic echocardiography (TTE) is the most commonly used imaging technique for the diagnostic evaluation of MR due to its safety, non-invasiveness, and efficiency [
5]. It plays a crucial role throughout the clinical diagnosis and treatment of MR, as it not only allows for direct visualization of the morphology and extent of MR but serves as a reference for determining the need for surgical intervention by monitoring MR progression [
6]. Currently, the assessment of MR primarily relies on the subjective judgment of clinicians based on their clinical experience, leading to issues such as high labor costs, poor reproducibility, and inconsistency. In this context, image segmentation techniques offer promising applications for the automatic and precise delineation of regurgitation regions. Effective segmentation can enhance the accuracy of ultrasound image analysis, facilitate the identification and localization of lesion areas, and ultimately improve the early detection and treatment of MR [
7].
In recent years, artificial intelligence (AI) has been increasingly utilized in ultrasound medicine, particularly in the field of cardiovascular diseases. Tim et al. [
8] developed a novel machine learning (ML) risk stratification tool for predicting the 5-year risk in hypertrophic cardiomyopathy (HCM). Ahmed S. Fahmy et al. [
9] proposed an ML-based model to identify individual HCM patients at high risk of developing advanced heart failure symptoms. Tae-Min Rhee et al. [
10] established ML-based models to discriminate major cardiovascular events in patients with HCM. However, there is limited research on the use of AI for the assessment of MR severity, particularly from TTE, which mainly focuses on two aspects: the classification of MR severity and the segmentation of the MR region. Balodi et al. [
11] utilized texture feature extraction with a multiresolution local binary pattern (MLBP) variant for the classification of MR severity and achieved high classification accuracy. Penso et al. [
12] explored the application of ML methods in predicting MR recurrence. However, the association between echocardiography and surgical variables with MR recurrence remains controversial, and the potential causes are not yet well understood. Regarding the segmentation of the MR region, Atika et al. [
13] conducted a preliminary study comparing the performance of multiple deep learning (DL) image segmentation algorithms for MR region segmentation, finding that U-Net3 was superior in performance. U-Net3 [
14] is a variant of U-Net architecture, but it is difficult to be applied to clinical application scenarios due to the high computational complexity and long inference time. Huang et al. [
15] proposed a deep learning (DL)-based automated MR and tricuspid regurgitation (TR) segmentation and classification method, VABC-UNet. Although the segmentation accuracy reached 0.85 for the TR region, it was only 0.7 for the MR region. The morphology of MR in medical images is highly variable and exhibits irregularity, this model may produce inaccurate segmentation when dealing with complex cases. Yang et al. [
16] also proposed a self-supervised learning algorithm for MR region segmentation, indicating that the accuracy of MR assessment still requires improvement. Moreover, there are end-to-end MR severity assessment studies. Zhang et al. [
17] attempted to use Mask Region-Based Convolutional Neural Network (Mask R-CNN) for automatic qualitative assessment of MR, finding that the assessment accuracy for moderate MR samples was only 0.81. This was primarily due to the partial overlap between the features of grade III (moderate) MR and grade IV (severe) MR, making it difficult to distinguish between moderate and severe MR. Long et al. [
18] proposed a DL system named DELINEATE-MR, which processes complete TTE videos to classify MR; however, the spatiotemporal convolution used in this model struggles with small-scale irregular targets, leading to inaccurate segmentation of MR region boundaries.
UNet [
19] is a convolutional neural network (CNN) architecture widely accepted in the field as a classical medical image segmentation model due to its high accuracy and effectiveness with small samples. Although UNet and its variants, such as UNet3 [
14], have been shown to segment the MR region efficiently, their segmentation accuracy still requires improvement due to the irregularities present in the MR region. ResNet [
20] is well-known in the field of DL for addressing issues such as gradient vanishing through the introduction of residual blocks, and it also demonstrates excellent performance when combined with UNet [
21]. By combining ResNet and UNet, it is possible to design a highly effective method for segmenting the MR region in TTE, which can subsequently be utilized for MR severity classification.
Based on this, in this study, we used UNet as the backbone and selected ResNet50 as the encoder. We then improved the Efficient Multi-Scale Attention (EMA) module for MR region segmentation, aiming to effectively capture multi-scale features to enhance segmentation accuracy, particularly for small-scale irregular targets. To further validate the effectiveness of the improved EMA module, we integrated it into the upsampling part of the UNet decoder.
2. Materials and Methods
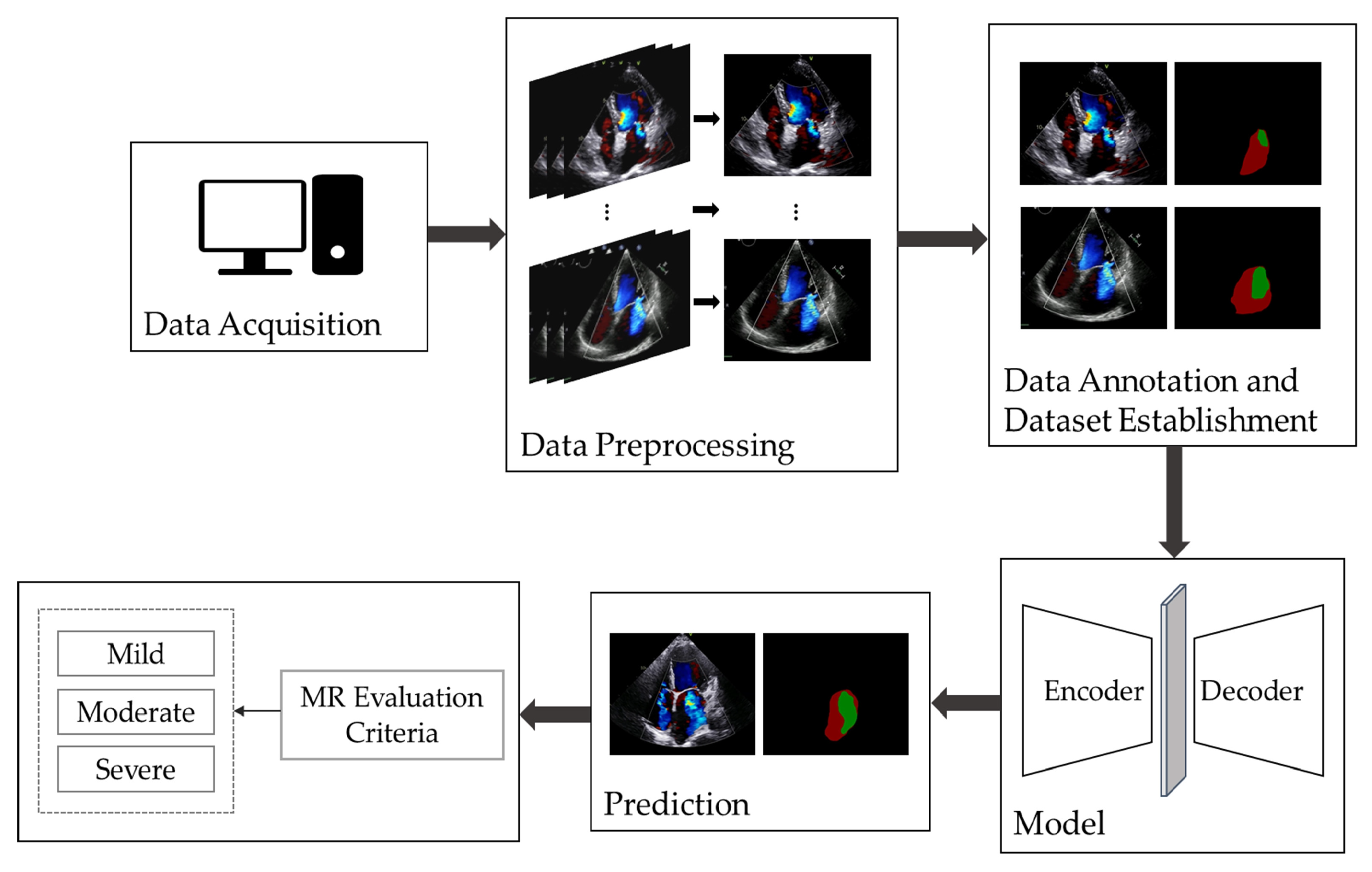
Figure 1 illustrates the overall workflow of automatic MR segmentation and evaluation in this study. We began by selecting apical four-chamber view color Doppler echocardiographic videos and extracted the frames displaying maximal regurgitation. Following this, we performed data annotation and constructed the dataset and proposed an improved UNet model for the automatic segmentation and evaluation of MR.
2.1. Establishment of Dataset
Since there is no publicly available dataset for MR echocardiography, this study was conducted using a private dataset constructed by our team. The dataset comprises 367 MR apical four-chamber view color Doppler echocardiographic images, with 100, 137, and 130 images categorized as having mild, moderate, and severe MR severity, respectively. All images were labeled and preprocessed accordingly.
2.1.1. Data Acquisition and Cleaning
This study utilized the ultrasound information system of Gulou Hospital, affiliated with Nanjing University School of Medicine, to select a total of 367 images from apical four-chamber color Doppler echocardiograms labeled with “mitral regurgitation”. These images were acquired by the Department of Echocardiography from January 2023 to October 2023. The dataset includes 100 images with mild MR, 137 with moderate MR, and 130 with severe MR. During the data acquisition process, low-quality and unclear images, as well as data from cases of easily overestimated eccentric MR, were excluded [
22,
23]. Statistical analysis revealed that 56.95% of the patients included in this study were female, and 73.56% were over 50 years of age. Additionally, the average age of the patients tended to increase with the severity of MR. The images were obtained using Philips Medical Systems and GE Vingmed Ultrasound devices, and they were saved in DICOM format.
2.1.2. Data Preprocessing and Annotation
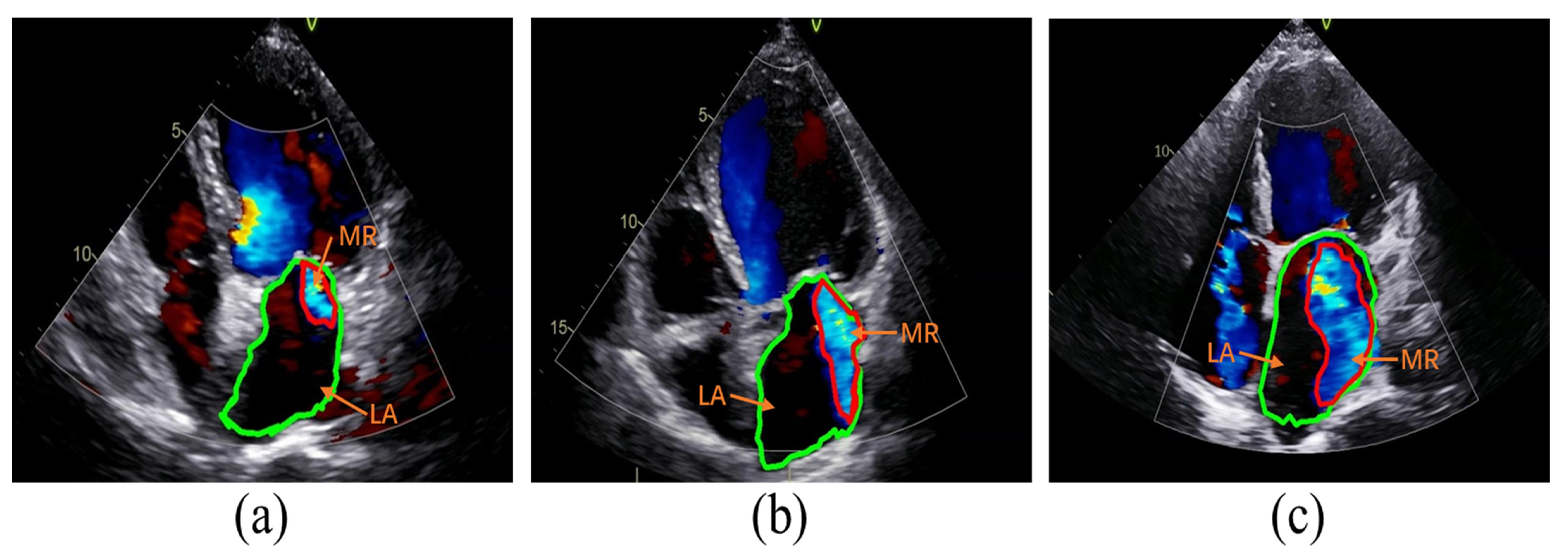
The classification of MR severity was based on the criteria outlined in the American Society of Echocardiography guidelines [
6]. Guideline references for assessing the severity of MR include vena contracta width (VCW), effective regurgitant orifice area (EROA), regurgitant volume (RVol), and regurgitation fraction (RF). To avoid discrepancies in the size of images acquired by different devices, RF was chosen as a semi-quantitative index of MR severity in this study. Specifically, the ratio of the area of MR to the area of the left atrium (LA) was used as RF. A fraction of less than 30% corresponds to mild MR, 30–49% corresponds to moderate MR, and greater than or equal to 50% corresponds to severe MR, as illustrated in
Figure 2.
To facilitate presentation and annotation, the collected color Doppler echocardiograms were converted from DICOM format to MP4 format. Frames that most accurately represented the regurgitation were selected from each video. Subsequently, all images were standardized by defining sectors as regions of interest (ROI) and then resized to 800 × 600 pixels after cropping. The MR regions and LA boundaries in all relevant frames were annotated by two specialized physicians using Labelme software (version 5.3.1). In cases of disagreement, a third physician was consulted for final judgment, as shown in
Figure 3. The labeled images were then divided into training and test sets at a ratio of 8:2. Specifically, 293 images were allocated to the training dataset, while 74 images were designated for the testing dataset, as detailed in
Table 1.
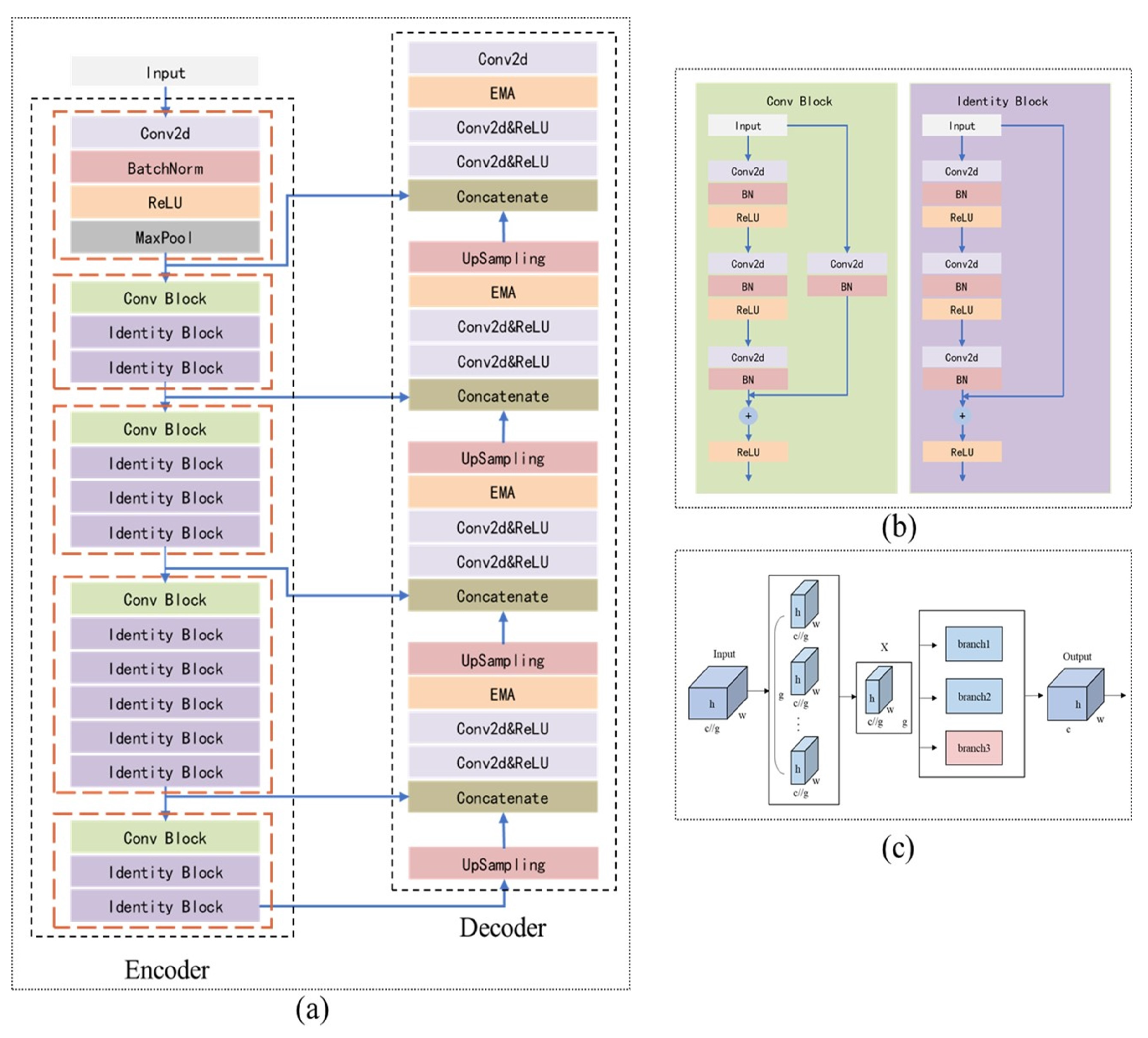
2.2. Establishment of the Model for Segmentation
In this study, we utilize ResUNet as the backbone, incorporating ResNet as the encoder in UNet, and introducing an improved Efficient Multi-Scale Attention (EMA) module during the upsampling stage of the decoder, as depicted in
Figure 4.
2.2.1. Model Building
The model proposed in this study is inspired by both the UNet and ResNet architectures. UNet [
19] is a CNN designed for image segmentation, characterized by its “U” shape, which consists of an encoder and a decoder. The encoder extracts image features, while the decoder recovers spatial resolution. During the UNet segmentation process, spatial information is compressed and subsequently recovered. The decoder’s upsampling layer employs 2 × 2 deconvolution to double the size of the feature maps, which are then integrated with the corresponding encoder outputs through skip connections, preserving essential details. However, this method does not completely prevent the loss of fine spatial information during the encoder’s downsampling phase, especially when the encoder has limited feature extraction capabilities.
ResNet [
20] is a simple yet effective CNN architecture known for its strong feature extraction capabilities. ResNet introduces a residual unit that simplifies the learning process by adding a shortcut connection, preserving the original output of the previous layer and transforming the network’s learning task into the learning of the residual function F(x) = H(x) − x. By addressing the issues of gradient vanishing and exploding in deep networks through residual learning, ResNet enables the effective training of networks with hundreds or even thousands of layers, thus extending the model’s potential performance limits.
ResNetU-Net [
21] is a variation of the U-Net architecture that replaces the “convolution-normalization-activation” layers with residual units to construct its basic blocks. The benefits of this approach include: (1) residual units simplify network training; and (2) internal skip connections and information propagation enhance design simplicity and performance. However, because the residual unit is based on convolution operations, which are fundamentally local filters, it can only capture relationships between local features. This limitation restricts the ability to model spatial information for multi-scale and irregularly shaped MR regions, potentially leading to inadequate restoration of spatial resolution during the upsampling stage.
To address these challenges, this study improves the UNet model by integrating the initial stages of ResNet50 into the UNet encoder-decoder structure, using it as the encoder (
Figure 4a,b). This enhancement boosts the model’s feature extraction capabilities and preserves as much spatial information as possible during downsampling. Additionally, an improved EMA module (
Figure 4c) is added to the decoder to enhance the model’s ability to recover spatial information.
2.2.2. Improved EMA Module
The Channel Attention Mechanism (CAM) [
24] enhances feature map representation by assigning higher weights to important channels. However, reducing channel dimensions to model cross-channel relationships may limit the extraction of deep visual representations.
The Efficient Multi-Scale Attention (EMA) module [
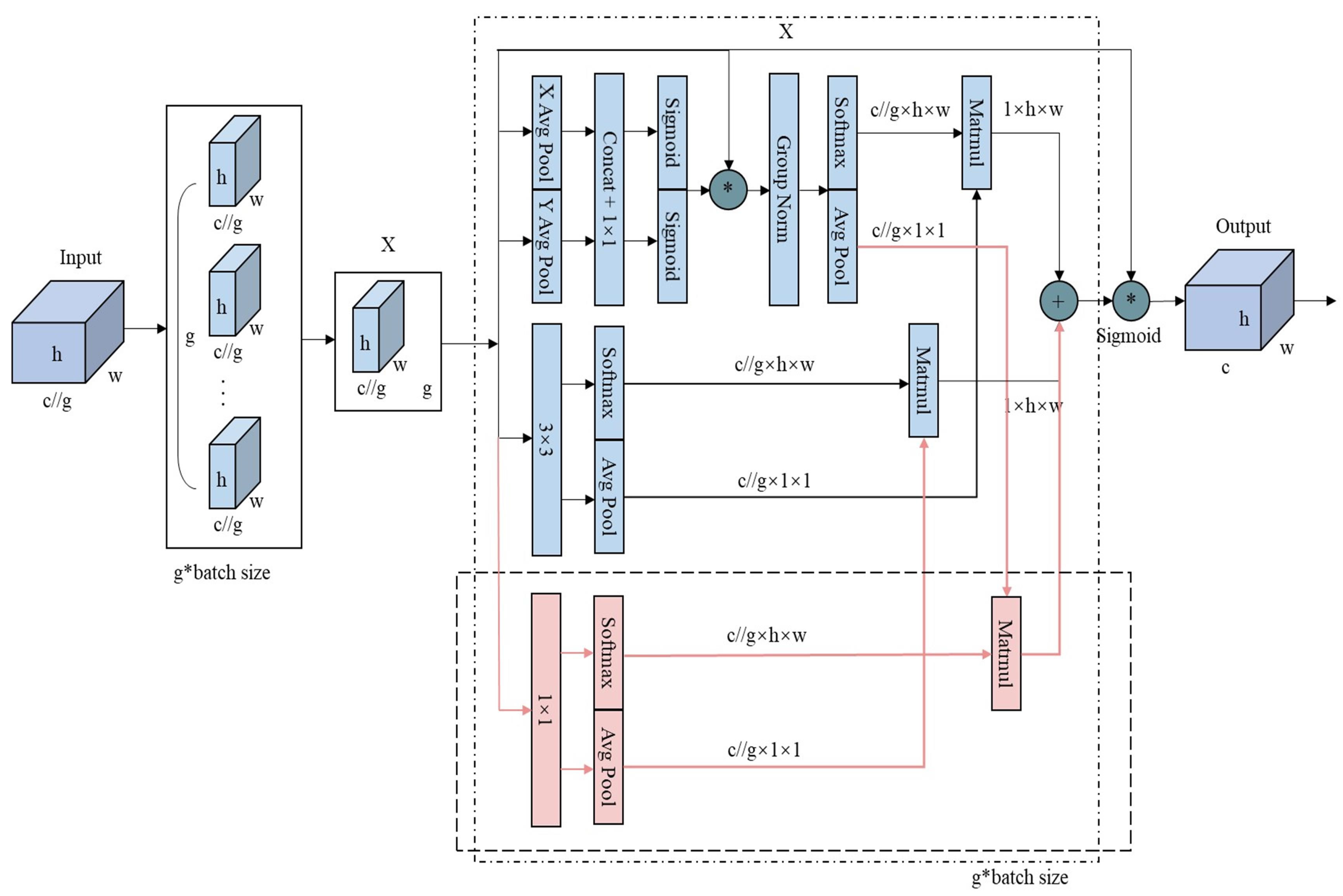
25] retains the information of each channel while reducing computational overhead. It reshapes partial channels into batch dimensions and groups channel dimensions into multiple sub-features, ensuring well-distributed spatial semantic features within each feature group. The EMA module recalibrates channel weights in each parallel branch by encoding global information and captures pixel-level pairwise relationships through cross-dimensional interactions. It employs two convolutional kernels in separate parallel subnets: a 1 × 1 branch that models cross-channel information using global average pooling and a 3 × 3 branch that aggregates multi-scale spatial structure information.
The original EMA module uses two parallel branches with relatively simple feature extraction methods: a 1 × 1 global pooling branch for global information and a 3 × 3 branch for local information. However, this setup may be insufficient for segmentation tasks involving multi-scale or small-scale irregular targets, as it struggles to balance weight and information complementation, limiting the richness of feature expression. To overcome this limitation and enhance the model’s ability to capture multi-scale information and complex patterns, this study introduces an additional 1 × 1 parallel branch. This new branch facilitates a more comprehensive integration of global and local information. As shown in
Figure 5, the average pooling (avgpool) output from the original 1 × 1 branch is separated from the softmax output of the 3 × 3 branch. The avgpool output from the original 1 × 1 branch is then multiplied by the softmax output of the newly added 1 × 1 branch, while the avgpool output of the newly added 1 × 1 branch is multiplied by the softmax output of the 3 × 3 branch. These results are summed with the outputs from the original branches, effectively integrating the new 1 × 1 branch with the original EMA module’s branches. Finally, the outputs from the three branches are adjusted using sigmoid activation and normalization to produce the final feature map.
2.2.3. Loss Function
The loss function employed in this study combines focal loss and Dice loss, as shown in Equation (1).
Focal loss [
26] is an improved cross-entropy loss method designed to address the category imbalance problem between the target object and the background class in semantic segmentation, helping to mitigate the impact of this imbalance. The calculation of focal loss is provided in Equation (2), where
represents the predicted probability,
is a weight factor that balances positive and negative samples, and γ is the focusing parameter that adjusts the weight distribution between easy and difficult samples.
Dice loss [
27] is derived from the Dice coefficient, designed to evaluate the similarity between segmentation results and ground truth labels. It directly optimizes the overlap between the predicted segmentation and the true labels, thereby improving segmentation accuracy, particularly for small-scale targets. The Dice loss calculation is presented in Equation (3), where
and
represent the predicted value and the ground truth label at the i-th pixel, respectively.
2.3. Implementation Details
The experiments were conducted on a system with an Intel(R) Core(TM) i5-10500 processor and a single GeForce RTX3060 GPU with 12 GB of video memory. The code was implemented in an environment configured with Windows 10, CUDA 11.1.3, cuDNN 8.0, and PyTorch (v1.9.0, Python 3.8). Given the limited dataset size, data augmentations such as random rotation and random scaling were applied.
The model was trained for 100 epochs using the Adam optimizer. The initial learning rate was set to 0.0001, with beta values of (0.9, 0.999) and a weight decay of 0. The batch size was set to 2. During the first 50 epochs, the initial weights of ResNet50, pre-trained on the IMAGENET1K_V2 dataset, were used, and the weights of the encoder were frozen to stabilize training.
2.4. Evaluation Metrics and Comparison Methods
In this study, the proposed model was compared with several classical segmentation models, including DeepLabv3+, PSPNet, UNet, ResUNet, ResUNet with the original EMA, and UNet with the improved EMA. DeepLabv3+ [
28] employs an encoder-decoder architecture, where the encoder stage leverages atrous convolution to capture multi-scale contextual information, while the decoder stage refines segmentation results, particularly at object boundaries. PSPNet [
29] achieves semantic segmentation through a pyramidal scene parsing network, integrating global contextual information across different regions to enhance prediction accuracy and reliability. Both of these models are extensively used in medical image segmentation and demonstrate notable performance advantages.
In the experiment, four evaluation metrics—Jaccard, Mean Pixel Accuracy (MPA), Precision, and Recall—are employed to quantitatively assess the model’s performance in segmenting regurgitation and atria. Additionally, Precision, Recall, Accuracy, and F1-score were used to evaluate the model’s classification performance. The formulas for these metrics are provided in Equations (4)–(9), where TP represents the number of true positives, TN denotes the number of true negatives, FP indicates the number of false positives, and FN stands for the number of false negatives. Detailed definitions of the metrics are included in the
Supplementary Materials.
4. Discussion
Mitral Regurgitation (MR) is a common and serious heart valve disease that significantly impacts patient prognosis. Accurate diagnosis and effective treatment are crucial for improving outcomes. Therefore, developing automated tools to enhance the accuracy and consistency of MR diagnosis is vital for evaluating the disorder, formulating treatment strategies, and conducting postoperative surveillance. Previous research on MR region segmentation using DL methods has faced challenges such as suboptimal accuracy [
13,
15], significant variability in category-specific accuracy [
17], and imprecise segmentation boundaries [
18], which complicate meeting clinical requirements. UNet is widely recognized as a classical model for medical image segmentation, and its variants have demonstrated excellent performance in valve regurgitation segmentation [
13,
15]. However, these models still have some limitations. In this study, we proposed an advanced UNet-based segmentation model designed to assess MR severity more accurately. This model utilizes ResNet as the encoder within the UNet architecture, enhancing feature extraction during the downsampling process to preserve maximal spatial information. Additionally, an improved EMA module is integrated during the upsampling phase to capture multi-scale data more effectively and improve the reconstruction of fine spatial details in anatomical structures.
Our improved UNet model was benchmarked against several prominent segmentation methods, including Deeplabv3+, PSPNet, UNet, ResUNet, and ResUNet with the EMA module, for the MR segmentation task. The experimental results demonstrate that our model significantly outperforms these methods, particularly in the Jaccard (84.37%) and MPA (92.39%) metrics, achieving top-tier performance in Precision (91.9%) and Recall (90.91%), leading the benchmarks in the former two metrics (
Table 2). Moreover, ResUNet augmented with the improved EMA module surpasses the original configuration across Jaccard, MPA, and Precision metrics (
Table 2). This improvement underscores the enhanced efficacy of the improved EMA module within the UNet framework, particularly noted in the Jaccard index against ResUNet with the EMA module (
Table 2). These findings highlight the advanced capability of the improved EMA module in MR segmentation tasks. In terms of MR severity classification, the segmentation masks derived from our model achieved an overall accuracy of 95.27%, with Precision at 88.52%, Recall at 91.13%, and an F1 score of 90.30%. The model accurately classifies mild, moderate, and severe MR stages with respective accuracies of 94%, 95%, and 96% (
Table 3), demonstrating its high precision. Qualitative analysis of the segmentation results from different models shows that our proposed model is more accurate in segmenting contour edges with less over-segmentation (
Figure 6). This suggests that diversifying the spatial information extraction by increasing the number of branches, each focusing on a different spatial semantic distribution, helps capture spatial relationships in the image more uniformly and meticulously. This enhances the spatial representation of the features and better adapts to the specific needs and characteristics of the date in this study. Furthermore, the combination of Focal Loss and Dice Loss enhances the model’s ability to handle category-imbalanced pixels while capturing finer edge details of the target (
Figure 7).
The quantitative results of segmentation and MR severity categorization in this study may differ significantly from those reported in other related studies. For instance, our model achieved a Jaccard score of 0.84, which is notably higher than the 0.70 reported by Huang et al. [
13]. This disparity can largely be attributed to differences in the size of the test sets and sample distributions between the studies. Huang et al. [
13] included both MR and TR data, whereas our study focused exclusively on MR. Moreover, we selected only the most representative frames from each echocardiographic sample to ensure high data quality. In terms of MR severity classification, the segmentation mask of our proposed model demonstrated superior results. This enhancement is likely due to the different classification criteria adopted in our study, which follows guidelines [
6] categorizing MR severity into mild, moderate, and severe. In contrast, studies like Zhang et al. [
17] employ a more granular classification: grade I (mild), grade II (mild–moderate), grade III (moderate), and grade IV (severe). The high degree of imaging similarity between grade III and grade IV in Zhang’s study posed challenges in accurately distinguishing between moderate and severe MR cases.
During this study, we encountered several challenges. A primary issue was the difficulty in acquiring moderate and severe MR data labeled by physicians in real clinical settings. Although data augmentation strategies partially mitigated the impact of data scarcity on model training; a more extensive and comprehensive evaluation using a larger dataset is essential for robust assessments. Additionally, in the data preprocessing stage, we manually selected the best frames from a single apical four-chamber view to assist model training, this step could be integrated into the model training process in future work. We also recommend incorporating multiple frames and views to enhance the comprehensiveness of the study. Overall, while the DL model demonstrated commendable performance in evaluating MR severity, metrics such as precision still require improvement, indicating a need for better handling of category imbalance in MR severity. Furthermore, this study utilized data from only two brands of ultrasound machines, which limits generalizability. To address these limitations, we plan to expand the dataset size and improve balance by incorporating more patient data across different MR severity levels. Future research will also consider factors such as left atrial size and individual chest wall structures, particularly focusing on eccentric MR, which is often overestimated. Finally, we aim to introduce multicenter studies to thoroughly assess the model’s generalization ability and segmentation accuracy, ultimately providing physicians with a more reliable tool for MR diagnosis.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}