


Automatic Detection and Classification of Hypertensive Retinopathy with Improved Convolution Neural Network and Improved SVM


Abstract
1. Introduction
Research Contributions
- The convolutional layers run only once on the full fundus image, which leads to a speedup and reduces the processing time to detect abnormalities in the vascular structure;
- Extracted 24 features and classified the vessels of the retinal fundus images;
- Retina vessel segmentation with the proposed model on multiple data sets. The proposed model boosts the performance, resulting in an increase in the segmentation accuracy of the blood vessels.
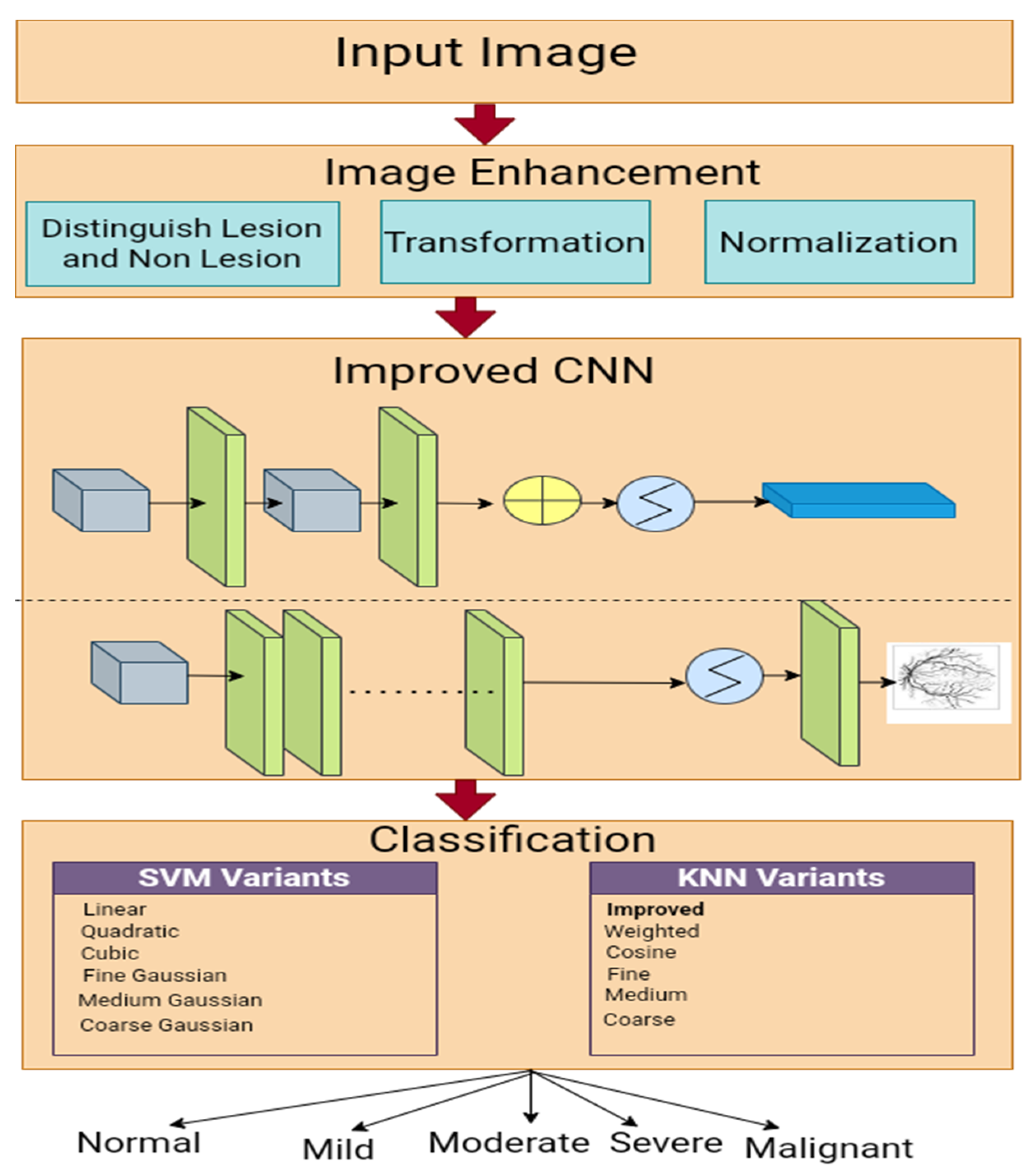
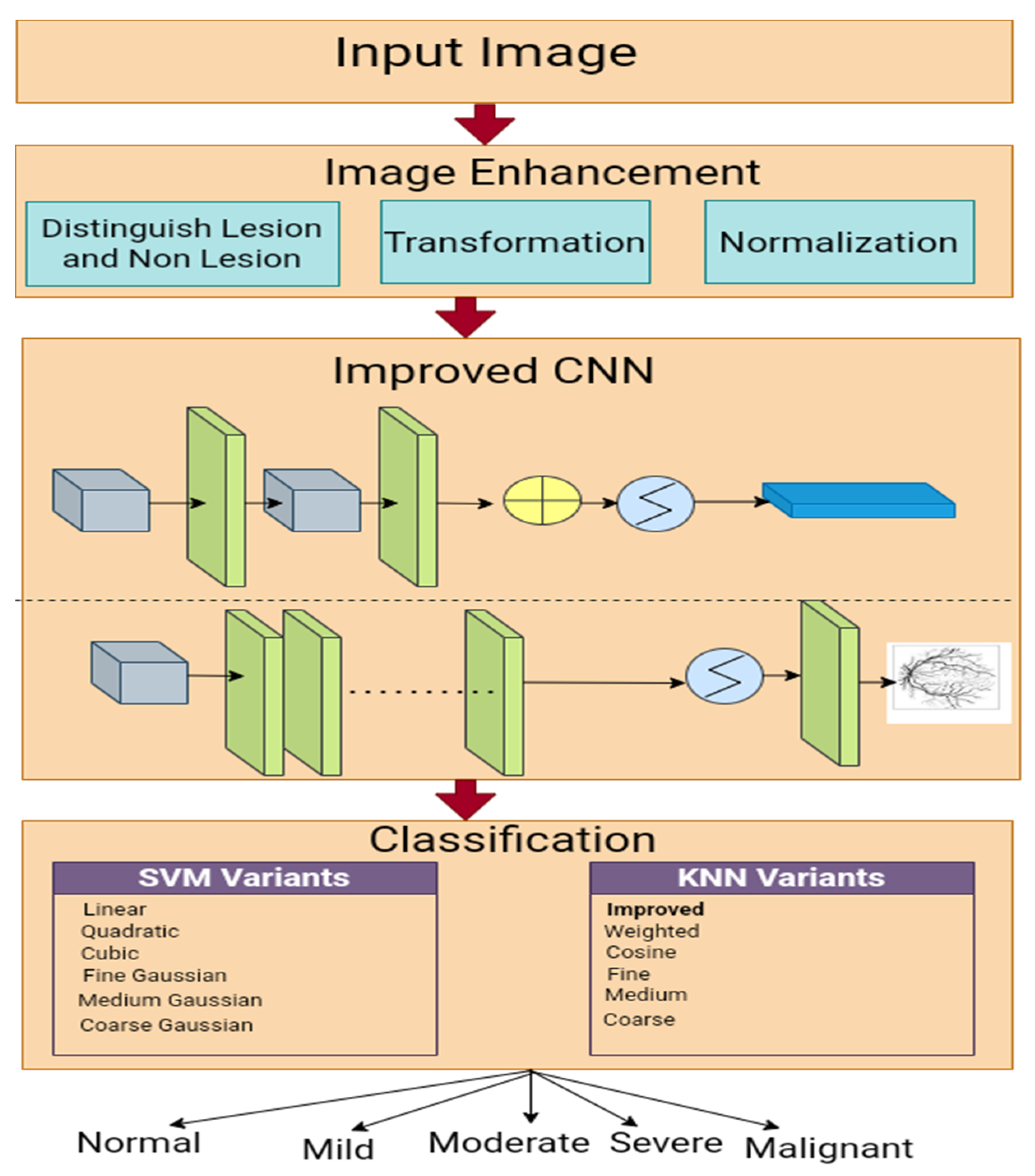
2. Methods and Materials
2.1. Image Collection
2.2. Pre-Processing
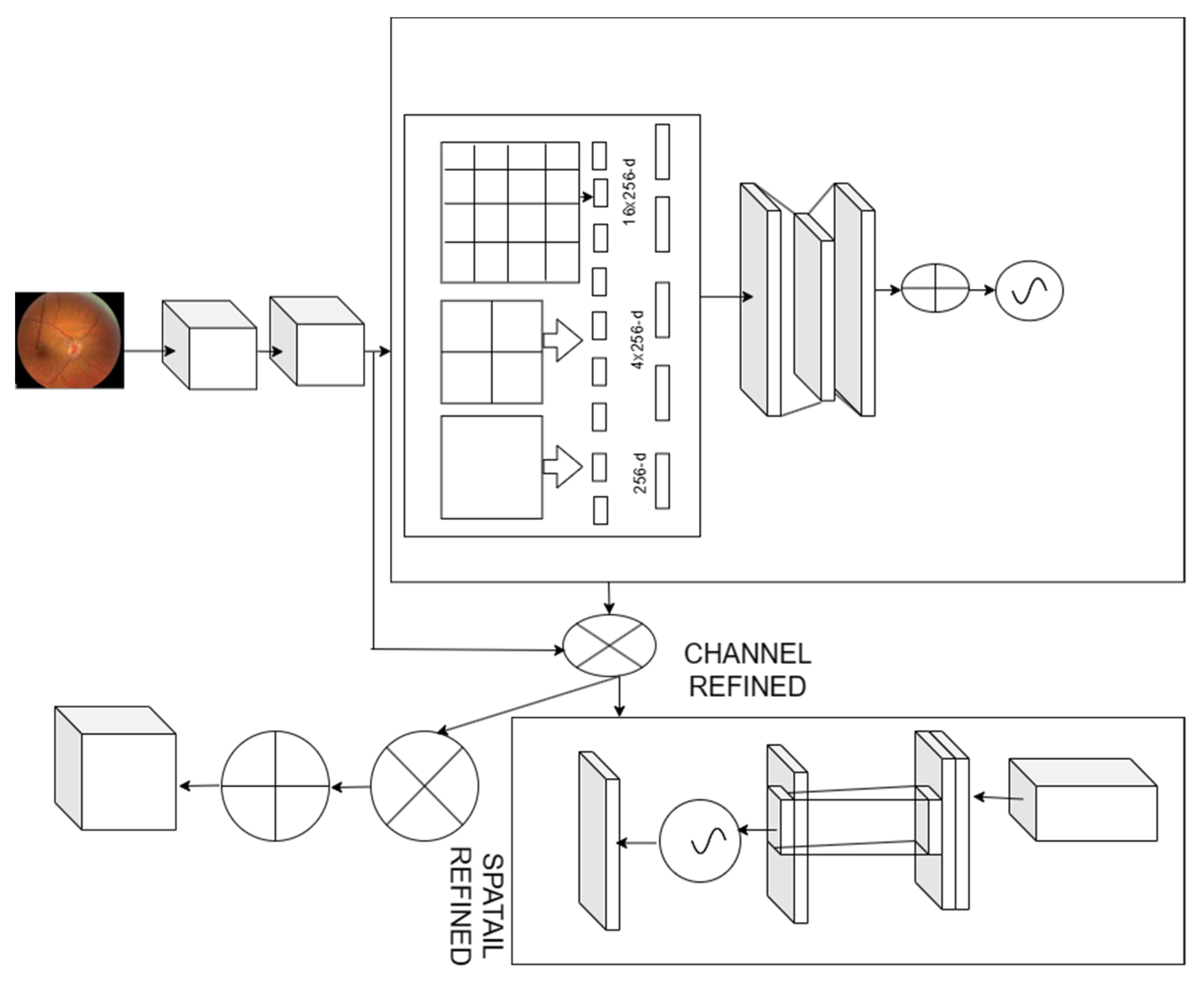
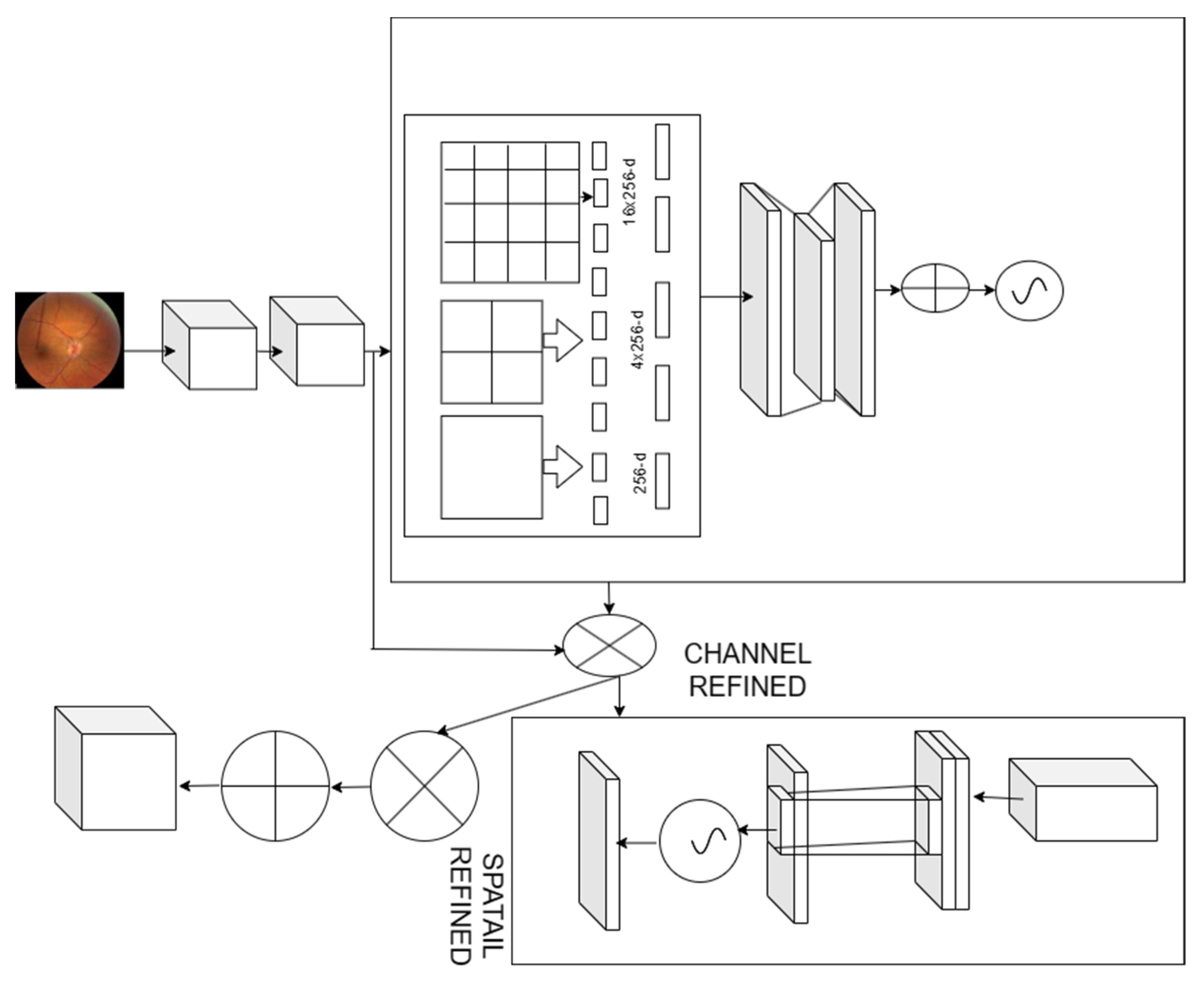
2.3. Spatial Convolution Neural Network
2.4. Optic Disk Segmentation
2.5. HR Classification
| Algorithm 1 Enhanced SVM |
| Input: Feature Vector Output: HR classification ⮚ Initialize all values ⮚ for i = 1 to N evaluate the loss extract the lesions in the fundus images ⮚ End for Evaluate the score vector for iterations i-1 to N Evaluate the SVM score vector ⮚ End for Evaluate output using the various weights. |
| Algorithm 2 Enhanced KNN |
| Input: Feature Vector Output: HR classification ⮚ For each fundus image Identify the lesion aspects ⮚ Create weak learners Wi ⮚ Determine whether the fundus image is healthy or diseased. ⮚ Integrate the results of the weak learners∑(Wi) ⮚ Determine the training variance ⮚ Reweight the n-learners that are considered weak. ⮚ Identify the best weak learner with the least amount of training ⮚ Acquire classification outcomes |
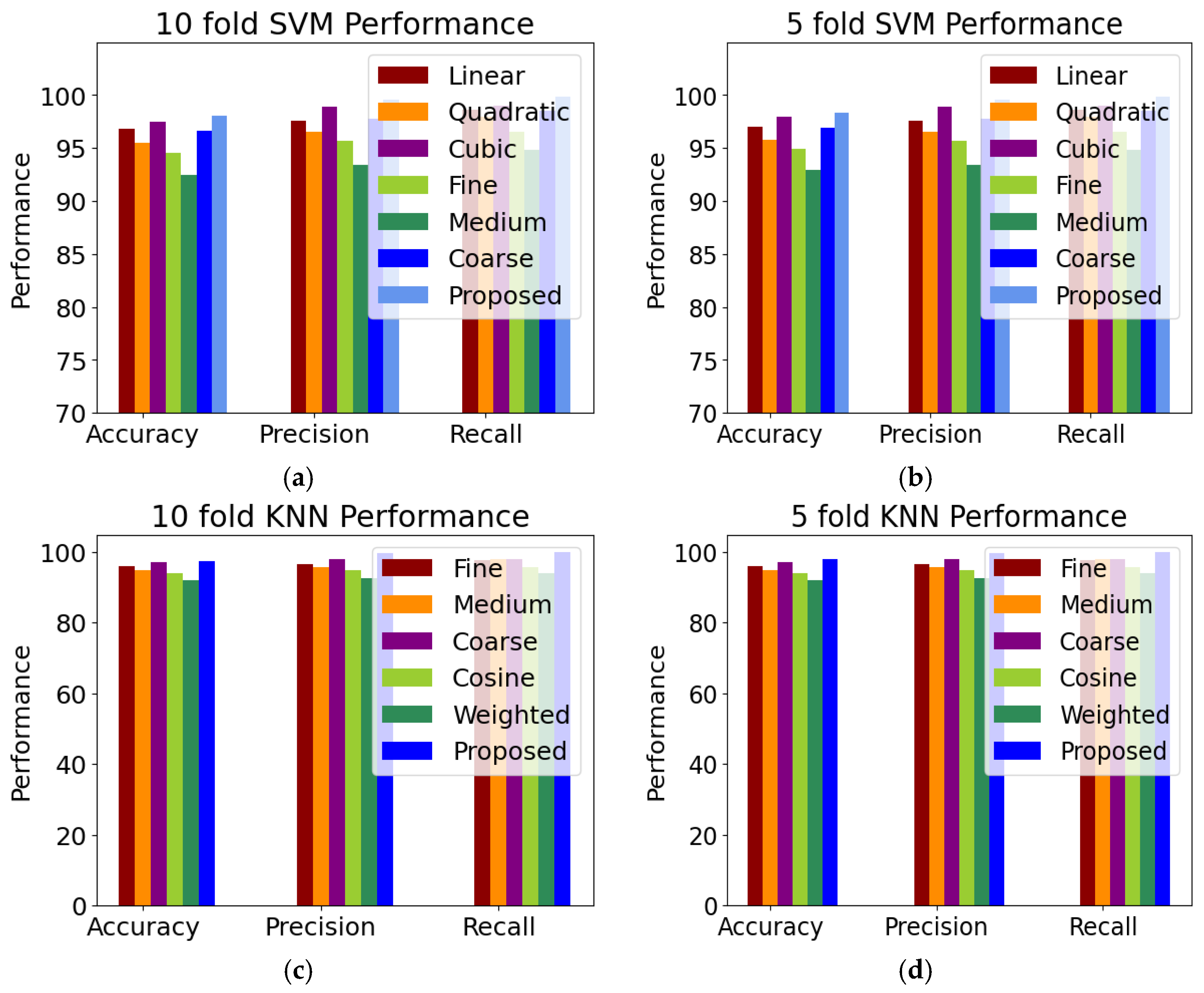
2.5.1. SVM Variants
2.5.2. KNN Variants
- (i)
- Fine KNN: A nearest neighbor classifier that makes finely detailed distinctions between classes with the number of neighbors set to 1;
- (ii)
- Medium KNN: A nearest neighbor classifier that makes fewer distinctions than a fine KNN with the number of neighbors set to 10;
- (iii)
- Coarse KNN: The nearest neighbor classifier that makes coarse distinctions between classes, with the number of neighbors set to 100;
- (iv)
- Cosine KNN: A nearest neighbor classifier that uses the cosine distance metric;
- (v)
- Weighted KNN: The nearest neighbor classifier that uses distance weighting.
2.6. Performance Metrics
3. Results
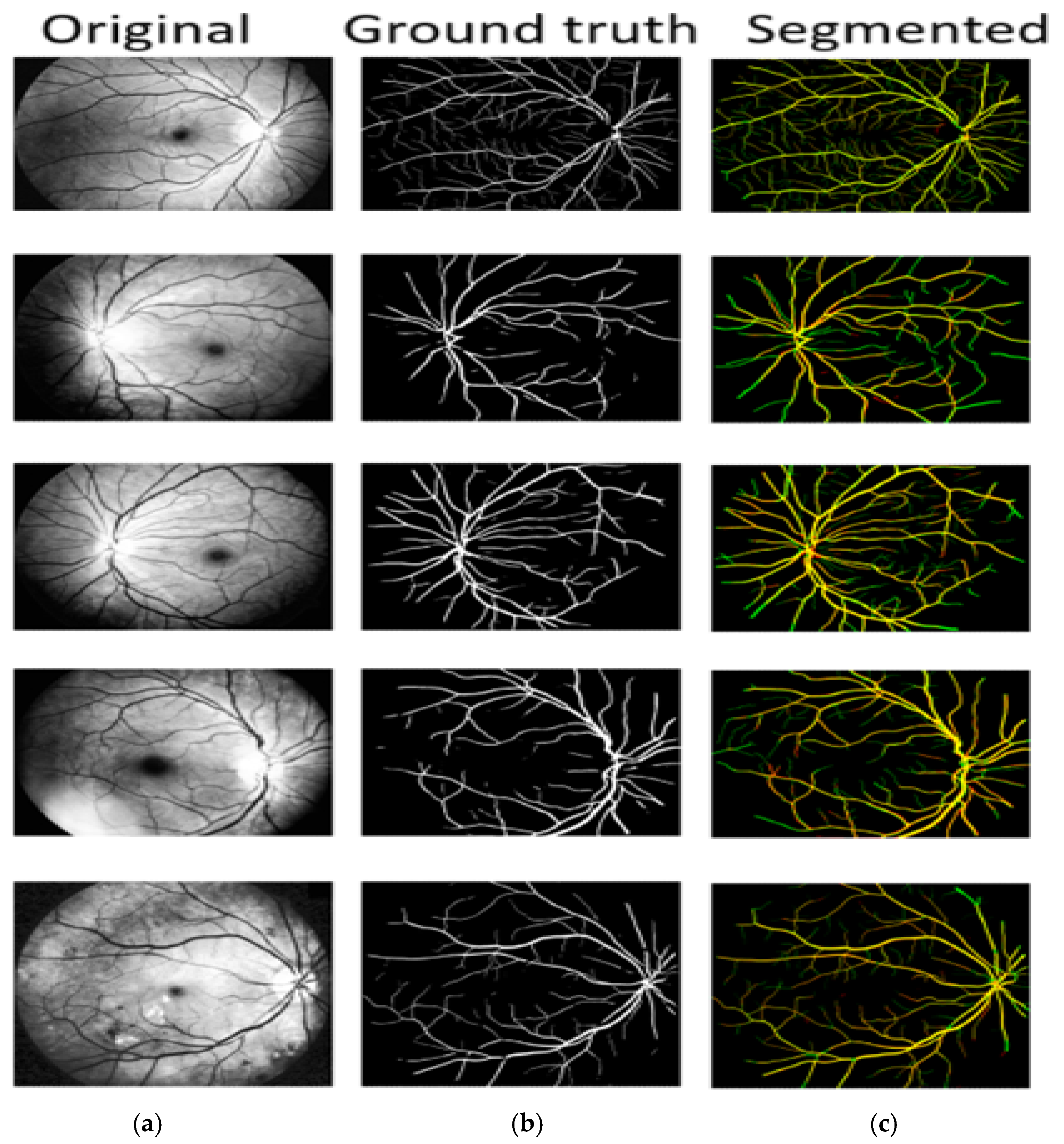
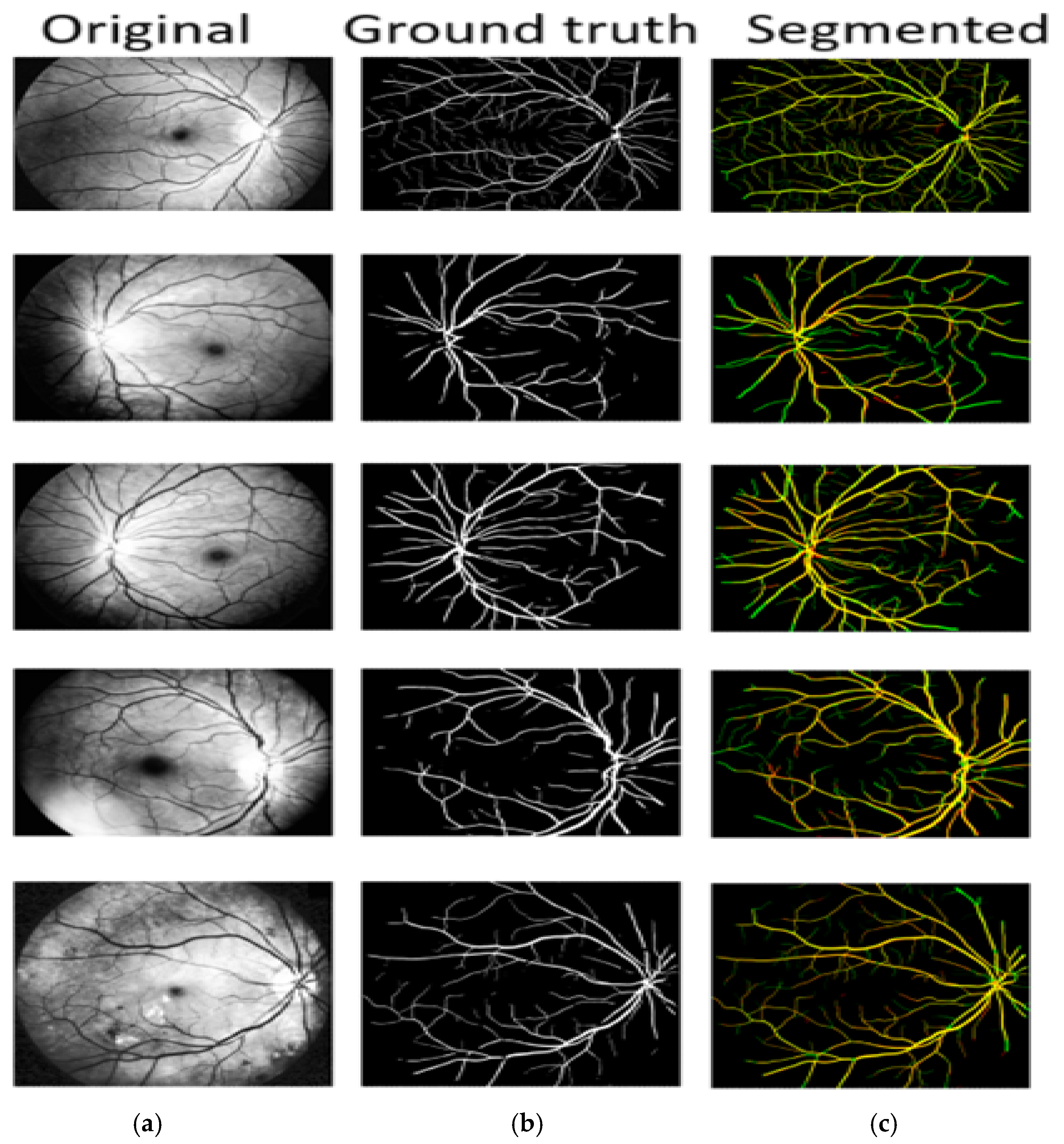
3.1. Segmentation Evaluation
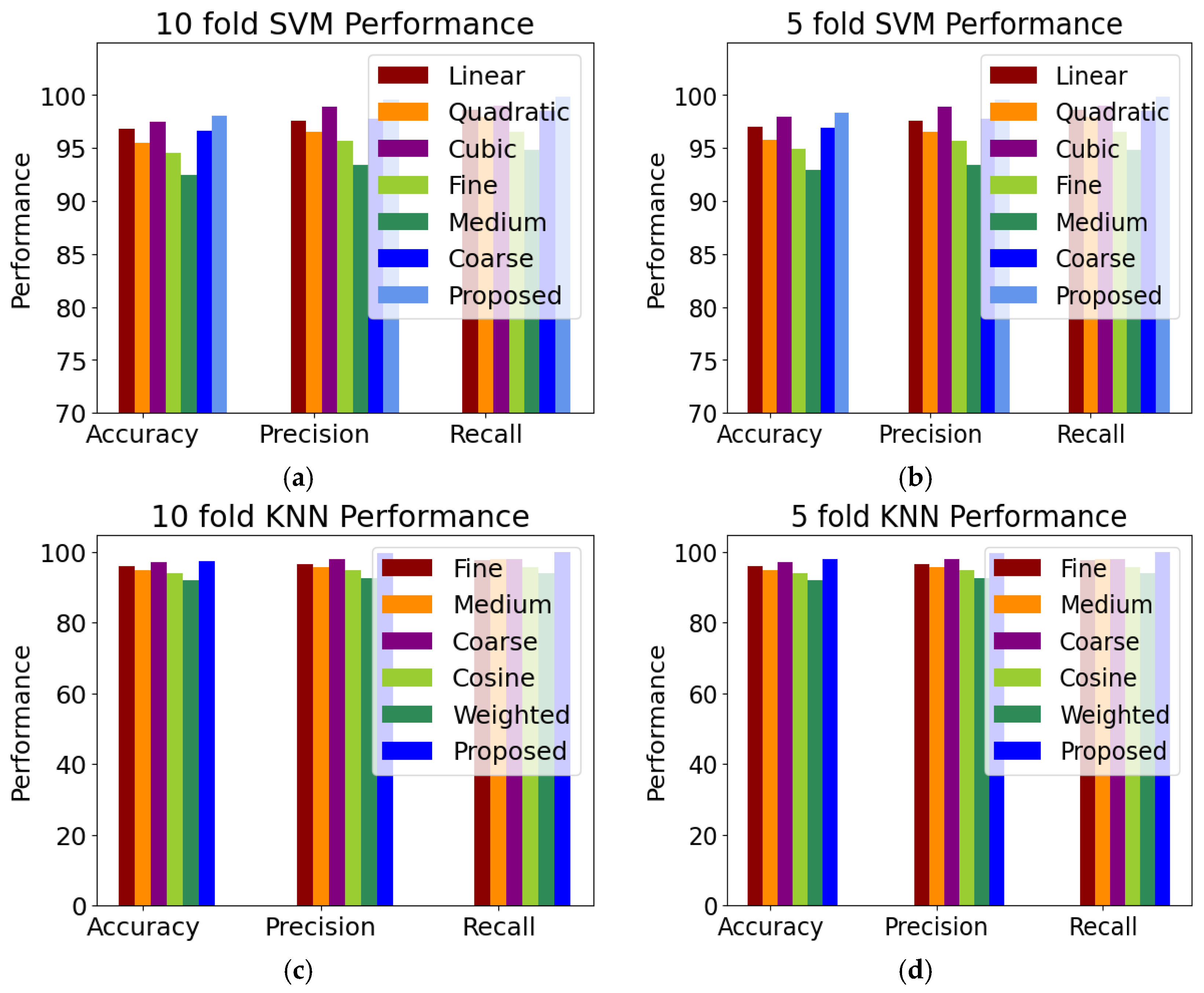
3.2. Classification Evaluation
3.3. Computational Cost Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ghembaza, M.A.; Senoussaoui, Y.; KendouciTani, M.; Meguenni, K. Impact of patient knowledge of hypertension complications on adherence to antihypertensive therapy. Curr. Hypertens. Rev. 2014, 10, 41–48. [Google Scholar] [CrossRef] [PubMed]
- Sundström, J.; Neovius, M.; Tynelius, P.; Rasmussen, F. Association of blood pressure in late adolescence with subsequent mortality: Cohort study of Swedish male conscripts. Bmj 2011, 342, d643. [Google Scholar] [CrossRef]
- Battistoni, A.; Canichella, F.; Pignatelli, G.; Ferrucci, A.; Tocci, G.; Volpe, M. Hypertension in young people: Epidemiology, diagnostic assessment and therapeutic approach. High Blood Press. Cardiovasc. Prev. 2015, 22, 381–388. [Google Scholar] [CrossRef] [PubMed]
- Tilea, I.; Petra, D.; Voidazan, S.; Ardeleanu, E.; Varga, A. Treatment adherence among adult hypertensive patients: A cross-sectional retrospective study in primary care in Romania. Patient Prefer. Adherence 2018, 12, 625–635. [Google Scholar] [CrossRef] [PubMed]
- Mirsharif, Q.; Tajeripour, F.; Pourreza, H. Automated characterization of blood vessels as arteries and veins in retinal images. Comput. Med. Imaging Graph. 2013, 37, 607–617. [Google Scholar] [CrossRef] [PubMed]
- Muramatsu, C.; Hatanaka, Y.; Iwase, T.; Hara, T.; Fujita, H. Automated detection and classification of major retinal vessels for determination of diameter ratio of arteries and veins. In Proceedings of the Medical Imaging 2010: Computer-Aided Diagnosis, San Diego, CA, USA, 13–18 February 2010; SPIE: San Diego, CA, USA, 2010; Volume 7624, pp. 153–160. [Google Scholar]
- Panchal, S.; Naik, A.; Kokare, M.; Pachade, S.; Naigaonkar, R.; Phadnis, P.; Bhange, A. Retinal Fundus Multi-Disease Image Dataset (RFMiD) 2.0: A Dataset of Frequently and Rarely Identified Diseases. Data 2023, 8, 29. [Google Scholar] [CrossRef]
- Jin, K.; Huang, X.; Zhou, J.; Li, Y.; Yan, Y.; Sun, Y.; Zhang, Q.; Wang, Y.; Ye, J. Fives: A fundus image dataset for artificial Intelligence based vessel segmentation. Sci. Data 2022, 9, 475. [Google Scholar] [CrossRef]
- Han, Y.; Li, W.; Liu, M.; Wu, Z.; Zhang, F.; Liu, X.; Tao, L.; Li, X.; Guo, X. Application of an anomaly detection model to screen for ocular diseases using color retinal fundus images: Design and evaluation study. J. Med. Internet Res. 2021, 23, e27822. [Google Scholar] [CrossRef]
- Vecsey-Nagy, M.; Szilveszter, B.; Kolossváry, M.; Boussoussou, M.; Vattay, B.; Gonda, X.; Rihmer, Z.; Merkely, B.; Maurovich-Horvat, P.; Nemcsik, J. Cyclothymic affective temperament is independently associated with left ventricular hypertrophy in chronic hypertensive patients. J. Psychosom. Res. 2022, 160, 110988. [Google Scholar] [CrossRef]
- Suman, S.; Tiwari, A.K.; Singh, K. Computer-aided diagnostic system for hypertensive retinopathy: A review. Comput. Methods Programs Biomed. 2023, 240, 107627. [Google Scholar] [CrossRef]
- Arsalan, M.; Haider, A.; Lee, Y.W.; Park, K.R. Detecting retinal vasculature as a key biomarker for deep Learning-based intelligent screening and analysis of diabetic and hypertensive retinopathy. Expert Syst. Appl. 2022, 200, 117009. [Google Scholar] [CrossRef]
- Kavitha, M.; Palani, S. Hierarchical classifier for soft and hard exudates detection of retinal fundus images. J. Intell. Fuzzy Syst. 2014, 27, 2511–2528. [Google Scholar] [CrossRef]
- Zhou, W.; Wu, C.; Chen, D.; Yi, Y.; Du, W. Automatic microaneurysm detection using the sparse principal component analysis-based unsupervised classification method. IEEE Access 2017, 5, 2563–2572. [Google Scholar] [CrossRef]
- Omar, M.; Khelifi, F.; Tahir, M.A. Detection and classification of retinal fundus images exudates using region based multiscale LBP texture approach. In Proceedings of the 2016 International Conference on Control, Decision and Information Technologies (CoDIT), Saint Julian’s, Malta, 6–8 April 2016; pp. 227–232. [Google Scholar]
- Vijayan, T.; Sangeetha, M.; Kumaravel, A.; Karthik, B. WITHDRAWN: Gabor filter and machine learning based diabetic retinopathy analysis and detection. Microprocess. Microsyst. 2020. [Google Scholar] [CrossRef]
- Zhang, C.; Mousavi, A.A.; Masri, S.F.; Gholipour, G.; Yan, K.; Li, X. Vibration feature extraction using signal processing techniques for structural health monitoring: A review. Mech. Syst. Signal Process. 2022, 177, 109175. [Google Scholar] [CrossRef]
- Ishtiaq, U.; Abdul Kareem, S.; Abdullah, E.R.M.F.; Mujtaba, G.; Jahangir, R.; Ghafoor, H.Y. Diabetic retinopathy detection through artificial intelligent techniques: A review and open issues. Multimed. Tools Appl. 2020, 79, 15209–15252. [Google Scholar] [CrossRef]
- Orlando, J.I.; Prokofyeva, E.; Del Fresno, M.; Blaschko, M.B. An ensemble deep learning based approach for red lesion detection in fundus images. Comput. Methods Programs Biomed. 2018, 153, 115–127. [Google Scholar] [CrossRef]
- Zhao, Y.Q.; Wang, X.H.; Wang, X.F.; Shih, F.Y. Retinal vessels segmentation based on level set and region growing. Pattern Recognit. 2014, 47, 2437–2446. [Google Scholar] [CrossRef]
- Ali, A.; Qadri, S.; Khan Mashwani, W.; Kumam, W.; Kumam, P.; Naeem, S.; Goktas, A.; Jamal, F.; Chesneau, C.; Anam, S.; et al. Machine learning based automated segmentation and hybrid feature analysis for diabetic retinopathy classification using fundus image. Entropy 2020, 22, 567. [Google Scholar] [CrossRef]
- Li, L.; Verma, M.; Nakashima, Y.; Nagahara, H.; Kawasaki, R. Iternet: Retinal image segmentation utilizing structural redundancy in vessel networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 3656–3665. [Google Scholar]
- Qureshi, I.; Abbas, Q.; Yan, J.; Hussain, A.; Shaheed, K.; Baig, A.R. Computer-Aided Detection of Hypertensive Retinopathy Using Depth-Wise Separable CNN. Appl. Sci. 2022, 12, 12086. [Google Scholar] [CrossRef]
- Kaggle Dataset. Available online: https://www.kaggle.com/datasets/andrewmvd/ocular-disease-recognition-odir5k (accessed on 10 May 2023).
- Inspire Dataset. Available online: https://medicine.uiowa.edu/eye/inspire-datasets (accessed on 10 May 2023).
- VICAVR Dataset. Available online: http://www.varpa.es/research/ophtalmology.html (accessed on 10 May 2023).
- Bird, A.C.; Bressler, N.M.; Bressler, S.B.; Chisholm, I.H.; Coscas, G.; Davis, M.D.; de Jong, P.T.; Klaver, C.C.; Klein, B.; Klein, R.; et al. An international classification and grading system for age-related maculopathy and age-related macular degeneration. Surv. Ophthalmol. 1995, 39, 367–374. [Google Scholar] [CrossRef] [PubMed]
- Ozaki, S.; Kaji, S.; Nawa, K.; Imae, T.; Aoki, A.; Nakamoto, T.; Ohta, T.; Nozawa, Y.; Yamashita, H.; Haga, A.; et al. Training of deep cross-modality conversion models with a small data set, and their application in megavoltage CT to kilovoltage CT conversion. Med. Phys. 2022, 49, 3769–3782. [Google Scholar] [CrossRef] [PubMed]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Sivic, Z. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1470–1477. [Google Scholar]
- Savas, C.; Dovis, F. The impact of different kernel functions on the performance of scintillation detection based on support vector machines. Sensors 2019, 19, 5219. [Google Scholar] [CrossRef] [PubMed]
- Ramella, G. Saliency-based segmentation of dermoscopic images using colour information. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2022, 10, 172–186. [Google Scholar] [CrossRef]
- Lian, S.; Li, L.; Lian, G.; Xiao, X.; Luo, Z.; Li, S. A global and local enhanced residual u-net for accurate retinal vessel segmentation. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 18, 852–862. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Wang, H.; Gao, S.; Bao, M.; Liu, T.; Wang, Y.; Zhang, J. S-unet: A bridge-style u-net framework with a saliency mechanism for retinal vessel segmentation. IEEE Access 2019, 7, 174167–174177. [Google Scholar] [CrossRef]
- Cheung, W.K.; Bell, R.; Nair, A.; Menezes, L.J.; Patel, R.; Wan, S.; Chou, K.; Chen, J.; Torii, R.; Davies, R.H.; et al. A computationally efficient approach to segmentation of the aorta and coronary arteries using deep learning. IEEE Access 2021, 9, 108873–108888. [Google Scholar] [CrossRef] [PubMed]
- Yuan, H.; Liu, Z.; Shao, Y.; Liu, M. ResD-Unet research and application for pulmonary artery segmentation. IEEE Access 2021, 9, 67504–67511. [Google Scholar] [CrossRef]
- Wang, D.; Haytham, A.; Pottenburgh, J.; Saeedi, O.; Tao, Y. Hard attention net for automatic retinal vessel segmentation. IEEE J. Biomed. Health Inform. 2020, 24, 3384–3396. [Google Scholar] [CrossRef]
- Mou, L.; Zhao, Y.; Fu, H.; Liu, Y.; Cheng, J.; Zheng, Y.; Su, P.; Yang, J.; Chen, L.; Frangi, A.F.; et al. CS2-Net: Deep learning segmentation of curvilinear structures in medical imaging. Med. Image Anal. 2021, 67, 101874. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]
- Xu, R.; Ye, X.; Jiang, G.; Liu, T.; Li, L.; Tanaka, S. Retinal vessel segmentation via a semantics and multi-scale aggregation network. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1085–1089. [Google Scholar]
- Zhang, Y.; He, M.; Chen, Z.; Hu, K.; Li, X.; Gao, X. Bridge-Net: Context-involved U-net with patch-based loss weight mapping for retinal blood vessel segmentation. Expert Syst. Appl. 2022, 195, 116526. [Google Scholar] [CrossRef]
- Liu, Y.; Shen, J.; Yang, L.; Bian, G.; Yu, H. ResDO-UNet: A deep residual network for accurate retinal vessel segmentation from fundus images. Biomed. Signal Process. Control 2023, 79, 104087. [Google Scholar] [CrossRef]
- Hellerstein, J.L.; Jayram, T.S.; Rish, I. Recognizing End-User Transactions in Performance Management; IBM Thomas J. Watson Research Division: Hawthorne, NY, USA, 2000. [Google Scholar]
- Jain, A.K.; Waller, W.G. On the optimal number of features in the classification of multivariate Gaussian data. Pattern Recognit. 1978, 10, 365–374. [Google Scholar] [CrossRef]
- Gopi, A.P.; Jyothi, R.N.; Narayana, V.L.; Sandeep, K.S. Classification of tweets data based on polarity using improved RBF kernel of SVM. Int. J. Inf. Technol. 2023, 15, 965–980. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Hatamizadeh, A.; Tang, Y.; Nath, V.; Yang, D.; Myronenko, A.; Landman, B.; Roth, H.R.; Xu, D. Unetr: Transformers for 3d medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 574–584. [Google Scholar]
- Trockman, A.; Kolter, J.Z. Patches are all you need? arXiv 2022, arXiv:2201.09792. [Google Scholar]
- Rodrigues, M.B.; Da Nobrega, R.V.M.; Alves, S.S.A.; ReboucasFilho, P.P.; Duarte, J.B.F.; Sangaiah, A.K.; De Albuquerque, V.H.C. Health of things algorithms for malignancy level classification of lung nodules. IEEE Access 2018, 6, 18592–18601. [Google Scholar] [CrossRef]
- Wang, Y.X.; Panda-Jonas, S.; Jonas, J.B. Optic nerve head anatomy in myopia and glaucoma, including parapapillary zones alpha, beta, gamma and delta: Histology and clinical features. Prog. Retin. Eye Res. 2021, 83, 100933. [Google Scholar] [CrossRef]
- Lona, G.; Hauser, C.; Köchli, S.; Infanger, D.; Endes, K.; Faude, O.; Hanssen, H. Blood pressure increase and microvascular dysfunction accelerate arterial stiffening in children: Modulation by physical activity. Front. Physiol. 2020, 11, 613003. [Google Scholar] [CrossRef]
- Relan, D.; Mokan, M.; Relan, R. An automatic AVR biomarker assessment system in retinal imaging. Multimed. Tools Appl. 2023, 82, 36553–36575. [Google Scholar] [CrossRef]
- Usher, D.; Dumskyj, M.; Himaga, M.; Williamson, T.H.; Nussey, S.; Boyce, J. Automated detection of diabetic retinopathy in digital retinal images: A tool for diabetic retinopathy screening. Diabet. Med. 2004, 21, 84–90. [Google Scholar] [CrossRef] [PubMed]
- Manikis, G.C.; Sakkalis, V.; Zabulis, X.; Karamaounas, P.; Triantafyllou, A.; Douma, S.; Zamboulis, C.; Marias, K. An image analysis framework for the early assessment of hypertensive retinopathy signs. In Proceedings of the 2011 E-Health and Bioengineering Conference (EHB), Iasi, Romania, 24–26 November 2011; pp. 1–6. [Google Scholar]
- Narasimhan, K.; Neha, V.C.; Vijayarekha, K. Hypertensive Retinopathy Diagnosis from Fundus Images by Estimation of Avr. Procedia Eng. 2012, 38, 980–993. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grade | Symptoms |
|---|---|
| Normal | Diagnosis of hypertension but no retinal abnormalities |
| Mild | Arteriolar narrowing |
| Moderate | Arteriolar narrowing with focal constriction |
| Severe | Retinal hemorrhage, focal and diffuse narrowing |
| Malignant | Hard exudates, optic disk edema |
| Model | Dataset | Dice | Jaccard Coefficient |
|---|---|---|---|
| GLUE [33] | DRIVE, STARE | 81.45 | 75.47 |
| SUNET [34] | DRIVE, CHASE DB1 | 81.74 | 77.46 |
| MUNET [35] | Private | 82.46 | 79.85 |
| RESDUNET [36] | Private | 77.36 | 78.47 |
| Proposed | ODIR, INSPIREVR, VICAVR | 83.27 | 83.93 |
| Model | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| Zhou et al. [39] | 95.35 | 84.73 | 98.35 |
| Xu et al. [40] | 95.57 | 89.53 | 98.07 |
| Wang et al. [37] | 95.81 | 89.91 | 98.13 |
| Li et al. [22] | 95.73 | 98.35 | 98.38 |
| Mouet al. [38] | 95.53 | 81.54 | 97.57 |
| Zhang et al. [41] | 95.65 | 88.57 | 96.18 |
| Liu et al. [42] | 97.61 | 89.85 | 97.91 |
| Proposed | 99.37 | 98.75 | 99.56 |
| Model | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| Partial least square [43] | 96.05 | 77.76 | 98.32 |
| SVM [44] | 97.46 | 83.78 | 83.08 |
| SVMRBF [45] | 98.58 | 81.86 | 81.95 |
| Proposed (improved SVM) | 98.99 | 98.45 | 99.46 |
| Proposed (improved KNN) | 98.72 | 98.26 | 99.39 |
| Model | Pre-Processing (s) | Segmentation | Training (s) | Prediction (s) | Overall (s) |
|---|---|---|---|---|---|
| GLUE [32] | 3.8 | 4.7 | 191.5 | 3.5 | 203.5 |
| SUNET [34] | 3.5 | 4.2 | 189.8 | 3.2 | 200.7 |
| MUNET [35] | 3.5 | 3.5 | 189.4 | 2.5 | 198.9 |
| RESDUNET [36] | 2.6 | 3.2 | 174.3 | 2.2 | 182.3 |
| Unet [46] | 2.4 | 2.1 | 168.4 | 1.9 | 174.8 |
| ViT [47] | 1.9 | 1.9 | 158.5 | 1.8 | 164.1 |
| ConvMixer [48] | 1.8 | 1.9 | 156.9 | 1.7 | 162.3 |
| Proposed | 1.5 | 1.8 | 155.5 | 1.6 | 160.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhimavarapu, U.; Chintalapudi, N.; Battineni, G. Automatic Detection and Classification of Hypertensive Retinopathy with Improved Convolution Neural Network and Improved SVM. Bioengineering 2024, 11, 56. https://doi.org/10.3390/bioengineering11010056
Bhimavarapu U, Chintalapudi N, Battineni G. Automatic Detection and Classification of Hypertensive Retinopathy with Improved Convolution Neural Network and Improved SVM. Bioengineering. 2024; 11(1):56. https://doi.org/10.3390/bioengineering11010056
Chicago/Turabian StyleBhimavarapu, Usharani, Nalini Chintalapudi, and Gopi Battineni. 2024. "Automatic Detection and Classification of Hypertensive Retinopathy with Improved Convolution Neural Network and Improved SVM" Bioengineering 11, no. 1: 56. https://doi.org/10.3390/bioengineering11010056
APA StyleBhimavarapu, U., Chintalapudi, N., & Battineni, G. (2024). Automatic Detection and Classification of Hypertensive Retinopathy with Improved Convolution Neural Network and Improved SVM. Bioengineering, 11(1), 56. https://doi.org/10.3390/bioengineering11010056