
Multitask Attention-Based Neural Network for Intraoperative Hypotension Prediction


Abstract
:1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Model | Data Source | Innovation | Year |
|---|---|---|---|---|
| Hatib et al. [24] | Logistic Regression | IBP | Machine Learning Fine-Tuning | 2018 |
| Lee et al. [27] | CNN | IBP, ECG, PPG, CO2 | Multi-Channel Data Source | 2021 |
| Choe et al. [23] | RNN and CNN | ABP | Weighted-Average of Deep-Learning Models | 2021 |
| Jo et al. [26] | ResNet | ABP, ECG, EEG | Multi-Channel Data Source | 2022 |
| Lee et al. [20] | Random Forests | IBP | Feature Extraction Model | 2022 |
2. Materials and Methods
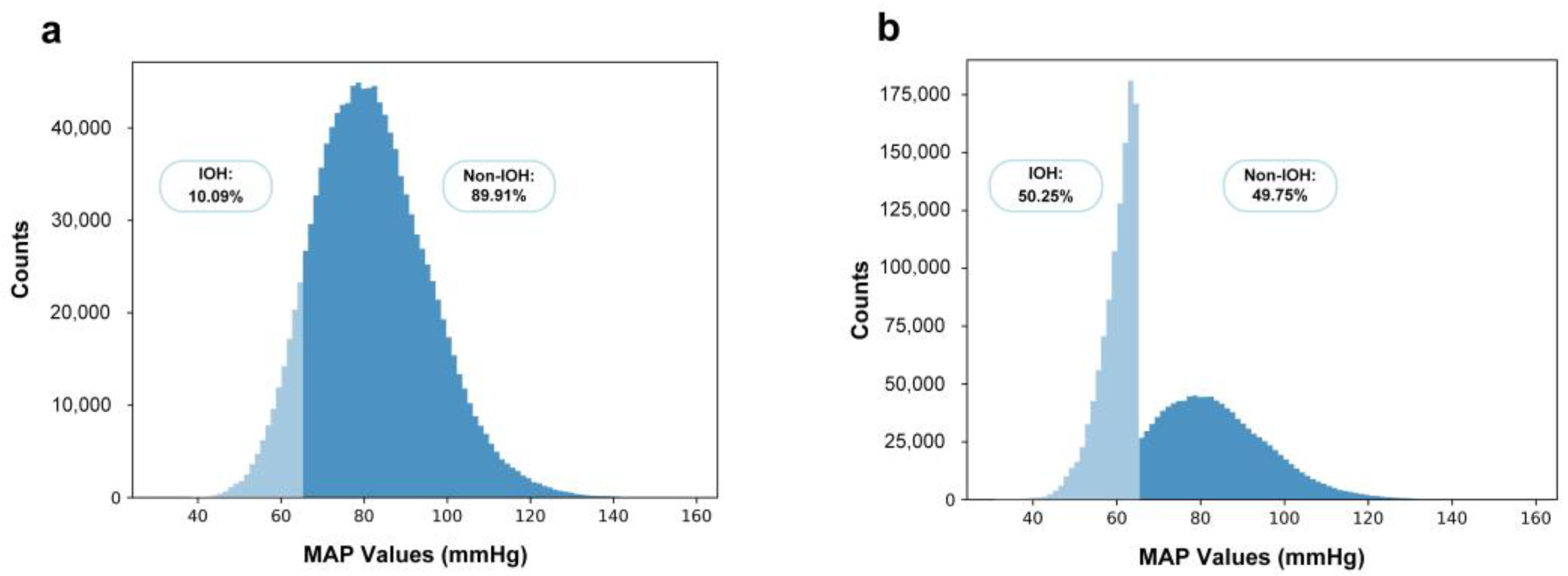
2.1. Dataset
2.2. Signal Preprocessing
- Cardiac cycles that were detected as too slow, too fast, or undetectable were flagged as invalid.
- Data segments containing abnormal values in any of the four channels (e.g., ABP > 160 mmHg, ABP < 20 mmHg, ECG < −1 mV, ECG > 1 mV) were also excluded.
- Only segments maintaining a consistent rhythm for at least 10 min were considered valid.
2.3. Evaluation Metrics
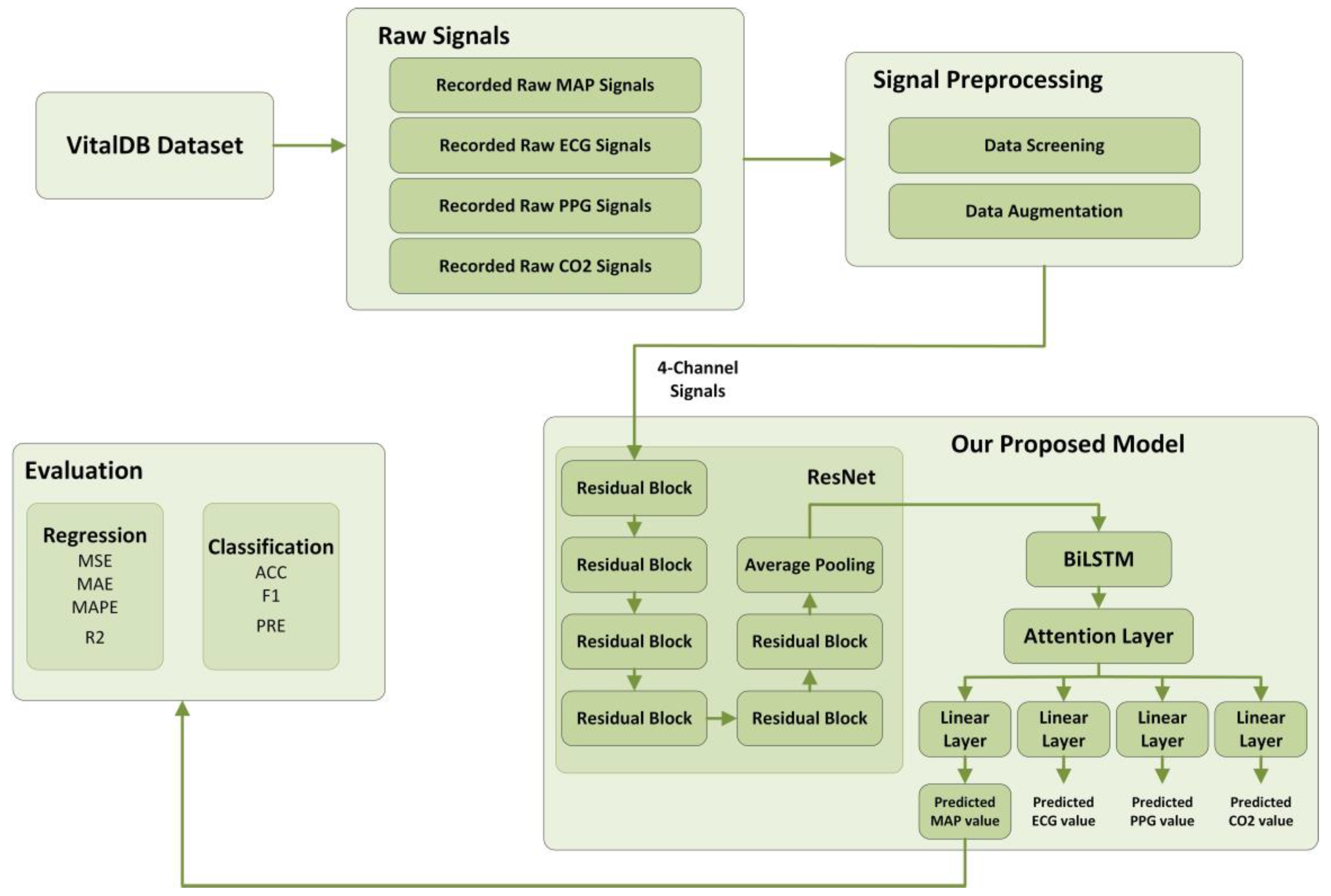
2.4. Deep Learning Model
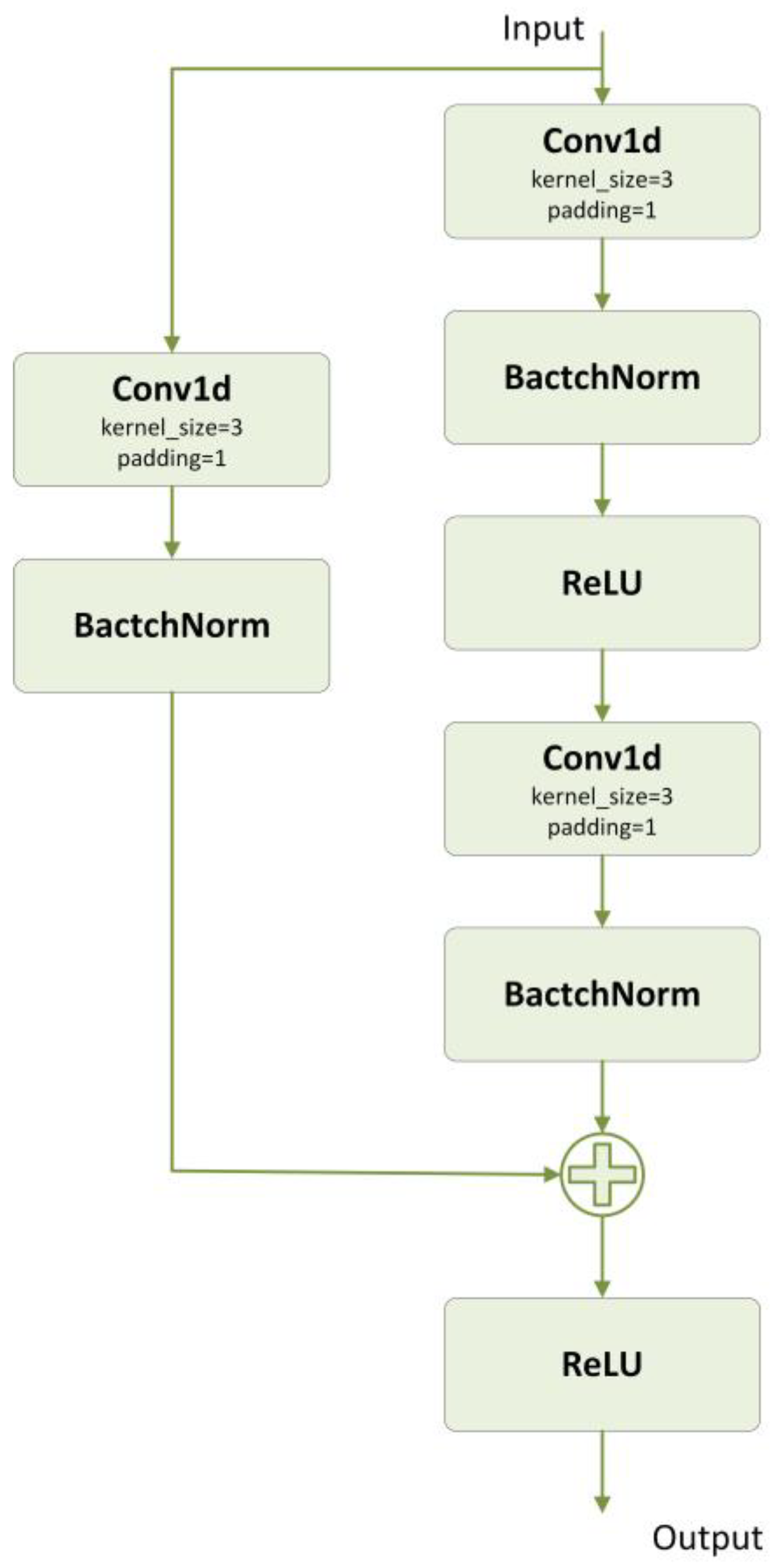
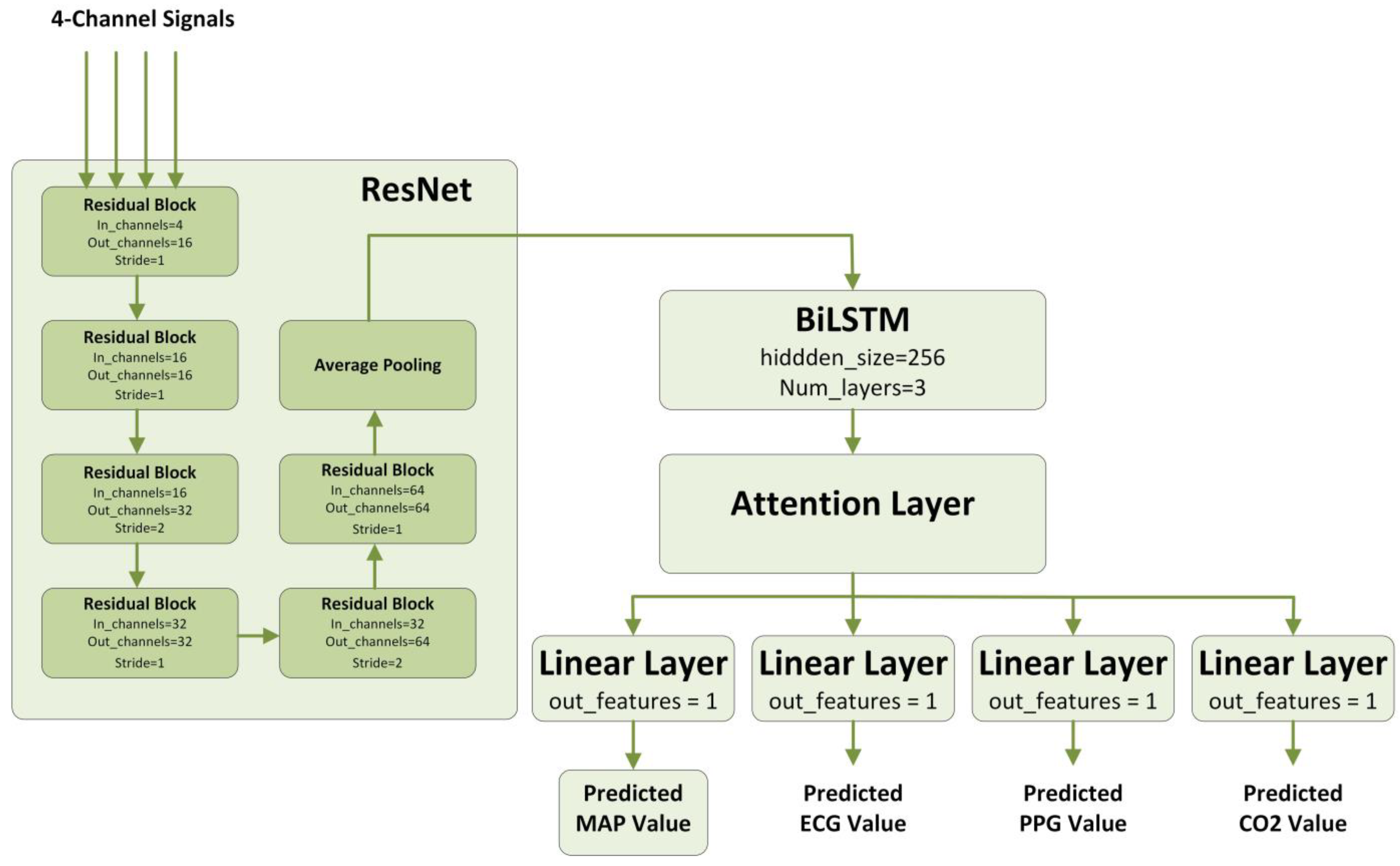
2.4.1. ResNet
2.4.2. BiLSTM
2.4.3. Attention
2.4.4. Multitask Learning
2.4.5. Our Proposed Model
2.5. Machine Learning Models for Comparison
2.5.1. CNN
2.5.2. WaveNet
2.5.3. TCN
3. Results
3.1. Experimental Settings
3.1.1. Dataset Split
3.1.2. Model Implementation and Training Details
3.1.3. Hardware Configuration
3.2. Experimental Results
3.2.1. Comparison Experiments
3.2.2. Ablation Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Maheshwari, K.; Turan, A.; Mao, G.; Yang, D.; Niazi, A.K.; Agarwal, D.; Sessler, D.I.; Kurz, A. The association of hypotension during non-cardiac surgery, before and after skin incision, with postoperative acute kidney injury: A retrospective cohort analysis. Anaesthesia 2018, 73, 1223–1228. [Google Scholar] [CrossRef]
- Salmasi, V.; Maheshwari, K.; Yang, D.; Mascha, E.J.; Singh, A.; Sessler, D.I.; Kurz, A. Relationship between Intraoperative Hypotension, Defined by Either Reduction from Baseline or Absolute Thresholds, and Acute Kidney and Myocardial Injury after Noncardiac Surgery: A Retrospective Cohort Analysis. Anesthesiology 2017, 126, 47–65. [Google Scholar] [CrossRef]
- Sun, L.Y.; Wijeysundera, D.N.; Tait, G.A.; Beattie, W.S. Association of intraoperative hypotension with acute kidney injury after elective noncardiac surgery. Anesthesiology 2015, 123, 515–523. [Google Scholar] [CrossRef] [PubMed]
- Sessler, D.I.; Khanna, A.K. Perioperative myocardial injury and the contribution of hypotension. Intensive Care Med. 2018, 44, 811–822. [Google Scholar] [CrossRef] [PubMed]
- Hallqvist, L.; Mårtensson, J.; Granath, F.; Sahlén, A.; Bell, M. Intraoperative hypotension is associated with myocardial damage in noncardiac surgery: An observational study. Eur. J. Anaesthesiol. 2016, 33, 450–456. [Google Scholar] [CrossRef] [PubMed]
- Nagre, A.S. Perioperative stroke–Prediction, Prevention, and Protection. Indian J. Anaesth. 2018, 62, 738–742. [Google Scholar] [CrossRef] [PubMed]
- Bijker, J.B.; Persoon, S.; Peelen, L.M.; Moons, K.G.; Kalkman, C.J.; Kappelle, L.J.; van Klei, W.A. Intraoperative hypotension and perioperative ischemic stroke after general surgery: A nested case-control study. Anesthesiology 2012, 116, 658–664. [Google Scholar] [CrossRef]
- Vincent, J.L.; De Backer, D. Circulatory shock. N. Engl. J. Med. 2013, 369, 1726–1734. [Google Scholar] [CrossRef]
- Mascha, E.J.; Yang, D.; Weiss, S.; Sessler, D.I. Intraoperative Mean Arterial Pressure Variability and 30-day Mortality in Patients Having Noncardiac Surgery. Anesthesiology 2015, 123, 79–91. [Google Scholar] [CrossRef]
- Monk, T.G.; Bronsert, M.R.; Henderson, W.G.; Mangione, M.P.; Sum-Ping, S.T.; Bentt, D.R.; Nguyen, J.D.; Richman, J.S.; Meguid, R.A.; Hammermeister, K.E. Association between Intraoperative Hypotension and Hypertension and 30-day Postoperative Mortality in Noncardiac Surgery. Anesthesiology 2015, 123, 307–319. [Google Scholar] [CrossRef]
- An, R.; Pang, Q.Y.; Liu, H.L. Association of intra-operative hypotension with acute kidney injury, myocardial injury and mortality in non-cardiac surgery: A meta-analysis. Int. J. Clin. Pract. 2019, 73, e13394. [Google Scholar] [CrossRef] [PubMed]
- He, J.; Baxter, S.L.; Xu, J.; Xu, J.; Zhou, X.; Zhang, K. The practical implementation of artificial intelligence technologies in medicine. Nat. Med. 2019, 25, 30–36. [Google Scholar] [CrossRef] [PubMed]
- Xiao, G.; Shi, M.; Ye, M.; Xu, B.; Chen, Z.; Ren, Q. 4D attention-based neural network for EEG emotion recognition. Cogn. Neurodynamics 2022, 16, 805–818. [Google Scholar] [CrossRef] [PubMed]
- Shi, M.; Huang, Z.; Xiao, G.; Xu, B.; Ren, Q.; Zhao, H. Estimating the Depth of Anesthesia from EEG Signals Based on a Deep Residual Shrinkage Network. Sensors 2023, 23, 1008. [Google Scholar] [CrossRef] [PubMed]
- Qin, C.; Li, Y.; Liu, C.; Ma, X. Cuff-Less Blood Pressure Prediction Based on Photoplethysmography and Modified ResNet. Bioengineering 2023, 10, 400. [Google Scholar] [CrossRef]
- Martino, L.; Read, J. A joint introduction to Gaussian processes and relevance vector machines with connections to Kalman filtering and other kernel smoothers. Inf. Fusion 2021, 74, 17–38. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Candela, J.Q.; Hansen, L.K. Learning with Uncertainty-Gaussian Processes and Relevance Vector Machines; Technical University of Denmark: Copenhagen, Denmark, 2004; pp. 1–152. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.; Kim, S.H.; Woo, J. Intraoperative Hypotension Prediction Model Based on Systematic Feature Engineering and Machine Learning. Sensors 2022, 22, 3108. [Google Scholar] [CrossRef]
- Guan, Y.; Li, D.; Xue, S.; Xi, Y. Feature-fusion-kernel-based Gaussian process model for probabilistic long-term load forecasting. Neurocomputing 2021, 426, 174–184. [Google Scholar] [CrossRef]
- Qiu, J.S.; Fan, Y.C.; Wang, S.L.; Yang, X.; Qiao, J.L.; Liu, D.L. Research on the remaining useful life prediction method of lithium-ion batteries based on aging feature extraction and multi-kernel relevance vector machine optimization model. Int. J. Energy Res. 2022, 46, 13931–13946. [Google Scholar] [CrossRef]
- Choe, S.; Park, E.; Shin, W.; Koo, B.; Shin, D.; Jung, C.; Lee, H.; Kim, J. Short-Term Event Prediction in the Operating Room (STEP-OP) of Five-Minute Intraoperative Hypotension Using Hybrid Deep Learning: Retrospective Observational Study and Model Development. JMIR Med. Inform. 2021, 9, e31311. [Google Scholar] [CrossRef]
- Hatib, F.; Jian, Z.; Buddi, S.; Lee, C.; Settels, J.; Sibert, K.; Rinehart, J.; Cannesson, M. Machine-learning Algorithm to Predict Hypotension Based on High-fidelity Arterial Pressure Waveform Analysis. Anesthesiology 2018, 129, 663–674. [Google Scholar] [CrossRef] [PubMed]
- Simjanoska, M.; Gjoreski, M.; Gams, M.; Madevska Bogdanova, A. Non-Invasive Blood Pressure Estimation from ECG Using Machine Learning Techniques. Sensors 2018, 18, 1160. [Google Scholar] [CrossRef]
- Jo, Y.Y.; Jang, J.H.; Kwon, J.M.; Lee, H.C.; Jung, C.W.; Byun, S.; Jeong, H.G. Predicting intraoperative hypotension using deep learning with waveforms of arterial blood pressure, electroencephalogram, and electrocardiogram: Retrospective study. PLoS ONE 2022, 17, e0272055. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Lee, H.C.; Chu, Y.S.; Song, S.W.; Ahn, G.J.; Lee, H.; Yang, S.; Koh, S.B. Deep learning models for the prediction of intraoperative hypotension. Br. J. Anaesth. 2021, 126, 808–817. [Google Scholar] [CrossRef] [PubMed]
- Ngan Kee, W.D. A Random-allocation Graded Dose-Response Study of Norepinephrine and Phenylephrine for Treating Hypotension during Spinal Anesthesia for Cesarean Delivery. Anesthesiology 2017, 127, 934–941. [Google Scholar] [CrossRef] [PubMed]
- Lee, H.C.; Jung, C.W. Vital Recorder-a free research tool for automatic recording of high-resolution time-synchronised physiological data from multiple anaesthesia devices. Sci. Rep. 2018, 8, 1527. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 1703. [Google Scholar]
- Chan, B.; Chen, B.; Sedghi, A.; Laird, P.; Maslove, D.; Mousavi, P. Generalizable deep temporal models for predicting episodes of sudden hypotension in critically ill patients: A personalized approach. Sci. Rep. 2020, 10, 11480. [Google Scholar] [CrossRef]



| Metrics | Formula | Description |
|---|---|---|
| MSE (Regression) | Mean Squared Error | |
| MAE (Regression) | Mean Absolute Error | |
| MAPE (Regression) | Mean Absolute Percentage Error | |
| R2 (Regression) | Coefficient of Determination | |
| ACC (Classification) | Accuracy | |
| F1 (Classification) | F1 Score | |
| PRE(Classification) | Precision |
| Metrics | WaveNet | CNN | TCN | Our Proposed Model |
|---|---|---|---|---|
| MSE | 51.52 | 318.52 | 62.31 | 43.83 |
| MAE | 4.86 | 16.49 | 5.74 | 4.46 |
| MAPE | 0.0589 | 0.2010 | 0.0678 | 0.0545 |
| R2 | 0.7502 | −0.6732 | 0.6611 | 0.7731 |
| ACC | 0.9087 | 0.5861 | 0.9045 | 0.9224 |
| F1 | 0.6625 | 0.3627 | 0.6129 | 0.6985 |
| PRE | 0.5355 | 0.2219 | 0.4678 | 0.6117 |
| Metrics | ResNet-BiLSTM | ResNet-BiLSTM + Attention | ResNet-BiLSTM + Multitask | ResNet-BiLSTM + Multitask + Attention |
|---|---|---|---|---|
| MSE | 50.67 | 48.27 | 45.56 | 43.83 |
| MAE | 4.91 | 4.76 | 4.74 | 4.46 |
| MAPE | 0.0604 | 0.0575 | 0.0579 | 0.0545 |
| R2 | 0.7234 | 0.7599 | 0.7578 | 0.7731 |
| ACC | 0.9018 | 0.9178 | 0.9185 | 0.9224 |
| F1 | 0.6014 | 0.6418 | 0.6484 | 0.6985 |
| PRE | 0.4820 | 0.5319 | 0.5457 | 0.6117 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, M.; Zheng, Y.; Wu, Y.; Ren, Q. Multitask Attention-Based Neural Network for Intraoperative Hypotension Prediction. Bioengineering 2023, 10, 1026. https://doi.org/10.3390/bioengineering10091026
Shi M, Zheng Y, Wu Y, Ren Q. Multitask Attention-Based Neural Network for Intraoperative Hypotension Prediction. Bioengineering. 2023; 10(9):1026. https://doi.org/10.3390/bioengineering10091026
Chicago/Turabian StyleShi, Meng, Yu Zheng, Youzhen Wu, and Quansheng Ren. 2023. "Multitask Attention-Based Neural Network for Intraoperative Hypotension Prediction" Bioengineering 10, no. 9: 1026. https://doi.org/10.3390/bioengineering10091026
APA StyleShi, M., Zheng, Y., Wu, Y., & Ren, Q. (2023). Multitask Attention-Based Neural Network for Intraoperative Hypotension Prediction. Bioengineering, 10(9), 1026. https://doi.org/10.3390/bioengineering10091026