


Lung Tumor Image Segmentation from Computer Tomography Images Using MobileNetV2 and Transfer Learning


Abstract
:1. Introduction
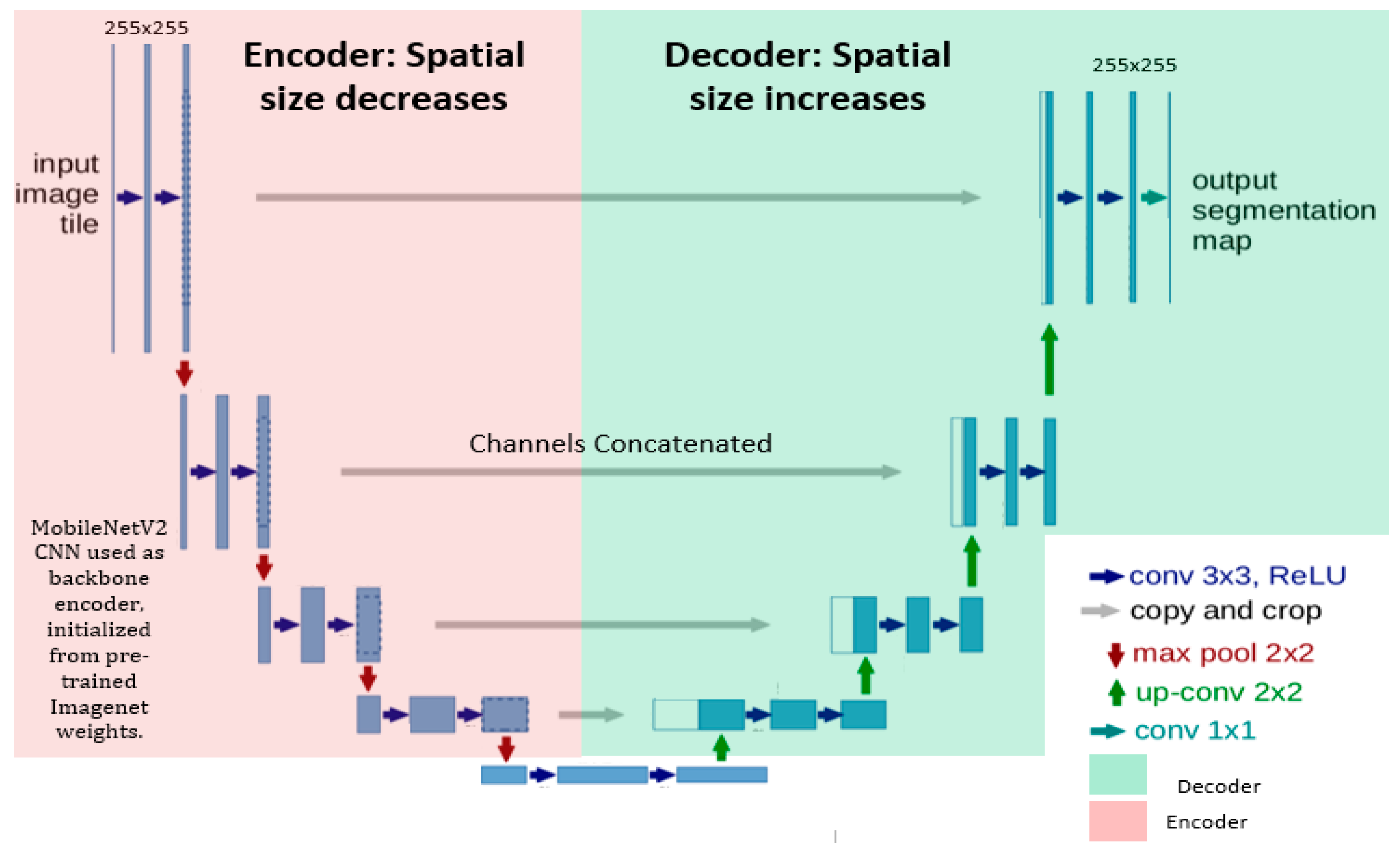
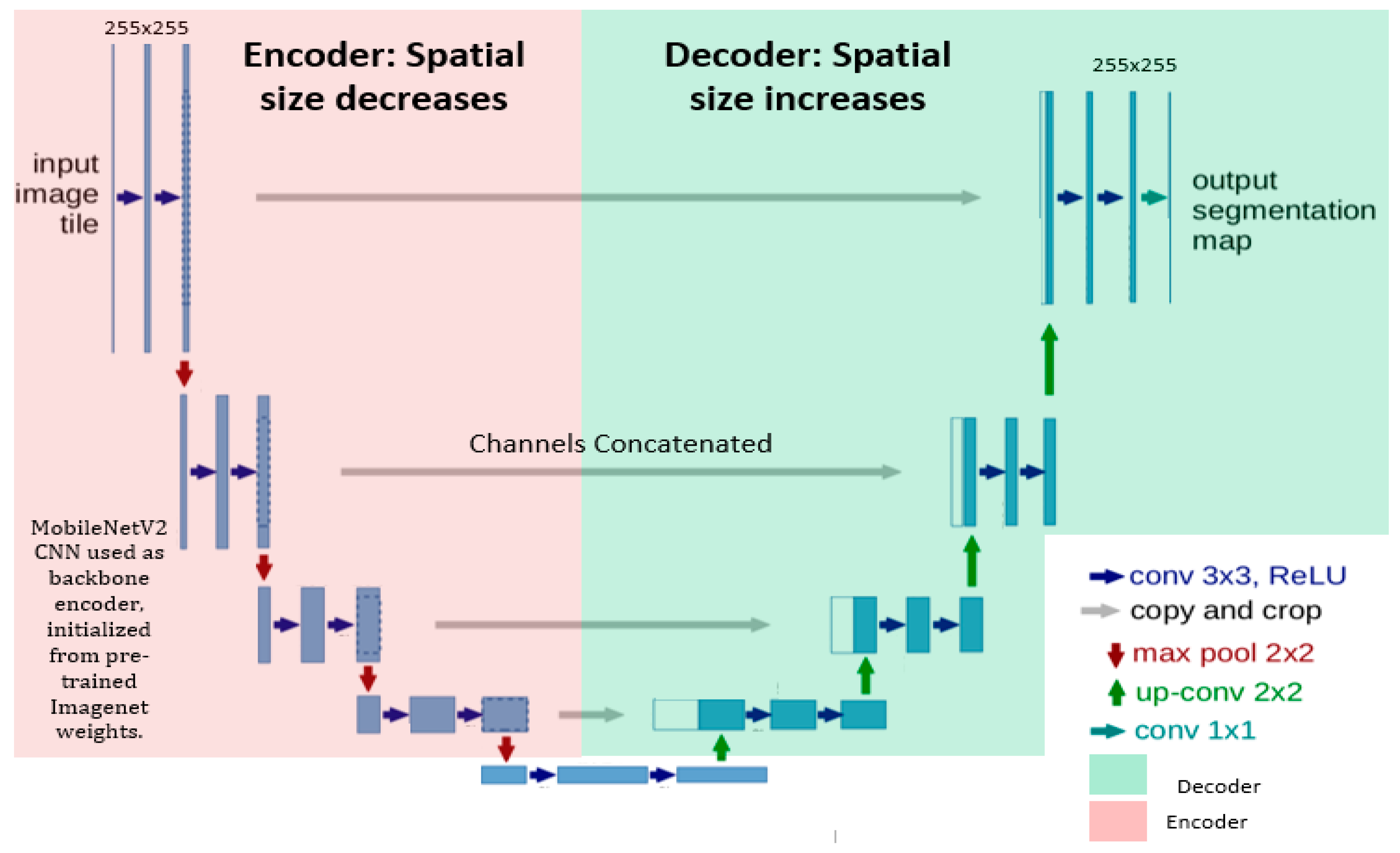
- We utilized a pre-trained MobileNetV2, retaining the convolutional layers, as the encoder of the classical UNET for generating more stable segmentation maps. The decoder part consists of up-sample layers and convolutional layers that recover the spatial resolution and refine the segmentation results.
- Skip connections were established with the Relu activation function for improving the model convergence to connect the encoder layers of MobileNetV2 to the decoder layers in UNet, which allows the concatenation of feature maps with different resolutions from the encoder to decoder. Thus, the decoder leverages both low-level and high-level features for accurate segmentation.
- Finally, we added a 1 × 1 convolution layer at the end of the decoder to reduce the number of channels and to obtain the number of output classes, such as tumor and background.
- The devised network was further trained and fine-tuned with optimized hyper-parameters on the training dataset obtained from the Medical Segmentation Decathlon (MSD) 2018 Challenge.
- The results indicate that the proposed approach is robust and significantly improved the segmentation accuracy.
2. Background
Deep Learning Techniques
3. Materials and Methods
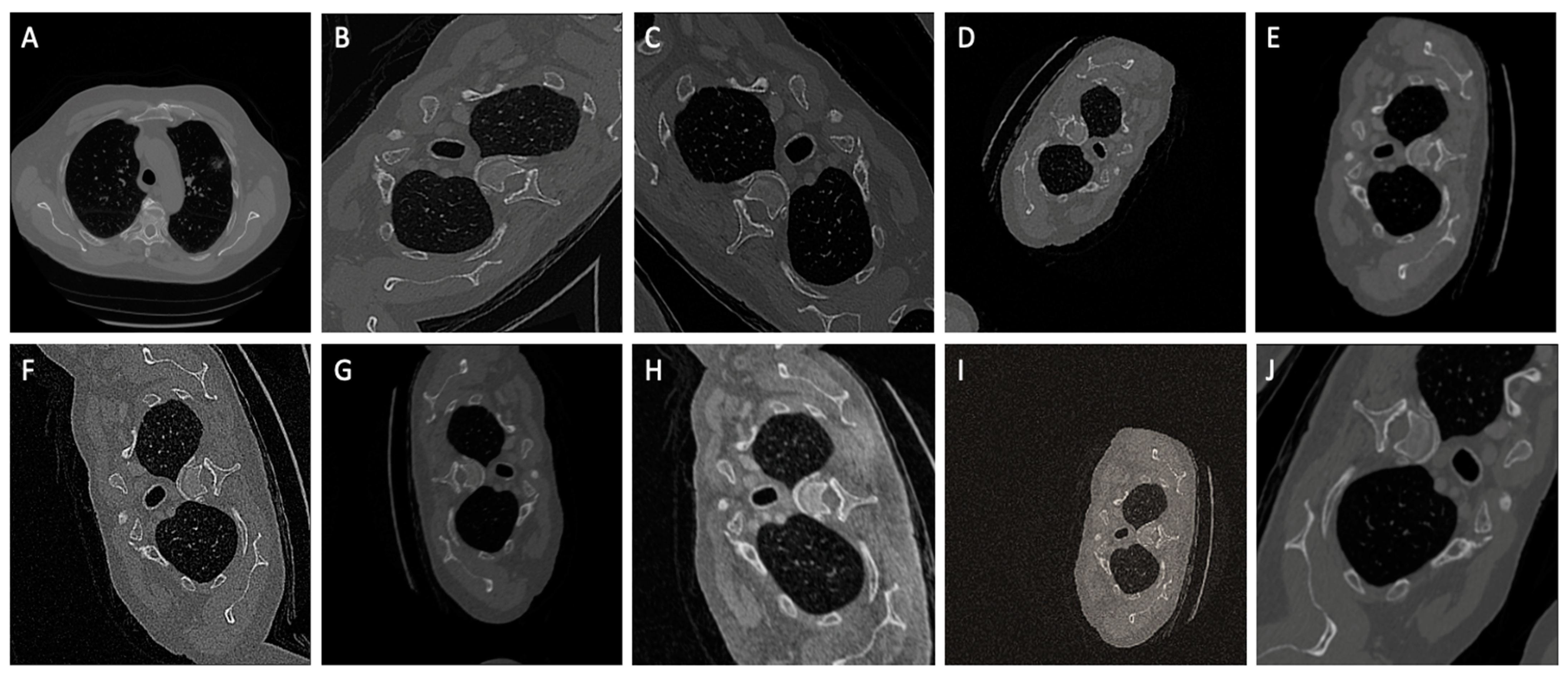
3.1. Dataset
3.2. Methodology
Preprocessing
3.3. Network Architecture
3.4. Model Training
3.5. Evaluation Parameters
3.5.1. Dice similarity Coefficient (DSC)
3.5.2. Dice Loss (DL)
3.5.3. Recall and Precision
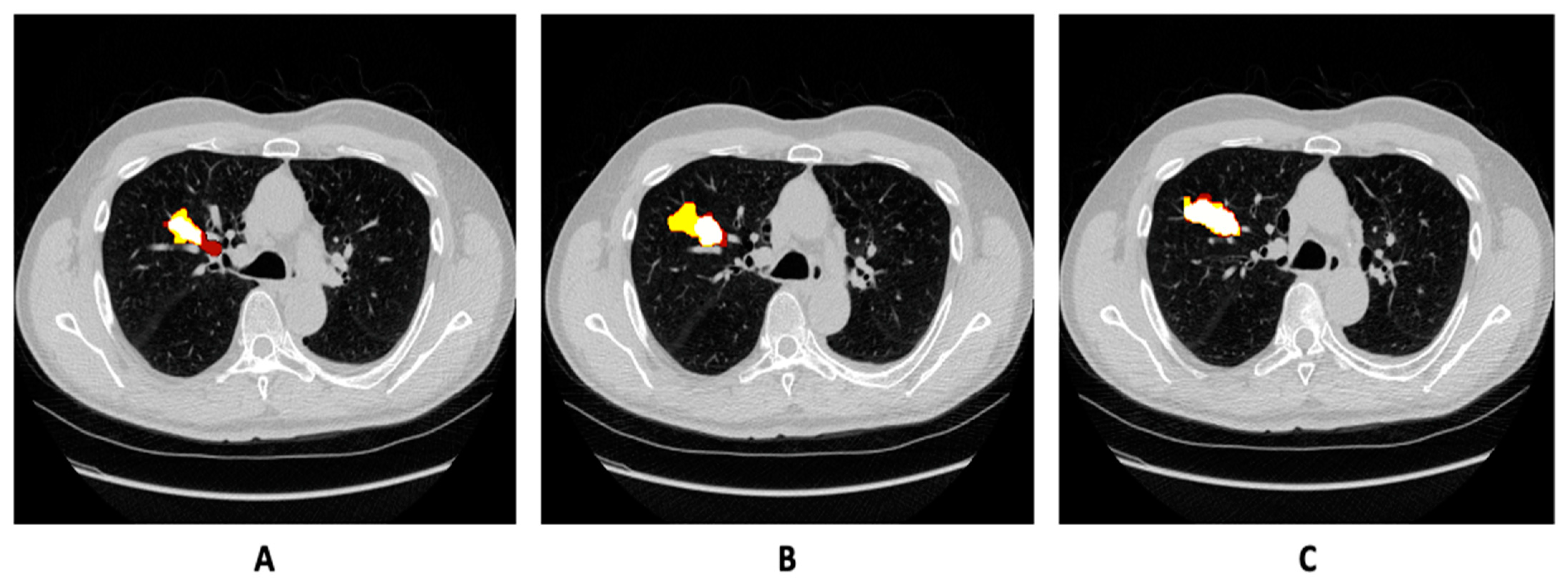
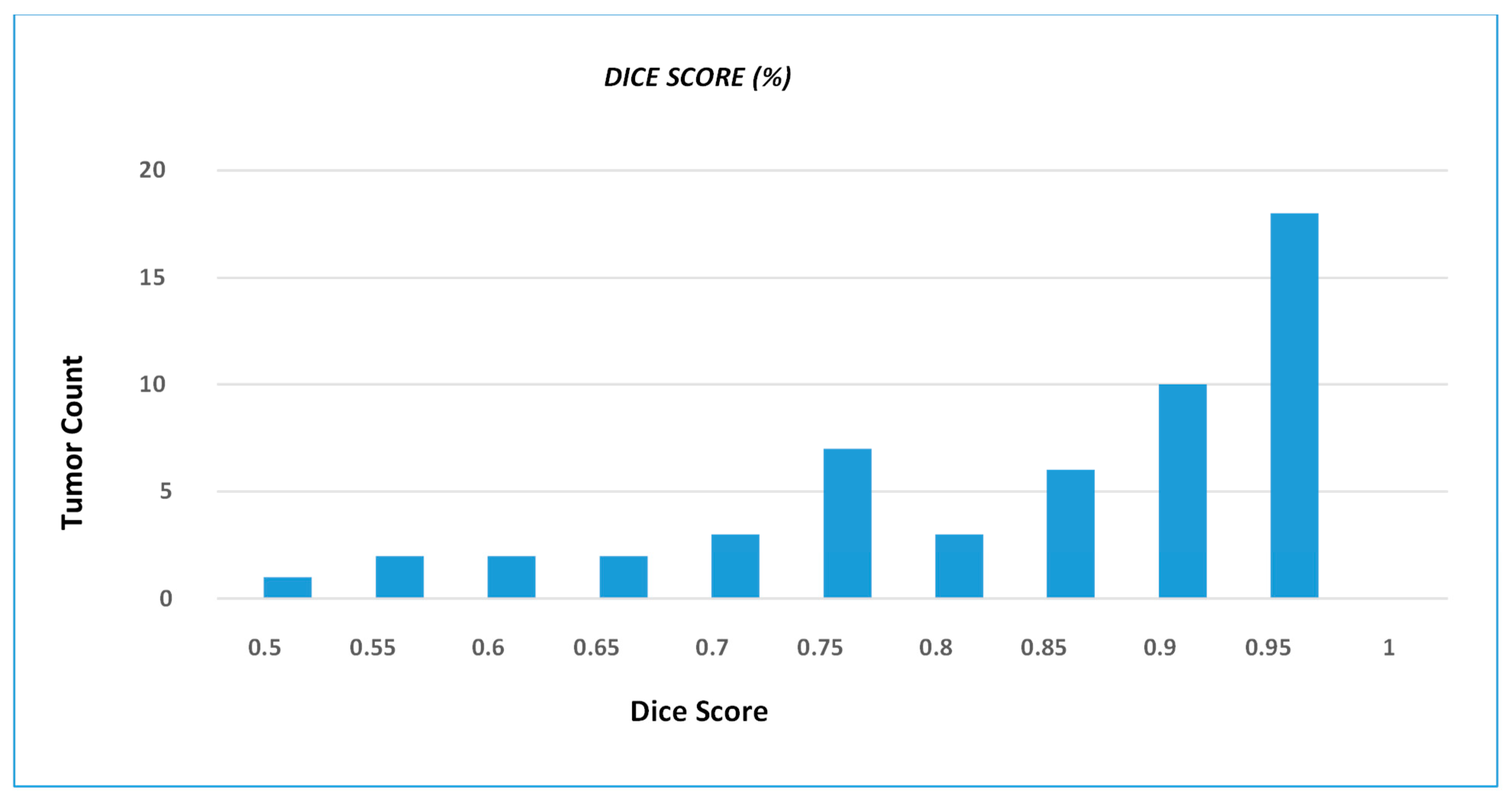
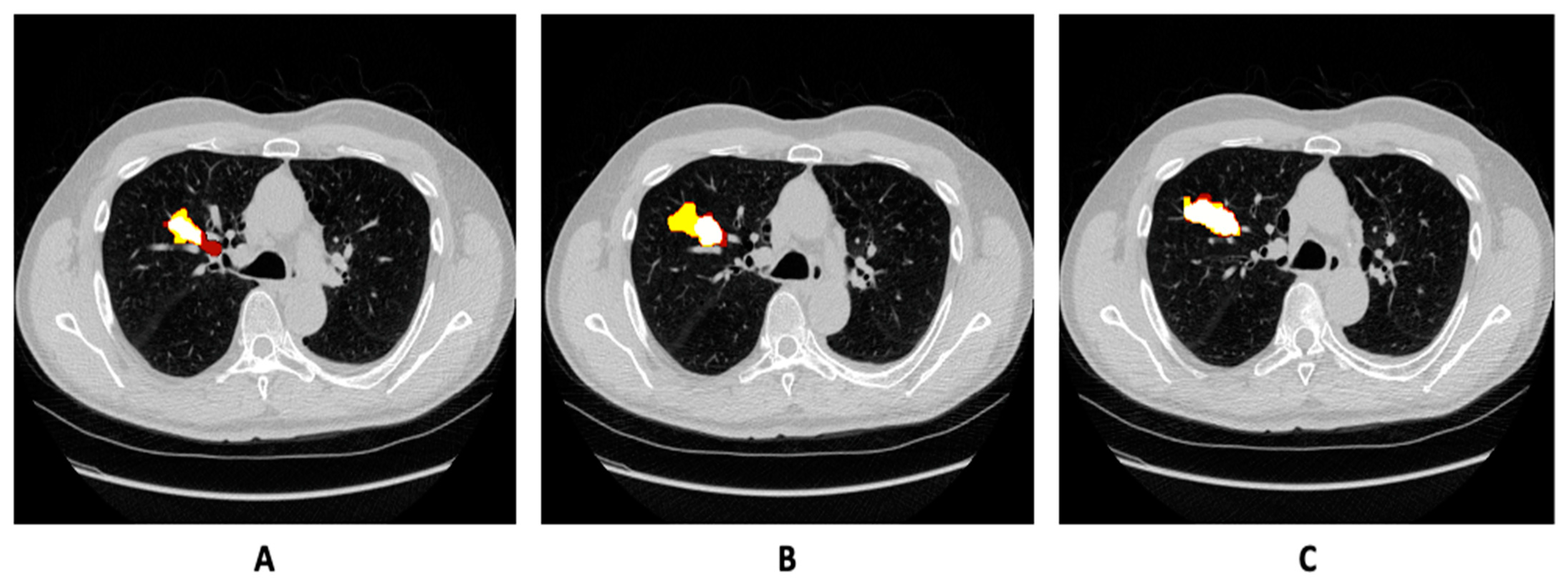
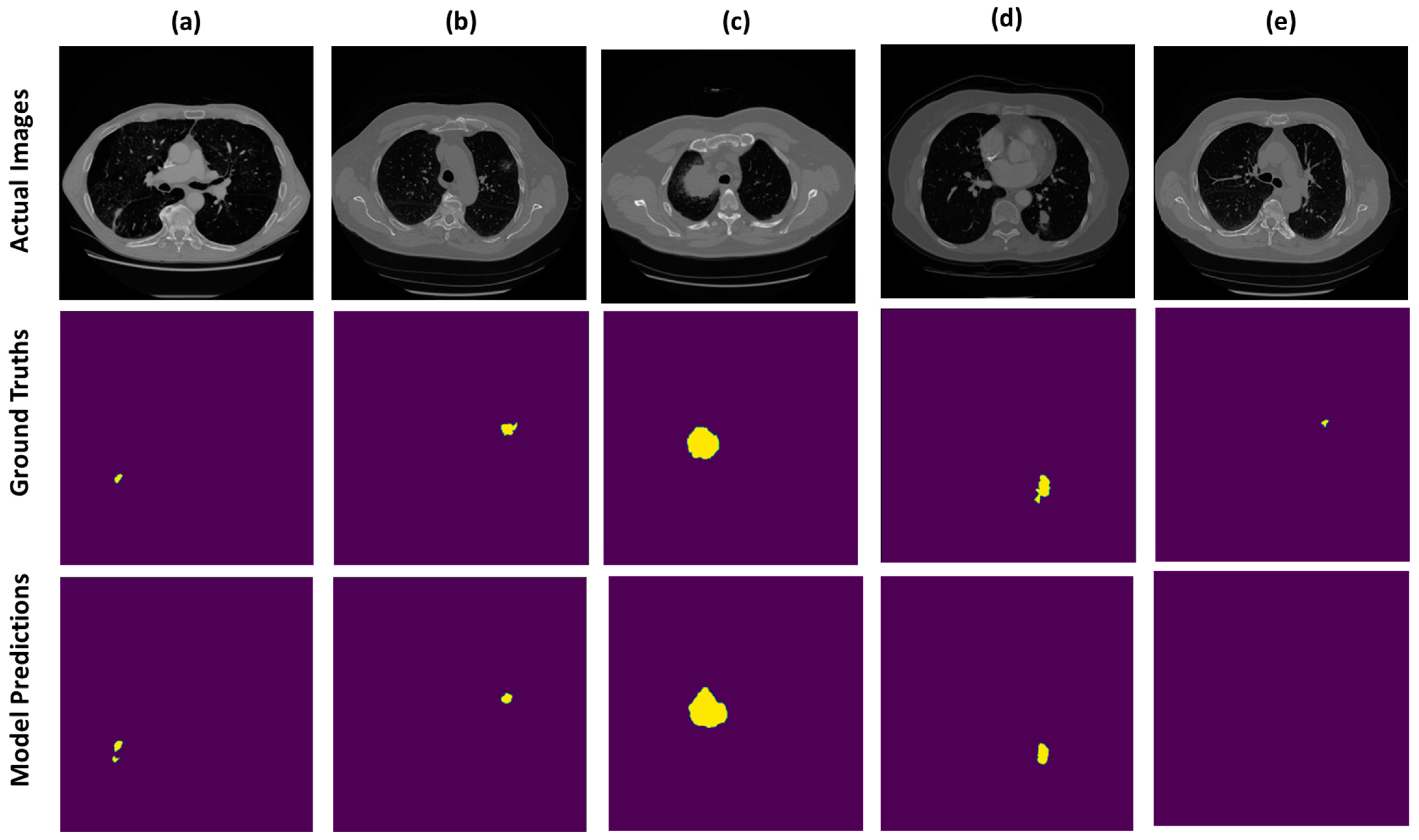
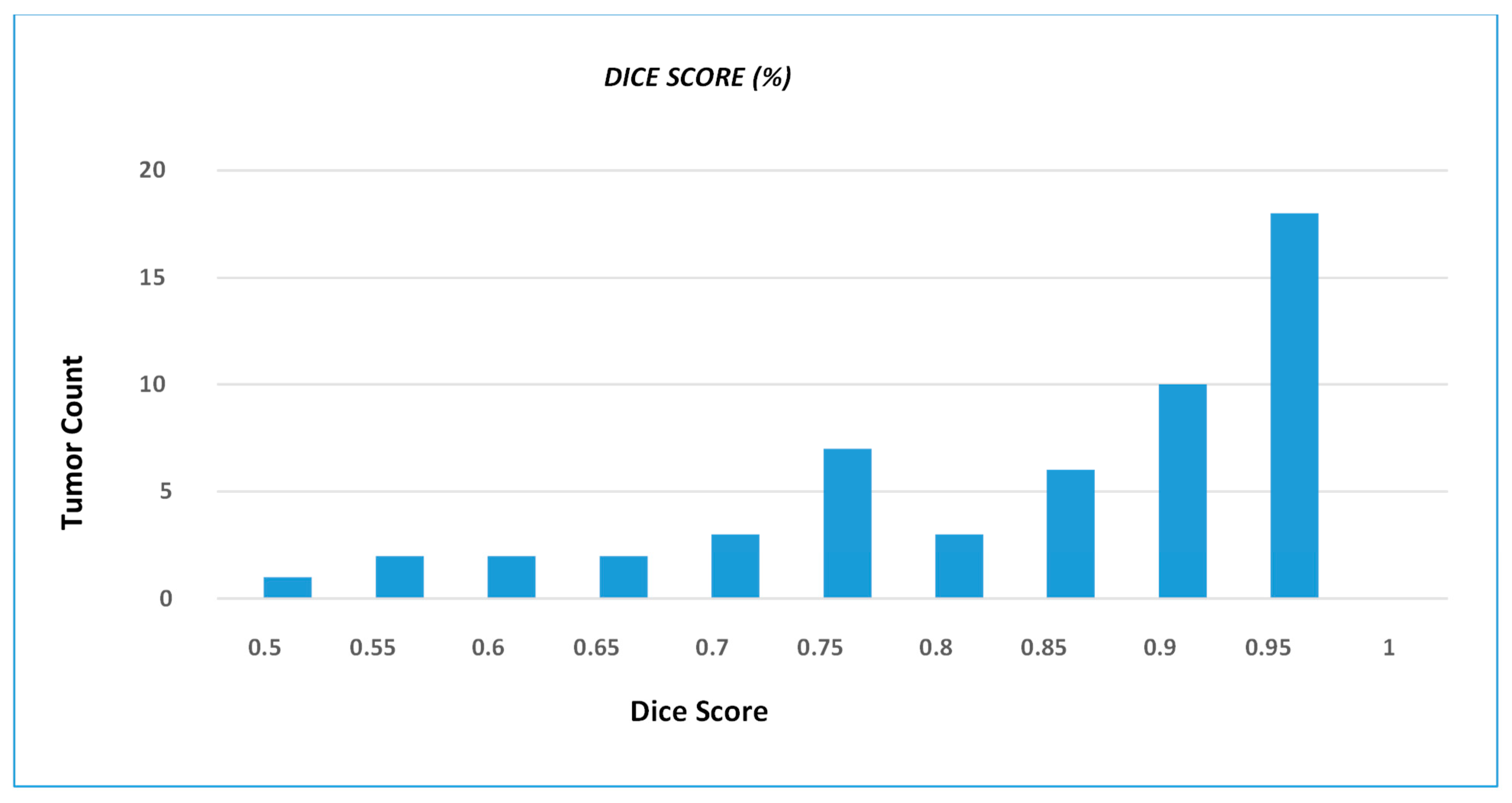
4. Results
Result Comparison with Existing Methods
5. Conclusions and Discussion
6. Limitations and Future Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Manikandan, T.; Devi, B.; Helanvidhya, T. A Computer-Aided Diagnosis System for Lung Cancer Detection with Automatic Region Growing, Multistage Feature Selection and Neural Network Classifier. Int. J. Innov. Technol. Explor. Eng. 2019, 9, 409–413. [Google Scholar]
- Drozdzal, M.; Chartrand, G.; Vorontsov, E.; Shakeri, M.; Di Jorio, L.; Tang, A.; Romero, A.; Bengio, Y.; Pal, C.; Kadoury, S. Learning normalized inputs for iterative estimation in medical image segmentation. Med. Image Anal. 2018, 44, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Kamal, U.; Rafi, A.M.; Hoque, R.; Wu, J.; Hasan, M.K. Lung cancer tumor region segmentation using recurrent 3D-denseunet. In Proceedings of the Thoracic Image Analysis: Second International Workshop, TIA 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, 8 October 2020; Springer International Publishing: Berlin/Heidelberg, Germany; pp. 36–47. [Google Scholar]
- Niranjana, G.; Ponnavaikko, M. A review on image processing methods in detecting lung cancer using CT images. In Proceedings of the 2017 International Conference on Technical Advancements in Computers and Communications (ICTACC), Melmaurvathur, India, 10–11 April 2017; pp. 18–25. [Google Scholar]
- Qureshi, I.; Yan, J.; Abbas, Q.; Shaheed, K.; Riaz, A.B.; Wahid, A.; Khan, M.W.J.; Szczuko, P. Medical image segmentation using deep semantic-based methods: A review of techniques, applications and emerging trends. Inf. Fusion 2022, 90, 316–352. [Google Scholar]
- Wang, R.; Lei, T.; Cui, R.; Zhang, B.; Meng, H.; Nandi, A.K. Medical image segmentation using deep learning: A survey. IET Image Process. 2022, 16, 1243–1267. [Google Scholar] [CrossRef]
- Zhou, Z.; Sodha, V.; Rahman Siddiquee, M.M.; Feng, R.; Tajbakhsh, N.; Gotway, M.B.; Liang, J. Models genesis: Generic autodidactic models for 3D medical image analysis. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019; Proceedings Part IV 22. pp. 384–393. [Google Scholar]
- Van Opbroek, A.; Achterberg, H.C.; Vernooij, M.W.; De Bruijne, M. Transfer learning for image segmentation by combining image weighting and kernel learning. IEEE Trans. Med. Imaging 2018, 38, 213–224. [Google Scholar] [CrossRef]
- Singh, G.A.P.; Gupta, P. Performance analysis of various machine learning-based approaches for detection and classification of lung cancer in humans. Neural Comput. Appl. 2019, 31, 6863–6877. [Google Scholar] [CrossRef]
- Anthimopoulos, M.; Christodoulidis, S.; Ebner, L.; Christe, A.; Mougiakakou, S. Lung pattern classification for interstitial lung diseases using a deep convolutional neural network. IEEE Trans. Med. Imaging 2016, 35, 1207–1216. [Google Scholar] [CrossRef]
- Kong, Z.; Zhang, M.; Zhu, W.; Yi, Y.; Wang, T.; Zhang, B. Data enhancement based on M2-Unet for liver segmentation in Computed Tomography. Biomed. Signal Process. Control 2023, 79, 104032. [Google Scholar] [CrossRef]
- Wang, Q.; Kang, W.; Wu, C.; Wang, B. Computer-aided detection of lung nodules by SVM based on 3D matrix patterns. Clin. Imaging 2013, 37, 62–69. [Google Scholar] [CrossRef]
- Hossain, S.; Najeeb, S.; Shahriyar, A.; Abdullah, Z.R.; Haque, M.A. A pipeline for lung tumor detection and segmentation from CT scans using dilated convolutional neural networks. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2019), Brighton, UK, 12–17 May 2019; pp. 1348–1352. [Google Scholar]
- Valente, I.R.S.; Cortez, P.C.; Neto, E.C.; Soares, J.M.; de Albuquerque, V.H.C.; Tavares, J.M.R. Automatic 3D pulmonary nodule detection in CT images: A survey. Comput. Methods Programs Biomed. 2016, 124, 91–107. [Google Scholar] [CrossRef]
- Mukhlif, A.A.; Al-Khateeb, B.; Mohammed, M. Classification of breast cancer images using new transfer learning techniques. Iraqi J. Comput. Sci. Math. 2023, 4, 167–180. [Google Scholar]
- Lu, S.; Zhu, Z.; Gorriz, J.M.; Wang, S.H.; Zhang, Y.D. NAGNN: Classification of COVID-19 based on neighboring aware representation from deep graph neural network. Int. J. Intell. Syst. 2022, 37, 1572–1598. [Google Scholar] [CrossRef]
- Naqi, S.M.; Sharif, M.; Lali, I.U. A 3D nodule candidate detection method supported by hybrid features to reduce false positives in lung nodule detection. Multimed. Tools Appl. 2019, 78, 26287–26311. [Google Scholar] [CrossRef]
- Choi, W.-J.; Choi, T.-S. Automated pulmonary nodule detection based on three-dimensional shape-based feature descriptor. Comput. Methods Programs Biomed. 2014, 113, 37–54. [Google Scholar] [CrossRef]
- Usman, M.; Lee, B.-D.; Byon, S.-S.; Kim, S.-H.; Lee, B.-I.; Shin, Y.-G. Volumetric lung nodule segmentation using adaptive roi with multi-view residual learning. Sci. Rep. 2020, 10, 12839. [Google Scholar] [CrossRef] [PubMed]
- Setio, A.A.A.; Ciompi, F.; Litjens, G.; Gerke, P.; Jacobs, C.; Van Riel, S.J.; Wille, M.M.W.; Naqibullah, M.; Sánchez, C.I.; Van Ginneken, B. Pulmonary nodule detection in CT images: False positive reduction using multi-view convolutional networks. IEEE Trans. Med. Imaging 2016, 35, 1160–1169. [Google Scholar] [CrossRef]
- Lu, S.; Wang, S.-H.; Zhang, Y.-D. Detection of abnormal brain in MRI via improved AlexNet and ELM optimized by chaotic bat algorithm. Neural Comput. Appl. 2021, 33, 10799–10811. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar]
- Dao, T.; Gu, A.; Ratner, A.; Smith, V.; De Sa, C.; Ré, C. A kernel theory of modern data augmentation. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 1528–1537. [Google Scholar]
- Havaei, M.; Davy, A.; Warde-Farley, D.; Biard, A.; Courville, A.; Bengio, Y.; Pal, C.; Jodoin, P.-M.; Larochelle, H. Brain tumor segmentation with deep neural networks. Med. Image Anal. 2017, 35, 18–31. [Google Scholar] [CrossRef]
- Brosch, T.; Tang, L.Y.; Yoo, Y.; Li, D.K.; Traboulsee, A.; Tam, R. Deep 3D convolutional encoder networks with shortcuts for multiscale feature integration applied to multiple sclerosis lesion segmentation. IEEE Trans. Med. Imaging 2016, 35, 1229–1239. [Google Scholar] [CrossRef]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.-W.; Heng, P.-A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [PubMed]
- Isensee, F.; Petersen, J.; Klein, A.; Zimmerer, D.; Jaeger, P.F.; Kohl, S.A.A.; Wasserthal, J.; Koehler, G.; Norajitra, T.; Wirkert, S.J.; et al. nnU-Net: Self-adapting Framework for U-Net-Based Medical Image Segmentation. arXiv 2018, arXiv:1809.10486. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016: 19th International Conference, Athens, Greece, 17–21 October 2016; Proceedings Part II 19. pp. 424–432. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings Part III 18. pp. 234–241. [Google Scholar]
- Mukhlif, A.A.; Al-Khateeb, B.; Mohammed, M.A. An extensive review of state-of-the-art transfer learning techniques used in medical imaging: Open issues and challenges. J. Intell. Syst. 2022, 31, 1085–1111. [Google Scholar]
- Mukhlif, A.A.; Al-Khateeb, B.; Mohammed, M.A. Incorporating a Novel Dual Transfer Learning Approach for Medical Images. Sensors 2023, 23, 570. [Google Scholar] [PubMed]
- Simpson, A.L.; Antonelli, M.; Bakas, S.; Bilello, M.; Farahani, K.; Van Ginneken, B.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B. A large annotated medical image dataset for the development and evaluation of segmentation algorithms. arXiv 2019, arXiv:1902.09063. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 4510–4520. [Google Scholar]
- Littman, A.J.; Thornquist, M.D.; White, E.; Jackson, L.A.; Goodman, G.E.; Vaughan, T.L. Prior lung disease and risk of lung cancer in a large prospective study. Cancer Causes Control 2004, 15, 819–827. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, M.; Liu, Z.; Liu, Z.; Gu, D.; Zang, Y.; Dong, D.; Gevaert, O.; Tian, J. Central focused convolutional neural networks: Developing a data-driven model for lung nodule segmentation. Med. Image Anal. 2017, 40, 172–183. [Google Scholar]
- Sun, W.; Zheng, B.; Qian, W. Automatic feature learning using multichannel ROI based on deep structured algorithms for computerized lung cancer diagnosis. Comput. Biol. Med. 2017, 89, 530–539. [Google Scholar]
- Shen, W.; Zhou, M.; Yang, F.; Yu, D.; Dong, D.; Yang, C.; Zang, Y.; Tian, J. Multi-crop convolutional neural networks for lung nodule malignancy suspiciousness classification. Pattern Recognit. 2017, 61, 663–673. [Google Scholar]
- Wang, S.; Zhou, M.; Gevaert, O.; Tang, Z.; Dong, D.; Liu, Z.; Jie, T. A multi-view deep convolutional neural networks for lung nodule segmentation. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Republic of Korea, 11–15 July 2017; pp. 1752–1755. [Google Scholar]
- Liu, H.; Cao, H.; Song, E.; Ma, G.; Xu, X.; Jin, R.; Jin, Y.; Hung, C.-C. A cascaded dual-pathway residual network for lung nodule segmentation in CT images. Phys. Medica 2019, 63, 112–121. [Google Scholar]
- Shakibapour, E.; Cunha, A.; Aresta, G.; Mendonça, A.M.; Campilho, A. An unsupervised metaheuristic search approach for segmentation and volume measurement of pulmonary nodules in lung CT scans. Expert Syst. Appl. 2019, 119, 415–428. [Google Scholar] [CrossRef]
- Mahbod, A.; Tschandl, P.; Langs, G.; Ecker, R.; Ellinger, I. The effects of skin lesion segmentation on the performance of dermatoscopic image classification. Comput. Methods Programs Biomed. 2020, 197, 105725. [Google Scholar] [PubMed]
- Monteiro, M.; Figueiredo, M.A.; Oliveira, A.L. Conditional random fields as recurrent neural networks for 3d medical imaging segmentation. arXiv 2018, arXiv:1807.07464. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Value |
|---|---|
| Input size | 255 × 255 |
| Batch size | 8 |
| Learning rate | 1 × 10–4 |
| Epoch Activation head | 90 sigmoid |
| Optimizer | Adam |
| Loss function | Ldice |
| Approach | DSC (%) |
|---|---|
| Central Focused CNN [35] | 0.821 |
| Multichannel ROI based on Deep Structured Algorithm [36] | 0.7701 |
| Multi-Crop CNN [37] | 0.7751 |
| Multi-View Deep CNN [38] | 0.7767 |
| Cascaded Dual-Pathway Residual Network [39] | 0.8158 |
| Unsupervised Metaheuristic [40] | 0.8235 |
| Proposed Method | 0.8793 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riaz, Z.; Khan, B.; Abdullah, S.; Khan, S.; Islam, M.S. Lung Tumor Image Segmentation from Computer Tomography Images Using MobileNetV2 and Transfer Learning. Bioengineering 2023, 10, 981. https://doi.org/10.3390/bioengineering10080981
Riaz Z, Khan B, Abdullah S, Khan S, Islam MS. Lung Tumor Image Segmentation from Computer Tomography Images Using MobileNetV2 and Transfer Learning. Bioengineering. 2023; 10(8):981. https://doi.org/10.3390/bioengineering10080981
Chicago/Turabian StyleRiaz, Zainab, Bangul Khan, Saad Abdullah, Samiullah Khan, and Md Shohidul Islam. 2023. "Lung Tumor Image Segmentation from Computer Tomography Images Using MobileNetV2 and Transfer Learning" Bioengineering 10, no. 8: 981. https://doi.org/10.3390/bioengineering10080981
APA StyleRiaz, Z., Khan, B., Abdullah, S., Khan, S., & Islam, M. S. (2023). Lung Tumor Image Segmentation from Computer Tomography Images Using MobileNetV2 and Transfer Learning. Bioengineering, 10(8), 981. https://doi.org/10.3390/bioengineering10080981