



Automated Diagnosis of Diabetic Retinopathy Using Deep Learning: On the Search of Segmented Retinal Blood Vessel Images for Better Performance

 , , and
, , and
Abstract
1. Introduction
1.1. State of the Art on Approaching DR Detection with Deep Learning Techniques
1.2. Research Gap
1.3. Seleciton of the Original Dataset and Derivation of the Segmented One for Our Study
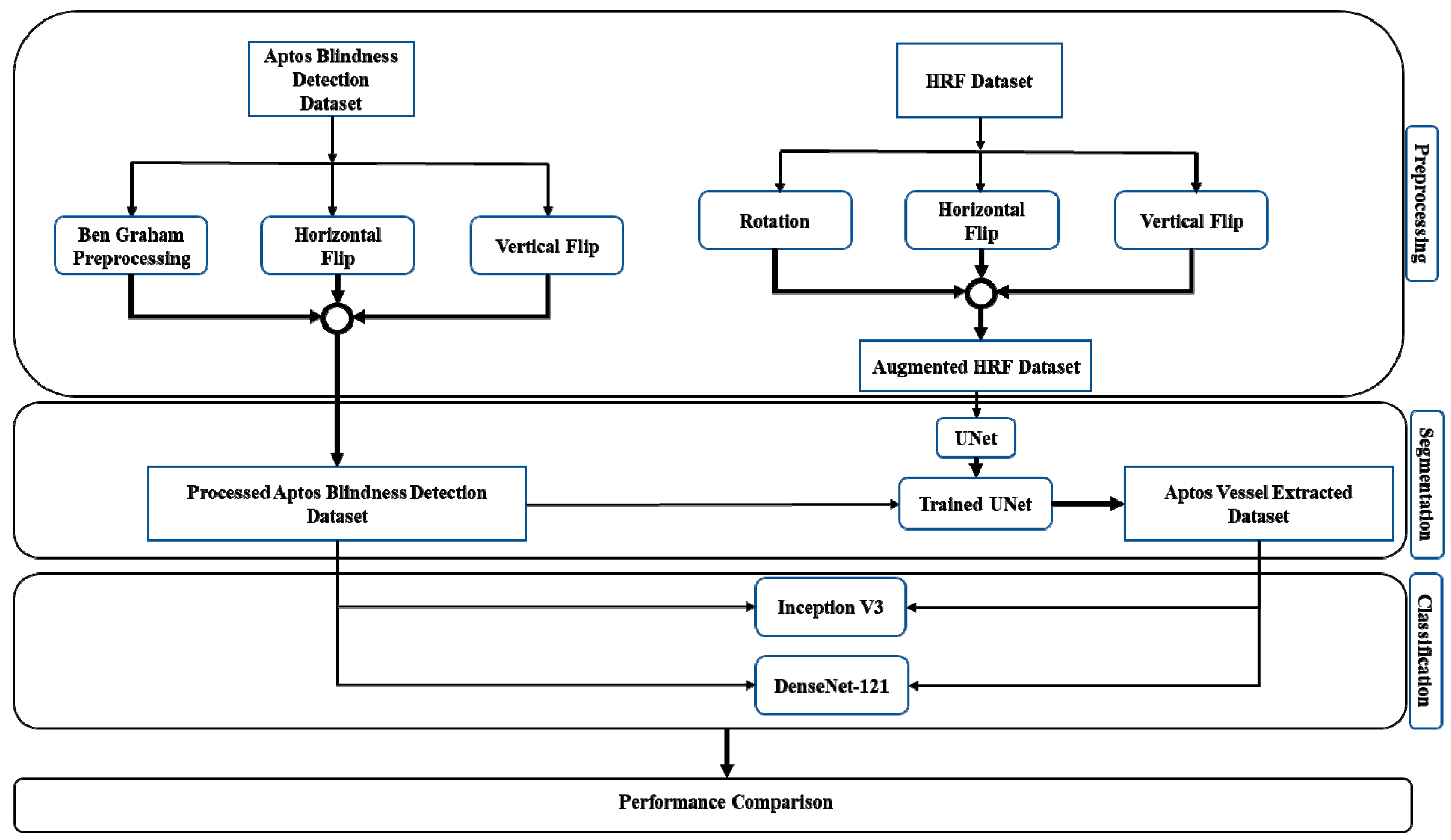
2. Proposed Methodology
2.1. Dataset Preprocessing and Enhancement
2.2. CNN Architectures and our Suggested Workflow
3. Pre-Trained CNN Architectures and Experimental Setups
3.1. Segmentation
3.1.1. U-Net
3.1.2. Transfer Learning with U-Net
3.2. Classification
3.3. Original and Segmented Image Classification
4. Experimental Results and Performance Matrices
4.1. Training and Validation Performance
4.2. Test Performance
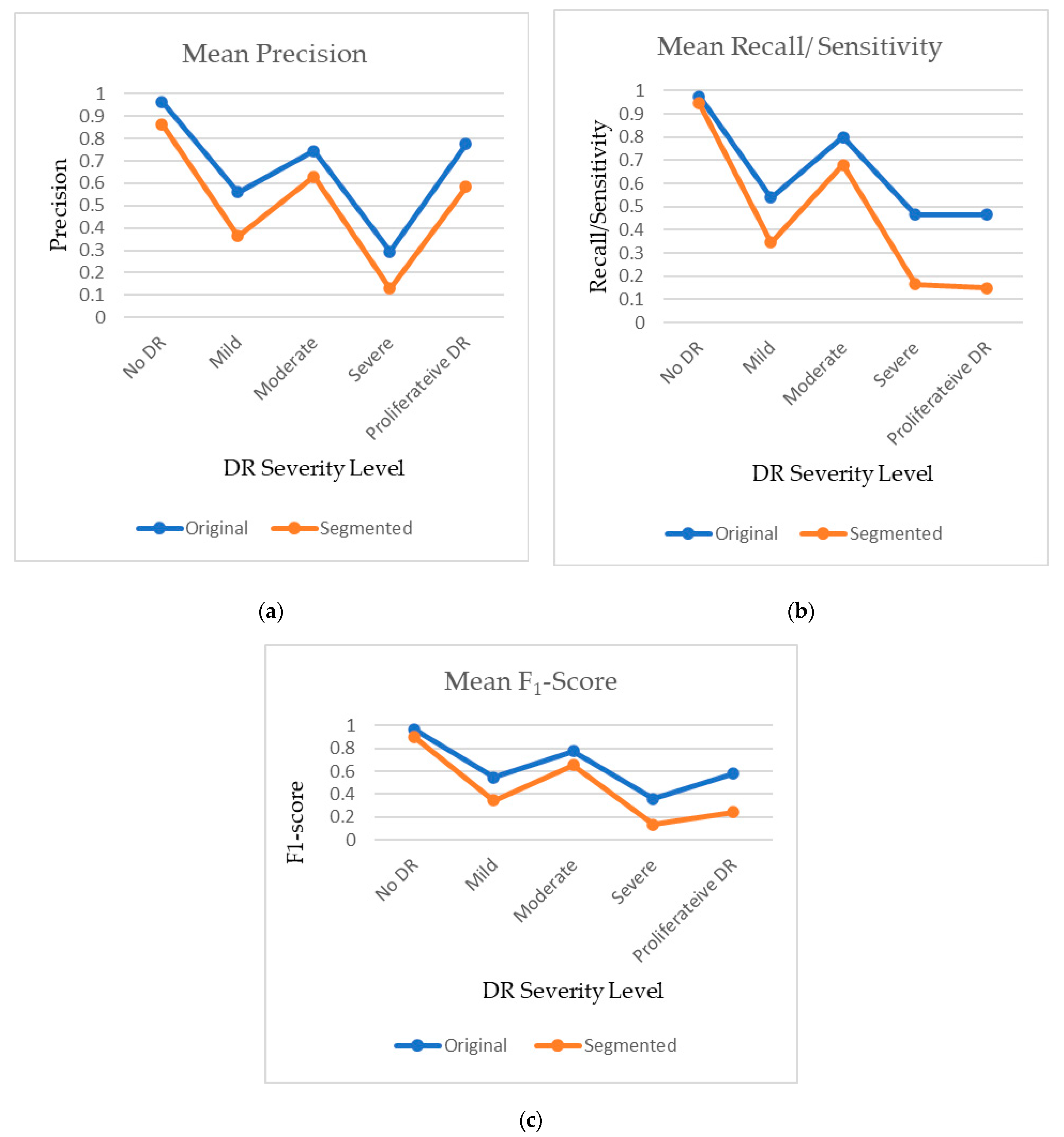
4.3. Comparison of Original and Segmented Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Teo, Z.L.; Tham, Y.-C.; Yu, M.C.Y.; Chee, M.L.; Rim, T.H.; Cheung, N.; Bikbov, M.M.; Wang, Y.X.; Tang, Y.; Lu, Y.; et al. Global Prevalence of Diabetic Retinopathy and Projection of Burden through 2045: Systematic Review and Meta-analysis. Ophthalmology 2021, 128, 1580–1591. [Google Scholar] [CrossRef]
- Olson, J.; Strachan, F.; Hipwell, J.; Goatman, K.A.; McHardy, K.; Forrester, J.V.; Sharp, P.F. A comparative evaluation of digital imaging, retinal photography and optometrist examination in screening for diabetic retinopathy. Diabet. Med. 2003, 20, 528–534. [Google Scholar] [CrossRef] [PubMed]
- Leontidis, G.; Al-Diri, B.; Hunter, A. Diabetic retinopathy: Current and future methods for early screening from a retinal hemodynamic and geometric approach. Expert Rev. Ophthalmol. 2014, 9, 431–442. [Google Scholar] [CrossRef]
- Cheung, N.; Wong, I.Y.; Wong, T.Y. Ocular anti-VEGF therapy for diabetic retinopathy: Overview of clinical efficacy and evolving applications. Diabetes Care 2014, 37, 900–905. [Google Scholar] [CrossRef]
- Tariq, N.H.; Rashid, M.; Javed, A.; Zafar, E.; Alotaibi, S.S.; Zia, M.Y.I. Performance Analysis of Deep-Neural-Network-Based Automatic Diagnosis of Diabetic Retinopathy. Sensors 2021, 22, 205. [Google Scholar] [CrossRef]
- Wejdan, L.; Alyoubi, W.; Shalash, M.; Maysoon, F.; Abulkhair Information Technology Department, University of King Abdul Aziz, Jeddah, Saudi Arabia. Diabetic retinopathy detection through deep learning techniques: A review. Inform. Med. Unlocked 2020, 20, 100377. [Google Scholar]
- Alemany, P.; Qaisar, A.; Irene, F.; Auxiliadora, S.; Soledad, J. Automatic recognition of severity level for diagnosis of diabetic retinopathy using the deep visual feature. Med. Biol. Eng. Comput. 2017, 55, 1959–1974. [Google Scholar]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Bhardwaj, C.; Jain, S.; Sood, M. Diabetic retinopathy severity grading employing quadrant-based Inception-V3 convolution neural network architecture. Int. J. Imaging Syst. Technol. 2021, 31, 592–608. [Google Scholar] [CrossRef]
- Hagos, M.T.; Kant, S. Transfer learning based detection of diabetic retinopathy from small dataset. arXiv 2019, arXiv:1905.07203. [Google Scholar]
- Batista, G.C.; de Oliveira, D.L.; Silva, W.L.S.; Saotome, O. Hardware Architectures of Support Vector Machine Applied in Pattern Recognition Systems. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017. [Google Scholar]
- Gonçalves, J.; Conceiçao, T.; Soares, F. Inter-Observer Reliability in Computer-Aided Diagnosis of Diabetic Retinopathy. In Proceedings of the 12th International Conference on Health Informatics—HEALTHINF 2019, Prague, Czech Republic, 22–24 February 2019; pp. 481–491. [Google Scholar]
- Prasad, D.K.; Vibha, L.; Venugopal, K.R. Early Detection of Diabetic Retinopathy from Digital Retinal Fundus Images. In Proceedings of the 2015 IEEE Recent Advances in Intelligent Computational Systems (RAICS), Trivandrum, India, 10–12 December 2015; pp. 240–245. [Google Scholar]
- Wan, P.S.; Liang, Y.; Zhang, Y. Deep convolutional neural networks for diabetic retinopathy detection by image classification. Comput. Electr. Eng. 2018, 72, 274–282. [Google Scholar] [CrossRef]
- Gargeya, R.; Leng, T. Automated identification of diabetic retinopathy using deep learning. Ophthalmology 2017, 124, 962–969. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Zhong, J.; Yang, S.; Gao, Z.; Hu, J.; Chen, Y.; Yi, Z. Automated identification and grading system of diabetic retinopathy using deep neural networks. Knowl. Based Syst. 2019, 175, 12–25. [Google Scholar] [CrossRef]
- Santhi, T.; Sabeenian, R.S. Modified Alexnet architecture for classification of diabetic retinopathy images. Comput. Electr. Eng. 2019, 76, 56–64. [Google Scholar] [CrossRef]
- Mobeen-Ur-Rehman; Khan, S.H.; Abbas, Z.; Danish, R.S.M. Classification of Diabetic Retinopathy Images Based on Customized CNN Architecture. In Proceedings of the 2019 Amity International Conference on artificial intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 244–248. [Google Scholar]
- Lu, J.; Xu, Y.; Chen, M.; Luo, Y. A coarse-to-fine fully convolutional neural network for fundus vessel segmentation. Symmetry 2018, 10, 607. [Google Scholar] [CrossRef]
- Hua, C.H.; Huynh-The, T.; Lee, S. Retinal Vessel Segmentation using Round-Wise Features Aggregation on Bracket-Shaped Convolutional Neural Networks. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and biology society (EMBS), Berlin, Germany, 23–27 July 2019; pp. 36–39. [Google Scholar]
- Zhou, Y.; He, X.; Huang, L.; Liu, L.; Zhu, F.; Cui, S.; Shao, L. Collaborative Learning of Semi-Supervised Segmentation and Classification for Medical Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2079–2088. [Google Scholar]
- Li, X.; Hu, X.; Yu, L.; Zhu, L.; Fu, C.-W.; Heng, P.-A. CANet: Cross-disease attention network for joint diabetic retinopathy and diabetic macular edema grading. IEEE Trans. Med. Imag. 2020, 39, 1483–1493. [Google Scholar] [CrossRef]
- Vengalil, S.K.; Sinha, N.; Kruthiventi, S.S.S.; Babu, R.V. Customizing CNNs for Blood Vessel Segmentation from Fundus Images. In Proceedings of the International Conference on Signal Processing and communications SPCOM 2016, Bangalore, India, 12–15 June 2016; pp. 1–4. [Google Scholar]
- Yan, Y.; Gong, J.; Liu, Y. A novel Deep Learning Method for Red Lesions Detection using the Hybrid Feature. In Proceedings of the 31st Chinese Control and Decision Conference CCDC 2019, Nanchang, China, 3–5 June 2019; pp. 2287–2292. [Google Scholar]
- Jiang, H.; Kang, Y.; Gao, M.; Zhang, D.; He, M.; Qian, W. An Interpretable Ensemble Deep Learning Model for Diabetic Retinopathy Disease Classification. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 2045–2048, ISBN 978-1-5386-1311-5. [Google Scholar]
- Wu, Y.; Xia, Y.; Song, Y.; Zhang, Y.; Cai, W. NFN+: A novel network followed network for retinal vessel segmentation. Neural Netw. 2020, 126, 153–162. [Google Scholar] [CrossRef]
- Kaggle Dataset. Available online: https://kaggle.com/c/diabetic-retinopathy-detection (accessed on 15 November 2022).
- Asia Pacific Tele-Ophthalmology Society (APTOS). Blindness Detection Dataset “Detect Diabetic Retinopathy to Stop Blindness Before It’s Too Late”. 2019. Available online: https://www.kaggle.com/competitions/aptos2019-blindness-detection/data (accessed on 15 November 2022).
- Kauppi, T.; Kalesnykiene, V.; Kamarainen, J.-K.; Lensu, L.; Sorri, I.; Raninen, A.; Voutilainen, R.; Pietila, J.; Kalviainen, H.; Uusitalo, H.; et al. The DIARETDB1 Diabetic Retinopathy Database and Evaluation Protocol. In Proceedings of the British Machine Vision Conference 2007, Coventry, UK, 10–13 September 2007; pp. 1–10. [Google Scholar]
- Budai, A.; Bock, R.; Maier, A.; Hornegger, J.; Michelson, G. Robust vessel segmentation in fundus images. Int. J. Biomed. Imag. 2013, 2013, 154860. [Google Scholar] [CrossRef]
- Decenciere, E.; Zhang, X.; Cazuguel, G.; Lay, B.; Cochener, B.; Trone, C.; Gain, P.; Ordonez, R.; Massin, P.; Erginay, A.; et al. Feedback on a publicly distributed image database: The messidor database. Image. Anal. Stereol. 2014, 33, 231–234. [Google Scholar] [CrossRef]
- Preprocessing in Diabetic Retinopathy. Available online: https://www.kaggle.com/ratthachat/aptoseye-preprocessing-in-diabetic-retinopathy (accessed on 25 August 2020).
- Hasan, N.; Hasan, M.M.; Alim, M.A. Design of EEG Based Wheel Chair by Using Color Stimuli and Rhythm Analysis. In Proceedings of the 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), Dhaka, Bangladess, 3–5 May 2019; pp. 1–4. [Google Scholar]
- Sharif, M.; Amin, J.; Haldorai, A.; Yasmin, M.; Nayak, R.S. Brain tumor detection and classification using machine learning: A comprehensive survey. Complex Intell. Syst. 2021, 8, 1–23. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Aldoj, N.; Biavati, F.; Michallek, F.; Stober, S.; Dewey, M. Automatic prostate and prostate zones segmentation of magnetic resonance images using DenseNet-like U-net. Sci. Rep. 2020, 10, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wang, P.; Li, Y.; Zhou, Y.; Liu, X.; Luan, K. Transfer Learning of Pre-Trained Inception-V3 Model for Colorectal Cancer Lymph Node Metastasis Classification. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 1650–1654. [Google Scholar]
- Estava, A.; Kuprel, B.; Novoa, R.; Ko, J.; Swetter, S.; Blau, H.; Thrun, S. Dermatologist level classification of 4skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Zhang, K.; Guo, Y.; Wang, X.; Yuan, J.; Ding, Q. Multiple features reweight DenseNet for image classification. IEEE Access 2019, 7, 9872–9880. [Google Scholar] [CrossRef]
- Zhang, Y.-D.; Satapathy, S.C.; Zhang, X.; Wang, S.-H. COVID-19 diagnosis via DenseNet and optimization of transfer learning setting. Cogn. Comput. 2021, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Kaushik, R.; Kumar, S. Image Segmentation Using Convolutional Neural Network. Int. J. Sci. Technol. Res. 2019, 8, 667–675. [Google Scholar]
- Helwan, A.; Ozsahin, D.U. Sliding window-based machine learning system for the left ventricle localization in MR cardiac images. Appl. Comput. Intell. Soft Comput. 2017, 2017, 3048181. [Google Scholar] [CrossRef]
- Ciresan, D.C.; Giusti, A.; Gambardella, L.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. Adv. Neural Inf. Process. Syst. 2012, 25, 2843–2851. [Google Scholar]
- Cheng, D.; Lam, E.Y. Transfer Learning U-Net Deep Learning for Lung Ultrasound Segmentation. arXiv 2021, arXiv:2110.02196. [Google Scholar]
- O’Brien, J.A. Why Are Neural Networks Becoming Deeper, But not Wider? Available online: https://stats.stackexchange.com/q/223637 (accessed on 23 November 2022).
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Jin, C.; Tanno, R.; Mertzanidou, T.; Panagiotaki, E.; Alexander, D.C. Learning to Downsample for Segmentation of Ultra-High Resolution Images. arXiv 2021, arXiv:2109.11071. [Google Scholar]
- Chalam, K.V.; Sambhav, K. Optical coherence tomography angiography in retinal diseases. J. Ophthalmic Vis. Res. 2016, 11, 84. [Google Scholar] [CrossRef]
- Cogan, D.G.; Toussaint, D.; Kuwabara, T. Retinal vascular patterns: IV. Diabet. Retin. Arch. Ophthalmol. 1961, 66, 366–378. [Google Scholar] [CrossRef] [PubMed]
- Niemeijer, M.; van Ginneken, B.; Russell, S.R.; Suttorp-Schulten, M.S.; Abramoff, M.D. Automated detection and differentiation of drusen, exudates, and cotton-wool spots in digital color fundus photographs for diabetic retinopathy diagnosis. Investig. Ophthalmol. Vis. Sci. 2007, 48, 2260–2267. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | DL Methods (Best Architectures) | Dataset | Performance Metrics | |||
|---|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | AUC | |||
| [15] | VGGNet | 5-class (EyePACS) | 95.68% | 86.47% | 97.43% | 0.979 |
| [16] | Custom CNN and Decision Tree | 2-class (EyePACS) 2-class (Messidor2) 2-class (E-Ophtha) | --- --- --- | 94% 90% 90% | 98% 87% 94% | 0.97 0.94 0.95 |
| [8] | CNN (Inception v3) | Messidor-2 (1748) EyePACS-1 (9963) | --- | 96.1% 97.5% | 93.9% 93.4% | --- |
| [17] | CNN (ResNet50, Inception v3, InceptionResNet v2, Xception, and DenseNets) | Their own dataset (13,767) | 96.5% | 98.1% | 98.9% | --- |
| [18] | CNN (modified Alexnet) | Messidor (1190) | 96.35% | 92.35% | 97.45% | --- |
| [19] | CNN (VGGNet16, AlexNet, and custom CNN) | MESSIDOR (1200) | 98.15% | 98.94% | 97.87% | |
| [20] | Fully CNN | STARE (20), HRF (45), DRIVE (40) and CHASE DB1 (28) | 0.9628 0.9608 0.9634 0.9664 | 0.8090 0.7762 0.7941 0.7571 | 0.9770 0.9760 0.9870 0.9823 | 0.9801 0.9701 0.9787 0.9752 |
| [21] | CNN (ResNet-101) | DRIVE (40) | 0.951 | 0.793 | 0.974 | 0.9732 |
| [22] | Custom CNN | 5-class (IDRiD) 5-class (EyePACS) | 91.3% 89.1% | --- --- | --- --- | --- --- |
| [23] | CNN (ResNet50) | Messidor (1200) IDRiD (516) | 92.6% 65.1% | 92% --- | --- --- | 0.963 --- |
| [24] | CNN | HRF(45) and DRIVE(40) | 93.94% | 0.934 | ||
| [25] | CNN (improved LeNet and U-net) | DIARETDB1 (89) | 48.71% | 0.4823 | ||
| [26] | Ensemble learning | 2-class (Private custom dataset) | 88.21% | 85.57% | 90.85% | 0.946 |
| [27] | CNN | DRIVE(40) STARE(20) CHASE(28) | 95.82% 96.72% 96.88% | 79.96% 79.63% 80.03% | 98.13% 98.63% 98.80% | 98.30% 98.75% 98.94% |
| Attribute | DenseNet-121 | Inception v3 |
|---|---|---|
| Optimizer | SGD | SGD |
| Base Learning Rate | 1 × 10−4 | 1× 10−4 |
| Momentum | 0.9 | 0.9 |
| Learning Decay Rate | 1 × 10−6 | 1× 10−6 |
| Train Batch Size | 32 | 32 |
| Trainable Parameters | 7,217,541 | 22,294,181 |
| Non-trainable Parameters | 83,648 | 34,452 |
| Total Parameters | 7,301,189 | 22,328,613 |
| Original | Segmented | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Inception v3 | DenseNet-121 | Inception v3 | DenseNet-121 | |||||||||||||
| STAGE | Precision | Recall/Sensitivity/TPR | F1-Score | Accuracy | Precision | Recall/Sensitivity/TPR | F1-Score | Accuracy | Precision | Recall/Sensitivity/TPR | F1-Score | Accuracy | Precision | Recall/Sensitivity/TPR | F1-Score | Accuracy |
| No DR | 0.97 | 0.97 | 0.97 | 0.8 | 0.96 | 0.98 | 0.97 | 0.83 | 0.89 | 0.93 | 0.91 | 0.72 | 0.84 | 0.96 | 0.9 | 0.69 |
| Mild | 0.49 | 0.52 | 0.5 | 0.63 | 0.56 | 0.59 | 0.38 | 0.46 | 0.41 | 0.35 | 0.23 | 0.28 | ||||
| Moderate | 0.73 | 0.78 | 0.76 | 0.76 | 0.82 | 0.79 | 0.64 | 0.72 | 0.68 | 0.62 | 0.64 | 0.63 | ||||
| Severe | 0.24 | 0.4 | 0.3 | 0.35 | 0.53 | 0.42 | 0.17 | 0.13 | 0.15 | 0.09 | 0.2 | 0.12 | ||||
| Proliferative DR | 0.77 | 0.43 | 0.55 | 0.78 | 0.5 | 0.61 | 0.59 | 0.18 | 0.27 | 0.58 | 0.12 | 0.21 | ||||
| Performance Metric | Type | No DR | Mild | Moderate | Severe | Proliferative DR |
|---|---|---|---|---|---|---|
| F1-Score | Original | 0.97 | 0.545 | 0.775 | 0.36 | 0.58 |
| Segmented | 0.905 | 0.345 | 0.655 | 0.135 | 0.24 | |
| Precision | Original | 0.965 | 0.56 | 0.745 | 0.295 | 0.775 |
| Segmented | 0.865 | 0.365 | 0.63 | 0.13 | 0.585 | |
| Recall/Sensitivity/TPR | Original | 0.975 | 0.54 | 0.8 | 0.465 | 0.465 |
| Segmented | 0.945 | 0.345 | 0.68 | 0.165 | 0.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.B.; Ahmad, M.; Yaakob, S.B.; Shahrior, R.; Rashid, M.A.; Higa, H. Automated Diagnosis of Diabetic Retinopathy Using Deep Learning: On the Search of Segmented Retinal Blood Vessel Images for Better Performance. Bioengineering 2023, 10, 413. https://doi.org/10.3390/bioengineering10040413
Khan MB, Ahmad M, Yaakob SB, Shahrior R, Rashid MA, Higa H. Automated Diagnosis of Diabetic Retinopathy Using Deep Learning: On the Search of Segmented Retinal Blood Vessel Images for Better Performance. Bioengineering. 2023; 10(4):413. https://doi.org/10.3390/bioengineering10040413
Chicago/Turabian StyleKhan, Mohammad B., Mohiuddin Ahmad, Shamshul B. Yaakob, Rahat Shahrior, Mohd A. Rashid, and Hiroki Higa. 2023. "Automated Diagnosis of Diabetic Retinopathy Using Deep Learning: On the Search of Segmented Retinal Blood Vessel Images for Better Performance" Bioengineering 10, no. 4: 413. https://doi.org/10.3390/bioengineering10040413
APA StyleKhan, M. B., Ahmad, M., Yaakob, S. B., Shahrior, R., Rashid, M. A., & Higa, H. (2023). Automated Diagnosis of Diabetic Retinopathy Using Deep Learning: On the Search of Segmented Retinal Blood Vessel Images for Better Performance. Bioengineering, 10(4), 413. https://doi.org/10.3390/bioengineering10040413