
Vision–Language Model for Visual Question Answering in Medical Imagery





Abstract
1. Introduction
2. Related Work
2.1. Visual Question Answering
2.2. Multi-Modal Transformer
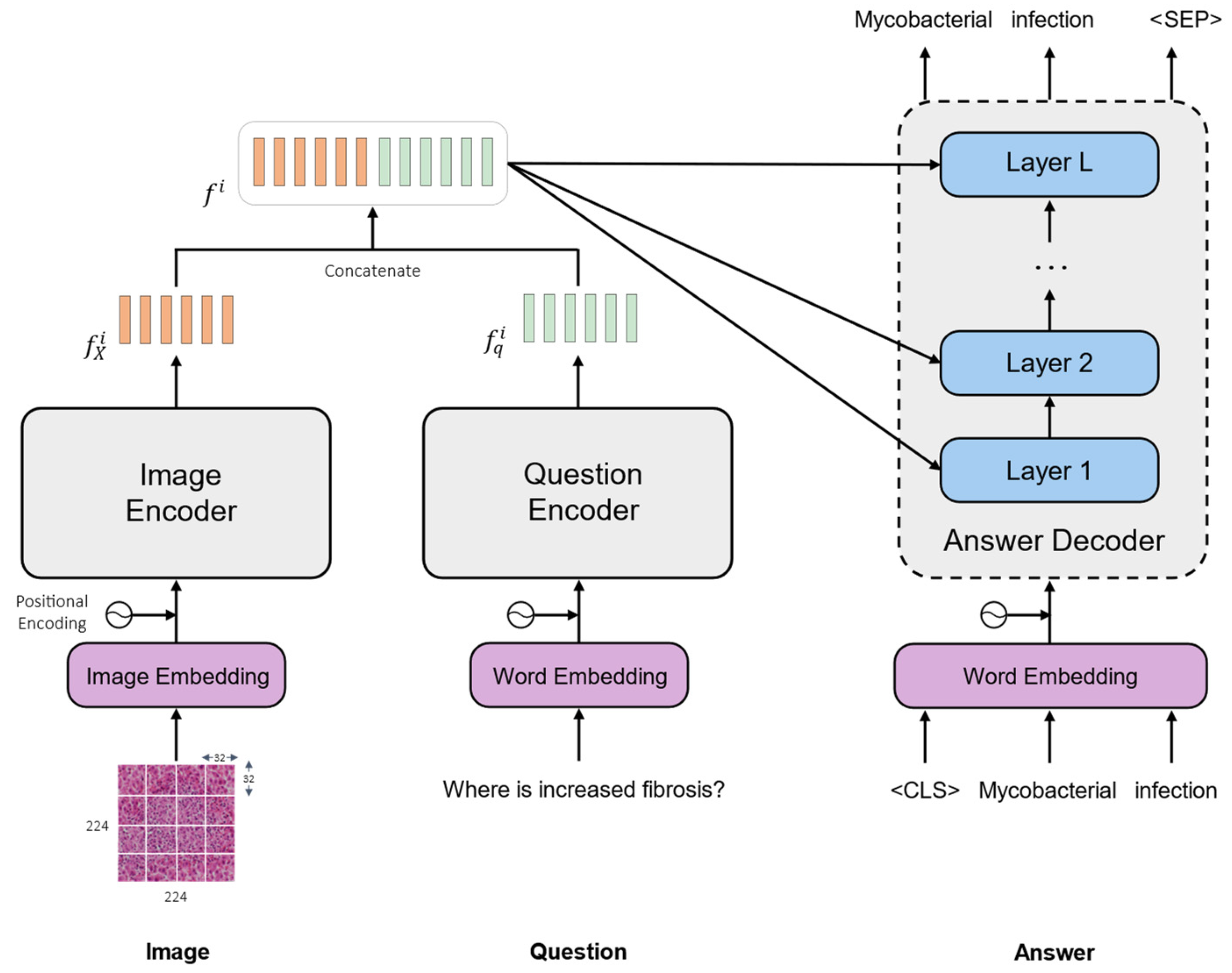
3. Methodology
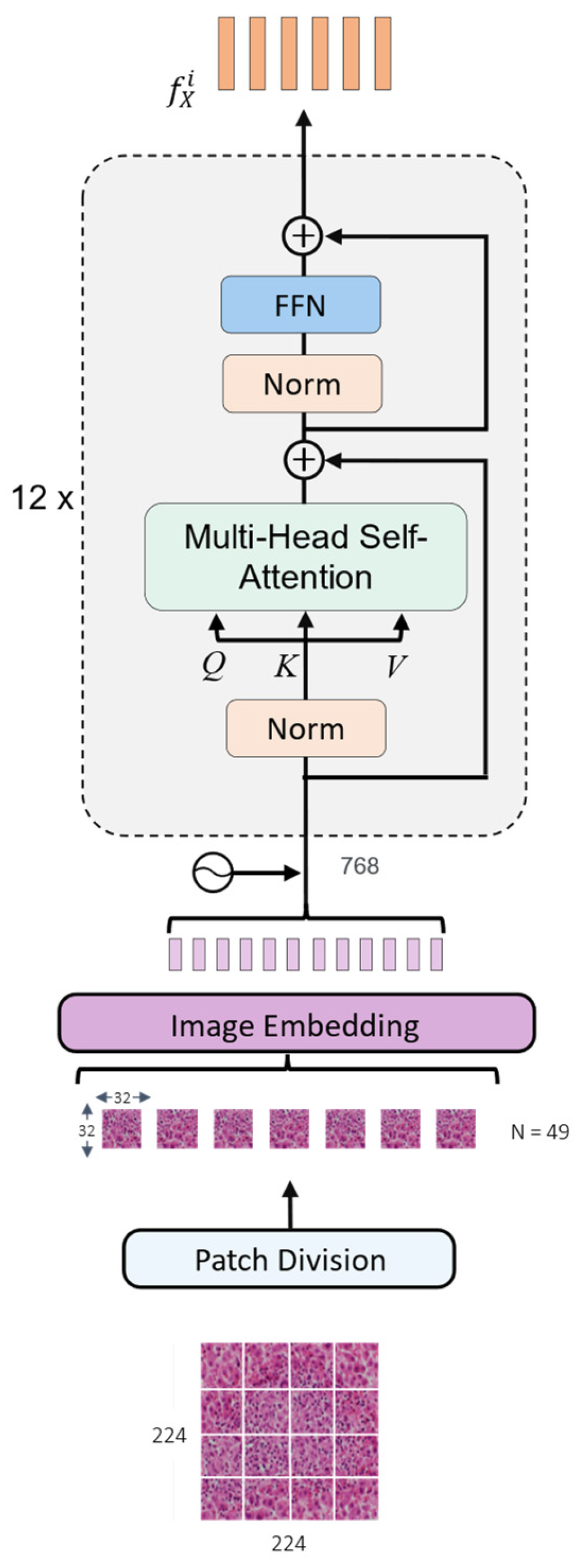
3.1. Image Encoder
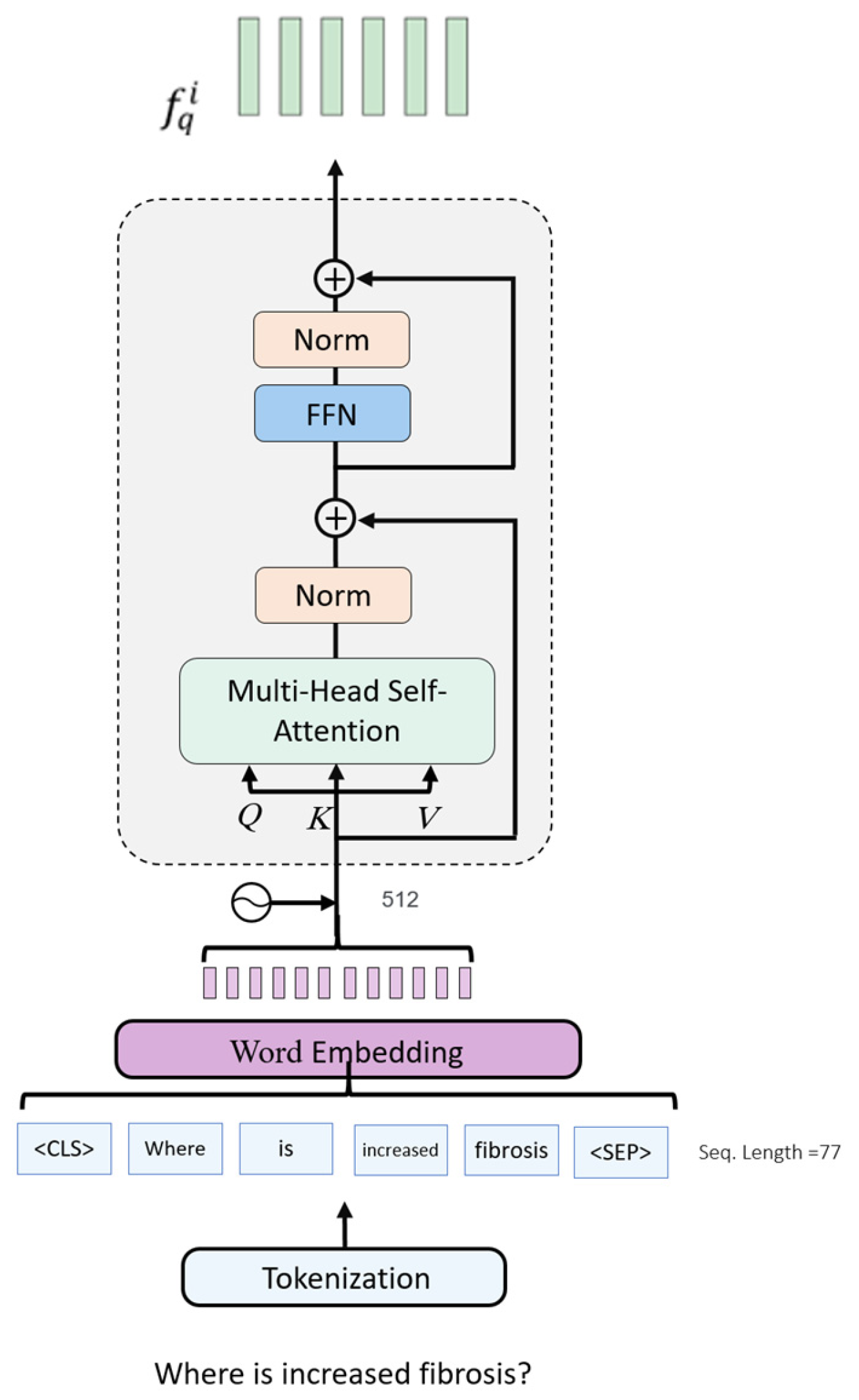
3.2. Question Encoder
3.3. Multi-Modal Representations
3.4. Answer Decoder
3.5. Network Optimization
4. Experimental Results
4.1. Dataset Description
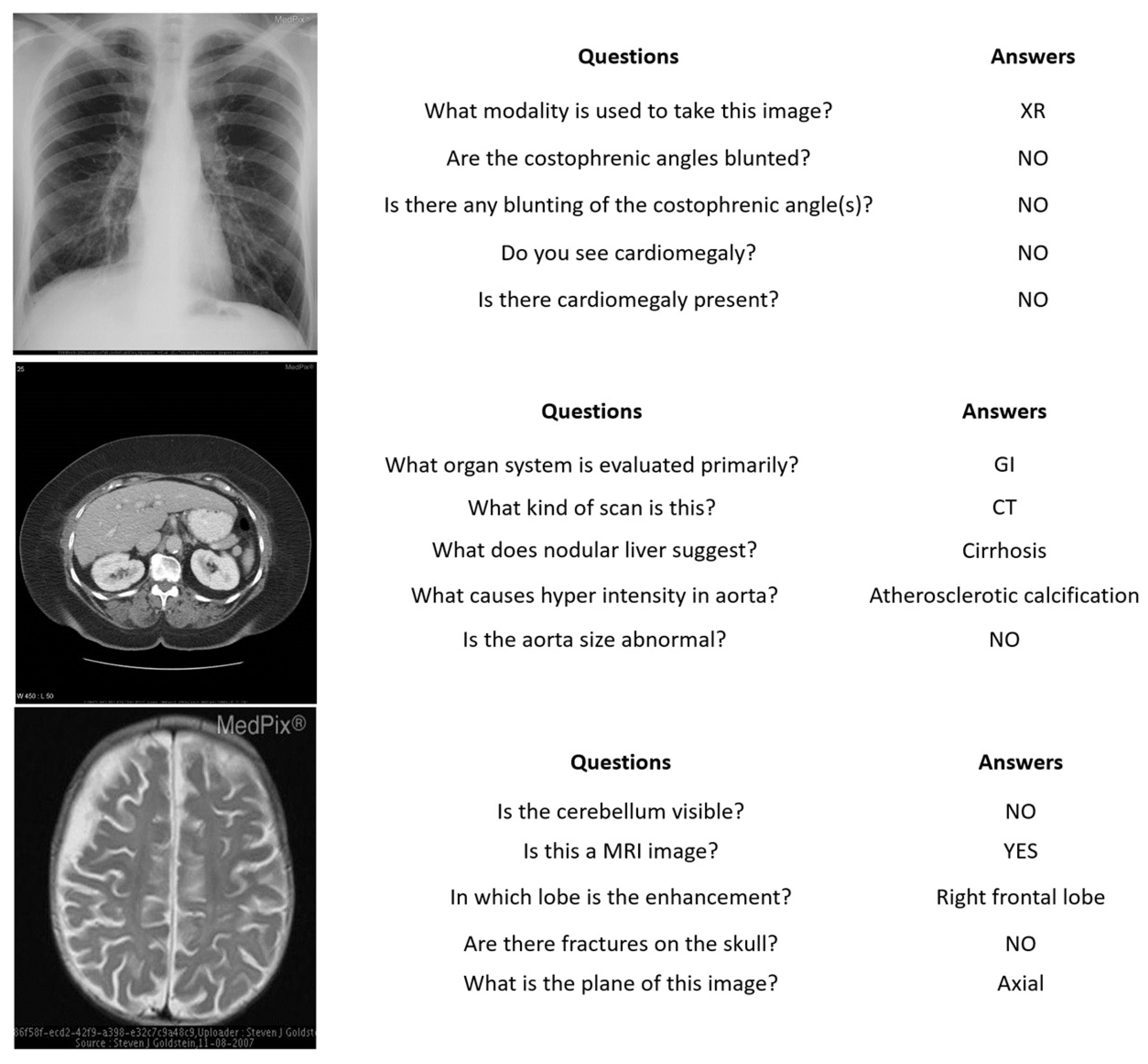
- VQA-RAD [41] is a manually constructed dataset in the field of medical VQA. It contains 3515 question–answer pairs generated by clinicians and 315 radiology images that are evenly distributed over the head, chest, and abdomen. Each image is associated with multiple questions. The questions are divided into a training set and a test set which contain 3064 and 451 question–answer pairs, respectively. Questions are categorized into 11 categories: abnormality, attribute, modality, organ system, color, counting, object/condition presence, size, plane, positional reasoning, and other. Half of the answers are closed-ended (i.e., yes/no type), while the rest are open-ended with either one-word or short phrase answers.
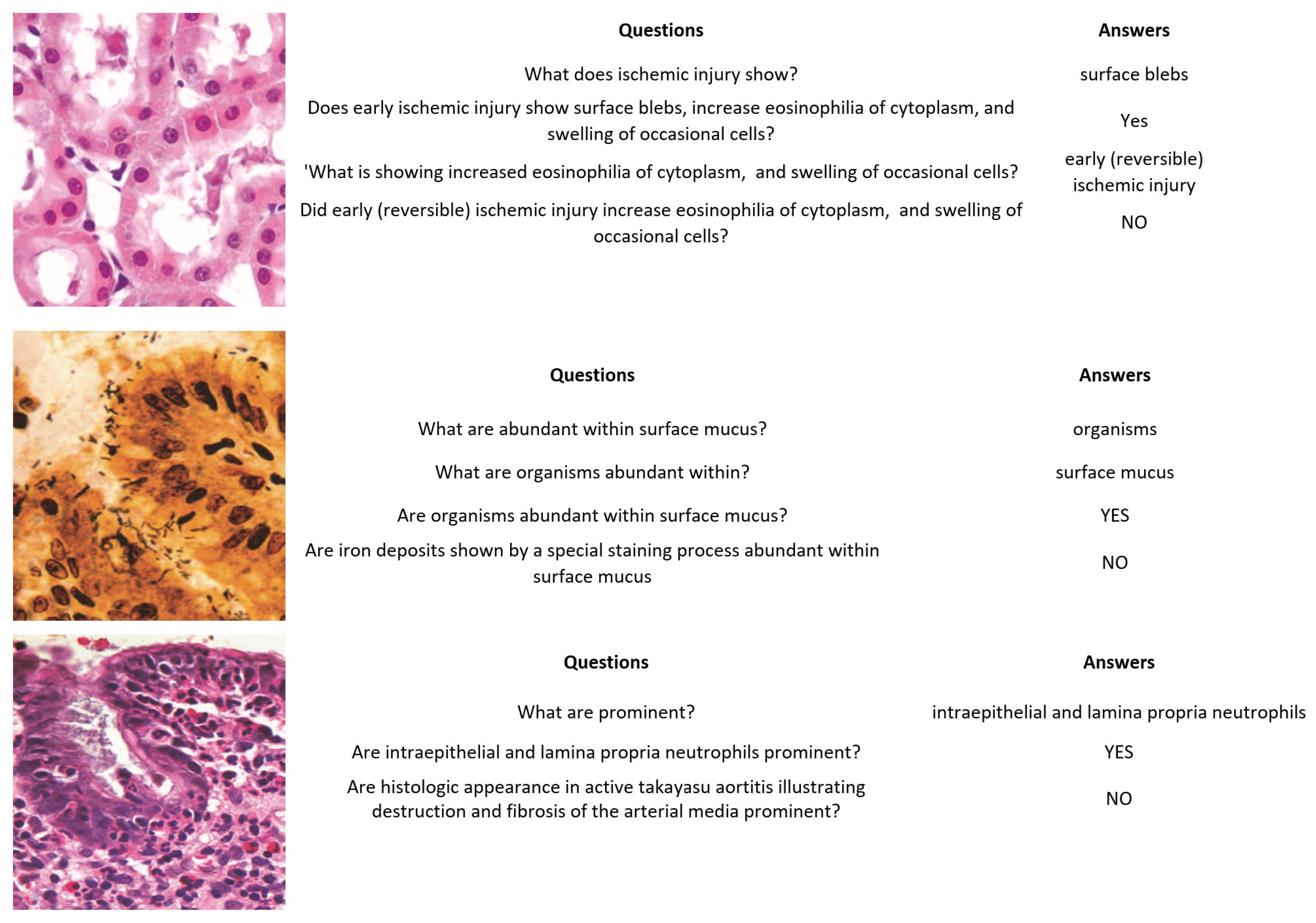
- PathVQA [40] is the first dataset of pathology images. It contains a total of 4998 pathology images with 32,799 question–answer pairs. The dataset is split into three sets: training, validation, and test sets. The validation set has 987 images and 6279 question–answer pairs, the test sets contain 990 images with 6761 question–answer pairs, and the training set includes 3021 images with 19,755 question–answer pairs. Every image has several questions that relate to multiple aspects such as location, shape, color, appearance, etc. The questions are categorized into two types, with several varieties: open-ended questions such as why, what, how, where, etc., and closed-ended questions.
4.2. Evaluation Measures
4.3. Experimental Setup
4.4. Results
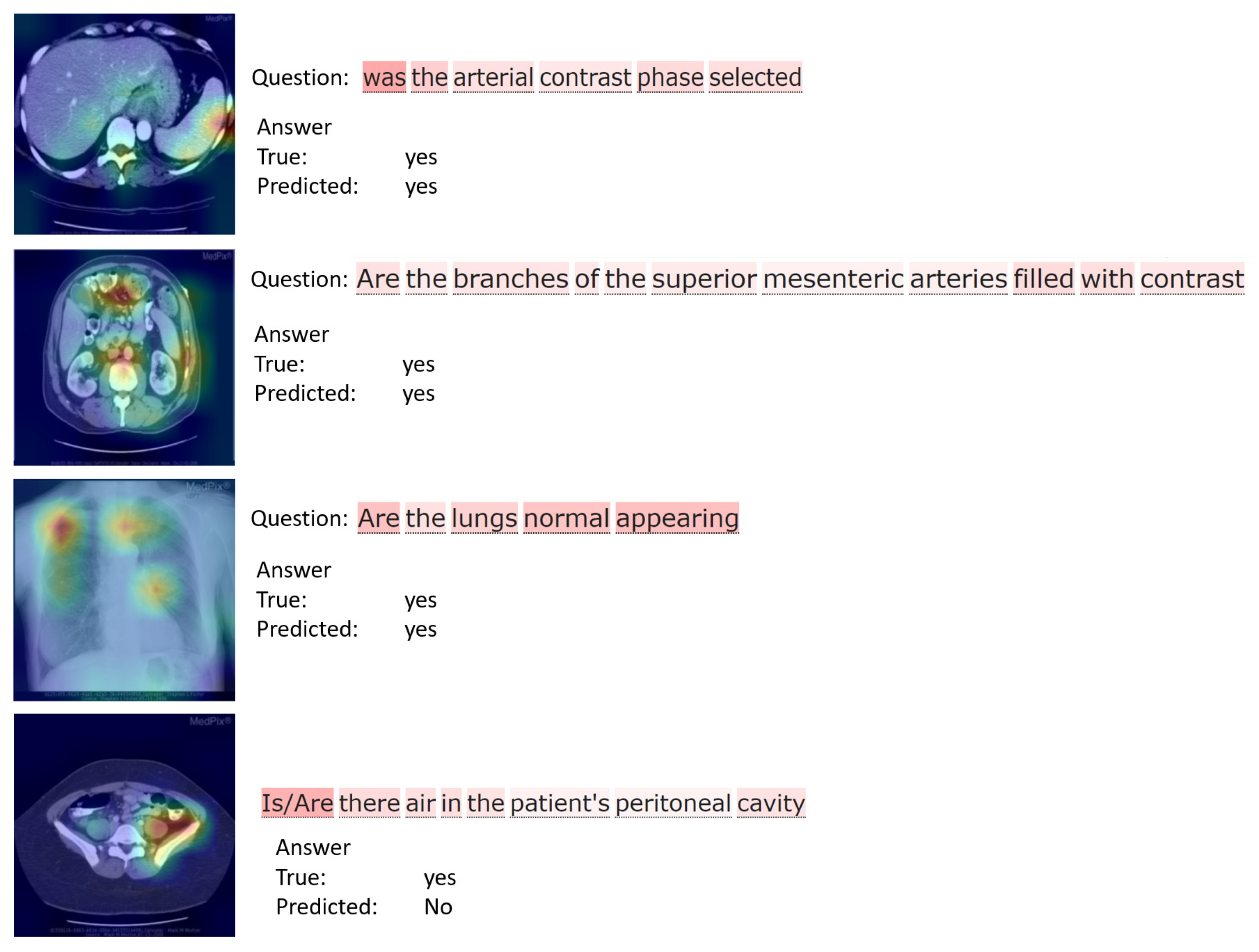
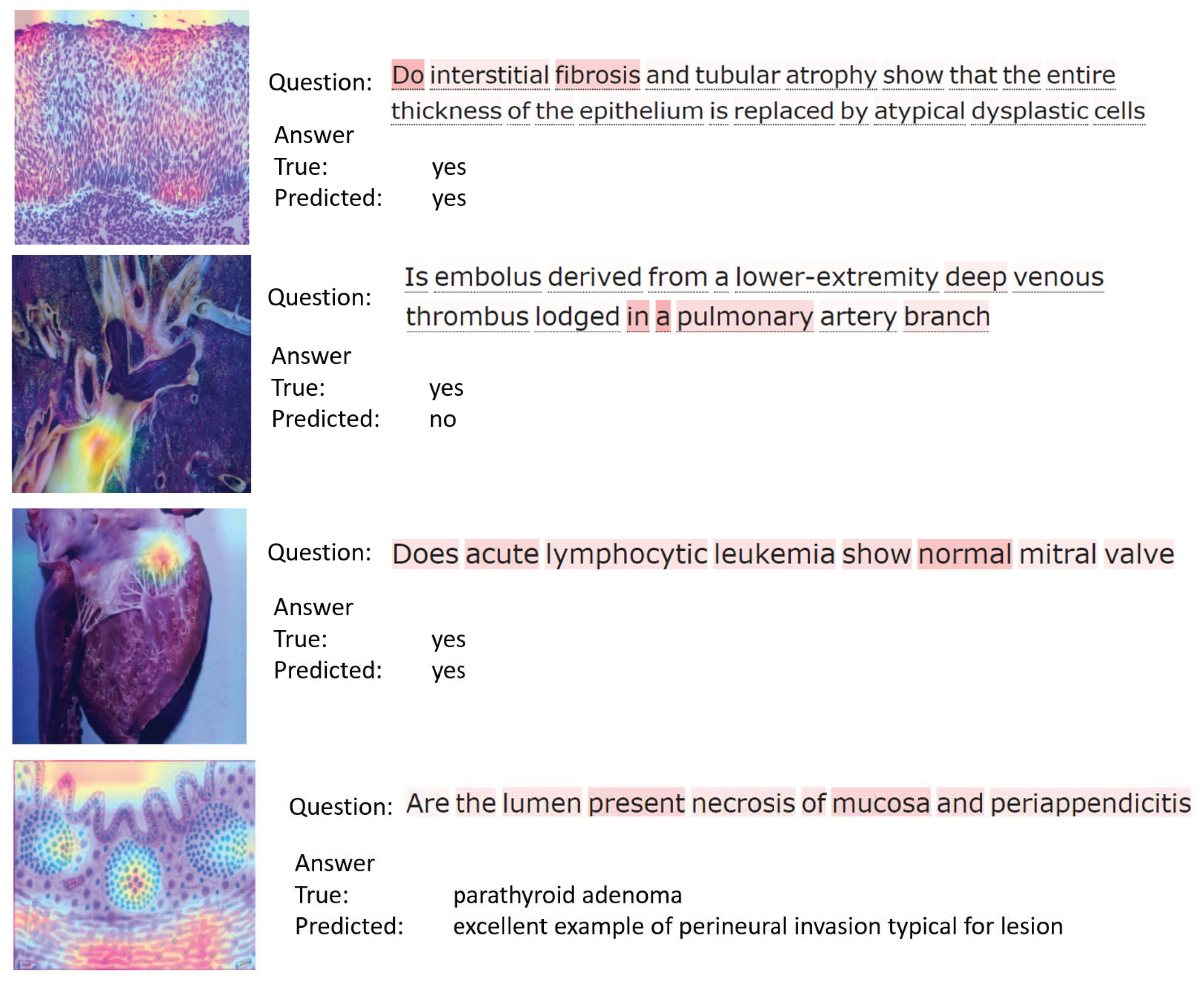
4.5. Discussions
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Guo, X.; Woo, P.Y.M.; Yuan, Y. Super-Resolution Enhanced Medical Image Diagnosis with Sample Affinity Interaction. IEEE Trans. Med. Imaging 2021, 40, 1377–1389. [Google Scholar] [CrossRef] [PubMed]
- Al, W.A.; Yun, I.D. Partial Policy-Based Reinforcement Learning for Anatomical Landmark Localization in 3D Medical Images. IEEE Trans. Med. Imaging 2020, 39, 1245–1255. [Google Scholar] [CrossRef]
- Doi, K. Computer-Aided Diagnosis in Medical Imaging: Historical Review, Current Status and Future Potential. Comput. Med. Imaging Graph. 2007, 31, 198–211. [Google Scholar] [CrossRef] [PubMed]
- Qiu, J.-J.; Yin, J.; Qian, W.; Liu, J.-H.; Huang, Z.-X.; Yu, H.-P.; Ji, L.; Zeng, X.-X. A Novel Multiresolution-Statistical Texture Analysis Architecture: Radiomics-Aided Diagnosis of PDAC Based on Plain CT Images. IEEE Trans. Med. Imaging 2021, 40, 12–25. [Google Scholar] [CrossRef]
- Vu, M.H.; Lofstedt, T.; Nyholm, T.; Sznitman, R. A Question-Centric Model for Visual Question Answering in Medical Imaging. IEEE Trans. Med. Imaging 2020, 39, 2856–2868. [Google Scholar] [CrossRef]
- Zhan, L.-M.; Liu, B.; Fan, L.; Chen, J.; Wu, X.-M. Medical Visual Question Answering via Conditional Reasoning. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; ACM: New York, NY, USA, 2020; pp. 2345–2354. [Google Scholar]
- Nguyen, B.D.; Do, T.-T.; Do, T.; Tjiputra, E.; Tran, Q.D. Overcoming Data Limitation in Medical Visual Question Answering. arXiv 2019, arXiv:1909.11867. [Google Scholar]
- Wang, D.; Zhang, Y.; Zhang, K.; Wang, L. FocalMix: Semi-Supervised Learning for 3D Medical Image Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3950–3959. [Google Scholar] [CrossRef]
- Zhou, T.; Ruan, S.; Canu, S. A review: Deep learning for medical image segmentation using multi-modality fusion. Array 2019, 3, 100004. [Google Scholar] [CrossRef]
- Huang, J.-H.; Wu, T.-W.; Worring, M. Contextualized Keyword Representations for Multi-Modal Retinal Image Captioning. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 645–652. [Google Scholar]
- Wu, Y.; Jiang, L.; Yang, Y. Switchable Novel Object Captioner. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1162–1173. [Google Scholar] [CrossRef]
- Li, L.; Lei, J.; Gan, Z.; Liu, J. Adversarial VQA: A New Benchmark for Evaluating the Robustness of VQA Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2022–2031. [Google Scholar]
- Mikolov, T.; Karafiat, M.; Burget, L.; Cernocky, J.; Khudanpur, S. Recurrent Neural Network Based Language Model. Interspeech 2010, 2, 1045–1048. [Google Scholar]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning Deep Transformer Models for Machine Translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Chen, N.; Watanabe, S.; Villalba, J.A.; Zelasko, P.; Dehak, N. Non-Autoregressive Transformer for Speech Recognition. IEEE Signal Process. Lett. 2021, 28, 121–125. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward Transformer-Based Object Detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Al Rahhal, M.M.; Al Dayil, R.; Al Ajlan, N. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2021, arXiv:2010.04159. [Google Scholar]
- Bashmal, L.; Bazi, Y.; Al Rahhal, M.; Alhichri, H.; Al Ajlan, N. UAV Image Multi-Labeling with Data-Efficient Transformers. Appl. Sci. 2021, 11, 3974. [Google Scholar] [CrossRef]
- Shi, Y.; Xiao, Y.; Quan, P.; Lei, M.; Niu, L. Document-level relation extraction via graph transformer networks and temporal convolutional networks. Pattern Recognit. Lett. 2021, 149, 150–156. [Google Scholar] [CrossRef]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-Memory Transformer for Image Captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10575–10584. [Google Scholar] [CrossRef]
- He, S.; Liao, W.; Tavakoli, H.R.; Yang, M.; Rosenhahn, B.; Pugeault, N. Image Captioning Through Image Transformer. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Chen, Y.-C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. UNITER: UNiversal Image-TExt Representation Learning. arXiv 2020, arXiv:1909.11740. [Google Scholar]
- Hu, R.; Singh, A. UniT: Multimodal Multitask Learning with a Unified Transformer. arXiv 2021, arXiv:2102.10772. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.-J.; Chang, K.-W. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. arXiv 2019, arXiv:1908.02265. [Google Scholar]
- Tan, H.; Bansal, M. LXMERT: Learning Cross-Modality Encoder Representations from Transformers. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 5100–5111. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. VL-BERT: Pre-Training of Generic Visual-Linguistic Representations. arXiv 2020, arXiv:1908.08530. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Cedarville, OH, USA, 2014; pp. 1532–1543. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked Attention Networks for Image Question Answering. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 21–29. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical Question-Image Co-Attention for Visual Question Answering. arXiv 2017, arXiv:1606.00061. [Google Scholar]
- He, X.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P. PathVQA: 30000+ Questions for Medical Visual Question Answering. arXiv 2020, arXiv:2003.10286. [Google Scholar]
- Lau, J.J.; Gayen, S.; Ben Abacha, A.; Demner-Fushman, D. A dataset of clinically generated visual questions and answers about radiology images. Sci. Data 2018, 5, 180251. [Google Scholar] [CrossRef]
- Liu, B.; Zhan, L.-M.; Wu, X.-M. Contrastive Pre-Training and Representation Distillation for Medical Visual Question Answering Based on Radiology Images. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2021; de Bruijne, M., Cattin, P.C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., Essert, C., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12902, pp. 210–220. ISBN 978-3-030-87195-6. [Google Scholar]
- Pan, H.; He, S.; Zhang, K.; Qu, B.; Chen, C.; Shi, K. MuVAM: A Multi-View Attention-Based Model for Medical Visual Question Answering. arXiv 2021, arXiv:2107.03216. [Google Scholar]
- Gong, H.; Chen, G.; Liu, S.; Yu, Y.; Li, G. Cross-Modal Self-Attention with Multi-Task Pre-Training for Medical Visual Question Answering. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 456–460. [Google Scholar]
- Do, T.; Nguyen, B.X.; Tjiputra, E.; Tran, M.; Tran, Q.D.; Nguyen, A. Multiple Meta-Model Quantifying for Medical Visual Question Answering. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2021; de Bruijne, M., Cattin, P.C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., Essert, C., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 64–74. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- He, X.; Cai, Z.; Wei, W.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P. Pathological Visual Question Answering. arXiv 2020, arXiv:2010.12435. [Google Scholar]
- He, X.; Cai, Z.; Wei, W.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P. Towards Visual Question Answering on Pathology Images. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 708–718. [Google Scholar]
- Sharma, D.; Purushotham, S.; Reddy, C.K. MedFuseNet: An attention-based multimodal deep learning model for visual question answering in the medical domain. Sci. Rep. 2021, 11, 19826. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, X.; Zhou, X.; Yang, J. BPI-MVQA: A bi-branch model for medical visual question answering. BMC Med. Imaging 2022, 22, 79. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2020, arXiv:1910.10683. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021, arXiv:2102.10772. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2020, arXiv:1906.08237. [Google Scholar]
- Kaiser, L.; Gomez, A.N.; Shazeer, N.; Vaswani, A.; Parmar, N.; Jones, L.; Uszkoreit, J. One Model To Learn Them All. arXiv 2017, arXiv:1706.05137. [Google Scholar]
- Zhu, C.; Ping, W.; Xiao, C.; Shoeybi, M.; Goldstein, T.; Anandkumar, A.; Catanzaro, B. Long-Short Transformer: Efficient Transformers for Language and Vision. arXiv 2021, arXiv:2107.02192. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2020, arXiv:1606.08415. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Malinowski, M.; Fritz, M. A Multi-World Approach to Question Answering about Real-World Scenes Based on Uncertain Input. arXiv 2015, arXiv:1410.0210. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; Association for Computational Linguistics: Cedarville, OH, USA, 2002; pp. 311–318. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Gong, H.; Chen, G.; Mao, M.; Li, Z.; Li, G. VQAMix: Conditional Triplet Mixup for Medical Visual Question Answering. IEEE Trans. Med. Imaging 2022, 41, 3332–3343. [Google Scholar] [CrossRef]
- Moon, J.H.; Lee, H.; Shin, W.; Kim, Y.-H.; Choi, E. Multi-Modal Understanding and Generation for Medical Images and Text via Vision-Language Pre-Training. IEEE J. Biomed. Health Inform. 2022, 26, 6070–6080. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | No. of Images | No. of Question/Answer Pairs | Question Types |
|---|---|---|---|
| VQA-RAD | 315 | 3515 | open-ended, closed-ended |
| PathVQA | 4998 | 32,799 |
| Dataset | Evaluation Metric | ||||||
|---|---|---|---|---|---|---|---|
| B1 | B2 | B3 | B4 | Closed | Open | All | |
| VQA-RAD | 71.03 ± 0.90 | 70.81 ± 0.95 | 67.01 ± 0.99 | 64.43 ± 0.99 | 82.47 ± 1.43 | 71.49 ± 0.73 | 75.41 ± 0.98 |
| PathVQA | 61.78 ± 0.03 | 61.16 ± 0.04 | 59.28 ± 0.02 | 58.19 ± 0.02 | 84.63 ± 0.83 | 58.29 ± 0.73 | 67.05 ± 0.58 |
| #Decoder Layers | VQA-RAD Dataset | PathVQA Dataset | ||||
|---|---|---|---|---|---|---|
| Closed | Open | All | Closed | Open | All | |
| 1 | 82.06 ± 1.21 | 70.98 ± 0.39 | 74.99 ± 0.85 | 83.13 ± 0.49 | 57.90 ± 0.49 | 66.17 ± 0.75 |
| 2 | 82.47 ± 1.43 | 71.49 ± 0.73 | 75.41 ± 0.98 | 84.63 ± 0.83 | 58.29 ± 0.73 | 67.05 ± 0.58 |
| 3 | 84.46 ± 1.43 | 72.51 ± 0.99 | 76.78 ± 1.09 | 86.90 ± 0.21 | 62.58 ± 0.04 | 70.65 ± 0.07 |
| 4 | 84.99 ± 1.15 | 72.97 ± 1.49 | 77.27 ± 1.37 | 86.83 ± 0.31 | 62.37 ± 0.22 | 70.54 ± 0.25 |
| Method | Evaluation Metric | |||
|---|---|---|---|---|
| BLEU-1 | BLEU-2 | BLEU-3 | F1 (%) | |
| GRU + Faster R-CNN [40] | 32.4 | 22.8 | 17.4 | 24.0 |
| CNN + LSTM [40] | 13.3 | 9.5 | 6.8 | 12.5 |
| SAN+ CNN + LSTM [40] | 19.2 | 17.9 | 15.8 | 19.7 |
| SAN+ CNN + LSTM+ Faster R-CNN [40] | 24.7 | 19.1 | 16.5 | 21.2 |
| SAN+ CNN + LSTM+ ResNet [40] | 19.9 | 18.0 | 16.0 | 19.8 |
| Proposed | 71.03 ± 0.90 | 70.81 ± 0.95 | 67.01 ± 0.99 | 72.85 ± 0.95 |
| Method | VQA-RAD Dataset | PathVQA Dataset | ||||
|---|---|---|---|---|---|---|
| Closed | Open | All | Closed | Open | All | |
| Zhan, L.M. et al. [6] | 79.3 | 60.0 | 68.5 | - | - | - |
| Nguyen, B.D. et al. [7] | 75.1 | 43.9 | 62.6 | 81.4 | 8.1 | 44.8 |
| Gong, H. et al. [45] | 77.8 | 52.8 | 67.9 | - | - | - |
| Do, T. et al. [43] | 72.4 | 52.0 | 64.3 | 82.1 ± 0.5 | 11.8 ± 0.6 | 47.1 ± 0.4 |
| Gong, H. et al. [64] | 69.7 | 38.2 | 57.1 | 75.3 | 5.4 | 40.5 |
| Gong, H. et al. [64] | 72.4 | 49.6 | 63.3 | 81.3 ± 0.3 | 9.1 ± 0.5 | 45.3 ± 0.4 |
| Gong, H. et al. [64] | 79.6 | 56.6 | 70.4 | 83.5 ± 0.2 | 13.4 ± 0.6 | 48.6 ± 0.3 |
| Moon, J.H. [65] | 77.7 ± 0.71 | 59.5 ± 0.32 | - | - | - | - |
| Proposed | 82.47 ± 1.43 | 71.49 ± 0.73 | 75.41 ± 0.98 | 85.61 ± 0.83 | 71.49 ± 0.73 | 66.68 ± 0.58 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bazi, Y.; Rahhal, M.M.A.; Bashmal, L.; Zuair, M. Vision–Language Model for Visual Question Answering in Medical Imagery. Bioengineering 2023, 10, 380. https://doi.org/10.3390/bioengineering10030380
Bazi Y, Rahhal MMA, Bashmal L, Zuair M. Vision–Language Model for Visual Question Answering in Medical Imagery. Bioengineering. 2023; 10(3):380. https://doi.org/10.3390/bioengineering10030380
Chicago/Turabian StyleBazi, Yakoub, Mohamad Mahmoud Al Rahhal, Laila Bashmal, and Mansour Zuair. 2023. "Vision–Language Model for Visual Question Answering in Medical Imagery" Bioengineering 10, no. 3: 380. https://doi.org/10.3390/bioengineering10030380
APA StyleBazi, Y., Rahhal, M. M. A., Bashmal, L., & Zuair, M. (2023). Vision–Language Model for Visual Question Answering in Medical Imagery. Bioengineering, 10(3), 380. https://doi.org/10.3390/bioengineering10030380