
A-GSTCN: An Augmented Graph Structural–Temporal Convolution Network for Medication Recommendation Based on Electronic Health Records

 , , ,
, , ,  and
and 
Abstract
:1. Introduction
- 1.
- Structural correlation: A patient’s EHRs can be seen as a combination of a set of diagnoses, procedures and medications, where the diagnoses, procedures and medications can be collectively referred to the medical events. Therefore, the EHRs can be expressed as a combination of multiple medical events, and the occurrences of medical events simultaneously in a medical record are referred to as structural correlations. For example, chemical ulcers are often accompanied by gastric perforation, and chickenpox can cause erysipelas. These phenomena can be considered as structural correlations between diagnostic events and diagnostic events themselves. Similarly, the combination of statins with cardiovascular drugs is more beneficial for recovery from coronary heart disease, and this phenomenon is thought to be structurally correlated with diagnostic events and medication combinations.
- 2.
- Temporal dependency: Chronic diseases, such as stroke, diabetes and high blood pressure, do not recover as quickly as common diseases. On the contrary, chronic diseases are often incurable and require multiple visits. Meanwhile, during the patient’s medical treatment process, different treatments and drugs can be used at different times. The connection of these medical events on a temporal level is referred to as temporal dependency. For the same patient, the EHRs at multiple admissions can be regarded as multiple continuous medical processes, which may have rich temporal characteristics. In addition, different medical events (diagnoses, procedures and medications) may show different temporal dependencies in different patients.
- 1.
- We treat EHRs as time-series records with structural correlation and use ICD-9 encoding and ATC encoding to standardize the records in pretraining. Meanwhile, the A-GSTCN model is proposed to realize personalized medication recommendation based on the standardized records, and the model has excellent performance and can be used in specific medical environments.
- 2.
- In the A-GSTCN model, we construct global structural correlation diagrams for diagnoses and procedures, capturing the structural correlation of EHRs based on these diagrams and augmented GAT. In addition, we learn the temporal dependency of EHRs by dilated convolution combined with residual connection. Furthermore, we employ a cache mechanism to enhance the medication recommendation accuracy of the proposed model.
- 3.
- The proposed model outperforms the baselines in all evaluation metrics (Jaccard, F1, PRAUC) for the MIMIC-III datasets and ZJ-CVD datasets. Compared to the baselines, the A-GSTCN model has more accurate drug recommendation ability and requires far fewer parameters, which greatly reduces the training time and significantly improves the inference speed.
2. Related Work
3. The A-GSTCN Model
3.1. Problem Formulation
3.1.1. Standardized EHRs
3.1.2. Medical Events Correlation Diagrams
3.1.3. Medication Recommendation Tasks
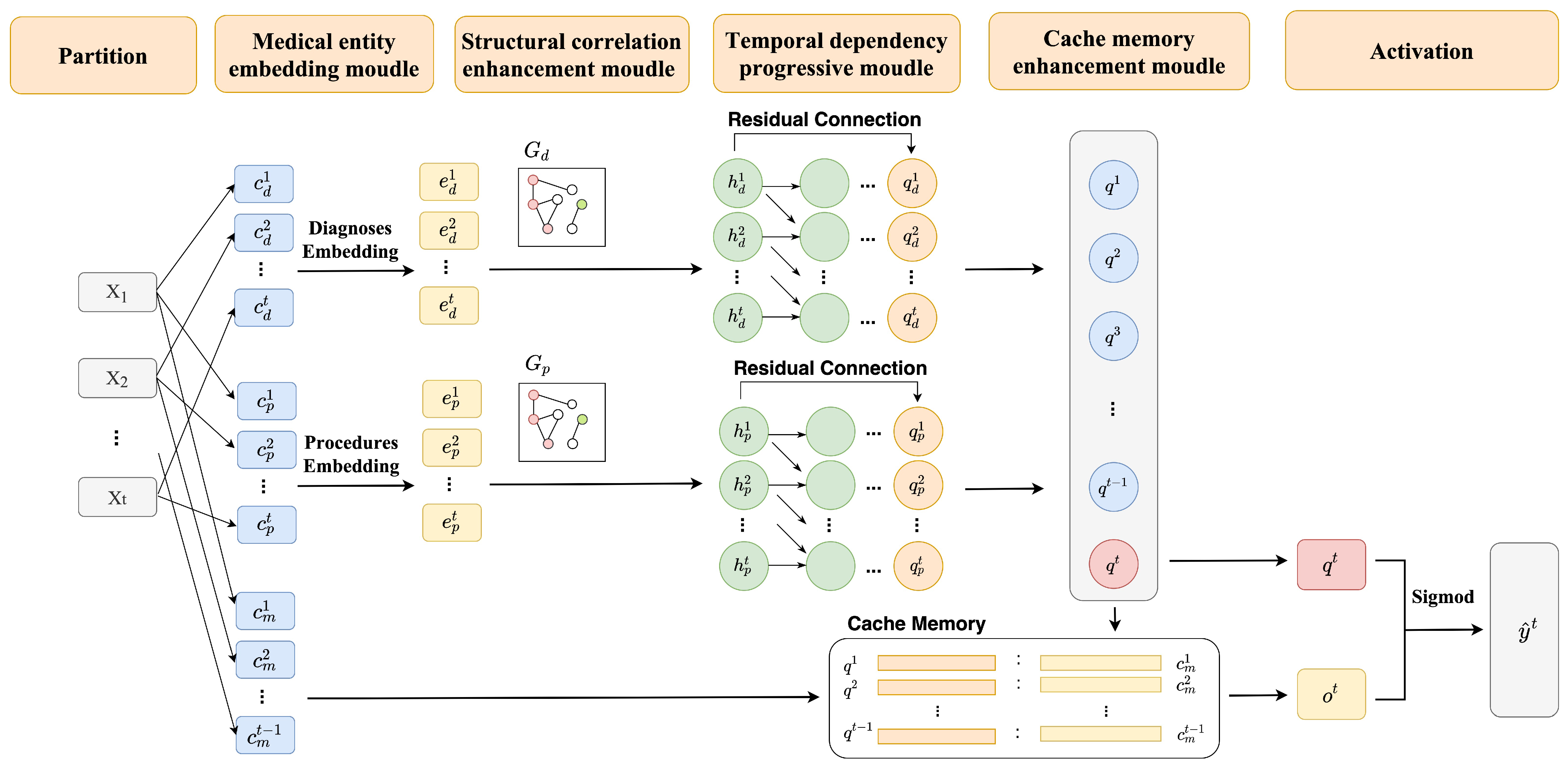
3.2. The Framework of A-GSTCN
3.2.1. Medical Entity Embedding Module
3.2.2. Structural Correlation Enhancement Module
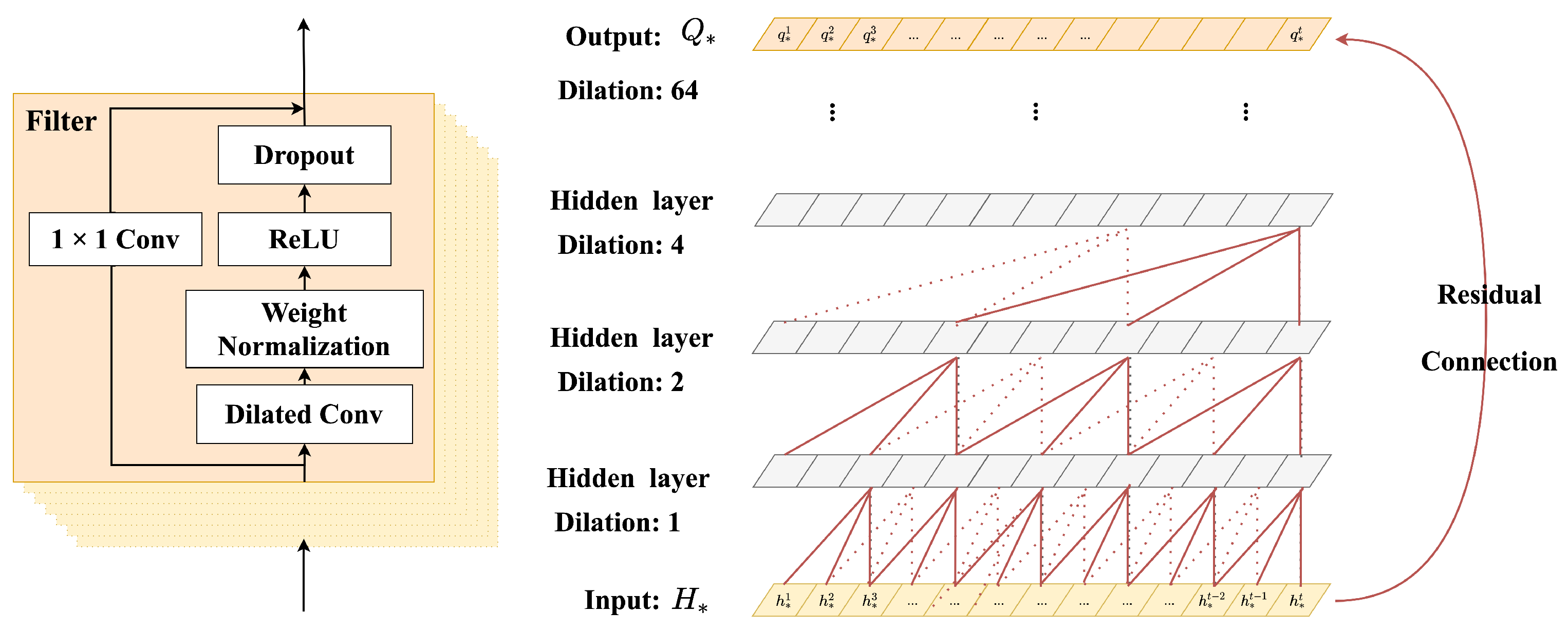
3.2.3. Temporal Dependency Progressive Module
3.2.4. Cache Memory Enhancement Module
- 1.
- Create a query vector of the tth visit. To be specific, from the set can be generated a query as follows:where represents a transformation function, and this function can connect the diagnosis representation and the procedure representation .
- 2.
- Use the and medication representation as dependent variables, and generate the cache records before the tth visit in the form of key-value pairs as follows:where is empty when t = 1, and represents the historical visit before the tth visit. : is denoted as the key vector, and : is denoted as the value vector to represent the history cache of the tth visit.
- 3.
- Based on the similarity between the representation vector and its historical cache, the attention strategy is applied as follows:where the similarity between the key vector matrix and the representation vector is first considered. Furthermore, the similarity relationship is obtained by matrix multiplication and activation, and the transposed vector matrix is further multiplied to obtain .
- 4.
- Activate and , obtain the multi-label recommended medication combination . The formula can be expressed as follows:where is the activation function.
3.3. Optimization
| Algorithm 1: Training algorithm of the A-GSTCN |
 |
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
- MIMIC-III is a sizable single-center database, which includes more than 50,000 cases admitted to intensive care units from 2001 to 2012 and 7870 newborns admitted from 2001 to 2008. To be specific, the MIMIC-III dataset includes medical orders, medications, procedures, diagnoses, and so on. Meanwhile, to improve the dataset availability, the records are generated into a temporal list of diagnosis, procedure and medication codes.
- ZJ-CVD is a Chinese medical dataset collected by our laboratory, which contains the medical records of more than 8000 patients with cerebrovascular disease from the First Hospital of Zhejiang Province, the Fourth Affiliated Hospital Zhejiang University of Medicine and Taizhou Municipal Hospital. Each patient may have multiple hospitalizations, so the number of EHRs in ZJ-CVD datasets exceeds 10,000. To be specific, ZJ-CVD datasets are cleaned and augmented in pretraining and consist of admission diagnosis, hospitalization, discharge medication and some other medical information.
4.1.2. Baselines
- Leap [39] can predict target event through an attention mechanism by establishing mappings between medical events and tensors.
- RETAIN [21] generates a medication recommendation through building a two-layer RNN with attention model, and this model can consider the influence of temporal factors.
- DMNC [38] strengthens the capturing of temporal characteristics for medical events by establishing a memory enhancement networks.
- GAMENet [27] integrates the drug–drug interactions and model longitudinal patient records as the query, which can capture the temporal dependency of EHRs.
- G-Bert [28] uses the BERT to pretrain the correlations between medical events in EHRs and constructs an ontological tree for medication recommendation.
4.1.3. Metrics
4.2. Experimental Results
4.2.1. Recommendation Performance
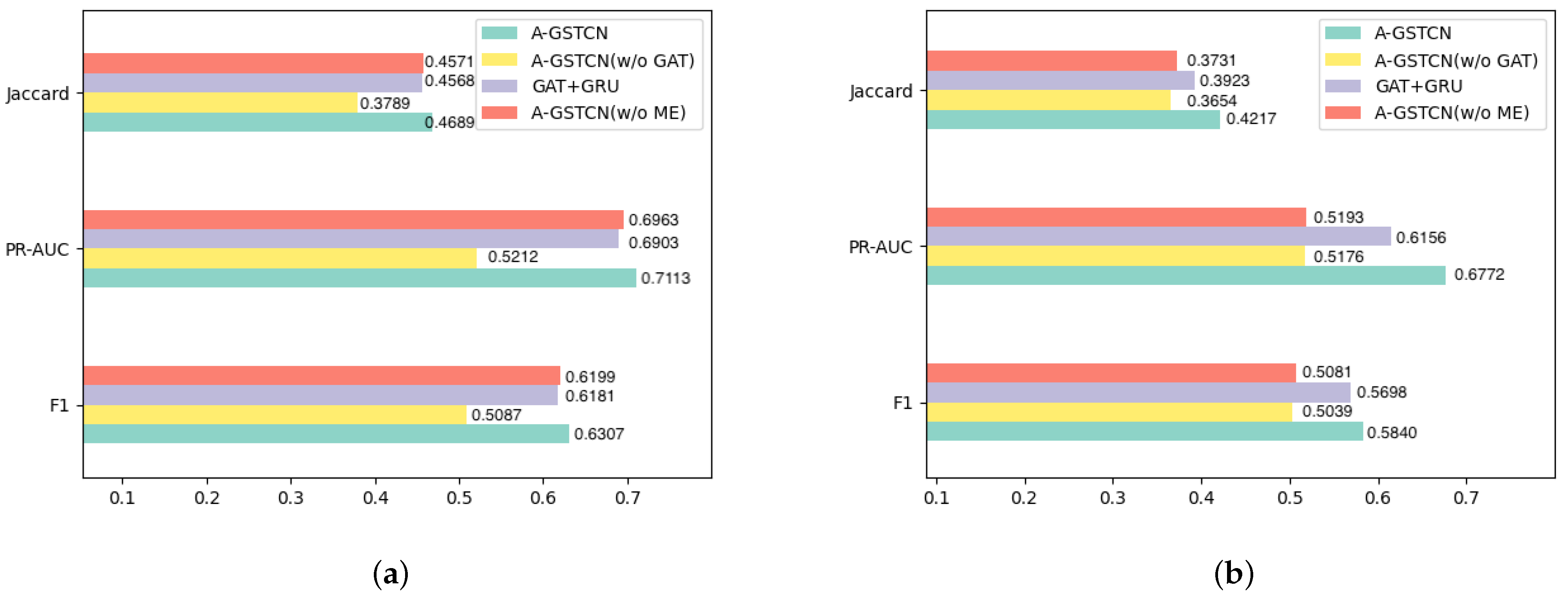
4.2.2. Module Validity
- A-GSTCN: the proposed model.
- A-GSTCN (w/o GAT): removes the structure correlation enhancement module of the A-GSTCN model.
- GAT + GRU: changes the temporal dependency progressive module into the GRU model for the A-GSTCN model.
- A-GSTCN (w/o ME): removes the cache memory enhancement module of the A-GSTCN model.
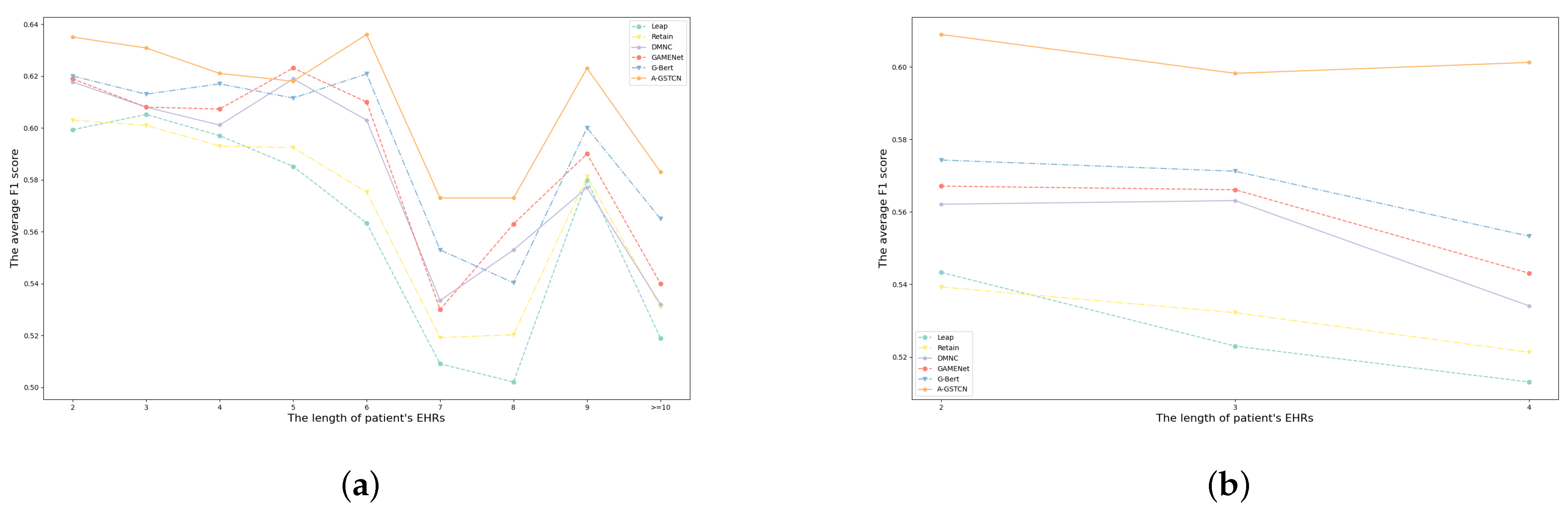
4.2.3. Comparison for Different Recommended Frequency Drugs
4.2.4. Comparison for Patients with Different Visits
4.3. Case Study
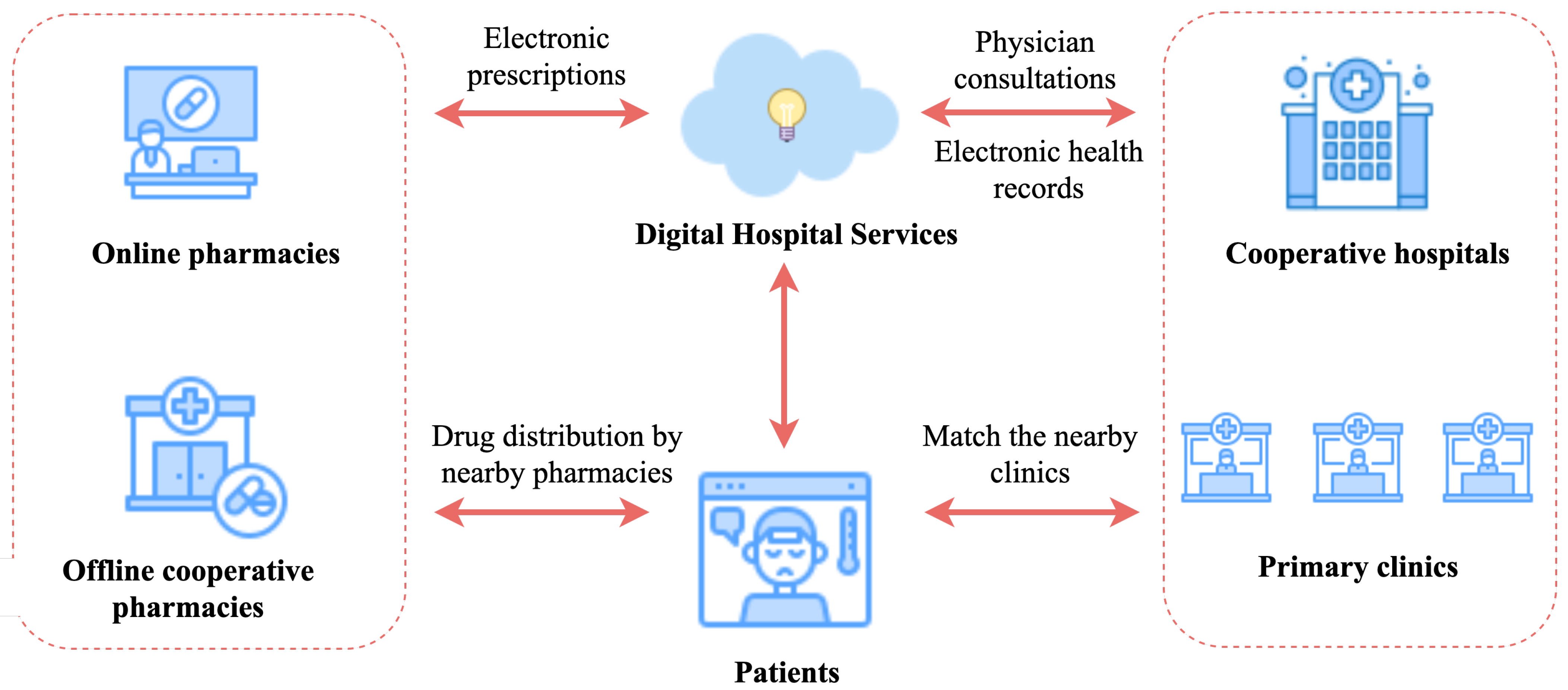
4.4. Engineering Applications
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- de Moraes, B.A.F.; Miraglia, J.; Donato, T.; Filho, A. COVID-19 Diagnosis Prediction in Emergency Care Patients: A Machine Learning Approach. 2020. Available online: https://www.medrxiv.org/content/medrxiv/early/2020/04/07/2020.04.04.20052092.full.pdf (accessed on 1 August 2023).
- Wagner, T.; Shweta, F.; Murugadoss, K.; Awasthi, S.; Venkatakrishnan, A.; Bade, S.; Puranik, A.; Kang, M.; Pickering, B.W.; O’Horo, J.C.; et al. Augmented curation of clinical notes from a massive EHR system reveals symptoms of impending COVID-19 diagnosis. eLife 2020, 9, e58227. [Google Scholar] [CrossRef]
- Wynants, L.; Van Calster, B.; Collins, G.S.; Riley, R.D.; Heinze, G.; Schuit, E.; Bonten, M.M.; Dahly, D.L.; Damen, J.A.; Debray, T.P.; et al. Prediction models for diagnosis and prognosis of COVID-19: Systematic review and critical appraisal. BMJ 2020, 369, m1328. [Google Scholar] [CrossRef]
- Arndt, B.G.; Beasley, J.W.; Watkinson, M.D.; Temte, J.L.; Tuan, W.J.; Sinsky, C.A.; Gilchrist, V.J. Tethered to the EHR: Primary care physician workload assessment using EHR event log data and time-motion observations. Ann. Fam. Med. 2017, 15, 419–426. [Google Scholar] [CrossRef]
- Boussadi, A.; Caruba, T.; Karras, A.; Berdot, S.; Degoulet, P.; Durieux, P.; Sabatier, B. Validity of a clinical decision rule-based alert system for drug dose adjustment in patients with renal failure intended to improve pharmacists’ analysis of medication orders in hospitals. Int. J. Med. Inform. 2013, 82, 964–972. [Google Scholar] [CrossRef]
- Kropf, M.; Modre-Osprian, R.; Gruber, K.; Fruhwald, F.; Schreier, G. Evaluation of a clinical decision support rule-set for medication adjustments in mHealth-based heart failure management. In eHealth; IOS Press: Amsterdam, The Netherlands, 2015; pp. 81–87. [Google Scholar]
- Mahmoud, N.; Elbeh, H. IRS-T2D: Individualize recommendation system for type2 diabetes medication based on ontology and SWRL. In Proceedings of the 10th International Conference on Informatics and Systems; Giza, Egypt, 9–11 May 2016, pp. 203–209.
- Farzi, S.; Farzi, S.; Alimohammadi, N.; Moladoost, A. Medication errors by the intensive care units’ nurses and the Preventive Strategies. Anesthesiol. Pain 2016, 6, 33–45. [Google Scholar]
- Elhoseny, M.; Shankar, K.; Uthayakumar, J. Intelligent diagnostic prediction and classification system for chronic kidney disease. Sci. Rep. 2019, 9, 9583. [Google Scholar] [CrossRef]
- Shickel, B.; Tighe, P.J.; Bihorac, A.; Rashidi, P. Deep EHR: A survey of recent advances in deep learning techniques for electronic health record (EHR) analysis. IEEE J. Biomed. Health Inform. 2017, 22, 1589–1604. [Google Scholar] [CrossRef] [PubMed]
- Erraguntla, M.; Zapletal, J.; Lawley, M. Framework for Infectious Disease Analysis: A comprehensive and integrative multi-modeling approach to disease prediction and management. Health Inform. J. 2019, 25, 1170–1187. [Google Scholar] [CrossRef]
- John, A.; Vasudevan, V. Medication recommendation system based on clinical documents. In Proceedings of the 2016 International Conference on Information Science (ICIS), Kochi, India, 12–13 August 2016; pp. 180–184. [Google Scholar]
- Zhang, Y.; Zhang, D.; Hassan, M.M.; Alamri, A.; Peng, L. CADRE: Cloud-assisted drug recommendation service for online pharmacies. Mob. Netw. Appl. 2015, 20, 348–355. [Google Scholar] [CrossRef]
- Syed-Abdul, S.; Nguyen, A.; Huang, F.; Jian, W.S.; Iqbal, U.; Yang, V.; Hsu, M.H.; Li, Y.C. A smart medication recommendation model for the electronic prescription. Comput. Methods Programs Biomed. 2014, 117, 218–224. [Google Scholar] [CrossRef]
- Liu, H.; Xie, G.; Mei, J.; Shen, W.; Sun, W.; Li, X. An efficacy driven approach for medication recommendation in type 2 diabetes treatment using data mining techniques. Stud. Health Technol. Inform. 2013, 192, 1071. [Google Scholar] [PubMed]
- Mao, C.; Yao, L.; Luo, Y. MedGCN: Medication recommendation and lab test imputation via graph convolutional networks. J. Biomed. Inform. 2022, 127, 104000. [Google Scholar] [CrossRef] [PubMed]
- Choi, E.; Bahadori, M.T.; Song, L.; Stewart, W.F.; Sun, J. GRAM: Graph-based attention model for healthcare representation learning. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 787–795. [Google Scholar]
- Gao, C.; Sun, H.; Wang, T.; Tang, M.; Bohnen, N.I.; Müller, M.L.; Herman, T.; Giladi, N.; Kalinin, A.; Spino, C.; et al. Model-based and model-free machine learning techniques for diagnostic prediction and classification of clinical outcomes in Parkinson’s disease. Sci. Rep. 2018, 8, 7129. [Google Scholar] [CrossRef] [PubMed]
- Tutty, M.A.; Carlasare, L.E.; Lloyd, S.; Sinsky, C.A. The complex case of EHRs: Examining the factors impacting the EHR user experience. J. Am. Med. Inform. Assoc. 2019, 26, 673–677. [Google Scholar] [CrossRef]
- Choi, E.; Bahadori, M.T.; Schuetz, A.; Stewart, W.F.; Sun, J. Doctor ai: Predicting clinical events via recurrent neural networks. In Proceedings of the Machine Learning for Healthcare Conference, PMLR, Los Angeles, CA, USA, 19–20 August 2016; pp. 301–318. [Google Scholar]
- Choi, E.; Bahadori, M.T.; Sun, J.; Kulas, J.; Schuetz, A.; Stewart, W. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Chen, Z.; Marple, K.; Salazar, E.; Gupta, G.; Tamil, L. A physician advisory system for chronic heart failure management based on knowledge patterns. Theory Pract. Log. Program. 2016, 16, 604–618. [Google Scholar] [CrossRef]
- Al-Ajmi, N.; Almulla, M.A. Rule-Based Expert System for Headache Diagnosis and Medication Recommendation. Int. J. Health Med. Eng. 2020, 14, 388–391. [Google Scholar]
- Almulla, M.A. Location-based Expert System for Diabetes Diagnosis. Kuwait J. Sci. 2021, 48. [Google Scholar] [CrossRef]
- Pang, C.; Jiang, X.; Kalluri, K.S.; Spotnitz, M.; Chen, R.; Perotte, A.; Natarajan, K. CEHR-BERT: Incorporating temporal information from structured EHR data to improve prediction tasks. In Proceedings of the Machine Learning for Health. PMLR, Virtual, 6–7 August 2021; pp. 239–260. [Google Scholar]
- Wang, Y.; Chen, W.; Pi, D.; Yue, L. Adversarially regularized medication recommendation model with multi-hop memory network. Knowl. Inf. Syst. 2021, 63, 125–142. [Google Scholar] [CrossRef]
- Shang, J.; Xiao, C.; Ma, T.; Li, H.; Sun, J. Gamenet: Graph augmented memory networks for recommending medication combination. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1126–1133. [Google Scholar]
- Shang, J.; Ma, T.; Xiao, C.; Sun, J. Pre-training of graph augmented transformers for medication recommendation. arXiv 2019, arXiv:1906.00346. [Google Scholar]
- Choi, E.; Xu, Z.; Li, Y.; Dusenberry, M.; Flores, G.; Xue, E.; Dai, A. Learning the graphical structure of electronic health records with graph convolutional transformer. In Proceedings of the AAAI conference on artificial intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 606–613. [Google Scholar]
- Wu, R.; Qiu, Z.; Jiang, J.; Qi, G.; Wu, X. Conditional generation net for medication recommendation. In Proceedings of the ACM Web Conference, Lyon, France, 25–29 April 2022; pp. 935–945. [Google Scholar]
- Khan, F.H.; Qamar, U.; Bashir, S. SentiMI: Introducing point-wise mutual information with SentiWordNet to improve sentiment polarity detection. Appl. Soft Comput. 2016, 39, 140–153. [Google Scholar] [CrossRef]
- Li, J.; Tu, Z.; Yang, B.; Lyu, M.R.; Zhang, T. Multi-head attention with disagreement regularization. arXiv 2018, arXiv:1810.10183. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Su, C.; Gao, S.; Li, S. GATE: Graph-attention augmented temporal neural network for medication recommendation. IEEE Access 2020, 8, 125447–125458. [Google Scholar] [CrossRef]
- Hewage, P.; Behera, A.; Trovati, M.; Pereira, E.; Ghahremani, M.; Palmieri, F.; Liu, Y. Temporal convolutional neural (TCN) network for an effective weather forecasting using time-series data from the local weather station. Soft Comput. 2020, 24, 16453–16482. [Google Scholar] [CrossRef]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Le, H.; Tran, T.; Venkatesh, S. Dual memory neural computer for asynchronous two-view sequential learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1637–1645. [Google Scholar]
- Esteban, C.; Tresp, V.; Yang, Y.; Baier, S.; Krompaß, D. Predicting the co-evolution of event and knowledge graphs. In Proceedings of the 2016 19th International Conference on Information Fusion (FUSION), Sun City, South Africa, 1–4 November 2016; pp. 98–105. [Google Scholar]
- Kwon, H.; An, S.; Lee, H.Y.; Cha, W.C.; Kim, S.; Cho, M.; Kong, H.J. Review of smart hospital services in real healthcare environments. Healthc. Inform. Res. 2022, 28, 3–15. [Google Scholar] [CrossRef]
- Duncan, R.; Eden, R.; Woods, L.; Wong, I.; Sullivan, C. Synthesizing dimensions of digital maturity in hospitals: Systematic review. J. Med. Internet Res. 2022, 24, e32994. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| the representation of the pretrained EHRs | |
| the historical visit representation of tth visit | |
| the representation of tth visit | |
| the diagnosis codes, procedure codes and medication codes of tth visit | |
| the global structural correlation diagrams for diagnoses and procedures | |
| the representation of and | |
| the total number of diagnoses, procedures and medications | |
| the representations for diagnoses and procedures through medical entity embedding module | |
| the representation of and | |
| the outputs through medical entity embedding module | |
| the representations for diagnoses and procedures through structural correlation enhancement module | |
| the representation of and | |
| the outputs through structural correlation enhancement module | |
| the representation of and | |
| the representation of and | |
| the representation of hidden-layer results obtained through dilated convolution | |
| the representations for diagnoses and procedures through temporal dependency progressive module | |
| the representation of and | |
| the representation of and | |
| the outputs through temporal dependency progressive module | |
| the query vector of the cache memory | |
| the tth visit of key vector and the tth visit of value vector in cache memory | |
| the cache records before the tth visit in the form of key-value pairs | |
| the memory outputs through the cache memory enhancement module | |
| the multi-label medication recommendation of tth visit | |
| the recommended medication set | |
| the ground truth of the medication set |
| MIMIC-III | ZJ-CVD | |
|---|---|---|
| patients | 35,886 | 8315 |
| - single-visit | 28,936 | 6835 |
| - multiple-visit | 6950 | 1480 |
| clinical events | 3529 | 1237 |
| - diagnosis | 1958 | 552 |
| - procedure | 1426 | 232 |
| - medication | 145 | 453 |
| max visits | 29 | 4 |
| average visits | 2.36 | 1.32 |
| average number of diagnosis | 10.51 | 4.15 |
| average number of procedure | 3.84 | 1.20 |
| average number of medication | 8.80 | 6.20 |
| MIMIC-III | ZJ-CVD | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Methods | Jaccard | PRAUC | F1 | Avg # of Med | Parameters | Jaccard | PRAUC | F1 | Avg # of Med | Parameters |
| Leap [39] | 0.3844 | 0.5501 | 0.5410 | 13.42 | 436,884 | 0.3738 | 0.5223 | 0.5187 | 11.47 | 303,286 |
| RETAIN [21] | 0.4168 | 0.6620 | 0.5781 | 16.68 | 289,490 | 0.3769 | 0.5261 | 0.5211 | 12.08 | 230,254 |
| DMNC [38] | 0.4343 | 0.6856 | 0.5934 | 20.00 | 527,979 | 0.3803 | 0.5399 | 0.5291 | 16.12 | 444,143 |
| GAMENet [27] | 0.4489 | 0.6911 | 0.6053 | 13.89 | 452,434 | 0.3811 | 0.5418 | 0.5369 | 10.71 | 323,147 |
| G-Bert [28] | 0.4511 | 0.6989 | 0.6121 | 16.11 | 2,411,138 | 0.3941 | 0.5935 | 0.5573 | 14.41 | 1,616,783 |
| A-GSTCN | 0.4689 | 0.7113 | 0.6307 | 15.34 | 97,626 | 0.4217 | 0.6772 | 0.5840 | 13.22 | 73,424 |
| Methods | Recommended Medication Combination (the Last Visit) |
|---|---|
| Leap | 8 correct + 2 unseen + 7 missed (Antigout, Anxiolytics, Cardiac glycosides, …) |
| RETAIN | 10 correct + 4 unseen + 5 missed (Antigout, Anxiolytics, Potassium, …) |
| DMNC | 11 correct + 6 unseen + 4 missed (Anxiolytics, Cardiac glycosides, Potassium, …) |
| GAMENet | 12 correct + 2 unseen + 3 missed (Antigout, Anxiolytics, Dopaminergic agents) |
| G-Bert | 13 correct + 4unseen + 2 missed (Anxiolytics, Potassium) |
| A-GSTCN | 14 correct + 3 unseen + 1 missed (Anxiolytics) |
| Methods | Recommended Medication Combination (the Last Visit) |
|---|---|
| Leap | 4 correct + 4 unseen + 4 missed (RSEC, BMT, THT, PAIT) |
| RETAIN | 4 correct + 2 unseen + 4 missed (RSEC, BMT, AESRT, PAIT) |
| DMNC | 5 correct + 2 unseen + 3 missed (RSEC, BMT, AESRT) |
| GAMENet | 5 correct + 3 unseen + 3 missed (RSEC, THT, PAIT) |
| G-Bert | 5 correct + 2 unseen + 3 missed (RSEC, BMT, THT) |
| A-GSTCN | 7 correct + 1 unseen + 1 missed (RSEC) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, W.; Wang, M.; Zhang, L.; Zhang, L.; Huang, J.; Wan, J.; Xiong, N.; Vasilakos, A.V. A-GSTCN: An Augmented Graph Structural–Temporal Convolution Network for Medication Recommendation Based on Electronic Health Records. Bioengineering 2023, 10, 1241. https://doi.org/10.3390/bioengineering10111241
Yue W, Wang M, Zhang L, Zhang L, Huang J, Wan J, Xiong N, Vasilakos AV. A-GSTCN: An Augmented Graph Structural–Temporal Convolution Network for Medication Recommendation Based on Electronic Health Records. Bioengineering. 2023; 10(11):1241. https://doi.org/10.3390/bioengineering10111241
Chicago/Turabian StyleYue, Weiqi, Maiqiu Wang, Lei Zhang, Lijuan Zhang, Jie Huang, Jian Wan, Naixue Xiong, and Athanasios V. Vasilakos. 2023. "A-GSTCN: An Augmented Graph Structural–Temporal Convolution Network for Medication Recommendation Based on Electronic Health Records" Bioengineering 10, no. 11: 1241. https://doi.org/10.3390/bioengineering10111241
APA StyleYue, W., Wang, M., Zhang, L., Zhang, L., Huang, J., Wan, J., Xiong, N., & Vasilakos, A. V. (2023). A-GSTCN: An Augmented Graph Structural–Temporal Convolution Network for Medication Recommendation Based on Electronic Health Records. Bioengineering, 10(11), 1241. https://doi.org/10.3390/bioengineering10111241