
An Extended Flood Characteristic Simulation Considering Natural Dependency Structures


Abstract
:1. Introduction
2. Extended Flood Characteristic Simulation according to Bender and Jensen
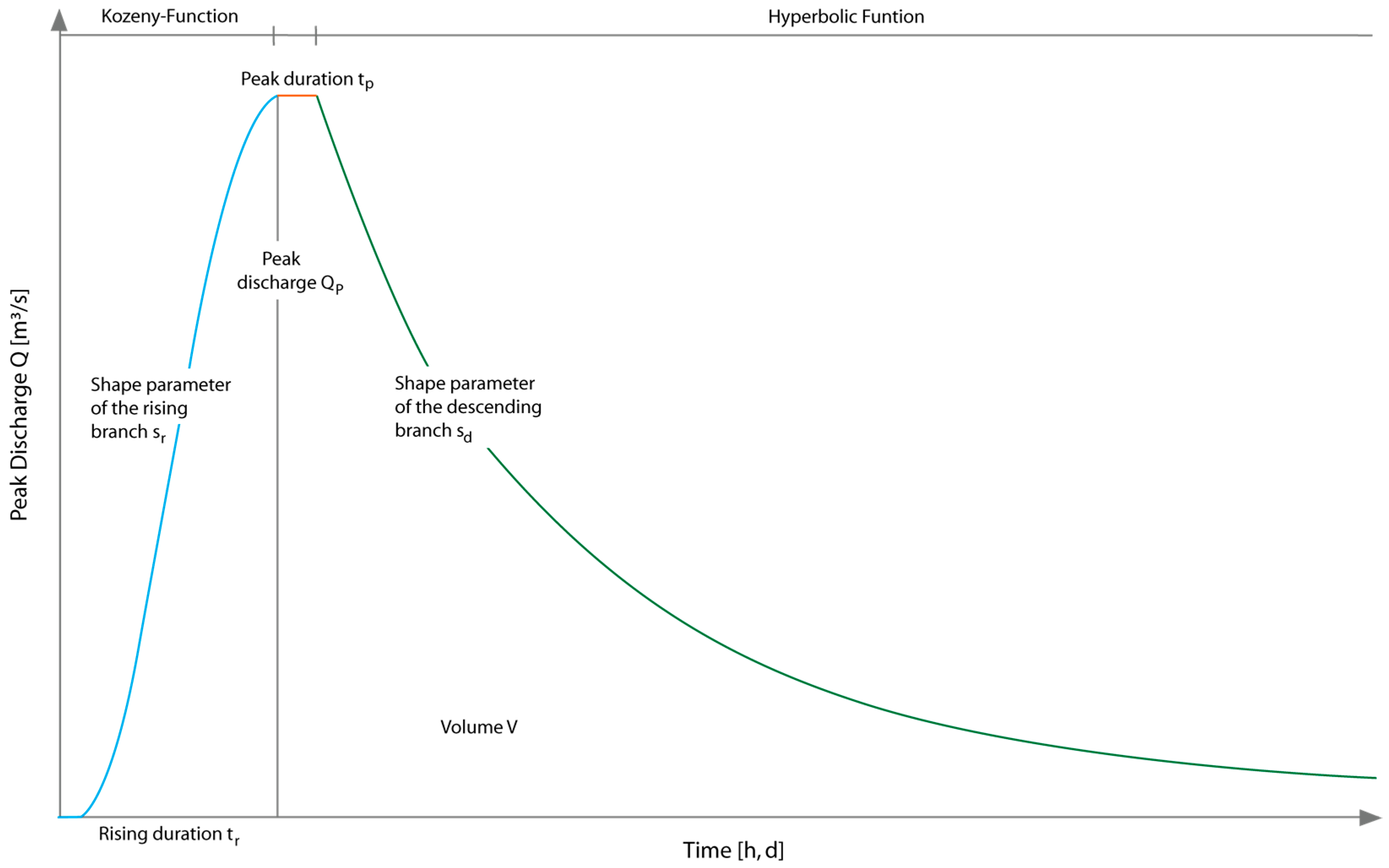
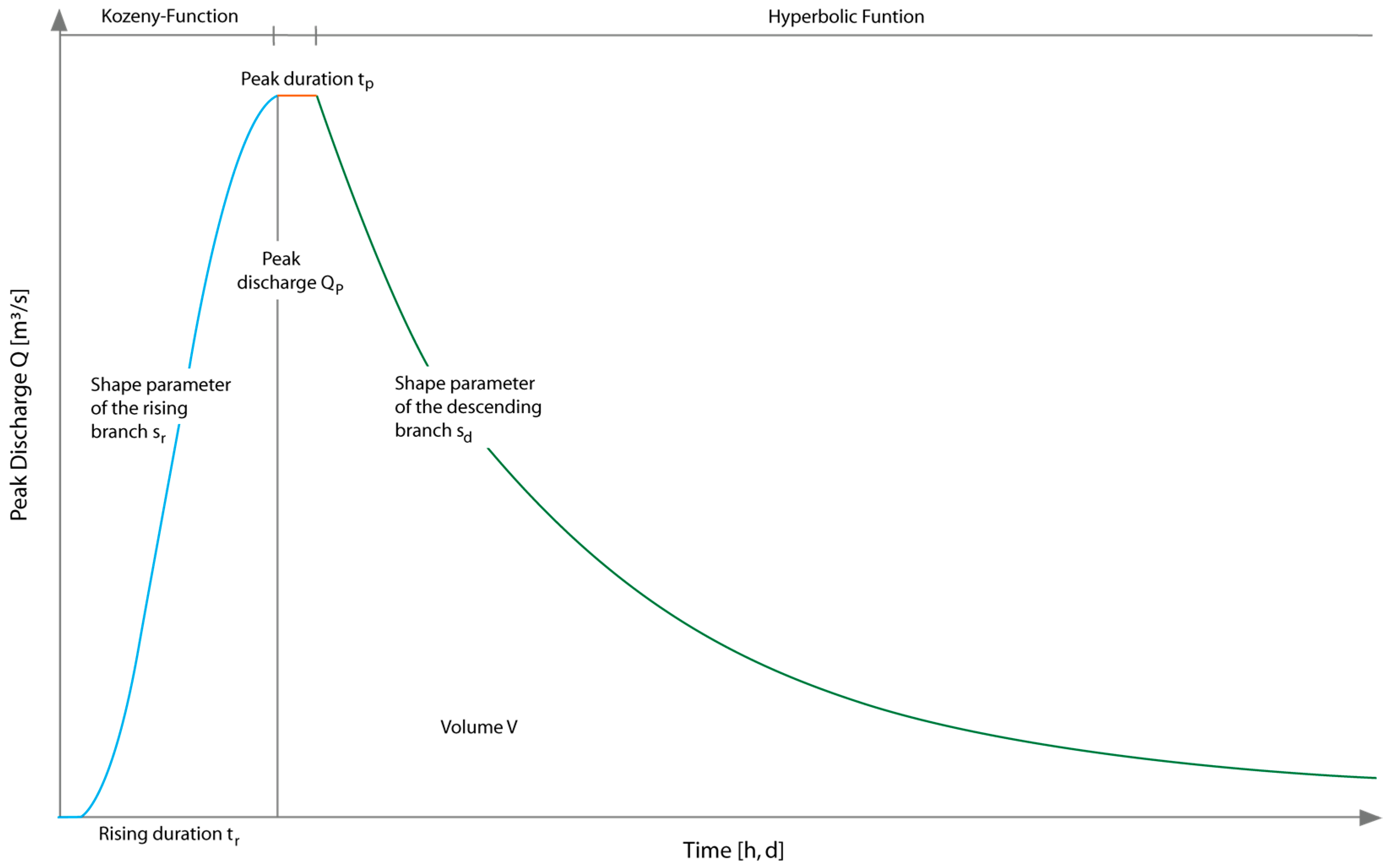
2.1. Hydrograph Functions
2.2. Parameter Identification and Creation of a Synthetic Hydrograph
2.3. Constraints and Enhancement Strategies for the Methodology
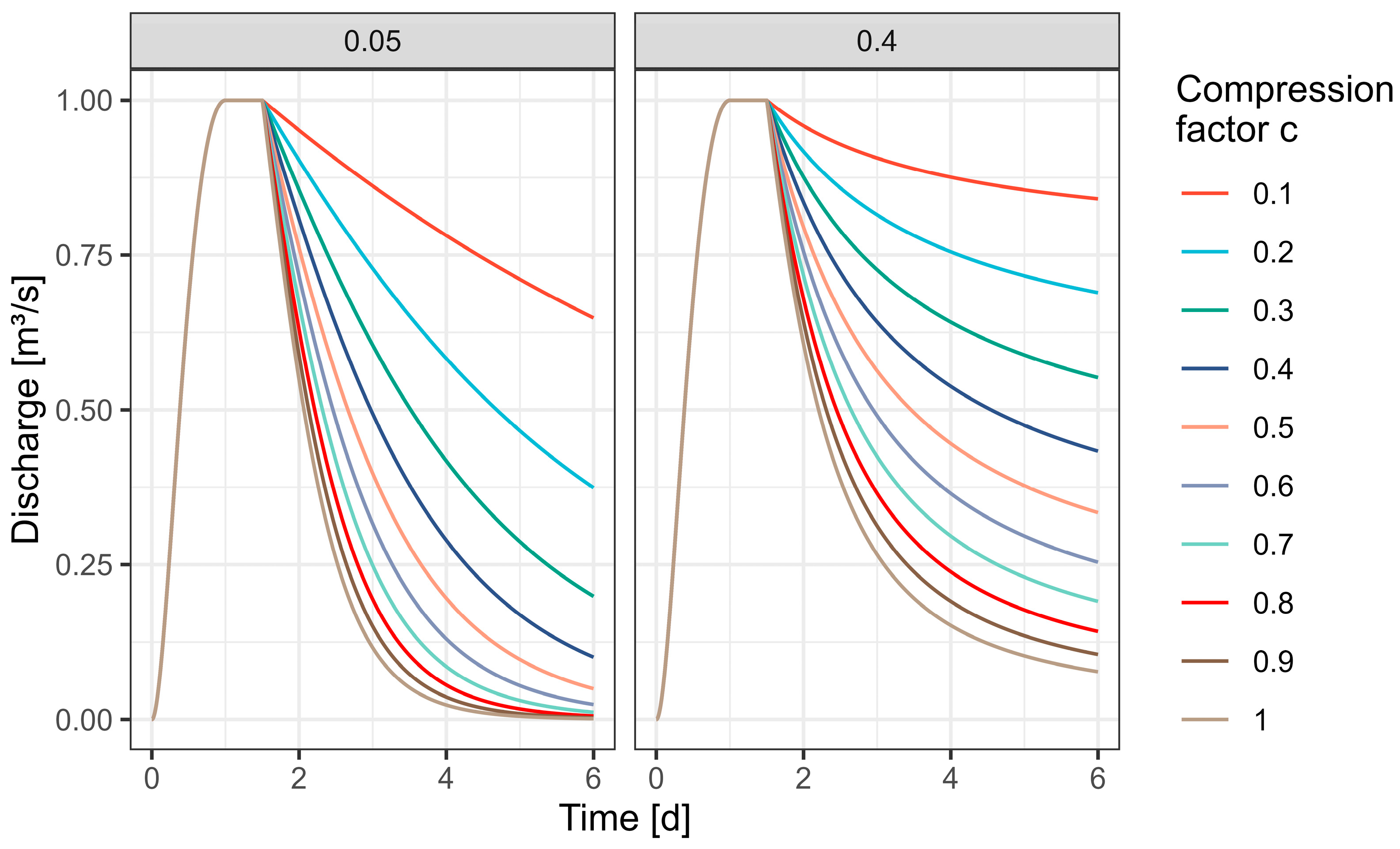
2.3.1. Limitations in Modifying the Descending Branch of the Hydrograph
- Genetic algorithm
2.3.2. Seasonal Statistics
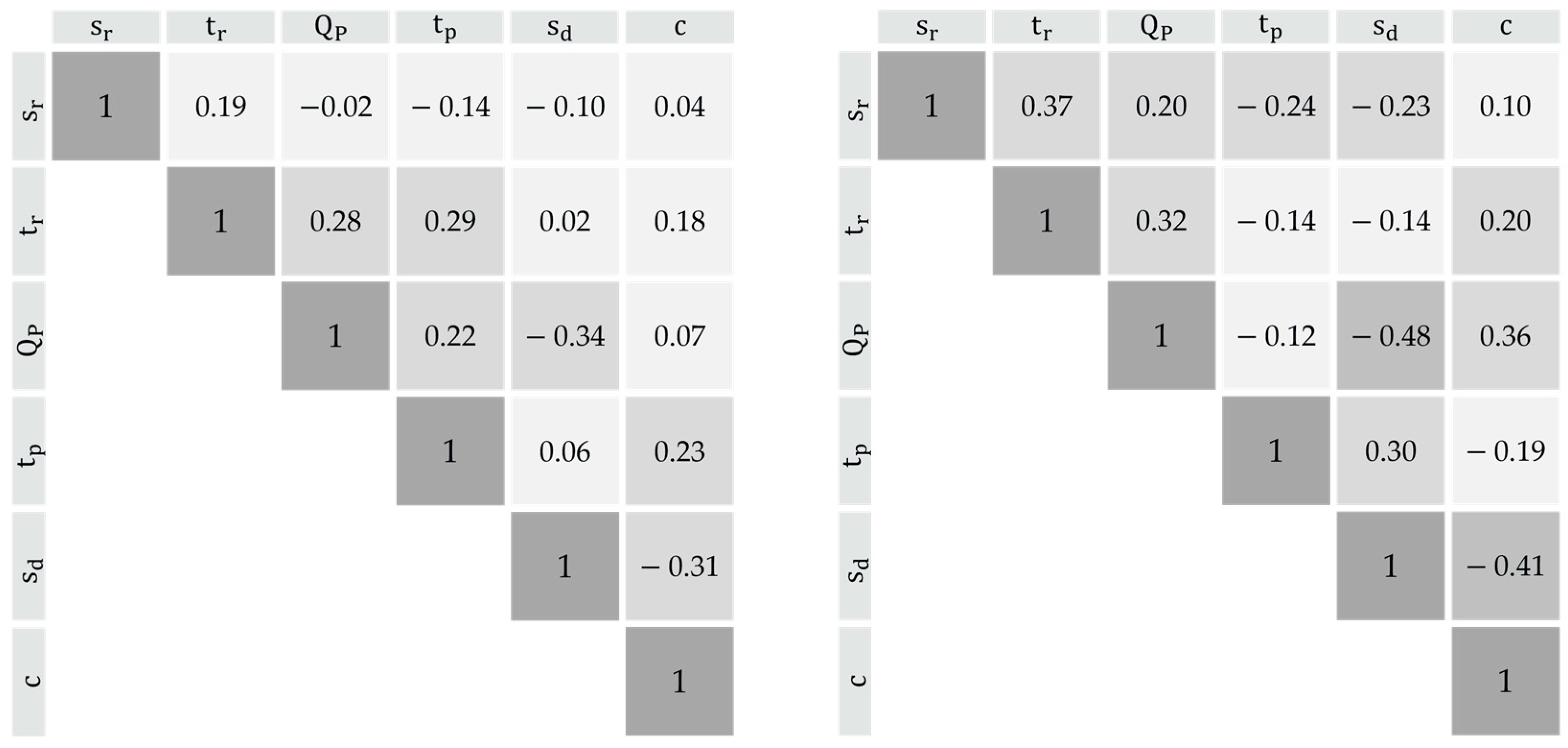
2.3.3. Assumption of Statistical Independence for Individual Parameters
- Correlation
- Copula functions
2.3.4. Multi-Peak Flood Events and Uncertainties
3. Results
3.1. Consideration of Combined Genetic Algorithms in Adapting the Descending Branch
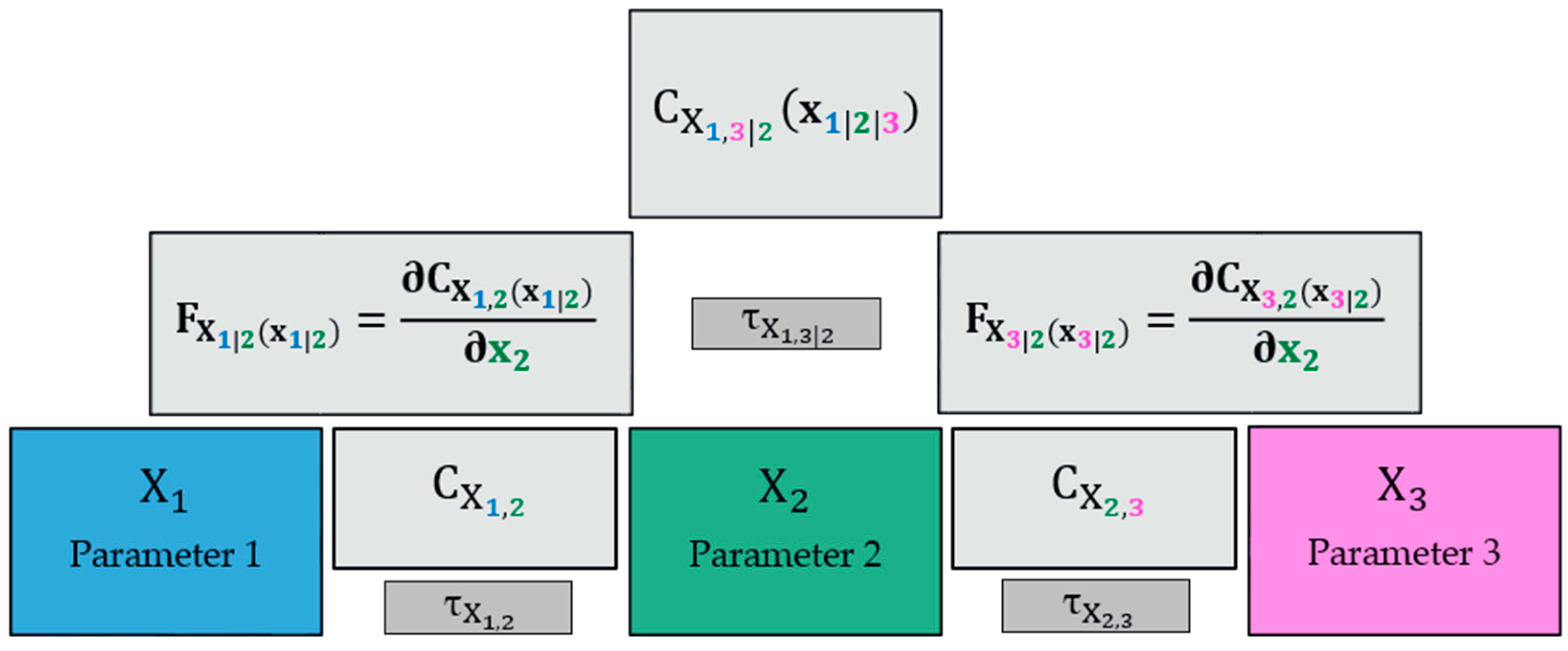
3.2. Consideration of the Dependency Structure between Correlated Random Variables in Terms of Copulas
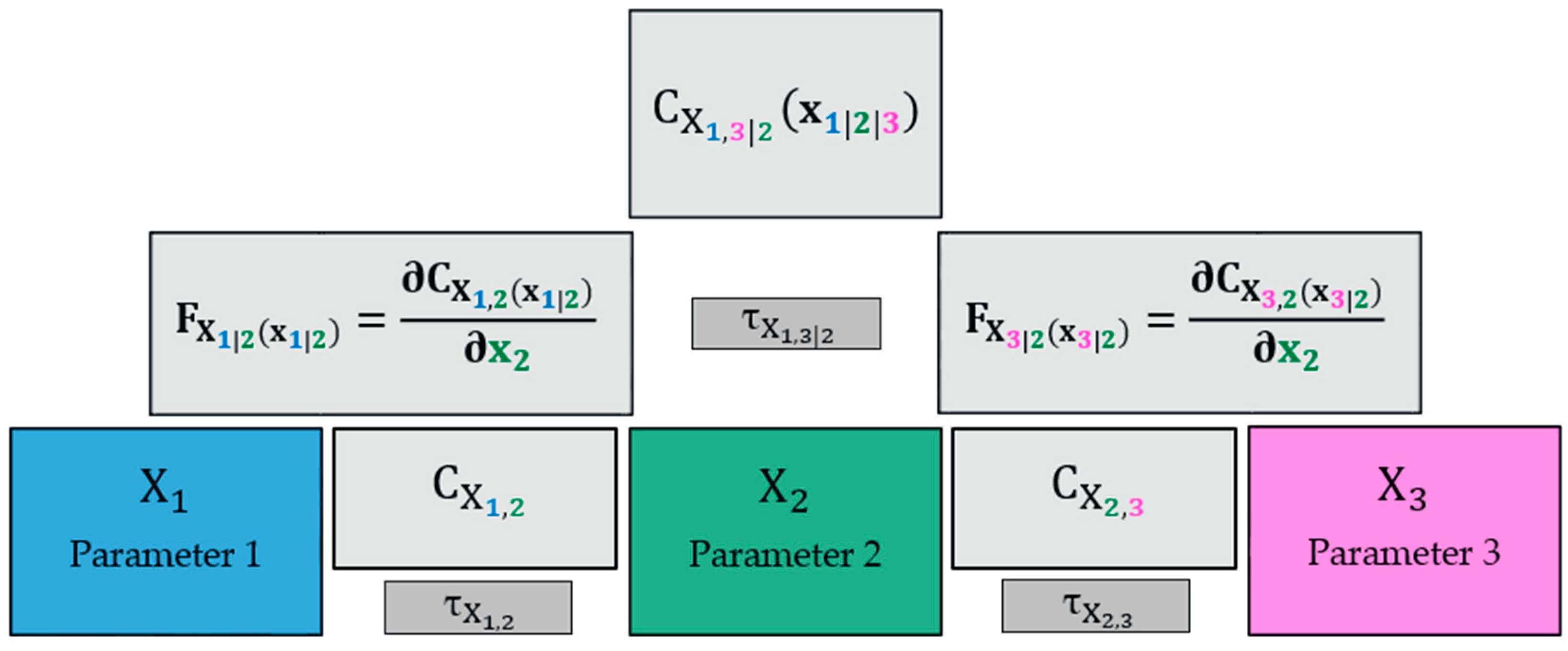
3.2.1. Utilizing D Vines for the Present Application
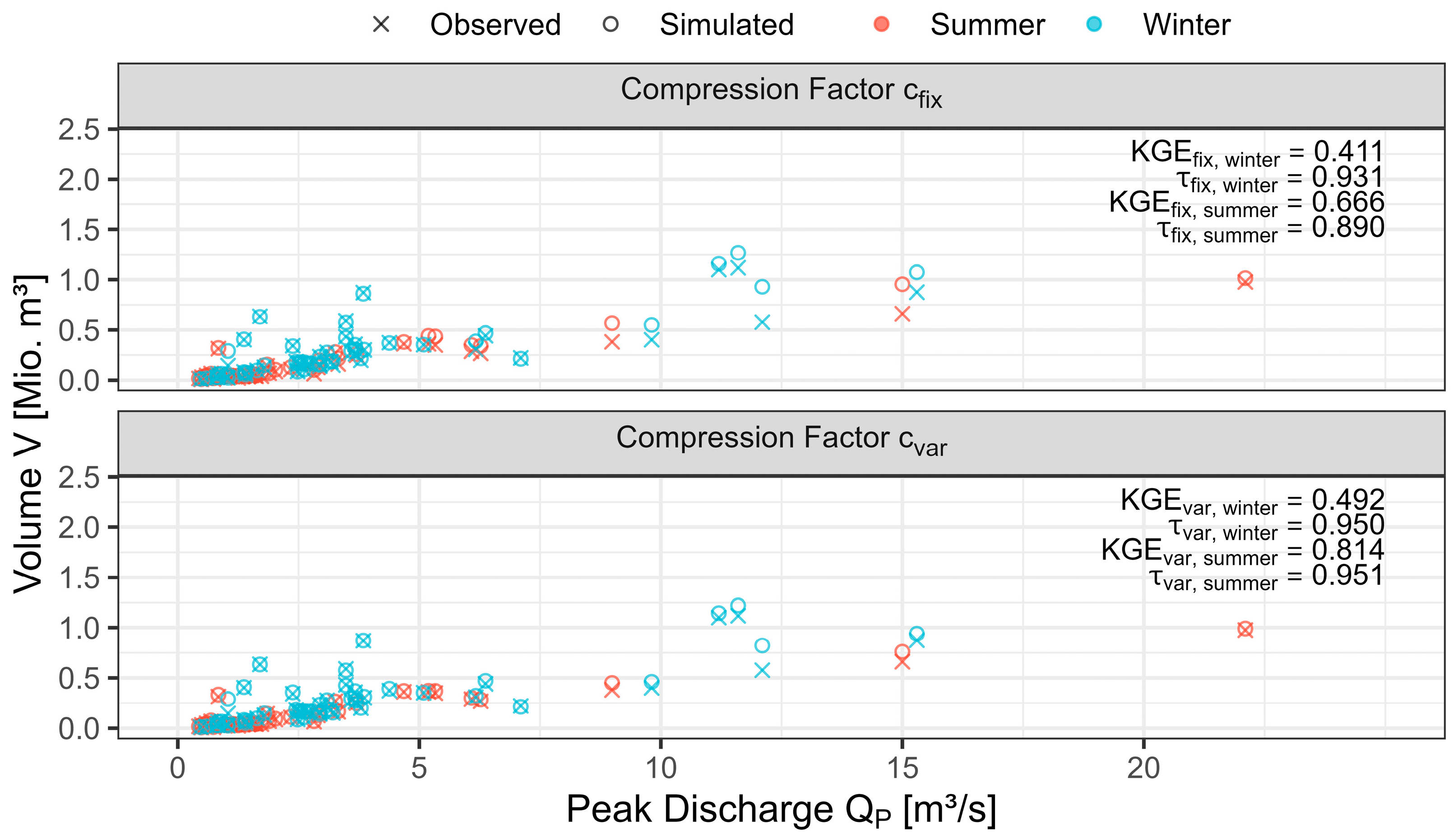
3.2.2. Plausibility Check
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- DIN 19700-10:2004-07; Dam Plants—Part 10: General Specifications. Beuth Publishing: Berlin, Germany, 2004; pp. 1–28. (In German) [CrossRef]
- Chow, T.V.; Maidment, D.R.; Mays, L.W. Applied Hydrology; McGraw-Hill: New York, NY, USA, 1988. [Google Scholar]
- Fouroud, N.; Broughton, R.S. Flood Hydrograph Simulation Model. J. Hydrol. 1981, 49, 139–172. [Google Scholar] [CrossRef]
- Bhuyan, M.K.; Kumar, S.; Jena, J.; Bhunya, P.K. Flood Hydrograph with Synthetic Unit Hydrograph Routing. Water Resour. Manag. 2015, 29, 5765–5782. [Google Scholar] [CrossRef]
- Bender, J.; Jensen, J. Ein erweitertes Verfahren zur Generierung synthetischer Bemessungshochwasserganglinien. Wasserwirtschaft 2012, 3, 35–39. (In German) [Google Scholar] [CrossRef]
- Wyncoll, D.; Gouldby, B. Application of a multivariate extreme value approach to system flood risk analysis. HR Wallingford Work. Water 2013, HRPP594, 1–17. [Google Scholar]
- Candela, A.; Brigandi, G.; Aronica, G.T. Estimation of synthetic flood design hydrographs using a distributed rainfall-runoff model coupled with a copula-based single storm rainfall generator. Nat. Hazards Earth Syst. Sci. 2014, 14, 1819–1833. [Google Scholar] [CrossRef]
- Chatzichristaki, C.; Stefanidis, S.; Stefanidis, P.; Stathis, D. Analysis of the flash floods in Rhodes Island (South Greece) on 22 November 2013. Silva Balc. 2015, 16, 76–86. [Google Scholar]
- Aranda, J.A.; Garcia-Bartual, R. Synthetic Hydrographs Generation Downstream of a River Junction Using a Copula Approach for Hydrological Risk Assessment in Large Dams. Water 2018, 10, 570. [Google Scholar] [CrossRef]
- Shatnawi, A.; Ibrahim, M. Derivation of flood hydrographs using SCS synthetic unit hydrograph technique for Housha catchment area. Water Supply 2022, 20, 4888–4901. [Google Scholar] [CrossRef]
- Fischer, S.; Schumann, D. Generation of type-specific synthetic design flood hydrographs. Hydrol. Sci. J. 2023, 68, 982–997. [Google Scholar] [CrossRef]
- MacPherson, L.; Arns, A.; Dangendorf, S.; Vafeididis, A.T.; Jensen, J. A Stochastic Extreme Sea Level Model for the German Baltic Sea Coast. J. Geophys. Res. Ocean. 2019, 124, 2054–2071. [Google Scholar] [CrossRef]
- Wahl, T.; Mudersbach, C.; Jensen, J. Assessing the hydrodynamic boundary conditions for risk analyses in coastal areas: A multivariate statistical approach based on Copula functions. Nat. Hazards Earth Syst. Sci. 2012, 12, 495–510. [Google Scholar] [CrossRef]
- Leichtfuss, A.; Lohr, H. Die stochastisch-deterministische Generierung extremer Abflusszustände. Schriftenreihe FG Wasserbau Und Wasserwirtsch. Univ. Kaiserslaut. 1999, 9. (In German) [Google Scholar]
- Ministry of Environment, Agriculture, and Consumer Protection of the state of North Rhine-Westphalia. Ermittlung von Bemessungsabflüssen nach DIN 19700 in Nordrhein-Westfalen. Merkblätter 2010, 46, 1–53. (In German) [Google Scholar]
- Dyck, S. Angewandte Hydrologie, Teile 1 und 2. In VEB Verlag für Bauwesen; VEB Verlag für Bauwesen: Berlin, Germany, 1980. (In German) [Google Scholar]
- Lohr, H. Generierung extremer Abflüsse für die Stauanlagenbemessung. Wasser Abfall 2003, 7–8, 20–24. (In German) [Google Scholar] [CrossRef]
- DWA-Merkblatt (Gelbdruck). Stochastische und deterministische Wege zur Ermittlung von Hochwasserwahrscheinlichkeit; DWA (Deutsche Vereinigung für Wasserwirtschaft, Abwasser und Abfall e.V.): Hennef, Germany, 2023; pp. 22–25. (In German) [Google Scholar]
- Mudersbach, C. Untersuchungen zur Ermittlung von hydrologischen Bemessungsgrößen mit Verfahren der Instationären Extremwertstatistik. Dissertation; Universität Siegen: Siegen, Germany, 2009. (In German) [Google Scholar]
- Rubinstein, R.Y.; Kroese, D.P. Simulation and the Monte Carlo Method; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2008; Volume 707. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Hodson, T.O. Root-mean-square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. 2022, 15, 5481–5487. [Google Scholar] [CrossRef]
- Schöneburg, E.; Heinzmann, F.; Feddersen, S. Genetische Algorithmen und Evolutionsstrategien—Eine Einführung in Theorie und Praxis der simulierten Evolution; Addison-Wesley: Bonn, Germany, 1981; pp. 1–481. ISBN 978-3-89319-493-3. (In German) [Google Scholar]
- Tanweer, A.; Shamimul, D.; Amit, D.; Mohamed, B. Genetic Algorithm: Reviews, Implementations, and Applications. Int. J. Eng. Pedagog. 2020, 20, 2–18. [Google Scholar] [CrossRef]
- Fischer, S.; Schumann, A. Berücksichtigung von Starkregenereignissen in der saisonalen Hochwasserstatistik mit Hilfe statistischer Mischungsmodelle. HyWa 2017, 61, 36–49. (In German) [Google Scholar] [CrossRef]
- Merz, R.; Blöschl, G. Flood frequency regionalization—Spatial proximity vs catchment attributes. J. Hydrol. 2005, 302, 283–306. [Google Scholar] [CrossRef]
- Tarasova, L.; Merz, R.; Kiss, A.; Basso, S.; Blöschl, G.; Merz, B.; Viglione, A.; Plötner, S.; Guse, B.; Schumann, A.; et al. Causative classification of river flood events. Wiley Interdiscip. Rev. Water 2019, 6, e1353. [Google Scholar] [CrossRef]
- Hartung, J.; Elpelt, B. Multivariate Statistik: Lehr- und Handbuch der angewandten Statistik; De Gruyter Oldenbourg: Berlin, Germany, 2006; Volume 6. (In German) [Google Scholar]
- Kendall, M.G. A New Measure of Rank Correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Sklar, A. Fonctions de Répartition à n Dimensions et Leurs Marges. In Publications de l’Institut Statistique de l’Université de Paris; l’Institut Statistique de l’Université de Paris: Paris, France, 1958; Volume 8, pp. 229–231. (In French) [Google Scholar]
- Naghettini, M. Fundamentals of Statistical Hydrology; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Roger, B.N. An Introduction to Copulas; Springer: New York, NY, USA, 2006; ISBN 978-1441921093. [Google Scholar]
- Favre, A.C.; El Adlouni, S.; Perreault, L.; Thiémonge, N.; Bobée, B. Multivariate hydrological frequency analysis using copulas. Water Resour. Res. 2004, 40, 1–12. [Google Scholar] [CrossRef]
- Clayton, D.G. A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence. Biometrika 1978, 65, 141–151. [Google Scholar] [CrossRef]
- Frank, M.J. On the simultaneous associativity of F(x,y) and x + y − F(x,y). Aequ. Math. 1979, 19, 194–266. [Google Scholar] [CrossRef]
- Joe, H. Multivariate Models and Dependence Concepts; Chapman and Hall: New York, NY, USA, 1997. [Google Scholar]
- Gumbel, E.J. Distributions des valeurs extremes en plusieurs dimensions. In Publications de l’Institut Statistique de l’Université de Paris; l’Institut Statistique de l’Université de Paris: Paris, France, 1960; Volume 9. (In French) [Google Scholar]
- Bender, J. Zur Ermittlung von hydrologischen Bemessungsgrößen an Flussmündungen mit Verfahren der multivariaten Statistik. In Mitteilungen des Forschungsinstituts Wasser und Umwelt der Universität Siegen Heft 9; Mitteilungen des Forschungsinstituts Wasser und Umwelt der Universität Siegen: Siegen, Germany, 2015. (In German) [Google Scholar]
- DWA-Merkblatt DWA-M520; Probabilistische Methoden im Wasserbau. DWA (Deutsche Vereinigung für Wasserwirtschaft, Abwasser und Abfall e.V.): Hennef, Germany, 2023; pp. 39–42. (In German)
- Genest, C.; Favre, A.C. Everything you always wanted to know about copula modelling but were afraid to ask. Water Resour. Res. 2007, 43, W090401. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. On the use of copulas in hydrology: Theory and practice. J. Hydrol. Eng. 2007, 12, 369–380. [Google Scholar] [CrossRef]
- Cooke, R.M. Markov and entropy properties of tree and vines—Dependent variables. In Proceedings of the ASA Section of Bayesian Statistical Science; American Statistical Association: Alexandria, VA, USA, 1997. [Google Scholar]
- Bedfort, T.J.; Cooke, R.M. Vines—A new graphical model for dependent random variables. Ann. Stat. 2002, 30, 1031–1068. [Google Scholar] [CrossRef]
- Lanzafame, R.; Timmermans, M.; Orlins, F.; Valls, S.S.; Napoles, O.M. Probabilistic Design for Civil Engineering Infrastructure Using Vine-Copulas. In Proceedings of the 31st European Safety and Reliability Conference, Angers, France, 19–23 September 2021. [Google Scholar] [CrossRef]
- Klein, B. Ermittlung von Ganglinien für die Risikoorientierte Hochwasserbemessung von Talsperren. Ph.D. Thesis, Schriftenreihe Hydrologie/Wasserwirtschaft an der Ruhr-Universität Bochum, Bochum, Germany, 2009. (In German). [Google Scholar]
- Quesada-Montano, B.; Di Baldassarre, G.; Rangecroft, S.; Van Loon, A.F. Hydrological change: Towards a consistent approach to assess changes on both floods and droughts. Adv. Water Resour. 2018, 111, 31–35. [Google Scholar] [CrossRef]
- Gaur, S.; Bandyopadhyay, A.; Singh, R. Modelling potential impact of climate change and uncertainty on streamflow projections: A case study. J. Water Clim. Chang. 2021, 12, 384–400. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Gräler, B.; Van den Berg, M.J.; Vandenberghe, S.; Petroselli, A.; Grimaldi, S.; De Baets, B.; Verhoest, N.E.C. Multivariate return periods in hydrology: A critical and practical review focusing on synthetic design hydrograph estimation. Hydrol. Earth Syst. Sci. 2013, 17, 1281–1296. [Google Scholar] [CrossRef]
- Taylor, R. Interpretation of the Correlation Coefficient: A Basic Review. J. Diagn. Med. Sonogr. 1990, 1, 35–39. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Initial Parameters |
|---|---|
Fouroud and Broughton (1981) [3] | Precipitation data |
Bender and Jensen (2012) [5] | Catchment area conditions |
Wyncoll and Couldby (2013) [6] | Geomorphological characteristics |
Candela et al. (2014) [7] | Land cover data, digital elevation model |
Chatzichristaki et al. (2015) [8] | Numerical simulations |
Bhuyan et al. (2015) [4] | Statistical analysis based on observation data |
Aranda and Garcia-Barthual (2018) [9] Shatnawi and Ibrahim (2022) [10]  Fischer and Schumann (2023) [11]  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Öttl, M.A.; Simon, F.; Bender, J.; Mudersbach, C.; Stamm, J. An Extended Flood Characteristic Simulation Considering Natural Dependency Structures. Hydrology 2023, 10, 233. https://doi.org/10.3390/hydrology10120233
Öttl MA, Simon F, Bender J, Mudersbach C, Stamm J. An Extended Flood Characteristic Simulation Considering Natural Dependency Structures. Hydrology. 2023; 10(12):233. https://doi.org/10.3390/hydrology10120233
Chicago/Turabian StyleÖttl, Marco Albert, Felix Simon, Jens Bender, Christoph Mudersbach, and Jürgen Stamm. 2023. "An Extended Flood Characteristic Simulation Considering Natural Dependency Structures" Hydrology 10, no. 12: 233. https://doi.org/10.3390/hydrology10120233
APA StyleÖttl, M. A., Simon, F., Bender, J., Mudersbach, C., & Stamm, J. (2023). An Extended Flood Characteristic Simulation Considering Natural Dependency Structures. Hydrology, 10(12), 233. https://doi.org/10.3390/hydrology10120233