1. Introduction
The current situation regarding disaster response and prediction is fraught with challenges and gaps in the research. Disasters, characterised as intense forms of collective stress caused by a disaster agent, have a profound physical impact on systems, altering their priorities and goals [
1]. These events often overwhelm communities, leaving them reliant on government and international agencies for response operations [
2]. Disaster phases are typically categorised in four phases [
3]: preparedness (planning and warning), response (evacuation and emergency), recovery (restoration and reconstruction) and mitigation (perceptions and adjustment). The focus of decision-making methods in the current literature is on “pre-” (preparedness) and “post-” (recovery and mitigation) phases. The “response phase” is under-studied in terms of demand forecasting [
4].
While there are some articles on disaster demand forecasting [
5,
6], they predominantly focus on optimising resource allocation assuming the demand is already known, and they just try to optimise its allocation [
7,
8,
9] or offer prediction in the pre-response phase [
10]. However, the demand during the critical first 72 h, prior to the release of crucial reports, such as the Multi-Cluster/Sector Initial Rapid Assessment (MIRA), remains largely unknown. Consequently, this paper highlights the urgent need for a predictive framework to support the response phase, necessitating sophisticated decision-making methods for data provision, needs estimation and efficient mobilisation of available resources.
The consequences of failing to predict needs during the response phase can result in the loss of human lives. This paper specifically focuses on natural onset disasters [
11], such as cyclones, tsunamis, flash floods, earthquakes and eruptions. These disasters have been increasing in frequency and impact over the past decade [
12,
13], occurring with little or no warning [
14]. Furthermore, isolating their natural impact from human-made disasters allows for simplified prediction. In contrast, man-made disasters, such as droughts, dam failures and socio-spatial famines, have been extensively researched in separate articles.
However, comparing the impact of natural onset disasters proves challenging due to the variety of disaster types and their respective impacts. Although magnitude scales [
15], such as the Fujita scale for tornadoes, Saffir-Simpson scale for hurricanes and Richter and Mercalli scales for earthquakes, have facilitated comparisons within specific disaster types, different types of disasters present difficulties in using existing methods. Additionally, the scarcity of impact data within the first 72 h of a disaster strike—before MIRA is released by UNHCR [
16]—further hampers comparisons between different disaster types.
To address these challenges, the paper proposes a framework that utilises historical data during the response phase to predict the impact of disasters. As official data is unavailable until the release of the MIRA report, which occurs after the critical response time, relying on historical data becomes crucial. The research question posed is: “To what extent is it possible to predict the impact of the disaster during the response phase to enable timely and efficient decision-making, minimising loss of lives, and reducing disaster impacts?”
By analysing past patterns of human impact data and considering the socio-economic characteristics of affected countries, the framework aims to predict the human impact of natural onset disasters where historical data is available. The study hypothesises the possibility of predicting the human impact of a disaster at the time of its occurrence and explores the relationship between the severity of the disaster and its human impact. Statistical and mathematical techniques are employed to develop a predictive model for human impacts, including fatality, injuries and homelessness, based on the socio-economic characteristics of the affected country and the type of disaster.
This research is necessary for several reasons. Firstly, by understanding and predicting the needs and demands during the understudied response phase, effective and timely decision-making can be facilitated, ultimately leading to more efficient resource allocation and potentially saving lives. Secondly, the scarcity of impact data during the critical initial 72 h after a disaster strike presents a significant challenge in comparing different types of disasters and predicting their respective impacts. By utilising historical data and exploring the relationship between the severity of the disaster and its human impact, this research aims to bridge this gap and provide a decision-making framework that can be applied during the response phase. This is crucial for ensuring a timely and efficient response, as the first 72 h following a disaster are often crucial for saving lives and minimising the overall impact. Ultimately, the need for this research stems from the potential consequences of not accurately predicting the needs and impacts during the response phase of disasters, leading to unnecessary loss of human lives and exacerbating the overall impact of disasters on affected communities. By developing a Predictive model for Estimating Data (PRED) and understanding the relationship between the severity of a disaster and its human impact, this research can contribute to more effective disaster response strategies, better allocation of resources, and ultimately, help mitigate the devastating effects of natural onset disasters.
2. Literature Review
The majority of the publications focusing on decision methods in disaster management are concerned with the pre- and post-disaster phases including mitigation, recovery and preparedness [
17]. Although the first MIRA report is released within 72 h into the response phase, only a few studies focus on these crucial hours of response phase. This includes fuzzy-based severity assessment [
12] or hybrid mathematical models [
18,
19]. The majority of these decision methods frameworks are designed for technical researchers with access to databases, such as user-generated demand data [
20] or surveillance [
21,
22]. To that end, this paper investigates the literature that predicts data that can be used in the first 72 h in the response phase decision methods.
The thematic analysis of the literature reveals that the decision methods approach to disaster management can be categorised into four main categories.
Table 1 shows these categories based on their estimation/prediction frameworks as well as their use of conceptual/numerical measures.
Table 1 highlights four groups of articles related to decision methods in disaster management.
In
Table 1, the first approach conceptually estimates the impact of a disaster without providing numeric data. For example, by stating that the earthquake has social consequences, these articles merely lead to conceptual frameworks. Their significance is to standardise the impact of disasters based on social and cultural factors [
23,
25,
38] where the resilience of the community is being affected, and therefore, can be potentially enforced by various socio-economic factors. However, the fact that these articles ceased publishing in the 80s indicates that the scholars diverted into more numerical approaches such as the second group.
The second group of approaches estimate the potential impact for disasters without prediction. It is noteworthy to emphasise the difference between estimation and prediction. An estimation is inferred for a population based on the assumption that the sample data is a representative of the population, and therefore, “estimates” an unknown part of the dataset. However, a prediction is inferred for a random variable (which is not part of the dataset) based on a sample data or the whole population. In other words, the estimation is a calibration of the population based on a dataset, whilst the prediction calculates a value out of the dataset. To do so, they provide scales for estimating a range. For example, the extent of potential destruction based on the type of the disaster [
39], human, material, temporal, and areal factor [
26,
27,
28,
40], magnitude [
41] and the coping capabilities of the affected population, such as vulnerability and exposure-proneness [
42], and resourcefulness [
43], in addition to damage to the infrastructure [
44] and humanitarian aid supplying power [
45]. This group of research basically estimates the potential impact that a disaster may cause by taking into account the physical and socio-economic factors of the affected area.
The third approach focuses on the human loss estimation based on other criteria (e.g., damage to the buildings). They are more specific in terms of assessing the human loss in disasters as a result of various factors, such as damage to the buildings [
31], the health and socio-economic status of the victims including wealth, age and gender, the location of individuals at the time of the disaster including outdoors, poorly constructed buildings, mobile homes and vehicles [
37], the number of displaced people, the vulnerability of the inhabitants/area [
33], the population density and expected number of people remaining during the flooding, dam failure, time available for evacuation or rescue [
39], resistance to loss and the ability to recover quickly [
35]
Probably due to the wealth of research in the third group, the fourth group of researchers went further and actually predicted the material and human loss of the disasters [
34]. Their predictions are based on expected geographical characteristics of the affected area, such as water depth and flow velocity, rise rate [
33], hazard rating drowning patterns [
36] or physical vulnerabilities of the land [
46]. The last group specifically provides predictions of human loss. In addition, a group of complicated models have been designed to combine some elements of the above studies to suggest a model with 100 variables [
47] or to provide a comparison based module (High-water Information System—Damage and Casualties Module) to calculate the expected damage and the number of casualties due to flooding. This utilises the geographically orientated data concerning economy, traffic, buildings and population [
33]. However, in the early hours after the disaster strike, it is difficult or impossible to obtain the data about the health or location of the people. In addition, the technical data about water depth and flow velocity are not available in all regions. Probably in response to this lack of data, a variety of articles introduced different disaster severity assessment frameworks by embedding the socio-economic characteristics of the affected population. These characteristics include the Disaster Risk Index provided by World Risk Reports since 2011, the Human Development Index provided by UNDP since 1980 and the density of the affected population [
26,
27,
42,
48,
49,
50]. However, this dispersed body of knowledge is yet to be combined into a holistic framework that takes into account these numeric characteristics of the population.
Research Gap—Predictive Disaster Response Framework
We identify four traces to articles that estimate/predict the impact of the disaster. The conceptual approach is limited to cultural and social distress without quantification. The scalable approach quantifies intensity/material/temporal/areal/infrastructural losses, occurrence, causes and detectability without qualitative factors, such as the capabilities. This issue is addressed in the third group, which quantifies the qualitative factors, such as the affected countries’ human development index (HDI), the disaster risk index (DRI), exposure and proneness to disasters and the resourcefulness of the affected population. Finally, the fourth group with predictive approaches focus on the physical characteristics of the disaster and the affected geographical area, without taking into account the people and their coping capabilities. To that end, a predictive framework, which employs both qualitative and quantitative factors whilst taking into account the socio-economic characteristic of the population, is missing. In conclusion, despite the existing research on the groups of literature above, a framework for predicting the human impact is yet to be developed. A number of reasons are associated with this claim. First, the majority of the existing literature focuses on a single type of disaster, such as flood, earthquake, eruption, etc. Therefore, a holistic framework to accommodate different types of disasters is missing. Second, the existing literature sometimes contradicts each other, for example, many research studies predict the fatalities based on the damage to the buildings [
29,
30,
31,
32] whereas some researchers have not found an easy correlation between the pattern of building damage and the fatalities [
51]. The third reason for developing a new model is that although a rich body of complex and technical papers is put forward, most of the findings are yet to be customised for practical use in real situations. For example, conceptual frameworks are impossible to use in practice. The framework with 100 variables is difficult and time-consuming to use for an average decision-maker, and the extremely technical frameworks, which require a wealth of technical data and complicated computer simulation support, might fall short in the disaster situation in many countries. The fourth reason is that the majority of the above criteria are drawn from data related to one or few events in specific countries, and their extrapolation and generalisation are unreliable. The literature review highlights the necessity of developing a model, which employs the data universally available at the time of the disaster.
4. Results
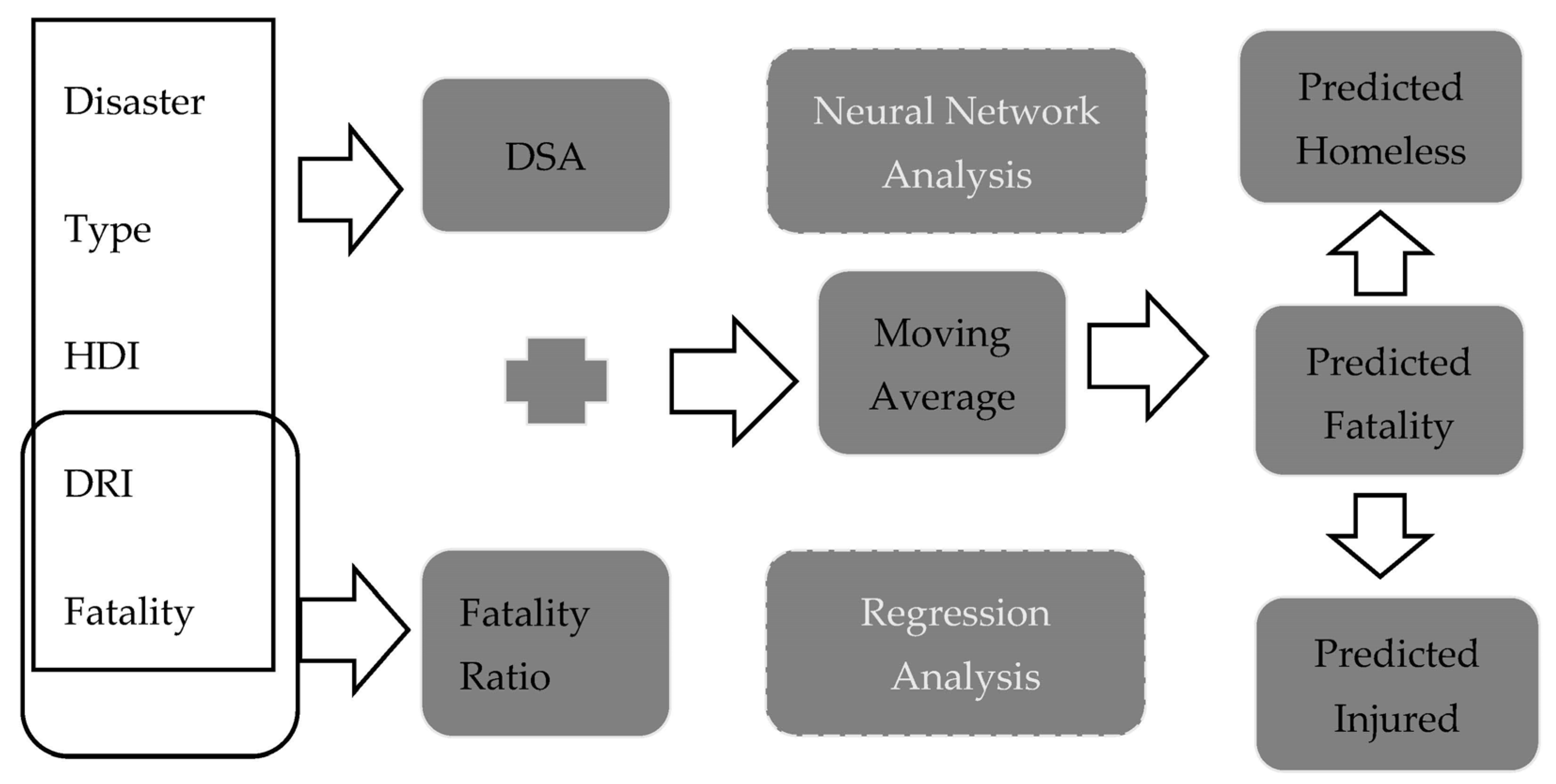
The null hypothesis (H0) was defined as “the available data at the time of the disaster has no predictive power in estimating the human impact”, while the alternative hypothesis (H1) proposes that the data can indeed be used to predict the human impact of the disaster. To validate this hypothesis is the essence of the study, which uses statistical and mathematical techniques to provide a predictive model for a disaster’s human impacts. This is designed based on the hypothesis that there is a relationship between the human impact of the disaster and the severity of the disaster. The application of above tools in the data set leads to prediction of fatality, injured and homeless based on the socio-economic characteristics of the affected country in the respective year as well as the type of the disaster as explained further. Three predictive models are built to test the predictive power of MA rules, regression analysis and neural network analysis as follows.
4.1. Application of DSA
Theoretically, in the DSA model, there are 102 scenarios; however some theoretical scenarios, such as disasters ranked 1 and 2, are non-existent in the database of actual previous disasters. This might be because they are yet to occur, or because their severity is so low that it deems unnecessary for the humanitarian sources to record them. These scenarios will be explained later in detail. The DSA ranked in combination with the criteria mentioned earlier produce a standard diagnosis tool capable of comparing the impact of the disaster on the different countries with different coping capabilities. An example of this comparison between some areas affected by the Indian Ocean Tsunami is presented in
Table 5.
Table 5 shows the DSA calculated for the countries affected by Indian Ocean Tsunami (2004). It shows that Indonesia had the highest severity (DSA = 16), and the Seychelles had the lowest (DSA = 7). The significance of this framework is that, with no knowledge of the data on the ongoing disaster and minutes after the disaster strike, the DSA predicted that Indonesia needed more aid than India, even with a lower population than India. In reality, weeks after the disaster, the reports showed that Indonesia sustained the highest human and material loss. This indication in the early hours of a disaster is highly valuable because it signals the highest need of channelling the humanitarian aid.
4.2. Prediction Based on Stepwise Regression Analysis
Based on the hypothesis defined earlier, the null hypothesis (H0) posits that the data available at the time of the disaster do not have any meaningful predictive ability in estimating the human impact. On the other hand, the alternative hypothesis (H1) suggests that the data possess the potential to forecast the human impact of the disaster. A series of stepwise regression analysis (
Table 6) on 4289 cases reveals that the DSE rank can explain 6.6% of the number of fatalities and the criteria used to calculate DSE, including HDI, DRI, population, population density and disaster type, can explain 13.4% of fatalities. Because the DRI was insignificant, the model was refitted without DRI and actually decreased the ability to explain the fatalities to 13.3% as shown in
Table 6.
In an attempt to improve the model, some unsuccessful efforts were made, for example, the population in a 100 km radius based on GDACS data and disaster magnitude were added to the model, which respectively showed the potential number of the affected population and potential destructive effect of the disaster. The available data for these two criteria for our sample size of 4289 were limited to 69 records. Repeating the regression analysis for these 69 records shows that adding the factors of magnitude and potential affected population in a 100 km radius actually decreased the model’s fit to 9.9%. Due to the low sample size of 69, which lacks the generalisability, in addition to the low predictive power, the latter regression was not refitted. One of the most common techniques for finding the pattern between variables and predicting one variable based on others is the regression analysis. As the regression analysis in Exhibit 67 shows, the fatality to some extent can be predicted using the following formula: Fatality = −1.412–1.709 × Country’s HDI + 0.257 × Population + 0.102 × Population Density + 0.316 × Type rank. However, the accuracy of this prediction is low because it could just explain 13.3% of the fatalities, as was explained before.
Table 6 shows that the DSA rank can explain 6.6% of the fatalities, whilst all original nine determinants explain up to 99% of the fatalities. When the determinants that were unavailable for all records (magnitude and population within 100 km of the disaster) were omitted from the model, the adjusted R-squared increased to 13.4%. However, there are two reasons why the authors did not use regression analysis for prediction. First, the R-squared is too low to be explanatory. In addition, based on the rule of large numbers, in the specific case of this research, R-squared is not meaningful.
This suggests that the predictive power of the regression model for the given dataset is not strong, which confirms the null hypothesis. Furthermore, when comparing the explanatory power of various variables, it is observed that all nine original determinants, including DSA rank, HDI, DRI, population, population density, disaster type, magnitude, potential affected population within 100 km, HDI and population density, collectively explain up to 99% of the fatalities. However, due to the unavailability of certain determinants (magnitude and population within 100 km) for all records, their exclusion from the model leads to an adjusted R-squared value of 13.4%. Considering the low explanatory power of the regression analysis, the authors decided not to rely solely on regression for prediction. This emphasises the need for alternative mathematical and statistical methods to enhance the predictive capability of the model.
4.3. Neural Network Analysis
Another unsuccessful attempt was to use a neural network for prediction. The data were divided into two groups, 4000 records were used for building the model and the remaining 289 to test the data. The neural network was built using the excel solver and NN-ad-in software based on five inputs acquired from the DSA framework (
Table 7) and one hidden layer. The built neural network was solved four times until the network could not be converged to any new solution; however, the comparison between the actual fatalities and the predicted number of fatalities were not a match.
Table 7 shows that, for example, in a cyclone rank 5 where the actual fatalities were 11, the neural network predicted the fatalities as −28.9 in round 1, 106,352 in round 2, 24,278 in round 3 and 228.95 in round 4. The result shows that the future disasters are not accurately predictable based on the previous records of data using the neural network. This will be further discussed in the next part.
4.4. Prediction Based on MA Rule
Using the MA rule and fatality ratio, the fatalities of various earthquakes in different countries can be calculated, as shown in
Table 8.
The first three rows provide information about the earthquake, including its geographical and temporal data, in addition to its DSA rank. The fourth column shows the fatalities caused by that particular disaster and the fifth column calculates the MA for that stream of data. The last column shows the changes in the moving average. When the new moving average is higher than before, the last column is positive and signals a change in the trend, otherwise it is negative, and trends stays the same. A snapshot of the calculation process is presented in
Table 9.
As is seen in
Table 9, the signal in earthquakes appears in DSA rank 9 for the New Zealand earthquake (2011), which spikes the changes in the direction of the prediction pattern when the MA jumps 120 points. The next change is signalled in the Bolivian earthquake (1998), with a DSA rank of 10, when the MA jumps 25 points, and the next change is in the Egyptian earthquake (1992) when the MA jumps 480 points. These signals and moving averages were calculated for each disaster type and rank in our 4252-size population. For example, in the category of Tsunami under 11, the fatalities are below 400 for 52 records, then there is a signal (jump in MA) to 30,000 fatalities when it comes to the severity 11, which changes the moving average from 50 to 2120. The calculation leads to the moving average for each degree of severity (DSA rank) in
Table 10.
Table 10 shows a set of rule-based scenarios where, for example, “if an earthquake’s DSA is under 10, the fatalities are less than 200”. However, because the extreme cases in the record show (as a cautionary factor, the outliers were still considered in the data set as an example of extreme cases or worst-case scenarios), it is wise to keep extra capacity as a contingency plan to support up to 1000 fatalities as a risk factor based on the extreme cases. To be more precise, the rules can be defined as “if the DSA is under 10, fatalities are more likely to be under 200 (basis for average fatality); however, in rare cases, fatalities can be in the range of thousands (basis for maximum fatality)”. The next step is to use the above fatality prediction framework to predict the fatalities for the whole population. A randomly selected sample of 2976 (70% of the population) was selected out of 4252 records of data to develop the framework. The created framework was tested on the remaining records of 1275 (30% of the population) disasters for prediction. An example of the predicted fatalities and actual fatalities with this framework is presented in
Table 11.
Table 11 indicates that in a flood rank 4, the actual fatality was 5, which means that it was almost successfully predicted within the range, because based on table, a flood rank 4 is a severe flood with fatalities between 17 to 161. Another example is the cyclone rank 9, where the fatalities were predicted to be between 47 and 1833 and the actual fatalities were 483, which is within the range.
4.5. Evaluating the Result of Fatality Prediction
Observations about the accuracy of the above three models allows us to calculate the prediction error for each, as exhibited in
Table 12.
The simple fatality model is the least (3.10%), and it is the most accurate model for predicting fatalities in this paper. The rest of the models have a very low accuracy because their prediction errors are 30.2%, 4071% and 53,157%, respectively, for the neural network prediction model, fatality ratio prediction model and regression analysis prediction model. For each individual disaster type, this pattern stands. As shown in
Table 13, the fatality ratio and regression analysis have a high level of error in all disaster types, whereases the fatality average is a slightly better predicter than the neural network in all types of disasters. The exception is flood, where the neural network predicts it with a 3.75% error and the fatality average predicts it with an 8.55% error. In addition, in case of storms, the neural network has a highly inaccurate prediction equal to 302.22% error.
To that end, the author suggests that wherever possible, the prediction of fatalities should be calculated by both methods of the fatality average and neural network, and the results compared in order to avoid mistakes. However, where is not possible, the fatality average is recommended for predicting the fatalities. At first glance, the DSA can be successfully used for predicting the number of fatalities using the MA rule. However, it fails to predict the fatalities accurately using regression analysis. In order to confirm these predictive capabilities further, NRMSE provides a comparison, as shown in
Table 14.
Table 14 confirms the preliminary observation about the accuracy of the models. It shows that the prediction error for the fatalities using the MA rule is the lowest (3.10%), and it is the most accurate model for predicting fatalities in this research. The prediction error for regression analysis is the highest (53,157%), next is NNA with 30.2%, and finally, the MA rule error is only 3.10%. To test this, using the MA rule, the whole population was predicted.
Table 15 shows the occasions where the predicted value falls below the actual observed value.
Table 15 shows that there were 29 occasions of failure out of 4252 records equal to 1% (0.68%) failure in prediction. In other words, 99.3% of the time, the decision maker can be sure to accurately predict the maximum number fatalities. In the PRED model, there is a minimal chance of not being able to meet the requirements of the affected population. Based on the above null hypothesis (H0), the data available at the time of the disaster does not have any meaningful predictive ability in estimating the human impact. On the other hand, the alternative hypothesis (H1) suggests that the data possess the potential to forecast the human impact of the disaster. The initial analysis indicates that the DSA method, specifically using the MA rule, shows promise in predicting the number of fatalities. However, regression analysis was proven to be inaccurate in this regard. To further validate the predictive capabilities, the NRMSE metric is employed, comparing different prediction methods.
Table 14 supports the initial findings, showing that the MA rule has the lowest prediction error (3.10%) and is the most accurate model for fatalities. In contrast, the regression analysis yields a high prediction error of 53,157%. To address concerns about the accuracy of NRMSE for the entire population, the authors performed a comparison based on disaster type using a smaller sample size (15% of the population). The results in
Table 12 demonstrate that, except for storms, the MA rule outperforms regression analysis for most disaster types. The NRMSE calculations indicate that, on average, the MA rule has a prediction error of less than 10% for most disaster types. However, due to limited observations, volcanic eruptions remain unsupported by evidence. Additionally, the authors argue that even for sceptical readers who question the reliance on NRMSE, the predictions align well. A significant portion (14.6%) of the predictions falls within the range of average to maximum fatalities, with the majority of the observed values being lower than the predicted maximum.
Table 16 presents instances where the predicted values fall below the actual observed values. Out of 4252 records, 29 predictions (1%) show such inaccuracies, mainly occurring in extreme cases of disasters. Based on these findings, decision-makers can be confident that following the maximum number of predictions in the PRED model will meet the requirements of the affected population in 99.3% of cases. This supports the alternative hypothesis (H1) that the data possess the potential to forecast the human impact of the disaster.
4.6. Predicting the Homeless and the Injured
By using the injured and homeless ratio discussed before, the number of injured and homeless are predicted and compared, with an example presented in
Table 16.
Table 16 indicates that the injured and homeless ratios vary across different types of disasters and countries. For instance, earthquakes in Afghanistan resulted in an injured ratio of 0.034 and a homeless ratio of 0.387. On the other hand, storms in certain countries had a higher injured ratio (1.9281) and homeless ratio (13.3824). These ratios provide valuable insights into the potential impact of disasters on affected communities.
4.7. Evaluating the Injured/Homeless Prediction
In order to evaluate if the above predictions could be trusted, they could be compared with the actual observed data. However, as mentioned above, the actual observed data are published in the accumulated form as the “total affected population”. Total affected population is defined as the sum of injured and homeless (Equation (5)).
Equation (5) Total affected population:
where the injured population is defined as the people suffering from physical injuries, trauma or an illness requiring medical treatment as a direct result of a disaster. In addition, the homeless population is defined as the people needing immediate assistance for shelter. Therefore, the predicted results were accumulated to make them comparable to the accumulated observed data. It also indicates that in some scenarios, the equations resulting from the regression are better predictors (such as the Philippines cyclone rank 13), whilst in others, the equations resulting from ratios are better predictors (Nigeria flood rank 12). NRMSE for these predictors is compared in
Table 17.
Table 17 shows that the average fatality (1.7% error for 4252 observations) is a better predictor than maximum fatality (4.4% error for 4252 observations). In addition, the error in the prediction of the accumulated number of injured and homeless is 2.41%, which shows that the error in predictions of the average observation (most probable) and maximum observation (the worst-case scenario) is 2.41%, which is less than errors in prediction for the fatality average observation (most probable) and maximum observation (the worst-case scenario), which is 4.48%. Thus, the overall the prediction of homeless and injured is more accurate than fatalities. For a better picture, the success of the prediction is defined as the percentage (out of 4252) of accurately predicted values within the range in
Table 18.
Table 18 shows that on average, the fatalities predicted for 3589 occasions is within the range of actual observation. On the other hand, for 631 occasions, the observations conform to the maximum fatalities predicted. Finally, for 35 occasions, the prediction was totally inaccurate. Overall, the observed fatalities conform to the prediction range in 99% of cases. The framework predicts the homeless and injured correctly in 43% of the cases.
5. Discussion
This study focuses on the humanitarian sector and aims to address the lack of real-time data during the response phase of disasters. The research question explores the extent to which it is possible to predict the impact of a disaster in order to make timely and efficient decisions to prevent loss of lives and minimise disaster impacts. The study finds that existing research in this area is limited to specific geographical areas or disaster types, and the data used for prediction is typically available days after the disaster.
To fill this gap, the study utilises various techniques to develop a decision-making tool called PRED for partner selection in a disaster response network within the first 72 h after a disaster strikes. The study accumulates, evaluates and analyses historical data from natural onset disasters registered between 1980 and 2013, sourced from multiple humanitarian databases. The data is filtered to focus on 4252 records that include five predictive variables: disaster type, human development index (HDI), disaster risk index (DRI), population and population density.
The study identifies a relationship between the impact of disasters (such as fatalities, homelessness and injuries) and the aforementioned criteria, including disaster type and socio-economic characteristics of the affected country. The severity of the disaster also shows a pattern based on these criteria, with the Moving Average (MA) rule providing the best prediction. The prediction model is developed using 60% of the dataset and tested using the remaining 30%, with the Normalised Root Mean Squared Error (NRMSE) used to evaluate the fitness of the prediction. Based on regression analysis and the MA rule, the study proposes a framework to estimate the human impact of a disaster (fatality, casualty, homelessness) based on its severity rank in the early hours of the disaster. The predictions are presented in two scenarios, representing the lower and higher ranges, and decision-makers can choose which range to proceed with based on personal preferences. The study acknowledges that the reasons behind decision-makers’ choices are beyond its scope but suggests it as an area for further research.
The research focuses on the prediction of human impact during a disaster and explores the relationship between disaster type, socio-economic factors (HDI, DRI, population and population density) [
44] and fatalities. The study confirms that it is possible to predict the human impact of a disaster within a certain range. The prediction model developed in the study has an error rate of 3.10% for fatalities (1.7% for the lower limit and 4.5% for the higher limit), and a 2.4% error rate for the accumulated number of homeless and injured individuals (both lower and higher limits).
The findings support the proposition that there is a relationship between disaster type and fatalities, with the fatality power of different disaster types ranked from lowest to highest as Storm/Flood/Volcano/Cyclone/Flashflood, Tsunami/Earthquake. This ranking aligns with previous linguistic measures identified in the Sphere project [
71].
Furthermore, the study reveals relationships between fatalities and socio-economic factors, such as HDI and DRI, as well as population and population density of the affected country. These findings are consistent with prior research that used fuzzy logic and linguistic measures characterised by NGO decision-makers.
A sceptical reader might point out that a range for prediction might be counted as a weakness for the model. The author argues that a prediction of a range has previously been conducted in the literature. For example, in a flood due to the dam break in Netherlands, eight methods for dam and dyke breaks were used to predict the impact within the range from 23 fatalities to 5236 fatalities [
36]. The study also shows that this prediction could be further strengthened if the data about population within 100 km and the magnitude of the disaster becomes available for all records in the database.
The initial understanding of the author is that the quality of prediction could be improved if the model is re-fitted for each country separately. For example, here the fatalities for each country have been used for pattern finding, but if we use the record of fatalities for each state in a country, then the predictions could possibly be improved and the prediction range would narrow. However, this requires the availability of a database for each state of each country for decades. This could be another area for the future research if that becomes available.
A critical overview of the findings by the authors sheds a light on the following, firstly, it addresses a critical need: The study addresses the lack of real-time data in the humanitarian sector during the response phase of disasters. By providing a framework to predict the impact of a disaster, it aims to enable timely and efficient decision-making to prevent loss of lives and minimise disaster impacts. Secondly it provides a comprehensive approach: The study utilises a variety of techniques, including pattern recognition and rule-based clustering, to analyse and evaluate historical data. It accumulates data from multiple humanitarian sources and covers a wide geographical dispersion, including every country where data was available, which enhances the robustness and generalisability of the findings. Thirdly it identifies the predictive factors: The study identifies key predictive variables such as disaster type, human development index (HDI), disaster risk index (DRI), population and population density. It establishes a relationship between these variables and the human impact of disasters, providing insights into the factors that contribute to the severity of a disaster. Finally, its practical application: The study presents a decision-making tool called PRED that can assist in partner selection for disaster response networks within the first 72 h after a disaster strikes. The tool provides estimations of the disaster’s human impact, allowing decision-makers to make informed choices during the critical early hours.
6. Conclusions, Contributions and Limitations
This paper has been structured to answer the following question: “To what extent is it possible to predict the impact of the disaster during the response phase to enable timely and efficient decision-making, minimising loss of lives and reducing disaster impacts?”. The PRED model presented in this paper demonstrates the potential to predict the impact of a disaster during the response phase, enabling timely and efficient decision-making while minimising loss of lives and reducing disaster impacts. By employing predictive frameworks and utilising pre-existing data, the model offers valuable insights into the severity of a disaster, including fatalities, casualties and homelessness, within the first 72 h of the event. The model’s ability to utilise available data at the time of the disaster, even in the absence of official data, allows decision-makers to estimate the population affected and allocate resources accordingly. This timely information aids in mobilising the necessary support and implementing effective response strategies. With an average predictive error of less than 3%, the model demonstrates a high level of accuracy in estimating the human impact of disasters. Furthermore, the PRED model surpasses existing frameworks by its flexibility in considering various types of disasters and geographical locations, making it applicable in diverse contexts. Decision-makers can compare the effects of different disaster scenarios and make informed choices based on budget constraints and personal preferences, as the model provides a range of predictions.
This paper addresses the lack of data at the time of the disaster by employing predictive frameworks. In total, it included 4252 filtered historic records of five variables (disaster type, HDI, DRI, population and population density). This data was processed through a combination of pattern recognition techniques and rule-based clustering for prediction and discrimination analysis. The significance of the model is in its ability to use the pre-existing data in order to predict the impact of the data before the release of the first official data within the first 72 h. The relationship found between the disaster human impact (fatality, homeless, injured) and these criteria gave rise to a DSA framework to estimate the disaster’s human impact (fatality, casualty, homeless) based on their severity rank in the early hours of a disaster strike. The NRMSE shows that the model’s predictive error is less than 3%.
The methodological contribution is to combine a multi-step approach, including DSA, fatality and injury prediction, in the area of prediction and decision-making in disaster management. The practical contribution is bridging the gap in the field by enriching the predictive power, which may hugely improve the performance of humanitarian operations. By relying on the available data at the time of the disaster, which are freely available to the public, the cost and the time required for collecting and analysing data could be reduced. Consequently, it speeds up the response time of the aid operation by almost 72 h, which is vital at the time of the disaster. In addition, it is the only existing framework that is not limited to a certain type of disaster (although it just considers the five types of natural onset disasters) or geographical or chronological order. These unique characteristics make it possible for decision makers to compare the effects of the different types of disasters affecting different areas at different times.
Another contribution is that the model has the capability to accommodate the socio- economic characteristics of the affected population, which hugely influences the required aid in humanitarian response practices. The model also has the capability to facilitate the predictions of damages, as required by the insurance industry. Another practical contribution is that by providing a range of predictions (average, maximum), it enables the decision maker to decide based on their budget limitations and personal preferences. It also gives different organisations the chance to customise the model using their own database if required. However, the authors believe that this model, in the long-term, could facilitate the establishment of a centralised database for humanitarian response, which is long overdue. This also could help in the long run to provide a basis for introducing universal performance measures and a framework for humanitarian operations because the universal data feed renders the organisations and their performance comparable to each other. The model can be used by decision makers to calculate the population affected during the first 72 h after the disaster strike, when no official data is available. This could be helpful in resource mobilisation and allocation. The model can help to weigh alternative scenarios in different disasters and the prediction can be updated annually to reflect new disasters. However, it is unlikely that the DSA and, therefore, predictions change drastically, unless very large outliers arrive in the data set regularly due to regular devastating disasters with high human impact. At that point, these outliers will become part of the pattern and the updated pattern will then require an updated DSA and will lead to different predictions.
Another argument is that the author believes that the PRED model presented here exceeds the existing frameworks in a variety of criteria. First of all, the existing methods, such as Hazard US or HAZUS [
72], require a high degree of precise data provided by highly funded and equipped entities, such as NASA, with extremely well trained staff and they are less applicable in developing countries. The model can work with the simple freely available data on variables such as population, HDI, DRI and disaster type, and it can be quickly employed in any country regardless of their level of socio-economic development. It can also be complimentary to the method developed to be used in the countries with less developed infrastructures [
31] as it focuses on mitigation and preparedness phases. To that end, the model presented in this paper can be used to inform the decisions further in the response phase after the planning for mitigation has been implemented and before the planning for recovery is launched. The model is also different from the decision support tools for severity assessment [
44], which aims to assist the NGOs in the prioritisation of their tasks after the disaster strike. Although their method is robust and sophisticated, it requires a great deal of mathematical and analytical expertise. The step-by-step guide of the PRED model with a platform of embedded formulas requires almost no technical expertise and any decision maker with a minimum level of literacy could benefit from it. PRED is also different from other methods, such as EMPROV, which are designed to support improvised decision-making [
72] because they assume the data are available and do not provide frameworks for predicting the unavailable data, such as fatalities during the disaster response. The method of pattern finding in this study is, to some extent, similar to rule-based clustering used for prediction in various studies [
72,
73]. However, it is unique in a sense that it uses the available data to predict the impact in the early hours of disaster strike, with no real-time data drawn from the area. All of the other frameworks discussed above use some level of data drawn from the disaster area days after the disaster strike. They also do not specifically address every disaster type and country.
However, it is important to acknowledge that the predictive accuracy of the model is contingent upon the quality and availability of data. Discrepancies may arise due to factors such as delayed reporting and population movements, which can affect the accuracy of predicted numbers of injured and homeless individuals. Nevertheless, the PRED model presents a promising approach that can continually improve through the integration of updated data and refinement of the prediction methodology. In summary, the PRED model offers a viable solution for predicting the impact of disasters during the response phase, enabling timely and efficient decision-making to minimise loss of lives and reduce disaster impacts. While there are inherent limitations, the model’s practical benefits and its ability to utilise available data make it a valuable tool for decision-makers in the field of disaster management.
One of the limitations of this study is the discrepancies between the observed and predicted numbers of injured and homeless. This can be explained in two ways. First, that there is no evidence whether the accumulated number of affected populations counts the injured people who are also homeless twice. This might cause discrepancies. The non-accumulated account of homeless and injured were not available from Munich RE, and CRED databases. In addition, it should be taken into account that the observations are reported months after a disaster strike and do not necessarily comply with the early hours of the disaster. For example, some of the injured people in the early hours of the disaster might, unfortunately, be reported later on. Some of the homeless people in the early hours after the disaster might be relocated to other cities to join family and friends later on, when the panic of the early hours has passed. Furthermore, some disasters, such as floods, could last months, whilst some disasters, such as earthquakes, happen in a matter of seconds. When a disaster lasts a long time, the number of the affected population could increase over the following weeks, and therefore, there is a huge discrepancy between the reported number in the early hours after the disaster strike and the numbers reported months later. Therefore, the above model needs to be applied, considering the above limitations. Another limitation is that the model is built upon secondary data from various sources [
11,
28,
40,
53], amongst others in which the data varies from case to case. Therefore, the model is only as accurate as its data feed. In addition, the prediction of the injured and the homeless population is based on the available aggregated data, in the absence of separate data sets. Despite the authors’ attempts, data individually reporting the injured and homeless were not found for any of the 4252 cases. However, if they become available in the future, the author believes that repeating the process of prediction may greatly improve the quality of the predictions.
Future research in this area can build upon the PRED model presented in this paper and explore the following directions. First, enhancing data accuracy: Since the model relies on secondary data from various sources, future research can focus on improving the accuracy and reliability of the data feed. This can be achieved by collecting more comprehensive and standardised data sets specifically targeting disaster-related variables, such as fatalities, injuries and homelessness. Second, including additional variables: The current model incorporates variables such as disaster type, HDI, DRI, population and population density. Future research can explore the inclusion of additional relevant variables that may influence the human impact of disasters, such as infrastructure resilience, early warning systems and response capabilities. Third, fine-tuning prediction accuracy: The study acknowledges discrepancies between observed and predicted numbers of injured and homeless individuals. Future research can delve deeper into understanding these discrepancies and work towards refining the prediction accuracy by accounting for factors such as population movement, delayed reporting and the varying duration of different types of disasters. Fourth, addressing geographical and temporal variations: While the PRED model considers multiple disasters and geographical locations, future research can focus on capturing the specific nuances and characteristics of different regions and countries. This can involve conducting case studies in diverse locations and examining the applicability and effectiveness of the model in various contexts. And finally, integration with decision support systems: The PRED model can be integrated into decision support systems for disaster management. Future research can explore ways to integrate the model into existing systems or develop new decision support tools that utilise the predictions provided by PRED to aid decision-making during the response phase of disasters.






{kind=link}