
Understanding the Effects of Smart-Speaker-Based Surveys on Panelist Experience in Immersive Consumer Testing

Abstract
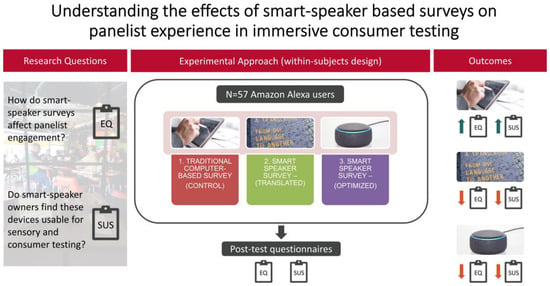
1. Introduction
2. Materials and Methods
2.1. Subjects
2.2. Ethics
2.3. Materials
2.3.1. Stimuli
2.3.2. Questionnaire Devices
2.4. Procedure
2.5. Data Analysis
3. Results
3.1. Assessment of Survey Technology Effects on Engagement and Usability
3.1.1. Survey Technology Effects on Engagement
3.1.2. Survey Technology Effects on Usability
3.2. Assessment of Panelist Response to Smart-Speaker-Survey Technical Difficulties
3.2.1. Effect of Smart-Speaker-Survey Technical Difficulties on Engagement
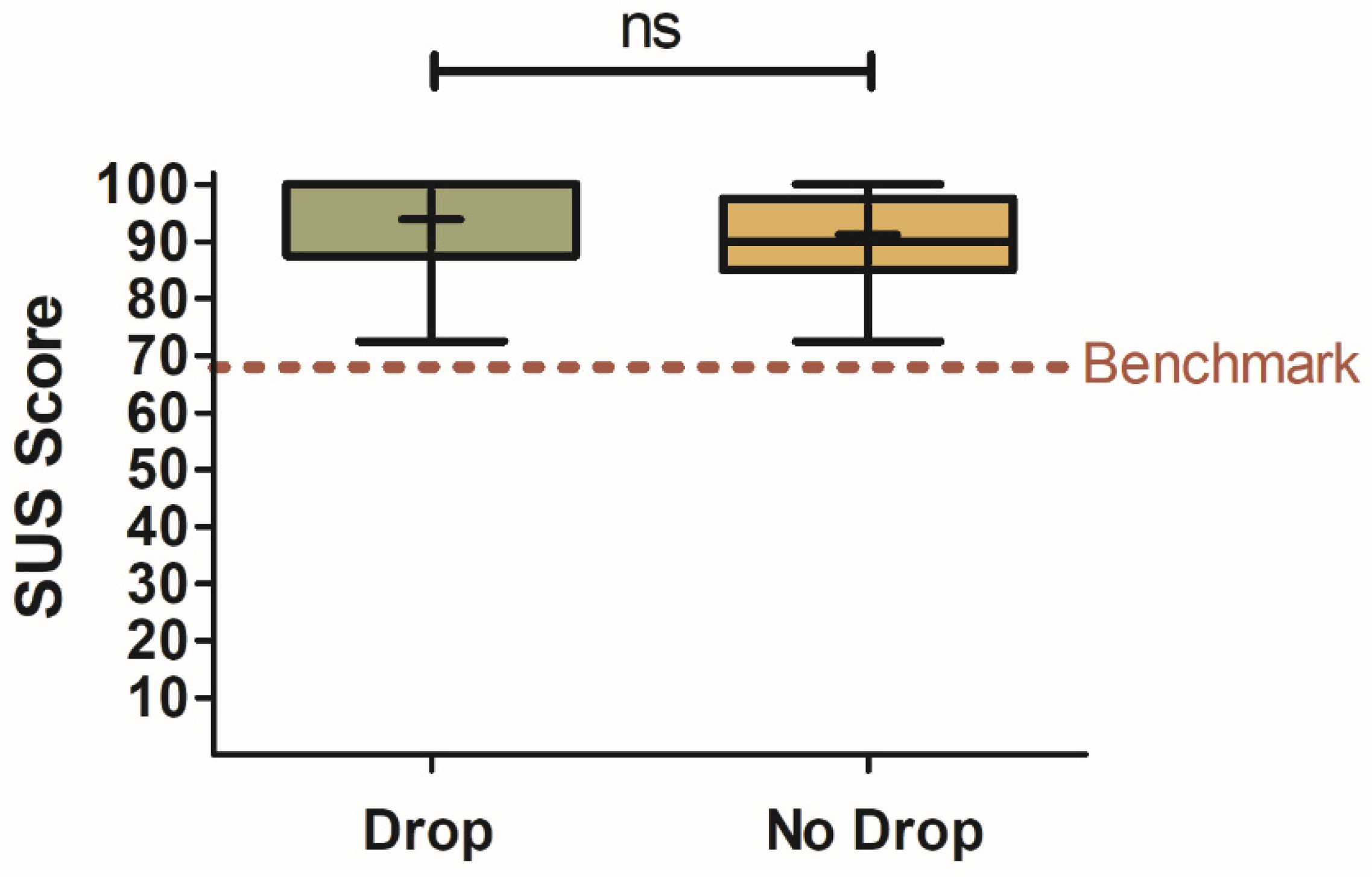
3.2.2. Effect of Smart-Speaker-Survey Technical Difficulties on Usability
3.3. Assessment of Panelist Rewarding Control Surveys
3.3.1. Rewarding Control Condition for Engagement
3.3.2. Rewarding Control Condition for Usability
4. Discussion
4.1. Assessment of Survey Technology Effect on Engagement and Usability
4.1.1. Survey Technology Effects on Engagement
4.1.2. Survey Technology Effects on Usability
4.2. Assessment of Panelist Response to Smart-Speaker-Survey Technical Difficulties
4.2.1. Effect of Smart-Speaker-Survey Technical Difficulties on Engagement
4.2.2. Effect of Smart-Speaker-Survey Technical Difficulties on Usability
4.3. Assessment of Panelist Rewarding Control Surveys
4.3.1. Rewarding Control Condition for Engagement
4.3.2. Rewarding Control Condition for Usability
4.4. Future Directions
4.5. Limitations of the Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Product Preparation Protocol
Appendix A.1. Night before Testing
- Label product containers with corresponding three-digit codes (and name if using GladWare);
- Weigh appropriate amount of Mesquite Liquid Smoke into 2 oz/59 mL plastic souffle cup (see table below);
- Pour/scoop product into plastic container with fitted lid (e.g., GladWare) for Simple Truth guacamoles and Herdez salsa. The other products have enough headspace for liquid to be added;
- Add liquid smoke to the product containers and stir until it is well incorporated;
- Place containers in refrigerator in sensory lab;
- Please note that the number of needed jars/containers of product will be determined based on the anticipated panel schedule/rotation plan for the following day.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Product Category | Product Name and Code | Mesquite Liquid Smoke to Add per Product Container |
|---|---|---|
| Guacamole | Sabra (201) | 0 g—no-smoke sample |
| Simple Truth (ST—Low), 453 g (196) | 11.3 g—low-smoke sample | |
| Simple Truth (ST—High), 453 g (498) | 22.7 g—high-smoke sample | |
| Salsa | La Mexicana (La Mxana) (988) | 0 g—no-smoke sample |
| Willy’s (Low), 454 g (729) | 3.8 g—low-smoke sample | |
| Herdez (High), 454 g (530) | 45.4 g—high-smoke sample | |
| Queso | Tostitos (652) | 0 g—no-smoke sample |
| Kroger (Low), 425 g (813) | 7.1 g—low-smoke sample | |
| Kroger (High), 425 g (374) | 21.3 g—high-smoke sample |
Appendix A.2. Morning of Testing
- Determine the number of times a sample will be evaluated for the day using the rotation plan and expected panel ID codes;
- Count out this number of pre-labeled 96 mL souffle cups and lids;
- Carefully match the labeled container in the refrigerator in 055 Howlett with the three-digit-code cup and fill with product until full (we will be serving approximately 89 mL of the sample at a time);
- Place lid on filled sample cup and put in refrigerator in Parker 055 back booth.
Appendix A.3. During the Test Session
- Match the panel code and day of testing to determine the sample presentation order (in case this is not already labeled on a tray for you);
- Label molcajetes with three-digit codes and place in order on tray (see Figure A1 below) (note that if trays are already labeled, then they will have three-digit codes in place of 1, 2, 3);

- When the panelist is ready, take out the correct three-digit-code sample from the refrigerator;
- Find the corresponding molcajete with matching three-digit code and, using a plastic spoon, transfer the product from the souffle cup into the molcajete;
- Additional step for queso;
- Place the molcajete filled with the queso sample in the microwave in Parker 055, and heat for 30 s;
- Press 30 s button on microwave and let heat for 15 s;
- Open microwave and stir;
- Click start to resume heating and open microwave door when it reaches 1 s. This is to prevent participants from hearing the microwave go off (we found this an issue during pilot testing);
- Stir before serving;
- Throw away spoon and souffle cup while waiting to prepare the next sample;
- Repeat until the panelist has finished their set for the day;
- Clean space in between sessions and prepare for the next participant;
- Once all participants have finished for the day, clean the area, discard any leftover product in the fridge, and wash containers;
- Follow Night Before Testing preparation procedure to prepare product for the next day.
Appendix B. Engagement Questionnaire and System Usability Scale Questions
| Factor | Item |
|---|---|
| Active Involvement | I lost interest in the task. * |
| I was distracted. * | |
| I felt myself zoning out during the task. * | |
| Purposeful Intent | I found the task meaningful. |
| I felt dedicated to finish the task. | |
| I wanted to devote my full attention to the task. | |
| My contribution was significant to the outcome of the task. | |
| Affective Value | I found the task captivating. |
| During the task, I was enjoying myself. | |
| I was motivated to expend extra effort during the task. |
| Type of User Experience being Captured | Statement |
|---|---|
| Positive | I think that I would like to use this smart-speaker for sensory evaluation frequently. |
| I thought the smart-speaker was easy to use. | |
| I found the various functions in the smart-speaker were well integrated. | |
| I would imagine most people would learn to use the smart-speaker very quickly. | |
| I felt very confident using the smart-speaker. | |
| Negative | I found the smart-speaker unnecessarily complex. |
| I think that I would need the support of a technical person to be able to use this smart-speaker. | |
| I thought that there was too much inconsistency in the smart-speaker. | |
| I found the smart-speaker very cumbersome (awkward) to use. | |
| I needed to learn a lot of things before I could get going with the smart-speaker. |
References
- Martini, S. Editorial overview: Sensory science and consumer perception. Curr. Opin. Food Sci. 2018, 21, 4–5. [Google Scholar] [CrossRef]
- Hannum, M.; Forzley, S.; Popper, R.; Simons, C.T. Does environment matter? Assessments of wine in traditional booths compared to an immersive and actual wine bar. Food Qual. Prefer. 2019, 76, 100–108. [Google Scholar] [CrossRef]
- Stelick, A.; Dando, R. Thinking outside the booth—The eating environment, context and ecological validity in sensory and consumer research. Curr. Opin. Food Sci. 2018, 21, 26–31. [Google Scholar] [CrossRef]
- Lawless, H.T.; Heymann, H. Chapter 15—Consumer field tests and questionnaire design. In Sensory Evaluation of Food: Principles and Practices; Springer: New York, NY, USA, 2010; pp. 354–355. [Google Scholar] [CrossRef]
- Bangcuyo, R.G.; Smith, K.J.; Zumach, J.L.; Pierce, A.M.; Guttman, G.A.; Simons, C.T. The use of immersive technologies to improve consumer testing: The role of ecological validity, context and engagement in evaluating coffee. Food Qual. Prefer. 2015, 41, 84–95. [Google Scholar] [CrossRef]
- Holthuysen, N.T.E.; Vrijhof, M.N.; de Wijk, R.A.; Kremer, S. “Welcome on board”: Overall liking and just-about-right ratings of airplane meals in three different consumption contexts-laboratory, re-created airplane, and actual airplane. J. Sens. Stud. 2017, 32, e12254. [Google Scholar] [CrossRef]
- Man, K.; Patterson, J.A.; Simons, C. The impact of personally relevant consumption contexts during product evaluations in virtual reality. Food Qual. Prefer. 2023, 109, 104912. [Google Scholar] [CrossRef]
- Young, S.N. The neurobiology of human social behavior: An important but neglected topic. J. Psychiatry Neurosci. 2008, 33, 391–392. [Google Scholar]
- Purington, A.; Taft, J.G.; Sannon, S.; Bazarova, N.N.; Taylor, S.H. “Alexa is my new BFF”: Social roles, user satisfaction, and personification of the amazon echo. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017. [Google Scholar]
- Kowalczuk, P. Consumer acceptance of smart speakers: A mixed methods approach. J. Res. Interact. Mark. 2018, 12, 418–431. [Google Scholar] [CrossRef]
- Lau, J.; Zimmerman, B.; Schaub, F. Alexa, are you listening? Privacy perceptions, concerns and privacy-seeking behaviors with smart speakers. In Proceedings of the ACM on Human-Computer Interaction, 2(CSCW); Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–31. [Google Scholar]
- Sung, E.; Bae, S.; Han, D.-I.D.; Kwon, O. Consumer engagement via interactive artificial intelligence and mixed reality. Int. J. Inf. Manag. 2021, 60, 102382. [Google Scholar] [CrossRef]
- Hannum, M.E.; Simons, C.T. Development of the engagement questionnaire (EQ): A tool to measure panelist engagement during sensory and consumer evaluations. Food Qual. Prefer. 2020, 81, 103840. [Google Scholar] [CrossRef]
- Brooke, J. SUS: A ‘quick and dirty’ usability scale. In Usability Evaluation in Industry; Jordan, P., Thomas, B., Weerdmeester, B., Eds.; Taylor & Francis: London, UK, 1995; pp. 189–194. [Google Scholar]
- Lewis, J.R.; Sauro, J. Item benchmarks for the system usability scale. J. Usability Stud. 2018, 13, 158–167. [Google Scholar]
- Sauro, J.; Lewis, J.R. Chapter 8—Standardized usability questionnaires. In Quantifying the User Experience, 2nd ed.; Sauro, J., Lewis, J.R., Eds.; Morgan Kaufmann: Boston, MA, USA, 2016; pp. 185–248. [Google Scholar] [CrossRef]
- Hannum, M.E.; Forzley, S.; Popper, R.; Simons, C.T. Application of the Engagement Questionnaire (EQ) to compare methodological differences in sensory and consumer testing. Food Res. Int. 2021, 140, 110083. [Google Scholar] [CrossRef] [PubMed]
- Kim, I.; Hopkinson, A.; van Hout, D.; Lee, H. A novel two-step rating-based ‘double-faced applicability’ test. Part 1: Its performance in sample discrimination in comparison to simple one-step applicability rating. Food Qual. Prefer. 2017, 56, 189–200. [Google Scholar] [CrossRef]
- Nicolas, L.; Marquilly, C.; O’mahony, M. The 9-point hedonic scale: Are words and numbers compatible? Food Qual. Prefer. 2010, 21, 1008–1015. [Google Scholar] [CrossRef]
- Zwislocki, J.; Goodman, D. Absolute scaling of sensory magnitudes: A validation. Percept. Psychophys. 1980, 28, 28–38. [Google Scholar] [CrossRef]
- Price, L. Responsibility: Identifying Purpose and Finding Meaning. Jurisprudence 2015, 6, 252–273. [Google Scholar] [CrossRef]
- Blicher, A.; Reinholdt-Dunne, M.L.; Hvenegaard, M.; Winding, C.; Petersen, A.; Vangkilde, S. Engagement and disengagement components of attentional bias to emotional stimuli in anxiety and depression. J. Exp. Psychopathol. 2020, 11, 2043808720943753. [Google Scholar] [CrossRef]
- Georgiou, G.; Bleakley, C.; Hayward, J.; Russo, R.; Dutton, K.; Eltiti, S.; Fox, E. Focusing on fear: Attentional disengagement from emotional faces. Vis. Cogn. 2005, 12, 145–158. [Google Scholar] [CrossRef]
- Larson, R.B. Controlling social desirability bias. Int. J. Mark. Res. 2019, 61, 534–547. [Google Scholar] [CrossRef]
- McCambridge, J.; de Bruin, M.; Witton, J. The Effects of Demand Characteristics on Research Participant Behaviours in Non-Laboratory Settings: A Systematic Review. PLoS ONE 2012, 7, e39116. [Google Scholar] [CrossRef] [PubMed]
- Baethge, A.; Vahle-Hinz, T.; Schulte-Braucks, J.; Van Dick, R. A matter of time? Challenging and hindering effects of time pressure on work engagement. Work. Stress 2017, 32, 228–247. [Google Scholar] [CrossRef]
- Kirsh, D. A few thoughts on cognitive overload. Intellectica 2000, 30, 19–51. [Google Scholar] [CrossRef]
- Speier, C.; Valacich, J.S.; Vessey, I. The influence of task interruption on individual decision making: An information overload perspective. Decis. Sci. 1999, 30, 337–360. [Google Scholar] [CrossRef]
- Wang, S.; Lilienfeld, S.O.; Rochat, P. The uncanny valley: Existence and explanations. Rev. Gen. Psychol. 2015, 19, 393–407. [Google Scholar] [CrossRef]
- Packard, G.; Berger, J. How concrete language shapes customer satisfaction. J. Consum. Res. 2021, 47, 787–806. [Google Scholar] [CrossRef]
- Amazon. Welcome to Amazon Sidewalk. 2021. Available online: https://www.amazon.com/Amazon-Sidewalk/b?ie=UTF8&node=21328123011 (accessed on 4 August 2021).
- Tempelaar, D.; Rienties, B.; Nguyen, Q. Subjective data, objective data and the role of bias in predictive modelling: Lessons from a dispositional learning analytics application. PLoS ONE 2020, 15, e0233977. [Google Scholar] [CrossRef]







| Product Category | Product Name | Product Company | Mesquite Liquid Smoke Added per Product Container |
|---|---|---|---|
| Guacamole | Sabra Classic Guacamole with Lime (454 g container) | Sabra Dipping Co., LLC. White Plains, NY, USA | 0 g No-smoke sample |
| Simple Truth Traditional Guacamole (453 g container) | The Kroger Co. Cincinnati, OH, USA | 11.3 g Low-smoke sample | |
| Simple Truth Traditional Guacamole (453 g container) | The Kroger Co. Cincinnati, OH, USA | 22.7 g High-smoke sample | |
| Salsa | La Mexicana Mild Salsa (453 g container) | Perimeter Brands LLC. Riviera Beach, FL, USA | 0 g No-smoke sample |
| Willy’s Original Mild Salsa (454 g container) | Willy’s Salsa Swanton, OH, USA | 3.8 g Low-smoke sample | |
| Herdez Mild Salsa Casera (454 g container) | MegaMex Foods, LLC. Orange, CA, USA | 45.4 g High-smoke sample | |
| Queso | Tostitos Queso Blanco Dip Medium (425.2 g container) | Frito-Lay North America, Inc. Plano, TX, USA | 0 g No-smoke sample |
| Kroger Monterey Jack Queso Dip Medium (425 g container) | The Kroger Co. Cincinnati, OH, USA | 7.1 g Low-smoke sample | |
| Kroger Monterey Jack Queso Dip Medium (425 g container) | The Kroger Co. Cincinnati, OH, USA | 21.3 g High-smoke sample |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soldavini, A.M.; Diaz, H.; Ennis, J.M.; Simons, C.T. Understanding the Effects of Smart-Speaker-Based Surveys on Panelist Experience in Immersive Consumer Testing. Foods 2023, 12, 2537. https://doi.org/10.3390/foods12132537
Soldavini AM, Diaz H, Ennis JM, Simons CT. Understanding the Effects of Smart-Speaker-Based Surveys on Panelist Experience in Immersive Consumer Testing. Foods. 2023; 12(13):2537. https://doi.org/10.3390/foods12132537
Chicago/Turabian StyleSoldavini, Ashley M., Hamza Diaz, John M. Ennis, and Christopher T. Simons. 2023. "Understanding the Effects of Smart-Speaker-Based Surveys on Panelist Experience in Immersive Consumer Testing" Foods 12, no. 13: 2537. https://doi.org/10.3390/foods12132537
APA StyleSoldavini, A. M., Diaz, H., Ennis, J. M., & Simons, C. T. (2023). Understanding the Effects of Smart-Speaker-Based Surveys on Panelist Experience in Immersive Consumer Testing. Foods, 12(13), 2537. https://doi.org/10.3390/foods12132537