FAIR Digital Objects for Science: From Data Pieces to Actionable Knowledge Units


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Principal Challenges for Data-Intensive Science
2.1. Addressing Grand Challenges is Linked to Scaled Cross-Disciplinary Capabilities
2.2. Drowning in Data?
2.3. Interpreting Scientific Evidence in a Trusted Context
2.4. Advancing Data to Actionable Knowledge Units
2.5. Tool Proliferation and Fundamental Decisions
3. FAIR Digital Objects
3.1. The Scientific View on FAIR Digital Objects
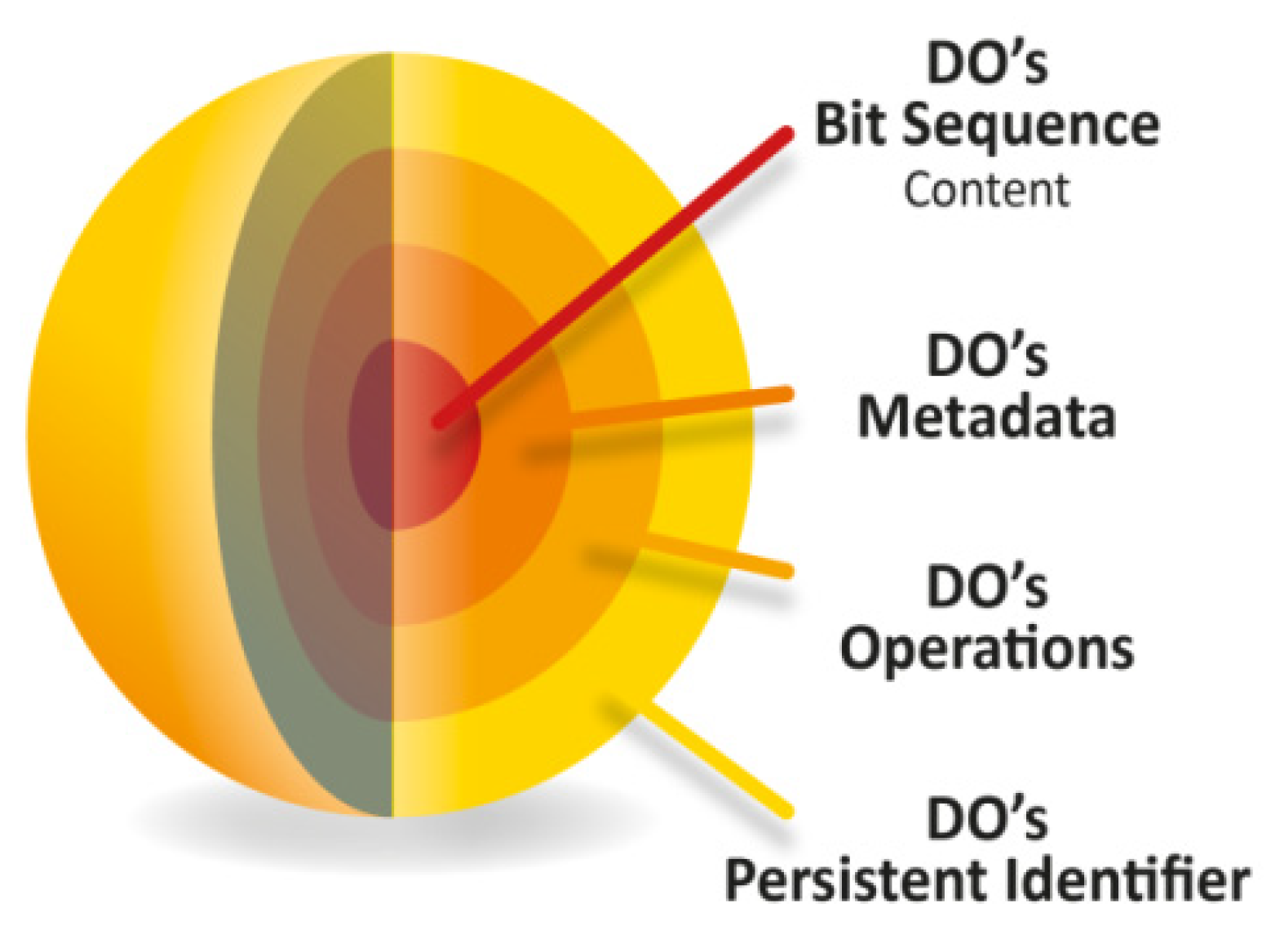
3.2. Digital objects in the DFT Core Model
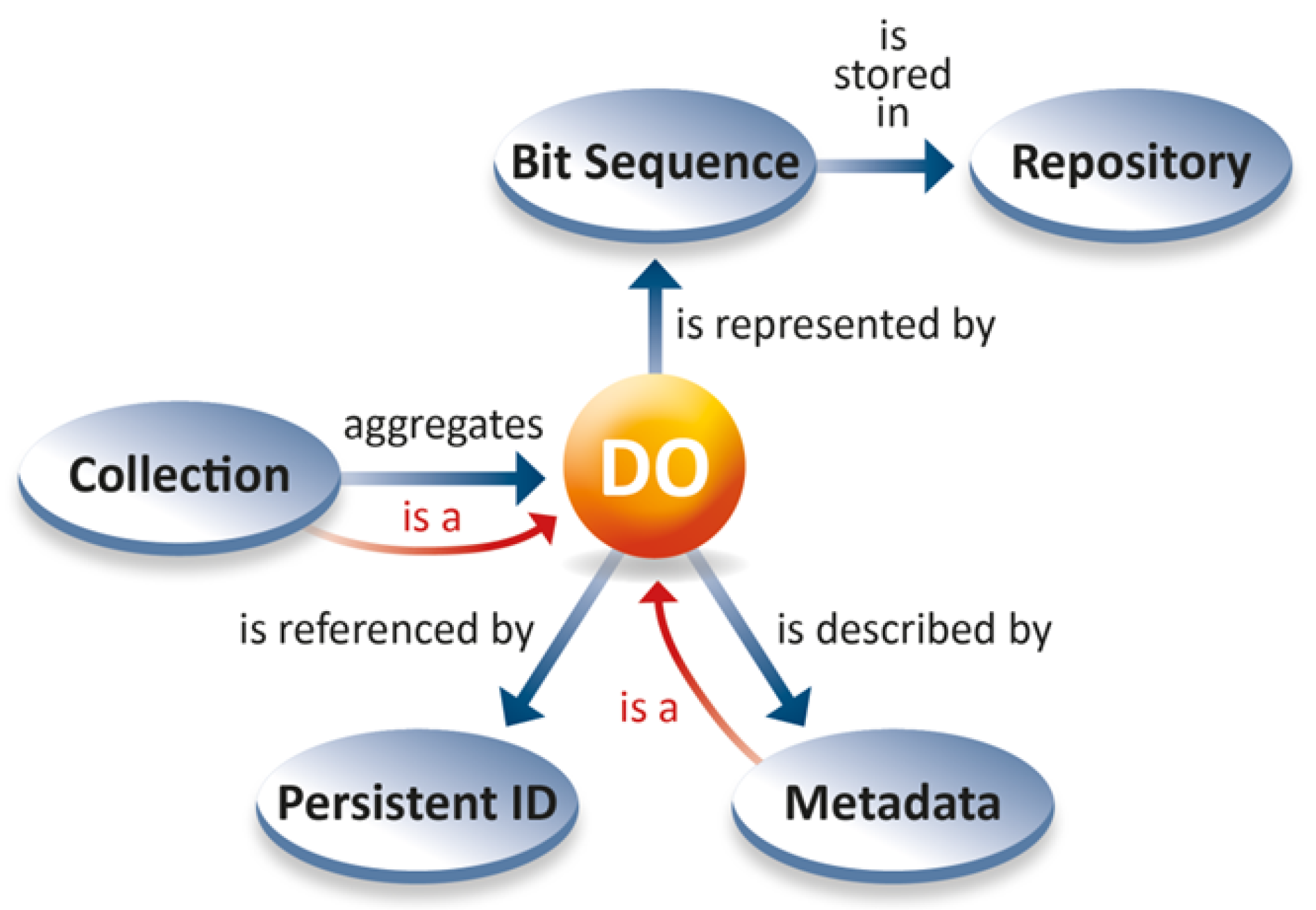
3.3. From Digital Objects towards FAIR Digital Objects
- The FDO model requires the definition of PID attributes and their registration in a trustworthy type registry or a more complex type ontology, while trustworthy repositories are requested to use these attributes in order to achieve interoperability and machine actionability.
- The FDO model requires metadata descriptions to be interpretable by machines. This implies that their semantic categories must be declared and registered. A moderate requirement could be to declare at least metadata categories strictly necessary for basic management, such as where to find the PIDs of relevant information components.
- The FDO model requires the construction of collections to be machine actionable, thus enabling machines to parse collection descriptions and to find its component DOs.
4. Scientific Use Cases
- knowledge extraction from increasing amounts of complex data, especially in an interdisciplinary context;
- the aggregation of knowledge which requires a broad domain of trust and compatibility to yield evidence and enable decision-taking; and
- the provisioning of an ecosystem of research infrastructures that enables efficient and effective work on the two previous points.
4.1. Scientific Interests
4.1.1. Automatic Processing and Workflows
- Assuming rich metadata and clear identifiers for data, researchers could specify requirement profiles for data and for trustworthy sources, leaving the job of finding suitable data to cyberspace agents that crawl FDO repositories and build useful collections; thus, researchers can focus more on the algorithms that will use the data and on the evaluation of the results.
- Workflow management tools could use rich metadata and identifiers in FDOs to track the status at every step of computation and determine which processes could be executed next in order to reach a certain goal. If properly designed by experts, such workflow managers would allow complex calculations to be carried out based on intentionally aggregated data collections.
- The introduction of actionable digital object collections, in which every included FDO is associated with a type, enables a high degree of automation. The creation or uploading of a new FDO with a specific type will trigger automatic procedures for data management or analytical tasks. Some research labs report that they are already doing something similar.
- Large existing software stacks, for example for distributed cloud computing, could be amended to support FDOs by recording rich metadata, thereby enabling responsible data science and increasing reproducibility, thanks to documentation in terms of data provenance and tracking production steps taken towards computational results.
4.1.2. Stable Domain of Scientific Entities and Relationships
4.1.3. Advanced Plans for Management and Security
4.2. Infrastructural and Networking Interests
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Borgman, C.L. The conundrum of sharing research data. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 1059–1078. [Google Scholar] [CrossRef]
- Koureas, D.; Arvanitidis, C.; Belbin, L.; Berendsohn, W.; Damgaard, C.; Groom, Q.; Güntsch, A.; Hagedorn, G.; Hardisty, A.; Hobern, D.; et al. Community engagement: The ‘last mile’ challenge for European research e-infrastructures. Res. Ideas Outcomes 2016, 2. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- O’Rourke, M.; Crowley, S.; Gonnerman, C. On the nature of cross-disciplinary integration: A philosophical framework. Stud. Hist. Philos. Sci. Part C Stud. Hist. Philos. Biol. Biomed. Sci. 2016, 56, 62–70. [Google Scholar] [CrossRef] [PubMed]
- Efstathiou, S. Is it possible to give scientific solutions to Grand Challenges? On the idea of grand challenges for life science research. Stud. Hist. Philos. Sci. Part C Stud. Hist. Philos. Biol. Biomed. Sci. 2016, 56, 48–61. [Google Scholar] [CrossRef] [PubMed]
- Bornmann, L.; Mutz, R. Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol. 2015, 66, 2215–2222. [Google Scholar] [CrossRef]
- Cai, L.; Zhu, Y. The Challenges of Data Quality and Data Quality Assessment in the Big Data Era. Data Sci. J. 2015, 14, 2. [Google Scholar] [CrossRef]
- Borgman, C.L. Data, Data, Everywhere, Nor Any Drop to Drink; Springer: Berlin/Heidelberg, Germany, 2014; Available online: https://works.bepress.com/borgman/322/ (accessed on 21 April 2020).
- Chen, S.; Gingras, Y.; Arsenault, C.; Larivière, V. Interdisciplinarity patterns of highly-cited papers: A cross-disciplinary analysis. Proc. Am. Soc. Inf. Sci. Technol. 2014, 51, 1–4. [Google Scholar] [CrossRef]
- Bromham, L.; Dinnage, R.; Hua, X. Interdisciplinary research has consistently lower funding success. Nature 2016, 534, 684–687. [Google Scholar] [CrossRef]
- Mons, B. FAIR science for social machines: Let’s share metadata Knowlets in the Internet of FAIR data and services. Data Intell. 2019, 1, 1–15. [Google Scholar] [CrossRef]
- Lannom, L. Digital Object Architecture Primer. Digital Objects- from RDA Results towards Implementation. RDA Side Meeting, Philadelphia. Available online: https://github.com/GEDE-RDA-Europe/GEDE/blob/master/Digital-Objects/DO-Workshops/Workshop-Philadelphia-2019/lannom-do-p13.pdf (accessed on 1 March 2020).
- Wittenburg, P.; Strawn, G.; Mons, B.; Bonino, L.; Schultes, E. Digital Objects as Drivers towards Convergence in Data Infrastructures; EUDAT: Helsinki, Finland, 2019. [Google Scholar] [CrossRef]
- Kahn, R.; Wilensky, R. A Framework for Distributed Digital Object Services; CNRI: Reston, VA, USA, 1995; Available online: https://www.cnri.reston.va.us/k-w.html (accessed on 21 April 2020).
- Kahn, R.; Wilensky, R. A framework for distributed digital object services. Int. J. Digit. Libr. 2006, 6, 115–123. [Google Scholar] [CrossRef]
- Bechhofer, S.; Buchan, I.; Roure, D.D.; Missier, P.; Ainsworth, J.; Bhagat, J.; Couch, P.; Cruickshank, D.; Delderfield, M.; Dunlop, I.; et al. Why linked data is not enough for scientists. Future Gener. Comput. Syst. 2013, 29, 599–611. [Google Scholar] [CrossRef]
- Wittenburg, P. Moving Forward on Data Infrastructure Technology Convergence: GEDE Workshop, Paris, 28–29 October 2019; Paris, France, 2019. Available online: https://github.com/GEDE-RDA-Europe/GEDE/tree/master/FAIR%20Digital%20Objects/Paris-FDO-workshop (accessed on 1 March 2020).
- Berg-Cross, G.; Ritz, R.; Wittenburg, P. RDA DFT Core Terms and Model; EUDAT: Helsinki, Finland, 2016; Available online: http://hdl.handle.net/11304/5d760a3e-991d-11e5-9bb4-2b0aad496318 (accessed on 21 April 2020).
- Schultes, E.; Wittenburg, P. FAIR Principles and Digital Objects: Accelerating Convergence on a Data Infrastructure; EUDAT: Helsinki, Finland, 2019. [Google Scholar] [CrossRef]
- Hodson, S.; Collins, S.; Genova, F.; Harrower, N.; Jones, S.; Laaksonen, L.; Mietchen, D.; Petrauskaité, R.; Wittenburg, P. Turning FAIR into reality: Final Report and Action Plan from the European Commission Expert Group on FAIR Data; European Union: Brussels, Belgium, 2018. [Google Scholar] [CrossRef]
- Strawn, G. Open Science, Business Analytics, and FAIR Digital Objects; EUDAT: Helsinki, Finland, 2019. [Google Scholar] [CrossRef]
- Bonino, L. Internet of FAIR Data and Services: Center of the Hourglass. Moving Forward on Data Infrastructure Technology Convergence: GEDE Workshop, Paris, 28–29 October 2019; Paris, France, 2019. Available online: https://github.com/GEDE-RDA-Europe/GEDE/blob/master/FAIR%20Digital%20Objects/Paris-FDO-workshop/GEDE_Paris_Session%201_Bonino.pptx (accessed on 1 March 2020).
- De Smedt, K.; Koureas, D.; Wittenburg, P. An Analysis of Scientific Practice towards FAIR Digital Objects; EUDAT: Helsinki, Finland, 2019. [Google Scholar] [CrossRef]
- Van Uytvanck, D. Digital Objects–Towards Implementation: The CLARIN Use Cases. Digital Objects– from RDA Results towards Implementation: RDA Side Meeting, Philadelphia, 2019. Available online: https://github.com/GEDE-RDA-Europe/GEDE/blob/master/Digital-Objects/DO-Workshops/Workshop-Philadelphia-2019/uytvanck-do-p13.pdf (accessed on 1 March 2020).
- Weigel, T. DO Management for Climate Data Infrastructure Support. Moving Forward on Data Infrastructure Technology Convergence: GEDE Workshop, Paris, French, 28–29 October 2019. Available online: https://github.com/GEDE-RDA-Europe/GEDE/blob/master/FAIR%20Digital%20Objects/Paris-FDO-workshop/GEDE_Paris_Session%202_Weigel.pptx (accessed on 1 March 2020).
- Addink, W.; Koureas, D.; Rubio, A.C. DiSSCo as a New Regional Model for Scientific Collections in Europe. Biodivers. Inf. Sci. Stand. 2019, 3, e37502. [Google Scholar] [CrossRef]
- Casino, A.; Raes, N.; Addink, W.; Woodburn, M. Collections Digitization and Assessment Dashboard, a Tool for Supporting Informed Decisions. Biodivers. Inf. Sci. Stand. 2019, 3, e37505. [Google Scholar] [CrossRef]
- Lannom, L.; Koureas, D.; Hardisty, A.R. FAIR Data and Services in Biodiversity Science and Geoscience. Data Intell. 2020, 2, 122–130. [Google Scholar] [CrossRef]
- Digital Object Roadmap Document (V 3.0); 2019. Available online: https://github.com/GEDE-RDA-Europe/GEDE/blob/master/Digital-Objects/Foundation-Documents/DORoadmap.pdf (accessed on 1 March 2020).
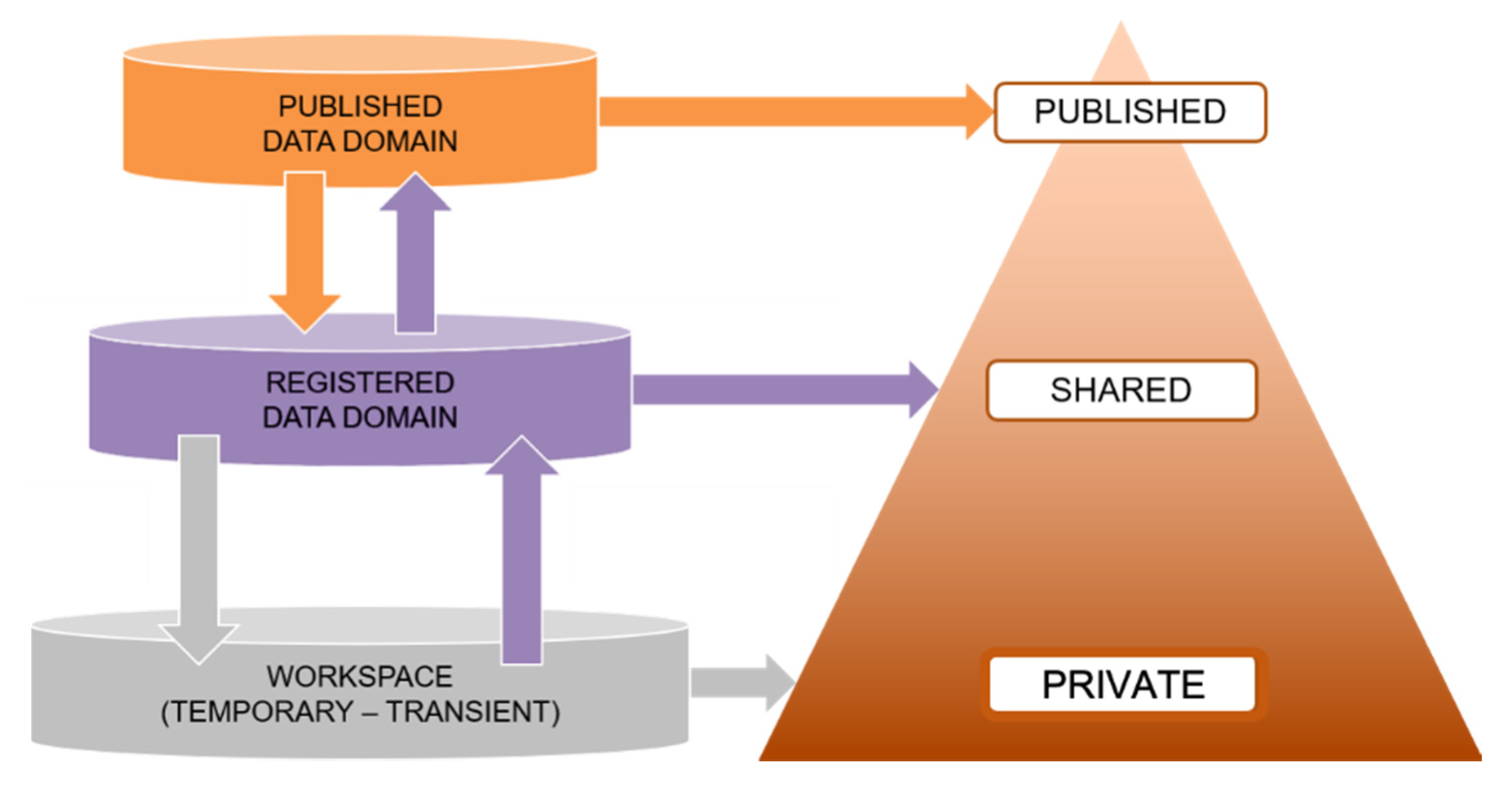
| 1 | Diagram adapted from EUDAT, a European Collaborative Data Infrastructure, https://eudat.eu/. |
| 2 | European Strategy Forum on Research Infrastructures, https://www.esfri.eu/. |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | The European Research Infrastructure for Language Resources and Technology, http://www.clarin.eu. |
| 13 | |
| 14 | Resource Description Framework, https://www.w3.org/2001/sw/wiki/RDF. |
| 15 | |
| 16 | Open Archives Initiative Protocol for Metadata Harvesting, https://www.openarchives.org/pmh/. |
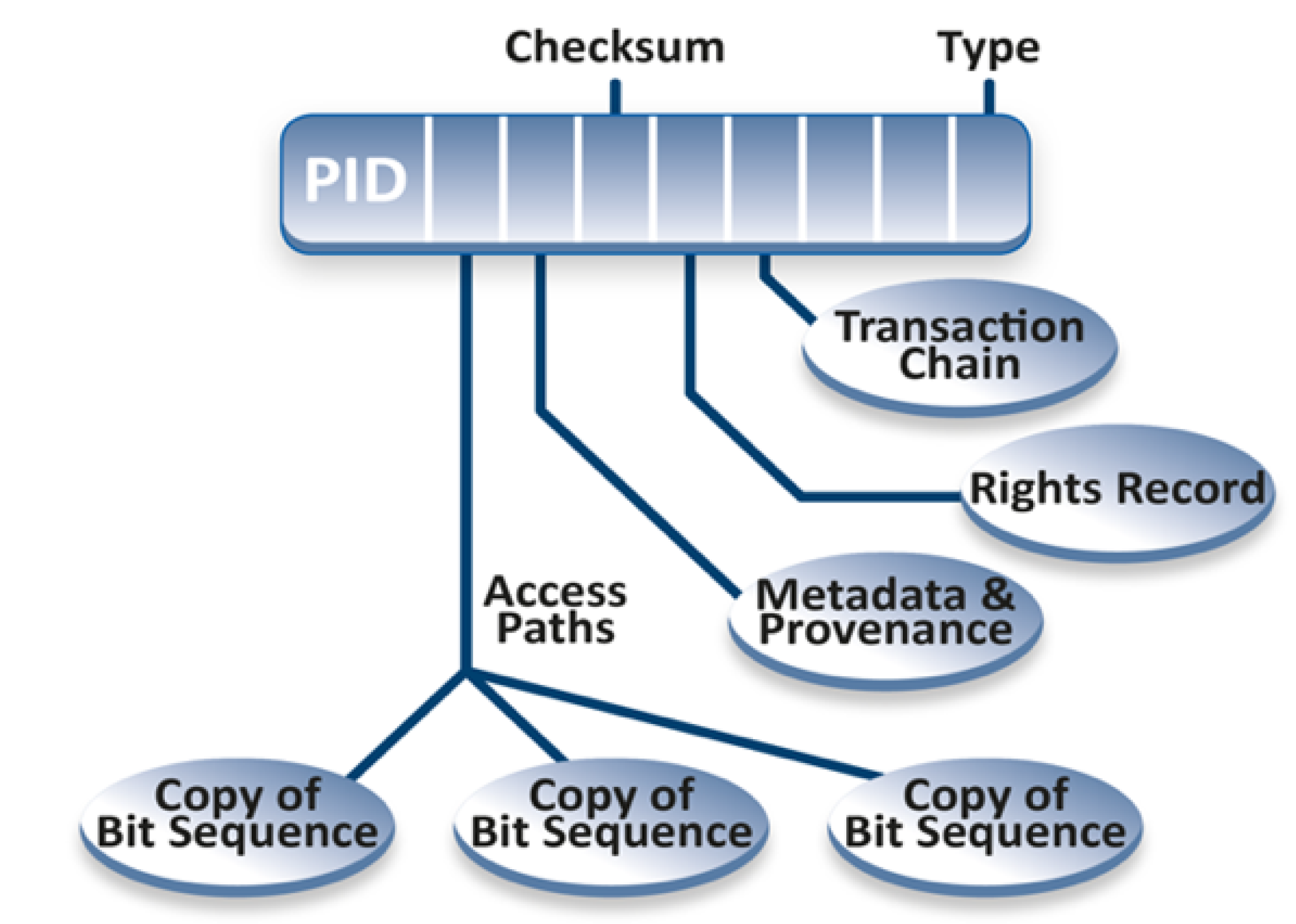
| 17 | On the Web, a PID has the form of a Persistent Uniform Resource Locator (PURL), which curates redirection by means of a resolver. This scheme attempts to solve the problem of transitory locators in location-based schemes like HTTP. Example types of persistent identifiers are the Handle, the Digital Object Identifier (DOI), and the Archival Resource Key (ARK). There are also different types of globally unique identifiers which do not involve automatic curation by a resolver, such as the International Standard Language Resource Number (ISLRN). |
| 18 | Diagram adapted from L. Lannom [12]. |
| 19 | |
| 20 | |
| 21 | |
| 22 | |
| 23 | |
| 24 | |
| 25 | |
| 26 | |
| 27 | |
| 28 | |
| 29 | |
| 30 | |
| 31 | |
| 32 | |
| 33 | |
| 34 | |
| 35 | |
| 36 | European Strategy Forum on Research Infrastructures, https://www.esfri.eu/. |
| 37 | |
| 38 | |
| 39 | |
| 40 | |
| 41 | |
| 42 | |
| 43 | |
| 44 | |
| 45 | |
| 46 | |
| 47 | |
| 48 | |
| 49 | |
| 50 | |
| 51 | |
| 52 | |
| 53 | |
| 54 | |
| 55 | |
| 56 | |
| 57 | |
| 58 | |
| 59 | |
| 60 | |
| 61 | |
| 62 | |
| 63 |





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Smedt, K.; Koureas, D.; Wittenburg, P. FAIR Digital Objects for Science: From Data Pieces to Actionable Knowledge Units. Publications 2020, 8, 21. https://doi.org/10.3390/publications8020021
De Smedt K, Koureas D, Wittenburg P. FAIR Digital Objects for Science: From Data Pieces to Actionable Knowledge Units. Publications. 2020; 8(2):21. https://doi.org/10.3390/publications8020021
Chicago/Turabian StyleDe Smedt, Koenraad, Dimitris Koureas, and Peter Wittenburg. 2020. "FAIR Digital Objects for Science: From Data Pieces to Actionable Knowledge Units" Publications 8, no. 2: 21. https://doi.org/10.3390/publications8020021
APA StyleDe Smedt, K., Koureas, D., & Wittenburg, P. (2020). FAIR Digital Objects for Science: From Data Pieces to Actionable Knowledge Units. Publications, 8(2), 21. https://doi.org/10.3390/publications8020021