
Content and Phrasing in Titles of Original Research and Review Articles in 2015: Range of Practice in Four Clinical Journals

Abstract
:1. Introduction
2. Materials and Methods
2.1. Corpus: Journals, Article Types, Time Frame, and Size
2.2. Rationale for the Research Questions and the Coding System
2.3. Coding Standardization and Quality Checks
2.4. Statistical Analysis
3. Results and Discussion
3.1. Main Findings and Limitations
3.2. Methods and Results Mentions in Original RA Titles
- Two observational studies:Intraoperative temperature monitoring with zero heat flux technology (3M SpotOn sensor) in comparison with sublingual and nasopharyngeal temperature: an observational study (EJA)Intraoperative core temperature patterns, transfusion requirement, and hospital duration in patients warmed with forced air (Anesthesiology)
- Two randomized controlled trials:Impact of a behavioural sleep intervention on symptoms and sleep in children with attention deficit hyperactivity disorder, and parental mental health: randomised controlled trial (BMJ)Efficacy of a tetravalent dengue vaccine in children in Latin America (NEJM)
Anaphylaxis is more common with rocuronium and succinylcholine than with atracurium(Anesthesiology, based on a retrospective cohort study)
The observation of Paiva et al. [16] that results-mention RA titles tended to attract more cites increases interest in continuing to use Q2a in future research. It is possible, however, that the association they observed may have been an artifact of studying a corpus of titles from all journals belonging to two open-access publishing houses with a mix of basic and clinical research journals (see their Table 1, p. 510). That mix might also explain why they saw a high rate of results mention (over 40%).Postoperative delirium is an independent risk factor for posttraumatic stress disorder in the elderly patient: a prospective observational study(EJA)
3.3. Other Content Mentions in RA and Review Titles
3.4. Phrasing Patterns in RA and Review Titles
Improved overall survival in melanoma with combined dabrafenib and trametinib(NEJM)
Effective reversal of edoxaban-associated bleeding with four-factor prothrombin complex concentrate in a rabbit model of acute hemorrhage(Anesthesiology).
It is interesting to note that while effective reversal clearly conveys a positive finding in the second title, beginning a title with efficacy of would be vague about results: a title with that beginning would merely suggest a clinical trial. Positive-sounding noun phrases were also used as points of departure (e.g., discovery of, practice improvements based on..., improvement in...). The third example above, with a postnominal modifier is stylistically subtle because it calls attention to the hot topic (a genetics study) first and names the positive result last: the authors have found a gene responsible for inducing the named condition. It is clearly possible to mention results without emphasizing them with a stylistically salient full sentence, something ERPP instructors, manuscript editors and translators might want to bear in mind.p.L1612P, a novel voltage-gated sodium channel nav1.7 mutation inducing a cold sensitive paroxysmal extreme pain disorder(Anesthesiology).
- Blood glucose concentration and risk of pancreatic cancer: systematic review and dose-response meta-analysis (BMJ, RA, a two-part title with two heads in each part).
- Sodium bicarbonate and renal function after cardiac surgery: a prospectively planned individual patient meta-analysis (NEJM, RA, a two-part title with two heads in the first part and one in the second).
- Best position and depth of anaesthesia for laryngeal mask airway removal in children: a randomised controlled trial (EJA, RA; a two-part title with two heads in the first part and one in the second).
- 4.
- Disorders of fluids and electrolytes: disorders of plasma sodium—causes, consequences, and correction (NEJM, review article, a three-part title; the first two parts have one head each, the third has three heads).
- 5.
- Intraoperative core temperature patterns, transfusion requirement, and hospital duration in patients warmed with forced air (Anesthesiology, RA, one part with three heads).
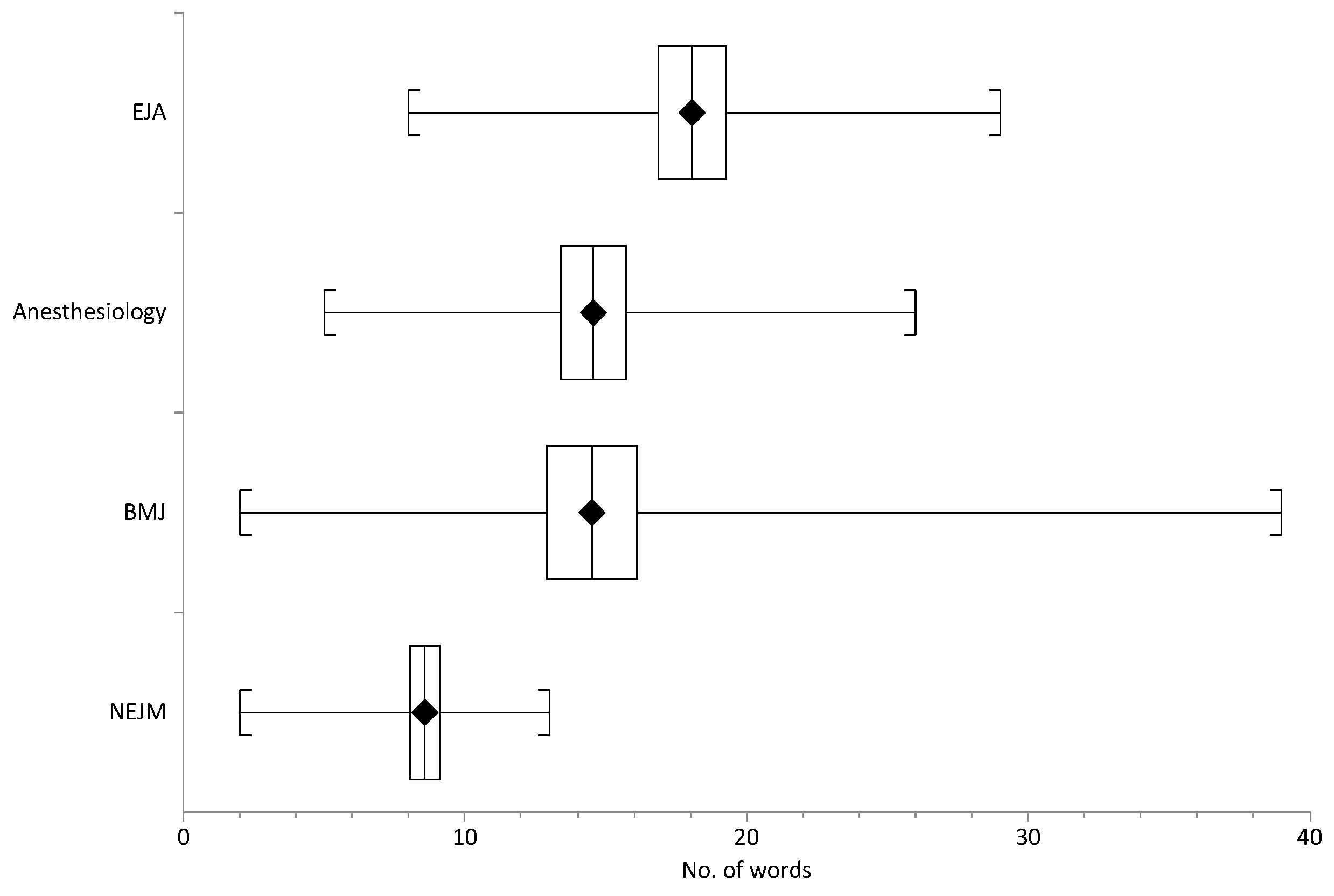
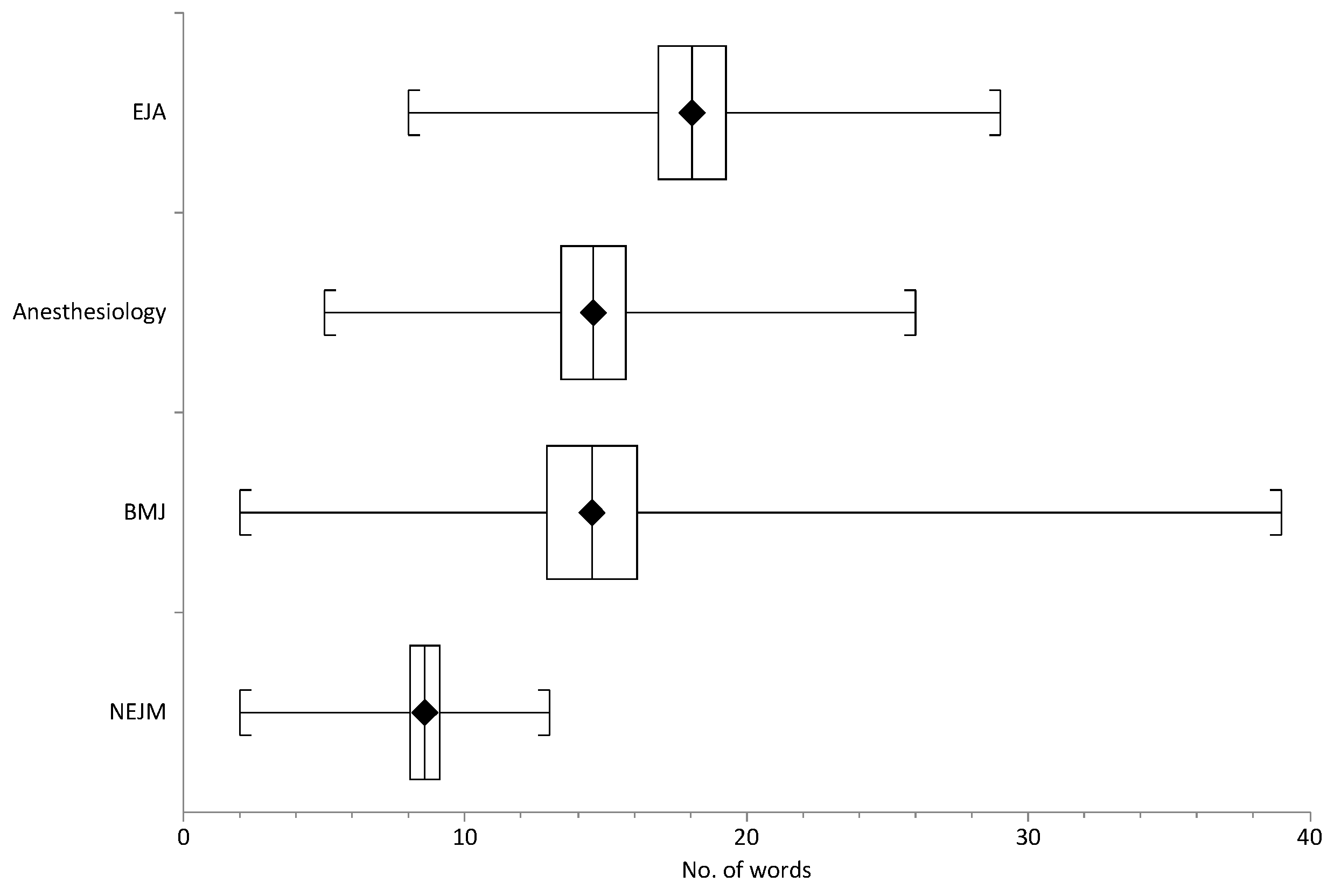
3.5. Length
3.6. Ease and Reliability of Coding: Inter-Rater Agreement
4. Conclusions
4.1. Medical Titles After 20 Years of Reporting Guidelines
4.2. Researching Medical Title Content and Phrasing Systematically or on the Fly
Supplementary Materials
Author Contributions
Conflicts of Interest
Abbreviations
| BMC | Biomed Central |
| BMJ | British Medical Journal |
| CONSORT | Consolidated Standards of Reporting |
| EAL | English as an additional language |
| EJA | European Journal of Anaesthesiology |
| ERPP | English for research publication purposes |
| ESP | English for specific purposes |
| IF | impact factor |
| JAMA | Journal of the American Medical Association |
| NEJM | New England Journal of Medicine |
| RA | research article |
| PLoS | Public Library of Science |
References
- Tenopir, C.; King, D.W.; Bush, A. Medical faculty’s use of print and electronic journals: Changes over time and in comparison with scientists. Med. Libr. Assoc. 2004, 92, 233–241. [Google Scholar]
- Khan, K.S.; Kunz, R.; Kleijnen, J.; Antes, G. Five steps to conducting a systematic review. J. R. Soc. Med. 2003, 96, 118–121. [Google Scholar] [CrossRef] [PubMed]
- Mateen, F.J.; Oh, J.; Tergas, A.I.; Bhayani, N.H.; Kamdar, B.B. Titles versus titles and abstracts for initial screening of articles for systematic reviews. Clin. Epidemiol. 2013, 5, 89–95. [Google Scholar] [CrossRef] [PubMed]
- Systematic reviews and meta-analyses: A step-by-step guide. Available online: http://www.webcitation.org/6eXMRFyg7 (accessed on 14 January 2016).
- Langdon-Neuner, E. Hangings at the bmj: What editors discuss when deciding to accept or reject research papers. Write Stuff 2008, 17, 84–85. [Google Scholar]
- Begg, C.; Cho, M.; Eastwood, S.; Horton, R.; Moher, D.; Olkin, I.; Pitkin, R.; Rennie, D.; Schulz, K.F.; Simel, D.; et al. Improving the quality of reporting of randomized controlled trials. The CONSORT statement. JAMA 1996, 276, 637–639. [Google Scholar] [CrossRef] [PubMed]
- Moher, D.; Schulz, K.F.; Altman, D.G.; for the CONSORT Group. The CONSORT Statement: Revised recommendations for improving the quality of reports of parallel-group randomized trials. Ann. Intern. Med. 2001, 134, 657–662. [Google Scholar] [CrossRef] [PubMed]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; the PRISMA Group. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. PLOS Med. 2009. [Google Scholar] [CrossRef] [PubMed]
- Schulz, K.F.; Altman, D.G.; Moher, D.; for the CONSORT Group. CONSORT 2010 Statement: Updated guidelines for reporting parallel group randomised trials. J. Clin. Epidemiol. 2010. [Google Scholar] [CrossRef] [PubMed]
- Goodman, R.A.; Thacker, S.B.; Siegel, P.Z. What’s in a title? A descriptive study of article titles in peer-reviewed medical journals. Sci. Editor 2001, 24, 75–78. [Google Scholar]
- Labassi, T. Reading titles of empirical research papers. Read. Matrix 2009, 9, 166–174. [Google Scholar]
- Siegel, P.Z.; Thacker, S.B.; Goodman, R.A.; Gillespie, C. Titles of articles in peer-reviewed journals lack information on study design: A structured review of contributions to four leading medical journals, 1995 and 2001. Sci. Editor 2006, 29, 183–185. [Google Scholar]
- Ubriani, R.; Smith, N.; Katz, K.A. Reporting of study design in titles and abstracts of articles published in clinically oriented dermatology journals. Br. J. Dermatol. 2007, 156, 557–559. [Google Scholar] [CrossRef] [PubMed]
- Jacques, T.S.; Sebire, N.J. The impact of article titles on citation hits: An analysis of general and specialist medical journals. J. R. Soc. Med. 2010, 1. [Google Scholar] [CrossRef] [PubMed]
- Habibzadeh, F.; Yadollahie, M. Are shorter article titles more attractive for citations? Cross-sectional study of 22 scientific journals. Croat. Med. J. 2010, 51, 165–170. [Google Scholar] [CrossRef] [PubMed]
- Paiva, C.E.; da Silveira Nogueira Lima, J.P.; Paiva, B.S. Articles with short titles describing the results are cited more often. Clinics 2012, 67, 509–513. [Google Scholar] [CrossRef]
- Wang, Y.; Bai, Y. A corpus-based syntactic study of medical research article titles. System 2007, 35, 388–399. [Google Scholar] [CrossRef]
- Soler, V. Writing titles in science: An exploratory study. Engl. Specif. Purp. 2007, 26, 90–102. [Google Scholar] [CrossRef]
- Cianflone, E. Scientific titles in veterinary medicine research papers. Engl. Specif. Purp. World 2010, 9, 1–8. [Google Scholar]
- Taylor, C.F.; Field, D.; Sansone, S.-A.; Aerts, J.; Apweiler, R.; Ashburner, M.; Ball, C.A.; Binz, P.-A.; Bogue, M.; Booth, T.; et al. Promoting coherent minimum reporting guidelines for biological and biomedical investigations: The MIBBI project. Nat. Biotechnol. 2008, 26, 889–896. [Google Scholar] [CrossRef] [PubMed]
- Oxford Centre for Evidence-based Medicine. Available online: http://www.webcitation.org/6eYfjBQ1i (accessed on 15 January 2016).
- Corpas Pastor, G.; Seghiri, M. Specialized corpora for translators: A quantitative method to determine representativeness. Transl. J. 2007, 11. Available online: http://www.webcitation.org/6gDtLCZWu (accessed on 23 March 2016). [Google Scholar]
- Maher, A.; Waller, S.; Kerans, M.E. Acquiring or enhancing a translation specialism: The monolingual corpus-guided approach. J. Spec. Transl. 2008, 10, 56–75. Available online: http://www.webcitation.org/6giYF6iGb (accessed on 12 April 2016). [Google Scholar]
- Buscemi, N.; Hartling, L.; Vandermeer, B.; Tjosvold, L.; Klassen, T. Single data extraction generated more errors than double data extraction in systematic reviews. J. Clin. Epidemiol. 2006, 59, 697–703. [Google Scholar] [CrossRef] [PubMed]
- Viera, A.J.; Garrett, A.M. Understanding interobserver agreement: The kappa statistic. Fam Med. 2005, 37, 360–363. [Google Scholar] [PubMed]
- Burrough-Boenisch, J. Shapers of published NNS research articles. J. Second. Lang Writ. 2002, 12, 223–243. [Google Scholar] [CrossRef]
- Jaime Sisó, M. Titles or headlines? Anticipating conclusions in biomedical research article titles as a persuasive journalistic strategy to attract busy readers. Miscelánea: J. Engl. Am. Stud. 2009, 39, 29–54. [Google Scholar]
- Goodman, N.W. Survey of active verbs in the titles of clinical trial reports. BMJ 2000, 320, 914–915. [Google Scholar] [CrossRef] [PubMed]
- Song, F.; Parekh, S.; Hooper, L.; Loke, Y.K.; Ryder, J.; Sutton, A.J.; Hing, C.; Kwok, C.S.; Pang, C.; Harvey, I. Dissemination and publication of research findings: An updated review of related biases. Health Technol. Assess. 2010, 14. Available online: http://www.webcitation.org/6giYZiKZN (accessed on 28 March 2016). [Google Scholar] [CrossRef] [PubMed]
- Léauté-Labrèze, C.; Dumas de la Roque, E.; Hubiche, T.; Boralevi, F.; Thambo, J.B.; Taïeb, A. Propranolol for severe hemangiomas of infancy. N. Engl. J. Med. 2008, 358, 2649–2651. [Google Scholar] [CrossRef] [PubMed]
- Day, R.A. How to Write and Publish a Scientific Paper, 5th ed.; Oryx Press: Phoenix, AZ, USA, 1998. [Google Scholar]
- Burgess, S.; Pallant, A. Teaching academic writing in Europe: Multilingual and multicultural contexts. In Supporting Research Writing: Roles and Challenges in Multilingual Settings; Matarese, V., Ed.; Chandos Publishing: Oxford, UK, 2013; pp. 1–14. [Google Scholar]
- Burgess, S.; Cargill, M. Using genre analysis and corpus linguistics to teach research article writing. In Supporting Research Writing: Roles and Challenges in Multilingual Settings; Matarese, V., Ed.; Chandos Publishing: Oxford, UK, 2013; pp. 55–71. [Google Scholar]
- Lounds, A. Abstracts and introductions: Genre analysis for editors and translators of research articles. Mediterranean Editors and Translators (workshop abstract). Available online: http://www.webcitation.org/6ebp6ZD7M (accessed on 17 January 2016).
- Elia, N.; Tramèr, R. How to write a good title. Eur. J. Anaesthesiol. 2011, 28, 819–820. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
| Significant Findings | ||||
|---|---|---|---|---|
| Author (date) | Aim | Method/corpus | Content | Length |
| Goodman et al. (2001) [10] | “To determine whether the titles included information about methods, results, and conclusions” | Journals: 4 top general medical journals—NEJM, JAMA (both US); Lancet, BMJ (both UK) No. of titles: 420 Type: original RAs Time: July–December 1995 | Methods mention: 29%–40%; none named less powerful study designs (e.g., “case series”) Results mention: 16%–21% “Topic only”: 40% | — |
| Editors were interviewed about title policies. | Only BMJ had a titles policy and peer-review protocol (favoring methods mention). | |||
| Siegel et al. (2006) [12] | To “report the information content of titles of articles” and “compare the results obtained for titles in the same journals in 1995” (i.e., [10]) | Journals: NEJM, JAMA, Lancet, BMJ No. of titles: 417 Type: original RAs Time: July–December 2001 | Methods mention: 96% (2001) in BMJ, up from 49% (1995); others tended to go up (JAMA) or down (Lancet, NEJM) non-significantly Results mention: down in all | — |
| Ubriani et al. (2007) [13] | “To assess the frequency of ... type of study design” in titles (or abstracts) “using standard key words” | Journals: 3 top dermatology journals—British Journal of Dermatology, Archives of Dermatology, Journal of the American Academy of Dermatology No. of titles: 95 Type: original RAs Time: 12 months (2004–2005) | Methods mention1: 50.6%–79.6% (title or abstract) | — |
| Jacques and Sebire (2010) [14] | To find “specific features of journal titles [that] may be related to citation rates” | Journals: Lancet, BMJ, Journal of Clinical Pathology No. of titles: 150 (25 most-cited titles vs. 25 least-cited in each journal Type: RAs (“primary” + meta-analyses) and reviews Time: 2005 | More cites: titles with methods mention or acronym 2 Fewer cites: geographic location mention | More cites: longer titles (median, 18 words vs. 9 words for least-cited) More cites: 2 parts (70%) with colon |
| Habibzadeh and Yadollahie (2010) [15] | “To investigate the correlation between title length and number of citations” | Journals: non-random “arbitrarily chosen” sample of 22 with IFs; clinical and non-clinical science No. of titles: 9031 Type: all | — | More cites: longer titles (association is stronger for higher IF journals) US titles longer than UK titles |
| Paiva et al. (2012) [16] | “To evaluate some features of titles ... from OA journals and to assess the possible impact of ... features on predicting ... views and ... citations” | Journals: OA journals (7 from PLoS journals, 12 from BMC); clinical and non-clinical science No. of titles: 423 Type: RAs Time: October 2008 | More cites: results mention (vs. methods mention) Fewer cites (non-significant trend): geographic location mention and questions | More cites: short titles |
| Author (Date) | Aim | Method/Corpus | Structure |
|---|---|---|---|
| Soler (2007) [19] | “To examine ... recurrent structural features of titles in two ... genres ... in the biological ... and social sciences” | Journals: American Journal of Cardiology, Journal of Hepatology (for RAs); Arteriosclerosis, Thrombosis and Vascular Biology, Archives of Internal Medicine, and Transfusion Medicine Reviews (for reviews) No. of titles: 15 RAs, 15 reviews Type: RAs and reviews Time: 1996–2002 | Phrasal 1 titles: RAs, 72%; reviews, 46% Compound titles: RAs, 12%; reviews, 40% (Soler’s Table 5, p. 95) Declaratives: RAs, 16%; reviews, 0% (Soler’s Table 4, p. 95) Questions: RAs, 1%; reviews, 6% Length: RAs, 15.5 words; reviews, 10.7 words. Biological science titles were longer than clinical titles. |
| Wang and Bai (2007) [17] | “To reveal the syntactic structures that English native speakers frequently use [to write concise titles]” | Journal: NEJM No. of titles: 417 Type: RAs and reviews Time: 2003–2005 | Phrasal titles: 99%, nominals (4 gerund phrases) Heads: 2 heads, 21.8%; ≥3, 3.6% Between heads: and, 73.3%; vs., 22.2%; or, 4.4% Length: shorter titles over the 3 years (2003–2005) |
| Cianflone (2010) [18] | “To discuss the format of titles (noun phrase, compound, full-sentence declarative or question) in a small corpus of veterinary medicine RAs” | Journals: Preventive Veterinary Medicine, The Veterinary Journal, Journal of Feline Medicine and Surgery and Journal of Comparative Pathology (current IFs 2.2, 1.8, 1.7 and 1.1) No. of titles: 63 Type: RAs Time: 2010 | All title patterns (phrasal, compound, declaratives and questions) were seen.2 All examples of compound sentences show methods were in the second part.1 |
| Type | Question | |
|---|---|---|
| Methods mention | Q1 | Is research design mentioned? If yes, in first or second position? |
| Other content | Q2a | Are results mentioned? |
| Q2b | Is clinical context indicated? | |
| Q2c | Is a geographic location indicated? | |
| Q2d | Is a treatment named? | |
| Q2e | Is a patient population named? | |
| Surface structure | Q3a | Full sentence? Question or declarative? |
| Q3b | Number of parts? | |
| Q3c | Punctuation between parts? | |
| Q3d | Number of heads in phrasal titles? | |
| Q3e | Link (e.g., and, but, vs., or) between heads? | |
| Content | Journals | All (N = 232) | p Value 2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NEJM (n = 53) | BMJ (n = 55) | Anesthesiology (n = 62) | EJA (n = 62) | ||||||||
| n | (%) | n | (%) | n | (%) | n | (%) | n | (%) | p < 0.0001 | |
| Methods (Q1) | |||||||||||
| No | 47 | (88.7) | 1 | (1.8) | 26 | (41.9) | 2 | (3.2) | 76 | (32.8) | |
| Yes, first position 3 | 6 | (11.3) | 0 | (0) | 11 | (17.7) | 1 | (1.6) | 18 | (7.8) | |
| Yes, second position 3 | 0 | (0) | 54 | (98.2) | 25 | (40.4) | 59 | (95.2) | 138 | (59.4) | |
| Results (Q2a) | p < 0.0001 | ||||||||||
| No | 52 | (98.1) | 55 | (100.0) | 44 | (71.0) | 53 | (85.5) | 204 | (87.9) | |
| Yes | 1 | (1.9) | 0 | (0) | 18 | (29.0) | 9 | (14.5) | 28 | (12.1) | |
| Content | Journals | p Value | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NEJM (n = 61) | BMJ (n = 76) | Anesthesiology (n = 68) | EJA (n = 64) | All (N = 269) | |||||||
| Clinical context (Q2b) | p = 0.2774 | ||||||||||
| No | 6 | (9.8) | 15 | (19.7) | 15 | (22.1) | 11 | (17.2) | 47 | (17.5) | |
| Yes | 55 | (90.2) | 61 | (80.3) | 53 | (77.9) | 53 | (82.8) | 222 | (82.5) | |
| Geography (Q2c) | p= 0.0012 2 | ||||||||||
| No | 52 | (85.2) | 64 | (84.2) | 68 | (100.0)† | 58 | (90.6) | 242 | (90.0) | |
| Yes | 9 | (14.8) | 12 | (15.8) | 0 | (0.0) | 6 | (9.4) | 27 | (10.0) | |
| Treatment (Q2d) | p = 0.0616 | ||||||||||
| No | 26 | (42.6) | 48 | (63.2) | 32 | (47.1) | 37 | (57.8) | 143 | (53.2) | |
| Yes | 35 | (57.4) | 28 | (36.8) | 36 | (52.9) | 27 | (42.2) | 126 | (46.8) | |
| Patient type (Q2e) | p = 0.3195 | ||||||||||
| No | 45 | (73.8) | 55 | (72.4) | 54 | (79.4) | 54 | (84.4) | 208 | (77.3) | |
| Yes | 16 | (26.2) | 21 | (27.6) | 14 | (20.6) | 10 | (15.6) | 61 | (22.7) | |
| Features | Journals | p Value | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NEJM (n = 61) | BMJ (n = 76) | Anesthesiology (n = 68) | EJA (n = 64) | All (N = 269) | |||||||
| Full sentence (Q3a) | p < 0.0001 2 | ||||||||||
| No | 61 | (100.0) 2 | 73 | (96.1) | 56 | (82.4) | 54 | (84.4) | 244 | (90.7) | |
| Yes, question | 0 | (0.0) | 3 | (3.9) | 0 | (0.0) | 1 | (1.6) | 4 | (1.5) | |
| Yes, affirmation | 0 | (0.0) | 0 | (0.0) | 12 | (17.6) 2 | 9 | (14.0) | 21 | (7.8) | |
| No. of parts (Q3b) | p < 0.0001 2 | ||||||||||
| 1 | 54 | (88.5) 2 | 19 | (25.0) | 45 | (66.2) | 3 | (4.7) | 121 | (45.0) | |
| 2 | 6 | (9.9) | 57 | (75.0) | 23 | (33.8) | 60 | (93.7) | 146 | (54.3) | |
| 3 | 1 | (1.6) | 0 | (0.0) | 0 | (0.0) | 1 | (1.6) | 2 | (0.7) | |
| Punctuation, multi-part titles (Q3c) 3 | p = 0.0001 2 | ||||||||||
| Colon | 2/7 | (28.6) | 57 | (100.0) 2 | 23 | (100.0) | 60/61 | (98.4) | 142/148 | (95.9) | |
| Colon + colon | 0 | (0.0) | 0 | (0.0) | 0 | (0.0) | 1/61 | (1.6) | 1/148 | (0.7) | |
| Colon + dash | 1/7 | (14.3) | 0 | (0.0) | 0 | (0.0) | 0 | (0.0) | 1/148 | (0.7) | |
| Dash | 4/7 | (57.1) | 0 | (0.0) | 0 | (0.0) | 0 | (0.0) | 4/148 | (2.7) | |
| No. of heads in multi-head phrases (Q3d) 4 | p = 0.5802 | ||||||||||
| 2 | 15/18 | (83.3) | 34/37 | (91.9) | 4/5 | (80.0) | 10/11 | (90.9) | 63/71 | (88.7) | |
| 3 | 3/18 | (16.7) | 2/37 | (5.4) | 1/5 | (20.0) | 1/11 | (9.1) | 7/71 | (9.9) | |
| 4 | 0 | (0.0) | 1/37 | (2.7) | 0 | (0.0) | 0 | (0.0) | 1/71 | (1.4) | |
| Link between heads (Q3e) 4 | p = 0.3202 | ||||||||||
| and | 15/22 | (68.2) | 35/41 | (85.4) | 5/6 | (83.3) | 9/12 | (75.0) | 64/81 | (79.0) | |
| vs. (or versus) | 4/22 | (18.2) | 3/41 | (7.3) | 0 | (0.0) | 3/12 | (25.0) | 10/81 | (12.4) | |
| comma | 3/22 | (13.6) | 3/41 | (7.3) | 1/6 | (16.7) | 0 | (0.0) | 7/81 | (8.6) | |
| Type | Question | κ Statistic | Interpretation 1 | |
|---|---|---|---|---|
| Methods mention | Q1 | Is research design mentioned? If yes, in first or second position? | 0.89 | Almost perfect |
| Other content | Q2a | Are results mentioned? | 0.80 | Substantial |
| Q2b | Is clinical context indicated? | 0.52 | Moderate | |
| Q2c | Is a geographic location indicated? | 0.87 | Almost perfect | |
| Q2d | Is a treatment named? | 0.65 | Substantial | |
| Q2e | Is a patient population named? | 0.66 | Substantial | |
| Surface structure | Q3a | Full sentence? Question or declarative? | 0.77 | Substantial |
| Q3b | Number of parts? | 0.93 | Almost perfect | |
| Q3c | Punctuation between parts? | 0.93 | Almost perfect | |
| Q3d | Number of heads? | 0.74 | Substantial | |
| Q3e | Link between heads? | 0.41 | Moderate | |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kerans, M.E.; Murray, A.; Sabatè, S. Content and Phrasing in Titles of Original Research and Review Articles in 2015: Range of Practice in Four Clinical Journals. Publications 2016, 4, 11. https://doi.org/10.3390/publications4020011
Kerans ME, Murray A, Sabatè S. Content and Phrasing in Titles of Original Research and Review Articles in 2015: Range of Practice in Four Clinical Journals. Publications. 2016; 4(2):11. https://doi.org/10.3390/publications4020011
Chicago/Turabian StyleKerans, Mary Ellen, Anne Murray, and Sergi Sabatè. 2016. "Content and Phrasing in Titles of Original Research and Review Articles in 2015: Range of Practice in Four Clinical Journals" Publications 4, no. 2: 11. https://doi.org/10.3390/publications4020011
APA StyleKerans, M. E., Murray, A., & Sabatè, S. (2016). Content and Phrasing in Titles of Original Research and Review Articles in 2015: Range of Practice in Four Clinical Journals. Publications, 4(2), 11. https://doi.org/10.3390/publications4020011