1. Introduction
The Global Quality Score was introduced by Bernard et al. back in 2007, in a “systematic review” of 34 websites that contained information for patients with inflammatory bowel disease (IBD) (
Bernard et al., 2007). In that paper, Bernard et al. evaluated the websites with multiple instruments, one of which was called the Global Quality Score (GQS), which was a “five-point Likert scale developed for this study” aimed to assess the general information quality, flow, ease of use; hence, the usefulness of the website to patients. Score 1 meant poor quality and not at all useful for patients, whereas score 5 meant excellent quality and very useful for patients. The validity of the GQS was not explicitly mentioned. The other instruments were the Quality Evaluation Instrument, readability assessment tools (
Jindal & MacDermid, 2017) of the Flesch Reading Ease score and Flesch–Kincaid Grade Level score, and the Integrity Score. Since these instruments were not relevant to the current study, they would not be further elaborated here.
The GQS has been frequently utilized by subsequent studies as a tool to evaluate the quality of online patient information materials. A recent systematic review identified GQS as the second most commonly used method for assessing online content quality (
Osman et al., 2022), ranking only behind customized assessment scales specific to each study, but ahead of established tools such as DISCERN (
Charnock et al., 1999) and the JAMA benchmark (
Silberg et al., 1997). This finding might be surprising, as the original papers that introduced DISCERN and the JAMA benchmark were dedicated to explaining the rationale and design of these tools (
Charnock et al., 1999;
Silberg et al., 1997). In contrast, the GQS was first introduced and used in a paper focused on evaluating IBD websites, making the GQS itself a “by-product” of the publication. Terminological precision is vital in health informatics to ensure research clarity and methodological rigor. Inaccurate usage, such as the use of “tortured phrases” (e.g., referring to Alzheimer’s disease as Alzheimer’s malady), creates confusion (
Teixeira da Silva, 2022). Similarly, diverse quality assessment tools in systematic reviews highlight the need for clear tool identification (
Gebrye et al., 2023). Despite the widespread use of the GQS, no study has systematically examined its misnaming or mis-citation, a gap this work addresses to promote reliable online health information evaluation.
In the field of ecology, it was found that 15% of citations unfairly gave credit to review papers instead of the original studies (
Teixeira et al., 2013). Some researchers refer to this practice of improper attribution as “lazy author syndrome” (
Gavras, 2002) or citing an “empty reference” (
Harzing, 2002). This mis-citation behavior matters as it distorts the academic record by undervaluing the contributions of original researchers, and potentially affecting their career advancement through reduced recognition in terms of citations. It also compromises scientific rigor, as the reliance on secondary sources may overlook critical details from the methodology or results interpretations and perpetuate inaccuracies. Therefore, ensuring proper attribution through accurate citations is essential for maintaining the quality of scientific research.
Before writing this report, the author observed improper citations for using the GQS that resembled the abovementioned examples. Moreover, the GQS was often described as the Global Quality Scale (instead of Score) and sometimes referred to as a “validated” tool, both of which were inaccurate. The term “Global Quality Score” refers to the specific metric developed by
Bernard et al. (
2007) to evaluate the quality of online health information based on defined criteria. Misnaming it as the “Global Quality Scale” implies a different measurement construct, potentially leading to confusion in its application and interpretation, which could affect the consistency and reliability of research findings. By naming it a scale, readers may assume it operates on a continuous rather than a discrete scoring system. Hence, this work aimed to survey the literature on the use of the GQS to assess the accuracy of the citations and descriptions of the tool. By examining the GQS as a case study, this work highlights systemic issues in the citation and naming of research tools, offering insights that can inform best practices for other indicators in health informatics and beyond. Such analyses are beneficial for ensuring methodological rigor and fostering trust in research outputs.
2. Materials and Methods
On 23 November 2023, the following literature searches were performed:
- (1)
Web of Science Core Collection was queried with the following search string: Topic = “global quality scale*” OR “global quality score*”. Document type was limited to article, and publication language was limited to English. This search yielded 387 publications.
- (2)
Scopus was queried with the following search string: TITLE-ABS-KEY = (“global quality scale*” OR “global quality score*”). Document type and language filters were similarly applied. This search yielded 391 publications.
- (3)
PubMed was queried with the following search string for all indexed fields: “global quality scale*” OR “global quality score*”. This search yielded 403 publications.
The first two searches looked for the presence of “global quality score*” or “global quality scale*” in the title, abstract, and keywords fields of original articles written in English. Meanwhile, the PubMed functionality was less versatile and hence the last search looked for all fields and did not place the filters. The search were not limited by a time frame. Yielded papers were all initially included. All the 1181 publication records were exported into an Excel spreadsheet. After removing duplicates, 471 papers remained. Among the 471 papers, 60 of them were excluded after screening due to the following reasons: no access to the full text (
n = 16), full text not in English (
n = 3), and irrelevance (e.g., no actual usage of the GQS, or the mentioned GQS was not the one used to evaluate online health information,
n = 41). For papers with no access to the full text, the authors were not contacted. Finally, 411 papers entered the analysis (
Figure 1).
Then, the 411 papers were manually coded for the following parameters:
- (1)
- (2)
What other references were cited as the source of the GQS.
- (3)
Whether the GQS was called the Global Quality Score or Global Quality Scale.
- (4)
What kind of online materials were evaluated.
- (5)
Descriptions of the validity of the GQS, if any.
A chi-squared test was conducted to assess if a higher proportion of the group of papers citing Bernard and co-workers as the source of the GQS would call the GQS the Global Quality Score, relative to the group of papers that did not cite Bernard and co-workers. Linear regressions were conducted to evaluate if there were linear trends in the ratio of papers calling the GQS the Global Quality Score, citing Bernard and co-workers, and citing nothing as the source of the GQS across publication years. Papers published before 2018 were grouped into papers published in 2018 together for the tests. Statistical analyses were performed with SPSS 28.0 (IBM, Armonk, NY, USA). Results were significant if p < 0.05.
3. Results
The coded data sheet for the 411 papers was provided as
Supplementary File S1. Nearly all (n = 398, 96.8%) have been published since 2019 (
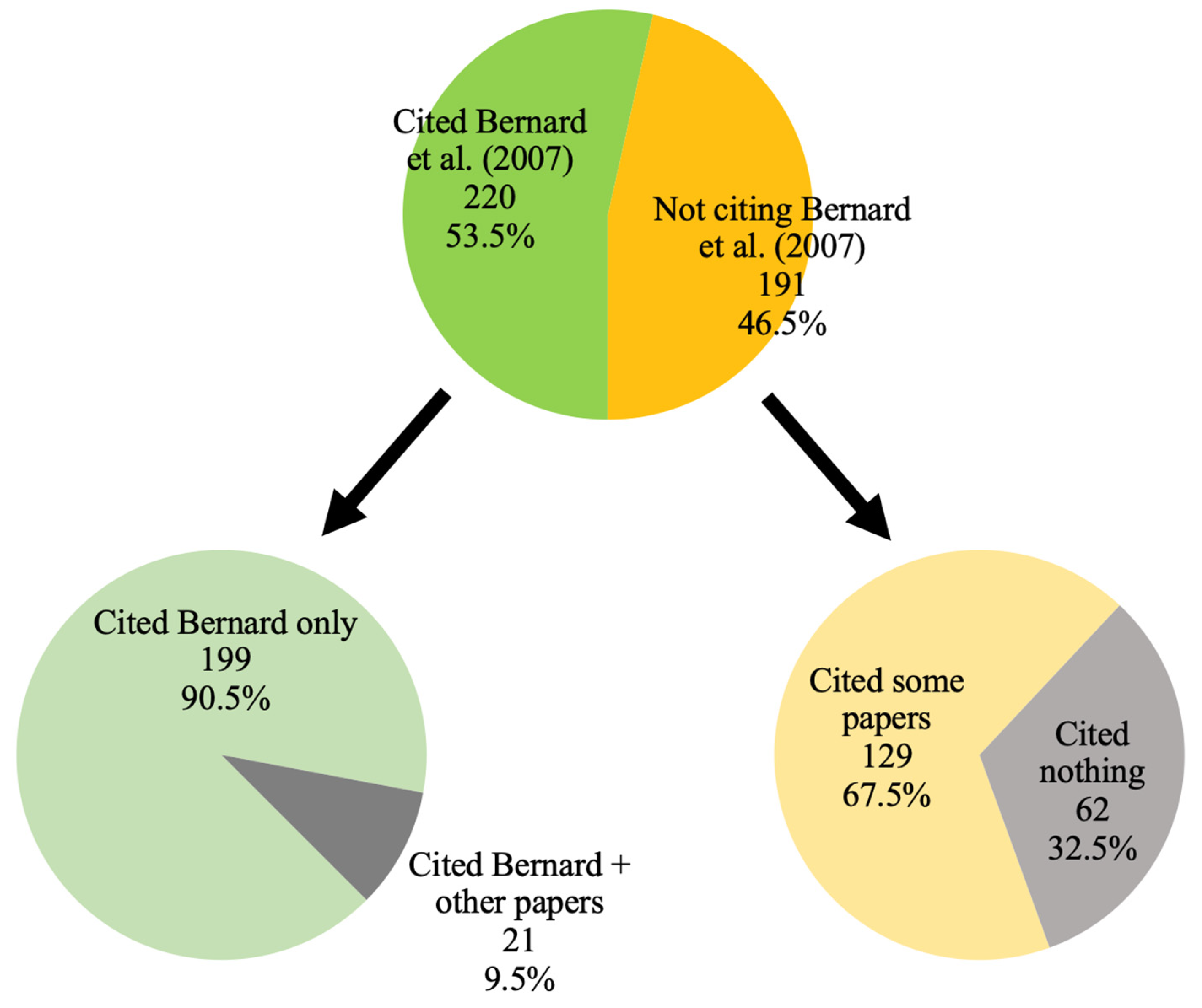
Figure 2). Overall, 218 papers cited
Bernard et al. (
2007) as the source of the GQS and two papers mentioned that Bernard and co-workers introduced the GQS without a citation in the reference list. It was unclear if the citation was accidentally omitted in the reference list due to a typesetting error during the publication process. For simplicity, these two papers were merged into the 218 papers for the rest of this report, rendering it a total of 220 papers giving proper credit to Bernard and co-workers as the source of the GQS (53.5%). Among these 220 papers, 21 papers also gave credit simultaneously to other researchers (
Figure 3). For those 191 papers that did not cite
Bernard et al. (
2007) as the source of the GQS, 62 papers did not cite any references at all. Upon closer examination, 80 other references were cited among the 411 papers as the source of the GQS, predominated by (
Singh et al., 2012) (n = 43), (
Erdem & Karaca, 2018) (n = 27), (
Kunze et al., 2019) (n = 8), and (
Langille et al., 2010) (n = 8).
Meanwhile, 226 papers (55.0%) referred to the GQS by the original name, the Global Quality Score, whereas 185 papers (45.0%) referred to it as the Global Quality Scale. A chi-squared test showed that a significantly higher proportion of papers citing Bernard and co-workers as the source of the GQS actually called it the Global Quality Scale than their counterparts (50.9% vs. 38.2%,
p = 0.010). Meanwhile, an exploratory chi-squared test showed that there was no significant difference in the proportion of papers that called the GQS the Global Quality Score regardless of whether
Singh et al. (
2012) was cited or not (48.8% vs. 55.7%,
p = 0.392).
Table 1 shows the number of papers referring to the GQS as the Global Quality Score and citing
Bernard et al. (
2007), respectively, per year. Linear regressions showed that there was no significant temporal trend in the ratio of papers calling the GQS the Global Quality Score (r
2 = 0.297,
p = 0.568), whereas there was a significant reduction in the ratio of papers citing Bernard and co-workers as the source of the GQS across the years (r
2 = 0.944,
p = 0.005). There was no significant temporal trend in the ratio of papers that cited nothing as the source of the GQS (r
2 = 0.463,
p = 0.355). The Result was unchanged if papers published in 2018 or before were disregarded (r
2= 0.849,
p = 0.069).
Only 24 papers (5.8%) mentioned or commented about the validity of the GQS. Interestingly, half of these 24 papers claimed that the GQS was a validated tool whereas the other half correctly claimed that the GQS was not validated.
Finally, most of the 411 papers solely evaluated YouTube videos (n = 360, 87.6%), whereas 18 papers evaluated the content of websites in general (4.4%) (
Table 2). Besides those commonly evaluated materials listed in
Table 2, other online information sparsely evaluated by the papers included the following: videos from Kwai, iQiYi, WebSurg, Youku, Tencent, Tudou, Xigua, and offline videos; and written materials from Wikipedia and Baidu Encyclopedia (see
Supplementary File S1).
4. Discussion
This study has several major findings regarding the use of the GQS in the literature. The foremost finding is that 45.0% of the analyzed papers misnamed the Global Quality Score as the Global Quality Scale. The term “Scale” was never mentioned in the original source of the GQS (
Bernard et al., 2007), but it was listed in the second most cited reference by
Singh et al. (
2012), in its abstract and table heading that described the rating. At the first glance, it might be assumed that researchers were influenced by the wording by
Singh et al. (
2012), leading more recent publications to use the term “Scale” instead of “Score”. However, current results indicated that citing
Singh et al. (
2012) did not significantly increase the likelihood of using the term “Scale”. In fact, citing
Bernard et al. (
2007) did. Moreover, the current results did not show an increasing trend in the use of the term “Scale” over the years. This phenomenon appears to be inexplicable.
Perhaps one possible explanation was that many researchers did not think that the exact name of the evaluation tool was an important issue. However, it is actually critical to ensure the identical tool with the correct name is applied as prior studies did. Otherwise, confusion may arise. In neuroscience and psychology fields, there is a 10-item questionnaire called the Edinburgh Handedness Inventory (EHI), devised by Oldfield back in 1971 to assess the handedness of human subjects (i.e., whether a subject is right-handed or not) (
Oldfield, 1971). Two large-scale literature surveys have indicated that many papers applying the EHI did not report whether the original format was maintained or simply changed the number/content of the items, response format, and cut-off score for right-handedness (
Edlin et al., 2015;
Yeung & Wong, 2022). Regardless, the issue of altering the original format of the tool should not affect the GQS too much, as it is only a five-point Likert scale with a simple and straightforward description indicating the overall content quality from very poor to excellent. In fact, the authors of one paper in the dataset reported that they modified the GQS into a four-point Likert scale (removing the category of very poor quality) (
Aldahlawi et al., 2023). This modification was described in the main text but the abstract simply mentioned that the GQS (“Scale”) was used. Misnaming it as “Global Quality Scale” is undesirable, as it implies a different measurement construct, potentially leading to confusion in its application and interpretation. By naming it a scale, readers may assume it operates on a continuous rather than a discrete scoring system. In short, researchers should avoid confusion by naming the tool correctly, and either briefly describing the content/format of the tool or citing the original source to guide readers to check its content/format.
Another important finding was the declining ratio of papers that cited
Bernard et al. (
2007) as the source of the GQS. One may argue that it follows a phenomenon called “obliteration by incorporation” (
Merton, 1965), meaning that a concept has become universally accepted and well known as common knowledge so that researchers no longer cite the original source or explain the concept itself (
Marx & Bornmann, 2010;
Yeung, 2021). The current results, however, indicated that although the ratio of papers citing nothing as the source of the GQS seemed to be higher during 2021–2023 compared to 2019 and 2020, the overall trend did not show any statistical significance. In other words, researchers recently might tend to cite other references more in the place of the original
Bernard et al. (
2007), instead of citing no reference at all. For example, nine papers cited both
Singh et al. (
2012) and
Erdem and Karaca (
2018) as the sources of the GQS; these were published more recently. In addition,
Erdem and Karaca (
2018) cited
Singh et al. (
2012) but not
Bernard et al. (
2007). Hence, subsequent researchers who referred to
Erdem and Karaca (
2018) might conveniently identify
Singh et al. (
2012) as the original source of the GQS, which should be inaccurate as
Singh et al. (
2012) correctly cited
Bernard et al. (
2007) as the source of the GQS. The key message here is that researchers should verify and hence cite the original source of information, instead of citing secondary sources (
Gavras, 2002;
Teixeira et al., 2013). As mentioned in the introduction, mis-citation behavior is discouraged as it undervalues the contributions of original researchers, undermines their recognition, and compromises scientific rigor by potentially overlooking critical details from the original methodology and results interpretations. Overall, 53.5% of papers cited the primary source of the GQS, namely
Bernard et al. (
2007). This percentage is higher than that reported by a recent study on the citation of a dental anxiety scale, in which 41.9% of surveyed papers correctly cited the primary source (
Yeung, 2024). Readers should be reminded to cite the primary source to properly credit the original contributors, ensuring accurate attributions in subsequent publications.
The claim of the GQS being a validated tool was another issue to be discussed. Interestingly, none of the 12 papers that described the GQS as an unvalidated tool cited
Bernard et al. (
2007), but 6 of the 12 papers that described the GQS as a validated tool did. One illustrative excerpt from P.3 of (
Vaira et al., 2023) was as follows: “The GQS, introduced and validated by Bernard et al., evaluates the quality and information flow of the videos and consequently their usefulness for the patient”. A careful examination of the text of
Bernard et al. (
2007) found no mention about the validity of the GQS, whereas another tool called QEI was indeed claimed to be validated by that paper. According to Bernard, the authors underwent several iterations of the GQS and finalized its content after pretesting (personal communication, 23 January 2025). Moreover, the face validity of the GQS is high, as the GQS was found to correlate well with validated metrics such as QEI (r = 0.81) (
Bernard et al., 2007) and DISCERN (r = 0.88) (
Langille et al., 2010). Also, the GQS was created to evaluate websites but not videos. Tools used to evaluate online health information were usually unvalidated but that did not deter researchers from using them. For instance, the original DISCERN tool was a validated 16-item tool that required users to answer in five-point Likert scale for all questions (
Charnock et al., 1999). Then, it was modified into a five-item tool that requires binary answers, rendering a total score ranged between 0 and 5, often referred to by researchers as the Reliability Score or modified/brief DISCERN. This modification was performed in the same paper by
Singh et al. (
2012) that is frequently (mis-)cited as the source of the GQS (
Singh et al., 2012). Again, this modified DISCERN was unvalidated. Similarly, the JAMA benchmark was a four-point scale that assessed the authorship, attribution, disclosure, and currency aspects of online health information (
Silberg et al., 1997). This tool was also not validated, and according to the own words of the original authors, the benchmarks “certainly are no guarantee of quality in and of themselves” (
Silberg et al., 1997). All these examples suggested that many common evaluation tools were not validated. Meanwhile, a validated tool means it has been scientifically proven. At times, however, it may be more efficient and pragmatic for researchers to devise or use a questionnaire with a good face validity, with careful considerations at various stages from item selection to small-sample pretesting, but untested for construct validity (
Guyatt et al., 1986). Ultimately, researchers should not mix up between being scientifically validated and being frequently cited.
At a first glance, it was strange to note that few papers used the GQS before 2019, given that Bernard and co-workers introduced it in 2007. Meanwhile, data showed that most of the 411 papers using the GQS were evaluating videos posted on the YouTube platform, which was founded in 2005. The literature shows a similar publication trend of papers evaluating YouTube videos on dentistry topics: fewer than 10 papers were published annually before 2019, but 20–30 papers have been published per year since 2020 (
Yeung et al., 2024). Another bibliometric study on the entire literature of YouTube similarly found a steeper publication growth since 2019 (
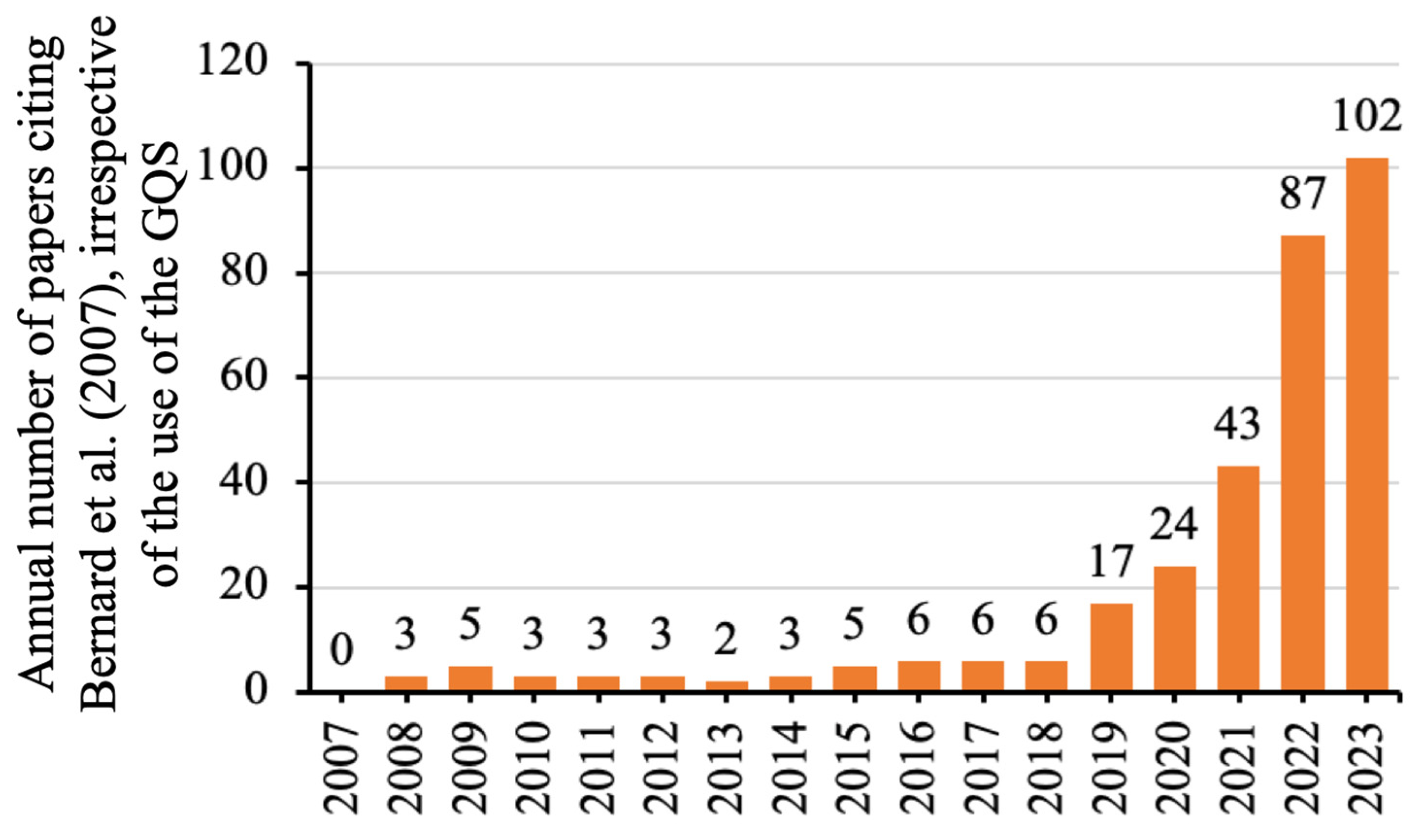
Mostafa et al., 2023). For exploratory purposes, a cited reference search was conducted via the Web of Science Core Collection to investigate the temporal trend of papers citing
Bernard et al. (
2007), regardless of whether these citing papers dealt with the GQS or not. The search similarly showed that
Bernard et al. (
2007) were cited a few times per year before 2019 (
Figure 4). Considering all these numbers together, one plausible reason could be that the COVID-19 pandemic hindered many research activities with social distancing and lockdowns. It might promote researchers to conduct research that did not require personal contact, such as evaluating YouTube videos.
The current work focused on the citation behavior and naming accuracy of the GQS. Future studies with a larger dataset can conduct a bibliometric analysis on authorship, country of origin, journal, and related altmetrics.






{kind=link}
{kind=link}
{kind=link}
{kind=link}