Abstract
Previous analysis has shown that the use of narrative devices in the biomedical literature has changed over time. The purpose of the present study was to measure the degree of narrativity in corpora of scientific abstracts obtained from Pubmed through the use of a proprietary software LIWC 2022, which, based on pre-set dictionaries, attributes scores for Staging, Plot Progression and Cognitive Tension to texts. Each text is automatically divided into a number of segments, so that the score change can be assessed throughout the different parts of a text, thus identifying its narrative arc. We systematically applied the scoring system to a corpus of 680,000 abstracts from manuscripts of any kind and genre published in the years 1989–2022 and indexed in MEDLINE, an independent corpus of 680,000 abstracts of Primary studies published in the same years, and finally a corpus of 680,000 abstracts of Review papers that appeared in the 1989–2022 interval. We were able to create plots of the pattern of how these three scores changed over time in each corpus and observed that the prototypical pattern observed in narrative texts, e.g., novels, is not seen in abstracts of the scientific literature, which, however, mostly possess a diverse but quite reproducible pattern. Overall, Reviews better conform to a higher degree of narrativity than Primary studies.
1. Introduction
Abstracts are among the best known and most relevant sections in a manuscript, as they are sometimes the only part of a text, besides the title, that is read by prospective readers [1]. Abstracts are a short summary of the content of scientific articles, and they are currently mostly used to screen for articles of interest [2]. We have shown that abstracts have slowly emerged over the last century replacing summaries, which were usually located at the end of a manuscript [3]. The main purpose of a summary was to serve as a mnemonic aid to readers, summing up the main conclusions and takeaway messages from what they had just read in the main body of the text and had therefore often a purely schematic nature, not seldom resorting to bullet points [4]. Abstracts, on the other hand, anticipate the structure of a study and are meant to be read before the manuscript, thus providing readers with clues as to whether the article is going to be useful for their needs.
It could be argued that, by providing some context to the study, abstracts allow experienced readers to utilize the remaining part of the text more effectively [5], but there has long been consensus that the main function of an abstract is to be found in literature searches [6,7]. These two sections—abstracts and summaries—are therefore to be interpreted within the specific context of the use of scientific literature in the historical period when they were developed [4]. As scientific literature flourished into thousands of journals, especially after the internet revolution, sorting the right piece of information out of the background noise of hundreds of thousands of similar articles that constitute the bibliome [8] has become an art of itself [9], which requires skills to skim through a vast amount of literature and pinpoint useful articles [10]. Bibliographic tools that may assist readers in this Sisyphean task have therefore been progressively developed, and abstracts are possibly a prime example of this. As bibliographic searching became more demanding and complex over time, abstracts may also have evolved to better adapt to the changing readers’ needs, and this may be possibly reflected by changes in the structure of abstracts, with simpler, more standardized and analytical formats that may simplify the screening process and information finding [11,12].
Narration plays an important role in scientific communication [13], and yet it has been shown that biomedical articles have progressively moved away from a more narrative style of reporting [14]. Although it is difficult to establish standardized properties of narrativity, most scholars still regard the work of Gustav Freytag as substantially valid [15,16]. According to Freytag, characters in a story usually go through a pre-defined sequence of five stages that trace a trajectory he famously named the ‘dramatic arc’ [16]. This includes an initial exposition, where the author outlines the background of the story, thus laying the foundations for the subsequent events that involve the characters and that, through struggles and conflicts, reach a peak, a climax, followed by decline and a resolution stage. Thus, most stories, as immensely diverse in content as they may be, would still share a common pattern, a unifying, content-free paradigm of narrative structure.
Many literary and linguistic scholars have been looking for automated solutions to identify such narrative stages within a text, and Pennebaker’s group has formulated a model, rooted in their previous experience with specific psycholinguistic dictionaries and recently published in Boyd et al. [17], which relies on three main parameters, devised to broadly align with Freytag’s assumptions: Staging, Plot Progression and Cognitive Tension. Staging refers to the use of a language that ‘sets the stage’ for the narration, through the use of nouns, denoting the new entities of the story, and their relations one to the other. Plot Progression refers to a language that is richer in words that denote actions and that drive the story forward. Finally, Cognitive Tension refers to a language associated to some sort of cognitive process or conflict, and the uncertainty for the main characters to reach their goals. Interestingly though, Boyd et al. do not propose to measure Staging and Plot Progression through the relative frequencies of content words (which, given the vast diversity of possible texts would make any dictionary-based approach unpractical) but on the much smaller portion of the lexicon represented by function words. These words, also known as empty words, are grammatical words, such as prepositions or pronouns, which are limited in number but account for up to 30–50% of the total wordcount in a typical text [17]. Pennebaker’s assumption is that the initial stage of narration requires articles and prepositions, because new entities enter the scene, and their relations must be introduced. Once this has occurred, authors can move on and use these entities and characters, referring to them through anaphoric pronouns and associating them to actions and events, which often requires auxiliary verbs. The Staging score is therefore calculated as the relative frequency of articles and prepositions in a text and the Plot Progression score is the relative frequency of pronouns and auxiliary verbs. Cognitive Tension, on the other hand, is computed as the relative frequency of words that are included in the cognitive process dictionary that Pennebaker’s group created for their Linguistic Inquiry and Word Count (LIWC) software, e.g., ‘think’, ‘believe’, etc. [18]. Using these scores, this group then evaluated several corpora that included novels, screenplays, scientific articles from The New York Times, transcripts from TED talks and even opinions of the Supreme Court and concluded that a normative narrative arc structure could be identified, which mostly agreed with Freytag’s ideas (Figure 1) [17].
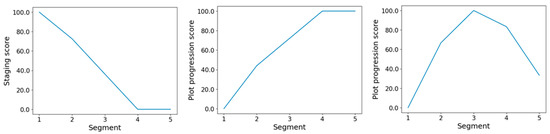
Figure 1.
Line plot representing the Staging, Plot Progression and Cognitive Tension scores for the publication ‘Sphingolipid signaling in the cardiovascular system: good, bad or both?’, which closely follows the prototypical narrative arc as described by Boyd et al. [17].
Clearly, abstracts are a very peculiar instance of micronarration. Abstracts allow readers to screen the papers of interest and capture their attention, thus making it more likely for them to read the whole study. There is not necessarily a ‘resolution’ stage in abstracts because they may only act as a foreword to the manuscript itself. However, abstracts can also differ in structure, especially those belonging to primary studies that report the answer to a meaningful research question through experimental procedures. Not unfrequently, these studies include a summary of their findings and conclusions in the abstract itself and are thus an actual summary of the subsequent manuscript. To this effect, it should be noted that Day distinguished two types of abstracts, which correspond to the distinction we traced: the former, referred to as descriptive, are only a description of the content or the work conducted, and do not replace the text to which they are a preface, while the latter, called informative abstracts, summarize the whole study, including the results [19]. The narrative structure of an abstract is therefore not necessarily obvious.
Pennebaker’s group made their model available as an analytical tool in their new LIWC release, and Figure 1 shows the shape of normative narrative arcs, according to Boyd et al.’s model, which we generated using LIWC on a review paper published in 2008 by Alewijnse AE and Peters SLM in the European Journal of Pharmacology, entitled ‘Sphingolipid signalling in the cardiovascular system: good, bad or both?’ [20] (Supplementary Materials S1). In this abstract, Staging scores are higher in segment one, where the topic of the review is first introduced and the main molecular players, i.e., sphingolipids, are mentioned and their importance acknowledged:
‘Sphingolipids are biologically active lipids that play important roles in various cellular processes and the sphingomyelin metabolites ceramide, sphingosine and sphingosine-1-phosphate can act as signalling molecules in most cell types …’
After setting the stage for the manuscript, the tone of the abstract changes quite distinctly, as the authors move on to discuss the main critical points that remain elusive, in segment three:
‘…the question was raised which pharmacological properties of drugs targeting sphingolipid signalling will affect cardiovascular function in vivo. The answer to this question will most likely also indicate…’
This section scores highest in Cognitive Tension, as the problems and the issues at stake are revealed. There are questions that are relevant and must be addressed and their answers will bear consequences on the clinical management of patients suffering from certain diseases. The intellectual horizons of the readers are being expanded here, and their view is shifted from a ‘narrow’ molecular perspective to broader considerations in clinics. There is ‘food for thought’, there are intellectual challenges and the dots are being connected, hence, understandably so, the Cognitive Tension is high. And once the readers are aware of the importance of the matter at hand, the abstract can wrap up in segment five, and the authors reveal their plan of action to the now captivated readers and introduce them to what is coming up next, i.e., the review itself, and the text gains in dynamicity, and thus it reaches its peak in Plot Progression score:
‘…we will give a brief overview of the pathophysiological role of sphingolipids in cardiovascular disease. In addition, we will try to answer how drugs that target sphingolipid signalling will potentially influence…’
It is all about action now, there is a journey ahead—a rich review—and it is time to set off along the path; there is movement, there are verbs indicating activity, e.g., giving an overview, providing evidence and obtaining answers.
As it has been shown that article narrativity, at least in some scientific fields, correlates with the success of its cultural journey, as assessed by the number of citations [21], a better understanding of the characteristics of abstract narrative structures becomes of interest. Furthermore, understanding whether the narrative structure has changed over time may provide additional clues as to the interaction between the role of abstracts, their adaptation to changing literature conditions and their internal structure.
We hypothesized that abstracts of biomedical nature may have peculiar narrative arcs that differ from Boyd et al.’s proposed normative arcs and these may depend on the genre of the article, which affects the use of narrative devices and that, more specifically, Review articles may be characterized by a higher degree of narrativity as compared to primary studies. The reason for this could be that Reviews are a genre of scientific article that comprises several sub-types including ‘Narrative reviews’ and the authors’ task in a Review is to illustrate, summarize and somehow narrate the findings of a selected corpus of articles, creating a thread that was not necessarily apparent beforehand and, thus, a story.
Based on these hypotheses, we set off to investigate the narrative structure of biomedical abstracts in corpora from the scientific literature using LIWC, to assess how well this tool may be used to investigate the biomedical literature, to characterize a prototypical narrative structure for abstracts from primary studies and from review articles and to assess whether narrative arcs changed over time, as previous analysis suggests.
2. Materials and Methods
For the present study, we decided to create three independent corpora of abstracts of scientific manuscripts that were indexed in MEDLINE. To generate the corpora, we used the python 3.9 litter-getter library [22], and we searched MEDLINE through the Pubmed API using the following search terms:
- #1
- ‘year[dp]’;
- #2
- ‘year[dp] NOT Review[pt]’; (1,699,999)
- #3
- ‘year[dp] AND Review[pt]’; (1,839,200)
where the ‘year’ parameter was set to iterate from 1972 through 2022, to screen for the last 50 years. Search #1 aimed at creating a corpus of abstracts published from 1972 to 2022. Search #2 had the objective of creating an independent corpus of abstracts that did not belong to the ‘Review’ type and were published between 1972–2022, and search #3 aimed at forming a corpus of ‘Review’ abstracts appearing in the 1972–2022 interval.
To obtain independent corpora, litter-getter was programmed to retrieve the Pubmed indexes (PMID) for the articles that matched the search terms and then randomly sort 50,000 PMIDs out of the total number of retrieved PMIDs for each year. As we went through the first search and we observed the distribution of the results, we noticed that the #1 search retrieved fewer than 20,000 PMIDS for the publication years prior to 1975, thus we decided to set the lower limit of our corpus to 1975 and we randomly sampled 20,000 articles per year. When we searched MEDLINE for Reviews, we then decided to set the lower limit for all searches to 1989, as we retrieved fewer than 20,000 reviews per year before that date for searches #2 and #3 and we again randomly sampled 20,000 articles per year, to balance the corpus.
We eventually obtained 3 independent corpora as follows:
- #1
- Abstracts published between 1989–2022 (n = 680,000), henceforth referred to as ‘All articles’
- #2
- Abstracts from Research articles (excluding Reviews), published between 1989–2022 (n = 680,000), henceforth referred to as ‘Primary studies’
- #3
- Abstracts from Review articles, published between 1989–2022 (n = 680,000), henceforth referred to as ‘Reviews’
For each individual indexed article, litter-getter yielded an XML file, and we then proceeded to create a Pandas Dataframe [23] using the BeautifulSoup library [24] to extract data from the XML file and clean them up.
The extracted data for each article were ‘PMID’, ‘Title’, ‘Abstract’ and ‘Year’. We lowercased the text of the abstracts and passed it into the proprietary text analysis software ‘Linguistic Inquiry and Word Count’—LIWC-22 [18]. LIWC relies on a series of pre-defined dictionaries [25], which are used to compute scoring variables associated to specific thematic areas, e.g., the Affective Processes—Positive emotions dictionary includes words such as ‘happy’, ‘pretty’ or ‘good’ and its corresponding score would be the relative frequency of any of these words in the analyzed text. LIWC 2022 also includes the narrativity analysis tools, which are based on Pennebaker’s previous published research on text corpora [17] and which we briefly outlined in the Introduction. To perform the narrativity analysis, each text is automatically split into 5 segments of equal length, as per Hyland [26]. Although the number of segments can be defined by the user, Pennebaker’s group set the default value to 5, to provide for enough resolution to detect the unfolding of the narration. Possibly, five segments could also ideally replicate Freytag’s five stages of a dramatic arc. We therefore used this tool to analyze the Staging, Progression and Cognitive properties of the texts in each text block. The Narrativity overall score is calculated as the degree of similarity between the narrative arcs of the examined texts and the standard arc defined by Boyd et al.
Matplotlib [27] and Seaborn [28] libraries were then used to plot the data. All the analyses were conducted on Jupyter notebooks [29]. Two-way ANOVA analyses were made to compare narrativity scores across segments and decades in different corpora. Dunn post tests were conducted for multiple pairwise comparisons and differences were considered significant when p < 0.05. Results of the statistical analysis are reported in Supplementary Materials.
The three corpora we selected were created independently of one another through three distinct searches followed by random sampling, and their degree of overlap is therefore quite small. There are 28,395 shared articles between corpus #1 ‘All articles’ and corpus #2 ‘Primary studies’ (4.17%), and 27,656 shared articles between corpus #1 ‘All articles’ and corpus #3 ‘Reviews’ (4.06%). There are—obviously—no common articles in both corpora #2 and #3, as they were selected in a complementary way. Given the limits we set when searching for the articles that are included in the Primary studies corpus, we expected to retrieve more than just research articles. A post hoc analysis on the corpus showed, however, that articles that belonged to the research report type accounted for 611,450 items out of the total 680,000, with 43,567 (7.1%) belonging to the comment, letter and editorial categories, which do not fall within our area of interest, and the remaining 24,983 characterized as less easily defined manuscript types, e.g., news, or historical articles.
3. Results
Figure 2 shows the average word count for the abstracts of the three corpora and highlights a slight but progressive increase in length for all the abstracts, which averaged around 150 words in 1989 for All articles and Primary studies and passed the 200-word mark by 2022. Abstracts of Reviews appear, however, always shorter, although they tend to increase in length over time, too.
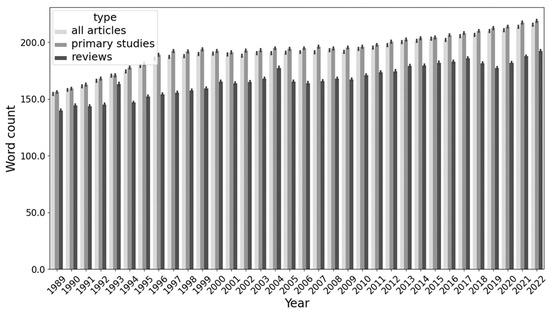
Figure 2.
Bar chart representing the word count for the abstracts of the three corpora from 1989 to 2022, expressed as mean ± standard deviation.
The abstracts were divided into five standard segments, following Boyd’s recommendations [17]. Figure 3 shows the Staging score for the three corpora over the five segments, stratified by decade. Decades were chosen over individual years solely to make graphs easier to interpret. Abstracts from all three corpora display a similar pattern, which broadly remained the same over the years, as suggested by two-way ANOVA tests, with a higher staging score in the first segment, followed by a decrease in the central segments and high scores back in the last segment. Interestingly, though the ‘valley’, or lowest score, is in the central segments for all the decades, it appears to have moved forward over time; in All Articles and Primary studies corpora, the valley is in the second segment in articles from the 1980s and the 1990s but has moved to the third segment by the last two decades, while the main valley is always in segment three for reviews. Reviews display, however, the highest variability in Staging score for segment five, with a progressive increase over time. Overall, the behavior of the Staging variable differs considerably from the standard assumption by Boyd et al., i.e., a progressive decrease in Staging score from segment one through five. As an example, we compared two abstracts from the Review corpus: the former is taken from the 1991 study ‘Locked-in syndrome: a team approach’ published in the Journal of Neuroscience Nursing by N. Mauss-Clum et al. [30], which had a Staging score = 0 in segment five. The latter was taken from the 2022 study ‘Sleep terrors-A parental nightmare’ published in Pediatric Pulmonology by F. Gigliotti et al. [31], which scored 100 in Staging for segment five. The two abstracts and their segments differ quite distinctly. The former text ends with the following sentence:
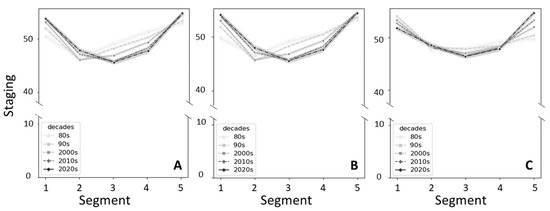
Figure 3.
Line plot representing the average Staging score over the five segments of the abstracts from the three corpora, stratified by decades of publication. (A) Abstracts from All articles; (B) abstracts from Primary studies; (C) abstracts from Reviews.
‘…Our clinical team has worked intensively with several LIS patients and has found that an interdisciplinary team approach is essential for providing creative patient care’.
The authors decided to end the abstract by describing their action (‘has worked’…‘has found’) and, briefly, their findings, but they are not really predicating anything on a given topic. As a consequence, the passage is quite rich in verbs, including auxiliary verbs, and, unsurprisingly, this segment scored fairly high (about 66) in Plot Progression, while being low in Staging and Cognitive Tension as well (about 25).
On the contrary, the study by Gigliotti et al. ends with general considerations on sleep terrors, the topic of the study. The text is therefore rich in entities, their characteristics and in establishing relations between them (and thus rich in prepositions), which again understandably yields a high Staging score:
‘…In spite of the fact that STs have long been considered benign disorders, which tend to reduce spontaneously over the years, they may have unexpected consequences on the child but also on the caregivers…’.
Figure 4 summarizes the Plot Progression scores for all articles, primary studies and reviews from the three corpora over the five segments of their abstracts. Plot Progression curves have remained constant over time in review articles, as indicated by ANOVA analysis, while it has significantly changed over time for the Primary studies and All articles corpora. Overall, the score tends to significantly increase from segment one through five, as expected, at least for articles up to the first decade of the year 2000, although recent manuscripts, published since 2010, have higher initial scores in segment one (Figure 4A,B). Reviews, however, maintained the same trend also in more recent manuscripts (Figure 4C).
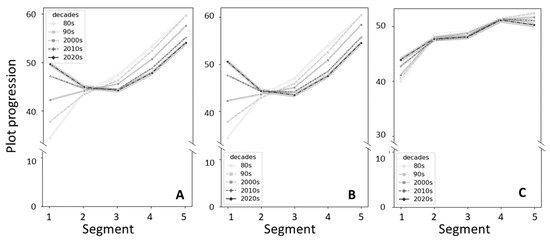
Figure 4.
Line plot representing the average Plot Progression score over the five segments of the abstracts from the three corpora, stratified by decades of publication. (A) Abstracts from All articles; (B) abstracts from Primary studies; (C) abstracts from Reviews.
Figure 5 shows the Cognitive Tension scores for the articles from the three corpora. The score pattern differs markedly in Primary studies and Reviews corpora, with a U shape in Primary studies (and in All articles) and a progressive increase in Reviews. Again, reviews have quite a marked consistency over time, as confirmed by two-way ANOVA, and the same pattern is preserved in Primary studies regardless of their publication date. Primary studies in the 1980s and 1990s had a valley in segment two and then the score progressively increased and reached a peak in segment five. More recent articles have a decrease in score from segment one to segment two but the subsequent increase in Cognitive Tension occurs later, in segments four and five.
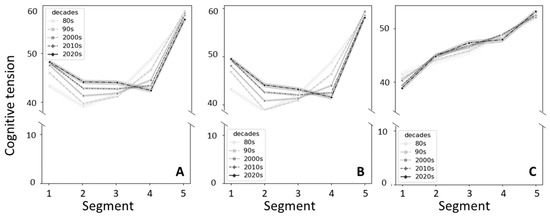
Figure 5.
Line plot representing the average Cognitive Tension score over the five segments of the abstracts from the three corpora, stratified by decades of publication. (A) Abstracts from All articles; (B) abstracts from Primary studies; (C) abstracts from Reviews.
Figure 6 shows the average ‘Narrativity overall’ score for Primary studies, Reviews and All articles. The Narrativity overall score reflects how well the text score matches Boyd’s prototypical scores, from 0 to 100, where 100 means identity. Review manuscripts consistently scored higher on the Narrativity index than Primary studies, whereas the difference between Primary studies and All articles was only marginal, albeit statistically significant. The two latter groups also displayed the tendency to a slow but progressive decrease in Narrativity over time, whereas the narrativity scores remained relatively constant for Review articles (Figure 6).
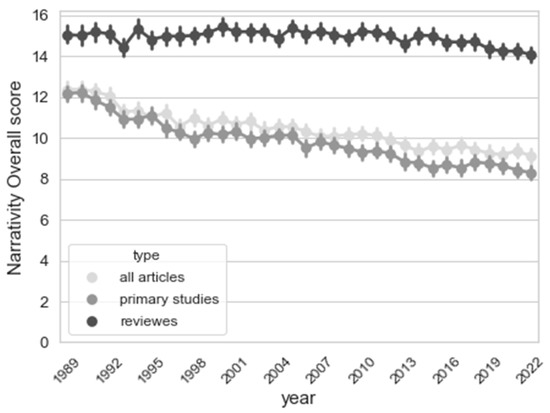
Figure 6.
Line plot representing the average Narrativity overall score for the abstracts of the three corpora from 1989 to 2022.
4. Discussion
The structure of abstracts’ discourse has been the subject of great attention by several research groups, which have outlined the complexity and diversity of abstracts, across languages, fields and over time [32,33,34,35,36].
Broadly speaking, it is quite apparent that abstracts in the STEM area present with a peculiar narrative structure. All corpora have low Narrativity overall scores, i.e., they do not closely replicate the prototypical patterns reported in the literature (Figure 6). However, of all text types, Reviews have significantly higher Narrativity scores, while Primary studies not only score lower in Narrativity, but their scores have been progressively declining over time, possibly because of the progressive adoption of standard formats for study reporting and abstract structure that are farther away from the prototypical narrative arcs that underlie LIWC models. Over the years, certain rhetorical templates have been elaborated that help researchers present their results in a clear and reproducible way, such as the Introduction-Materials-Results-Discussion model, which replicates the structure of a scientific article, or the CARS model. Interestingly, the latter recommends researchers to start off by establishing a research field, delineating a niche—which can be easily compared to a text paragraph with a high score for Staging—and then move on to occupy such niche, by outlining the action to be taken and the course of research, which can correspond to a text segment with a high score for Plot Progression.
Of the three parameters that were analyzed, Plot Progression resembles Boyd et al.’s results most closely, i.e., Plot Progression scores progressively increase over the five segments of abstracts (Figure 4). This may be an obvious consequence of the need of authors to first provide readers with a few intellectual tools to then be able to appreciate the study or set of experiments described in the paper and in the abstract itself. Once again, Reviews more closely replicate the prototype, while Primary studies have progressively increased their Plot Progression score in segment one over time. This may reflect the adoption of more ‘active’ incipits, which include the purpose of the work, and not just an initial description of the status quo.
The Staging parameter possesses a characteristic U shape, instead of constantly decreasing, as predicted by Boyd et al. (Figure 3). This shape is caused by high scores in segment five and can be explained by the presence of a conclusions passage at the end of many abstracts, where new concepts are usually introduced that consider the results of the work presented and may require an increase in the use of articles and prepositions.
It is difficult to interpret the forward shift in the Staging score valley from segment two to segment three, which we observed in our corpora (Figure 3). It is possible that in more recent years, the central part of the abstract has become more regularly occupied by the material and methods/result sections, which might be richer in activity words rather than descriptive sentences, although this shift is also observed with Reviews, though not as apparent (Figure 3C).
Interestingly, the Staging score has progressively increased in segment five in Reviews, while it tended to be lower in works published in the 1980s and 1990s. This may once again be associated to a stronger accent on the conclusions section, where new ideas and well-defined take-home messages are clearly stated [30,31].
The most striking difference we observed in our corpora from the paradigm, however, lies in Cognitive Tension, which, instead of reaching a climax and then a decrease, tends to increase toward the end of the abstract, either quite abruptly as in Primary studies or more gradually as in Reviews (Figure 5). Unlike prototypical novels, where a central moment of crisis is associated with a lexicon that reflects the ongoing struggle, which is then overcome and resolved by the end of the text, in the case of abstracts, results are first presented and are then analyzed and interpreted, and this requires a lexicon that reflects the cognitive efforts of making sense of data and findings. So, unlike a novel, which is about resolving a crisis, an informative abstract is mostly about laying out the pieces of a puzzle, which will then be composed by the end of the text, by means of refined intellectual processes, as is the case with the article ‘The sphingolipid anteome: implications for evolution of the sphingolipid metabolic pathway’, appearing in 2022 on FEBS Letters, by T.C.B. Santos et al. [37]:
‘…We also suggest that the current origin of life and evolutionary models lack appropriate experimental support to explain the appearance of this complex metabolic pathway and its anteome’.
Alternatively, descriptive abstracts serve only as a springboard to introduce readers into the challenges that lie ahead, without really anticipating the findings contained in the manuscript, especially when they are too complex and nuanced to be summarized in a few words. It could be the case with the abstract from the 2022 manuscript ‘The function and biosynthesis of callose in high plants’ published on Heliyon by B. Wang et al. [38], which culminates and ends as follows:
‘…This review therefore compares and analyzes the regulation of callose and cellulose synthesis, and further emphasize [sic] the future research direction of callose synthesis’.
The ending of this abstract is clearly steeped in a language that, while being low on Staging and high on Plot Progression, also heavily draws on cognitive efforts, to take data apart and identify their true meaning, again scoring very high for Cognitive Tension.
Taken together, our results, obtained on three corpora that include more than 2,000,000 abstracts, seem to suggest that, using the LIWC narrativity analysis tool, specific narrativity paradigms can be traced for Life Science abstracts, in light of a peculiar narrative structure that responds to the needs and the purpose of abstracts in a scientific publication.
5. Conclusions
Based on the analysis of more than 2,000,000 abstracts of biomedical publications from three distinct corpora over the three parameters of Staging, Plot Progression and Cognitive Tension, we propose a distinct pattern of narrativity for Life Science publications, which differs from the normative arcs identified in the literature in other non-academic corpora, and which do not seem to be applicable to abstracts of scientific articles in this field. Furthermore, the type of publication affects the narrative arc, with different score distributions in Primary studies and Reviews. More specifically, although Plot Progression tends to increase constantly, Staging and Cognitive Tension display a peculiar U shape in Primary studies, while the latter parameter increases constantly in Reviews. These narrative arcs have evolved over time and are possibly still undergoing changes and the differences from more standard arcs appear to be growing over time.
There are, however, differences among the papers that are included in our corpora and future research will have to determine what has driven the narrative changes in the scientific production, by investigating the textual elements that were involved in these changes and whether distancing from the prevalent narrative arc affects the cultural impact of the article, as assessed by citation counts.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/publications11020026/s1.
Author Contributions
Conceptualization, C.G. and S.G.; methodology, C.G. and M.T.C.; formal analysis, C.G.; resources, S.G. and P.M.; writing—original draft preparation, C.G.; writing—review and editing, P.M.; visualization, C.G.; supervision, S.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data are available on request.
Acknowledgments
The authors would like to thank Silvana Belletti for her advice on corpora.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Derntl, M. Basics of Research Paper Writing and Publishing. Int. J. Technol. Enhanc. Learn. 2014, 6, 105. [Google Scholar] [CrossRef]
- Bahadoran, Z.; Mirmiran, P.; Kashfi, K.; Ghasemi, A. The Principles of Biomedical Scientific Writing: Abstract and Keywords. Int. J. Endocrinol. Metab. 2020, 18, e100159. [Google Scholar] [CrossRef] [PubMed]
- Galli, C.; Colangelo, M.T.; Guizzardi, S. Striving for Modernity: Layout and Abstracts in the Biomedical Literature. Publications 2020, 8, 38. [Google Scholar] [CrossRef]
- Galli, C.; Colangelo, M.T.; Guizzardi, S. Linguistic Changes in the Transition from Summaries to Abstracts: The Case of the Journal of Experimental Medicine. Learn. Publ. 2022, 35, 271–284. [Google Scholar] [CrossRef]
- Sanganyado, E. How to Write an Honest but Effective Abstract for Scientific Papers. Sci. Afr. 2019, 6, e00170. [Google Scholar] [CrossRef]
- Thompson, C.W.N. The Functions of Abstracts in the Initial Screening of Technical Documents by the User. J. Am. Soc. Inf. Sci. 1973, 24, 270–276. [Google Scholar] [CrossRef]
- Bondi, M.; Lorés-Sanz, R. Abstracts in Academic Discourse: Variation and Change; Peter Lang AG: Lausanne, Switzerland, 2014; ISBN 978-3034314831. [Google Scholar]
- Grivell, L. Mining the Bibliome: Searching for a Needle in a Haystack? EMBO Rep. 2002, 3, 200–203. [Google Scholar] [CrossRef]
- Lu, Z. PubMed and beyond: A Survey of Web Tools for Searching Biomedical Literature. Database 2011, 2011, baq036. [Google Scholar] [CrossRef]
- Landhuis, E. Scientific Literature: Information Overload. Nature 2016, 535, 457–458. [Google Scholar] [CrossRef]
- Nakayama, T.; Hirai, N.; Yamazaki, S.; Naito, M. Adoption of Structured Abstracts by General Medical Journals and Format for a Structured Abstract. J. Med. Libr. Assoc. 2005, 93, 237–242. [Google Scholar]
- Swales, J. Genre Analysis: English in Academic and Research Settings; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Gotti, M.; Sancho Guinda, C. Narratives in Academic and Professional Genres; Peter Lang: Lausanne, Switzerland, 2013; Volume 172, ISBN 3034313713. [Google Scholar]
- Galli, C.; Guizzardi, S. Change in Format, Register and Narration Style in the Biomedical Literature: A 1948 Example. Publications 2020, 8, 10. [Google Scholar] [CrossRef]
- Freytag, G. Freytag’s Technique of the Drama; Scott, Foresman: Northbrook, IL, USA, 1894. [Google Scholar]
- Cohen, I.; Dreyer-Lude, M. Shaping the Dramatic Arc. In Finding Your Research Voice; Springer International Publishing: Cham, Switzerland, 2019; pp. 19–32. [Google Scholar]
- Boyd, R.L.; Blackburn, K.G.; Pennebaker, J.W. The Narrative Arc: Revealing Core Narrative Structures through Text Analysis. Sci. Adv. 2020, 6, eaba2196. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Boyd, R.L.; Jordan, K.; Blackburn, K. The Development and Psychometric Properties of LIWC2015; University of Texas at Austin: Austin, TX, USA, 2015. [Google Scholar]
- Day, R.A. How to Write and Publish a Scientific Paper; ISI Press: Philadelphia, PA, USA, 1983. [Google Scholar]
- Alewijnse, A.E.; Peters, S.L.M. Sphingolipid Signalling in the Cardiovascular System: Good, Bad or Both? Eur. J. Pharmacol. 2008, 585, 292–302. [Google Scholar] [CrossRef]
- Hillier, A.; Kelly, R.P.; Klinger, T. Narrative Style Influences Citation Frequency in Climate Change Science. PLoS ONE 2016, 11, e0167983. [Google Scholar] [CrossRef]
- Shapiro, A. Littler-Getter. Available online: https://pypi.org/project/litter-getter/ (accessed on 20 January 2023).
- Mckinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 51–56. [Google Scholar]
- Richardson, L. Beautiful Soup Documentation. April 2007. Available online: https://www.crummy.com/software/BeautifulSoup/bs4/doc/ (accessed on 21 January 2023).
- Pennebaker, J.W.; Mehl, M.R.; Niederhoffer, K.G. Psychological Aspects of Natural Language Use: Our Words, Our Selves. Annu. Rev. Psychol. 2003, 54, 547–577. [Google Scholar] [CrossRef]
- Hyland, K. Disciplinary Discourses: Social Interactions in Academic Writing; Classics, M., Ed.; University of Michigan Press: Ann Arbor, MI, USA, 2004; ISBN 0472030248. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M. Seaborn: Statistical Data Visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A Publishing Format for Reproducible Computational Workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas—Proceedings of the 20th International Conference on Electronic Publishing; ELPUB; IOS Press BV: Amsterdam, The Netherlands, 2016; pp. 87–90. [Google Scholar]
- Mauss-Clum, N.; Cole, M.; McCort, T.; Eifler, D. Locked-In Syndrome: A Team Approach. J. Neurosci. Nurs. 1991, 23, 273–286. [Google Scholar] [CrossRef] [PubMed]
- Gigliotti, F.; Esposito, D.; Basile, C.; Cesario, S.; Bruni, O. Sleep Terrors—A Parental Nightmare. Pediatr. Pulmonol. 2022, 57, 1869–1878. [Google Scholar] [CrossRef]
- Hu, G.; Cao, F. Hedging and Boosting in Abstracts of Applied Linguistics Articles: A Comparative Study of English- and Chinese-Medium Journals. J. Pragmat. 2011, 43, 2795–2809. [Google Scholar] [CrossRef]
- Hyland, K.; Jiang (Kevin), F. Metadiscourse Choices in EAP: An Intra-Journal Study of JEAP. J. Engl. Acad. Purp. 2022, 60, 101165. [Google Scholar] [CrossRef]
- Gillaerts, P.; van de Velde, F. Interactional Metadiscourse in Research Article Abstracts. J. Engl. Acad. Purp. 2010, 9, 128–139. [Google Scholar] [CrossRef]
- Martín-Martín, P. The Rhetoric of the Abstract in English and Spanish Scientific Discourse: A Cross-Cultural Genre-Analytic Approach; Peter Lang: Lausanne, Switzerland, 2005; Volume 279, ISBN 3039106384. [Google Scholar]
- Lorés, R. On RA Abstracts: From Rhetorical Structure to Thematic Organisation. Engl. Specif. Purp. 2004, 23, 280–302. [Google Scholar] [CrossRef]
- Santos, T.C.B.; Dingjan, T.; Futerman, A.H. The Sphingolipid Anteome: Implications for Evolution of the Sphingolipid Metabolic Pathway. FEBS Lett. 2022, 596, 2345–2363. [Google Scholar] [CrossRef]
- Wang, B.; Andargie, M.; Fang, R. The Function and Biosynthesis of Callose in High Plants. Heliyon 2022, 8, e09248. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).