1. Introduction
Super-resolution (SR) algorithms [
1,
2] serve the purpose of reconstructing high-resolution (HR) images from either single or multiple low-resolution (LR) images. Due to the inherent characteristics of the photoelectric imaging system, normally, it is challenging to obtain HR images [
3]. In this regard, the SR algorithm provides a feasible solution to restore HR images from LR images recorded by sensors. As one of the essential sources of information acquisition in a low illumination environment, a low light level (LLL) imaging detection system [
4] employs high sensitivity optoelectronic devices to enhance and record weak target and valuable environment information.
Unfortunately, due to the insufficient spatial sampling of the image detector and the trade-off between pixel size and photosensitivity, the ability of current imaging sensors to obtain both high spatial resolution and a large field-of-view is limited [
5]. However, in traditional optical imaging, obtaining a slight improvement in imaging performance usually means a dramatic increase in hardware cost and, thus, causes difficulty in engineering applications.
The emergence of computational imaging [
6,
7,
8] ideas has reversed this circumstance, drawing an exceptional opportunity for the remote sensing field. Image resolution is no longer only dependent on physical devices and, in turn, on the joint design of front-end optics and back-end image processing, to achieve sub-pixel imaging. With the development of deep learning methods, single image SR [
9] has made significant progress. Utilizing this method, the non-linear function can be generated more effectively to deal with complex degradation models.
To date, image SR methods can be generally classified into traditional multi-frame image SR methods [
10,
11] and deep-learning-based methods [
12,
13,
14]. In the conventional passive multi-frame image SR imaging algorithm, multiple frames with relative sub-pixel shifts based on the target scene are formed by the random relative motion [
15,
16,
17] between the target and the sensor. Similarly, scholars proposed using computational imaging methods to reconstruct an HR image from one or more low-resolution images. However, non-ideal global panning, alignment errors, and non-uniform sampling are still problems in multi-image reconstruction algorithms.
The appearance of the convolutional neural network [
18,
19] reversed this situation. Deep-learning-based methods focus on exploiting external training data to learn a mapping function in accordance with the degradation process [
20]. Its extraordinary fitting ability and efficient processing algorithms have enabled it to be generally utilized. Similarly, the processing method of single-frame image SR based on deep learning is not omnipotent, which has the disadvantages [
21] of a slow training speed, poor network convergence, and the demand for an abundant amount of data. Therefore, how to achieve high speed, accurate, and effective image enhancement is still an essential issue to be solved.
In order to solve the above problems and make full use of the advantages of deep learning networks in feature extraction and information mapping, an SR neural network based on feature extraction is proposed, as shown in
Figure 1. Compared with other single image SR methods, the significant advantage of MSFE is that it can draw out otherwise available information from the different scale observations of the same scene. The innovations of this paper are mainly in the following four aspects:
High-frequency information and low-frequency components can be fused in different scales by applying the skip connection structure.
The channel attention module and the residual block are combined to make the network focus on the most promising high-frequency information, mostly overcoming the main locality limitations of convolutional operations.
The dimension of the extracted high-frequency information is improved by sub-pixel convolution, and the low-frequency components are fused by element addition.
The network structure is expanded to realize grayscale image colorization and procure HR color images with a low-cost, LR monochromatic LLL detector in real-time.
The rest of the paper is structured as follows. In
Section 2, some classical super-resolution imaging methods are briefly reviewed. In
Section 3, the basic structure of our network is described in detail. In
Section 4, the method of dataset building, details of training, comparison of the SR results, and color imaging results are presented.
Section 5 is a summary of the article.
2. Related Works
The most common SR method is based on interpolation, including bicubic linear interpolation and bilinear interpolation. Although the speed of these methods is perfect, each pixel is calculated according to the surrounding pixels, which only enlarges the image and cannot effectively restore the details of the image. The multi-reconstruction method [
22] is to establish an observation model for the image acquisition process and then achieve SR reconstruction by solving the inverse problem of the observation model. However, the degradation model is often different from the actual situation, which cannot predict the image correctly.
The super-resolution method based on the sparse representation (SCSR) method [
23,
24] treats HR images and LR images as a dictionary multiplied by atoms. By training the dictionary, HR images can be obtained from multi-LR images. Insufficiently, it is evident that the dictionary training time is longer, and the reconstructed image has an apparent sawtooth phenomenon. Another key technology to realize SR reconstruction is micro-scanning SR imaging [
25,
26], which is realized by the vibration of the detector or the rotation of the scanning mirror or the flat plate to obtain the steerable displacement between the optical system and the sensor.
In addition, the method of controlled micro scanning can simplify the steps of image registration and improve the accuracy of the reconstruction results. However, sub-pixel scanning requires HR optoelectronic devices, such as motors and piezoelectric drivers, dramatically increasing the cost and complicating the whole imaging system. Therefore, the traditional image SR reconstruction method [
27] still has the limitations of multi-frame image reconstruction, algorithm complexity, a complex imaging system, and a precise control system.
Learning-based methods build upon the relation between LR-HR images, and there have been many recent advancements in this approach, mostly due to deep convolutional neural networks. In the pursuit of higher image quality, the super resolution convolutional neural network (SRCNN) [
28] applied a convolutional neural network (CNN) to image SR reconstruction for the first time, and the SR images obtained were superior to traditional SR algorithms.
Based on SRCNN, the fast super-resolution convolutional neural network (FSRCNN) [
29] was ] proposed, which directly sent LR images to the network for training and used a deconvolution structure to obtain reconstructed images. The improved network not only improved the depth of the network but also significantly reduced the amount of calculations and improved the speed of calculations. In deep residual networks (Res Net) [
30], the residuals were directly learned through skip connections, which effectively solved the problem of gradient disappearance or explosion in deep network training.
Next, the Laplacian pyramid networks (LapSRN) [
31,
32] realized parameter sharing in different levels of amplification modules, reduced the calculation amount, and effectively improved the accuracy through the branch reconstruction structure. The wide activation super-resolution network (WDSR) [
33] ensured more information passing through by expanding the number of channels before the activation function and also provided nonlinearity fitting of the neural network.
After that, the channel attention (CA) mechanism was used in deep residual channel attention networks (RCAN) [
34], which can focus on the most useful channels and improve the SR effect. However, to achieve the additional benefits of the CNN, a multitude of problems needs to be solved. For the most current super-resolution imaging methods, if the input image is a single channel gray image, the output image is also a single channel gray image. Human eye recognition objects can be identified by the brightness information and color information.
Colorizing images can produce more completed and accurate psychological representation, leading to better scene recognition and understanding, faster reaction times, and more accurate object recognition. Therefore, color fusion images [
35] can make the naked eye recognize the target more accurately and faster. Directed against the above problems, this paper proposes a convolution neural network based on feature extraction, which is employed to SR imaging of LLL images under dark and weak conditions to achieve HR and high sensitivity all-weather color imaging. The network uses a multi-scale feature extraction module and low-frequency fusion module to combine multiple LR images.
3. Super-Resolution Principles
According to the sampling theory, an imaging detector can sample the highest spatial frequency information that is the half of the sampling frequency of its sensor. When the sensor’s pixel size becomes the main factor restricting the resolution of an imaging system, the simplest way to improve the imaging resolution is to reduce the pixel size to enhance the imaging resolution. However, in practical applications, due to the limitations of the detector manufacturing process, the pixel size of some detectors, such as the LLL camera, cannot be further reduced.
This means that, in some cases, the LR image will lose some information compared with the HR image; inevitably, there will exist the pixel aliasing phenomenon. Therefore, the sampling frequency of the imaging sensor will be the key factor to limit the imaging quality. The SR method improves the spatial resolution of the image from LR to HR. From the perspective of imaging theory, the SR process can be regarded as the inverse solution of blur and down-sampling. SR is an inherently ill-posed problem in either case since multiple different solutions exist for any LR image. Hence, it is an underdetermined inverse problem with unique solutions. Based on a representation learning model, our proposed methodology aims to generate a super-resolved image function from the HR image to the LR image.
3.1. Image Super-Resolution Forward Model
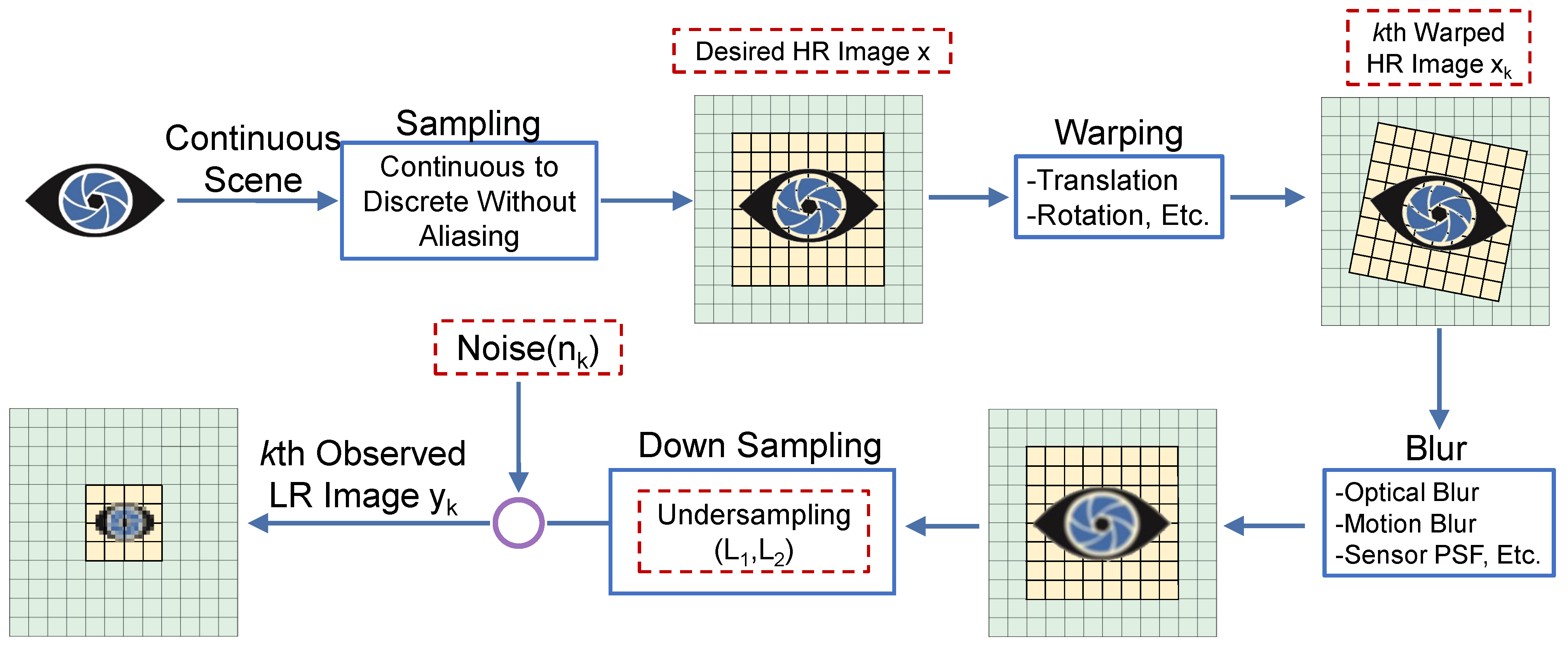
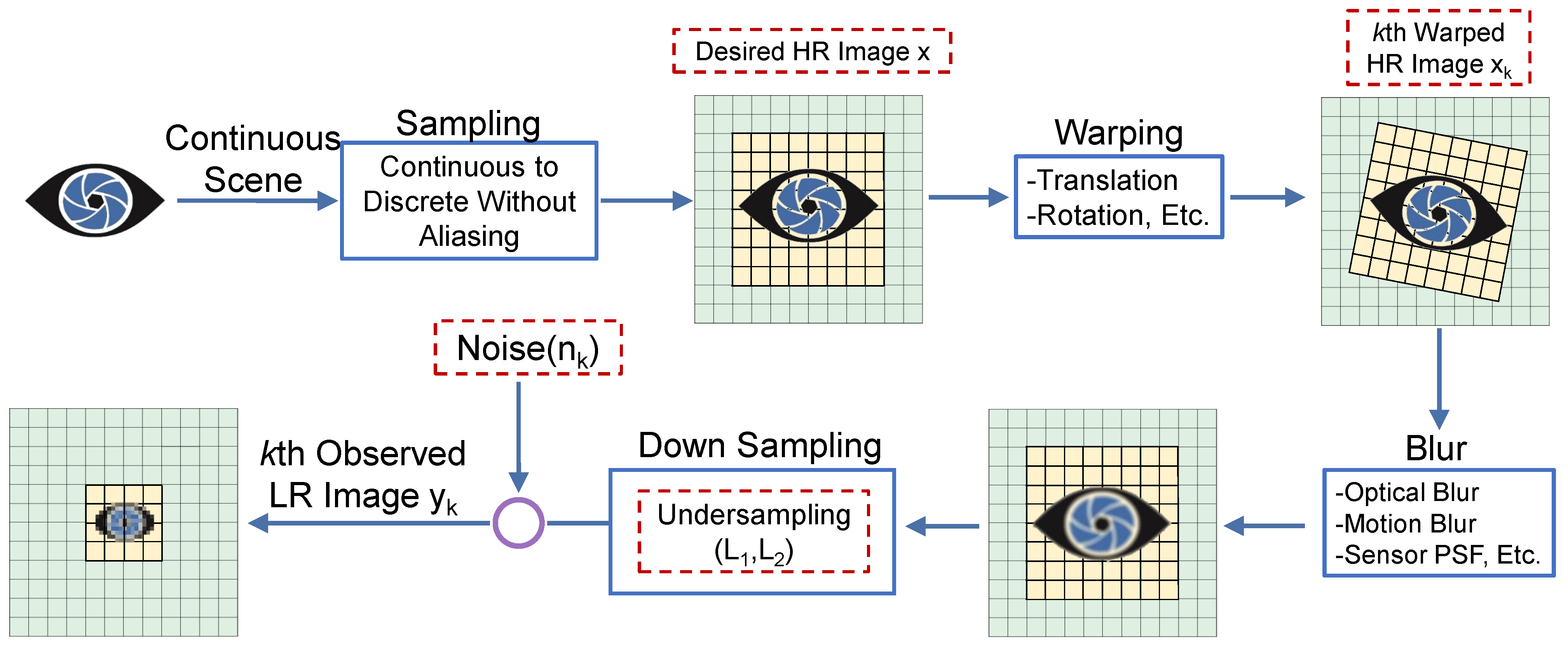
A flow chart for the observation model is illustrated in
Figure 2. For an imaging system, the image degradation process is first affected by the optical system’s lens, leading to the diffraction limit, aberration, and defocusing in an optical lens, which can be modeled as linear space invariant (LSI). Unfortunately, it is more problematic that pixel aliasing will occur if the detector pixel size exceeds a specific limitation, making the high-frequency part of the imaging object unavailable in the imaging process.
It is inevitable to introduce the subsampling matrix, which generates aliased LR images from forward-generating the blurring HR image into the imaging model. Conventionally, SR image reconstruction technology utilizes multiple LR observation images to reconstruct the underlying HR scene with noisy and slight movement. Consequently, assuming a perfect registration between each HR and LR image, we can derive the expressions of the observation HR image, sampled scene
x in matrix form as:
where
D is a subsampling matrix,
B typifies a blurring matrix,
x symbolizes the desired HR image,
y represents the observed LR image, and
n is the zero-mean white Gaussian noise associated with the observation image. Different from the traditional multi-frame super-resolution imaging, the deep learning reconstruction method establishes the mapping relationship between the LR image and the HR image. Through the information extraction of different dimensions, the problem of image pixelation imaging is effectively solved, and super-pixel resolution imaging is realized.
3.2. Network Structure
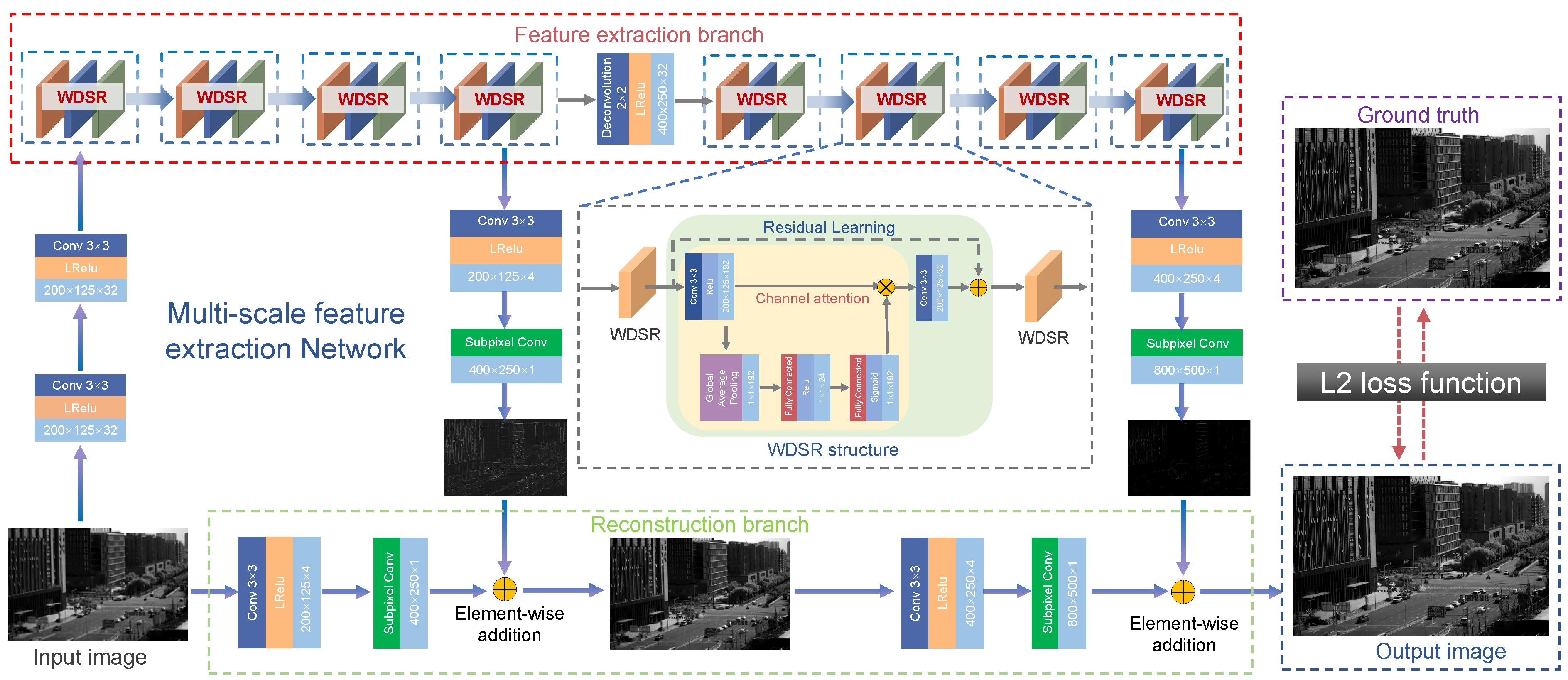
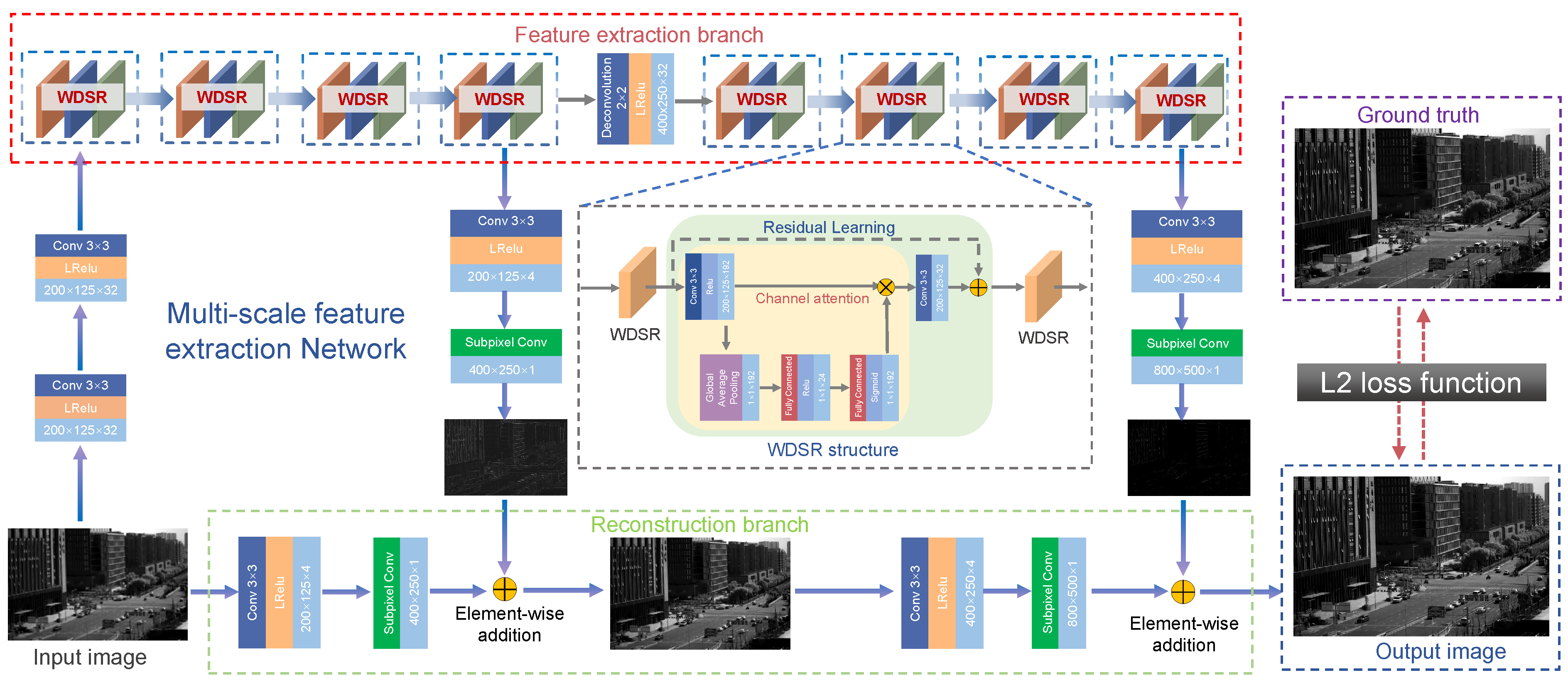
An overview of the RAMS network is depicted in
Figure 3. The whole network is a pyramid model, which is cascaded by two layers of the model, and each layer of the model realizes twice the LR LLL image feature extraction. Vertically, the model is composed of two branches, the upper part is the feature extraction branch of the LLL image, and the lower part is the reconstruction branch of the LLL image.
The feature extraction branch obtained the high-frequency information of the corresponding input image. High-frequency features are more helpful for HR reconstruction, while LR images contain abundant low-frequency information, which directly forwards to the network tail-ends. The reconstruction branch obtains the up-sampled image corresponding to the size of the HR image. In order to express the SR of the network more clearly, the network model can be defined as:
where
represents the nonlinear mapping function of the network,
and
, respectively, depict the trainable parameters of weight and deviation in the network,
describes the LR LLL input image, and
typifies the HR image predicted by the network. The specific convolution layer number and parameters of the super-resolution network structure are shown in
Table 1.
The main task of low-level feature extraction, high-level feature extraction, and feature mapping is mainly to collect the promising compositions from the input image into the CNN network and to express all information into feature maps. It is noteworthy that the corner, edge, and line can be dug out from the feature maps. The attention mechanism module focuses on the most promising features and reduces the interference of irrelevant features.
We formulate the procedure as , which consists of four parts:
Low-Level Feature Extraction: This step aims to extract the fundamental information from the input image and forward it as a series of feature maps.
High-Level Feature Extraction: In this operation, through a convolution operation of different dimensions and channel attention mechanism module, the calculation of the network is mostly focused on the acquisition of high-frequency information.
Features Mapping: In order to reduce the hyperparameters, the mapping process from high-dimensional vector to low ones is designed.
Reconstruction: This operation integrates all the information to reconstruct an HR image .
In the following paragraphs, we present the overall architecture of the network with a detailed overview of the main blocks. Finally, we conclude the methodology section with precise details of the optimization process for training the network.
3.2.1. Feature Extraction Branch
The feature extraction branch of each pyramid model mainly includes a convolution layer, wide activation residual module, and sub-pixel convolution layer. The purpose of the feature extraction branch is to realize the feature extraction of the LLL image. The wide activation residual module mainly includes a channel attention mechanism and skip connection. The channel attention mechanism is similar to the human selective visual attention mechanism. The core goal is to select the more critical information to the current task from several details.
In the deep learning network, the channel attention mechanism can adjust each channel’s weight and retain valuable information beneficial to obtain HR LLL image to achieve SR reconstruction of the LLL image. In addition, the current mainstream network structure models are developing in a deeper direction. A deeper network structure model means a more dependable nonlinear expression ability, acquiring more complex transformation, and fitting more input complex features. To this end, we employed a long skip connection for the shallow features and several short skip connections inside each feature attention block to let the network focus on more valuable high-frequency components.
In addition, the skip connection in the residual structure efficiently enhanced the gradient propagation and alleviated the problem of gradient disappearance caused by the deepening of the network. Therefore, the skip connection was introduced in the wide activation residual module, to extract the image detail information and improve the super-resolution performance of the network structure. As shown in
Figure 4a, the experiments of wide activation residual module without skip connection and with skip connection were carried out, respectively. The network structure with a skip connection produced a more robust SR performance and better expressed the details of the image.
Similarly, as shown in
Figure 4b, the number of wide activation residual modules in each pyramid model was verified. In the verification experiment, only the number of wide activation residual modules was changed. By this, it can be seen from the impact that the network structure with multiple wide activated residuals had a higher fidelity SR performance than those with single wide activated residuals as shown in
Figure 4b.
3.2.2. Reconstruction Branch
The reconstruction branch mainly includes a convolution layer and sub-pixel convolution layer to enlarge the feature image. In general deconvolution, there will be several values of zero, which may reduce the performance of SR reconstruction. In order to maximize the effectiveness of the image information to enhance the imaging resolution, we employed the sub-pixel convolution with reconstruction from the LR image to the HR image by pixel shuffling. Subpixel convolution combines a single pixel on a multichannel feature map into a unit on a feature map. That is to say, the pixels on each feature map are equivalent to the subpixels on the new feature map.
In the reconstruction process, we set the number of output layers to a specified size to ensure that the total number of pixels is consistent with the number of pixels of the HR image. By doing so, the pixels can be rearranged through the sub-pixel convolution layer, and we finally obtain the enlarged LLL image. This method utilizes the ability of the sub-pixel deconvolution process to learn complex mapping functions and effectively reduces the error caused by spatial aliasing. The model predicts and regresses the HR image gradually in the process of reconstruction through gradual reconstruction.
This feature makes the SR method more applicable. For example, depending on the available computing resources, the same network can be applied to enhance the different video resolutions. The existing techniques based on the convolutional neural network cannot provide such flexibility for the scene with limited computing resources. In contrast, our model with four-times magnification can still perform two times better than the SR and only requires bypassing the more refined residual calculation.
3.2.3. Loss Function
Let
denote the LR LLL input image, and
represents the HR LLL image predicted by the network.
and
depict the trainable parameters weight and deviation in the network. Our goal is to learn a nonlinear mapping function
to generate a HR LLL image
, which is as close as possible to the real image
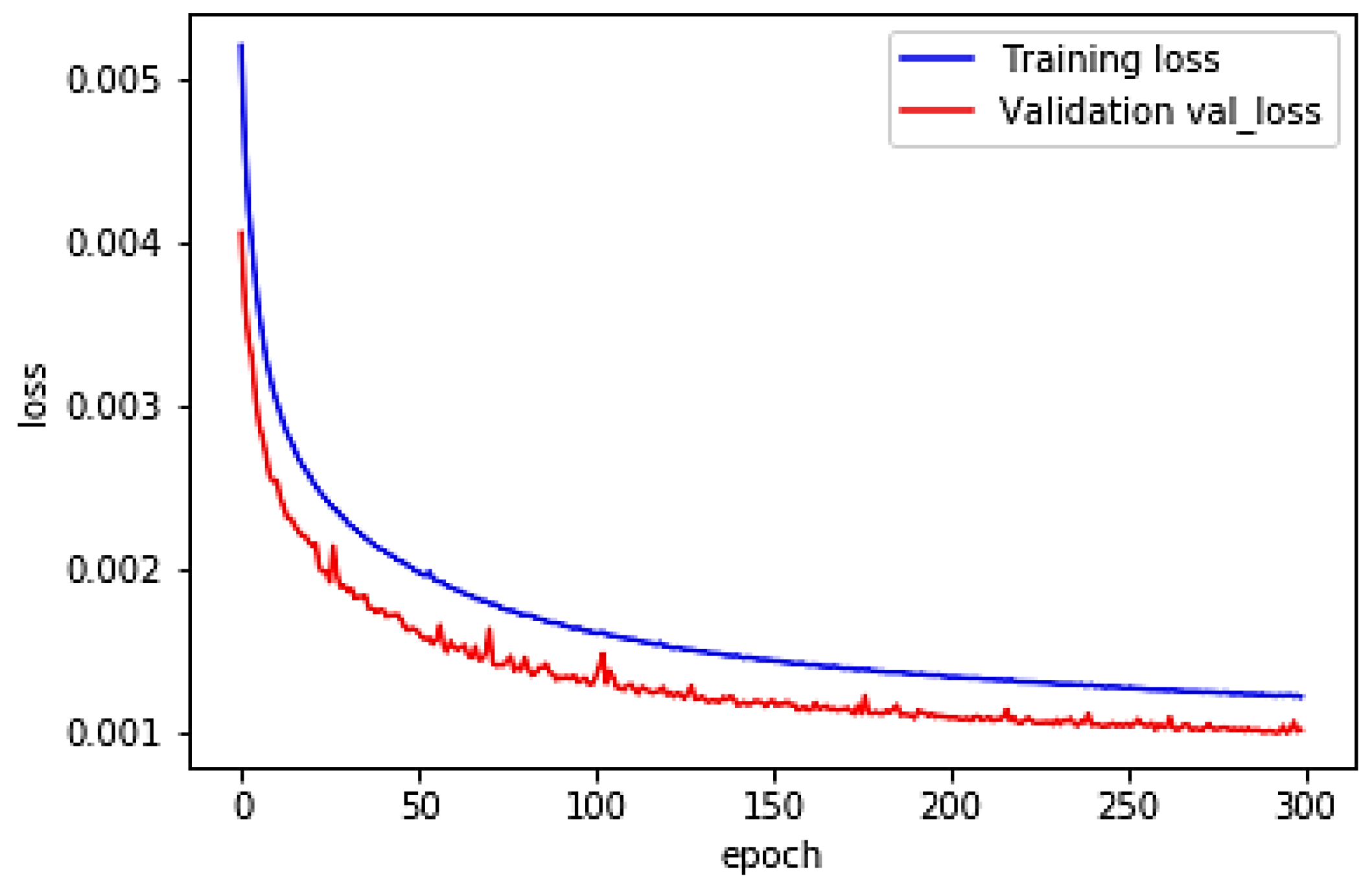
. The loss function used in the training is the mean square error, which can be expressed by the following formula:
where
is the number of training samples. The curve of the loss function during training is shown in
Figure 5.
4. Analysis and Discussion
In this section, first, the details of the data set and the experimental setup are introduced, and then the LR LLL images are input into four different networks to quantitatively evaluate the SR reconstruction results. After that, the network is extended to RGB color image reconstruction, and its colorization ability is verified.
4.1. Data Set Establishment
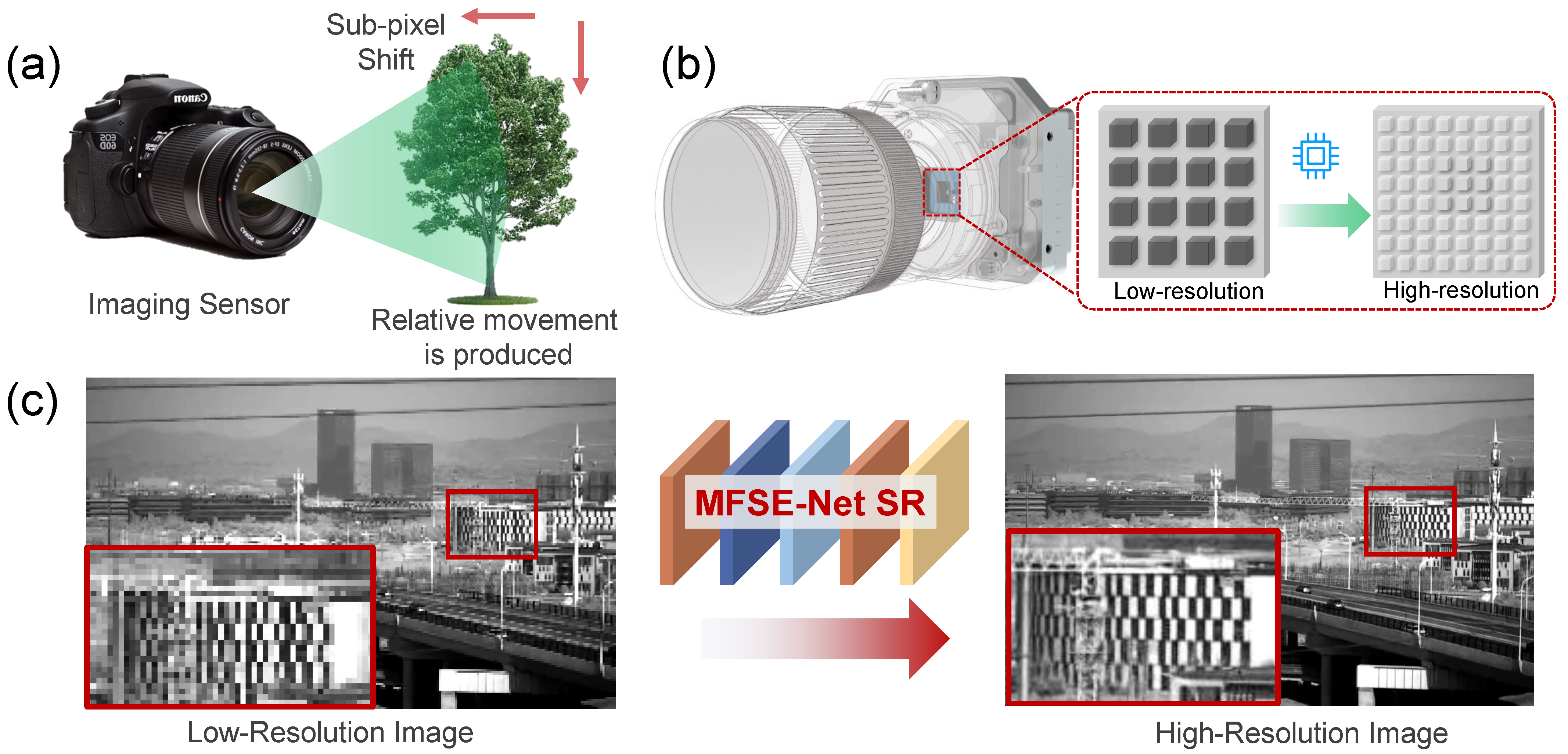
We utilized the telescope to obtain the LLL image resolution of 800 × 600. After clipping, LLL images with the size of 800 × 500 were obtained. Then, multiple images with the size of 128 × 128 were cropped to the size of 800 × 500. In this paper, 500 images were input as the training set, 50 images were input as the verification set, and some of the representative training sets are shown in
Figure 6. Finally, the original LLL images size of 128 × 128 were taken as the ground truth, and then the LLL images were down-sampled four times to obtain the LR LLL images resolution of 32 × 32 as input to form the training set.
4.2. Experimental Setup
In the network, the batch size was set to 4, and the epoch was set to 300. Empirically, we employed an Adam optimizer to optimize the network structure, and the initial learning rate was set to . The activation function was Leaky Rectified Linear Unit (LReLU), and the parameter was 0.2. The hardware platform of the network for model training was an Intel Core i7-9700K CPU @ 3.60 GHz × 8, and the graphics card was RTX2080Ti. The software platform was TensorFlow 1.1.0 under the Ubuntu 16.04 operating system.
The LR LLL image dimension of 32 × 32 and the corresponding HR LLL image dimension of 128 × 128 were sent into the program as the original image to train the neural network. The network training took 3.2 h. In the test, the input LLL image size was 200 × 125, and the HR LLL image size was 800 × 500. The test time of each image was 0.016 s. Therefore, our proposed network not only realized SR imaging but also realized all-weather real-time imaging. Part of the real-time images are shown in
Figure 7.
4.3. Comparison of Super-Resolution Results with Different Networks
The imaging ability of three traditional SR neural networks (CDNMRF [
36], VDSR [
37], and MultiAUXNet [
38]) was compared with our network. We utilized the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) as specific numerical evaluation indexes, and the particular results are shown in
Table 2. In the case of four up-sampling scales, we compared the experimental results with CDNMRF, VDSR, and MultiAUXNet, and the results are shown in
Figure 8. Subjectively, our method reconstructed the most similar details of the wall, iron frame, window, car, and so on, and the edges of the images were the clearest. In the objective evaluation, PSNR and SSIM were calculated and compared.
In terms of PSNR, our results were 0.96 db higher than CDNMRF, 1.67 db higher than VDSR, and 0.15 dB higher than MultiAUXNet. In terms of SSIM, our results were 0.06 higher than CDNMRF, 0.06 higher than VDSR, and 0.03 higher than MultiAUXNet. In general, our network structure showed better super-resolution performance in the wide FOV LLL images.
4.4. Application for RGB Images
Remote imaging detection requires the imaging system to provide detailed high-frequency information and visible spectral information in the imaging process. The color information of most color images is quite different from that of the natural scene, which is not realistic. Nevertheless, the observer can further segment the image by distinguishing the color contrast of the fused image to recognize different objects in the image.
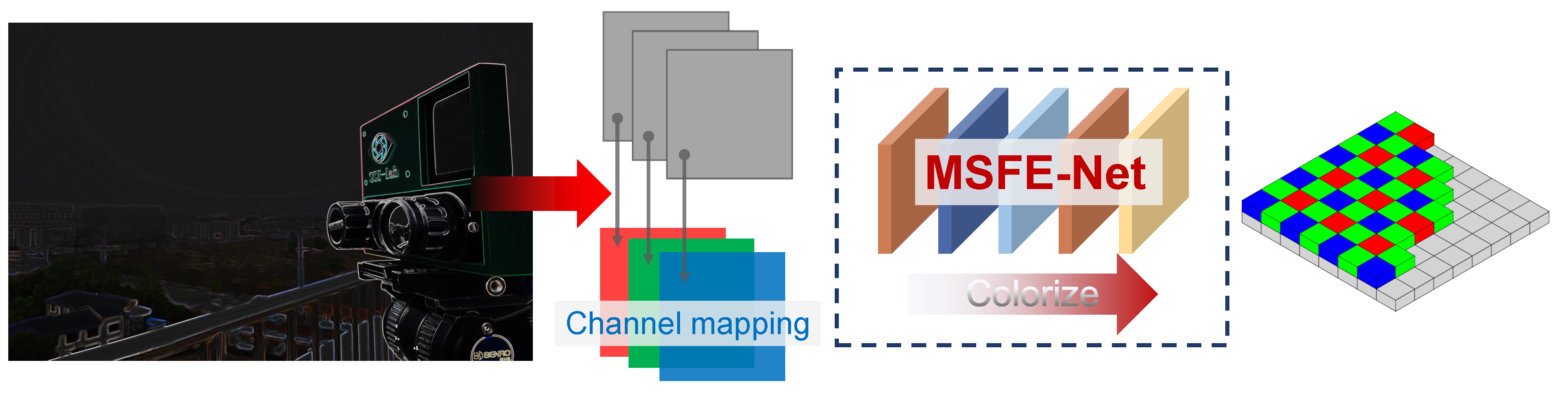
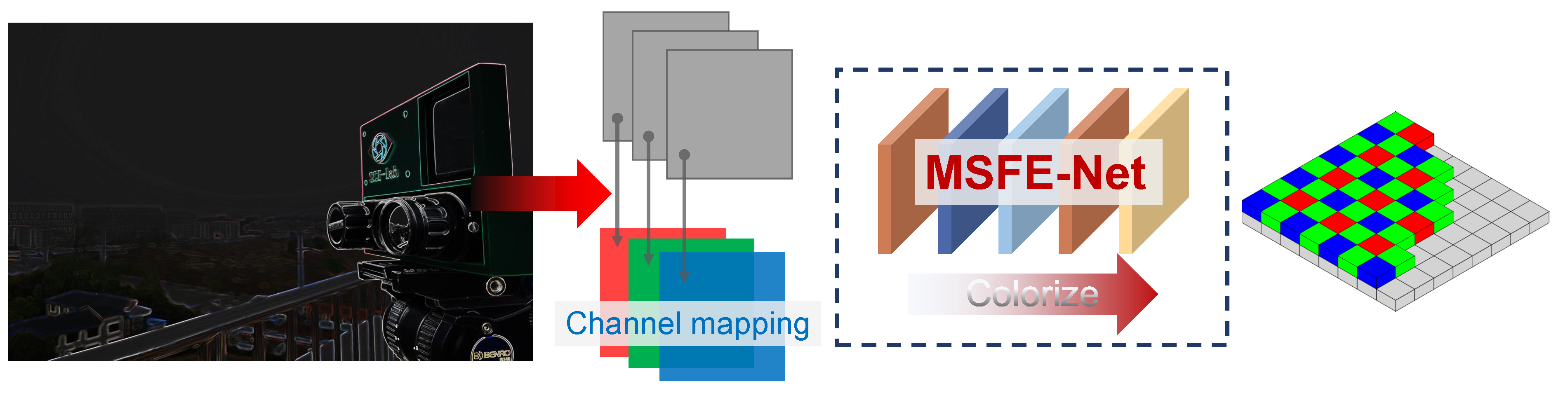
In addition to the SR task of the gray image, we also extended the network performance in our work. As shown in
Figure 9, by expanding the number of channels in the original network, the color image’s RGB channel corresponded to one gray level output, and gray images of different scenes were colorized under the condition of LLL imaging.
The proposed LLL image colorization was combined with the existing scene image library for supervised learning. First, the input LLL gray image was classified, and the category label was obtained. Then, the natural color fusion image was recovered by color transfer. Compared with the color look-up table method, the proposed method can adaptively match the most suitable reference image for color fusion without acquiring the natural image of the scene in advance. As shown in
Figure 10, we realized the color image reconstruction based on the jungle and urban environments, respectively.
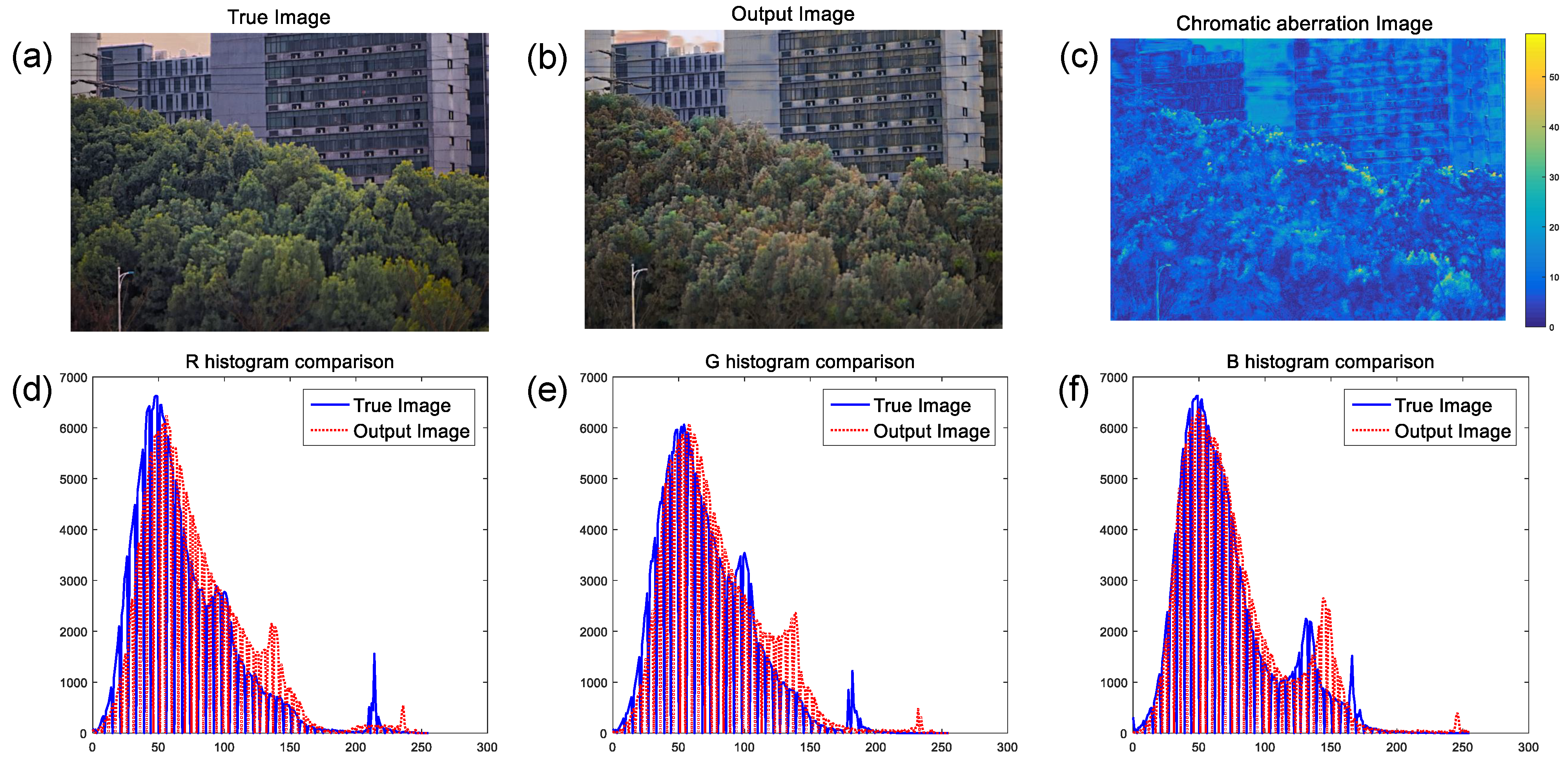
Similarly, we also evaluated the color image output by the network, as shown in
Figure 11.
Figure 11c describes the difference between the network output image and the actual color image captured by the visible light detector. We can see that only the local color information was wrong. Furthermore, we quantitatively evaluated the histogram distribution similarity of the two images. The color distribution was basically the same, and the similarity of the final histogram distribution was 0.728, as shown in
Figure 11. In general, the imaging results met the requirements of human visual characteristics and intuitively handled the scene information in HR.
5. Conclusions
In summary, we demonstrated an SR network structure based on multi-scale feature extraction. The proposed network learned an end-to-end mapping function to reconstruct an HR image from its LR version, which could robustly reproduce the visual richness of natural scenes under different conditions and output photos with high quality. The network, which is based on high-frequency component calculation, effectively improved the peak signal-to-noise ratio of the reconstructed image by 1.67 dB.
The effective network structure realized the image output of 0.016 s per frame and, thus, guarantees real-time imaging. In order to realize the output of the color image, we expanded the number of channels of the network to achieve the mapping of a single channel image to a three-channel image. The similarity between the histogram distribution of the final output color image and the authentic image captured by the visible detector reached 0.728. The experimental results indicate that the proposed method offers superior image fidelity and detail enhancement, which suggests promising applications in remote sensing, detection, and intelligent security monitoring.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}