Single-Pixel Imaging Reconstruction Network with Hybrid Attention and Enhanced U-Net

Abstract
1. Introduction
2. Methods
2.1. Imaging Scheme of L2-Norm
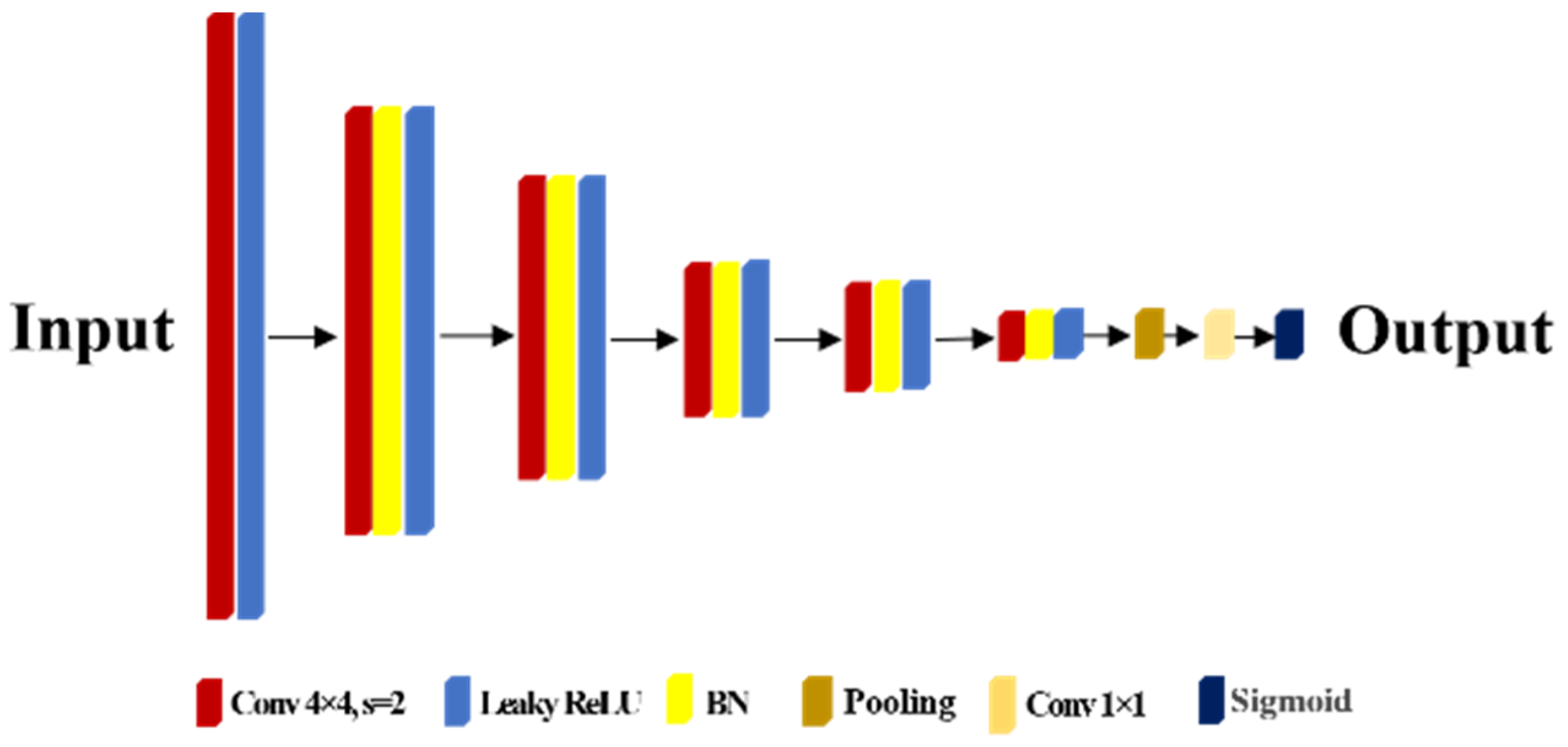
2.2. Network Structure
2.3. Loss Function
3. Results and Discussion
3.1. Training Data Preparation
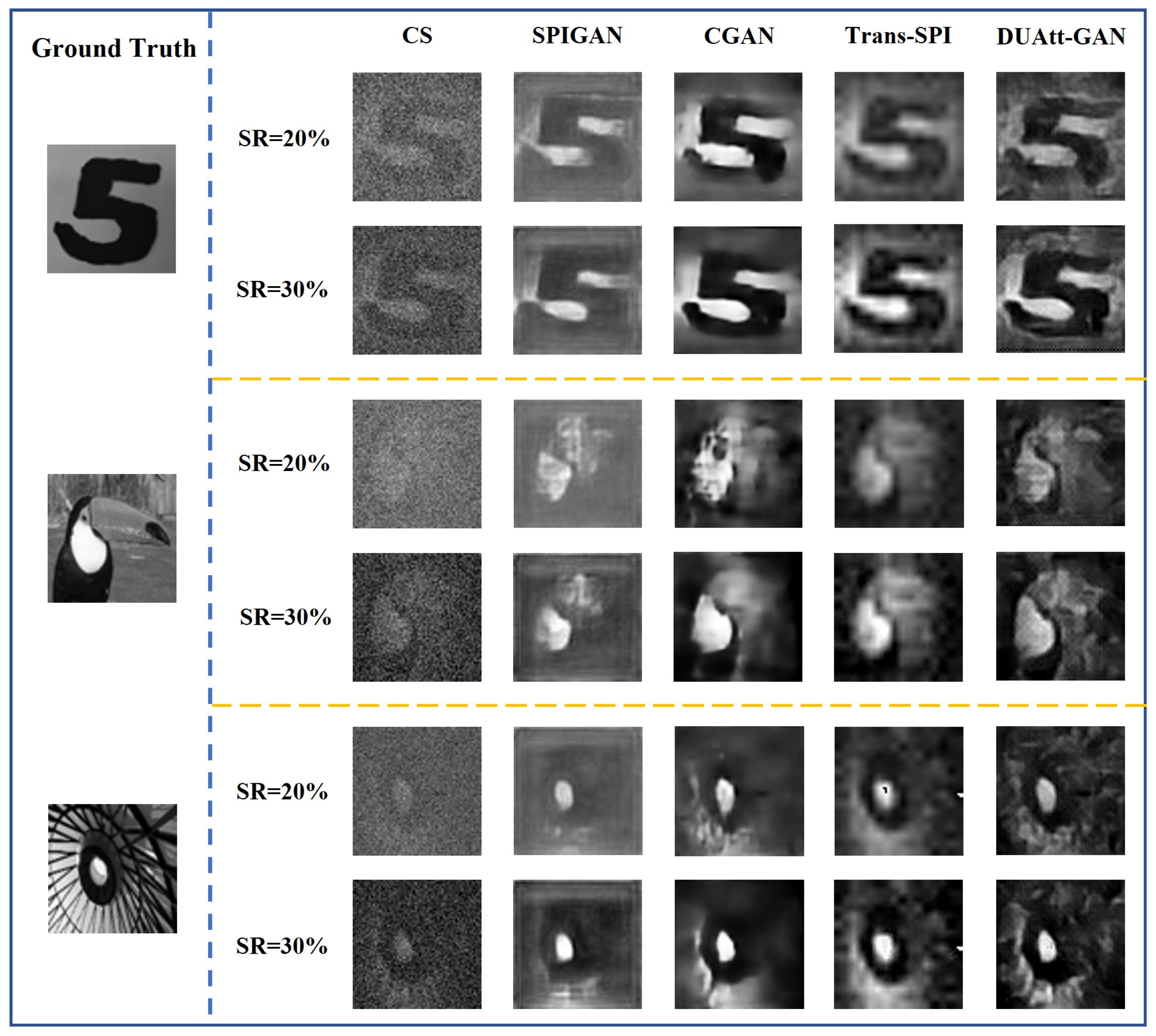
3.2. Numerical Simulations
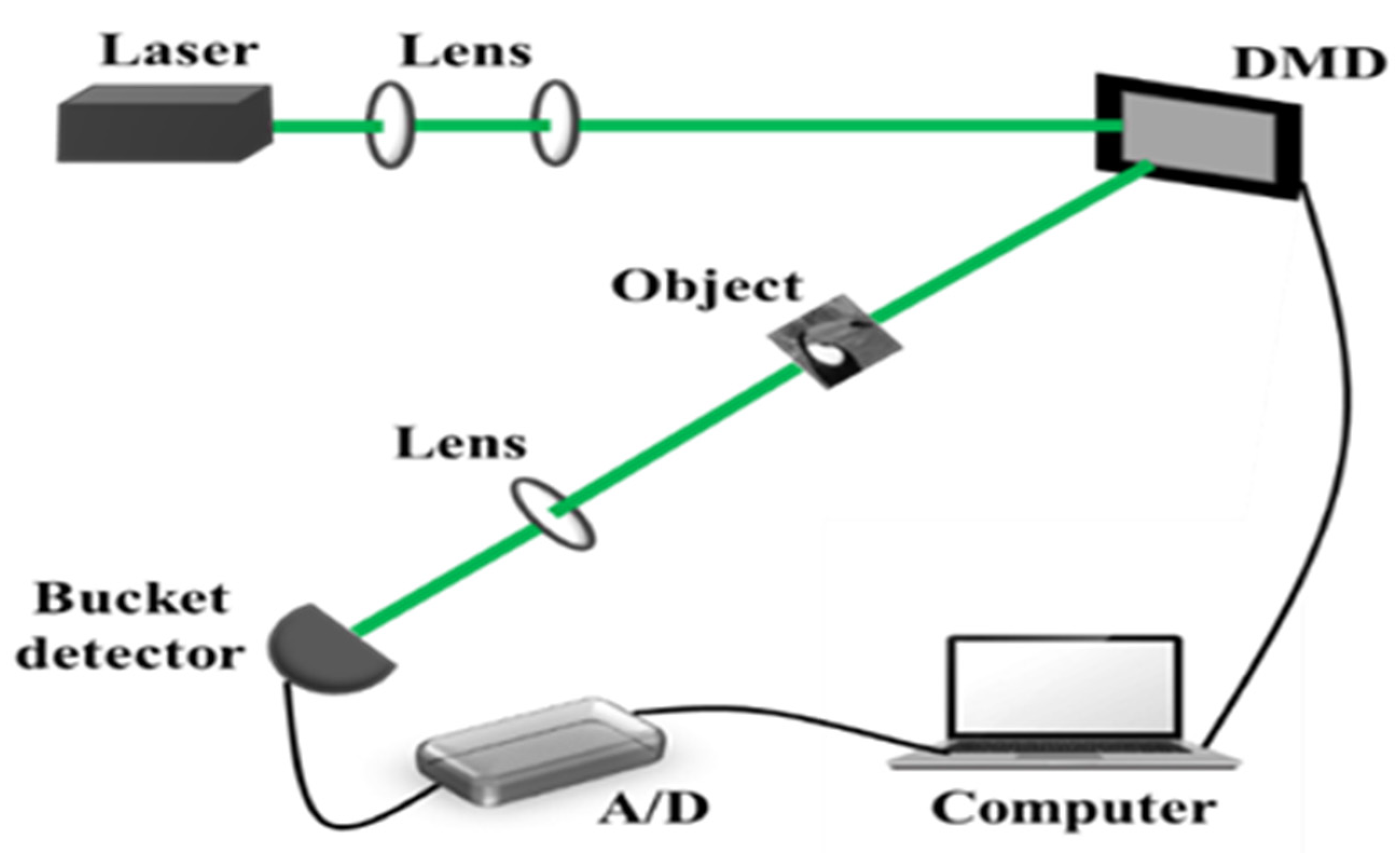
3.3. Real Experiments
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, C.; Hu, X.; Li, X.; Li, X.; Suo, J.; Zhang, Z.; Dai, Q. High fidelity single-pixel imaging. IEEE Photonics J. 2019, 11, 1–9. [Google Scholar] [CrossRef]
- Zhai, X.; Wu, Y.; Sun, Y.; Shi, J.; Zeng, G. Theory and approach of single-pixel imaging. ILE 2021, 50, 20211061. [Google Scholar]
- Duarte, M.; Davenport, M.; Takhar, D.; Laska, J.; Sun, T.; Kelly, K. Single-pixel imaging via compressive sampling. IEEE Signal Process. Mag. 2008, 25, 83–91. [Google Scholar] [CrossRef]
- Zhang, Z.; Ma, X.; Zhong, J. Single-pixel imaging by means of Fourier spectrum acquisition. Nat. Commun. 2015, 6, 6225. [Google Scholar] [CrossRef]
- Wu, H.; Wang, R.; Zhao, G.; Xiao, H.; Zhang, X. Deep-learning denoising computational ghost imaging. Opt. Lasers Eng. 2020, 134, 106183. [Google Scholar] [CrossRef]
- Wu, H.; Zhao, G.; Chen, M.; Cheng, L.; Xiao, H.; Xu, L.; Wang, D.; Liang, J.; Xu, Y. Hybrid neural network-based adaptive computational ghost imaging. Opt. Lasers Eng. 2021, 140, 106529. [Google Scholar] [CrossRef]
- Ye, Z.; Zheng, P.; Hou, W.; Dian, S.; Wei, Q.; Hong, C.; Jun, X. Computationally convolutional ghost imaging. Opt. Lasers Eng. 2022, 159, 107191. [Google Scholar] [CrossRef]
- Yu, W.; Wei, N.; Li, Y.; Yang, Y.; Wang, S. Multi-party interactive cryptographic key distribution protocol over a public network based on computational ghost imaging. Opt. Lasers Eng. 2022, 155, 107067. [Google Scholar] [CrossRef]
- Bu, T.; Kumar, S.; Zhang, H.; Huang, Y. Single-pixel pattern recognition with coherent nonlinear optics. Opt. Lett. 2020, 45, 6771–6774. [Google Scholar] [CrossRef]
- Mizutani, Y.; Kataoka, S.; Uenohara, T.; Takaya, Y.; Matoba, O. Fast and accurate single pixel imaging using estimation uncertainty in explainable CNNs. AI Opt. Data Sci. V 2024, 12903, 96–98. [Google Scholar]
- Xia, J.; Zhang, L.; Zhai, Y.; Zhang, Y. Reconstruction method of computational ghost imaging under atmospheric turbulence based on deep learning. Laser Phys. 2024, 34, 015202. [Google Scholar]
- Dai, Q.; Yan, Q.; Zou, Q.; Li, Y.; Yan, J. Generative adversarial network with the discriminator using measurements as an auxiliary input for single-pixel imaging. Opt. Commun. 2024, 560, 130485. [Google Scholar] [CrossRef]
- Jiang, P.; Liu, J.; Wu, L.; Xu, L.; Hu, J.; Zhang, J.; Zhang, Y.; Yang, X. Fourier single pixel imaging reconstruction method based on the U-net and attention mechanism at a low sampling rate. Opt. Express 2022, 30, 18638–18654. [Google Scholar] [CrossRef]
- Feng, W.; Zhou, S.; Li, S.; Yi, Y.; Zhai, Z. High-turbidity underwater active single-pixel imaging based on generative adversarial networks with double Attention U-Net under low sampling rate. Opt. Commun. 2023, 538, 129470. [Google Scholar] [CrossRef]
- Quero, C.; Leykam, D.; Ojeda, I. Res-U2Net: Untrained deep learning for phase retrieval and image reconstruction. J. Opt. Soc. Am. A 2024, 41, 766–773. [Google Scholar] [CrossRef] [PubMed]
- Qu, G.; Wang, P.; Yuan, X. Dual-Scale Transformer for Large-Scale Single-Pixel Imaging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 25327–25337. [Google Scholar]
- Zhu, Z.; Chi, H.; Jin, T.; Zheng, S.; Jin, X.; Zhang, X. Single-pixel imaging based on compressive sensing with spectral-domain optical mixing. Opt. Commun. 2017, 402, 119–122. [Google Scholar] [CrossRef]
- Pastuszczak, A.; Czajkowski, K.M.; Kotyński, R. Single-pixel video imaging with DCT sampling. In Proceedings of the Imaging and Applied Optics 2019 (COSI, IS, MATH, pcAOP), Munich, Germany, 24–27 June 2019; OSA: Washington, DC, USA, 2019. [Google Scholar]
- Zhang, Z.; Wang, X.; Zheng, G.; Zhong, J. Fast Fourier single-pixel imaging via binary illumination. Sci. Rep. 2017, 7, 12029. [Google Scholar] [CrossRef]
- Baraniuk, R.G. Compressive sensing. IEEE Signal Process. Mag. 2007, 24, 118–121. [Google Scholar] [CrossRef]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17 October 2016; Springer: Berlin, Germany, 2016; pp. 424–432. [Google Scholar]
- Ouidadi, H.; Guo, S. MPS-GAN: A multi-conditional generative adversarial network for simulating input parameters’ impact on manufacturing processes. J. Manuf. Process. 2024, 131, 1030–1045. [Google Scholar] [CrossRef]
- Liu, Y.; Pu, H.; Sun, D. Efficient extraction of deep image features using convolutional neural network (CNN) for applications in detecting and analysing complex food matrices. Trends Food Sci. Technol. 2021, 113, 193–204. [Google Scholar] [CrossRef]
- Ghayoumi, M. Generative Adversarial Networks in Practice, 1st ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2023. [Google Scholar]
- Tan, R.; Patade, O.; Wang, H.; Yang, C.; Lee, D. Optimizing Spatial Sensing Performance with Kriging and SRGAN—A Feasibility Study. In Proceedings of the 2023 IEEE SENSORS, Vienna, Austria, 29 October–1 November 2023. [Google Scholar]
- Karim, N.; Rahnavard, N. SPI-GAN: Towards single-pixel imaging through generative adversarial network. arXiv 2021, arXiv:2107.01330. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Gong, W.; Han, S. A method to improve the visibility of ghost images obtained by thermal light. Phys. Lett. A 2010, 374, 1005–1008. [Google Scholar] [CrossRef]
- Ferri, F.; Magatti, D.; Lugiato, L.; Gatti, A. Differential ghost imaging. Phys. Rev. Lett. 2010, 104, 253603. [Google Scholar] [CrossRef]
- Bian, L.; Suo, J.; Dai, Q.; Feng, C. Experimental comparison of single-pixel imaging algorithms. J. Opt. Soc. Am. A 2017, 35, 78–84. [Google Scholar] [CrossRef]
- Wu, H.; Wang, R.; Zhao, G.; Xiao, H.; Zhang, X. Sub-Nyquist computational ghost imaging with deep learning. Opt. Express 2020, 28, 3846–3853. [Google Scholar] [CrossRef]
- Zhao, M.; Zhang, X.; Zhang, R. High-Quality Computational Ghost Imaging with a Conditional GAN. Photonics 2023, 10, 353. [Google Scholar] [CrossRef]
- Tian, Y.; Fu, Y.; Zhang, J. Transformer-Based Under-Sampled Single-Pixel Imaging. CJE 2023, 32, 1151–1159. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | DU Blocks Integration | DA Blocks Integration | Loss Function | PSNR (dB) | SSIM |
|---|---|---|---|---|---|
| DUAtt-GAN | Yes | Yes | 22.905 | 0.782 | |
| w/o DU blocks | No | Yes | 22.028 | 0.699 | |
| w/o DA blocks | Yes | No | 20.986 | 0.619 | |
| w/o DU and DA blocks | No | No | 20.220 | 0.596 | |
| w/o TV loss | Yes | Yes | 20.026 | 0.578 | |
| w/o content loss | Yes | Yes | 20.706 | 0.667 |
| α | β | γ | PSNR (dB) | SSIM |
|---|---|---|---|---|
| 0.003 | 5 × 10−4 | 10−8 | 21.305 | 0.6774 |
| 0.003 | 5 × 10−4 | 5 × 10−8 | 21.315 | 0.6801 |
| 0.006 | 10−3 | 5 × 10−8 | 21.325 | 0.6822 |
| 0.006 | 2 × 10−3 | 5 × 10−8 | 21.231 | 0.6754 |
| 0.009 | 5 × 10−4 | 10−8 | 21.304 | 0.6792 |
| 0.009 | 10−3 | 2 × 10−8 | 21.314 | 0.6791 |
| Dataset | SR = 20% | SR = 30% | ||
|---|---|---|---|---|
| PSNR/dB | SSIM | PSNR/dB | SSIM | |
| BSD100 | 29.08 | 0.6360 | 29.51 | 0.6743 |
| Set5 | 16.47 | 0.4285 | 16.00 | 0.4783 |
| Set14 | 20.12 | 0.4791 | 19.43 | 0.5453 |
| Urban100 | 23.04 | 0.5139 | 22.83 | 0.5704 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, B.; Wang, H.; Bu, Y. Single-Pixel Imaging Reconstruction Network with Hybrid Attention and Enhanced U-Net. Photonics 2025, 12, 607. https://doi.org/10.3390/photonics12060607
Xiao B, Wang H, Bu Y. Single-Pixel Imaging Reconstruction Network with Hybrid Attention and Enhanced U-Net. Photonics. 2025; 12(6):607. https://doi.org/10.3390/photonics12060607
Chicago/Turabian StyleXiao, Bingrui, Huibin Wang, and Yang Bu. 2025. "Single-Pixel Imaging Reconstruction Network with Hybrid Attention and Enhanced U-Net" Photonics 12, no. 6: 607. https://doi.org/10.3390/photonics12060607
APA StyleXiao, B., Wang, H., & Bu, Y. (2025). Single-Pixel Imaging Reconstruction Network with Hybrid Attention and Enhanced U-Net. Photonics, 12(6), 607. https://doi.org/10.3390/photonics12060607