Abstract
The Generalized Tempered Stable (GTS) distribution extends classical stable laws through exponential tempering, preserving the power-law behavior while ensuring finite moments. This makes it especially suitable for modeling heavy-tailed financial data. However, the lack of closed-form densities poses significant challenges for simulation. This study provides a comprehensive and systematic comparison of GTS simulation methods, including rejection-based algorithms, series representations, and an enhanced Fast Fractional Fourier Transform (FRFT)-based inversion method. Through extensive numerical experiments on major financial assets (Bitcoin, Ethereum, the S&P 500, and the SPY ETF), this study demonstrates that the FRFT method outperforms others in terms of accuracy and ability to capture tail behavior, as validated by goodness-of-fit tests. Our results provide practitioners with robust and efficient simulation tools for applications in risk management, derivative pricing, and statistical modeling.
1. Introduction
In many areas of applied statistics and data analysis—particularly in finance, insurance, and environmental modeling—empirical data often exhibit heavy tails, skewness, and discontinuous jumps that deviate significantly from Gaussian assumptions [1,2,3]. Classical models based on normal distributions frequently fail to capture these features, especially when modeling extreme events or tail risks [4].
The Generalized Tempered Stable (GTS) distribution has emerged as a flexible and powerful framework for modeling such phenomena. By introducing exponential tempering to the Lévy measure, it extends classical stable distributions while preserving their heavy-tailed behavior and ensuring finite moments [5,6]. These properties make GTS distributions particularly valuable for modeling Lévy processes with jump activity in financial applications [7]. Moreover, the GTS family encompasses several notable special cases [6,8,9,10,11], further highlighting its flexibility and relevance across various applications.
Despite their theoretical appeal, simulating GTS random variates remains a challenging task. The absence of closed-form probability densities precludes the use of standard techniques that rely on explicit cumulative distribution evaluations [12]. In practice, simulation from the GTS distribution is essential for conducting Monte Carlo experiments, performing risk assessments, fitting models to data, and generating synthetic datasets for testing algorithms [13].
To address this challenge, several approaches have been developed, including rejection-based algorithms (e.g., Standard Stable Rejection, Double Rejection, and Two-Dimensional Single Rejection) [12,14,15,16,17], series representations (e.g., Shot Noise and Inverse Tail Integral methods) [5,18,19], and inversion-based techniques leveraging the characteristic function [1,20]. While each has advantages, they also face limitations in efficiency, accuracy, or robustness—particularly when applied to financial assets with very small stability indices or extreme tempering parameters (, ). Moreover, the literature lacks a systematic empirical comparison of these methods under realistic, data-driven conditions.
This paper aims to fill that gap by providing a comprehensive review, implementation, and empirical evaluation of simulation methods for GTS random variates. We categorize the algorithms into exact methods (rejection-based) and numerical approaches (series representations and inversion techniques). Our key contributions are as follows:
- 1.
- Systematic Empirical Benchmarking: We perform an extensive numerical study using high-frequency daily return data from major financial assets (Bitcoin, Ethereum, S&P 500, SPY ETF), whose parameters often push simulation methods to their limits. This provides a realistic benchmark absent in purely theoretical comparisons.
- 2.
- Implementation and Analysis of Exact Methods: We implement and evaluate key rejection-based algorithms (Standard Stable Rejection, Double Rejection, Two-Dimensional Single Rejection), providing a clear analysis of their computational complexity and identifying their breaking points, particularly for equity indices with extremely low stability index values.
- 3.
- Implementation and Analysis of Series Representations: We investigate the inverse Lévy measure and Shot Noise series representation methods, demonstrating their theoretical elegance but also their practical limitations and sensitivity to parameter values.
- 4.
- An Enhanced FRFT-Based Inversion Framework: We propose and implement an advanced numerical inversion method that leverages the characteristic function of the GTS distribution, combining [21] a Fast Fractional Fourier Transform (FRFT) and Newton–Cotes quadrature. This method achieves high accuracy and robustness across parameter regimes, addressing key shortcomings of rejection and series methods.
- 5.
- Rigorous Validation: Beyond visual Q-Q plot analysis, we use statistical goodness-of-fit tests (Kolmogorov–Smirnov and Anderson–Darling) to assess the fidelity of each method, with a particular focus on tail behavior.
Our results show that the enhanced FRFT-based inversion method consistently outperforms existing techniques in both accuracy and robustness. This establishes it as a practical and reliable tool for applications in risk management, derivative pricing, and statistical modeling where accurate reproduction of heavy-tailed dynamics is essential.
The remainder of this paper is structured as follows: Section 2 reviews the mathematical foundations of GTS distributions. Section 3, Section 4, Section 5, Section 6 and Section 7 present the simulation algorithms. Section 8.2 reports empirical results and comparisons. Section 9 concludes with practical recommendations and directions for future research.
2. Generalized Tempered Stable (GTS) Distribution
The Generalized Tempered Stable (GTS) distribution is a family of infinitely divisible distributions that generalizes the classical stable laws by introducing exponential tempering into the Lévy measure. This modification preserves the power-law behavior in the central part of the distribution while damping the tails, ensuring the existence of moments and improving the tractability of the model in applications.
Formally, a random variable has a Lévy measure given by
where
- are stability index parameters, controlling the heaviness of the tails on the positive and negative axes, respectively;
- are scale parameters, determining the overall intensity of jumps;
- are tempering parameters, governing the exponential decay of large jumps in either direction.
Remark 1.
The Lévy measure is a Borel measure on that satisfies the following condition:
- No Jump at Zero: ;
- Integrability of Small Jumps: .
The importance of the Lévy measure is shown by the Lévy–Khintchine representation, which states that the characteristics of any Lévy process are uniquely defined by a triplet , consisting of
- A drift term (a);
- A diffusion or variance coefficient (σ), which controls the continuous, Gaussian-motion component;
- The Lévy measure (V), which precisely quantifies the frequency and size of the jumps.
Thus, the triplet offers a unique and exhaustive signature for any Lévy process.
The activity process of the GTS distribution can be studied from the integral (2) of the Lévy measure (1):
As shown in Equation (2), for , the Lévy density () is not integrable as it goes off to infinity too rapidly as x goes to zero, due to a large number of very small jumps. The GTS distribution is described as an infinite activity process with an infinite number of jumps within any given time interval.
In addition to the infinite activities process, the variation of the process can be studied by solving the following integral [22]:
Refer to [11] for further development of Equation (3).
As shown in Equation (3), GTS distribution is a finite variation process, and generates a type B Lévy process [23], which is a purely non-Gaussian infinite activity Lévy process of finite variation whose sample paths have an infinite number of small jumps and a finite number of large jumps in any finite time interval. In particular, being of bounded variation shows that can be written as the difference of two independent subordinators [22,24]:
where and are subordinators.
By adding a drift parameter, we have the following expression:
Theorem 1.
Consider a variable . The characteristic exponent can be written as
See [25,26,27] for Theorem 1’s proof.
Maximum Likelihood GTS Parameter Estimation for Four Key Financial Assets
The GTS parameter estimation results for Bitcoin and Ethereum are presented in Table 1, while those for the S&P 500 index and the SPY ETF are shown in Table 2. The values in brackets represent the asymptotic standard errors, computed using the inverse of the Hessian matrix.

Table 1.
GTS parameter estimation for Bitcoin and Ethereum [26].
Table 2.
GTS parameter estimation for S&P 500 Index and SPY ETF [26].
For all financial assets considered, the maximum likelihood estimates indicate that is negative, while other parameters are positive, as expected in the literature. However, the relatively large standard errors suggest that is not statistically significant at the 5% level.
As shown in Table 1 and Table 2, except for the index of stability parameters (), the tempering parameters (, ) and the scale parameters (, ) are all statistically significant at the 5% level.
Remark 2.
A comprehensive methodology for fitting the seven-parameter Generalized Tempered Stable (GTS) distribution—along with parameter estimation results—is presented in [26]. The data source and some empirical findings are summarized as follows:
- Data Sources:
- –
- Historical price data for Bitcoin (BTC) and Ethereum (ETH) were collected from CoinMarketCap. The time span covers 28 April 2013 to 4 July 2024 for BTC, and 7 August 2015 to 4 July 2024 for ETH.
- –
- Historical price data for the S&P 500 Index and the SPY ETF were obtained from Yahoo Finance, covering the period from 4 January 2010 to 22 July 2024. The prices were adjusted for stock splits and dividends.
- GTS parameter estimation: The methodology for estimating the seven parameters using the Enhanced Fast Fractional Fourier Transform (FRFT) has been extensively developed in [26,28,29,30,31], providing a comprehensive approach for fitting the rich class of GTS distributions.
- Model Comparison: Based on log-likelihood, Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC), the seven-parameter GTS distribution outperforms the classical two-parameter normal distribution (Geometric Brownian Motion, GBM).
- Goodness-of-Fit Tests: The Kolmogorov–Smirnov, Anderson–Darling, and Pearson chi-squared tests confirm the superior fit of the GTS model, especially in capturing heavy tails and asymmetries in return distributions.
- Benchmarking Against Alternative Models: The GTS distribution demonstrates improved empirical performance over
- –
- The KoBoL distribution ();
- –
- The Carr–Geman–Madan–Yor (CGMY) model ( and );
- –
- The Bilateral Gamma distribution ().
3. β-Stable Distributions and Simulation Algorithms
3.1. -Stable Distributions: Review
We consider the class of all stable distributions with four parameters , denoted by . means that X is a stable random variable (r.v) with parameters . is the notation used in [2]. In the literature, various notational conventions are commonly used; for instance, the parameterization is employed in [4]. A random variable X is said to have a stable distribution, , if and only if the logarithm of its characteristic function has the following canonical form [32,33,34]:
where
Corollary 1.
Let ; there exists such that X can be expressed as follows:
The proof of Corollary 1 follows from Proposition 1.2.2 and Proposition 1.2.3 in [2].
Remark 3.
is called the class of standard stable distribution. Four parameters characterize the class and can be described as follows:
- The skewness parameter (): The distribution is considered positively (negatively) skewed if ().
- The stability parameter or index (): It affects the shape of the distribution and its tails. The class lacks a closed-form probability density function, except for the Gaussian distribution (, ), the Cauchy distribution (, ), and the Lévy distribution (, ) [2,35].
- The scale or dispersion parameter (): This is not the standard deviation of non-Gaussian stable distributions, as the variance is infinite when .
- The location or drift parameter (): This is not the mean but has a drifting effect on the distribution.
3.2. Sampling from -Stable Distributions: Review
Remark 4.
The discontinuity in the characteristic function of canonical representation (7) with respect to its parameters causes numerical instabilities in simulations. Thus, smoother alternatives, such as parametrization (B) and parametrization (M) in [33,36], are preferred. The canonical representation (7) is called parametrization (A) in [33].
Theorem 2
(Transition from parametrization (B) to parametrization (A)). Let and . and follow the parametrization (B) and (A), respectively. We have the following relationship:
where
Refer to [32] for the proof of Theorem 2.
Theorem 3
(Representation of stable laws by integrals). The distribution function of a standard stable distribution () can be written as follows:
- 1.
- If and , then for any ,wherewhere
- 2.
- If and , then for any ,where
For the proof of Theorem 3, refer to [4,33,36,37].
Theorem 4 (Sampling standard stable distribution
()). Let U and W be independent with U uniformly distributed on and W exponentially distributed with mean 1.
Then, Z can be simulated by representation.
where
For the proof of Theorem 4, refer to [4,37].
Equation (16) is referred to as the Chambers–Mallows–Stuck (CMS) method for generating standard stable variables (.
Remark 5.
Certain special cases of (16) are worth noting.
- Standard stable distribution () with , : we havewhich is a Box-Muller algorithm [38] for generating a normal random variable with mean 0 and variance 2.
- Standard stable distribution () with , : we haveFor , we have the algorithm [39] for generating Cauchy distribution .The Cauchy distribution function [33] can be written as follows:
- Standard stable distribution () with , : we have andwhereWe have a well-known relationship between the standard Lévy distribution and the standard normal distribution.
4. Generalized Tempered Stable (GTS) and Exponentially Titled Stable Distributions
The Generalized Tempered Stable (GTS) distribution, denoted as , is a finite variation process when and . Any random variable X following such a GTS distribution can be represented as the difference of two independent subordinators:
where and are subordinators on the positive half-line and belong to the class of Tempered Stable distributions, denoted .
Remark 6.
A subordinator is a one-dimensional Lévy process , such that is a non-decreasing function.
Lemma 1
(Characteristic Exponents of and ). The characteristic exponents of the subordinators and are
Proof.
The Lévy–Khintchine representation [40] for non-negative Lévy process is applied on .
Additional information can be found in [25,26,27] □
4.1. Exponentially Titled Unilateral Stable Variable
A standard stable variable X with stability parameter belongs to the class . Its corresponding Lévy measure is given by
We consider , the probability density function (PDF) of the standard stable variable X. For , we introduce the exponentially titled random variable [12] defined by the tilted density function :
Theorem 5
(Characteristic exponent of ). For the exponentially titled random variable , its characteristic exponent satisfies
Moreover, we have the following expression for PDF and :
Proof.
X is the standard stable variable correspond to and Lévy density in Equation (19). Equation (18) becomes
Applying the moment-generating function by taking ,
By substitution, we have the PDF of (21).
The last relation, , can be shown as follows:
Applying the logarithmic function on Equation (24), we have the characteristic exponent described in Equation(17).
Therefore, we have
is also a Tempered Stable distribution (). □
Remark 7.
In the literature, other papers [12,14,15] dealing with exponential tilted stable used alternative parameterization for characteristic functions, which can be recovered quickly by the transformation of parameters.
- Alternative Parameterization of the Characteristic Function:
- Transformation of Parameters:We have a new parameter (θ) and a transformed variable:
- Setting : Without loss of generality, we set and the Laplace transform of becomes
4.2. Tempered Stable Distribution
We now consider Theorem 5 in Section 4.2, by setting . As previously shown in Equation (20), the Laplace transform of the exponential tilted stable variable is given by
The probability density function (PDF) of can be written as
where is the PDF of the stable variable with the stability paramater . The analytical expression for is given by Zolotarev’s integral representation [36]:
where is defined as follows:
Remark 8.
is obtained from (13) by removing the transitional parameter and transforming the interval to using the function .
Substituting into the expression , we obtain
We define a bivariated density function over the domain x as
plays a crucial role in constructing the Two-Dimensional Single Rejection algorithm [14] for simulating the exponentially tilted sable variable .
To further simplify the integral, we introduce a change of variable, , in the following integral.
From the integrand in Equation (29), we define another bivariate density function over x:
plays a crucial role in constructing the Double Rejection algorithm [12] to sample .
5. Exact Sampling Method for Simulating
5.1. Standard Stable Rejection (SSR) Method
The Acceptance–Rejection Sampling technique [13] generates samples from a target distribution by first generating candidates from a more convenient distribution and then rejecting a random subset of the generated candidates. Let Y be a stable random variable with distribution . The Chambers–Mallows–Stuck (CMS) method (16) provides an efficient approach for simulating stable random variables [41]. To simulate an exponentially tilted random variable (or tempered stable variable) from Y, each candidate Y is accepted with probability . If Y is rejected, independent trials follow until acceptance. It is well-known [42] that the number of trials N before acceptance is geometrically distributed, and its mean is given by
Hence, a smaller implies fewer trials on average, thus increasing the efficiency of the SSR technique.
Figure 1a,b illustrate how behaves under empirical return distributions:
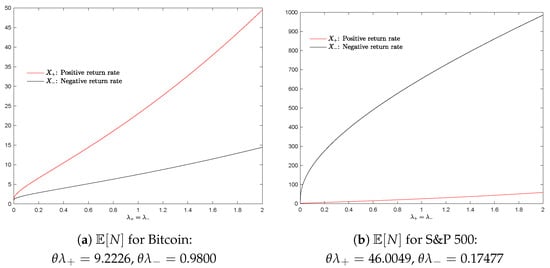
Figure 1.
Empirical behavior of for Bitcoin and S&P 500 index.
- For negative Bitcoin returns (black curve) and positive S&P 500 returns (red curve), grows slowly.
- However, for negative S&P 500 returns (also shown in black), increases exponentially, leading to a prohibitively large number of trials.
The rapid increase in the expected number of trials results in a poor acceptance rate for large values of or for small values of . The expected number of trials () is referred to as the “expected complexity” in the literature [12,14,16,43]. The high expected complexity results in a high rejection rate, rendering the SSR algorithm inefficient and limiting its practical application.
The empirical values of for financial assets, including the S&P 500 index, SPY ETF, Bitcoin, and Ethereum, were computed and summarized in Table 3.
Table 3.
Transformed parameters and GTS parameters.
The transformed parameters and exhibit significantly larger values for the S&P 500 index and SPY ETF, with the expected complexities of and 6.8 , respectively. The high values make the SSR algorithm not applicable to the financial assets: S&P 500 index and SPY ETF.
Algorithm 1 outlines the SSR sampling approach [16,43,44], commonly used for sampling from exponentially tilted stable distributions, also known as generalized gamma distributions [41].
| Algorithm 1 Standard Stable Rejection (SSR) sampling [14]. |
|
To evaluate the performance of Algorithm 1, we generated a sample of 80,000 data points to mimic the two financial assets: Bitcoin and Ethereum. As shown in Figure 2b and Figure 3b, the Q-Q plots maintain smooth linear patterns, confirming the alignment of the empirical and theoretical distributions.
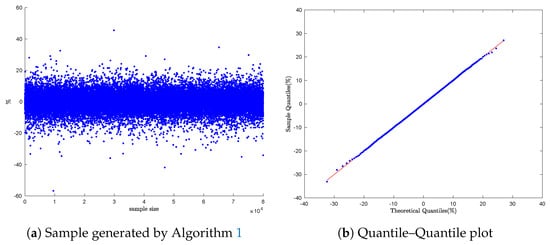
Figure 2.
Bitcoin daily return simulation: Q-Q Plot with Algorithm 1.
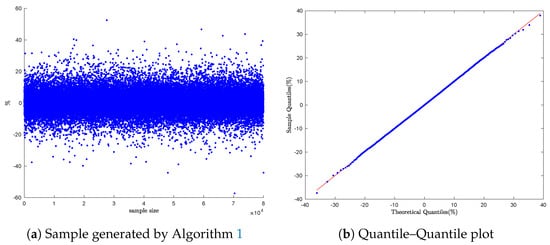
Figure 3.
Ethereum daily return simulation: Q-Q Plot with Algorithm 1.
Remark 9.
The theoretical quantiles (represented by the red line in the Q-Q plot) and the observed quantiles were computed by the Enhanced Fast Fractional Fourier Transform (FRFT) scheme. The Enhanced Fast FRFT scheme improves the accuracy of the one-dimensional Fast FRFT by leveraging closed Newton–Cotes quadrature rules [45,46]. For more details on the methodology and its applications, refer to [21,47,48].
The Standard Stable Rejection (SSR) method is theoretically appealing but becomes impractical for large tempering parameters () or small stability index parameter () due to unbounded computational complexity. While useful for small-scale simulations with moderate parameters, its limitations make it unsuitable for financial modeling, where extreme parameter values are common.
The Fast Rejection Algorithm [16,43] significantly reduces the expected complexity of SSR sampling down to logarithmic expected complexity. However, like SSR, its expected runtime is still unbounded, meaning performance can degrade for extreme parameter values (). By contrast, both the Double Rejection and Two-Dimensional Single Rejection algorithms ensure a bounded expected complexity for all and .
5.2. Double Rejection Method
The joint density function in (30) serves as the target distribution for sampling the marginal random variable .
The marginal density of is given by the integral in (32), which does not have a closed-form expression:
To generate samples of , one approach is to first sample U and then generate from the conditional density . However, the lack of a closed-form expression for complicates this process. The Double Rejection method addresses this challenge by selecting an appropriate bivariate density function and a univariate density function such that
These functions are chosen to facilitate efficient sampling of . The first-level rejection method is used to sample U from the marginal density , while the second-level rejection method generates the bivariate random variable with density function . The Double Rejection method, introduced by [12], uses the following bivariate and univariate density functions.
- ; ; ; .
- , is normal density with and .
- , is beta density with and .
- , is uniform distribution over .
The following theorem from [12] establishes that the expected complexity of the Double Rejection method is uniformly bounded for all values of and .
Theorem 6.
Let be the expected number of iterations required to generate a random variable using the Double Rejection method. Then,
The proof of Theorem 6 can be found in [12].
The GTS parameter estimates presented in Table 1 and Table 2 were used to simulate the daily returns of each financial asset. For each asset, empirical quantiles were computed from the observed daily return samples. The Q-Q plots shown in Figure 4a,b and Figure 5a,b compare these sample quantiles with the theoretical quantiles derived from the General Tempered Stable (GTS) distribution. The plots display a smooth non-linear pattern in the central region and noticeable discrepancies in the tails.
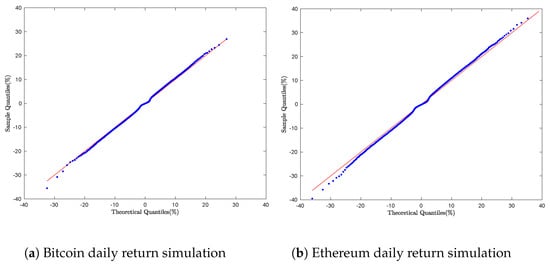
Figure 4.
Cryptocurrency daily return simulation: Q-Q Plot with Algorithm 2.
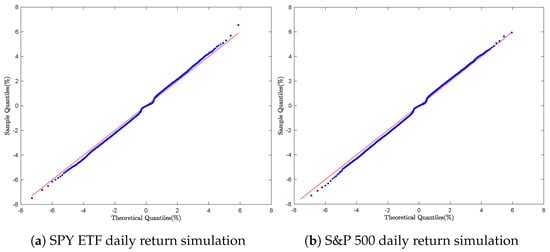
Figure 5.
Equity daily return simulation: Q-Q Plot with Algorithm 2.
The graphical results suggest that the empirical return distributions exhibit heavier tails than those predicted by the GTS model, indicating limitations in the Double Rejection method’s ability to accurately capture the GTS model’s extreme values.
Despite its theoretically established complexity bounds, the Double Rejection technique proves inadequate for accurate GTS simulations, as it fails to capture the heavy-tailed characteristics of the distribution.
| Algorithm 2 Double Rejection sampling. |
|
5.3. Two-Dimensional Single Rejection Method
The joint density function in (28) serves as the target distribution for sampling the bivariate variable . The Two-Dimensional Single Rejection method [14] uses a proposal bivariate density function , along with a constant such that
This method generates samples from the target distribution by first generating candidates from the proposal density function and then rejecting a subset of these candidates based on the relationship in (36).
Algorithm 3 outlines the Two-Dimensional Single Rejection sampling approach.
| Algorithm 3 Two-Dimensional Single Rejection sampling [14]. |
|
For a given , the two types of proposal bivariate density function, denoted as , are considered by the Two-Dimensional Single Rejection method:
- First proposal bivariate density function: A product of the gamma density function and the uniform density function. This approach has expected complexities denoted by and , yielding the target random variable .
- Second proposal bivariate density function: A product of a gamma density function and a normal density function. The expected complexities in this case are and , resulting in the target random variable .
Table 4 provides additional details on the implementation of the Two-Dimensional Single Rejection algorithm (Algorithm 3).
Table 4.
Describtion of the proposal bivariate density functions [14].
The expected complexities , , , and are further examined using empirical values based on parameters derived from financial assets, including the S&P 500 index, SPY ETF, Bitcoin, and Ethereum. As shown in Table 5, and demonstrate greater stability and are less affected by large parameter values, such as for the S&P 500 index and for the SPY ETF.
Table 5.
Expected complexity empirical values.
The overall complexity () of the Two-Dimensional Single Rejection is defined as follows:
Theorem 7.
The complexity in Equation (37) for Algorithm 3 is uniformly bounded, satisfying the following relationship:
Consult [14] for the proof of Theorem 7.
As shown in Table 5, the overall complexity () remains more stable and below the upper bound of . However, the individual expected complexities and do not satisfy the relationship in (38) for S&P 500 index and SPY ETF data.
To evaluate the performance of Algorithm 3, we generated a sample of 8000 daily returns for each financial asset. The empirical distributions were compared against the theoretical distributions using Q-Q plots. The results of this distributional analysis are presented in Figure 6a,b and Figure 7a,b.
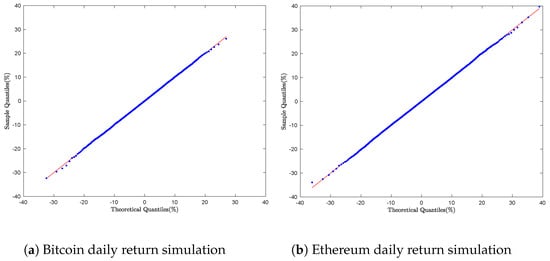
Figure 6.
Cryptocurrency daily return simulation: Q-Q Plot with Algorithm 3.
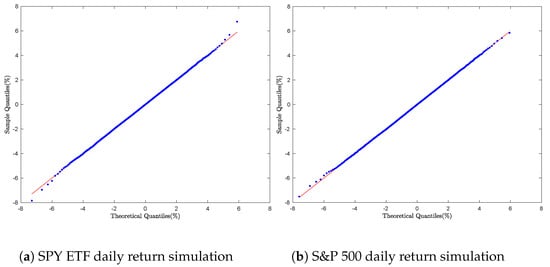
Figure 7.
Equity daily return simulation: Q-Q Plot with Algorithm 3.
As shown in each plot, the Q-Q plots display a smooth linear pattern, indicating a strong alignment between the empirical distributions and the theoretical GTS distribution.
The Two-Dimensional Single Rejection method outperforms other rejection-based approaches by offering greater stability across parameter ranges. It effectively captures both the central and tail behavior of the GTS distribution, making it more accurate and reliable for simulations.
Remark 10.
In a Q-Q plot, the quantiles of the observed distribution are plotted against those of the theoretical distribution. When the two distributions are similar, their quantiles will be nearly equal, and the points will closely follow the line . Any deviation from this line reveals differences between the distributions. The following scenarios, commonly observed in the literature [49,50,51,52,53], are worth noting:
- 1.
- Q-Q Plots and Skewed Distributions: A left-skewed distribution typically results in a concave downward Q-Q plot, while a right-skewed distribution shows a U-shaped or “humped” pattern. A symmetric distribution, on the other hand, will usually produce a symmetric and linear Q-Q plot around the center of the data.
- 2.
- Q-Q Plots and Short-Tailed Distributions: Short-tailed distributions may exhibit an S-shaped curve in the Q-Q plot. More specifically, the deviation from the straight line appears in the opposite direction at the tails compared to long-tailed distributions (above the line in the lower tail and below the line in the upper tail).
- 3.
- Q-Q Plots and Long-Tailed Distributions: Long-tailed distributions typically show deviations from the straight line at both ends of the Q-Q plot, with the lower tail curving downward and the upper tail curving upward.
- 4.
- S-shaped Curves in Q-Q Plots: An S-shaped curve can indicate several potential issues, such as longer or shorter tails than the theoretical distribution, or systematic differences between the distributions being compared.
6. Series Representation Methods for Simulating GTS Lévy Processes
We develop a simulation framework for Generalized Tempered Stable (GTS) Lévy processes based on almost surely convergent series representations. These representations, originally proposed by Rosiński [19] and later adapted to Tempered Stable distributions in [54], offer theoretically sound methods for generating sample paths of Lévy processes. In this context, we focus on two principal constructions: the inverse Lévy measure series representation and the Shot Noise series representation. These representations will serve as the basis for simulating GTS random variates.
Let , be a d-dimensional Lévy process with stationary, independent increments, stochastically continuous, and starting at zero. Its characteristic function is
where
with
- : characteristic exponent;
- : drift vector;
- : Lévy measure, defining the intensity and distribution of jumps in the process, and satisfying ;
- : characteristic triplet of X.
According to the Lévy–Itô decomposition theorem [19,55], admits the following decomposition:
where N is a Poisson random measure on . Equivalently,
with i.i.d. and as the associated jump sizes, independent from the . For further details, please refer to [19,56,57].
For , we define
By replacing (42) in (43), we have
where
As , this converges almost surely to
and we have
In the special case of GTS distribution where , and the characteristic exponent becomes
The Lévy–Itô decomposition Equation (41) becomes Equation (48):
Following the procedure developed previously (from Equation (41) to Equation (45)), Equation (46) becomes Equation (49):
with i.i.d. and as the associated jump sizes, independent from the . Similarly on the left side, i.i.d. and are the associated jump sizes, independent from the .
6.1. Sampling GTS Distribution via the Inverse Lévy Measure Series Representation
Let , where denotes a Tempered Stable distribution. The Lévy measure of is concentrated on and the Tail Integral function is defined as follows:
Using integration by parts, Equation(50) becomes
where is the upper incomplete gamma function.
The inverse of the Tail Integral function is defined as follows:
The series representation generated by the inverse Lévy measure method of has the following expression:
where
- , are i.i.d. exponential random variables with mean 1, and we set ;
- are i.i.d. uniform random variables on ;
- All the random elements , are mutually independent.
Algorithm 4 outlines the simulation of on [0, 1] using the series representation generated by the inverse Lévy measure method.
| Algorithm 4 Series representation using the inverse Lévy measure method. |
|
Daily return samples for Bitcoin, Ethereum, the S&P 500, and the SPY ETF were generated using the series representation in Equation (53). For each asset, empirical quantiles were computed and compared to theoretical quantiles through Q-Q plots.
As illustrated in Figure 8 and Figure 9, Figure 8a,b and Figure 9a,b exhibit smooth linearity patterns, indicating a strong agreement between the empirical and theoretical distributions for each asset.
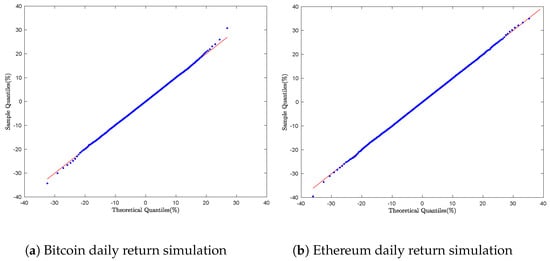
Figure 8.
Cryptocurrency daily return simulation: Q-Q Plot with Algorithm 4.
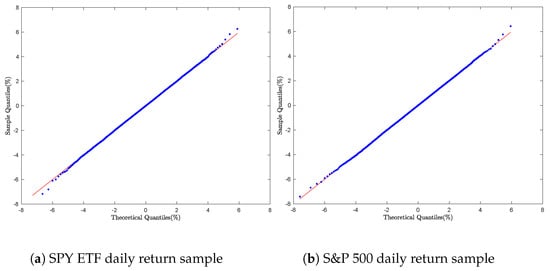
Figure 9.
Equity daily return simulation: Q-Q Plot with Algorithm 4.
The inverse Lévy measure method achieves exact simulation by inverting , offering a precise series representation, strong empirical performance, and better tail-fitting than rejection-based techniques. However, because it relies on iterative numerical inversion, it is computationally intensive, making it practical only for moderate-scale simulations rather than large-scale applications.
6.2. Sampling GTS Distribution via the Shot Noise Series Representation
The inverse of the tail of the Lévy measure for a Tempered Stable distribution lacks a closed-form expression, as shown in Equation (50). As a result, the inverse Lévy measure method becomes practically intractable. To address this difficulty, Rosiński [5,18,19,54] proposes a series representation based on the generalized Shot Noise framework, which is more revealing about the structure of the Tempered Stable distribution:
Theorem 8
(Theorem 5.1 [18]). Let , , be a tempered stable Lévy process in with ; if , or ν is symmetric and , then
where the equality holds in the sense of finite-dimensional distributions, and the infinite series converges almost surely, uniformly in . Here,
- , are i.i.d. uniform random variables on .
- , are i.i.d. exponential random variables with mean 1, and we set .
- are i.i.d. random vectors in with common distribution , defined via the Lévy measure ν by
- All the random elements , , , , and are mutually independent.
Refer to [5] for the proof of Theorem 8.
For the one-sided case, let denote a Tempered Stable distribution. The Lévy measure of is concentrated on with dimension . Using the notation from [5], we have for a time horizon :
The common distribution is related to the Dirac measure , implying that is deterministic.
The sampling of daily returns for Bitcoin, Ethereum, the S&P 500, and the SPY ETF was performed using Equation (57), which corresponds to a version of Equation (56) with time horizon :
Algorithm 5 describes how to simulate using the Shot Noise series representation.
| Algorithm 5 Shot Noise representation for . |
|
For each financial asset, empirical quantiles were computed and compared to theoretical quantiles through Q-Q plots, As illustrated in Figure 10 and Figure 11.
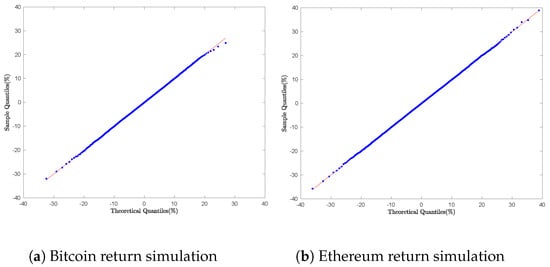
Figure 10.
Cryptocurrency daily return simulation: Q-Q Plot with Algorithm 5.
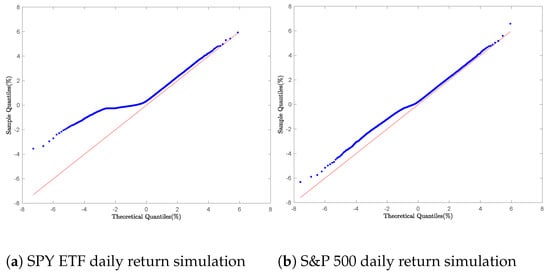
Figure 11.
Equity daily return simulation: Q-Q Plot with Algorithm 5.
Figure 10a,b exhibit smooth linear patterns, indicating strong agreement between the empirical and theoretical GTS distributions. However, this pattern does not hold for the S&P 500 and SPY ETF daily returns, as shown in Figure 11a,b, where discrepancies between empirical and theoretical quantiles are notably larger in the left tails of the Q-Q plots.
Although the Shot Noise representation delivers theoretically sound convergence, its practical utility is constrained by two significant challenges: (1) dependence on careful truncation of the series expansion and (2) high sensitivity to critical parameters (). The empirical results demonstrate satisfactory performance for cryptocurrencies like Bitcoin and Ethereum, but the method proves unreliable for equities with a very low instability index parameter (), such as the S&P 500 () and the SPY ETF (). These inconsistencies, often leading to computational failures, reduce its practicality in financial modeling [58,59,60].
7. FRFT-Based Inverse Transform Sampling Method
The characteristic function (CF)-based inverse sampling method provides a powerful alternative to series representations and rejection sampling, especially when the CF is known but the probability density function (PDF) is unknown [1,5,6,7,8,9,10,11]. Inverse sampling via characteristic functions relies on numerical inversion of the CF to recover the distribution function, enabling sampling through interpolation or numerical root-finding. This idea can be traced back to foundational work on the Gil-Pelaez inversion formula [61], which expresses the cumulative distribution function (CDF) directly in terms of the CF :
where Im is the imaginary part of a complex number.
Modern computational techniques enable efficient numerical inversion of the CF to approximate the CDF or PDF. Subsequently, inverse transform sampling can be carried out by interpolating the approximate CDF and inverting it numerically [62,63]. In this section, we construct a practical and flexible inverse sampling framework based on the following key components:
- Numerical inversion of the characteristic function using the Enhanced Fast Fractional Fourier Transform (FRFT) algorithm [21];
- Construction of a high-resolution approximate GTS cumulative distribution function (CDF) on a discrete grid;
- Efficient inversion of the CDF using interpolation based on a fourth-degree polynomial approximation;
- Validation through simulation of the daily returns for Bitcoin, Ethereum, the S&P 500 index, and the SPY ETF.
We recall the characteristic exponent of the GTS distribution in Theorem 1:
The Fourier Transform () and the density function (f) of the GTS process Y can be written as follows:
and
7.1. Fast FRFT and Composite Newton–Cotes Quadrature Rules
The conventional Fast Fourier Transform (FFT) algorithm is widely used to compute discrete convolutions, Discrete Fourier Transforms (DFTs) of sparse sequence, and to perform high-resolution trigonometric interpolation [64,65].
We assume that in (58) is zero outside the interval ; is the step size of the M input values of , defined by for . Similarly, is the step size of the M output values of , defined by with .
By choosing the step size on the input side and the step size in the output side, we fix the FRFT parameter and compute the density function f (59) at [27].
We have
where is the FRFT setup on the M-long sequence .
The numerical integration of functions, also called a Direct Integration Method, is another method to evaluate the inverse Fourier integrals in (59). One of the sophisticated procedures is the Newton–Cotes rule, where the interval is approximated by some interpolating polynomials, usually in Lagrange form. See [28,47,48] for further development.
We assume ; is the step size of the m input values , defined by for and . Similarly, the output values of are defined by with , and , as follows:
where is the weight. See [30,45,46] for further details on the weight computation.
For , the implementation of the composite Newton–Cote’s rule provides great accuracy. The error analysis [46] shows that the global error is .
7.2. Enhanced Fast FRFT Scheme: Composite of Fast FRFT
The Enhanced Fast FRFT algorithm improves the accuracy of the one-dimensional Fractional Fourier Transform (FRFT) by leveraging closed Newton–Cotes quadrature rules. Using the weights derived from the composite Newton–Cotes rules of order QN, we demonstrate that the FRFT of a QN-long weighted sequence can be expressed as two composites of FRFTs [21].
7.2.1. Composite of FRFTs: FRFT of Q-Long Weighted Sequence and FRFT of N-Long Sequence
We assume that is zero outside the interval , and is the step size of the M input values , defined by for and . Similarly, the output values of is defined by for , and . We assume that is zero outside the interval , , , and is the step size of the m input values , defined by for and . Similarly, the output values of are defined on for , , and .
is the approximation of and Equation (62) becomes
where .
7.2.2. Composite of FRFTs: FRFT of N-Long Sequence and FRFT of Q-Long Weighted Sequence
is the approximation of and Equation (62) becomes
where .
Additional methodological details can be found in [21].
The numerical computation of (63) and (65) in Figure 12 shows that the composite FRFTs in (64) and (66) are equal not only algebraically but also numerically.
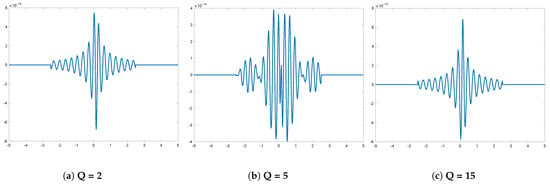
Figure 12.
VG* probability density error ().
7.3. Simulation via the Characteristic Function
The GTS distribution lacks a closed-form probability density function (58), making direct sampling challenging. However, we know the closed form of the Fourier Transform of the density function, (58), and the relationship in (69) provides the Fourier Transform of the cumulative distribution function, . The GTS distribution function, in (70), was computed from the inverse of the Fourier Transform of the cumulative distribution ():
See Appendix A in [27] for (70) proof.
Theorem 9.
Let a cumulative probability function be at least four times continuously differentiable and let be a sample of on a sequence of evenly spaced input values , with . We also consider , a quantile defined by , with and . There exists a unique value, , and , , , , coefficients such that y is a solution of the polynomial equation of degree 4 (71):
The quantile () can be written as follows:
Refer to [25] for the proof of Theorem 9.
Given the sample of a cumulative probability function , Algorithm 6 outlines the inverse transform sampling method.
| Algorithm 6 Inverse sampling for a discrete distribution. |
|
The sampling of daily returns for Bitcoin, Ethereum, the S&P 500 index, and the SPY ETF was performed using the inverse sampling Algorithm 6. Empirical quantiles were computed to construct the Q–Q plots as shown in Figure 13b and Figure 14b.
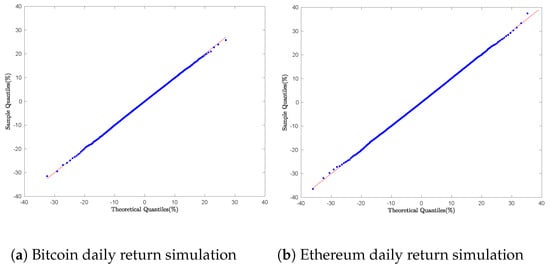
Figure 13.
Cryptocurrency daily return simulation: Q-Q Plot with Algorithm 6.
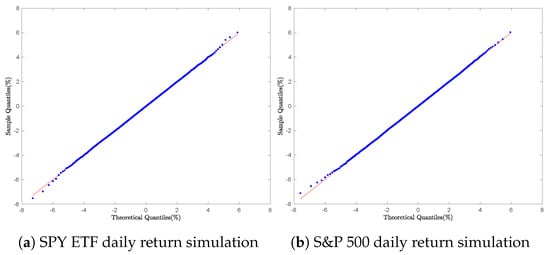
Figure 14.
Equity daily return simulation: Q-Q Plot with Algorithm 6.
Graphically, Figure 13a,b and Figure 14a,b. display nearly perfect straight-line relationships; the plotted quantile points fall right on the 45° diagonal. This tight alignment clearly indicates that the simulated samples match the assumed GTS distributions for each asset. In other words, the fit is so accurate that it rules out any meaningful effects from heavy tails or skewness.
The Enhanced FRFT-based inversion sampling method: leveraging the Fast Fractional Fourier Transform (FRFT) combined with high-order Newton–Cotes quadrature rules, this method utilizes the characteristic function to generate highly accurate density estimates for Generalized Tempered Stable (GTS) distributions. This approach achieves
- Superior numerical stability and improved tail accuracy, especially in the presence of heavy-tailed and asymmetric behavior;
- Elimination of truncation and rejection sampling, thereby avoiding common sources of bias and computational inefficiencies inherent in alternative approaches;
- Consistent outperformance relative to existing methods in terms of both theoretical robustness and computational efficiency.
Empirical evaluations confirm the method’s robustness across a range of heavy-tailed and asymmetric distributions, making it particularly well-suited for applications in financial modeling and risk analysis.
8. Goodness-of-Fit Analysis
In addition to the graphical assessment provided by the Q–Q plot, we reinforce our analysis through formal statistical validation using the Kolmogorov–Smirnov (K–S) and Anderson–Darling goodness-of-fit tests. These tests quantitatively evaluate the alignment between the empirical return data and the GTS distribution. By computing test statistics and corresponding p-values, they help determine whether the observed deviations are sufficiently small to consider the GTS model a plausible generator of the return data.
8.1. Kolmogorov–Smirnov (KS) Test
Given a sample of daily returns of size m, and the corresponding empirical cumulative distribution function for each financial asset, the Kolmogorov–Smirnov (KS) test is performed to assess the goodness-of-fit. The null hypothesis assumes that the sample is drawn from the GTS distribution with cumulative distribution function . To carry out the test, the theoretical distribution function must be computed explicitly. The two-sided KS goodness-of-fit statistic is defined as
The distribution of Kolmogorov’s goodness-of-fit statistic, , has been extensively studied in the statistical literature. It has been established by Massey [66] that the distribution of is independent of the underlying theoretical cumulative distribution function , provided the null hypothesis holds, that is, the data sample is drawn from a continuous distribution. Extensions to discrete, mixed, and discontinuous distributions have also been addressed in more recent work [67].
Under the null hypothesis , it was first shown by Kolmogorov [68] and later refined by Smirnov [69], that the asymptotic distribution of the scaled test statistic converges to the so-called Kolmogorov distribution as the sample size . The cumulative distribution function (CDF) of this limiting distribution is given by the series expansion,
where the first expression is the classical Kolmogorov series [68], and the second form is derived via the transformation of Jacobi theta functions [70].
As illustrated in Figure 15, the distribution of the asymptotic Kolmogorov statistic is positively skewed. Marsaglia et al. [70] further analyzed its moments, showing that the mean and standard deviation of this distribution are given by
At risk level, the risk threshold () corresponds to the area in the shaded region under the probability density function.
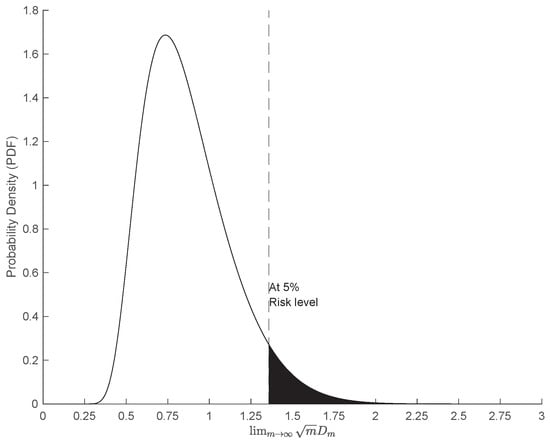
Figure 15.
Asymptotic statistic () PDF.
The KS test is one of the most widely used goodness-of-fit tests based on the empirical distribution function (EDF). It provides a non-parametric method for testing whether a sample comes from a specified continuous distribution. Comprehensive comparisons and applications of EDF-based statistics, including the KS test, can be found in [71,72,73].
To evaluate the test, the p-value associated with the observed KS statistic, , is calculated using the asymptotic distribution defined in Equation (74). More precisely, the p-value can be expressed as follows:
Here, the p-value represents the probability of observing a test statistic as extreme as, or more extreme than, , under the assumption that the null hypothesis is true. In the context of goodness-of-fit testing, a small p-value (less than 5%) indicates that the empirical distribution deviates significantly from the theoretical distribution , casting doubt on the validity of .
The value represents the observed realization of the KS test statistic , computed from the empirical sample . Following the method described in [74], the estimator is defined as
To illustrate the computation, consider the SSR method to sample a Bitcoin (BTC) daily return. KS statistics and the p-values are provided as follows:
The p-value of 57% suggests that the null hypothesis , that the data follow the theoretical GTS distribution, cannot be rejected at conventional significance levels.
Similar calculations were carried out for the financial asset and the sampling technique. The resulting KS statistics , and their corresponding p-values are summarized in Table 6. The KS test results show that the FRFT-based inversion method performed the best, with high p-values (63–99%) across all assets (Bitcoin, Ethereum, S&P 500, SPY ETF), indicating an excellent distributional fit. The Two-Dimensional Single Rejection method showed moderate performance, with p-values ranging from 41% to 72%, while the Inverse Tail Integral approach exhibits greater variability, with p-values ranging from 17% to 72%. In contrast, both the Double Rejection and Shot Noise Representation methods perform poorly, with maximum p-values of just 0.008 and 0.455, respectively, failing to adequately capture the distributional properties. The Standard Stable Rejection method, while acceptable for cryptocurrencies (with p-values ranging from 0.411 to 0.570), proves computationally impractical for equity assets. The findings suggest that Fourier-based methods outperform traditional rejection sampling approaches in both statistical accuracy and computational robustness for Tempered Stable distributions.
Table 6.
Kolmogorov–Smirnov test results for different sampling methods.
8.2. Anderson–Darling Test
The Anderson–Darling (AD) test [71,75,76] is a widely used goodness-of-fit test that assesses whether the sample distribution aligns with a specified theoretical distribution. This test belongs to the family of quadratic EDF statistics [72,73], which are designed to quantify the discrepancy between the EDF and the hypothesized CDF. It is mathematically defined as
where m is the sample size, the weighting function, and the empirical distribution function defined on the sample size m.
When the weighting function is , the statistic in Equation (79) becomes the Cramér–von Mises statistic [77]. In contrast, the Anderson–Darling statistic [78] is derived by choosing the weighting function , where is the hypothesized cumulative distribution function. The key difference between the two statistics lies in the weighting applied to the data. Specifically, the Anderson–Darling (AD) statistic places more weight on the tails of the distribution, making it more sensitive to deviations in the extreme values compared to the Cramér–von Mises statistic, which treats the distribution more uniformly across the entire range. The AD statistic is mathematically defined as
It can be shown that the asymptotic distribution of the AD statistic, , is independent of the theoretical distribution under the null hypothesis. The asymptotic distribution [79,80,81] is defined as follows:
As shown in Figure 16, the asymptotic distribution of the Anderson–Darling statistic, , is positively skewed, with a mean and standard deviation [76,82] defined as follows:
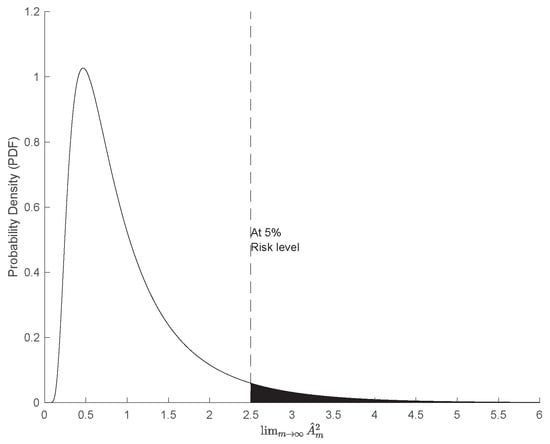
Figure 16.
Asymptotic Anderson–Darling (AD) statistic () PDF.
At a 5% risk level, the associated risk threshold () corresponds to the area in the shaded region under the probability density function. The p-value of the test statistic, , is defined as follows:
To compute the AD statistic, , in Equation (80), the sample of daily returns of size m is arranged in ascending order:
The Anderson–Darling statistic [80] is then computed as follows:
For each financial asset, and each sampling method, the AD statistic, as defined in Equation (84), is computed along with the corresponding p-value statistic, as shown in Table 7. The AD test results show performance differences among sampling methods. The FRFT-based inversion method leads, with p-values exceeding 94% for Bitcoin, Ethereum, and the S&P 500, and 54% for the SPY ETF, demonstrating unmatched accuracy in GTS distributions. The Inverse Tail Integral method appears promising for Ethereum (97% p-value) but underperforms elsewhere (p-values between 43% and 49%). The Two-Dimensional Single Rejection method yields modest results (p-values from 55% to 71%), while the Standard Stable Rejection method is mostly effective with cryptocurrencies (74% to 76%). Both the Double Rejection and Shot Noise methods fail, with 0% p-values for most assets. Like the KS test, the AD results emphasize the FRFT method as the most reliable for capturing heavy-tailed behavior in financial data.
Table 7.
Anderson–Darling test results for different sampling methods.
9. Conclusions
This paper addressed the challenge of simulating random variates from the Generalized Tempered Stable (GTS) distribution, a flexible framework for modeling heavy-tailed data. While GTS models are theoretically powerful, their lack of closed-form densities has limited practical simulation. We provided a comprehensive and systematic comparison of existing simulation techniques, spanning rejection-based algorithms, series representations, and numerical inversion methods.
Our findings demonstrate that classical rejection algorithms, such as the Standard Stable Rejection and Double Rejection methods, have theoretical value. However, they exhibit poor performance under extreme parameter conditions (). While enhanced variants like the Double Rejection method demonstrate improved efficiency, they still fall short in accurately capturing tail behavior—a critical requirement for risk-sensitive financial applications. Similarly, the series representation techniques, such as the Shot Noise series representation, provide valuable theoretical insights into GTS processes but exhibit numerical instability when dealing with extreme parameter values, limiting their practical utility.
The comparative evaluation identifies three particularly effective methods: the Two-Dimensional Single Rejection technique, the inverse Lévy measure series representation, and the Fast Fractional Fourier Transform (FRFT)-based inversion approach. Among these methods, the Enhanced Fast Fractional Fourier Transform (FRFT)-based inversion method, consistently achieves the highest accuracy in goodness-of-fit tests (Kolmogorov–Smirnov and Anderson–Darling) across all tested assets—Bitcoin, Ethereum, the S&P 500, and the SPY ETF—while maintaining competitive computational efficiency. This positions the FRFT approach as the most reliable and versatile option for GTS simulation, particularly in risk-sensitive financial applications where accurate tail modeling is essential. Our research contributes to the literature in three main ways. First, it offers a unified and systematic comparison of available GTS simulation methods, clearly articulating their respective strengths and limitations. Second, it introduces an enhanced FRFT-based algorithm that sets a new standard for accurate and efficient GTS simulations. Third, it highlights practical implications for financial modeling, where capturing tail risk with high fidelity is essential.
The development of efficient simulation methods for multivariate GTS distributions remains a crucial challenge. Future research should focus on extending the FRFT approach to higher dimensions while preserving computational efficiency. This advancement would facilitate more realistic modeling of portfolio risk and the dependence structures among financial assets.
Author Contributions
Conceptualization, A.N. and D.M.; methodology, A.N. and D.M.; visualization, A.N. and D.M.; resources, A.N. and D.M.; and writing—original draft and editing, A.N. and D.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
- Detailed MATLAB R2023b code and implementation specifics for Algorithms 1–6, which underpin the results presented in this paper, are available from the authors via email upon request. The code will be provided promptly to individuals or institutions providing a clear and reasonable justification for their intended use.
Acknowledgments
The authors would like to thank the University of Limpopo for supporting the publication of this study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Cont, R.; Tankov, P. Financial Modelling with Jump Processes; Chapman & Hall/CRC: Boca Raton, FL, USA, 2004. [Google Scholar]
- Samorodnitsky, G.; Taqqu, M.S. Stable Non-Gaussian Random Processes: Stochastic Models with Infinite Variance; CRC Press: New York, NY, USA, 1994. [Google Scholar]
- Nzokem, A.H. Comparing Bitcoin and Ethereum Tail Behavior via QQ Analysis of Cryptocurrency Returns. arXiv 2025, arXiv:2507.01983. [Google Scholar]
- Nolan, J.P. Univariate Stable Distributions: Models for Heavy Tailed Data; Springer Series in Operations Research and Financial Engineering: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Rosiński, J. Tempering Stable Processes. Stoch. Process. Their Appl. 2007, 117, 677–707. [Google Scholar] [CrossRef]
- Küchler, U.; Tappe, S. Tempered Stable Distributions and Processes. Stoch. Process. Their Appl. 2013, 123, 4256–4293. [Google Scholar] [CrossRef]
- Carr, P.; Geman, H.; Madan, D.B.; Yor, M. Stochastic Volatility for Lévy Processes. Math. Financ. 2003, 13, 345–382. [Google Scholar] [CrossRef]
- Rachev, S.T.; Kim, Y.S.; Bianchi, M.L.; Fabozzi, F.J. Stable and Tempered Stable Distributions. In Financial Models with Lévy Processes and Volatility Clustering; The Frank J. Fabozzi Series; Rachev, S.T., Kim, Y.S., Bianchi, M.L., Fabozzi, F.J., Eds.; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 187, pp. 57–85. [Google Scholar] [CrossRef]
- Boyarchenko, S.I.; Levendorskiĭ, S.Z. Non-Gaussian Merton-Black-Scholes Theory; Advanced Series on Statistical Science & Applied Probability; World Scientific: Singapore, 2002; Volume 9. [Google Scholar] [CrossRef]
- Küchler, U.; Tappe, S. Bilateral Gamma Distributions and Processes in Financial Mathematics. Stoch. Process. Their Appl. 2008, 118, 261–283. [Google Scholar] [CrossRef]
- Nzokem, A.H. Self-Decomposable Laws Associated with General Tempered Stable (GTS) Distribution and Their Simulation Applications. arXiv 2024, arXiv:2405.16614. [Google Scholar] [CrossRef]
- Devroye, L. Random Variate Generation for Exponentially and Polynomially Tilted Stable Distributions. ACM Trans. Model. Comput. Simul. 2009, 19, 1–20. [Google Scholar] [CrossRef]
- Glasserman, P. Generating Random Numbers and Random Variables. In Monte Carlo Methods in Financial Engineering; Springer: New York, NY, USA, 2003; pp. 39–77. [Google Scholar] [CrossRef]
- Qu, Y.; Dassios, A.; Zhao, H. Random Variate Generation for Exponential and Gamma Tilted Stable Distributions. ACM Trans. Model. Comput. Simul. 2021, 31, 1–21. [Google Scholar] [CrossRef]
- Dassios, A.; Qu, Y.; Zhao, H. Exact simulation for a class of tempered stable and related distributions. ACM Trans. Model. Comput. Simul. (TOMACS) 2018, 28, 1–21. [Google Scholar] [CrossRef]
- Hofert, M. Sampling Exponentially Tilted Stable Distributions. ACM Trans. Model. Comput. Simul. 2011, 22, 3. [Google Scholar] [CrossRef]
- Nzokem, A.H.; Maposa, D. Exact Simulation for General Tempered Stable Random Variates: Review and Empirical Analysis. In Proceedings of the 2025 International Conference on Artificial Intelligence, Computer, Data Sciences and Applications (ACDSA), Antalya, Turkiye, 7–9 August 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 1–6. [Google Scholar] [CrossRef]
- Rosiński, J. Tempered Stable Processes. In Proceedings of the Second MaPhySto Conference on Lévy Processes: Theory and Applications, Aarhus, Denmark, 21–25 January 2002; Volume 22, pp. 215–220. Available online: http://www.maphysto.dk/publications/MPS-misc/2002/22.pdf (accessed on 20 May 2025).
- Rosiński, J. Series Representations of Lévy Processes from the Perspective of Point Processes. In Lévy Processes: Theory and Applications; Barndorff-Nielsen, O.E., Resnick, S.I., Mikosch, T., Eds.; Birkhäuser: Boston, MA, USA, 2001; pp. 401–415. [Google Scholar] [CrossRef]
- Shephard, N. From Characteristic Function to Distribution Function: A Simple Framework for the Theory. Econom. Theory 1991, 7, 519–529. [Google Scholar] [CrossRef]
- Nzokem, A.; Maposa, D.; Seimela, A.M. Enhanced Fast Fractional Fourier Transform (FRFT) Scheme Based on Closed Newton-Cotes Rules. Axioms 2025, 14, 543. [Google Scholar] [CrossRef]
- Kyprianou, A.E. Fluctuations of Lévy Processes with Applications: Introductory Lectures; Universitext; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Sato, K.I. Basic Results on Lévy Processes. In Lévy Processes: Theory and Applications; Barndorff-Nielsen, O.E., Mikosch, T., Resnick, S.I., Eds.; Birkhäuser: Boston, MA, USA, 2001; pp. 1–37. [Google Scholar] [CrossRef]
- Tankov, P. Financial Modeling with Lévy Processes: Lecture Notes. 2010. Available online: https://cel.hal.science/cel-00665021v1 (accessed on 20 May 2025).
- Nzokem, A.H.; Maposa, D. Bitcoin versus S&P 500 Index: Return and Risk Analysis. Math. Comput. Appl. 2024, 29, 44. [Google Scholar] [CrossRef]
- Nzokem, A.; Maposa, D. Fitting the Seven-Parameter Generalized Tempered Stable Distribution to Financial Data. J. Risk Financ. Manag. 2024, 17, 531. [Google Scholar] [CrossRef]
- Nzokem, A.H. Fitting Infinitely Divisible Distribution: Case of Gamma-Variance Model. arXiv 2021, arXiv:2104.07580. [Google Scholar] [CrossRef]
- Nzokem, A.H. Five-Parameter Variance-Gamma Process: Lévy versus Probability Density. AIP Conf. Proc. 2024, 3005, 020030. [Google Scholar] [CrossRef]
- Nzokem, A.H.; Montshiwa, V.T. Fitting Generalized Tempered Stable Distribution: Fractional Fourier Transform (FRFT) Approach. arXiv 2022, arXiv:2205.00586. [Google Scholar] [CrossRef]
- Nzokem, A.H. Gamma Variance Model: Fractional Fourier Transform (FRFT). J. Physics Conf. Ser. 2021, 2090, 012094. [Google Scholar] [CrossRef]
- Nzokem, A.H. Pricing European options under stochastic volatility models: Case of five-parameter variance-gamma process. J. Risk Financ. Manag. 2023, 16, 55. [Google Scholar] [CrossRef]
- Uchaikin, V.V.; Zolotarev, V.M. Chance and Stability: Stable Distributions and their Applications; Modern Probability and Statistics; De Gruyter: Berlin, Germany, 2011. [Google Scholar]
- Zolotarev, V.M. One-Dimensional Stable Distributions; American Mathematical Society: Providence, RI, USA, 1986; Volume 65. [Google Scholar]
- Feller, W. An Introduction to Probability Theory and Its Applications, 2nd ed.; John Wiley & Sons: New York, NY, USA, 1971; Volume 2. [Google Scholar]
- Kring, S.; Rachev, S.T.; Höchstötter, M.; Fabozzi, F.J. Estimation of α-stable sub-Gaussian distributions for asset returns. In Risk Assessment: Decisions in Banking and Finance; Springer: Berlin/Heidelberg, Germany, 2009; pp. 111–152. [Google Scholar]
- Zolotarev, V.M. On the Representation of Stable Laws by Integrals. Tr. Mat. Instituta Im. V. A. Steklova 1964, 71, 46–50. [Google Scholar]
- Borak, S.; Härdle, W.; Weron, R. Stable Distributions. In Statistical Tools for Finance and Insurance; Springer: Berlin/Heidelberg, Germany, 2005; pp. 21–44. [Google Scholar] [CrossRef]
- Box, G.E.P.; Muller, M.E. A Note on the Generation of Random Normal Deviates. Ann. Math. Stat. 1958, 29, 610–611. [Google Scholar] [CrossRef]
- Chambers, J.M.; Mallows, C.L.; Stuck, B.W. A Method for Simulating Stable Random Variables. J. Am. Stat. Assoc. 1976, 71, 340–344. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O.E.; Shephard, N. Financial Volatility, Lévy Processes and Power Variation. 2002. Available online: https://www.olsendata.com/data_products/client_papers/papers/200206-NielsenShephard-FinVolLevyProcessPowerVar.pdf (accessed on 20 May 2025).
- Brix, A. Generalized Gamma Measures and Shot-Noise Cox Processes. Adv. Appl. Probab. 1999, 31, 929–953. [Google Scholar] [CrossRef]
- Ripley, B.D. Stochastic Simulation; John Wiley & Sons: New York, NY, USA, 2009. [Google Scholar]
- Hofert, M. Efficiently Sampling Nested Archimedean Copulas. Comput. Stat. Data Anal. 2011, 55, 57–70. [Google Scholar] [CrossRef]
- Cerquetti, A. A Note on Bayesian Nonparametric Priors Derived from Exponentially Tilted Poisson-Kingman Models. Stat. Probab. Lett. 2007, 77, 1705–1711. [Google Scholar] [CrossRef]
- Nzokem, A.H. Numerical Solution of a Gamma-Integral Equation Using a Higher Order Composite Newton-Cotes Formulas. J. Phys. Conf. Ser. 2021, 2084, 012019. [Google Scholar] [CrossRef]
- Nzokem, A.H. Stochastic and Renewal Methods Applied to Epidemic Models. Ph.D. Thesis, York University, Toronto, ON, Canada, 2020. [Google Scholar]
- Nzokem, A.H. European Option Pricing Under Generalized Tempered Stable Process: Empirical Analysis. arXiv 2023, arXiv:2304.06060. [Google Scholar] [CrossRef]
- Nzokem, A.H.; Montshiwa, V.T. The Ornstein-Uhlenbeck Process and Variance Gamma Process: Parameter Estimation and Simulations. Thai J. Math. 2023, 160–168. [Google Scholar]
- Loy, A.; Follett, L.; Hofmann, H. Variations of Q-Q Plots: The Power of Our Eyes! Am. Stat. 2016, 70, 202–214. [Google Scholar] [CrossRef]
- Thode, H.C. Testing for Normality; Statistics, Textbooks and Monographs; CRC Press: New York, NY, USA, 2002; Volume 164. [Google Scholar]
- Wang, M.C.; Bushman, B.J. Using the Normal Quantile Plot to Explore Meta-Analytic Data Sets. Psychol. Methods 1998, 3, 46–54. [Google Scholar] [CrossRef]
- Wilk, M.B.; Gnanadesikan, R. Probability Plotting Methods for the Analysis of Data. Biometrika 1968, 55, 1–17. [Google Scholar] [CrossRef]
- Dodge, Y. Q-Q Plot (Quantile to Quantile Plot). In The Concise Encyclopedia of Statistics; Springer: New York, NY, USA, 2008; pp. 437–439. [Google Scholar] [CrossRef]
- Rachev, S.T. Tempered Stable Models in Finance: Theory and Applications. Ph.D. Thesis, University of Bergamo, Bergamo, Italy, 2009. [Google Scholar]
- Ivanenko, D.; Knopova, V.; Platonov, D. On Approximation of Some Lévy Processes. Austrian J. Stat. 2025, 54, 177–199. [Google Scholar] [CrossRef]
- Kallenberg, O. Foundations of Modern Probability; Springer: New York, NY, USA, 1997; Volume 2. [Google Scholar]
- Ferguson, T.S.; Klass, M.J. A Representation of Independent Increment Processes Without Gaussian Components. Ann. Math. Stat. 1972, 43, 1634–1643. [Google Scholar] [CrossRef]
- Nzokem, A. Simulation of Generalized Tempered Stable (GTS) Random Variates via Series Representations: A Case Study of Bitcoin and Ethereum. Preprint 2025. [Google Scholar] [CrossRef]
- Yuan, S.; Kawai, R. Numerical aspects of shot noise representation of infinitely divisible laws and related processes. Probab. Surv. 2021, 18, 201–271. [Google Scholar] [CrossRef]
- Godsill, S.; Kontoyiannis, I.; Tapia Costa, M. Generalised shot-noise representations of stochastic systems driven by non-Gaussian Lévy processes. Adv. Appl. Probab. 2024, 56, 1215–1250. [Google Scholar] [CrossRef]
- Gil-Pelaez, J. Note on the Inversion Theorem. Biometrika 1951, 38, 481–482. [Google Scholar] [CrossRef]
- Carr, P.; Madan, D.B. Option Valuation Using the Fast Fourier Transform. J. Comput. Financ. 1999, 2, 61–73. [Google Scholar] [CrossRef]
- Fang, F.; Oosterlee, C.W. A Novel Pricing Method for European Options Based on Fourier-Cosine Series Expansions. SIAM J. Sci. Comput. 2008, 31, 826–848. [Google Scholar] [CrossRef]
- Bailey, D.H.; Swarztrauber, P.N. The Fractional Fourier Transform and Applications. SIAM Rev. 1991, 33, 389–404. [Google Scholar] [CrossRef]
- Bailey, D.H.; Swarztrauber, P.N. A Fast Method for the Numerical Evaluation of Continuous Fourier and Laplace Transforms. SIAM J. Sci. Comput. 1994, 15, 1105–1110. [Google Scholar] [CrossRef]
- Massey, F.J. The Kolmogorov-Smirnov Test for Goodness of Fit. J. Am. Stat. Assoc. 1951, 46, 68–78. [Google Scholar] [CrossRef]
- Dimitrova, D.S.; Kaishev, V.K.; Tan, S. Computing the Kolmogorov-Smirnov Distribution When the Underlying CDF is Purely Discrete, Mixed, or Continuous. J. Stat. Softw. 2020, 95, 1–42. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Sulla Determinazione Empirica di una Legge di Distribuzione. G. Dell’Istituto Ital. Degli Attuari 1933, 4, 83–91. [Google Scholar]
- Smirnov, N.V. Table for Estimating the Goodness of Fit of Empirical Distributions. Ann. Math. Stat. 1948, 19, 279–281. [Google Scholar] [CrossRef]
- Marsaglia, G.; Tsang, W.W.; Wang, J. Evaluating Kolmogorov’s Distribution. J. Stat. Softw. 2003, 8, 1–4. [Google Scholar] [CrossRef]
- D’Agostino, R.B.; Stephens, M.A. Goodness-of-Fit Techniques; Marcel Dekker: New York, NY, USA, 1986. [Google Scholar]
- Stephens, M.A. EDF Statistics for Goodness of Fit and Some Comparisons. J. Am. Stat. Assoc. 1974, 69, 730–737. [Google Scholar] [CrossRef]
- Shorack, G.R.; Wellner, J.A. Empirical Processes with Applications to Statistics; John Wiley & Sons: New York, NY, USA, 1986. [Google Scholar]
- Krysicki, W.; Bartos, J.; Dyczka, W.; Królikowska, K.; Wasilewski, M. Rachunek Prawdopodobieństwa i Statystyka Matematyczna w zadaniach; Wydawnictwo Naukowe PWN: Warszawa, Poland, 1999; Volume 2. [Google Scholar]
- Anderson, T.W. Anderson-Darling Test. In The Concise Encyclopedia of Statistics; Dodge, Y., Ed.; Springer: New York, NY, USA, 2008; pp. 12–14. [Google Scholar] [CrossRef]
- Anderson, T.W.; Darling, D.A. A Test of Goodness of Fit. J. Am. Stat. Assoc. 1954, 49, 765–769. [Google Scholar] [CrossRef]
- von Mises, R. Wahrscheinlichkeit, Statistik und Wahrheit; Julius Springer: Berlin/Heidelberg, Germany, 1931; English translation: Probability, Statistics and Truth, Macmillan, 1957. [Google Scholar]
- Anderson, T.W.; Darling, D.A. Asymptotic Theory of Certain “Goodness of Fit” Criteria Based on Stochastic Processes. Ann. Math. Stat. 1952, 23, 193–212. [Google Scholar] [CrossRef]
- Durbin, J. Distribution Theory for Tests Based on the Sample Distribution Function; SIAM: Philadelphia, PA, USA, 1973. [Google Scholar]
- Lewis, P.A.W. Distribution of the Anderson-Darling Statistic. Ann. Math. Stat. 1961, 32, 1118–1124. [Google Scholar] [CrossRef]
- Marsaglia, G.; Marsaglia, J. Evaluating the Anderson-Darling Distribution. J. Stat. Softw. 2004, 9, 1–5. [Google Scholar] [CrossRef]
- Anderson, T.W. Anderson-Darling Tests of Goodness-of-Fit. In International Encyclopedia of Statistical Science; Lovric, M., Ed.; Springer: Berlin/eidelberg, Germany, 2011; pp. 52–54. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).