
A Novel Framework for Mental Illness Detection Leveraging TOPSIS-ModCHI-Based Feature-Driven Randomized Neural Networks


Abstract
1. Introduction
1.1. Research Gaps and Motivations
1.2. Contributions
- Developing a text classifier using RandNN for efficiently categorizing multiclass unbalanced text documents.
- Selecting an optimal set of features for the classifier by utilizing a hybrid TOPSIS-ModCHI-based FS technique.
- Assessing the performance of four RandNNs, including BLS, RVFLN, KRVFLN, and ELM, to determine whether a user exhibits linguistic markers indicative of a specific mental illness by analyzing the user’s posts on social media.
- Addressing mental illness detection as an unbalanced multiclass TC task.
- Analyzing the impact of hidden layer size and activation functions on the overall performance of each RandNN is evaluated by experimenting with various hidden layer sizes and three different activation functions.
2. Literature Review
3. Materials and Methods
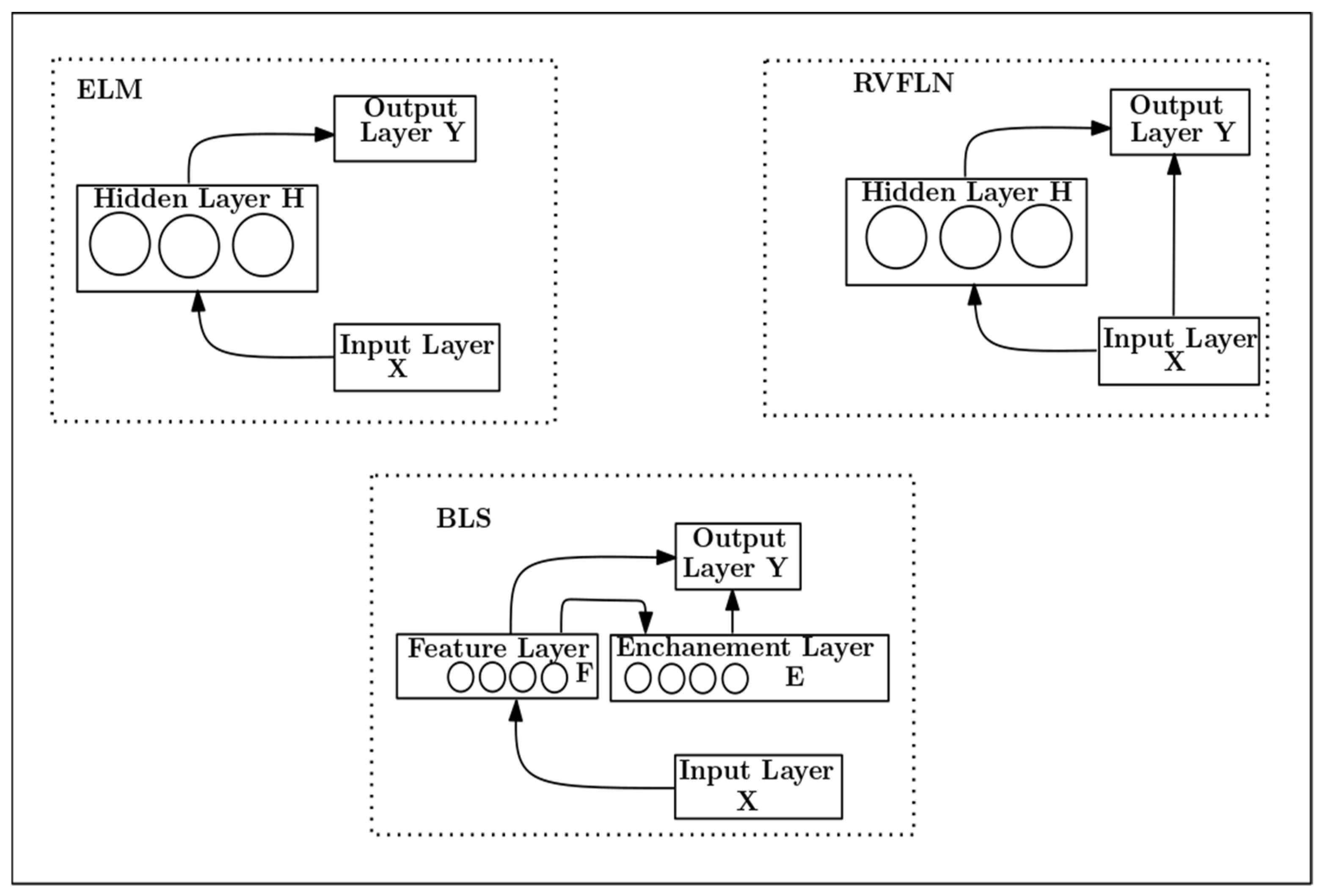
3.1. Randomized Neural Networks
3.1.1. Extreme Learning Machine (ELM)
3.1.2. Random Vector Functional Link Neural Network (RVFLN)
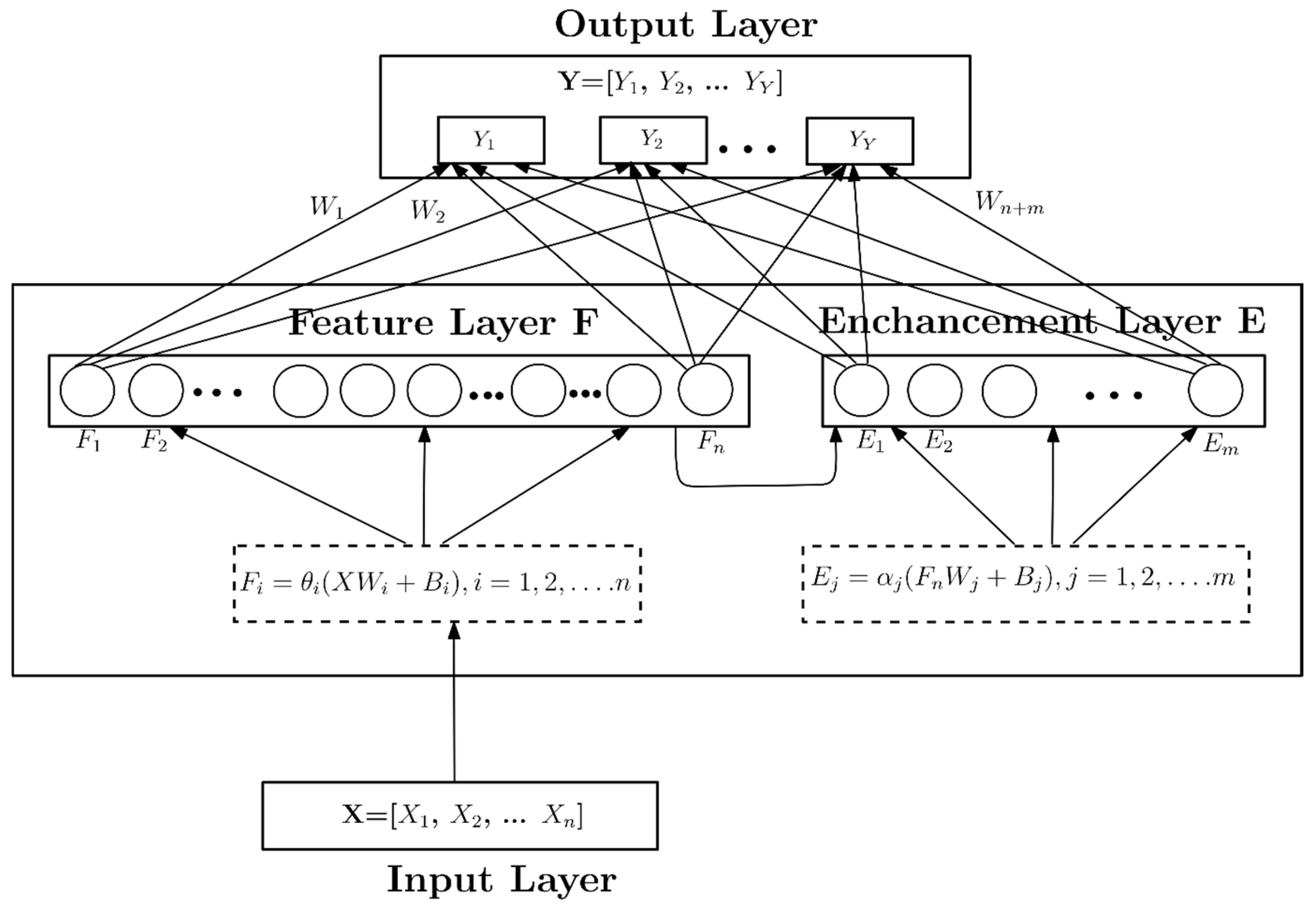
3.1.3. Board Learning System
3.2. Proposed RandNN-Based Text Classification Model Utilizing TOPSIS-ModCHI-Based FS
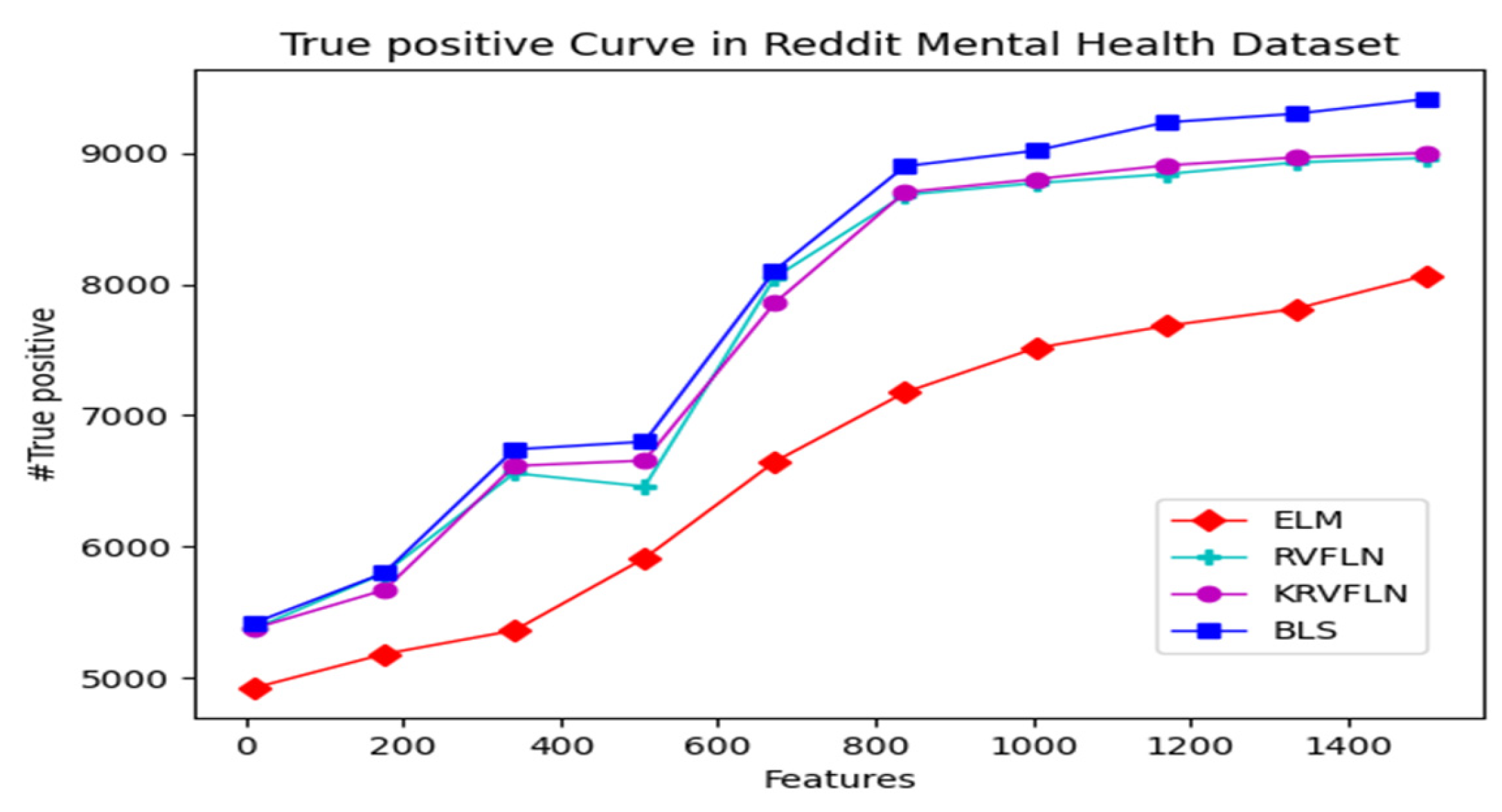
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- WHO. 2021. Available online: https://www-who-int.ezproxy.uio.no/news-room/fact-sheets/detail/suicide (accessed on 10 May 2024).
- Available online: https://www.theguardian.com/society/2021/aug/29/strain-on-mental-health-care-leaves-8m-people-without-help-say-nhs-leaders (accessed on 10 May 2024).
- Giuntini, F.T.; Cazzolato, M.T.; Reis, M.d.J.D.d.; Campbell, A.T.; Traina, A.J.M.; Ueyama, J. A review on recognizing depression in social networks: Challenges and opportunities. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 4713–4729. [Google Scholar] [CrossRef]
- Garg, M. Mental Health Analysis in Social Media Posts: A Survey. Arch. Comput. Methods Eng. 2023, 30, 1819–1842. [Google Scholar] [CrossRef] [PubMed]
- Islam, R.; Kabir, M.A.; Ahmed, A.; Kamal, A.R.M.; Wang, H.; Ulhaq, A. Depression detection from social network data using machine learning techniques. Health Inf. Sci. Syst. 2018, 6, 8. [Google Scholar] [CrossRef] [PubMed]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Detection of depression-related posts in reddit social media forum. IEEE Access 2019, 7, 44883–44893. [Google Scholar] [CrossRef]
- Priya, A.; Garg, S.; Tigga, N.P. Predicting anxiety, depression and stress in modern life using machine learning algorithms. Procedia Comput. Sci. 2020, 167, 1258–1267. [Google Scholar] [CrossRef]
- Zulfiker, S.; Kabir, N.; Biswas, A.A.; Nazneen, T.; Uddin, M.S. An in-depth analysis of machine learning approaches to predict depression. Curr. Res. Behav. Sci. 2021, 2, 100044. [Google Scholar] [CrossRef]
- Priya, S.K.; Karthika, K.P. An embedded feature selection approach for depression classification using short text sequences. Appl. Soft Comput. 2023, 147. [Google Scholar]
- Kim, J.; Lee, J.; Park, E.; Han, J. A deep learning model for detecting mental illness from user content on social media. Sci. Rep. 2020, 10, 11846. [Google Scholar] [CrossRef]
- Li, Z.; Li, W.; Wei, Y.; Gui, G.; Zhang, R.; Liu, H.; Chen, Y.; Jiang, Y. Deep learning based automatic diagnosis of first-episode psychosis, bipolar disorder and healthy controls. Comput. Med Imaging Graph. 2021, 89, 101882. [Google Scholar] [CrossRef]
- Kour, H.; Gupta, M.K. An hybrid deep learning approach for depression prediction from user tweets using feature-rich CNN and bi-directional LSTM. Multimed. Tools Appl. 2022, 81, 23649–23685. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Dysthe, K.K.; Følstad, A.; Brandtzaeg, P.B. Deep learning for prediction of depressive symp-toms in a large textual dataset. Neural Comput. Appl. 2022, 34, 721–744. [Google Scholar] [CrossRef]
- Ang, C.S.; Venkatachala, R. Generalizability of Machine Learning to Categorize Various Mental Illness Using Social Media Activity Patterns. Societies 2023, 13, 117. [Google Scholar] [CrossRef]
- Bhavani, B.H.; Naveen, N.C. An Approach to Determine and Categorize Mental Health Condition using Machine Learning and Deep Learning Models. Eng. Technol. Appl. Sci. Res. 2024, 14, 13780–13786. [Google Scholar] [CrossRef]
- Alkahtani, H.; Aldhyani, T.H.H.; Alqarni, A.A. Artificial Intelligence Models to Predict Disability for Mental Health Disorders. J. Disabil. Res. 2024, 3, 20240022. [Google Scholar] [CrossRef]
- Ezerceli, Ö.; Dehkharghani, R. Mental disorder and suicidal ideation detection from social media using deep neural networks. J. Comput. Soc. Sci. 2024, 7, 2277–2307. [Google Scholar] [CrossRef]
- Revathy, J.S.; Maheswari, N.U.; Sasikala, S.; Venkatesh, R. Automatic diagnosis of mental illness using optimized dynamically stabilized recurrent neural network. Biomed. Signal Process. Control 2024, 95, 106321. [Google Scholar] [CrossRef]
- Dinu, A.; Moldovan, A.C. Automatic detection and classification of mental illnesses from general social media texts. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2021), Online, 1–3 September 2021; pp. 358–366. [Google Scholar]
- Chen, Z.; Yang, R.; Fu, S.; Zong, N.; Liu, H.; Huang, M. Detecting Reddit Users with Depression Using a Hybrid Neural Network SBERT-CNN. In Proceedings of the 2023 IEEE 11th International Conference on Healthcare Informatics (ICHI), Houston, TX, USA, 26–29 June 2023; pp. 193–199. [Google Scholar]
- Chen, C.L.P.; Liu, Z. Broad learning system: An effective and efficient incremental learning system without the need for deep architecture. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 10–24. [Google Scholar] [CrossRef]
- Malik, A.; Gao, R.; Ganaie, M.; Tanveer, M.; Suganthan, P.N. Random vector functional link network: Recent developments, applications, and future directions. Appl. Soft Comput. 2023, 143, 110377. [Google Scholar] [CrossRef]
- Zhang, L.; Suganthan, P.N. A survey of randomized algorithms for training neural networks. Inf. Sci. 2016, 364–365, 146–155. [Google Scholar] [CrossRef]
- Suganthan, P.N.; Katuwal, R. On the origins of randomization-based feedforward neural networks. Appl. Soft Comput. 2021, 105, 107239. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Pao, Y.H.; Park, G.H.; Sobajic, D.J. Learning and generalization characteristics of the random vector functional-link net. Neurocomputing 1994, 6, 163–180. [Google Scholar] [CrossRef]
- Zhang, L.; Suganthan, P.N. A comprehensive evaluation of random vector functional link networks. Inf. Sci. 2016, 367, 1094–1105. [Google Scholar] [CrossRef]
- Liu, Z.; Huang, S.; Jin, W.; Mu, Y. Broad learning system for semi-supervised learning. Neurocomputing 2021, 444, 38–47. [Google Scholar] [CrossRef]
- Chauhan, V.; Tiwari, A. Randomized neural networks for multilabel classification. Appl. Soft Comput. 2022, 115, 108184. [Google Scholar] [CrossRef]
- Behera, S.K.; Dash, R. A novel feature selection technique for enhancing performance of unbalanced text classification problem. Intell. Decis. Technol. 2022, 16, 51–69. [Google Scholar] [CrossRef]
- Behera, S.K.; Dash, R. Performance Enhancement of the Unbalanced Text Classification Problem Through a Modified Chi Square-Based Feature Selection Technique: A Mod-Chi based FS technique. Int. J. Intell. Inf. Technol. (IJIIT) 2022, 18, 1–23. [Google Scholar] [CrossRef]
- Dash, R.; Dash, R.; Rautray, R. Enhancing performance of a LENN based CCFD model with a hybrid TOPSIS-ReliefF based feature selection technique. In Proceedings of the 2022 2nd Odisha International Conference on Electrical Power Engineering, Communication and Computing Technology (ODICON), Bhubaneswar, India, 11–12 November 2022; pp. 1–6. [Google Scholar]
- Zheng, W.; Qian, Y.; Lu, H. Text categorization based on regularization extreme learning machine. Neural Comput. Appl. 2012, 22, 447–456. [Google Scholar] [CrossRef]
- Sabbah, T.; Selamat, A.; Selamat, M.H.; Al-Anzi, F.S.; Viedma, E.H.; Krejcar, O.; Fujita, H. Modified fre-quency-based term weighting schemes for text classification. Appl. Soft Comput. 2017, 58, 193–206. [Google Scholar] [CrossRef]
- Li, M.; Xiao, P.; Zhang, J. Text classification based on ensemble extreme learning machine. arXiv 2018, arXiv:1805.06525. [Google Scholar]
- Behera, S.K.; Dash, R. Performance of ELM using max-min document frequency-based feature selection in multilabeled text classification. In Intelligent and Cloud Computing: Proceedings of ICICC 2019; Springer: Singapore, 2021; Volume 1, pp. 425–433. [Google Scholar]
- Peng, S.; Zeng, R.; Liu, H.; Chen, G.; Wu, R.; Yang, A.; Yu, S. Emotion classification of text based on BERT and broad learning system. In Web and Big Data, Proceedings of the 5th International Joint Conference, APWeb-WAIM 2021, Guangzhou, China, 23–25 August 2021, Proceedings, Part I 5; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 382–396. [Google Scholar]
- Du, J.; Vong, C.-M.; Chen, C.L.P. Novel Efficient RNN and LSTM-Like Architectures: Recurrent and Gated Broad Learning Systems and Their Applications for Text Classification. IEEE Trans. Cybern. 2020, 51, 1586–1597. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Wu, X.; Li, C. Node slicing broad learning system for text classification. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022; pp. 4788–4792. [Google Scholar]
- Low, D.M.; Rumker, L.; Talkar, T.; Torous, J.; Cecchi, G.; Ghosh, S.S. Natural Language Processing Reveals Vulnerable Mental Health Support Groups and Heightened Health Anxiety on Reddit During COVID-19: Observational Study. J. Med Internet Res. 2020, 22, e22635. [Google Scholar] [CrossRef] [PubMed]
- Dietterich, T.G. Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms. Neural Comput 1998, 10, 1895–1923. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Author (Year) | ML Model | FS Technique | Dataset | Type of Mental Illness Addressed | Evaluation Metrics |
|---|---|---|---|---|---|---|
| [5] | Islam et al. (2018) | DT, KNN, SVM, ensemble | --- | Facebook data | Depression | Accuracy |
| [6] | Tadesse et al., (2019) | MLP, LR, SVM, RF | LDA | Depression | Accuracy, F1-score | |
| [7] | Priya et al., (2020) | NB, DT, RF, SVM, KNN | --- | DASS-21 | Anxiety, depression, stress | Accuracy, precision, recall, specificity, F1-score |
| [8] | Zulfiker et al., (2021) | KNN, AdaBoost, Gradient boosting (GB), Extreme GB, Bagging, Weighted voting | SelectKBest, mRMR, Boruta | Self-prepared dataset | Depression | Sensitivity, specificity, precision, F1-score, AUC |
| [9] | Priya & Karthika, (2023) | NB, SVM | Hybrid FS using Chi and Whale Optimization | Four bench mark short text datasets such as Stack Overflow, Short Messaging Service (SMS), Sentiment Labeled Sentences (SLS), and Sentiment 140 dataset | Depression | Accuracy, F1-scores, sensitivity |
| [10] | Kim et al., (2020) | CNN, XGBoost | --- | Depression, anxiety, bipolar, borderline personality disorder, schizophrenia, autism | Accuracy, precision, recall, F1-score | |
| [12] | Kour & Gupta (2022) | CNN-biLSTM, CNN, RNN | Embedding layer of CNN | Twitter data | Depression | Precision, recall, F1-score, accuracy, specificity, AUC |
| [13] | Uddin et al., (2022) | LSTM, LR, DT, SVM, CNN | LDA | Young user’s text data obtained from ung.no Norwegian | Depression | Precision, recall, F1-score, support |
| [14] | Ang & Venkatachala, (2023) | CNN, XGBoost | --- | Reddit, | Depression, anxiety, bipolar, BPD, schizophrenia, autism | Precision, recall, F1-score, accuracy |
| [15] | Bhavani & Naveen, (2024) | LSTM, KNN, RF, SVM, LR, AdaBoost, MLP | --- | Self-prepared dataset through questionaries | Stress | Accuracy, precision, recall, F1-score |
| [16] | Alkahtani (2024) | LSTM, KNN, RF | --- | Mental disorder dataset collected from Kaggle | ADHD, ASD, loneliness, MDD, OCD, PDD, PTSD, anxiety, BD, eating disorder, psychotic depression, and sleeping disorder | Accuracy, precision, recall, F1-score |
| [17] | Ezerceli & Dehkharghani, (2024) | RNN, CNN, LSTM, BERT, SVM, NB, RF, LR, DT | --- | Depression/suicidal ideation | AUC, precision, recall F1-score | |
| [18] | Revathy et al., (2024) | Dynamically Stabilized RNN, CNN, SVM | Siberian tiger optimization algorithm | OSMI dataset | Mentally ill for getting treatment or not | F1-score, accuracy |
| [19] | Dinu & Moldovan, (2021) | BERT, XLNet, RoBERT | NB | Schizophrenia, bipolar, depression, anxiety, obsessive-compulsive disorders, eating disorders, autism, post-traumatic stress disorder, attention-deficit/hyperactivity disorder | Precision, Recall, F1-score | |
| [20] | Chen et al., (2023) | SBERT-CNN, CNN, LSTM, BERT, RoBERT, XLNET, LSVM, LR, XGBoost | --- | SMHD dataset including Reddit posts | Depression | Accuracy, Precision, Recall, F1-score |
| Our approach | BLS, ELM, RVFLN, K-RVFLN | TOPSIS-ModCHI | Depression, suicide, anxiety, schizophrenia, autism, PSTD, alcoholism, bipolar, neutral | Pmicro, Rmicro, Fmicro, Haming loss (HL), true positive rate | ||
| Reference | Author (Year) | Type of RandNN | FS Technique | Dataset (Number of Classes) |
|---|---|---|---|---|
| [29] | Chauhan & Tiwari (2022) | RVFLN, KRVFLN, BLS, Fuzzy BLS | --- | Bibtex (159), Emotions (6), Scene (6) |
| [31] | Behera & Dash (2022) | RVFLN, LSVM, RF, DT, MLKNN | ModCHI, Chi, MI, Tf-idf | Reuters-21578 (90) 20 Newsgroups (20) |
| [33] | Zheng et al. (2013) | RELM, ELM, BP,SVM | Singular value decomposition applied on TFIDF matrix | Reuters-21578 (10), WebKB (4) |
| [34] | Sabbah et al. (2017) | SVM, KNN,ELM, NB | Modified frequency-based term weighting scheme | Reuters-21578 (8) 20 Newsgroups (20), WebKB (7) |
| [35] | Li et al., (2018) | AE1WELM, Weighted ELM, RELM, ELM, SVM, KNN, NB | Information entropy | Reuters-52 (52) 20 Newsgroups (20), WebKB (4) |
| [36] | Behera & Dash (2021) | ELM | Max-min document frequency | Reuters-21578 (90) |
| [38] | Du et al., (2020) | Recurrent BLS, Gated BLS, LSTM | --- | New Years resolutions (10), Political-media (9), Twitter sentiment (6), Objective-sentence (5), Apple-Twitter sentiment (4), Corporate messaging (4), Progressive tweet (4), Weather sentiment (4), Claritin-October twitter (3), Airline-sentiment (3), Tweet-global warming (3), Electronic sentiment (2), Books sentiment (2) |
| [39] | Liu et al., (2022) | NSBLS, ELM, CNN-BLS, LSTM-BLS | --- | Reddit sentiment (3), Twitter sentiment (3) |
| Our approach | BLS, RVFLN, KRVFLN, ELM | TOPSIS-ModCHI | Reuters-21578 (90) 20 Newsgroups (20), Reddit Mental Health (9) | |
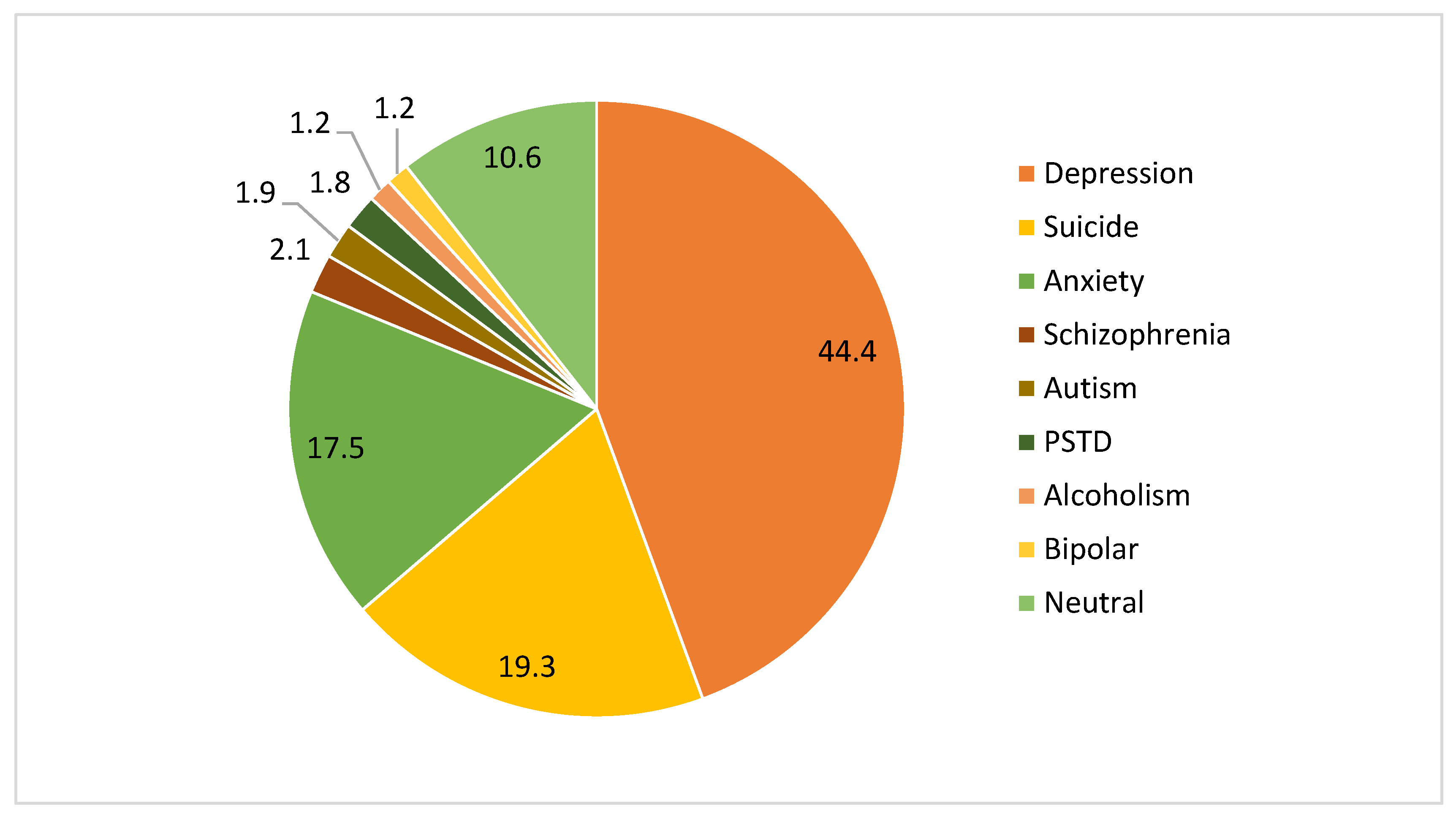
| Dataset Name | Total Number of Documents | Total Number of Class | Total Number of Training Documents | Total Number of Testing Documents |
|---|---|---|---|---|
| Reddit Mental Health | 75,559 | 9 | 60,446 | 15,112 |
| Reuters-21578 | 10,788 | 90 | 7769 | 3019 |
| 20 Newsgroups | 5226 | 20 | 4180 | 1046 |
| Class Name | Number of Documents | Number of Training Documents | Number of Testing Documents |
|---|---|---|---|
| Depression | 33,554 | 26,838 | 6716 |
| Suicide | 14,592 | 11,679 | 2913 |
| Anxiety | 13,213 | 10,590 | 2623 |
| Schizophrenia | 1550 | 1224 | 326 |
| Autism | 1401 | 1111 | 290 |
| PSTD | 1397 | 1127 | 270 |
| Alcoholism | 942 | 755 | 187 |
| Bipolar | 910 | 702 | 208 |
| Neutral | 7999 | 6420 | 1579 |
| Total | 75,558 | 60,446 | 15,112 |
| Sl.no | Post | Subreddit |
|---|---|---|
| 1 | HELP If life was a dream, what would we have to do to wake up from it. | Depression |
| 2 | How should I end my life Girls get a ton of attention so they either ignore me or treat me like shit. The human race sucks. Im going to be alone forever | Suicide |
| 3 | I got a job interview on Monday at 11. Not going as I’m too anxious Thats it. First interview after studying and getting my diploma. I’m too nervous that ill screw it over. Advice needed | Anxiety |
| 4 | I put out a lit cigarette on my leg. My thoughts are uncontrollable. The violent urges and thoughts are uncontrollable now, they just keep coming. | Schizophrenia |
| 5 | Is autism genetic? I’m a teenager with autism spectrum disorder. My dad also has it. If I eventually have kids, what are the chances that they will also be autistic? | Autism |
| 6 | I am afraid to attribute to my trauma every bad thing that I feel. Hey guys, Just wanted to know if anyone can relate to. It has been roughly a year since my traumatic episode took place and ever since my life has became a mess. | PSTD |
| 7 | Been an alcoholic for past 3 years Like my title says I’ve been struggling with drinking for past few years. My drink of choice is vodka. I occasionally drink beer as well. | Alcoholism |
| 8 | Enjoy life with this one weird trick. Yes, you are bipolar--or maybe you are the SO of a bipolar person. Here is one trick that will make 2019 better than any other year has been. | Bipolar |
| 9 | I’m meeting up with one of my besties tonight! Can’t wait!! | Neutral |
| Reuters dataset | |||||
| Top 3 class name with training and testing documents | Class name | Training: Testing | Bottom 3 class name with training and testing documents | Class name | Training: Testing |
| Earn | 2877:1087 | Sun-meal | 1:1 | ||
| Acq | 1650:719 | Lin-oil | 1:1 | ||
| Money-fx | 538:179 | Coconut-oil | 1:2 | ||
| 20 Newsgroups dataset | |||||
| Top 3 class name with training and testing documents | Class name | Training: Testing | Bottom 3 class name with training and testing documents | Class name | Training: Testing |
| rec.autos | 485:109 | soc.religion.christian | 58:12 | ||
| rec.sport.hockey | 476:124 | alt.atheism | 45:8 | ||
| rec.motorcycles | 475:123 | talk.politics.misc | 43:9 | ||
| Performance with ELM | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.9 | 0.91 | 0.92 | 0.93 | 0.94 | 0.94 | 0.95 | 0.94 | 0.94 | 0.94 |
| Rmicro | 0.33 | 0.43 | 0.56 | 0.68 | 0.69 | 0.68 | 0.7 | 0.71 | 0.72 | 0.73 |
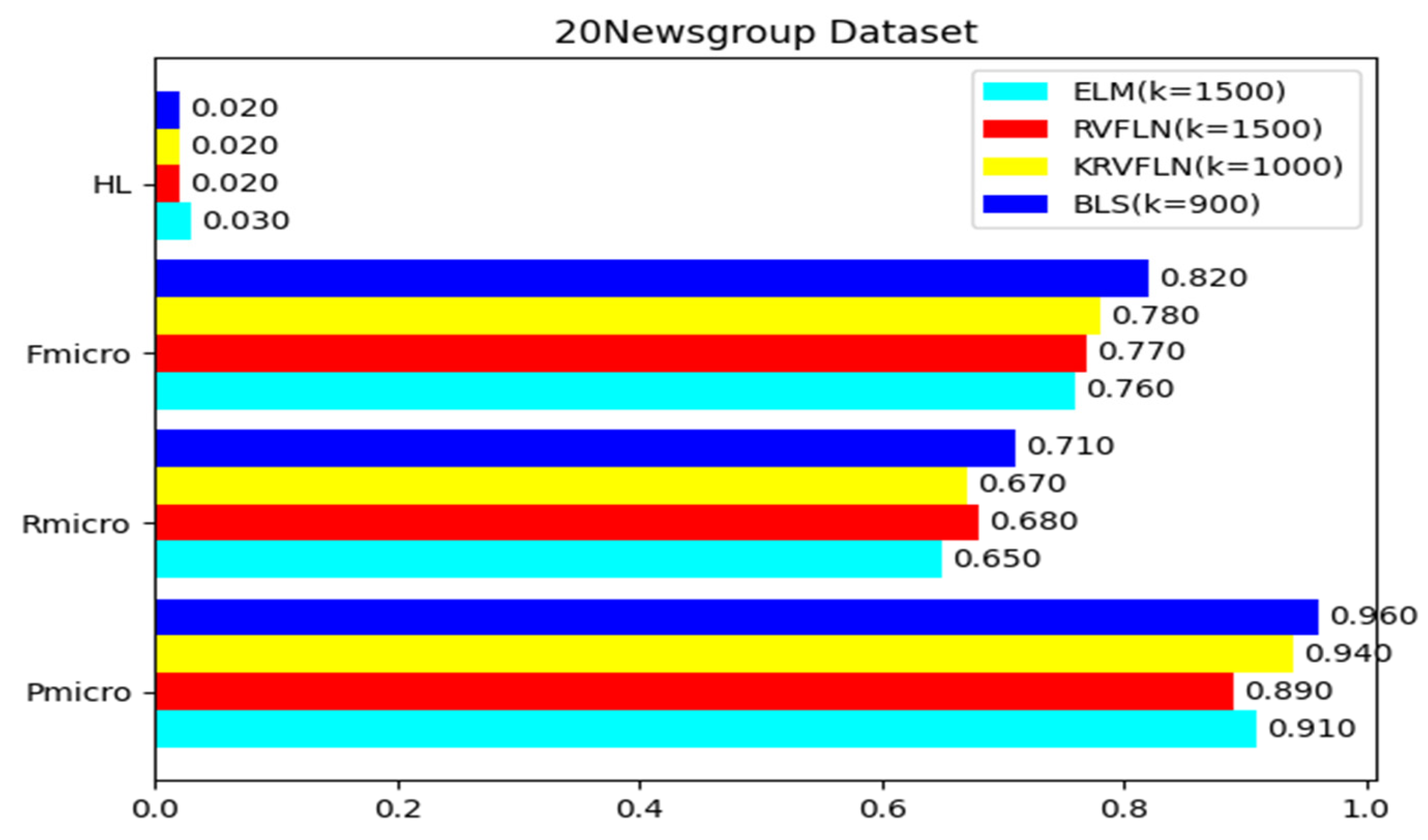
| Fmicro | 0.48 | 0.58 | 0.70 | 0.79 | 0.80 | 0.79 | 0.81 | 0.81 | 0.82 | 0.82 |
| HL | 0.009 | 0.008 | 0.007 | 0.007 | 0.006 | 0.006 | 0.005 | 0.005 | 0.004 | 0.004 |
| Performance with RVFLN | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.94 | 0.94 | 0.95 | 0.94 | 0.95 | 0.93 | 0.95 | 0.94 | 0.94 | 0.94 |
| Rmicro | 0.38 | 0.47 | 0.67 | 0.71 | 0.77 | 0.78 | 0.79 | 0.79 | 0.81 | 0.81 |
| Fmicro | 0.54 | 0.63 | 0.79 | 0.81 | 0.85 | 0.85 | 0.86 | 0.86 | 0.87 | 0.87 |
| HL | 0.008 | 0.007 | 0.006 | 0.004 | 0.004 | 0.004 | 0.003 | 0.003 | 0.003 | 0.003 |
| Performance with KRVFLN | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.94 | 0.94 | 0.95 | 0.96 | 0.96 | 0.97 | 0.96 | 0.97 | 0.96 | 0.97 |
| Rmicro | 0.4 | 0.47 | 0.68 | 0.72 | 0.78 | 0.79 | 0.8 | 0.81 | 0.8 | 0.81 |
| Fmicro | 0.56 | 0.63 | 0.79 | 0.82 | 0.86 | 0.87 | 0.87 | 0.88 | 0.87 | 0.88 |
| HL | 0.008 | 0.007 | 0.006 | 0.006 | 0.004 | 0.004 | 0.004 | 0.003 | 0.003 | 0.003 |
| Performance with BLS | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.94 | 0.94 | 0.95 | 0.95 | 0.97 | 0.97 | 0.98 | 0.98 | 0.97 | 0.98 |
| Rmicro | 0.38 | 0.50 | 0.67 | 0.72 | 0.78 | 0.79 | 0.83 | 0.83 | 0.83 | 0.83 |
| Fmicro | 0.54 | 0.65 | 0.79 | 0.82 | 0.86 | 0.87 | 0.90 | 0.90 | 0.89 | 0.90 |
| HL | 0.008 | 0.007 | 0.006 | 0.004 | 0.004 | 0.002 | 0.002 | 0.003 | 0.002 | 0.002 |
| Performance with ELM | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.79 | 0.81 | 0.84 | 0.87 | 0.89 | 0.91 | 0.91 | 0.92 | 0.91 | 0.91 |
| Rmicro | 0.19 | 0.28 | 0.32 | 0.36 | 0.48 | 0.55 | 0.60 | 0.61 | 0.62 | 0.65 |
| Fmicro | 0.31 | 0.42 | 0.46 | 0.51 | 0.62 | 0.69 | 0.72 | 0.73 | 0.74 | 0.76 |
| HL | 0.05 | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 | 0.04 | 0.03 | 0.03 | 0.03 |
| Performance with RVFLN | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.83 | 0.85 | 0.89 | 0.92 | 0.92 | 0.92 | 0.91 | 0.90 | 0.90 | 0.89 |
| Rmicro | 0.23 | 0.33 | 0.34 | 0.39 | 0.54 | 0.59 | 0.62 | 0.62 | 0.62 | 0.68 |
| Fmicro | 0.36 | 0.48 | 0.49 | 0.55 | 0.68 | 0.72 | 0.74 | 0.73 | 0.73 | 0.77 |
| HL | 0.04 | 0.03 | 0.03 | 0.03 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 |
| Performance with KRVFLN | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.82 | 0.86 | 0.89 | 0.92 | 0.92 | 0.93 | 0.93 | 0.93 | 0.94 | 0.94 |
| Rmicro | 0.25 | 0.37 | 0.38 | 0.40 | 0.55 | 0.60 | 0.64 | 0.67 | 0.67 | 0.67 |
| Fmicro | 0.38 | 0.52 | 0.53 | 0.56 | 0.69 | 0.73 | 0.76 | 0.78 | 0.78 | 0.78 |
| HL | 0.03 | 0.03 | 0.03 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 |
| Performance with BLS | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.84 | 0.87 | 0.9 | 0.93 | 0.94 | 0.95 | 0.96 | 0.96 | 0.96 | 0.96 |
| Rmicro | 0.24 | 0.36 | 0.39 | 0.41 | 0.57 | 0.65 | 0.68 | 0.71 | 0.7 | 0.70 |
| Fmicro | 0.37 | 0.51 | 0.54 | 0.57 | 0.71 | 0.77 | 0.80 | 0.82 | 0.81 | 0.81 |
| HL | 0.04 | 0.04 | 0.03 | 0.03 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 |
| Performance with ELM | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.74 | 0.78 | 0.79 | 0.81 | 0.83 | 0.84 | 0.86 | 0.87 | 0.87 | 0.87 |
| Rmicro | 0.34 | 0.39 | 0.41 | 0.45 | 0.47 | 0.49 | 0.52 | 0.55 | 0.57 | 0.59 |
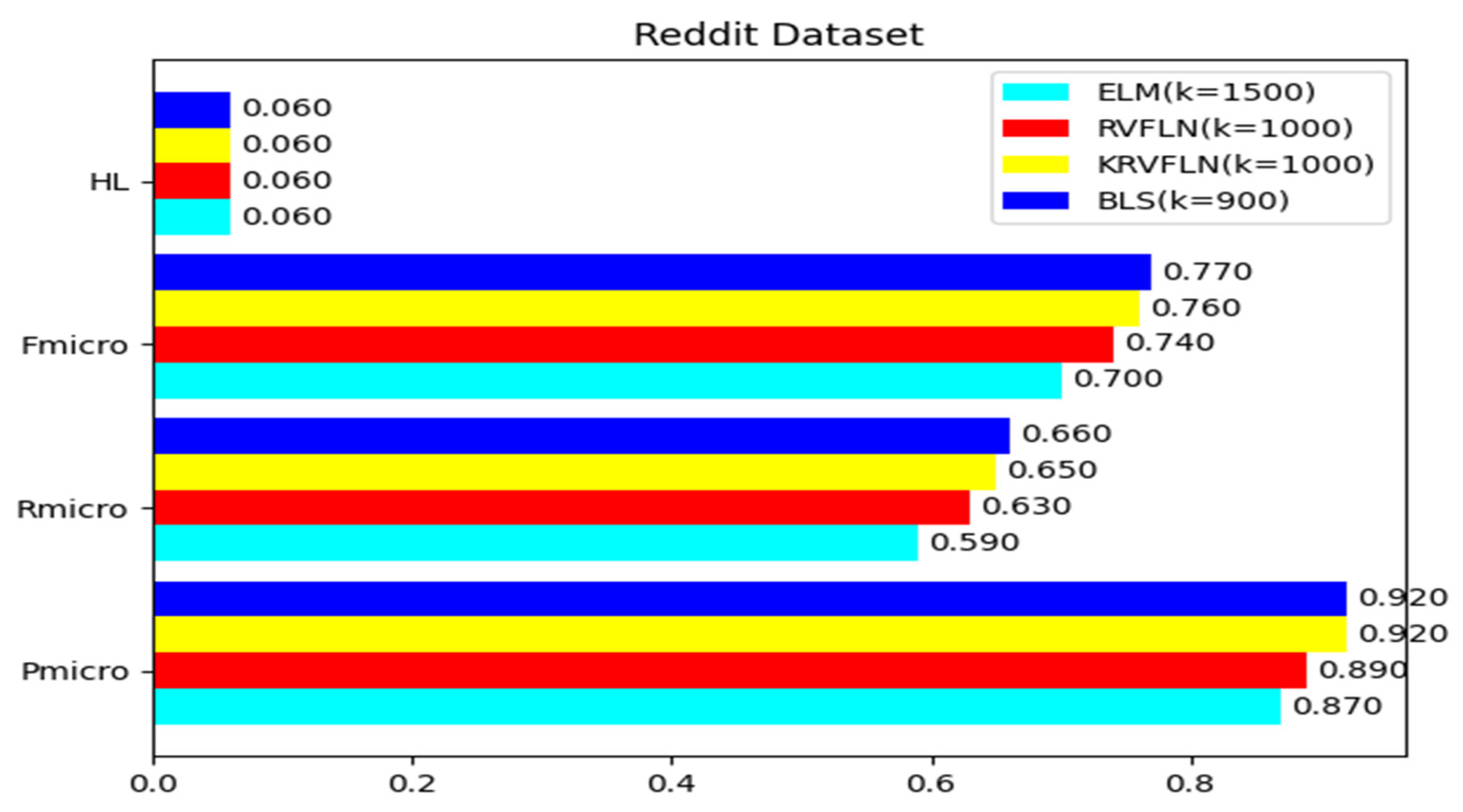
| Fmicro | 0.47 | 0.52 | 0.54 | 0.58 | 0.60 | 0.62 | 0.65 | 0.67 | 0.69 | 0.70 |
| HL | 0.08 | 0.08 | 0.08 | 0.07 | 0.07 | 0.07 | 0.06 | 0.06 | 0.06 | 0.06 |
| Performance with RVFLN | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.77 | 0.79 | 0.79 | 0.81 | 0.83 | 0.85 | 0.86 | 0.88 | 0.89 | 0.89 |
| Rmicro | 0.35 | 0.39 | 0.44 | 0.48 | 0.53 | 0.56 | 0.60 | 0.61 | 0.63 | 0.63 |
| Fmicro | 0.48 | 0.52 | 0.56 | 0.60 | 0.63 | 0.65 | 0.68 | 0.69 | 0.74 | 0.74 |
| HL | 0.08 | 0.08 | 0.07 | 0.07 | 0.07 | 0.07 | 0.07 | 0.06 | 0.06 | 0.06 |
| Performance with KRVFLN | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.78 | 0.79 | 0.81 | 0.83 | 0.84 | 0.85 | 0.87 | 0.89 | 0.92 | 0.92 |
| Rmicro | 0.35 | 0.38 | 0.45 | 0.49 | 0.54 | 0.57 | 0.61 | 0.63 | 0.65 | 0.63 |
| Fmicro | 0.48 | 0.51 | 0.58 | 0.62 | 0.66 | 0.68 | 0.72 | 0.74 | 0.76 | 0.75 |
| HL | 0.08 | 0.08 | 0.07 | 0.07 | 0.07 | 0.06 | 0.06 | 0.06 | 0.06 | 0.06 |
| Performance with BLS | ||||||||||
| Evaluation Metrics | Feature Size (k) | |||||||||
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | |
| Pmicro | 0.79 | 0.80 | 0.82 | 0.84 | 0.86 | 0.88 | 0.90 | 0.92 | 0.92 | 0.92 |
| Rmicro | 0.36 | 0.39 | 0.45 | 0.50 | 0.55 | 0.57 | 0.62 | 0.66 | 0.64 | 0.66 |
| Fmicro | 0.49 | 0.52 | 0.58 | 0.63 | 0.67 | 0.69 | 0.73 | 0.77 | 0.75 | 0.77 |
| HL | 0.08 | 0.08 | 0.08 | 0.07 | 0.07 | 0.07 | 0.06 | 0.06 | 0.06 | 0.06 |
| Dataset | Type of RandNN | Feature Size (k) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 20 | 40 | 100 | 300 | 500 | 700 | 900 | 1000 | 1500 | ||
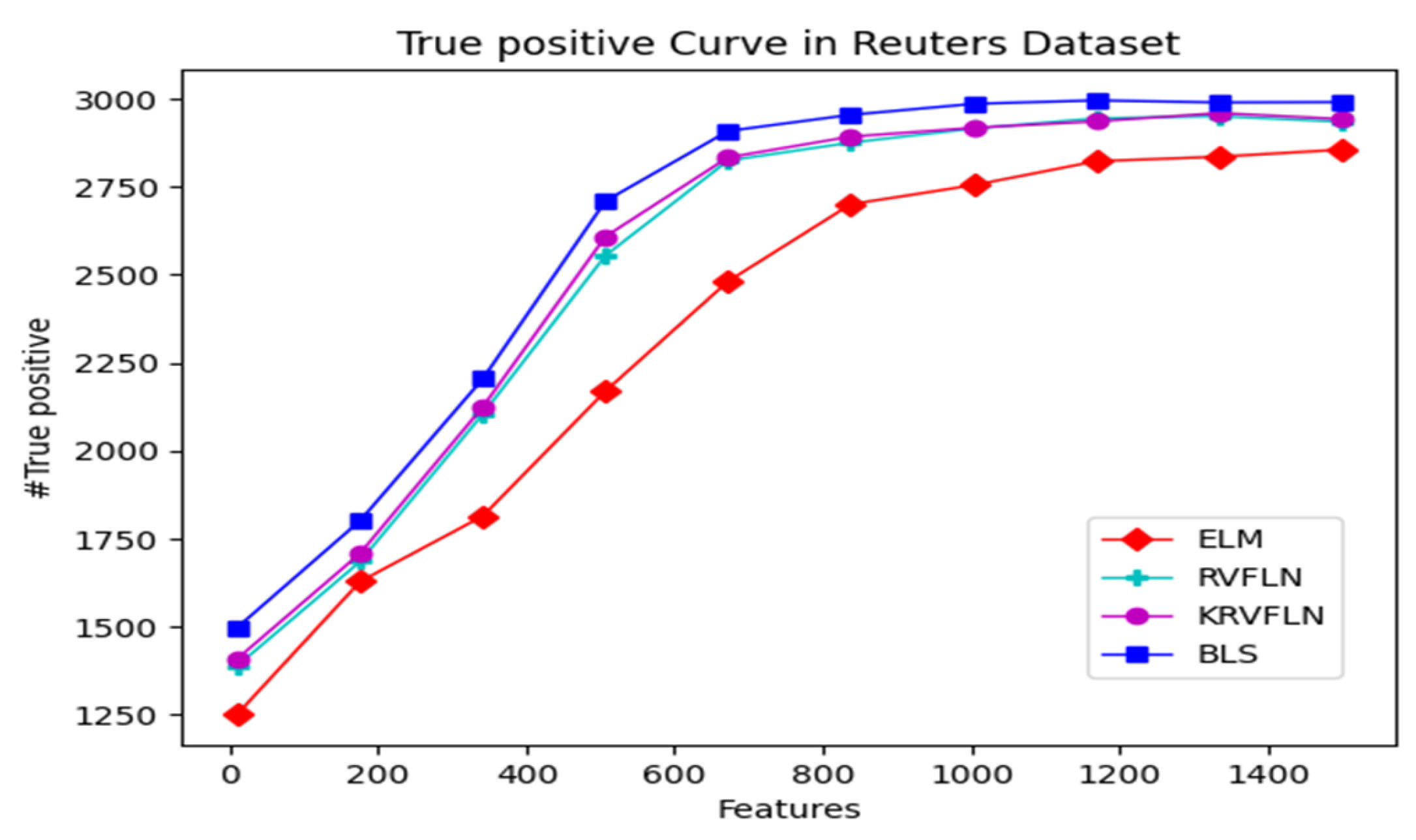
| Reuters | ELM | 10 | 9 | 8 | 7 | 5 | 6 | 4 | 3 | 2 | 1 |
| RVFLN | 10 | 9 | 8 | 7 | 5 | 6 | 3 | 4 | 1 | 2 | |
| KRVFLN | 10 | 9 | 8 | 7 | 6 | 4 | 5 | 1 | 3 | 2 | |
| BLS | 10 | 9 | 8 | 7 | 6 | 4 | 1 | 5 | 3 | 2 | |
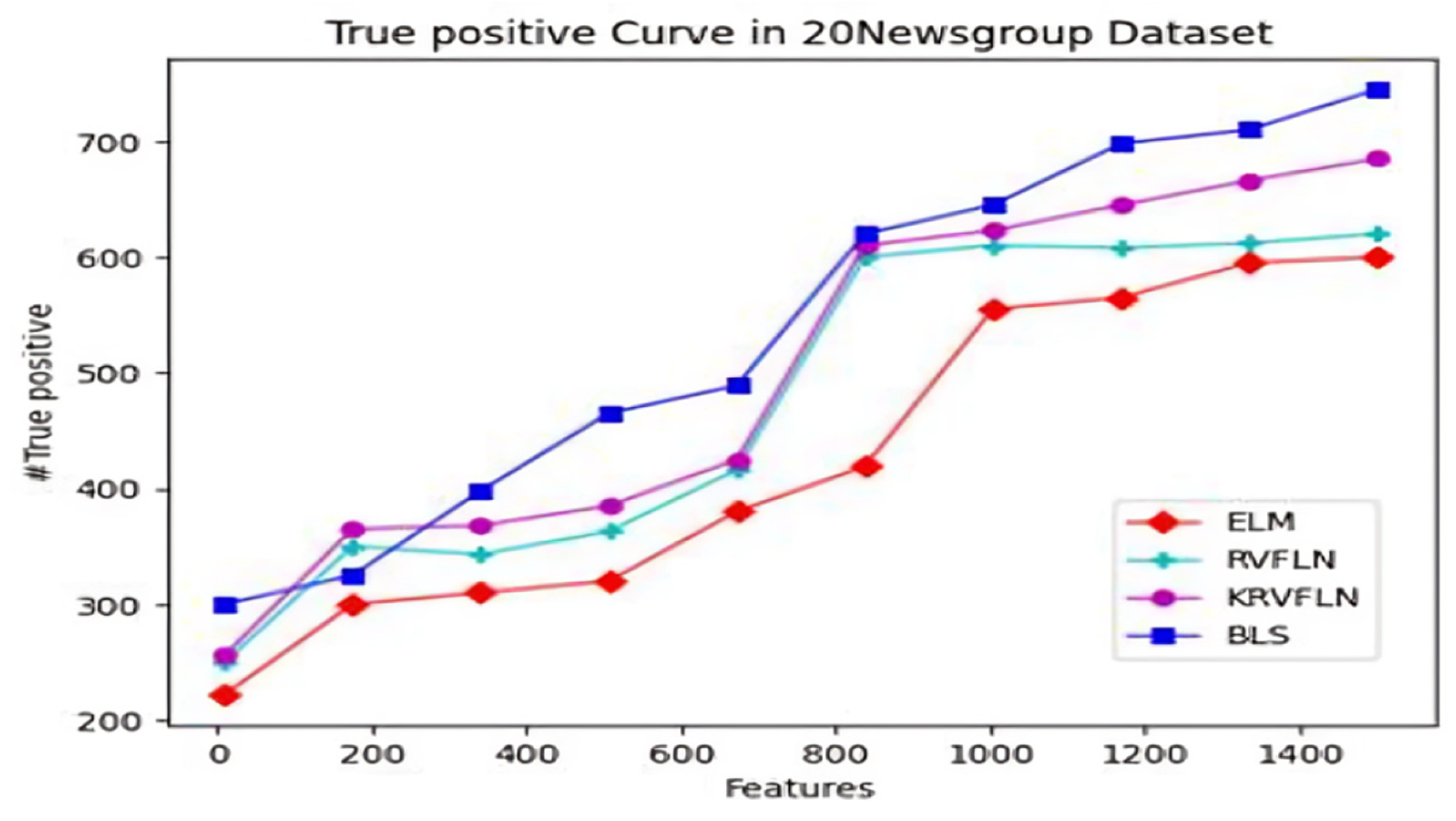
| 20 Newsgroup | ELM | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| RVFLN | 10 | 9 | 8 | 7 | 6 | 5 | 2 | 3 | 4 | 1 | |
| KRVFLN | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 1 | 2 | |
| BLS | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 1 | 2 | 3 | |
| ELM | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | |
| RVFLN | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 1 | 2 | |
| KRVFLN | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 1 | 2 | |
| BLS | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 1 | 3 | 2 | |
| Models | Reuters | 20 Newsgroups | |
|---|---|---|---|
| Feature Size | Feature Size | Feature Size | |
| ELM | 1500 | 1500 | 1500 |
| RVFLN | 1000 | 1500 | 1000 |
| KRVFLN | 900 | 1000 | 1000 |
| BLS | 700 | 900 | 900 |
| Dataset: Reuters | ||||||||||||
| Models | Activation functions | |||||||||||
| Sigmoid | Tanh | Relu | ||||||||||
| Pmicro | Rmicro | Fmicro | HL | Pmicro | Rmicro | Fmicro | HL | Pmicro | Rmicro | Fmicro | HL | |
| ELM | 0.94 | 0.73 | 0.82 | 0.004 | 0.93 | 0.71 | 0.80 | 0.004 | 0.93 | 0.72 | 0.81 | 0.004 |
| RVFLN | 0.94 | 0.81 | 0.87 | 0.003 | 0.92 | 0.78 | 0.84 | 0.003 | 0.92 | 0.78 | 0.84 | 0.003 |
| KRVFLN | 0.97 | 0.81 | 0.88 | 0.003 | 0.95 | 0.77 | 0.85 | 0.004 | 0.94 | 0.67 | 0.78 | 0.005 |
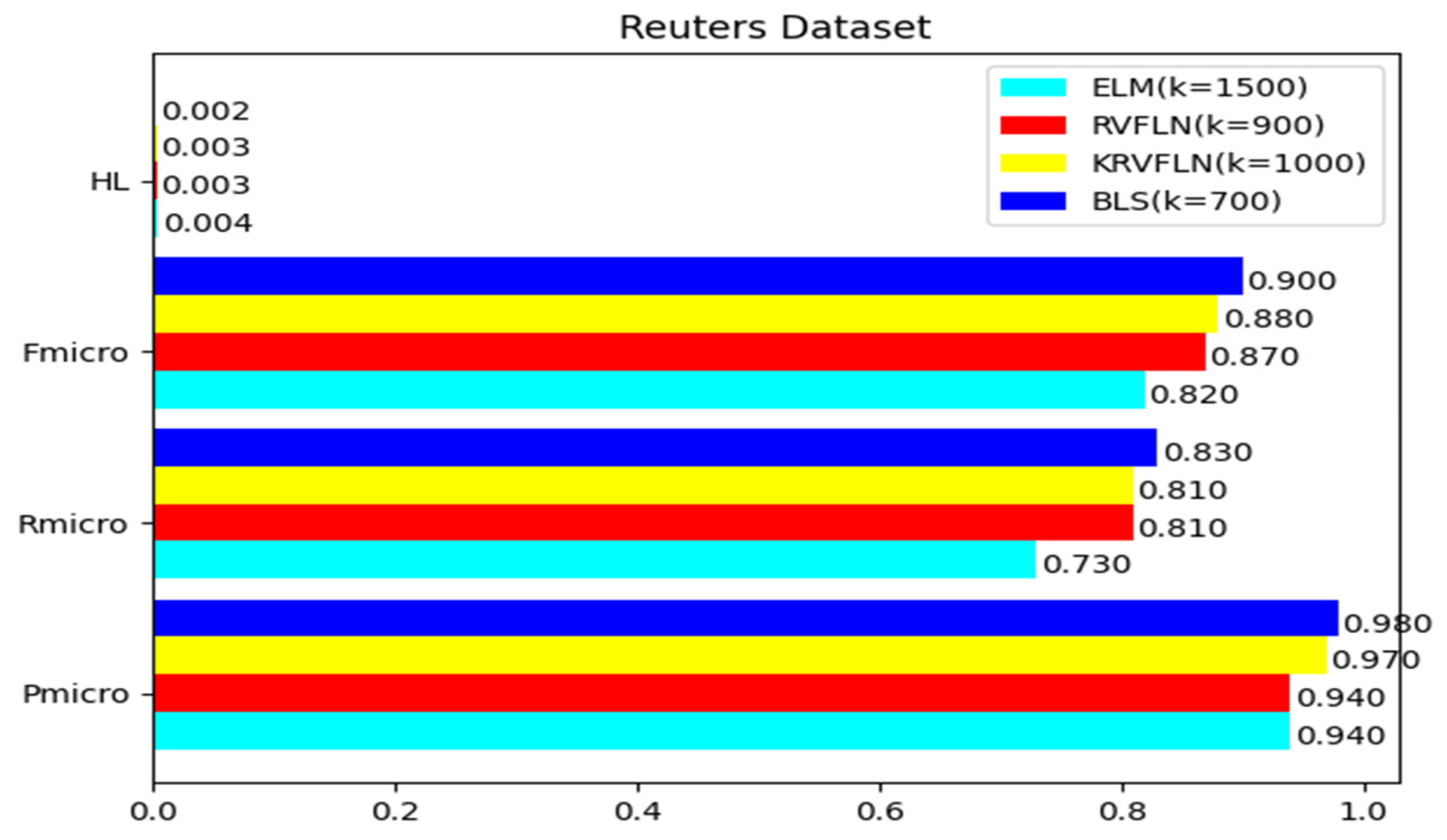
| BLS | 0.98 | 0.83 | 0.90 | 0.002 | 0.97 | 0.78 | 0.86 | 0.003 | 0.97 | 0.77 | 0.85 | 0.003 |
| Dataset: 20 Newsgroups | ||||||||||||
| Models | Activation functions | |||||||||||
| Sigmoid | Tanh | Relu | ||||||||||
| Pmicro | Rmicro | Fmicro | HL | Pmicro | Rmicro | Fmicro | HL | Pmicro | Rmicro | Fmicro | HL | |
| ELM | 0.91 | 0.65 | 0.76 | 0.03 | 0.90 | 0.62 | 0.73 | 0.03 | 0.89 | 0.64 | 0.74 | 0.03 |
| RVFLN | 0.89 | 0.68 | 0.77 | 0.02 | 0.87 | 0.66 | 0.75 | 0.03 | 0.87 | 0.65 | 0.74 | 0.02 |
| KRVFLN | 0.94 | 0.67 | 0.78 | 0.02 | 0.92 | 0.65 | 0.76 | 0.02 | 0.91 | 0.63 | 0.74 | 0.03 |
| BLS | 0.96 | 0.71 | 0.82 | 0.02 | 0.95 | 0.67 | 0.78 | 0.03 | 0.92 | 0.65 | 0.76 | 0.03 |
| Dataset: Reddit | ||||||||||||
| Models | Activation functions | |||||||||||
| Sigmoid | Tanh | Relu | ||||||||||
| Pmicro | Rmicro | Fmicro | HL | Pmicro | Rmicro | Fmicro | HL | Pmicro | Rmicro | Fmicro | HL | |
| ELM | 0.87 | 0.59 | 0.70 | 0.06 | 0.86 | 0.57 | 0.68 | 0.06 | 0.84 | 0.55 | 0.66 | 0.07 |
| RVFLN | 0.89 | 0.63 | 0.74 | 0.06 | 0.87 | 0.61 | 0.71 | 0.06 | 0.87 | 0.60 | 0.71 | 0.06 |
| KRVFLN | 0.92 | 0.65 | 0.76 | 0.06 | 0.90 | 0.63 | 0.74 | 0.06 | 0.90 | 0.62 | 0.73 | 0.06 |
| BLS | 0.92 | 0.66 | 0.77 | 0.06 | 0.91 | 0.66 | 0.76 | 0.07 | 0.90 | 0.65 | 0.75 | 0.06 |
| Dataset: Reuters | Dataset: 20 Newsgroups | Dataset: Reddit | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Evaluation Metrics | Hidden Layer Size | Hidden Layer Size | Hidden Layer Size | ||||||||||||
| 100 | 200 | 323 | 400 | 500 | 100 | 200 | 320 | 400 | 500 | 100 | 200 | 309 | 400 | 500 | |
| Pmicro | 0.95 | 0.96 | 0.98 | 0.98 | 0.98 | 0.91 | 0.94 | 0.96 | 0.95 | 0.97 | 0.89 | 0.90 | 0.92 | 0.92 | 0.93 |
| Rmicro | 0.79 | 0.82 | 0.83 | 0.83 | 0.82 | 0.66 | 0.68 | 0.71 | 0.72 | 0.71 | 0.62 | 0.64 | 0.66 | 0.65 | 0.64 |
| Fmicro | 0.86 | 0.88 | 0.90 | 0.90 | 0.89 | 0.76 | 0.78 | 0.82 | 0.81 | 0.81 | 0.73 | 0.74 | 0.77 | 0.76 | 0.75 |
| HL | 0.003 | 0.003 | 0.003 | 0.003 | 0.003 | 0.03 | 0.02 | 0.02 | 0.02 | 0.02 | 0.05 | 0.05 | 0.06 | 0.06 | 0.06 |
| Dataset | BLS/KRVFLN | BLS/RVFLN | BLS/ELM | |||
|---|---|---|---|---|---|---|
| t-Statistics | p | t-Statistics | p | t-Statistics | p | |
| Reuters | 6.19 | 7.99 × 10−5 | 14.23 | 8.9 × 10−8 | 33.41 | 4.74 × 10−11 |
| 20 Newsgroup | 20.12 | 4.29 × 10−9 | 14.45 | 7.77 × 10−8 | 28.94 | 1.70 × 10−10 |
| 8.51 | 6.72 × 10−6 | 15.46 | 4.33 × 10−8 | 33.46 | 4.67 × 10−11 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Behera, S.K.; Dash, R. A Novel Framework for Mental Illness Detection Leveraging TOPSIS-ModCHI-Based Feature-Driven Randomized Neural Networks. Math. Comput. Appl. 2025, 30, 67. https://doi.org/10.3390/mca30040067
Behera SK, Dash R. A Novel Framework for Mental Illness Detection Leveraging TOPSIS-ModCHI-Based Feature-Driven Randomized Neural Networks. Mathematical and Computational Applications. 2025; 30(4):67. https://doi.org/10.3390/mca30040067
Chicago/Turabian StyleBehera, Santosh Kumar, and Rajashree Dash. 2025. "A Novel Framework for Mental Illness Detection Leveraging TOPSIS-ModCHI-Based Feature-Driven Randomized Neural Networks" Mathematical and Computational Applications 30, no. 4: 67. https://doi.org/10.3390/mca30040067
APA StyleBehera, S. K., & Dash, R. (2025). A Novel Framework for Mental Illness Detection Leveraging TOPSIS-ModCHI-Based Feature-Driven Randomized Neural Networks. Mathematical and Computational Applications, 30(4), 67. https://doi.org/10.3390/mca30040067