
Hybrid Deep Learning Models for Predicting Student Academic Performance


Abstract
1. Introduction
- We developed a deep learning model that combines a convolutional neural network (CNN) and a recurrent neural network (RNN). This method uses the strengths of both neural networks to improve prediction accuracy.
- Our work demonstrates the effective hybridization of a convolutional neural network with the bidirectional gated recurrent unit (BiGRU) to improve model performance. This unique hybridization is specifically designed to improve the accuracy of student academic prediction.
- We improved academic dataset quality by handling missing values, using the synthetic minority over-sampling technique (SMOTE) to handle class imbalance, selecting useful features to increase model accuracy, and also incorporating advanced regularization techniques.
- We conducted experiments with other baseline models to validate our model’s superiority and compare it with other high-rated models in the literature.
2. Related Works
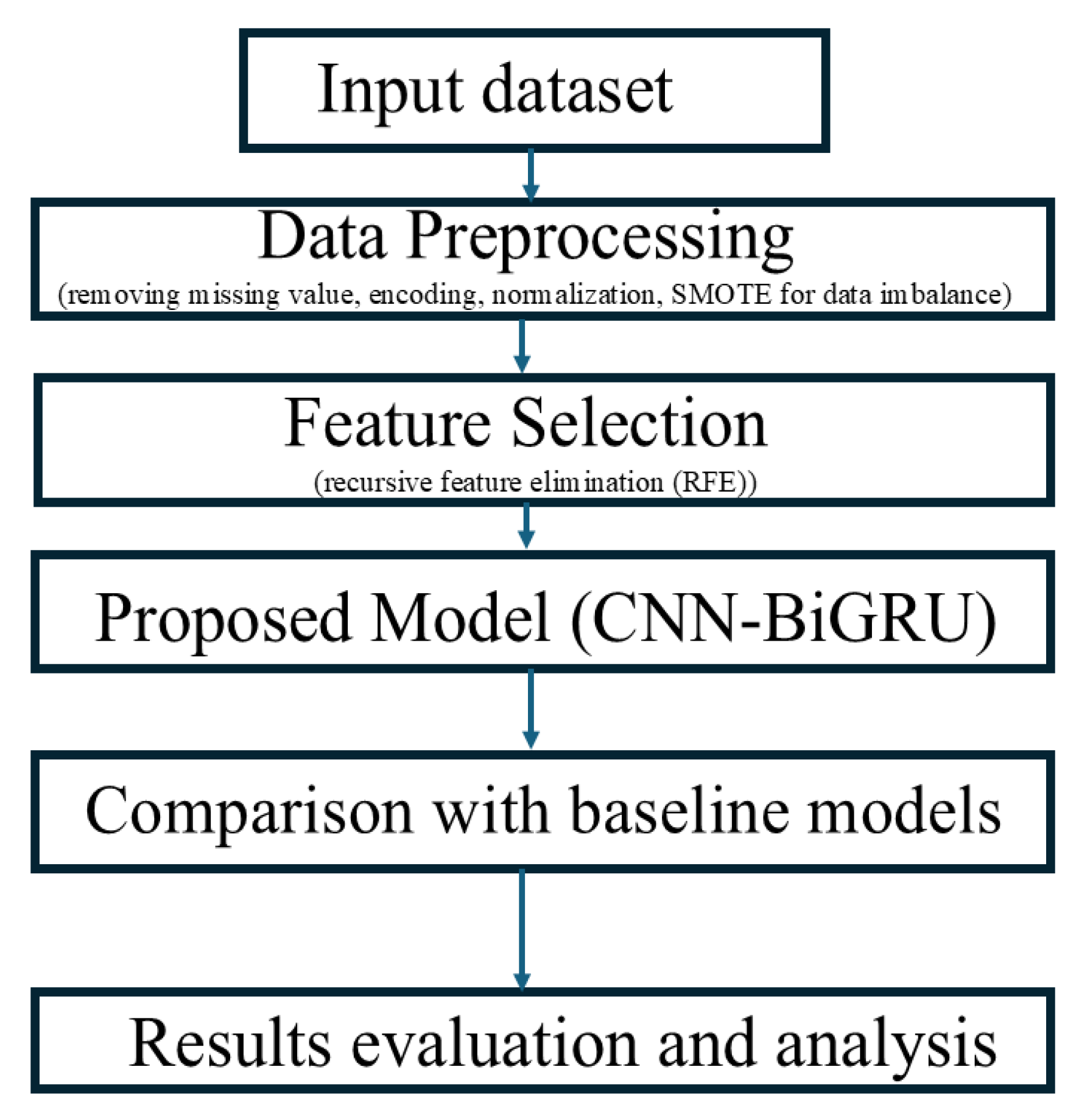
3. Materials and Methods
3.1. Datasets Description
3.1.1. HESP Dataset
3.1.2. XAPI Dataset
3.1.3. HEI Dataset
3.2. Data Preprocessing
3.2.1. Missing Data
3.2.2. Data Encoding
3.2.3. Normalization of Data
3.2.4. Data Imbalance
3.2.5. Feature Selection
3.2.6. Data Splitting
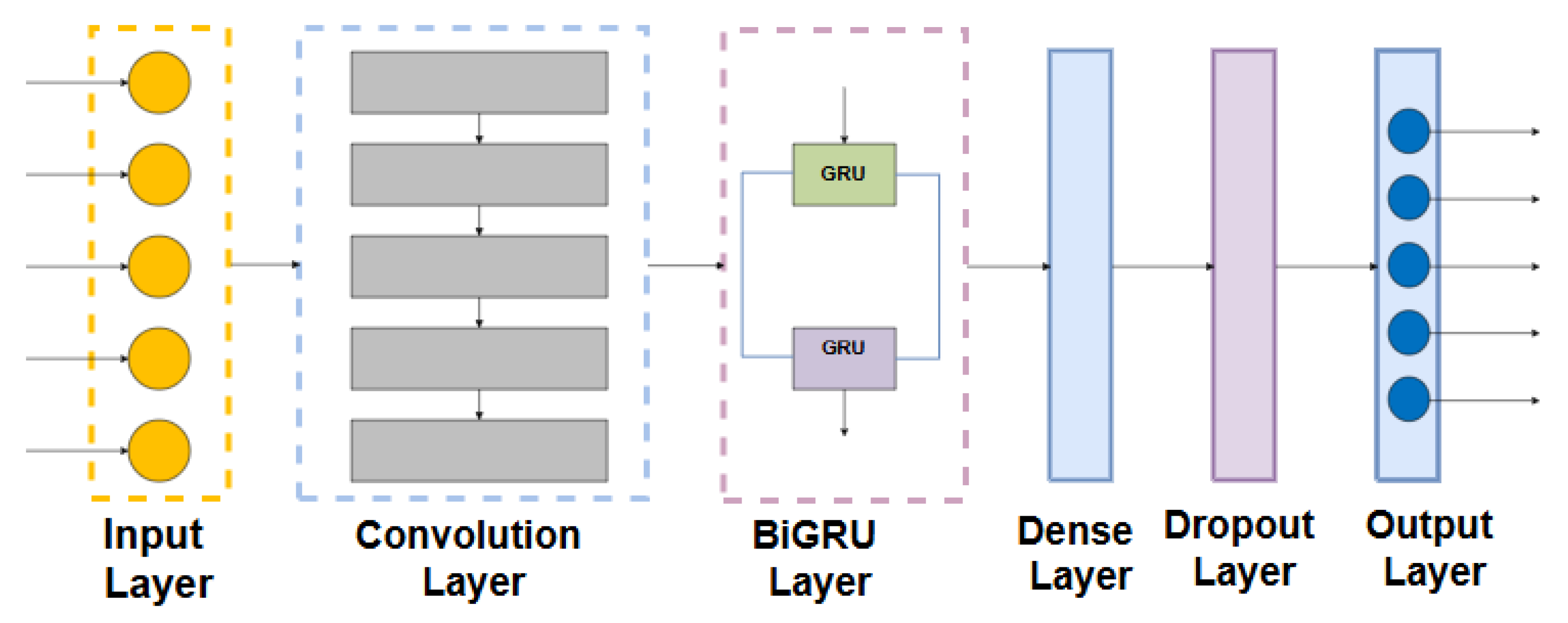
3.3. Deep Learning Models Description
3.3.1. Convolutional Neural Networks (CNNs)
3.3.2. Bidirectional Gated Recurrent Units (BiGRUs)
3.4. Baseline Methods
3.4.1. Artificial Neural Networks (ANNs)
3.4.2. Long Short-Term Memory (LSTM) Network
3.5. Proposed CNN-BiGRU Model Architecture
3.6. Experimental Setup
3.7. Performance Evaluation
4. Results and Discussion
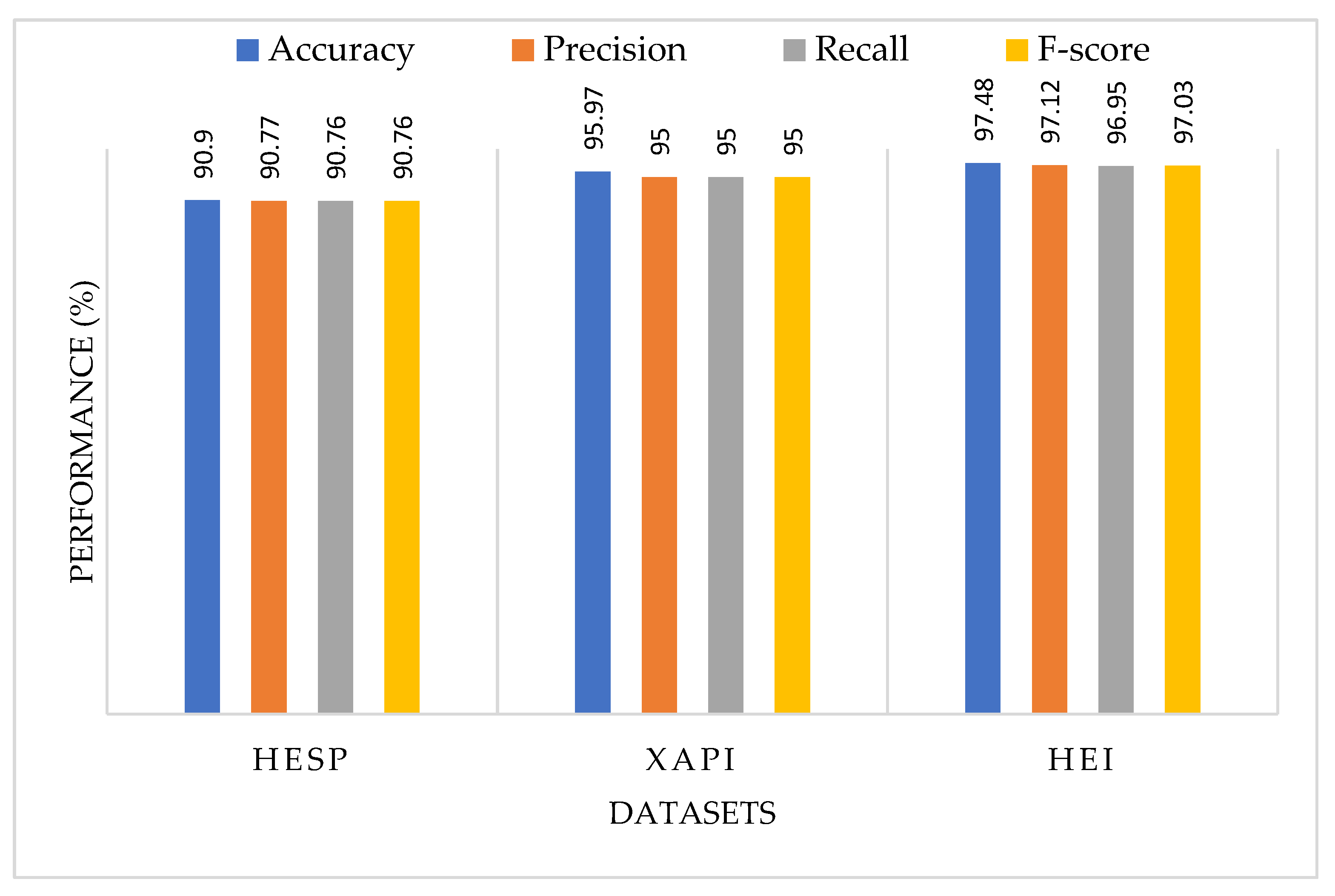
4.1. Proposed CNN-BiGRU Model Results
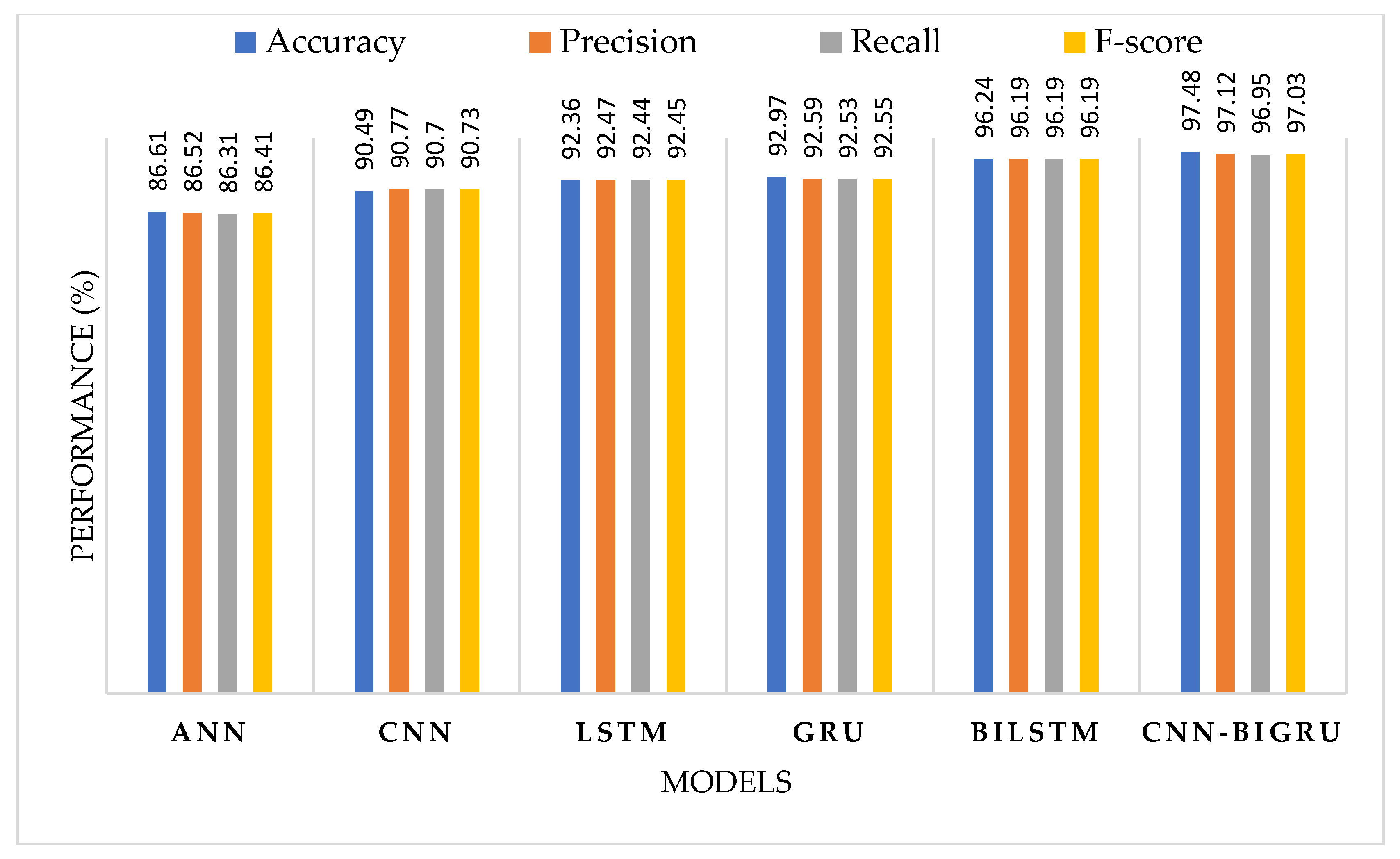
4.2. Performance Comparison of the Proposed Model with the Baseline Models
4.3. Proposed Models Training and Prediction Time
4.4. Proposed Model Decision Interpretation
4.5. Performance Comparison with Previous Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AFSA | Adaptive Feature Selection Algorithm |
| ANN | Artificial Neural Network |
| Bi-GRU | Bidirectional Gated Recurrent Unit |
| CNN | Convolutional Neural Network |
| DT | Decision Tree |
| DNN | Deep Neural Network |
| EDM | Educational data mining |
| GAN | Generative Adversarial Network |
| GRU | Gated Recurrent Unit |
| KNN | K-Nearest Neighbour |
| LR | Logistic Regression |
| PSO | Particle Swarm Optimization |
| RF | Random Forest |
| SSP | Secondary Student Performance |
| SVM | Support Vector Machine |
| SMOTE | Synthetic Minority Over-sampling Technique |
References
- Ramaphosa, K.I.M.; Zuva, T.; Kwuimi, R. Educational Data Mining to Improve Learner Performance in Gauteng Primary Schools. In Proceedings of the 2018 International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 6–7 August 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Ahmed, E. Student performance prediction using machine learning algorithms. Appl. Comput. Intell. Soft Comput. 2024, 2024, 4067721. [Google Scholar] [CrossRef]
- Pelima, L.R.; Sukmana, Y.; Rosmansyah, Y. Predicting university student graduation using academic performance and machine learning: A systematic literature review. IEEE Access 2024, 12, 23451–23465. [Google Scholar] [CrossRef]
- Bellaj, M.; Dahmane, A.B.; Boudra, S.; Sefian, M.L. Educational Data Mining: Employing Machine Learning Techniques and Hyperparameter Optimization to Improve Students’ Academic Performance. Int. J. Online Biomed. Eng. 2024, 20, 3. [Google Scholar] [CrossRef]
- Pecuchova, J.; Drlik, M. Enhancing the Early Student Dropout Prediction Model Through Clustering Analysis of Students’ Digital Traces. IEEE Access 2024, 12, 159336–159367. [Google Scholar] [CrossRef]
- Almaghrabi, H.; Soh, B.; Li, A.; Alsolbi, I. SoK: The Impact of Educational Data Mining on Organisational Administration. Information 2024, 15, 738. [Google Scholar] [CrossRef]
- Kok, C.L.; Ho, C.K.; Chen, L.; Koh, Y.Y.; Tian, B. A Novel Predictive Modeling for Student Attrition Utilizing Machine Learning and Sustainable Big Data Analytics. Appl. Sci. 2024, 14, 9633. [Google Scholar] [CrossRef]
- Roy, K.; Farid, D.M. An adaptive feature selection algorithm for student performance prediction. IEEE Access 2024, 12, 75577–75598. [Google Scholar] [CrossRef]
- Bognár, L. Predicting Student Attrition in University Courses. In Machine Learning in Educational Sciences: Approaches, Applications and Advances; Springer Nature: Singapore, 2024; pp. 129–157. [Google Scholar]
- Cheng, B.; Liu, Y.; Jia, Y. Evaluation of students’ performance during the academic period using the XG-Boost Classifier-Enhanced AEO hybrid model. Expert Syst. Appl. 2024, 238, 122136. [Google Scholar] [CrossRef]
- Yağcı, M. Educational data mining: Prediction of students’ academic performance using machine learning algorithms. Smart Learn. Environ. 2022, 9, 11. [Google Scholar] [CrossRef]
- Baashar, Y.; Alkawsi, G.; Mustafa, A.; Alkahtani, A.A.; Alsariera, Y.A.; Ali, A.Q.; Hashim, W.; Tiong, S.K. Toward predicting student’s academic performance using artificial neural networks (ANNs). Appl. Sci. 2022, 12, 1289. [Google Scholar] [CrossRef]
- Pallathadka, H.; Wenda, A.; Ramirez-Asís, E.; Asís-López, M.; Flores-Albornoz, J.; Phasinam, K. Classification and prediction of student performance data using various machine learning algorithms. Mater. Today Proc. 2023, 80, 3782–3785. [Google Scholar] [CrossRef]
- Monteverde-Suárez, D.; González-Flores, P.; Santos-Solórzano, R.; García-Minjares, M.; Zavala-Sierra, I.; de la Luz, V.L.; Sánchez-Mendiola, M. Predicting students’ academic progress and related attributes in first-year medical students: An analysis with artificial neural networks and Naïve Bayes. BMC Med. Educ. 2024, 24, 74. [Google Scholar] [CrossRef] [PubMed]
- Tirumanadham, N.K.M.K.; Thaiyalnayaki, S.; SriRam, M. Evaluating boosting algorithms for academic performance prediction in E-learning environments. In Proceedings of the 2024 International Conference on Intelligent and Innovative Technologies in Computing, Electrical and Electronics (IITCEE), Bangalore, India, 24–25 January 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–8. [Google Scholar]
- Alsalem, G.M.; Sarhan, N.; Hammad, M.; Zawaideh, B. Predicting Students’ Performance using Machine Learning Classifiers. In Proceedings of the 2024 25th International Arab Conference on Information Technology (ACIT), Zarqa, Jordan, 10–12 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–5. [Google Scholar]
- Rabelo, A.M.; Zárate, L.E. A model for predicting dropout of higher education students. Data Sci. Manag. 2025, 8, 72–85. [Google Scholar] [CrossRef]
- AlShaikh-Hasan, M.; Ghinea, G. Evaluating the Impact of Multi-Layer Data on Machine Learning Classifiers for Predicting Student Academic Performance. In Proceedings of the 2024 25th International Arab Conference on Information Technology (ACIT), Zarqa, Jordan, 10–12 December 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Chen, M.; Liu, Z. Predicting performance of students by optimizing tree components of random forest using genetic algorithm. Heliyon 2024, 10, e12262. [Google Scholar] [CrossRef]
- Adu-Twum, H.T.; Sarfo, E.A.; Nartey, E.; Adesola Adetunji, A.; Ayannusi, A.O.; Walugembe, T.A. Role of Advanced Data Analytics in Higher Education: Using Machine Learning Models to Predict Student Success. J. Data Sci. Artif. Intell. 2024, 3, 1. [Google Scholar]
- Nabil, A.; Seyam, M.; Abou-Elfetouh, A. Prediction of students’ academic performance based on courses’ grades using deep neural networks. IEEE Access 2021, 9, 140731–140746. [Google Scholar] [CrossRef]
- Yousafzai, B.K.; Khan, S.A.; Rahman, T.; Khan, I.; Ullah, I.; Ur Rehman, A.; Baz, M.; Hamam, H.; Cheikhrouhou, O. Student-performulator: Student academic performance using hybrid deep neural network. Sustainability 2021, 13, 9775. [Google Scholar] [CrossRef]
- Alshamaila, Y.; Alsawalqah, H.; Aljarah, I.; Habib, M.; Faris, H.; Alshraideh, M.; Salih, B.A. An automatic prediction of students’ performance to support the university education system: A deep learning approach. Multimed. Tools Appl. 2024, 83, 46369–46396. [Google Scholar] [CrossRef]
- Beseiso, M. Enhancing Student Success Prediction: A Comparative Analysis of Machine Learning Technique. TechTrends 2025, 69, 372–384. [Google Scholar] [CrossRef]
- Albahli, S. Advancing Sustainable Educational Practices Through AI-Driven Prediction of Academic Outcomes. Sustainability 2025, 17, 1087. [Google Scholar] [CrossRef]
- Yin, C.; Tang, D.; Zhang, F.; Tang, Q.; Feng, Y.; He, Z. Students Learning Performance Prediction Based on Feature Extraction Algorithm and Attention-Based Bidirectional Gated Recurrent Unit Network. PLoS ONE 2023, 18, e0286156. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Yu, Z.; Zhang, C.; Yang, Z. Research on MOOC Dropout Prediction by Combining CNN-BiGRU and GCN. In Proceedings of the Fourth International Conference on Computer Vision, Application, and Algorithm (CVAA 2024), Online, 30 August–1 September 2024; Volume 13486, pp. 683–690. [Google Scholar]
- Shiri, F.M.; Perumal, T.; Mustapha, N.; Mohamed, R. A Comprehensive Overview and Comparative Analysis on Deep Learning Models: CNN, RNN, LSTM, GRU. arXiv 2023, arXiv:2305.17473. [Google Scholar]
- Leelaluk, S.; Tang, C.; Minematsu, T.; Taniguchi, Y.; Okubo, F.; Yamashita, T.; Shimada, A. Attention-Based Artificial Neural Network for Student Performance Prediction Based on Learning Activities. IEEE Access 2024, 12, 1–10. [Google Scholar] [CrossRef]
- Hussain, M.M.; Akbar, S.; Hassan, S.A.; Aziz, M.W.; Urooj, F. Prediction of Student’s Academic Performance through Data Mining Approach. J. Inform. Web Eng. 2024, 3, 241–251. [Google Scholar] [CrossRef]
- Kala, A.; Torkul, O.; Yildiz, T.T.; Selvi, I.H. Early Prediction of Student Performance in Face-to-Face Education Environments: A Hybrid Deep Learning Approach with XAI Techniques. IEEE Access 2024, 12, 191635–191649. [Google Scholar]
- Zhang, X.; Wang, X.; Zhao, J.; Zhang, B.; Zhang, F. IC-BTCN: A Deep Learning Model for Dropout Prediction of MOOCs Students. IEEE Trans. Educ. 2024, 67, 974–982. [Google Scholar] [CrossRef]
- Kukkar, A.; Mohana, R.; Sharma, A.; Nayyar, A. A novel methodology using RNN + LSTM + ML for predicting student’s academic performance. Educ. Inform. Technol. 2024, 29, 14365–14401. [Google Scholar] [CrossRef]
- Chui, K.T.; Liu, R.W.; Zhao, M.; De Pablos, P.O. Predicting Students’ Performance with School and Family Tutoring Using Generative Adversarial Network-Based Deep Support Vector Machine. IEEE Access 2020, 8, 86745–86752. [Google Scholar] [CrossRef]
- Venkatachalam, B.; Sivanraju, K. Enhanced Student Performance Prediction Using Data Augmentation with Ensemble Generative Adversarial Network. Indian J. Sci. Technol. 2024, 17, 4619–4632. [Google Scholar] [CrossRef]
- Bansal, V.; Buckchash, H.; Raman, B. Computational Intelligence Enabled Student Performance Estimation in the Age of COVID-19. SN Comput. Sci. 2022, 3, 41. [Google Scholar] [CrossRef]
- Yunus, F.A.; Olanrewaju, R.F.; Ajayi, B.A.; Salihu, A.A. Harnessing the Power of a Bidirectional Long Short-Term Memory-Based Prediction Model: A Case of Student Academic Performance. In Proceedings of the 2023 9th International Conference on Computer and Communication Engineering (ICCCE), Kuala Lumpur, Malaysia, 15–16 August 2023; pp. 306–310. [Google Scholar]
- Song, W.; Xing, J.; Ning, K.; Guo, W. Research on the Prediction of Academic Performance Based on ANN-BiLSTM Hybrid Neural Network Model. In Proceedings of the 2024 IEEE 4th International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 6–8 December 2024; Volume 4, pp. 1375–1380. [Google Scholar]
- Manigandan, E.; Anispremkoilraj, P.; Suresh Kumar, B.; Satre, S.M.; Chauhan, A.; Jeyaganthan, C. An Effective BiLSTM-CRF Based Approach to Predict Student Achievement: An Experimental Evaluation. In Proceedings of the 2024 2nd International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT), Tirunelveli, India, 4–6 January 2024; pp. 779–784. [Google Scholar]
- Yılmaz, N.; Sekeroglu, B. Student performance classification using artificial intelligence techniques. In Proceedings of the International Conference on Theory and Application of Soft Computing, Computing with Words and Perceptions, Prague, Czech Republic, 27–28 August 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 596–603. [Google Scholar]
- Amrieh, E.A.; Hamtini, T.; Aljarah, I. Mining educational data to predict student’s academic performance using ensemble methods. Int. J. Database Theory Appl. 2016, 9, 119–136. [Google Scholar] [CrossRef]
- Martins, M.V.; Tolledo, D.; Machado, J.; Baptista, L.M.T.; Realinho, V. Early prediction of student’s performance in higher education: A case study. In Proceedings of the Trends and Applications in Information Systems and Technologies: Volume 1, Azores, Portugal, 30 March–2 April 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 166–175. [Google Scholar]
- Mustapha, M.T.; Ozsahin, I.; Ozsahin, D.U. Convolution neural network and deep learning. In Artificial Intelligence and Image Processing in Medical Imaging; Academic Press: Cambridge, MA, USA, 2024; pp. 21–50. [Google Scholar]
- Sekar, A. Performance Analysis: LSTMs, GRUs, Single & Bidirectional RNNs in Classification & Regression Problems. Available online: https://www.researchgate.net/publication/381654032_Performance_Analysis_LSTMs_GRUs_Single_Bidirectional_RNNs_in_Classification_Regression_Problems (accessed on 1 April 2025).
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1143–1146. [Google Scholar]
- Adefemi Alimi, K.O.; Ouahada, K.; Abu-Mahfouz, A.M.; Rimer, S.; Alimi, O.A. Refined LSTM Based Intrusion Detection for Denial-of-Service Attack in Internet of Things. J. Sens. Actuator Netw. 2022, 11, 32. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | Source | Attributes | Instances | Features |
|---|---|---|---|---|---|
| HESP [40] | 2019 | UCI | 31 | 145 | Demographic, Academic, and Behavior |
| XAPI [41] | 2016 | Kaggle | 16 | 480 | Demographic, Academic, and Behavior |
| HEI [42] | 2021 | UCI | 36 | 4424 | Academic Path, Demographic and Social Economic Factors |
| Parameters | Configuration/Value |
|---|---|
| Learning rate | 0.001 |
| Number of epochs | 50 |
| Batch sizes | 64 |
| Activation function | ReLU and Softmax |
| Loss function | Categorical cross-entropy |
| Optimization algorithm | Adam optimizer |
| Hyperparameter optimization | Grid search |
| Regularization techniques | Dropout technique |
| Dropout rate | 0.5 |
| Dataset | Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|
| HEI | CNN | 90.49 | 90.77 | 90.70 | 90.73 |
| GRU | 92.97 | 92.59 | 92.53 | 92.55 | |
| ANN | 86.61 | 86.52 | 86.31 | 86.41 | |
| LSTM | 92.36 | 92.47 | 92.44 | 92.45 | |
| BiLSTM | 96.24 | 96.19 | 96.19 | 96.19 | |
| CNN-BiGRU | 97.48 | 97.12 | 96.95 | 97.03 | |
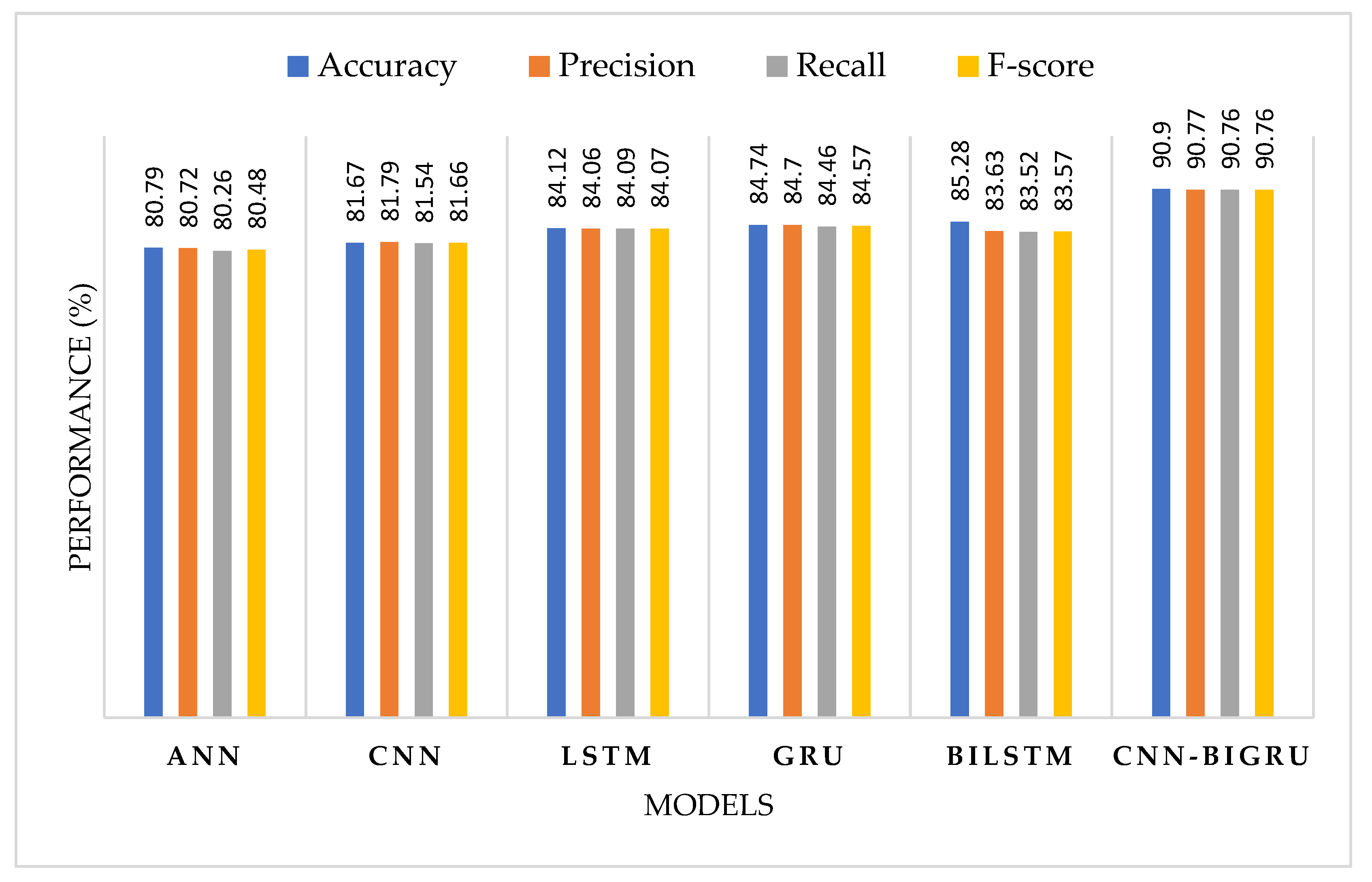
| HESP | CNN | 81.67 | 81.79 | 81.54 | 81.66 |
| GRU | 84.74 | 84.70 | 84.46 | 84.57 | |
| ANN | 80.79 | 80.72 | 80.26 | 80.48 | |
| LSTM | 84.12 | 84.06 | 84.09 | 84.07 | |
| BiLSTM | 85.28 | 84.63 | 84.52 | 84.57 | |
| CNN-BiGRU | 90.90 | 90.77 | 90.76 | 90.76 | |
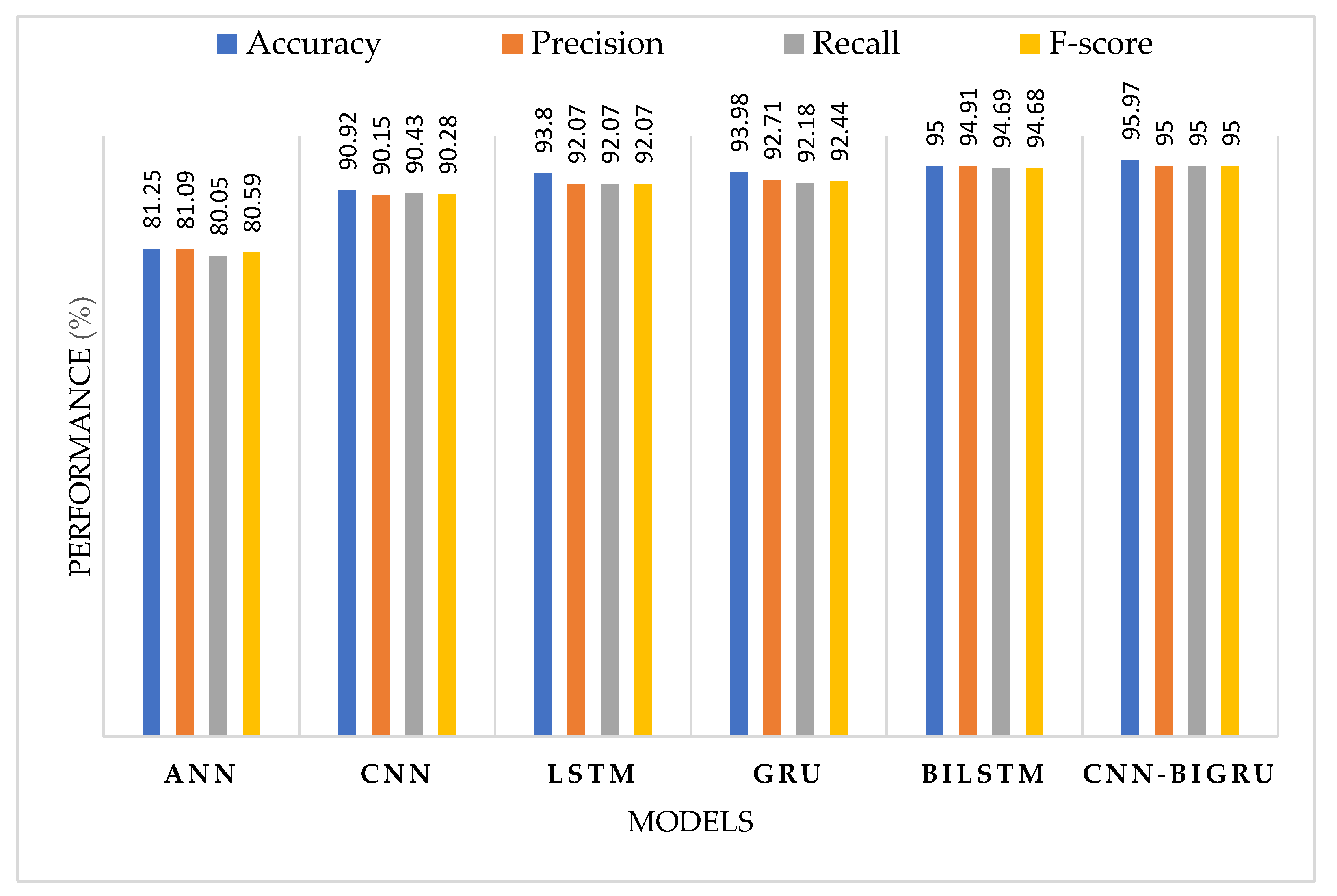
| XAPI | CNN | 90.92 | 90.15 | 90.43 | 90.28 |
| GRU | 93.98 | 92.71 | 92.18 | 92.44 | |
| ANN | 81.25 | 81.09 | 80.05 | 80.59 | |
| LSTM | 93.80 | 92.07 | 92.07 | 92.07 | |
| BiLSTM | 95.00 | 94.91 | 94.69 | 94.68 | |
| CNN-BiGRU | 95.97 | 95.00 | 95.00 | 95.00 |
| Model | Training Time (sec) | Prediction Time (sec) |
|---|---|---|
| ANN | 0.11 | 0.08 |
| CNN | 0.12 | 0.08 |
| LSTM | 0.17 | 0.09 |
| GRU | 0.13 | 0.08 |
| BiLSTM | 0.19 | 0.10 |
| CNN-BiGRU | 0.16 | 0.06 |
| Dataset | T-Statistic | p-Value | Significance |
|---|---|---|---|
| HEI | 3.63 | 0.0221 | Significant (p < 0.05) |
| HESP | 8.58 | 0.0010 | Highly Significant (p < 0.05) |
| XAPI | 3.38 | 0.01 | Significant (p < 0.05) |
| Articles | Year | Model | Dataset | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|---|---|---|
| [2] | 2024 | TMLs | University Data | 96.03 | 94.18 | 98.43 | - |
| [8] | 2024 | TMLs | XAPI, SSP, HESP, & Western-OC2-Lab Data | 75 | 76 | 75 | 74 |
| [21] | 2021 | DNN | XAPI & University Data | 89 | - | 89 | 89 |
| [29] | 2024 | ATTN-ANN | Kyushu University Data | 89.5 | - | - | 83.4 |
| [30] | 2024 | LMA | University Data | 88.6 | 96.3 | 89.6 | 93.3 |
| [32] | 2024 | IC-BTCN | KDD Cup 2015 | 89.3 | 96.5 | 90.5 | 93.4 |
| [33] | 2024 | RNN & LSTM | OULAD | 96.78 | 90.86 | 95.00 | 92.89 |
| Our Work | CNN-BiGRU | 97.48 | 97.12 | 96.95 | 97.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adefemi, K.O.; Mutanga, M.B.; Jugoo, V. Hybrid Deep Learning Models for Predicting Student Academic Performance. Math. Comput. Appl. 2025, 30, 59. https://doi.org/10.3390/mca30030059
Adefemi KO, Mutanga MB, Jugoo V. Hybrid Deep Learning Models for Predicting Student Academic Performance. Mathematical and Computational Applications. 2025; 30(3):59. https://doi.org/10.3390/mca30030059
Chicago/Turabian StyleAdefemi, Kuburat Oyeranti, Murimo Bethel Mutanga, and Vikash Jugoo. 2025. "Hybrid Deep Learning Models for Predicting Student Academic Performance" Mathematical and Computational Applications 30, no. 3: 59. https://doi.org/10.3390/mca30030059
APA StyleAdefemi, K. O., Mutanga, M. B., & Jugoo, V. (2025). Hybrid Deep Learning Models for Predicting Student Academic Performance. Mathematical and Computational Applications, 30(3), 59. https://doi.org/10.3390/mca30030059