
A Bivariate Beta from Gamma Ratios for Determining a Potential Variance Change Point: Inspired from a Process Control Scenario


Abstract
1. Introduction
1.1. Problem Contextualisation
- present and contextualise this problem within the quality control environment;
- follow a systematic approach to build up the distributional foundations from this practical perspective;
- exploratively focus on the development of the (new) resulting bivariate beta distribution;
- compare this model with an existing approach; and
- determine whether and if this is indeed the case, to determine , the location of where the shift in the variance occurred.
- The index variable i ranges from 0 to m: a total of independent rational subgroups or samples.
- At least two samples are needed for a potential shift between them to be possible, therefore we assume .
- The sample size can vary between different samples.
- is necessary since the process mean and variance are both assumed to be unknown and have to be estimated.
- The pooling approach here is to use and r sample means and variances in the construction of the test statistic in Section 1.2. Alternatively one can consider a single mean/variance in this construction, which would result in additional information and such that and probability density functions are valid. In this case, the approach would reduce to a two sample comparison testing for a change in the variance.

1.2. A Solution: Sequential Statistic Framework
- The statistic ’s numerator will contain only sample variances that come from a distribution, whereas the denominator will contain only sample variances that come from a distribution.
- If is some integer value such that , then the statistic will contain sample variances in its numerator that are from a distribution. This will reduce the weighted average of the sample variances of ’s numerator in comparison to the numerator of .
- Similarly, if is some integer value such that , then the statistic will contain sample variances in its denominator that are from a distribution. This will increase the weighted average of sample variances of ’s denominator in comparison to the denominator of .
- Thus, any statistic other than the one immediately following the shift in the process variance, will contain either smaller sample variances in its numerator, or larger sample variances in its denominator (on average). Either of these scenarios result in a high probability that all other statistics are smaller relative to .
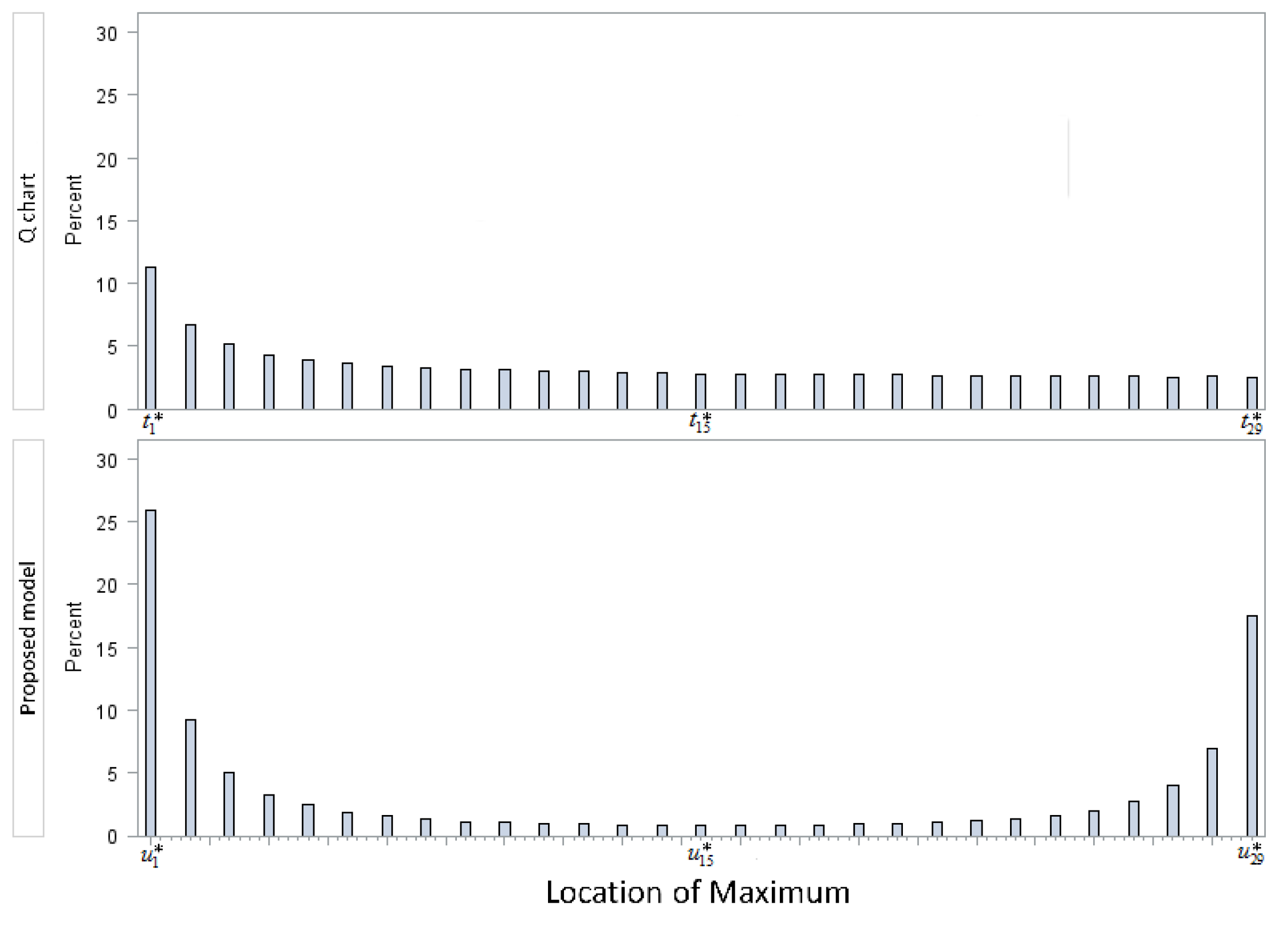
- This leads to the conclusion that the most probable place where an upwards shift in the process variance will be detected is at the statistic immediately following the shift. The value that this statistic assumes also has a high likelihood of being the maximum value of all the statistics.
- As such, the most reasonable method of calculating the critical value to detect an upwards shift in the process variance is to calculate the maximum order statistic of the charting statistics , (under the null hypothesis) and to set the critical value equal to some percentile of the distribution of the maximum order statistic.
1.3. Outline of Paper
2. Proposed Model
2.1. Bivariate Probability Density Function
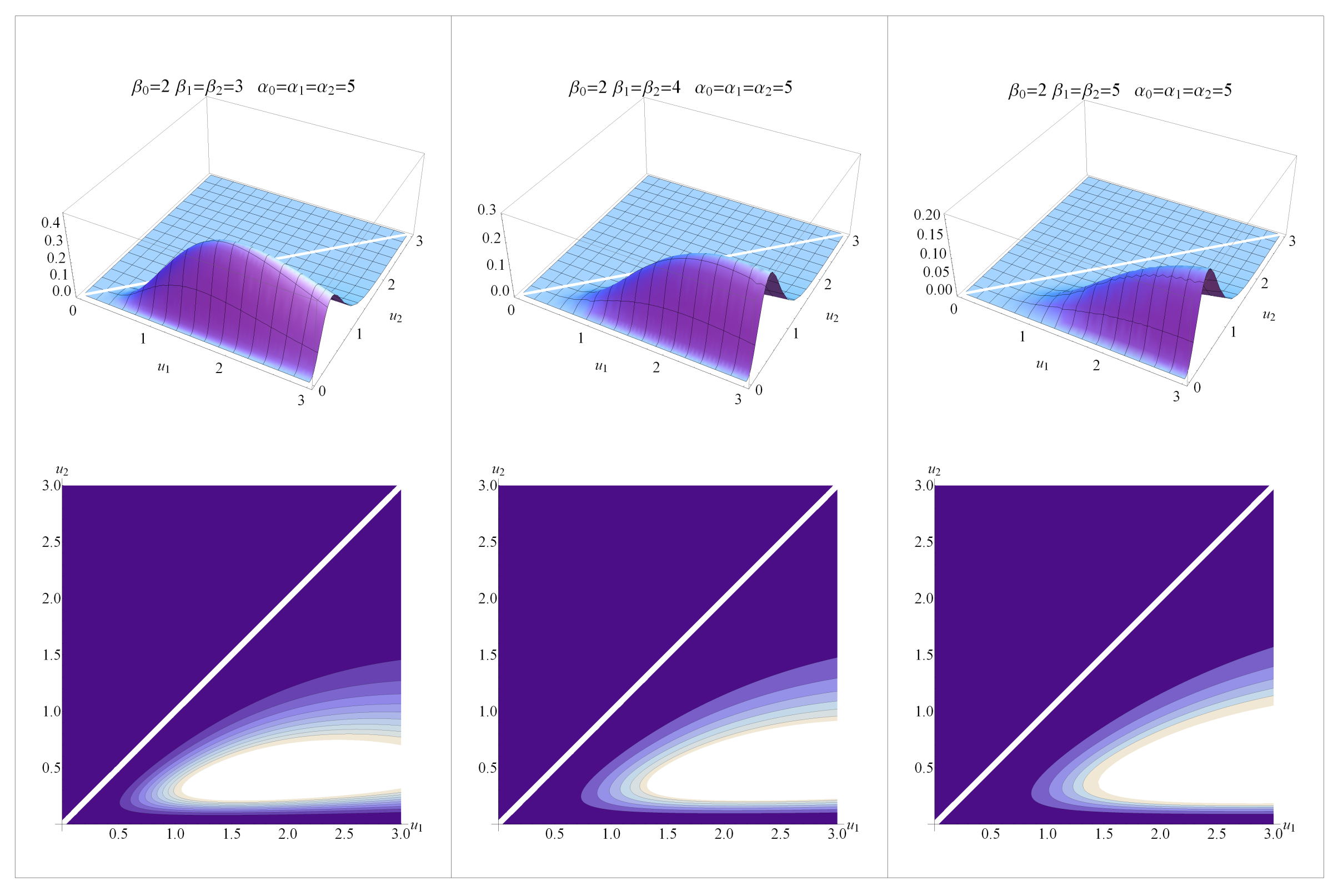
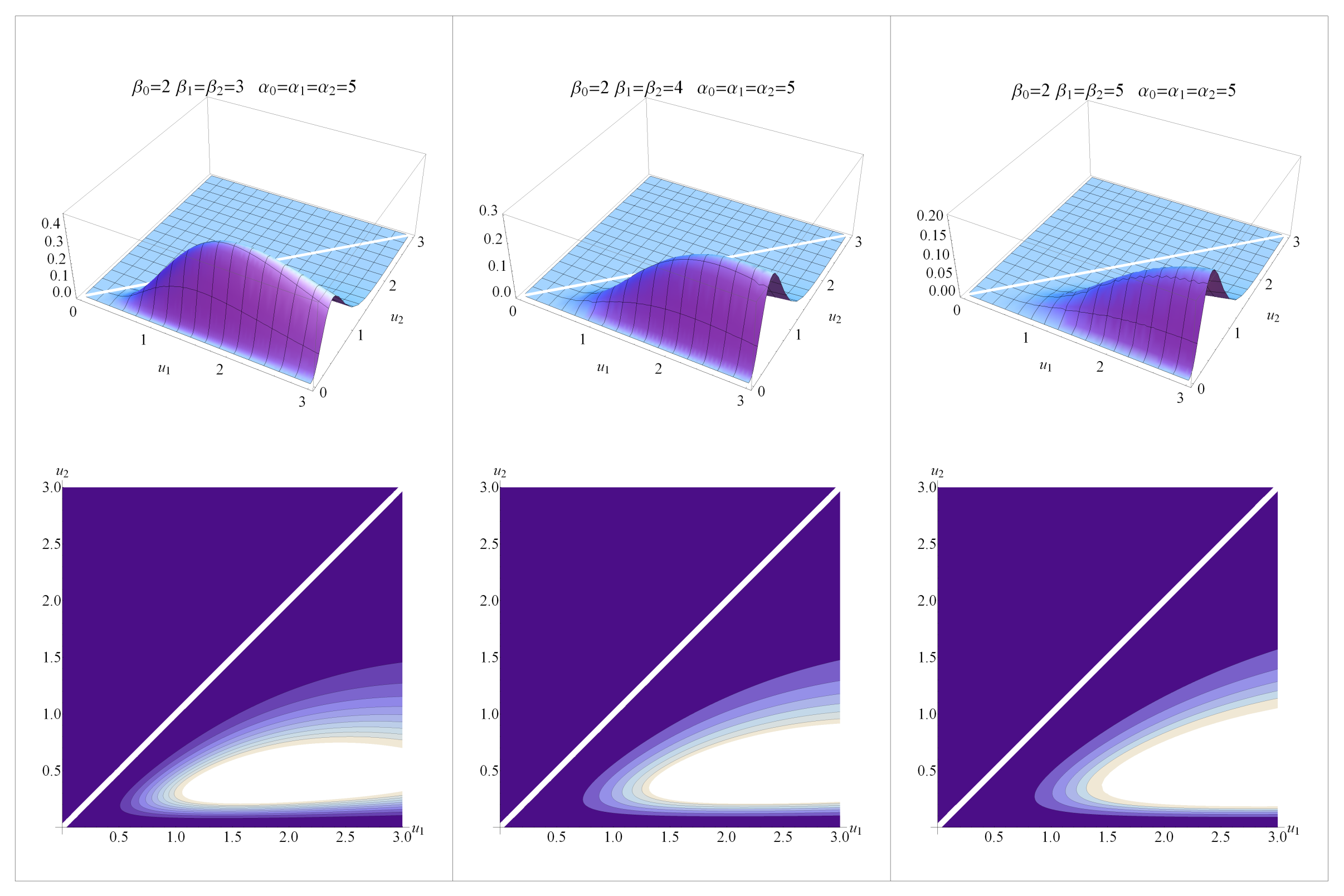
2.2. Shape Analysis
2.3. Marginal Probability Density Functions
2.4. Product Moment and Order Statistics
3. Comparison Study and Discussion
3.1. Comparison When the Process Is in Control
- Since the critical values of the distribution are derived under the assumption of the null hypothesis, the equations for the maximum order statistic can be simplified to be constructed out of chi-square random variables instead of the more complex gamma case.
3.2. Comparisons When the Process Is out of Control
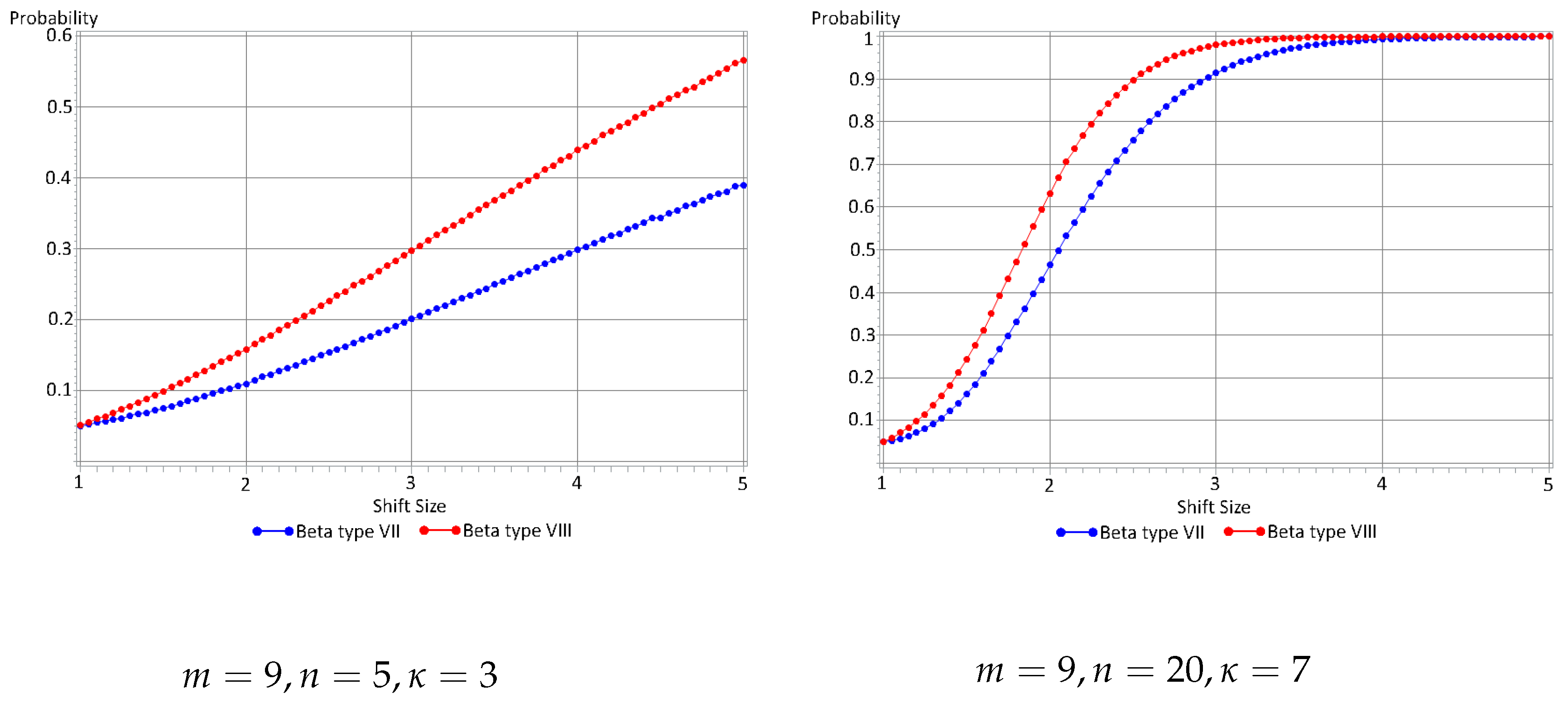
- When , irrespective of the number of samples, the newly proposed model outperforms the Q chart. There are some caveats however that should be noted:
- In the above graphs, each plotted point was simulated 500,000 times during the Monte Carlo process. For all the graphs, the points vary erratically between each 0.05 increases in the shift size, and thus even for a large number of simulations the process cannot be described as “stable”.
- The Q chart seems to be completely incapable of detecting an increase in the process variance when , with the probability of detecting a shift remaining at roughly 5%, irrespective of the size of the shift.
- While the new model’s probability of detecting a shift does increase as the size of the shift increases, it remains relatively low, at roughly 7% to 10%, just marginally higher than the 5% chance when the process is actually IC. This implies that while it might be theoretically possible to implement the new model for samples sizes of 2, it would likely not be a practically useful technique.
- The new model’s probability of detecting a shift does not increase as the number of samples increases, as would be expected (and as is the case for the other choices of n).
- From these points above, it can be concluded that using a sample size of 2 does not lead to an effective control chart.
- For a small numbers of samples , the newly proposed model outperforms the Q chart for all simulated sample sizes as well as locations of shifts (for all shift sizes).
- When there are 20 samples , the newly proposed model outperforms the Q chart in nearly all situations. The Q chart does have a higher probability of detecting a shift in the process variance only when the sample sizes are small , and the shift occurs relatively late in the process , for shifts in the process variance between and . Since a 300% to 475% increase in the process variance is unlikely to occur in practice, the newly proposed model would likely be more effective for .
- For , sweeping statements about the performances of the two methods are more difficult to make since the plotted percentage lines cross often. However it can be said that:
- For small sample sizes , the proposed model outperforms the Q chart for small shifts in the process variance, whereas the Q chart performs better for larger shifts.
- The Q chart performs at its best when the shift in the process variance occurs late in the series of samples.
- For larger sample sizes the proposed model outperforms the Q chart when the shift in the process variance occurs early, but when the shift occurs roughly half way through the series of samples, or further, the performance of the two methods are very similar.
4. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Positioning
- If then has a bivariate beta type II distribution [14].
- If Then has a bivariate beta type V distribution. If and , the bivariate beta type V reduces to the bivariate beta type I [19].
- If then has a bivariate beta type VI distribution. This joint probability density function has not yet been derived in the literature and could potentially be applied to detecting shifts in a process variance.
- If then be referred to as the bivariate beta type VII distribution, ([5]).
- If then has a bivariate beta type VIII distribution. This is the model that this article proposes in terms of gamma variables in Section 2, but in its special case it can be reduced to be constructed from chi-square variables.

Appendix B. Proofs
References
- Bain, L.J.; Engelhardt, M. Introduction to Probability and Mathematical Statistics; Duxbury Press: Belmont, CA, USA, 1992; Volume 4. [Google Scholar]
- Pavlović, D.Č.; Sekulović, N.M.; Milovanović, G.V.; Panajotović, A.S.; Stefanović, M.Č.; Popović, Z.J. Statistics for ratios of Rayleigh, Rician, Nakagami-, and Weibull distributed random variables. Math. Probl. Eng. 2013, 2013, 252804. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Bilankulu, V.; Bekker, A.; Marques, F. The ratio of independent generalized gamma random variables with applications. Comput. Math. Methods 2021, 3, e1061. [Google Scholar] [CrossRef]
- Leonardo, E.J.; da Costa, D.B.; Dias, U.S.; Yacoub, M.D. The ratio of independent arbitrary α-μ random variables and its application in the capacity analysis of spectrum sharing systems. IEEE Commun. Lett. 2012, 16, 1776–1779. [Google Scholar] [CrossRef]
- Adamski, K. Generalised Beta Type II Distributions-Emanating from a Sequential Process. Ph.D. Thesis, University of Pretoria, Pretoria, South Africa, 2013. [Google Scholar]
- Gradshteyn, I.S.; Ryzhik, I.M. Table of Integrals, Series, and Products; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Adamski, K.; Human, S.W.; Bekker, A. A generalized multivariate beta distribution: Control charting when the measurements are from an exponential distribution. Stat. Pap. 2012, 53, 1045–1064. [Google Scholar] [CrossRef]
- Quesenberry, C.P. SPC Q charts for start-up processes and short or long runs. J. Qual. Technol. 1991, 23, 213–224. [Google Scholar] [CrossRef]
- Bekker, A.; Ferreira, J.T.; Human, S.W.; Adamski, K. Capturing a Change in the Covariance Structure of a Multivariate Process. Symmetry 2022, 14, 156. [Google Scholar] [CrossRef]
- David, H.A.; Nagaraja, H.N. Order Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Ferreira, J.T.; Bekker, A.; Marques, F.; Laidlaw, M. An enriched α-μ model as fading candidate. Math. Probl. Eng. 2020, 2020, 5879413. [Google Scholar] [CrossRef]
- Gupta, R.D.; Richards, D.S.P. The history of the Dirichlet and Liouville distributions. Int. Stat. Rev. 2001, 69, 433–446. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Lai, C.D. Continuous Bivariate Distributions; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Tiao, G.G.; Cuttman, I. The inverted Dirichlet distribution with applications. J. Am. Stat. Assoc. 1965, 60, 793–805. [Google Scholar] [CrossRef]
- Cardeno, L.; Nagar, D.K.; Sánchez, L.E. Beta type 3 distribution and its multivariate generalization. Tamsui Oxf. J. Math. Sci. 2005, 21, 225–242. [Google Scholar]
- Ehlers, R. Bimatrix Variate Distributions of Wishart Ratios with Application. Ph.D. Thesis, University of Pretoria, Pretoria, South Africa, 2011. [Google Scholar]
- Jones, M. Multivariate t and beta distributions associated with the multivariate F distribution. Metrika 2002, 54, 215–231. [Google Scholar] [CrossRef]
- Olkin, I.; Liu, R. A bivariate beta distribution. Stat. Probab. Lett. 2003, 62, 407–412. [Google Scholar] [CrossRef]
- Ehlers, R.; Bekker, A.; Roux, J.J. Triply noncentral bivariate beta type V distribution. S. Afr. Stat. J. 2012, 46, 221–246. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| mn | 2 | 5 | 10 | 15 | 20 | 25 | 30 | 50 | 100 | 500 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 214.286 | 6.652 | 3.230 | 2.512 | 2.189 | 1.998 | 1.872 | 1.615 | 1.399 | 1.160 |
| 4 | 242.046 | 6.229 | 3.047 | 2.385 | 2.093 | 1.919 | 1.805 | 1.569 | 1.371 | 1.150 |
| 9 | 254.592 | 5.992 | 2.908 | 2.301 | 2.023 | 1.863 | 1.755 | 1.534 | 1.349 | 1.142 |
| 14 | 251.747 | 5.874 | 2.871 | 2.266 | 1.997 | 1.842 | 1.739 | 1.522 | 1.341 | 1.139 |
| 19 | 255.413 | 5.836 | 2.851 | 2.254 | 1.987 | 1.831 | 1.730 | 1.517 | 1.337 | 1.137 |
| 24 | 257.880 | 5.813 | 2.837 | 2.243 | 1.980 | 1.827 | 1.723 | 1.514 | 1.335 | 1.137 |
| 29 | 259.105 | 5.815 | 2.824 | 2.238 | 1.977 | 1.822 | 1.720 | 1.512 | 1.334 | 1.136 |
| 49 | 259.963 | 5.799 | 2.818 | 2.228 | 1.968 | 1.815 | 1.715 | 1.508 | 1.331 | 1.135 |
| 99 | 258.810 | 5.797 | 2.803 | 2.222 | 1.959 | 1.811 | 1.710 | 1.504 | 1.329 | 1.134 |
| 499 | 263.017 | 5.772 | 2.801 | 2.215 | 1.957 | 1.808 | 1.707 | 1.501 | 1.328 | 1.133 |
| mn | 2 | 5 | 10 | 15 | 20 | 25 | 30 | 50 | 100 | 500 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 399.762 | 12.091 | 5.933 | 4.638 | 4.072 | 3.735 | 3.513 | 3.062 | 2.688 | 2.275 |
| 4 | 1151.103 | 29.015 | 14.061 | 11.045 | 9.708 | 8.958 | 8.434 | 7.411 | 6.553 | 5.618 |
| 9 | 2413.470 | 57.222 | 27.649 | 21.699 | 19.101 | 17.623 | 16.615 | 14.615 | 12.984 | 11.184 |
| 14 | 3691.861 | 85.496 | 41.144 | 32.376 | 28.469 | 26.292 | 24.837 | 21.864 | 19.419 | 16.754 |
| 19 | 4944.966 | 112.744 | 54.656 | 43.071 | 37.870 | 34.913 | 33.020 | 29.081 | 25.816 | 22.318 |
| 24 | 6187.147 | 141.315 | 68.325 | 53.653 | 47.313 | 43.549 | 41.182 | 36.293 | 32.248 | 27.887 |
| 29 | 7528.303 | 170.174 | 81.753 | 64.408 | 56.621 | 52.313 | 49.397 | 43.531 | 38.678 | 33.457 |
| 49 | 12,560.904 | 281.708 | 135.824 | 107.163 | 94.200 | 86.900 | 82.168 | 72.395 | 64.349 | 55.728 |
| 99 | 25,774.144 | 565.834 | 270.688 | 213.065 | 187.991 | 173.740 | 164.160 | 144.638 | 128.625 | 111.365 |
| 499 | 126,434.246 | 2815.186 | 1353.458 | 1064.841 | 939.259 | 868.035 | 819.248 | 722.038 | 642.752 | 556.808 |
| Methodn | 2 | 5 | 10 | 15 | 20 | 25 | 30 | 50 | 100 | 500 |
|---|---|---|---|---|---|---|---|---|---|---|
| Simulated values | 399.762 | 12.091 | 5.933 | 4.638 | 4.072 | 3.735 | 3.513 | 3.062 | 2.688 | 2.275 |
| Theoretical values | 399.000 | 12.083 | 5.920 | 4.640 | 4.068 | 3.735 | 3.515 | 3.064 | 2.688 | 2.276 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Human, S.W.; Bekker, A.; Ferreira, J.T.; Mijburgh, P.A. A Bivariate Beta from Gamma Ratios for Determining a Potential Variance Change Point: Inspired from a Process Control Scenario. Math. Comput. Appl. 2022, 27, 61. https://doi.org/10.3390/mca27040061
Human SW, Bekker A, Ferreira JT, Mijburgh PA. A Bivariate Beta from Gamma Ratios for Determining a Potential Variance Change Point: Inspired from a Process Control Scenario. Mathematical and Computational Applications. 2022; 27(4):61. https://doi.org/10.3390/mca27040061
Chicago/Turabian StyleHuman, Schalk W., Andriette Bekker, Johannes T. Ferreira, and Philip Albert Mijburgh. 2022. "A Bivariate Beta from Gamma Ratios for Determining a Potential Variance Change Point: Inspired from a Process Control Scenario" Mathematical and Computational Applications 27, no. 4: 61. https://doi.org/10.3390/mca27040061
APA StyleHuman, S. W., Bekker, A., Ferreira, J. T., & Mijburgh, P. A. (2022). A Bivariate Beta from Gamma Ratios for Determining a Potential Variance Change Point: Inspired from a Process Control Scenario. Mathematical and Computational Applications, 27(4), 61. https://doi.org/10.3390/mca27040061