ssMousetrack—Analysing Computerized Tracking Data via Bayesian State-Space Models in R


Abstract
1. Introduction
2. Model
- (i)
- -scaled logistic function:with representing the contribution of the stimuli on .
- (ii)
- -scaled Gompertz function:where has the same meaning as before.
2.1. Estimation and Inference
2.2. Model Assessment
3. The ssMousetrack Package
3.1. Generate Artificial Data
- params, which contains the model parameters generated for the M datasets:## List of 4## $ sigmax: num [1:2] 1 1## $ lambda: num [1:12] 1 1 1 1 1 ...## $ gamma : num [1:75, 1:2] 0.228 -0.378 ...## $ beta : num [1:75, 1:12] 0.228 -0.378 ...
- data, which contains the matrices of latent states and trajectories , together with , , and :## List of 5## $ Y : num [1:75, 1:61, 1:12] 1.54 1.53 ...## $ X : num [1:75, 1:61, 1:2] 1e-04 1e-04 1e-04 1e-04 1e-04 ...## $ MU: num [1:75, 1:61, 1:12] 1.57 1.57 ...## $ D : num [1:75, 1:61, 1:12] 0.785 0.785 ...## $ Z : num [1:12, 1:2] 1 1 1 1 1 ...
- design, which contains the experimental design used as template to generate the data:## sbj trial Z1## 1 1 1 100## 2 1 2 100## 3 1 3 100
3.2. Run State-Space Analysis
- params, which contains the posterior samples for the free parameters and :## List of 6## $ sigmax : num 1## $ lambda : num 1## $ kappa_bnds: num [1:2] 5 300## $ gamma :’data.frame’: 4000 obs. of 4 variables:## $ beta : num [1:4000, 1:60] -0.26 -0.146 ...## $ :function (z, ...)
- data, which contains the posterior samples for the latent states and the moving means :## List of 6## $ Y : num [1:101, 1:60] 1.56 1.7 ...## $ X : num [1:4000, 1:101, 1:5] 1e-04 1e-04 1e-04 1e-04 1e-04 ...## $ MU : num [1:4000, 1:101, 1:60] 1.76 1.68 ...## $ D : num [1:101, 1:60] 0.592 0.474 ...## $ Z : num [1:60, 1:4] 1 1 1 1 1 ...## $ X_smooth: num [1:4000, 1:101, 1:5] -0.0878 -0.0635 ...
- stan_table, containing the typical Stan output (i.e., point estimates, credibility intervals, and Gelman–Rubin index) for the sampling() method as implemented in the rstan package:## mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat## gamma[1] -0.05 0 0.19 -0.43 -0.18 -0.05 0.08 0.33 3047 1## gamma[2] -0.02 0 0.06 -0.13 -0.06 -0.02 0.02 0.09 2764 1## gamma[3] 0.16 0 0.06 0.04 0.12 0.16 0.20 0.28 2782 1
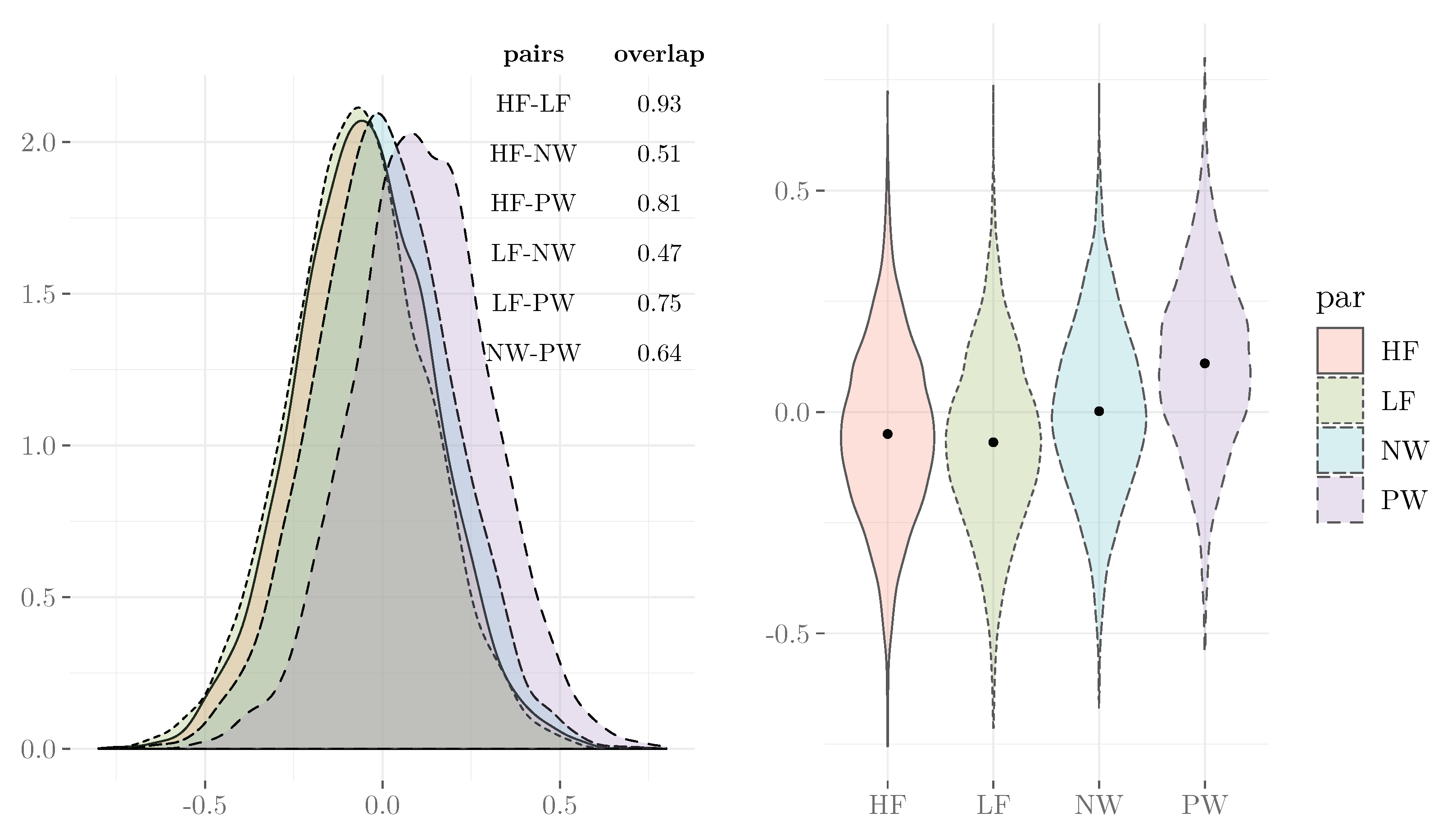
3.3. Evaluate the Model Results
4. Application
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Freeman, J.B.; Ambady, N. Software for studying real-time mental processing using a computer mouse-tracking method. Behav. Res. Methods 2010, 42, 226–241. [Google Scholar] [CrossRef] [PubMed]
- Michael Schulte-Mecklenbeck, A.K.; Johnson, J.G. A Handbook of Process Tracing Methods, 2nd ed.; Routledge: New York, NY, USA, 2019. [Google Scholar]
- Freeman, J.B. Doing psychological science by hand. Curr. Dir. Psychol. Sci. 2018, 27, 315–323. [Google Scholar] [CrossRef] [PubMed]
- Coco, M.I.; Duran, N.D. When expectancies collide: Action dynamics reveal the interaction between stimulus plausibility and congruency. Psychon. Bull. Rev. 2016, 23, 1920–1931. [Google Scholar] [CrossRef][Green Version]
- Stolier, R.M.; Freeman, J.B. A neural mechanism of social categorization. J. Neurosci. 2017, 37, 5711–5721. [Google Scholar] [CrossRef]
- Ruitenberg, M.F.; Duthoo, W.; Santens, P.; Seidler, R.D.; Notebaert, W.; Abrahamse, E.L. Sequence learning in Parkinson’s disease: Focusing on action dynamics and the role of dopaminergic medication. Neuropsychologia 2016, 93, 30–39. [Google Scholar] [CrossRef]
- Monaro, M.; Gamberini, L.; Sartori, G. The detection of faked identity using unexpected questions and mouse dynamics. PLOS ONE 2017, 12, e0177851. [Google Scholar] [CrossRef]
- Calcagnì, A.; Lombardi, L.; Sulpizio, S. Analyzing spatial data from mouse tracker methodology: An entropic approach. Behav. Res. Methods 2017, 49, 2012–2030. [Google Scholar] [CrossRef]
- Kieslich, P.J.; Henninger, F. Mousetrap: An integrated, open-source mouse-tracking package. Behav. Res. Methods 2017, 49, 1652–1667. [Google Scholar] [CrossRef] [PubMed]
- Coco, M.; Duran, N. mousetrack: Process and Analyze Mouse-Tracking Data. Available online: https://cran.r-project.org/web/packages/mousetrack/ (accessed on 9 July 2020).
- Kieslich, P.; Henninger, F.; Wulff, D.U.; Haslbeck, J.M.B.; Schulte-Mecklenbeck, M. Mouse-tracking: A practical guide to implementation and analysis. In A Handbook of Process Tracing Methods; Schulte-Mecklenbeck, M., Ed.; Routledge: New York, NY, USA, 2019. [Google Scholar]
- Pebesma, E.; Klus, B. trajectories: Classes and Methods for Trajectory Data. Available online: https://cran.r-project.org/web/packages/trajectories/ (accessed on 9 July 2020).
- Frick, H.; Kosmidis, I. trackeR: Infrastructure for Running and Cycling Data from GPS-Enabled Tracking Devices. Available online: https://cran.r-project.org/web/packages/tracker/ (accessed on 9 July 2020).
- Calenge, C. The package adehabitat for the R software: A tool for the analysis of space and habitat use by animals. Ecol. Model. 2006, 197, 516–519. [Google Scholar] [CrossRef]
- Kranstauber, B.; Smolla, M.; Scharf, A. move: Visualizing and Analyzing Animal Track Data. Available online: https://cran.r-project.org/web/packages/move/ (accessed on 9 July 2020).
- Helske, J. KFAS: Exponential Family State Space Models in R. J. Stat. Softw. 2017, 78. [Google Scholar] [CrossRef]
- Helske, J.; Vihola, M. bssm: Bayesian Inference of Non-Linear and Non-Gaussian State Space Models. Available online: https://cran.r-project.org/web/packages/bssm/ (accessed on 9 July 2020).
- King, A.A.; Nguyen, D.; Ionides, E.L. Statistical Inference for Partially Observed Markov Processes via the R Package pomp. J. Stat. Softw. 2016, 69, 1–43. [Google Scholar] [CrossRef]
- Jacob, P.E.; Anthony Lee, L.M.M.S.F.; Abbott, S. rbi: Interface to LibBi. Available online: https://cran.r-project.org/web/packages/rbi/ (accessed on 9 July 2020).
- Calcagnì, A.; Lombardi, L.; D’Alessandro, M.; Freuli, F. A state space approach to dynamic modeling of mouse-tracking data. Front. Psychol. 2019, 10, 2716. [Google Scholar] [CrossRef] [PubMed]
- Stan, D.T. rstan: The R interface to Stan. Available online: https://cran.r-project.org/web/packages/rstan (accessed on 9 July 2020).
- Stan, D.T. shinystan: Interactive Visual and Numerical Diagnostics and Posterior Analysis for Bayesian Models. Available online: https://cran.r-project.org/web/packages/shinystan (accessed on 9 July 2020).
- Xavier, F.i.M. ggmcmc: Tools for Analyzing MCMC Simulations from Bayesian Inference. Available online: https://cran.r-project.org/web/packages/ggmcmc (accessed on 9 July 2020).
- Hehman, E.; Stolier, R.M.; Freeman, J.B. Advanced mouse-tracking analytic techniques for enhancing psychological science. Group Process. Intergr. Relat. 2015, 18, 384–401. [Google Scholar] [CrossRef]
- McNeish, D.; Dumas, D. Nonlinear growth models as measurement models: A second-order growth curve model for measuring potential. Multivar. Behav. Res. 2017, 52, 61–85. [Google Scholar] [CrossRef] [PubMed]
- Brockwell, A.E.; Rojas, A.L.; Kass, R. Recursive Bayesian decoding of motor cortical signals by particle filtering. J. Neurophysiol. 2004, 91, 1899–1907. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications: With R Examples; Springer Science & Business Media: New York, NY, USA, 2006. [Google Scholar]
- Andrieu, C.; Doucet, A.; Holenstein, R. Particle markov chain monte carlo methods. J. R. Stat. Soc. B Stat. Methodol. 2010, 72, 269–342. [Google Scholar] [CrossRef]
- Särkkä, S. Bayesian Filtering and Smoothing; Cambridge University Press: Cambridge, UK, 2013; Volume 3. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; CRC Press: Boca Raton, FL, USA, 2014; Volume 2. [Google Scholar]
- Kruschke, J. Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Kamil, A.A. Bayesian approach for robust parameter tracking. Electron. J. Appl. Stat. Anal. 2008, 1, 24–32. [Google Scholar]
- Bhattacharjee, S.; Das, K.K. Estimation of circular-circular probability distribution. Electron. J. Appl. Stat. Anal. 2018, 11, 155–167. [Google Scholar]
- Kiers, H.A. Techniques for rotating two or more loading matrices to optimal agreement and simple structure: A comparison and some technical details. Psychometrika 1997, 62, 545–568. [Google Scholar] [CrossRef]
- Giorgino, T. Computing and visualizing dynamic time warping alignments in R: The dtw package. J. Stat. Softw. 2009, 31, 1–24. [Google Scholar] [CrossRef]
- Gabry, J.; Simpson, D.; Vehtari, A.; Betancourt, M.; Gelman, A. Visualization in Bayesian workflow. J. R. Stat. Soc. Stat. Soc. 2019, 182, 389–402. [Google Scholar] [CrossRef]
- Gabry, J.; Mahr, T. bayesplot: Plotting for Bayesian Models. Available online: https://cran.r-project.org/web/packages/bayesplot (accessed on 9 July 2020).
- Carpenter, B.; Gelman, A.; Hoffman, M.D.; Lee, D.; Goodrich, B.; Betancourt, M.; Brubaker, M.; Guo, J.; Li, P.; Riddell, A. Stan: A probabilistic programming language. J. Stat. Softw. 2017, 76. [Google Scholar] [CrossRef]
- Barca, L.; Pezzulo, G. Unfolding visual lexical decision in time. PLOS ONE 2012, 7, e35932. [Google Scholar] [CrossRef] [PubMed]
- Pastore, M. Overlapping: A R package for Estimating Overlapping in Empirical Distributions. J. Open Source Softw. 2018, 3, 1023. [Google Scholar] [CrossRef]
- Murray, L.M. Bayesian State-Space Modelling on High-Performance Hardware Using LibBi. J. Stat. Softw. 2015, 67. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Type | Description |
|---|---|---|
| generate_data() | main | simulate data according to a user-defined experimental design. |
| run_ssm() | main | run state-space model on a given mouse-tracking dataset. |
| check_prior() | main | allows users to define a list of priors for prior running run_ssm(). |
| prepare_data() | main | pre-process raw tracking data prior running run_ssm(). |
| evaluate_ssm() | main | run model evaluation given an output of run_ssm(). The function can plot results if requested by users. |
| compute_D() | internal | compute the matrix of distances given the observed data (see Equation (5)). |
| generate_Z() | internal | generate the Boolean trial-by-variable (design) matrix (see Equation (4)). |
| generate_design() | internal | allows users to specify an experimental design in terms individuals, trials, variables, and design matrix . |
| congruency | dataset | subset of data from Reference [4]. |
| language | dataset | subset of data from Reference [39]. |
| Mean | sd | 25% | 50% | 75% | n_eff | Rhat | |
|---|---|---|---|---|---|---|---|
| gamma1 | 0.19 | 0.08 | 3047.00 | 1.00 | |||
| gamma2 | 0.06 | 0.02 | 2764.00 | 1.00 | |||
| gamma3 | 0.16 | 0.06 | 0.12 | 0.16 | 0.20 | 2782.00 | 1.00 |
| gamma4 | 0.05 | 0.06 | 0.01 | 0.05 | 0.09 | 2680.00 | 1.00 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calcagnì, A.; Pastore, M.; Altoé, G. ssMousetrack—Analysing Computerized Tracking Data via Bayesian State-Space Models in R. Math. Comput. Appl. 2020, 25, 41. https://doi.org/10.3390/mca25030041
Calcagnì A, Pastore M, Altoé G. ssMousetrack—Analysing Computerized Tracking Data via Bayesian State-Space Models in R. Mathematical and Computational Applications. 2020; 25(3):41. https://doi.org/10.3390/mca25030041
Chicago/Turabian StyleCalcagnì, Antonio, Massimiliano Pastore, and Gianmarco Altoé. 2020. "ssMousetrack—Analysing Computerized Tracking Data via Bayesian State-Space Models in R" Mathematical and Computational Applications 25, no. 3: 41. https://doi.org/10.3390/mca25030041
APA StyleCalcagnì, A., Pastore, M., & Altoé, G. (2020). ssMousetrack—Analysing Computerized Tracking Data via Bayesian State-Space Models in R. Mathematical and Computational Applications, 25(3), 41. https://doi.org/10.3390/mca25030041