1. Introduction
Many applications require the solution of partial differential equations (PDEs). Frequently, these are solved by Finite Element Methods (FEM), or related approaches like Isogeometric Analysis, which discretize the continuous PDE. To obtain accurate solutions, we eventually need to solve huge linear systems of equations. This may become a challenging task since the computational effort increases rapidly. Hence, solvers that are able to handle large-scale linear systems are required. This gives rise to specialized solvers, that are adapted towards a specific PDE. In this work, we focus on efficient parallel solvers for problems in phase-field fracture (PFF) propagation.
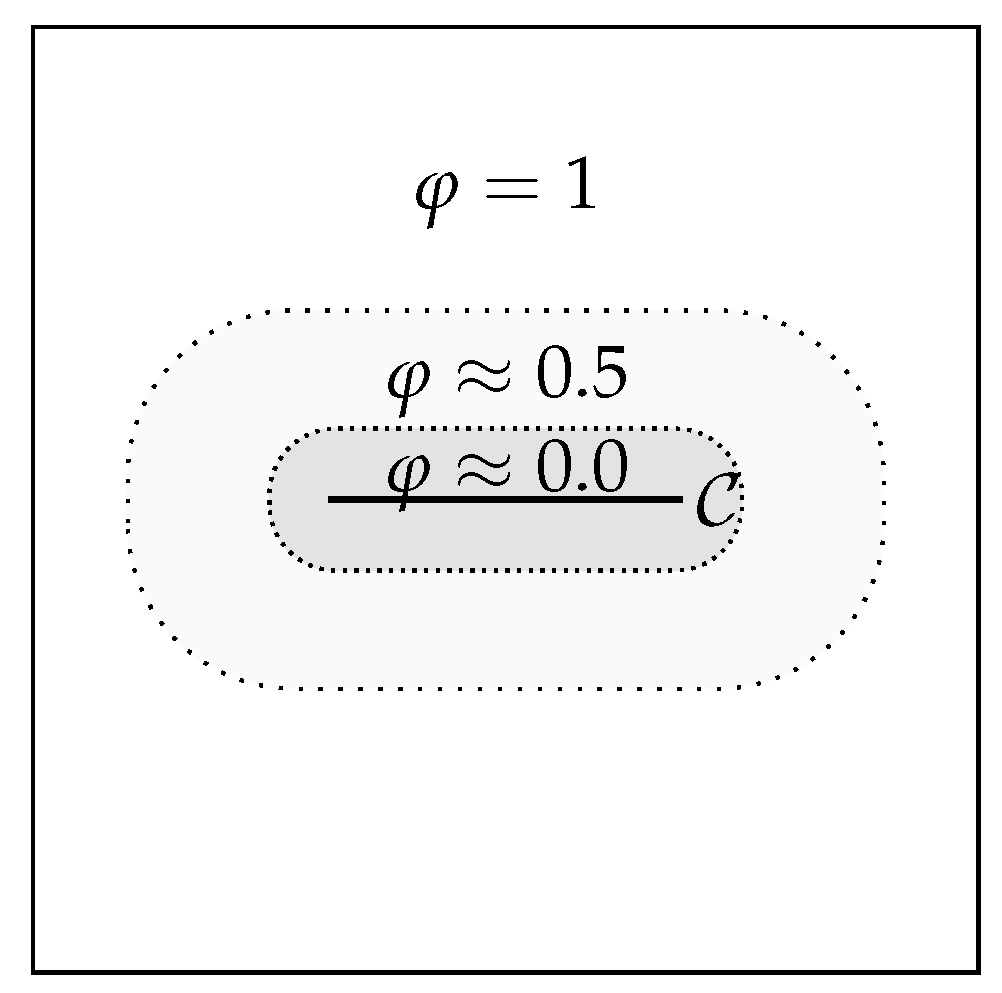
The origin of crack modeling dates back to Griffith [
1] in 1921, who proposed the first model for fractures in brittle materials. The phase-field approach we are using was developed by Francfort and Marigo [
2], who put the fracture model in an energy minimization context. Therein, the originally low-dimension crack is approximated by means of a continuous phase-field function. The PFF model was extended in [
3,
4,
5] by decomposing the stress terms into tensile and compressive parts. However, the physically correct way to do this splitting is disputed within the fracture community. Examples exist where either one or the other method is superior. There has been developed a multitude of further extensions of the original model, e.g., to pressure-driven fractures [
6,
7,
8] in porous-media [
9,
10,
11,
12], multi-physics [
13] and many more; see also the survey papers [
14,
15,
16] and the monograph [
17].
PFF problems have the advantage that they reduce to a system of PDEs, which can be solved by adapting well-known strategies. On the other hand, a smooth approximation of an originally sharp fracture comes with some drawbacks, e.g., crack-length computation or interface boundary conditions along the fracture. There exist different approaches than PFF that allow treatment of sharp cracks, e.g., [
18,
19,
20].
The numerical solution of PFF problems is particularly challenging, mainly due to the so-called no-heal condition. This ensures that a crack does not regenerate itself. Mathematically, this leads to an additional variational inequality. The solution gets further complicated by the non-convexity of the underlying energy functionals. Many different approaches have been proposed in the literature to handle PFF; see, e.g., [
21,
22,
23,
24,
25]. In this work, we use the primal-dual active-set method, a version of the semi-smooth Newton method [
26], which was applied to PFF in [
24].
The most time consuming part in the simulation of PDEs is the solution of the arising linear systems of equations. In the context of nonlinear PDEs, these appear after linearization within Newton’s algorithm, or similar linearization approaches. Hence, multiple linear systems need to be solved per simulation step. For increasing problem sizes, this becomes a severe bottleneck, and well optimized solvers are required. In [
27], we present a solver based on the matrix-free framework of the C++ FEM library deal.II [
28]. Matrix-free methods avoid storing the huge linear system, which can become a real issue in terms of memory consumption. Further strategies treating the linear systems in phase-field fracture are presented in [
24,
29,
30]. However, we notice that a competitive parallel linear solver was only presented in [
30] to date. Therein, an algebraic multigrid (AMG) based solver with a block-diagonal preconditioner was employed. In regard to parallel matrix-free solutions, the closest work is the very recently published study [
31] for finite-strain hyperelasticity. However, the implementation of the lastly mentioned solver to phase-field fracture (i.e., a nonlinear coupled problem with inequality constraints) is novel to the best of our knowledge.
To solve the linear systems, we use the iterative Generalized Minimum Residual (GMRES) method. Like many iterative solvers, this only requires matrix-vector multiplications, which can be carried out without assembling the matrix beforehand. To accelerate convergence, we employ a geometric multigrid (GMG) preconditioner with Chebyshev-Jacobi smoother. Again, all components of the GMG (level transfer, coarse operators, smoother) can be executed without explicit access to the matrix entries. For the Jacobi part, we additionally require the inverse diagonal of the matrix, which can be efficiently precomputed and stored also in the matrix-free context.
Matrix-free approaches are particularly favorable for high-polynomial degree shape-functions. In these cases, the number of non-zero entries per row within the sparse-matrix grows. This increases the storage cost per dof and also the computational effort of the sparse-matrix-vector multiplication (SpMV). On the other hand, matrix-free methods are less affected by higher polynomial degrees. These approaches originate from the field of spectral methods [
32,
33], where high-order ansatz functions are used.
The goal of this paper is a GMG preconditioned, matrix-free parallel primal-dual active-set method for nonlinear problems with inequality constraints, i.e., in our case, PFF. Moreover, we extend our previous work [
27] to higher-order polynomial degrees. First, we are interested in the distributed solution of the whole problem. Therein, the computational work is split across multiple CPUs (ranks), each with its own independent memory. Necessary data exchange among CPUs is done using the Message Passing Interface (MPI). Using multiple CPUs gives us the possibility to fit larger problems into memory, as each core only stores small, almost independent parts of computational domain. All cores run in parallel, resulting in faster computations. Secondly, we explicitly utilize vector instruction sets provided by modern CPUs. These are special instructions for the CPU that are capable of performing multiple computations at once. This is more thoroughly described in
Section 4.2.
In addition to the previously mentioned developments, we compare the performance of the AMG-based solver by [
30] and the matrix-free geometric multigrid from our previous work [
27]. Both approaches as well as the treatment of the nonlinearities are given in
Section 3. In
Section 6, we compare both approaches with respect to (wrt) computational time, memory consumption and parallel efficiency. Details on the parallelization are presented in
Section 4. We focus on dependence on the polynomial degree of the finite elements. For studies regarding
h-dependence, we refer to the respective papers.
Section 5 describes the numerical examples and compares the results to those found in the literature to validate our implementations. Details on the phase-field model are briefly described in
Section 2, for more information we refer to the corresponding literature. We also added a discussion on the derivative of the eigensystem in
Section 3.5.
6. Performance Studies
In the upcoming subsections, we compare our matrix-free version with the AMG based preconditioner described in [
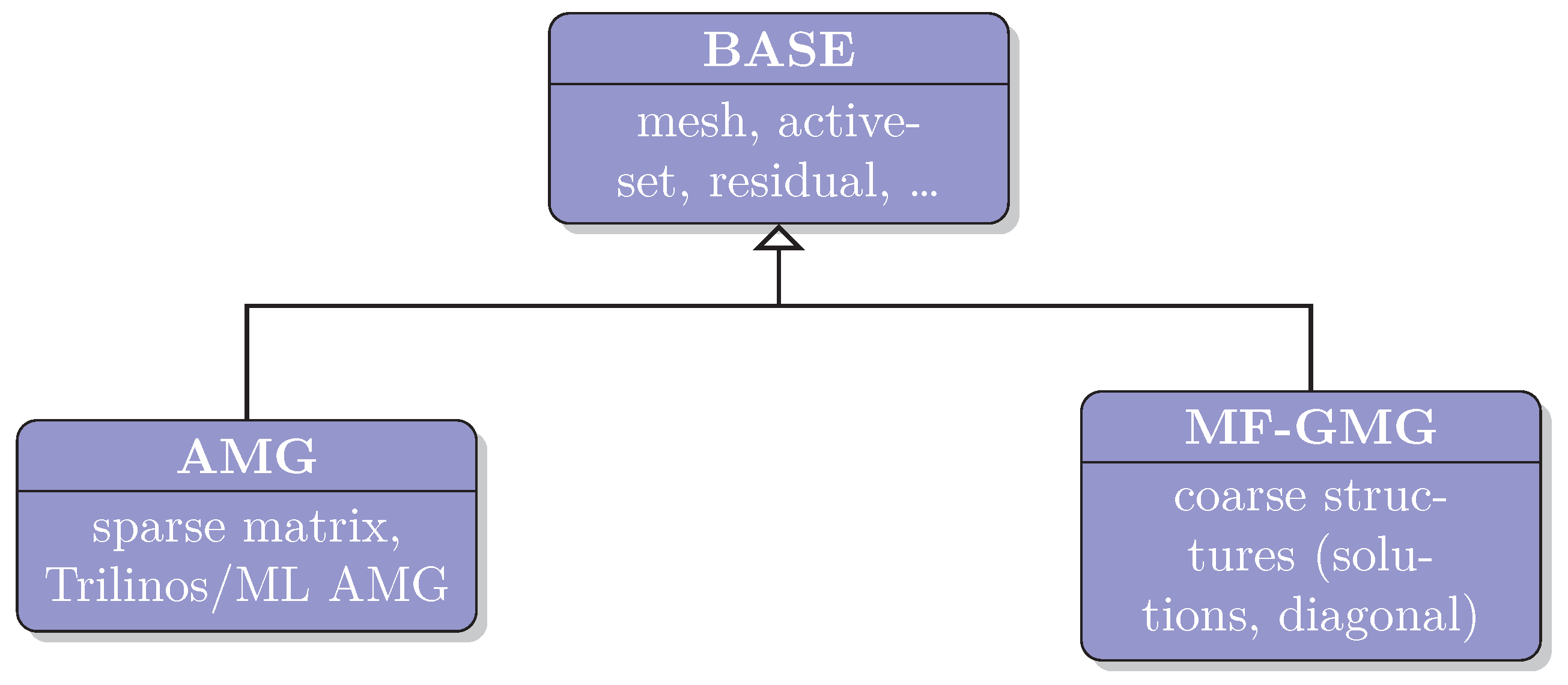
30] in terms of iteration counts, memory requirements, computational time and scalability. We would like to point out that most of the code is shared between the two implementations, i.e., only the parts related to handle the linear system differ, as visualized in
Figure 7. This allows for a fair comparison of the results.
6.1. Memory Requirements
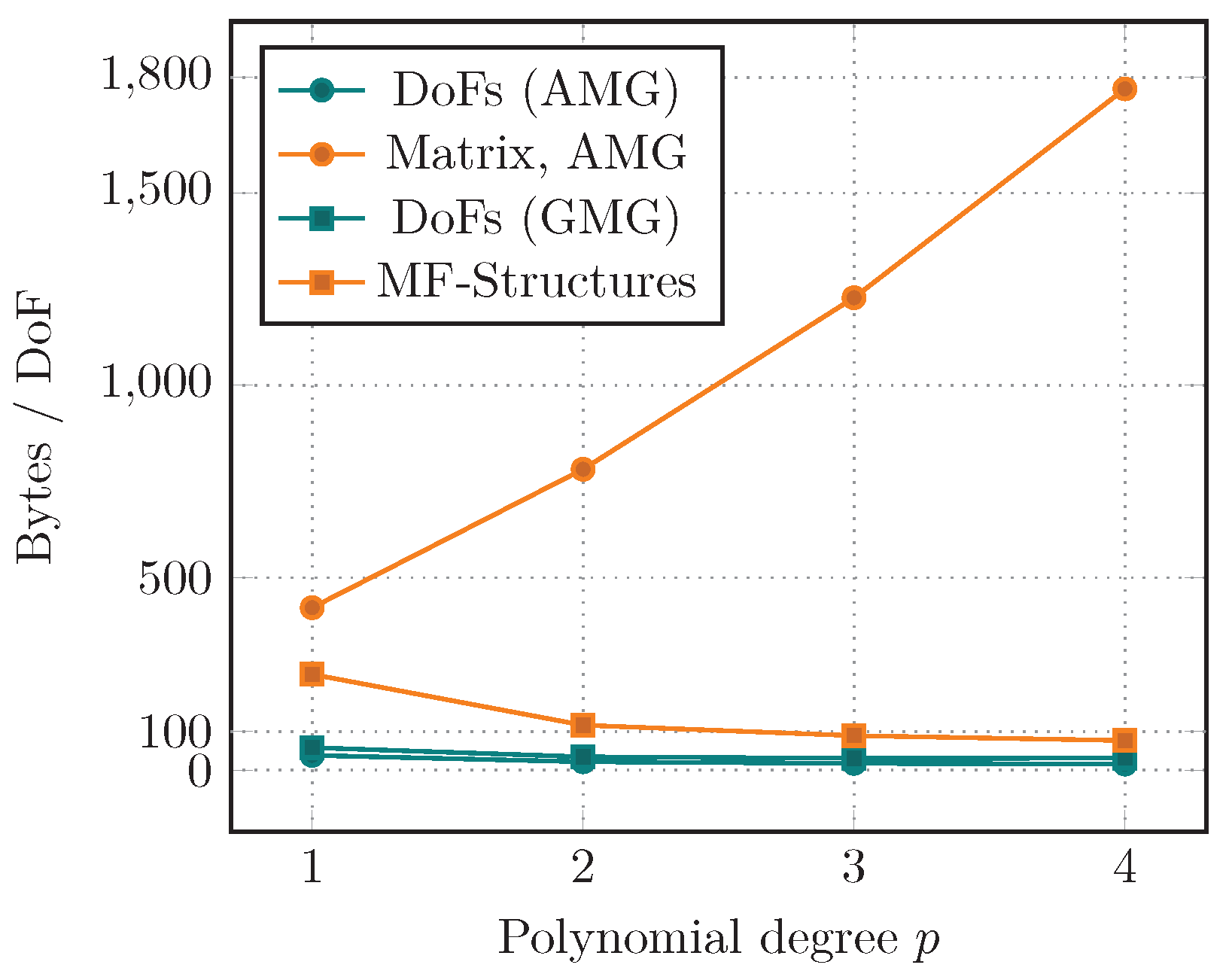
We start by investigating the memory requirements of the two approaches, which should be an obvious advantage of the matrix-free framework. Due to the required multigrid dofs for the geometric multigrid, the dof structures require slightly more memory compared to the AMG version. This is more than compensated by larger storage requirements of the sparse matrix and AMG hierarchies compared to the multilevel matrix-free structures in the GMG implementation. In particular for high-order polynomial degrees p, the sparse matrix gets increasingly dense, leading to huge memory costs. In fact, the number of non-zero entries per row (dof) increases as . Unlike that, the cost for a dof within the matrix-free approach is almost independent of p.
All these effects are shown in
Figure 8 for varying polynomial degree
p. There, the average storage requirements per dof are visualized for several quantities:
DoFs (AMG): handling of dofs on the fine level;
Matrix, AMG: both the sparse-matrix and the AMG preconditioner;
DoFs (GMG): handling of dofs including multigrid levels;
MF-Structures: all necessary matrix-free and GMG structures.
Estimates on memory consumption are provided by objects from deal.II, as well as the AMG solver by ML. For a degree of 4, we save approximately a factor of 20 in terms of memory. These results are shown for a 2d test case. In 3d, this gap would even be more prominent.
6.2. Iteration Counts
Next, we have a look at the number of iterations required to solve the arising linear systems of equations. We would like to point out that these counts are highly dependent on the actual settings used, i.e., which simulation is run, selected number of smoothing steps, coarse level and further parameters. For the AMG solver, we use the Trilinos package ML [
64], with Chebyshev–Jacobi smoother of degree 2, an aggregation threshold of
, damping
and maximum coarse problem size of 2000. The GMG uses
as coarse grid, i.e., 16 elements, and five Chebyshev–Jacobi smoothing sweeps. Increasing the number of smoothing steps would decrease the number of iterations. Finding a good balance between smoothing quality and iteration count to obtain the best performance is a very challenging task, which we did not consider in detail by now. In all our simulations, we use relative convergence criteria of
for the linear solver and
for the active-set strategy.
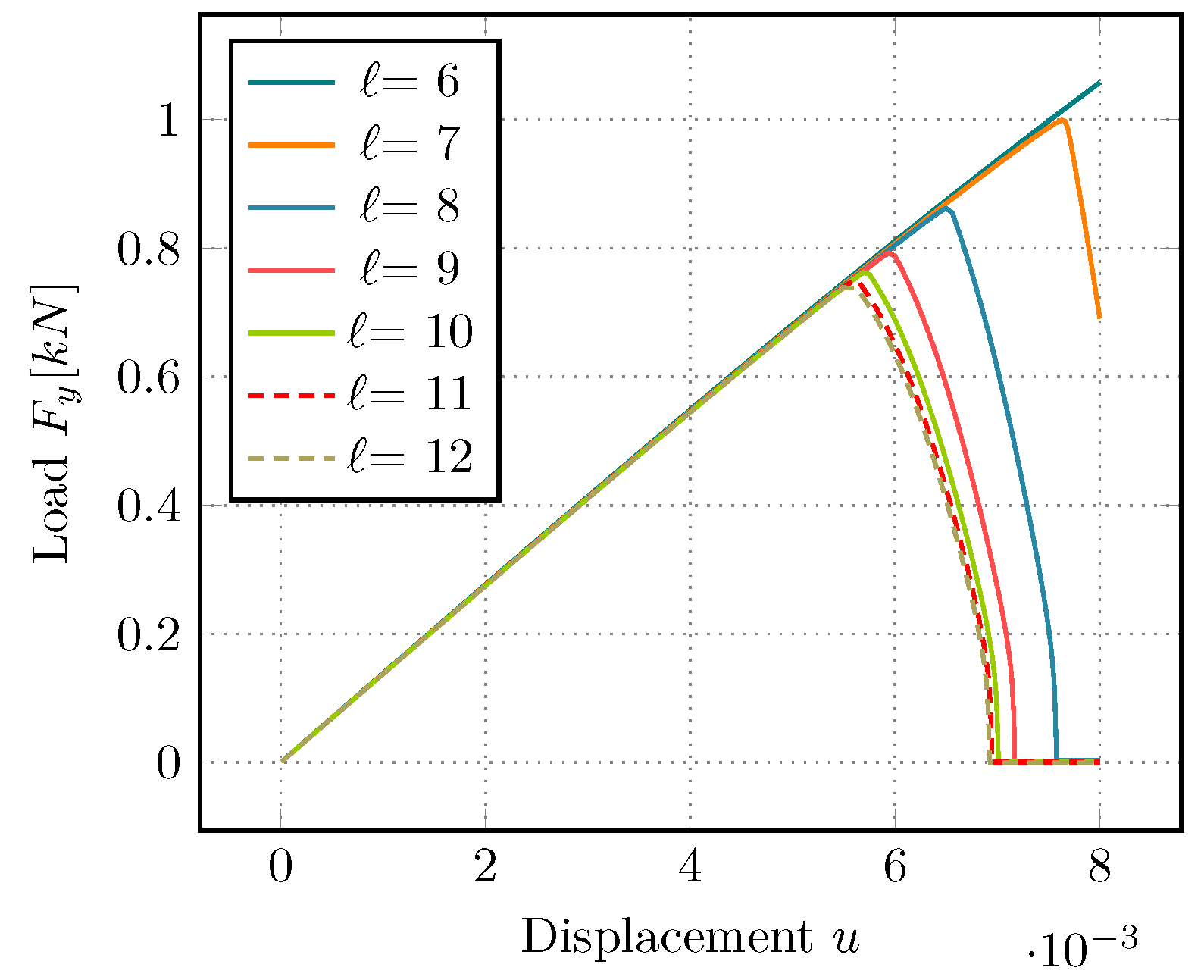
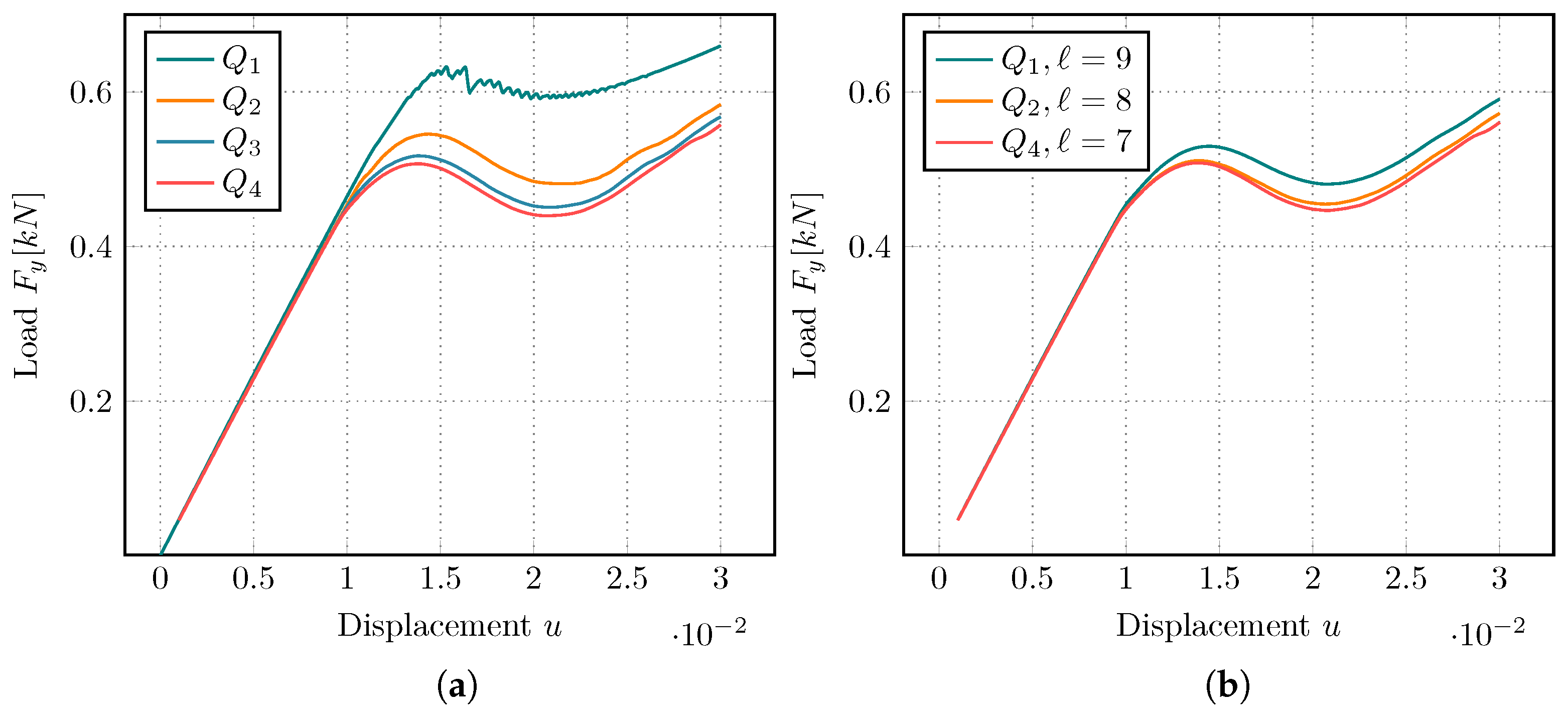
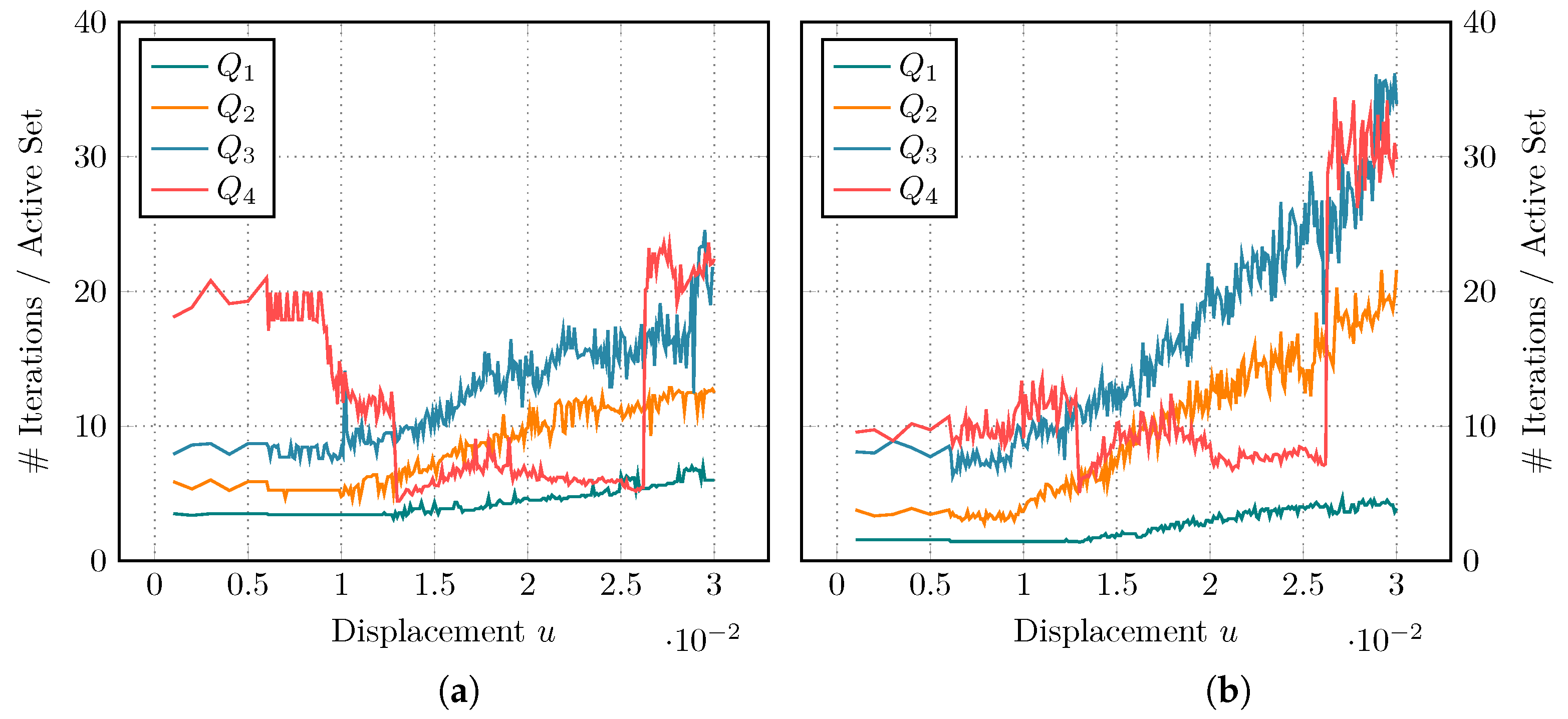
A representative comparison of the iteration behavior is given in
Figure 9, with AMG results on the left and GMG results on the right side. Again, we vary the polynomial degree for the shear test, as this scenario shows more interesting behavior. Both approaches show an expected growth in the number of iterations for increasing
p. We also observe that both solvers require more work as the fracture grows. Degree
behaves somewhat surprisingly. It requires less steps in the middle of the simulation for both the AMG and GMG strategy. The iteration count jumps up towards the end of the simulation, when the domain is close to total failure.
6.3. Performance Analysis
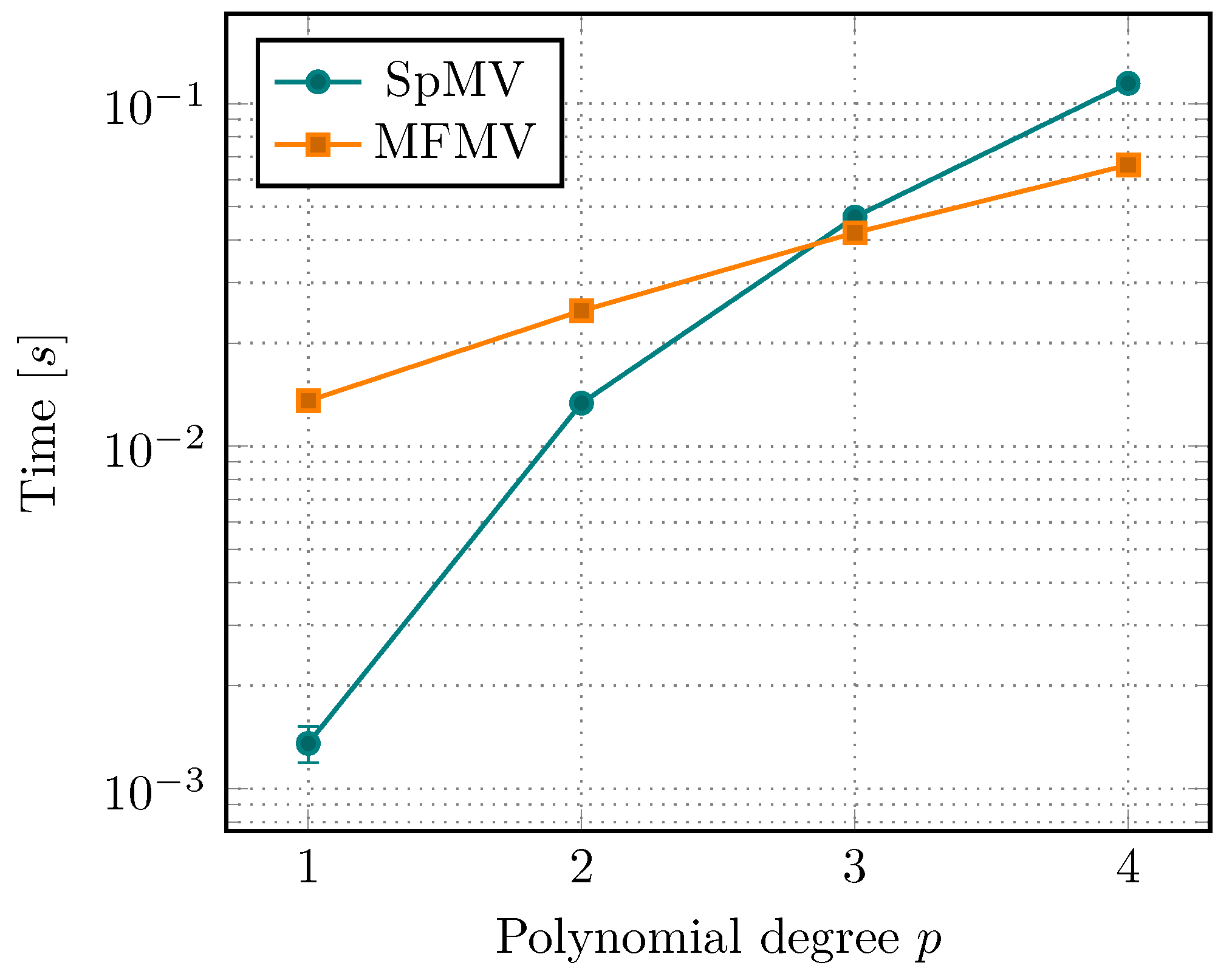
We continue to investigate the computational performance of the matrix-free approach. To this end, we start by comparing the sparse-matrix vector multiplication (SpMV) time with the corresponding matrix-free evaluation (MFMV). In
Section 3.4, we learned that MFMV should be faster given high enough polynomial degrees. For all tests, we use explicit vectorization based on AVX-256 in the matrix-free parts as described in
Section 4.2.
In [
27], we compared the behavior with respect to
h-refinement. Here, we want to focus on the dependence on the polynomial degree
p. In
Figure 10, we observe that SpMV is faster for linear and quadratic elements. However, this only considers the raw matrix-vector multiplication. In particular, it does not include the time that is required to assemble the matrix. We also notice, that starting from degree 3, MFMV starts to outperform SpMV even for single evaluations.
The results shown here are using the Miehe-type splitting, which is computationally expensive due to its dependence on the eigensystem. Compared to the isotropic model (no splitting), the performance of the MFMV drops by roughly 20–25% (2d) and 30–35% (3d). The assembly of the sparse-matrix is affected by approximately 7–10% in 2d, and 70% in 3d. A hybrid approach has been presented in [
5] in order to overcome the high cost of the Miehe splitting. To speed-up the MFMV, approximations to
could be a viable option, in particular if combined with caching of certain quantities as done in [
31]. However, we did not consider this so far.
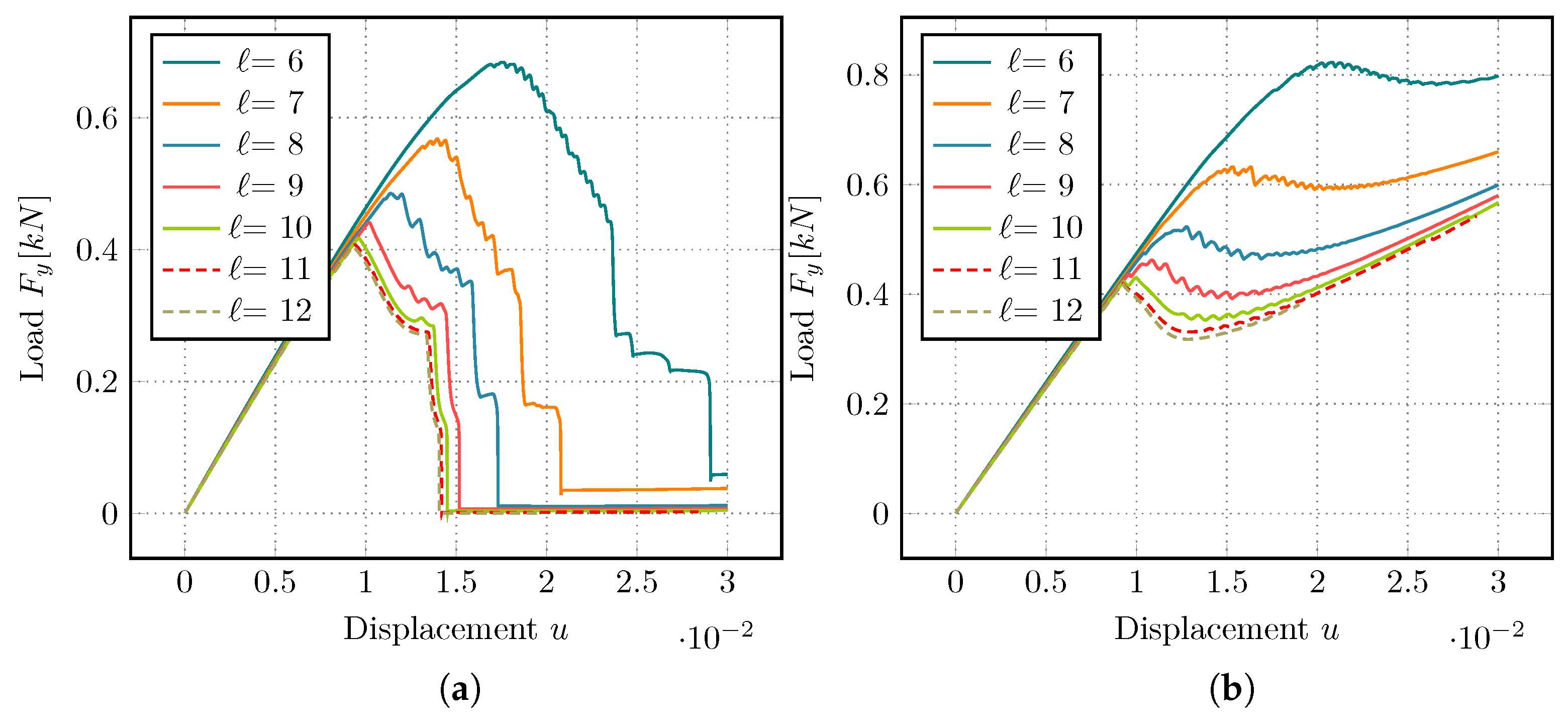
Let us now look at the performance of a full simulation. This is visualized in
Figure 11, where the total time spent in the linear solvers, i.e., GMRES with either AMG or GMG as preconditioners, is plotted. Here, only a single simulation of the single-edged notched shear test is performed. Possible fluctuations in the timings should be evened out over the length of the simulation.
The observed behavior is very similar to the vmult-times presented before. The faster SpMV for linear and quadratic elements is able to overcome the time of assembling the matrix and initializing the AMG solver, thus ending up faster than the matrix-free solver. The situation shifts in favor of the MF-GMG preconditioner for polynomial degrees 3 and higher.
6.4. Parallel Scalability
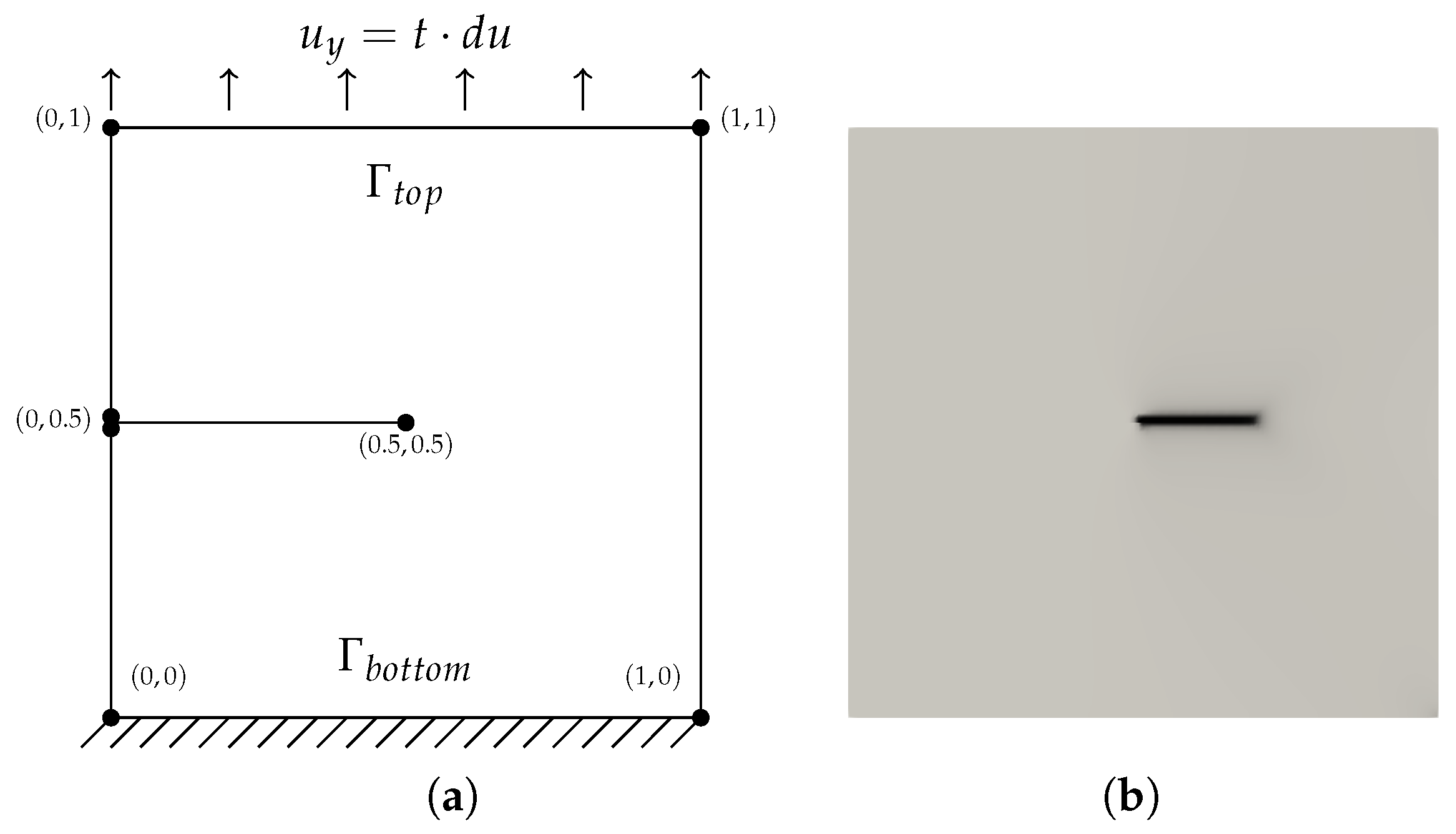
Finally, we investigate the parallel performance of both solvers. We consider again the shear test, but similar results can be expected for other scenarios as well. For this test, we take the mesh at
, and consider
and 4 leading to problem sizes of
,
,
, and
dofs, respectively, see
Table 4.
We notice that, for low degrees, the AMG approach is faster than our MF-GMG solver, which we have already observed in
Figure 11. However, the solution time for the GMG solver grows slower than that for AMG solver with increasing
p.
The parallel scaling behavior is similar for both preconditioners, as seen in
Figure 12. For large enough problem sizes, strong scaling is close to perfect. As soon as the local size gets too small for each CPU, the communication overhead starts to become noticeable. Both solvers scale well up to 32 cores for
, 64 cores for
and more than 128 cores for
, although the AMG solver seems to perform slightly better. This corresponds to local problems of approximately 25 k–50 k dofs per core. This is due to the bad scaling behavior on the coarse grids of the GMG hierarchy, which only contain very few cells.
Both approaches do not show perfect weak scaling behavior. However, due to the complexity of the PDE considered here, these are more than satisfying results.
We mentioned earlier that memory consumption is a huge advantage of matrix-free methods. In fact, the matrix-based AMG simulation for exceeded our available RAM (128 GB) on a single core.
7. Conclusions
We presented and compared two approaches to solve the linear systems arising in the PFF problem. First, we considered our matrix-free based geometric multigrid implementation from [
27]. Compared to our previous work, we extended our solver to handle higher polynomial degrees, which is a huge improvement for the matrix-free approach.
We compared our MF-GMG solver to the AMG-based approach from [
30]. This method is comparably easy to implement since the AMG solvers by MueLu (multigrid library in Trilinos) [
53] are almost black-box algorithms. These only require the sparse matrix, and compute the multigrid hierarchies by themselves. Implementing the MF-GMG approach is a lot more involved since we have to define the operators on each level. This can be particularly challenging in the presence of nonlinear terms and varying constraints (active-set), as it is the case in PFF.
The matrix-free approach really excels at high-order polynomial elements. It requires less storage per dof as we increase the polynomial order p, whereas the sparse-matrix becomes more and more costly. This is also reflected in the performance of the linear solver, i.e., the time spent for solving the equations using AMG increases faster than using GMG during p-refinement. Nonetheless, the AMG approach is slightly faster for degrees less than 3. Furthermore, the AMG solver requires a lot less implementational effort. The situation shifts more in favor of the matrix-free approach in 3 dimensions, as storage costs tend to be even more limiting.
So far, we only considered parallelization using SIMD instructions and distributed computing via MPI. Fine-grained parallelization within a node using threads (e.g., by means of OpenMP, TBB, std::thread) could improve the performance even more. An entirely different programming model is given by Graphic Processing Units (GPUs) using CUDA. GPUs are able to run several thousand threads in parallel, giving them a huge boost in performance for suitable application. Currently, an extension of the matrix-free framework in deal.II using GPUs is under development.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
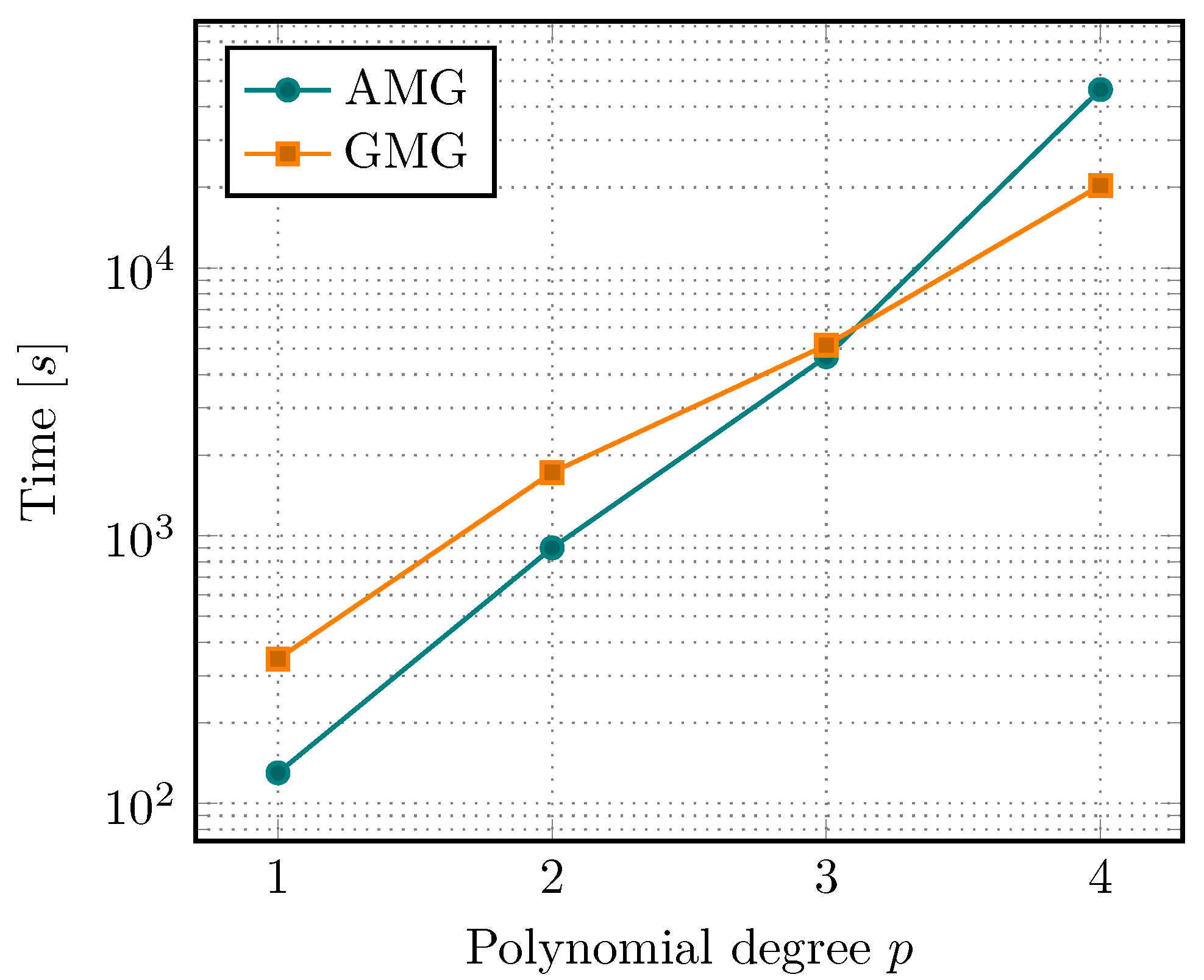{kind=link}
{kind=link}