1. Introduction
Consider the following constrained optimization problem:
where the functions
, are continuously differentiable functions.
Let be the feasible solution set and we assume that is not empty.
For a general constrained optimization problem, the penalty function method has attracted many researchers in both theoretical and practical aspects. However, to obtain an optimal solution for the original problem, the conventional quadratic penalty function method usually requires that the penalty parameter tends to infinity, which is undesirable in practical computation. In order to overcome the drawbacks of the quadratic penalty function method, exact penalty functions were proposed to solve problem
. Zangwill [
1] first proposed the
exact penalty function
where
is a penalty parameter, and
. It was proved that there exists a fixed constant
, for any
, and any global solution of the exact penalty problem is also a global solution of the original problem. Therefore, the exact penalty function methods have been widely used for solving constrained optimization problems (see, e.g., [
2,
3,
4,
5,
6,
7,
8,
9]).
Recently, the nonlinear penalty function of the following form has been investigated in [
10,
11,
12,
13]:
where
is assumed to be positive and
. It is called the
k-th power penalty function in [
14,
15]. Obviously, if
, the nonlinear penalty function
is reduced to the
exact penalty function. In [
12], it was shown that the exact penalty parameter corresponding to
is substantially smaller than that of the
exact penalty function. Rubinov and Yang [
13] also studied a penalty function as follows:
where
such that
for any
, and
. The corresponding penalty problem of
is defined as
In fact, the original problem
is equivalent to the problem as follows:
Obviously, the penalty problem
is the
exact penalty problem of problem
defined as (
1).
It is noted that these penalty functions
and
are not differentiable at
x such that
for some
, which prevents the use of gradient-based methods and causes some numerical instability problems in its implementation, when the value of the penalty parameter becomes large [
3,
5,
6,
8]. In order to use existing gradient-based algorithms, such as a Newton method, it is necessary to smooth the exact penalty function. Thus, the smoothing of the exact penalty function attracts much attention [
16,
17,
18,
19,
20,
21,
22,
23,
24]. Pinar and Zenios [
21] and Wu et al. [
22] discussed a quadratic smoothing approximation to nondifferentiable exact penalty functions for constrained optimization. Binh [
17] and Xu et al. [
23] proposed a second-order differentiability technique to the
exact penalty function. It is shown that the optimal solution of the smoothed penalty problem is an approximate optimal solution of the original optimization problem. Zenios et al. [
24] discussed an algorithm for the solution of large-scale optimization problems.
In this study, we aim to develop the smoothing technique for the nonlinear penalty function (
3). First, we define the following smoothing function
by
where
and
. By considering this smoothing function, a new smoothing nonlinear penalty function is obtained. We use this smoothing nonlinear penalty function that is able to convert a constrained optimization problem into minimizations of a sequence of continuously differentiable functions and propose a corresponding algorithm for solving constrained optimization problems.
The rest of this paper is organized as follows. In
Section 2, we propose a new smoothing penalty function for inequality constrained optimization problems, and some fundamental properties of its are proved. In
Section 3, an algorithm based on the smoothed penalty function is presented and its global convergence is proved. In
Section 4, we report results on application of this algorithm to three test problems and compare the results obtained with other similar algorithms. Finally, conclusions are discussed in
Section 5.
2. Smoothing Nonlinear Penalty Functions
In this section, we first construct a new smoothing function. Then, we introduce our smoothing nonlinear penalty function and discuss its properties.
Let
be as follows:
where
. Obviously, the function
is
on
for
, but it is not
for
. It is useful in defining exact penalty functions for constrained optimization problems (see, e.g., [
14,
15,
21]). Consider the nonlinear penalty function
and the corresponding penalty problem
As previously mentioned, for any
and
, the function
is defined as:
where
.
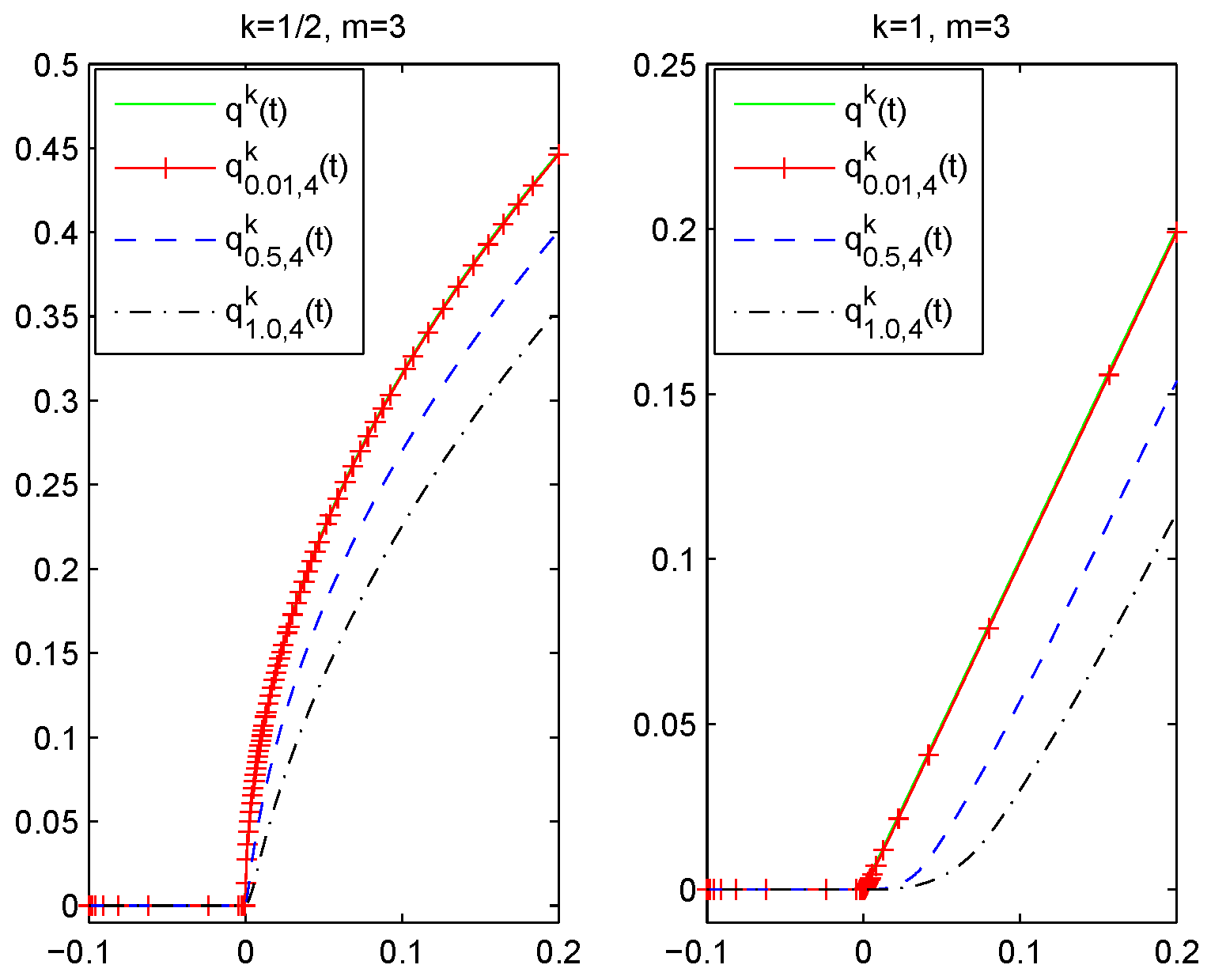
Figure 1 shows the behavior of
and
.
In the following, we discuss the properties of .
Lemma 1. For and any , we have
- (i)
is continuously differentiable for on , where - (ii)
.
- (iii)
.
Proof. (i) First, we prove that is continuous. Obviously, the function is continuous at any . We only need to prove that continuous at the separating points: 0 and .
(1) For
, we have
which implies
Thus, is continuous at .
(2) For
, we have
which implies
Thus, is continuous at .
Next, we will show that is continuously differentiable, i.e., is continuous. Actually, we only need to prove that is continuous at the separating points: 0 and .
(1) For
, we have
which implies
Thus, is continuous at .
(2) For
, we have
which implies
Thus, is continuous at .
(ii) For
, by the definition of
and
we have
When
, let
. Then, we have
. Consider the function:
and we have
Obviously,
for
. Moreover,
and
. Hence, we have
When
, we have
(iii) For
, from (ii), we have
which is
.
This completes the proof. ☐
In this study, we always assume that
and
is large enough, such that
for all
. Let
Then,
is continuously differentiable at any
and is a smooth approximation of
. We have the following smoothed penalty problem:
Lemma 2. We have thatfor any and . Proof. For any
, we have
Note that
for any
.
By Lemma 1, we have
which implies
Hence,
This completes the proof. ☐
Lemma 3. Let and be optimal solutions of problem and problem respectively. If is a feasible solution to problem , then is an optimal solution for problem .
Proof. Under the given conditions, we have that
Therefore, , which is .
Since
is an optimal solution and
is feasible to problem
, which is
Therefore, is an optimal solution for problem .
This completes the proof. ☐
Theorem 1. Let and be the optimal solutions of problem and problem respectively, for some and . Then, we have thatFurthermore, if satisfies the conditions of Lemma 3 and is feasible to problem , then is an optimal solution for problem . Proof. By Lemma 2, for
and
, we obtain
From the definition of
and the fact that
are feasible for problem
, we have
Note that
, and from (
8), we have
Therefore, , which is .
As
is feasible to
and by Lemma 3,
is an optimal solution to
, we have
Thus, is an optimal solution for problem .
This completes the proof. ☐
Definition 1. A feasible solution of problem is called a KKT point, if there exists a such that the solution pair satisfies the following conditions: Theorem 2. Suppose the functions in problem (P) are convex. Let and be the optimal solutions of problem and problem respectively. If is feasible to problem , and there exists a such that the pair satisfies the conditions in Equations (9) and (10), then we have that Proof. Since the functions
are continuously differentiable and convex, we see that
After applying the conditions given in Equations (
9), (10), (
12) and (13), we see that
Therefore,
. Thus,
Since
is feasible to
, which is
then
and, by
, we have
Combining Equations (
14) and (
15), we have that
which is
This completes the proof. ☐
3. Algorithm
In this section, by considering the above smoothed penalty function, we propose an algorithm to find an optimal solution of problem , defined as Algorithm 1.
Definition 2. For , a point is called an ϵ-feasible solution to , if it satisfies .
| Algorithm 1: Algorithm for solving problem |
Step 1: Let the initial point . Let and choose a constant such that , let and go to Step 2.
Step 2: Use as the starting point to solve the following problem: Let be an optimal solution of (the solution of we obtained by the BFGS method given in [25]).
Step 3: If is -feasible for problem , then the algorithm stops and is an approximate optimal solution of problem . Otherwise, let and . Then, go to Step 2. |
Remark 1. From we can easily see that as , the sequence and the sequence .
Theorem 3. For , suppose that for and the setLet be the sequence generated by Algorithm 1. If and the sequence is bounded, then is bounded and the limit point of is the solution of . Proof. First, we prove that
is bounded. Note that
From the definition of
, we have
Suppose, on the contrary, that the sequence
is unbounded and without loss of generality
as
, and
. Then,
, and from Equations (
17) and (
18), we have
which contradicts with the sequence
being bounded. Thus,
is bounded.
Next, we prove that the limit point of is the solution of problem . Let be a limit point of . Then, there exists the subset such that for , where is the set of natural numbers. We have to show that is an optimal solution of problem . Thus, it is sufficient to show and .
(i) Suppose . Then, there exists and the subset , such that for any and some .
If
, from the definition of
and
is the optimal solution according
j-th values of the parameters
for any
, we have
which contradicts with
and
.
If
or
, from the definition of
and
is the optimal solution according
j-th values of the parameters
for any
, we have
which contradicts with
and
.
Thus, .
(ii) For any
, we have
We know that , so . Therefore, holds.
This completes the proof. ☐
4. Numerical Examples
In this section, we apply the Algorithm 1 to three test problems. The proposed algorithm is implemented in Matlab (R2011A, The MathWorks Inc., Natick, MA, USA).
In each example, we take . Then, it is expected to get an -solution to problem with Algorithm 1, and the numerical results are presented in the following tables.
Example 1. Consider the following problem ([20], Example 4.1) For
, let
and choose
. The results are shown in
Table 1.
For
, let
and choose
. The results are shown in
Table 2.
The results in
Table 1 and
Table 2 show that the convergence of Algorithm 1 and the objective function values are almost the same. By
Table 1, we obtain that an approximate optimal solution
after two iterations with function value
. In [
20], the obtained approximate optimal solution is
with function value
. Numerical results obtained by our algorithm are slightly better than the results in [
20].
Example 2. Consider the following problem ([22], Example 3.2) For
, let
, and choose
. The results are shown in
Table 3.
For
, let
and choose
. The results are shown in
Table 4.
The results in
Table 3 and
Table 4 show that the convergence of Algorithm 1 and the objective function values are almost the same. By
Table 3, we obtain an approximate optimal solution is
after 2 iterations with function value
. In [
22], the obtained global solution is
with function value
. Numerical results obtained by our algorithm are much better than the results in [
22].
Example 3. Consider the following problem ([26], Example 4.1) For
, let
and choose
. The results are shown in
Table 5.
For
, let
, and choose
. The results are shown in
Table 6.
The results in
Table 5 and
Table 6 show that the convergence of Algorithm 1 and the objective function values are almost the same. By
Table 5, we obtain that an approximate optimal solution is
after two iterations with function value
. In [
26], the obtained approximate optimal solution is
with function value
. Numerical results obtained by our algorithm are slightly better than the results in [
26].



{kind=link}