
A Novel, Energy-Aware Task Duplication-Based Scheduling Algorithm of Parallel Tasks on Clusters

Abstract
:1. Introduction
2. Related Work
3. Computation Model
3.1. Task Model
3.2. Energy Model
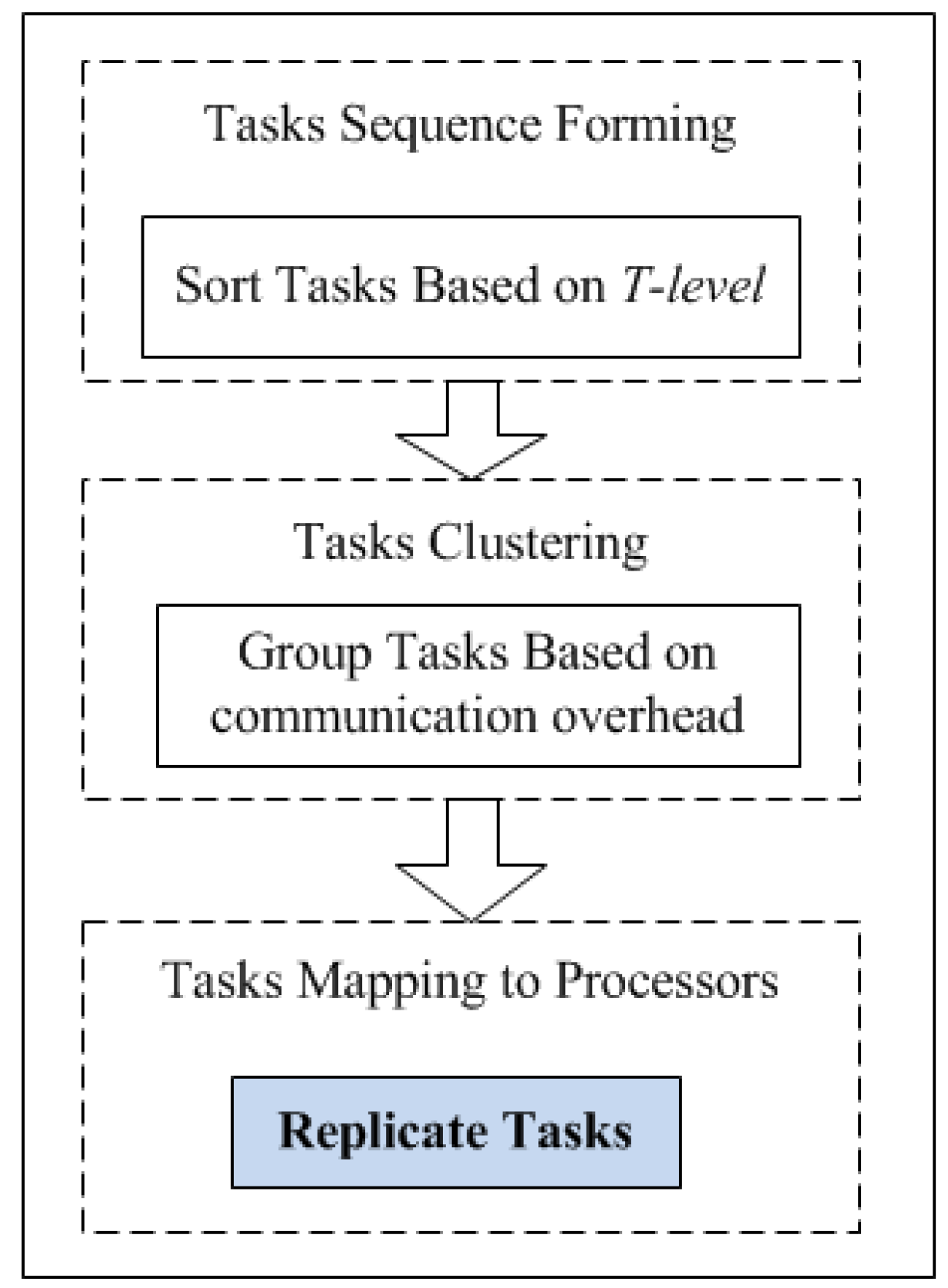
4. Energy-Aware Task Duplication
4.1. Parameters Calculation
4.2. Task Duplication
- LAST(vi) − LACT(vj) < cij
- EP(vi) − EC(eij) ≤ threshold
5. Energy Efficiency Evaluation
5.1. Test Set and Metrics
5.2. Baseline Algorithms
- TDS: The goal of TDS is to improve performance, which attempts to generate the shortest schedule length through task duplication. All tasks that can shorten schedule length would be replicated. The same task may be executed on different processors.
- EADS: EADS is based on TDS and aims to reduce the energy consumption due to replicating tasks. The FP of the current task is judged based upon the replication condition in the bottom-up manner. Some indirect tasks may be duplicated in the same tasks.
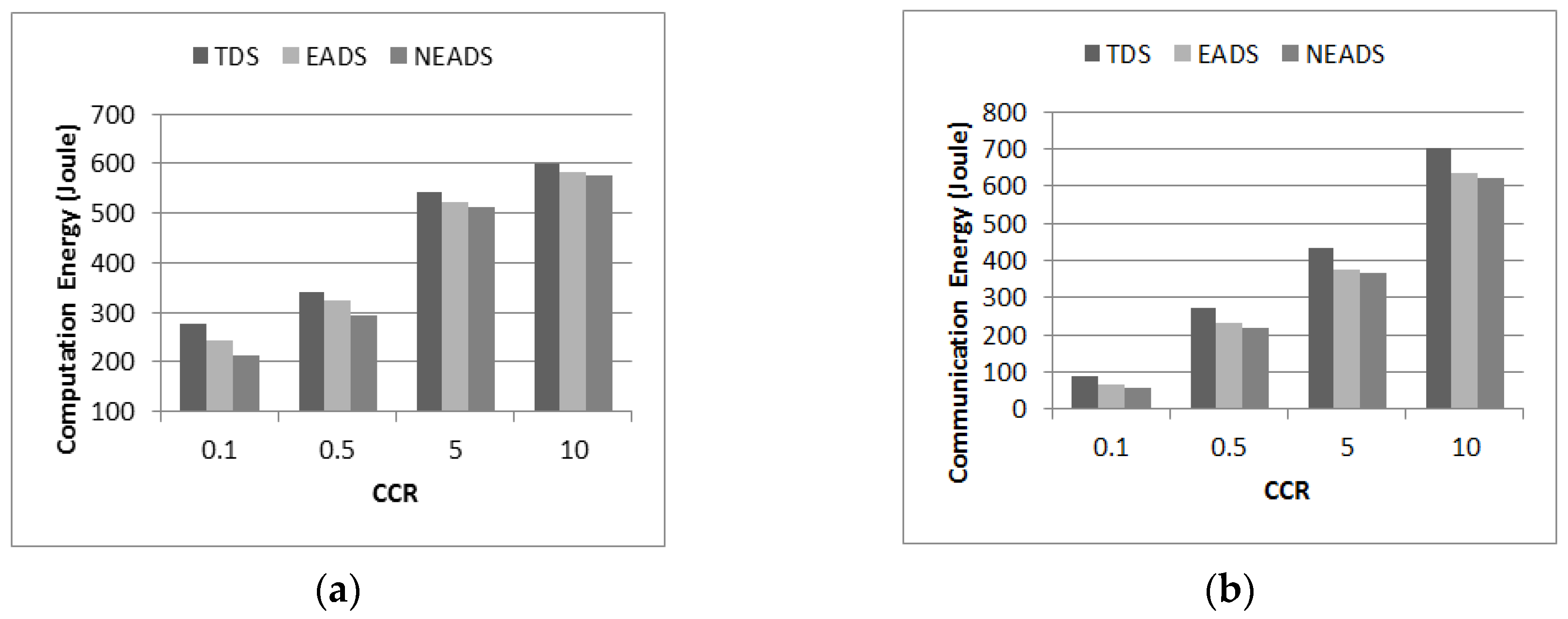
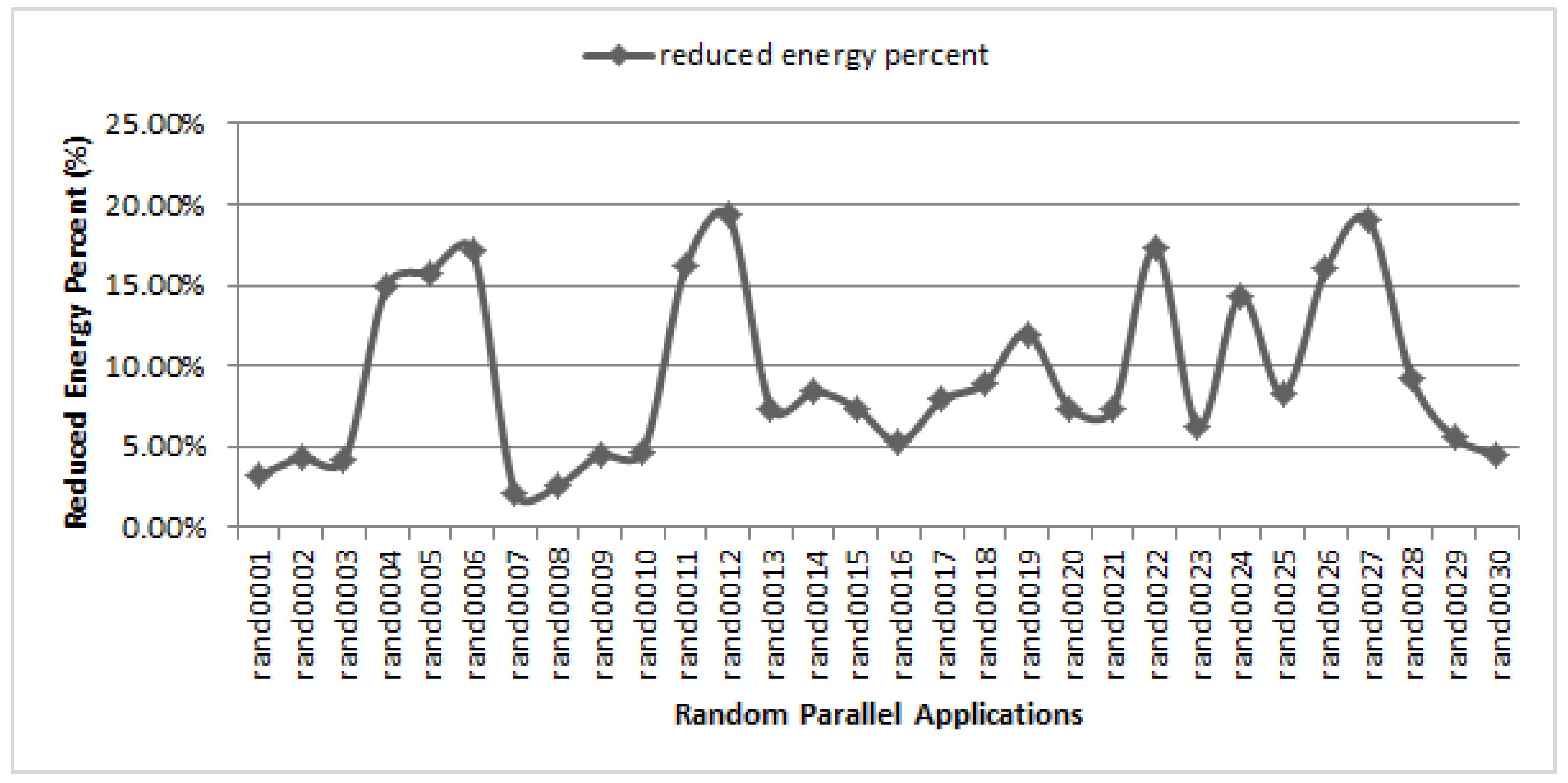
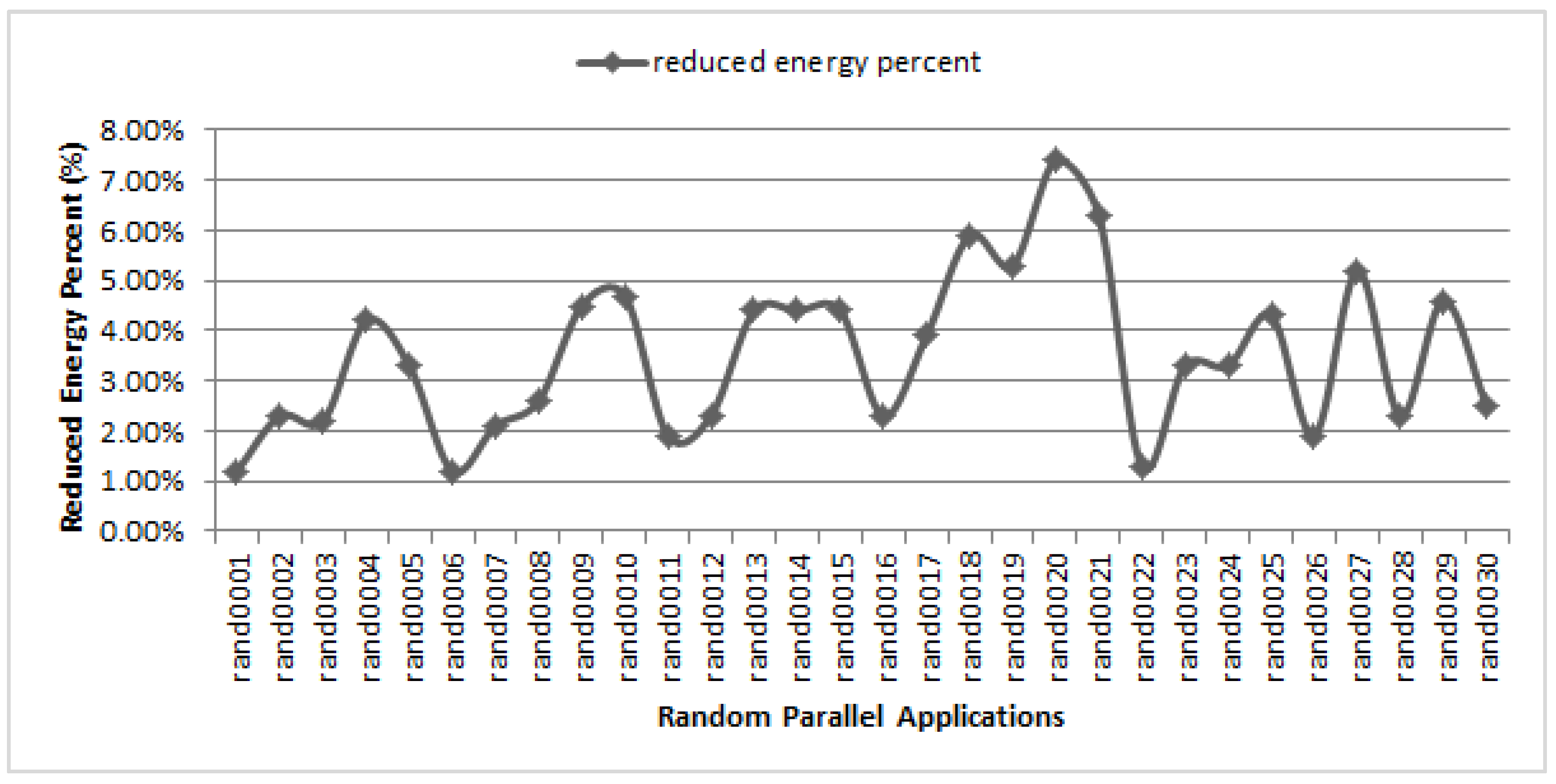
5.3. Impact of CCR
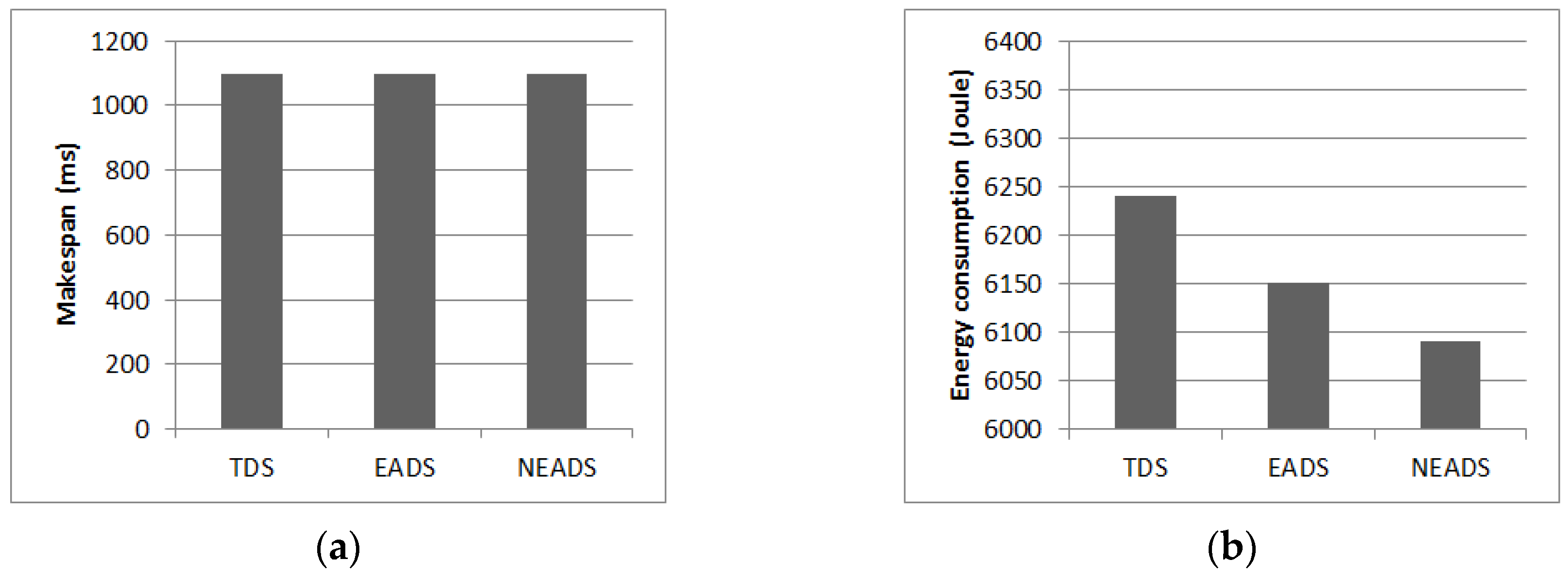
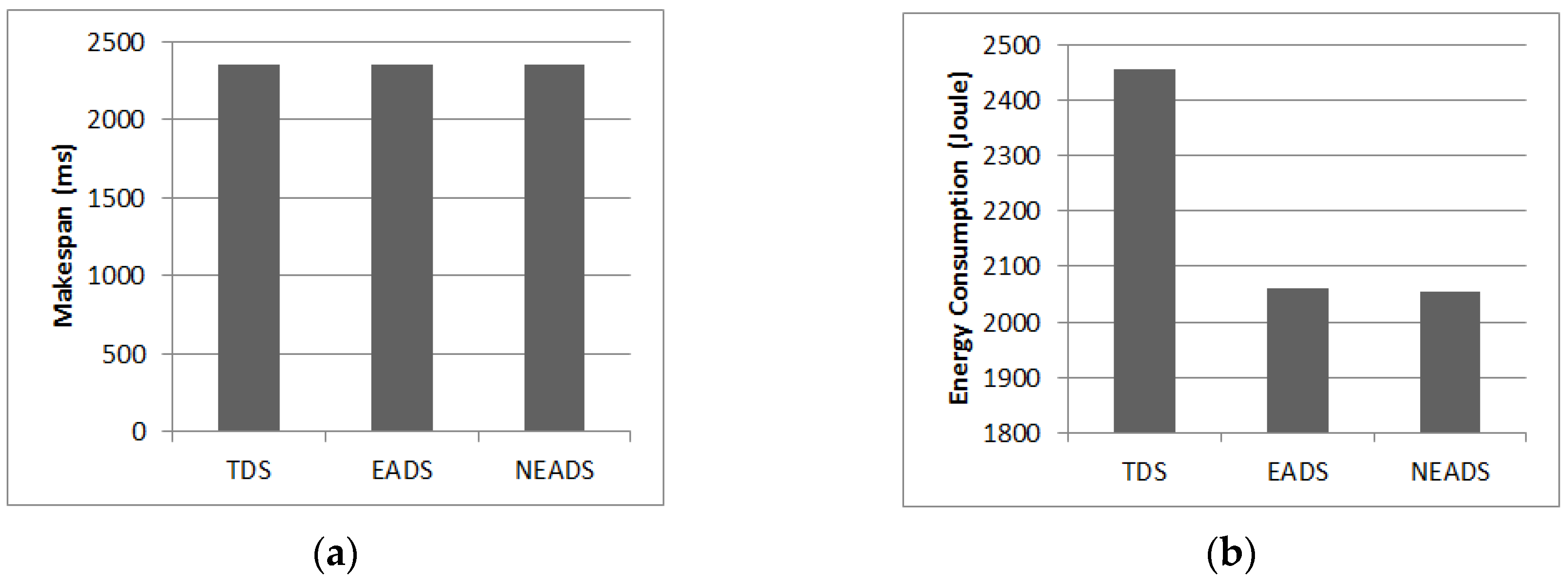
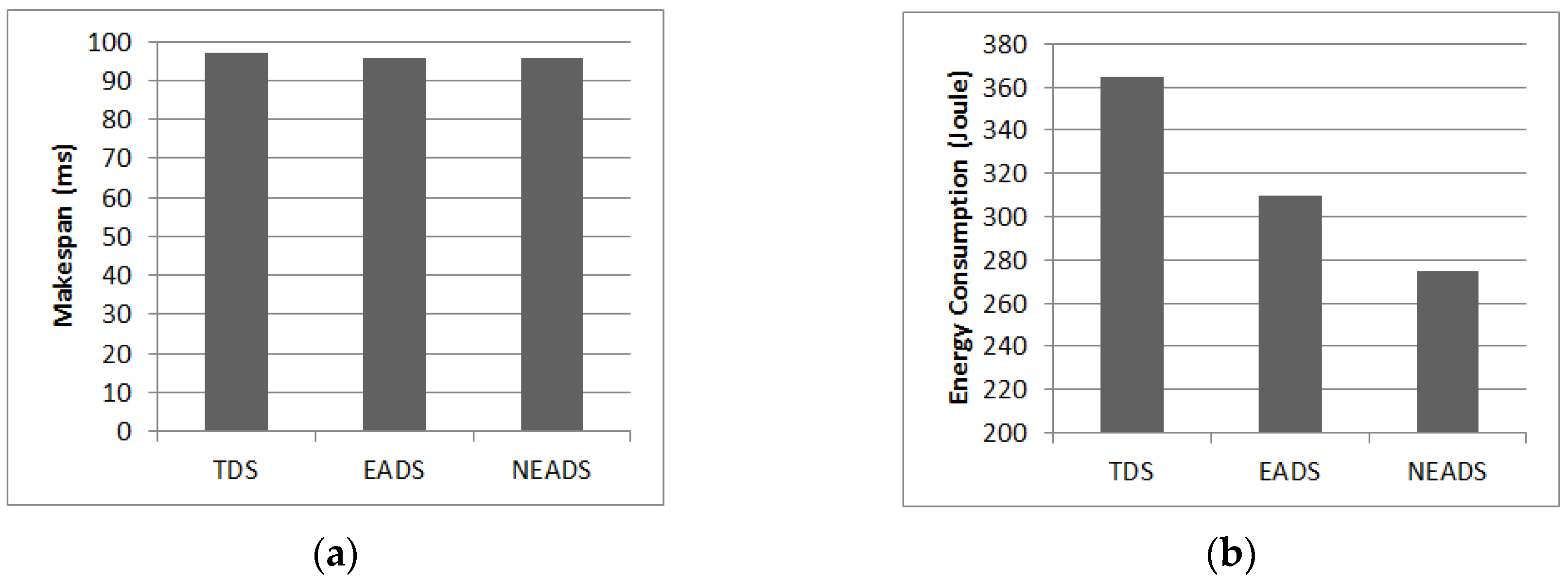
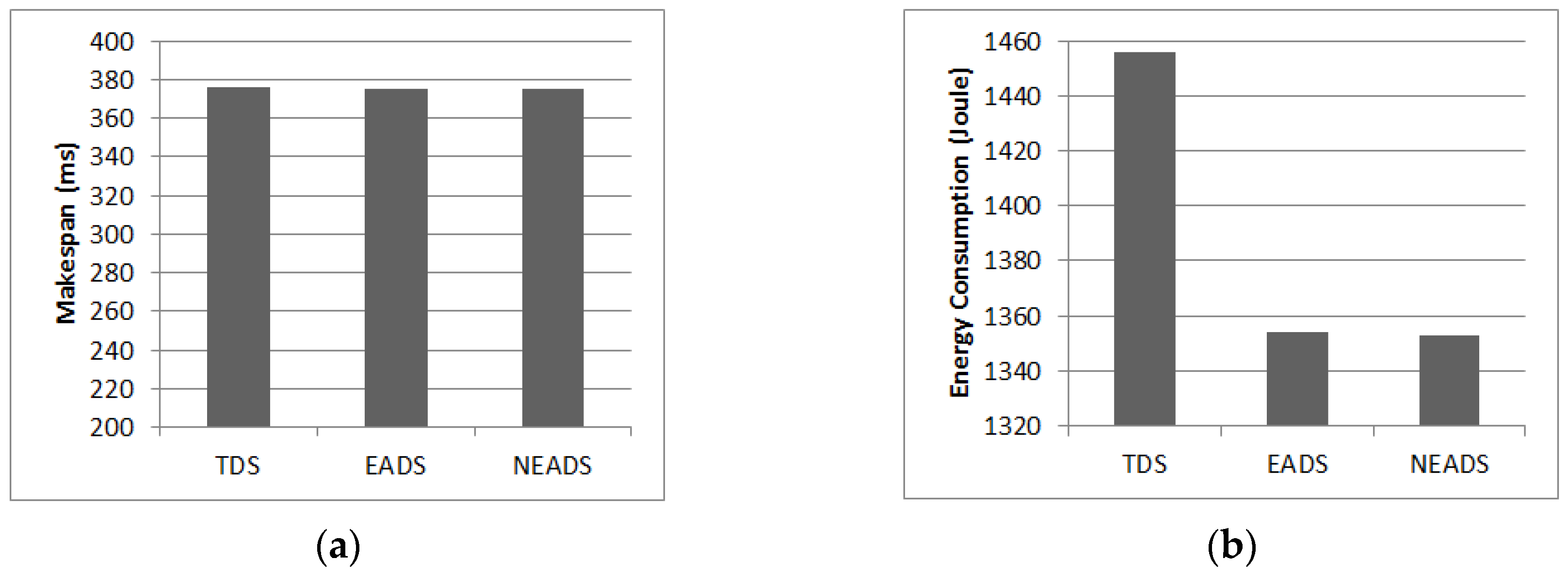
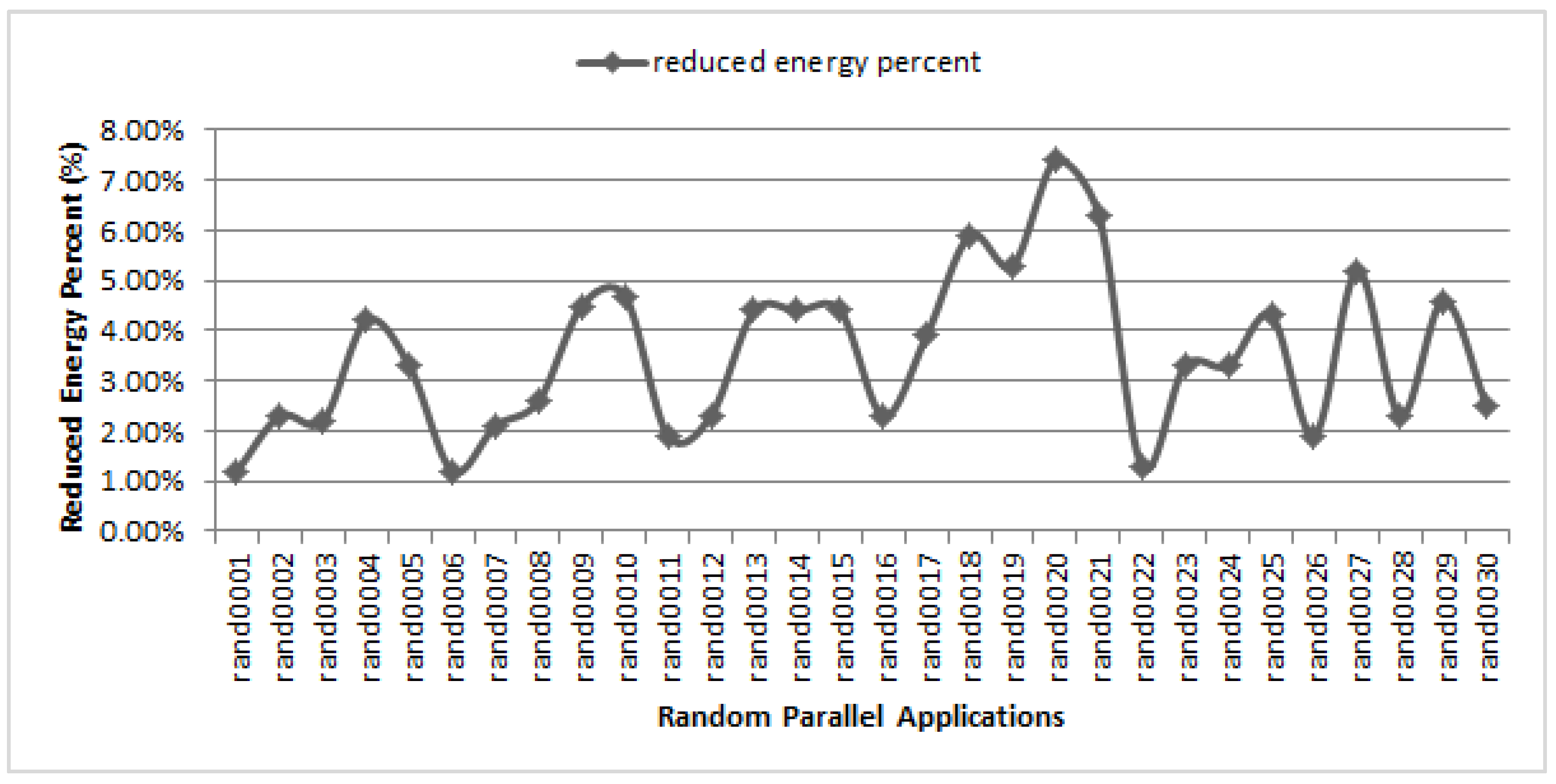
5.4. Impact of Applications
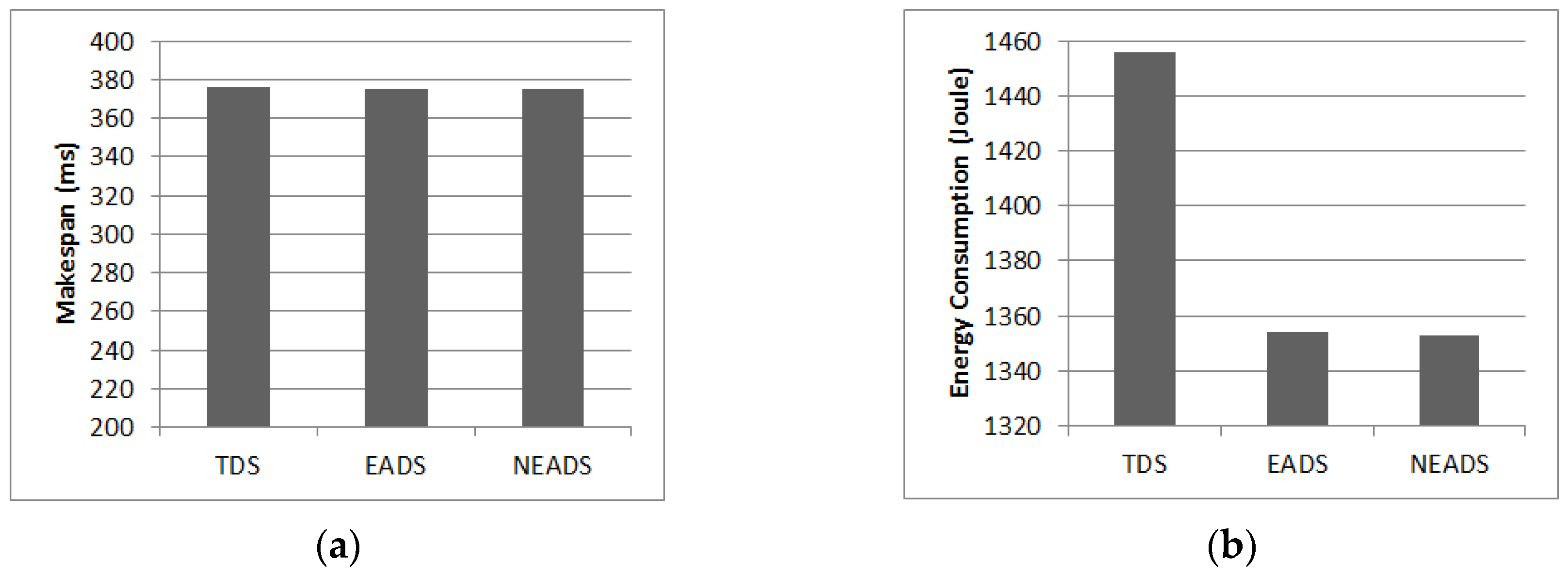
5.5. Overall Energy Efficiency
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chedid, W.; Yu, C. Survey on Power Management Techniques for Energy Efficient Computer Systems; Technical Report; Department of Electrical and Computer Engineering, Cleveland State University: Cleveland, OH, USA, 2002. [Google Scholar]
- TOP500 Team: The TOP500 List. Available online: http://www.top500.org/lists/2015/11 (accessed on 15 January 2016).
- Dally, W.J.; Carvey, P.P.; Dennison, L.R. The Avici Terabit Switch/Router. In Proceedings of the 6th Symposium on Hot Interconnects, Stanford, CA, USA, 13–15 August 1998; pp. 41–55.
- Ranaweera, S.; Agrawal, D.P. A Task Duplication Based Scheduling Algorithm for Heterogeneous Systems. In Proceedings of the Parallel and Distributed Processing Symposium, Orlando, FL, USA, 29 May–2 June 2000; pp. 445–450.
- Bansal, S.; Kumar, P.; Singh, K. An Improved Duplication Strategy for Scheduling Precedence Constrained Graphs in Multiprocessor Systems. IEEE Trans. Parallel Distrib. Syst. 2003, 14, 533–544. [Google Scholar] [CrossRef]
- Liang, A.; Xiao, L.; Ruan, L. Adaptive workload driven dynamic power management for high performance computing clusters. Comput. Electr. Eng. 2013, 39, 2357–2368. [Google Scholar] [CrossRef]
- Wang, L.; Laszewski, G.; Von Dayal, J. Towards energy aware scheduling for precedence constrained parallel tasks in a cluster with DVFS. In Proceedings of the 10th IEEE/ACM International Conference Symposium on Cluster, Cloud and Grid Computing (CCGrid), Melbourne, Australia, 17–20 May 2010; pp. 368–377.
- Saravanan, V.; Anpalagan, A.; Kothari, D.P. A comparative simulation study on the power performance of multi-core architecture. J. Supercomput. 2014, 70, 465–487. [Google Scholar] [CrossRef]
- Mishraa, A.; Tripathib, A. Energy efficient voltage scheduling for multi-core processors with software controlled dynamic voltage scaling. Appl. Math. Model. 2014, 38, 3456–3466. [Google Scholar] [CrossRef]
- Zhu, X.; He, C.; Li, K.; Qin, X. Adaptive energy-efficient scheduling for real-time tasks on DVS-enabled heterogeneous clusters. J. Parallel Distrib. Comput. 2012, 72, 751–763. [Google Scholar] [CrossRef]
- Sridharan, R.; Gupta, N.; Mahapatra, R. Feedback-controlled reliability-aware power management for real-time embedded systems. In Proceedings of the 45th Annual Design Automation Conference, Anaheim, CA, USA, 08–13 June 2008; pp. 185–190.
- Marzollaa, M.; Mirandolab, R. Dynamic power management for QoS-aware applications. Sustain. Comput. Inform. Syst. 2013, 3, 231–248. [Google Scholar] [CrossRef]
- Falzon, G.; Li, M. Enhancing list scheduling heuristics for dependent job scheduling in grid computing environments. J. Supercomput. 2012, 59, 104–130. [Google Scholar] [CrossRef]
- Liu, W.; Duan, Y.; Du, W. An energy efficient clustering-based scheduling algorithm for parallel tasks on homogeneous DVS-enabled clusters. In Proceedings of the 16th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Wuhan, China, 23–25 May 2012; pp. 575–582.
- Tang, X.; Li, K.; Liao, G.; Li, R. List scheduling with duplication for heterogeneous computing systems. J. Parallel Distrib. 2010, 70, 323–329. [Google Scholar] [CrossRef]
- Lai, K.-C.; Yang, C.-T. A dominant predecessor duplication scheduling algorithm for heterogeneous systems. J. Supercomput. 2007, 44, 126–145. [Google Scholar] [CrossRef]
- Sanjeev, B.; Rabab, A. Energy aware DAG scheduling on heterogeneous systems. Cluster Comput. 2010, 13, 373–383. [Google Scholar]
- Sinnen, O.; Sousa, L.A. Communication contention in task scheduling. IEEE Trans. Parallel Distrib. Syst. 2005, 16, 503–515. [Google Scholar] [CrossRef]
- Sinnen, O.; To, A.; Kaur, M. Contention-aware scheduling with task duplication. J. Parallel Distrib. Comput. 2011, 71, 77–86. [Google Scholar] [CrossRef]
- Choi, G.S.; Kim, J.; Ersoz, D.; Yoo, A.; Das, C. Coscheduling in clusters: Is it a viable alternative? In Proceedings of the ACM/IEEE Conference Supercomputing (SC ‘04), Pittsburgh, PA, USA, 6–12 November 2004.
- Maosko, L.; Tudruj, M.; Mounie, G. Comparison of program task scheduling algorithms for dynamic SMP clusters with communication on the fly. In Proceedings of the Parallel Processing and Applied Mathematics, Wroclaw, Poland, 13–16 September 2009; pp. 31–41.
- Shojafar, M.; Cordeschi, N.; Amendola, D.; Baccarelli, E. Energy-Saving Adaptive Computing and Traffic Engineering for Real-Time-Service Data Centers. In Proceedings of the 22nd IEEE ICC WORKSHOP, London, UK, 8–12 June 2015.
- Shojafar, M.; Cordeschi, N.; Baccarelli, E. Energy-efficient Adaptive Resource Management for Real-time Vehicular Cloud Services. IEEE Trans. Cloud Comput. 2016, 99, 1–14. [Google Scholar] [CrossRef]
- Shojafar, M.; Javanmardi, S.; Abolfazli, S.; Cordeschi, N. Erratum to: FUGE: A joint meta-heuristic approach to cloud jobs cheduling algorithm using fuzzy theory and a genetic method. Cluster Comput. 2015, 18, 845. [Google Scholar] [CrossRef]
- Zong, Z.; Mais, N.; Adam, M. Energy efficient scheduling for parallel applications on mobile clusters. Cluster Comput. 2008, 11, 91–113. [Google Scholar] [CrossRef]
- Zong, Z.; Adam, M.; Ruan, X.; Qin, X. EAD and PEBD: Two Energy-Aware Duplication Scheduling Algorithms for Parallel Tasks on Homogeneous Clusters. IEEE Trans. Comput. 2011, 60, 360–374. [Google Scholar] [CrossRef]
- Standard Task Graph Set. Available online: http://www.kasahara.elec.waseda.ac.jp/schedule (accessed on 10 October 2015).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| CCR | Communication-computation ratio |
| PRED(vi) | The predecessor of vi |
| SUCC(vi) | The successor of vi |
| EST(vi) | The earliest start time of vi |
| ECT(vi) | The earliest complete time of vi |
| LAST(vi) | The latest allowed start time of vi |
| LACT(vi) | The latest allowed complete time of vi |
| B-level(vi) | The longest distance from vi to exit task |
| T-level(vi) | The longest distance from entry task to vi |
| FP(vi) | Favorite predecessor of vi |
| SFP(vi) | Second favorite predecessor of vi |
| Parallel Application | Task Number | Edge Number |
|---|---|---|
| fpppp | 334 | 1145 |
| Random | 50 | 164 |
| Robot control | 88 | 131 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, A.; Pang, Y. A Novel, Energy-Aware Task Duplication-Based Scheduling Algorithm of Parallel Tasks on Clusters. Math. Comput. Appl. 2017, 22, 2. https://doi.org/10.3390/mca22010002
Liang A, Pang Y. A Novel, Energy-Aware Task Duplication-Based Scheduling Algorithm of Parallel Tasks on Clusters. Mathematical and Computational Applications. 2017; 22(1):2. https://doi.org/10.3390/mca22010002
Chicago/Turabian StyleLiang, Aihua, and Yu Pang. 2017. "A Novel, Energy-Aware Task Duplication-Based Scheduling Algorithm of Parallel Tasks on Clusters" Mathematical and Computational Applications 22, no. 1: 2. https://doi.org/10.3390/mca22010002
APA StyleLiang, A., & Pang, Y. (2017). A Novel, Energy-Aware Task Duplication-Based Scheduling Algorithm of Parallel Tasks on Clusters. Mathematical and Computational Applications, 22(1), 2. https://doi.org/10.3390/mca22010002