1. Introduction
Control charts are an important tool in statistical process control (SPC) used to determine if a manufacturing or business process is in a state of statistical control. When a non-random pattern appears in the control chart, it means that one or more assignable causes which will gradually degrade the process quality exist. The importance of non-random pattern lies in the fact that it can provide relevant information about process diagnosis. Montgomery [
1] pointed out that every non-random pattern can be mapped to a set of assignable causes. Therefore, if the pattern type can be correctly recognized and identified, it will help to diagnose the possible causes of the manufacturing process problem. Some real-world examples that used non-random patterns to identify potential causes can be found in [
2,
3].
Western Electric Company [
4] first identified various types of non-random patterns and developed a set of sensitizing rules for analysis. Nelson [
5,
6] further established a set of run rules for non-random patterns.
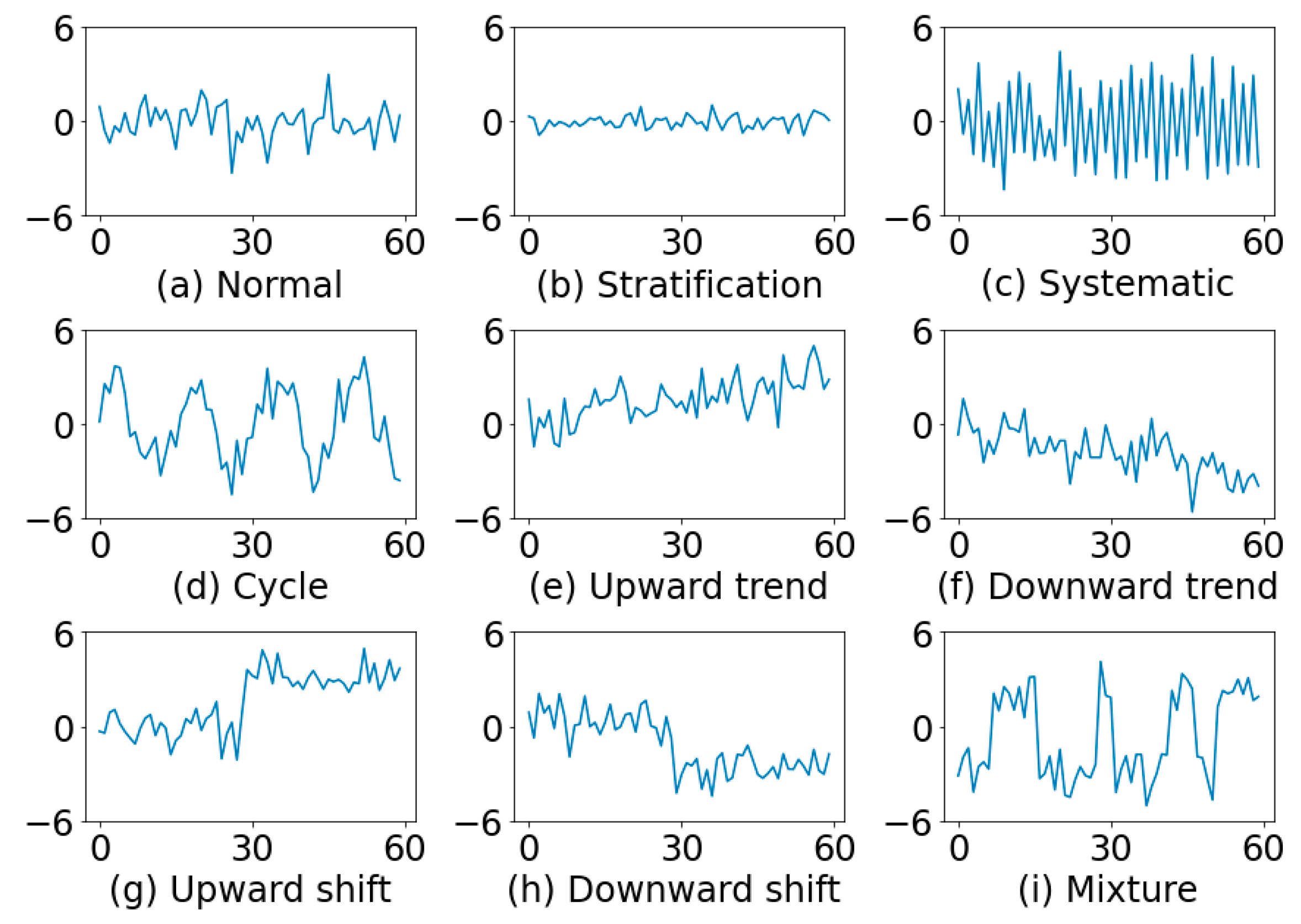
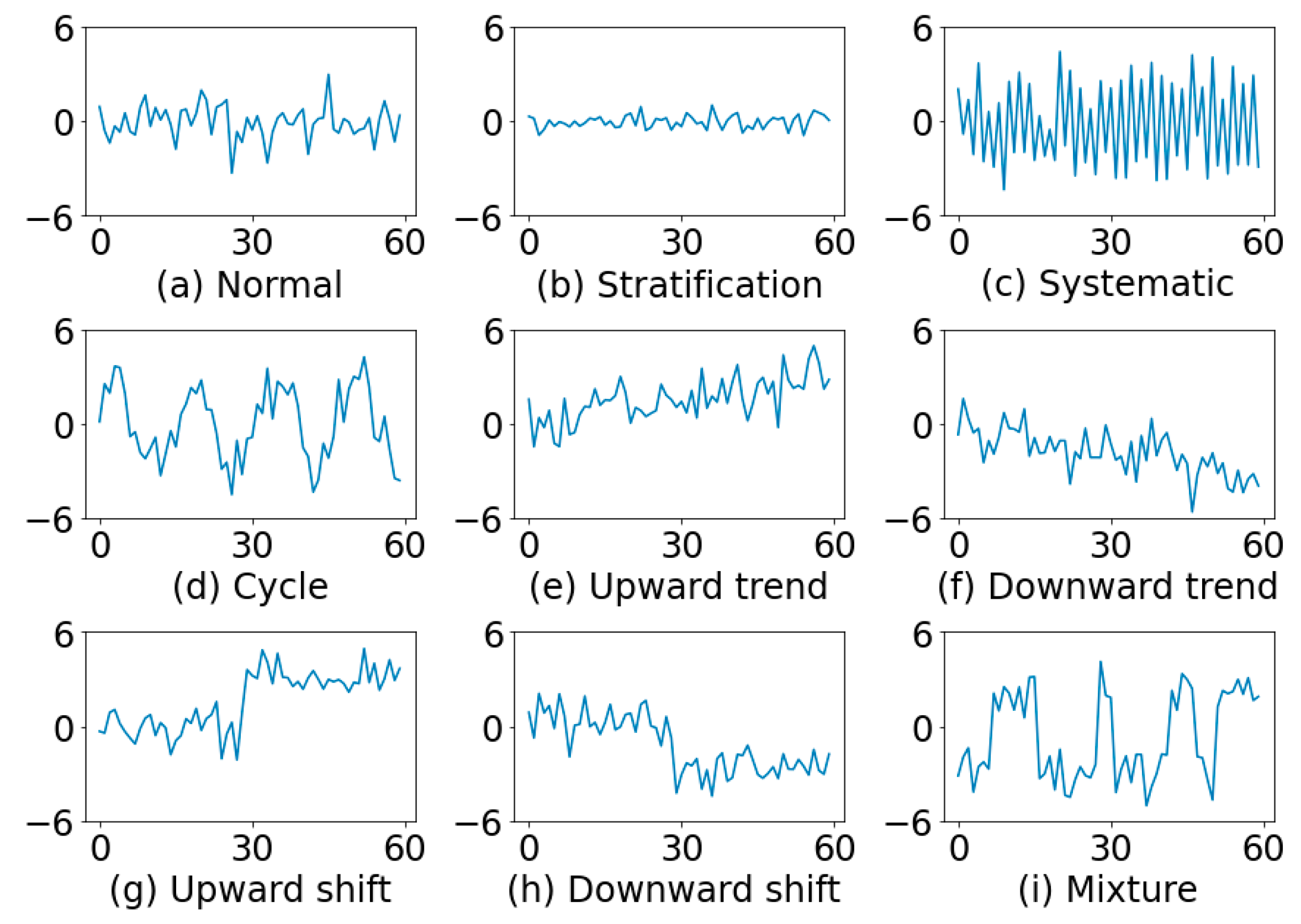
Figure 1 illustrates some typical examples of control chart patterns. A normal pattern (NOR) will exhibit only random variations (
Figure 1a). In stratification (STRA), there is a lack of natural variability, the points tend to cluster around the center line (
Figure 1b). In systematic variations (SYS), a high point is always followed by a low one, or vice versa (
Figure 1c). A cycle (CYC) can be recognized by a series of high portions or peaks interspersed with low portions or troughs (
Figure 1d). A trend can be defined as a continuous movement in one direction.
Figure 1e shows an upward trend (UT) and
Figure 1f a downward trend (DT). A shift may be defined as a sudden or abrupt change in the average of the process.
Figure 1g indicates an upward shift (US) and
Figure 1h a downward shift (DS). In a mixture (MIX) pattern, the points tend to fall near the high and low edge of the pattern with an absence of normal fluctuations near the middle (
Figure 1i). A mixture can be thought of as a combination of data from separate distributions.
Although supplementary rules [
4,
5,
6] are useful in identifying the out-of-control situations, Cheng [
7] pointed out that there is no one-to-one mapping between a supplementary rule and a non-random pattern. It is worth noting here that the control chart pattern recognition task has its own unique challenges and difficulties, such as high intra-class variability (due to different magnitudes and translation of the pattern) and high inter-class similarity (due to the preceding in-control data and some resemblance between patterns). All these challenges make it highly desirable to develop an intelligent-based approach to effectively classify the non-random control chart patterns.
In recent years, a great deal of research has been devoted to the application of machine learning (ML)-based approaches to control chart pattern recognition (CCPR) with the purposes of improving the classification performance and serving as a supplementary tool to traditional control charts [
8]. It is anticipated that the ML-based classification models can replicate engineers’ analysis mechanisms. With the development of the Industrial Internet of Things (IIOT) and artificial intelligence (AI), it has become increasingly feasible to collect process data and use intelligent decision-making models for analysis. The intelligent-based detection and diagnosis system is more important than ever before [
9]. Hachicha and Ghorbel [
10] conducted a comprehensive review of recent research on control chart pattern recognition. The classification approaches include rule-based [
11,
12], decision tree (DT) [
13,
14], artificial neural network (ANN) [
7,
15,
16], support vector machine (SVM) [
17,
18]. Previous studies focused on the recognition of basic non-random patterns. Some studies [
16,
18,
19,
20] have conducted research on the recognition of concurrent patterns (the combination of two or more basic patterns simultaneously).
In previous studies, the input vector of the classification model can be raw data [
7,
15] or hand-crafted features [
13,
14,
21,
22,
23]. When taking raw data as inputs, each observation is treated as an individual feature. The major drawback with ML algorithms like DT, ANN, and SVM is that these methods consider each input feature individually and do not consider the sequence which these features follow. In other words, different orders of the same features are treated as the same inputs. However, in SPC application, the input features are observations which follow a sequence that characterizes the specific pattern class. The classification approach may be sensitive to the location in time of the discriminative features.
In addition to raw data-based models, feature-based methods have also been widely used in control chart pattern recognition, they are heuristic and highly depend on human experts. The features from feature extraction carry information of the time series, which is not based on individual time points, they are less sensitive to the variation of control chart pattern. Nevertheless, the feature-based approach is not without its problems and limitations. In traditional approaches, features were heuristically engineered based on prior knowledge about non-random patterns. However, the patterns that appeared in the analysis window were too simple. Excepting shift patterns, the starting point for other non-random patterns was often assumed to be the first observation in the window. The hand-crafted features for this kind of pattern behavior may not be applicable to other variants of patterns. In addition, the existing feature-based machine learning methods utilize expert knowledge to extract features, which is both time consuming and error-prone. The feature extraction method may have signal loss and does not describe the characteristics of control chart patterns well. The problem would become more severe when considering the variants of non-random patterns.
Here, we would like to emphasize the important concept of translation invariance [
24,
25]. The CCPR is often implemented in an analysis window approach. The observed values at multiple time steps are grouped to form an input vector for a classification model. The width of the analysis window (i.e., the number of consecutive observations) can be varied to include more or less previous time steps, depending on the complexity of the problem. Most previous studies overlooked the importance of translation invariance property of CCPR classifiers. When the window moves over the time, one may see different variants of a specific type of pattern (see
Figure 2). For CCPR, the translational invariance means that the classifier would recognize the pattern regardless of where it appears in the window.
One critical issue needs to be addressed in ML-based CCPR is the scarcity of data. Previous research often relied on simulations to generate training and test data since field data collection can be expensive, time consuming, and difficult [
10,
21]. This approach is acceptable if the underlying distribution is known or can be correctly identified. However, a high diversity in the training data is still required so that the classification model becomes robust to intra-class variability. As discussed above, the analysis window may produce many variants of a pattern when it slides along the time series data.
Apart from the above issues, some researchers have commented on the practical application of CCPR. Woodall and Montgomery [
26] stated that machine learning-based CCPR methods do not have a practical impact on SPC. Weese et al. [
27] further pointed out some gaps that hinder the application of the CCPR methods in practice. They recommended some research directions in the practical application of CCPR methods, including the robustness of CCPR methods to the baseline training sample size, the selection of CCPR structures, etc.
For a long time, researchers have focused on using advanced methods to improve the classification accuracy of CCPR. Recently, the application of deep learning to CCPR has been investigated. Hong et al. [
28] applied a convolutional neural network (CNN) to the concurrent pattern recognition problem. Miao and Yang [
29] selected statistical and shape features used them to train a CNN. They addressed concurrent CCPR problems. Xu et al. [
30] developed a 1D CNN for recognition of control chart patterns. They showed that CNN was robust to the deviation between the distribution of test data and training data. Yu et al. [
31] presented a deep learning method known as stacked denoising autoencoder for CCPR feature learning. Chu et al. [
32] proposed a data enhancement method to improve the performance of the deep belief network in CCPR. Fuqua and Razzaghi [
33] designed a CNN to address the imbalanced CCPR problem. Most recently, Zan et al. [
8] applied a 1D CNN to CCPR. They demonstrated the benefits of CNN using simulated data and a real-world dataset. Zan et al. [
34] proposed a method based on multilayer bidirectional long short-term memory network (Bi-LSTM) to learn the features from the raw data. Using a simulation study, they demonstrated that Bi-LSTM performed better than other methods including 1D CNN.
A review of previous studies indicates that there are research gaps in the literature. First, the variations of non-random patterns used to evaluate the CCPR performance are oversimplified. After surveying more than 120 papers published on CCPR studies, Hachicha and Ghorbel [
10] criticized the fact that past research trained the model in a static mode without considering the dynamic nature of the non-random patterns. They further pointed out that future work should address the problem of the misalignment of the pattern in time. Zan et al. [
8] pointed out the importance of increasing the variability of training dataset. They suggested that training patterns should be carefully prepared to ensure the closeness to the real patterns. The above arguments indicate the needs of creating a diversified dataset in order to enhance the robustness of the CCPR model the dynamic nature of non-random patterns.
To address the aforementioned issues, we propose a control chart pattern recognition method based on an end-to-end one-dimensional convolutional neural network model (1D CNN) architecture. CNN is a deep learning neural network algorithm, most commonly applied to computer vision [
35,
36,
37]. Recently, researchers have demonstrated that it is possible to apply CNN not only to image recognition tasks but also to time series classification tasks [
38,
39]. The main advantage of CNN is that it automatically learns the important features without any hand-crafted feature extraction. The end-to-end classification system performs feature extraction jointly with classification. More importantly, CNN is capable to learn the translation invariance features from the input.
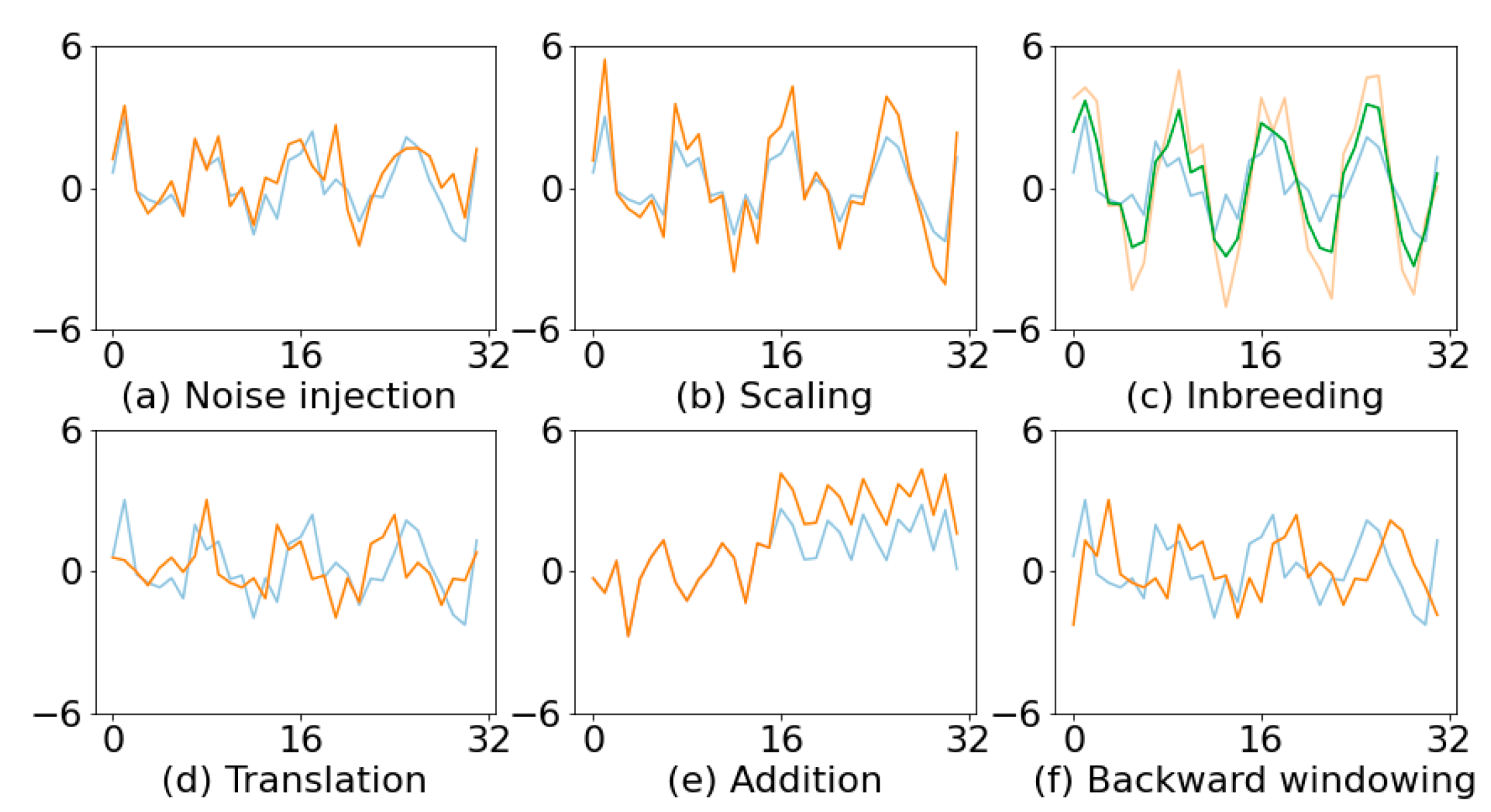
If patterns can be generated by simulation, we proposed a flexible method to generate dataset with high intra-class diversity. When patterns cannot be generated by explicit formulas, some data augmentation operations suitable for CCPR are proposed and investigated. With the purpose to deal with data scarcity and long model training rime, we also examined the application of transfer learning to CCPR. A pre-trained model based on frequently encountered data, can be applied to other unknown data types with minor retrain. The major contributions of this work are summarized as follows:
We propose a new pattern generator to produce high diversity in the dataset so that the classification model becomes robust to the dynamic nature of the non-random patterns.
We propose an end-to-end classification model based on 1D CNN architecture to classify control chart patterns directly without preprocessing or feature engineering. We conduct a thorough comparison with other feature-based approaches, including time-domain and frequency-domain features. Through exhaustive evaluation, we prove our method achieves better classification accuracy than the existing ML-based methods.
We present some data augmentation methods for control chart patterns and perform an analysis of the effects of data augmentation on classification accuracy.
We explore the application of transfer learning to CCPR by investigating if CNN trained on normally distributed data can still perform well for any continuous distribution data.
The rest of the paper is organized as follows.
Section 2 first describes the architecture of 1D CNN for classification and the concepts of transfer learning, and then the brief introduction of traditional classification models relevant to this research.
Section 3 presents the proposed methods, including pattern generation, data augmentation methods and the proposed 1D CNN for control chart pattern recognition.
Section 4 presents the performance evaluation results for the 1D CNN and other methods using different datasets, including real-world data, publicly available dataset, and simulated dataset. This section also provides the results of using different transfer learning approaches.
Section 5 summarizes the contributions of this study and provides remarks on limitations and future research directions.
4. Results and Discussion
In this study, a series of experiments were used to assess the performance of the 1D CNN. The performance of 1D CNN was compared with traditional classifiers (i.e., RF, TSF and SVC) to provide a comprehensive evaluation. We also studied the effect of training sample size on the performance. In the last experiment, we investigated the application of transfer learning to the CCPR tasks. The RF and SVC models were implemented in Python using scikit-learn v0.24.1 [
42]. The TSF was implemented in sktime—a scikit-learn compatible Python library for machine learning with time series [
53]. With the exception of SVC, the performance of other classifiers was based on ten runs due to the fact that these classifiers were not deterministic. All the experiments were executed on a machine with an Intel Core i7-8700 3.20 GHz CPU and 32.0 GB RAM.
The first experiment in this study used the data collected from printed circuit board (PCB) industry. The data were collected from various processes (e.g., plating, etching, and cleaning) involving monitoring of chemical solutions. The manufacturer applied individuals and moving range chart (
-
Chart) with supplementary rules [
4,
5,
6] to monitor the concentration of chemical solutions. The chemical concentration may present abnormal variations due to various reasons (i.e., the assignable causes). For example, the initial bath make-up, the mistake in dose calculations, wrong dosing formula, the irregular manual dosing operation, the malfunction of automatic dosing system, etc. The production variations due to irregular demand may also lead to abnormal variation of concentration.
As a practical solution to reducing the burden of engineer with regard to analysis of control chart data, a ML-based CCPR was developed. To implement the CCPR system, the analysis window size was set to 32 (the most common window size in literature). The observations from the same process were standardized using the corresponding in-control mean and standard deviation. If the data in a window triggered the supplementary rules, then the data were classified as non-random. The class labels were manually annotated (labelled) by human experts. Although the number of in-control data was much more than data from non-random patterns, the dataset was kept balanced for ease of performance evaluation. A total of 315 samples of seven pattern types were examined and selected by human experts. The collected samples were randomly split into training and test sets of 210 and 105, respectively.
In the remainder of this section, a series of experiments are used to unveil the effects of hyperparameters associated with each classification model. It is hoped that the experimental results may provide guidance for the practitioners on the selection and design of a classification model.
Table 1 summarizes the hyperparameter values of each algorithm. For RF model, the number of features used for each decision split was set to the square root of the number of input features. We did not restrict the maximum depth of each tree. The number of trees was evaluated over a range of values. We increased the tree number until no further improvement was seen. From
Figure 7, the RF model with 1000 trees achieved the best accuracy. Using the same method, the number of trees was set to 700 for TSF. The minimum length of interval was set to 4.
For SVC, the best combination of
and
is often selected by a grid search with exponentially growing sequences of
and
. In this study we fixed the kernel function as Radial Basis Function (RBF). The best performance of SVC was achieved when it was used with an RBF kernel with the parameters
and
set to 4.0 and
, respectively.
Figure 8 illustrates the effects of
and
on the performance of SVC.
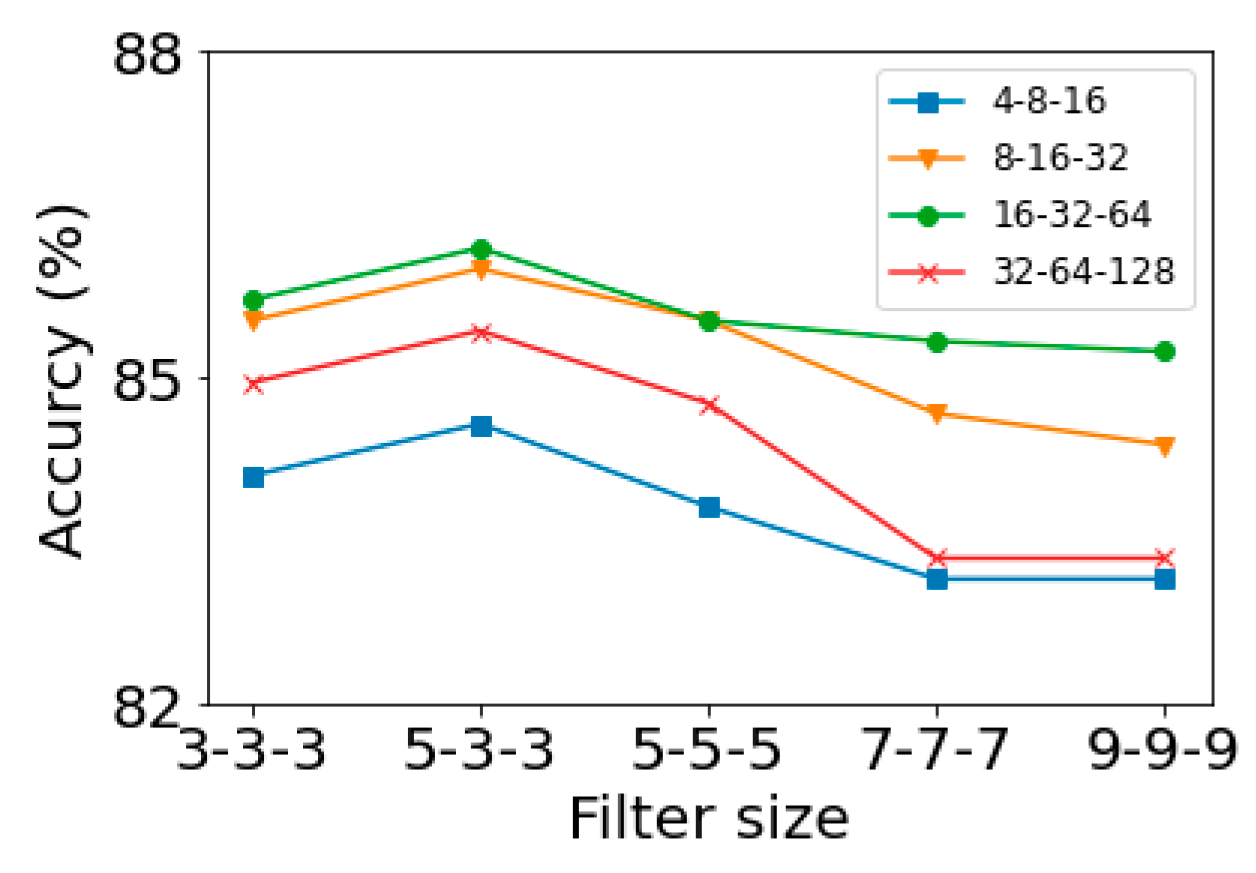
Tuning hyperparameters for CNN is difficult as it has many parameters to setup and requires long training time. For 1D CNN, we first focused on the size of filters and the number of filters. By fixing the training parameters, the grid search method was used to determine the filter size and the number of filters.
Figure 9 illustrates the results obtained from various combinations of the above two parameters. Several observations can be made based on
Figure 9. First, we can see that the classification accuracy decreased as the filter size increased. Second, it can be seen that using a larger filter size in the first convolution layer can improve the classification accuracy. Finally, there must be sufficient number of filters in order to have a good classification accuracy.
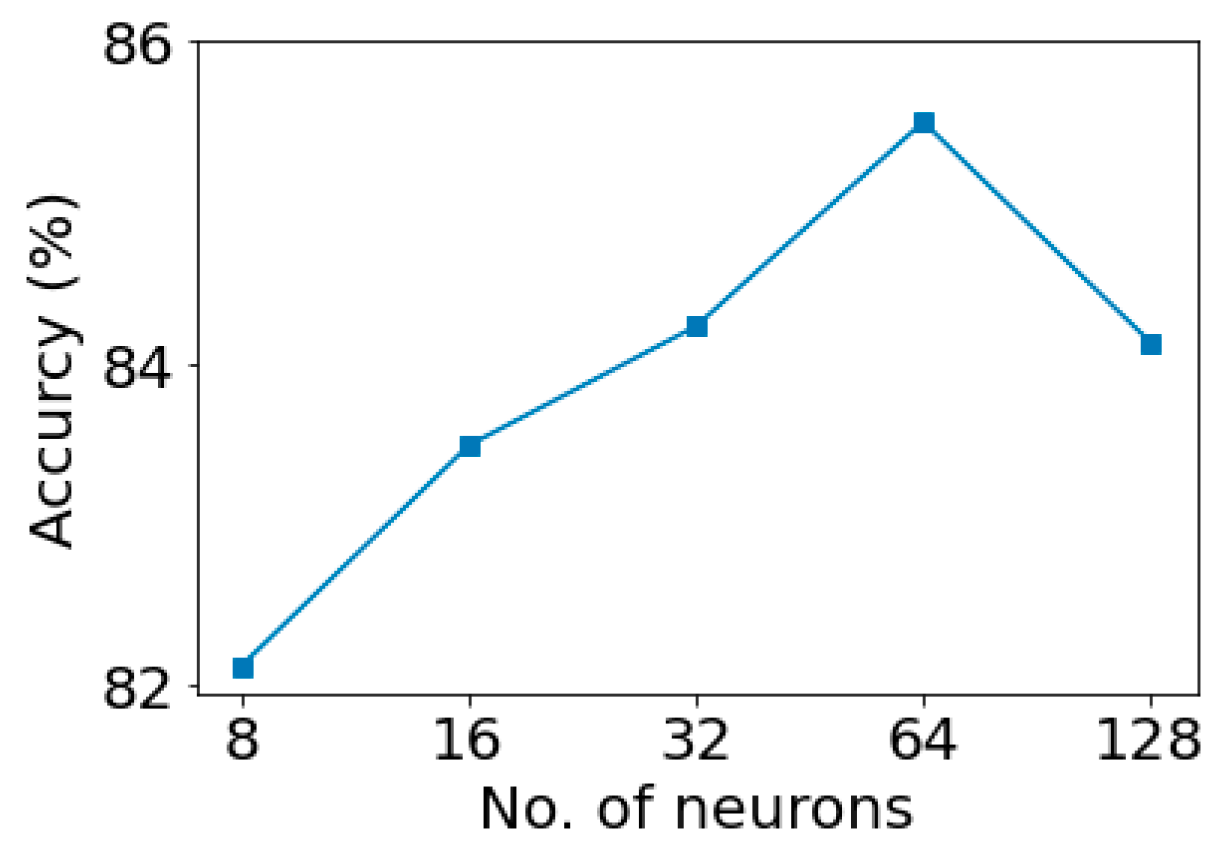
According to the results shown in
Figure 10, changing the number of neurons (between 8 and 128) in the fully connected layer can improve the performance of our proposed CNN network. Based on this, the number of neurons was set to 64.
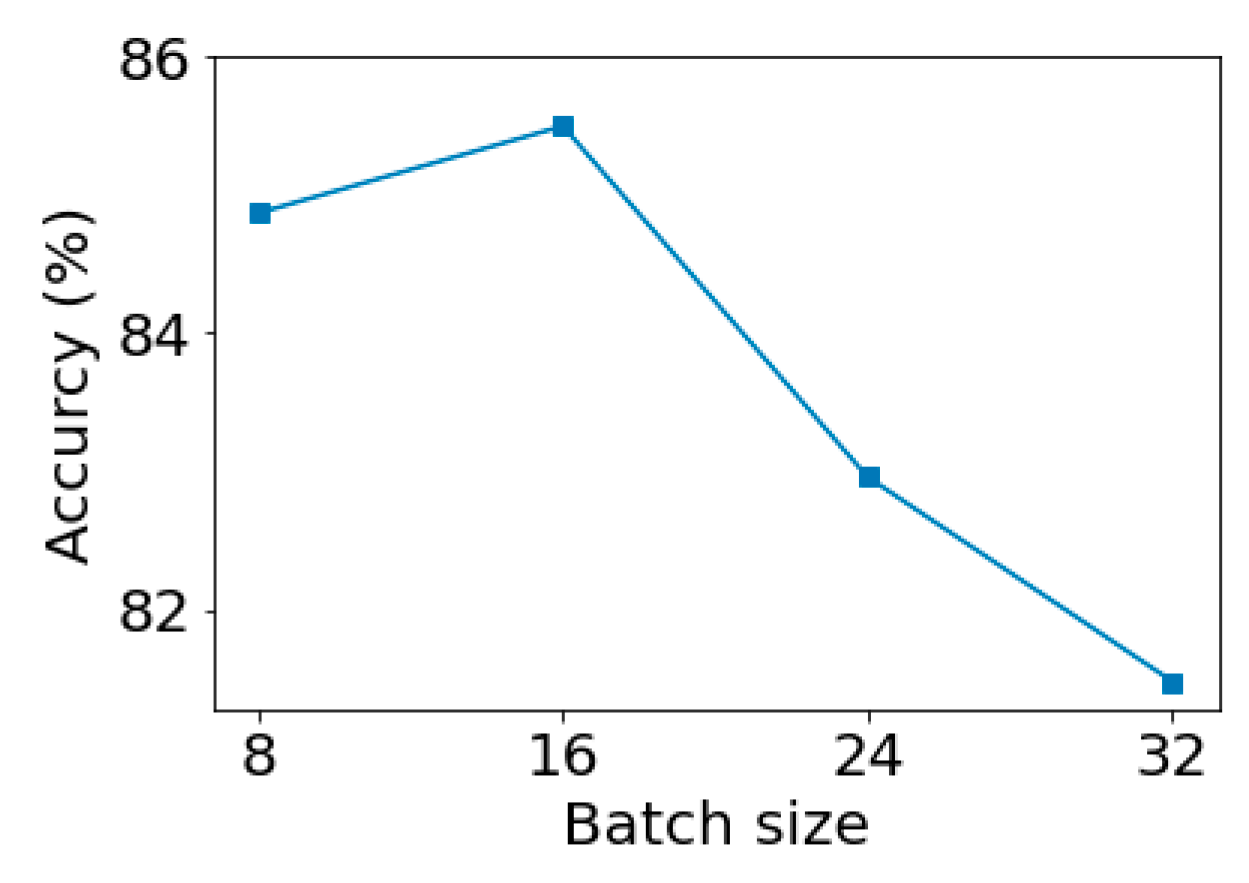
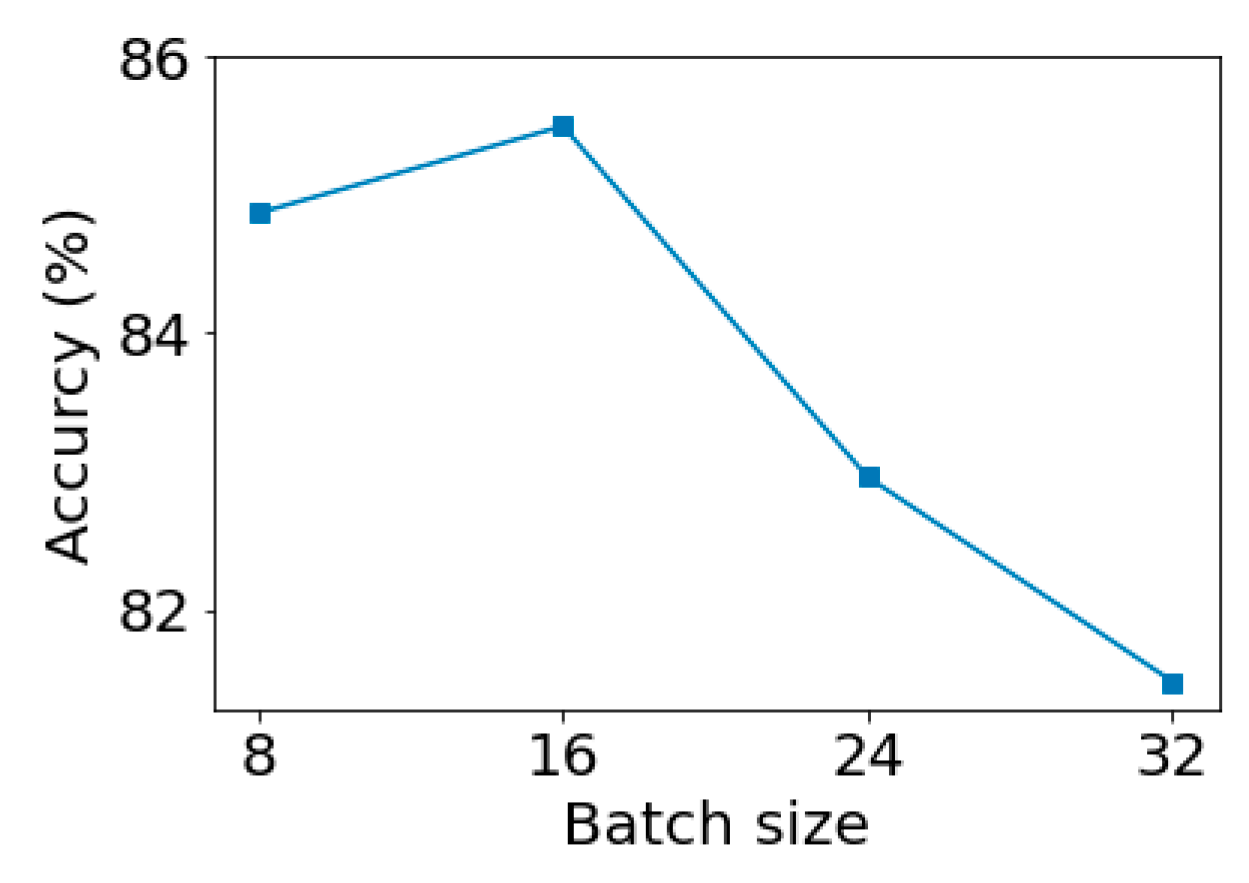
Next, we studied the effect of batch size under the condition that filter size and filter number were fixed.
Figure 11 shows that the batch size influenced the accuracy of the trained model. We can see from
Figure 11 that using batch size of 16 can achieve the best classification result.
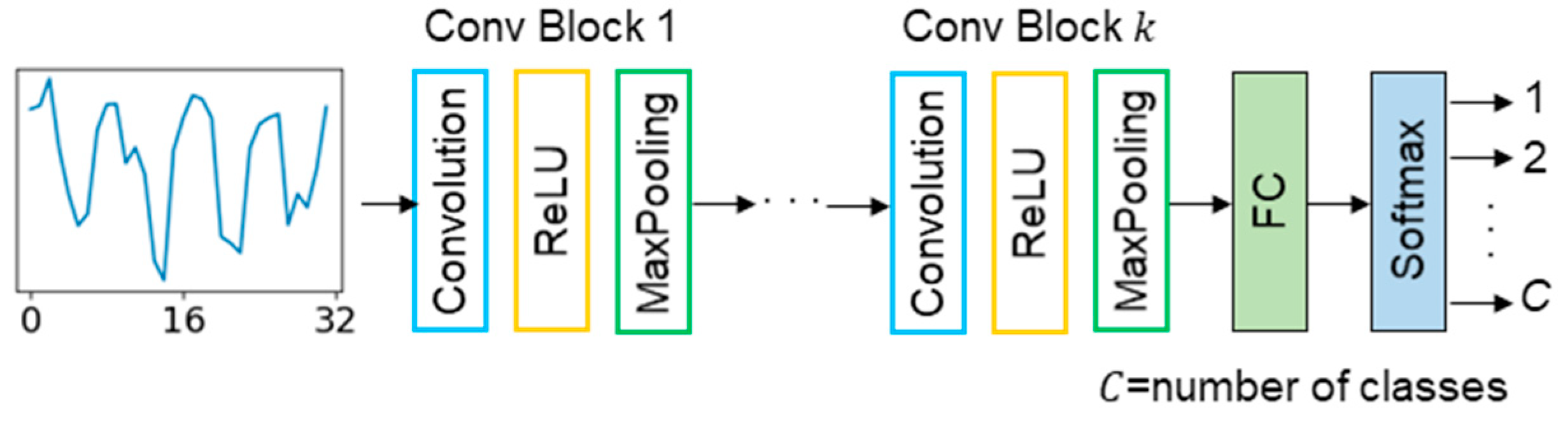
With the above optimization procedure, the optimal architecture was a 1D CNN model with 3 Conv Blocks. The filter number of the convolutional layer started with 32. The filter number was increased by multiplication of 2. The filter sizes in all layers were set to 5, 3 and 3. Each convolutional layer was followed by a ReLU activation layer and a max pooling layer with the size of 2. The padding type was set to “same” to ensure that the filter could be applied to all the elements of the input. In the 1D CNN, the dropout layer was added in the second block and the third block to avoid overfitting. The dropout layer will randomly choose a ratio of neurons and update only the weights of the remaining neurons during training. The dropout ratios for the second and the third Conv Blocks were 0.2 and 0.3, respectively. After the last pooling layer, there was one fully connected layer with 64 neurons on which a dropout was applied with a ratio of 0.3. The full architecture of the 1D CNN network is summarized in
Table 2.
The Adam optimization algorithm (learning rate 0.001) and categorical cross-entropy loss function were used to train the 1D CNN with a batch size of 16. It was trained up to 100 epochs. To avoid overfitting, early stopping criteria were implemented. This method involves stopping the training if the monitored metric has stopped improving within the five previous epochs.
The major challenge in CCPR is that many variants may encounter in real-time and on-line applications. It is useful to increase the diversity in training dataset to improve the classification accuracy. We created an augmented training dataset using the methods described above. The augmented dataset contained a total of 3150 patterns, evenly distributed among the seven pattern types.
Table 3 summarizes the number of samples for each pattern before and after using data augmentation.
Table 4 compares the experimentation results between with or without data augmentation. Using the original training dataset, CNN achieved the highest overall classification accuracy (85.81%) followed by SVC with 67.62%, TSF with 60.29% and RF with 65.43%. On the basis of the results shown in
Table 4, it can be observed that augmentation operation improved performance regardless of the model. This can be explained by the fact that augmentation increases the diversity of the training dataset and thus the robustness of the classification model. After data augmentation, CNN had the highest classification accuracy, at 99.05%, while SVC, TSF and RF had 88.57%, 73.24%, and 83.62%, respectively. The experimental results suggest that the data augmentation techniques can enhance the learning capability of the 1D CNN thus improving the classification performance.
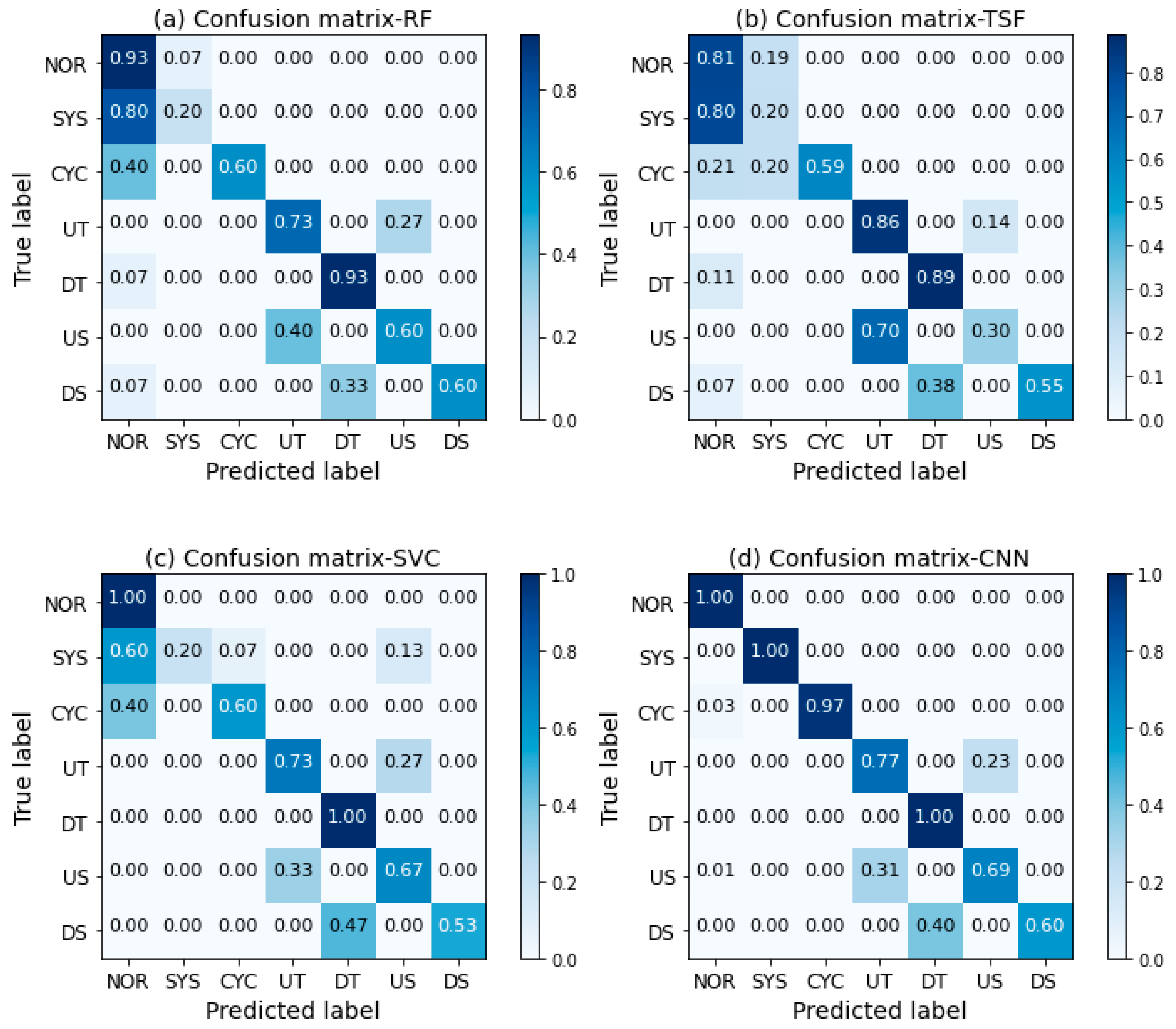
From the above results, we can see that the proposed CNN method consistently performs better than others in both settings of with/without the data augmentation strategy in terms of classification accuracy. To further examine the performance of the classification models, we check the confusion matrices shown in
Figure 12 (average of 10 runs). For 1D CNN, the entries on the main diagonal are much higher than off-diagonal elements indicating a good classification model. The worse accuracies for SVC, TSF, and RF classifiers may be due to the unseen variants of non-random patterns. For RF and SVC, the systematic and cyclic pattern were the most difficult pattern types to classify. As we pointed out earlier, these classifiers treat each observation as an individual feature. Therefore, they are sensitive to the starting location of the patterns. As depicted in
Figure 12, the most misclassified patterns by the feature-based TSF classifier were normal pattern, systematic and cyclic patterns. This may be explained by the fact that the features used in TSF cannot provide discriminative information among these patterns. In other words, these patterns may have similar features. This can be justified in the following experiments.
For an in-depth analysis of the deficiencies of the traditional classifiers, we studied the natures of the misclassified samples.
Figure 13 illustrates some examples of misclassification by traditional classifiers. For systematic patterns, the location of the first point may affect the classification result (
Figure 13a). In addition, the misclassification may be due to pattern discontinuity (
Figure 13b,c). For this pattern type, discontinuity refers to the discontinued alternating up and down. The misclassification of cyclic patterns may be attributable to the translation shift or pattern discontinuity (
Figure 13d–f). Here, the pattern discontinuity means the corrupted sequence of peak and valley. In practice, this may be caused by operating irregularity. Ongoing implementation of the CCPR might result in the translation shift of a pattern shown in an analysis window. The change location of trends and shifts in the analysis window might affect the classification accuracy to a great extent. If the change locations of trends were not considered in the training set, they might be misclassified as other patterns.
Figure 13g,h shows the examples of misclassifying trends as shifts. Due to the same reason, the shifts may be misclassified as other pattern type (
Figure 13i).
Figure 14 displays the confusion matrix for each classification model using augmented training dataset. All models gained a significant improvement in accuracy, except for TSF model. This may imply that the features adopted in TSF are not useful for patterns with observations fluctuating around the mean level. Based on the results shown in
Figure 14, it can be noted that 1D CNN had much higher accuracy than RF and SVC for systematic and cyclic patterns. It appears that 1D CNN possesses the translation invariance property.
Experiment 2: Dataset from Yu [54]
The dataset was taken from the work of Yu [
54], which applied a Gaussian mixture model (GMM) for control chart pattern recognition. The author has demonstrated the adaptive capability of the proposed model with respect to novel or unknown patterns. There were six pattern types in Yu’s study, including a normal pattern and five non-random patterns (CYC, UT, DT, US, and DS). Systematic and mixture patterns were used as novel patterns. For all non-random patterns, the change points were randomly chosen around half of the time window (64). This setting makes it unique from other studies. Its uniqueness lies in the fact that there were many in-control observations preceded the non-random pattern. In the training set, there were 200 samples for each pattern, and in the test data set, there were 100 samples for each pattern. Statistical and wavelet features were generated as the inputs of GMM to implement control chart pattern recognition.
In this experiment, the proposed architecture contained three convolutional blocks, one fully connected layer, and a softmax as the output layer. The first Conv Block comprised 32 filters with a filter size of 5, and the second Conv Block comprised 128 filters with a filter size of 3. The last Conv Block had 256 filters with a filter size of 3. Each convolutional layer was followed by a ReLU activation layer and a max pooling layer with the size of 2. The dropout ratios for the second and the third Conv Blocks were set to 0.3. After the last pooling layer, there was one fully connected layer with 32 neurons on which a dropout was applied with a ratio of 0.1. The training procedure was exactly the same as that described in experiment 1.
Using the procedure described in experiment 1, the number of trees for RF was 900. TSF was trained with 600 trees with minimum interval set to 5. SVC used RBF kernel function. After a grid search study, the parameters and were set to 8.0 and , respectively.
Following the evaluation of 10 different runs used by the original paper, the classification results of each classifier are summarized in
Table 5. We report the mean, standard deviation, minimum and maximum classification accuracy. The classification model developed by Yu [
54] yielded an accuracy rate of 94.28%. The proposed 1D CNN obtained an accuracy of 99.07%. Results has also shown that CNN had the best results compared with other competitors. It is important to note that TSF outperformed RF and SVC. This is due to the fact that systematic patterns were not considered in this experiment. As explained in experiment 1, the features of TSF are not helpful for distinguishing normal and systematic patterns.
Figure 15 illustrates the confusion matrices of the worst case for Yu’s work and our 1D CNN. Matrix(a) was taken from [
54] with a rearrangement of presentation order. Both methods provided perfect classification for normal and cyclic patterns. However, the method of Yu [
54] had difficulty in distinguishing trends from shifts while 1D CNN performed quite well for these two pattern types.
For further assessment of the CNN model, a visualization of the learned features from different layers of 1D CNN is provided to illustrate the separation in the feature space. This was accomplished by using the t-stochastic neighbor embedded (t-SNE) clustering algorithm [
55] on different layer features of the 1D CNN. The learning results for some selected layers of the CNN are visualized sequentially in
Figure 16. It is clear that data points of the six pattern types in the input layer were mixed together. After the first convolution layer, data points of six classes gradually split. In the FC layers, samples of six classes were complete separate. The results show a layer by layer improvement in classification performance by transforming the low-level input data into high-level features.
In this experiment, we evaluated and compared the performances of our proposed CNN using the publicly available dataset (SyntheticControl) from UCR time series classification archive [
56]. This dataset was originally constructed by Alcock and Manolopoulos [
57]. The window size was set to 60. The dataset included data from six control chart patterns, including NOR, CYC, UT, DT, US, and DS. There were 600 samples in total with 100 samples for each pattern type. In UCR, the original dataset has been split into training and test sets of the same size. The explicit split of training/test set of this dataset allows a direct comparison of different classification methods.
The distinguishing feature of this dataset is that the random noises follow a uniform distribution instead of normal distribution. The time series has been scaled such that each individual series has zero mean and unit variance. With this scaling, the magnitude of the individual series will be lost. In other words, the classifier receives inputs of similar magnitude.
Considering that the complexity of this dataset is not high, the selected architecture was a 1D CNN model with 2 Conv Blocks. The first Conv Block comprised 32 filters with a filter size of 5, and the second Conv Block had 128 filters with a filter size of 3. Drop out was applied to the second convolution layer with ratio 0.3. Each convolutional layer was followed by a ReLU activation layer and a max pooling layer with the size of 2. The fully connected layer included 64 neurons, followed by a dropout layer with a ratio of 0.3. The learning batch size was set to 16. The training procedure followed that described in experiment 1.
By means of the procedure described in experiment 1, the number of trees for RF and TSF were 900 and 1500, respectively. The minimum interval length of TSF was set to 3. SVC used RBF as kernel function. Using a grid search, the parameters and were set to 8.0 and , respectively.
The results of different classifiers on UCR dataset are shown in
Table 6. On the basis of the results shown in
Table 6, it can be seen that our 1D CNN had the highest accuracy, followed by TSF, SVC and then RF.
The results of our proposed model also outperformed most published results on this dataset. The Supervised Time Series Forest (STSF) algorithm developed by Cabello et al. [
58] obtained an accuracy of 99.03% (average of ten runs). STSF is a time series forest for classification and feature extraction based on some discriminatory intervals. The time series classification with a bag of features proposed by Baydogan et al. [
59] achieved accuracy of 99.1% (average of ten runs). Chen and Shi [
60] reported an accuracy of 99.7% using a multi-scale convolutional neural network (MCNN). They used recurrence plot to transform original input data into 2D images. The best classification accuracy for this dataset was 100% accuracy using a collective of transformation-based ensembles (COTE) developed by Bagnall et al. [
61]. However, the high computational demand of COTE is a problem in practical application.
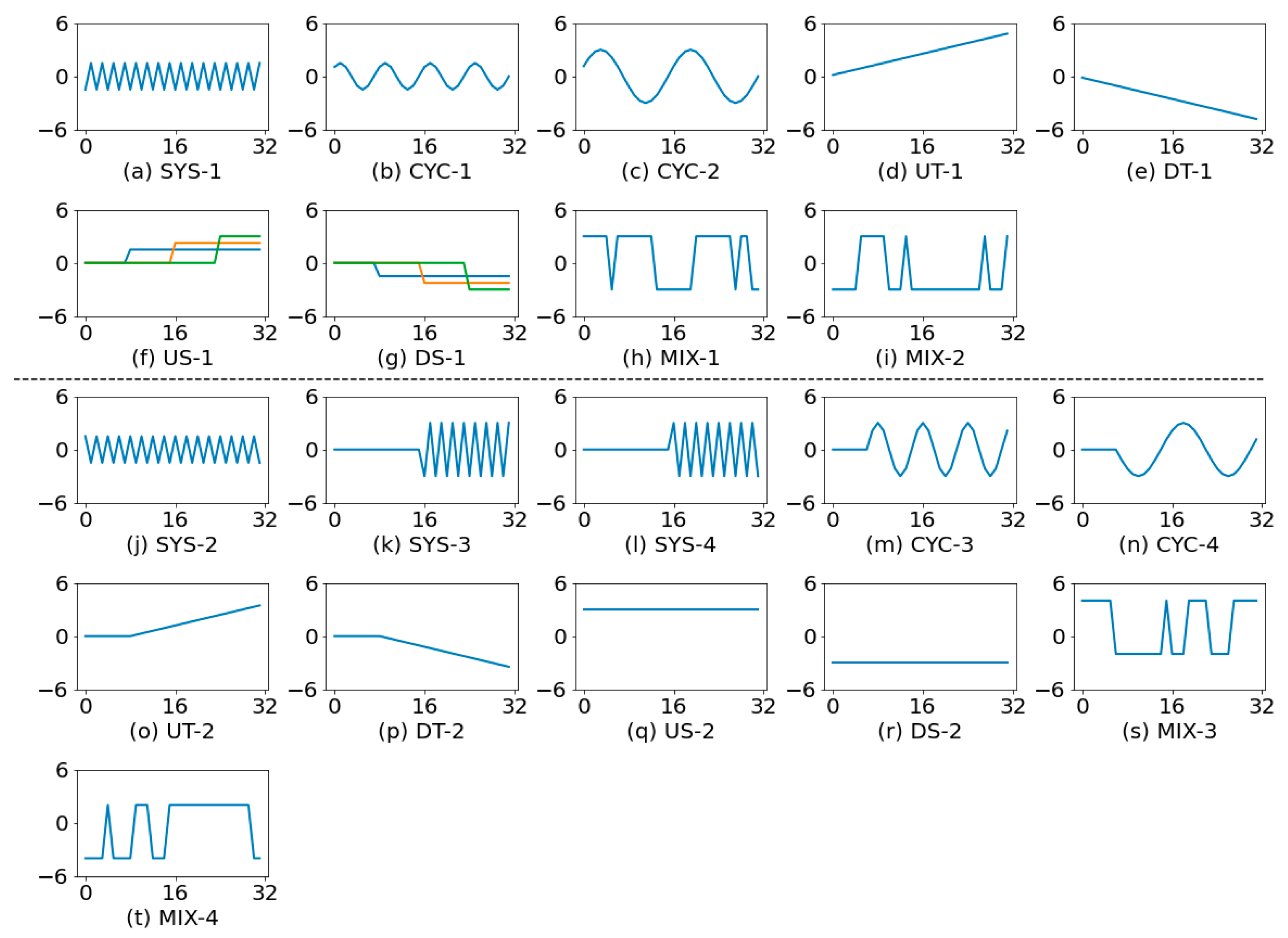
The purpose of experiment 4 is to investigate the performance of CNN under a complicated situation involving high intra-class variability and high inter-class similarity. The formulas described in earlier section were used to generate the training and test datasets. The window size was set to 32. There were eight pattern types in this experiment, including a normal pattern (NOR) and seven non-random patterns (SYS, CYC, UT, DT, US, DS, and MIX). For all non-random patterns, the change point was determined by the quantity
, which is randomly chosen from a predefined range. In the training set, there were 1000 samples for each pattern, and in the test data set, there were also 1000 samples for each pattern. The pattern parameters are summarized in
Table 7. The parameters are expressed in terms of standard deviation units.
The unique features of the dataset created in this experiment include the following points. For systematic pattern, it can be preceded by a certain number of in-control data. The first point of the pattern may be located above or below the mean in the analysis window. For cyclic pattern, we considered phase shift of pattern. The cycle can also be preceded by a certain number of in-control data. The trends can be preceded by a certain number of in-control data. For shift patterns, we considered the partial-shifted or full-shifted patterns in the window. For mixture, the first point may locate above or below the mean. The shifting of distributions is controlled by a random number.
Following the procedure described in experiment 1, the number of trees for RF and TSF were set to 1200 and 900, respectively. The minimum interval length of TSF was set to 5. For SVC, the parameters and were set to 1.0 and , respectively.
The optimal 1D CNN architecture included three Conv Blocks. The first convolution layer was composed of 32 filters with a filter size of 5, and the second convolution layer comprised 128 filters with a filter size of 3. The last convolution layer had 256 filters with a filter size of 3. Each convolutional layer was followed by a ReLU activation layer and a max pooling layer with the size of 2. The dropout ratios for the second and the third Conv Blocks were set to 0.3. After the last pooling layer, there was one fully connected layer with 128 neurons. We applied a dropout layer after the fully connected layer and used a ratio of 0.3. The batch size was set to 512.
For the nondeterministic classifiers (e.g., RF, TSF, and CNN), we computed the average classification accuracy over 10 runs. A quantitative comparison of accuracy for individual classifier is summarized in
Table 8. The results show that the proposed 1D CNN model outperformed all other methods in terms of mean accuracy and standard deviation.
In this experiment, we investigated the effect of training sample size on the classification performance. The aforementioned four datasets were considered. Using resampling from the original training dataset, we computed the classification performance on the original test dataset. For each training sample size, we performed ten runs using different random seeds. We reported the results under different numbers of training samples per class. The results are summarized in
Figure 17. The x-axis shows the number of samples used per class, ranging from 1 to the full training dataset. It can be seen that the accuracy rate increased as the sample size increased. However, after the training data reached sufficient size, additional training data had a little effect on performance. We can see that the sample number required for an acceptable performance level depends on complexity of the problem to be solved. For data with extra high intra-class diversity (e.g., dataset for experiment 4), a minimum of 200 samples per class is required. For moderate intra-class diversity (e.g., datasets for experiments 1 and 2), using 20 samples per class can achieve a satisfactory performance level. For dataset with high inter-class diversity and low intra-class diversity (e.g., experiment 3), using 10 samples per class could yield an adequate performance level.
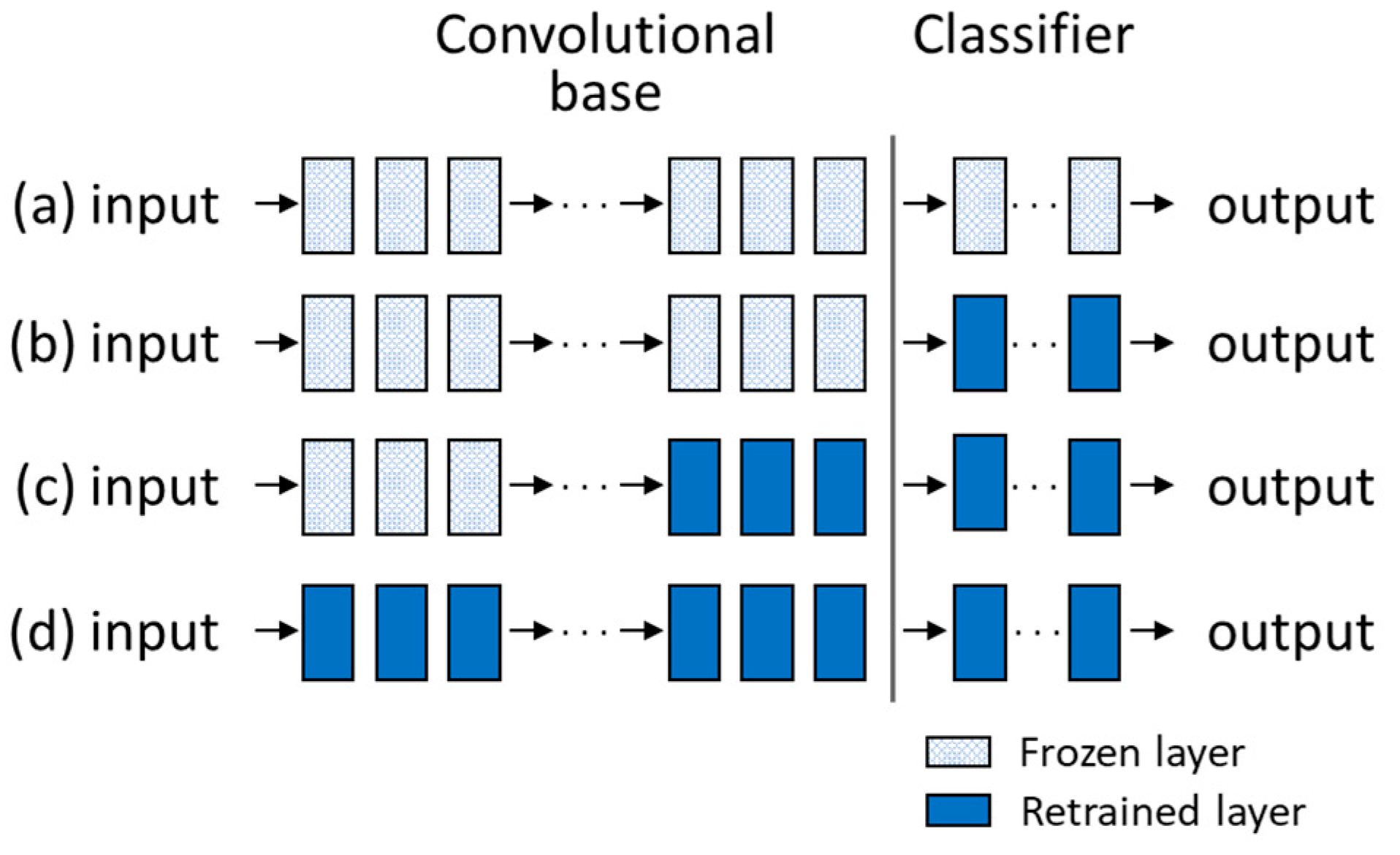
Machine learning requires a large amount of training data to establish an effective classification model. In CCPR, training data are expensive or difficult to collect. If the underlying distribution of the non-random patterns is known, one can resort to the simulation approach to create the required amount of data. However, in real-world applications we may encounter the situations where data distribution type is not known or the pattern cannot be expressed as a simple equation. In this experiment we studied the application of transfer learning to the CCPR tasks. We applied the pre-trained model developed for normally distributed data (source data) to other unknown distribution data (target data) to demonstrate the benefits of transfer learning. Labels for both the source and target data were assumed available.
In this experiment, we studied the strategy that may yield the best results on control chart pattern recognition. In the first approach, the pre-trained model was used as a classifier, in other words, the whole model was frozen. In the second approach, we used the pre-trained model as a feature extractor for the new task. We froze the convolutional base and trained the fully connected layer. In the third approach, the whole pre-trained model was allowed to be retrained. The weights of the pre-trained model were used as the starting point of the new task.
The model described in experiment 4 was used as the basis for transfer learning in CCPR applications. We selected the gamma distribution to represent the case of skewed distributions and the uniform distribution to represent symmetric distributions with heavier tails than the normal. The gamma distribution with shape parameter
and scale parameter
will be denoted here by
. We assume
without any loss of generality. Notice that as shape parameter
increases, the gamma distribution becomes more like a normal distribution [
1].
The classification performances of the CNN for various non-normal distributions are summarized in
Table 9. The number in parentheses denotes the standard deviation over ten runs. The classification performances of the models trained from scratch are also provided for ease of reference. From the results of model trained from scratch, we can observe that the highly skewed distributions lead to a large increase in classification rate. If the pre-trained model was used as a classifier, the classification accuracy for each non-normal distribution was much lower than that of the model trained from scratch. The largest discrepancy occurred when the target data followed a uniform distribution. When the pre-trained model was applied directly to
, it performed similar to the model trained from scratch. This is understandable because the distributional characteristics of
are similar to those used in the pre-trained model (i.e., normally distributed data). For the other two transfer learning approaches, we can see that the pre-trained model still performed well in the cases of non-normal distributions. It is obvious that weight initialization approach performed consistently better than just using the extracted features. This approach even performed better than the model trained from scratch (starting from random initialized parameters).
In order to further examine the benefit of using transfer learning where labelled training data on the target dataset are scarce, we carried out additional experiments with reduced amounts of training data. For all target datasets, we randomly reduced the training dataset to 5, 20, 40, and 60% of its original size. The classification performances were computed on the original test dataset.
Table 10 displays the classification accuracy (%) for different training sample sizes. The number in parentheses denotes the standard deviation over ten runs. After close examination of the results, some interesting findings can be highlighted. First, the results indicate that the performance was affected by the variations in quantity of the training data on the target domain. A noticeable decrease in the classification accuracy occurred when the proportion of the training data was lower than 5% of the original size. When the training dataset reached 60% of its original size, the classification model nearly had the same performance as the model trained with full dataset (results of weight initialization in
Table 9). The overall results suggest that transfer learning is a promising approach for CCPR when the data are scarce.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}