
On the Application of ARIMA and LSTM to Predict Order Demand Based on Short Lead Time and On-Time Delivery Requirements




Abstract
:1. Introduction
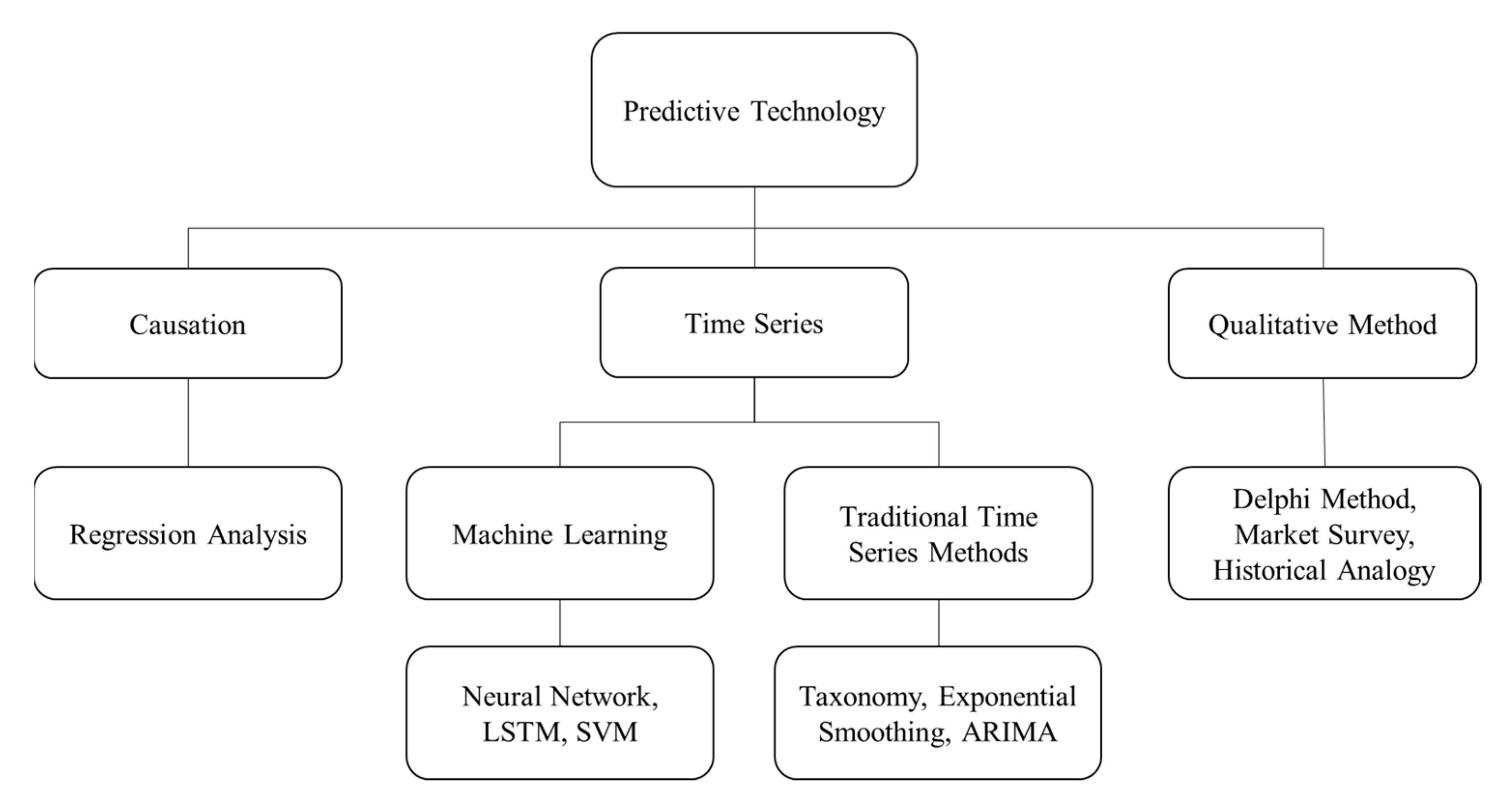
2. Literature Review
3. IC Factory Scenario and Analysis Framework
3.1. Problem Description
3.2. Data Collection and Adjustment
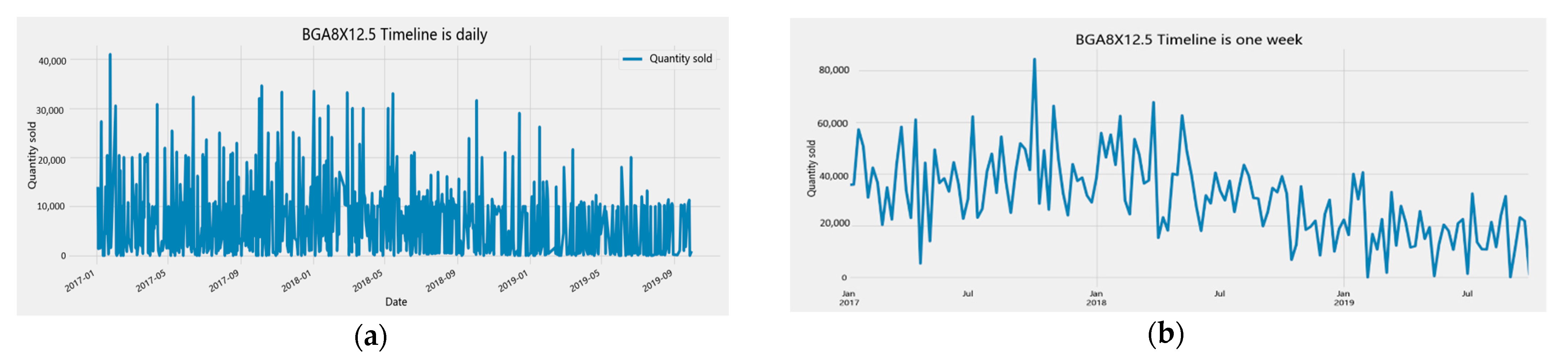
- Timeline conversion: the case companies provide data on the number of goods sold in “days,” and the frequency is converted to the “week” period data. There is no trend and seasonal information for the company’s top five products, as shown in Figure 3. Due to high order volatility, short lead times, and workweek considerations, the prediction horizon is to make short-term sales volume forecasts for the next three weeks. The purpose is to meet customer demand and improve competitiveness with quick response and good forecasting ability. Therefore, this study decided to forecast the periodic data to improve effective management and meet the unstable market demand.Figure 3. Timeline conversion of the difference graph. (a) BGA8X 12.5 timeline is daily; (b) BGA8X 12.5 timeline is on week.Figure 3. Timeline conversion of the difference graph. (a) BGA8X 12.5 timeline is daily; (b) BGA8X 12.5 timeline is on week.
![Processes 09 01157 g003]()
- Missing value processing.
- (i)
- Remove the missing value.
- (ii)
- Average interpolation.
- (iii)
- High-frequency data
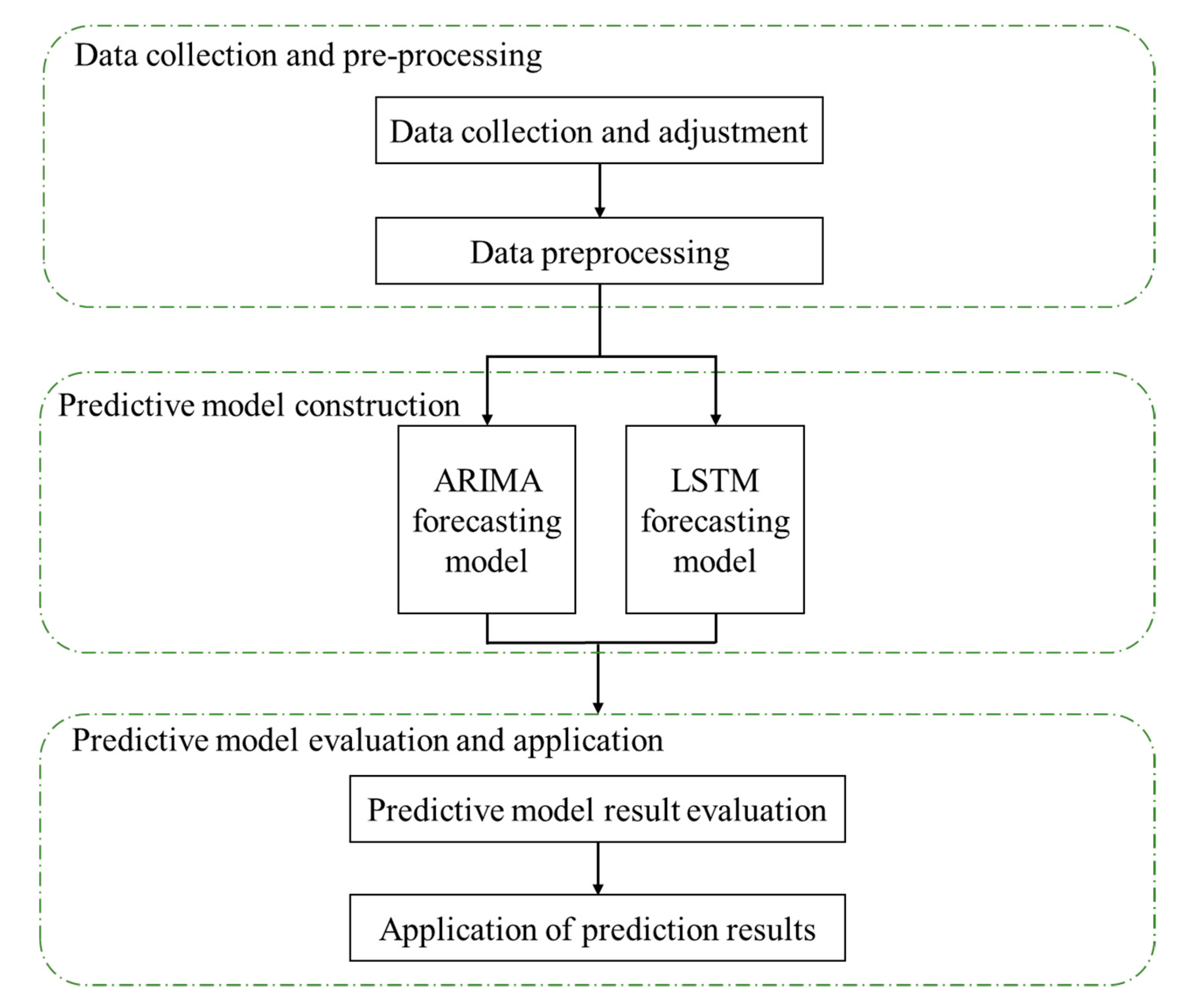
3.3. Model Create and Evaluate
3.3.1. ARIMA Model
- Step 1: check whether the data are a steady-state sequence.
- Step 2: single-root verification determines the number of differences (d).
- Step 3: determine the lagging period p and q of ARIMA(p, d, q).
- Step 4: ARIMA (p, d, q) model selection.
- Step 5: check that the residuals are white noise.
- (i)
- Standardized residual plot.
- (ii)
- Normal quantile–quantile plot.
- (iii)
- Residual histogram.
3.3.2. LSTM Model
- Step 1:
- forget the door (forget unnecessary messages).
- Step 2:
- determine and save the newly input message from the memory unit.
- Step 3:
- determine the output content.
3.4. Predictive Evaluation Indicators
- (1).
- Mean absolute error (MAE): the error between each datum’s predicted and actual value is measured. The MAE method sums up the absolute values of each datum error and then calculates the average error with the following formula:
- (2).
- Mean absolute percent error (MAPE): MAPE (%) is measured by the relative prediction error of each data to avoid the shortcomings of the MAD method and MSE method, where the calculation results could be too large due to the large data values. When MAPE is less than 10, the model is highly accurate; MAPE is between 10 and 20, the model is a good predictor; MAPE is between 20 and 50, the model is a reasonable predictor and MAPE is greater than 50, the model is not accurate [31].
- (3).
- Root mean square error (RMSE): the root mean square error, also known as the standard error, is the square root of the ratio of the square of the deviation of the observed value to the actual value to the number of observations. The root mean square error is used to measure the deviation between the observed and actual values. The standard error is susceptible to very large or very small errors in a set of measurements. Therefore, the standard error is a good indicator of the precision of the measurement. The standard error can be used as a criterion to assess the accuracy of this measurement process, and the formula is as follows:where is the actual value, is the predicted value, k is the sample size.
4. Analysis Results
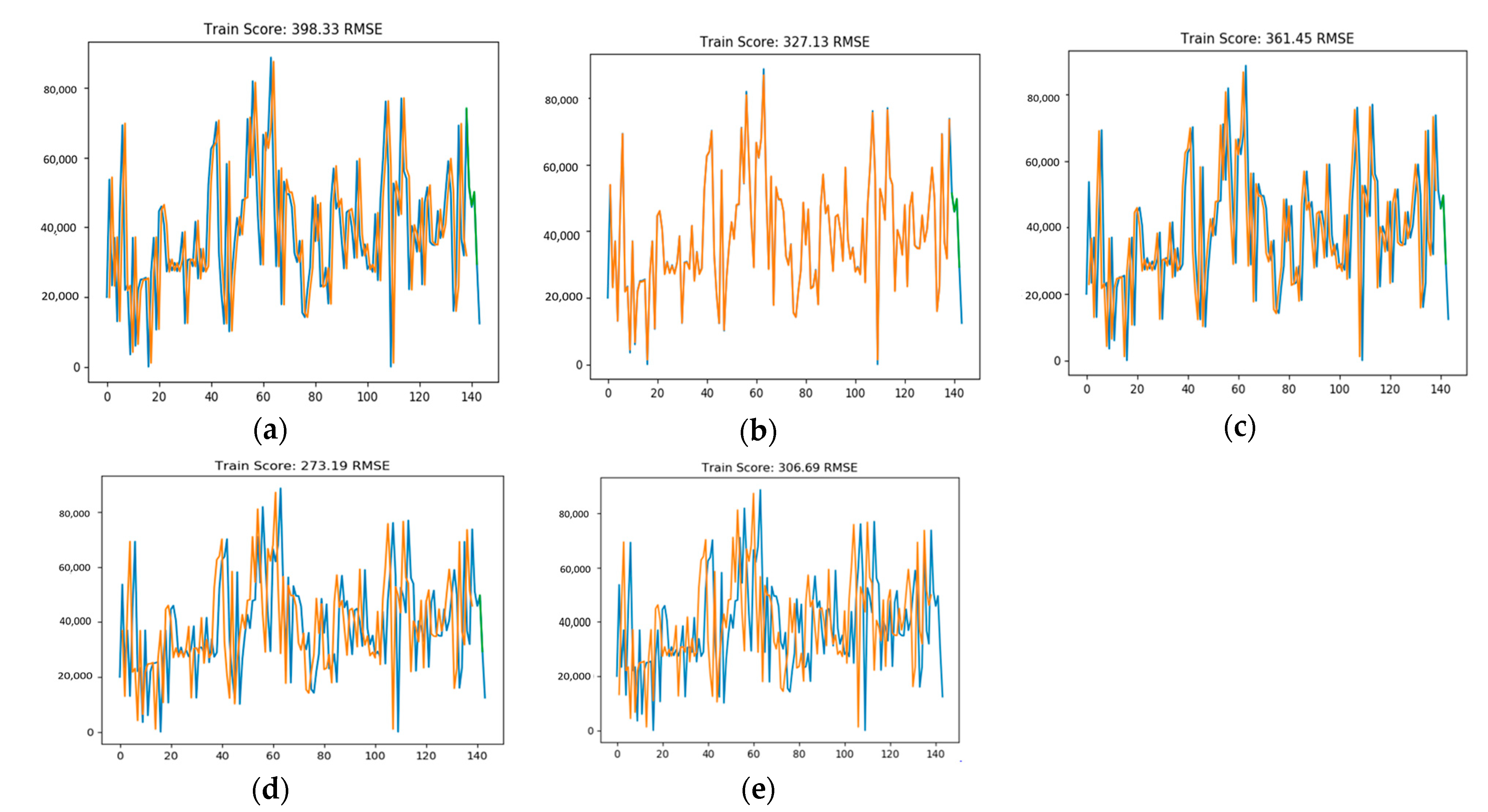
4.1. Rolling Forecast Structure
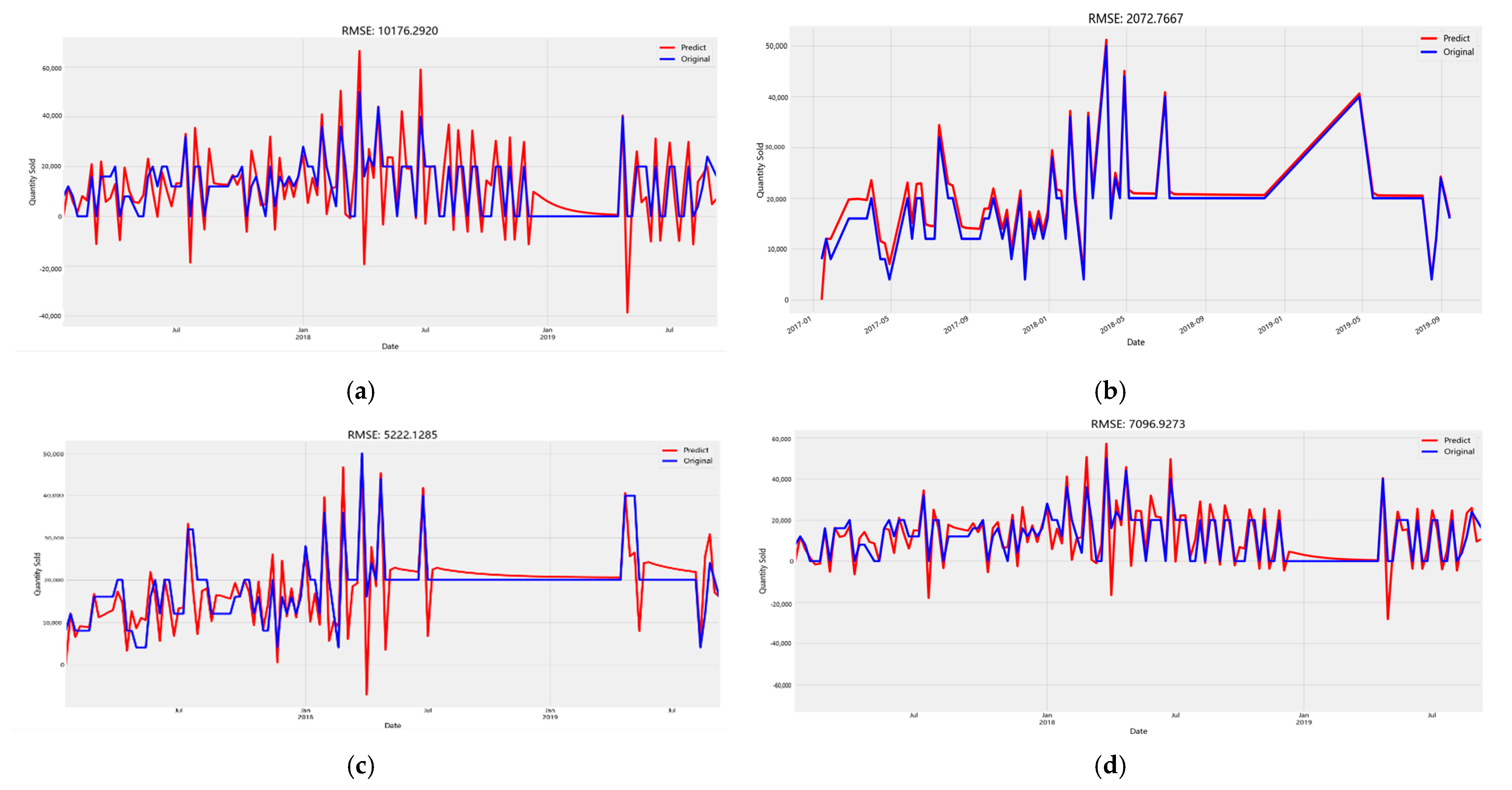
4.2. Model Prediction Results Are Compared
5. Discussion and Conclusions
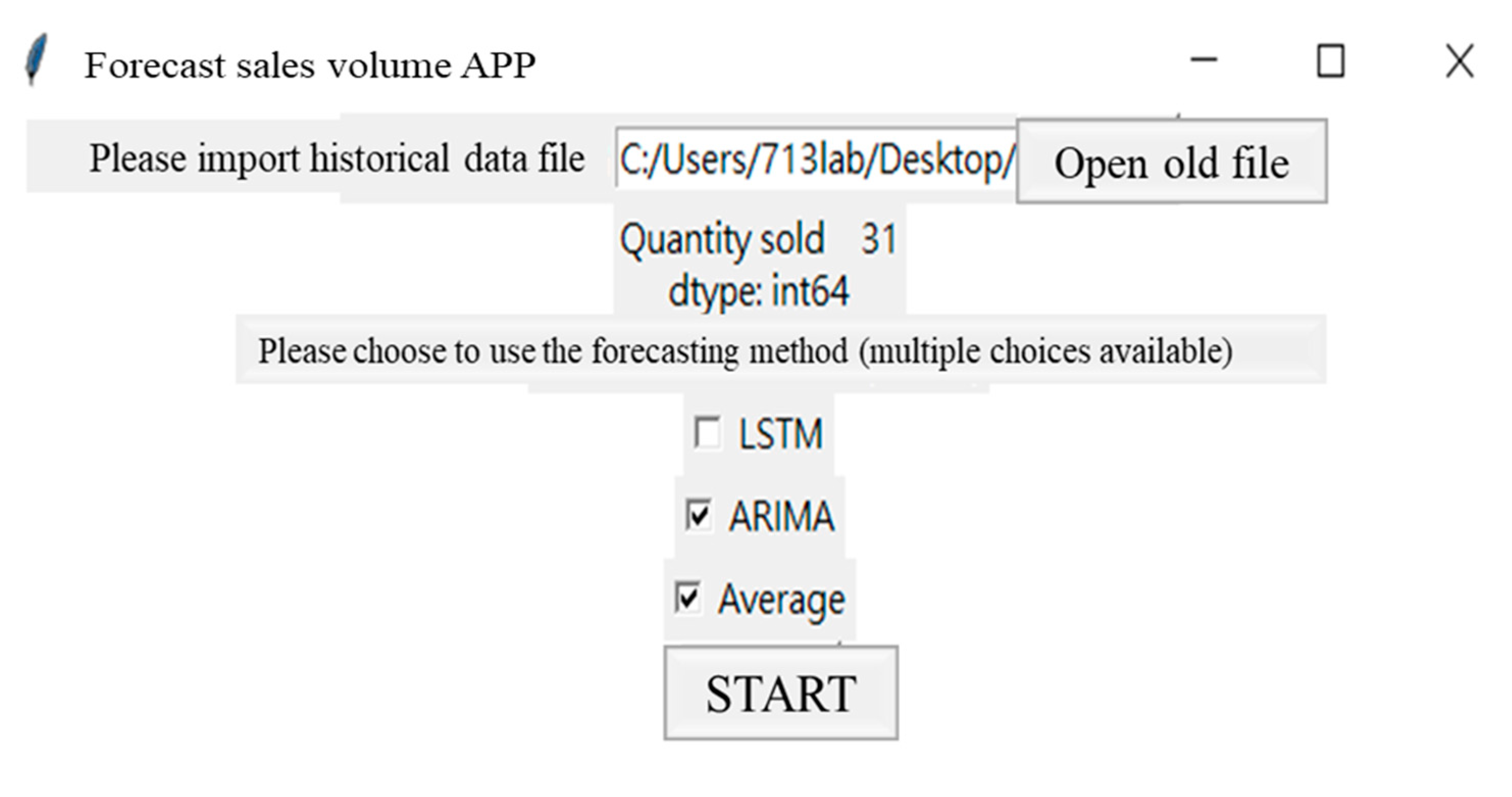
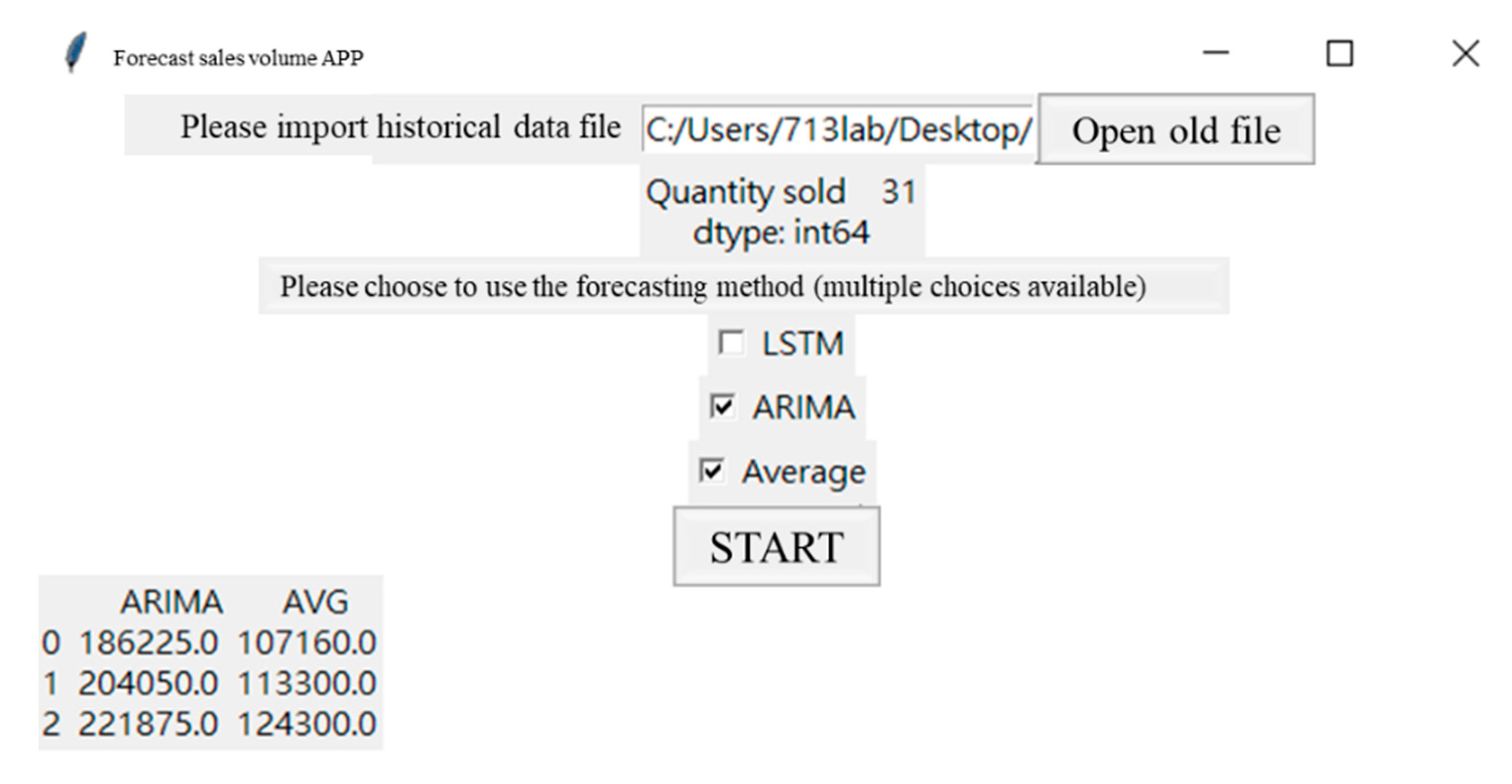
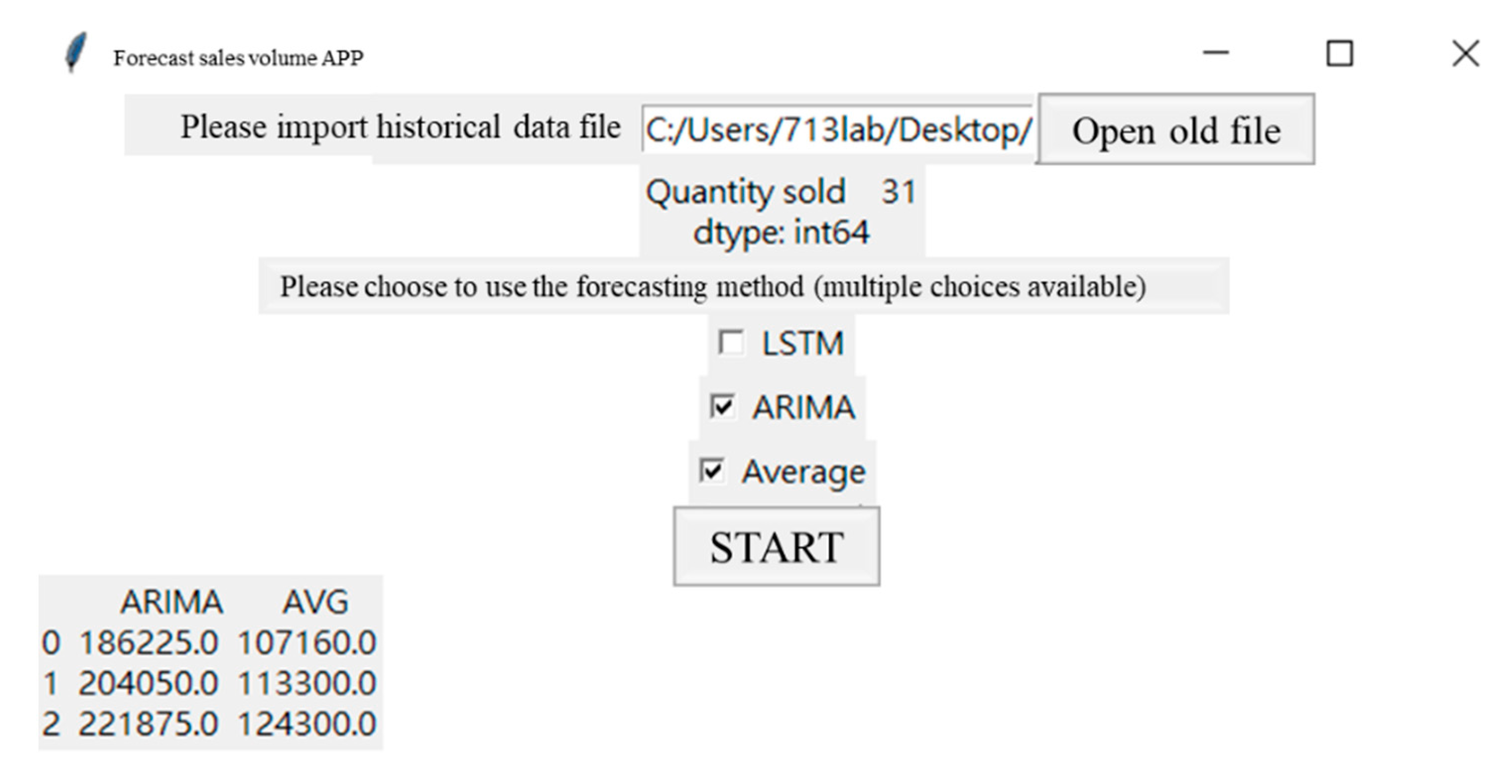
- Step 1:
- select the forecast item number.
- Step 2:
- select prediction method.
- Step 3:
- forecast sales quantity.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, H.Y.; Chen, I.S.; Chen, J.K.; Chien, C.F. The R&D efficiency of the Taiwanese semiconductor industry. Measurement 2019, 137, 203–213. [Google Scholar]
- International Data Corporation. Worldwide Semiconductor Revenue Grew 5.4% in 2020 Despite COVID-19 and Further Growth Is Forecast in 2021, According to IDC. Available online: https://www.idc.com/getdoc.jsp?containerId=prUS47424221 (accessed on 11 February 2021).
- Taiwan Semiconductor Industry Association. TSIA Q4 2020 and Year 2020 Statistics on Taiwan IC Industry. TSIA Report. Available online: https://www.tsia.org.tw/PageContent?pageID=1 (accessed on 20 February 2021).
- Nian, S.C.; Fang, Y.C.; Huang, M.S. In-mold and machine sensing and feature extraction for optimized IC-tray manufacturing. Polymers 2019, 11, 1348. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karimnezhad, A.; Moradi, F. Bayes, E-Bayes and robust Bayes prediction of a future observation under precautionary prediction loss functions with applications. Appl. Math. Model. 2016, 40, 7051–7061. [Google Scholar] [CrossRef]
- Moon, M.A. Demand and Supply Integration: The Key to World-Class Demand Forecasting; Walter de Gruyter GmbH & Co KG: Berlin, Germany, 2018. [Google Scholar]
- Bruzda, J. Demand forecasting under fill rate constraints—The case of re-order points. Int. J. Forecast. 2020, 36, 1342–1361. [Google Scholar] [CrossRef]
- Abadi, S.N.R.; Kouhikamali, R. CFD-aided mathematical modeling of thermal vapor compressors in multiple effects distillation units. Appl. Math. Model. 2016, 40, 6850–6868. [Google Scholar] [CrossRef]
- Nia, A.R.; Awasthi, A.; Bhuiyan, N. Industry 4.0 and demand forecasting of the energy supply chain: A. Comput. Ind. Eng. 2021, 154, 107128. [Google Scholar]
- Hu, M.; Qiu, R.T.; Wu, D.C.; Song, H. Hierarchical pattern recognition for tourism demand forecasting. Tour. Manag. 2021, 84, 104263. [Google Scholar] [CrossRef]
- Kozik, P.; Sp, J. Aircraft engine overhaul demand forecasting using ANN. Manag. Prod. Eng. Rev. 2012, 3, 21–26. [Google Scholar]
- Gutierrez, R.S.; Solis, A.O.; Mukhopadhyay, S. Lumpy demand forecasting using neural networks. Int. J. Prod. Econ. 2008, 111, 409–420. [Google Scholar] [CrossRef]
- Willemain, T.R.; Smart, C.N.; Schwarz, H.F. A new approach to forecasting intermittent demand for service parts inventories. Int. J. Forecast. 2004, 20, 375–387. [Google Scholar] [CrossRef]
- Dunn, W.N. Poblicy Analysis: An Introduction, 2nd ed.; Prentice Hall Englewood Cliffs: Hoboken, NJ, USA, 1994. [Google Scholar]
- Rosienkiewicz, M.; Chlebus, E.; Detyna, J. A hybrid spares demand forecasting method dedicated to mining industry. Appl. Math. Model. 2017, 49, 87–107. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1976. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A comparison of ARIMA and LSTM in forecasting time series. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1394–1401. [Google Scholar]
- Fattah, J.; Ezzine, L.; Aman, Z.; El Moussami, H.; Lachhab, A. Forecasting of demand using ARIMA model. Int. J. Eng. Bus. Manag. 2018, 10, 1847979018808673. [Google Scholar] [CrossRef] [Green Version]
- Salman, A.G.; Kanigoro, B. Visibility forecasting using autoregressive integrated moving average (ARIMA) models. Procedia Comput. Sci. 2021, 179, 252–259. [Google Scholar] [CrossRef]
- Roondiwala, M.; Patel, H.; Varma, S. Predicting stock prices using LSTM. Int. J. Sci. Res. 2017, 6, 1754–1756. [Google Scholar]
- Pacella, M.; Papadia, G. Evaluation of deep learning with long short-term memory networks for time series forecasting in supply chain management. Procedia CIRP 2021, 99, 604–609. [Google Scholar] [CrossRef]
- Pak, U.; Ma, J.; Ryu, U.; Ryom, K.; Juhyok, U.; Pak, K.; Pak, C. Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China. Sci. Total Environ. 2020, 699, 133561. [Google Scholar] [CrossRef]
- Chien, C.F.; Hong, T.Y.; Guo, H.Z. An empirical study for smart production for TFT-LCD to empower Industry 3.5. J. Chin. Inst. Eng. 2017, 40, 552–561. [Google Scholar] [CrossRef]
- Dickey, D.A.; Fuller, W.A. Distribution of the estimators for autoregressive time series with a unit root. J. Am. Stat. Assoc. 1979, 74, 427–431. [Google Scholar]
- Kwiatkowski, D.; Phillips, P.C.; Schmidt, P.; Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]
- Said, S.E.; Dickey, D.A. Testing for unit roots in autoregressive-moving average models of unknown order. Biometrika 1984, 71, 599–607. [Google Scholar] [CrossRef]
- Abbasimehr, H.; Shabani, M.; Yousefi, M. An optimized model using LSTM network for demand forecasting. Comput. Ind. Eng. 2020, 143, 106435. [Google Scholar] [CrossRef]
- Priya, C.B.; Arulanand, N. Univariate and multivariate models for Short-term wind speed forecasting. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Shi, H.; Xu, M.; Li, R. Deep learning for household load forecasting—A novel pooling deep RNN. IEEE Trans. Smart Grid 2017, 9, 5271–5280. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- Lewis, C.D. International and Business Forecasting Methods; Butterworths: London, UK, 1982. [Google Scholar]
- Weng, B.; Martinez, W.; Tsai, Y.T.; Li, C.; Lu, L.; Barth, J.R.; Megahed, F.M. Macroeconomic indicators alone can predict the monthly closing price of major US indices: Insights from artificial intelligence, time-series analysis and hybrid models. Appl. Soft Comput. 2018, 71, 685–697. [Google Scholar] [CrossRef]
- Qiao, W.; Wang, Y.; Zhang, J.; Tian, W.; Tian, Y.; Yang, Q. An innovative coupled model in view of wavelet transform for predicting short-term PM10 concentration. J. Environ. Manag. 2021, 289, 112438. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Company’s Empirical Law | ARIMA | LSTM | |||
|---|---|---|---|---|---|---|
| MAPE (%) | RMSE | MAPE (%) | RMSE | MAPE (%) | RMSE | |
| BGA8X13mm | 29.89 | 19,885.207 | 6 | 3507.88 | 0.2 | 113.45 |
| BGA8X12.5 | 3979.29 | 12,222.978 | 3015 | 9108.20 | 28.3 | 272.00 |
| TSOP II | 1324.73 | 8954.882 | 5 | 1061.47 | 1.21 | 293.01 |
| TSOP I | 30.00 | 7689.993 | 12 | 5647.35 | 0.84 | 116.25 |
| BGA11.5X13 | 34.20 | 13,744.552 | 8 | 10,273.37 | 0.62 | 139.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.-C.; Chien, C.-H.; Trappey, A.J.C. On the Application of ARIMA and LSTM to Predict Order Demand Based on Short Lead Time and On-Time Delivery Requirements. Processes 2021, 9, 1157. https://doi.org/10.3390/pr9071157
Wang C-C, Chien C-H, Trappey AJC. On the Application of ARIMA and LSTM to Predict Order Demand Based on Short Lead Time and On-Time Delivery Requirements. Processes. 2021; 9(7):1157. https://doi.org/10.3390/pr9071157
Chicago/Turabian StyleWang, Chien-Chih, Chun-Hua Chien, and Amy J. C. Trappey. 2021. "On the Application of ARIMA and LSTM to Predict Order Demand Based on Short Lead Time and On-Time Delivery Requirements" Processes 9, no. 7: 1157. https://doi.org/10.3390/pr9071157
APA StyleWang, C.-C., Chien, C.-H., & Trappey, A. J. C. (2021). On the Application of ARIMA and LSTM to Predict Order Demand Based on Short Lead Time and On-Time Delivery Requirements. Processes, 9(7), 1157. https://doi.org/10.3390/pr9071157