
Introducing Parameter Clustering to the OED Procedure for Model Calibration of a Synthetic Inducible Promoter in S. cerevisiae


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
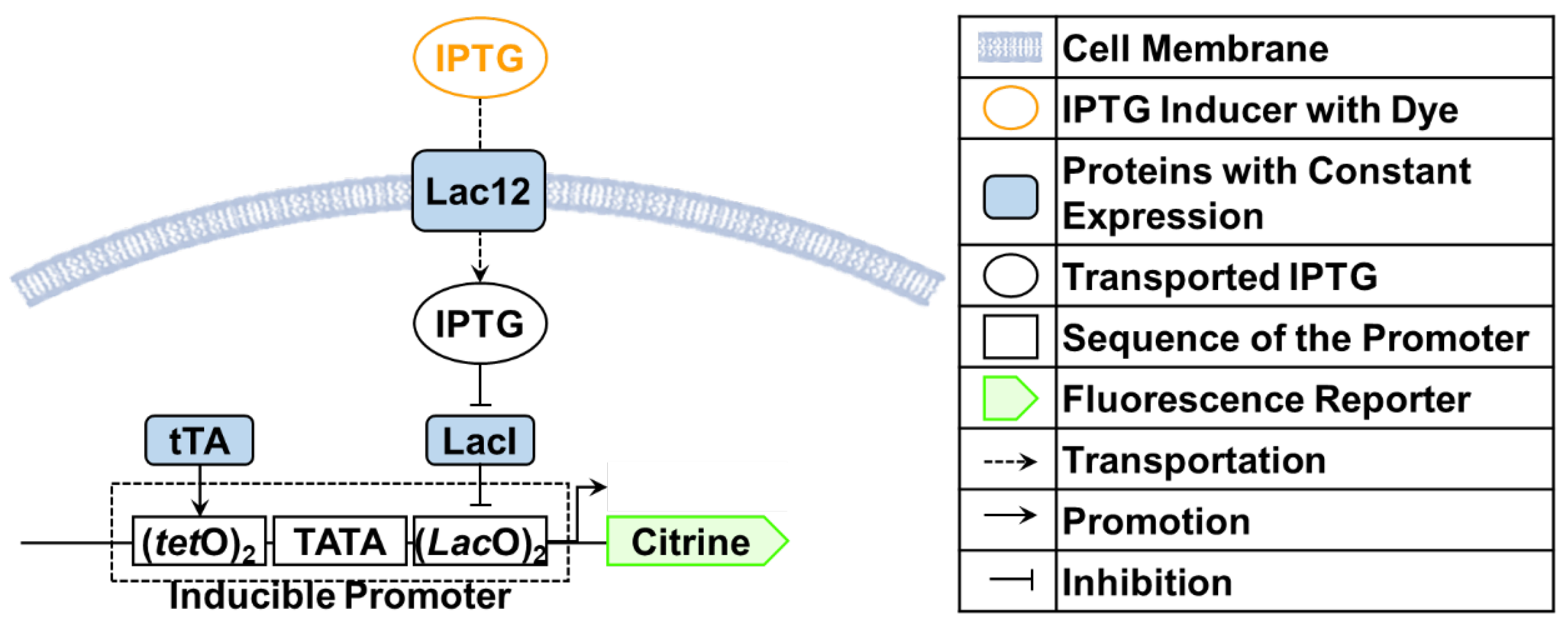
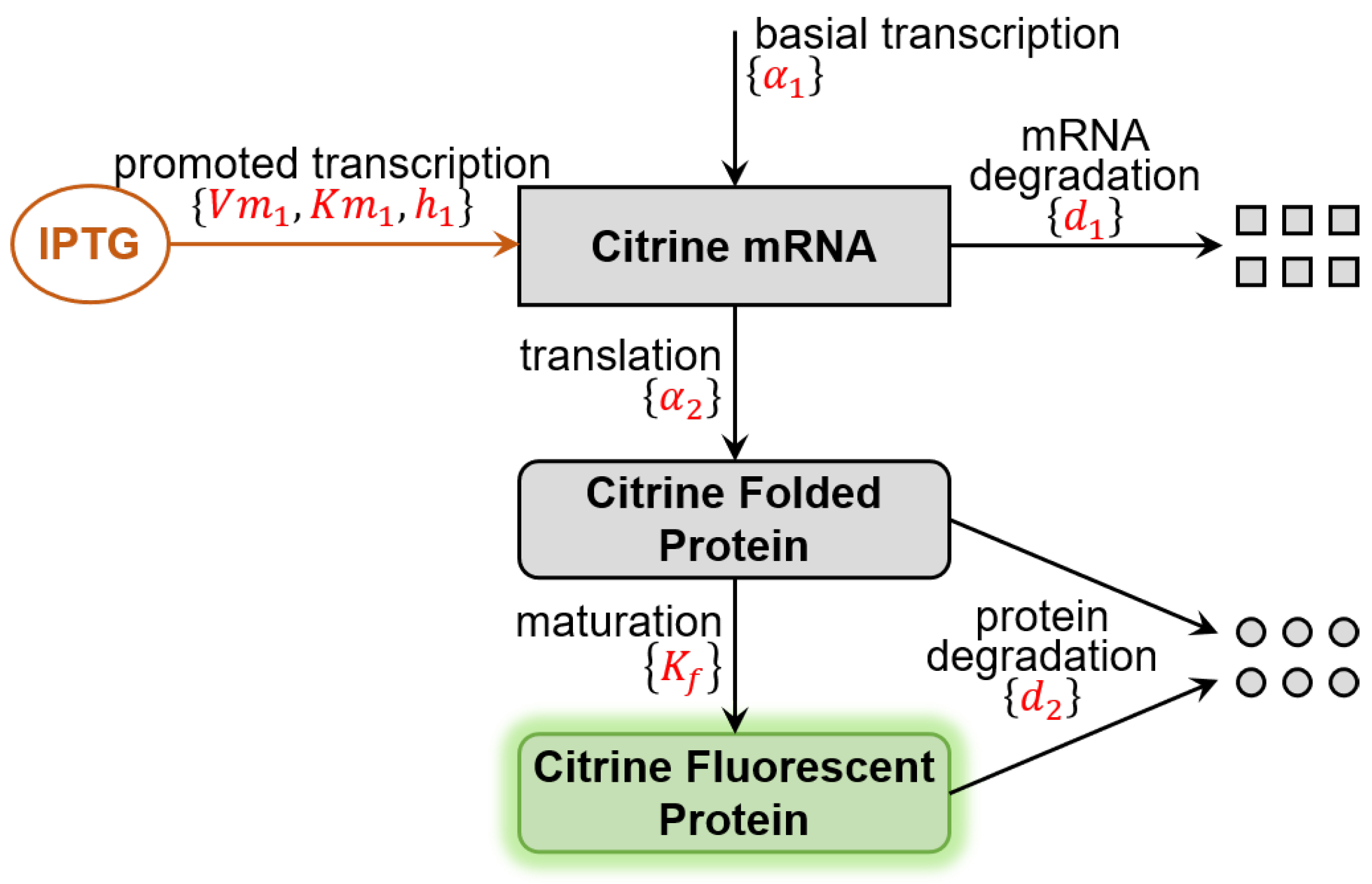
2.1. Benchmark Model for Calibration
2.2. Optimal Experimental Design Based on the Fisher Information Matrix
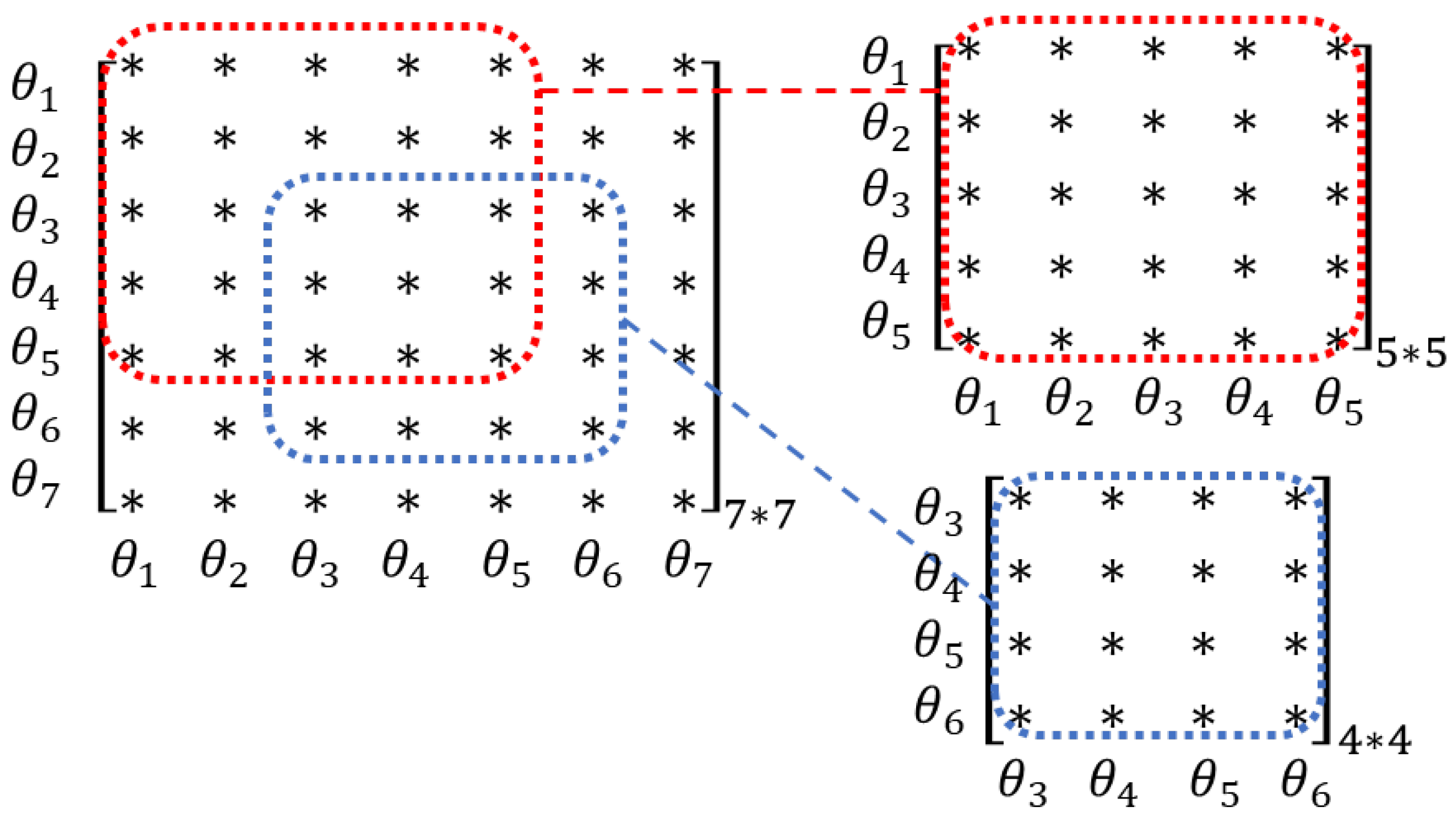
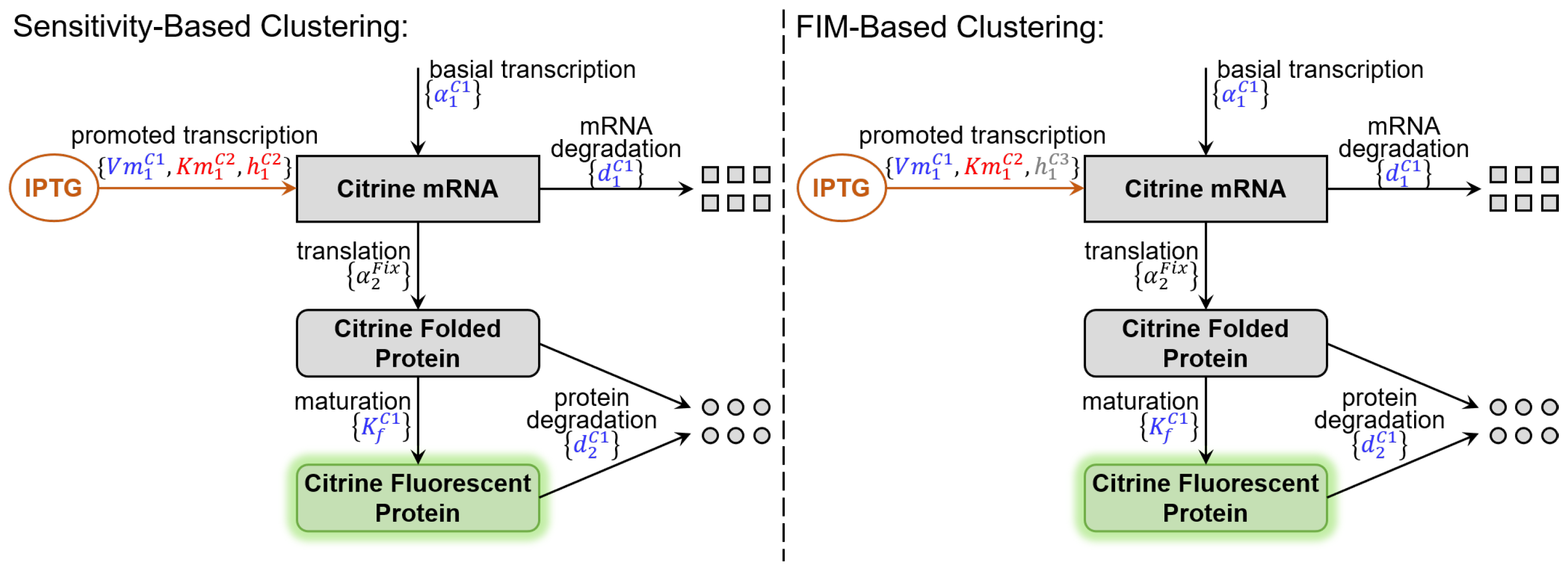
2.3. Parameter Clustering Based on Sensitivity Vectors
2.4. Parameter Clustering Based on FIM
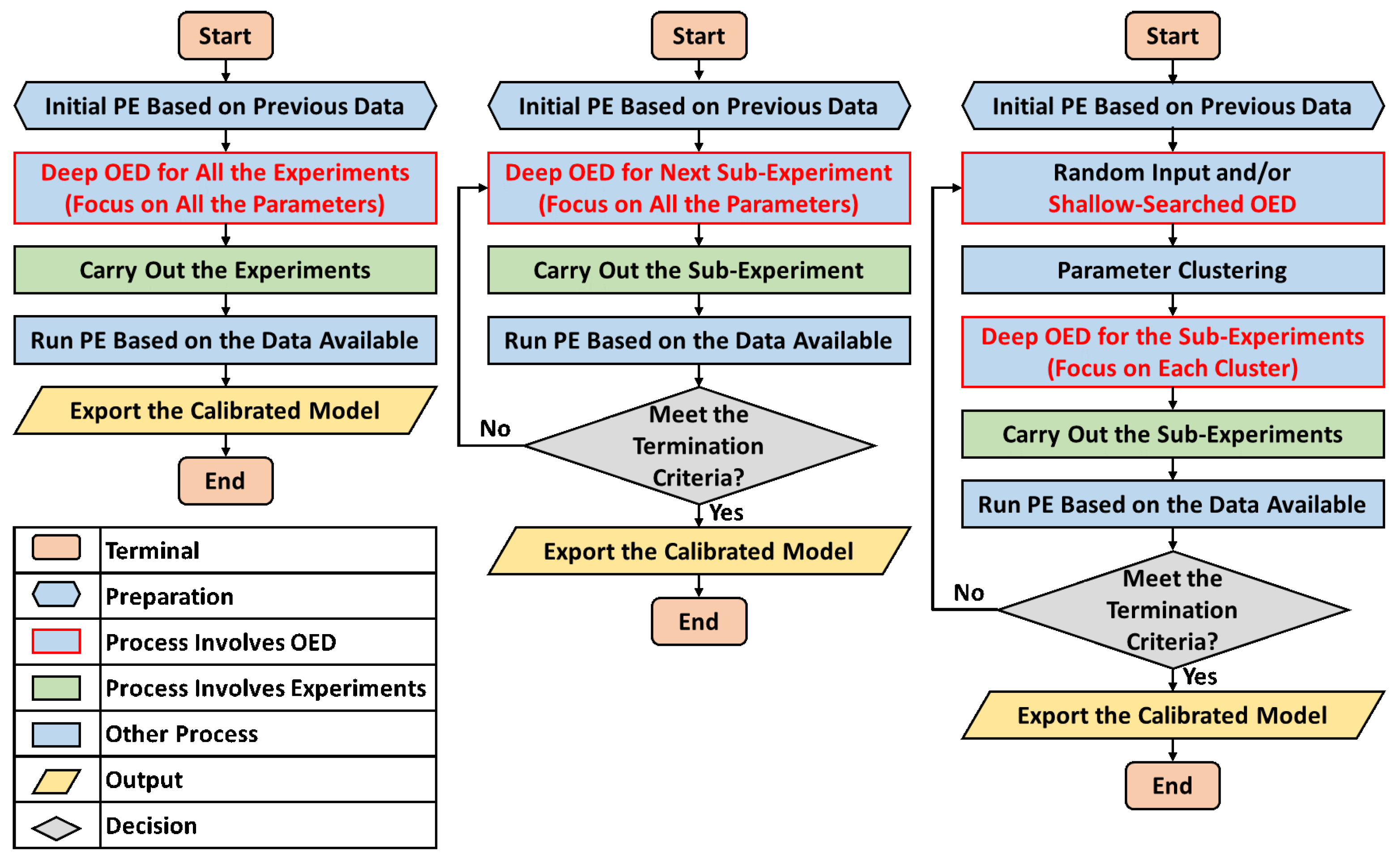
2.5. Details of the Experimental Design
3. Results
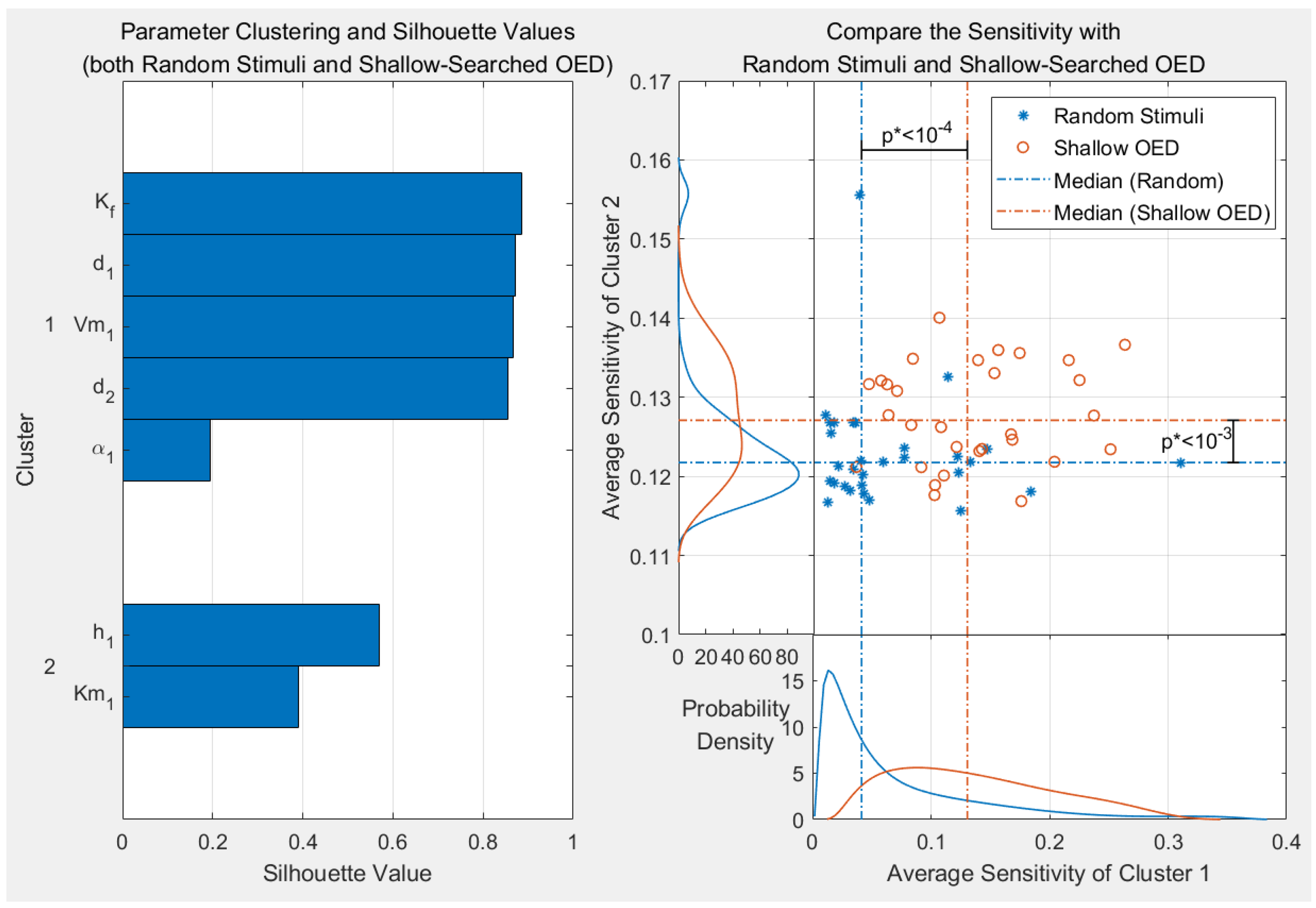
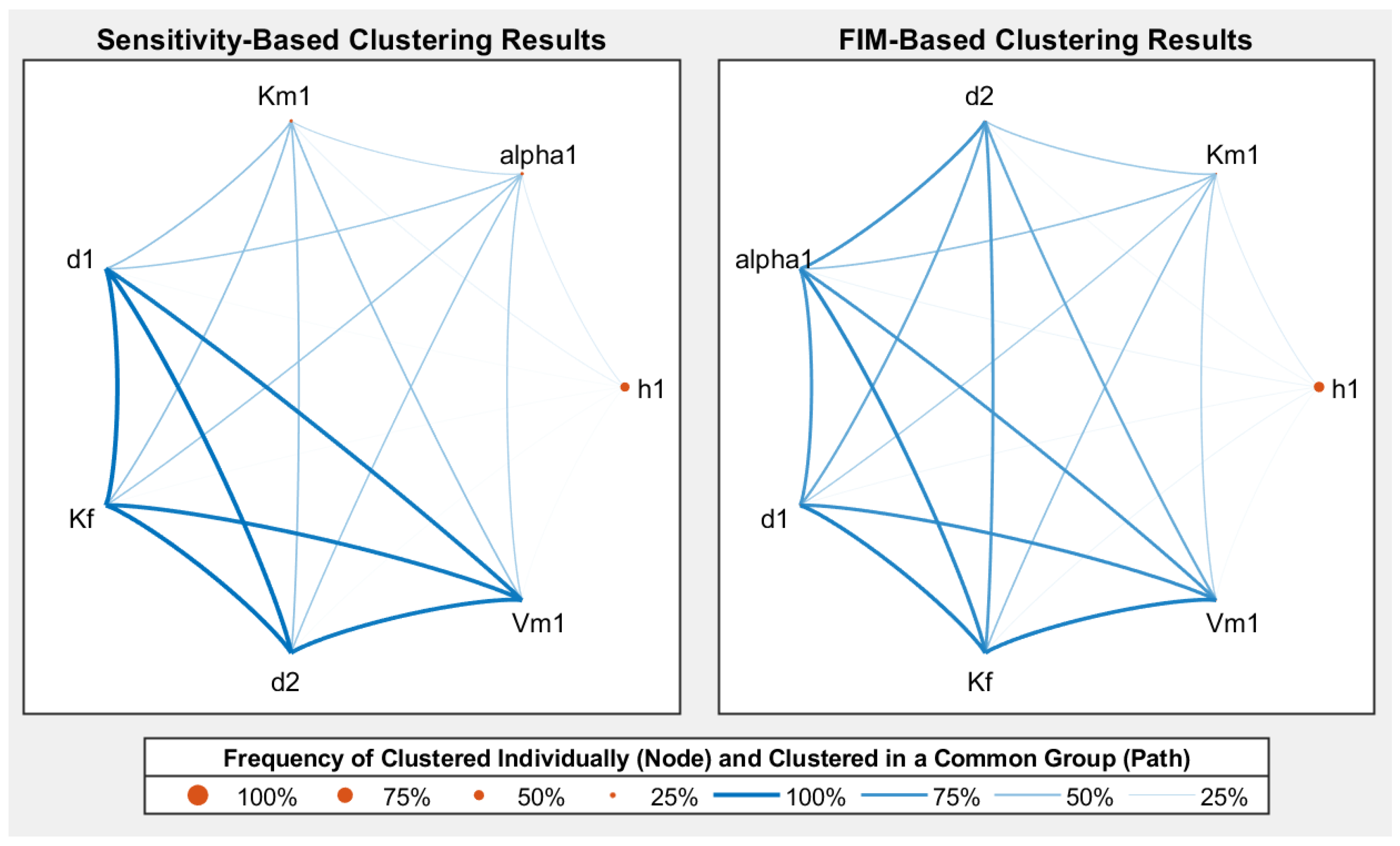
3.1. Results of Parameter Clustering
3.1.1. Clustering Results with the Best Estimated Value Set
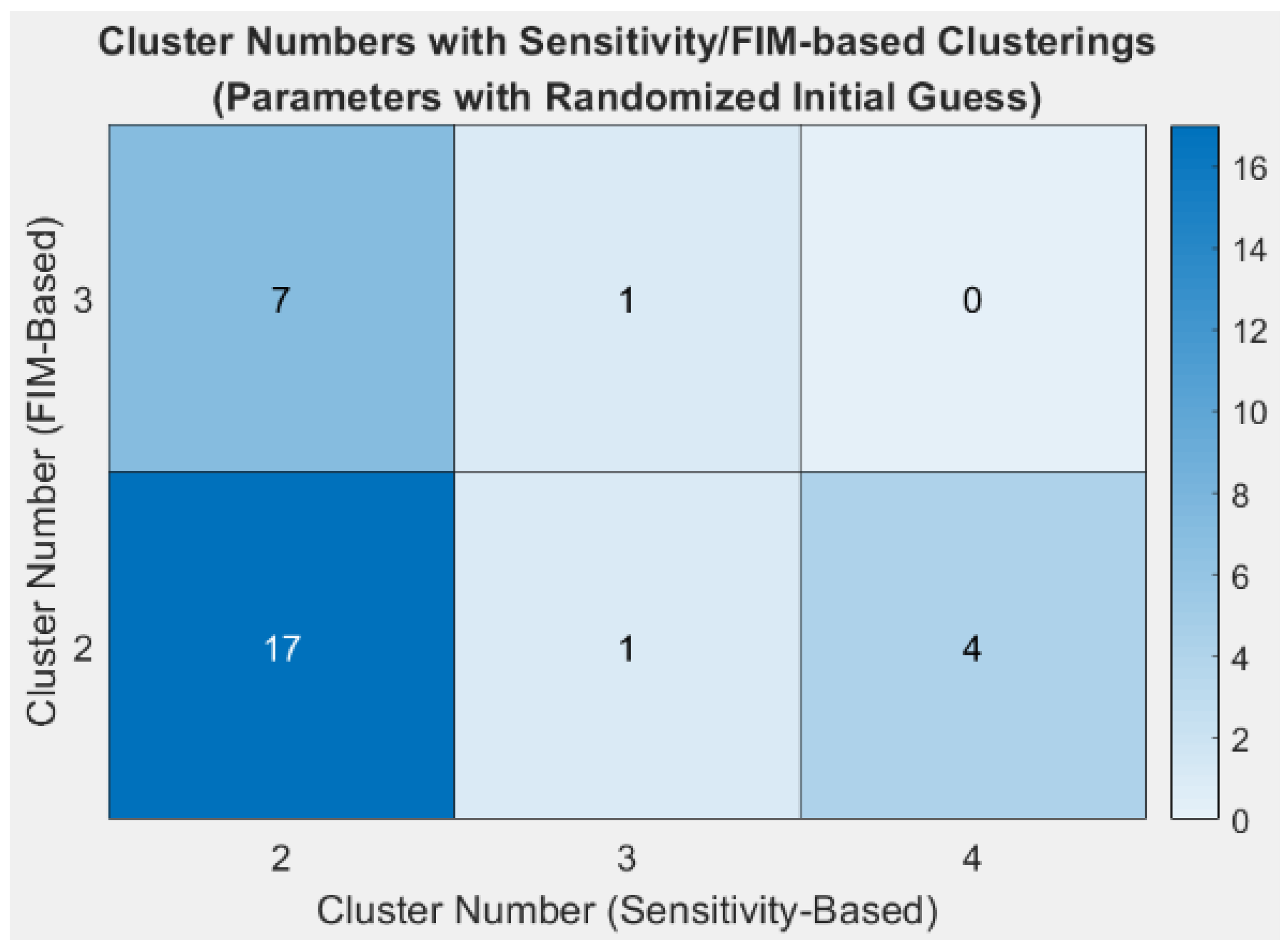
3.1.2. Clustering Results with Randomised Value Sets
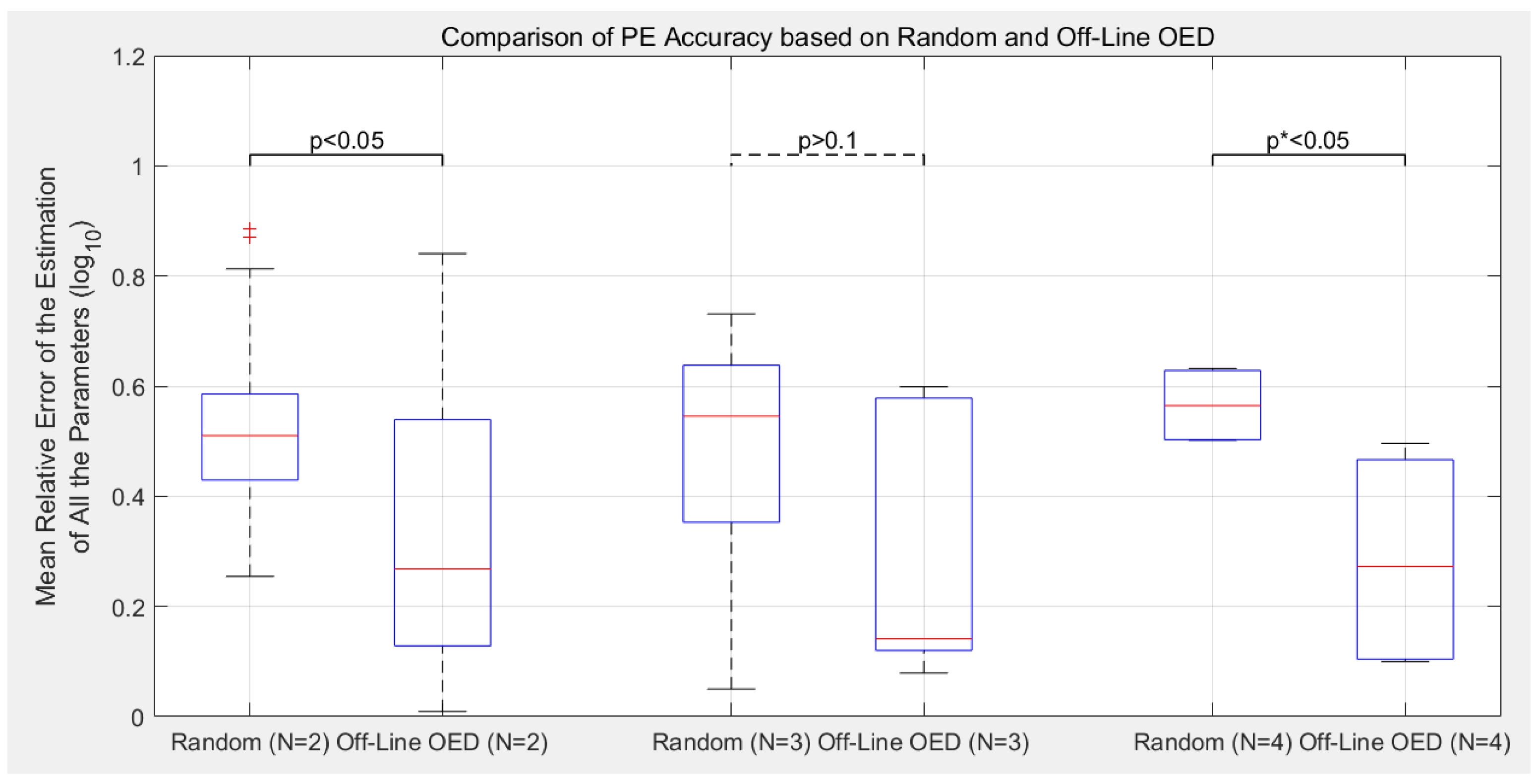
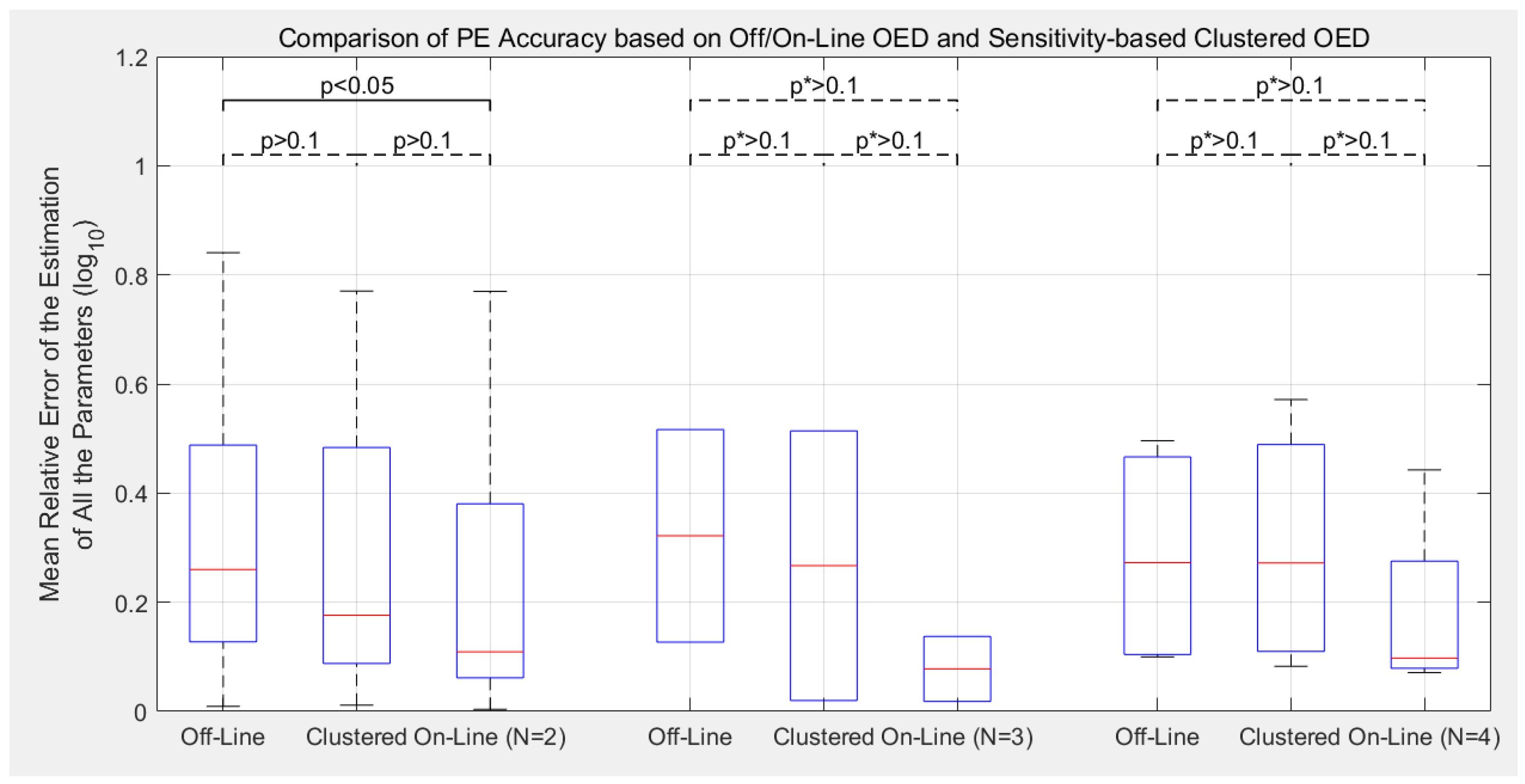
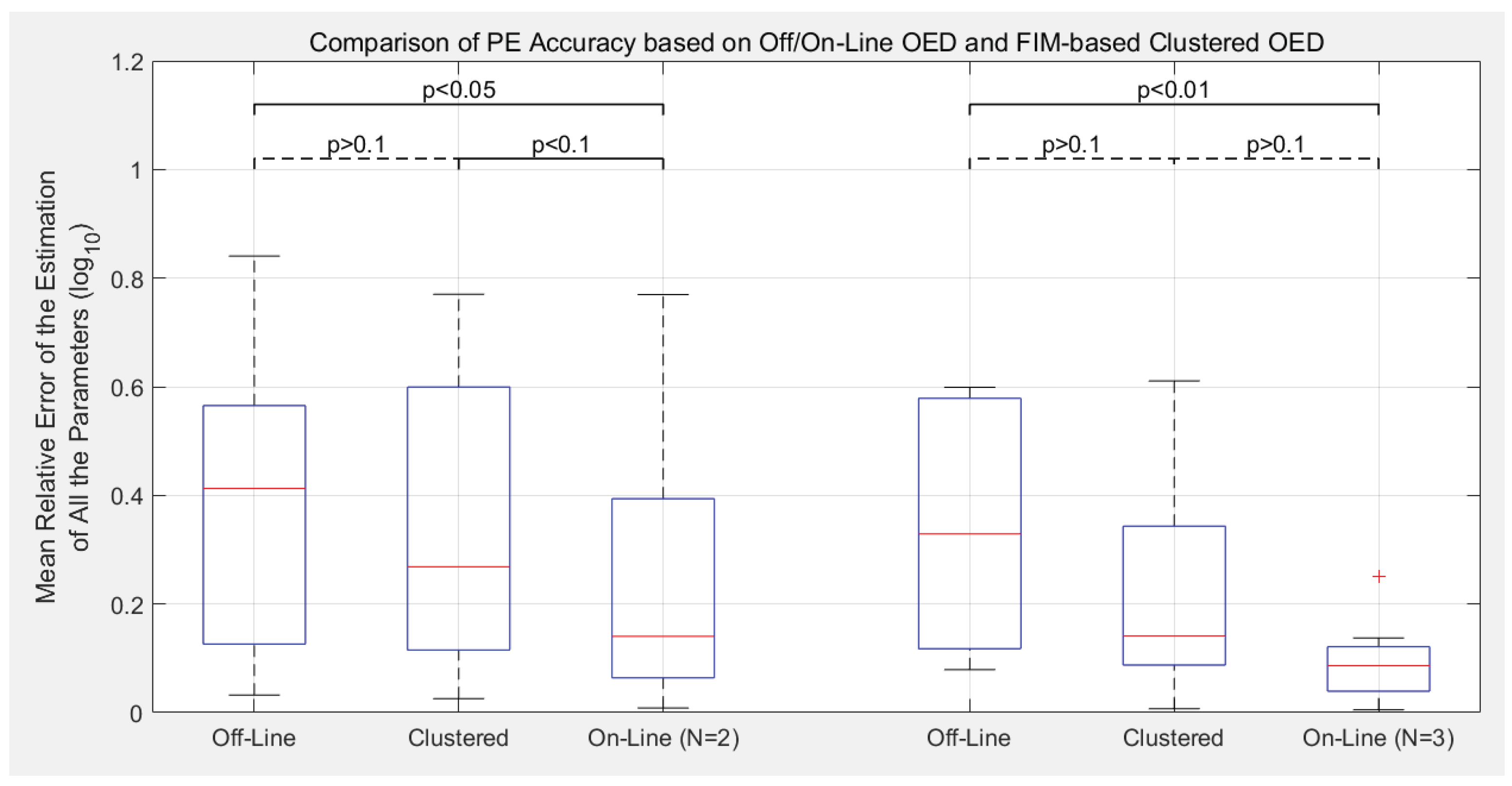
3.2. Estimation Accuracy with Different Experimental Designs
4. Conclusions and Prospect
- Compared to the previous off-line OED approach, the proposed cluster-based OED with either the sensitivity-based or FIM-based approaches could achieve equal or even slightly better calibration accuracy with at least 49.0% reduction in computational cost;
- Although the main purpose of introducing parameter clustering is for reducing the computational cost of OED, not for increasing the PE accuracy, cluster-based OEDs lead to lower estimation error in average in this benchmark. Sensitivity-based approach reduces the mean relative error of parameter estimation (defined as Equation (8)) by 19.6% in average, and the FIM-based approach reduces by 11.8%;
- Compare to the previously proposed on-line OED approach, the model calibration accuracy of cluster-based OED does not statistically out-compete the current approach in this benchmark test. Meanwhile, it is worth mentioning that cluster-based OED is suitable for parallel experiments, but on-line OED is not;
- Compared to previous applications of parameter clustering in the OED procedure, this study provides a completely different approach of using the clustering results. Instead of guiding the selection of fitting parameters, the proposed methods keep the initial selection of fitting parameters and aim at achieving more informative experimental designs;
- Both sensitivity-based and FIM-based clustering provide understandable parameter clustering results, which could provide a reference for understanding the model structure and simplifying the OED procedure.
- The proposed method for visualising the clustering results is of great potential to provide efficient graphical help to understand the model mechanisms and inner properties.
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| OED | Optimal experimental design |
| FIM | Fisher information matrix |
| PE | Parameter estimation |
| eSS | Enhanced Scatter Search |
| IPTG | Isopropyl -D-thiogalactoside |
References
- Gutenkunst, R.N.; Waterfall, J.J.; Casey, F.P.; Brown, K.S.; Myers, C.R.; Sethna, J.P. Universally sloppy parameter sensitivities in systems biology models. PLoS Comput. Biol. 2007, 3, e189. [Google Scholar] [CrossRef] [PubMed]
- Bouvin, J.; Cajot, S.; D’Huys, P.J.; Ampofo-Asiama, J.; Anné, J.; Van Impe, J.; Geeraerd, A.; Bernaerts, K. Multi-objective experimental design for 13C-based metabolic flux analysis. Math. Biosci. 2015, 268, 22–30. [Google Scholar] [CrossRef] [PubMed]
- Bandiera, L.; Hou, Z.; Kothamachu, V.B.; Balsa-Canto, E.; Swain, P.S.; Menolascina, F. On-line optimal input design increases the efficiency and accuracy of the modelling of an inducible synthetic promoter. Processes 2018, 6, 148. [Google Scholar] [CrossRef]
- Nimmegeers, P.; Bhonsale, S.; Telen, D.; Van Impe, J. Optimal experiment design under parametric uncertainty: A comparison of a sensitivities based approach versus a polynomial chaos based stochastic approach. Chem. Eng. Sci. 2020, 221, 115651. [Google Scholar] [CrossRef]
- Moles, C.G.; Mendes, P.; Banga, J.R. Parameter estimation in biochemical pathways: A comparison of global optimization methods. Genome Res. 2003, 13, 2467–2474. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Fernandez, M.; Mendes, P.; Banga, J.R. A hybrid approach for efficient and robust parameter estimation in biochemical pathways. Biosystems 2006, 83, 248–265. [Google Scholar] [CrossRef] [PubMed]
- Franceschini, G.; Macchietto, S. Model-based design of experiments for parameter precision: State of the art. Chem. Eng. Sci. 2008, 63, 4846–4872. [Google Scholar] [CrossRef]
- Rojas, C.R.; Welsh, J.S.; Goodwin, G.C.; Feuer, A. Robust optimal experiment design for system identification. Automatica 2007, 43, 993–1008. [Google Scholar] [CrossRef]
- Telen, D.; Houska, B.; Logist, F.; Van Derlinden, E.; Diehl, M.; Van Impe, J. Optimal experiment design under process noise using Riccati differential equations. J. Process Control 2013, 23, 613–629. [Google Scholar] [CrossRef]
- Bandara, S.; Schlöder, J.P.; Eils, R.; Bock, H.G.; Meyer, T. Optimal experimental design for parameter estimation of a cell signaling model. PLoS Comput. Biol. 2009, 5, e1000558. [Google Scholar] [CrossRef] [PubMed]
- Kreutz, C.; Timmer, J. Systems biology: Experimental design. FEBS J. 2009, 276, 923–942. [Google Scholar] [CrossRef] [PubMed]
- Komorowski, M.; Costa, M.J.; Rand, D.A.; Stumpf, M.P. Sensitivity, robustness, and identifiability in stochastic chemical kinetics models. Proc. Natl. Acad. Sci. USA 2011, 108, 8645–8650. [Google Scholar] [CrossRef] [PubMed]
- Gorman, J.D.; Hero, A.O. Lower bounds for parametric estimation with constraints. IEEE Trans. Inf. Theory 1990, 36, 1285–1301. [Google Scholar] [CrossRef]
- Stoica, P.; Ng, B.C. On the Cramér-Rao bound under parametric constraints. IEEE Signal Process. Lett. 1998, 5, 177–179. [Google Scholar] [CrossRef]
- Baltes, M.; Schneider, R.; Sturm, C.; Reuss, M. Optimal experimental design for parameter estimation in unstructured growth models. Biotechnol. Prog. 1994, 10, 480–488. [Google Scholar] [CrossRef]
- Lindner, P.F.O.; Hitzmann, B. Experimental design for optimal parameter estimation of an enzyme kinetic process based on the analysis of the Fisher information matrix. J. Theor. Biol. 2006, 238, 111–123. [Google Scholar] [CrossRef] [PubMed]
- Chu, Y.; Hahn, J. Parameter set selection via clustering of parameters into pairwise indistinguishable groups of parameters. Ind. Eng. Chem. Res. 2009, 48, 6000–6009. [Google Scholar] [CrossRef]
- Guedj, J.; Thiébaut, R.; Commenges, D. Practical identifiability of HIV dynamics models. Bull. Math. Biol. 2007, 69, 2493–2513. [Google Scholar] [CrossRef] [PubMed]
- Riviere, M.K.; Ueckert, S.; Mentré, F. An MCMC method for the evaluation of the Fisher information matrix for non-linear mixed effect models. Biostatistics 2016, 17, 737–750. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.T.; Mentré, F. Evaluation of the Fisher information matrix in nonlinear mixed effect models using adaptive Gaussian quadrature. Comput. Stat. Data Anal. 2014, 80, 57–69. [Google Scholar] [CrossRef]
- Telen, D.; Logist, F.; Van Derlinden, E.; Tack, I.; Van Impe, J. Optimal experiment design for dynamic bioprocesses: A multi-objective approach. Chem. Eng. Sci. 2012, 78, 82–97. [Google Scholar] [CrossRef]
- Manesso, E.; Sridharan, S.; Gunawan, R. Multi-objective optimization of experiments using curvature and fisher information matrix. Processes 2017, 5, 63. [Google Scholar] [CrossRef]
- Ueckert, S.; Mentré, F. A new method for evaluation of the Fisher information matrix for discrete mixed effect models using Monte Carlo sampling and adaptive Gaussian quadrature. Comput. Stat. Data Anal. 2017, 111, 203–219. [Google Scholar] [CrossRef]
- Arora, S.; Barak, B. Computational Complexity: A Modern Approach; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Pronzato, L.; Walter, É. Robust experiment design via stochastic approximation. Math. Biosci. 1985, 75, 103–120. [Google Scholar] [CrossRef]
- Machado, V.C.; Tapia, G.; Gabriel, D.; Lafuente, J.; Baeza, J.A. Systematic identifiability study based on the Fisher Information Matrix for reducing the number of parameters calibration of an activated sludge model. Environ. Model. Softw. 2009, 24, 1274–1284. [Google Scholar] [CrossRef]
- Hassanein, W.; Kilany, N. DE-and EDP _{M}-compound optimality for the information and probability-based criteria. Hacet. J. Math. Stat. 2019, 48, 580–591. [Google Scholar]
- Logist, F.; Telen, D.; Van Derlinden, E.; Van Impe, J.F. Multi-objective optimisation approach to optimal experiment design in dynamic bioprocesses using ACADO toolkit. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2011; Volume 29, pp. 462–466. [Google Scholar]
- Balsa-Canto, E.; Alonso, A.A.; Banga, J.R. Computational procedures for optimal experimental design in biological systems. IET Syst. Biol. 2008, 2, 163–172. [Google Scholar] [CrossRef] [PubMed]
- Kravaris, C.; Hahn, J.; Chu, Y. Advances and selected recent developments in state and parameter estimation. Comput. Chem. Eng. 2013, 51, 111–123. [Google Scholar] [CrossRef]
- Dai, W.; Bansal, L.; Hahn, J. Parameter set selection for signal transduction pathway models including uncertainties. IFAC Proc. Vol. 2014, 47, 815–820. [Google Scholar] [CrossRef]
- Gábor, A.; Villaverde, A.F.; Banga, J.R. Parameter identifiability analysis and visualization in large-scale kinetic models of biosystems. BMC Syst. Biol. 2017, 11, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.; Jayaraman, A.; Kwon, J.S.I. Identification of a time-varying intracellular signalling model through data clustering and parameter selection: Application to NF-κ B signalling pathway induced by LPS in the presence of BFA. IET Syst. Biol. 2019, 13, 169–179. [Google Scholar] [CrossRef] [PubMed]
- Nienałtowski, K.; Włodarczyk, M.; Lipniacki, T.; Komorowski, M. Clustering reveals limits of parameter identifiability in multi-parameter models of biochemical dynamics. BMC Syst. Biol. 2015, 9, 1–9. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Walter, É.; Pronzato, L. Qualitative and quantitative experiment design for phenomenological models—A survey. Automatica 1990, 26, 195–213. [Google Scholar] [CrossRef]
- Aster, R.C.; Borchers, B.; Thurber, C.H. Parameter Estimation and Inverse Problems; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Gnugge, R.; Dharmarajan, L.; Lang, M.; Stelling, J. An orthogonal permease–inducer–repressor feedback loop shows bistability. ACS Synth. Biol. 2016, 5, 1098–1107. [Google Scholar] [CrossRef] [PubMed]
- Raue, A.; Schilling, M.; Bachmann, J.; Matteson, A.; Schelke, M.; Kaschek, D.; Hug, S.; Kreutz, C.; Harms, B.D.; Theis, F.J.; et al. Lessons learned from quantitative dynamical modeling in systems biology. PLoS ONE 2013, 8, e74335. [Google Scholar] [CrossRef]
- Liepe, J.; Filippi, S.; Komorowski, M.; Stumpf, M.P. Maximizing the information content of experiments in systems biology. PLoS Comput. Biol. 2013, 9, e1002888. [Google Scholar] [CrossRef] [PubMed]
- Vanlier, J.; Tiemann, C.; Hilbers, P.; Van Riel, N. Parameter uncertainty in biochemical models described by ordinary differential equations. Math. Biosci. 2013, 246, 305–314. [Google Scholar] [CrossRef] [PubMed]
- Raue, A.; Steiert, B.; Schelker, M.; Kreutz, C.; Maiwald, T.; Hass, H.; Vanlier, J.; Tönsing, C.; Adlung, L.; Engesser, R.; et al. Data2Dynamics: A modeling environment tailored to parameter estimation in dynamical systems. Bioinformatics 2015, 31, 3558–3560. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Li, F.; Wang, S.; Cao, Y. Stochastic modeling and simulation of reaction-diffusion system with Hill function dynamics. BMC Syst. Biol. 2017, 11, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Wachtel, A.; Rao, R.; Esposito, M. Thermodynamically consistent coarse graining of biocatalysts beyond Michaelis–Menten. New J. Phys. 2018, 20, 042002. [Google Scholar] [CrossRef]
- Gilchrist, M.A.; Wagner, A. A model of protein translation including codon bias, nonsense errors, and ribosome recycling. J. Theor. Biol. 2006, 239, 417–434. [Google Scholar] [CrossRef] [PubMed]
- Pelechano, V.; Chávez, S.; Pérez-Ortín, J.E. A complete set of nascent transcription rates for yeast genes. PLoS ONE 2010, 5, e15442. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Liu, C.L.; Storey, J.D.; Tibshirani, R.J.; Herschlag, D.; Brown, P.O. Precision and functional specificity in mRNA decay. Proc. Natl. Acad. Sci. USA 2002, 99, 5860–5865. [Google Scholar] [CrossRef] [PubMed]
- Belle, A.; Tanay, A.; Bitincka, L.; Shamir, R.; O’Shea, E.K. Quantification of protein half-lives in the budding yeast proteome. Proc. Natl. Acad. Sci. USA 2006, 103, 13004–13009. [Google Scholar] [CrossRef] [PubMed]
- Gordon, A.; Colman-Lerner, A.; Chin, T.E.; Benjamin, K.R.; Richard, C.Y.; Brent, R. Single-cell quantification of molecules and rates using open-source microscope-based cytometry. Nat. Methods 2007, 4, 175–181. [Google Scholar] [CrossRef] [PubMed]
- Fisher, R.A. Design of experiments. Br. Med. J. 1936, 1, 554. [Google Scholar] [CrossRef]
- Balsa-Canto, E.; Henriques, D.; Gábor, A.; Banga, J.R. AMIGO2, a toolbox for dynamic modeling, optimization and control in systems biology. Bioinformatics 2016, 32, 3357–3359. [Google Scholar] [CrossRef] [PubMed]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Jang, J.; Smyth, A.W. Model updating of a full-scale FE model with nonlinear constraint equations and sensitivity-based cluster analysis for updating parameters. Mech. Syst. Signal Process. 2017, 83, 337–355. [Google Scholar] [CrossRef]
- Shahverdi, H.; Mares, C.; Wang, W.; Mottershead, J. Clustering of parameter sensitivities: Examples from a helicopter airframe model updating exercise. Shock Vib. 2009, 16, 75–87. [Google Scholar] [CrossRef]
- Everitt, B.S.; Landau, S.; Leese, M.; Stahl, D. Hierarchical clustering. In Cluster Analysis; Wiley: Chichester, UK, 2011; Volume 5, pp. 71–110. [Google Scholar]
- Hartigan, J.A. A K-means clustering algorithm: Algorithm AS 136. Appl. Stat. 1979, 28, 126–130. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-Means++: The Advantages of Careful Seeding; Technical Report; Stanford University: Stanford, CA, USA, 2006. [Google Scholar]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Lallement, G.; Piranda, J. Localization methods for parametric updating of finite elements models in elastodynamics. In Proceedings of the 8th International Modal Analysis Conference, Kissimmee, FL, USA, 29 January–1 February 1990; pp. 579–585. [Google Scholar]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Ferry, M.S.; Razinkov, I.A.; Hasty, J. Microfluidics for synthetic biology: From design to execution. Methods Enzymol. 2011, 497, 295–372. [Google Scholar] [PubMed]
- Scheler, O.; Postek, W.; Garstecki, P. Recent developments of microfluidics as a tool for biotechnology and microbiology. Curr. Opin. Biotechnol. 2019, 55, 60–67. [Google Scholar] [CrossRef] [PubMed]
- Balsa-Canto, E.; Bandiera, L.; Menolascina, F. Optimal Experimental Design for Systems and Synthetic Biology Using AMIGO2. In Synthetic Gene Circuits; Springer: Berlin/Heidelberg, Germany, 2021; pp. 221–239. [Google Scholar]
- Villaverde, A.F.; Fröhlich, F.; Weindl, D.; Hasenauer, J.; Banga, J.R. Benchmarking optimization methods for parameter estimation in large kinetic models. Bioinformatics 2019, 35, 830–838. [Google Scholar] [CrossRef] [PubMed]
- Egea, J.A.; Martí, R.; Banga, J.R. An evolutionary method for complex-process optimization. Comput. Oper. Res. 2010, 37, 315–324. [Google Scholar] [CrossRef]
- Lagarias, J.C.; Reeds, J.A.; Wright, M.H.; Wright, P.E. Convergence properties of the Nelder–Mead simplex method in low dimensions. SIAM J. Optim. 1998, 9, 112–147. [Google Scholar] [CrossRef]
- Hansen, N.; Müller, S.D.; Koumoutsakos, P. Reducing the time complexity of the derandomized evolution strategy with covariance matrix adaptation (CMA-ES). Evol. Comput. 2003, 11, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Hansen, N. The CMA evolution strategy: A comparing review. In Towards a New Evolutionary Computation; Springer: Heidelberg/Berlin, Germany, 2006; pp. 75–102. [Google Scholar]
- Nobile, M.S.; Cazzaniga, P.; Besozzi, D.; Colombo, R.; Mauri, G.; Pasi, G. Fuzzy Self-Tuning PSO: A settings-free algorithm for global optimization. Swarm Evol. Comput. 2018, 39, 70–85. [Google Scholar] [CrossRef]
- Bashor, C.J.; Patel, N.; Choubey, S.; Beyzavi, A.; Kondev, J.; Collins, J.J.; Khalil, A.S. Complex signal processing in synthetic gene circuits using cooperative regulatory assemblies. Science 2019, 364, 593–597. [Google Scholar] [CrossRef] [PubMed]
- Bashor, C.J.; Horwitz, A.A.; Peisajovich, S.G.; Lim, W.A. Rewiring cells: Synthetic biology as a tool to interrogate the organizational principles of living systems. Annu. Rev. Biophys. 2010, 39, 515–537. [Google Scholar] [CrossRef] [PubMed]
- Ferrell, J.E., Jr.; Xiong, W. Bistability in cell signaling: How to make continuous processes discontinuous, and reversible processes irreversible. Chaos Interdiscip. J. Nonlinear Sci. 2001, 11, 227–236. [Google Scholar] [CrossRef] [PubMed]
- Babu, B.; Angira, R. Modified differential evolution (MDE) for optimization of non-linear chemical processes. Comput. Chem. Eng. 2006, 30, 989–1002. [Google Scholar] [CrossRef]
- Onwubolu, G.C.; Babu, B. New Optimization Techniques in Engineering; Springer: Berlin/Heidelberg, Germany, 2013; Volume 141. [Google Scholar]
- Avriel, M. Nonlinear Programming: Analysis and Methods; Courier Corporation: North Chelmsford, MA, USA, 2003. [Google Scholar]
- Gong, W.; Cai, Z.; Ling, C.X.; Li, H. Enhanced differential evolution with adaptive strategies for numerical optimization. IEEE Trans. Syst. Man Cybern. Part B 2010, 41, 397–413. [Google Scholar] [CrossRef] [PubMed]
- Gong, W.; Fialho, A.; Cai, Z.; Li, H. Adaptive strategy selection in differential evolution for numerical optimization: An empirical study. Inf. Sci. 2011, 181, 5364–5386. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Z. Introducing Parameter Clustering to the OED Procedure for Model Calibration of a Synthetic Inducible Promoter in S. cerevisiae. Processes 2021, 9, 1053. https://doi.org/10.3390/pr9061053
Hou Z. Introducing Parameter Clustering to the OED Procedure for Model Calibration of a Synthetic Inducible Promoter in S. cerevisiae. Processes. 2021; 9(6):1053. https://doi.org/10.3390/pr9061053
Chicago/Turabian StyleHou, Zhaozheng. 2021. "Introducing Parameter Clustering to the OED Procedure for Model Calibration of a Synthetic Inducible Promoter in S. cerevisiae" Processes 9, no. 6: 1053. https://doi.org/10.3390/pr9061053
APA StyleHou, Z. (2021). Introducing Parameter Clustering to the OED Procedure for Model Calibration of a Synthetic Inducible Promoter in S. cerevisiae. Processes, 9(6), 1053. https://doi.org/10.3390/pr9061053